数据挖掘(3)特征化
从数据分析角度,DM分为两类,描述式数据挖掘,预测式数据挖掘。描述式数据挖掘是以简介概要的方式描述数据,并提供数据的一般性质。预测式数据挖掘分析数据建立模型并试图预测新数据集的行为。
DM的分类:
- 描述式DM:以简洁、概要的方式描述数据、提供数据的有趣的一般性质。
- 用以产生数据的特征化和比较描述:
- 特征化:提供给定数据集的简洁汇总(一个数据集)。
- 比较(区分):提供两个或多个数据集的比较描述,其中一个为主数据集,其他数据集与其进行对比分析。
- 预测式DM:分析数据,建立模型,试图预测新数据集的行为。
一、数据概化与基于汇总的特征化
1. 数据概化
- 以更一般的(而不是较低的) 抽象层描述数据。
- 将大量的相关数据从一个较低的概念层次转化到一个比较高的层次。
- 例如:把location维度上将地区概化为城市,甚至是省份
- 方法
- 数据立方体(或OLAP)方法
- 面向属性的归纳方法
2. 数据立方体(OLAP)方法
- 在数据立方体上进行计算和存储结果
- 优点:
- 数据概化的一种有效实现。
- 能计算多种不同的度量值。(count、ave、sum、min、max)
- 概化与特征分析通过一系列的数据立方体操作完成,上钻、下钻操作。

- 限制:
* 只能为 非数值类型(离散的)维产生的概念分层。
* 非数值类型:名义型、序数型(属于离散化的属性)。
* 缺乏智能分析,不能自动确定分析中该使用哪些维,概化到哪个层次。
3. 面向属性归纳(AOI)(重点)
- 前提:有大量不同的取值
- 可处理连续性数据,比数据立方体更加智能
- 基本思想:
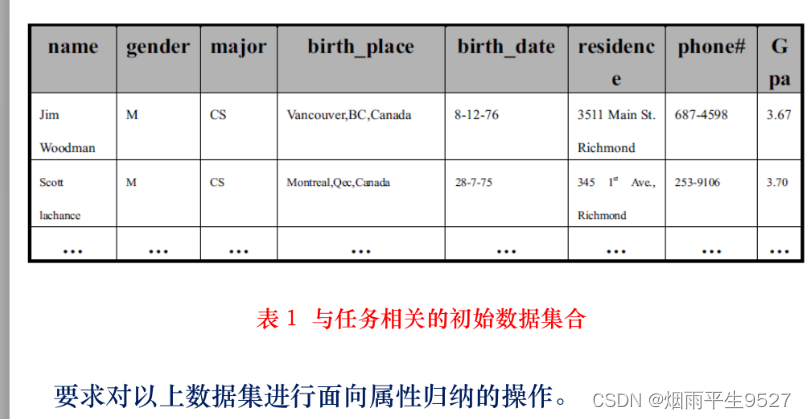
- 首先使用DB 收集任务相关的数据。
- 对每个属性的不同值的个数进行概化(属性删除、属性概化)。
- 基本思想:
- 首先使用DB 收集任务相关的数据。
- 对每个属性的不同值的个数进行概化(属性删除、属性概化)。
- 属性删除(重点)
- 一个属性有许多不同数值:且
- 该属性没有定义概化操作符(没有概念分层)。
- 一个属性拥有许多不同的数值,却没有定义对他的泛化操作。
- 或较高层概念可以用其他属性表示。
- eg:出生日期:birth_date:1995-1-1,出生日期是年龄的更高层次,可以将其表现,所以可以将birth_date删除。
- 该属性没有定义概化操作符(没有概念分层)。
- 一个属性有许多不同数值:且
- 属性概化(重点)
- 若一个属性有许多不同数值,且:在该属性上存在概化操作符(有概念分层),则应当选择该概化操作符,并逐层进行概化。
- 概化操作符:层次性,比如birth_day:年月日。
4.特征化(面向属性归纳)
两种方法:
- 属性概化阈值控制:(控制属性取值个数)
- 取值范围:[2-8]
- 属性的不同值个数大于属性概化阈值,则应当删除或概化。
- 概化层次太高,可加大阈值(属性下钻);反之,减小阈值(属性上卷)。
- 概化关系阈值控制:(控制最后的广义元组数量)
- 控制最后关系、规则的大小。(最后生成广义元组)
- 设置阈值:[10-30]
- 概化关系中不同元组的个数超过属性概化阈值,则概化。
- 概化关系太少,可加大阈值(属性下钻);反之,减小阈值(属性上卷)。
- 概化到最高层(最底层)也不满足,则需要将其删除。


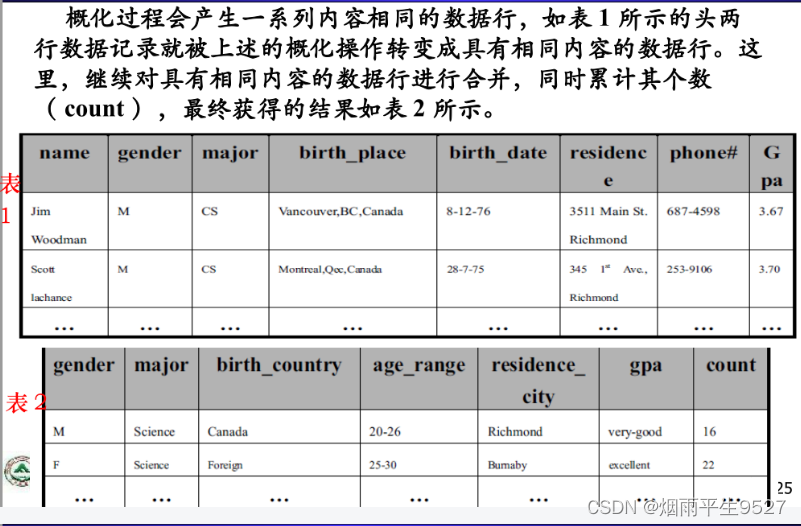
5.例子分析

二、属性相关分析(重点)
- 在处理数据中,包含很多与挖掘任务不相关或弱相关的属性,引入属性相关分析。
- 如果某个属性可以很好区分该类与其他类,则该属性是任务高度相关的。
- 在处理数据中,包含很多与挖掘任务不相关或弱相关的属性,引入属性相关分析。
- 如果某个属性可以很好区分该类与其他类,则该属性是任务高度相关的。
1. 属性相关分析法基本思想
- 基本思想:给定的数据集,计算某种度量,用于量化属性与给定的类或概念间的相关性。
- 常用的度量:信息增益、相关系数、GINI索引、不确定性
2.信息增益法(重点)
-
信息增益法:
- 决策树归纳学习算法(ID3,C4.5),删除信息量较少的属性,保留信息量较大的属性。
-
ID3算法
- 熵概念为启发函数。
-

-
熵越大、携带的信息量越大、越不容易被预测
-
- 选择具有最大信息增益的属性作为当前划分节点。
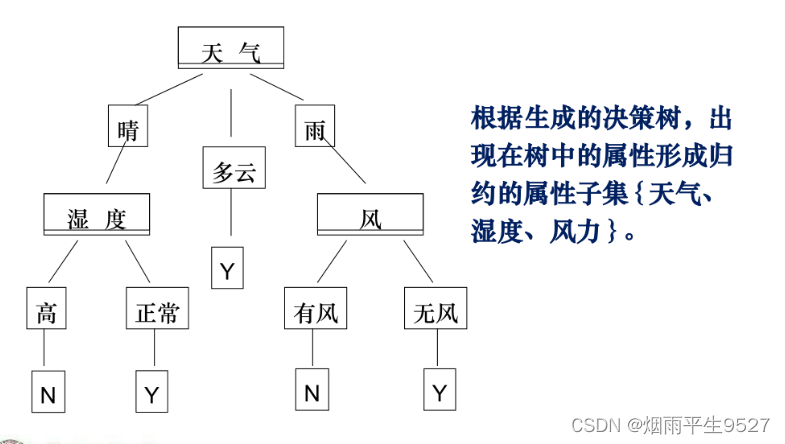
- 基本原理:
- 根据类别已知的训练数据集构造一颗决策树;根据决策树再对类别未知的数据对象进行分类。
- 每一步选择都是选择最大信息增益。
- 决策树:每个节点的选择:选择信息增益最大的属性为当前节点。
- 本步骤只是求出不确定性


- 熵概念为启发函数。
3. 通过熵来进行选择



4.属性相关分析步骤
- 数据收集:建立目标数据集,以及对比数据集,目标数据集与对比数据集不相交。
- 利用保守的AOI方法进行属性相关分析。对初始的数据集进行删除、概化等操作形成候选数据集。
- 删除不相关、弱相关的属性。如信息增益度量
- 使用AOI产生概念描述:利用更严格的属性概化控制阈值进行属性的归纳。
- 任务是:概念描述,使用初始目标数据集。
- 任务是:比较概念描述,使用初始目标数据集,对比数据集。
三、挖掘类比较:区分不同的类


- 比较概念中,同一个属性要概化到同一个层次。
- d—权
- qa所包含的Cj中数据行数与qa所涵盖的所有数据行数(包括目标数据集及所有对比数据集)之比
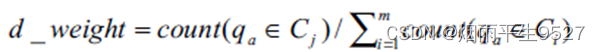
- qa所包含的Cj中数据行数与qa所涵盖的所有数据行数(包括目标数据集及所有对比数据集)之比
 四、常见的统计度量指标
四、常见的统计度量指标

- 中心趋势:均值、中位数、模(众数)
- 众数:如果每个数值仅出现1次则无众数
- 数据分布:四分位数、方差、标准差
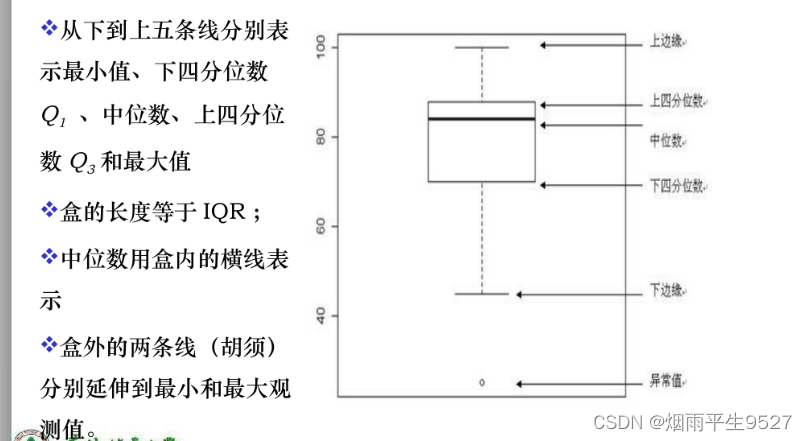
- 四分位数:
- 数值下数据集合的第k个百分位数。
- 中位数:第50个百分位数
- 第一个四分位数
第25个百分位数;第三个百分位数
:第75个百分位数
- 中间四分位区间
- 识别孤立点:

- 四分位数:
相关文章:
数据挖掘(3)特征化
从数据分析角度,DM分为两类,描述式数据挖掘,预测式数据挖掘。描述式数据挖掘是以简介概要的方式描述数据,并提供数据的一般性质。预测式数据挖掘分析数据建立模型并试图预测新数据集的行为。 DM的分类: 描述式DM&#…...
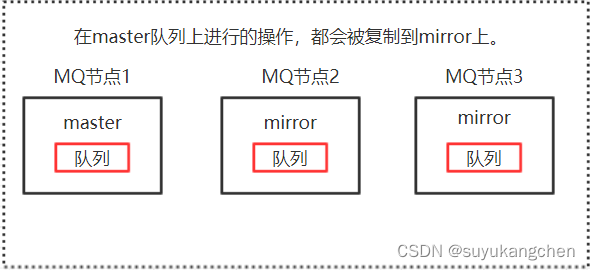
【RabbitMQ 实战】08 集群原理剖析
上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理 一、基础概念 1.1 元数据 前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息…...

2023年 2月3月 工作经历
2月 #pragma make_public(type) 托管C导出传统C类,另一个托管C项目使用不了。传统C类make_public后,就可以使用了。对模板类无效,比如:std::string。 C#线程绑定CPU 我的方案: 假定我们想把 CPU0 设置成专有CPU。 定…...

selenium京东商城爬取
该项目主要参考与:http://c.biancheng.net/python_spider/selenium-case.html 你看完上述项目内容之后,会发现京东登录是一个比较坑的点,selenium控制浏览器没有登录京东,导致我们自动爬取网页被重定向到京东登录注册页面。 因此,我们要单独…...

用pandas处理数据时,使变量能够在不同的Notebook会话页面进行传递,魔法命令%store
【需求来源】 在使用pandas时,有的时候我想将.ipynb文件分开写 其中一个写清洗数据代码另外一个写数据可视化代码 【解决方案】 但是会涉及到变量转移问题,这个时候我通常使用的方法是: 1、在清洗完数据后导出到本地 2、在文件后面增加当…...

选择适合户外篷房企业的企业云盘解决方案
“户外篷房企业用什么企业云盘好?Zoho WorkDrive企业网盘可以帮助户外篷房企业实现文档统一管理、提高工作效率、加强团队协作,并且支持各种文件类型的预览和编辑。” S公司是一家注重管理规范的大型户外篷房企业,已经有10余年的经验。作为设…...
松鼠搜索算法(SSA)(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...

折半+dp之限制转状态+状压:CF1767E
https://vjudge.net/problem/CodeForces-1767E/origin 首先40,必然折半。然后怎么做? 分析性质。每次可以走1步or2步,等价什么?等价任意相邻2个必选一个!然后就可以建图 这个图是个限制图,我们折半后可以…...

如何写出优质代码
(本文转载自其他博主但是个人忘记了出处) 优质代码是什么? 优质代码是指那些易于理解、易于维护、可读性强、结构清晰、没有冗余、运行效率高、可复用性强、稳定性好、可扩展性强的代码。 这类代码不仅能够准确执行预期功能,同时也便于其他开发者理解…...
ChatGLM2-6B的通透解析:从FlashAttention、Multi-Query Attention到GLM2的微调、源码解读
前言 本文最初和第一代ChatGLM-6B的内容汇总在一块,但为了阐述清楚FlashAttention、Multi-Query Attention等相关的原理,以及GLM2的微调、源码解读等内容,导致之前那篇文章越写越长,故特把ChatGLM2相关的内容独立抽取出来成本文 …...
3D人脸生成的论文
一、TECA 1、论文信息 2、开源情况:comming soon TECA: Text-Guided Generation and Editing of Compositional 3D AvatarsGiven a text description, our method produces a compositional 3D avatar consisting of a mesh-based face and body and NeRF-based ha…...

解决问题:可以用什么方式实现自动化部署
自动化部署可以使用多种工具来实现: 脚本编写:可以使用 Bash、Python 等编写脚本来实现自动化部署。例如,可以使用 Bash 脚本来自动安装、配置和启动应用程序。 配置管理工具:像 Ansible、Puppet、Chef、Salt 等配置管理工具可以…...

【数据结构】链表栈
目录: 链表栈 1. 链式栈的实现2. 链表栈的创建3. 压栈4. 弹栈 链表栈 栈的主要表示方式有两种,一种是顺序表示,另一种是链式表示。本文主要介绍链式表示的栈。 链栈实际上和单链表差别不大,唯一区别就在于只需要对链表限定从头…...

Android笔记:Android 组件化方案探索与思考
组件化项目,通过gradle脚本,实现module在编译期隔离,运行期按需加载,实现组件间解耦,高效单独调试。 先来一张效果图 组件化初衷 APP版本不断的迭代,新功能的不断增加,业务也会变的越来越复杂…...
MeterSphere v2.10.X-lts 双节点HA部署方案
一、MeterSphere高可用部署架构及服务器配置 1.1 服务器信息 序号应用名称操作系统要求配置要求描述1负载均衡器CentOS 7.X /RedHat 7.X2C,4G,200GB部署Nginx,实现负载路由。 部署NFS服务器。2MeterSphere应用节点1CentOS 7.X /RedHat 7.X8C,16GB,200G…...
Java进阶篇--网络编程
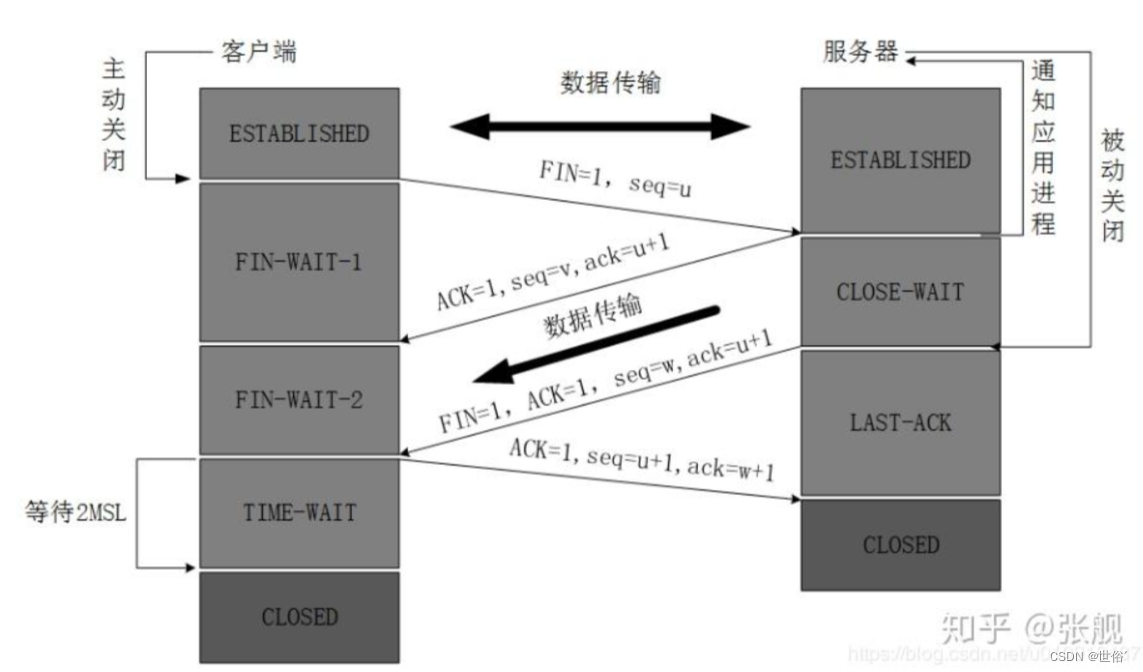
目录 计算机网络体系结构 什么是网络协议? 为什么要对网络协议分层? 网络通信协议 TCP/IP 协议族 应用层 运输层 网络层 数据链路层 物理层 TCP/IP 协议族 TCP的三次握手四次挥手 TCP报文的头部结构 三次握手 四次挥手 …...

PyTorch入门之【CNN】
参考:https://www.bilibili.com/video/BV1114y1d79e/?spm_id_from333.999.0.0&vd_source98d31d5c9db8c0021988f2c2c25a9620 书接上回的MLP故本章就不详细解释了 目录 traintest train import torch from torchvision.transforms import ToTensor from torchvi…...

马斯洛需求层次模型之安全需求之云安全浅谈
在互联网云服务领域,安全需求是用户首要考虑的因素之一。用户希望在将数据和信息托付给云服务提供商时,这些数据和信息能够得到充分的保护,避免遭受未经授权的访问、泄露或破坏。这种安全需求的满足,对于用户来说是至关重要的&…...
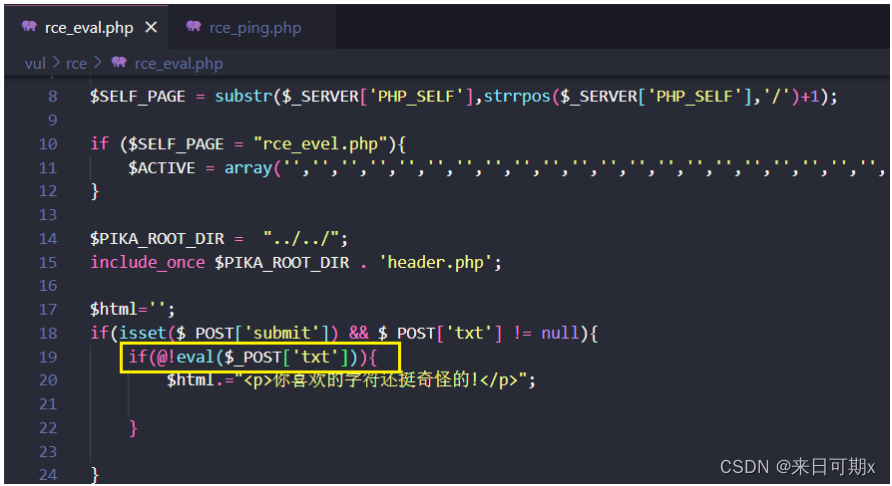
Pikachu靶场——远程命令执行漏洞(RCE)
文章目录 1. RCE1.1 exec "ping"1.1.1 源代码分析1.1.2 漏洞防御 1.2 exec "eval"1.2.1 源代码分析1.2.2 漏洞防御 1.3 RCE 漏洞防御 1. RCE RCE(remote command/code execute)概述: RCE漏洞,可以让攻击者直接向后台服务器远程注入…...
【WSN】无线传感器网络 X-Y 坐标到图形视图和位字符串前缀嵌入方法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

别再只玩开发板了!用吃灰的STM32核心板DIY一个专属游戏手柄,实战HID协议
从零构建STM32游戏手柄:深入解析HID协议与实战开发 你是否曾盯着抽屉里积灰的STM32核心板思考它能做什么?与其重复点亮LED的基础实验,不如挑战一个既实用又有趣的项目——打造专属游戏手柄。这不仅能让硬件资源重获新生,更是深入理…...

VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案
VRM-VRChat双向转换引擎:打破虚拟角色平台壁垒的技术解决方案 【免费下载链接】VRMConverterForVRChat 项目地址: https://gitcode.com/gh_mirrors/vr/VRMConverterForVRChat VRM格式转换、VRChat SDK3兼容、Unity编辑器扩展、虚拟角色迁移、跨平台角色转换…...

工业物联网长距离蓝牙环境监测方案解析
1. 项目概述在工业物联网和远程环境监测领域,如何实现低功耗、长距离的数据传输一直是个技术难点。传统蓝牙技术受限于通信距离(通常10米以内),而Wi-Fi方案又面临功耗过高的问题。最近我在一个工厂环境监测项目中,成功…...

团队知识管理的失效:人员流动如何不导致知识流失
一、软件测试团队知识管理的特殊价值与脆弱性在软件测试领域,知识是保障产品质量的核心资产。不同于开发环节的代码沉淀,测试知识兼具显性与隐性双重属性:显性知识体现在测试用例、缺陷报告、自动化脚本等文档中,而隐性知识则蕴含…...

从‘一个材质’到‘上百个Shader’:用UE4材质实例化彻底搞懂Static Switch的代价与正确用法
从‘一个材质’到‘上百个Shader’:UE4材质实例化中Static Switch的陷阱与优化实践 在Unreal Engine 4的材质创作中,Static Switch Parameter(静态开关参数)就像一把双刃剑——它能让美术师快速切换不同材质效果,却也暗…...

为什么83%的Enterprise客户在第6个月触发License超额预警?揭秘后台用量监控盲区与动态配额优化公式
更多请点击: https://intelliparadigm.com 第一章:License超额预警现象的全局观测与根本归因 License超额预警并非孤立事件,而是软件许可治理体系中多维耦合失衡的外在表征。在企业级 DevOps 平台(如 GitLab Ultimate、JetBrains…...

Honey Select 2终极优化指南:HS2-HF Patch完整解决方案
Honey Select 2终极优化指南:HS2-HF Patch完整解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是专为《Honey Select 2》游戏设…...
)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查)
从PCB走线到天线:手把手教你搞定Sx1262射频前端阻抗匹配(附常见错误排查) 在LoRa终端硬件开发中,射频前端的阻抗匹配往往是决定通信质量的关键因素。许多工程师在完成Sx1262芯片外围电路设计后,常会遇到通信距离不理想…...

智能设备语音交互进阶:从‘慢交互’到‘快交互’,详解ONESHOT模式下的音频残留音过滤实战
智能设备语音交互进阶:ONESHOT模式下的音频残留音过滤实战 在智能语音交互领域,ONESHOT模式已经成为提升用户体验的关键技术。这种允许用户在唤醒设备后无需二次唤醒即可直接下达指令的交互方式,正在重塑人机对话的自然流畅度。然而ÿ…...

Ubuntu16.04高效桌面管理全攻略:多工作区、分屏与终端Terminator进阶技巧
1. Ubuntu16.04多工作区高效管理 刚接触Ubuntu时,最让我惊喜的功能就是多工作区。这个功能相当于给你的电脑桌面"扩容",把不同任务分散到不同虚拟桌面,再也不用在一堆窗口里来回切换了。在Ubuntu16.04上设置多工作区特别简单&#…...