Pytorch笔记之分类
文章目录
- 前言
- 一、导入库
- 二、数据处理
- 三、构建模型
- 四、迭代训练
- 五、模型评估
- 总结
前言
使用Pytorch进行MNIST分类,使用TensorDataset与DataLoader封装、加载本地数据集。
一、导入库
import numpy as np
import torch
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader # 数据集工具
from load_mnist import load_mnist # 本地数据集
二、数据处理
1、导入本地数据集,将标签值设置为int类型,构建张量
2、使用TensorDataset与DataLoader封装训练集与测试集
# 构建数据
x_train, y_train, x_test, y_test = \load_mnist(normalize=True, flatten=False, one_hot_label=False)
# 数据处理
x_train = torch.from_numpy(x_train.astype(np.float32))
y_train = torch.from_numpy(y_train.astype(np.int64))
x_test = torch.from_numpy(x_test.astype(np.float32))
y_test = torch.from_numpy(y_test.astype(np.int64))
# 数据集封装
train_dataset = TensorDataset(x_train, y_train)
test_dataset = TensorDataset(x_test, y_test)
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)三、构建模型
输入到全连接层之前需要把(batch_size,28,28)展平为(batch_size,784)
交叉熵损失函数整合了Softmax,在模型中可以不添加Softmax
# 继承模型
class FC(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 10)self.softmax = nn.Softmax(dim=1)def forward(self, x):y = self.fc1(x.view(x.shape[0],-1))y = self.softmax(y)return y
# 定义模型
model = FC()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)四、迭代训练
从DataLoader中取出x和y,进行前向和反向的计算
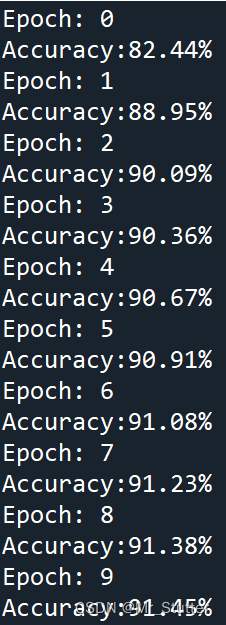
for epoch in range(10):print('Epoch:', epoch)for i,data in enumerate(train_loader):x, y = datay_pred = model.forward(x)loss = loss_function(y_pred, y)optimizer.zero_grad()loss.backward()optimizer.step()五、模型评估
在测试集中进行验证
使用.item()获得tensor的取值
correct = 0for i,data in enumerate(test_loader):x, y = datay_pred = model.forward(x)_, y_pred = torch.max(y_pred, 1)correct += (y_pred == y).sum().item()acc = correct / len(test_dataset)print('Accuracy:{:.2%}'.format(acc))
总结
记录了TensorDataset与DataLoader的使用方法,模型的构建与训练和上一篇Pytorch笔记之回归相似。
相关文章:
Pytorch笔记之分类
文章目录 前言一、导入库二、数据处理三、构建模型四、迭代训练五、模型评估总结 前言 使用Pytorch进行MNIST分类,使用TensorDataset与DataLoader封装、加载本地数据集。 一、导入库 import numpy as np import torch from torch import nn, optim from torch.uti…...
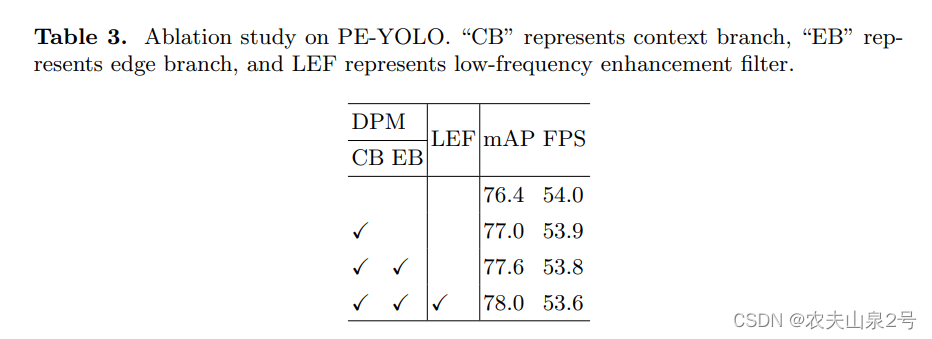
【目标检测】——PE-YOLO精读
yolo,暗光目标检测 论文:PE-YOLO 1. 简介 卷积神经网络(CNNs)在近年来如何推动了物体检测的发展。许多检测器已经被提出,而且在许多基准数据集上的性能正在不断提高。然而,大多数现有的检测器都是在正常条…...

Java 数组转集合
数组转集合 如果仅仅这样转化Arrays.asList(数组),导致集合只能查询,无法进行其他操作,因此,对该方法进行优化: List<实体> list1 new ArrayList<>(Arrays.asList(数组))以上方法就可以使用集合的所有操…...
Elasticsearch:ES|QL 查询语言简介
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。 Elastic 将尽最大努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。在目前的 Elastic Stack 8.10 中此功能还没有提供。 Elasticsearch 查询语言 (ES|…...

qt qml中listview出现卡顿情况时的常用处理方法
如果在qt QML中使用ListView时出现卡顿情况,可能是因为渲染大量的数据或者在模型中进行复杂的数据处理。以下是常用的解决方法: 1. 设置ListView的缓存策略:通过设置ListView的cacheBuffer属性为适当的值,可以提高滚动的流畅性。…...

Elasticsearch基础操作演示总结
一、索引操作 (一)创建索引 创建Elasticsearch(ES)索引是在ES中存储和管理数据的重要操作之一。索引是用于组织和检索文档的结构化数据存储。 当创建Elasticsearch索引时,通常需要同时指定索引的设置(Se…...

Spring 作用域解析器AnnotationScopeMetadataResolver
博主介绍:✌全网粉丝近5W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经…...
如何发布一个 NPM 包
首先初始化: npm init 文件夹结构 .gitignore Git 库忽略文件清单.npmignore 不包括在 npm 注册库中的文件清单LECENSE 模块的授权文件README.md 说明文档bin 保存模块可执行文件的文件夹doc 保存模块文档的文件夹example 保存模块实际示例lib 保存模块代码man 保存模块的手册…...
)
Flask小项目教程(含MySQL与前端部分)
CONTENTS 1. 环境配置2. 快速搭建Flask应用程序 1. 环境配置 首先我们在项目的根目录下创建一个 Python 虚拟环境,打开命令行输入以下指令: python -m venv venv启动虚拟环境: .\venv\Scripts\Activate.ps1如果遇到报错:.\venv…...
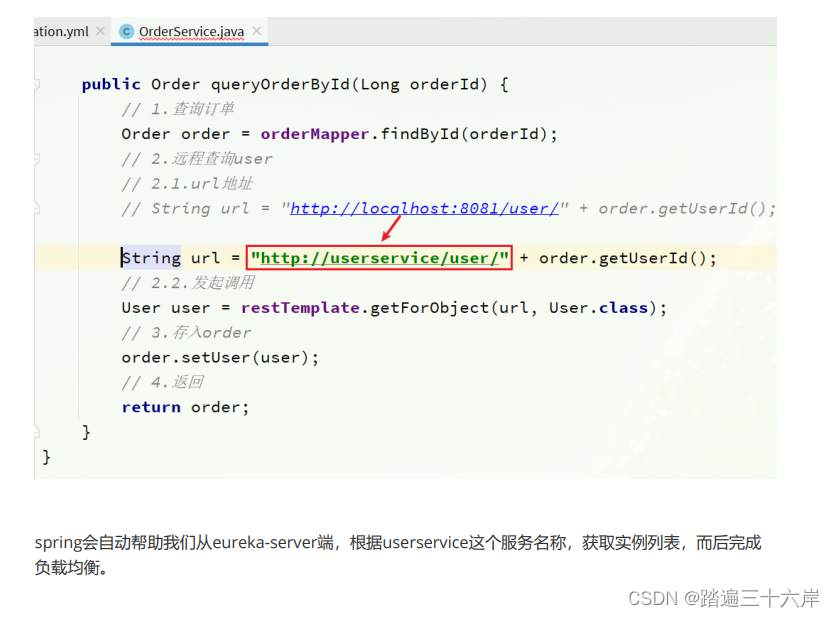
Eureka
大家好我是苏麟今天带来Eureka的使用 . 提供者和消费者 在服务调用关系中,会有两个不同的角色: 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务) 服务消费者:一次业务…...
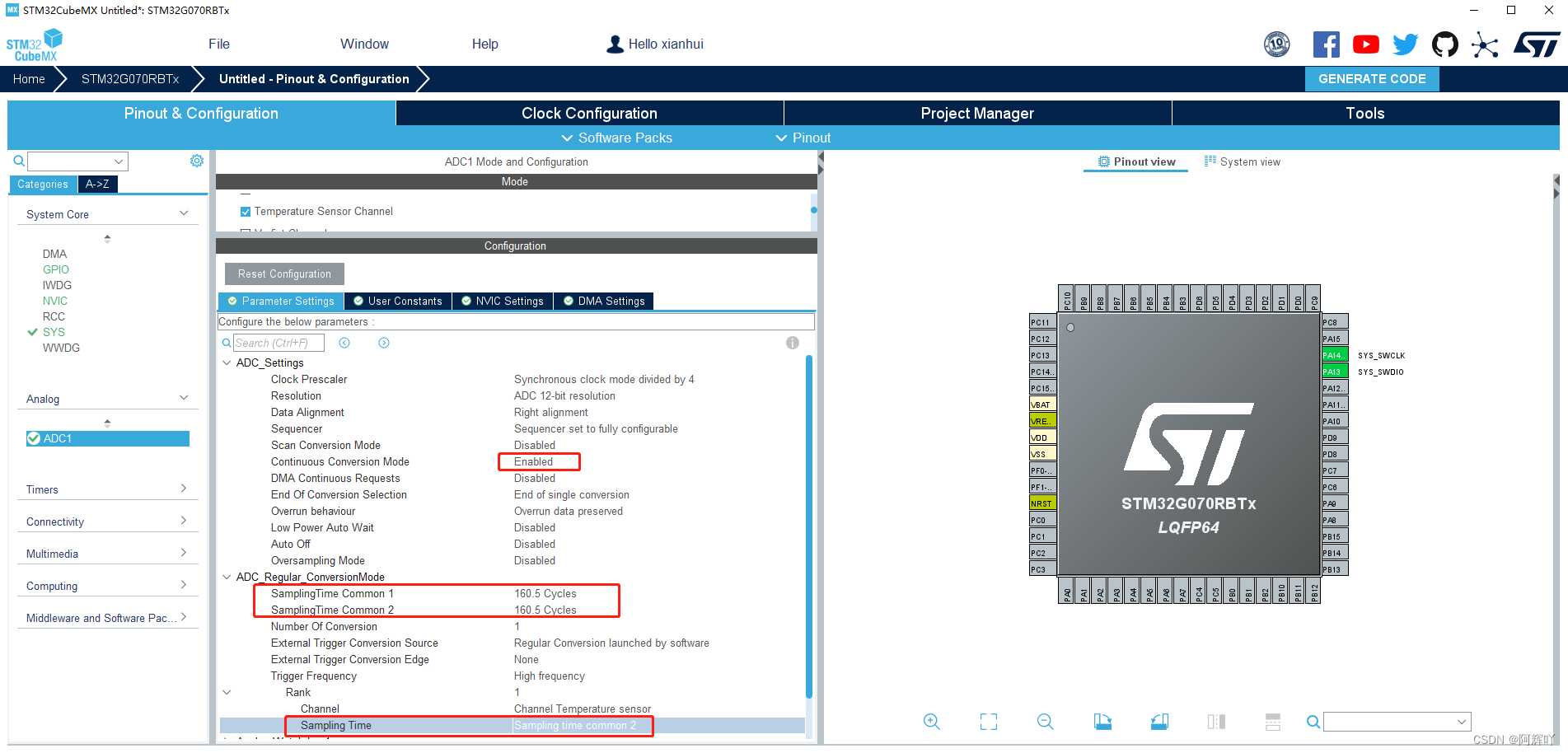
STM32G070RBT6-MCU温度测量(ADC)
1、借助STM32CubeMX生成系统及外设相关初始化代码。 在以上配置后就可以生成相关初始化代码了。 /* ADC1 init function */ void MX_ADC1_Init(void) {/* USER CODE BEGIN ADC1_Init 0 *//* USER CODE END ADC1_Init 0 */ADC_ChannelConfTypeDef sConfig {0};/* USER COD…...

数据结构之带头双向循环链表
目录 链表的分类 带头双向循环链表的实现 带头双向循环链表的结构 带头双向循环链表的结构示意图 空链表结构示意图 单结点链表结构示意图 多结点链表结构示意图 链表创建结点 双向链表初始化 销毁双向链表 打印双向链表 双向链表尾插 尾插函数测试 双向链表头插 …...

adb详细教程(四)-使用adb启动应用、关闭应用、清空应用数据、获取设备已安装应用列表
adb对于安卓移动端来说,是个非常重要的调试工具。本篇介绍常用的adb指令 文章目录 一、启动应用:adb shell am start二、使用浏览器打开指定网址:adb shell am start三、杀死应用进程adb shell am force-stop/adb shell am kill四、删除应用所…...
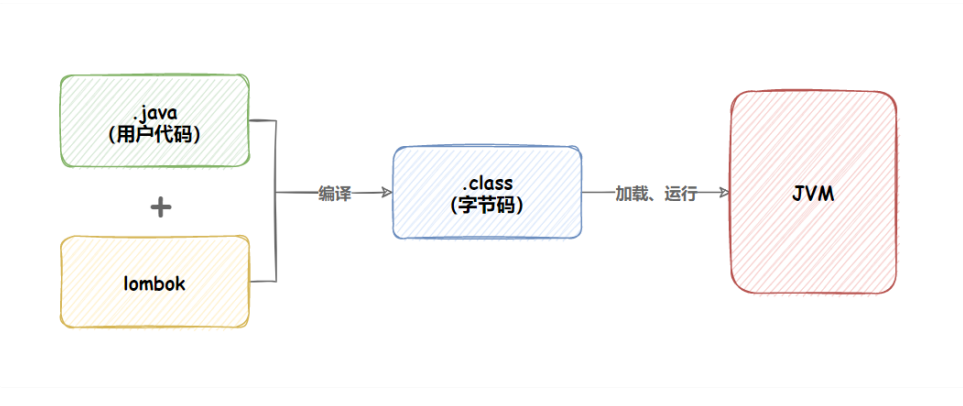
【Spring Boot】日志文件
日志文件 一. 日志文件有什么用二. 日志怎么用三. ⾃定义⽇志打印1. 在程序中得到⽇志对象2. 使⽤⽇志对象打印⽇志3. ⽇志格式说明 四. 日志级别1. ⽇志级别有什么⽤2. ⽇志级别的分类与使⽤ 五. 日志持久化六. 更简单的⽇志输出—lombok1. 添加 lombok 依赖2. 输出⽇志3. lom…...

图像处理与计算机视觉--第五章-图像分割-Canny算子
文章目录 1.边缘检测算子分类2.Canny算子核心理论2.1.Canny算子简单介绍2.2.Canny算子边缘检测指标2.3.Canny算子基本原理 3.Canny算子处理流程3.1.高斯滤波去噪声化3.2.图像梯度搜寻3.3.非极大值抑制处理3.4.双阈值边界处理3.5.边界滞后技术跟踪3.6.Canny算子边缘检测的特点 4…...
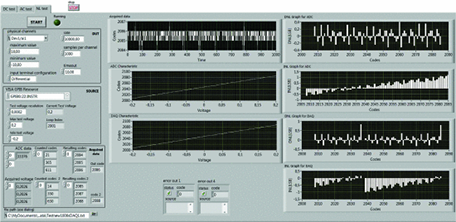
LabVIEW开发教学实验室自动化INL和DNL测试系统
LabVIEW开发教学实验室自动化INL和DNL测试系统 如今,几乎所有的测量仪器都是基于微处理器的设备。模拟输入量在进行数字处理之前被转换为数字量。对于参加电气和电子测量课程的学生来说,了解ADC以及如何欣赏其性能至关重要。ADC的不确定性可以根据其传输…...
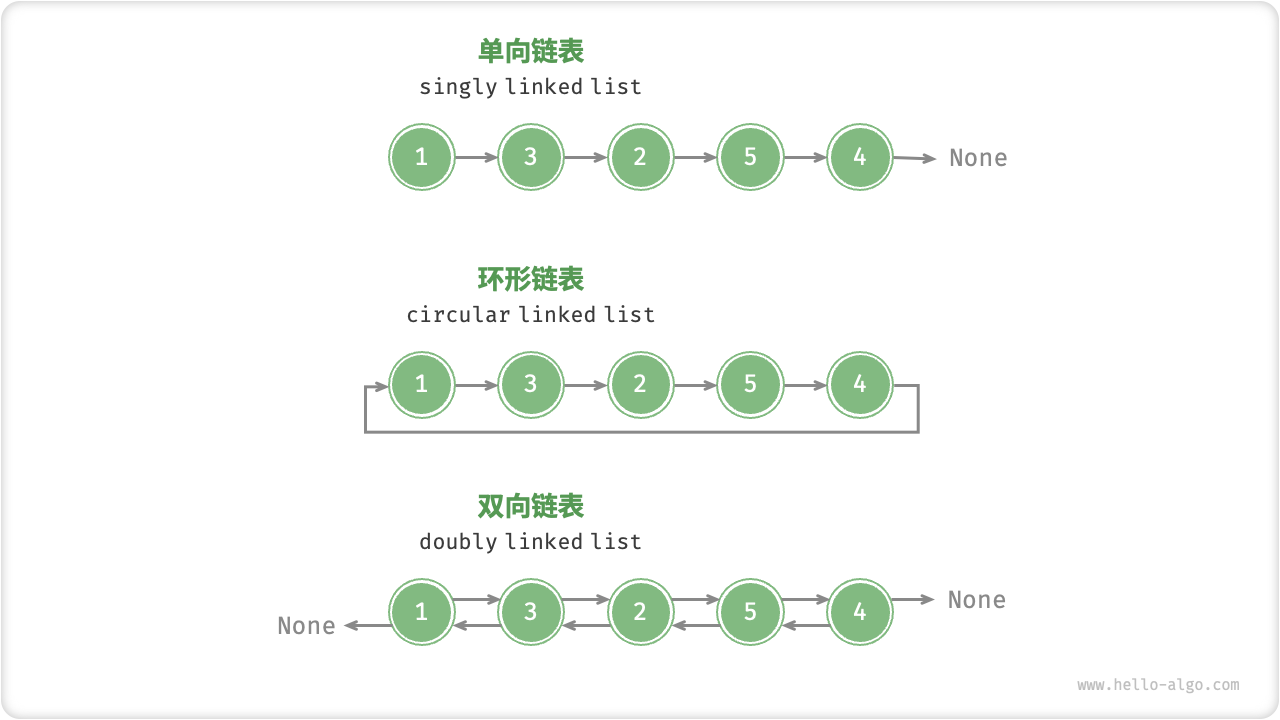
数据结构: 数组与链表
目录 1 数组 1.1 数组常用操作 1. 初始化数组 2. 访问元素 3. 插入元素 4. 删除元素 5. 遍历数组 6. 查找元素 7. 扩容数组 1.2 数组优点与局限性 1.3 数组典型应用 2 链表 2.1 链表常用操作 1. 初始化链表 2. 插入节点 3. 删除…...
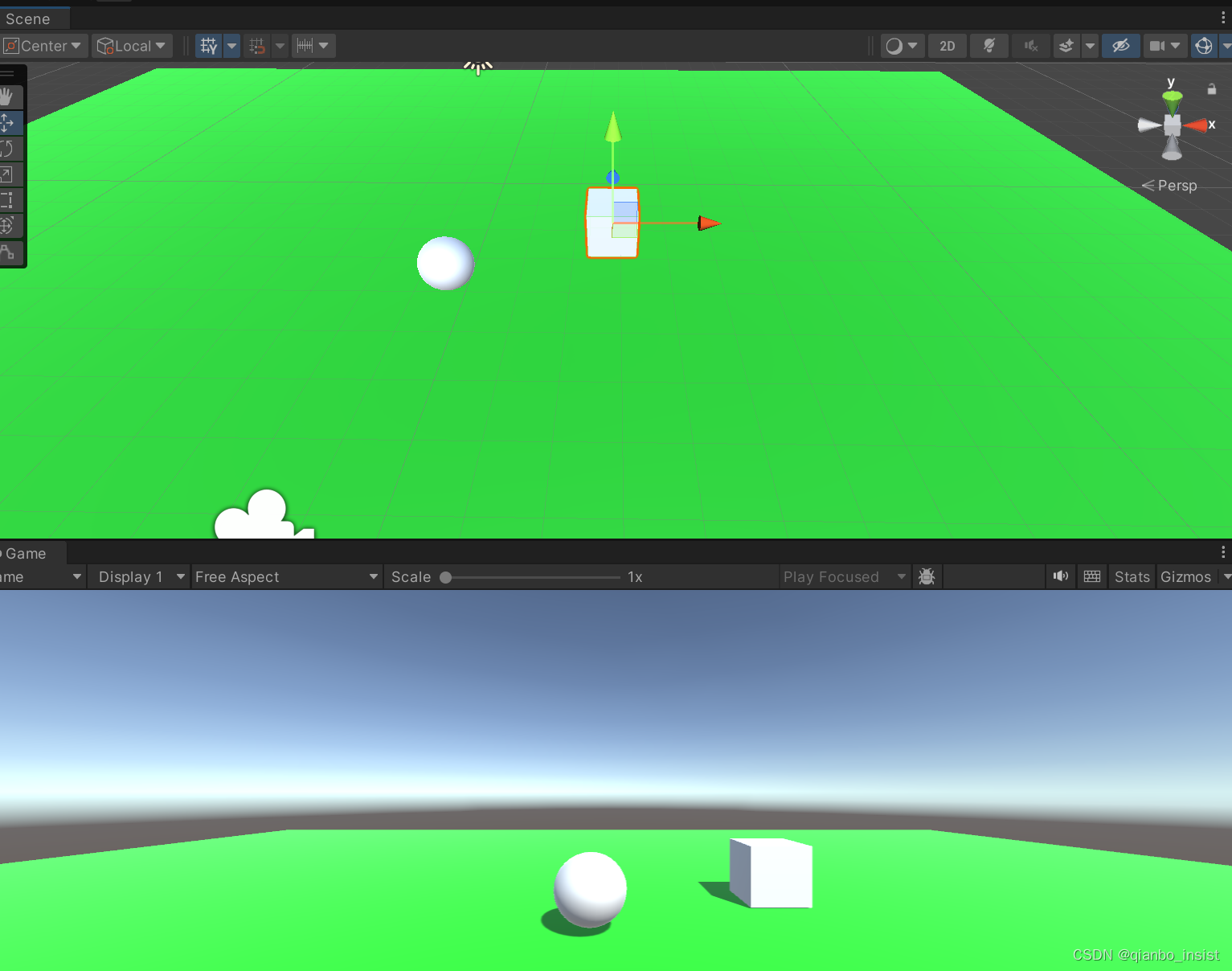
unity 控制玩家物体
创建场景 放上一个plane,放上一个球 sphere,假定我们的球就是我们的玩家,使用控制键w a s d 来控制球也就是玩家移动。增加一个材质,把颜色改成绿色,把材质赋给plane,区分我们增加的白球。 增加组件和脚…...
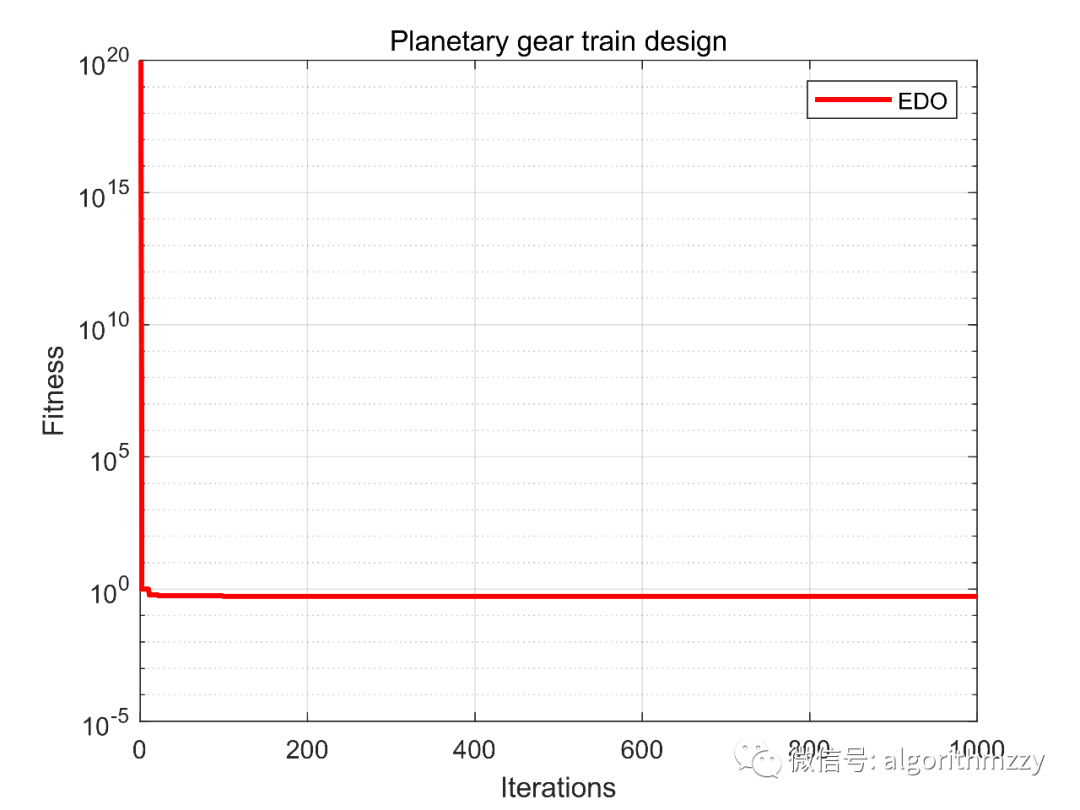
指数分布优化器(EDO)(含MATLAB代码)
先做一个声明:文章是由我的个人公众号中的推送直接复制粘贴而来,因此对智能优化算法感兴趣的朋友,可关注我的个人公众号:启发式算法讨论。我会不定期在公众号里分享不同的智能优化算法,经典的,或者是近几年…...

Java 时间的加减处理
时间的加减处理 Date date new Date(操作时间(类型Date)-(60000*60*1));600001分钟 60000*60*1 1小时...

光纤偏振测量:从琼斯矢量到庞加莱球,六种工具深度解析与工程实践
1. 从一道周五小测题说起:光纤测量中的偏振态表征上周五,我在整理旧资料时,翻到了EE Times在2015年发布的一篇“周五小测”文章,主题是光纤光学测量。其中第一道题就很有意思,它问的是:“以下哪种工具不能用…...

Windows风扇控制终极解决方案:FanControl深度配置指南
Windows风扇控制终极解决方案:FanControl深度配置指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa…...

5分钟免费解锁iPhone激活锁:applera1n终极使用指南
5分钟免费解锁iPhone激活锁:applera1n终极使用指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否刚入手了一部二手iPhone,却发现自己被困在激活锁界面无法前进…...

Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化
Notero:终极Zotero与Notion同步插件,简单快速实现文献管理一体化 【免费下载链接】notero A Zotero plugin for syncing items and notes into Notion 项目地址: https://gitcode.com/gh_mirrors/no/notero 你是否正在为文献管理与笔记整理之间的…...

【信息科学与工程学】【通信工程】第十篇 光通信工程
光通信理论基础、材料基础和算法基础分级分类表 一、理论基础 1. 电磁场理论 麦克斯韦方程组 微分形式、积分形式 本构关系 边界条件 波动方程 亥姆霍兹方程 平面波解 高斯光束 偏振光学 偏振态表示(Jones矢量,Stokes参数) 偏振演化(琼斯矩阵,穆勒矩阵) 双折射…...

路由55555555
LSW2:先进入vlan,再添加mac地址,mac地址在主机处复制(此时只添加PC1还有PC2的mac地址就好了)给G0/0/1接口配置不带标签的vlan 启动mac 地址:LSW3:设置网关,看是否能够通...

开源图表实时编辑器:从代码到可视化的无缝创作解决方案
开源图表实时编辑器:从代码到可视化的无缝创作解决方案 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-edito…...

[MTCNN]2. 级联卷积神经网络样本工程与偏移量奥秘
1. 为什么样本工程是MTCNN成功的关键 在计算机视觉领域,数据质量往往比算法本身更重要。MTCNN作为经典的人脸检测算法,其成功很大程度上依赖于精心设计的样本工程。我曾在多个实际项目中验证过,同样的网络结构,使用不同质量的训练…...

django-flask基于python实验室资产管理系统 实验室器材租赁系统
目录基于Python的实验室资产与器材租赁管理系统(Django/Flask)摘要关于博主开发技术路线相关技术介绍核心代码参考示例结论源码lw获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!基于Python的实验室资产与器材租赁管理系统…...

ROFL Player终极指南:英雄联盟回放分析工具完整使用教程
ROFL Player终极指南:英雄联盟回放分析工具完整使用教程 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟回放…...