Day 04 python学习笔记
Python数据容器
元组
元组的声明
变量名称=(元素1,元素2,元素3,元素4…….) (元素类型可以不同)
eg:
tuple_01 = ("hello", 1, 2,-20,[11,22,33])
print(type(tuple_01))结果:
<class 'tuple'>元组的定义
定义空元组
变量名称=()
变量名称=tuple()
元组的嵌套
((),())
下标索引取出元素====与列表相同
元组的强制转换
typle() 强制转换
元组与列表的区别:
- 符号:元组( ) 列表[ ]
- 元组的元素一旦定义,不可更改 而列表可以 (最大的区别)
eg:
tuple_01[1] = "l love you"结果:
Traceback (most recent call last):File "D:\pycharm\main.py", line 5, in <module>tuple_01[1] = "l love you"
TypeError: 'tuple' object does not support item assignment因为元组的元素一旦定义,不可更改
但是:元组里列表元素里的值可以改变
eg:
tuple_01 = ("hello", 1, 2,20,[11,22,33])
print(tuple_01)
tuple_01[-1][0] = "l love you"
print(tuple_01)结果:
('hello', 1, 2, 20, [11, 22, 33])
('hello', 1, 2, 20, ['l love you', 22, 33])
元组切片
元组的切片和字符串、列表的切片是一样的
eg:
tuple_01 = ("hello", 1, 2,-20,[11,22,33])
print(tuple_01[1:4]) 结果:
(1, 2, 20)推荐网站:python在线演示 Python compiler - visualize, debug, get AI help from ChatGPT
这个可以让你清晰的观看到python的运行过程 (这是python官方网站,用图清晰的表示代码的运行顺序)
元组、列表、字符串公用的方法
len () 求元组的长度(与字符串、列表用法相同)
eg:
tuple_01 = ("hello", 1, 2,20,[11,22,33])
len(tuple_01)
print(len(tuple_01))结果:
5
max (列表/字符串/元组名) 求最大 值 (若是字符、字母按照ASCII码表进行比较)
min (列表/字符串/元组名) 求最小值(若是字符、字母按照ASCII码表进行比较)
元组的注意事项:
元组的特殊写法:t = 1, 2, 3 也是元组
eg:
t = (1, 2, 3)
print(type(t))
t1 = 1, 2, 3
print(type(t1))结果:
<class 'tuple'>
<class 'tuple'>
单个数字 t = (2) 这是整型,因为解释器认为 () 是运算符
解决方法 t = (2, ) 这即是元组
结论:只有一个元素时,元组后面必须带 ,
eg:
t1 = (2)
print(type(t1))
t2 = (2, )
print(type(t2))结果:
<class 'int'>
<class 'tuple'>
元组的乘法
eg:
>>> t=(22,)
>>> t*10
(22, 22, 22, 22, 22, 22, 22, 22, 22, 22)
>>>元组的方法:
index
元组.index(元素) 查询某元素下标
eg:
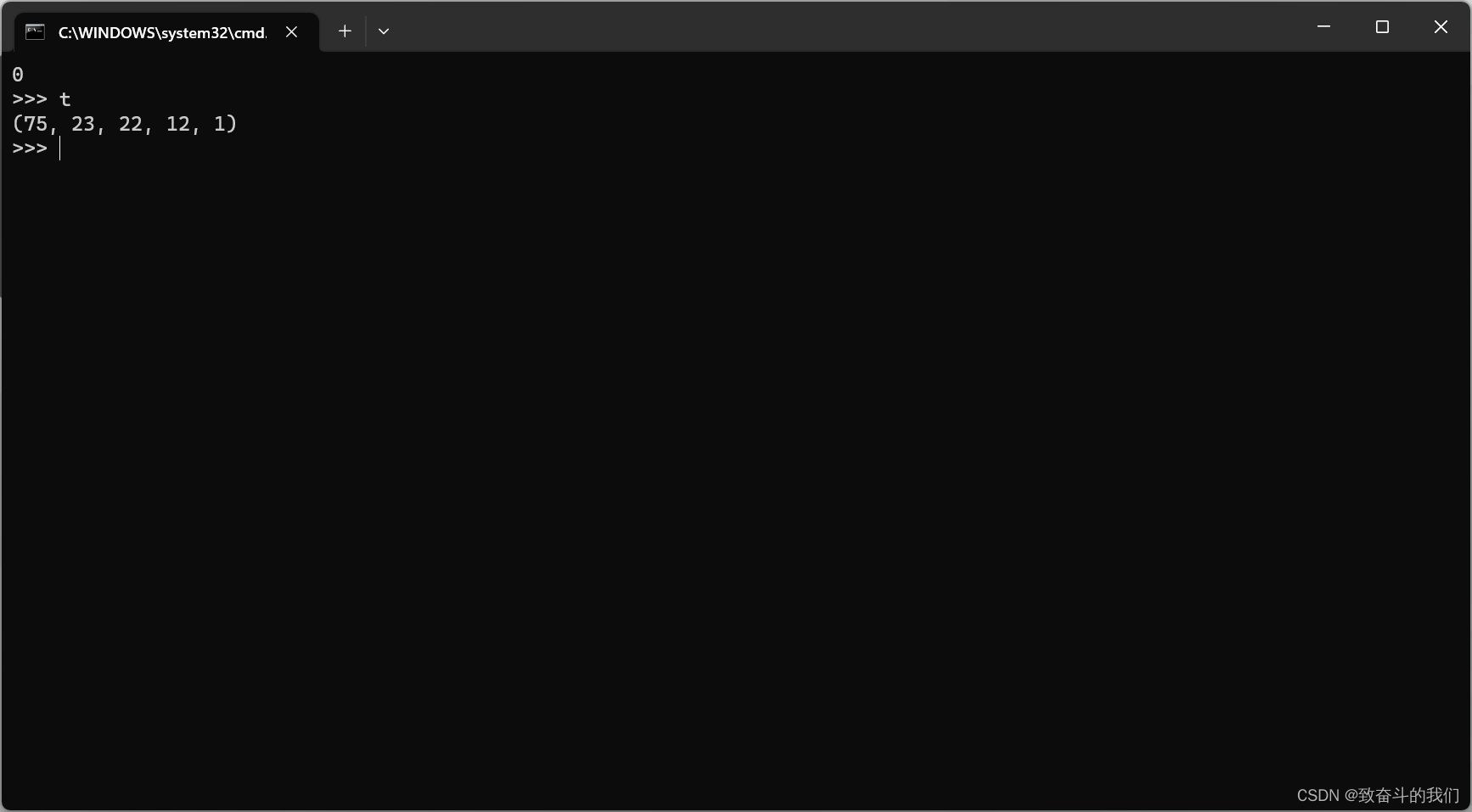
>>> t=(75,23,22,12,1)
>>> t
(75, 23, 22, 12, 1)
>>> t.index(22)
2 #索引下标为2时为22
>>> t.index(222) #没有时报错
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: tuple.index(x): x not in tuple
>>>count
元组.count(元素) 统计某元素在列表中的数量
eg:
>>> t1=(1,2,3,4,2,2,2,3)
>>> t1
(1, 2, 3, 4, 2, 2, 2, 3)
>>> t1.count(2)
4
>>>因为元组不能更改,所以他的方法只有两种
并且看过我Day 03学习笔记的应该了解,这两种方法在列表里也有
集合
不支持元素重复,内部元素无序 (可用于去重)
变量名称={元素,元素,元素..........}
变量名称=set() (创建空集合的唯一办法)注意:{ 元素 } { }内至少有一个元素,此时才是集合,无元素为空集合
set_01={'gouxin','zhangsan','gouxin','zhangsan','gouxin','zhangsan'}
print(set_01)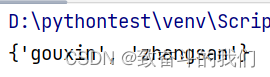
eg:
set_01 = set("12345") #名称尽量不要起set,这是关键字,set()函数,
print(set_01) #大部分解释器会报错
set_02 = set("123451111111122223333444")
print(set_02)
set_03 = set([1,2,3,4]) #可能解释器会爆红,这是不推荐,但可以
print(set_03)
set_04 = set([1,2,3,4,1,1,1,1,2,2,2])
print(set_04)
set_05 = set((10,20,30,1,1,1))
print(set_05)d = {"姓名":"zs","年龄":18
} #简单的字典形式,后面会详细讲
set_06 = set(d) #转换为集合
print(set_06)结果:
{'2', '3', '4', '1', '5'} #无序的,你第二遍运行可能就会不同
{'2', '3', '4', '1', '5'} #去除重复的元素
{1, 2, 3, 4} #按大小顺序给我们显示出来
{1, 2, 3, 4} #也会给我们去重
{1, 10, 20, 30} #按大小顺序给我们显示出来,同时去重
{'年龄', '姓名'} #会把字典里的键名放在集合里变量名称 = set( 元素 ) 元素数据类型只能是字符串、列表、元组、字典
变量名称 = { 元素} 元素数据类型只能是数字、字符串、元组
集合的方法
常用操作
不支持下标索引访问(因为集合本身是无序的)
允许修改
| 集合.add(元素) | 将指定的元素添加到集合内 |
| 1集合.update(2集合) | 将两集合合并,合并到1集合里(2集合不变) |
| 集合.remove(元素) | 将指定的元素,从集合中移除 |
| 集合.pop() | 随机取出一个元素 |
| 集合.discard(元素) | 删除指定元素,不存在不做任何操作 |
| 集合一.intersection(集合二) | 集合一与集合二的交集,原集合不变 |
| 集合一.union(集合二) | 两个集合进行合并 ,原集合不变 |
| 集合一.difference(集合二) | 差集,取出集合一有而集合二没有的,原集合不改变 |
集合一.difference_update(集合二) | 消除差集:在集合一内,删除和集合二相同的元素 集合一改变,集合二不变 |
| 集合.clear() | 清空集合 |
| len(集合) | 统计集合中元素的数量 |
| 集合.copy() | 拷贝集合 |
| for in | 集合的遍历 |
add
集合.add(元素) 将指定的元素添加到集合内
eg:
set_01 = {1,2,3,"l love"}
print(set_01)
set_01.add("you")
print(set_01)结果:
{1, 2, 3, 'l love'}
{'you', 1, 2, 3, 'l love'} #因为集合本身是无序的
update
1集合.update(2集合) 将两集合合并,合并到1集合里(2集合不变)
eg:
print(set_01)
set_02 =(4,5,6)
print(set_02)
set_01.update(set_02)
print(set_01)
print(set_02)结果:
{1, 2, 3, 'l love', 'you'}
(4, 5, 6)
{1, 2, 3, 'l love', 4, 5, 6, 'you'} #集合的排列是随机排列的
(4, 5, 6)remove
集合.remove(元素) 将指定的元素,从集合中移除
eg:
print(set_01)
set_01.remove(4)
print(set_01)
set_01.remove(4)结果:
{1, 2, 3, 4, 5, 6, 'you', 'l love'}
{1, 2, 3, 5, 6, 'you', 'l love'}
Traceback (most recent call last): #4不存在,报错File "D:\pycharm\main.py", line 39, in <module>set_01.remove(4)
KeyError: 4pop
集合.pop() 随机取出一个元素
eg:
print(set_01)
set_01.pop()
print(set_01)结果:
{1, 2, 3, 4, 5, 6, 'l love', 'you'}
{2, 3, 4, 5, 6, 'l love', 'you'}discard
集合.discard(元素) 删除指定元素,不存在,则不做任何操作
eg:
print(set_01)
set_01.discard("you")
print(set_01)
set_01.discard("you") #不存在,也不会报错
print(set_01)结果:
{1, 2, 3, 4, 5, 6, 'you', 'l love'}
{1, 2, 3, 4, 5, 6, 'l love'}
{1, 2, 3, 4, 5, 6, 'l love'} #不存在,则不做任何操作交集和并集
& 交集 求相交的(共有的)
| 并集 求合并的(两集合合并,并且去重)
eg:
set_01 = {1,2,3,5,6,"l love"}
set_02 = {4,5,6,"l love","you"}
print(set_01 & set_02) #求相交的(共有的)
print(set_01 | set_02) #求合并的(两集合合并,并且去重)
print(set_01)
print(set_02)结果:
{'l love', 5, 6}
{1, 2, 3, 'you', 5, 6, 4, 'l love'}
{1, 2, 3, 5, 6, 'l love'} #不会改变集合本身
{'you', 4, 5, 6, 'l love'}intersection
集合一.intersection(集合二) 求集合一与集合二的交集
eg:
print(set_01)
print(set_02)
set_01.intersection(set_02) #与&的效果相同
print(set_01.intersection(set_02))
print(set_01) #不会改变集合本身
print(set_02)结果:
{1, 2, 3, 5, 6, 'l love'}
{4, 5, 6, 'l love', 'you'}
{'l love', 5, 6}
{1, 2, 3, 5, 6, 'l love'}
{4, 5, 6, 'l love', 'you'}
union
集合一.union(集合二) 两个集合进行合并 ,原集合不变
eg:
print(set_01)
print(set_02)
set_01.union(set_02)
print(set_01.union(set_02))
print(set_01) #不会改变集合本身
print(set_02)结果:
{1, 2, 3, 5, 6, 'l love'}
{4, 5, 'l love', 6, 'you'}
{1, 2, 3, 4, 5, 6, 'l love', 'you'} #与 | 的效果相同,会去重
{1, 2, 3, 5, 6, 'l love'}
{4, 5, 'l love', 6, 'you'}difference
集合一.difference(集合二) 差集,取出集合一有而集合二没有的,原集合不改变
eg:
print(set_01)
print(set_02)
set_01.difference(set_02)
print(set_01.difference(set_02))
print(set_01)
print(set_02)结果:
{1, 2, 3, 'l love', 5, 6}
{'l love', 4, 5, 6, 'you'}
{1, 2, 3} #取出合一有而集合二没有的,原集合不改变
{1, 2, 3, 'l love', 5, 6}
{'l love', 4, 5, 6, 'you'}
difference_update
集合一.difference_update(集合二) 消除差集:在集合一内,删除和集合二相同的元素 集合一改变,集合二不变
eg:
print(set_01)
print(set_02)
set_01.difference_update(set_02)
print(set_01.difference_update(set_02))
print(set_01)
print(set_02)结果:
{1, 2, 3, 5, 6, 'l love'}
{4, 5, 6, 'l love', 'you'}
None #因为已经进行过一次了,使集合一已经发生改变,无操作返回None
{1, 2, 3} #集合一改变
{4, 5, 6, 'l love', 'you'} #集合二不变clear
集合.clear() 清空集合
eg:
print(set_01)
print(set_02)
set_01.clear()
print(set_01)
print(set_01.clear())
print(set_01)
print(set_02)结果:
{1, 2, 3, 5, 6, 'l love'}
{'you', 4, 5, 6, 'l love'}
set() #清空集合后返回一个set()函数,表示空集合
None #空集合无可清空,即返回None
set() #返回一个set()函数,表示空集合
{'you', 4, 5, 6, 'l love'}
len
len(集合) 集合中元素的数量
eg:
print(set_01)
len(set_01) #统计集合中元素的个数,不会直接打印
print(len(set_01))
print(set_01)结果:
{1, 2, 3, 'l love', 5, 6}
6
{1, 2, 3, 'l love', 5, 6} #不改变集合本身copy
集合.copy() 拷贝集合
eg:
print(set_01)
set_01.copy() #拷贝集合的内容,不打印
print(set_01.copy())
print(type(set_01.copy()))
print(set_01)结果:
{1, 2, 3, 'l love', 5, 6}
{1, 2, 3, 'l love', 5, 6}
<class 'set'> #类型还是集合
{1, 2, 3, 'l love', 5, 6} #不改变集合本身扩展:
在python内置解释器里,对于上述操作显示不需要了,可以用于清屏,之前的操作还是存在的
>>>import os
>>>os.system("cls")
字典
字典的定义:
字典:键值对的形式存在 (key(键):value(值))
关键字(即键)不可变 不重复(重复会爆红) 无下标索引
按照key找到value
键 可以为任意不可变数据(元组,数字,字符串)
eg:
my_dict={
key:value, #键值对
key:value,
key:value
}创建空字典
my_dict={ }
my_dict=dict()
eg:
dict_00 = {} #注意:这是字典不是集合
print(type(dict_01))
print(dict_00)dict_01 = {"uname":"zhangsan", #键是字符串(最常见)"age":18,1:18, #键是数字(1,2,3):18 #键是元组
}
print(type(dict_01))
print(dict_01)dict_02 = dict()
print(type(dict_02))
print(dict_02)dict_03 = dict((["uname","zhangsan"],["age",18])) #赋值方式
print(type(dict_03))
print(dict_03)结果:
<class 'dict'>
{}
<class 'dict'> #类型字典
{'uname': 'zhangsan', 'age': 18, 1: 18, (1, 2, 3): 18} #字典的内容
<class 'dict'>
{} #空字典
<class 'dict'>
{'uname': 'zhangsan', 'age': 18} 字典的方法
| 字典[key]=value | 新增元素 |
| del 字典[key] | 删除元素 |
| 字典[key]=value | 更新元素 |
| 字典[key] | 查询元素(值) |
| 字典.get(key) | 查询元素(值) |
| 字典.pop(key) | 删除元素 |
| 字典.clear() | 清空元素 |
| 字典.keys() | 获取全部key |
| 1、for key in keys: 2、for key in 字典 | 遍历字典 |
| len() | 统计字典的元素数量 |
增
字典[key]=value 新增元素
eg:
dict_01 = {"姓名":"张三","年龄":18
}
print(dict_01)dict_01["技能"] = "python"
print(dict_01)结果:
{'姓名': '张三', '年龄': 18}
{'姓名': '张三', '年龄': 18, '技能': 'python'}删(del关键字)
del 字典[key] 删除元素
eg:
print(dict_01)
del dict_01["姓名"]
print(dict_01)结果:
{'姓名': '张三', '年龄': 18, '技能': 'python'}
{'年龄': 18, '技能': 'python'}改(重新赋值)
字典[key]=value 更新元素
eg:
print(dict_01)
dict_01["技能"] = "安全渗透"
print(dict_01)结果:
{'年龄': 18, '技能': 'python'}
{'年龄': 18, '技能': '安全渗透'}查
字典[key] 查询元素(值)
eg:
print(dict_01)
print(dict_01["技能"])结果:
{'年龄': 18, '技能': '安全渗透'}
安全渗透查(get函数)
字典.get(key) 查询元素(值)
get函数用于在字典中获取指定键的值,可以设置默认返回值,在找的键不存在时,就会将默认值返回出来
eg:
print(dict_01)
print(dict_01.get("技能"))
print(dict_01.get("姓名"))
print(dict_01.get("姓名","l love you")) #修改默认值结果:
{'年龄': 18, '技能': '安全渗透'}
安全渗透
None #若获取的东西没有时,返回None(表示无)
l love you #将默认值修改
字典的嵌套
my_dict={
key:{
key:value, #键值对
key:value,
key:value
}}
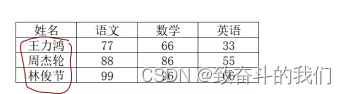
eg:
my_dict={
"王力宏":{"语文":77,"数学":66,"英语":33},
"周杰伦":{"语文":88,"数学":86,"英语":55},
"林俊杰":{"语文":99,"数学":96,"英语":66}
}
print(my_dict["王力宏"]["语文"])结果:
77
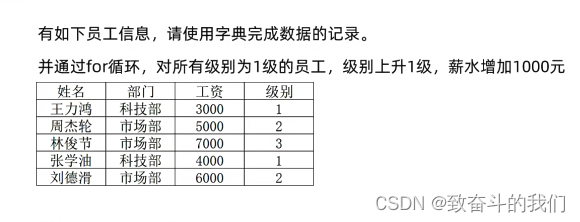
练习:

相关文章:
Day 04 python学习笔记
Python数据容器 元组 元组的声明 变量名称(元素1,元素2,元素3,元素4…….) (元素类型可以不同) eg: tuple_01 ("hello", 1, 2,-20,[11,22,33]) print(type(tuple_01))结果&#x…...
Moonbeam Ignite强势回归
参与Moonbeam上最新的流动性计划 还记得新一轮的流动性激励计划吗?Moonbeam Ignite社区活动带着超过300万枚GLMR奖励来啦!体验新项目,顺便薅一把GLMR羊毛。 本次Moonbeam Ignite活动的参与项目均为第二批Moonbeam生态系统Grant资助提案中获…...

【改造后序遍历算法】95. 不同的二叉搜索树 II
95. 不同的二叉搜索树 II 解题思路 遍历每一个节点查看以k为根节点的二叉搜索树储存所有左子树的根节点储存所有右子树的根节点将左子树和右子树组装起来 将根节点储存在向量中 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeN…...
)
栈的基本操作(数据结构)
顺序栈的基本操作 #include <stdlib.h> #include <iostream> #include <stdio.h> #define MaxSize 10typedef struct{int data[MaxSize];int top; }SqStack;//初始化栈 void InitStack(SqStack &S){S.top -1; } //判断栈空 bool StackEmpty(SqStack S)…...
)
D. Jellyfish and Mex Codeforces Round 901 (Div. 2)
Problem - D - Codeforces 题目大意:有一个n个数的数组a,数m初始为0,每次操作可以删除任意一个数,然后m加上那个数,求n次操作和m的最小值 1<n<5000;0<a[i]<1e9 思路:可以发现&am…...
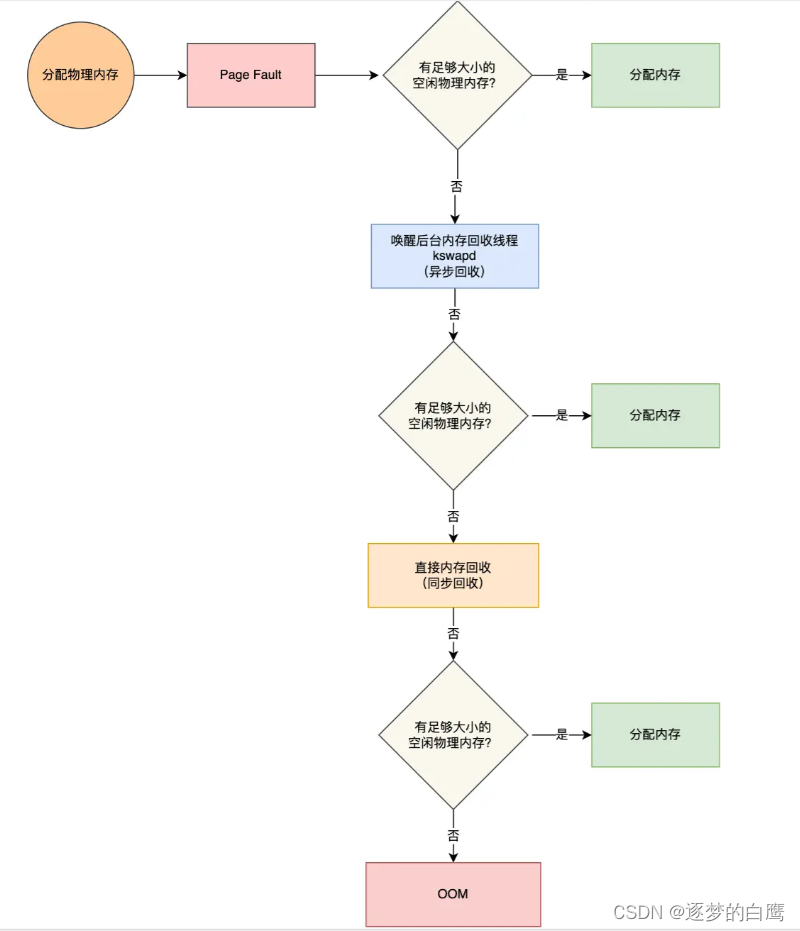
操作系统内存管理相关
1. 虚拟内存 1.1 什么是虚拟内存 虚拟内存是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存。不要单纯认为虚拟内存只是“使用硬盘空间来扩展内存“的技术。虚拟内存的重要意义是它定义了一个连续的虚拟地址空间,并且 把内存扩展到硬…...

Sui流动性质押黑客松获胜者公布,助力资产再流通
Sui流动质押黑客松于日前结束Demo Day演示,其中有五个团队获奖、六个团队荣誉提名,共有超过30个项目获得参赛资格。此外,有两个团队赢得了Sui上DeFi协议提供的赏金。 本次黑客松的目的是挖掘并奖励将流动质押功能集成到其apps和产品中的开发…...
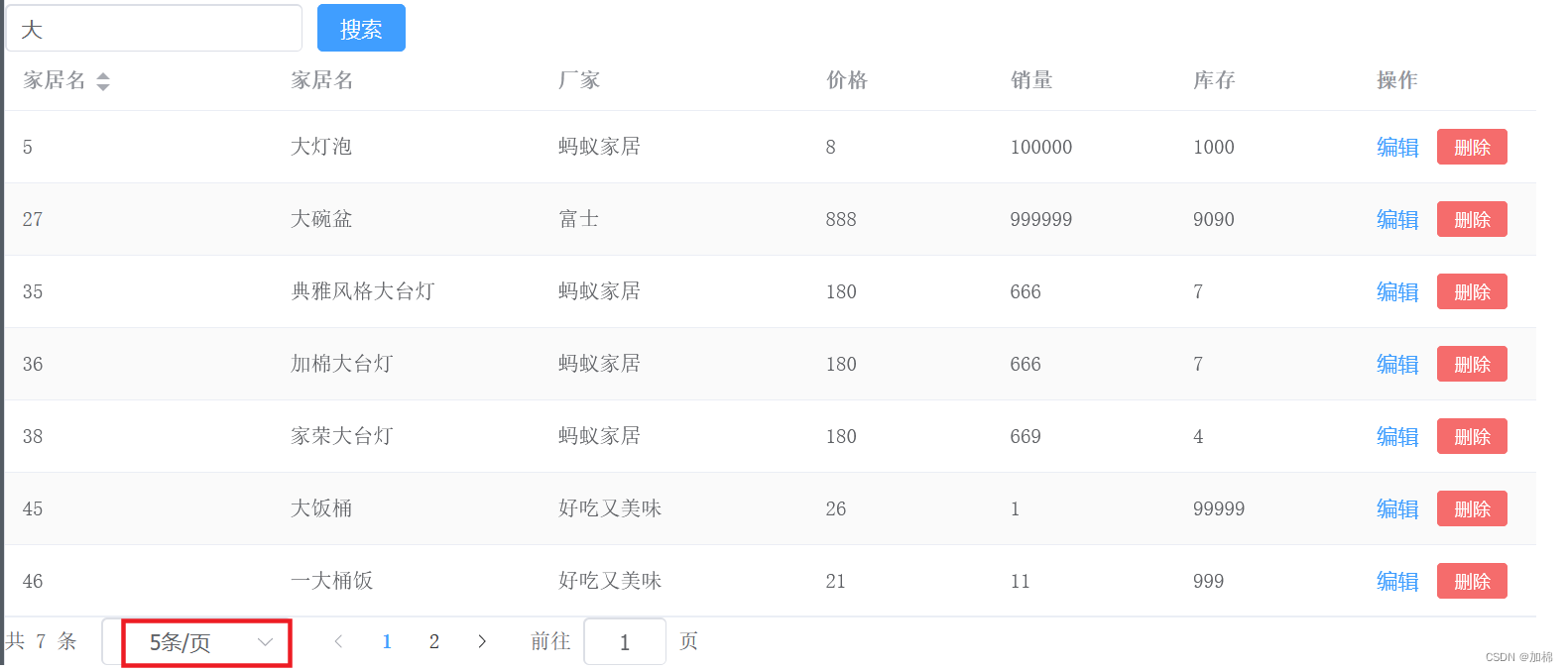
为什么在使用PageHelper插件时,指定的每页记录数大小失效?显示所有的记录数
1.问题现象: 这里指定每页显示5条,却把所有的记录数都显示出来了 2.分析: 之前是可以的,然后发现:PageHelper.startPage(pageNum,pageSize) 和执行sql的语句 顺序颠倒了,然后就出错了。 3.验证…...

XML文档基础
什么是XML XML (eXtensible Markup Language,可扩展标记语言) 是一种用于存储和传输数据的文本文件格式。用户可以按照XML规则自定义标记,XML 的设计目标是传输数据,而不是显示数据,因此它是一种通用的标记语言,可用于…...

软考知识汇总-软件工程
软件工程 1 能力成熟度模型(CMM)2 能力成熟度模型集成(CMMI)2.1阶段式模型2.2 连续式模型 3 软件过程模型 1 能力成熟度模型(CMM) 将软件工程成熟度分为5个级别 初始级:杂乱无章,很…...
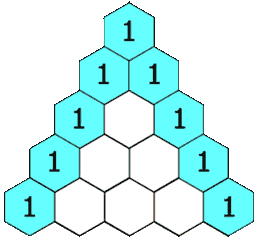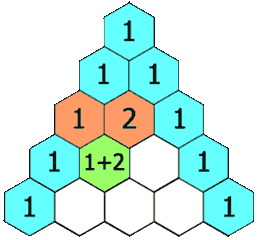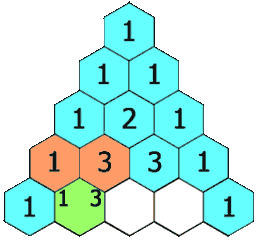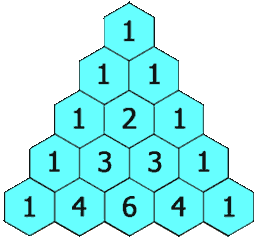
力扣:119. 杨辉三角 II(Python3)
题目: 给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 来源:力扣(LeetCode) 链接:力扣(LeetCode)…...
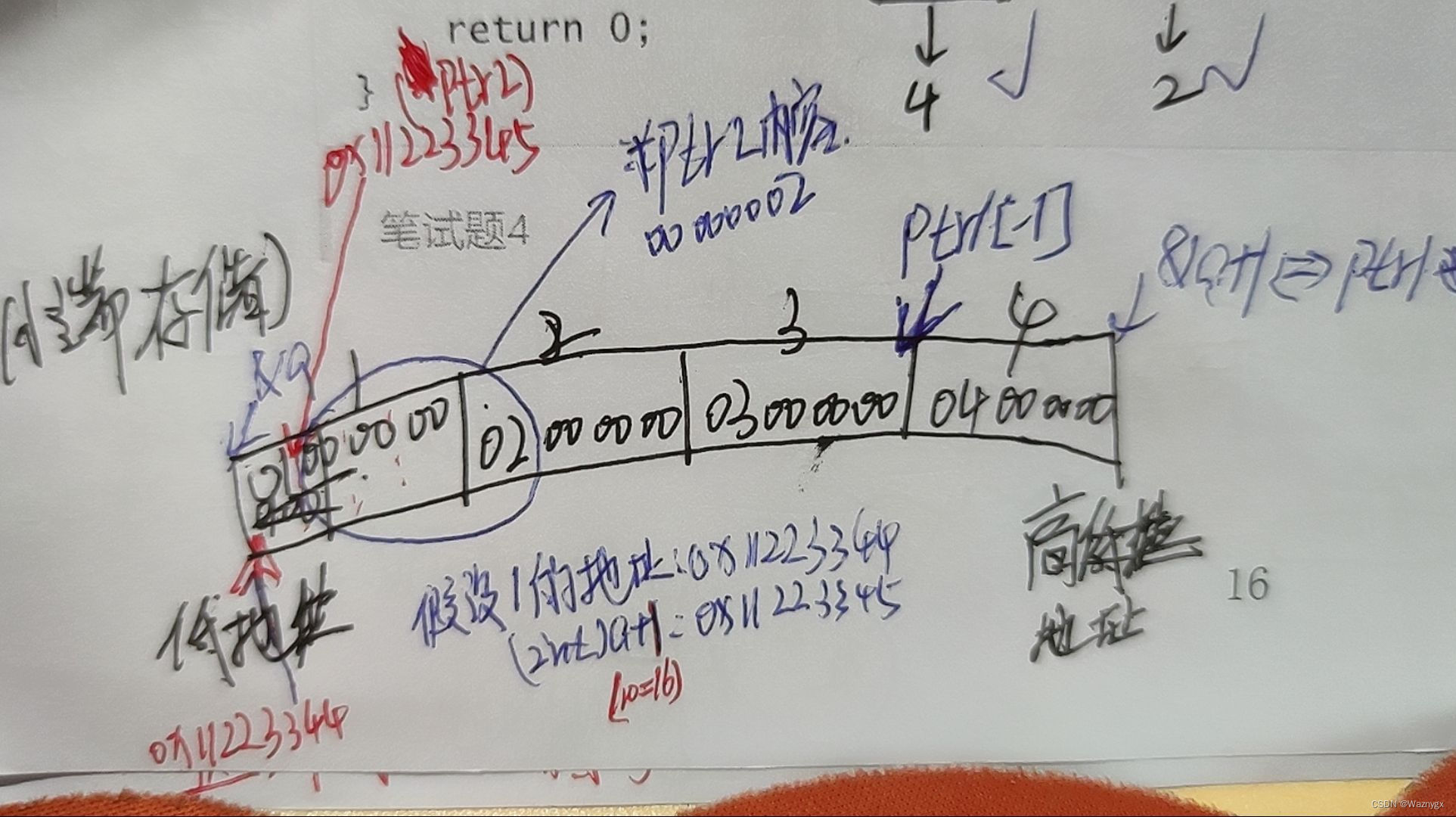
指针笔试题(带解析版)
题目2: struct MyStruct {int num;char* pcname;short sdate;char cha[2];short sba[4]; }*p; //结构体大小为32字节 //p0x100000 int main() {p 0x100000;printf("%p\n", p 0x1);//p:结构体指针,1下一个结构体指针,…...
服务器搭建(TCP套接字)-libevent版(服务端)
Libevent 是一个开源的事件驱动库,用于开发高性能、并发的网络应用程序。它提供了跨平台的事件处理和网络编程功能,具有高性能、可扩展性和可移植性。下面详细讲解 Libevent 的主要组成部分和使用方法。 一、事件基础结构(event_base&#x…...
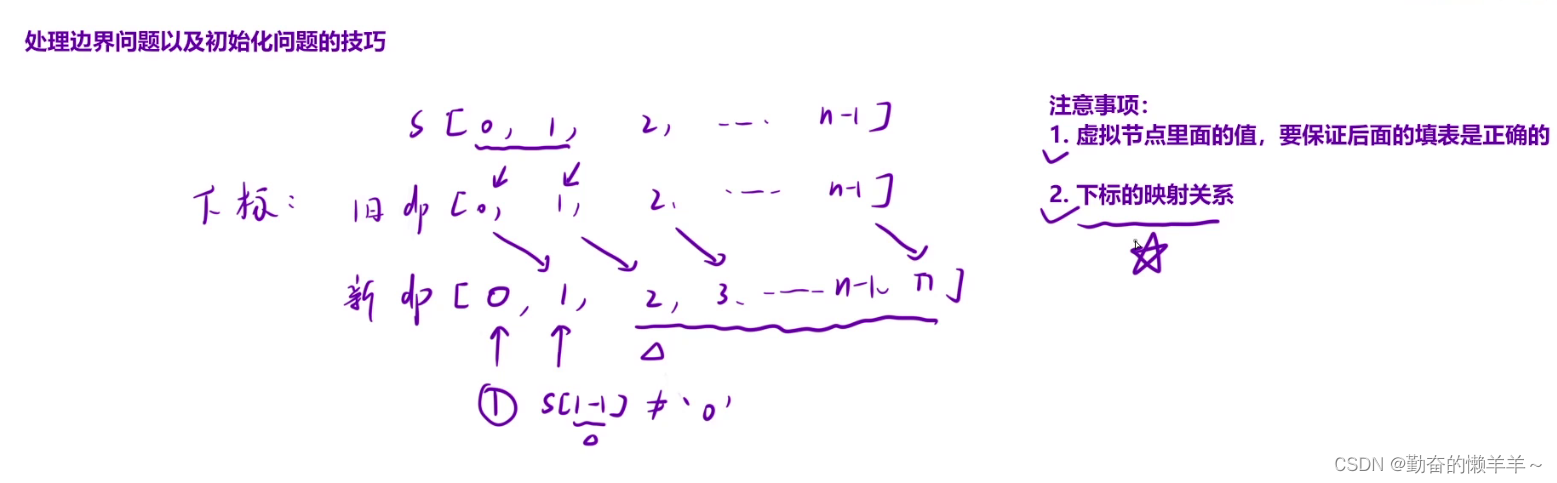
斐波那契模型系列【动态规划】
动态规划步骤 1、状态表示 是什么:dp表(可能是一维或二维数组)里的值所表示的含义。 怎么来: 1、题目要求 2、经验题目要求 3、发现重复子问题 2、状态转移方程 dp[i]... 3、初始化 保证填表不越界 4、填表顺序 5、返回值 写代码时…...

【Java】微服务——Nacos注册中心
目录 1.Nacos快速入门1.1.服务注册到nacos1)引入依赖2)配置nacos地址3)重启 2.服务分级存储模型2.1.给user-service配置集群2.2.同集群优先的负载均衡 3.权重配置4.环境隔离4.1.创建namespace4.2.给微服务配置namespace 5.Nacos与Eureka的区别…...

Redis Cluster Gossip Protocol: PING, PONG, MEET
返回目录 PING / PONG / MEET 的发送 过程 计算freshNodes。freshNodes表示在消息中能携带的,在cluster节点字典中的节点总数,但需要减去myself和对端节点,因为myself的信息会存储在消息头中。实际上,并非所有在cluster节点字典…...
httpserver 下载服务器demo 以及libevent版本的 httpserver
实现效果如下: 图片可以直接显示 cpp h 这些可以直接显示 其他的 则是提示是否要下载 单线程 还有bug 代码如下 先放上来 #include "httpserver.h" #include "stdio.h" #include <stdlib.h> #include <arpa/inet.h> #include…...

构建强大的RESTful API:@RestController与@Controller的对比与应用
构建强大的RESTful API:RestController与Controller的对比与应用 前言什么是RESTful APIRestController,Controller,ResponseBody1. Controller注解:2. RestController注解:3. ResponseBody注解: 示例非thy…...
-当不存在一个简单的正确答案时)
【Java-LangChain:使用 ChatGPT API 搭建系统-10】评估(下)-当不存在一个简单的正确答案时
第十章,评估(下)-当不存在一个简单的正确答案时 在上一章中,了解了如何评估 LLM 模型在 有明确正确答案 的情况下的输出,我们可以编写一个函数来判断 LLM 输出是否正确地分类并列出产品。 然而,如果 LLM …...

【微服务的集成测试】python实现-附ChatGPT解析
1.题目 微服务的集成测试 知识点:深搜 时间限制: 1s 空间限制: 256MB 限定语言:不限 题目描述: 现在有n个容器服务,服务的启动可能有一定的依赖性 (有些服务启动没有依赖)其次服务自身启动加载会消耗一些时间。 给你一个 nxn 的二维矩阵 useTime,其中 useTime[i][i]=10 表示…...

半导体放电管TSS选型避坑指南:从RS485到CAN接口的实战经验分享
半导体放电管TSS选型避坑指南:从RS485到CAN接口的实战经验分享 在工业通信设备的电路保护设计中,浪涌防护是一个不可忽视的关键环节。作为一名长期奋战在一线的硬件工程师,我深知半导体放电管(TSS)选型过程中的种种陷阱…...

新手避坑指南:用DJI NAZA-LITE飞控组装F450无人机,从焊接电调到GPS校准的完整流程
新手避坑指南:用DJI NAZA-LITE飞控组装F450无人机,从焊接电调到GPS校准的完整流程 第一次组装无人机就像玩一场高风险的拼图游戏——每个零件的位置、每根接线的顺序都可能影响最终能否安全起飞。作为过来人,我清楚地记得焊接电调时锡珠飞溅的…...

OpenClaw安全加固:nanobot镜像的权限控制最佳实践
OpenClaw安全加固:nanobot镜像的权限控制最佳实践 1. 为什么需要关注OpenClaw的安全配置 去年夏天,我在本地部署OpenClaw时犯过一个致命错误——直接以管理员权限运行了未经审查的自动化脚本。结果这个脚本在半夜执行时误删了我整个项目目录的源码&…...

3个实用技巧:让Mermaid图表创作效率翻倍的秘密武器
3个实用技巧:让Mermaid图表创作效率翻倍的秘密武器 【免费下载链接】mermaid mermaid-js/mermaid: 是一个用于生成图表和流程图的 Markdown 渲染器,支持多种图表类型和丰富的样式。适合对 Markdown、图表和流程图以及想要使用 Markdown 绘制图表和流程图…...
)
基于springboot大学生兼职管理系统设计与开发(源码+精品论文+答辩PPT等资料)
博主介绍:CSDN毕设辅导第一人、靠谱第一人、全网粉丝50W,csdn特邀作者、博客专家、腾讯云社区合作讲师、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交…...

macOS Unlocker V3.0:在Windows和Linux上免费运行macOS虚拟机的终极解决方案 [特殊字符]
macOS Unlocker V3.0:在Windows和Linux上免费运行macOS虚拟机的终极解决方案 🚀 【免费下载链接】unlocker 项目地址: https://gitcode.com/gh_mirrors/unlo/unlocker macOS Unlocker V3.0是一款革命性的开源工具,让您能够在Windows或…...

破解MSG文件解析难题:自动化处理工具让邮件数据提取效率提升90%
破解MSG文件解析难题:自动化处理工具让邮件数据提取效率提升90% 【免费下载链接】msg-extractor Extracts emails and attachments saved in Microsoft Outlooks .msg files 项目地址: https://gitcode.com/gh_mirrors/ms/msg-extractor 在日常办公中&#x…...

Wan2.1-umt5辅助数学公式处理:从图片或LaTeX中理解与转换数学表达式
Wan2.1-umt5辅助数学公式处理:从图片或LaTeX中理解与转换数学表达式 如果你在科研、教育或者出版行业工作过,一定遇到过这样的烦恼:看到一篇论文里的复杂公式,想把它录入到自己的文档里,只能一个字一个字地对着敲&…...

新手友好:通过快马用自然语言生成你的第一个openclaw卸载脚本
作为一个刚接触编程的新手,想要自己动手写一个软件卸载脚本确实会有点无从下手。最近我在学习Python时,发现用InsCode(快马)平台可以很轻松地通过自然语言描述生成完整代码,特别适合我们这样的初学者。下面我就分享一下如何用这个平台快速创建…...

魔兽世界API开发助手:从新手到专家的全流程解决方案
魔兽世界API开发助手:从新手到专家的全流程解决方案 【免费下载链接】wow_api Documents of wow API -- 魔兽世界API资料以及宏工具 项目地址: https://gitcode.com/gh_mirrors/wo/wow_api 价值定位:如何避免90%的插件开发陷阱? 在魔…...