一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
Lambda
Lambda介绍
Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。
Lambda表达式的结构
-
一个 Lambda 表达式可以有零个或多个参数
-
参数的类型既可以明确声明,也可以根据上下文来推断。例如:(int a)与(a)效果相同
-
所有参数需包含在圆括号内,参数之间用逗号相隔。例如:(a, b) 或 (int a, int b) 或 (String a, int b, float c)
-
空圆括号代表参数集为空。例如:() -> 42
-
当只有一个参数,且其类型可推导时,圆括号()可省略。例如:a -> return a*a
-
Lambda 表达式的主体可包含零条或多条语句
-
如果 Lambda 表达式的主体只有一条语句,花括号{}可省略。匿名函数的返回类型与该主体表达式一致
-
如果 Lambda 表达式的主体包含一条以上语句,则表达式必须包含在花括号{}中(形成代码块)。匿名函数的返回类型与代码块的返回类型一致,若没有返回则为空
Lambda 表达式的使用
下面我们先使用一个简单的例子来看看Lambda的效果吧。
比如我们对Map 的遍历 传统方式遍历如下:
Map<String, String> map = new HashMap<>();map.put("a", "a");map.put("b", "b");map.put("c", "c");map.put("d", "d");System.out.println("map普通方式遍历:");for (String key : map.keySet()) {System.out.println("k=" + key + ",v=" + map.get(key));}
使用Lambda进行遍历:
System.out.println("map拉姆达表达式遍历:");map.forEach((k, v) -> {System.out.println("k=" + k + ",v=" + v);});
List也同理,不过List还可以通过双冒号运算符遍历:
List<String> list = new ArrayList<String>();list.add("a");list.add("bb");list.add("ccc");list.add("dddd");System.out.println("list拉姆达表达式遍历:");list.forEach(v -> {System.out.println(v);});System.out.println("list双冒号运算符遍历:");list.forEach(System.out::println);
输出结果:
map普通方式遍历:k=a,v=ak=b,v=bk=c,v=ck=d,v=dmap拉姆达表达式遍历:k=a,v=ak=b,v=bk=c,v=ck=d,v=dlist拉姆达表达式遍历:abbcccddddlist双冒号运算符遍历:abbcccdddd
Lambda 除了在for循环遍历中使用外,它还可以代替匿名的内部类。比如下面这个例子的线程创建:
//使用普通的方式创建Runnable r1 = new Runnable() {@Overridepublic void run() {System.out.println("普通方式创建!");}};//使用拉姆达方式创建Runnable r2 = ()-> System.out.println("拉姆达方式创建!");
注: 这个例子中使用Lambda表达式的时候,编译器会自动推断:根据线程类的构造函数签名 Runnable r { },将该 Lambda 表达式赋 Runnable 接口。
Lambda 表达式与匿名类的区别使用匿名类与 Lambda 表达式的一大区别在于关键词的使用。对于匿名类,关键词 this 解读为匿名类,而对于 Lambda 表达式,关键词 this 解读为写就 Lambda 的外部类。
Lambda表达式使用注意事项
Lambda虽然简化了代码的编写,但同时也减少了可读性。
Stream
Stream介绍
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
Stream特性:
-
不是数据结构:它没有内部存储,它只是用操作管道从 source(数据结构、数组、generator function、IO channel)抓取数据。它也绝不修改自己所封装的底层数据结构的数据。例如 Stream 的 filter 操作会产生一个不包含被过滤元素的新 Stream,而不是从 source 删除那些元素。
-
不支持索引访问:但是很容易生成数组或者 List 。
-
惰性化:很多 Stream 操作是向后延迟的,一直到它弄清楚了最后需要多少数据才会开始。Intermediate 操作永远是惰性化的。
-
并行能力。当一个 Stream 是并行化的,就不需要再写多线程代码,所有对它的操作会自动并行进行的。
-
可以是无限的:集合有固定大小,Stream 则不必。limit(n) 和 findFirst() 这类的 short-circuiting 操作可以对无限的 Stream 进行运算并很快完成。
-
注意事项:所有 Stream 的操作必须以 lambda 表达式为参数。
Stream 流操作类型:
-
Intermediate:一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
-
Terminal:一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
Stream使用
这里我们依旧使用一个简单示例来看看吧。在开发中,我们有时需要对一些数据进行过滤,如果是传统的方式,我们需要对这批数据进行遍历过滤,会显得比较繁琐,如果使用steam流方式的话,那么可以很方便的进行处理。
首先通过普通的方式进行过滤:
List<String> list = Arrays.asList("张三", "李四", "王五", "xuwujing");System.out.println("过滤之前:" + list);List<String> result = new ArrayList<>();for (String str : list) {if (!"李四".equals(str)) {result.add(str);}}System.out.println("过滤之后:" + result);
使用Steam方式进行过滤:
List<String> result2 = list.stream().filter(str -> !"李四".equals(str)).collect(Collectors.toList());
System.out.println("stream 过滤之后:" + result2);
输出结果:
过滤之前:[张三, 李四, 王五, xuwujing]
过滤之后:[张三, 王五, xuwujing]
stream 过滤之后:[张三, 王五, xuwujing]
是不是很简洁和方便呢。其实Stream流还有更多的使用方法,filter只是其中的一角而已。那么在这里我们就来学习了解下这些用法吧。
1.构造Stream流的方式
Stream stream = Stream.of("a", "b", "c");String[] strArray = new String[] { "a", "b", "c" };stream = Stream.of(strArray);stream = Arrays.stream(strArray);List<String> list = Arrays.asList(strArray);stream = list.stream();
2.Stream流的之间的转换
注意:一个Stream流只可以使用一次,这段代码为了简洁而重复使用了数次,因此会抛出 stream has already been operated upon or closed 异常。
try {Stream<String> stream2 = Stream.of("a", "b", "c");// 转换成 ArrayString[] strArray1 = stream2.toArray(String[]::new);// 转换成 CollectionList<String> list1 = stream2.collect(Collectors.toList());List<String> list2 = stream2.collect(Collectors.toCollection(ArrayList::new)); Set set1 = stream2.collect(Collectors.toSet());Stack stack1 = stream2.collect(Collectors.toCollection(Stack::new));// 转换成 StringString str = stream.collect(Collectors.joining()).toString();} catch (Exception e) {e.printStackTrace();}
3.Stream流的map使用
map方法用于映射每个元素到对应的结果,一对一。
示例一:转换大写
List<String> list3 = Arrays.asList("zhangSan", "liSi", "wangWu");System.out.println("转换之前的数据:" + list3);List<String> list4 = list3.stream().map(String::toUpperCase).collect(Collectors.toList());System.out.println("转换之后的数据:" + list4); // 转换之后的数据:[ZHANGSAN, LISI,WANGWU]
示例二:转换数据类型
List<String> list31 = Arrays.asList("1", "2", "3");System.out.println("转换之前的数据:" + list31);List<Integer> list41 = list31.stream().map(Integer::valueOf).collect(Collectors.toList());System.out.println("转换之后的数据:" + list41); // [1, 2, 3]
示例三:获取平方
List<Integer> list5 = Arrays.asList(new Integer[] { 1, 2, 3, 4, 5 });List<Integer> list6 = list5.stream().map(n -> n * n).collect(Collectors.toList());System.out.println("平方的数据:" + list6);// [1, 4, 9, 16, 25]
4.Stream流的filter使用
filter方法用于通过设置的条件过滤出元素。
示例二:通过与 findAny 得到 if/else 的值
List<String> list = Arrays.asList("张三", "李四", "王五", "xuwujing");
String result3 = list.stream().filter(str -> "李四".equals(str)).findAny().orElse("找不到!");
String result4 = list.stream().filter(str -> "李二".equals(str)).findAny().orElse("找不到!");System.out.println("stream 过滤之后 2:" + result3);
System.out.println("stream 过滤之后 3:" + result4);
//stream 过滤之后 2:李四
//stream 过滤之后 3:找不到!
示例三:通过与 mapToInt 计算和
List<User> lists = new ArrayList<User>();lists.add(new User(6, "张三"));lists.add(new User(2, "李四"));lists.add(new User(3, "王五"));lists.add(new User(1, "张三"));// 计算这个list中出现 "张三" id的值int sum = lists.stream().filter(u -> "张三".equals(u.getName())).mapToInt(u -> u.getId()).sum();System.out.println("计算结果:" + sum); // 7
5.Stream 流的 flatMap 使用
flatMap 方法用于映射每个元素到对应的结果,一对多。
示例:从句子中得到单词
String worlds = "The way of the future";List<String> list7 = new ArrayList<>();list7.add(worlds);List<String> list8 = list7.stream().flatMap(str -> Stream.of(str.split(" "))).filter(world -> world.length() > 0).collect(Collectors.toList());System.out.println("单词:");list8.forEach(System.out::println);// 单词:// The // way // of // the // future
6.Stream流的limit使用
limit 方法用于获取指定数量的流。
示例一:获取前n条数的数据
Random rd = new Random();System.out.println("取到的前三条数据:");rd.ints().limit(3).forEach(System.out::println);// 取到的前三条数据:// 1167267754// -1164558977// 1977868798
示例二:结合skip使用得到需要的数据
skip表示的是扔掉前n个元素。
List<User> list9 = new ArrayList<User>();for (int i = 1; i < 4; i++) {User user = new User(i, "pancm" + i);list9.add(user);}System.out.println("截取之前的数据:");// 取前3条数据,但是扔掉了前面的2条,可以理解为拿到的数据为 2<=i<3 (i 是数值下标)List<String> list10 = list9.stream().map(User::getName).limit(3).skip(2).collect(Collectors.toList());System.out.println("截取之后的数据:" + list10);// 截取之前的数据:// 姓名:pancm1// 姓名:pancm2// 姓名:pancm3// 截取之后的数据:[pancm3]
注:User实体类中 getName 方法会打印姓名。
7.Stream流的sort使用
sorted方法用于对流进行升序排序。
示例一:随机取值排序
Random rd2 = new Random();System.out.println("取到的前三条数据然后进行排序:");rd2.ints().limit(3).sorted().forEach(System.out::println);// 取到的前三条数据然后进行排序:// -2043456377// -1778595703// 1013369565
示例二:优化排序
tips: 先获取在排序效率会更高!
//普通的排序取值List<User> list11 = list9.stream().sorted((u1, u2) -> u1.getName().compareTo(u2.getName())).limit(3).collect(Collectors.toList());System.out.println("排序之后的数据:" + list11);//优化排序取值List<User> list12 = list9.stream().limit(3).sorted((u1, u2) -> u1.getName().compareTo(u2.getName())).collect(Collectors.toList());System.out.println("优化排序之后的数据:" + list12);//排序之后的数据:[{"id":1,"name":"pancm1"}, {"id":2,"name":"pancm2"}, {"id":3,"name":"pancm3"}]//优化排序之后的数据:[{"id":1,"name":"pancm1"}, {"id":2,"name":"pancm2"}, {"id":3,"name":"pancm3"}]
8.Stream流的peek使用
peek对每个元素执行操作并返回一个新的Stream
示例: 双重操作
System.out.println("peek使用:");Stream.of("one", "two", "three", "four").filter(e -> e.length() > 3).peek(e -> System.out.println("转换之前: " + e)).map(String::toUpperCase).peek(e -> System.out.println("转换之后: " + e)).collect(Collectors.toList());// 转换之前: three// 转换之后: THREE// 转换之前: four// 转换之后: FOUR
9.Stream流的parallel使用
parallelStream 是流并行处理程序的代替方法。
示例:获取空字符串的数量
List<String> strings = Arrays.asList("a", "", "c", "", "e","", " ");// 获取空字符串的数量long count = strings.parallelStream().filter(string -> string.isEmpty()).count();System.out.println("空字符串的个数:"+count);
10.Stream流的max/min/distinct使用
示例一:得到最大最小值
List<String> list13 = Arrays.asList("zhangsan","lisi","wangwu","xuwujing");int maxLines = list13.stream().mapToInt(String::length).max().getAsInt();int minLines = list13.stream().mapToInt(String::length).min().getAsInt();System.out.println("最长字符的长度:" + maxLines+",最短字符的长度:"+minLines);//最长字符的长度:8,最短字符的长度:4
示例二:得到去重之后的数据
String lines = "good good study day day up";List<String> list14 = new ArrayList<String>();list14.add(lines);List<String> words = list14.stream().flatMap(line -> Stream.of(line.split(" "))).filter(word -> word.length() > 0).map(String::toLowerCase).distinct().sorted().collect(Collectors.toList());System.out.println("去重复之后:" + words);//去重复之后:[day, good, study, up]
11.Stream流的Match使用
-
allMatch:Stream 中全部元素符合则返回 true ;
-
anyMatch:Stream 中只要有一个元素符合则返回 true;
-
noneMatch:Stream 中没有一个元素符合则返回 true。
示例:数据是否符合
boolean all = lists.stream().allMatch(u -> u.getId() > 3);System.out.println("是否都大于3:" + all);boolean any = lists.stream().anyMatch(u -> u.getId() > 3);System.out.println("是否有一个大于3:" + any);boolean none = lists.stream().noneMatch(u -> u.getId() > 3);System.out.println("是否没有一个大于3的:" + none); // 是否都大于3:false// 是否有一个大于3:true// 是否没有一个大于3的:false
12.Stream流的reduce使用
reduce 主要作用是把 Stream 元素组合起来进行操作。
示例一:字符串连接
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
System.out.println("字符串拼接:" + concat);
示例二:得到最小值
double minValue = Stream.of(-4.0, 1.0, 3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);System.out.println("最小值:" + minValue);//最小值:-4.0
示例三:求和
// 求和, 无起始值int sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();System.out.println("有无起始值求和:" + sumValue);// 求和, 有起始值sumValue = Stream.of(1, 2, 3, 4).reduce(1, Integer::sum);System.out.println("有起始值求和:" + sumValue);// 有无起始值求和:10// 有起始值求和:11
示例四:过滤拼接
concat = Stream.of("a", "B", "c", "D", "e", "F").filter(x -> x.compareTo("Z") > 0).reduce("", String::concat);
System.out.println("过滤和字符串连接:" + concat);//过滤和字符串连接:ace
13.Stream流的iterate使用
iterate 跟 reduce 操作很像,接受一个种子值,和一个UnaryOperator(例如 f)。然后种子值成为 Stream 的第一个元素,f(seed) 为第二个,f(f(seed)) 第三个,以此类推。在 iterate 时候管道必须有 limit 这样的操作来限制 Stream 大小。
示例:生成一个等差队列
System.out.println("从2开始生成一个等差队列:");Stream.iterate(2, n -> n + 2).limit(5).forEach(x -> System.out.print(x + " "));// 从2开始生成一个等差队列:// 2 4 6 8 10
14.Stream流的 Supplier 使用
通过实现Supplier类的方法可以自定义流计算规则。
示例:随机获取两条用户信息
System.out.println("自定义一个流进行计算输出:");Stream.generate(new UserSupplier()).limit(2).forEach(u -> System.out.println(u.getId() + ", " + u.getName()));//第一次://自定义一个流进行计算输出://10, pancm7//11, pancm6//第二次://自定义一个流进行计算输出://10, pancm4//11, pancm2//第三次://自定义一个流进行计算输出://10, pancm4//11, pancm8class UserSupplier implements Supplier<User> {private int index = 10;private Random random = new Random();@Overridepublic User get() {return new User(index++, "pancm" + random.nextInt(10));}
}
15.Stream流的groupingBy/partitioningBy使用
-
groupingBy:分组排序;
-
partitioningBy:分区排序。
示例一:分组排序
System.out.println("通过id进行分组排序:");Map<Integer, List<User>> personGroups = Stream.generate(new UserSupplier2()).limit(5).collect(Collectors.groupingBy(User::getId));Iterator it = personGroups.entrySet().iterator();while (it.hasNext()) {Map.Entry<Integer, List<User>> persons = (Map.Entry) it.next();System.out.println("id " + persons.getKey() + " = " + persons.getValue());}// 通过id进行分组排序:// id 10 = [{"id":10,"name":"pancm1"}] // id 11 = [{"id":11,"name":"pancm3"}, {"id":11,"name":"pancm6"}, {"id":11,"name":"pancm4"}, {"id":11,"name":"pancm7"}]class UserSupplier2 implements Supplier<User> {private int index = 10;private Random random = new Random();@Overridepublic User get() {return new User(index % 2 == 0 ? index++ : index, "pancm" + random.nextInt(10));}}
示例二:分区排序
System.out.println("通过年龄进行分区排序:");Map<Boolean, List<User>> children = Stream.generate(new UserSupplier3()).limit(5).collect(Collectors.partitioningBy(p -> p.getId() < 18));System.out.println("小孩: " + children.get(true));System.out.println("成年人: " + children.get(false));// 通过年龄进行分区排序:// 小孩: [{"id":16,"name":"pancm7"}, {"id":17,"name":"pancm2"}]// 成年人: [{"id":18,"name":"pancm4"}, {"id":19,"name":"pancm9"}, {"id":20,"name":"pancm6"}]class UserSupplier3 implements Supplier<User> {private int index = 16;private Random random = new Random();@Overridepublic User get() {return new User(index++, "pancm" + random.nextInt(10));}}
16.Stream流的summaryStatistics使用
IntSummaryStatistics 用于收集统计信息(如count、min、max、sum和average)的状态对象。
示例:得到最大、最小、之和以及平均数。
List<Integer> numbers = Arrays.asList(1, 5, 7, 3, 9);IntSummaryStatistics stats = numbers.stream().mapToInt((x) -> x).summaryStatistics();System.out.println("列表中最大的数 : " + stats.getMax());System.out.println("列表中最小的数 : " + stats.getMin());System.out.println("所有数之和 : " + stats.getSum());System.out.println("平均数 : " + stats.getAverage());// 列表中最大的数 : 9// 列表中最小的数 : 1// 所有数之和 : 25// 平均数 : 5.0
Stream 介绍就到这里了,JDK1.8中的Stream流其实还有很多很多用法,更多的用法则需要大家去查看JDK1.8的API文档了。
LocalDateTime
介绍
JDK1.8除了新增了lambda表达式、stream流之外,它还新增了全新的日期时间API。在JDK1.8之前,Java处理日期、日历和时间的方式一直为社区所诟病,将 java.util.Date设定为可变类型,以及SimpleDateFormat的非线程安全使其应用非常受限。因此推出了java.time包,该包下的所有类都是不可变类型而且线程安全。
关键类
-
Instant:瞬时时间。
-
LocalDate:本地日期,不包含具体时间, 格式 yyyy-MM-dd。
-
LocalTime:本地时间,不包含日期. 格式 yyyy-MM-dd HH:mm:ss.SSS 。
-
LocalDateTime:组合了日期和时间,但不包含时差和时区信息。
-
ZonedDateTime:最完整的日期时间,包含时区和相对UTC或格林威治的时差。
使用
1.获取当前的日期时间
通过静态工厂方法now()来获取当前时间。
//本地日期,不包括时分秒LocalDate nowDate = LocalDate.now();//本地日期,包括时分秒LocalDateTime nowDateTime = LocalDateTime.now();System.out.println("当前时间:"+nowDate);System.out.println("当前时间:"+nowDateTime);// 当前时间:2018-12-19// 当前时间:2018-12-19T15:24:35.822
2.获取当前的年月日时分秒
获取时间之后,直接get获取年月日时分秒。
//获取当前的时间,包括毫秒LocalDateTime ldt = LocalDateTime.now();System.out.println("当前年:"+ldt.getYear()); //2018System.out.println("当前年份天数:"+ldt.getDayOfYear());//172 System.out.println("当前月:"+ldt.getMonthValue());System.out.println("当前时:"+ldt.getHour());System.out.println("当前分:"+ldt.getMinute());System.out.println("当前时间:"+ldt.toString());// 当前年:2018// 当前年份天数:353// 当前月:12// 当前时:15// 当前分:24// 当前时间:2018-12-19T15:24:35.833
3.格式化时间
格式时间格式需要用到DateTimeFormatter类。
LocalDateTime ldt = LocalDateTime.now();
System.out.println("格式化时间: "+ ldt.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS")));
//格式化时间:2018-12-19 15:37:47.119
4.时间增减
在指定的时间进行增加/减少年月日时分秒。
LocalDateTime ldt = LocalDateTime.now();System.out.println("后5天时间:"+ldt.plusDays(5));System.out.println("前5天时间并格式化:"+ldt.minusDays(5).format(DateTimeFormatter.ofPattern("yyyy-MM-dd"))); //2018-06-16System.out.println("前一个月的时间:"+ldt2.minusMonths(1).format(DateTimeFormatter.ofPattern("yyyyMM"))); //2018-06-16System.out.println("后一个月的时间:"+ldt2.plusMonths(1)); //2018-06-16System.out.println("指定2099年的当前时间:"+ldt.withYear(2099)); //2099-06-21T15:07:39.506// 后5天时间:2018-12-24T15:50:37.508// 前5天时间并格式化:2018-12-14// 前一个月的时间:201712// 后一个月的时间:2018-02-04T09:19:29.499// 指定2099年的当前时间:2099-12-19T15:50:37.508
5.创建指定时间
通过指定年月日来创建。
LocalDate ld3=LocalDate.of(2017, Month.NOVEMBER, 17);LocalDate ld4=LocalDate.of(2018, 02, 11);
6.时间相差比较
比较相差的年月日时分秒。
示例一: 具体相差的年月日
LocalDate ld=LocalDate.parse("2017-11-17");LocalDate ld2=LocalDate.parse("2018-01-05");Period p=Period.between(ld, ld2);System.out.println("相差年: "+p.getYears()+" 相差月 :"+p.getMonths() +" 相差天:"+p.getDays());// 相差年: 0 相差月 :1 相差天:19
注:这里的月份是不满足一年,天数是不满足一个月的。这里实际相差的是1月19天,也就是49天。
示例二:相差总数的时间
ChronoUnit 日期周期单位的标准集合。
LocalDate startDate = LocalDate.of(2017, 11, 17);LocalDate endDate = LocalDate.of(2018, 01, 05);System.out.println("相差月份:"+ChronoUnit.MONTHS.between(startDate, endDate));System.out.println("两月之间的相差的天数 : " + ChronoUnit.DAYS.between(startDate, endDate));// 相差月份:1// 两天之间的差在天数 : 49
注:ChronoUnit也可以计算相差时分秒。
示例三:精度时间相差
Duration 这个类以秒和纳秒为单位建模时间的数量或数量。
Instant inst1 = Instant.now();System.out.println("当前时间戳 : " + inst1);Instant inst2 = inst1.plus(Duration.ofSeconds(10));System.out.println("增加之后的时间 : " + inst2);System.out.println("相差毫秒 : " + Duration.between(inst1, inst2).toMillis());System.out.println("相毫秒 : " + Duration.between(inst1, inst2).getSeconds());// 当前时间戳 : 2018-12-19T08:14:21.675Z// 增加之后的时间 : 2018-12-19T08:14:31.675Z// 相差毫秒 : 10000// 相毫秒 : 10
示例四:时间大小比较
LocalDateTime ldt4 = LocalDateTime.now();LocalDateTime ldt5 = ldt4.plusMinutes(10);System.out.println("当前时间是否大于:"+ldt4.isAfter(ldt5));System.out.println("当前时间是否小于"+ldt4.isBefore(ldt5));// false// true
7.时区时间计算
得到其他时区的时间。
示例一:通过Clock时钟类获取计算
Clock时钟类用于获取当时的时间戳,或当前时区下的日期时间信息。
Clock clock = Clock.systemUTC();System.out.println("当前时间戳 : " + clock.millis());Clock clock2 = Clock.system(ZoneId.of("Asia/Shanghai"));System.out.println("亚洲上海此时的时间戳:"+clock2.millis());Clock clock3 = Clock.system(ZoneId.of("America/New_York"));System.out.println("美国纽约此时的时间戳:"+clock3.millis());// 当前时间戳 : 1545209277657// 亚洲上海此时的时间戳:1545209277657// 美国纽约此时的时间戳:1545209277658
示例二: 通过ZonedDateTime类和ZoneId
ZoneId zoneId= ZoneId.of("America/New_York");ZonedDateTime dateTime=ZonedDateTime.now(zoneId);System.out.println("美国纽约此时的时间 : " + dateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSS")));System.out.println("美国纽约此时的时间 和时区: " + dateTime);// 美国纽约此时的时间 : 2018-12-19 03:52:22.494// 美国纽约此时的时间 和时区: 2018-12-19T03:52:22.494-05:00[America/New_York]
Java 8日期时间API总结:
-
提供了javax.time.ZoneId 获取时区。
-
提供了LocalDate和LocalTime类。
-
Java 8 的所有日期和时间API都是不可变类并且线程安全,而现有的Date和Calendar API中的java.util.Date和SimpleDateFormat是非线程安全的。
-
主包是 java.time,包含了表示日期、时间、时间间隔的一些类。里面有两个子包java.time.format用于格式化, java.time.temporal用于更底层的操作。
-
时区代表了地球上某个区域内普遍使用的标准时间。每个时区都有一个代号,格式通常由区域/城市构成(Asia/Tokyo),在加上与格林威治或 UTC的时差。例如:东京的时差是+09:00。
-
OffsetDateTime类实际上组合了LocalDateTime类和ZoneOffset类。用来表示包含和格林威治或UTC时差的完整日期(年、月、日)和时间(时、分、秒、纳秒)信息。
-
DateTimeFormatter 类用来格式化和解析时间。与SimpleDateFormat不同,这个类不可变并且线程安全,需要时可以给静态常量赋值。DateTimeFormatter类提供了大量的内置格式化工具,同时也允许你自定义。在转换方面也提供了parse()将字符串解析成日期,如果解析出错会抛出DateTimeParseException。DateTimeFormatter类同时还有format()用来格式化日期,如果出错会抛出DateTimeException异常。
-
再补充一点,日期格式“MMM d yyyy”和“MMM dd yyyy”有一些微妙的不同,第一个格式可以解析“Jan 2 2014”和“Jan 14 2014”,而第二个在解析“Jan 2 2014”就会抛异常,因为第二个格式里要求日必须是两位的。如果想修正,你必须在日期只有个位数时在前面补零,就是说“Jan 2 2014”应该写成 “Jan 02 2014”。
原文链接:
一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
相关文章:

一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
Lambda Lambda介绍 Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。 Lambda表达式的结构 一个 Lamb…...

WebSocket实战之二协议分析
一、前言 上一篇 WebSocket实战之一 讲了WebSocket一个极简例子和基础的API的介绍,这一篇来分析一下WebSocket的协议,学习网络协议最好的方式就是抓包分析一下什么就都明白了。 二、WebSocket协议 本想盗一张网络图,后来想想不太好&#x…...
)
LeetCode //C - 208. Implement Trie (Prefix Tree)
208. Implement Trie (Prefix Tree) A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and s…...
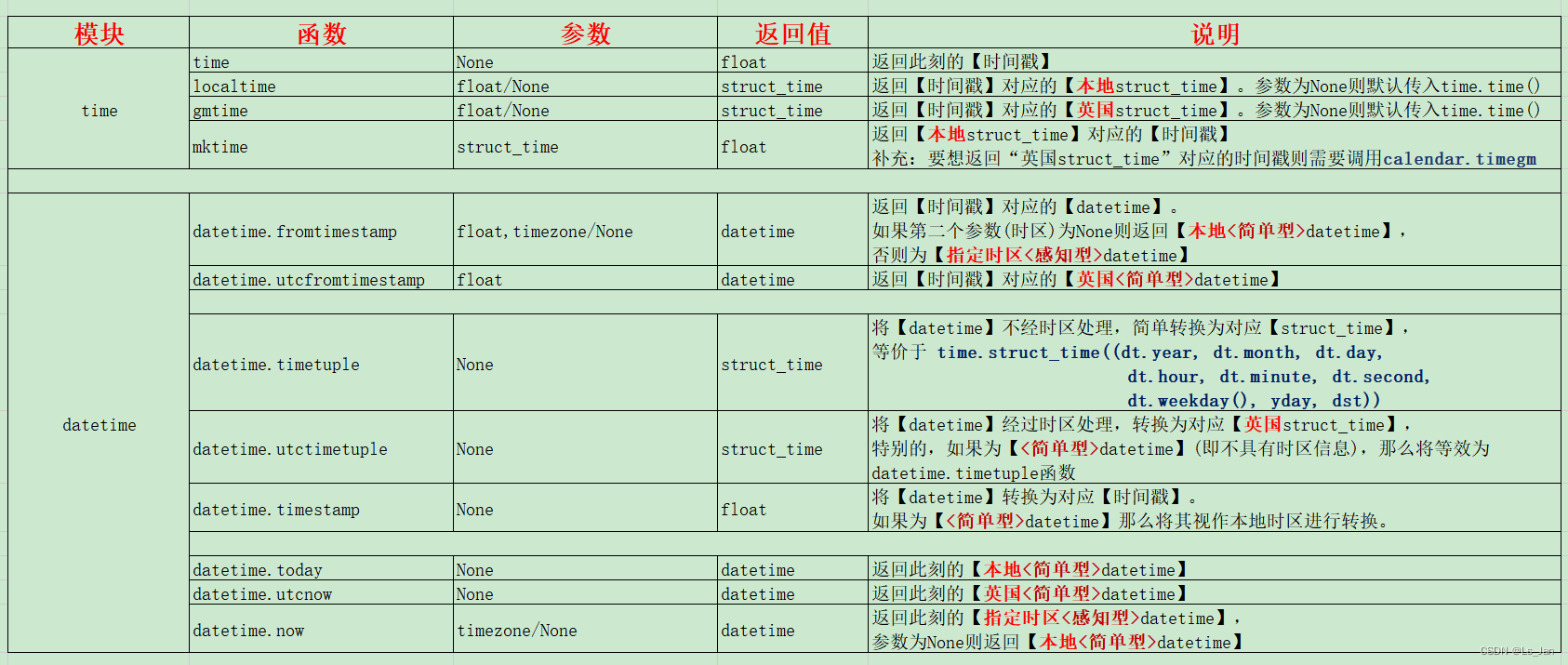
【Python】time模块和datetime模块的部分函数说明
时间戳与日期 在说到这俩模块之前,首先先明确几个概念: 时间戳是个很单纯的东西,没有“时区”一说,因为时间戳本质上是经过的时间。日常生活中接触到的“日期”、“某点某时某分”准确的说是时间点,都是有时区概念的…...

Python 无废话-基础知识元组Tuple详讲
“元组 Tuple”是一个有序、不可变的序列集合,元组的元素可以包含任意类型的数据,如整数、浮点数、字符串等,用()表示,如下示例: 元组特征 1) 元组中的各个元素,可以具有不相同的数据类型,如 T…...

【Win】Microsoft Spy++学习笔记
参考资料 《用VisualStudio\Spy查窗口句柄,监控窗口消息》 1. 安装 Spy是VS中的工具,所以直接安装VS就可以了; 2. 检查应用程序架构 ChatGPT-Bing: 对于窗口应用程序分析,确定应用程序是32位还是64位是很重要的,因…...
如何解决版本不兼容Jar包冲突问题
如何解决版本不兼容Jar包冲突问题 引言 “老婆”和“妈妈”同时掉进水里,先救谁? 常言道:编码五分钟,解冲突两小时。作为Java开发来说,第一眼见到ClassNotFoundException、 NoSuchMethodException这些异常来说&…...
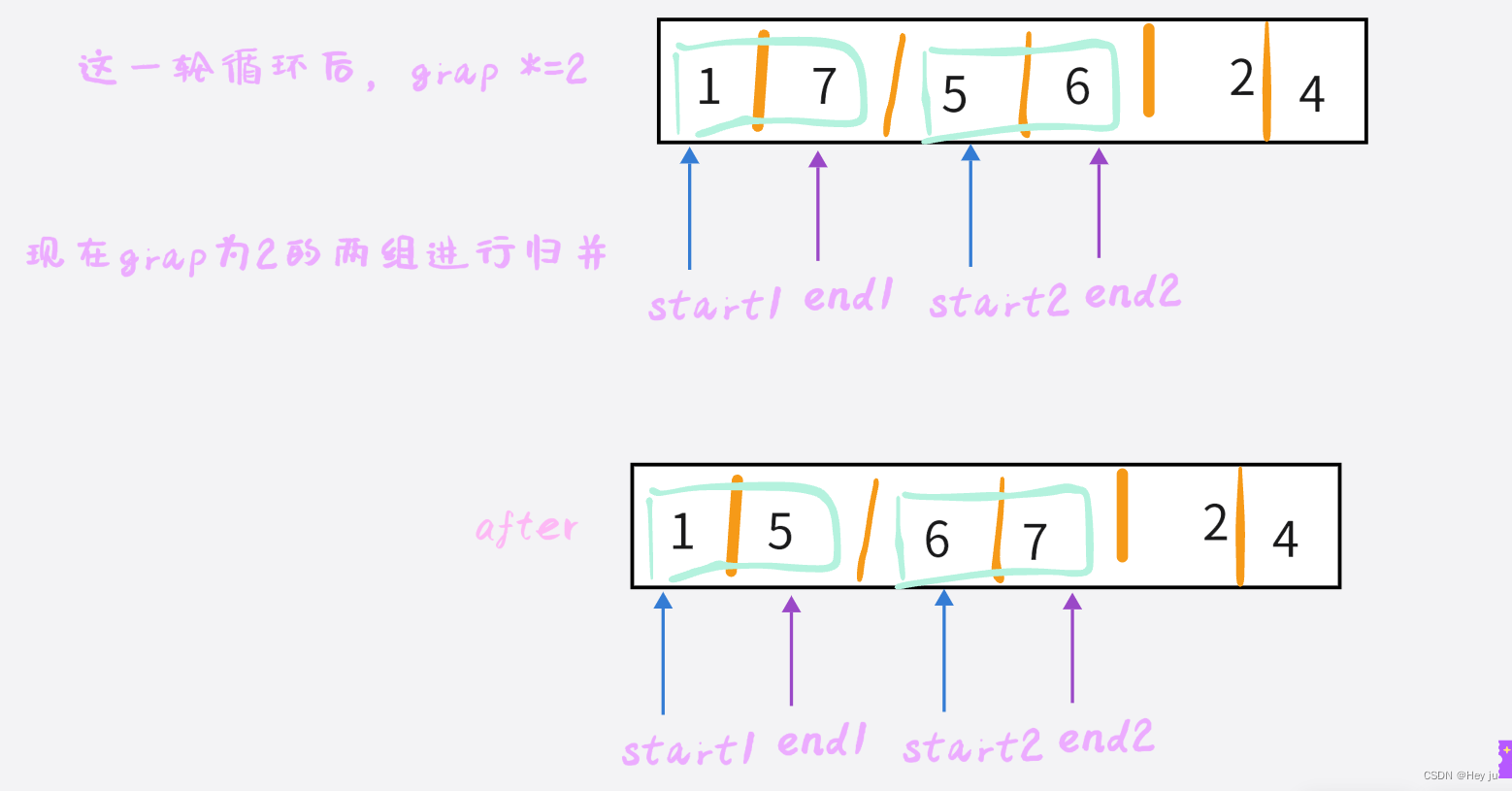
数据结构—归并排序-C语言实现
引言:归并排序跟快速排序一样,都运用到了分治的算法,但是归并排序是一种稳定的算法,同时也具备高效,其时间复杂度为O(N*logN) 算法图解: 然后开始归并: 就是这个思想,拆成最小子问题…...
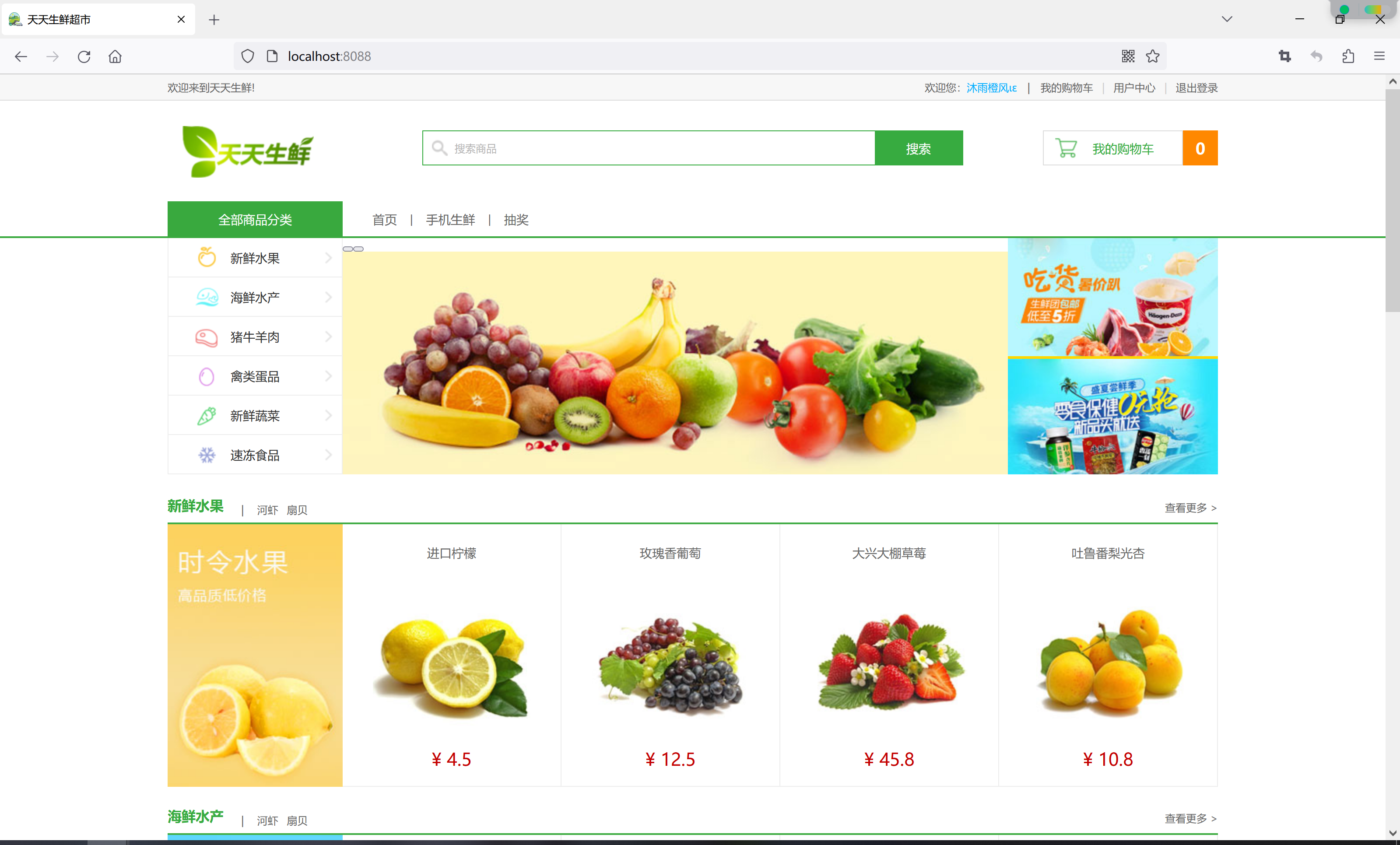
Multiple CORS header ‘Access-Control-Allow-Origin‘ not allowed
今天在修改天天生鲜超市项目的时候,因为使用了前后端分离模式,前端通过网关统一转发请求到后端服务,但是第一次使用就遇到了问题,比如跨域问题: 但是,其实网关里是有配置跨域的,只是忘了把前端项…...
msvcp100.dll丢失怎样修复,msvcp100.dll丢失问题全面解析
msvcp100.dll是一个动态链接库文件,属于 Microsoft Visual C Redistributable 的一个组件。它包含了 C 运行时库,这些库在运行程序时会被加载到内存中。msvcp100.dll文件的主要作用是为基于 Visual C 编写的程序提供必要的运行时支持。 当您运行一个基于…...
最新AI智能问答系统源码/AI绘画系统源码/支持GPT联网提问/Prompt应用+支持国内AI提问模型
一、AI创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的AI智能问答系统和AI绘画系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图…...
全连接网络实现回归【房价预测的数据】
也是分为data,model,train,test import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optimclass FCNet(nn.Module):def __init__(self):super(FCNet,self).__init__()self.fc1 nn.Linear(331,200)s…...
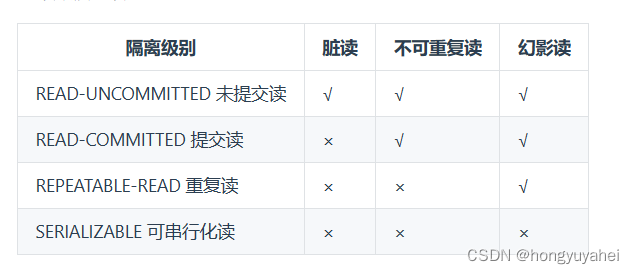
mysql八股
1、请你说说mysql索引,以及它们的好处和坏处 检索效率、存储资源、索引 索引就像指向表行的指针,是一个允许查询操作快速确定哪些行符合WHERE子句中的条件,并检索到这些行的其他列值的数据结构索引主要有普通索引、唯一索引、主键索引、外键…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【优化算法】狐猴优化器(LO)(附MATLAB代码实现)
代码实现 MATLAB LO.m %======================================================================= % Lemurs Optimizer: A New Metaheuristic Algorithm % for Global Optimization (LO)% This work is published in Journal of "Applied …...

C#WPF动态资源和静态资源应用实例
本文实例演示C#WPF动态资源和静态资源应用 一、资源概述 静态资源(StaticResource)指的是在程序载入内存时对资源的一次性使用,之后就不再访问这个资源了。 动态资源(DynamicResource)指的是在程序运行过程中然会去访问资源。 WPF中,每个界面元素都含有一个名为Resources…...

游戏逆向中的 NoClip 手段和安全应对方式
文章目录 墙壁边界寻找碰撞 NoClip 是一种典型的黑客行为,允许你穿过墙壁,所以 NoClip 又可以认为是避免碰撞体积的行为 墙壁边界 游戏中设置了碰撞体作为墙壁边界,是 玩家对象 和墙壁发生了碰撞,而不是 相机 玩家对象有他的 X…...
nodejs+vue流浪猫狗救助领养elementui
第三章 系统分析 10 3.1需求分析 10 3.2可行性分析 10 3.2.1技术可行性:技术背景 10 3.2.2经济可行性 11 3.2.3操作可行性: 11 3.3性能分析 11 3.4系统操作流程 12 3.4.1管理员登录流程 12 3.4.2信息添加流程 12 3.4.3信息删除流程 13 第四章 系统设计与…...

Css Flex 弹性布局中的换行与溢出处理方法
Css Flex 弹性布局中的换行与溢出处理方法 CSS弹性布局(Flex)是CSS3中的一种新的布局方式,它能够帮助我们更加灵活地布局元素。在Flex弹性布局中,元素的布局仅依赖于父容器的设置,而不再需要复杂的相对或绝对定位。本…...
linux系统与应用
Windows中的硬盘和盘符的关系; 硬盘通常为一块到两块;数量与盘符没有直接关系;一块硬盘可以分为多个盘符,如c,d,e,f,g等;当然理论上也可以一块硬盘只有一个盘符;学习linux时,最好使用固态硬盘&a…...

MySQL的结构化语言 DDL DML DQL DCL
一、SQL结构化语言介绍 数据查询语言DQL:其语句称为“数据检索语言”,用以从库中获取数据,确定数据怎样在应用程序给出,保留select是dql(也是所有sql)用的最多的动词 数据操作语言DML:其语句包括动词insert…...

韩式健康板供应商筛选:企业采购决策策略深度解析
韩式健康板供应商筛选:企业采购决策6步策略,避开80%行业坑点“韩式健康板供应商筛选不是只看价格,掌握6个关键步骤才能选到靠谱伙伴”——这是行业内资深采购的共识。本文针对企业采购韩式健康板的核心痛点,从需求梳理到持续监控&…...

Windows下OpenClaw安装指南:一键连接GLM-4.7-Flash模型
Windows下OpenClaw安装指南:一键连接GLM-4.7-Flash模型 1. 为什么选择OpenClawGLM-4.7-Flash组合 去年我在处理日常办公自动化时,发现很多重复性工作既耗时又容易出错。尝试过多个自动化工具后,最终被OpenClaw的"本地化AI智能体"…...

BULLM_ExtendMotor:8通道I²C电机驱动Arduino HAL库
1. 项目概述BULLM_ExtendMotor 是专为牛明工作室(BULLM Studio)8通道电机驱动扩展板设计的嵌入式控制库。该扩展板采用 IC 总线通信,集成 8 路独立可逆直流电机驱动通道,每通道支持 PWM 调速与方向控制,适用于多轴运动…...

从零开始:Windows与Ubuntu20.04双系统安装全指南
1. 为什么需要双系统? 对于很多刚接触Linux的朋友来说,直接在物理机上安装Ubuntu可能会有点担心。毕竟Windows用习惯了,万一Ubuntu用不顺手怎么办?这时候双系统就是最好的解决方案。我自己的第一台开发机就是WindowsUbuntu双系统&…...

RT-Thread消息邮箱机制解析与应用实践
RT-Thread消息邮箱机制深度解析1. 消息邮箱概述1.1 线程通信基础机制在实时操作系统中,线程间通信(IPC)是系统设计的关键组成部分。RT-Thread提供了两种基础通信机制:消息邮箱和消息队列。消息邮箱以其轻量级和高效性著称,特别适合小数据量的…...

【Unity3D】从零打造动态天空盒:Cubemap生成与实时环境映射实战
1. 动态天空盒的核心原理与场景价值 第一次在Unity里看到动态天空盒效果时,我盯着屏幕愣了三秒——云层在头顶流动,夕阳的光影实时投射在建筑表面,整个场景瞬间有了生命力。这种魔法般的体验,其实都建立在立方体贴图(C…...
相对位置偏置在视觉Transformer中的应用:为什么Swin Transformer离不开它?
相对位置偏置:视觉Transformer中空间建模的隐形引擎 在计算机视觉领域,Transformer架构正逐步取代传统CNN成为图像理解的新范式。然而,将最初为序列数据设计的Transformer直接应用于二维图像数据时,一个关键挑战浮现:…...

python vue医院健康体检系统
目录技术选型与架构设计核心模块划分关键功能实现安全与合规措施部署方案开发里程碑计划项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 后端采用Python的Django框架,提供RESTful API接口。Djan…...

STM32实战:为小米CyberGear/灵足电机构建机械限位零点与位置模式正弦轨迹
1. 小米CyberGear电机零点丢失问题解析 第一次用小米CyberGear电机做项目时,我就被它断电后零点丢失的问题坑得不轻。早上调好的机械臂,下午上电就歪了30度,这种体验相信很多开发者都遇到过。这其实是大多数伺服电机的通病——断电后编码器位…...

IEC102协议报文解析:从格式到传输的实战指南
1. IEC102协议基础入门:电力系统的"语言密码" 第一次接触IEC102协议时,我完全被那些十六进制代码和术语搞晕了。直到有一次在变电站调试电表,看到主站和终端设备用这种"暗号"流畅对话,才真正理解它的价值。简…...