Flask入门(10):Flask使用SQLAlchemy
目录
- 11.SQLAlchemy
- 11.1 简介
- 11.2 安装
- 11.3 基本使用
- 11.4 连接
- 11.5 数据类型
- 11.6 执行原生sql
- 11.7 插入数据
- 11. 8 删改操作
- 11.9 查询
11.SQLAlchemy
11.1 简介
SQLAlchemy的是Python的SQL工具包和对象关系映射,给应用程序开发者提供SQL的强大功能和灵活性。它提供了一套完整的企业级的持久性模式,专为高效率和高性能的数据库访问,改编成简单的Python的领域语言。
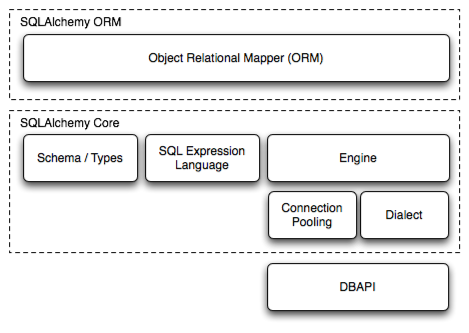
SQLAlchemy是Python界的ORM(Object Relational Mapper)框架,它两个主要的组件: SQLAlchemy ORM 和 SQLAlchemy Core 。
11.2 安装
pip install SQLAlchemy
11.3 基本使用
创建表
类使用声明式至少需要一个__tablename__属性定义数据库表名字,并至少一Column是主键
# SQLAlchemy练习
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String, UniqueConstraint, Index
from sqlalchemy.ext.declarative import declarative_base
# declarative_base类维持了一个从类到表的关系,通常一个应用使用一个base实例,所有实体类都应该继承此类对象Base = declarative_base()# 类使用声明式至少需要一个__tablename__属性定义数据库表名字,并至少一Column是主键
# 创建单表
class User(Base):__tablename__ = 'users'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(32))extra = Column(String(16))def init_db():# 数据库链接引擎engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)# 创建表Base.metadata.create_all(engine)def drop_db():engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)# 删除表Base.metadata.drop_all(engine)if __name__ == "__main__":init_db()# drop_db()
插入数据
# SQLAlchemy练习
import models
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)se = sessionmaker(bind=engine)
session = se()u1 = models.User(name='a1', extra='aa')
u2 = models.User(name='a2', extra='bb')session.add(u1)
session.add(u2)session.commit()
# session.rollback() # 回滚
session.rollback()表示回滚
11.4 连接
SQLAlchemy 把一个引擎的源表示为一个连同设定引擎选项的可选字符串参数的 URI。URI 的形式是:
dialect+driver://username:password@host:port/database
该字符串中的许多部分是可选的。如果没有指定驱动器,会选择默认的(确保在这种情况下 不 包含 + )。
Postgres:
postgresql://scott:tiger@localhost/mydatabase
MySQL:
mysql://scott:tiger@localhost/mydatabaseOracle:
oracle:
//scott:tiger@127.0.0.1:1521/sidname
SQLite (注意开头的四个斜线):
sqlite:absolute/path/to/foo.db
11.5 数据类型
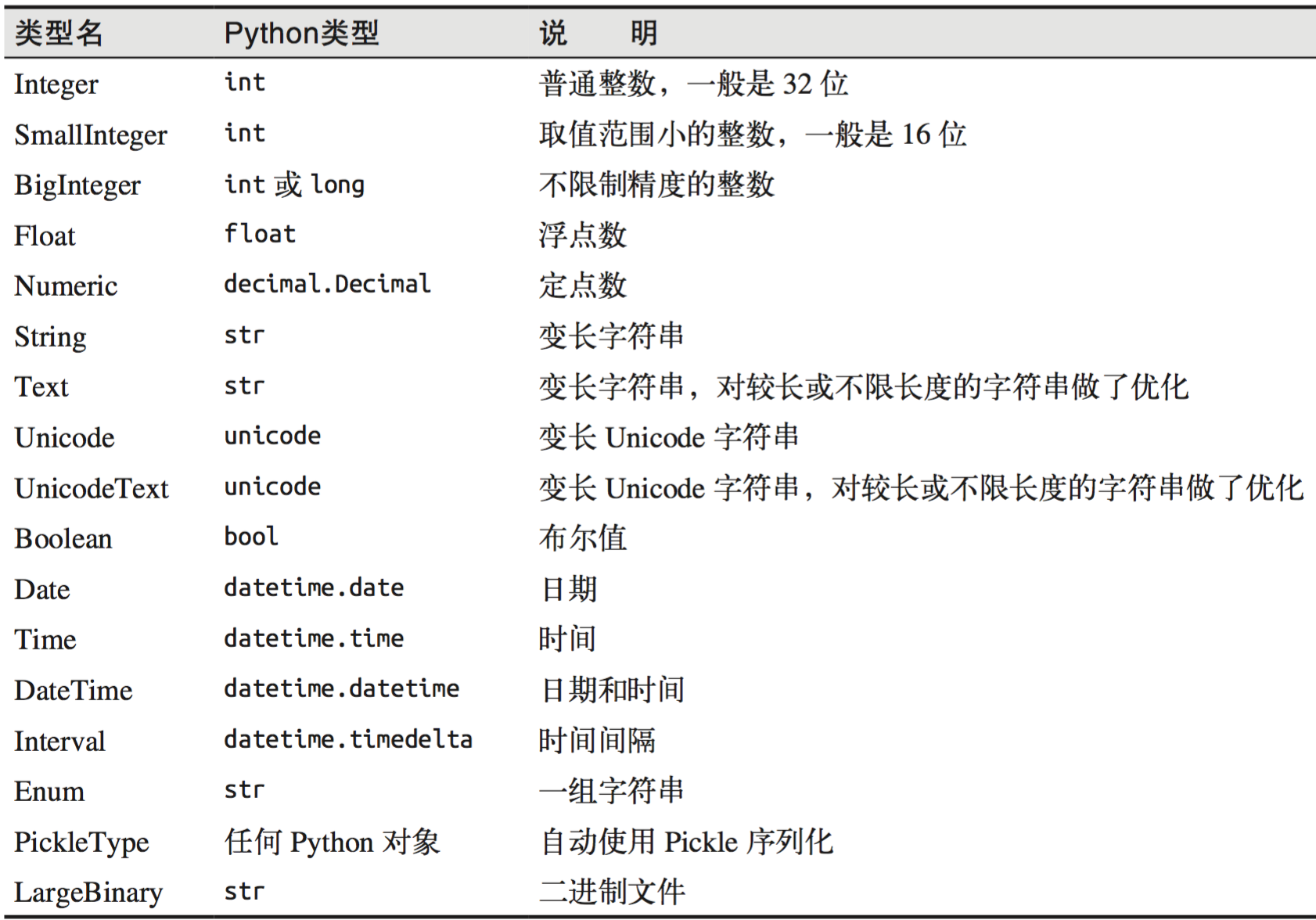
SQLAlchemy列选项:
11.6 执行原生sql
from sqlalchemy import create_engineengine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)# 执行SQL
cur = engine.execute("select * from users"
)# 获取第一行数据
re1 = cur.fetchone()
# 获取第n行数据
# re2 = cur.fetchmany(2)
# 获取所有数据
re3 = cur.fetchall()print(re3)
# 注意:当执行fetchone()后,数据已经被去除一条了,即使fetchall(),取出的数据也是从第二条数据开始的
engine.execute默认使用了数据库连接池,也可以使用DBUtils + pymysql做连接池
11.7 插入数据
创建如下表供后面增删改查使用。
models2.py
# sqlalchemy创建多个关联表
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String, UniqueConstraint, Index, DateTime, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
import datetimeBase = declarative_base()class Classes(Base):__tablename__ = 'classes'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(32), nullable=False, unique=True)class Student(Base):__tablename__ = 'student'id = Column(Integer, primary_key=True, autoincrement=True)username = Column(String(32), nullable=False, unique=True)password = Column(String(32), nullable=False)ctime = Column(DateTime, default=datetime.datetime.now) # 注意now后不要加()# 外键:对应的班级class_id = Column(Integer, ForeignKey('classes.id'))class Hobby(Base):__tablename__ = 'hobby'id = Column(Integer, primary_key=True, autoincrement=True)caption = Column(String(32), default='篮球')# 建立多对多的关系
class Student2Hobby(Base):__tablename__ = 'student2hobby'id = Column(Integer, primary_key=True, autoincrement=True)student_id = Column(Integer, ForeignKey('student.id'))hobby_id = Column(Integer, ForeignKey('hobby.id'))# 增加联合唯一索引__table_args__ = (UniqueConstraint('student_id', 'hobby_id', name='uni_student_id_hobby_id'),)def init_db():# 数据库链接引擎engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)# 创建表Base.metadata.create_all(engine)def drop_db():engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)# 删除表Base.metadata.drop_all(engine)if __name__ == "__main__":init_db()# drop_db()
上面创建完表后,开始执行插入操作:
# sqlalchemy的增删改查import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)se = sessionmaker(bind=engine)
session = se()# 单条增加
# c1 = models2.Classes(name='python入门')
# session.add(c1)
# session.commit()
# session.close()# 多条增加
# c2 = [
# models2.Classes(name='python进阶'),
# models2.Classes(name='python高级'),
# models2.Classes(name='python web')
# ]
# session.add_all(c2)
# session.commit()
# session.close()11. 8 删改操作
# sqlalchemy的增删改查import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)se = sessionmaker(bind=engine)
session = se()# 删除
# session.query(models2.Classes).filter(models2.Classes.id > 2).delete()
# session.commit()# 修改
# session.query(models2.Classes).filter(models2.Classes.id > 2).update({"name" : "099"})
session.query(models2.Classes).filter(models2.Classes.id > 2).update({models2.Classes.name: models2.Classes.name + "099"}, synchronize_session=False)
synchronize_session = False # 对字段执行字符串操作
# session.query(models2.Classes).filter(models2.Classes.id > 2).update({"num": models2.Classes.num + 1}, synchronize_session="evaluate")
# synchronize_session = 'evaluate' # 对字段执行数值型操作
session.commit()
11.9 查询
参考:Flask-SQLAlchemy - 武沛齐 - 博客园 (cnblogs.com)
1.以下的方法都是返回一个新的查询,需要配合执行器使用。
filter(): 过滤,功能比较强大,多表关联查询。
filter_by():过滤,一般用在单表查询的过滤场景。
order_by():排序。默认是升序,降序需要导包:from sqlalchemy import * 。然后引入desc方法。比如order_by(desc(“email”)).按照邮箱字母的降序排序。
group_by():分组。
2.以下都是一些常用的执行器:配合上面的过滤器使用。
get():获得id等于几的函数。
比如:查询id=1的对象。
get(1),切记:括号里没有“id=”,直接传入id的数值就ok。因为该函数的功能就是查询主键等于几的对象。
all():查询所有的数据。
first():查询第一个数据。
count():返回查询结果的数量。
paginate():分页查询,返回一个分页对象。
paginate(参数1,参数2,参数3)=>参数1:当前是第几页;参数2:每页显示几条记录;参数3:是否要返回错误。
返回的分页对象有三个属性:items:获得查询的结果,pages:获得一共有多少页,page:获得当前页。
3.常用的逻辑符:
需要导入包才能用的有:from sqlalchemy import *
not_、and_、or_ 还有上面说的排序desc。
常用的内置的有:in_:表示某个字段在什么范围之中。
4.其他关系的一些数据库查询:
endswith():以什么结尾。
startswith():以什么开头。
contains():包含
# sqlalchemy的增删改查import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)se = sessionmaker(bind=engine)
session = se()# 查询r1 = session.query(models2.Classes).all() # 返回models2.Classes对象# label相当于sql里的as,取别名,后面结果集使用也是使用别名
r2 = session.query(models2.Classes.name.label('xx'), models2.Classes.name).all()# 查询课程名字为python入门的课程
r3 = session.query(models2.Classes).filter(models2.Classes.name == "python入门").all()
# 也可使用filter_by,注意filter_by的传参和filter不一样
r4 = session.query(models2.Classes).filter_by(name='python入门').all()# 查询课程名字为python入门的课程的第一个
r5 = session.query(models2.Classes).filter_by(name='python入门').first()# 查询id<2且课程名字为python入门的课程
r6 = session.query(models2.Classes).filter(text("id<:value and name=:name")).params(value=2, name='python入门').order_by(models2.Classes.id).all()# from_statement相当于子查询
r7 = session.query(models2.Classes).from_statement(text("SELECT * FROM Classes where name=:name")).params(name='python入门').all()print(r7)
session.close()
# 注意:除了r2,其他结果都为models2.Classes对象
# 条件
ret = session.query(Users).filter_by(name='alex').all()
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2,and_(Users.name == 'eric', Users.id > 3),Users.extra != "")).all()# 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()# 限制
ret = session.query(Users)[1:2]# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()# 分组
from sqlalchemy.sql import funcret = session.query(Users).group_by(Users.extra).all()
ret = session.query(func.max(Users.id),func.sum(Users.id),func.min(Users.id)).group_by(Users.name).all()ret = session.query(func.max(Users.id),func.sum(Users.id),func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()# 连表ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
# 默认使用外键进行连表
ret = session.query(Person).join(Favor).all() # 内连接ret = session.query(Person).join(Favor, isouter=True).all() # 左连接# 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()参考:
https://blog.csdn.net/u011146423/article/details/87605812
Python开发【第十九篇】:Python操作MySQL - 武沛齐 - 博客园 (cnblogs.com)
SQLAlchemy 学习笔记_JP.Zhang-CSDN博客
相关文章:

Flask入门(10):Flask使用SQLAlchemy
目录11.SQLAlchemy11.1 简介11.2 安装11.3 基本使用11.4 连接11.5 数据类型11.6 执行原生sql11.7 插入数据11. 8 删改操作11.9 查询11.SQLAlchemy 11.1 简介 SQLAlchemy的是Python的SQL工具包和对象关系映射,给应用程序开发者提供SQL的强大功能和灵活性。它提供了…...

我的 System Verilog 学习记录(4)
引言 本文简单介绍 System Verilog 语言的 数据类型。 前文链接: 我的 System Verilog 学习记录(1) 我的 System Verilog 学习记录(2) 我的 System Verilog 学习记录(3) 数据类型简介 Sys…...

Git : 本地分支与远程分支的映射关系
概述 本文介绍 git 环境中本地分支与远程分支的映射关系的查看和调整。 1、查看本地分支与远程分支的映射关系 执行如下命令: git branch -vv注意就是两个 v ,没有写错。 可以获得分支映射结果: dev fa***** [github/dev] update * main…...
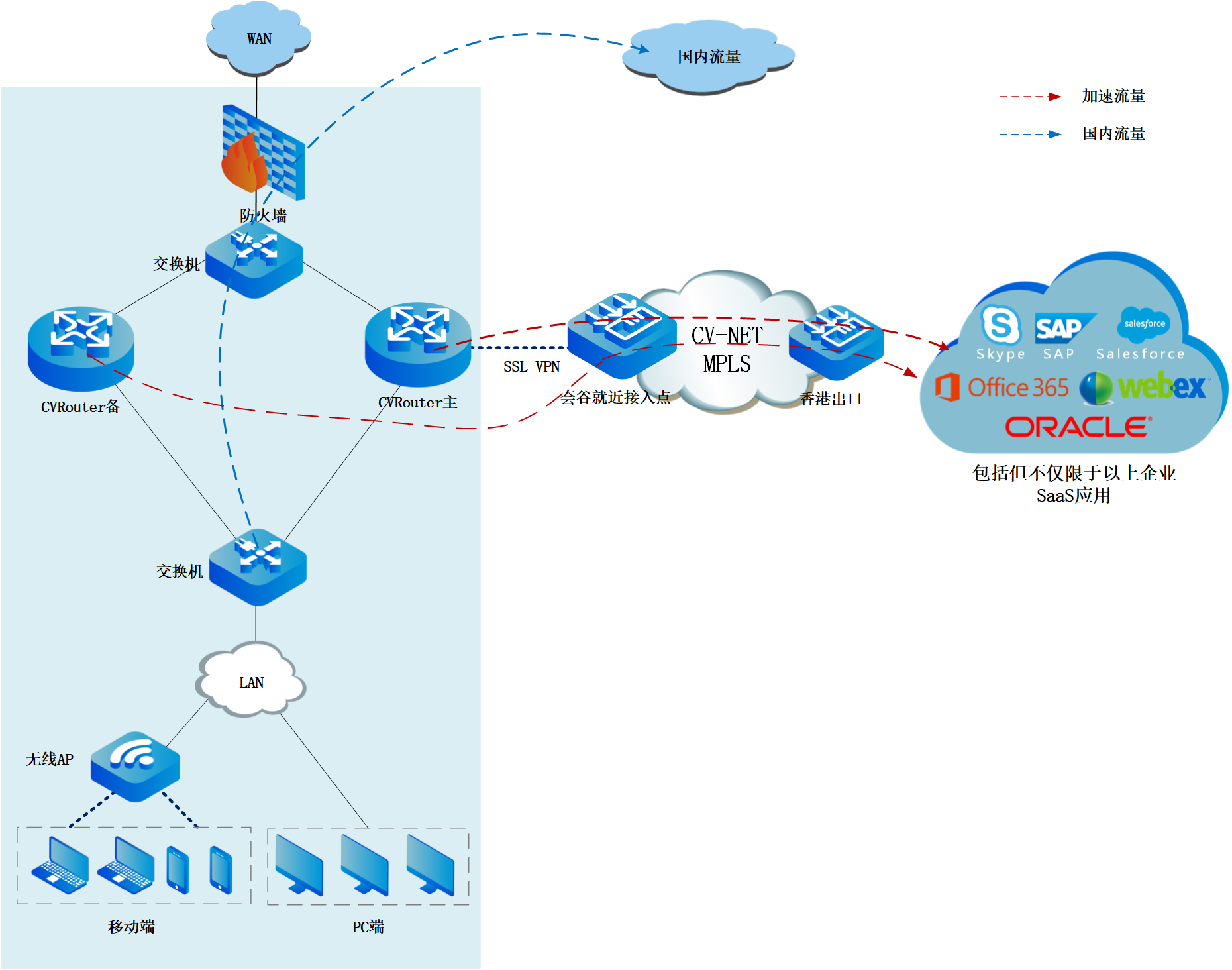
运维必看|跨国公司几千员工稳定访问Office365,怎么实现?
【客户背景】本次分享的客户是全球传感器领域的领导者,其核心产品为电流和电压传感器,被广泛应用于驱动和焊接、可再利用能源以及电源、牵引、高精度、传统和新能源汽车等领域。 作为一家中等规模的全球化公司,该公司在北京、日本、西欧、东欧…...

Python GDAL读取栅格数据并基于质量评估波段QA对指定数据加以筛选掩膜
本文介绍基于Python语言中gdal模块,对遥感影像数据进行栅格读取与计算,同时基于QA波段对像元加以筛选、掩膜的操作。本文所要实现的需求具体为:现有自行计算的全球叶面积指数(LAI).tif格式栅格产品(下称“自…...

Vue3:有关v-model的用法
目录 前言: 回忆基本的原生用法: 原生input的封装: 自定义v-model参数: 对el-input的二次封装: 多个v-model进行绑定: v-model修饰符: v-model自定义参数与自定义修饰符的结合: 前言&am…...

CF1692C Where‘s the Bishop? 题解
CF1692C Wheres the Bishop? 题解题目链接字面描述题面翻译题目描述题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示代码实现题目 链接 https://www.luogu.com.cn/problem/CF1692C 字面描述 题面翻译 题目描述 有一个888\times888的棋盘,列编号从…...
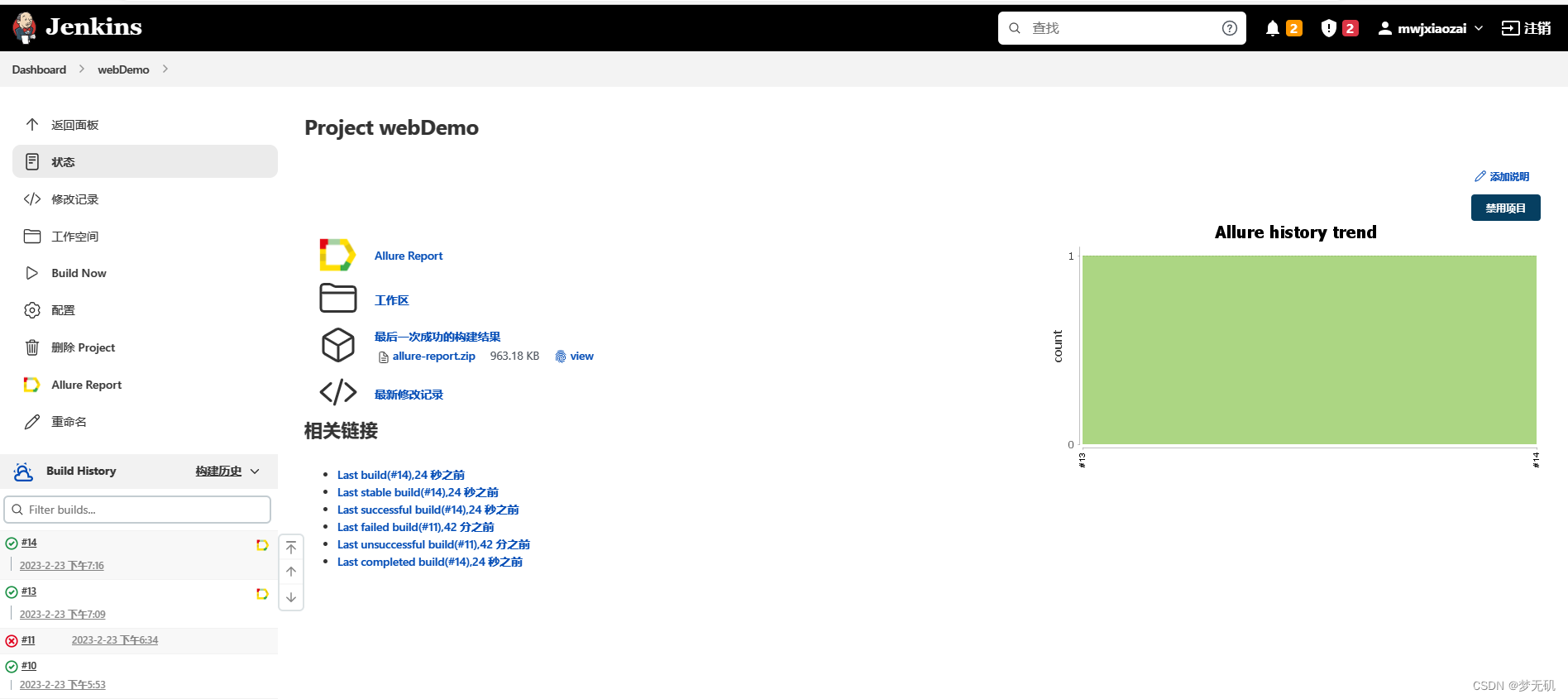
Jenkins集成Allure报告
Jenkins集成Allure报告 紧接上文:Jenkins部署及持续集成——傻瓜式教程 使用Allure报告 1、在插件库下载Allure插件Allure Jenkins Plugin 2、在构建后操作中加入allure执行的报告目录(相对于项目的路径) 3、run.py代码改成如下 import p…...
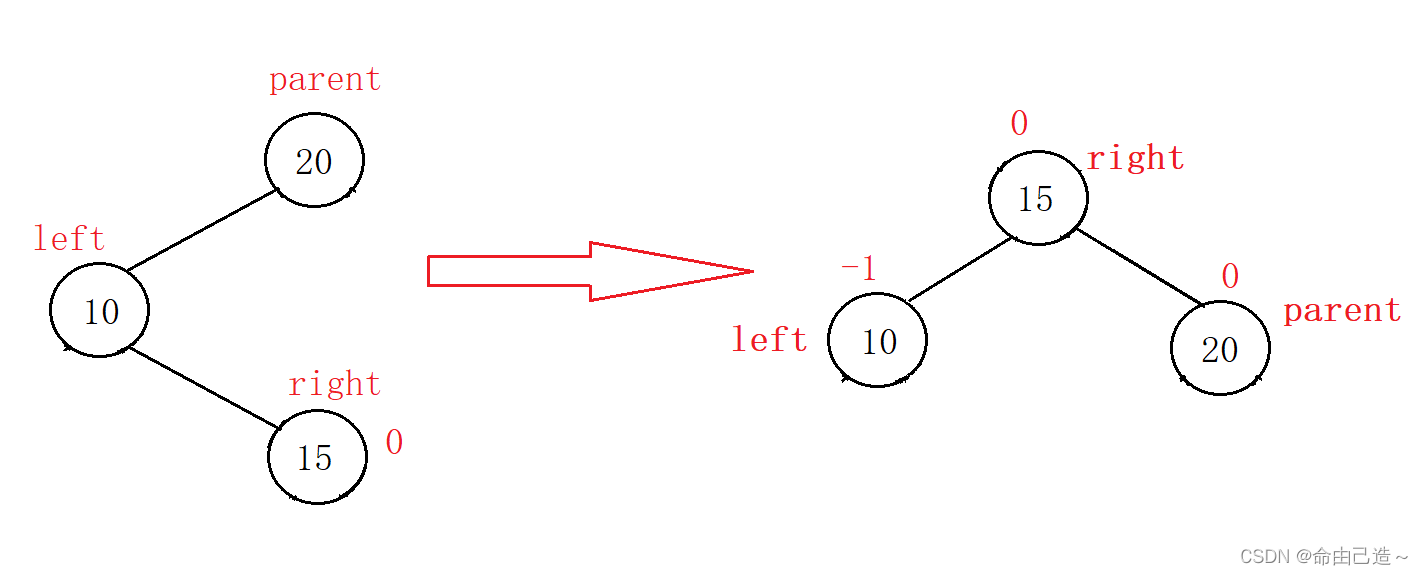
【数据结构】AVL树
AVL树一、AVL树的概念二、AVL的接口2.1 插入2.2 旋转2.2.1 左单旋2.2.2 右单旋2.2.3 左右双旋2.2.4 右左双旋三、验证四、源码一、AVL树的概念 当我们用普通的搜索树插入数据的时候,如果插入的数据是有序的,那么就退化成了一个链表,搜索效率…...

这一次我不再低调,老板法拉利的车牌有我的汗水
起源: 5Why分析法最初是由丰田佐吉提出的,后来,丰田汽车公司在发展完善其制造方法学的过程中持续采用该方法。5Why分析法作为丰田生产系统的入门课程之一,是问题求解的关键培训课程。丰田生产系统的设计师大野耐一曾将5Why分析法描述为:“丰田科学方法的基础,重复五次,问…...

通过连接另一个数组的子数组得到一个数组
给你一个长度为 n 的二维整数数组 groups ,同时给你一个整数数组 nums 。 你是否可以从 nums 中选出 n 个 不相交 的子数组,使得第 i 个子数组与 groups[i] (下标从 0 开始)完全相同,且如果 i > 0 ,那么…...

公派访问学者的申请条件
知识人网海外访问学者申请老师为大家分享公派访问学者申请的基本条件以及哪些人员的申请是暂不受理的,供大家参考:一、 申请人基本条件:1.热爱社会主义祖国,具有良好的思想品德和政治素质,无违法违纪记录。2.具有良好专…...
多点电容触摸屏实验
目录 一、简介 二、硬件原理 编辑1、CT_INT 2、I2C2_SCL和I2C2_SDA 3、RESET复位引脚 三、FT54x6/FT52x6电容触摸芯片 四、代码编写 1、编写ft5426.h 2、编写ft5426.c 3、main函数 一、简介 电容屏只需要手指轻触即可,而电阻屏是需要手指给予一定的压力才…...

【算法与数据结构(C语言)】栈和队列
文章目录 目录 前言 一、栈 1.栈的概念及结构 2.栈的实现 入栈 出栈 获取栈顶元素 获取栈中有效元素个数 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 销毁栈 二、队列 1.队列的概念及结构 2.队列的实现 初始化队列 队尾入队列 队头出队列 获…...
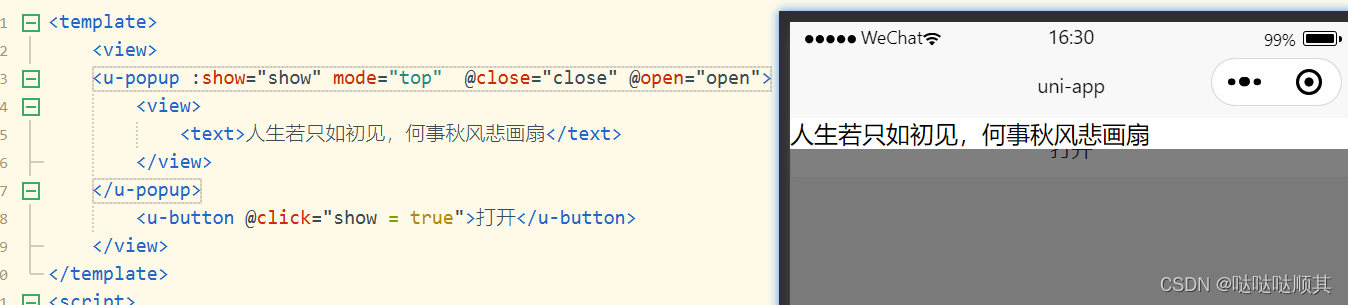
Uni-app使用vant和uview组件
目录 1.安装vant组件 1.1安装前需知 1.2.安装 1.3.创建uni-app项目 2.安装uview-ui组件 2.1官网 2.2安装 2.3安装成功 1.安装vant组件 1.1安装前需知 小程序能使用vant-weapp组件,且官网的安装是直接导入小程序中,不能直接导入uni-app框架中 V…...
2023年PMP考试应该注意些什么?
首先注意(报考条件) 2023年PMP考试报名流程: 一、PMP英文报名: 英文报名时间无限制,随时可以报名,但有一年的有效期,所以大家尽量提前报名,在英文报名有效期内进行中文报名。 英…...
selenium环境安装及使用
selenium简介官网https://www.selenium.dev简介用于web浏览器测试的工具支持的浏览器包括IE,Firefox,Chrome,edge等使用简单,可使用java,python等多种语言编写用例脚本主要由三个工具构成,webdriver,IDE,web自动化环境…...
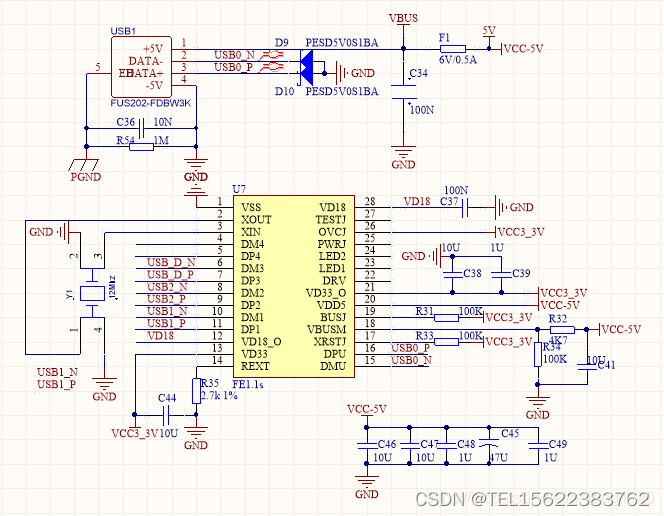
高性能低功耗4口高速USB2.0 HUB 完美替代FE1.1S和FE8.1
该NS1.1s是一个高度集成的,高品质,高性能,低功耗,为USB 2.0高速4端口集线器又低成本的解决方案。 (点击即可咨询芯片详细信息) NS1.1s的特点 1.通用串行总线规范修订版2.0(USB 2.0)完…...
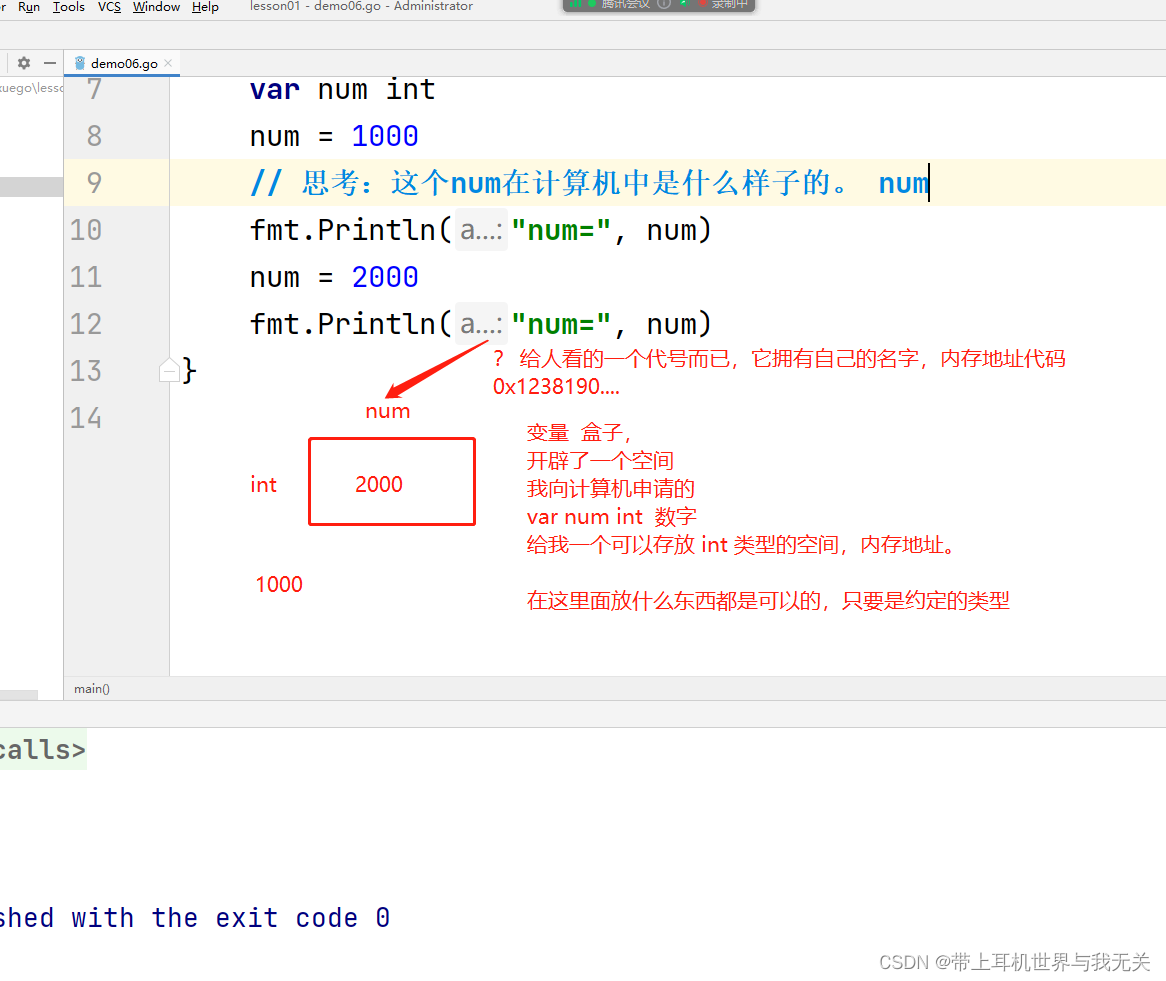
Go全栈学习(一)基础语法
Go语言基础语法 文章目录Go语言基础语法注释变量变量的定义变量的交换理解变量(内存地址)匿名变量变量的作用域常量2023.2.4日 总结// 关于Goland 中 执行的问题// 1、包下执行 (一个 main 函数来执行,如果有多个,无法…...
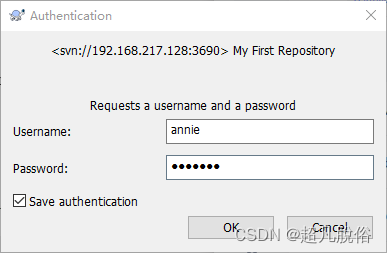
centos7搭建svn配置
基本概述 Apache Subversion(简称SVN,svn),一个开放源代码的版本控制系统,相较于RCS、CVS,它采用了分支管理系统,它的设计目标就是取代CVS。互联网上很多版本控制服务已从CVS转移到Subversion。…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...

如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南
如何用Untrunc拯救损坏视频?2025年终极MP4修复工具完全指南 【免费下载链接】untrunc Restore a damaged (truncated) mp4, m4v, mov, 3gp video. Provided you have a similar not broken video. 项目地址: https://gitcode.com/gh_mirrors/unt/untrunc 当你…...

终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣
终极崩坏星穹铁道自动化指南:3分钟掌握解放双手的智能游戏伴侣 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://git…...

VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案
VideoDownloadHelper终极指南:解锁浏览器视频下载的完整解决方案 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网…...

如何用OpenHRMS打造企业级人力资源管理系统:30+模块完全指南
如何用OpenHRMS打造企业级人力资源管理系统:30模块完全指南 【免费下载链接】OpenHRMS 项目地址: https://gitcode.com/gh_mirrors/op/OpenHRMS 还在为繁琐的人力资源管理头疼吗?🤔 面对员工考勤、薪酬计算、绩效评估等复杂流程&…...

条件Shapley值:用shapr包实现更公平的模型可解释性
1. 项目概述与核心价值 如果你在数据科学或机器学习领域工作过一段时间,尤其是在需要向业务方或非技术团队解释模型决策的场景里,你肯定遇到过这样的困境:模型预测准确率很高,但当别人问“为什么这个客户的贷款申请被拒绝了&#…...
)
【仅限首批200家认证用户】DeepSeek v3.2.1重复检测私有化部署补丁包(含GPU内存泄漏热修复+增量扫描加速模块)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力…...

SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用
SillyTavern桌面版终极指南:三步打造你的专属AI聊天桌面应用 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 还在为复杂的命令行启动和浏览器标签混乱而烦恼吗?Sill…...

023、深度可分离卷积:MobileNet背后的计算优化
深度可分离卷积:MobileNet背后的计算优化 一个让我加了两天班的bug 去年调试一块基于Cortex-M7的AI推理引擎,跑MobileNetV1时发现推理速度比理论计算慢了整整一个数量级。当时我盯着逻辑分析仪上的波形,CPU在卷积层卡了将近300ms——这不对劲,理论计算应该只要30ms。 排…...

3分钟学会Avidemux:开源视频编辑器的完整快速入门指南
3分钟学会Avidemux:开源视频编辑器的完整快速入门指南 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾因为视频编辑软件过于复杂而放弃剪辑?或者因为专业软件价格昂…...