EasyNLP集成K-Global Pointer算法,支持中文信息抽取
作者:周纪咏、汪诚愚、严俊冰、黄俊
导读
信息抽取的三大任务是命名实体识别、关系抽取、事件抽取。命名实体识别是指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等;关系抽取是指识别文本中实体之间的关系;事件抽取是指识别文本中的事件信息并以结构化的形式呈现出来。信息抽取技术被广泛应用于知识图谱的构建、机器阅读理解、智能问答和信息检索系统中。信息抽取的三大任务不是相互独立的关系,而是相互依存、彼此依赖的关系。命名实体识别是关系抽取、事件抽取的基础,关系抽取是事件抽取的基础。同时,关系抽取、事件抽取对命名实体识别任务有帮助,事件抽取对关系抽取任务有帮助。但目前关于仅使用一个模型完成中文信息抽取三大任务的研究相对较少,因此,我们提出K-Global Pointer算法并集成进EasyNLP算法框架中,使用户可以使用自定义数据集训练中文信息抽取模型并使用。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI团队基于PyTorch开发的简单易⽤且功能丰富的中⽂NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式NLP开发体验。EasyNLP提供了简洁的接⼝供⽤户开发NLP模型,包括NLP应⽤AppZoo和预训练ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也⽀持各种跨模态模型,特别是中⽂领域的跨模态模型,推向开源社区,希望能够服务更多的NLP和多模态算法开发者和研究者,也希望和社区⼀起推动NLP/多模态技术的发展和模型落地。
本⽂简要介绍K-Global Pointer的技术解读,以及如何在EasyNLP框架中使⽤K-Global Pointer模型。
K-Global Pointer模型详解
Global Pointer模型是由苏剑林提出的解决命名实体识别任务的模型,n∗nn*nn∗n 的矩阵 AAA(nnn为序列长度),A[i,j]A[i,j]A[i,j]代表的是序列 iii到序列jjj组成的连续子串为对应实体类型的概率,通过设计门槛值BBB即可将文本中具有特定意义的实体识别出来。
K-Global Pointer模型是在Global Pointer模型的基础之上改进的。首先我们将仅支持命名实体识别的模型拓展成支持中文信息抽取三大任务的模型。然后,我们使用了MacBERT预训练语言模型来将文本序列转换成向量序列。最后我们针对不同的任务设计了一套prompt模板,其能帮助预训练语言模型“回忆”起自己在预训练时“学习”到的内容。接下来,我们将根据中文信息抽取三大任务分别进行阐述。
针对命名实体识别任务,我们有文本w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn以及需要提取的实体类型entity_type,对应的prompt为“找到文章中所有【entity_type】类型的实体?”,对应的输入模型的文本HHH为“找到文章中所有【entity_type】类型的实体?文章:【w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn】”,模型经过相应的处理即可输出文本中实体类型为entity_type的实体。
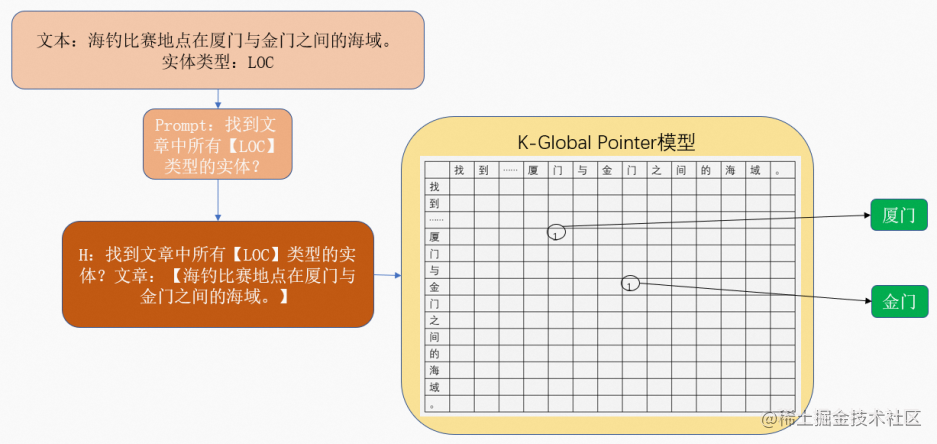
针对关系抽取任务,我们有文本w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn以及需要提取的关系类型relation_type(subject_type-predicate-object_type),分为两步。第一步,对应的prompt为“找到文章中所有【subject_type】类型的实体?”,对应的输入模型的文本HHH为“找到文章中所有【subject_type】类型的实体?文章:【w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn】”,模型经过相应的处理即可输出文本中实体类型为subject_type的实体e1e_{1}e1。第二步,对应的prompt为“找到文章中所有【e1e_{1}e1】的【predicatepredicatepredicate】?”,对应的输入模型的文本HHH为“找到文章中所有【e1e_{1}e1】的【predicatepredicatepredicate】?文章:【w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn】”,模型经过相应的处理即可输出实体e2e_{2}e2。即可构成关系三元组(e1、predicate、e2e_{1}、predicate、e_{2}e1、predicate、e2)。
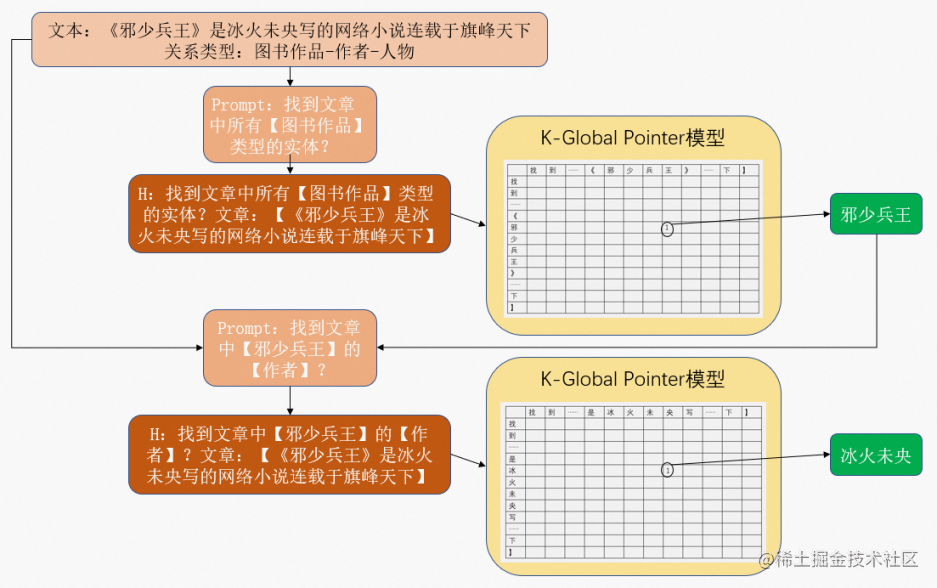
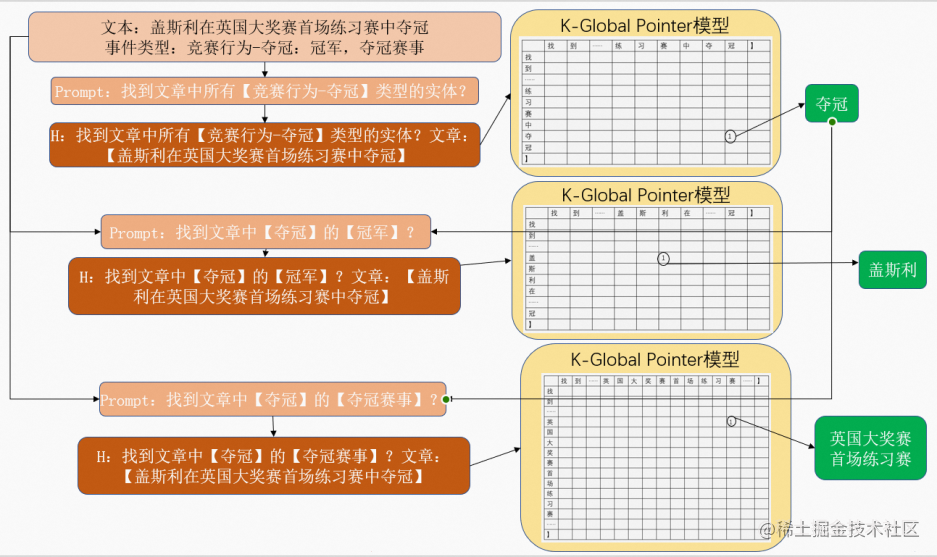
针对事件抽取任务,我们有文本w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn以及需要提取的事件类型classclassclass,每个classclassclass包含event_type以及role_list(r_{1},r_{2},…),分为两步。第一步,对应的prompt为“找到文章中所有【event_type】类型的实体?”,对应的输入模型的文本HHH为“找到文章中所有【event_type】类型的实体?文章:【w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn】”,模型经过相应的处理即可输出的实体eee。第二步,针对role_list中不同的rxr_{x}rx,对应的prompt为“找到文章中所有【eee】的【rxr_{x}rx】?”,对应的输入模型的文本HHH为“找到文章中所有【eee】的【rxr_{x}rx】?文章:【w1,w2,w3,...,wnw_{1},w_{2},w_{3},...,w_{n}w1,w2,w3,...,wn】”,模型经过相应的处理即可输出实体exe_{x}ex。即可构成事件{event_type:eee,role_list:{r_{1}:e_{1},r_{2}:e_{2},…}}。
K-Global Pointer模型的实现与效果
在EasyNLP框架中,我们在模型层构建了K-Global Pointer模型的Backbone,其核⼼代码如下所示:
self.config = AutoConfig.from_pretrained(pretrained_model_name_or_path)
self.backbone = AutoModel.from_pretrained(pretrained_model_name_or_path)
self.dense_1 = nn.Linear(self.hidden_size, self.inner_dim * 2)
self.dense_2 = nn.Linear(self.hidden_size, self.ent_type_size * 2)context_outputs = self.backbone(input_ids, attention_mask, token_type_ids)
outputs = self.dense_1(context_outputs.last_hidden_state)
qw, kw = outputs[..., ::2], outputs[..., 1::2]pos = SinusoidalPositionEmbedding(self.inner_dim, 'zero')(outputs)
cos_pos = pos[..., 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos[..., ::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[..., ::2]], 3)
qw2 = torch.reshape(qw2, qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[..., ::2]], 3)
kw2 = torch.reshape(kw2, kw.shape)
kw = kw * cos_pos + kw2 * sin_poslogits = torch.einsum('bmd,bnd->bmn', qw, kw) / self.inner_dim ** 0.5
bias = torch.einsum('bnh->bhn', self.dense_2(last_hidden_state)) / 2
logits = logits[:, None] + bias[:, ::2, None] + bias[:, 1::2, :, None]mask = torch.triu(attention_mask.unsqueeze(2) * attention_mask.unsqueeze(1))
y_pred = logits - (1-mask.unsqueeze(1))*1e12
y_true = label_ids.view(input_ids.shape[0] * self.ent_type_size, -1)
y_pred = y_pred.view(input_ids.shape[0] * self.ent_type_size, -1)
loss = multilabel_categorical_crossentropy(y_pred, y_true)
为了验证EasyNLP框架中K-Global Pointer模型的有效性,我们使用DuEE1.0、DuIE2.0、CMeEE-V2、CLUENER2020、CMeIE、MSRA、People’s_Daily 7个数据集联合进行训练,并在各个数据集上分别进行验证。其中CMeEE-V2、CLUENER2020、MSRA、People’s_Daily数据集适用于命名实体识别任务,DuIE2.0、CMeIE数据集适用于关系抽取任务,DuEE1.0数据集适用于事件抽取任务。结果如下所示:
| 数据集 | DuEE1.0 | DuIE2.0 | CMeEE-V2 | CLUENER2020 | CMeIE | MSRA | People’s_Daily |
|---|---|---|---|---|---|---|---|
| 参数设置B=0.6 | 0.8657 | 0.8725 | 0.8266 | 0.889 | 0.8155 | 0.9856 | 0.9933 |
可以通过上述结果,验证EasyNLP框架中K-Global Pointer算法实现的正确性、有效性。
K-Global Pointer模型使用教程
以下我们简要介绍如何在EasyNLP框架使⽤K-Global Pointer模型。分为三种情况,分别是①用户使用数据训练模型②用户验证训练好的模型③用户使用训练好的模型完成中文信息抽取任务。我们提供了联合DuEE1.0、DuIE2.0、CMeEE-V2、CLUENER2020、CMeIE、MSRA、People’s_Daily 7个数据集的数据,可以通过sh run_train_eval_predict_user_defined_local.sh来下载获取train.tsv、dev.tsv、predict_input_EE.tsv、predict_input_NER.tsv文件,其中train.tsv文件可用于训练、dev.tsv文件可用于验证、predict_input_EE.tsv、predict_input_NER.tsv文件可用于测试。用户也可以使用自定义数据。
⽤户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。然后cd EasyNLP/examples/information_extraction。
①用户使用数据训练模型
数据准备
训练模型需要使用训练数据和验证数据。用户可以使用我们提供的数据,也可以使用自定义数据。数据表示为train.tsv文件以及dev.tsv文件,这两个⽂件都包含以制表符\t分隔的五列,第一列是标签,第二列是上文K-Global Pointer模型详解中提到的,第三列是答案的开始,第四列是答案的的结束,第五列是答案。样例如下:
People's_Daily-train-0 ['找到文章中所有【LOC】类型的实体?文章:【海钓比赛地点在厦门与金门之间的海域。】'] [29, 32] [31, 34] 厦门|金门
DuIE2.0-train-0 ['找到文章中所有【图书作品】类型的实体?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [24] [28] 邪少兵王
DuIE2.0-train-1 ['找到文章中【邪少兵王】的【作者】?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [28] [32] 冰火未央
DuEE1.0-train-25900 ['找到文章中所有【竞赛行为-夺冠】类型的实体?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [41] [43] 夺冠
DuEE1.0-train-25901 ['找到文章中【夺冠】的【冠军】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [19] [22] 盖斯利
DuEE1.0-train-25902 ['找到文章中【夺冠】的【夺冠赛事】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [25] [35] 英国大奖赛首场练习赛
训练模型
代码如下:
python main.py \
--mode train \
--tables=train.tsv,dev.tsv \
--input_schema=id:str:1,instruction:str:1,start:str:1,end:str:1,target:str:1 \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=2 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='pretrain_model_name_or_path=hfl/macbert-large-zh' \
--save_checkpoint_steps=500 \
--gradient_accumulation_steps=8 \
--epoch_num=3 \
--learning_rate=2e-05 \
--random_seed=42
训练好的模型保存在information_extraction_model文件夹中。
②用户验证训练好的模型
数据准备
验证模型需要使用验证数据。用户可以使用我们提供的数据,也可以使用自定义数据。数据表示为dev.tsv文件,这个⽂件包含以制表符\t分隔的五列,第一列是标签,第二列是上文K-Global Pointer模型详解中提到的HHH,第三列是答案的开始,第四列是答案的的结束,第五列是答案。样例如下:
People's_Daily-train-0 ['找到文章中所有【LOC】类型的实体?文章:【海钓比赛地点在厦门与金门之间的海域。】'] [29, 32] [31, 34] 厦门|金门
DuIE2.0-train-0 ['找到文章中所有【图书作品】类型的实体?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [24] [28] 邪少兵王
DuIE2.0-train-1 ['找到文章中【邪少兵王】的【作者】?文章:【《邪少兵王》是冰火未央写的网络小说连载于旗峰天下】'] [28] [32] 冰火未央
DuEE1.0-train-25900 ['找到文章中所有【竞赛行为-夺冠】类型的实体?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [41] [43] 夺冠
DuEE1.0-train-25901 ['找到文章中【夺冠】的【冠军】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [19] [22] 盖斯利
DuEE1.0-train-25902 ['找到文章中【夺冠】的【夺冠赛事】?文章:【盖斯利在英国大奖赛首场练习赛中夺冠】'] [25] [35] 英国大奖赛首场练习赛
验证模型
代码如下:
python main.py \
--mode evaluate \
--tables=dev.tsv \
--input_schema=id:str:1,instruction:str:1,start:str:1,end:str:1,target:str:1 \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=2 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5
③用户使用训练好的模型完成中文信息抽取任务
数据准备
测试模型需要使用测试数据。用户可以使用我们提供的数据,也可以使用自定义数据。
对于命名实体识别任务,数据表示为predict_input_NER.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是实体类型,第三列是文本。我们支持对同一个文本识别多种实体类型,仅需要在第二列中将不同的实体类型用;分隔开。样例如下:
1 LOC;ORG 海钓比赛地点在厦门与金门之间的海域。
对于关系抽取任务,数据表示为predict_input_RE.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是关系类型,第三列是文本。我们支持对同一个文本识别多种关系类型,仅需要在第二列中将不同的关系类型用;分隔开。对于一个关系类型relation_type(subject_type-predicate-object_type)表示为subject_type:predicate,样例如下:
1 图书作品:作者 《邪少兵王》是冰火未央写的网络小说连载于旗峰天下
对于事件抽取任务,数据表示为predict_input_EE.tsv文件,这个⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是事件类型class,第三列是文本。我们支持对同一个文本识别多种事件类型,仅需要在第二列中将不同的事件类型用;分隔开。对于一个事件类型class包含event_type以及role_list(r1,r2,……)表示为event_type:r1,r2,……,样例如下:
1 竞赛行为-夺冠:夺冠赛事,裁员人数 盖斯利在英国大奖赛首场练习赛中夺冠
测试模型
对于命名实体识别任务,代码如下:
python main.py \
--tables=predict_input_NER.tsv \
--outputs=predict_output_NER.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=NER'
模型输出结果见predict_output_NER.tsv文件
对于关系抽取任务,代码如下:
python main.py \
--tables=predict_input_RE.tsv \
--outputs=predict_output_RE.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=RE'
模型输出结果见predict_output_RE.tsv文件
对于事件抽取任务,代码如下:
python main.py \
--tables=predict_input_EE.tsv \
--outputs=predict_output_EE.tsv \
--input_schema=id:str:1,scheme:str:1,content:str:1 \
--output_schema=id,content,q_and_a \
--worker_gpu=4 \
--app_name=information_extraction \
--sequence_length=512 \
--weight_decay=0.0 \
--micro_batch_size=4 \
--checkpoint_dir=./information_extraction_model/ \
--data_threads=5 \
--user_defined_parameters='task=EE'
模型输出结果见predict_output_EE.tsv文件
在阿里云机器学习PAI-DSW上进行中文信息抽取
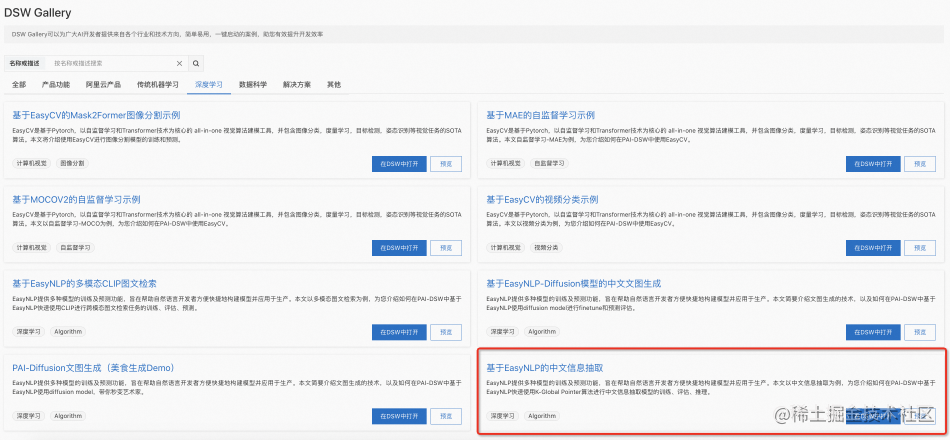
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向不同水平的开发者,提供了交互式的编程环境(文档)。在DSW Gallery中,提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了使用PAI-Diffusion模型进行中文信息抽取的Sample Notebook,欢迎大家体验!
未来展望
在未来,我们计划进一步改进K-Global Pointer模型,敬请期待。我们将在EasyNLP框架中集成更多中⽂模型,覆盖各个常⻅中⽂领域,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型,来⽀持各种NLP和多模态任务。此外,阿⾥云机器学习PAI团队也在持续推进中⽂NLP和多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊我们的开源社区,共建中⽂NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- GlobalPointer:https://kexue.fm/archives/8373
阿里灵杰回顾
- 阿里灵杰:阿里云机器学习PAI开源中文NLP算法框架EasyNLP,助力NLP大模型落地
- 阿里灵杰:预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里灵杰:EasyNLP带你玩转CLIP图文检索
- 阿里灵杰:EasyNLP中文文图生成模型带你秒变艺术家
- 阿里灵杰:EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune
- 阿里灵杰:中文稀疏GPT大模型落地 — 通往低成本&高性能多任务通用自然语言理解的关键里程碑
- 阿里灵杰:EasyNLP玩转文本摘要(新闻标题)生成
- 阿里灵杰:跨模态学习能力再升级,EasyNLP电商文图检索效果刷新SOTA
- 阿里灵杰:EasyNLP带你实现中英文机器阅读理解
- 阿里灵杰:EasyNLP发布融合语言学和事实知识的中文预训练模型CKBERT
- 阿里灵杰:当大火的文图生成模型遇见知识图谱,AI画像趋近于真实世界
- 阿里灵杰:PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋
- 阿里灵杰:阿里云PAI-Diffusion功能再升级,全链路支持模型调优,平均推理速度提升75%以上
相关文章:
EasyNLP集成K-Global Pointer算法,支持中文信息抽取
作者:周纪咏、汪诚愚、严俊冰、黄俊 导读 信息抽取的三大任务是命名实体识别、关系抽取、事件抽取。命名实体识别是指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等;关系抽取是指识别文本中实体之间的关系;…...

mysql lesson3
DQL查找语句续集.............................. 分组函数(也叫多行处理函数) 1: select sum(sal) from emp;select min(sal)from emp;select max(sal)from emp;select avg(sal)from emp;select count(ename)from emp;2:分组函…...
python源码保护
文章目录代码混淆打包exe编译为字节码源码加密项目发布部署时,为防止python源码泄漏,可以通过几种方式进行处理代码混淆 修改函数、变量名 打包exe 通过pyinstaller 将项目打包为exe可执行程序,不过容易被反编译。 编译为字节码 py_comp…...

第51讲:SQL优化之COUNT查询的优化
文章目录 1.COUNT查询优化的概念2.COUNT函数的用法1.COUNT查询优化的概念 在很多的业务场景下可能需要统计一张表中的总数据量,当表的数据量很大时,使用COUNT统计表数据量时,也是非常耗时的。 MyISAM引擎会把一个表的总行记录在磁盘中,当执行count(*)的时候会直接从磁盘中…...

ArrayBlockingQueue
同步队列超出长度时,不同的返回形式可以分为以下四种。 会抛异常不会抛异常,有返回值死等,直到可以插入值或者取到值设置等待超时时间添加方法add()offfer()put()offer(E e,long timeout, TimeUnit unit)删除方法remove()poll()take()poll(l…...

DeepLabV3+:对预测处理的详解
相信大家对于这一部分才是最感兴趣的,能够实实在在的看到效果。这里我们就只需要两个.py文件(deeplab.py、predict_img.py)。 创建DeeplabV3类 deeplab.py的作用是为了创建一个DeeplabV3类,提供一个检测图片的方法,而…...
【Git】与“三年经验”就差个分支操作的距离
前言 Java之父于胜军说过,曾经一位“三年开发经验”的程序员粉丝朋友,刚入职因为不会解决分支问题而被开除,这是不是在警示我们什么呢? 针对一些Git的不常用操作,我们通过例子来演示一遍 1.版本回退 1.1已提交但未p…...
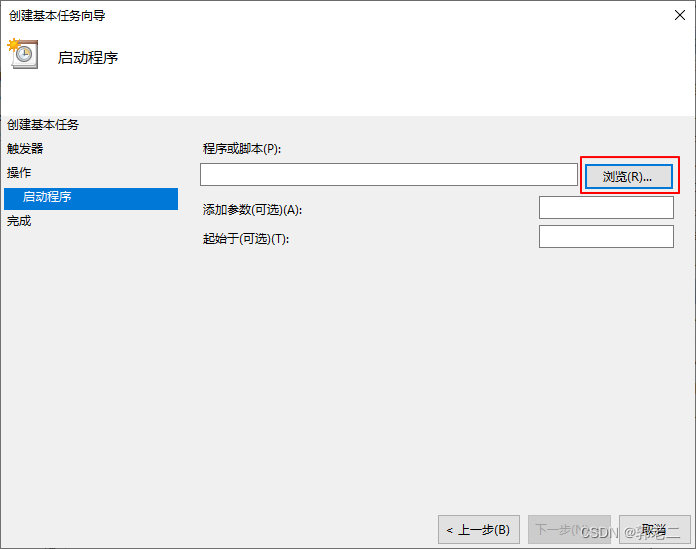
【经验】win10设置自启动
方法一:自启动文件夹 按下winr快捷键,弹出运行窗口,输入:shell:startup,弹出自启动文件夹窗口,将要开机自启的程序或快捷方式复制到此窗口中即可。 自启动文件夹路径:C:\Users\【用户名】\Ap…...

Linux SPI-NAND 驱动开发指南
文章目录Linux SPI-NAND 驱动开发指南1 概述1.1 编写目的1.2 适用范围1.3 相关人员3 流程设计3.1 体系结构3.2 源码结构3.3 关键数据定义3.3.1 flash 设备信息数据结构3.3.2 flash chip 数据结构3.3.3 aw_spinand_chip_request3.3.4 ubi_ec_hdr3.3.5 ubi_vid_hdr3.4 关键接口说…...
【THREE.JS学习(3)】使用THREEJS加载GeoJSON地图数据
本文接着系列文章(2)进行介绍,以VUE2为开发框架,该文涉及代码存放在HelloWorld.vue中。相较于上一篇文章对div命名class等,该文简洁许多。<template> <div></div> </template>接着引入核心库i…...

在windows搭建Redis集群并整合入Springboot项目
搭建集群配置规划Redis集群编写bat来启动每个redis服务安装Ruby安装Redis的Ruby驱动出现错误镜像过期SSL证书过期安装集群脚本redis-trib启动每个节点并执行集群构建脚本测试搭建是否成功配置springboot项目中配置规划Redis集群 我们搭建三个节点的集群,每个节点有…...

C++【内存管理】
文章目录C内存管理一、C/C内存分布1.1.C/C内存区域划分图解:1.2.根据代码进行内存区域分析二、C内存管理方式2.1.new/delete操作内置类型2.2.new和delete操作自定义类型三、operator new与operator delete函数四、new和delete的实现原理4.1.内置类型4.2.自定义类型4…...
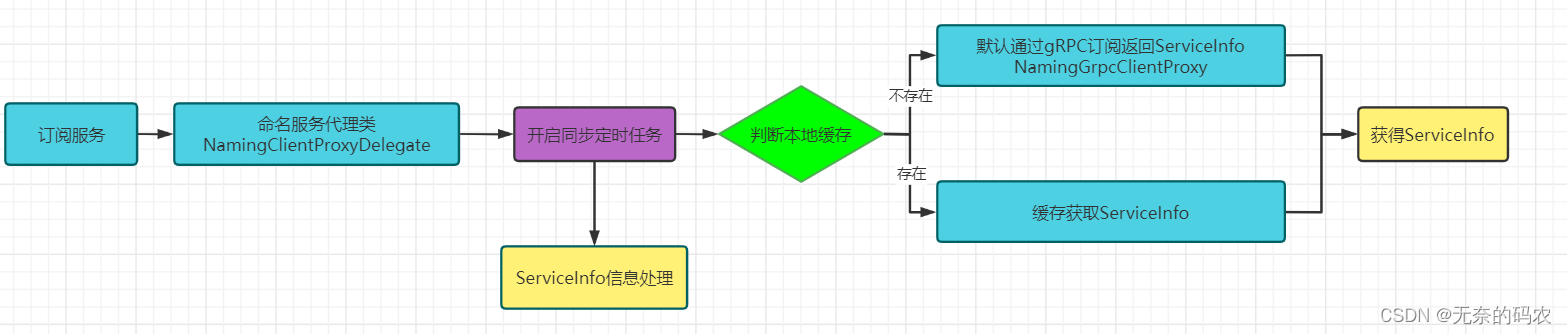
Spring Cloud Nacos源码讲解(六)- Nacos客户端服务发现
Nacos客户端服务发现源码分析 总体流程 首先我们先通过一个图来直观的看一下,Nacos客户端的服务发现,其实就是封装参数、调用服务接口、获得返回实例列表。 但是如果我们要是细化这个流程,会发现不仅包括了通过NamingService获取服务列表…...

华为OD机试题,用 Java 解【计算最大乘积】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...

蓝牙运动耳机哪个好,比较好的运动蓝牙耳机
很多想选择蓝牙运动耳机的朋友都不知道应该如何选择,运动首先需要注意的就是耳机的防水能力以及耳机佩戴舒适度,在运动当中会排出大量的汗水,耳机防水等级做到越高,可以更好地保护耳机不受汗水浸湿,下面就分享五款适合…...

苹果设计可变色Apple Watch表带,智能穿戴玩法多
苹果最新技术专利显示,苹果正在为 Apple Watch 设计一款可变色的表带,可以根据佩戴者所穿着的服装、所在的环境等自动改变颜色。据介绍,这款表带里的灯丝具有电致变色功能,可以通过施加不同的电压,来实现显示多种颜色或…...

Elasticsearch集群Yellow亚健康状态修复
Elasticsearch集群Yellow亚健康状态修复问题背景排查流程解决办法问题背景 Elasticsearch集群健康状态为Yellow,涉及到多个索引。 排查流程 在浏览器打开Kibana Console进行问题排查,console地址为: http://{Kibana_IP}:5601/app/dev_too…...

第52讲:SQL优化之UPDATE更新操作的优化
文章目录 1.UPDATE更新语句的优化2.UPDATE更新语句优化案例1.UPDATE更新语句的优化 我们在使用UPDATE更新语句更改表中数据时,可能会导致表中产生行级锁或者是表级锁。 UPDATE语句的优化就是为了避免表中出现表级锁,从而影响并发的性能。 当UPDATE语句更新表数据时,WHERE…...
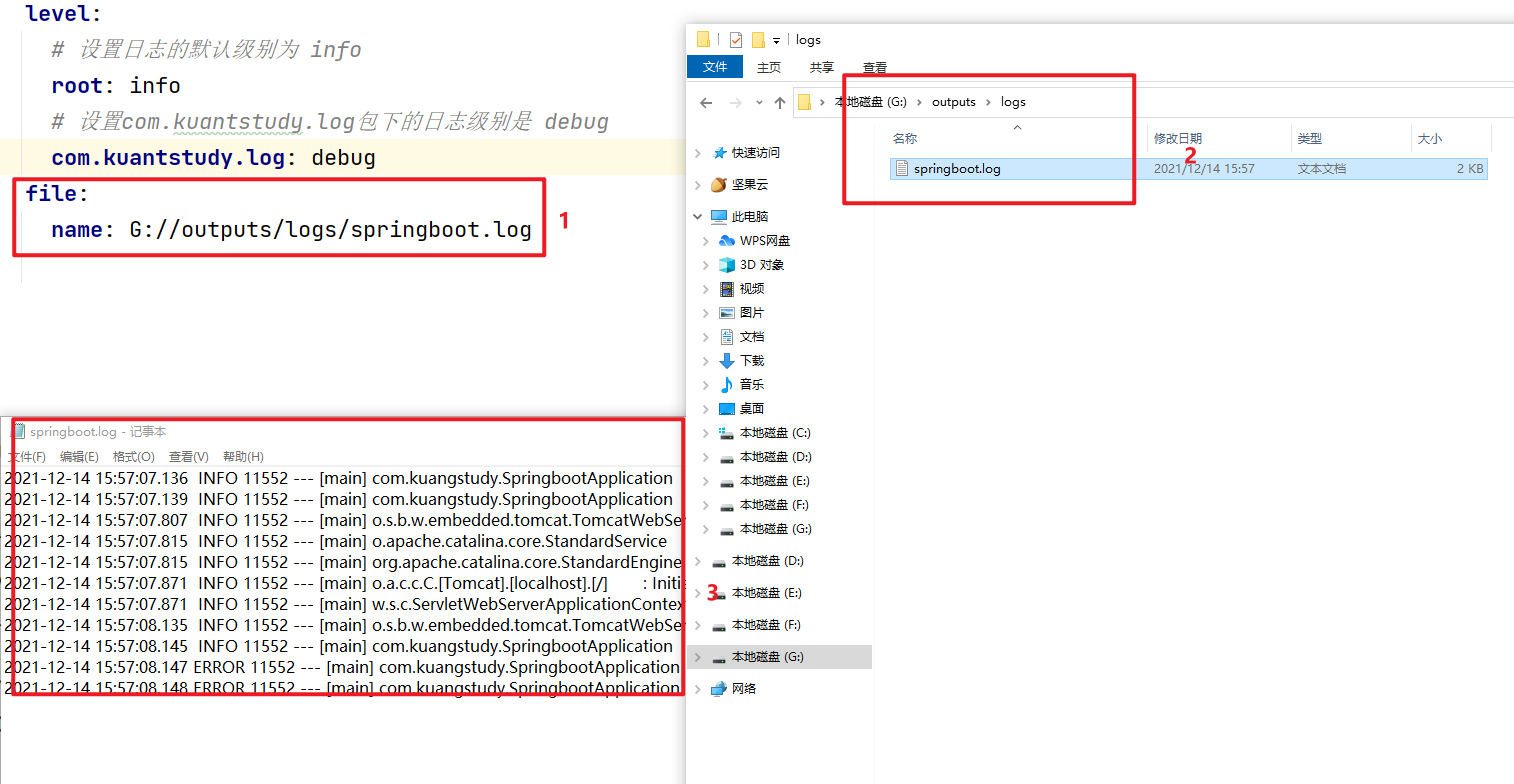
logback 自定义日志输出到数据库
项目日志格式 Spring Boot 的默认日志输出类似于以下示例: 2021-12-14 22:40:14.159 INFO 20132 --- [ main] com.kuangstudy.SpringbootApplication : Started SpringbootApplication in 2.466 seconds (JVM running for 3.617)输出以下项目&…...

< elementUi 组件插件: el-table表格拖拽修改列宽及行高 及 使用注意事项 >
elementUi 组件插件: el-table拖拽修改列宽及行高 及 使用注意事项👉 资源Js包下载及说明👉 使用教程> 实现原理> 局部引入> 全局引入 (在main.js中)👉 注意事项往期内容 💨Ǵ…...

ARM SME架构下BFloat16矩阵运算优化实践
1. ARM SME架构与BFloat16计算概述在当今高性能计算领域,特别是机器学习和人工智能应用中,计算效率和内存带宽利用率成为了关键瓶颈。ARMv9架构引入的SME(Scalable Matrix Extension)扩展正是针对这一需求而设计,其中B…...

Mac上高效调试HTTPS流量:Charles抓包配置与SSL解密实战
1. 为什么Mac用户绕不开Charles——它不是“又一个抓包工具”,而是调试链路的中枢神经在Mac上做前端联调、App接口验证、小程序网络行为分析,甚至排查第三方SDK异常请求时,我见过太多人卡在第一步:看不到真实发出去的请求。有人用…...

第 12 周 周报
牛 客 :周赛144,DEF C F :(dive2 1097) C D (dive2 1098)B (dive2 1099)BCD...

Claude Code 基础配置篇-三层配置体系详解
基础配置篇 —— Rules、Memory、Custom Instructions 三层配置体系详解系列导读: Claude Code 最让新手头疼的问题是"每次写的代码风格都不一样"、“总要重新解释项目架构”。本篇将彻底解决这个问题。通过建立三层配置体系,你可以让 Claude …...
昇腾CANN ops-transformer FlashAttention 反向传播:不存 Attention 矩阵怎么求梯度
FlashAttention 前向传播的精髓:不存 NN 的 attention 矩阵,只存 O(N) 的输出和 softmax 归一化因子。反向传播时,需要 attention 矩阵来计算梯度——但矩阵没存。解法:重新算一遍。用额外的计算换显存——这是典型的 compute-for…...

融合模糊决策与ECSA优化的软件项目智能风险评估框架
1. 项目概述与核心价值在软件工程这个行当里摸爬滚打十几年,我见过太多项目因为对风险的“视而不见”或“束手无策”而走向失败。项目延期、预算超支、质量滑坡,这些问题的根源往往不是技术本身,而是对潜在威胁的评估和应对失当。传统的风险管…...

告别电脑休眠烦恼:MouseJiggler鼠标抖动工具完全指南
告别电脑休眠烦恼:MouseJiggler鼠标抖动工具完全指南 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. 项目…...

在Node.js服务端项目中集成Taotoken聚合大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务端项目中集成Taotoken聚合大模型能力 对于Node.js后端开发者而言,在构建需要AI能力的Web服务时ÿ…...

跨平台资源包管理工具VPKEdit:游戏开发者的终极解决方案
跨平台资源包管理工具VPKEdit:游戏开发者的终极解决方案 【免费下载链接】VPKEdit A CLI/GUI tool to create, read, and write several pack file formats. 项目地址: https://gitcode.com/gh_mirrors/vp/VPKEdit 在游戏开发和MOD制作过程中,资源…...

随机森林与Bagging回归器在农业产量时序预测中的集成学习应用
1. 项目概述与核心价值在农业领域,精准预测作物产量从来都不是一个简单的数学问题,它直接关系到从田间地头到国家粮仓的资源配置效率。过去,我们更多地依赖农艺师的经验和简单的历史平均数据,但面对日益复杂的气候变化和市场波动&…...