Pytorch目标分类深度学习自定义数据集训练
目录
一,Pytorch简介;
二,环境配置;
三,自定义数据集;
四,模型训练;
五,模型验证;
一,Pytorch简介;
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch 基于 Python: PyTorch 以 Python 为中心或“pythonic”,旨在深度集成 Python 代码,而不是作为其他语言编写的库的接口。Python 是数据科学家使用的最流行的语言之一,也是用于构建机器学习模型和 ML 研究的最流行的语言之一。由于其语法类似于 Python 等传统编程语言,PyTorch 比其他深度学习框架更容易学习。
二,环境配置;
版本:
系统:window10;
Python:3.11.5;
pytorch:2.0.1;
Python安装:
Python官网:python.org;
下载3.11.5版本Python安装版进行安装;
配置Python环境变量;
在系统变量path中添加Python的bin路径和Script路径;
查看Python是否安装成功;
正常如上显示表示安装成功。
同时查看Python对应的Pip版本;
Pytorch安装:
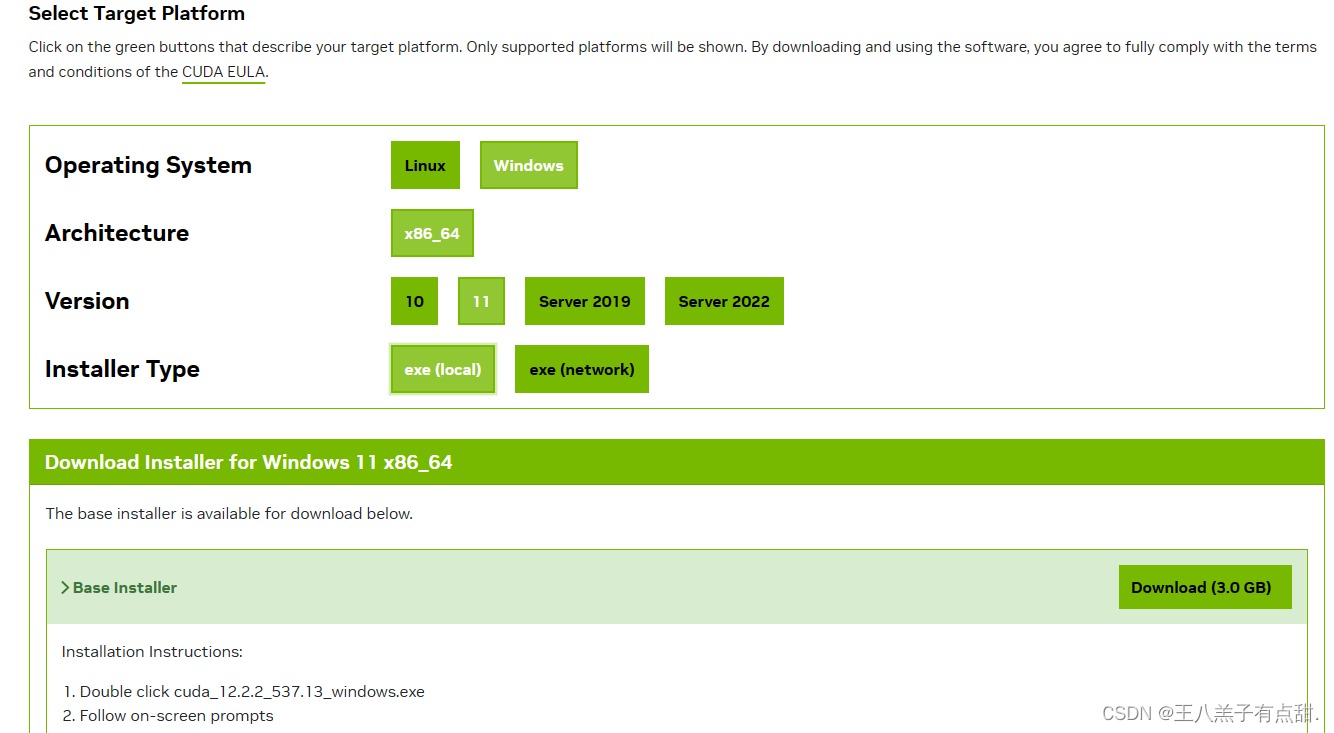
pytorch官网:PyTorch;
进入Pytorch官网后点击左上角Get Started查看Pytorch对于的Python版本,GPU版本。默认安装的是CPU版本,本文使用Pip安装Pytorch方式,直接运行Run this Command会报错,安装了几次都不行,所以自己找对应的安装文件进行安装更方便。
根据Pytorch官网介绍的对应版本找到我们需要的依赖文件。
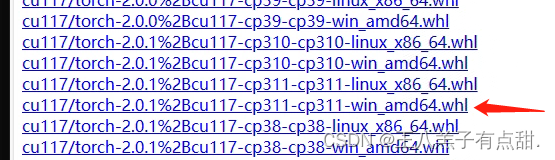
网址:download.pytorch.org/whl/torch_stable.html
找到对应安装的版本,cu开头表示是GPU版本和版本号,torch后面对应的是Pytorch版本号,cp对应Python版本;点击下载安装文件;
下载好以后打开文件所在位置,进入window命令界面,执行命令;
pip install torch-2.0.1+cu117-cp311-cp311-win_amd64.whl英伟达GPU安装:
选择对应的GPU版本安装,安装完成后验证下是否安装成功,正常显示版本表示安装成功。





三,自定义数据集;
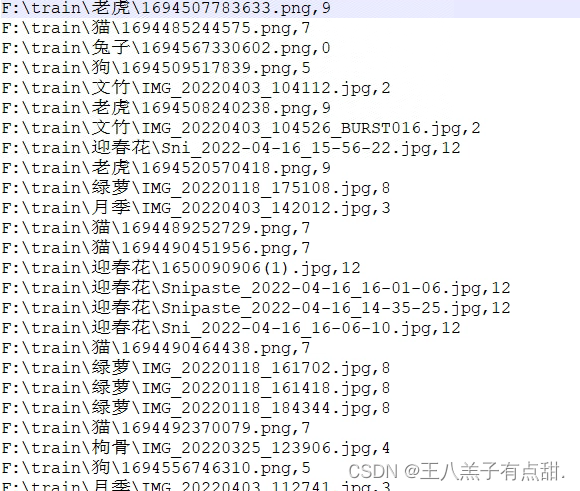
从网上下载数据集,按照文件夹分类,首先将数据集制作成包含图片路径,和对应索引的csv文件。
import torch import os, glob import random, csv# 所有自定义数据集的一个母类 from torch.utils.data import Dataset, DataLoader # 常用的图片变换器 from torchvision import transforms # 从图片读取出数据 from PIL import Image# 自定义数据集的类,继承自Dataset class Pokemon(Dataset):# 一、初始化函数init# 第一个参数root:总的图片所在的位置,可以是任意的位置,我们的图片可以放在任意的位置,我们这里就存储在当前目录文件夹下。# 第二个参数resize:图片输出的size,是由这个参数所进行设定。# 第三个参数mode:这里我们需要做train、validation以及test,对应这三种数据结构,因此我们用一个list[0,1,2]来代表是哪个模式。def __init__(self, root, resize, mode):# 先调用母类的初始化函数:super(Pokemon, self).__init__()# 1、首先我们将这个参数保存下来self.root = rootself.resize = resize# 2、给每一个分类做一个映射,即当前的皮卡丘、妙蛙种子等这个string类型所对应的label是多少,这个是需要我们人为进行编码的。self.name2label = {} # 用字典来表示映射关系# 通过循环方式,将root路径下的文件夹名进行编码for name in sorted(os.listdir(os.path.join(root))):# 过滤掉非文件夹:如果不是dir,就过滤掉,此外我们还通过sorted排序的方法,将键值对关系固定下来if not os.path.isdir(os.path.join(root, name)):continue# 文件名做key,当前name2label的长度做valueself.name2label[name] = len(self.name2label.keys())print(self.name2label)# image, labelself.load_csv('images.csv')# 二、创建一个csv,用于保存图片全路径和对应的标签label# 这个函数接受一个参数filename# 这个函数中需要将所有图片都load进来def load_csv(self, filename):images = []for name in self.name2label.keys():# 类别信息我们可以使用路径来判断# 上面路径的mewtwo就是类别images += glob.glob(os.path.join(self.root, name, '*.png'))images += glob.glob(os.path.join(self.root, name, '*.jpg'))images += glob.glob(os.path.join(self.root, name, '*.jpeg'))print(len(images), images)# 将images顺序打乱random.shuffle(images)# 打开这个文件with open(os.path.join(self.root, filename), mode='w', newline='') as f:# 新建writer,获得csv这个文件对象writer = csv.writer(f)for img in images: # 获得每行信息# 通过分割符,将每行信息的内容分割开,取导数第二个,类型name = img.split(os.sep)[-2]# 通过获取的类型名来获取labellabel = self.name2label[name]# 将这个label信息写到csv中# csv是以逗号作为分割的writer.writerow([img, label])print('writen into csv file:', filename)# 三、完成两个自定义的逻辑# 1、样本的总体数量(图片总体数量),返回的是一个数字,总体图片大概有1168张,60%用于training,因此返回6-7百张图片def __len__(self):pass# 2、用于返回当前index上面元素的值,这里是返回两个数据:# 需要返回当前image的data,以及image所对应的label[0,1,2,3,4]def __getitem__(self, idx):pass# 创建一个调试函数: def main():db = Pokemon('F:\\train', 224, 'train')if __name__ == '__main__':main()将图片路径改成自己数据的文件夹路径,运行代码在对应路径下生成.csv格式文件
类别索引根据文件夹种类顺序生成,要和csv文件中索引对应。数据集制作完成后就可以开始训练了。
首先定义加载数据集类;
import torch import os, glob import random, csv# 所有自定义数据集的一个母类 from torch.utils.data import Dataset, DataLoader# 常用的图片变换器 from torchvision import transforms # 从图片读取出数据 from PIL import Image# 自定义数据集的类,继承自Dataset class Pokemon(Dataset):# 一、初始化函数init# 第一个参数root:总的图片所在的位置,可以是任意的位置,我们的图片可以放在任意的位置,我们这里就存储在当前目录文件夹下。# 第二个参数resize:图片输出的size,是由这个参数所进行设定。# 第三个参数mode:这里我们需要做train、validation以及test,对应这三种数据结构,因此我们用一个list[0,1,2]来代表是哪个模式。def __init__(self, root, resize, mode):# 先调用母类的初始化函数:super(Pokemon, self).__init__()# 1、首先我们将这个参数保存下来self.root = rootself.resize = resize# 2、给每一个分类做一个映射,这个string类型所对应的label是多少,这个是需要我们人为进行编码的。self.name2label = {} # 用字典来表示映射关系# 通过循环方式,将root路径下的文件夹名进行编码for name in sorted(os.listdir(os.path.join(root))):# 过滤掉非文件夹:如果不是dir,就过滤掉,此外我们还通过sorted排序的方法,将键值对关系固定下来if not os.path.isdir(os.path.join(root, name)):continue# 文件名做key,当前name2label的长度做valueself.name2label[name] = len(self.name2label.keys())# print(self.name2label)# 将self.load_csv的返回值images, labels赋予self.images, self.labelsself.images, self.labels = self.load_csv('images.csv')# 四、不同比例模式下对图片数量进行划分if mode == 'train': # 取60%做training# len(self.images)的长度是1167,取60%做为train模式的图片self.images = self.images[:int(0.6 * len(self.images))]self.labels = self.labels[:int(0.6 * len(self.labels))]elif mode == 'val': # 取20%做validation, 60%-80%self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]else: # mode为test,取80%到最末尾self.images = self.images[int(0.8 * len(self.images)):]self.labels = self.labels[int(0.8 * len(self.labels)):]# 二、创建一个csv,用于保存图片全路径和对应的标签label# 这个函数接受一个参数filename# 这个函数中需要将所有图片都load进来def load_csv(self, filename):# 需要一个判断,如果文件不存在,就需要创建csv,直接读取创建好的csv文件内容即可:# 如果不存在,就需要创建csvif not os.path.exists(os.path.join(self.root, filename)):images = []for name in self.name2label.keys():# 类别信息我们可以使用路径来判断# 上面路径的mewtwo就是类别images += glob.glob(os.path.join(self.root, name, '*.png'))images += glob.glob(os.path.join(self.root, name, '*.jpg'))images += glob.glob(os.path.join(self.root, name, '*.jpeg'))print(len(images), images)# 将images顺序打乱random.shuffle(images)# 打开这个文件with open(os.path.join(self.root, filename), mode='w', newline='') as f:# 新建writer,写入csv这个文件对象writer = csv.writer(f)for img in images:# 通过分割符,将每行信息的内容分割开,取导数第二个,类型name = img.split(os.sep)[-2]# 通过获取的类型名来获取labellabel = self.name2label[name]# 将这个label信息写到csv中# csv是以逗号作为分割的writer.writerow([img, label])print('writen into csv file:', filename)# 三、读取csv文件过程:# 这里需要在开头有一个判断,如果csv存在,就不用写入csv了,直接进行读取# 下次运行的时候只需加载进来即可images, labels = [], []with open(os.path.join(self.root, filename)) as f:# 新建reader,读取csv这个文件对象reader = csv.reader(f)for row in reader:img, label = rowlabel = int(label) # 将这个label转码为int类型# 将img每个图片路径,以及label保存在建立好的列表对象中。images.append(img)labels.append(label)assert len(images) == len(labels)return images, labels# 完成两个自定义的逻辑:# 1、样本的总体数量(图片总体数量),返回的是一个数字,总体图片大概有1168张,60%用于training,因此返回6-7百张图片# 五、完成总体样本数量函数的内容def __len__(self):# 这里的样本长度是跟模型类别来决定的,上面已经根据不同模型类型划分了样本数量了。# 不同模式下,样本长度是不同的。# 因此这里的总体样本长度,就是不同模式下的样本数量。return len(self.images)# 九、解决normalize处理后,visdom无法正常显示的问题# 这里传入的参数x是normalize过后的def denormalize(self, x_hat):mean = [0.485, 0.456, 0.406]std = [0.229, 0.224, 0.225]mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)std = torch.tensor(std).unsqueeze(1).unsqueeze(1)print('mean.shape,std.shape:', mean.shape, std.shape)x = x_hat * std + meanreturn x# 2、用于返回当前index上面元素的值,这里是返回两个数据:# 需要返回当前image的data,以及image所对应的label[0,1,2,3,4]# 六、完成index与样本的一一对应def __getitem__(self, idx):# idx数值范围是[0-len(images)]# self.images保存了所有的数据;self.labels保存了所有数据对应的label信息;# img是一个string类型(还不是具体的图片,只是路径)# label是一个整数类型img, label = self.images[idx], self.labels[idx]# 这里就需要将img所对应的路径读取出图片,并转为tensor类型# 这里我们可以Compose组合操作步骤# 八、增加数据预处理的工作,在Compose中增加这些内容,data augmentation数据增强# 这里我们做放大、旋转、裁切这三个数据增强的操作tf = transforms.Compose([# 这里需要将路径变成具体的图片数据类型# 即:string path => image datalambda x: Image.open(x).convert('RGB'),# Resize工作,这里的size是我们实例化时的self.resize的值# 1、data augmentation放大:在Resize设置的基础上,稍微调大一些size, 调整为1.25倍transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),# 2、data augmentation旋转:增加随机旋转,注意:这里旋转角度不能太大,会增加学习的难度。transforms.RandomRotation(15),# 3、data augmentation中心裁切:裁切为我们所需要的大小transforms.CenterCrop(self.resize),# 将数据变为tensor类型transforms.ToTensor(),# 4、normalize处理,希望图片数值范围在0左右分布,而不希望数值只分布在0的右侧或只在左侧# 其中参数统计的所有image net数据集几百万张图片的mean=[R的mean,G的mean,B的mean]和std=[R的方差,G的方差,B的方差]# 基本上这个数值是通用的# 数据通过Normalize处理后,就是在-1到1之间分布了。transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])img = tf(img)label = torch.tensor(label)return img, label# 创建一个调试函数: def main():# 七、验证自定义数据集# 验证需要一些辅助函数,用visdom做一些可视化。import visdomimport timeimport torchvision # 通过API较为简便的加载自定义数据集,需要引入torchvision# 创建一个visdom这个对象viz = visdom.Visdom()# 十一、通过API较为简便的加载自定义数据集(前提是数据集按照不同类型存储在对应类型命名的文件夹下面,并且这些不同类别的文件夹都存储在统一的一个文件夹下,只有这种固定的二级目录存储形式才能用这个API进行加载。)tf = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()])# 参数1:传入路径# 参数2:变换器,这个变换器就是进行resize操作db = torchvision.datasets.ImageFolder(root='F:\\train', transform=tf)loader = DataLoader(db, batch_size=32, shuffle=True)print(db.class_to_idx) # 通过这个就能知道不同类别是如何编码的了。if __name__ == '__main__':main()将上面代码修改即可;
四,模型训练;
这里我们需要用到可视化工具来查看我们训练效果。
安装visdom:
pip install visdom在pycharm命令界面启动visdom:
python -m visdom.server正常启动在浏览器输入localhost:8097打开可视化界面;
准备工作完成,编写模型训练代码,这么我们直接使用Pytorch自带的神经网络resnet18模型;
import torch from torch import optim, nn import visdom import torchvision from torch.utils.data import DataLoaderfrom pokemon import Pokemonfrom torchvision.models import resnet18 # 这个resnet18是已经training好的状态from utils import Flatten # 用于打平,这个是自己来实现的打平层batchsz = 32 lr = 1e-3 epochs = 40device = torch.device('cuda') torch.manual_seed(1234) # 这个是随机数种子,保证每次都能复现出来。# 这里是需要实例化Pokemon类 # 这里之所以使用224,是因为是ResNet最适合的大小。 train_db = Pokemon('F:\\train', 224, 'train') val_db = Pokemon('F:\\train', 224, 'val') test_db = Pokemon('F:\\train', 224, 'test')# 批量加载数据 # 参数num_workers表示工作线程数: train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True, num_workers=4)val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)# 需要把train的进度保存下来,需要用到visdom viz = visdom.Visdom()# 建立一个测试函数:测试函数针对validation和test功能是一样的 def evalute(model, loader):# 用于统计总的预测正确的数量correct = 0# 总的测试数量total = len(loader.dataset)for x, y in loader:x, y = x.to(device), y.to(device)with torch.no_grad(): # test和validation是不需要梯度信息的logits = model(x)pred = logits.argmax(dim=1) # 最大的值所在的位置# 总的预测正确的数量,累加操作correct += torch.eq(pred, y).sum().float().item()accuracy = correct / totalreturn accuracydef main():# 实例化模型# 使用已经训练好的resnet18模型,一定要设置这个参数pretrained=Truetrained_model = resnet18(pretrained=True)# 我们要使用训练好的resnet18模型的A部分,即取出前17层:# Sequential结束的是一个打散的数据,所有我们在list前加一个*,*args:接收若干个位置参数,转换成元组tuple形式。model = nn.Sequential(*list(trained_model.children())[:-1] # model的前17层(即A部分)返回的结果是:[b,512,1,1], Flatten() # 打平操作从[b,512,1,1]=>[b,512], nn.Linear(512, 14) # 这层是最后那层,用于从新学习分成14类。(第二个参数为自定义数据集实际训练种类数量,根据自己数据集的种类数据传递实际值)).to(device)# 我们从已经训练好的resnet18开始训练效果会好很多# # 这里我们测试一下# x = torch.randn(2,3,224,224)# print(model(x).shape)#打印结果为:torch.Size([2, 5])# #这样就实现了transfer learning# ======================================================# 创建一个优化器Adam,这个优化器比较好optimizer = optim.Adam(model.parameters(), lr=lr)# Loss的计算方法:CrossEntropyLoss;# 这个Loss所接受的参数是logits,logits是不需要经过一个softmax的,只需要得到logits即可。criteon = nn.CrossEntropyLoss()# 用于保存模型的训练状态best_acc, best_epoch = 0, 0# step每次都是从0开始的,因此这里我们创建一个全局stepglobal_step = 0# 用visdom工具保存下accuracy和loss# training和loss的曲线# x=0,y=-1是初始状态viz.line([0], [-1], win='loss', opts=dict(title='loss(损失值)'))# training和validation accuracy的曲线viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc(准确率)'))# training逻辑for epoch in range(epochs):for step, (x, y) in enumerate(train_loader):# x:[b,3,224,224]; y:[b]x, y = x.to(device), y.to(device) # x和y都转移到cuda上面# 执行forward函数logits = model(x) # 学出的预测结果# 在pytorch中crossEntropyLoss中,传入的真实值y不需要进行one-hot操作,不需要做one-hot编码,会在内部做one-hot。# 所以我们直接传入y就可以了。loss = criteon(logits, y) # 预测结果与真实值进行交叉熵计算# 前向传播和迭代过程# 优化器optimizer.zero_grad()loss.backward()optimizer.step()# 用visdom工具保存下accuracy和loss# 每一个step我都要记录下来# validation和loss的曲线# x=loss.item()loss是一个tensor,因此需要通过item转为具体数值,y=-1是初始状态# 参数update为append,表示添加到曲线的末尾。viz.line([loss.item()], [global_step], win='loss', update='append')global_step += 1# 这里我们每完成两个epoch就做一组validationif epoch % 1 == 0:# 我们根据validation accuracy来选择要不要保存这个模型的训练状态。val_acc = evalute(model, val_loader)# 如果当前accuracy大于best_acc,就保存当前的状态:if val_acc > best_acc:best_epoch = epochbest_acc = val_acc# 保存当前模型的状态:# 参数一:模型状态值# 参数二:模型状态保存的文件名,文件名后缀随意torch.save(model, 'best-pro.pth')# validation和 accuracy的曲线# 这里val_acc是数值型,所以不需要转换。viz.line([val_acc], [global_step], win='val_acc', update='append')print('best acc:', best_acc, 'best epoch:', best_epoch)# 从最好的状态加载模型:# model.load_state_dict(torch.load('best-pro.ptl'))# print('loaded from check point!')## # 上面加载了最好的模型状态,这里使用的模型也是最好的状态时的模型# test_acc = evalute(model, test_loader)# print('test_acc:', test_acc)if __name__ == '__main__':main()这里我们用到了一个util:
from matplotlib import pyplot as plt import torch from torch import nn# 该函数是一个标准的打平层 class Flatten(nn.Module):# 该文件utils包含一些辅助函数。def __init__(self):super(Flatten, self).__init__()def forward(self, x):shape = torch.prod(torch.tensor(x.shape[1:])).item()return x.view(-1, shape)# 该函数是将img打印到matplotlib上 def plot_image(img, label, name):fig = plt.figure()for i in range(6):plt.subplot(2, 3, i + 1)plt.tight_layout()plt.imshow(img[i][0] * 0.3081 + 0.1307, cmap='gray', interpolation='none')plt.title("{}: {}".format(name, label[i].item()))plt.xticks([])plt.yticks([])plt.show()运行函数打开可视化界面,查看训练情况;
刚开始训练的情况,使用数据量大概1.6w张最终结果大概是准确率96%。已经非常好了。


五,模型验证;
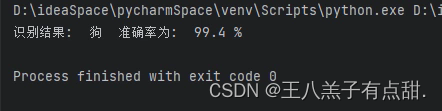
import numpy as np import torch import torch.nn.functional as F import torchvision.transforms as transforms from PIL import Imagedevice = torch.device('cuda')def main():labels = ['兔子', '吊兰', '文竹', '月季', '枸骨', '狗', '狮子', '猫', '绿萝', '老虎', '菊花', '蛇', '迎春花', '龟背竹']image_path = "C:/Users/LENOVO/Desktop/dog.png"image = Image.open(image_path)image = image.resize((256, 256), Image.BILINEAR).convert("RGB")image = np.array(image)to_tensor = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])image = to_tensor(image)image = torch.unsqueeze(image, 0)image = image.cuda()model = torch.load("刚才训练好的模型")model.eval()model.to(device)output = model(image)output1 = F.softmax(output, dim=1)predicted = torch.max(output1, dim=1)[1].cpu().item()outputs2 = output1.squeeze(0)confidence = outputs2[predicted].item()confidence = round(confidence, 3)print("识别结果: ", labels[predicted], " 准确率为: ", confidence * 100, "%")if __name__ == '__main__':main()测试图片:
labels为我们训练的类别数组,和cvs的索引对应。

多次测试结果全对,准确率不低于95%。
相关文章:
Pytorch目标分类深度学习自定义数据集训练
目录 一,Pytorch简介; 二,环境配置; 三,自定义数据集; 四,模型训练; 五,模型验证; 一,Pytorch简介; PyTorch是一个开源的Python机…...

2023 年 Web 安全最详细学习路线指南,从入门到入职(含书籍、工具包)【建议收藏】
第一个方向:安全研发 你可以把网络安全理解成电商行业、教育行业等其他行业一样,每个行业都有自己的软件研发,网络安全作为一个行业也不例外,不同的是这个行业的研发就是开发与网络安全业务相关的软件。 既然如此,那其…...
qt常用控件1
QLabel QLabel用于显示文本或图像。不提供用户交互功能。标签的视觉外观可以通过多种方式进行配置,并且可用于为另一个小组件指定焦点助记键。 常用API介绍: 获取对应的文本信息: 设置对其方式: 设置能否进行换行 获取及设置标…...

想提高网站访问速度?CDN加速了解下
随着数字时代的到来,网站已成为企业展示自身实力和吸引目标受众的关键平台之一。然而,网站的成功与否往往取决于一个关键因素 - 速度。网站访问速度的快慢不仅影响用户体验,还对搜索引擎排名和转化率产生深远的影响。因此,网站加速…...

验证回文串[简单]
优质博文:IT-BLO-CN 一、题目 如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个回文串。 字母和数字都属于字母数字字符。 给你一个字符串s,如果它是回文串࿰…...

Golang编译生成可执行程序的三种方法
目录 前言 正文 方法一、 方法二、 方法三、 结尾 前言 Golang是一种强类型、编译型、跨平台的编程语言,相同代码在不同平台上都可以编译出对应的可执行程序。今天就来简单介绍一下如何使用命令编译出可执行程序,本文以windows平台为例进行介绍。 …...

LabVIEW使用机器学习分类模型探索基于技能课程的学习
LabVIEW使用机器学习分类模型探索基于技能课程的学习 教育中的学习评估对教育工作者来说是一项繁琐的工作,但评估的好处是显着的。由于其开放性和复杂性,使用传统的评估方法为学生提供及时的支持一直具有挑战性。在Covid-19大流行期间突然转向在线学习&…...
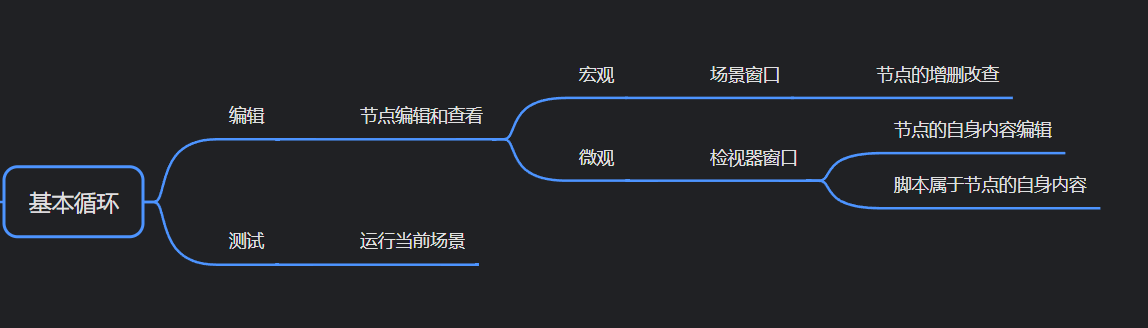
凉鞋的 Godot 笔记 103. 检视器 :节点的微观编辑和查看
在上一篇,笔者简单介绍了场景与节点的增删改查,如下所示: 在这一篇,我们接着往下学习。 我们知道在场景窗口,可以对节点进行增删改查。 在 Godot 引擎使用过程中,场景窗口的使用频率是非常高的。 但是场景窗口只能编…...

伟大不能被计划
假期清理书单,把这个书读完了,结果发现出奇的好,可以说是值得亲身去读的书,中间的一些论述提供了人工智能专业方面的视角来论证这这个通识观点,可信度很不错; 这篇blog也不是对书的总结,更多的是…...
找不到msvcp140.dll是什么意思?三个快速解决msvcp140.dll丢失问题的方法
msvcp140.dll 丢失意味着您的计算机上缺少Microsoft Visual C 2015 Redistributable中的一个动态链接库文件。msvcp140.dll是该软件包中的一个组件,许多应用程序和游戏都需要这个动态链接库文件才能正常运行。当您尝试运行需要 msvcp140.dll 的应用程序或游戏时&…...
[React源码解析] React的设计理念和源码架构 (一)
任务分割异步执行让出执法权 文章目录 1.React的设计理念1.1 Fiber1.2 Scheduler1.3 Lane1.4 代数效应 2.React的源码架构2.1 大概图示2.2 jsx2.3 Fiber双缓存2.4 scheduler2.5 Lane模型2.6 reconciler2.7 renderer2.8 concurrent 3.React源码调试 1.React的设计理念 Fiber: 即…...

[论文工具] LaTeX论文撰写常见用法及实战技巧归纳(持续更新)
祝大家中秋国庆双节快乐! 回过头来,我们在编程过程中,经常会遇到各种各样的问题。然而,很多问题都无法解决,网上夹杂着各种冗余的回答,也缺乏系统的实战技巧归纳。为更好地从事科学研究和编程学习ÿ…...

多媒体应用设计师
1.多媒体技术基础 1.1.媒体与技术 1.1.媒体 维基百科:传播信息载体 国际电信联盟(ITU-T):感知、表示、存储和传输的手段和方法。 两层含义:存储信息的实体,媒质。传递信息载体,媒介。 1.2.国…...
socket.error: [Errno 10049]错误
今天在pycharm运行rl_server_no_training.py欲启动服务器时,却出现如下错误 Traceback (most recent call last):File "xxx/rl_server_no_training.py", line 333, in <module>main()File "xxx/rl_server_no_training.py", line 326, in…...
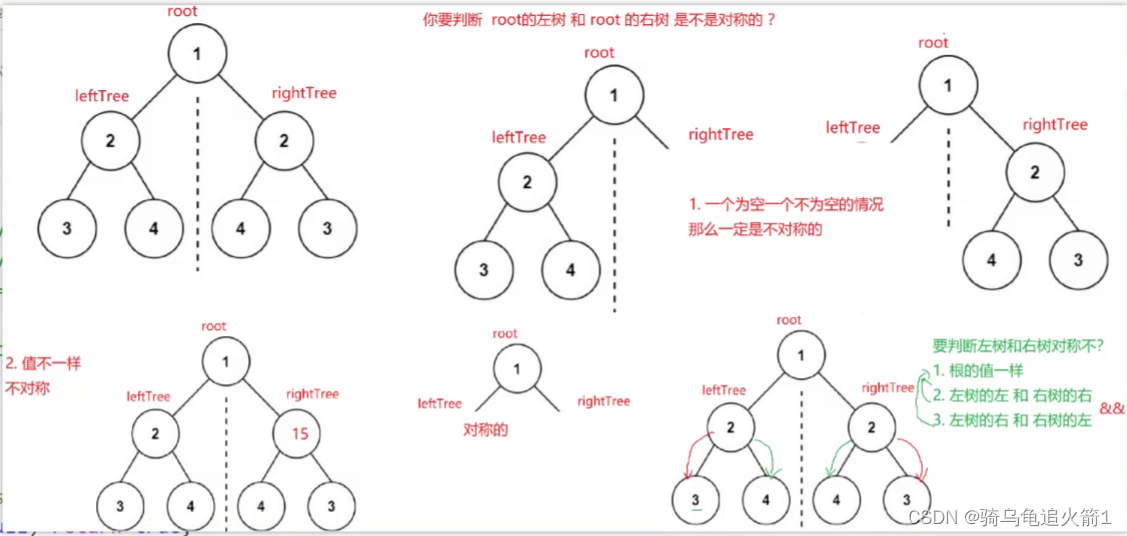
二叉树的经典OJ题
对称二叉树 1.题目2.图形分析3.代码实现 1.题目 2.图形分析 3.代码实现 class Solution {public boolean isSymmetric(TreeNode root) {if(root null){return true;}return isSymmetricchild(root.left,root.right);}private boolean isSymmetricchild(TreeNode leftTree,Tre…...
)
统一建模语言UML(1~8章在线测试参考答案)
目录 UML概述 UML概念模型 参与者和用例 用例图之间的关系 用例模型 类图中的类 类图建模 顺序图的构成 UML概述 一 单项选择题(3分) 1、关于UML描述不正确的是()。(1分) UML是由信息系统和面向对象领域三位专家Grady Booch、James Rumbaugh和Ivar Jac…...
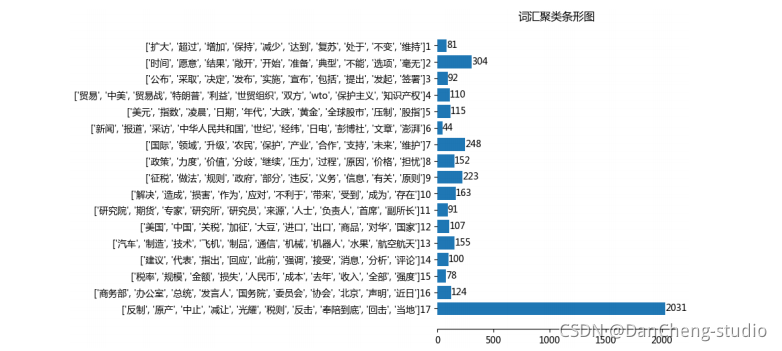
计算机竞赛 题目:基于FP-Growth的新闻挖掘算法系统的设计与实现
文章目录 0 前言1 项目背景2 算法架构3 FP-Growth算法原理3.1 FP树3.2 算法过程3.3 算法实现3.3.1 构建FP树 3.4 从FP树中挖掘频繁项集 4 系统设计展示5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于FP-Growth的新闻挖掘算法系统的设计与实现…...

String 类型的变量和常量做 “+” 运算时发生了什么?
先看看字符串不加 final 关键字拼接的情况(jdk1.8): String str1 "str" String str2 "ing" String str3 "str" "ing" String str4 str1 str2 String str5 "string" System.out.println(str3 …...

【Java互联网技术】MinIO分布式文件存储服务
应用场景 互联网海量非结构化数据的存储 基本概念 Object:存储的基本对象,如文件、字节流等 Bucket:存储Object的逻辑空间,相当于顶层文件夹 Drive:存储数据的磁盘,在MinIO启动时,以参数的…...
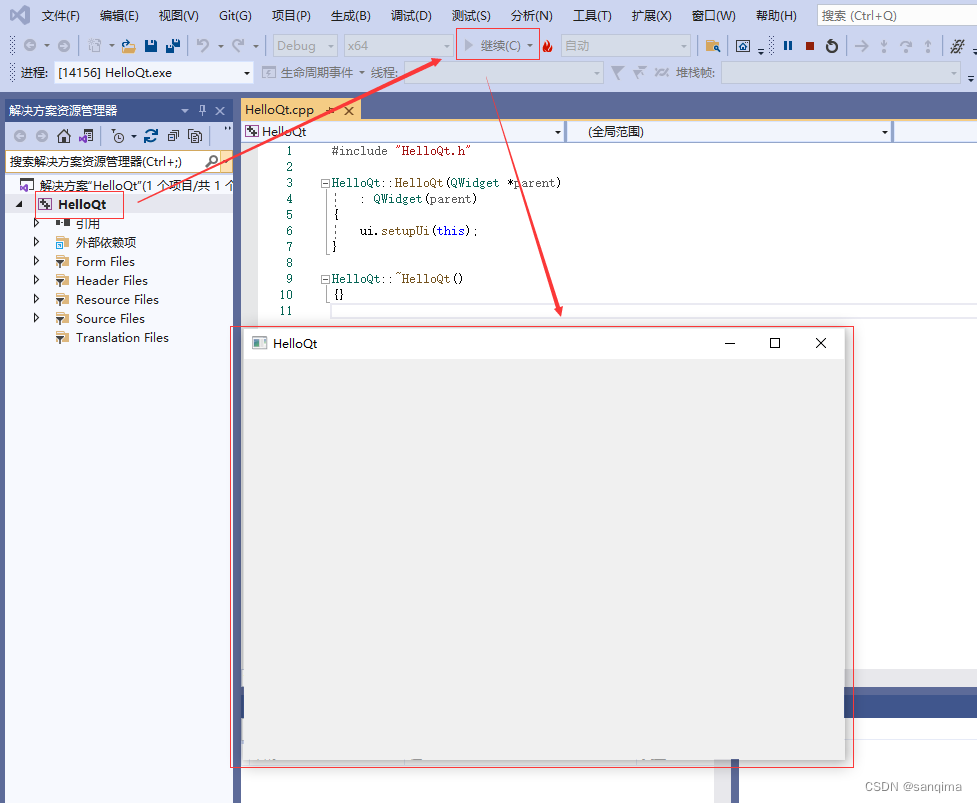
在visual studio里配置Qt插件并运行Qt工程
Qt插件,也叫qt-vsaddin,它以*.vsix后缀名结尾。visual studio简称为VS,从visual studio 2010版本开始,VS支持Qt框架的开发,Qt以插件方式集成到VS里。这里简述在visual studio 2019里配置Qt 5.14.2插件,并配…...

量子机器学习中的噪声效应与抗噪策略
1. 量子机器学习中的噪声效应全景解析在量子计算与机器学习交叉领域,噪声问题正成为制约实际应用的关键瓶颈。去年我在参与一个医疗影像分类项目时,首次亲身体验到量子噪声的破坏力——当我们将经典卷积神经网络迁移到量子变分电路架构时,准确…...

RO-ViT:区域感知预训练如何革新开放词汇目标检测
1. 项目概述:从“闭门造车”到“开箱即用”的视觉检测新范式在计算机视觉领域,目标检测一直是个硬骨头。传统的检测模型,比如我们熟悉的Faster R-CNN、YOLO系列,都遵循一个“闭集”范式:模型在训练时见过多少类物体&am…...

OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现
OpenCore Legacy Patcher深度解析:让老旧Mac重获新生的技术实现 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 对于拥有2008年至2017年Intel Mac…...

Casbin Talent 2026:高校开发者开源进阶与工业级项目实战指南
1. 项目概述:Casbin Talent 2026,一个为高校开发者量身定制的开源进阶通道如果你是一名在校大学生,对开源世界充满好奇,渴望在真实的工业级项目中打磨技术,但又觉得像Google Summer of Code(GSoC࿰…...

AsyncRun.vim 项目根目录管理:智能识别和高效利用
AsyncRun.vim 项目根目录管理:智能识别和高效利用 【免费下载链接】asyncrun.vim :rocket: Run Async Shell Commands in Vim 8.0 / NeoVim and Output to the Quickfix Window !! 项目地址: https://gitcode.com/gh_mirrors/as/asyncrun.vim AsyncRun.vim 是…...
)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析)
手把手教你用C语言实现三相锁相环(附完整源码与仿真波形分析) 在电力电子和电机控制领域,锁相环(PLL)技术是实现电网同步、逆变器控制的核心组件。传统教材往往停留在理论推导,而实际工程中,如何…...

AI Agent Harness Engineering 未来生态:开源 vs 闭源的竞争与合作格局
AI Agent Harness Engineering 未来生态:开源 vs 闭源的竞争与合作格局 引言:AI Agent不是终点,Harness才是通用智能落地的核心阀门 1.1 从“AI大模型(LLM)元年”到“AI Agent生态元年”:技术拐点的悄然发…...

晶体功率测试原理与MAX9485音频时钟应用实践
1. 晶体功率测试的背景与意义在音频时钟系统设计中,晶体振荡器的功率控制是个容易被忽视却至关重要的参数。以我们常用的MAX9485音频时钟发生器为例,其核心的VCXO(压控晶体振荡器)模块直接决定了整个系统的时钟精度。记得2013年参…...

MarkFlowy:基于智能感知的Markdown写作流工具设计与实现
1. 项目概述:一个为Markdown而生的高效写作流工具 如果你和我一样,每天的工作都离不开Markdown——写技术文档、整理项目笔记、构思博客文章,那你一定体会过那种在“专注写作”和“格式调整”之间反复横跳的痛苦。刚进入心流状态,…...

电力系统网络安全:从风险认知到威胁建模的实战指南
1. 从日常运维到风险认知:重新审视大容量电力系统的安全基线在能源行业干了十几年,我见过太多同行把大容量电力系统(Bulk Energy System, BES)的运维简化为“确保别停电”。日常的告警处理、设备巡检、工单流转构成了工作的全部叙…...