Mysql技术文档--设计表规范式-一次性扫盲
阿丹:
在设计表的时候经常出现一些问题,其实自己很清楚就是因为在设计表的时候没有规范。导致后期加表的时候出现了问题。所以趁着这个假期卷一卷。同时只有在开始的时候
几大范式
在关系型数据库中,数据表设计的基本原则、规则就称为范式。
第一范式(1NF)
原文:
第一范式(1NF)数据库规范化的一种级别,它要求每个属性都是不可分的原子值,即每个属性都必须是不可分的最小数据单元。
解释/理解:
第一范式(1NF)是数据库设计的基础,它确保了每个数据表中的每个列都有唯一的含义,并且每个列都不能可分。这意味着每个字段都是最小的数据单元,不能包含其他的数据单元。例如,如果一个表中的“地址”列包含了省份、城市、街道等多个信息,那么这个表就不符合第一范式。为了满足第一范式,需要将这种多信息列拆分为多个独立的列,每个列表示一个最小、不可分的数据单元。
举例:
假设有一个名为“用户信息”的表,其中包含用户的姓名、年龄、性别、地址等信息。如果该表中的“地址”列包含了省份、城市、街道等多个信息,那么这个表就不符合第一范式。为了满足第一范式,需要将“地址”列拆分为“省份”、“城市”和“街道”三个独立的列,每个列表示一个最小、不可分的数据单元。拆分后的表如下:
用户信息表:
| 列名 | 类型 |
|---|---|
| 姓名 | 字符串 |
| 年龄 | 整数 |
| 性别 | 字符串 |
| 省份 | 字符串 |
| 城市 | 字符串 |
| 街道 | 字符串 |
这个例子中,“地址”列被拆分为三个独立的列:“省份”、“城市”和“街道”,每个列都表示一个最小、不可分的数据单元。这样的表就满足了第一范式的要求。
第二范式(2NF)
原文:
第二范式(2NF)是数据库规范化的一种级别,它建立在第一范式的基础上,要求非主键列之间必须完全依赖于主键,而不是部分依赖。
解释/理解:
第二范式(2NF)是在第一范式的基础上进行的规范化,它要求非主键列之间必须完全依赖于主键,而不是部分依赖。在第一范式中,表中的每个列都是不可分的最小数据单元,而在第二范式中,非主键列之间必须是相互独立的,不能存在依赖关系。
举例:
假设有一个名为“订单”的表,其中包含订单号、客户号、日期、商品数量等信息。该表中有一个主键为订单号和客户号,即每个订单都有一个唯一的订单号和客户号。现在考虑一个场景,需要查询某个客户的所有订单信息。在第二范式之前的设计中,我们可能需要一个单独的“订单”表来存储订单信息,然后使用一个外键来关联“订单”表和“客户”表。这样做的缺点是会产生大量的数据冗余,因为每个订单都需要在“订单”表中单独存储一份数据,而且如果某个客户的订单数量很大,那么“客户”表中就会包含很多冗余数据。
为了解决这个问题,我们可以将“订单”表拆分为两个表:“订单信息”表和“订单详情”表,“订单信息”表中包含订单号、客户号和日期等基本信息,而“订单详情”表中则包含每个订单的商品数量等信息。这样设计的好处是避免了数据冗余,同时也能更好地满足查询需求。
通过将表拆分为两个表,我们可以更好地组织数据,减少数据冗余并提高查询效率。同时,由于每个表中的列都是不可分的最小数据单元,因此也避免了数据不一致性的问题。
第三范式(3NF)
原文:
第三范式(3NF)是数据库规范化的一种级别,它建立在第二范式的基础上,要求非主键列之间必须相互独立,不存在传递依赖关系。
解释/理解:
第三范式(3NF)是在第二范式的基础上进行的规范化,它要求非主键列之间必须相互独立,不存在传递依赖关系。在第二范式中,非主键列之间必须是相互独立的,不能存在依赖关系,而第三范式则更进一步,要求非主键列之间不能存在传递依赖关系。
举例:
假设有一个名为“员工薪资”的表,其中包含员工号、姓名、薪资、所属部门等信息。该表的主键为员工号和姓名,即每个员工都有一个唯一的员工号和姓名。现在考虑一个场景,需要查询某个部门的所有员工的薪资情况。在第二范式之前的设计中,我们可能需要一个单独的“员工薪资”表来存储员工薪资信息,然后使用一个外键来关联“员工薪资”表和“员工”表。这样做的话,会产生大量的数据冗余,因为每个员工都需要在“员工薪资”表中单独存储一份数据。而且如果某个部门的员工数量很大,那么“员工薪资”表中就会包含很多冗余数据。
为了解决这个问题,我们可以将“员工薪资”表拆分为两个表:“员工信息”表和“薪资信息”表,“员工信息”表中包含员工号、姓名和所属部门等基本信息,而“薪资信息”表中则包含每个员工的薪资信息。这样设计的好处是避免了数据冗余,同时也能更好地满足查询需求。
通过将表拆分为两个表,我们可以更好地组织数据,减少数据冗余并提高查询效率。同时,由于每个表中的列都是不可分的最小数据单元,因此也避免了数据不一致性的问题。
巴斯-科德范式(BCNF)
原文:
巴斯-科德范式(BCNF)是数据库规范化的一种级别,它要求每个非主键子集必须完全依赖于主键,而不是部分依赖。
解释/理解:
巴斯-科德范式(BCNF)是在第三范式的基础上进行的规范化,它要求每个非主键子集必须完全依赖于主键,而不是部分依赖。在第三范式中,非主键列之间不能存在传递依赖关系,而巴斯-科德范式则更加强调非主键子集与主键之间的依赖关系。
举例:
假设有一个名为“商品订单”的表,其中包含订单号、商品号、数量、客户号等信息。该表的主键为订单号和商品号,即每个订单都有一个唯一的订单号和商品号。现在考虑一个场景,需要查询某个客户的所有订单信息。在第三范式之前的设计中,我们可能需要一个单独的“商品订单”表来存储商品订单信息,然后使用一个外键来关联“商品订单”表和“客户”表。这样做的话,会产生大量的数据冗余,因为每个订单都需要在“商品订单”表中单独存储一份数据。而且如果某个客户的订单数量很大,那么“商品订单”表中就会包含很多冗余数据。
为了解决这个问题,我们可以将“商品订单”表拆分为两个表:“订单信息”表和“订单详情”表,“订单信息”表中包含订单号、客户号等基本信息,而“订单详情”表中则包含每个订单的商品号、数量等信息。这样设计的好处是避免了数据冗余,同时也能更好地满足查询需求。
通过将表拆分为两个表,我们可以更好地组织数据,减少数据冗余并提高查询效率。同时,由于每个表中的列都是不可分的最小数据单元,因此也避免了数据不一致性的问题。
第四范式(4NF)
原文:
第四范式(4NF)是数据库规范化的一种级别,它要求非主键子集之间不存在依赖关系,或者说每个非主键子集必须独立于其他非主键子集。
解释/理解:
第四范式(4NF)在巴斯-科德范式的基础上进一步强调非主键子集之间的相互独立性。在巴斯-科德范式中,每个非主键子集必须完全依赖于主键,而且相互之间没有依赖关系。而在第四范式中,进一步要求每个非主键子集之间不存在任何依赖关系,或者说每个非主键子集都是独立的,不依赖于其他非主键子集。
举例:
假设有一个名为“客户订单”的表,其中包含客户号、订单号、日期、商品号、数量等信息。该表的主键为客户号和订单号,即每个订单都有一个唯一的客户号和订单号。现在考虑一个场景,需要查询某个客户的所有订单信息,并显示每个订单的商品号和数量。在第四范式之前的设计中,我们可能需要在“客户订单”表中存储每个订单的商品号和数量,然后使用客户号和订单号作为主键来关联该表和其他表。这样做的话,会产生大量的数据冗余,因为每个订单都需要在“客户订单”表中单独存储一份数据。而且如果某个客户的订单数量很大,那么“客户订单”表中就会包含很多冗余数据。
为了解决这个问题,我们可以将“客户订单”表拆分为两个表:“订单信息”表和“订单详情”表,“订单信息”表中包含客户号、订单号、日期等基本信息,而“订单详情”表中则包含每个订单的商品号、数量等信息。这样设计的好处是避免了数据冗余,同时也能更好地满足查询需求。
通过将表拆分为两个表,我们可以更好地组织数据,减少数据冗余并提高查询效率。同时,由于每个表中的列都是不可分的最小数据单元,因此也避免了数据不一致性的问题。
第五范式(5NF,又称完美范式)
原文:
第五范式(5NF,又称完美范式)是数据库规范化的一种级别,它要求在第四范式的基础上,非主键子集之间不存在任何依赖关系,或者说每个非主键子集必须独立于其他所有非主键子集。
解释/理解:
第五范式(5NF)在第四范式的基础上进一步强调非主键子集之间的相互独立性。在第四范式中,每个非主键子集必须独立于其他非主键子集,不依赖于其他非主键子集。而在第五范式中,要求每个非主键子集之间不存在任何依赖关系,或者说每个非主键子集都是完全独立的,不依赖于其他任何非主键子集。
举例: 考虑一个订单管理系统的数据库设计。假设有一个名为“订单详情”的表,其中包含订单号、商品号、数量等信息。该表的主键为订单号和商品号,即每个订单详情都有一个唯一的订单号和商品号。现在考虑一个场景,需要查询某个客户的所有订单信息,并显示每个订单的商品号和数量。在第五范式之前的设计中,我们可能需要在“订单详情”表中存储每个订单的商品号和数量,然后使用订单号作为主键来关联该表和其他表。这样做的话,会产生大量的数据冗余,因为每个订单详情都需要在“订单详情”表中单独存储一份数据。而且如果某个客户的订单数量很大,那么“订单详情”表中就会包含很多冗余数据。
为了解决这个问题,我们可以将“订单详情”表拆分为两个表:“订单信息”表和“订单明细”表,“订单信息”表中包含订单号、日期等基本信息,而“订单明细”表中则包含每个订单的商品号、数量等信息。这样设计的好处是避免了数据冗余,同时也能更好地满足查询需求。
通过将表拆分为两个表,我们可以更好地组织数据,减少数据冗余并提高查询效率。同时,由于每个表中的列都是不可分的最小数据单元,因此也避免了数据不一致性的问题。
相关文章:

Mysql技术文档--设计表规范式-一次性扫盲
阿丹: 在设计表的时候经常出现一些问题,其实自己很清楚就是因为在设计表的时候没有规范。导致后期加表的时候出现了问题。所以趁着这个假期卷一卷。同时只有在开始的时候 几大范式 在关系型数据库中,数据表设计的基本原则、规则就称为范式。…...

python socket 传输opencv读取的图像
python socket网络编程 将ros机器人摄像头捕捉的画面在上位机实时显示,需要用到socket网络编程,提供了TCP和UDP两种方式 TCP服务器端代码: 创建TCP套接字: s socket(AF_INET, SOCK_STREAM) 创建了一个TCP套接字。SOCK_STREAM 表示这是一个TCP套接字&…...
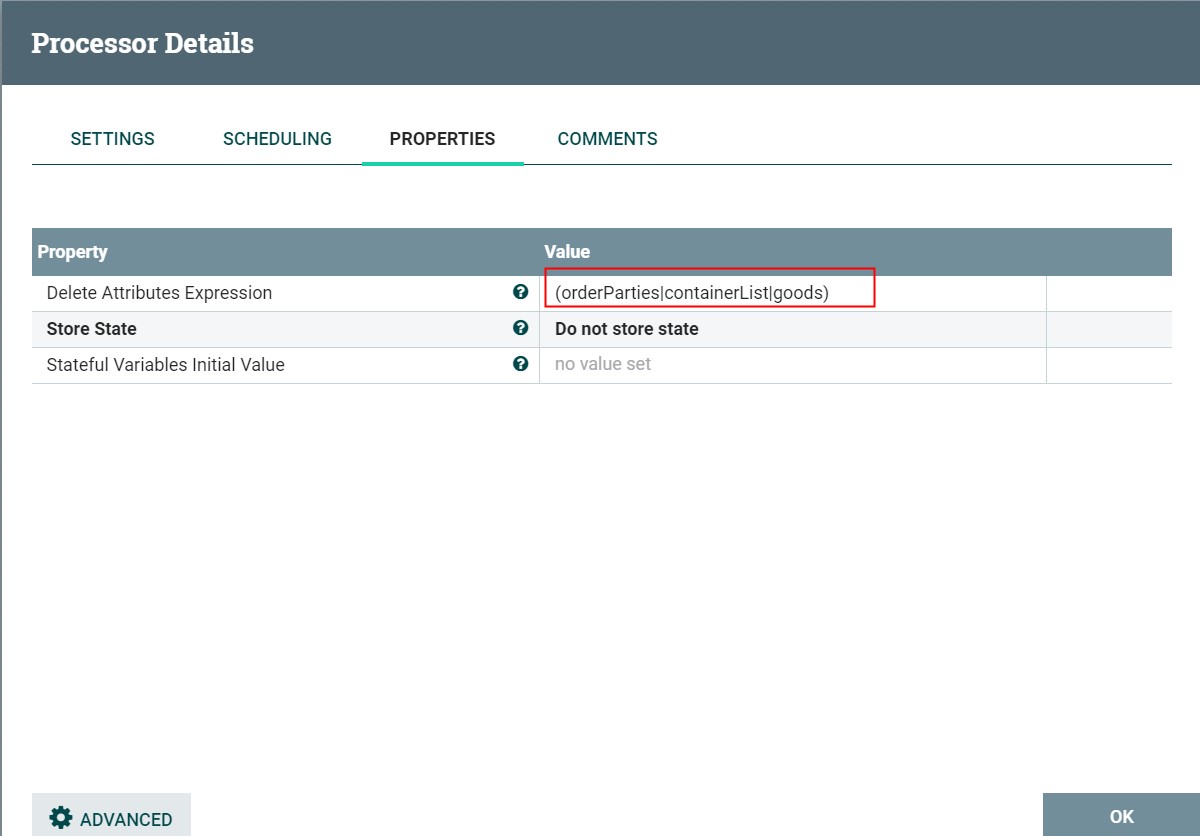
APACHE NIFI学习之—UpdateAttribute
UpdateAttribute 描述: 通过设置属性表达式来更新属性,也可以基于属性正则匹配来删除属性 标签: attributes, modification, update, delete, Attribute Expression Language, state, 属性, 修改, 更新, 删除, 表达式 参数: 如下列表中,必填参数则…...
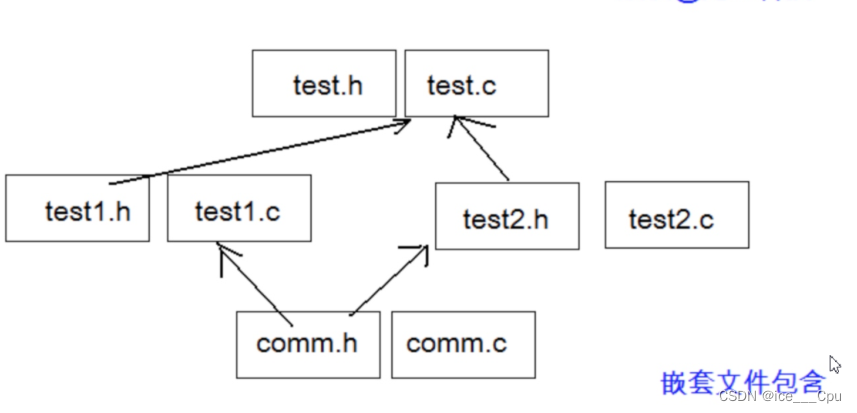
BIT-7文件操作和程序环境(16000字详解)
一:文件 1.1 文件指针 每个被使用的文件都在内存中开辟了一个相应的文件信息区,用来存放文件的相关信息(如文件的名字,文件状态及文件当前的位置等)。这些信息是保存在一个结构体变量中的。该结构体类型是有系统声明…...

冥想第九百二十八天
1.今天周三,今天晚上日语课上了好久,天气也不好, 2.项目上全力以赴的一天。 3.感谢父母,感谢朋友感谢家人,感谢不断进步的自己。...

深入浅出,SpringBoot整合Quartz实现定时任务与Redis健康检测(一)
目录 前言 环境配置 Quartz 什么是Quartz? 应用场景 核心组件 Job JobDetail Trigger CronTrigger SimpleTrigger Scheduler 任务存储 RAM JDBC 导入依赖 定时任务 销量统计 Redis检测 使用 编辑 注意事项 前言 在悦享校园1.0中引入了Quart…...
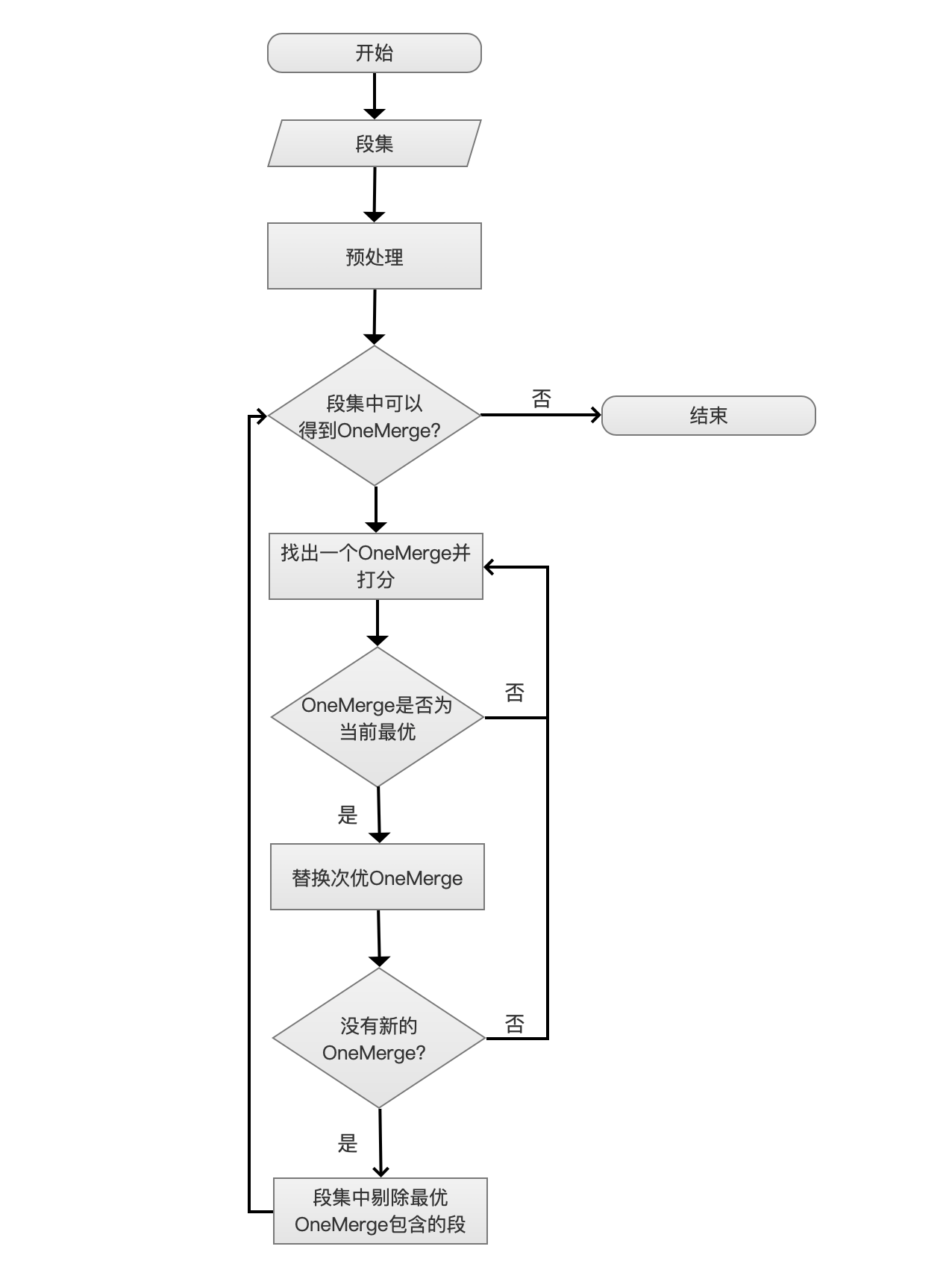
Lucene-MergePolicy详解
简介 该文章基于业务需求背景,因场景需求进行参数调优,下文会尽可能针对段合并策略(SegmentMergePolicy)的全参数进行说明。 主要介绍TieredMergePolicy,它是Lucene4以后的默认段的合并策略,之前采用的合并…...

数据的加解密
文章目录 分类特点业务的使用补充 分类 对称加密算法非对称加密算法 特点 对称加密算法 : 加密效率高 !加密和解密都使用同一款密钥 但是有一个问题 : 密钥如何从服务端发给客户端? (假如你直接先将密钥发给对方,要是在过程中被黑客技术破解了,那后面的消息也就泄漏了) (后…...

【Spring】更简单的读取和存储对象
更简单的读取和存储对象 一. 存储 Bean 对象1. 前置工作:配置扫描路径2. 添加注解存储 Bean 对象Controller(控制器存储)Service(服务存储)Repository(仓库存储)Component(组件存储&…...
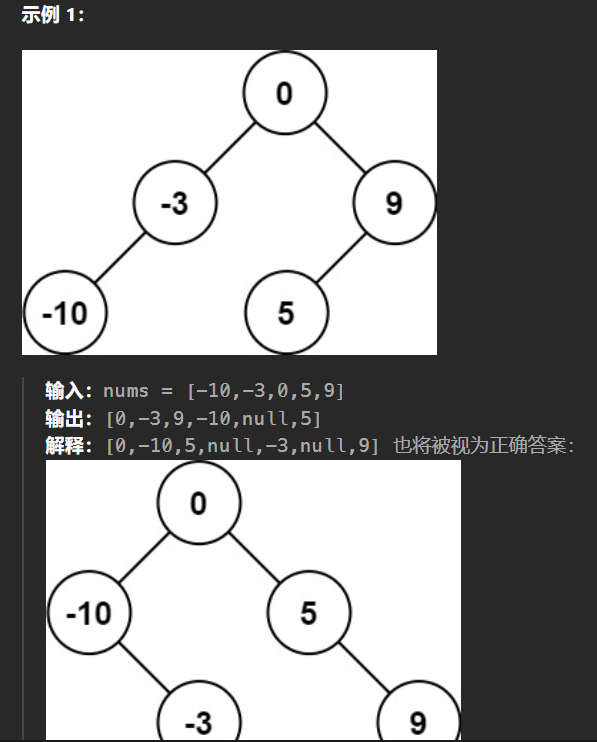
【LeetCode热题100】--108.将有序数组转换为二叉搜索树
108.将有序数组转换为二叉搜索树 给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。 高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。 二叉搜索树的中序遍历是升序…...

Redis学习笔记(下):持久化RDB、AOF+主从复制(薪火相传,反客为主,一主多从,哨兵模式)+Redis集群
十一、持久化RDB和AOF 持久化:将数据存入硬盘 11.1 RDB(Redis Database) RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。 备份…...

【智能家居项目】裸机版本——设备子系统(LED Display 风扇)
🐱作者:一只大喵咪1201 🐱专栏:《智能家居项目》 🔥格言:你只管努力,剩下的交给时间! 输入子系统中目前仅实现了按键输入,剩下的网络输入和标准输入在以后会逐步实现&am…...

[Linux]记录plasma-wayland下无法找到HDMI接口显示器的问题解决方案
内核:Linux 6.5.5-arch1-1 Plasma 版本:5.27.8 窗口系统:Wayland 1 问题 在前些时候置入了一块显示器,接口较多,有 HDMI 接口,type-C 接口。在 X11 中可以找到外接显示器,但是卡顿明显…...

【计算机网络】高级IO之select
文章目录 1. 什么是IO?什么是高效 IO? 2. IO的五种模型五种IO模型的概念理解同步IO与异步IO整体理解 3. 阻塞IO4. 非阻塞IOsetnonblock函数为什么非阻塞IO会读取错误?对错误码的进一步判断检测数据没有就绪时,返回做一些其他事情完整代码myt…...

如何设计一个高效的应用缓冲区【一个动态扩容的buffer类】
文章目录 前言一、为什么需要设计应用层缓冲区必须要有 output buffer目的问题output buffer的解决方案: 必须要有 input buffer总结 二、设计要点三、buffer设计思路基础函数关于iovec与readv readfd如何实现动态扩容 问题 前言 在上一个博客,我们介绍…...

图像处理初学者导引---OpenCV 方法演示项目
OpenCV 方法演示项目 项目地址:https://github.com/WangQvQ/opencv-tutorial 项目简介 这个开源项目是一个用于演示 OpenCV 方法的工具,旨在帮助初学者快速理解和掌握 OpenCV 图像处理技术。通过这个项目,你可以轻松地对图像进行各种处理&a…...
管道-匿名管道
一、管道介绍 管道(Pipe)是一种在UNIX和类UNIX系统中用于进程间通信的机制。它允许一个进程的输出直接成为另一个进程的输入,从而实现数据的流动。管道是一种轻量级的通信方式,用于协调不同进程的工作。 1. 创建和使用管道&#…...

【JavaEE基础学习打卡08】JSP之初次认识say hello!
目录 前言一、JSP技术初识1.动态页面2.JSP是什么3.JSP特点有哪些 二、JSP运行环境配置1.JDK安装2.Tomcat安装 三、编写JSP1.我的第一个JSP2.JSP执行过程3.在IDEA中开发JSP 总结 前言 📜 本系列教程适用于JavaWeb初学者、爱好者,小白白。我们的天赋并不高…...
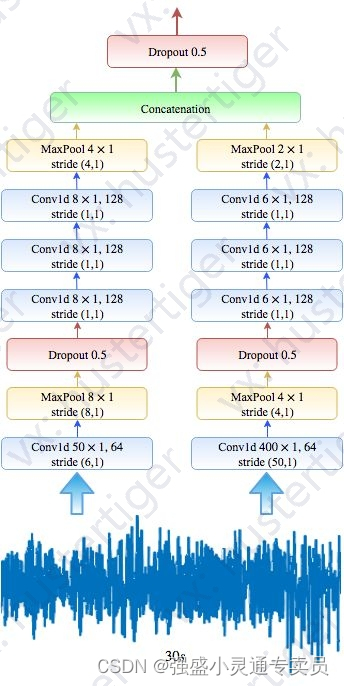
使用序列到序列深度学习方法自动睡眠阶段评分
深度学习方法,用于使用单通道脑电图进行自动睡眠阶段评分。 def build_firstPart_model(input_var,keep_prob_0.5):# List to store the output of each CNNsoutput_conns []######### CNNs with small filter size at the first layer ########## Convolutionnetw…...
【算法】排序——选择排序和交换排序(快速排序)
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法头疼记:算法专栏…...

FPGA设计实战:别再乱用复位了!同步、异步与异步复位同步释放的Verilog代码避坑指南
FPGA设计实战:复位电路设计的黄金法则与Verilog避坑指南 在FPGA开发的世界里,复位电路就像交响乐团的指挥——它决定了整个系统能否从混沌走向有序。许多工程师往往低估了复位设计的重要性,直到项目后期遭遇难以追踪的亚稳态问题或时序收敛失…...

微信聊天记录完整导出指南:无需越狱的本地化解决方案
微信聊天记录完整导出指南:无需越狱的本地化解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录承载着珍贵的工作沟…...
)
KUKA机器人FSoE安全地址丢了别慌!手把手教你用WorkVisual 6.0找回(附KRC4标准柜地址表)
KUKA机器人FSoE安全地址丢失应急修复指南:WorkVisual 6.0实战全解析 当产线突然报警停机,示教器闪烁"FSoE安全地址丢失"的红色警告时,经验丰富的维护工程师都知道——这往往是EtherCAT网络拓扑结构异常引发的紧急故障。尤其在采用K…...

深入解析Arm Cortex-A53 Cache架构:从原理到多核一致性与性能优化实践
1. 项目概述:为什么我们需要深入理解A53的Cache?在嵌入式系统和移动计算领域,Arm Cortex-A53处理器是一个绕不开的名字。作为Armv8-A架构下的“小核”常青树,它以其出色的能效比,广泛存在于从智能手表到智能电视&#…...

Head Activator ;pPPGGSKVILF
一、基础信息多肽名称:头部激活因子三字母序列:Pyr-Pro-Pro-Gly-Gly-Ser-Lys-Val-Ile-Leu-Phe单字母序列:pPPGGSKVILF氨基酸数量:11 aa分子式:C54H84N12O14分子量:1125.34结构特征:N 端 Pyr&…...

卡尔曼滤波:从原理到工程实践,掌握状态估计的核心算法
1. 从“猜”到“算”:一个工程师眼中的卡尔曼滤波 如果你在自动驾驶、机器人导航、无人机飞控或者金融数据分析等领域摸爬滚打过,那么“卡尔曼滤波”这个名字对你来说,可能既熟悉又陌生。熟悉是因为它无处不在,是解决“状态估计”…...

基于HalloWing的动态眼睛驯鹿面具制作:嵌入式系统与互动艺术的融合实践
1. 项目概述:当驯鹿面具“活”过来几年前我第一次在Maker Faire上看到那些会眨眼、会转动的电子眼睛道具时,就被深深吸引了。那种将静态面具赋予生命力的魔法,一直让我心痒痒。直到我遇到了Adafruit的HalloWing开发板,这个专为“眼…...
基于CircuitPython与NeoPixel的智能圣诞树:从硬件搭建到动态灯光算法
1. 项目概述:从零打造一棵会“思考”的圣诞树又到年底了,看着家里那棵年复一年、只会默默发光的传统圣诞树,总觉得少了点“灵魂”。作为一个常年和微控制器、代码打交道的创客,我总琢磨着能不能给节日装饰加点科技感,让…...

KRTS实时内核开发环境搭建:手把手教你配置隔离CPU与Visual Studio联调
KRTS实时内核开发环境搭建:手把手教你配置隔离CPU与Visual Studio联调 在工业自动化、机器人控制和高频交易等硬实时应用领域,毫秒级的延迟差异可能导致整个系统失效。KRTS(Kithara RealTime Suite)作为Windows平台上的实时扩展解…...

【软考高级架构】论文范文21——论Kappa架构在大数据平台中的设计与应用
论Kappa架构在大数据平台中的设计与应用 摘要 随着大数据技术的快速发展,传统Lambda架构因需要同时维护批处理和流处理两套系统,导致开发复杂度高、数据口径不一致、运维成本大等问题日益突出。Kappa架构作为一种精简的统一处理范式,通过将数据全部视为流、以消息队列为核…...