目标检测算法改进系列之Backbone替换为FocalNet
FocalNet
近些年,Transformers在自然语言处理、图像分类、目标检测和图像分割上均取得了较大的成功,归根结底是自注意力(SA :self-attention)起到了关键性的作用,因此能够支持输入信息的全局交互。但是由于视觉tokens的大量存在,自注意力的计算复杂度高,尤其是在高分辨的输入时,因此针对该缺陷,论文《Focal Modulation Networks》提出了FocalNet网络。
论文地址:Focal Modulation Networks
原理:使用新提出的Focal Modulation替代之前的SA自注意力模块,解耦聚合和单个查询过程,先将查询周围的上下文信息进行聚合,再根据聚合信息获取查询结果。如下图所示,图中红色表示query token。对比来看,Window-wise Self-Attention (SA)利用周围的token(橙色)来捕获空间上下文信息;在此基础上,Focal Attention扩大了感受野,还可以使用更远的summarized tokens(蓝色);而Focal Modulation更为强大,先利用诸如depth-wise convolution的方式将不同粒度级别的空间上下文编码为summarized tokens (橙色、绿色和蓝色),再根据查询内容,选择性的将这些summarized tokens融合为query token。而本文新提出的方式便是进行轻量化,将聚合和单个查询进行解耦,减少计算量。
在前两者中,绿色和紫色箭头分别代表注意力交互和基于查询的聚合,但是都存在一个缺陷,即:均需要涉及大量的交互和聚合操作。而Focal Modulation计算过程得到大量简化。

FocalNet代码实现
# --------------------------------------------------------
# FocalNets -- Focal Modulation Networks
# Copyright (c) 2022 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Jianwei Yang (jianwyan@microsoft.com)
# --------------------------------------------------------import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal___all__ = ['focalnet_tiny_srf', 'focalnet_tiny_lrf', 'focalnet_small_srf', 'focalnet_small_lrf', 'focalnet_base_srf', 'focalnet_base_lrf', 'focalnet_large_fl3', 'focalnet_large_fl4', 'focalnet_xlarge_fl3', 'focalnet_xlarge_fl4', 'focalnet_huge_fl3', 'focalnet_huge_fl4']def update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictclass Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x) x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass FocalModulation(nn.Module):def __init__(self, dim, focal_window, focal_level, focal_factor=2, bias=True, proj_drop=0., use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.focal_window = focal_windowself.focal_level = focal_levelself.focal_factor = focal_factorself.use_postln_in_modulation = use_postln_in_modulationself.normalize_modulator = normalize_modulatorself.f = nn.Linear(dim, 2*dim + (self.focal_level+1), bias=bias)self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=bias)self.act = nn.GELU()self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.focal_layers = nn.ModuleList()self.kernel_sizes = []for k in range(self.focal_level):kernel_size = self.focal_factor*k + self.focal_windowself.focal_layers.append(nn.Sequential(nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, groups=dim, padding=kernel_size//2, bias=False),nn.GELU(),)) self.kernel_sizes.append(kernel_size) if self.use_postln_in_modulation:self.ln = nn.LayerNorm(dim)def forward(self, x):"""Args:x: input features with shape of (B, H, W, C)"""C = x.shape[-1]# pre linear projectionx = self.f(x).permute(0, 3, 1, 2).contiguous()q, ctx, gates = torch.split(x, (C, C, self.focal_level+1), 1)# context aggreationctx_all = 0 for l in range(self.focal_level): ctx = self.focal_layers[l](ctx)ctx_all = ctx_all + ctx * gates[:, l:l+1]ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))ctx_all = ctx_all + ctx_global * gates[:,self.focal_level:]# normalize contextif self.normalize_modulator:ctx_all = ctx_all / (self.focal_level+1)# focal modulationmodulator = self.h(ctx_all)x_out = q * modulatorx_out = x_out.permute(0, 2, 3, 1).contiguous()if self.use_postln_in_modulation:x_out = self.ln(x_out)# post linear porjectionx_out = self.proj(x_out)x_out = self.proj_drop(x_out)return x_outdef extra_repr(self) -> str:return f'dim={self.dim}'def flops(self, N):# calculate flops for 1 window with token length of Nflops = 0flops += N * self.dim * (self.dim * 2 + (self.focal_level+1))# focal convolutionfor k in range(self.focal_level):flops += N * (self.kernel_sizes[k]**2+1) * self.dim# global gatingflops += N * 1 * self.dim # self.linearflops += N * self.dim * (self.dim + 1)# x = self.proj(x)flops += N * self.dim * self.dimreturn flopsclass FocalNetBlock(nn.Module):r""" Focal Modulation Network Block.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.drop (float, optional): Dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormfocal_level (int): Number of focal levels. focal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, input_resolution, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,focal_level=1, focal_window=3,use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.mlp_ratio = mlp_ratioself.focal_window = focal_windowself.focal_level = focal_levelself.use_postln = use_postlnself.norm1 = norm_layer(dim)self.modulation = FocalModulation(dim, proj_drop=drop, focal_window=focal_window, focal_level=self.focal_level, use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)self.gamma_1 = 1.0self.gamma_2 = 1.0 if use_layerscale:self.gamma_1 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)self.gamma_2 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)self.H = Noneself.W = Nonedef forward(self, x):H, W = self.H, self.WB, L, C = x.shapeshortcut = x# Focal Modulationx = x if self.use_postln else self.norm1(x)x = x.view(B, H, W, C)x = self.modulation(x).view(B, H * W, C)x = x if not self.use_postln else self.norm1(x)# FFNx = shortcut + self.drop_path(self.gamma_1 * x)x = x + self.drop_path(self.gamma_2 * (self.norm2(self.mlp(x)) if self.use_postln else self.mlp(self.norm2(x))))return xdef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, " \f"mlp_ratio={self.mlp_ratio}"def flops(self):flops = 0H, W = self.input_resolution# norm1flops += self.dim * H * W# W-MSA/SW-MSAflops += self.modulation.flops(H*W)# mlpflops += 2 * H * W * self.dim * self.dim * self.mlp_ratio# norm2flops += self.dim * H * Wreturn flopsclass BasicLayer(nn.Module):""" A basic Focal Transformer layer for one stage.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.focal_level (int): Number of focal levelsfocal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, out_dim, input_resolution, depth,mlp_ratio=4., drop=0., drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False, focal_level=1, focal_window=1, use_conv_embed=False, use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.depth = depthself.use_checkpoint = use_checkpoint# build blocksself.blocks = nn.ModuleList([FocalNetBlock(dim=dim, input_resolution=input_resolution,mlp_ratio=mlp_ratio, drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer,focal_level=focal_level,focal_window=focal_window, use_layerscale=use_layerscale, layerscale_value=layerscale_value,use_postln=use_postln, use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator, )for i in range(depth)])if downsample is not None:self.downsample = downsample(img_size=input_resolution, patch_size=2, in_chans=dim, embed_dim=out_dim, use_conv_embed=use_conv_embed, norm_layer=norm_layer, is_stem=False)else:self.downsample = Nonedef forward(self, x, H, W):for blk in self.blocks:blk.H, blk.W = H, Wif self.use_checkpoint:x = checkpoint.checkpoint(blk, x)else:x = blk(x)if self.downsample is not None:x = x.transpose(1, 2).reshape(x.shape[0], -1, H, W)x, Ho, Wo = self.downsample(x)else:Ho, Wo = H, W return x, Ho, Wodef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"def flops(self):flops = 0for blk in self.blocks:flops += blk.flops()if self.downsample is not None:flops += self.downsample.flops()return flopsclass PatchEmbed(nn.Module):r""" Image to Patch EmbeddingArgs:img_size (int): Image size. Default: 224.patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, img_size=(224, 224), patch_size=4, in_chans=3, embed_dim=96, use_conv_embed=False, norm_layer=None, is_stem=False):super().__init__()patch_size = to_2tuple(patch_size)patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]self.img_size = img_sizeself.patch_size = patch_sizeself.patches_resolution = patches_resolutionself.num_patches = patches_resolution[0] * patches_resolution[1]self.in_chans = in_chansself.embed_dim = embed_dimif use_conv_embed:# if we choose to use conv embedding, then we treat the stem and non-stem differentlyif is_stem:kernel_size = 7; padding = 2; stride = 4else:kernel_size = 3; padding = 1; stride = 2self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)else:self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):B, C, H, W = x.shapex = self.proj(x) H, W = x.shape[2:]x = x.flatten(2).transpose(1, 2) # B Ph*Pw Cif self.norm is not None:x = self.norm(x)return x, H, Wdef flops(self):Ho, Wo = self.patches_resolutionflops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])if self.norm is not None:flops += Ho * Wo * self.embed_dimreturn flopsclass FocalNet(nn.Module):r""" Focal Modulation Networks (FocalNets)Args:img_size (int | tuple(int)): Input image size. Default 224patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Focal Transformer layer.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4drop_rate (float): Dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.patch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False focal_levels (list): How many focal levels at all stages. Note that this excludes the finest-grain level. Default: [1, 1, 1, 1] focal_windows (list): The focal window size at all stages. Default: [7, 5, 3, 1] use_conv_embed (bool): Whether use convolutional embedding. We noted that using convolutional embedding usually improve the performance, but we do not use it by default. Default: False use_layerscale (bool): Whether use layerscale proposed in CaiT. Default: False layerscale_value (float): Value for layer scale. Default: 1e-4 use_postln (bool): Whether use layernorm after modulation (it helps stablize training of large models)"""def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,embed_dim=96, depths=[2, 2, 6, 2], mlp_ratio=4., drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, patch_norm=True,use_checkpoint=False, focal_levels=[2, 2, 2, 2], focal_windows=[3, 3, 3, 3], use_conv_embed=False, use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False, **kwargs):super().__init__()self.num_layers = len(depths)embed_dim = [embed_dim * (2 ** i) for i in range(self.num_layers)]self.num_classes = num_classesself.embed_dim = embed_dimself.patch_norm = patch_normself.num_features = embed_dim[-1]self.mlp_ratio = mlp_ratio# split image into patches using either non-overlapped embedding or overlapped embeddingself.patch_embed = PatchEmbed(img_size=to_2tuple(img_size), patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim[0], use_conv_embed=use_conv_embed, norm_layer=norm_layer if self.patch_norm else None, is_stem=True)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.patches_resolutionself.patches_resolution = patches_resolutionself.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=embed_dim[i_layer], out_dim=embed_dim[i_layer+1] if (i_layer < self.num_layers - 1) else None, input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],mlp_ratio=self.mlp_ratio,drop=drop_rate, drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer, downsample=PatchEmbed if (i_layer < self.num_layers - 1) else None,focal_level=focal_levels[i_layer], focal_window=focal_windows[i_layer], use_conv_embed=use_conv_embed,use_checkpoint=use_checkpoint, use_layerscale=use_layerscale, layerscale_value=layerscale_value, use_postln=use_postln,use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator)self.layers.append(layer)self.norm = norm_layer(self.num_features)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {''}@torch.jit.ignoredef no_weight_decay_keywords(self):return {''}def forward(self, x):input_size = x.size(2)scale = [4, 8, 16, 32]x, H, W = self.patch_embed(x)x = self.pos_drop(x)features = [x, None, None, None]for layer in self.layers:x, H, W = layer(x, H, W)if input_size // H in scale:features[scale.index(input_size // H)] = x# features[-1] = self.norm(features[-1]) # B L Cfor i in range(len(features)):features[i] = torch.transpose(features[i], dim0=2, dim1=1).view(-1,features[i].size(2), int(features[i].size(1) ** 0.5), int(features[i].size(1) ** 0.5))return featuresdef flops(self):flops = 0flops += self.patch_embed.flops()for i, layer in enumerate(self.layers):flops += layer.flops()flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)flops += self.num_features * self.num_classesreturn flopsmodel_urls = {"focalnet_tiny_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_tiny_srf.pth","focalnet_tiny_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_tiny_lrf.pth","focalnet_small_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_small_srf.pth","focalnet_small_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_small_lrf.pth","focalnet_base_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_base_srf.pth","focalnet_base_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_base_lrf.pth", "focalnet_large_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_large_lrf_384.pth", "focalnet_large_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_large_lrf_384_fl4.pth", "focalnet_xlarge_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_xlarge_lrf_384.pth", "focalnet_xlarge_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_xlarge_lrf_384_fl4.pth", "focalnet_huge_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_huge_lrf_224.pth", "focalnet_huge_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_huge_lrf_224_fl4.pth",
}def focalnet_tiny_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_tiny_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_small_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)if pretrained:url = model_urls['focalnet_base_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_tiny_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_tiny_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_small_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)if pretrained:url = model_urls['focalnet_base_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_tiny_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_tiny_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=384, **kwargs)if pretrained:url = model_urls['focalnet_small_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=768, focal_levels=[3], focal_windows=[3], use_layerscale=True, use_postln=True, **kwargs)if pretrained:url = model_urls['focalnet_base_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return model# FocalNet large+ models
def focalnet_large_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_large_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_large_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_large_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_xlarge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_xlarge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_huge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, **kwargs)if pretrained:url = model_urls['focalnet_huge_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_huge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, **kwargs)if pretrained:url = model_urls['focalnet_huge_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modelif __name__ == '__main__':from copy import deepcopyimg_size = 640x = torch.rand(16, 3, img_size, img_size).cuda()model = focalnet_tiny_srf(pretrained=True).cuda()# model_copy = deepcopy(model)for i in model(x):print(i.size())flops = model.flops()print(f"number of GFLOPs: {flops / 1e9}")n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"number of params: {n_parameters}")print(list(model_urls.keys()))
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {focalnet_tiny_srf}: #可添加更多Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建新的.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, focalnet_tiny_srf, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
相关文章:
目标检测算法改进系列之Backbone替换为FocalNet
FocalNet 近些年,Transformers在自然语言处理、图像分类、目标检测和图像分割上均取得了较大的成功,归根结底是自注意力(SA :self-attention)起到了关键性的作用,因此能够支持输入信息的全局交互。但是由于…...
buuctf-[BSidesCF 2020]Had a bad day 文件包含
打开环境 就两个按钮,随便按按 url变了 还有 像文件包含,使用php伪协议读取一下,但是发现报错,而且有两个.php,可能是自己会加上php后缀 所以把后缀去掉 /index.php?categoryphp://filter/convert.base64-encode/resourcei…...
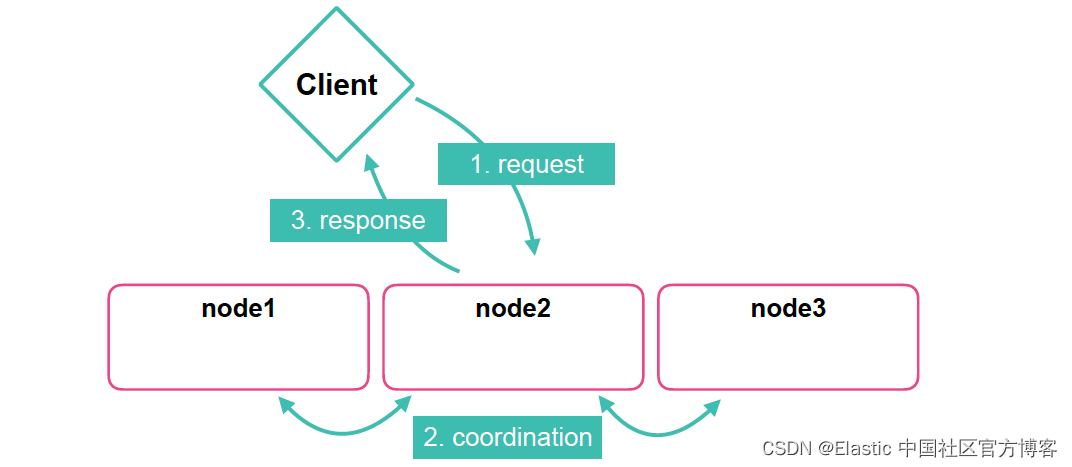
Elasticsearch:什么时候应该考虑在 Elasticsearch 中添加协调节点?
仅协调节点(coordinating only nodes)充当智能负载均衡器。 仅协调节点的这种特殊角色通过减轻数据和主节点的协调责任,为广泛的集群提供了优势。 加入集群后,这些节点与任何其他节点类似,都会获取完整的集群状态&…...
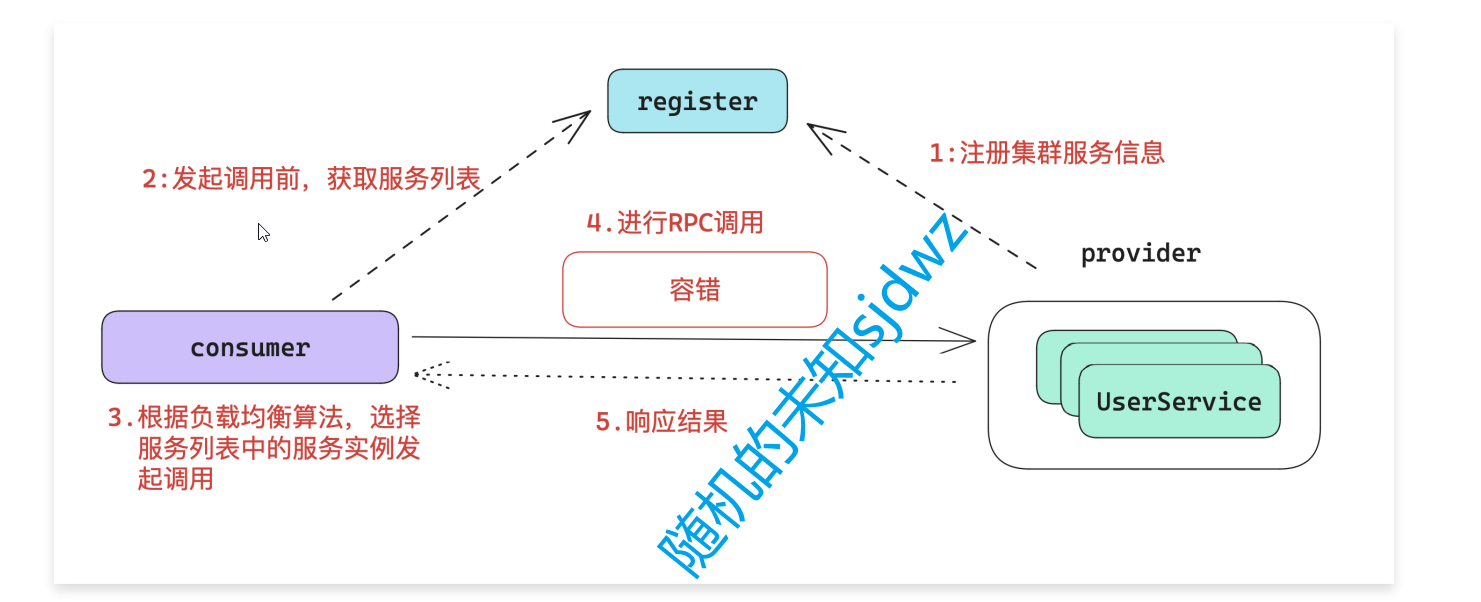
Dubbo3应用开发—Dubbo注册中心引言
Dubbo注册中心引言 什么是Dubbo注册中心 Dubbo的注册中心,是Dubbo服务治理的⼀个重要的概念,他主要用于 RPC服务集群实例的管理。 注册中心的运行流程 使用注册中心的好处 可以有效的管理RPC集群的健康情况,动态的上线或者下线服务。让我…...
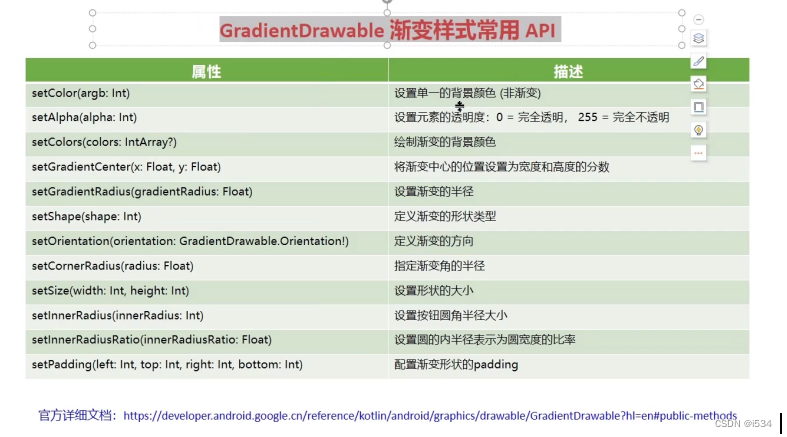
AS环境,版本问题,android开发布局知识
项目模式下有一个build.gradle,每个模块也有自己的build.gradle Android模式下有多个build.gradle,汇总在一起。(都会有标注是哪个模块下的) C:\Users\Administrator\AndroidStudioProjects 项目默认位置 Java web项目与android项目的区别…...
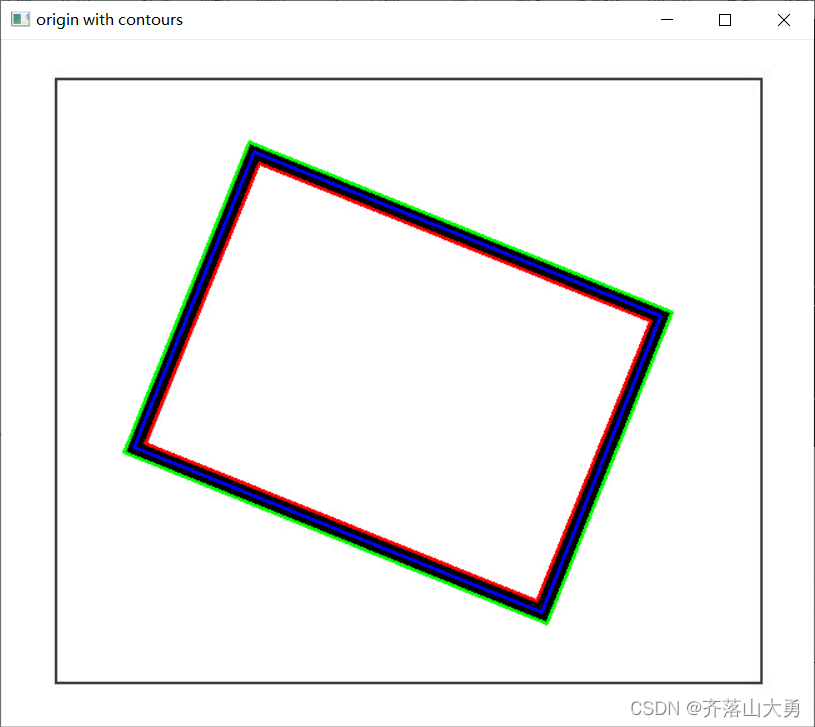
OpenCV查找和绘制轮廓:findContours和drawContours
1 任务描述: 绘制图中粗线矩形的2个边界,并找到其边界的中心线 图1 原始图像 2.函数原型 findContours( InputOutputArray image, OutputArrayOfArrays contours, OutputArray hierarchy, int mode, …...
毕设-原创医疗预约挂号平台分享
医疗预约挂号平台 不是尚医通项目,先看项目质量(有源码论文) 项目链接:医疗预约挂号平台git地址 演示视频:医疗预约挂号平台 功能结构图 登录注册模块:该模块具体分为登录和注册两个功能,这些…...
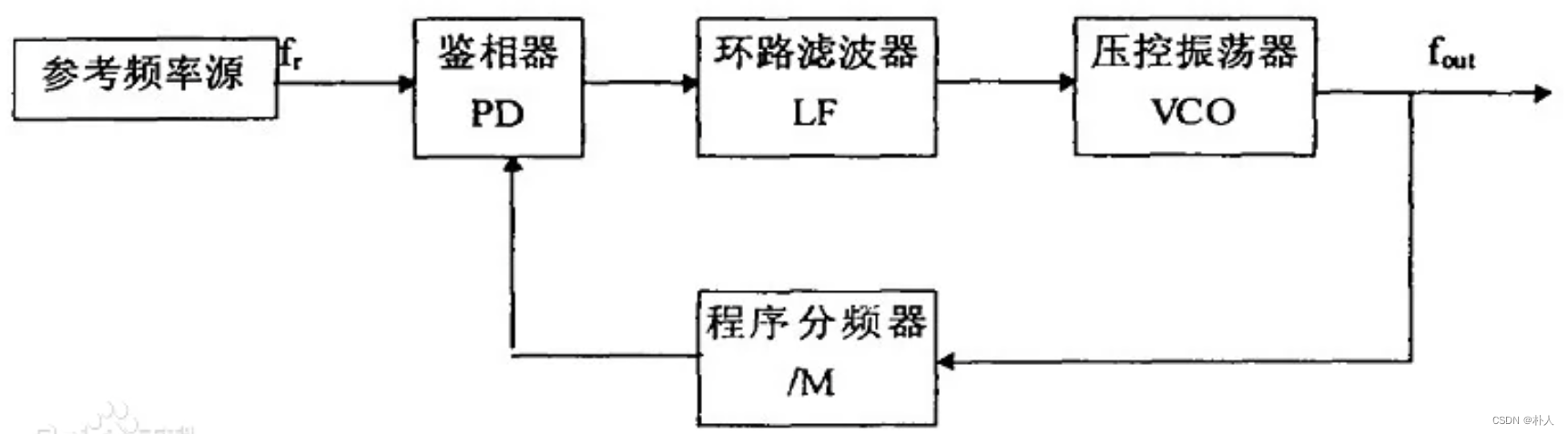
PLL锁相环倍频原理
晶振8MHz,但是处理器输入可以达到72MHz,是因为PLL锁相环提供了72MHz。 锁相环由PD(鉴相器)、LP(滤波器)、VCO(压控振荡器)组成。 处理器获得的72MHz并非晶振提供,而是锁…...
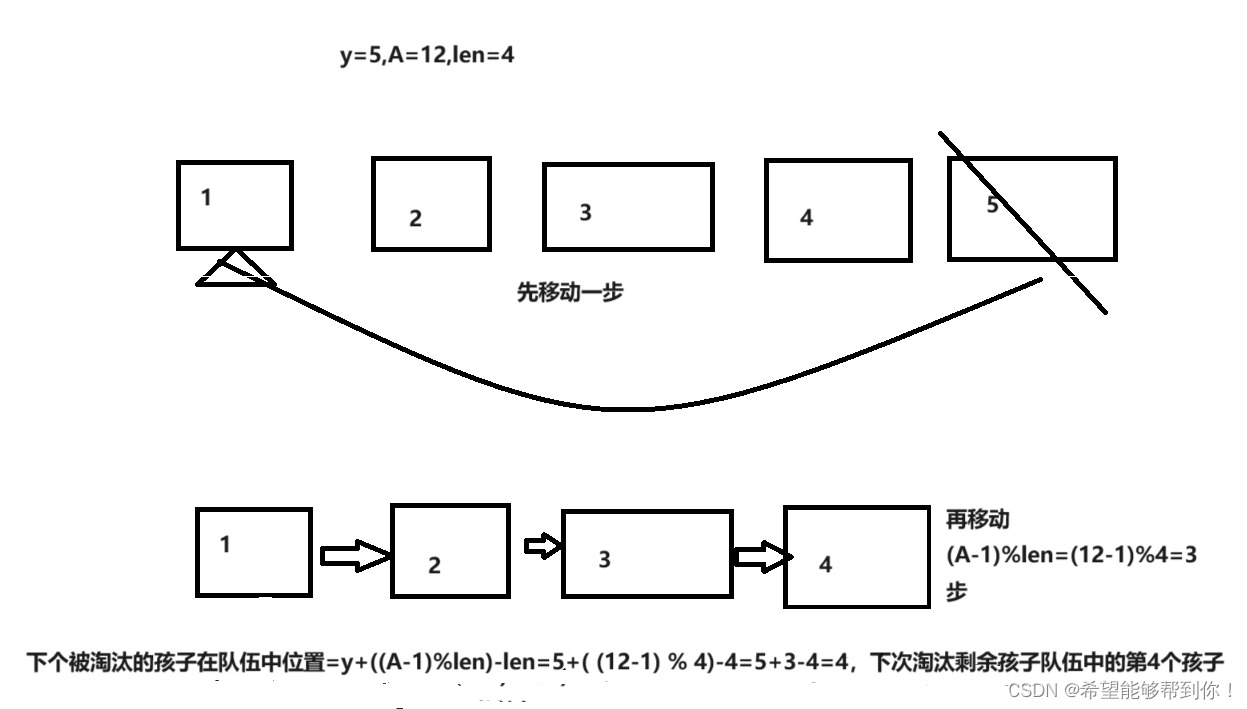
POJ 2886 Who Gets the Most Candies? 树状数组+二分
一、题目大意 我们有N个孩子,每个人带着一张卡片,一起顺时针围成一个圈来玩游戏,第一回合时,第k个孩子被淘汰,然后他说出他卡片上的数字A,如果A是一个正数,那么下一个回合他左边的第A个孩子被淘…...

阿里云服务器镜像系统Anolis OS龙蜥详细介绍
阿里云服务器Anolis OS镜像系统由龙蜥OpenAnolis社区推出,Anolis OS是CentOS 8 100%兼容替代版本,Anolis OS是完全开源、中立、开放的Linux发行版,具备企业级的稳定性、高性能、安全性和可靠性。目前阿里云服务器ECS可选的Anolis OS镜像系统版…...

数学建模Matlab之基础操作
作者由于后续课程也要学习Matlab,并且之前也进行了一些数学建模的练习(虽然是论文手),所以花了几天零碎时间学习Matlab的基础操作,特此整理。 基本运算 a55 %加法,同理减法 b2^3 %立方 c5*2 %乘法 x 1; …...
[计算机入门] Windows附件程序介绍(工具类)
3.14 Windows附件程序介绍(工具类) 3.14.1 计算器 Windows系统中的计算器是一个内置的应用程序,提供了基本的数学计算功能。它被设计为一个方便、易于使用的工具,可以满足用户日常生活和工作中的基本计算需求。 以下是计算器程序的主要功能:…...

队列(循环数组队列,用队列实现栈,用栈实现队列)
基础知识 队列(Queue):先进先出的数据结果,底层由双向链表实现 入队列:进行插入操作的一端称为队尾出队列:进行删除操作的一端称为对头 常用方法 boolean offer(E e) 入队 E(弹出元素的类型) poll() 出队 peek() 获取队头 int size 获取队列元素个数 boolean isEmpty(…...
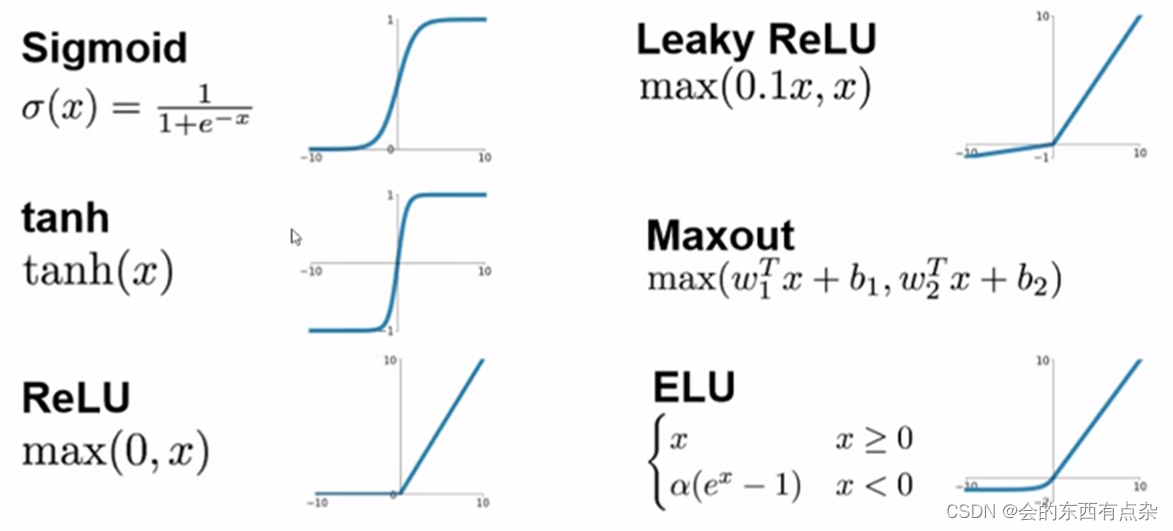
卷积神经网络-池化层和激活层
2.池化层 根据特征图上的局部统计信息进行下采样,在保留有用信息的同时减少特征图的大小。和卷积层不同的是,池化层不包含需要学习的参数。最大池化(max-pooling)在一个局部区域选最大值作为输出,而平均池化(average pooling)计算一个局部区…...
API基础————包
什么是包,package实际上就是一个文件夹,便于程序员更好的管理维护自己的代码。它可以使得一个项目结构更加清晰明了。 Java也有20年历史了,这么多年有这么多程序员写了无数行代码,其中有大量重复的,为了更加便捷省时地…...

【C++】一文带你走入vector
文章目录 一、vector的介绍二、vector的常用接口说明2.1 vector的使用2.2 vector iterator的使用2.3 vector空间增长问题2.4 vector 增删查改 三、总结 ヾ(๑╹◡╹)ノ" 人总要为过去的懒惰而付出代价ヾ(๑╹◡╹)ノ" 一、vector的介绍 vector…...
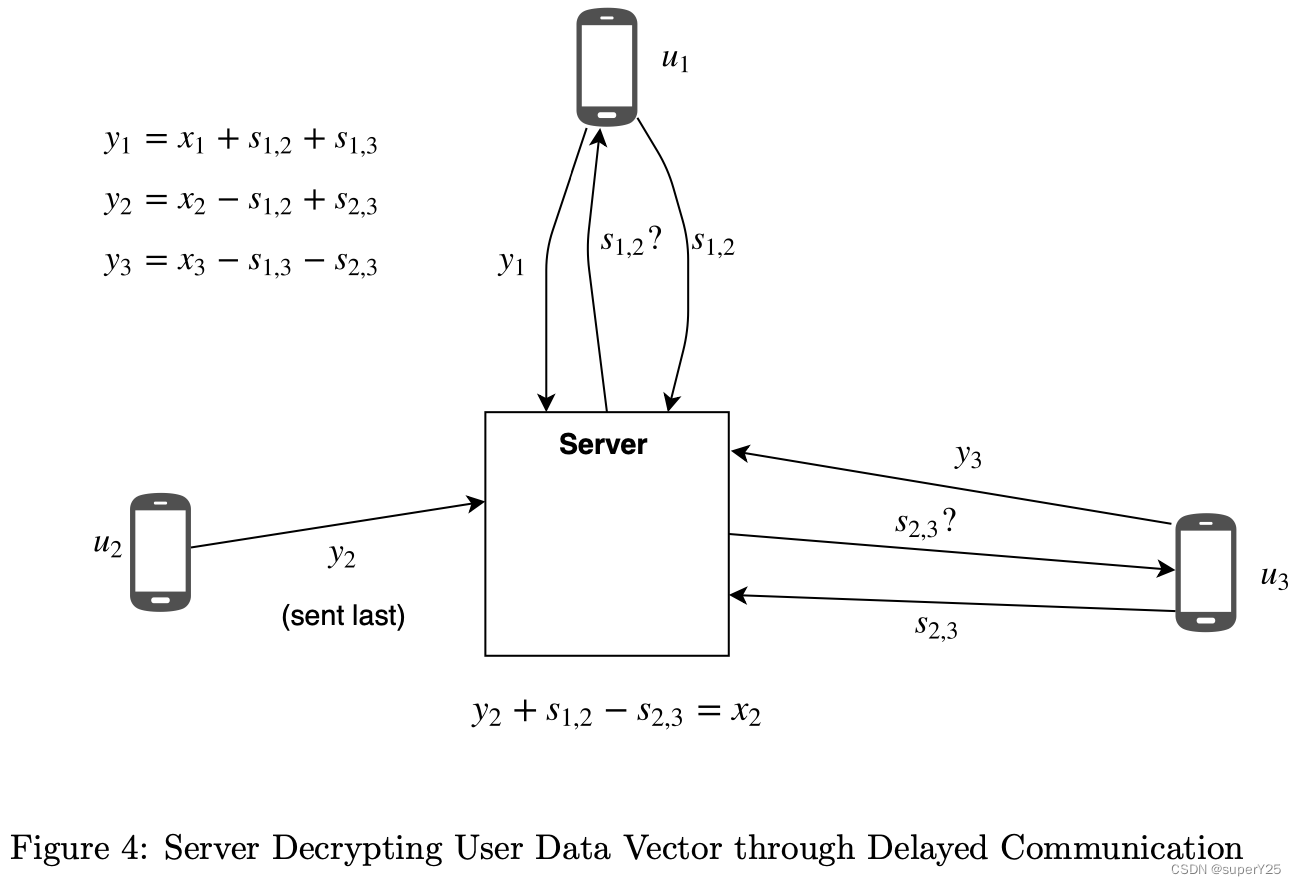
《Secure Analytics-Federated Learning and Secure Aggregation》论文阅读
背景 机器学习模型对数据的分析具有很大的优势,很多敏感数据分布在用户各自的终端。若大规模收集用户的敏感数据具有泄露的风险。 对于安全分析的一般背景就是认为有n方有敏感数据,并且不愿意分享他们的数据,但可以分享聚合计算后的结果。 联…...
十三、Django之添加用户(原始方法实现)
修改urls.py path("user/add/", views.user_add),添加user_add.html {% extends layout.html %} {% block content %}<div class"container"><div class"panel panel-default"><div class"panel-heading"><h3 c…...

Elasticsearch数据操作原理
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...

gitgitHub
在git中复制CtrlInsert、粘贴CtrlShif 一、用户名和邮箱的配置 查看用户名 :git config user.name 查看密码: git config user.password 查看邮箱:git config user.email 查看配置信息: $ git config --list 修改用户名 git co…...

五分钟用Python为嵌入式应用接入Taotoken大模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟用Python为嵌入式应用接入Taotoken大模型服务 为嵌入式设备或物联网项目添加智能对话能力,可以极大地提升产品的…...

JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购
JDspyder终极指南:如何用Python自动化脚本实现京东茅台抢购 【免费下载链接】JDspyder 京东预约&抢购脚本,可以自定义商品链接 项目地址: https://gitcode.com/gh_mirrors/jd/JDspyder 在电商促销和限量商品抢购的激烈竞争中,手动…...

WSA Toolbox:Windows 11上5分钟搭建Android应用生态的终极指南
WSA Toolbox:Windows 11上5分钟搭建Android应用生态的终极指南 【免费下载链接】wsa-toolbox A Windows 11 application to easily install and use the Windows Subsystem For Android™ package on your computer. 项目地址: https://gitcode.com/gh_mirrors/ws…...

RAG和向量索引
为特定用例设计代理时,需要确保语言模型已建立基础并使用与用户所需内容相关的事实信息。 虽然语言模型针对大量数据进行了训练,但它们可能无权访问你想要向用户提供的知识。 若要确保代理基于特定数据提供准确且特定于域的响应,可使用检索增…...

阿里从蚂蚁收到股息33亿:AI投入加大致后者年利润153亿 同比降60%
雷递网 乐天 5月13日阿里今日发布财报。财报披露,蚂蚁在2026年第一季度给阿里带来的投资收益为3.75亿(约5500万美元),较上年同期的17.63亿元下降78.7%。截至2026年3月31日,阿里对蚂蚁集团在全面摊薄基础上的股权为33%。…...

开源任务恢复工具openclaw-task-recovery:轻量级断点续做解决方案
1. 项目概述:一个关于任务恢复的开源工具最近在整理自己的自动化脚本和任务调度系统时,遇到了一个老生常谈但又非常棘手的问题:任务中断后的恢复。无论是数据处理流水线、爬虫任务,还是长时间运行的批处理作业,网络抖动…...

外卖点餐连锁店餐饮生鲜奶茶外卖店内扫码点餐源码同城外卖校园外卖源码的扫码逻辑
📱 扫码点餐系统 - 完整扫码逻辑 源码示例外卖点餐 | 连锁店 | 餐饮生鲜 | 奶茶 | 店内扫码点餐 | 同城外卖 | 校园外卖🎯 扫码业务场景总览场景扫码后行为核心逻辑🍽️ 店内扫码点餐进入店铺菜单页识别店铺ID → 加载菜单🏃 外卖…...
---ESP32-S3-RGB-LED矩阵开发板之全屏循环显示七种颜色)
【花雕学编程】Arduino动手做(252)---ESP32-S3-RGB-LED矩阵开发板之全屏循环显示七种颜色
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里准备逐一动手试试多做实验,不管成功与否,都会记录下来——小小的…...

HBM高带宽内存:从立体堆叠到2.5D封装的性能革命
1. 从平面到立体:HBM如何重塑内存性能天花板在半导体行业里,我们常把“摩尔定律”挂在嘴边,仿佛性能提升的唯一路径就是晶体管越做越小。但大约十年前,当工艺微缩的红利开始放缓,功耗墙和信号完整性问题日益严峻时&…...
zotero-pdf-translate自动翻译失效:5步快速诊断与修复指南
zotero-pdf-translate自动翻译失效:5步快速诊断与修复指南 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode.com/gh_mirr…...