【数据结构---排序】很详细的哦
本篇文章介绍数据结构中的几种排序哦~
文章目录
- 前言
- 一、排序是什么?
- 二、排序的分类
- 1.直接插入排序
- 2.希尔排序
- 3.选择排序
- 4.冒泡排序
- 5.快速排序
- 6.归并排序
- 总结
前言
排序在我们的生活当中无处不在,当然,它在计算机程序当中也是一种很重要的操作,排序的主要目的是为了便于查找。
一、排序是什么?
所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的一种擦作。
二、排序的分类
框架图:
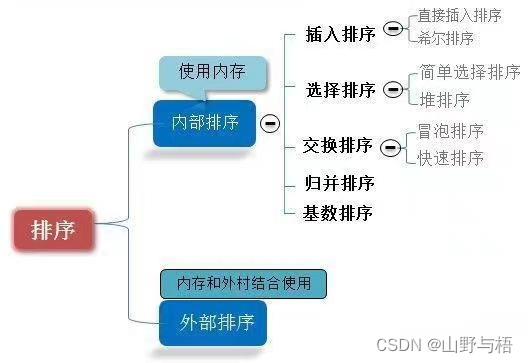
这里呢我们就介绍几种比较重要的排序算法。
1.直接插入排序
扑克牌是我们几乎每个人都可能玩过的游戏吧,最基本的扑克玩法大多都是一边摸牌,一边理牌的。
这里先看个动图吧,你是否看完动图就已经知道这种排序方式的思路了呢?
动态图演示:
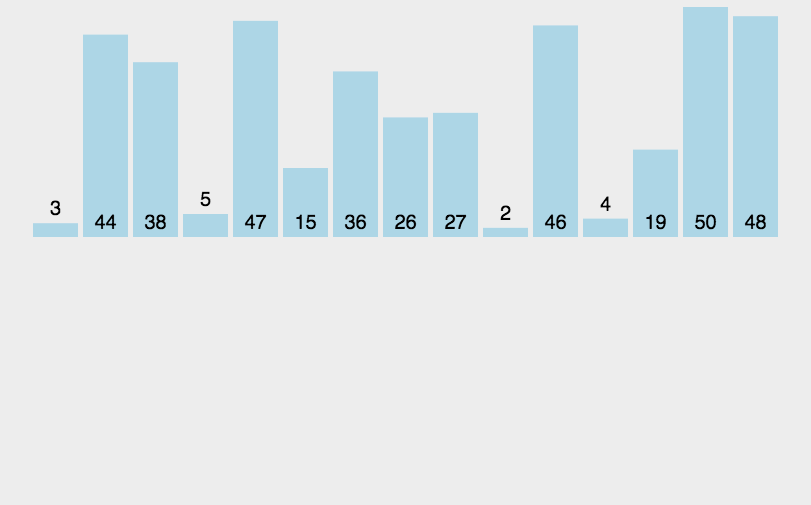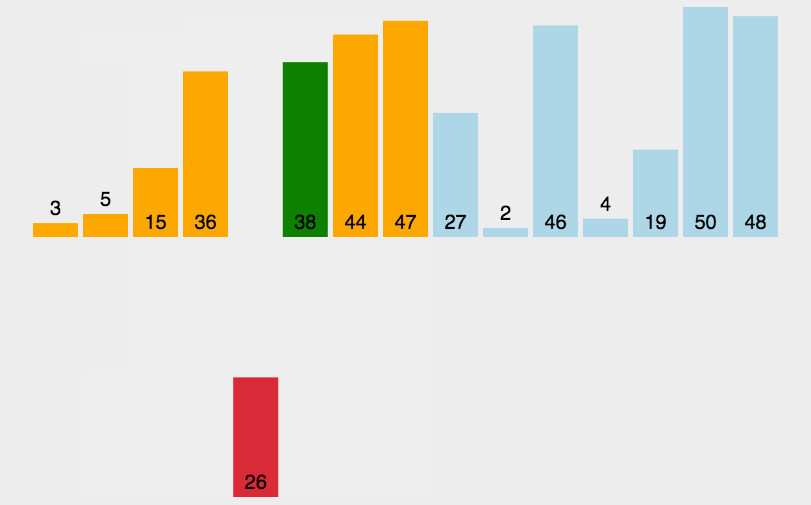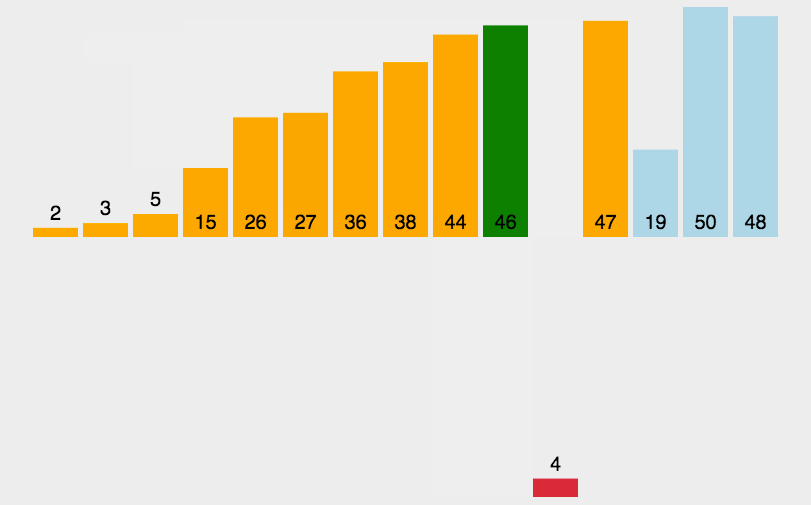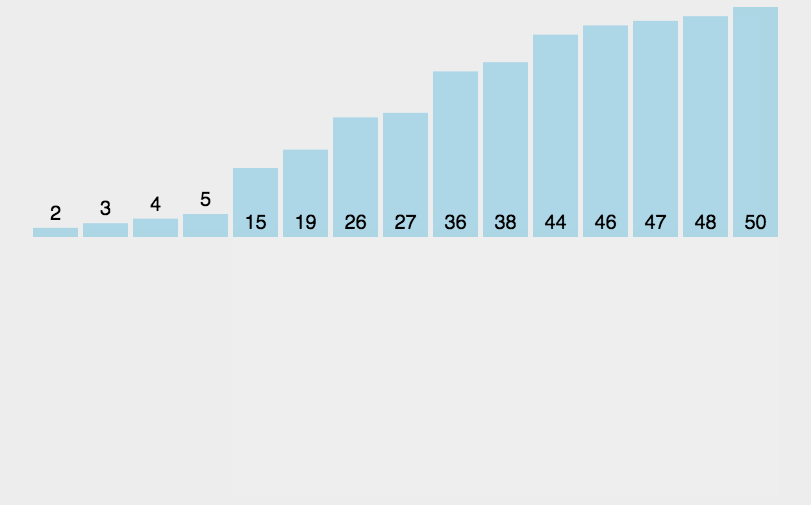
思路:
直接插入排序的思路呢就是每次将一个等待排序的元素与已经排序的元素进行一一比较,直到找到合适的位置按大小插入。它的基本操作就是将一个记录插入到已经排好序的有序表中,从而得到一个新的,记录数增1的有序表。
代码如下:
//插入排序 #include<stdio.h>void PrintArray(int* a, int n) {for (int i = 0;i < n;i++){printf("%d", a[i]);}printf("\n"); } void InsertSort(int* a, int n) {for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];}else{break;}--end;}a[end + 1] = tmp;} }//测试 void TestInsertSort() {int a[] = { 9,1,5,7,4,8,3 };InsertSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int)); } void TestOP() {srand(time(0));const int N = 10000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1;i >= 0;--i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();printf("InsertSort:%d\n", end1 - begin1);free(a1);free(a2); } int main() {TestOP();TestInsertSort();return 0; }
执行结果:
2.希尔排序(缩小增量排序)
首先,给大家说明一下,希尔排序是D.L.Shell于1959年提出来的一种排序算法,在这之前呢,排序算法的时间复杂度大多基本都是O(n^2)的,而希尔排序算法可以说是突破这个时间复杂度的第一批算法之一了,换句话说,希尔排序算法的发明,使得我们终于突破了慢速排序的时代。之后,更为高效的排序算法也就相继出现了。
有条件了很好,没条件我们去创造条件也是可以去做的,那么,在科学家希尔对直接插入排序进行打磨之后就可以增加效率了。一个问题的解决务必是因为该问题的诞生,那如何让待排序的记录个数变少呢?分割成若干个子序列,此时每个序列待排序的记录个数就比较少了,接着在这些子序列内分别进行直接插入排序,当整个序列都基本有序时,这里可要注意啦,是基本有序时,再次对全体记录进行一次直接插入排序。
强调一下:这里的基本有序指的是小的关键字基本在前边,大的关键字基本在后边,不大不小的基本在中间。就和我们高中跑早操排队一样嘛,但是偶尔会出现一两对身高不太一样的好朋友往一块站对嘛。
可是这里分割待排序记录的目的是减少待排序记录的个数,并且使整个序列向基本有序发展·,不过按照这样的方式好像并不能满足我们让分完组后就各自排序的这种要求哦,所以,我们需要采取的措施是:将相距某个“增量”的记录组成一个子序列,这样的话才能够保证在子序列内部分别进行直接插入排序后得到的结果是基本有序而不是局部有序的。
总结:希尔排序的基本思想就是:先选定一个整数,把待排序文件中所有记录分成gap组,所有距离为gap的记录在同一组内,并且对每一组内的记录进行排序。然后,重复上述分组和排序的工作。当达到gap = 1时,所有记录在同一组内排好序。
代码如下:
//希尔排序 void PrintArray(int* a, int n) {for (int i = 0;i < n;i++){printf("%d", a[i]);}printf("\n"); }void ShellSort(int* a, int n) {int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; ++i){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end = end - gap;}else{break;}}a[end + gap] = tmp;}} } //测试 void TestShellSort() {int a[] = { 9,1,5,7,4,8,3 };ShellSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int)); } void TestOP() {srand(time(0));const int N = 10000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1;i >= 0;--i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();ShellSort(a1, N);int end1 = clock();printf("ShellSort:%d\n", end1 - begin1);free(a1);free(a2); } int main() {TestOP();TestShellSort();return 0; }
执行结果;
希尔排序的特性总结:
(1)当gap > 1时其实都是预排序,目的是让数组更接近于有序。
当gap == 1 时,其实就是直接插入排序,数组已经接近有序了,这样就会很快。就整体而言,可以达到优化的效果。
(2)希尔排序的时间复杂度不是很好计算,因为gap的取值方法很多,导致很难去计算。
说明:gap的取法有很多种,Shell提出取 gap = n / 2, gap = gap / 2,直到gap为1;
后来,Knuth提出取gap = (gap / 3) + 1。
无论哪一种,都没有得到证明! ! !
注:在Knuth所著的《计算机程序设计技巧》第三卷中,利用大量的实验统计资料得出,当n很大时,关键码平均比较次数和对象平均移动次数在n^1.25~1.6*n^1.25范围内,这是在利用直接插入排序作为子序列排序方法的情况下得到的。
3.选择排序
动态图演示:
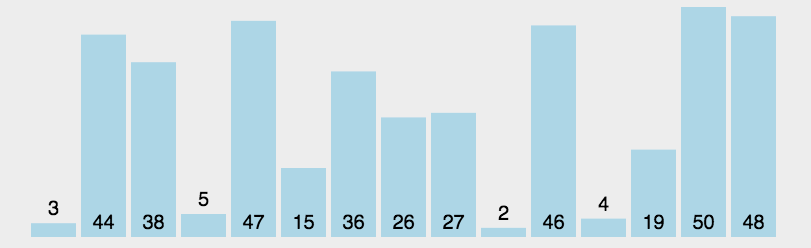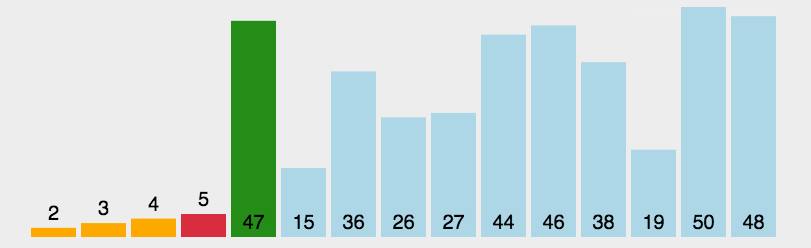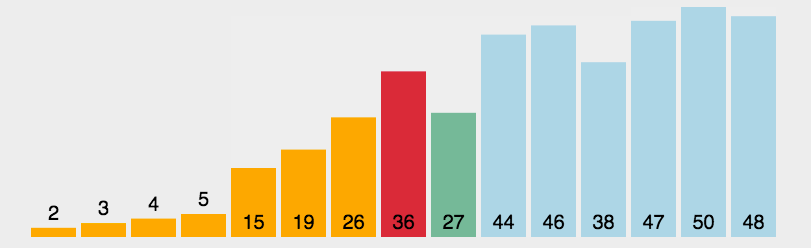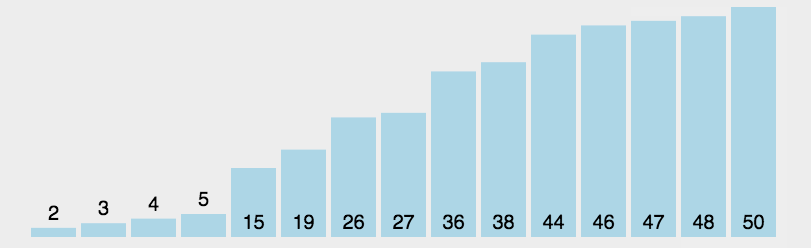
看完图有没有思路呢?其实选择排序的思路蛮简单的,就是每一次从待排序的数据元素中选出最小/最大的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。这种排序也就是通过n-i次关键字间的比较,从n - i + 1个记录中选出关键字最小的记录,并且和第 i (1 <= i <= n)个记录交换。
代码如下:
//选择排序 void PrintArray(int* a, int n) {for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n"); }void Swap(int* x, int* y) {int tmp = *x;*x = *y;*y = tmp; }void SelectSort(int* a, int n) {int begin = 0, end = n - 1;while (begin < end){int mini = begin, maxi = begin;for (int i = begin + 1; i <= end; i++){if (a[i] > a[maxi]){maxi = i;}if (a[i] < a[mini]){mini = i;}}Swap(&a[begin], &a[mini]);if (maxi == begin){maxi = mini;}Swap(&a[end], &a[maxi]);++begin;--end;} }//测试 void TestSelectSort() {int a[] = { 9,1,5,7,4,8,3 };SelectSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int)); }void TestOP() {srand(time(0));const int N = 100;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1; i >= 0; --i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();SelectSort(a1, N);int end1 = clock();printf("SelectSort:%d\n", end1 - begin1);free(a1);free(a2); } int main() {TestOP();TestSelectSort();return 0; }
执行结果:
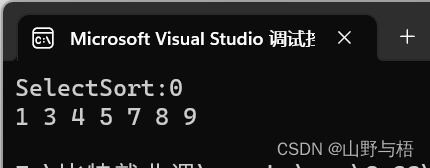
从选择排序的过程来看,它最大的特点就是交换移动数据次数相对较少,这样也就节约了相应的时间。
总结:选择排序它的思路很好理解,但是其效率并不是很好,很少用到。
4.冒泡排序
无论你学习哪种编程语言,在学到循环和数组的时候,通常都会介绍一种排序算法,而这个算法一般就是冒泡排序。并不是说它的名字好听,而是说这个算法的思路最简单,最容易理解哦。
冒泡排序呢我们可以理解为一种交换排序,其基本思想是:对数组进行遍历,每次对相邻两个进行比较大小,如果大的数值在前面,那么交换位置也可以理解为升序,完成一趟遍历后数组中最大的数值到了数组的末尾位置,再对前面n-1个数值进行相同的遍历,一共完成n-1次遍历就实现了排序完成。
动态图演示:
代码如下:
//冒泡排序 void PrintArray(int* a, int n) {for (int i = 0;i < n;i++){printf("%d", a[i]);}printf("\n"); } void Swap(int* x, int* y) {int tmp = *x;*x = *y;*y = tmp; } void BubbleSort(int* a, int n) {for (int j = 0; j < n; j++){int exchange = 0;for (int i = 1; i < n - j; i++){if (a[i - 1] > a[i]){Swap(&a[i - 1], &a[i]);exchange = 1;}}if (exchange == 0){break;}} }//测试 void TestBubbleSort() {int a[] = { 9,1,5,7,4,8,3 };BubbleSort(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int)); } void TestOP() {srand(time(0));const int N = 100;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1; i >= 0; --i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();BubbleSort(a1, N);int end1 = clock();printf("BubbleSort:%d\n", end1 - begin1);free(a1);free(a2); } int main() {TestOP();TestBubbleSort();return 0; }
执行结果:

在这里呢简单提一下冒泡排序的效率,冒泡排序是稳定的排序算法,在相同数据排序时不会影响原来的顺序,对结构体类型有影响的。它的时间复杂度是O(n^2),空间复杂度是O(1)。
5.快速排序
终于,我们的高手就要出场啦!假如说未来你在工作后,你的老板让你写个排序算法,而你会的算法中竟然没有快速排序,那么我建议你还是火速把快速排序算法找来敲入你排序算法的大队伍中吧,哈哈哈哈……
简单介绍一下快速排序吧,快速排序算法最早是由图灵奖获得者Tony Hoare设计出来的。他在形式化方法理论以及ALGOL60编程语言的发明中都有卓越的贡献,是上世纪最伟大的计算机科学家之一。而这快速排序算法只是他众多贡献中小小的一个发明而已。你们知道吗,我们接下来要学习的这个快速排序算法可是被列为20世纪十大算法之一的哦~
这段话大家好好看看哦~
希尔排序可以说是直接插入排序的升级,都属于插入排序这一大类哦;
快速排序可以说是冒泡排序的升级,都属于交换排序这一大类哦。也就是通过不断比较和移动交换来实现排序,不过它的实现相较其他而言,就是增大了记录的比较和移动的距离,将关键字大的记录从前面直接移动到后面去,关键字较小的记录从后面直接移动到前面,从而减少了总的比较次数和移动交换次数。
基本思想:任取待排序元素序列中的某个元素作为基准值,按照该排序码将待排序码集合分割成两个子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
在这里呢,我们主要对hoare排序以及对其的几种优化进行介绍:
(1)hoare版本
hoare版本是快速排序最原始的情况,(看看单趟的过程)
这里单趟的目的是:要求左边的key要小,右边的key要大
动态图演示:
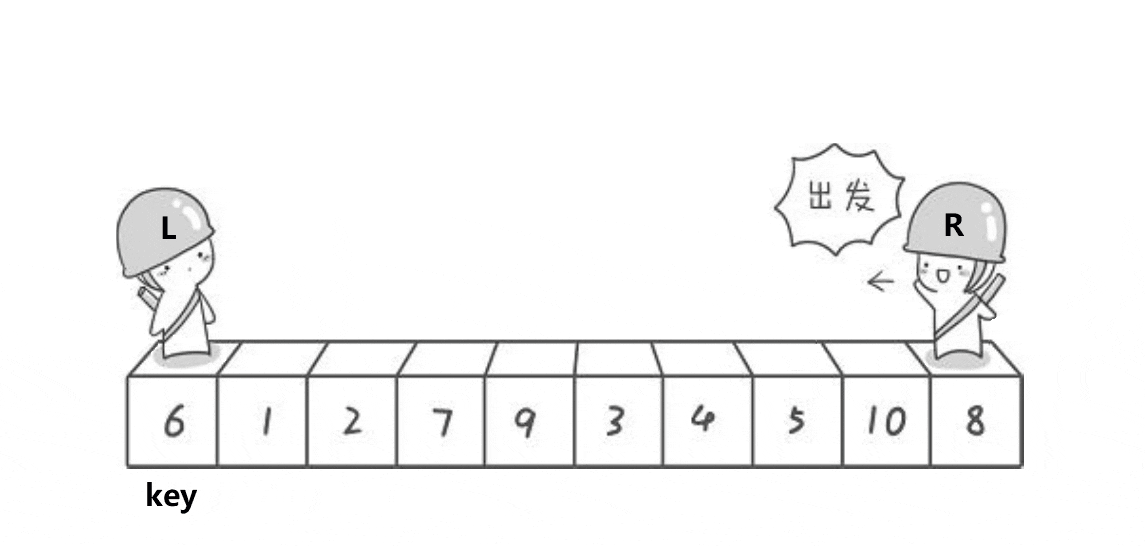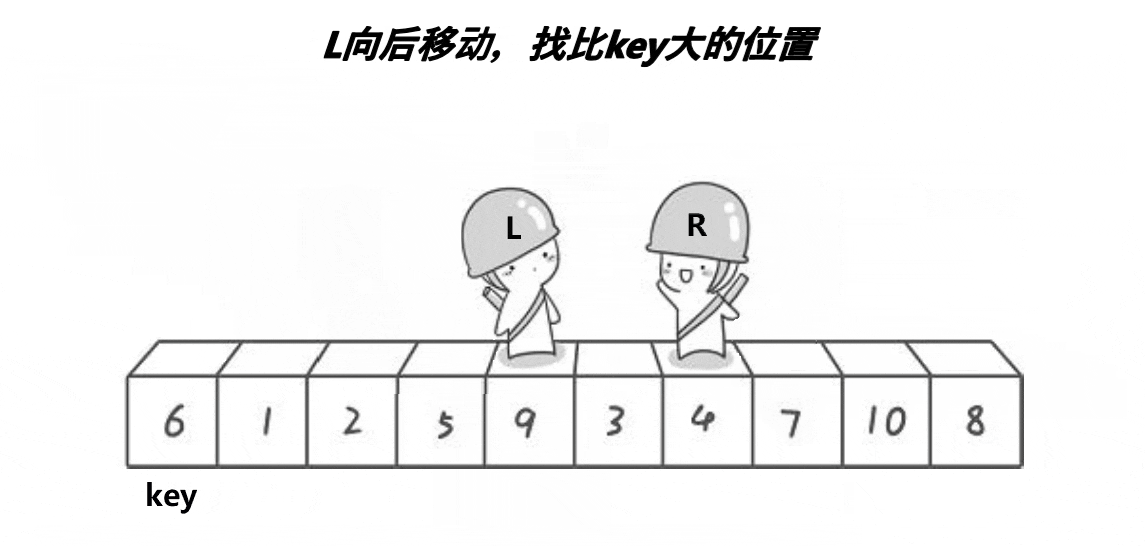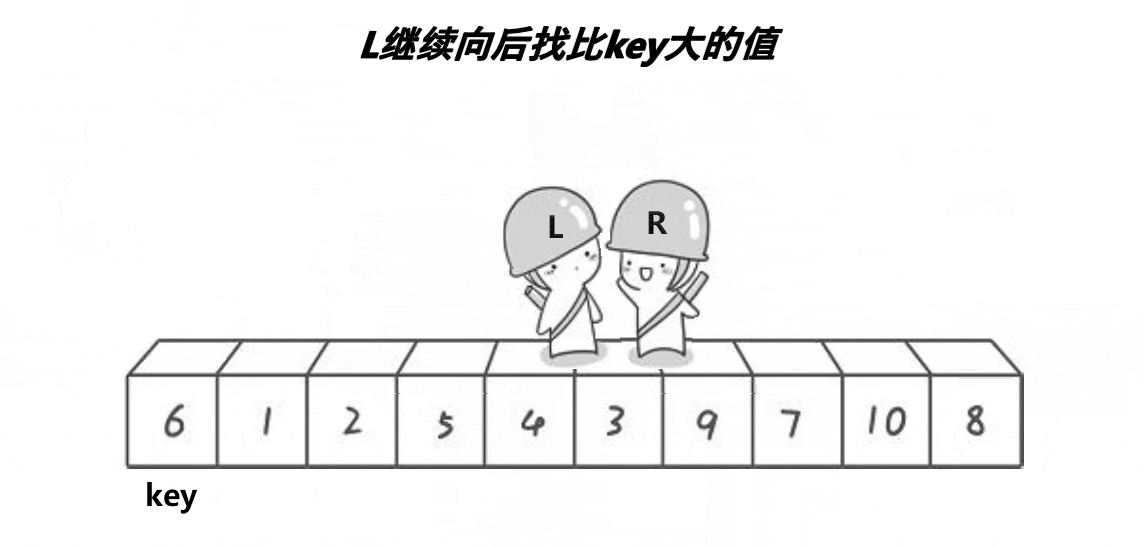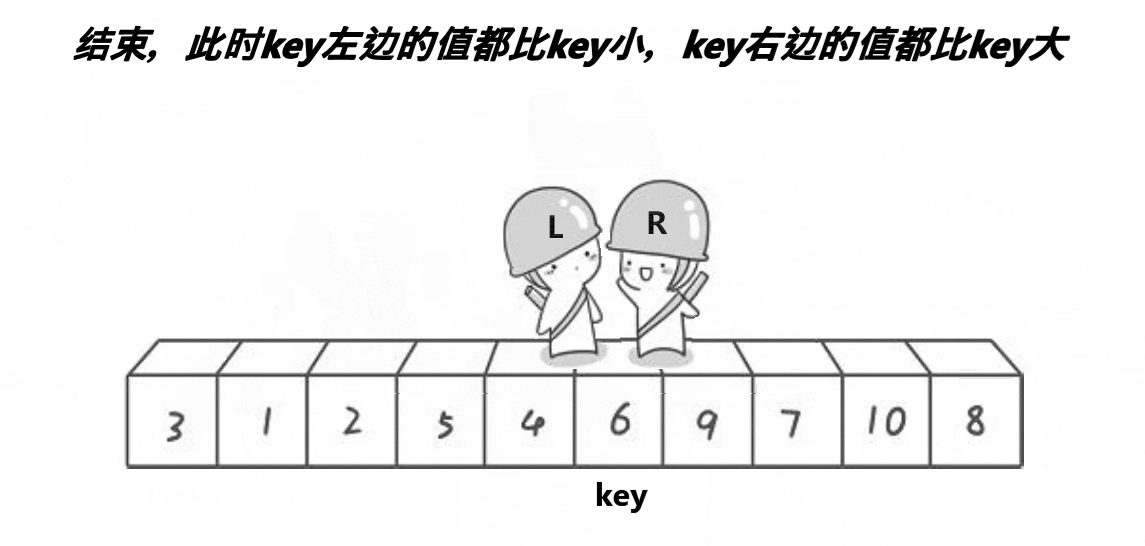
看完图,是否稍微有一点点思路呢?因为快速排序在排序中很重要,所以这里可能会说的详细一点,大家不要嫌我啰嗦哦~
思路:
a:先记录下keyi的位置,接着 left 和 right 分别从数组两端开始往中间走;
b:当right先开始向中间行动,如果right处的值小于keyi处所对应的值,则停止等待left走;
c:此时left开始行动,当left找到比keyi处小的值的时候,left 和 right处的值进行交换;
d:当两个位置相遇时,将两个相遇位置的值与keyi处所对应的值进行交换,并且将相遇的位置记为新的keyi;
代码如下:
//这里出现了一种三数取中的方法,这样的话快速排序就不会出现最坏情况 // 三数取中void PrintArray(int* a, int n) {for (int i = 0;i < n;i++){printf("%d", a[i]);}printf("\n"); } void Swap(int* x, int* y) {int tmp = *x;*x = *y;*y = tmp; } int GetMidi(int* a, int left, int right) {int mid = (left + right) / 2;// left mid rightif (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]) // mid是最大值{return left;}else{return right;}}else // a[left] > a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]) // mid是最小{return left;}else{return right;}} }
//快速排序hoare版本
int PartSort1(int* a, int left, int right)
{int keyi = left;while (left < right){//找小while (left < right && a[right] >= a[keyi]){--right;}//找大while (left < right && a[left] <= a[keyi]){++left;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left;
};
void QuickSort(int* a, int left, int right)
{if (left >= right)return;if ((right - left + 1) > 10){int keyi = PartSort1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}else{InsertSort(a + left, right - left + 1);}
}
执行结果:

(2)挖坑法版本
动态图演示:
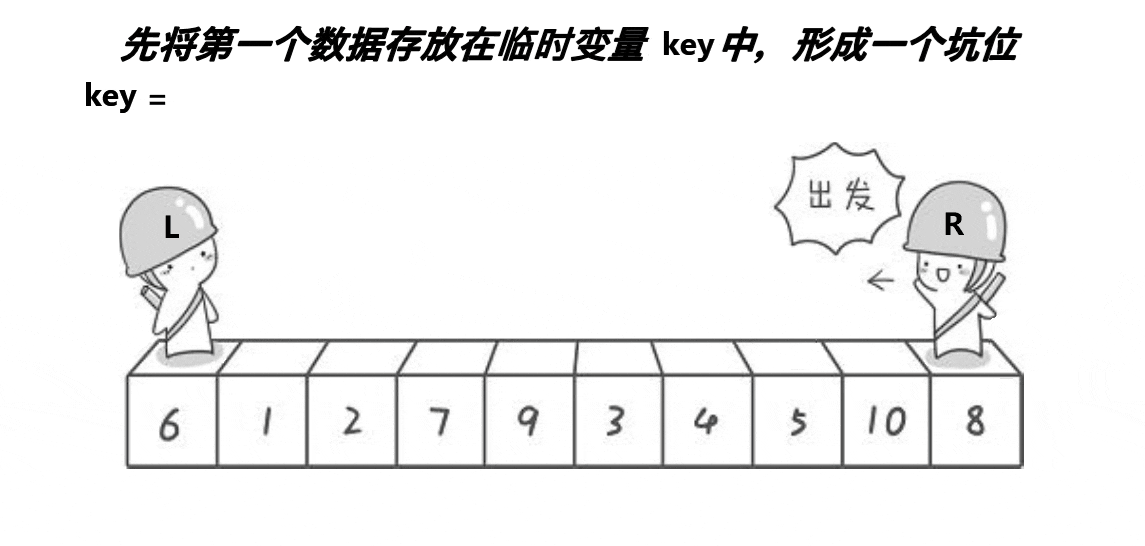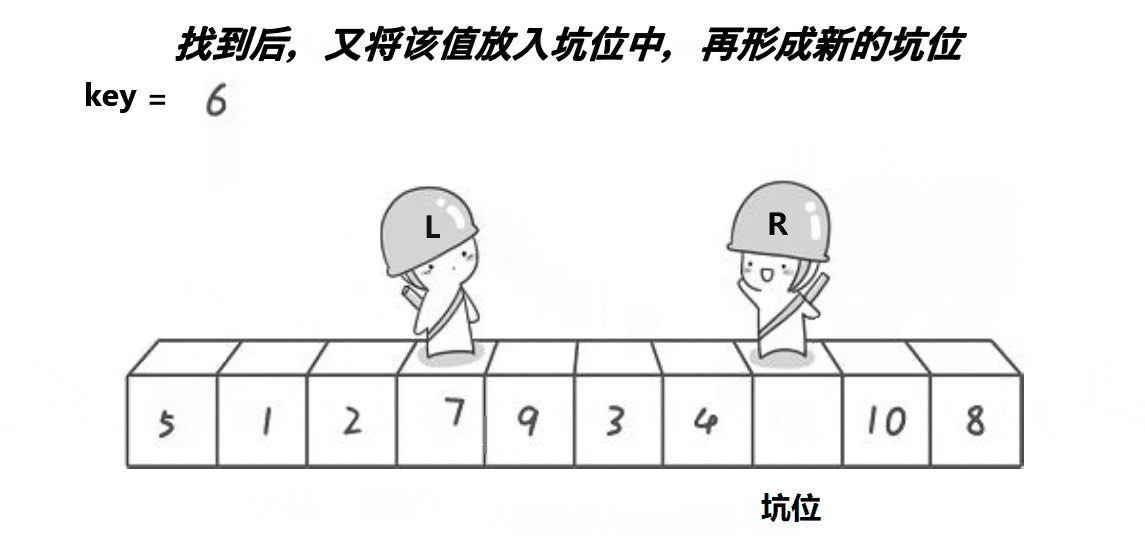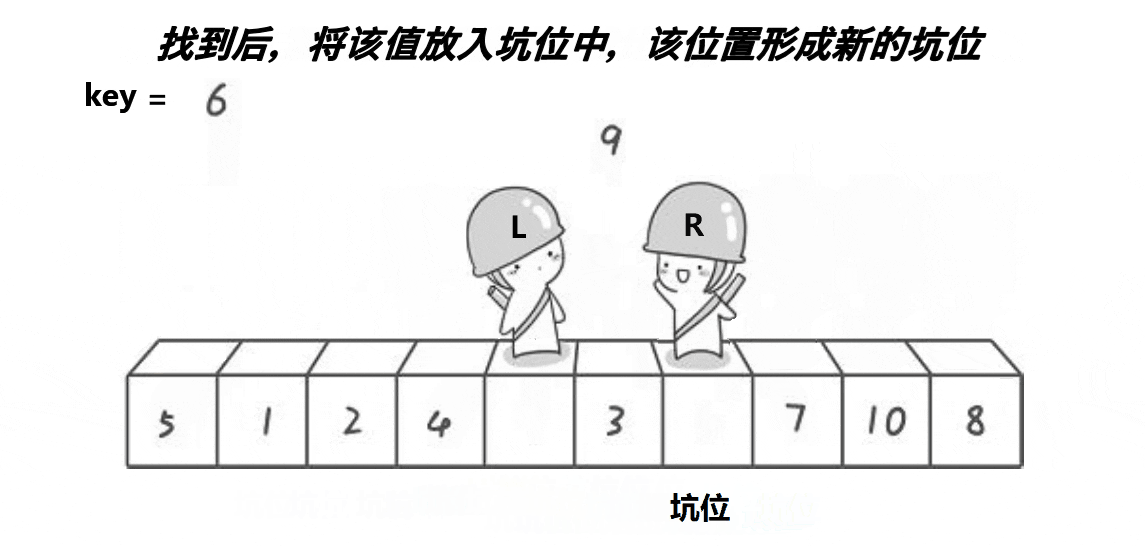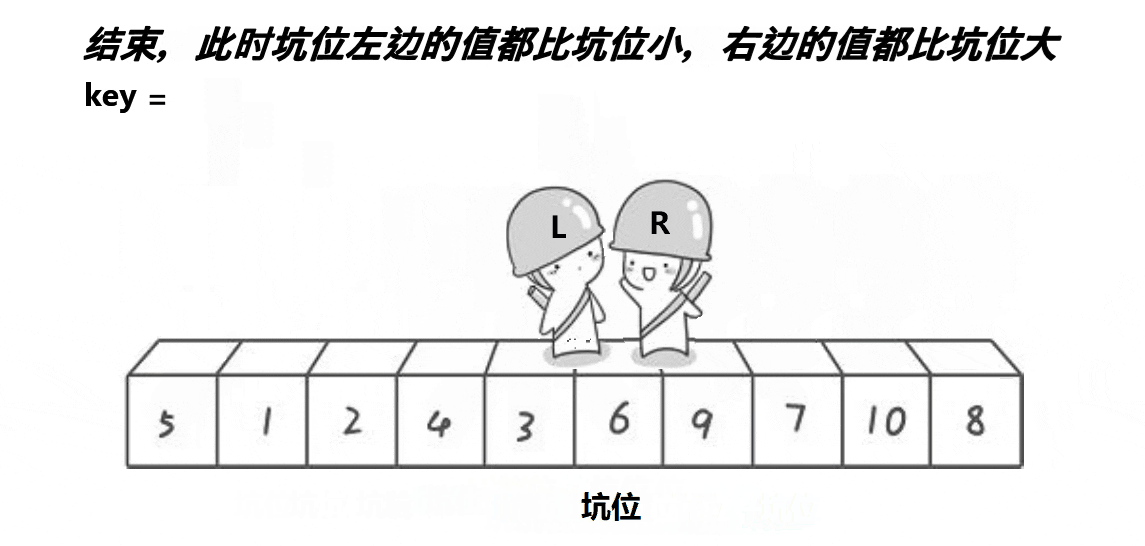
看完图,有什么想法吗,或许有些同学对快速排序的第一个原始版本中,左边设置为keyi之后,右边就要先走是不太能理解的吧,这里就有脑洞大开的大佬想出了另外一种快速排序的方法,可能思路不太一样,不过相比而言,对我们这些小白来说更容易理解哦~
思路:
a:首先将begin处的值放到key中,然后将其设置为坑位,接着right抗下任务开始行动找值从而补坑;
b:right找到比key小的值后将这个值放到刚才的坑位中,然后将这个新的位置重新设置为坑位;
c:此时left也开始找值来进行补坑啦,找到比key大的值,然后将这个值放到坑位中,接着将这个新的位置重新设置为坑位;
d:当left与right碰面时,再将key放入到坑位中;
代码如下:
//三数取中那一部分在前面哦!
//挖坑法int PartSort2(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int key = a[left];// 保存key值以后,左边形成第一个坑int hole = left;while (left < right){// 右边先走,找小,填到左边的坑,右边形成新的坑位while (left < right && a[right] >= key){--right;}a[hole] = a[right];hole = right;// 左边再走,找大,填到右边的坑,左边形成新的坑位while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;int keyi = PartSort2(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}执行结果:
(3)前后指针法版本
动态图演示:
这里呢,前后指针法与前面两种版本相比的话,无论是从哪个方面考虑都是有很大的提升的,也是一种很常见的写法。
思路:
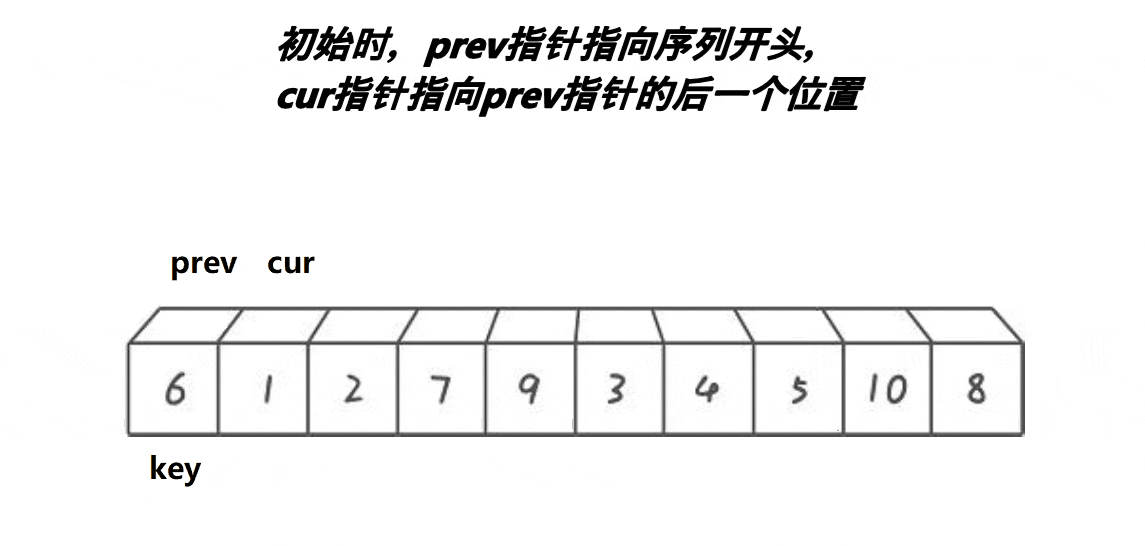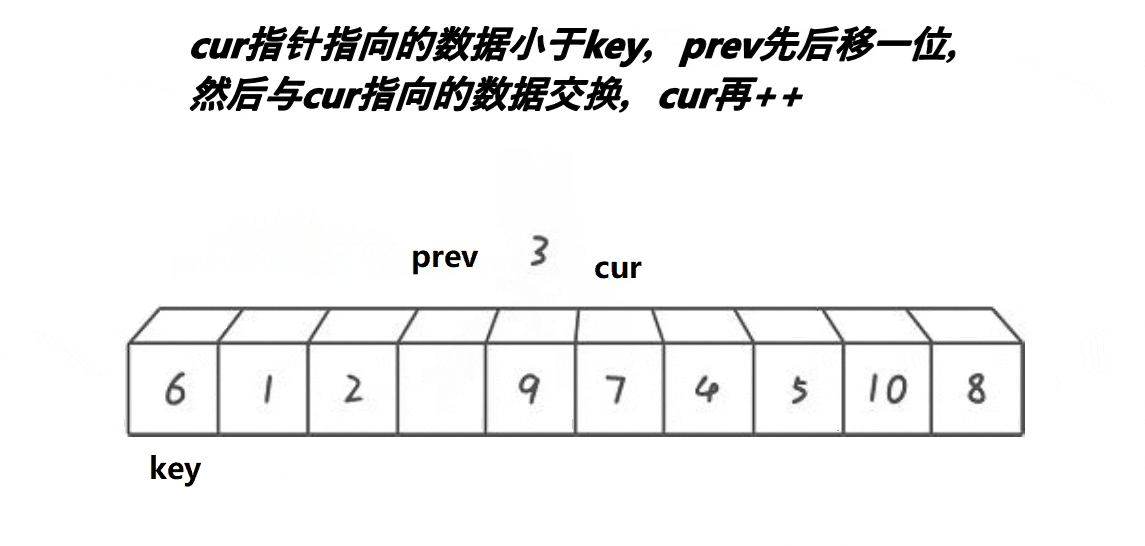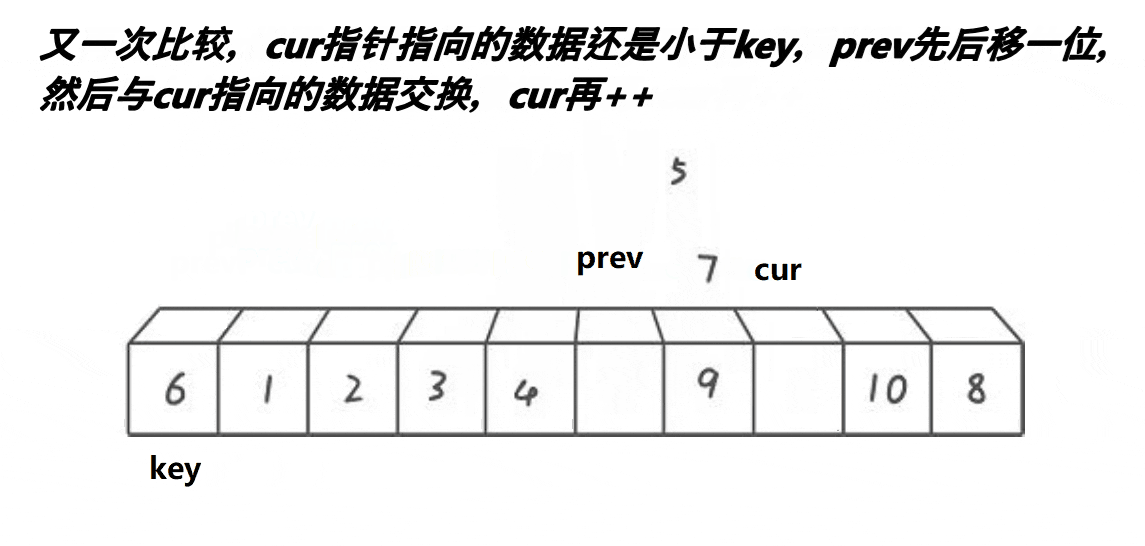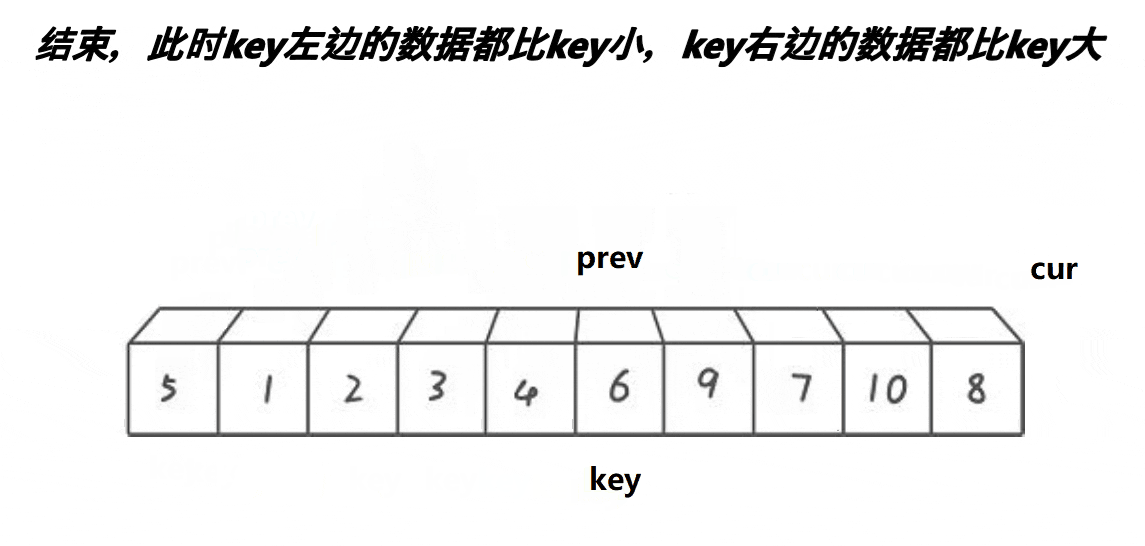
a:cur位于begin+1的位置,prev位于begin的位置,keyi先存放begin处的值;
b:cur不断往前+1,直到cur大于等于end时停止循环;
c:如果cur处的值小于key处的值,而且prev+1不等于cur,那么与prev处的值进行交换;
d:当循环结束时,将prev处的值与keyi处的值进行交换,而且将其置为新的keyi值
代码如下:
//前后指针
int PartSort3(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int prev = left;int cur = prev + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);return prev;
}// [begin, end]
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;int keyi = PartSort3(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);
}执行结果:

说明:
这里,在遍历的整个过程中,cur是不断向前的,只是cur处的值小于keyi处的值时才进行交换,使其进行判断;在cur位置处的值小于keyi处的值时,需要进行判断prev++是否等于cur,如果等于的话,则会出现自己交换自己的情形,当然,如果相等的话不用进行交换哦~
//这是上面三种情况的测试代码 void TestQuickSort() {int a[] = { 9,1,5,7,4,8,3 };QuickSort(a,0, sizeof(a) / sizeof(int)-1);PrintArray(a, sizeof(a) / sizeof(int)); }void TestOP() {srand((unsigned)time(0));const int N = 1000000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1; i >= 0; --i){a1[i] = rand();a2[i] = a1[i];}int begin1 = clock();QuickSort(a1, 0, N-1);int end1 = clock();printf("QuickSort:%d\n", end1 - begin1);free(a1);free(a2); } int main() {TestOP();TestQuickSort();return 0; }
6.归并排序
归并排序,归并归并,从字面意思来看,我们就可以有着把两个合并到一起的感觉。在数据结构中的定义呢是将两个或两个以上的有序表组合成一个新的有序表。
我想问一下大家知道我们高考完那个所谓的一本,二本,还有专科线是怎么划分出来的吗,简而言之,假设各个高校的本科专业要在甘肃省高三学理科的学生中打算招收一万名学生,那么将全省参加高考的理科生进行一个倒排序,那么,这位排名在一万名的这位幸运同学的分数就会是本科线。换个思路想,如果你是年级第一,但你的分数没有高于这个分数线,那么很遗憾,你也就失去了上本科的机会。换言之,所谓的排名,其实也就是这个省份中的每个市一直到每个县城的每个学校的每个班级的排名合并之后,从而得到的。
为了让大家更清楚的理解思路,这里给大家看个动态图吧~
动态图演示:
看完动态图,有没有稍微理解一点呢,话说回来,这就是我们要说的归并排序。
归并排序用到了分治的思想,借助递归的方式对一串数字进行排序,整个过程分为分开和合并这两个过程,其实,这里的思想也没有那么难理解,就是在代码实现的过程中我们需要写两个函数分别实现分开合并以及每一次排序的这个过程。
通过上面的动图演示,我们不难发现,首先是要将整个待排序的数逐步分成小块,然后再进行归并。
思路:
归并排序的思路就是对于左右子区间都有序的序列,通过借助一个临时数组进行归并。
然后定义两个指针begin1和begin2,分别指向两个子区间的头部,另外定义两个指针end1和end2,分别指向两个子区间的尾部。然后依次挨个比较begin1和begin2指向的值,将小的放入下面的临时数组中,直到其中的一个区间遍历完成后,我们就停下来,然后接着将没有走完的那个区间剩下的值直接拷贝给新数组。
看到这的时候,我们应该能知道,当区间里只有1个数的时候,那么我们就可以理解为有序了,也就是可以进行归并操作了。所以,当左右这两个子区间都没有序的时候,我们就分治递归,不断的分割区间,直到区间分割到只剩下1个数的时候,此时,我们就进行归并啦~
代码实现:
//sort.c
#include"Sort.h"
#include"Stack.h"
#include<stdlib.h>void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++){printf("%d ", a[i]);}printf("\n");
}void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}归并排序递归实现
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (end <= begin)return;int mid = (end + begin) / 2;_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid + 1, end);int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int index = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);
}我们常说,没有最好,只有更好。虽然说归并排序大量引用了递归,尽管在代码上是比较清晰的,可以使我们容易理解,但是这会造成时间和空间上的性能损耗,我们排序追求的不就是效率吗,有没有可能将递归转化为迭代呢?当然可以,而且改进之后,性能上可是进一步提高了哦~
前面提到的是归并排序的递归思想,那接下来就说一下归并排序的非递归是怎么样的。
思路:
a:申请空间,使它的大小为两个已经排序的序列的和,然后该空间用来存放合并后的序列;
b:设定两个指针,最开始的两个位置分别为两个已经排序的序列的起始位置;
c:比较两个指针所指向的元素,选择相对小的元素放入到合并的空间中,并且移动指针到下一个位置;
d:对上一步的步骤进行重复,直到某一指针超出序列尾部将另一个序列剩下的所有元素怒直接复制到合并的序列尾部。
代码实现:
//sort.c
void TestMergeNonRSort()
{int a[] = { 9,1,2,5,7,4,3,9,3,1,2 };MergeSortNonR(a, sizeof(a) / sizeof(int));PrintArray(a, sizeof(a) / sizeof(int));
}void TestOP()
{srand(time(0));const int N = 10000000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);for (int i = N - 1; i >= 0; --i){a1[i] = rand() + i;a2[i] = a1[i];}int begin1 = clock();MergeSortNonR(a1, N);int end1 = clock();printf("MergeSortNonR:%d\n", end1 - begin1);free(a1);free(a2);
}int main()
{//TestOP();TestMergeNonRSort();return 0;
}说明:非递归的方法,虽然说不是很好理解,也有点难,但是其避免了递归时深度为log2n的栈空间,并且避免递归也在时间性能上有一定的提升,可以说,使用归并排序时,尽可能考虑用非递归的方法。
7.计数排序
这里要说的计数排序呢,它的原理就是通过遍历数组,记录每一个数字出现的次数,最终在新数组中体现出来,那么是如何实现的呢?
思路:
a:首先我们先遍历整个数组,找到数组中数值最大的数字max,并且申请max+1个桶(随便起的名字哈)来存储每个数字出现的次数,此时用下表记录;
b:然后我们遍历原来的数组,找到每个数字对应的桶号,并且计数;
c:遍历桶数组,看对应的桶内计数是多少,那么就取出几个下标值,放到原数组中。
代码实现:
//sort.c
//计数排序
void CountSort(int* a, int n)
{int min = a[0], max = a[0];for (int i = 0; i < n; i++){if (a[i] < min)min = a[i];if (a[i] > max)max = a[i];}int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);printf("range:%d\n",range);if (count == NULL){perror("malloc fail");return;}memset(count, 0, sizeof(int) * range);for (int i = 0; i < n; i++){count[a[i] - min]++;}//排序int j = 0;for (int i = 0;i < range;i++){while (count[i]--){a[j++] = i + min;}}
}运行结果和前面的一样,就不贴出来啦,大家主要要体会每种排序的精髓在哪,完全理解它的思路,要领,核心还有它之所以叫这个排序,是为什么,到底哪里和其他的排序方式有差别,我想,如果大家报着这个态度去学习每一种排序,那数据结构中的几种排序不得被你狠狠拿捏了……
总结
这里呢,就对几种排序的时间复杂度,空间复杂度进行一个简单的总结哦~
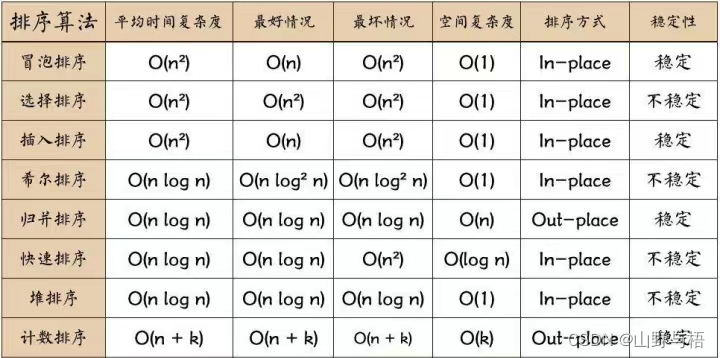
图片贴到这里啦,大家格外要理解稳定性不稳的几种排序的理由哦~
好啦,关于数据结构中几种常见排序就先介绍到这里啦,如果哪里出错了,欢迎大家留言和我一起进步嘞。
相关文章:
【数据结构---排序】很详细的哦
本篇文章介绍数据结构中的几种排序哦~ 文章目录 前言一、排序是什么?二、排序的分类 1.直接插入排序2.希尔排序3.选择排序4.冒泡排序5.快速排序6.归并排序总结 前言 排序在我们的生活当中无处不在,当然,它在计算机程序当中也是一种很重要的操…...
GitHub爬虫项目详解
前言 闲来无事浏览GitHub的时候,看到一个仓库,里边列举了Java的优秀开源项目列表,包括说明、仓库地址等,还是很具有学习意义的。但是大家也知道,国内访问GitHub的时候,经常存在访问超时的问题,…...
-NOA领航辅助系统-上汽荣威)
辅助驾驶功能开发-功能对标篇(7)-NOA领航辅助系统-上汽荣威
1.横向对标参数 厂商上汽荣威车型荣威RX5(燃油车)上市时间2022Q3方案10V3R摄像头前视摄像头1*(8M)侧视摄像头4后视摄像头1环视摄像头4DMS摄像头1雷达毫米波雷达34D毫米波雷达/超声波雷达12激光雷达/域控供应商1*(宏景智驾)辅助驾驶软件供应商地平线高精度地图中海庭芯片J3合作…...

第0次 序言
突然想起有好多书没有看,或者看了也没留下任何记录,以后有空必须得好好整理才行,这次就从《Linux命令行和shell脚本编程大全开始》 本文完全是闲聊,自娱自乐,我觉得做开发是一件很快乐的事情,但是工作是开发…...

ESP32设备驱动-OLED显示单个或多个DS18B20传感器数据
OLED显示单个或多个DS18B20传感器数据 文章目录 OLED显示单个或多个DS18B20传感器数据1、DS18B20介绍2、硬件准备3、软件准备4、代码实现4.1 读取单个DS18B20数据4.2 驱动多个DS18B20传感器4.3 OLED显示DS18B20数据在本文中,我们将介绍如何ESP32驱动单个或多个DS18B20传感器,…...
MongoDB快速上手
文章目录 1、mongodb相关概念1.1、业务应用场景1.2、MongoDB简介1.3、体系结构1.3.1 数据库 (databases) 管理语法1.3.2 集合 (collection) 管理语法 1.4、数据模型1.5、MongoDB的特点 2、单机部署3、基本常用命令3.1、案例需求3.2、数据库操作3.2.1 选择和创建数据库3.2.2 数据…...
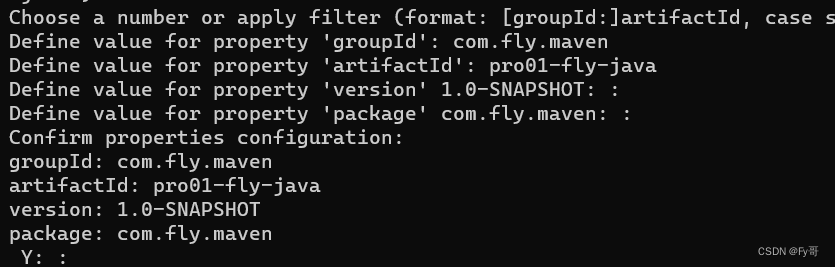
maven 初学
1. maven 安装 配置安装 路径 maven 下载位置: D:\software\apache-maven-3.8.6 默认仓库位置: C:\Users\star-dream\.m2\repository 【已更改】 本地仓库设置为:D:\software\apache-maven-3.8.6\.m2\repository 镜像已更改为阿里云中央镜像仓库 <mirrors>…...
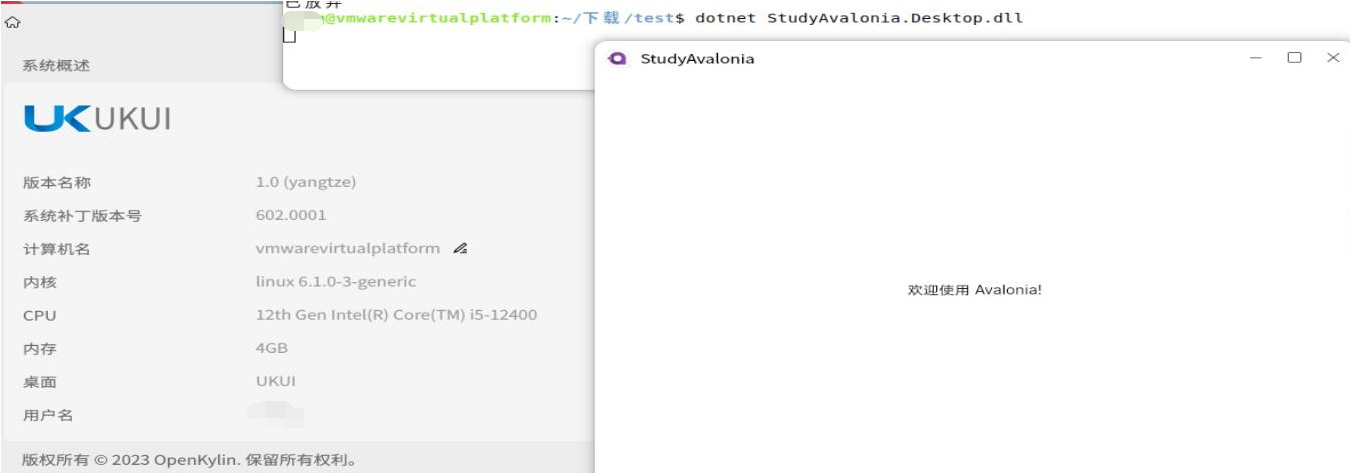
解决WPF+Avalonia在openKylin系统下默认字体问题
一、openKylin简介 openKylin(开放麒麟) 社区是在开源、自愿、平等和协作的基础上,由基础软硬件企业、非营利性组织、社团组织、高等院校、科研机构和个人开发者共同创立的一个开源社区,致力于通过开源、开放的社区合作ÿ…...
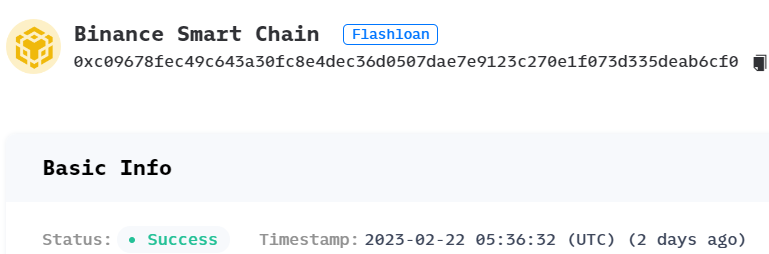
智能合约漏洞,Dyna 事件分析
智能合约漏洞,Dyna 事件分析 1. 漏洞简介 https://twitter.com/BlockSecTeam/status/1628319536117153794 https://twitter.com/BeosinAlert/status/1628301635834486784 2. 相关地址或交易 攻击交易 1: https://bscscan.com/tx/0x7fa89d869fd1b89e…...
:Elasticsearch7.x的官方文档学习(Set up Elasticsearch))
Elasticsearch基础篇(四):Elasticsearch7.x的官方文档学习(Set up Elasticsearch)
Set up Elasticsearch 1 Configuring Elasticsearch(配置 Elasticsearch)1.1 Setting JVM Options(设置JVM选项)1.2 Secure Settings(安全设置)Introduction(介绍)Using the Keystore(使用密钥库)Applying Changes(应用更改)Reloadable Secure Settings(可重新加载的安全设置)R…...
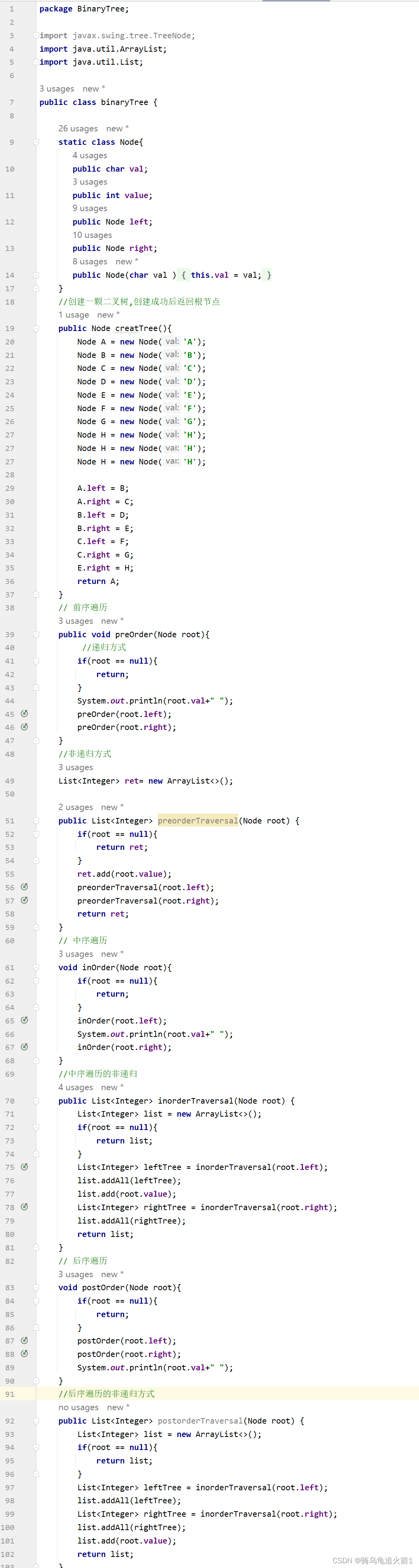
二叉树的遍历方式和代码
二叉树的三种遍历和代码 1.前序遍历2.中序遍历3.后序遍历4.三种遍历方式的代码实现 1.前序遍历 学习二叉树结构,最简单的方式就是遍历。所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。访问结点所做的操作依赖于具…...

小样本学习——匹配网络
目录 匹配网络 (1)简单介绍: (2)专业术语 (3)主要思想 (4)训练过程 问题 回答 MANN 匹配网络 (1)简单介绍: Matching netwo…...

CSS 常用样式 之字体属性
font-weight(字体粗细) 字体粗细用于设置文本的粗细程度,可以使用如下的值: normal:正常字体(默认)bold:加粗字体bolder:更加加粗lighter:更加细 代码实例…...
nodejs+vue游戏测评交流系统elementui
可以实现首页、发布招募、公司资讯、我的等,另一方面来说也可以提高在游戏测评交流方面的效率给相关管理人员的工作带来一定的便利。在我的页面可以对游戏攻略、我的收藏管理、实际上如今信息化成为一个未来的趋势或者可以说在当前现代化的城市典范中,发布招募等功能…...

1.2.OpenCV技能树--第一单元--OpenCV安装
目录 1.文章内容来源 2.OpenCV安装 3.课后习题代码复现 4.易错点总结与反思 1.文章内容来源 1.题目来源:https://edu.csdn.net/skill/opencv/opencv-662dbd65c89d4ddb9e392f44ffe16e1a?category657 2.资料来源:https://edu.csdn.net/skill/opencv/opencv-662dbd65c89d4ddb…...
全志ARM926 Melis2.0系统的开发指引⑥
全志ARM926 Melis2.0系统的开发指引⑥ 编写目的9. 系统启动流程9.1. Shell 部分9.2.Orange 和 desktop 部分9.3. app_root 加载部分9.4. home 加载部分 10. 显示相关知识概述10.1. 总体结构10.2. 显示过程10.3. 显示宽高参数关系 -. 全志相关工具和资源-.1 全志固件镜像修改工具…...

Junit单元测试为什么不能有返回值?
这个问题的产生来源于我们老师上节课说的我们班一个男生问他的想法,刚开始听到这个还觉得挺有意思,我之前使用单元测试好像下意识的就将它的返回值写为void,一般都是进行简单的测试,也从没思考过在某个单元测试中调用另一个单元测试ÿ…...
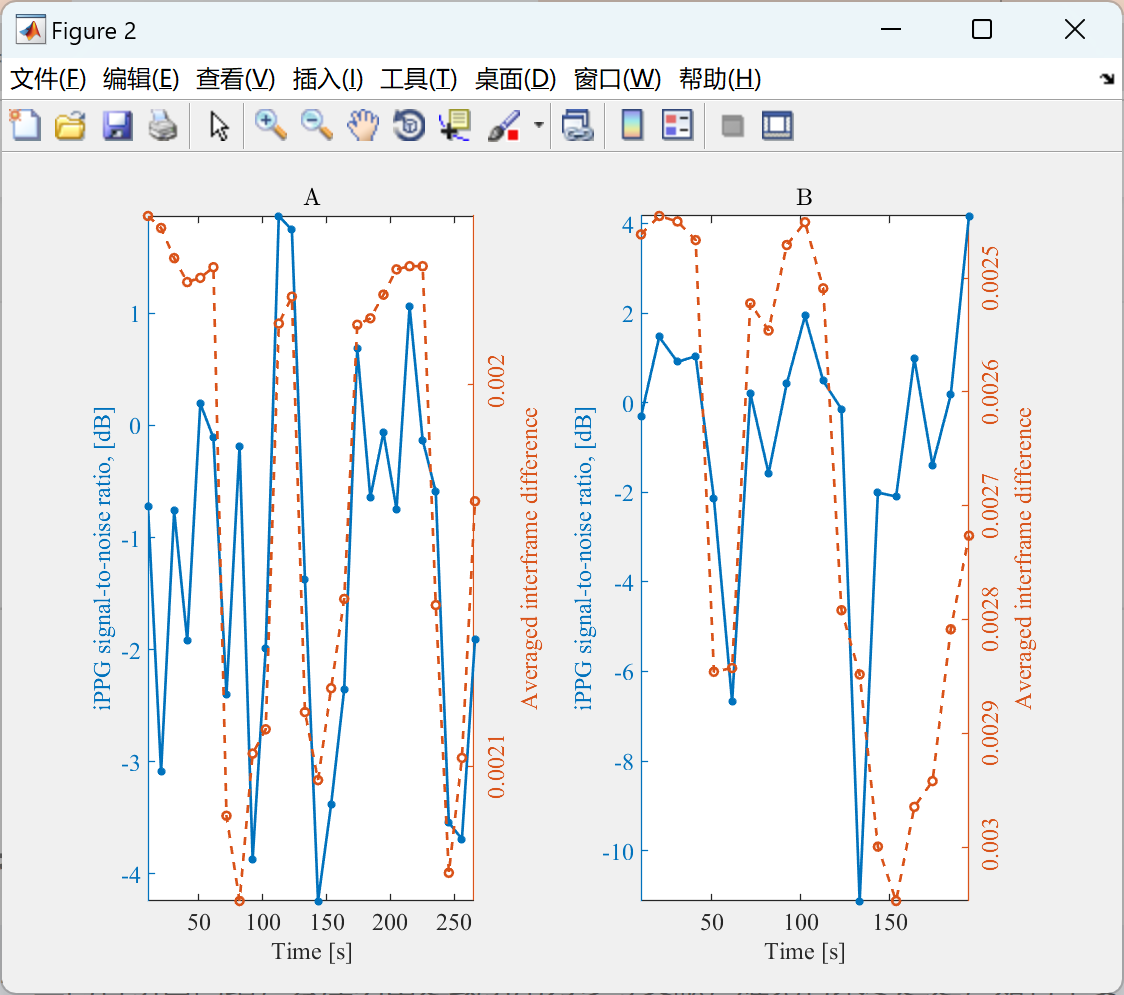
【成像光敏描记图提取和处理】成像-光电容积描记-提取-脉搏率-估计(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
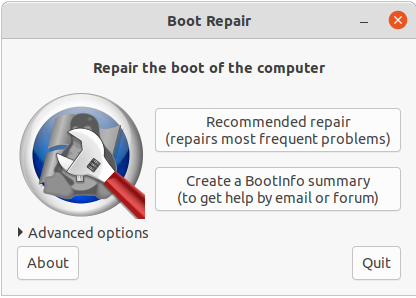
Ubuntu无法引导启动的修复
TLDR:使用Boot-Repair工具。 Boot-Repair Boot-Repair是一个简单的工具,用于修复您在Ubuntu中可能遇到的常见启动问题,例如在安装Windows或其他Linux发行版后无法启动Ubuntu时,或者在安装Ubuntu后无法启动Windows时,…...

Windows电脑上的多开软件是否安全?
在Windows电脑上使用多开软件可以让使用者同时运行多个相同或不同的程序,这对于某些需要同时操作多个账号或实例的用户来说非常有用。但是很多人担心使用多开软件是否安全。 多开软件的安全问题主要在于它们可能会破坏操作系统的稳定性和安全性,导致系统…...

高级渗透测试:KitHack多平台后门生成与持久化技术
高级渗透测试:KitHack多平台后门生成与持久化技术 【免费下载链接】KitHack Hacking tools pack & backdoors generator. 项目地址: https://gitcode.com/gh_mirrors/ki/KitHack KitHack是一款功能强大的渗透测试工具包,专为安全研究人员和渗…...

协作边缘AI与联邦学习如何重塑去中心化能源系统
1. 项目概述:当边缘智能遇见分布式能源如果你和我一样,在能源或者物联网行业摸爬滚打多年,就会深刻感受到一个趋势:能源系统的“大脑”正在从云端下沉,从中心走向边缘。过去,我们习惯于将海量的传感器数据—…...

基于OpenTelemetry的LLM应用可观测性实践:从黑盒到白盒的调试革命
1. 项目概述:当可观测性遇上大语言模型最近在折腾大语言模型应用时,我遇到了一个非常典型的痛点:应用跑起来了,但内部发生了什么,完全是个黑盒。Prompt 到底是怎么被处理的?模型调用的耗时都花在哪一步了&a…...

TTS推理优化:低精度计算与硬件协同设计实践
1. 项目概述:TTS推理的经济学重构在语音技术领域,文本转语音(TTS)系统正从实验室走向生产环境,成为智能助手、无障碍工具和实时通信系统的核心组件。与大型语言模型(LLM)不同,TTS需要…...

当出海合规压力持续上升时,多云服务容易忽略哪些细节
摘要:本文梳理出海企业多云架构的完整成本构成,拆解显性运营成本与极易被忽视的隐性成本陷阱,结合当下全球数据合规趋严的行业趋势,分析多云服务落地的成本变化逻辑,为大中小不同规模的出海团队,提供科学、…...

AI推理延迟超标?资源利用率不足35%?SITS2026动态编排引擎实测压测报告:单节点吞吐提升4.8倍,,附YAML配置模板
更多请点击: https://intelliparadigm.com 第一章:AI原生应用部署方案:SITS2026 SITS2026(Scalable Intelligent Training & Serving 2026)是一套面向生产环境的AI原生应用部署框架,专为大模型微服务…...

Visual Studio AI助手深度集成:提升.NET开发效率的实战指南
1. 项目概述:当AI助手住进你的IDE 如果你是一名.NET开发者,每天大部分时间都在Visual Studio里度过,那你一定经历过这样的时刻:盯着一段复杂的业务逻辑,思考如何重构;或者为一个方法编写单元测试ÿ…...

Flutter 路由导航完全指南
Flutter 路由导航完全指南 引言 路由导航是任何移动应用的核心功能之一。Flutter 提供了强大而灵活的路由系统,支持多种导航方式。本文将深入探讨 Flutter 路由导航的各种技巧和最佳实践。 基础导航 Navigator.push Navigator.push(context,MaterialPageRoute(…...

Flutter 状态管理架构设计完全指南
Flutter 状态管理架构设计完全指南 引言 状态管理是 Flutter 应用开发的核心问题之一。一个好的状态管理架构能够使代码更加清晰、可维护和可测试。本文将深入探讨 Flutter 状态管理的各种架构模式和最佳实践。 状态管理概述 Flutter 中的状态可以分为以下几类: 局部…...

TrollInstallerX终极指南:深度解析iOS 14-16.6.1越狱级安装技术
TrollInstallerX终极指南:深度解析iOS 14-16.6.1越狱级安装技术 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 在iOS生态系统中,系统限制与应用…...