操作系统内存管理相关
1. 虚拟内存
1.1 什么是虚拟内存
虚拟内存是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存。不要单纯认为虚拟内存只是“使用硬盘空间来扩展内存“的技术。虚拟内存的重要意义是它定义了一个连续的虚拟地址空间,并且 把内存扩展到硬盘空间。
1.2 为什么需要虚拟内存?
我们了解单片机是没有操作系统的,所以每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。另外,单片机的 CPU 是直接操作内存的「物理地址」。
在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在 3000 的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。(也就是每次CPU都直接操作内存导致不能多进程)
那么操作系统应该如何避免这种情况?
(这里关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的)
因此我们可以把进程所使用的地址「隔离」开来,即让操作系统为每个进程分配独立的一套「虚拟地址」,人人都有,互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的。

操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
于是,这里就引出了两种地址的概念:
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
- 实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)。
操作系统引入了虚拟内存,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存,如下图所示:

1.3 如何管理虚拟地址与物理地址之间的关系?
内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB
虚拟地址与物理地址之间通过页表来映射,在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址,见下图:

因此内存转化的步骤为:
- CPU将虚拟内存地址切分为页号和偏移量
- 根据页号在页表中查询对应的物理页号
- 页号加上前面的偏移量,就得到了物理内存地址
但是如果这样给每一个程序分配一个页表去管理虚拟内存的话会出现下面的问题:
在32位系统上,虚拟内存大小约为4G(2^32),一个页的大小为4K(2^12),那么我们映射4G虚拟内存空间需要100 多万(2^20)个页,一个「页表项」(一个页的内容)需要4个字节,也就是需要4M的内存空间存储这个页表。
一个进程映射整个虚拟内存空间需要4M,那么100个进程就需要400M存储页表。这是非常大的内存了,更别说 64 位的环境了。
为了解决空间大小的问题,提出了多级页表的方法
多级页表
通过上面的例子我们得知32位系统下,要映射整个4G虚拟地址空间的页表大小为4M,且这个页表有100 多万(2^20)「页表项」。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。如下图所示:

此时你会发现,进行二级分页去映射4G虚拟内存空间,需要 4KB(一级页表)+ 4M(二级页表),这比之前不分多级(只有一级表)花费的4M还要大吗?
其实:每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB,这对比单级页表的 4MB 是不是一个巨大的节约?
2. malloc原理
2.1 Linux内存分布长什么样?
Linux操作系统中,虚拟地址空间分为内核空间和用户空间

接下来看看32位中用户空间的具体分布情况:
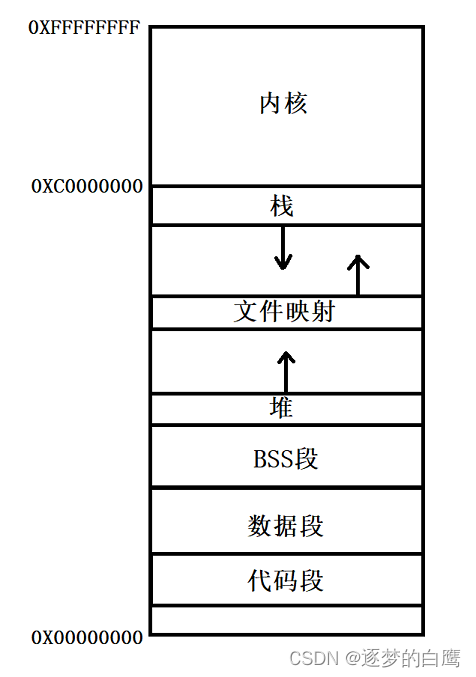
- 代码段:包括二进制可执行代码;
- 数据段:包括已初始化的静态常量和全局变量;
- BSS 段:包括未初始化的静态变量和全局变量;
- 堆段:包括动态分配的内存,从低地址开始向上增长;
- 文件映射段:包括动态库、共享内存等,从低地址开始向上增长
- 栈段:包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
在这 6 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
2.1 malloc 是如何分配内存的?
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
- 方式一:如果用户分配的内存小于 128 KB,通过 brk() 系统调用从堆分配内存
- 方式二:如果用户分配的内存大于 128 KB,通过 mmap() 系统调用在文件映射区分配内存
原理:
方式一:通过 brk() 函数将「堆顶」指针向高地址移动,获得新的内存空间。

方式二:通过 mmap() 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷”了一块内存。

2.2 malloc 分配的是物理内存吗?
不是的,malloc() 分配的是虚拟内存。
如果分配后的虚拟内存没有被访问的话,虚拟内存是不会映射到物理内存的,这样就不会占用物理内存了。
只有在访问已分配的虚拟地址空间的时候,操作系统通过查找页表,发现虚拟内存对应的页没有在物理内存中,就会触发缺页中断,然后操作系统会建立虚拟内存和物理内存之间的映射关系。
2.3 malloc(1) 会分配多大的内存?
malloc() 在分配内存的时候,并不是老老实实按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池。
我们以以下代码为例,看看malloc(1)究竟分配了多大内存:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>int main()
{printf("使用cat /proc/%d/maps查看内存分配\n",getpid());//申请1字节的内存void *addr = malloc(1);printf("此1字节的内存起始地址:%x\n", addr);printf("使用cat /proc/%d/maps查看内存分配\n",getpid());//将程序阻塞,当输入任意字符时才往下执行getchar();//释放内存free(addr);printf("释放内存\n");//阻塞去查看内存是否归还给系统getchar();return 0;
}执行代码:

我们可以通过 /proc//maps 文件查看进程的内存分布情况。我在 maps 文件通过此 1 字节的内存起始地址过滤出了内存地址的范围。

这个例子分配的内存小于 128 KB,所以是通过 brk() 系统调用向堆空间申请的内存,因此可以看到最右边有 [heap] 的标识。
可以看到,堆空间的内存地址范围是 561e7890c000-561e7892d000,这个范围大小是 132KB,也就说明了 malloc(1) 实际上预分配 132K 字节的内存。
2.4 free 释放内存,会归还给操作系统吗?
1. 我们以上面的程序为例(申请小于128K的空间),我们在free(addr)结束后,再使用cat /proc/%d/maps去查看内存时候还在:

释放malloc(1)的内存后在执行一次cat

可以看到,通过 free 释放内存后,堆内存还是存在的,并没有归还给操作系统。
2. 我们这次申请大于128K的内存来看看:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>int main()
{printf("使用cat /proc/%d/maps查看内存分配\n",getpid());//申请1字节的内存void *addr = malloc(200*1024);printf("此1字节的内存起始地址:%x\n", addr);printf("使用cat /proc/%d/maps查看内存分配\n",getpid());//将程序阻塞,当输入任意字符时才往下执行getchar();//释放内存free(addr);printf("释放200K内存\n");getchar();return 0;
}

查看进程的内存的分布情况,可以发现最右边没有 [heap] 标志,说明是通过 mmap 以匿名映射的方式从文件映射区分配的匿名内存。
然后我们释放掉这个内存看看:

再次查看该 200KB 内存的起始地址

可以发现已经不存在了,说明归还给了操作系统。
3. 内存满了会发生什么?
应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。
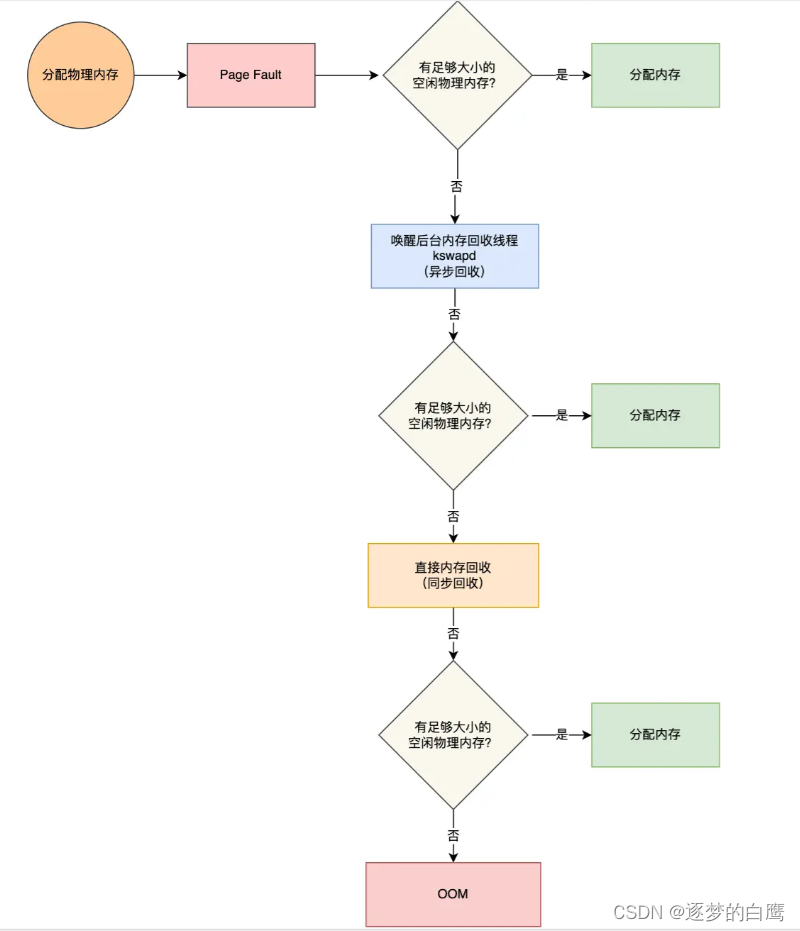
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了 ——触发 OOM (Out of Memory)机制。
OOM机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
申请物理内存的过程如下图:
相关文章:
操作系统内存管理相关
1. 虚拟内存 1.1 什么是虚拟内存 虚拟内存是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存。不要单纯认为虚拟内存只是“使用硬盘空间来扩展内存“的技术。虚拟内存的重要意义是它定义了一个连续的虚拟地址空间,并且 把内存扩展到硬…...

Sui流动性质押黑客松获胜者公布,助力资产再流通
Sui流动质押黑客松于日前结束Demo Day演示,其中有五个团队获奖、六个团队荣誉提名,共有超过30个项目获得参赛资格。此外,有两个团队赢得了Sui上DeFi协议提供的赏金。 本次黑客松的目的是挖掘并奖励将流动质押功能集成到其apps和产品中的开发…...
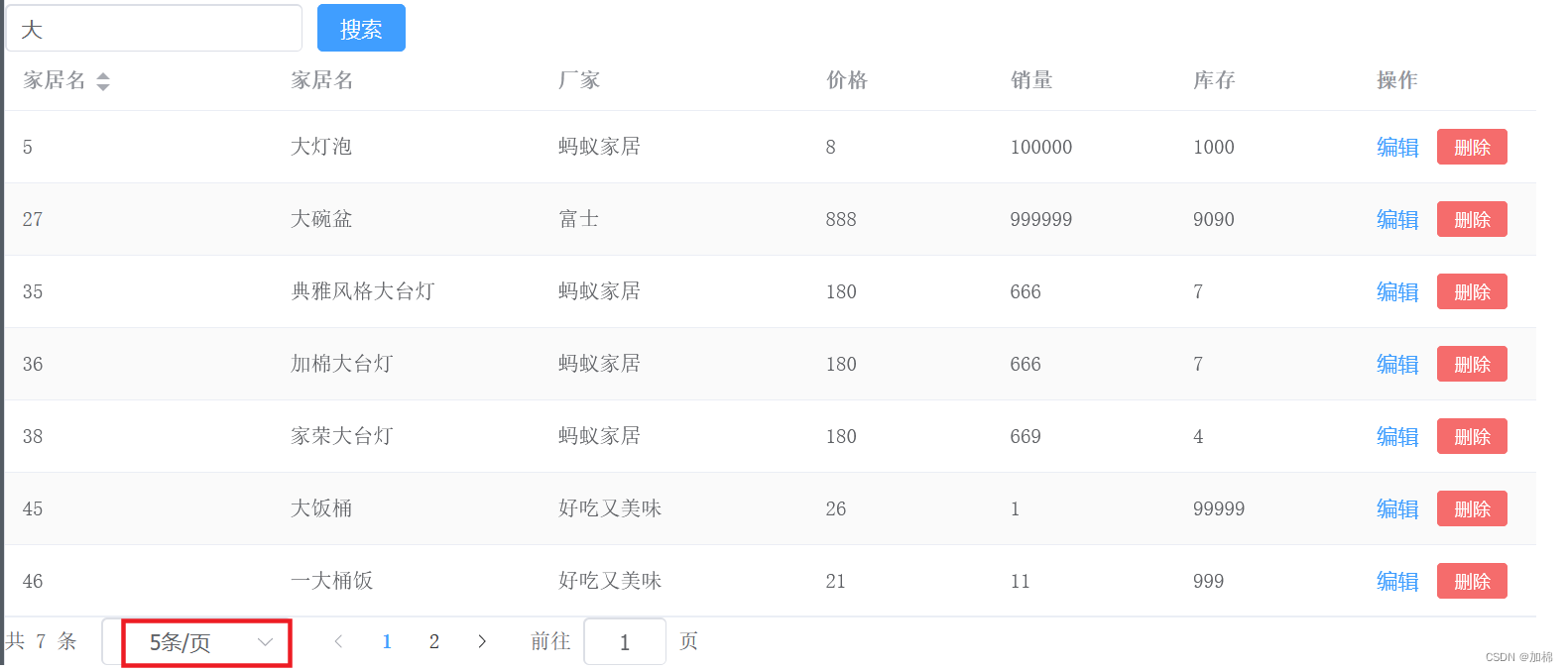
为什么在使用PageHelper插件时,指定的每页记录数大小失效?显示所有的记录数
1.问题现象: 这里指定每页显示5条,却把所有的记录数都显示出来了 2.分析: 之前是可以的,然后发现:PageHelper.startPage(pageNum,pageSize) 和执行sql的语句 顺序颠倒了,然后就出错了。 3.验证…...

XML文档基础
什么是XML XML (eXtensible Markup Language,可扩展标记语言) 是一种用于存储和传输数据的文本文件格式。用户可以按照XML规则自定义标记,XML 的设计目标是传输数据,而不是显示数据,因此它是一种通用的标记语言,可用于…...

软考知识汇总-软件工程
软件工程 1 能力成熟度模型(CMM)2 能力成熟度模型集成(CMMI)2.1阶段式模型2.2 连续式模型 3 软件过程模型 1 能力成熟度模型(CMM) 将软件工程成熟度分为5个级别 初始级:杂乱无章,很…...
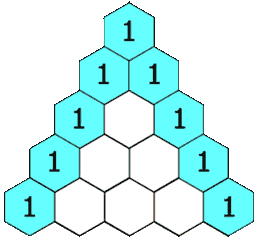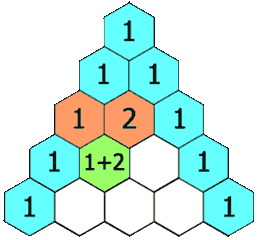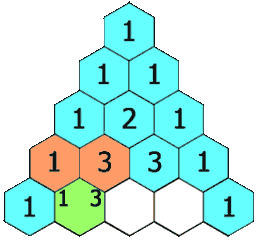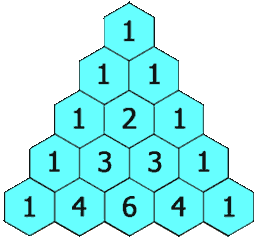
力扣:119. 杨辉三角 II(Python3)
题目: 给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 来源:力扣(LeetCode) 链接:力扣(LeetCode)…...
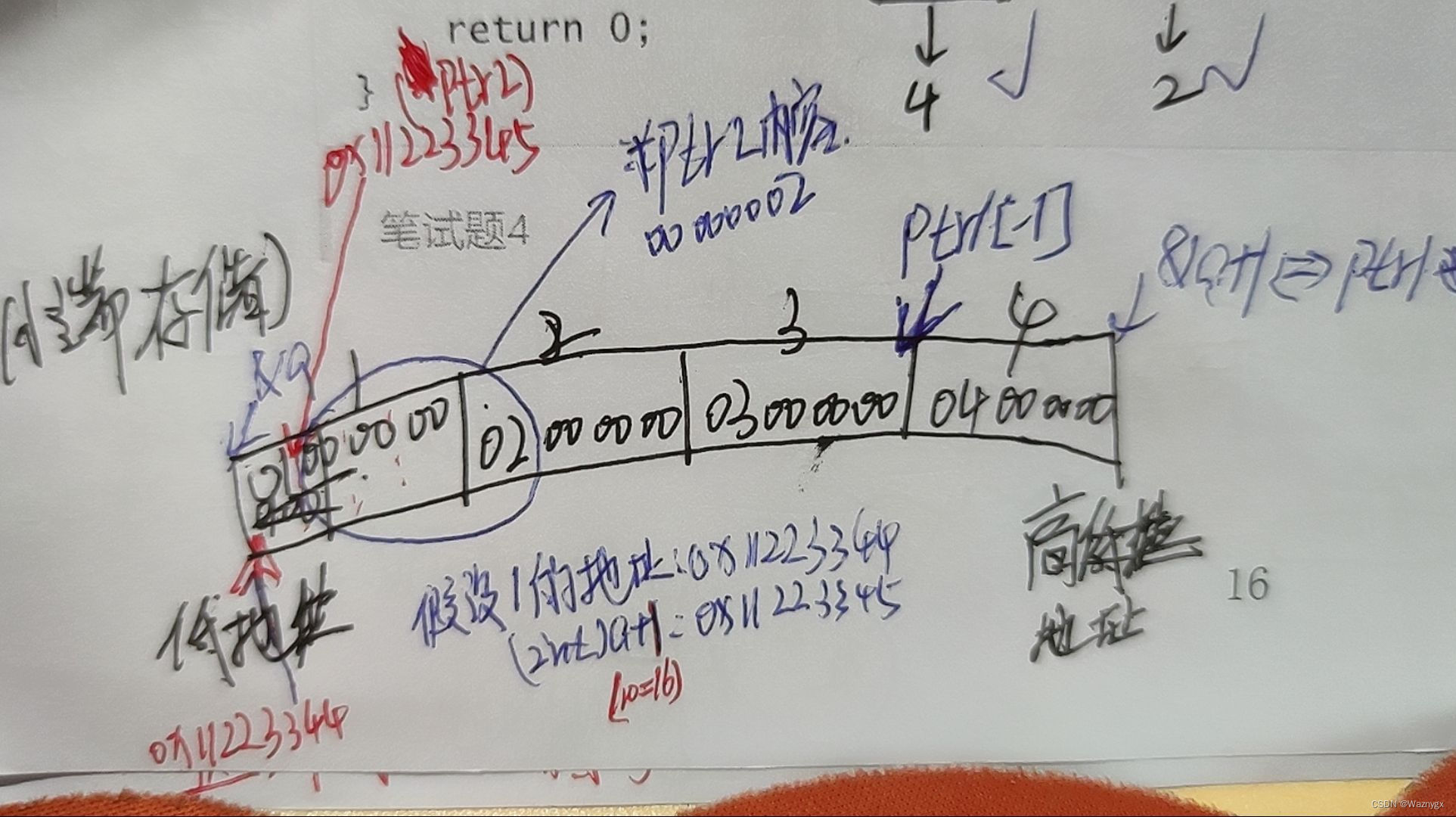
指针笔试题(带解析版)
题目2: struct MyStruct {int num;char* pcname;short sdate;char cha[2];short sba[4]; }*p; //结构体大小为32字节 //p0x100000 int main() {p 0x100000;printf("%p\n", p 0x1);//p:结构体指针,1下一个结构体指针,…...
服务器搭建(TCP套接字)-libevent版(服务端)
Libevent 是一个开源的事件驱动库,用于开发高性能、并发的网络应用程序。它提供了跨平台的事件处理和网络编程功能,具有高性能、可扩展性和可移植性。下面详细讲解 Libevent 的主要组成部分和使用方法。 一、事件基础结构(event_base&#x…...
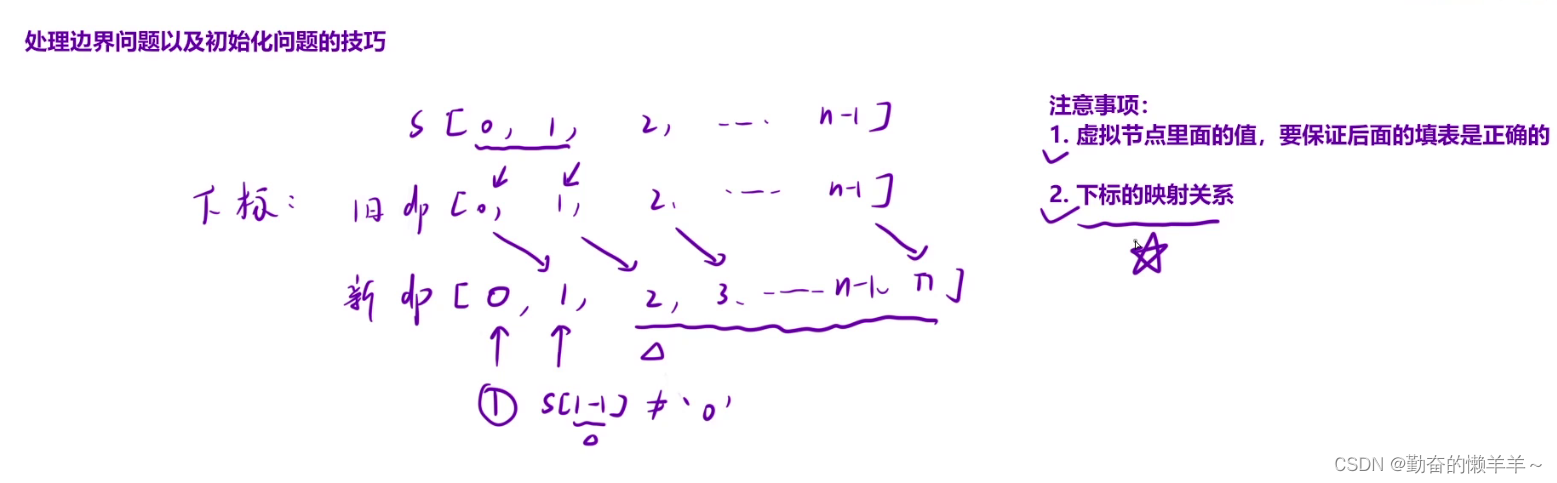
斐波那契模型系列【动态规划】
动态规划步骤 1、状态表示 是什么:dp表(可能是一维或二维数组)里的值所表示的含义。 怎么来: 1、题目要求 2、经验题目要求 3、发现重复子问题 2、状态转移方程 dp[i]... 3、初始化 保证填表不越界 4、填表顺序 5、返回值 写代码时…...

【Java】微服务——Nacos注册中心
目录 1.Nacos快速入门1.1.服务注册到nacos1)引入依赖2)配置nacos地址3)重启 2.服务分级存储模型2.1.给user-service配置集群2.2.同集群优先的负载均衡 3.权重配置4.环境隔离4.1.创建namespace4.2.给微服务配置namespace 5.Nacos与Eureka的区别…...

Redis Cluster Gossip Protocol: PING, PONG, MEET
返回目录 PING / PONG / MEET 的发送 过程 计算freshNodes。freshNodes表示在消息中能携带的,在cluster节点字典中的节点总数,但需要减去myself和对端节点,因为myself的信息会存储在消息头中。实际上,并非所有在cluster节点字典…...
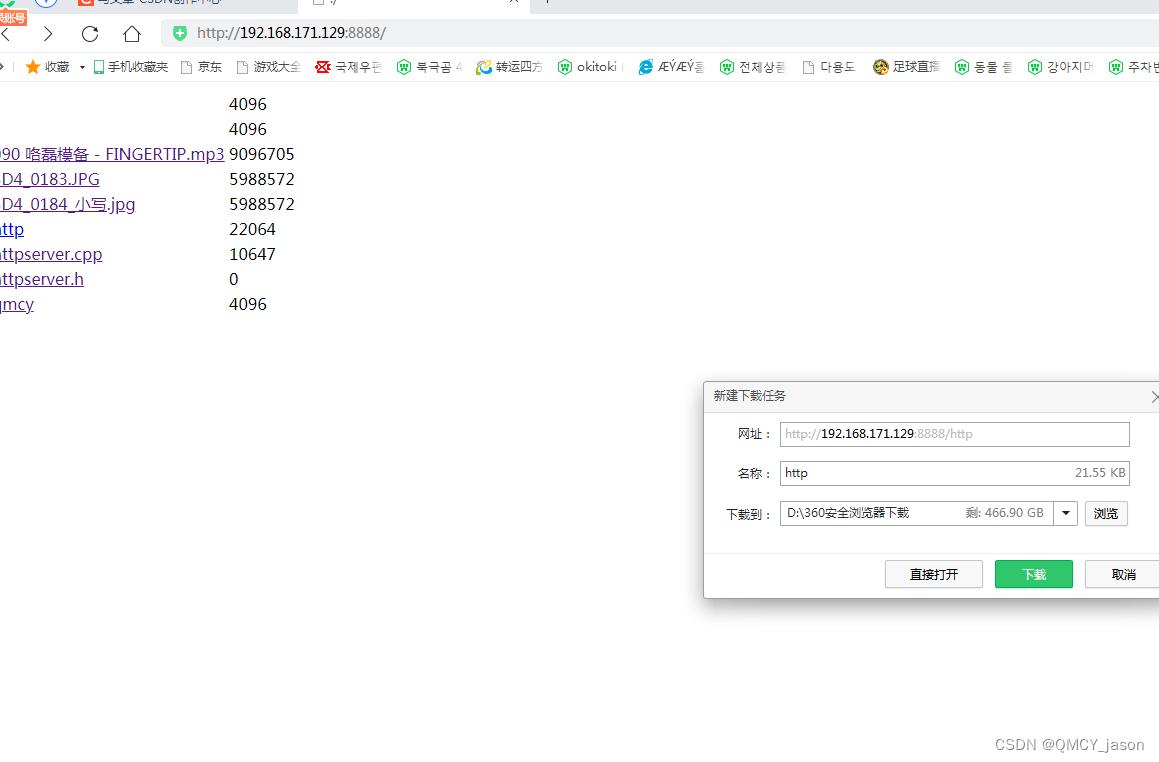
httpserver 下载服务器demo 以及libevent版本的 httpserver
实现效果如下: 图片可以直接显示 cpp h 这些可以直接显示 其他的 则是提示是否要下载 单线程 还有bug 代码如下 先放上来 #include "httpserver.h" #include "stdio.h" #include <stdlib.h> #include <arpa/inet.h> #include…...

构建强大的RESTful API:@RestController与@Controller的对比与应用
构建强大的RESTful API:RestController与Controller的对比与应用 前言什么是RESTful APIRestController,Controller,ResponseBody1. Controller注解:2. RestController注解:3. ResponseBody注解: 示例非thy…...
-当不存在一个简单的正确答案时)
【Java-LangChain:使用 ChatGPT API 搭建系统-10】评估(下)-当不存在一个简单的正确答案时
第十章,评估(下)-当不存在一个简单的正确答案时 在上一章中,了解了如何评估 LLM 模型在 有明确正确答案 的情况下的输出,我们可以编写一个函数来判断 LLM 输出是否正确地分类并列出产品。 然而,如果 LLM …...

【微服务的集成测试】python实现-附ChatGPT解析
1.题目 微服务的集成测试 知识点:深搜 时间限制: 1s 空间限制: 256MB 限定语言:不限 题目描述: 现在有n个容器服务,服务的启动可能有一定的依赖性 (有些服务启动没有依赖)其次服务自身启动加载会消耗一些时间。 给你一个 nxn 的二维矩阵 useTime,其中 useTime[i][i]=10 表示…...

Mesa新版来袭
Mesa 17.1.6 发布了,Mesa 是一个三维(3D)图形库的开源集合,其主要目标是在 Linux / UNIX 操作系统下实现各种 API(应用程序编程接口)和 OpenGL 规范。 它面向 3D 计算机图形,硬件加速 3D 渲染和…...
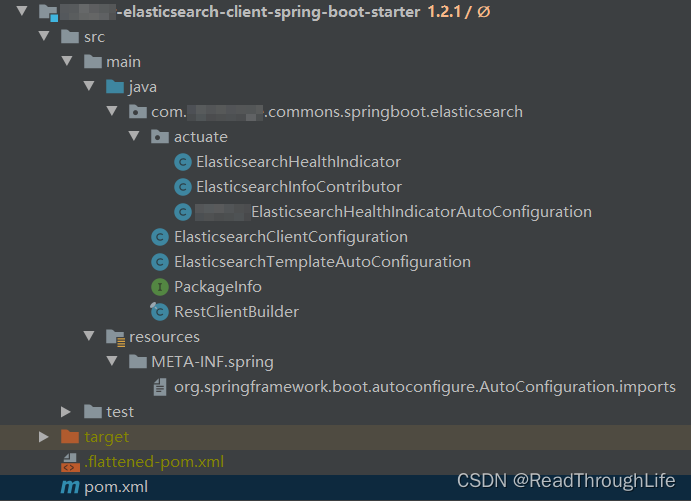
基于 SpringBoot 2.7.x 使用最新的 Elasticsearch Java API Client 之 ElasticsearchClient
1. 从 RestHighLevelClient 到 ElasticsearchClient 从 Java Rest Client 7.15.0 版本开始,Elasticsearch 官方决定将 RestHighLevelClient 标记为废弃的,并推荐使用新的 Java API Client,即 ElasticsearchClient. 为什么要将 RestHighLevelC…...
-NOA领航辅助系统-吉利)
辅助驾驶功能开发-功能对标篇(15)-NOA领航辅助系统-吉利
1.横向对标参数 厂商吉利车型FX11/EX11/DCY11/G636上市时间2022Q4方案6V5R+1DMS摄像头前视摄像头1*(8M)侧视摄像头/后视摄像头1环视摄像头4DMS摄像头1雷达毫米波雷达54D毫米波雷达/超声波雷达12激光雷达/域控供应商福瑞泰克辅助驾驶软件供应商福瑞泰克高精度地图百度芯片TDA4 T…...
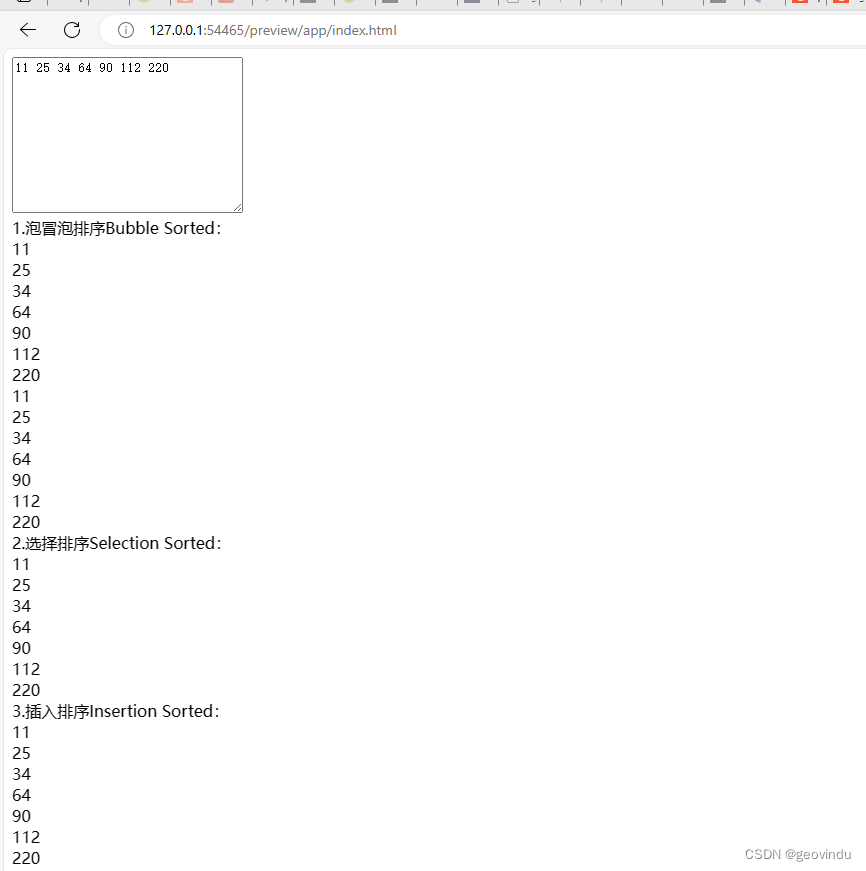
javascript: Sorting Algorithms
// Sorting Algorithms int JavaScript https://www.geeksforgeeks.org/sorting-algorithms/ /** * file Sort.js * 1. Bubble Sort冒泡排序法 * param arry * param nszie */ function BubbleSort(arry, nszie) {var i, j, temp;var swapped;for (i 0; i < nszie - 1; i)…...

嵌入式Linux应用开发-驱动大全-同步与互斥④
嵌入式Linux应用开发-驱动大全-同步与互斥④ 第一章 同步与互斥④1.5 自旋锁spinlock的实现1.5.1 自旋锁的内核结构体1.5.2 spinlock在UP系统中的实现1.5.3 spinlock在SMP系统中的实现 1.6 信号量semaphore的实现1.6.1 semaphore的内核结构体1.6.2 down函数的实现1.6.3 up函数的…...

突破百度网盘限速限制:baidu-wangpan-parse工具的技术实现与应用指南
突破百度网盘限速限制:baidu-wangpan-parse工具的技术实现与应用指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源获取日益频繁的今天,许…...

高效获取Sketchfab 3D资源:Firefox专属下载工具使用指南
高效获取Sketchfab 3D资源:Firefox专属下载工具使用指南 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在3D设计与开发领域,获取高质量模型…...

3MF格式终极指南:如何在Blender中轻松导入导出3D打印文件
3MF格式终极指南:如何在Blender中轻松导入导出3D打印文件 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 想要在Blender中处理3D打印文件却苦于格式转换&…...

从Bootloader到App的优雅跳转:关键步骤与实战解析
1. 为什么需要Bootloader跳转App? 在嵌入式开发中,Bootloader和App的关系就像电脑的BIOS和操作系统。Bootloader负责硬件初始化、固件更新等底层工作,而App则是实现具体业务逻辑的主程序。两者分工明确,但最终需要无缝衔接。 我遇…...

别再死记硬背!用拖拽和右键菜单玩转汇川CodeSys网络与硬件组态
汇川CodeSys图形化组态实战:拖拽与右键菜单的高效玩法 第一次打开汇川CodeSys的组态界面时,那些密密麻麻的菜单和复杂的参数设置确实让人望而生畏。但当我发现可以用鼠标拖拽完成90%的配置工作时,整个PLC编程体验彻底改变了——就像从DOS命令…...

基于遗忘因子递推最小二乘法的电池模型参数在线辨识与优化
1. 电池模型参数辨识为什么需要FFRLS算法 我第一次接触电池参数辨识是在开发一款智能硬件时,当时发现传统最小二乘法有个致命问题——它会把所有历史数据同等对待。这就像用算盘计算平均数时,不管数据是昨天还是去年的,都按相同权重处理。但在…...

实战笔记:基于STM32F4的LWIP+FreeRTOS系统移植与网络任务创建
1. 为什么需要LWIPFreeRTOS组合 在嵌入式开发中,网络功能越来越成为标配需求。STM32F4系列凭借其出色的性能和丰富的外设资源,成为许多物联网设备的首选。但要让这个硬件平台真正发挥网络能力,我们需要解决两个核心问题:实时任务调…...
)
【2026年阿里巴巴春招- 3月28日-算法岗-第二题- 隐式素数计算】(题目+思路+JavaC++Python解析+在线测试)
题目内容 我们称一个正整数为隐式素数,如果它不同的正因子的个数是一个素数。给定一个闭区间$ [l,r]$,请计算该区间内隐式素数的个数 输入描述 每个测试文件均包含多组测试数据。第一行输入一个整数$ T (1 ≤ T ≤ 10^4)$,代表数据组数,每组测试数据描述如下: 在一行上…...

GG3M 元模型完整详解:从东方哲学数学化到文明级智慧操作系统
GG3M 元模型完整详解:从东方哲学数学化到文明级智慧操作系统摘要: GG3M 是全球首个以贾子理论(Kucius Theory)为核心、定位文明级智慧操作系统的 AGI 项目。其元模型(Meta-Model)以 3M 三层架构(…...

Karabiner-Elements设备过滤与条件判断深度解析
Karabiner-Elements设备过滤与条件判断深度解析 【免费下载链接】Karabiner-Elements Karabiner-Elements is a powerful utility for keyboard customization on macOS Sierra (10.12) or later. 项目地址: https://gitcode.com/gh_mirrors/ka/Karabiner-Elements Kara…...