问 ChatGPT 关于 GPT 的事情:数据准备篇
一、假如你是一名人工智能工程师,手里有一个65B的GPT大模型,但你需要一个6B左右的小模型,你会怎么做?
答:作为人工智能工程师,如果我手里有一个65B的GPT大模型,而我需要一个6B左右的小模型,我会采取以下步骤:
数据子集选择:对于训练大模型的数据集,我会从中选择一个子集,以便在构建小模型时使用。这个子集应该保留足够的多样性和代表性,以确保小模型在各种任务上的表现仍然良好。
参数剪枝:我会使用剪枝技术来减少大模型的参数数量。剪枝可以通过删除不重要的连接和神经元来减小模型的规模。这可以通过诸如敏感度分析、结构化剪枝、稀疏训练等技术来实现。
微调:在剪枝后,我会对小模型进行微调,以便在尽可能保留性能的同时进一步优化其参数。微调可以使用较小的学习率和较少的迭代次数来防止过拟合。
模型压缩:如果小模型的大小仍然超过所需的6B左右,我可以考虑使用模型压缩技术。这包括权重量化、参数共享、低秩分解等方法,以减小模型的内存占用。
通过以上步骤,我可以将原始的65B的GPT大模型转换为一个6B左右的小模型。
它只提到了剪枝,但是不可能剪掉90%吧,我试试再引导它回答最优方案。
二、你选择的数据子集应当包含什么样的数据?
对于选择数据子集,可以根据具体的任务和需求来确定所包含的数据类型和内容。一般来说,数据子集应当包含以下几种数据:
目标数据:针对所解决的问题或任务,选择与之相关的目标数据。比如,如果是进行情感分析,数据子集应包含带有情感标签的文本数据。
多样性数据:确保数据子集具有多样性,包含不同领域、不同类型、不同长度的数据样本。这样可以提高模型的泛化能力和适应性。
平衡数据:在数据子集中,应尽量保持各类别或标签的平衡,避免某一类别的样本过多或过少,以免引发模型偏见或不准确性。
高质量数据:选择高质量的数据样本,确保数据的准确性、完整性和可靠性。可以通过专业的数据源、标准化的标注流程等来保证数据质量。
这里,我当然知道长文本+短文本+新闻+论文/百科就能覆盖全部,但是它没有直接回答出来,还需要引导。
三、假设你只能抓取四个网站上的全部数据,你会如何选择网站来准备GPT的预训练数据?
对于准备GPT的预训练数据,我会选择以下四个网站来抓取全部数据:
Wikipedia:作为一个丰富的知识库,Wikipedia包含了大量的文章和信息,可以提供广泛的领域知识和语言表达。
Reddit:作为一个社交论坛,Reddit上有各种不同主题的讨论帖和评论,可以提供丰富的实时、多样化的对话内容。
Stack Exchange:作为一个问答社区,Stack Exchange上有丰富的专业领域问题和答案,可以提供专业知识和相关讨论。
News websites:选择一家新闻网站,如BBC、CNN或New York Times,可以获得各种新闻报道和评论,涵盖了全球范围内的各种话题和事件。
这样的选择可以提供广泛的主题、语言风格和领域知识,为GPT的预训练提供多样性和通用性。
这里跟我的预想完全一样:新闻站点提供长文本,Rediit提供对话,SE提供开放问答,也就是指令微调数据,WIKI提供知识。
四、再看看中文的:
针对准备GPT的预训练数据,我会选择以下四个中文网站:
百度百科(https://baike.baidu.com):作为最大的中文百科网站,百度百科涵盖了广泛的主题和领域。其中的文章丰富多样,可以提供丰富的知识和语言样本。
新浪新闻(https://news.sina.com.***娱乐等各个领域,能够提供丰富的实时信息和语言样本。
知乎(https://www.zhihu.com):知乎是一个知识问答社区,用户在该平台上提问、回答和分享各种话题。这里聚集了大量有深度和专业知识的用户,他们的回答和讨论能够提供多样化的语言样本。
豆瓣读书(https://book.douban.com):豆瓣读书是一个图书推荐和社交平台,用户可以在这里发布书评、评分、评论和讨论。这些评论和讨论覆盖了各种类型的书籍,从小说到学术著作,提供了多样化的语言样本。
这四个网站涵盖了不同领域的知识和信息,能够提供丰富的中文文本数据,有助于训练出更全面和多样化的GPT模型。
百科提供知识,新闻提供长文本,知乎提供开放问答,豆瓣读书不知道干嘛的,如果是小组可以提供对话。
五:我可不可以拿笔趣阁等小说文本代替新浪新闻,为GPT提供长文本的训练数据?
你可以使用笔趣阁等小说文本作为GPT的训练数据,但需要注意以下几点:
版权问题:确保你有合法的授权或许可,以使用这些小说文本作为训练数据。尊重作者的权益是非常重要的。
文本质量:小说文本和新闻文本在内容和风格上存在很大差异。小说通常更加虚构和富有想象力,而新闻更加注重事实和客观性。因此,使用小说文本作为训练数据可能会影响到GPT在生成新闻文本时的准确性和可靠性。
数据多样性:为了使GPT具有更好的泛化能力,建议使用多样性的训练数据。单一来源的数据可能会导致模型在特定领域或风格上过拟合。
和我预想的一样,是可行的。
六、你推荐的网站里面不包含中文多轮对话数据集,请列举几个包含中文多轮对话的网站。
对于中文多轮对话数据集,以下是一些包含的网站:
THU Chat Corpus:清华大学提供的多轮中文对话数据集,包含了来自微博、论坛等多个领域的对话数据。
DuConv:百度开放的多轮中文对话数据集,主要包括了知识问答和聊天对话两种类型。
ECDT:哈尔滨工业大学提供的多轮中文对话数据集,覆盖了不同领域的实际对话情景。
七、请判断以下网站中是否包含中文多轮对话:百度贴吧、新浪微博、豆瓣小组
以下是对三个网站的判断:
百度贴吧:百度贴吧是一个中文社区网站,用户可以在各个贴吧中进行中文多轮对话,因此包含中文多轮对话。
新浪微博:新浪微博是一个中文社交媒体平台,用户可以发表微博并与其他用户进行评论和互动,因此也包含中文多轮对话。
豆瓣小组:豆瓣小组是一个中文社区网站,用户可以在小组中进行讨论和互动,因此也包含中文多轮对话。
这一点和人类表现一样,你不限定范围直接问它,它就想不到,但是如果你给定一个范围让它判断,它就能判断出来。
八、GPT模型的模型训练分为哪几个阶段?这些阶段分别使用什么样的数据集?
GPT模型的模型训练分为两个阶段:预训练和微调。
在预训练阶段,GPT模型使用了一个大规模的无监督文本数据集。通常情况下,这个数据集是从互联网上的各种来源收集而来的,比如维基百科、新闻文章、论坛帖子等。预训练的目标是让模型学会预测下一个词语出现的概率,通过这个任务来学习语言的统计规律和语义信息。
在微调阶段,GPT模型使用了一个特定的监督任务的数据集。这个数据集通常是由人工标注的,包含了输入和对应的目标输出。比如,在生成对话的任务中,数据集可以由对话文本和对应回答组成。微调的目标是让模型在特定任务上表现得更好,通过有监督学习的方式进一步调整模型参数。
可以,不过微调比预训练复杂得多。需要展开叙述以下。
九、给你一个语言生成模型,他能根据一段文本生成下一段文本,如何把它变成一个对话模型?
要将一个语言生成模型转变为对话模型,可以引入一个上下文环境。传统的语言生成模型会根据前面的文本生成下一段文本,而对话模型则可以根据前面的对话历史生成下一段对话。为此,我们可以将对话历史作为模型输入的一部分,并训练模型生成下一段对话。
具体来说,可以将对话历史拼接成一个长文本,并加上一些特殊标记来分隔对话历史和当前回答的文本。这样,模型可以根据整个文本序列来生成回答。
在训练时,我们需要提供包含对话历史和模型期望生成的回答的样本对。模型会学习如何根据对话历史生成合适的回答。
十、你现在有了一个模型,可以进行语言生成和多轮对话,如何让它执行多种自然语言任务,例如做规划,总结文本和做翻译?
对于这些自然语言任务,可以通过针对特定任务的指导性示例来训练模型。例如,对于规划任务,可以提供一些关于规划的示例问题和相应的答案,让模型学会生成合适的规划建议。对于总结文本任务,可以提供一些文本段落和相应的摘要,让模型学会总结文本的能力。对于翻译任务,可以提供一些双语对照的句子,让模型学会将一种语言翻译成另一种语言。
在训练过程中,可以使用一种称为"无监督预训练"的方法,先让模型自己学习语言的一般模式和结构,然后再使用有监督的任务来进一步微调模型。这样做可以提高模型在各种自然语言任务上的表现。
正确答案是加上提示词把这些都变成对话任务。
十一、提示词的作用是什么
提示词在对话中起到引导和提示的作用。它们可以帮助对话参与者更好地理解问题的意思,提供更准确的回答。提示词可以是具体的关键词或短语,也可以是一段描述性的句子,都有助于限定对话的主题和范围。
例如,在搜索引擎中输入关键词时,提示词会自动补全搜索内容,提供与关键词相关的建议。在对话中,提示词可以指导对话者提供更具体或相关的信息,以满足对方的需求。
还是这个现象,我必须告诉他正确答案。
总结
ChatGPT 有一个很令人无语的现象,就是你问一个事情,它不能给出答案,但是你给它答案,它反而能推出问题。
就比如你问【提示词作用是什么】,显然正常人的a思路就是告诉模型你所需要的任务类型,或者从工程师的角度,把任何自然语言任务都转化成对话任务,统一建模和处理。但是你直接问它【你有了一个多轮对话模型,如何让它做各种自然语言任务】,它就根本不会想到提示词这个东西。
相关文章:

问 ChatGPT 关于 GPT 的事情:数据准备篇
一、假如你是一名人工智能工程师,手里有一个65B的GPT大模型,但你需要一个6B左右的小模型,你会怎么做? 答:作为人工智能工程师,如果我手里有一个65B的GPT大模型,而我需要一个6B左右的小模型&…...

leetcode_17电话号码的组合
1. 题意 输出电话号码对应的字母左右组合 电话号码的组合 2. 题解 回溯 class Solution { public:void gen_res(vector<string> &res, vector<string> &s_m,string &digits, string &t, size_t depth) {if (depth digits.size()) {if ( !t.em…...

记录使用vue-test-utils + jest 在uniapp中进行单元测试
目录 前情安装依赖package.json配置jest配置测试文件目录编写setup.js编写第一个测试文件jest.fn()和jest.spyOn()jest 解析scss失败测试vuex$refs定时器测试函数调用n次手动调用生命周期处理其他模块导入的函数测试插槽 前情 uniapp推荐了测试方案dcloudio/uni-automator&…...

《C和指针》笔记30:函数声明数组参数、数组初始化方式和字符数组的初始化
文章目录 1. 函数声明数组参数2. 数组初始化方式2.1 静态初始化2.2 自动变量初始化 2.2 字符数组的初始化 1. 函数声明数组参数 下面两个函数原型是一样的: int strlen( char *string ); int strlen( char string[] );可以使用任何一种声明,但哪个“更…...

VBA技术资料MF64:遍历单元格搜索字符并高亮显示
【分享成果,随喜正能量】不要在乎他人的评论,不必理论与他人有关的是非,你只要做好自己就够了。苔花如米小,也学牡丹开。无论什么时候,都要有忠于自己的勇气,去做喜欢的事,去认识喜欢的人&#…...

一键智能视频编辑与视频修复算法——ProPainter源码解析与部署
前言 视频编辑和修复确实是随着电子产品的普及变得越来越重要的技能。有许多视频编辑工具可以帮助人们轻松完成这些任务如:Adobe Premiere Pro,Final Cut Pro X,Davinci Resolve,HitFilm Express,它们都提供一些视频修…...

Flutter开发环境的配置
2023-10最新版本 flutter SDK版本下载地址 https://flutter.cn/docs/development/tools/sdk/releases gradle各版本快速下载地址 https://blog.csdn.net/ii950606/article/details/109105402 JAVA SDK下载地址 https://www.oracle.com/java/technologies/downloads/#java…...

【超详细】Wireshark教程----Wireshark 分析ICMP报文数据试验
一,试验环境搭建 1-1 试验环境示例图 1-2 环境准备 两台kali主机(虚拟机) kali2022 192.168.220.129/24 kali2022 192.168.220.3/27 1-2-1 网关配置: 编辑-------- 虚拟网路编辑器 更改设置进来以后 ,先选择N…...
之rm)
Linux命令(92)之rm
linux命令之rm 1.rm介绍 linux命令rm是用来删除一个或多个文件/目录,由于其删除的不可逆性,建议在日常工作中一定要慎用 2.rm用法 rm [参数] 文件/目录 rm常用参数 参数说明-r递归删除文件或目录-f不提示强制删除-i删除文件或目录前进行确认-v详细显…...
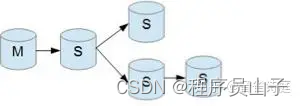
Mysql主从复制数据架构全面解读
大家好,我是山子,今天给大家分析Mysql 实现主从复制的方方面面,主从复制当然也是我们做读写分离的前提,以下内容是从各网络平台摘录整理总结归纳在一起的;内容已经从主从复制的各方面的维度进行了阐述;非常…...
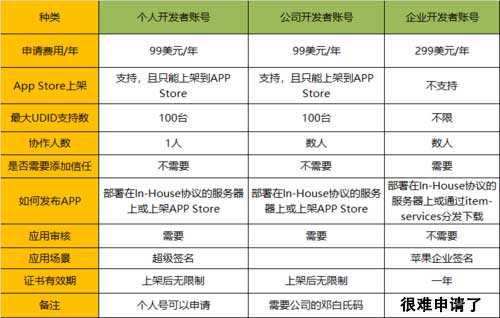
ios证书类型及其作用说明
ios证书类型及其作用说明 很多刚开始接触iOS证书的开发者可能不是很了解iOS证书的类型功能和概念。下面对iOS证书的几个方面进行介绍。 apple开发账号分类: 免费账号: 无需支付费用给apple,使用个人信息注册的账号 可以开发测试安装&…...

警告-Ubuntu提示W: Possible missing firmware xxx解决方法
目录 现象原因解决方法 现象 当执行 sudo apt-get update或者sudo apt-get dist-upgrade时,有如下警告: W: Possible missing firmware /lib/firmware/rtl_nic/rtl8125a-3.fw for module r8169 W: Possible missing firmware /lib/firmware/rtl_nic/rt…...
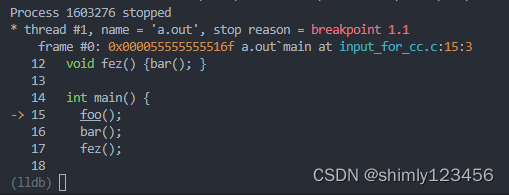
有时候,使用 clang -g test.c 编译出可执行文件后,发现 gdb a.out 进行调试无法读取符号信息,为什么?
经过测试,gdb 并不是和所有版本的 llvm/clang 都兼容的 当 gdb 版本为 9.2 时,能支持 9.0.1-12 版本的 clang,但无法支持 16.0.6 版本的 clang 可以尝试使用 LLVM 专用的调试器 lldb 我尝试使用了 16.0.6 版本的 lldb 调试 16.0.6 的 clan…...
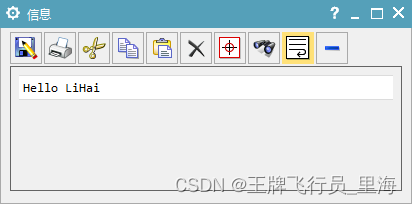
UG\NX二次开发 信息窗口的一些操作 NXOpen/ListingWindow
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,里海BlockUI专栏,C\C++-CSDN博客 简介: UG\NX二次开发 信息窗口的一些操作 NXOpen/ListingWindow 效果: 代码: #include "me.hpp" #include <NXOpen/ListingWindow.hxx> #include <…...

macbook电脑磁盘满了怎么删东西?
macbook是苹果公司的一款高性能笔记本电脑,受到很多用户的喜爱。但是,如果macbook的磁盘空间不足,可能会导致一些问题,比如无法开机、运行缓慢、应用崩溃等。那么,macbook磁盘满了无法开机怎么办,macbook磁…...

解释 RESTful API,以及如何使用它构建 web 应用程序
RESTful API是一种基于HTTP协议,使用REST架构风格设计的API。其核心思想是将所有的Web应用程序资源抽象为一组资源集合,并通过HTTP协议中的GET、POST、PUT、DELETE等几个方法对这些资源进行操作,使得Web应用程序能够方便地、高效地进行管理和…...

qml使用c++自定义listmodel数据
qml要使用c中自定义的model,首先该model类需要继承QAbstractListModel类,然后需要重写其中的三个函数,分别是 int rowCount(const QModelIndex &parent); QVariant data(const QModelIndex &index, int role Qt::DisplayRole); QHas…...

cf 解题报告 01
E. Power of Points Problem - 1857E - Codeforces 题意: 给你 n n n 个点,其整数坐标为 x 1 , … x n x_1,\dots x_n x1,…xn,它们位于一条数线上。 对于某个整数 s s s,我们构建线段[ s , x 1 s,x_1 s,x1], [ s , x…...
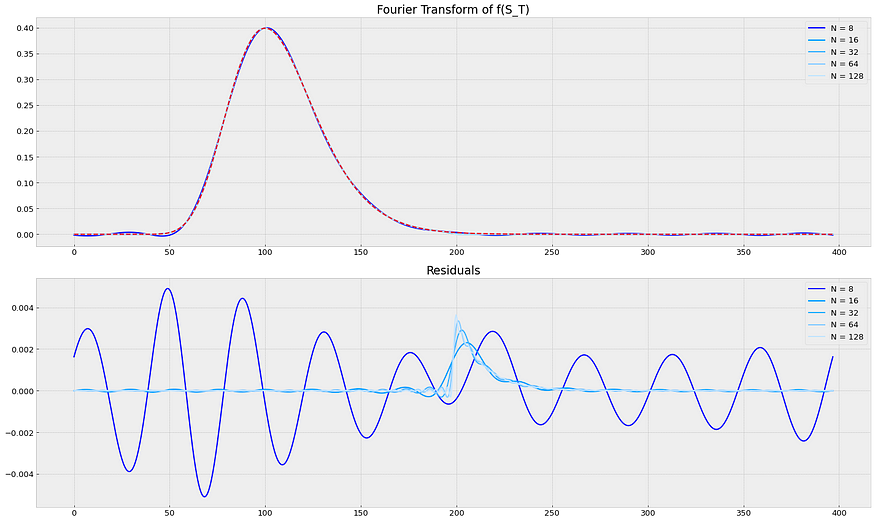
傅里叶系列 P1 的定价选项
如果您想了解更多信息,请查看第 2 部分和第 3 部分。 一、说明 这是第一篇文章,我将帮助您获得如何使用这个新的强大工具来解决金融中的半分析问题并取代您的蒙特卡洛方法的直觉。 我们都知道并喜欢蒙特卡洛数字积分方法,但是如果我告诉你你可…...

第二十届北京消防展即将开启,汉威科技即将精彩亮相
10月10日~13日,第二十届中国国际消防设备技术交流展览会,将在北京市顺义区中国国际展览中心新馆隆重举行。该展会由中国消防协会举办,是世界三大消防品牌展会之一,本届主题为“助力产业发展,服务消防救援”。届时将有4…...
)
K8s原生ML编排进入“编译期优化”时代(SITS 2026首次披露:eBPF驱动的模型感知调度器Alpha版已交付头部5家云厂商)
更多请点击: https://intelliparadigm.com 第一章:AI原生Kubernetes编排:SITS 2026 K8s for ML工作负载 SITS 2026 引入了专为机器学习工作负载深度优化的 AI-native Kubernetes 编排层,突破传统 K8s 在资源弹性、异构设备调度与…...

大部分 App 没准备好被 Agent 操作——这是设计缺陷,不是功能缺失
大部分 App 没准备好被 Agent 操作——这是设计缺陷,不是功能缺失 2025 年被很多人称为「AI Agent 元年」。 Claude Code、Cursor、Windsurf……一批 agentic 工具密集涌现,Agent 不再只是聊天框里的助手,它开始真正「做事」:自己…...

5步精通:Windows风扇智能控制终极指南
5步精通:Windows风扇智能控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.Rel…...

Shinkai Node:无代码AI智能体平台架构解析与实战部署
1. 项目概述:Shinkai Node,一个无需代码的AI智能体构建平台 最近在折腾AI智能体(AI Agent)的时候,发现了一个挺有意思的开源项目—— Shinkai Node 。它来自dcSpark团队,核心目标非常明确: …...

S32K144开发板调试实战:除了点灯,如何用S32DS的调试窗口快速排查变量异常问题?
S32K144开发板调试实战:变量异常排查与高效调试技巧 调试嵌入式系统时,最令人头疼的莫过于程序看似正常运行,但某些变量值却莫名其妙地偏离预期。作为一名长期使用S32 Design Studio(S32DS)进行S32K144开发的工程师&a…...

碧蓝航线脚本补丁Perseus:原生库的无偏移皮肤解锁技术实现
碧蓝航线脚本补丁Perseus:原生库的无偏移皮肤解锁技术实现 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 在移动游戏修改领域,实现版本兼容性一直是技术挑战的核心。Perseus项目通…...

BIGEMAP自定义在线地图源:从零到一构建专属底图库
1. 为什么需要自定义地图源? 在日常工作中,我们经常会遇到这样的场景:项目需要特殊的地图底图,但软件内置的地图源无法满足需求;或者需要叠加多个地图源进行对比分析;又或者某些专业领域需要特定的地图数据…...

告别调参烦恼:用MATLAB Simulink手把手教你实现直流无刷电机的模糊PID控制
直流无刷电机模糊PID控制实战:从Simulink建模到参数自整定 在工业自动化领域,电机控制算法的优劣直接决定了设备性能的上限。传统PID控制器虽然结构简单,但当面对直流无刷电机这类非线性系统时,工程师往往需要花费大量时间反复调整…...

魔兽争霸3终极优化指南:如何让经典游戏在现代系统上完美运行
魔兽争霸3终极优化指南:如何让经典游戏在现代系统上完美运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3的兼容…...

《线性代数思维》:以代码和案例开启线性代数实用学习之旅!
《线性代数思维》介绍《线性代数思维》以代码为先导、以案例为基础,介绍了线性代数中最常用的概念,专为那些想理解并应用这些概念,而非仅抽象学习的读者设计。每一章都围绕一个现实世界的问题展开,如模拟网络流量、仿真鸟群飞行或…...