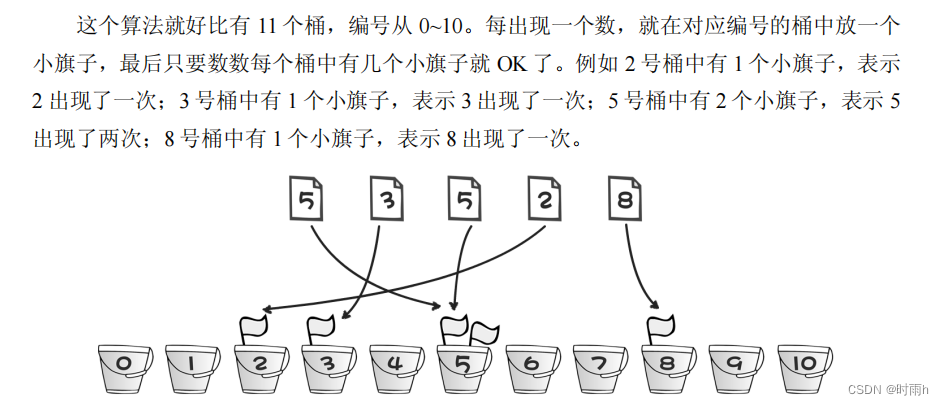
啊哈 算法读书笔记 第 1 章 一大波数正在靠近——排序
目录
排序算法:
时间复杂度:
排序算法和冒泡排序之间的过渡:
冒泡排序
冒泡排序和快速排序之间的过渡:
快速排序
排序算法:

#include <stdio.h>
int main()
{ int a[11],i,j,t; for(i=0;i<=10;i++) a[i]=0; //初始化为0 for(i=1;i<=5;i++) //循环读入5个数{
scanf("%d",&t); //把每一个数读到变量t中a[t]++; //进行计数} for(i=0;i<=10;i++) //依次判断a[0]~a[10] for(j=1;j<=a[i];j++) //出现了几次就打印几次printf("%d ",i); getchar();getchar(); //这里的getchar();用来暂停程序,以便查看程序输出的内容//也可以用system("pause");等来代替return 0;
}
#include <stdio.h>
int main()
{ int book[1001],i,j,t,n; for(i=0;i<=1000;i++) book[i]=0; scanf("%d",&n);//输入一个数n,表示接下来有n个数for(i=1;i<=n;i++)//循环读入n个数,并进行桶排序{ scanf("%d",&t); //把每一个数读到变量t中book[t]++; //进行计数,对编号为t的桶放一个小旗子} for(i=1000;i>=0;i--) //依次判断编号1000~0的桶for(j=1;j<=book[i];j++) //出现了几次就将桶的编号打印几次printf("%d ",i); getchar();getchar(); return 0;
}时间复杂度:
排序算法和冒泡排序之间的过渡:
冒泡排序

#include <stdio.h>
int main()
{ int a[100],i,j,t,n; scanf("%d",&n); //输入一个数n,表示接下来有n个数for(i=1;i<=n;i++) //循环读入n个数到数组a中scanf("%d",&a[i]);
//混混藏书阁:http://book-life.blog.163.com
//啊哈!算法//冒泡排序的核心部分for(i=1;i<=n-1;i++) //n个数排序,只用进行n-1趟{ for(j=1;j<=n-i;j++) //从第1位开始比较直到最后一个尚未归位的数,想一想为什
么到n-i就可以了。{ if(a[j]<a[j+1]) //比较大小并交换{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; } } } for(i=1;i<=n;i++) //输出结果printf("%d ",a[i]); getchar();getchar(); return 0;
}将上面代码稍加修改,就可以解决第 1 节遗留的问题,如下。
#include <stdio.h>
struct student
{ char name[21]; char score;
};//这里创建了一个结构体用来存储姓名和分数
int main()
{ struct student a[100],t; int i,j,n; scanf("%d",&n); //输入一个数n for(i=1;i<=n;i++) //循环读入n个人名和分数scanf("%s %d",a[i].name,&a[i].score); //按分数从高到低进行排序for(i=1;i<=n-1;i++) { for(j=1;j<=n-i;j++) { if(a[j].score<a[j+1].score)//对分数进行比较{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; } } } for(i=1;i<=n;i++)//输出人名printf("%s\n",a[i].name); getchar();getchar(); return 0;
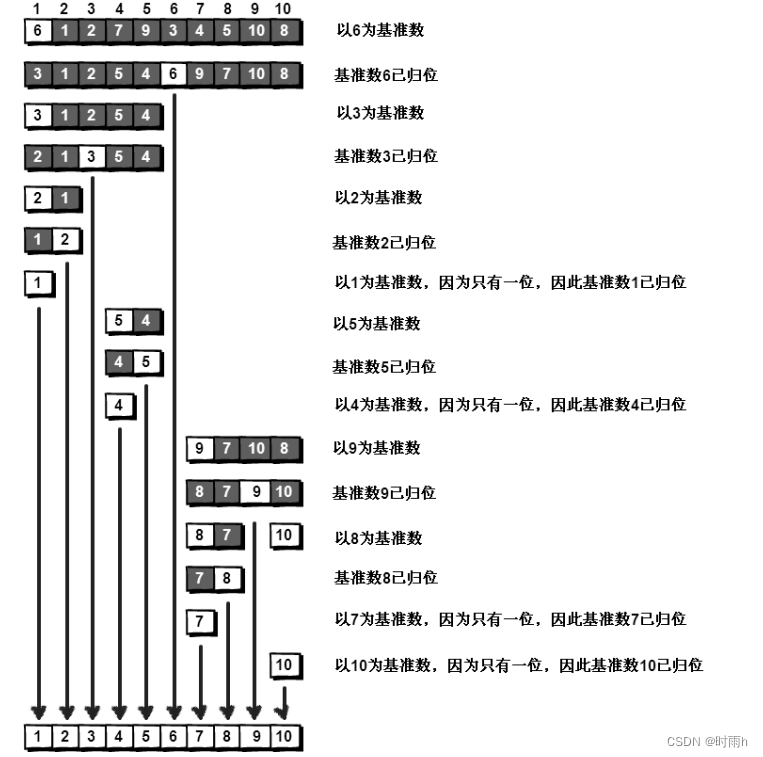
}冒泡排序和快速排序之间的过渡:
快速排序
#include <stdio.h>
int a[101],n;//定义全局变量,这两个变量需要在子函数中使用
void quicksort(int left,int right)
{ int i,j,t,temp; if(left>right) return; temp=a[left]; //temp中存的就是基准数 i=left; j=right; while(i!=j) { //顺序很重要,要先从右往左找 while(a[j]>=temp && i<j) j--; //再从左往右找 while(a[i]<=temp && i<j) i++; //交换两个数在数组中的位置 if(i<j)//当哨兵i和哨兵j没有相遇时{ t=a[i]; a[i]=a[j]; a[j]=t; } } //最终将基准数归位 a[left]=a[i]; a[i]=temp; quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程 quicksort(i+1,right);//继续处理右边的,这里是一个递归的过程
}
int main()
{ int i,j,t; //读入数据 scanf("%d",&n); for(i=1;i<=n;i++) scanf("%d",&a[i]); quicksort(1,n); //快速排序调用 //输出排序后的结果 for(i=1;i<=n;i++) printf("%d ",a[i]); getchar();getchar(); return 0;
}书上对冒泡排序法的拓展介绍:快速排序由 C. A. R. Hoare(东尼·霍尔,Charles Antony Richard Hoare)在 1960 年提出,之后又有许多人做了进一步的优化。如果你对快速排序感兴趣,可以去看看东尼·霍尔1962 年在 Computer Journal 发表的论文“Quicksort”以及《算法导论》的第七章。快速排序算法仅仅是东尼·霍尔在计算机领域才能的第一次显露,后来他受到了老板的赏识和重用,公司希望他为新机器设计一种新的高级语言。你要知道当时还没有 PASCAL 或者 C 语言这些高级的东东。后来东尼·霍尔参加了由 Edsger Wybe Dijkstra(1972 年图灵奖得主,这个大神我们后面还会遇到的,到时候再细聊)举办的 ALGOL 60 培训班,他觉得自己与其没有把握地去设计一种新的语言,还不如对现有的 ALGOL 60 进行改进,使之能在公司的新机器上使用。于是他便设计了 ALGOL 60 的一个子集版本。这个版本在执行效率和可靠性上都在当时 ALGOL 60 的各种版本中首屈一指,因此东尼·霍尔受到了国际学术界的重视。后来他在 ALGOL X 的设计中还发明了大家熟知的 case 语句,也被各种高级语言广泛采用,比如PASCAL、C、Java 语言等等。当然,东尼·霍尔在计算机领域的贡献还有很多很多,他在1980 年获得了图灵奖。
啊哈算法---小哼买书(练习快速排序)_慢慢走比较快k的博客-CSDN博客
方法一:
#include <stdio.h>
int main()
{ int a[1001],n,i,t; for(i=1;i<=1000;i++) a[i]=0; //初始化scanf("%d",&n); //读入n for(i=1;i<=n;i++) //循环读入n个图书的ISBN号{ scanf("%d",&t); //把每一个ISBN号读到变量t中a[t]=1; //标记出现过的ISBN号} for(i=1;i<=1000;i++) //依次判断1~1000这个1000个桶{ if(a[i]==1)//如果这个ISBN号出现过则打印出来printf("%d ",i); } getchar();getchar(); return 0;
}#include <stdio.h>
int main()
{
int a[101],n,i,j,t;scanf("%d",&n); //读入n
for(i=1;i<=n;i++) //循环读入n个图书ISBN号
{
scanf("%d",&a[i]);
}//开始冒泡排序
for(i=1;i<=n-1;i++)
{
for(j=1;j<=n-i;j++)
{
if(a[j]>a[j+1])
{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; }
}
}
printf("%d ",a[1]); //输出第1个数
for(i=2;i<=n;i++) //从2循环到n
{
if( a[i] != a[i-1] ) //如果当前这个数是第一次出现则输出
printf("%d ",a[i]);
}
getchar();getchar();
return 0;
}原书中的总结:接下来我们还需要看下数据范围。每个图书 ISBN 号都是 1~1000 之间的整数,并且参加调查的同学人数不超过 100,即 n≤100。之前已经说过,在粗略计算时间复杂度的时候,我们通常认为计算机每秒钟大约运行 10 亿次(当然实际情况要更快)。因此以上两种方法都可以在 1 秒钟内计算出解。如果题目中图书的 ISBN 号范围不是在 1~1000 之间,而是-2147483648~2147483647 之间的话,那么第一种方法就不可行了,因为你无法申请出这么大的数组来标记每一个 ISBN 号是否出现过。另外如果 n 的范围不是小于等于 100,而是小于等于 10 万,那么第二种方法的排序部分也不能使用冒泡排序。因为题目要求的时间限制是 1 秒,使用冒泡排序对 10 万个数进行排序,计算机要运行 100 亿次,需要 10 秒钟,因此要替换为快速排序,快速排序只需要 100000×log2100000≈100000×17≈170 万次,这还不到0.0017 秒。是不是很神奇?同样的问题使用不同的算法竟然有如此之大的时间差距,这就是算法的魅力!我们来回顾一下本章三种排序算法的时间复杂度。桶排序是最快的,它的时间复杂度是O(N+M);冒泡排序是 O(N 2 );快速排序是 O(NlogN)
相关文章:
啊哈 算法读书笔记 第 1 章 一大波数正在靠近——排序
目录 排序算法: 时间复杂度: 排序算法和冒泡排序之间的过渡: 冒泡排序 冒泡排序和快速排序之间的过渡: 快速排序 排序算法: 首先出场的是我们的主人公小哼,上面这个可爱的娃就是啦。期末考试完了老…...
:HTTP请求与响应)
Servlet笔记(5):HTTP请求与响应
1、HTTP请求 当浏览器请求网页时,它会向Web服务器发送特定信息,这些信息不能被直接读取,而是通过传输HTTP请求时,封装进请求头中。 有哪些头信息? 头信息描述Accept这个头信息指定浏览器或其他客户端可以处理的 MIME…...
信号的运算与变换
目录 前言 本章内容介绍 信号的运算与变换 相加 相乘 时移 反折 尺度变换 微分(差分) 积分(累加) 信号的奇偶求解 信号的实虚分解 合适的例题 1、时移反折 2、时移尺度 3、时移反折尺度 4、反求x(t) 前言 《信号…...

【GO】K8s 管理系统项目9[API部分--Secret]
K8s 管理系统项目[API部分–Secret] 1. 接口实现 service/dataselector.go // secret type secretCell corev1.Secretfunc (s secretCell) GetCreation() time.Time {return s.CreationTimestamp.Time }func (s secretCell) GetName() string {return s.Name }2. Secret功能…...
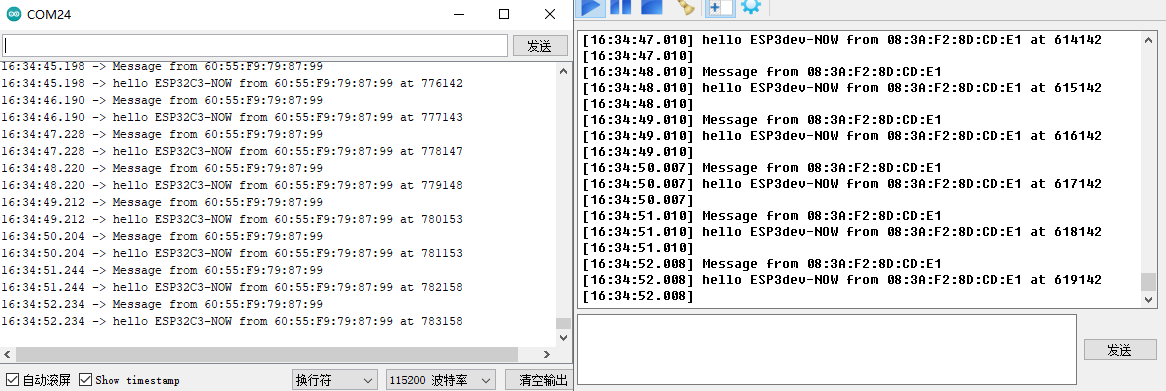
ESP32 Arduino EspNow点对点双向通讯
ESP32 Arduino EspNow点对点双向通讯✨本案例分别采用esp32和esp32C3之间点对点单播无线通讯方式。 🌿esp32开发板 🌾esp32c3开发板 🔧所需库(需要自行导入到Arduino IDE library文件夹中,无法在IDE 管理库界面搜索下载到该库)&am…...
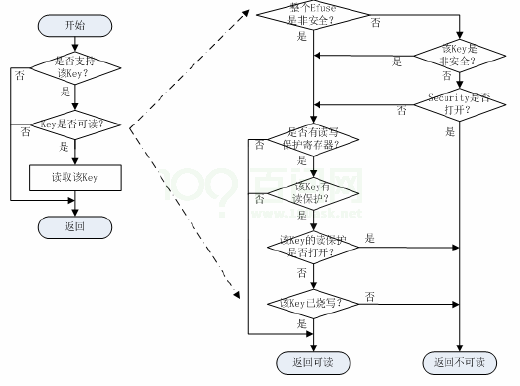
Linux SID 开发指南
Linux SID 开发指南 1 前言 1.1 编写目的 介绍Linux 内核中基于Sunxi 硬件平台的SID 模块驱动的详细设计,为软件编码和维护提供基 础。 1.2 适用范围 内核版本Linux-5.4, Linux-4.9 的平台。 1.3 相关人员 SID 驱动、Efuse 驱动、Sysinfo 驱动的维护、应用开…...
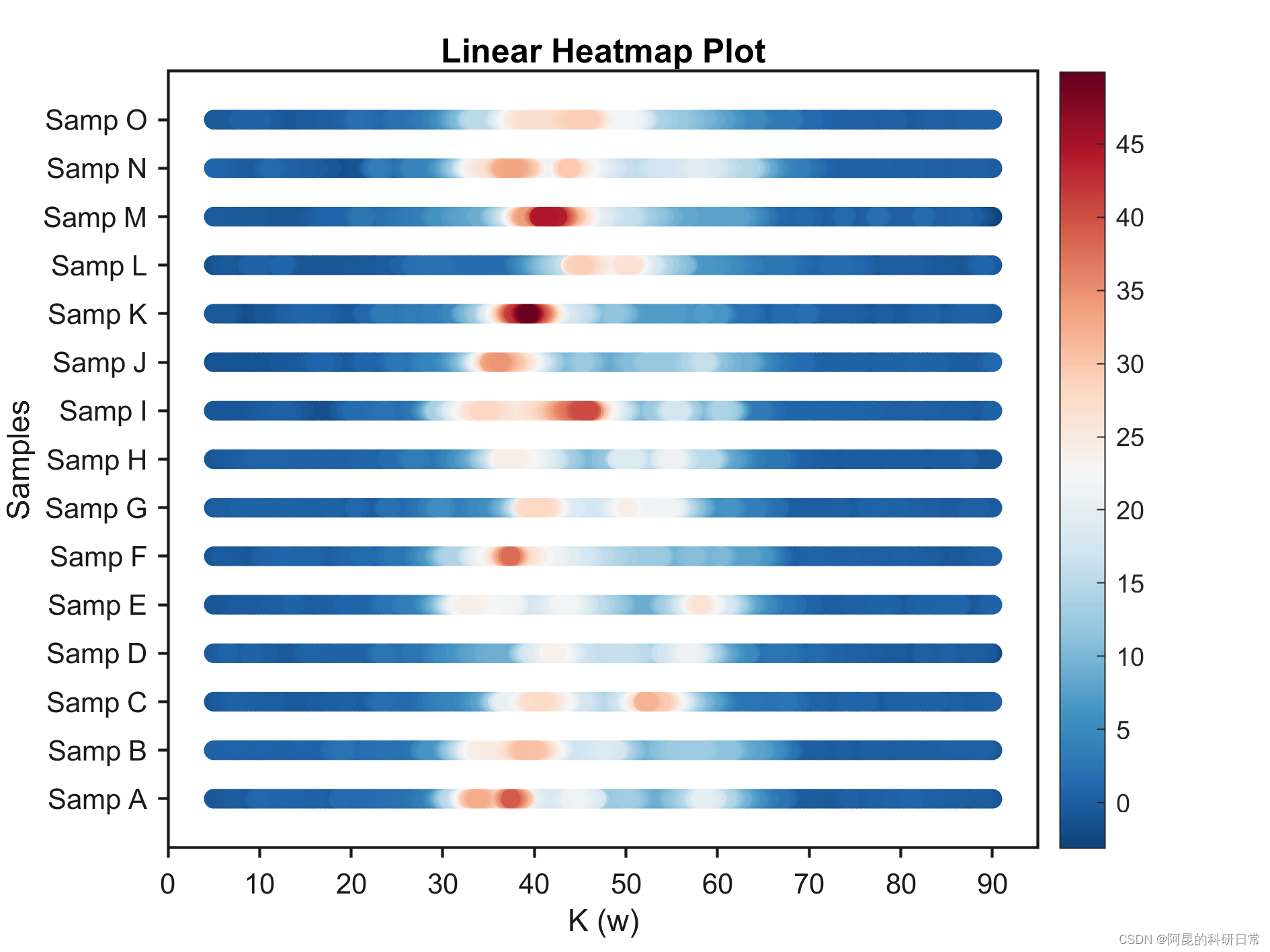
Matlab进阶绘图第2期—线型热图
线型热图由共享X轴的多条渐变直线组成,其颜色表示某一特征值。 与传统热图相比,线型热图适应于X轴数据远多于Y轴(条数)的情况,可以很好地对不同组数据间的分布情况进行比较,也因此可以在一些期刊中看到它的…...

【Redis中bigkey你了解吗?bigkey的危害?】
一.Redis中bigkey你了解吗?bigkey的危害? 如果面试官问到了这个问题,不必惊慌,接下来我们从什么是bigkey?bigkey划分的类型?bigkey危害之处? 二.什么是bigkey?会有什么影响ÿ…...
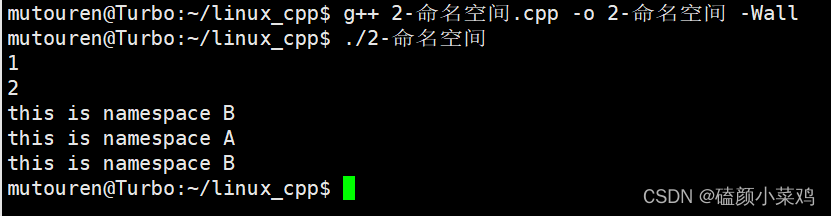
C++回顾(一)——从C到C++
前言 在学习了C语言的基础上,C到底和C有什么区别呢? 1.1 第一个C程序 #include <iostream>// 使用名为std的命名空间 using namespace std;int main() {// printf ("hello world\n");// cout 标准输出 往屏幕打印内容 相当于C语言的…...

CRF条件随机场 | 关键原理+面试知识点
😄 CRF之前跟人生导师:李航学习过,这里结合自己的理解,精简一波CRF,总结一下面试中高频出现的要点。个人觉得没网上说的那么复杂,我看网上很大部分都是一长篇先举个例子,然后再说原理。没必要原理其实不难,直接从原理下手更好理解。 文章目录 1、概率无向图(马尔可夫…...
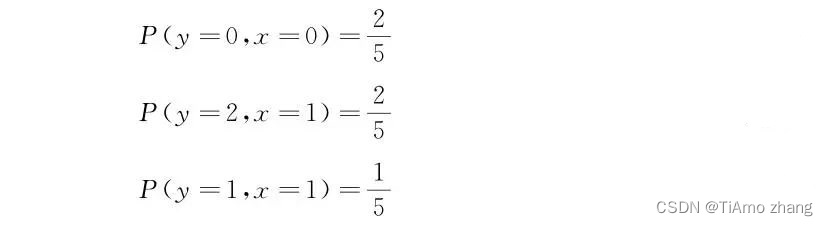
秒懂算法 | 回归算法中的贝叶斯
在本文中,我们会用概率的观点来看待机器学习模型,用简单的例子帮助大家理解判别式模型和生成式模型的区别。通过思考曲线拟合的问题,发现习以为常的损失函数和正则化项背后有着深刻的意义 01、快速理解判别式模型和生成式模型 从概率的角度来理解数据有着两个不同的角度,假…...

用Netty实现物联网01:XML-RPC和JSON-RPC
最近十年,物联网和云计算、人工智能等技术一道,受到业内各方追捧,被炒得火热,甚至还诞生了AIoT这样的技术概念。和(移动)互联网不同,物联网针对的主要是一些资源有限的硬件设备,比如监控探头、烟雾感应器、温湿度感应器、车载OBD诊断器、智能电表、智能血压计等。这些硬…...

腾讯云服务器centos7安装python3.7+,解决ssl问题
使用requests模块访问百度,报错如下: requests.exceptions.SSLError: HTTPSConnectionPool(hostwww.baidu.com, port443): Max retries exceeded with url: / (Caused by SSLError("Cant connect to HTTPS URL because the SSL module is not avail…...

C++【模板STL简介】
文章目录C模板&&STL初阶一、泛型编程二、函数模板2.1.函数模板概念2.2.函数模板格式2.3.函数模板的实例化2.4.模板参数的匹配原则三、 类模板3.1.模板的定义格式3.2.类模板的实例化STL简介一、STL的概念、组成及缺陷二、STL的版本C模板&&STL初阶 一、泛型编程…...

该学会是自己找bug了(vs调试技巧)
前言 🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻推荐专栏: 🍔🍟🌯 c语言初阶 🔑个人信条: 🌵知行合一 🍉本篇简介:>:介绍c语言初阶的最后一篇.有关调试的重要性. 金句分享…...
)
Redis大全(概念与下载安装)
目录 一、概念 1.非关系型数据库(NoSQL)的介绍 2.什么是redis 3.redis的作者 4.Redis的特点 5.redis的应用场景 6.高度概括知识 一、二 缓存穿透、缓存击穿、缓存雪崩的概念 (一)缓存穿透 (二)缓…...

指针的进阶【上篇】
文章目录📀1.字符指针📀2.指针数组📀3.数组指针💿3.1.数组指针的定义💿3.2. &数组名VS数组名💿3.3.数组指针的使用📀1.字符指针 int main() {char ch w;char* pc &ch;// pc就是字符指…...

MATLAB | 如何用MATLAB绘制花里胡哨的山脊图
本期推送教大家如何绘制各种样式的山脊图,这里做了一个工具函数用来实现好看的山脊图的绘制,编写不易请多多点赞,大体绘制效果如下: 依旧工具函数放在文末。 教程部分 0 数据准备 数据为多个一维向量放在元胞数组中,…...
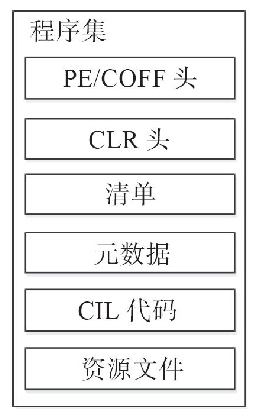
.Net与程序集
一个简单的C#程序回想一下我们第一个.net 程序 hello world,它具有那些步骤呢?打开visual studio创建一个C# console的项目build运行程序这时候就有一个命令行窗口弹出来,上面打印着hello world。我们打开文件夹的bin目录,会发现里…...

软考中级之数据库系统(重点)
涉及考点:数据库模式,ER模型,关系代数与元祖演算,规范化理论,并发控制,分布式数据库系统,数据仓库和数据挖掘 数据库模式 三级模式-二级映射 常考选择题 三级模式,两种映射的这种涉及属于层次架构体的设计,这种设计为我们在应用数据库的时候提供了很多便利,同时提高了整个体…...

腾讯元宝生成的很多公式,复制到WORD中会乱码,我应该怎么做?
从“公式乱码”到“无损流转”:企业级AI导出工程的架构实践与反思 当AI生成的专业内容在复制粘贴中“死”于格式鸿沟,我们需要的不只是工具,而是一套结构化数据流转范式。 一、痛点复盘:一个架构师眼中的“乱码危机” 在AI辅助研…...

mysql视图和用户管理
视图 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。视图的数据变化会影响到基表,基表的数据变化也会影响到视图。视图很简单,就是把我们后面的select之前我们使用的时候是形成一…...

Java NIO.2 异步基石:AsynchronousChannel 接口契约与并发安全深度剖析
前言:异步 I/O 的“宪法级”契约 在 Java NIO.2(AIO)的宏大架构中,AsynchronousChannel 是所有异步通道的根接口。它不定义任何具体的读写方法,也不关心网络拓扑或文件偏移——它只做一件事:确立异步 I/O 操…...
)
别再让Ubuntu卡成PPT!手把手教你用swapfile把交换空间从1G扩容到64G(附权限修复)
Ubuntu系统Swap空间扩容实战:从1G到64G的完整解决方案当你在Ubuntu上运行内存密集型任务时,是否遇到过系统突然变得异常缓慢,甚至完全卡死的情况?很多拥有大内存(如32GB或更高)的用户可能会惊讶地发现&…...

统信UOS 20.1060专业版美化全攻略:从桌面到开机GRUB,一张图搞定所有壁纸
统信UOS 20.1060专业版视觉定制指南:全系统美学统一方案当你第一次启动全新安装的统信UOS专业版时,那个默认的蓝色渐变桌面或许会让你感到一丝失望——它专业、稳重,但缺乏个性。作为一名追求效率与美感并存的技术爱好者,我一直在…...

随记-关于当下大学生就业现状的个人感想
近来身边不少人都在讨论,如今不少大学生毕业后选择返乡务工,或是回到家乡工厂就业。前两天和家人通话,也听闻不少人毕业后,最终回乡进厂务工、帮衬家里。昨天大学老师也发来消息,和我聊起当下本科毕业生就业压力大、求…...

002-AI客服-RAG优化分析
文章目录前言项目结构概览与实现状态总结当前状态📊 项目概况🏗️ 技术架构✅ 已实现功能⚠️ 有待修复的问题📝 下一步规划📊 当前 RAG 现状🧭 RAG 优化全景图🥇 强烈推荐的 5 个优化(按性价比…...
)
Win10升级21H2后远程桌面黑屏?一个组策略设置帮你搞定(附gpedit.msc详细路径)
Windows 10 21H2远程桌面黑屏故障深度解析与精准修复方案当你从Windows 10 1909版本升级到21H2后,是否遇到过这样的场景:远程桌面连接看似成功,却在15秒后突然黑屏断开,只留下"您的远程桌面会话已结束"的模糊提示&#…...

小学期学习——第二周
一、本周学习视频6-7学习了单电源供电的二阶低通滤波器以及电子计数法,并对仿真进行了改进。二、绘制了PCB原理图学习使用嘉立创EDA,并且绘制了PCB原理图。...

3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南
3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 想让你的Blender动画瞬间拥有电影级的真实感吗?Camera Shakify这款神奇的插件就是你…...