大语言模型之十三 LLama2中文推理
在《大语言模型之十二 SentencePiece扩充LLama2中文词汇》一文中已经扩充好了中文词汇表,接下来就是使用整理的中文语料对模型进行预训练了。这里先跳过预训练环节。先试用已经训练好的模型,看看如何推理。
合并模型
这一步骤会合并LoRA权重,生成全量模型权重。此处可以选择输出PyTorch版本权重(.pth文件)或者输出HuggingFace版本权重(.bin文件)。执行以下命令:
$ python scripts/merge_llama2_with_chinese_lora_low_mem.py \--base_model path_to_original_llama2_hf_dir \--lora_model path_to_chinese_llama2_or_alpaca2_lora \--output_type huggingface \--output_dir path_to_output_dir
参数说明:
- –base_model:存放HF格式的Llama-2模型权重和配置文件的目录,这可以在《大语言模型之十二 SentencePiece扩充LLama2中文词汇》的1.下载原版LLama-2模型小节找到如何将原始meta的LlaMA-2模型转为Huggingface的格式。
- –lora_model:中文LLaMA-2/Alpaca-2 LoRA解压后文件所在目录,也可使用🤗Model Hub模型调用名称(会自动下载),这里使用Chinese-LLaMA-Alpaca-2给出的预训练好的7B模型。
- –output_type:指定输出格式,可为pth或huggingface。若不指定,默认为huggingface
- –output_dir:指定保存全量模型权重的目录,默认为./
- (可选)–verbose:显示合并过程中的详细信息
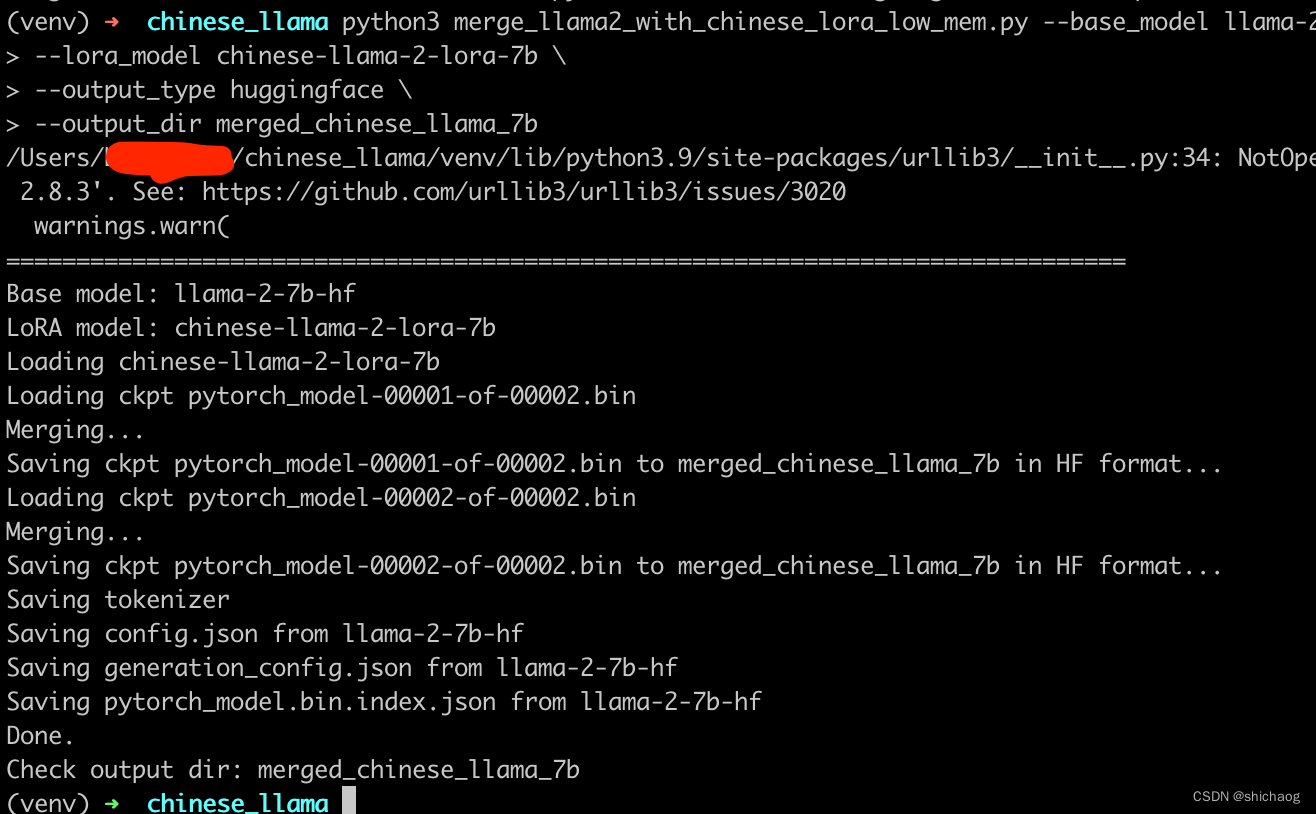
转换好格式之后,内容如下(时间戳为11:28的即为转换生成文件):
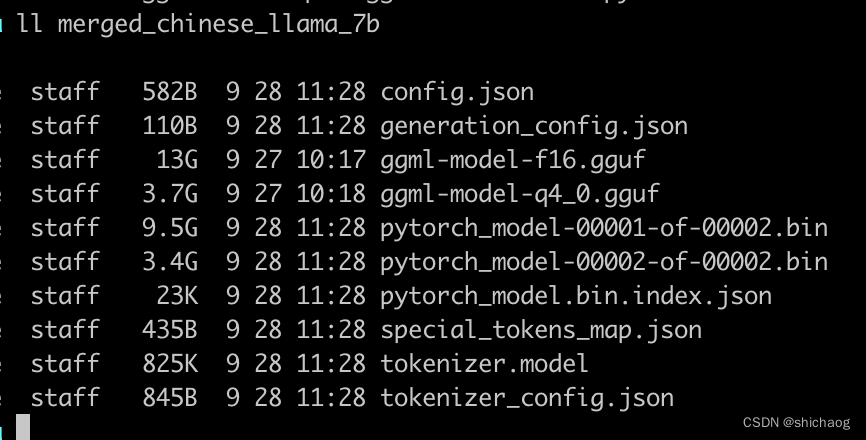
其中的ggml开头的事量化文件是用于模型推理。
推理
在attn_and_long_ctx_patches.py实现了基于NTK的自适应上下文适配方法,其中基于transformers的推理脚本。
- 当上下文小于4K时,默认关闭,因为原生的效果更好
- 大于4K时开启NTK,AUTO_COEFF默认为1.0
以下是不同AUTO_COEFF下,在不同上下文长度上的PPL变化(越低越好),供使用参考。
对NTK方法熟悉的用户可直接修改代码中的ALPHA取值。 - 12K以下:几乎和原生4K的PPL没有显著差异
- 12K-16K:开始存在一定损失,大约是3比特量化级别的效果
- 18K+:存在较大损失,大约是2比特量化级别效果,20K+不可用
以上结果仅供参考,应在实际场景中测试调整AUTO_COEFF或者ALPHA取值。
使用llama.cpp推理
Step 1: 克隆和编译llama.cpp
- (可选)如果已下载旧版仓库,建议git pull拉取最新代码,并执行make clean进行清理
- 拉取最新版llama.cpp仓库代码
$ git clone https://github.com/ggerganov/llama.cpp
- 对llama.cpp项目进行编译,生成./main(用于推理)和./quantize(用于量化)二进制文件。
$ make
Step 2: 生成量化版本模型
目前llama.cpp已支持.pth文件以及huggingface格式.bin的转换。将完整模型权重转换为GGML的FP16格式,生成文件路径为zh-models/7B/ggml-model-f16.gguf。进一步对FP16模型进行4-bit量化,生成量化模型文件路径为zh-models/7B/ggml-model-q4_0.gguf。不同量化方法的性能对比见本Wiki最后部分。
python3 convert.py ../merged_chinese_llama_7b
$ ./quantize ../merged_chinese_llama_7b/ggml-model-f16.gguf ../merged_chinese_llama_7b/ggml-model-q4_0.gguf q4_0
Step 3: 加载并启动模型
llama.cpp git:(master) ✗ ./main -s 1 -m ../merged_chinese_llama_7b/ggml-model-q4_0.gguf -p "中国的首都是" --ignore-eos -c 64 -n 128 -t 3 -ngl 10
-
GPU推理:通过Metal编译则只需在./main中指定-ngl 1;cuBLAS编译需要指定offload层数,例如-ngl 40表示offload 40层模型参数到GPU
-
加载长上下文模型(16K):
- 启动模型(./main)后debug信息中显示llm_load_print_meta: freq_scale = 0.25,则表示模型转换时已载入相应超参,无需其他特殊设置
- 如果上述debug信息显示为llm_load_print_meta: freq_scale = 1.0,则需在./main中额外指定–rope-scale 4
-
默认的量化方法为q4_0,虽然速度最快但损失也较大,推荐使用Q4_K作为替代
-
机器资源够用且对速度要求不是那么苛刻的情况下可以使用q8_0或Q6_K,非常接近F16模型的效果
如果使用的是Mac Intel可能报如下错:
ggml_metal_init: load pipeline error: Error Domain=CompilerError Code=2 "SC compilation failure
There is a call to an undefined label" UserInfo={NSLocalizedDescription=SC compilation failure
There is a call to an undefined label}
llama_new_context_with_model: ggml_metal_init() failed
llama_init_from_gpt_params: error: failed to create context with model '../merged_chinese_llama_7b/ggml-model-q4_0.gguf'
main: error: unable to load model
可以按这里的修改
$ make clean
$ brew update && brew install clblast
#disable metal and enable clblast
$ make LLAMA_CLBLAST=1 LLAMA_NO_METAL=1
#这时可以用main进行推理
$./main -s 1 -m ../merged_chinese_llama_7b/ggml-model-q4_0.gguf -p "中国的首都是" --ignore-eos -c 64 -n 128 -t 3 -ngl 10
对应的终端输出为:
(venv) ➜ llama.cpp git:(master) ✗ ./main -s 1 -m ../merged_chinese_llama_7b/ggml-model-q4_0.gguf -p "中国的首都是" --ignore-eos -c 64 -n 128 -t 3 -ngl 10
Log start
main: warning: changing RoPE frequency base to 0 (default 10000.0)
main: warning: scaling RoPE frequency by 0 (default 1.0)
main: build = 1273 (99115f3)
main: built with Apple clang version 14.0.3 (clang-1403.0.22.14.1) for x86_64-apple-darwin22.5.0
main: seed = 1
ggml_opencl: selecting platform: 'Apple'
ggml_opencl: selecting device: 'Intel(R) UHD Graphics 630'
ggml_opencl: device FP16 support: false
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from ../merged_chinese_llama_7b/ggml-model-q4_0.gguf (version GGUF V2 (latest))
llama_model_loader: - tensor 0: token_embd.weight q4_0 [ 4096, 55296, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 2: blk.0.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 3: blk.0.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 4: blk.0.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 5: blk.0.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 6: blk.0.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 7: blk.0.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 8: blk.0.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 9: blk.0.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 10: blk.1.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 11: blk.1.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 12: blk.1.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 13: blk.1.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 14: blk.1.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 15: blk.1.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 16: blk.1.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 17: blk.1.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 18: blk.1.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 19: blk.2.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 20: blk.2.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 21: blk.2.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 22: blk.2.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 23: blk.2.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 24: blk.2.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 25: blk.2.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 26: blk.2.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 27: blk.2.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 28: blk.3.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 29: blk.3.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 30: blk.3.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 31: blk.3.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 32: blk.3.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 33: blk.3.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 34: blk.3.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 35: blk.3.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 36: blk.3.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 37: blk.4.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 38: blk.4.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 39: blk.4.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 40: blk.4.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 41: blk.4.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 42: blk.4.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 43: blk.4.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 44: blk.4.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 45: blk.4.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 46: blk.5.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 47: blk.5.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 48: blk.5.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 49: blk.5.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 50: blk.5.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 51: blk.5.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 52: blk.5.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 53: blk.5.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 54: blk.5.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 55: blk.6.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 56: blk.6.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 57: blk.6.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 58: blk.6.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 59: blk.6.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 60: blk.6.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 61: blk.6.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 62: blk.6.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 63: blk.6.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 64: blk.7.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 65: blk.7.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 66: blk.7.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 67: blk.7.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 68: blk.7.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 69: blk.7.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 70: blk.7.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 71: blk.7.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 72: blk.7.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 73: blk.8.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 74: blk.8.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 75: blk.8.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 76: blk.8.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 77: blk.8.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 78: blk.8.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 79: blk.8.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 80: blk.8.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 81: blk.8.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 82: blk.9.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 83: blk.9.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 84: blk.9.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 85: blk.9.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 86: blk.9.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 87: blk.9.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 88: blk.9.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 89: blk.9.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 90: blk.9.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 91: blk.10.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 92: blk.10.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 93: blk.10.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 94: blk.10.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 95: blk.10.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 96: blk.10.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 97: blk.10.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 98: blk.10.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 99: blk.10.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 100: blk.11.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 101: blk.11.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 102: blk.11.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 103: blk.11.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 104: blk.11.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 105: blk.11.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 106: blk.11.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 107: blk.11.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 108: blk.11.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 109: blk.12.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 110: blk.12.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 111: blk.12.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 112: blk.12.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 113: blk.12.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 114: blk.12.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 115: blk.12.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 116: blk.12.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 117: blk.12.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 118: blk.13.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 119: blk.13.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 120: blk.13.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 121: blk.13.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 122: blk.13.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 123: blk.13.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 124: blk.13.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 125: blk.13.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 126: blk.13.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 127: blk.14.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 128: blk.14.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 129: blk.14.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 130: blk.14.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 131: blk.14.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 132: blk.14.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 133: blk.14.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 134: blk.14.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 135: blk.14.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 136: blk.15.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 137: blk.15.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 138: blk.15.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 139: blk.15.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 140: blk.15.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 141: blk.15.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 142: blk.15.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 143: blk.15.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 144: blk.15.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 145: blk.16.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 146: blk.16.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 147: blk.16.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 148: blk.16.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 149: blk.16.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 150: blk.16.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 151: blk.16.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 152: blk.16.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 153: blk.16.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 154: blk.17.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 155: blk.17.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 156: blk.17.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 157: blk.17.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 158: blk.17.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 159: blk.17.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 160: blk.17.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 161: blk.17.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 162: blk.17.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 163: blk.18.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 164: blk.18.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 165: blk.18.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 166: blk.18.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 167: blk.18.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 168: blk.18.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 169: blk.18.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 170: blk.18.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 171: blk.18.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 172: blk.19.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 173: blk.19.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 174: blk.19.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 175: blk.19.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 176: blk.19.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 177: blk.19.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 178: blk.19.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 179: blk.19.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 180: blk.19.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 181: blk.20.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 182: blk.20.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 183: blk.20.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 184: blk.20.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 185: blk.20.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 186: blk.20.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 187: blk.20.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 188: blk.20.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 189: blk.20.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 190: blk.21.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 191: blk.21.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 192: blk.21.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 193: blk.21.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 194: blk.21.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 195: blk.21.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 196: blk.21.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 197: blk.21.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 198: blk.21.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 199: blk.22.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 200: blk.22.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 201: blk.22.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 202: blk.22.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 203: blk.22.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 204: blk.22.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 205: blk.22.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 206: blk.22.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 207: blk.22.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 208: blk.23.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 209: blk.23.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 210: blk.23.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 211: blk.23.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 212: blk.23.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 213: blk.23.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 214: blk.23.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 215: blk.23.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 216: blk.23.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 217: blk.24.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 218: blk.24.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 219: blk.24.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 220: blk.24.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 221: blk.24.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 222: blk.24.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 223: blk.24.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 224: blk.24.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 225: blk.24.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 226: blk.25.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 227: blk.25.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 228: blk.25.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 229: blk.25.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 230: blk.25.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 231: blk.25.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 232: blk.25.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 233: blk.25.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 234: blk.25.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 235: blk.26.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 236: blk.26.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 237: blk.26.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 238: blk.26.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 239: blk.26.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 240: blk.26.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 241: blk.26.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 242: blk.26.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 243: blk.26.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 244: blk.27.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 245: blk.27.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 246: blk.27.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 247: blk.27.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 248: blk.27.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 249: blk.27.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 250: blk.27.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 251: blk.27.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 252: blk.27.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 253: blk.28.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 254: blk.28.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 255: blk.28.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 256: blk.28.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 257: blk.28.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 258: blk.28.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 259: blk.28.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 260: blk.28.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 261: blk.28.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 262: blk.29.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 263: blk.29.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 264: blk.29.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 265: blk.29.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 266: blk.29.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 267: blk.29.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 268: blk.29.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 269: blk.29.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 270: blk.29.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 271: blk.30.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 272: blk.30.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 273: blk.30.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 274: blk.30.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 275: blk.30.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 276: blk.30.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 277: blk.30.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 278: blk.30.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 279: blk.30.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 280: blk.31.attn_q.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 281: blk.31.attn_k.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 282: blk.31.attn_v.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 283: blk.31.attn_output.weight q4_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 284: blk.31.ffn_gate.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 285: blk.31.ffn_up.weight q4_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 286: blk.31.ffn_down.weight q4_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 287: blk.31.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 288: blk.31.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 289: output_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 290: output.weight q6_K [ 4096, 55296, 1, 1 ]
llama_model_loader: - kv 0: general.architecture str
llama_model_loader: - kv 1: general.name str
llama_model_loader: - kv 2: llama.context_length u32
llama_model_loader: - kv 3: llama.embedding_length u32
llama_model_loader: - kv 4: llama.block_count u32
llama_model_loader: - kv 5: llama.feed_forward_length u32
llama_model_loader: - kv 6: llama.rope.dimension_count u32
llama_model_loader: - kv 7: llama.attention.head_count u32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32
llama_model_loader: - kv 10: llama.rope.freq_base f32
llama_model_loader: - kv 11: general.file_type u32
llama_model_loader: - kv 12: tokenizer.ggml.model str
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr
llama_model_loader: - kv 14: tokenizer.ggml.scores arr
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr
llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32
llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32
llama_model_loader: - kv 18: general.quantization_version u32
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q4_0: 225 tensors
llama_model_loader: - type q6_K: 1 tensors
llm_load_print_meta: format = GGUF V2 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 55296
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 2048
llm_load_print_meta: n_ctx = 64
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: freq_base = 10000.0
llm_load_print_meta: freq_scale = 1
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = mostly Q4_0
llm_load_print_meta: model params = 6.93 B
llm_load_print_meta: model size = 3.69 GiB (4.57 BPW)
llm_load_print_meta: general.name = ..
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.09 MB
llm_load_tensors: using OpenCL for GPU acceleration
llm_load_tensors: mem required = 2687.86 MB (+ 32.00 MB per state)
llm_load_tensors: offloading 10 repeating layers to GPU
llm_load_tensors: offloaded 10/33 layers to GPU
llm_load_tensors: VRAM used: 1086 MB
..............................................................................................
llama_new_context_with_model: kv self size = 32.00 MB
llama_new_context_with_model: compute buffer total size = 15.97 MBsystem_info: n_threads = 3 / 12 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 64, n_batch = 512, n_predict = 128, n_keep = 0中国的首都是世界上政治、军事和文化中心。长安古称"京师",后为北京;北宋时期,东京开封府一度升格为"中都"或"大都"。《长安志》记载:"自建都以来,因得名曰'长安'者有…
一些说明
这里将两个基座模型和LORA fine tune模型merge的原因在于扩充词汇表之后,Embedding也进行了扩充,词汇表比原始的LlaMA-2 32k大,因而要将Embedding层merge(实际是替换),此外Attention(q,k,v)以及MLP(feedforward,w1,w2,w3)基本都进行了merge操作。由于改动如此之大,以至于《大语言模型之七- Llama-2单GPU微调SFT》博客里微调方法是一样的,但是改动量和训练的资源需求是不一样的,这也导致了扩充中文的微调训练在colab免费的12G GPU内存上是无法完成训练的。
PEFT是 Hugging Face提供的模型训练的高效库,LORA是其提供的方法之一,LORA方式是2021年论文 LoRA: Low-rank adaptation of Large Language Models.首先引入的方法。
其核心思想是可以在仅调整一小部分权重的同时实现出色的性能,进而无需在多台机器上调整数十亿个参数,使整个微调过程更加实用且经济可行。使用PEFT和量化允许在单个GPU上微调具有数十亿个参数的大型模型。比如Embedding是词向量的编码,虽然任务不同,如问答、摘要、协作类的大模型,虽然应用不同,但是词向量编码是可以复用的,不需要改,因而在微调的时候,就不改词向量了,这样就节省存储和运算资源。
相关文章:
大语言模型之十三 LLama2中文推理
在《大语言模型之十二 SentencePiece扩充LLama2中文词汇》一文中已经扩充好了中文词汇表,接下来就是使用整理的中文语料对模型进行预训练了。这里先跳过预训练环节。先试用已经训练好的模型,看看如何推理。 合并模型 这一步骤会合并LoRA权重࿰…...

iOS AVAudioSession 详解
iOS AVAudioSession 详解 - 简书 默认没有options,category 7种即可满足条件 - (BOOL)setCategory:(AVAudioSessionCategory)category error:(NSError **)outError API_AVAILABLE(ios(3.0), watchos(2.0), tvos(9.0)) API_UNAVAILABLE(macos); 有optionsÿ…...
26-网络通信
网络通信 什么是网络编程? 可以让设备中的程序与网络上其他设备中的程序进行数据交互(实现网络通信的)。 java.net.包下提供了网络编程的解决方案! 基本的通信架构有2种形式:CS架构( Client客户端/Server服…...

嵌入式Linux应用开发-基础知识-第十九章驱动程序基石③
嵌入式Linux应用开发-基础知识-第十九章驱动程序基石③ 第十九章 驱动程序基石③19.5 定时器19.5.1 内核函数19.5.2 定时器时间单位19.5.3 使用定时器处理按键抖动19.5.4 现场编程、上机19.5.5 深入研究:定时器的内部机制19.5.6 深入研究:找到系统滴答 1…...
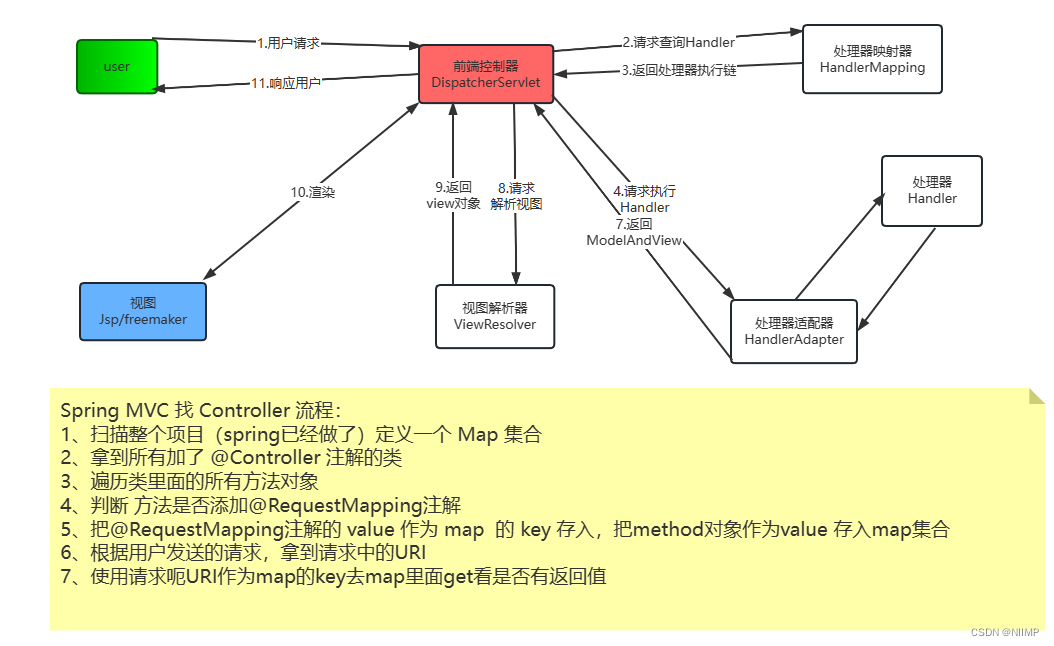
一文拿捏SpringMVC的调用流程
SpringMVC的调用流程 1.核心元素: DispatcherServlet(前端控制器)HandlerMapping(处理器映射器)HandlerAdapter(处理器适配器) ---> Handler(处理器)ViewResolver(视图解析器 )---> view(视图) 2.调用流程 用户发送请求到前端控制器前端控制器接收用户请求…...

一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
Lambda Lambda介绍 Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。 Lambda表达式的结构 一个 Lamb…...

WebSocket实战之二协议分析
一、前言 上一篇 WebSocket实战之一 讲了WebSocket一个极简例子和基础的API的介绍,这一篇来分析一下WebSocket的协议,学习网络协议最好的方式就是抓包分析一下什么就都明白了。 二、WebSocket协议 本想盗一张网络图,后来想想不太好&#x…...
)
LeetCode //C - 208. Implement Trie (Prefix Tree)
208. Implement Trie (Prefix Tree) A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and s…...
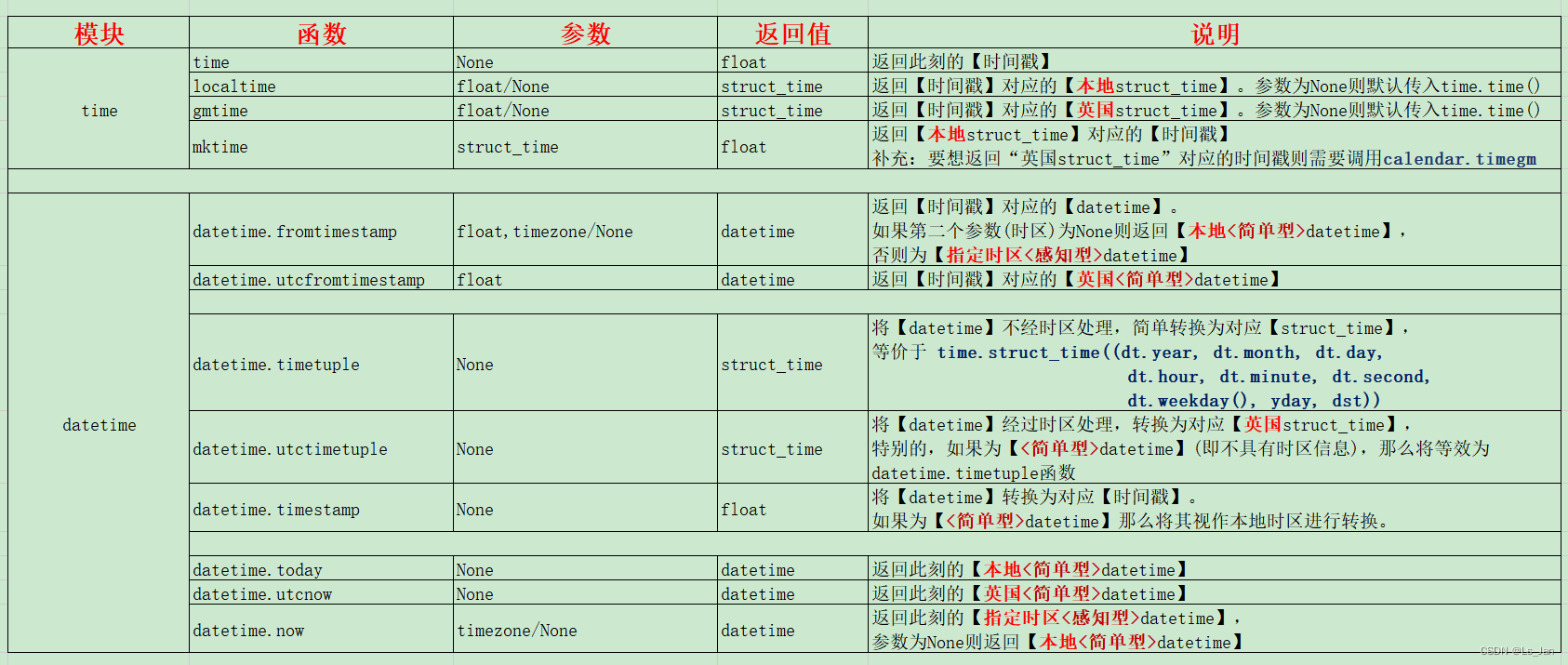
【Python】time模块和datetime模块的部分函数说明
时间戳与日期 在说到这俩模块之前,首先先明确几个概念: 时间戳是个很单纯的东西,没有“时区”一说,因为时间戳本质上是经过的时间。日常生活中接触到的“日期”、“某点某时某分”准确的说是时间点,都是有时区概念的…...

Python 无废话-基础知识元组Tuple详讲
“元组 Tuple”是一个有序、不可变的序列集合,元组的元素可以包含任意类型的数据,如整数、浮点数、字符串等,用()表示,如下示例: 元组特征 1) 元组中的各个元素,可以具有不相同的数据类型,如 T…...

【Win】Microsoft Spy++学习笔记
参考资料 《用VisualStudio\Spy查窗口句柄,监控窗口消息》 1. 安装 Spy是VS中的工具,所以直接安装VS就可以了; 2. 检查应用程序架构 ChatGPT-Bing: 对于窗口应用程序分析,确定应用程序是32位还是64位是很重要的,因…...
如何解决版本不兼容Jar包冲突问题
如何解决版本不兼容Jar包冲突问题 引言 “老婆”和“妈妈”同时掉进水里,先救谁? 常言道:编码五分钟,解冲突两小时。作为Java开发来说,第一眼见到ClassNotFoundException、 NoSuchMethodException这些异常来说&…...
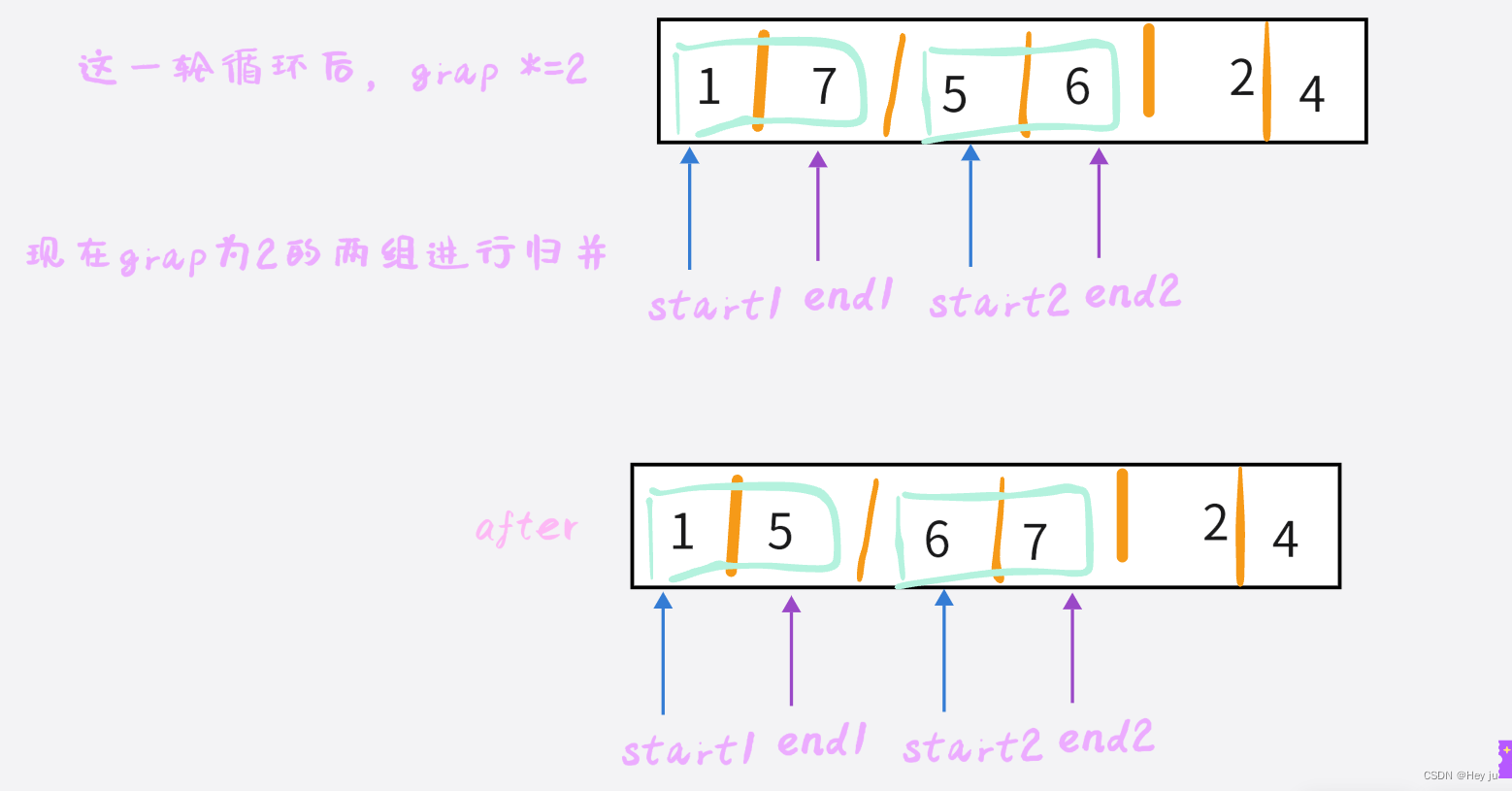
数据结构—归并排序-C语言实现
引言:归并排序跟快速排序一样,都运用到了分治的算法,但是归并排序是一种稳定的算法,同时也具备高效,其时间复杂度为O(N*logN) 算法图解: 然后开始归并: 就是这个思想,拆成最小子问题…...
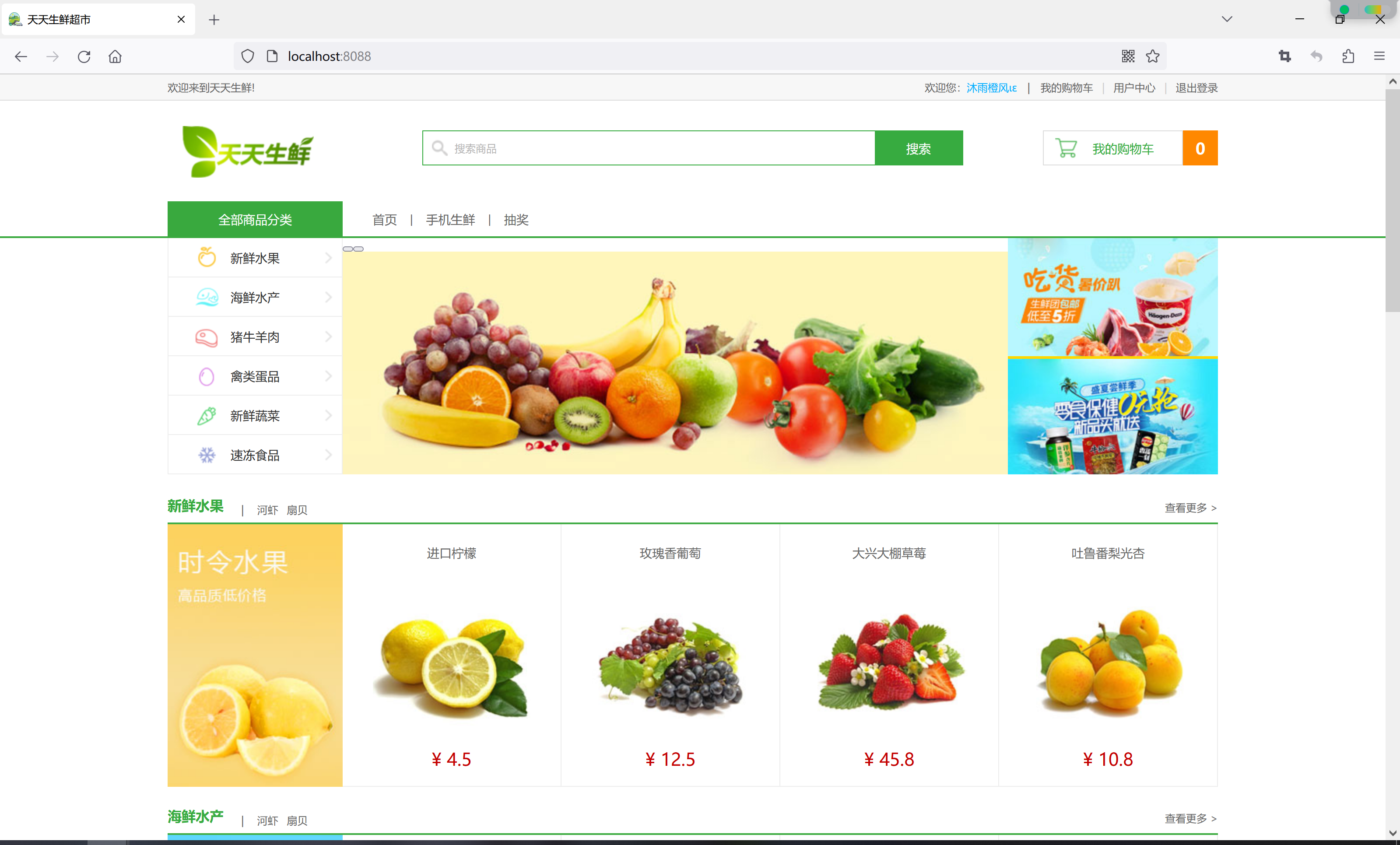
Multiple CORS header ‘Access-Control-Allow-Origin‘ not allowed
今天在修改天天生鲜超市项目的时候,因为使用了前后端分离模式,前端通过网关统一转发请求到后端服务,但是第一次使用就遇到了问题,比如跨域问题: 但是,其实网关里是有配置跨域的,只是忘了把前端项…...
msvcp100.dll丢失怎样修复,msvcp100.dll丢失问题全面解析
msvcp100.dll是一个动态链接库文件,属于 Microsoft Visual C Redistributable 的一个组件。它包含了 C 运行时库,这些库在运行程序时会被加载到内存中。msvcp100.dll文件的主要作用是为基于 Visual C 编写的程序提供必要的运行时支持。 当您运行一个基于…...
最新AI智能问答系统源码/AI绘画系统源码/支持GPT联网提问/Prompt应用+支持国内AI提问模型
一、AI创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的AI智能问答系统和AI绘画系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图…...
全连接网络实现回归【房价预测的数据】
也是分为data,model,train,test import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optimclass FCNet(nn.Module):def __init__(self):super(FCNet,self).__init__()self.fc1 nn.Linear(331,200)s…...
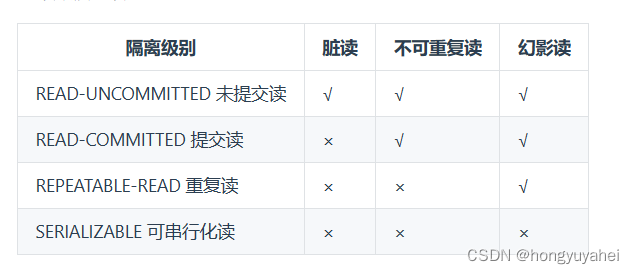
mysql八股
1、请你说说mysql索引,以及它们的好处和坏处 检索效率、存储资源、索引 索引就像指向表行的指针,是一个允许查询操作快速确定哪些行符合WHERE子句中的条件,并检索到这些行的其他列值的数据结构索引主要有普通索引、唯一索引、主键索引、外键…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【优化算法】狐猴优化器(LO)(附MATLAB代码实现)
代码实现 MATLAB LO.m %======================================================================= % Lemurs Optimizer: A New Metaheuristic Algorithm % for Global Optimization (LO)% This work is published in Journal of "Applied …...

C#WPF动态资源和静态资源应用实例
本文实例演示C#WPF动态资源和静态资源应用 一、资源概述 静态资源(StaticResource)指的是在程序载入内存时对资源的一次性使用,之后就不再访问这个资源了。 动态资源(DynamicResource)指的是在程序运行过程中然会去访问资源。 WPF中,每个界面元素都含有一个名为Resources…...

面试被问烂的20道编程基础题,你必须全会,不然别去面试
文章目录前言一、Python基础篇(6道)1. Python中list和tuple有什么区别?2. Python 3.7之后普通dict已经有序了,那OrderedDict还有存在的必要吗?3. Python中的深拷贝和浅拷贝有什么区别?4. Python中的*args和…...

太流批了,发票合并神器
今天给大家推荐两款软件,一款是图片转PDF,一款是发票合并工具。有需要的小伙伴可以下载收藏。 第一款:png2pdf png2pdf是一款png图片转PDF的小工具,这类的工具之前也有推荐过,但是今天这款比较特殊。 只要把图片拖入软…...

从“抄答案”到“会解题”:我是如何利用头歌实训平台,真正掌握Python数据分析的?
从“抄答案”到“会解题”:我的Python数据分析思维进阶之路 记得第一次打开头歌实训平台的Python数据分析题目时,我像大多数初学者一样,迫不及待地寻找"正确答案"。复制、粘贴、运行——看到绿色通过提示的瞬间,以为自己…...
)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录(附Sigrity仿真文件)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录 去年负责一款数据中心加速卡的设计时,我遇到了职业生涯中最棘手的高速信号完整性问题。这块板卡需要同时支持PCIe 5.0 x16和四个USB3.2 Gen2x2接口,当第一批工程样机回来进行信号测试时…...

手把手复现1G通话:用Python模拟FM调制、FSK信令与FDMA多用户通信
手把手复现1G通话:用Python模拟FM调制、FSK信令与FDMA多用户通信 在移动通信的演进史中,1G系统如同数字时代的罗塞塔石碑,用模拟信号承载了人类首次无线对话的自由。今天我们将穿越回1983年摩托罗拉DynaTAC 8000X面世的年代,用Py…...

高级技巧:利用SharpShooter实现COM Staging和应用程序白名单绕过
高级技巧:利用SharpShooter实现COM Staging和应用程序白名单绕过 【免费下载链接】SharpShooter Payload Generation Framework 项目地址: https://gitcode.com/gh_mirrors/sh/SharpShooter SharpShooter 是一款功能强大的Payload生成框架,专为安…...

HEIF Utility:Windows平台HEIF格式兼容性完整解决方案实战
HEIF Utility:Windows平台HEIF格式兼容性完整解决方案实战 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 对于使用iPhone或iPad的Windows用户而言&a…...

League Akari:3步打造你的英雄联盟智能游戏助手,告别繁琐操作
League Akari:3步打造你的英雄联盟智能游戏助手,告别繁琐操作 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League A…...

解码Voron 2.4:开源高速CoreXY 3D打印机的架构哲学与工程实践
解码Voron 2.4:开源高速CoreXY 3D打印机的架构哲学与工程实践 【免费下载链接】Voron-2 Voron 2 CoreXY 3D Printer design 项目地址: https://gitcode.com/gh_mirrors/vo/Voron-2 Voron 2.4作为开源3D打印机领域的标杆产品,代表了CoreXY架构在高…...

AI账号自动化管理工具集:从注册到运维的全流程实战指南
1. 项目概述:一个AI账号自动化管理的“军火库”如果你正在批量使用ChatGPT、Claude、Gemini这些AI服务,或者在做一些相关的开发和研究,那你肯定遇到过这些让人头疼的问题:注册账号需要接码、管理几十上百个API密钥手忙脚乱、临时邮…...