【Pandas】数据分组groupby
本文目标:
- 应用groupby 进行分组
- 对分组数据进行聚合,转换和过滤
- 应用自定义函数处理分组之后的数据
文章目录
- 1. 数据聚合
- 1.1 单变量分组聚合
- 1.2 Pandas内置聚合方法
- 1.3 聚合方法
- 使用Numpy的聚合方法
- 自定义方法
- 同时计算多种特征
- 向agg/aggregate传入字典
- 2. 数据转换
- 3. 数据过滤
1. 数据聚合
- 在SQL中我们经常使用 GROUP BY 将某个字段,按不同的取值进行分组, 在pandas中也有groupby函数
- 分组之后,每组都会有至少1条数据, 将这些数据进一步处理返回单个值的过程就是聚合,比如分组之后计算算术平均值, 或者分组之后计算频数,都属于聚合
1.1 单变量分组聚合
# 数据片段
'''country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
'''
df = pd.read_csv('data/gapminder.tsv', sep='\t')
# 单变量分组聚合
df.groupby('year').lifeExp.mean()'''
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
Name: lifeExp, dtype: float64
'''
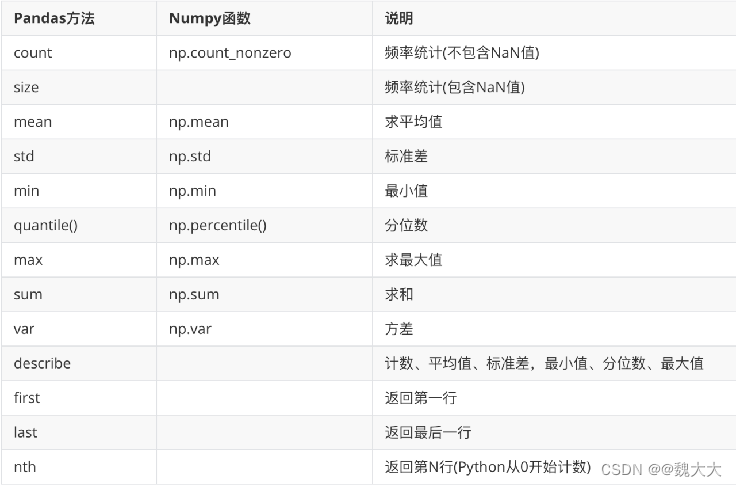
1.2 Pandas内置聚合方法
-
可以与groupby一起使用的方法和函数
-
分组之后取平均也可以使用describe函数同时计算多个统计量
df.groupby('year').lifeExp.describe()
'''count mean std min 25% 50% 75% max
year
1952 142.0 49.057620 12.225956 28.801 39.05900 45.1355 59.76500 72.670
1957 142.0 51.507401 12.231286 30.332 41.24750 48.3605 63.03675 73.470
1962 142.0 53.609249 12.097245 31.997 43.46850 50.8810 65.23450 73.680
1967 142.0 55.678290 11.718858 34.020 46.03375 53.8250 67.41950 74.160
1972 142.0 57.647386 11.381953 35.400 48.50025 56.5300 69.24750 74.720
1977 142.0 59.570157 11.227229 31.220 50.47550 59.6720 70.38250 76.110
1982 142.0 61.533197 10.770618 38.445 52.94000 62.4415 70.92125 77.110
1987 142.0 63.212613 10.556285 39.906 54.94075 65.8340 71.87725 78.670
1992 142.0 64.160338 11.227380 23.599 56.12175 67.7030 72.58250 79.360
1997 142.0 65.014676 11.559439 36.087 55.63375 69.3940 74.16975 80.690
2002 142.0 65.694923 12.279823 39.193 55.52225 70.8255 75.45925 82.000
2007 142.0 67.007423 12.073021 39.613 57.16025 71.9355 76.41325 82.603
'''
1.3 聚合方法
使用Numpy的聚合方法
df.groupby('year').lifeExp.agg(np.mean)
# df.groupby('year').lifeExp.aggregate(np.mean)
'''
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
Name: lifeExp, dtype: float64
'''
agg()和aggregate()是一样的
自定义方法
计算每年的平均年纪:
def my_mean(values):n = len(values)sum = 0for v in values:sum += vreturn (sum / n)df.groupby('year').lifeExp.agg(my_mean)
多个参数的自定义方法:
def my_mean_diff(values,diff):n = len(values)sum = 0for v in values:sum+=vmean = sum/nreturn mean - diffdf.groupby('year').lifeExp.agg(my_mean_diff,diff=1)
同时计算多种特征
import numpy as np
df.groupby('year').lifeExp.agg([np.count_nonzero, np.mean, np.std])
'''count_nonzero mean std
year
1952 142 49.057620 12.225956
1957 142 51.507401 12.231286
1962 142 53.609249 12.097245
1967 142 55.678290 11.718858
1972 142 57.647386 11.381953
1977 142 59.570157 11.227229
1982 142 61.533197 10.770618
1987 142 63.212613 10.556285
1992 142 64.160338 11.227380
1997 142 65.014676 11.559439
2002 142 65.694923 12.279823
2007 142 67.007423 12.073021
'''
向agg/aggregate传入字典
分别对分组后的不同列使用不同聚合方法:
df.groupby('year').agg({'lifeExp': 'mean','pop': 'median','gdpPercap': 'median'}
)
'''lifeExp pop gdpPercap
year
1952 49.057620 3943953.0 1968.528344
1957 51.507401 4282942.0 2173.220291
1962 53.609249 4686039.5 2335.439533
1967 55.678290 5170175.5 2678.334740
1972 57.647386 5877996.5 3339.129407
1977 59.570157 6404036.5 3798.609244
1982 61.533197 7007320.0 4216.228428
1987 63.212613 7774861.5 4280.300366
1992 64.160338 8688686.5 4386.085502
1997 65.014676 9735063.5 4781.825478
2002 65.694923 10372918.5 5319.804524
2007 67.007423 10517531.0 6124.371108
'''
一步到位,把计算后的数据列进行命名:
df.groupby('year').agg({'lifeExp':'mean','pop':'median','gdpPercap':'median'
}).rename(columns={'lifeExp':'平均寿命','pop':'人口中位数','gdpPercap':'人均GDP中位数'
})'''平均寿命 人口中位数 人均GDP中位数
year
1952 49.057620 3943953.0 1968.528344
1957 51.507401 4282942.0 2173.220291
1962 53.609249 4686039.5 2335.439533
1967 55.678290 5170175.5 2678.334740
1972 57.647386 5877996.5 3339.129407
1977 59.570157 6404036.5 3798.609244
1982 61.533197 7007320.0 4216.228428
1987 63.212613 7774861.5 4280.300366
1992 64.160338 8688686.5 4386.085502
1997 65.014676 9735063.5 4781.825478
2002 65.694923 10372918.5 5319.804524
2007 67.007423 10517531.0 6124.371108
'''
2. 数据转换
- transform 需要把DataFrame中的值传递给一个函数, 而后由该函数"转换"数据。
- aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量
def zscore(x):return (x-x.mean())/x.std()
df.groupby('year').lifeExp.transform(zscore)
'''
0 -1.656854
1 -1.731249
2 -1.786543
3 -1.848157
4 -1.894173...
1699 -0.081621
1700 -0.336974
1701 -1.574962
1702 -2.093346
1703 -1.948180
Name: lifeExp, Length: 1704, dtype: float64
'''
使用Transform之后,产生的结果和原数据的数量是一样的。
使用Transform,可以对缺失值进行填充:
def fill_na_mean(bills):return bills.fillna(bills.mean())tips_10.groupby('sex')['total_bill'].transform(fill_na_mean)
3. 数据过滤
tips['size'].value_counts()
'''
2 156
3 38
4 37
5 5
1 4
6 4
Name: size, dtype: int64
'''
tips_filtered =tips.groupby('size').filter(lambda x:x['size'].count()>30)
tips_filtered['size'].value_counts()
'''
2 156
3 38
4 37
Name: size, dtype: int64
'''
相关文章:
【Pandas】数据分组groupby
本文目标: 应用groupby 进行分组对分组数据进行聚合,转换和过滤应用自定义函数处理分组之后的数据 文章目录 1. 数据聚合1.1 单变量分组聚合1.2 Pandas内置聚合方法1.3 聚合方法使用Numpy的聚合方法自定义方法同时计算多种特征向agg/aggregate传入字典 2. 数据转换…...
【图像处理GIU】图像分割(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
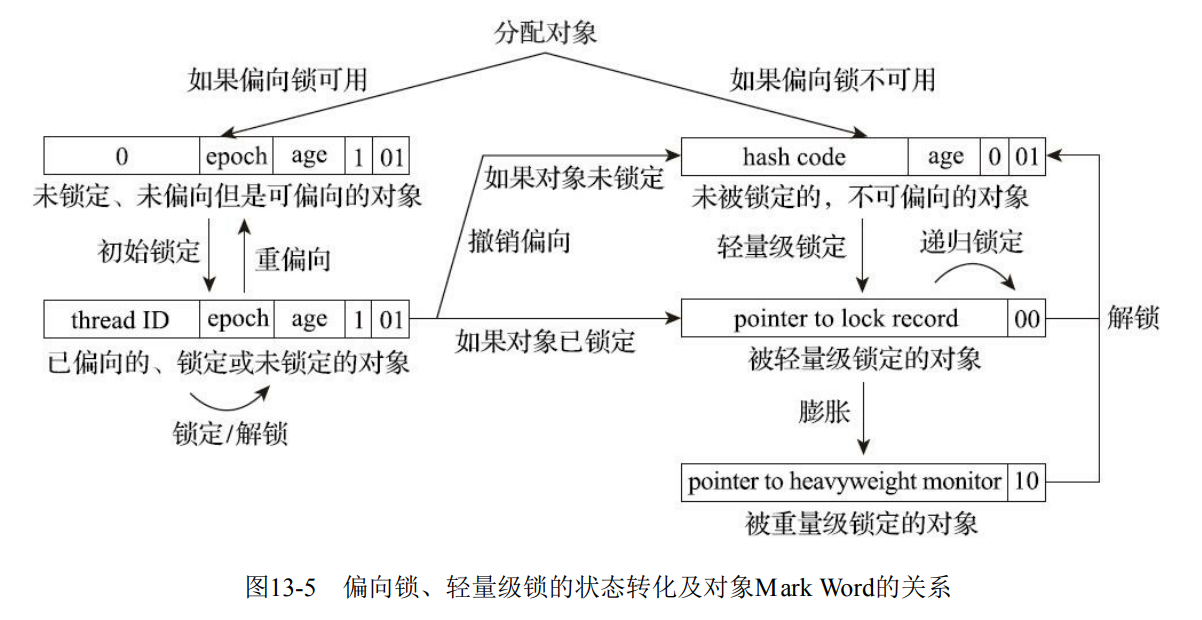
Java中的锁与锁优化技术
文章目录 自旋锁与自适应自旋锁消除锁粗化轻量级锁偏向锁重量级锁 自旋锁与自适应自旋 自旋锁是一种锁的实现机制,其核心思想是当一个线程尝试获取锁时,如果锁已经被其他线程持有,那么这个线程会在一个循环中不断地检查锁是否被释放…...
布局与打包
属性栏直接输入值,比代码更直观方便。 打包:...

UVa11324 - The Largest Clique
Online Judge 题目大意:有一张n个点m条边的图,现对于每一个点u,建立一条边连接它和所有它能到达的点,问满足所有点之间都有边的分量的大小最大是多少 0<n<1000;0<m<50000 思路:根据建新图的规则可知&am…...

【Linux】TCP的服务端(守护进程) + 客户端
文章目录 📖 前言1. 服务端基本结构1.1 类成员变量:1.2 头文件1.3 初始化:1.3 - 1 全双工与半双工1.3 - 2 inet_aton1.3 - 3 listen 2. 服务端运行接口2.1 accept:2.2 服务接口: 3. 客户端3.1 connect:3.2 …...

1.7. 找出数组的第 K 大和原理及C++实现
题目 给你一个整数数组 nums 和一个 正 整数 k 。你可以选择数组的任一 子序列 并且对其全部元素求和。 数组的 第 k 大和 定义为:可以获得的第 k 个 最大 子序列和(子序列和允许出现重复) 返回数组的 第 k 大和 。 子序列是一个可以由其他数…...
基于微信小程序的付费自习室
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 1 简介2 技术栈3 需求分析3.1用户需求分析3.1.1 学生用户3.1.3 管理员用户 4 数据库设计4.4.1 E…...

纪念在CSDN的2048天
时间真快~...

云原生Kubernetes:简化K8S应用部署工具Helm
目录 一、理论 1.HELM 2.部署HELM2 3.部署HELM3 二、实验 1.部署 HELM2 2.部署HELM3 三、问题 1.api版本过期 2.helm初始化报错 3.pod状态为ImagePullBackOff 4.helm 命令显示 no repositories to show 的错误 5.Helm安装报错 6.git命令报错 7.CentOS 7 下git c…...

qml保姆级教程五:视图组件
💂 个人主页:pp不会算法v 🤟 版权: 本文由【pp不会算法v】原创、在CSDN首发、需要转载请联系博主 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦 QML系列教程 QML教程一:布局组件 文章目录 列表视图ListVi…...

2310d编译不过
struct A {this(int[] data) safe { a data; }int[] a; }void main() safe {int[3] test [1, 2, 3];A a A(test); }应该给data参数加上return scope.或让构造器为模板参数来推导,否则,构造器可以把栈分配切片赋值给全局变量....
CleanMyMac X4.14.1最新版本下载
CleanMyMac X是一个功能强大的Mac清理软件,它的设计理念是提供多个模块,包括垃圾清理、安全保护、速度优化、应用程序管理和文档管理粉碎等,以满足用户的不同需求。软件的界面简洁直观,让用户能够轻松进行日常的清理操作。 使用C…...
芯驰D9评测(3)--建立开发环境
1. 建立交叉编译链接环境 官网下载的SDK包中就有交叉工具链,米尔提供的这个 SDK 中除了包含各种源代码外还提供了必要的交叉工具链,可以直接用于编译应用程序等。 用户可以直接使用次交叉编译工具链来建立一个独立的开发环境,可单独编译…...
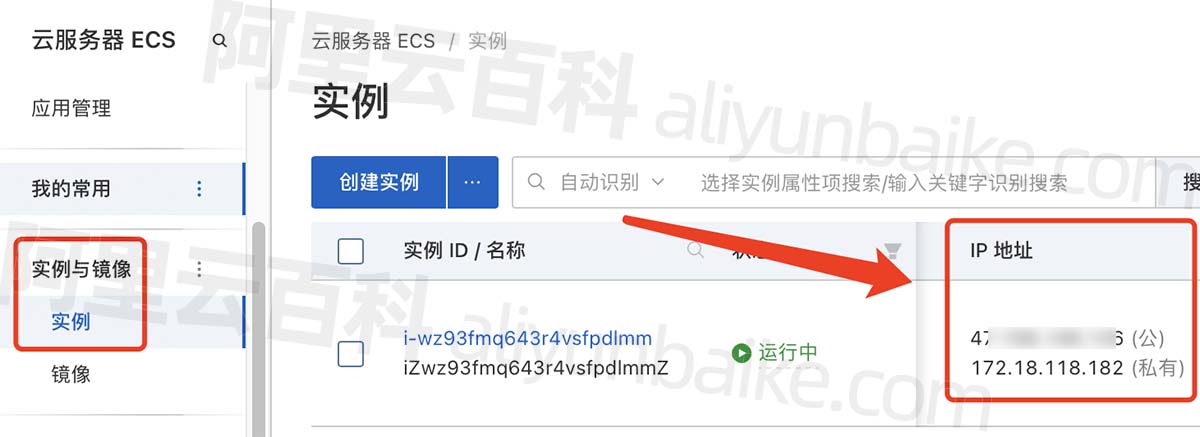
阿里云服务器IP地址查询方法(公网IP和私网IP)
阿里云服务器IP地址在哪查看?在云服务器ECS管理控制台即可查看,阿里云服务器IP地址包括公网IP和私有IP地址,阿里云百科分享阿里云服务器IP地址查询方法: 目录 阿里云服务器IP地址查询 阿里云服务器IP地址查询 1、登录到阿里云服…...

第47节——使用bindActionCreators封装actions模块
一、什么是action creators 1、概念 在Redux中,Action Creators是一种函数,它用于创建一个描述应用程序状态变化的action对象。Action对象是一个普通JavaScript对象,它包含一个描述action类型的字符串属性(通常称为“type”&…...

QT、c/c++通过宏自动判断平台
QT、c/c通过宏自动判断平台 Chapter1 QT、c/c通过宏自动判断平台 Chapter1 QT、c/c通过宏自动判断平台 原文链接:https://blog.csdn.net/qq_32348883/article/details/123063830 背景 为了更好的进行跨平台移植、编译、调试。 具体操作 宏操作 #ifdef _WIN32//d…...

对比表:阿里云轻量应用服务器和服务器性能差异
阿里云服务器ECS和轻量应用服务器有什么区别?轻量和ECS优缺点对比,云服务器ECS是明星级云产品,适合企业专业级的使用场景,轻量应用服务器是在ECS的基础上推出的轻量级云服务器,适合个人开发者单机应用访问量不高的网站…...
中国1km分辨率月最低温和最高温度数据集(1901-2020)
简介: 中国1km分辨率月最低温度数据集(1901-2020)是根据CRU发布的全球0.5气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国地区降尺度生成的。使用了496个独立气象观测点数据进行验证&#x…...
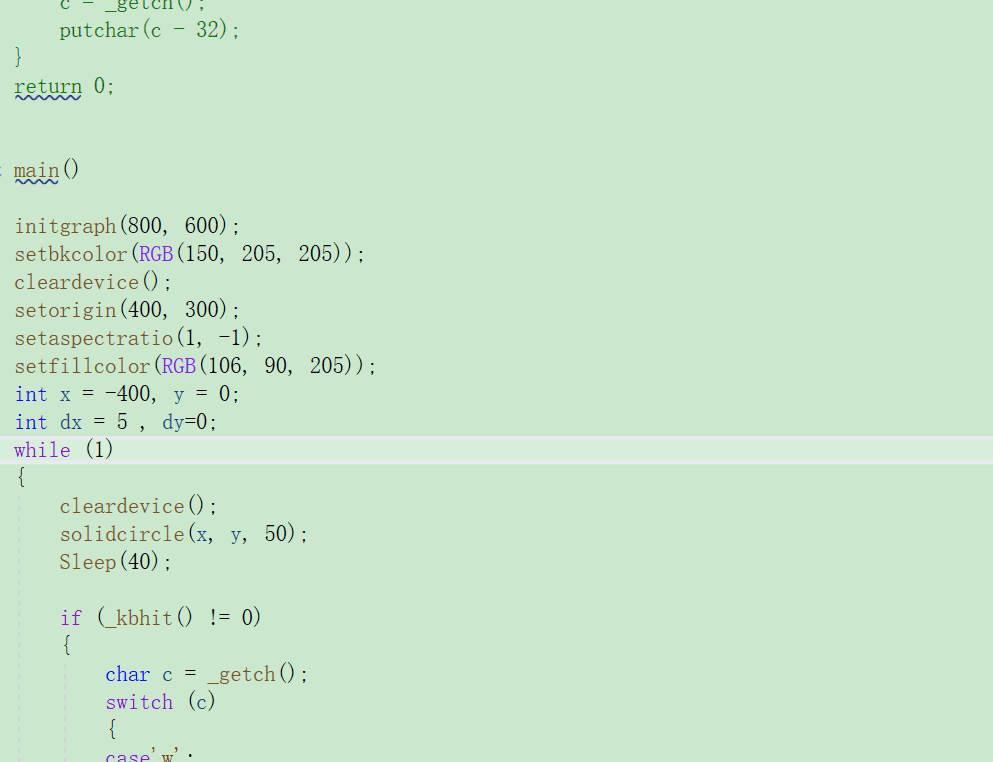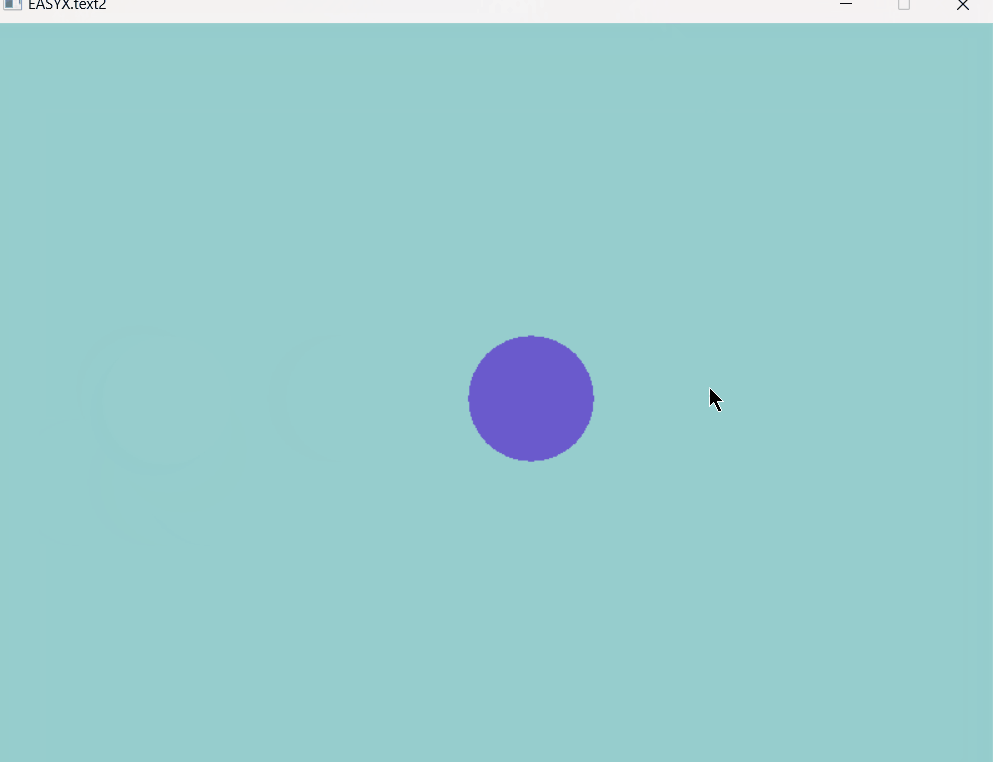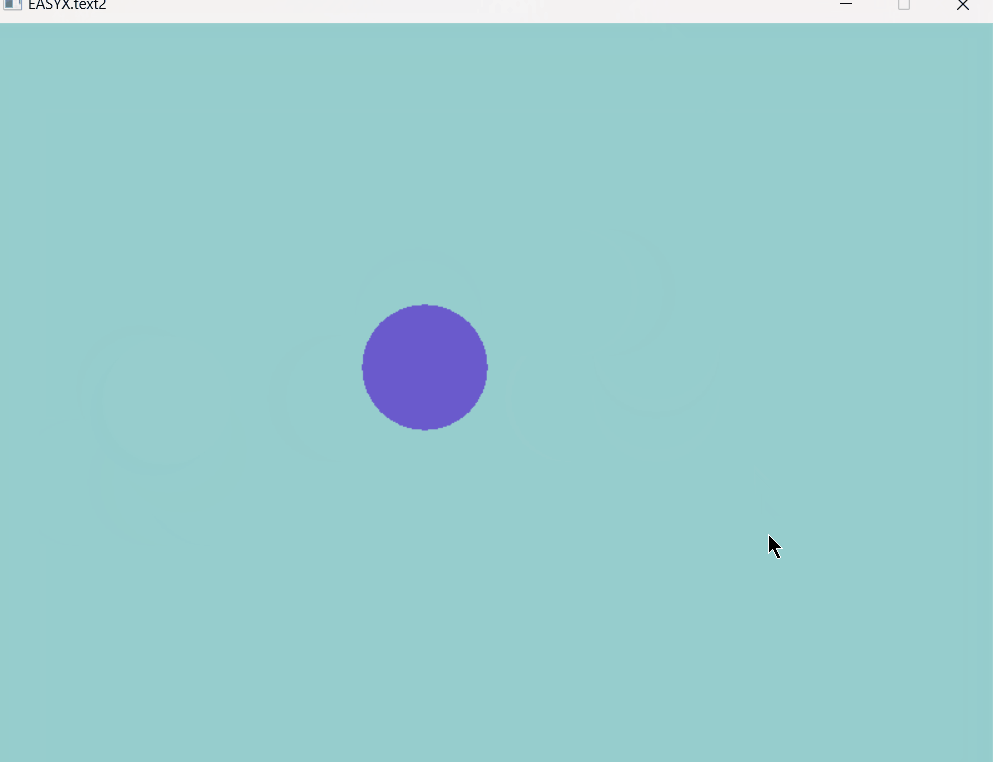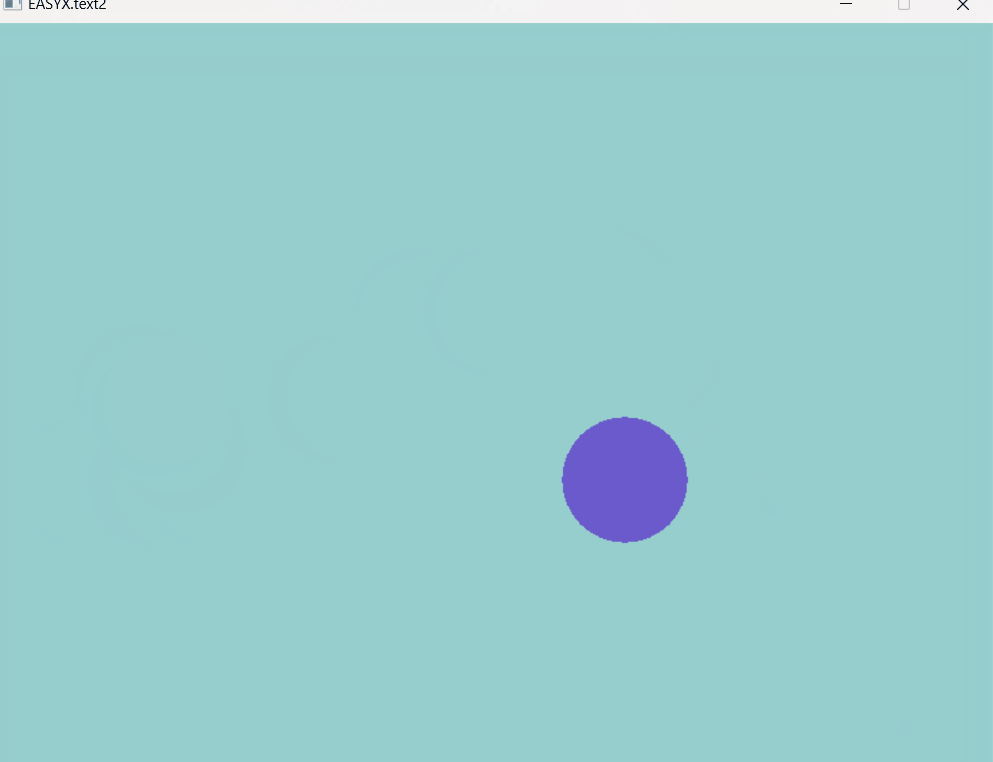
EasyX图形库note4,动画及键盘交互
大家好,这里是Dark Flame Master,专栏从这篇开始就会变得很有意思,我们可以利用今天所学的只是实现很多功能,同样为之后的更加好玩的内容打下基础,从这届开始将会利用所学的知识制作一些小游戏,废话不多说&…...

【面试篇】ConcurrentHashMap 1.7与1.8:从分段锁到CAS+synchronized的演进之路
1. 从分段锁到CASsynchronized的演进背景 在Java并发编程中,HashMap是线程不安全的典型代表。当多个线程同时操作HashMap时,可能会出现数据丢失、环形链表等问题。为了解决这个问题,早期我们通常使用以下两种方式: HashTable&am…...

基于Bing搜索的GPT智能体:实现大语言模型实时联网搜索
1. 项目概述:一个基于Bing搜索的GPT智能体 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫 bujnlc8/gptbing 。光看名字,你可能会觉得这又是一个“GPT套壳”应用,无非是把OpenAI的API包装一下。但如果你仔细琢磨一…...

构建可信AI系统:从黑箱到透明决策的工程实践
1. 项目概述:当AI开始“思考”自己是谁最近和几个做AI安全的朋友聊天,大家不约而同地提到了一个越来越棘手的问题:我们怎么知道一个AI系统在“想”什么?或者说,我们怎么判断它给出的答案、做出的决策,是“可…...

Conforme配置管理范式:类型安全与约定优先的实践指南
1. 项目概述:Conforme,一个被低估的配置管理范式在软件开发和系统运维的日常里,我们总在和“配置”打交道。数据库连接字符串、API密钥、功能开关、环境变量……这些看似零散的信息,却像乐谱上的音符,共同决定了应用如…...

Flutter 性能优化完全指南
Flutter 性能优化完全指南 引言 性能优化是移动应用开发中至关重要的一环。Flutter 虽然天生具有较好的性能表现,但在复杂应用中仍需要开发者进行针对性优化。本文将深入探讨 Flutter 性能优化的各种技巧和最佳实践。 性能问题定位 使用 DevTools // 在 pubspec.yam…...

Go语言服务网格egress:外部服务访问
Go语言服务网格egress:外部服务访问 1. Egress代理 package egressimport ("net/http""net/url" )type EgressProxy struct {dialer *net.Dialertransport *http.Transport }func NewEgressProxy() *EgressProxy {return &EgressProxy{d…...
)
用NE5532和LM1875T手搓一个9V供电的双工对讲机(附完整电路图与Multisim仿真文件)
用NE5532和LM1875T打造9V供电的双工对讲机:从电路设计到实物调试全指南 周末整理零件箱时翻出几片NE5532和LM1875T,突然想起学生时代用这些经典芯片做的第一个对讲机项目。那种通过自己设计的电路实现实时对话的成就感,至今记忆犹新。本文将…...

Agent 一接通知中心就开始误清未读:从 Notification Scope 到 Action Claim 的工程实战
通知中心最容易被低估的,不是消息多,而是 Agent 明明只想处理一条提醒,最后却把整页未读一起清掉。⚠️ 这类事故会直接抹掉待办线索、告警入口和审批提醒。📩图 1:通知中心真正危险的不是消息多,而是动作作…...

探索Taotoken模型广场如何帮助开发者快速选型与切换模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 探索Taotoken模型广场如何帮助开发者快速选型与切换模型 当启动一个需要集成大语言模型的新项目时,开发者面临的首要问…...
)
MongoDB 4.2.7安装后,除了‘show dbs’你还能用命令行做这些事(新手快速上手)
MongoDB 4.2.7安装后命令行实战:从零开始玩转数据库 当你看到show dbs成功显示数据库列表时,说明MongoDB已经准备就绪。但接下来呢?命令行界面就像一片未知海域,而我们将带你从浅滩开始探索。以下是几个能让新手快速获得成就感的实…...