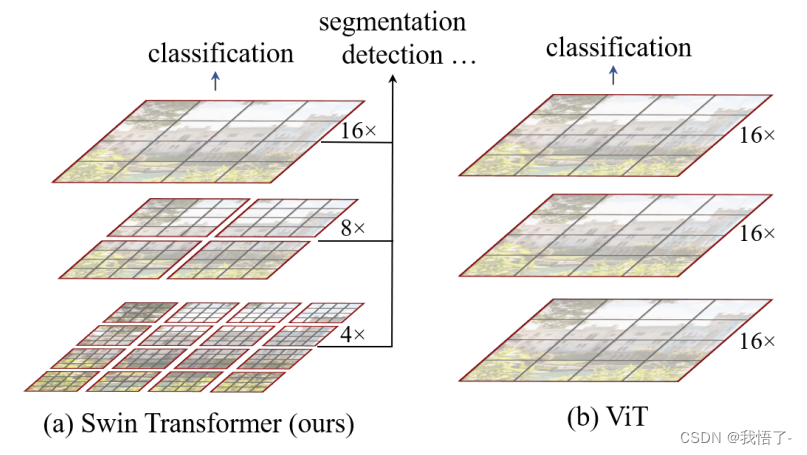
目标检测算法改进系列之Backbone替换为Swin Transformer
Swin Transformer简介
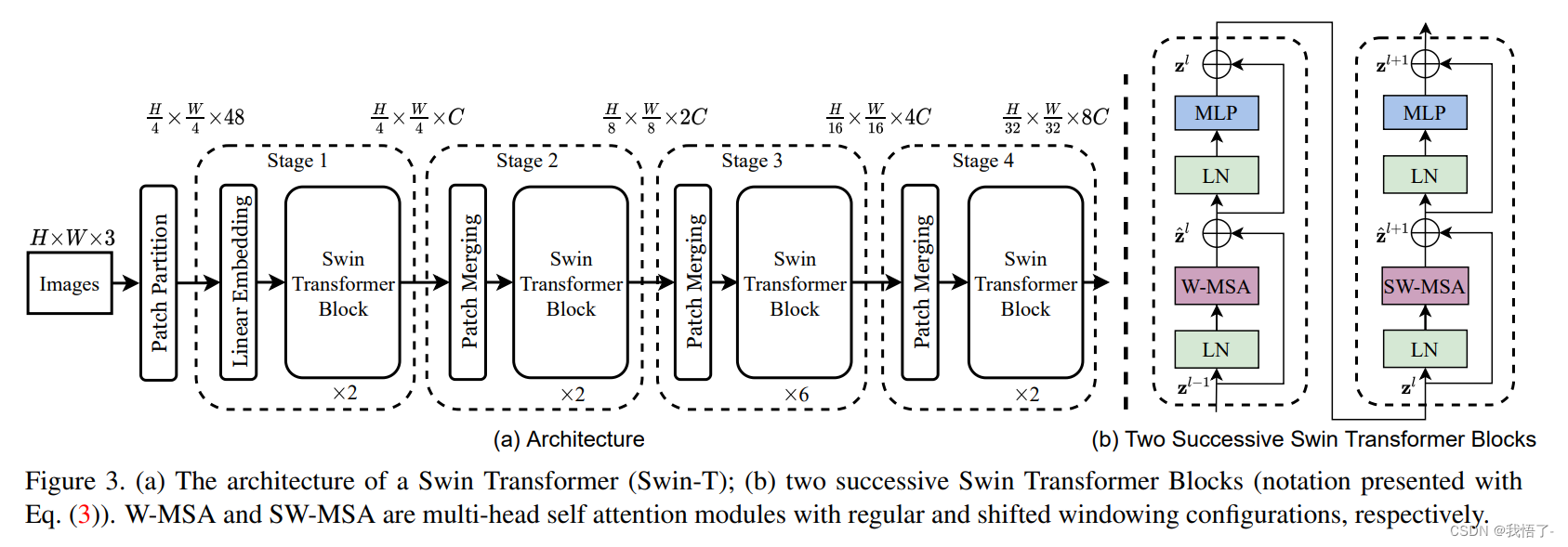
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》作为2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机视觉领域通用的backbone。它基于了ViT模型的思想,创新性的引入了滑动窗口机制,让模型能够学习到跨窗口的信息,同时也。同时通过下采样层,使得模型能够处理超分辨率的图片,节省计算量以及能够关注全局和局部的信息。而本文将从原理和代码角度详细解析Swin Transformer的架构。
目前将 Transformer 从自然语言处理领域应用到计算机视觉领域主要有两大挑战:
(1)视觉实体的方差较大,例如同一个物体,拍摄角度不同,转化为二进制后的图片就会具有很大的差异。同时在不同场景下视觉 Transformer 性能未必很好。
(2)图像分辨率高,像素点多,如果采用ViT模型,自注意力的计算量会与像素的平方成正比。针对上述两个问题,论文中提出了一种基于滑动窗口机制,具有层级设计(下采样层) 的 Swin Transformer。
其中滑窗操作包括不重叠的 local window,和重叠的 cross-window。将注意力计算限制在一个窗口(window size固定)中,一方面能引入 CNN 卷积操作的局部性,另一方面能大幅度节省计算量,它只和窗口数量成线性关系。通过下采样的层级设计,能够逐渐增大感受野,从而使得注意力机制也能够注意到全局的特征。
Swin Transformer代码实现
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu, Yutong Lin, Yixuan Wei
# --------------------------------------------------------import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import numpy as np
from timm.models.layers import DropPath, to_2tuple, trunc_normal___all__ = ['SwinTransformer_Tiny']class Mlp(nn.Module):""" Multilayer perceptron."""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xdef window_partition(x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window sizeH (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass WindowAttention(nn.Module):""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):""" Forward function.Args:x: input features with shape of (num_windows*B, N, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass SwinTransformerBlock(nn.Module):""" Swin Transformer Block.Args:dim (int): Number of input channels.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratioassert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)self.H = Noneself.W = Nonedef forward(self, x, mask_matrix):""" Forward function.Args:x: Input feature, tensor size (B, H*W, C).H, W: Spatial resolution of the input feature.mask_matrix: Attention mask for cyclic shift."""B, L, C = x.shapeH, W = self.H, self.Wassert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# pad feature maps to multiples of window sizepad_l = pad_t = 0pad_r = (self.window_size - W % self.window_size) % self.window_sizepad_b = (self.window_size - H % self.window_size) % self.window_sizex = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))_, Hp, Wp, _ = x.shape# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))attn_mask = mask_matrix.type(x.dtype)else:shifted_x = xattn_mask = None# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xif pad_r > 0 or pad_b > 0:x = x[:, :H, :W, :].contiguous()x = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass PatchMerging(nn.Module):""" Patch Merging LayerArgs:dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, norm_layer=nn.LayerNorm):super().__init__()self.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x, H, W):""" Forward function.Args:x: Input feature, tensor size (B, H*W, C).H, W: Spatial resolution of the input feature."""B, L, C = x.shapeassert L == H * W, "input feature has wrong size"x = x.view(B, H, W, C)# paddingpad_input = (H % 2 == 1) or (W % 2 == 1)if pad_input:x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 Cx1 = x[:, 1::2, 0::2, :] # B H/2 W/2 Cx2 = x[:, 0::2, 1::2, :] # B H/2 W/2 Cx3 = x[:, 1::2, 1::2, :] # B H/2 W/2 Cx = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*Cx = x.view(B, -1, 4 * C) # B H/2*W/2 4*Cx = self.norm(x)x = self.reduction(x)return xclass BasicLayer(nn.Module):""" A basic Swin Transformer layer for one stage.Args:dim (int): Number of feature channelsdepth (int): Depths of this stage.num_heads (int): Number of attention head.window_size (int): Local window size. Default: 7.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self,dim,depth,num_heads,window_size=7,mlp_ratio=4.,qkv_bias=True,qk_scale=None,drop=0.,attn_drop=0.,drop_path=0.,norm_layer=nn.LayerNorm,downsample=None,use_checkpoint=False):super().__init__()self.window_size = window_sizeself.shift_size = window_size // 2self.depth = depthself.use_checkpoint = use_checkpoint# build blocksself.blocks = nn.ModuleList([SwinTransformerBlock(dim=dim,num_heads=num_heads,window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,qk_scale=qk_scale,drop=drop,attn_drop=attn_drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer)for i in range(depth)])# patch merging layerif downsample is not None:self.downsample = downsample(dim=dim, norm_layer=norm_layer)else:self.downsample = Nonedef forward(self, x, H, W):""" Forward function.Args:x: Input feature, tensor size (B, H*W, C).H, W: Spatial resolution of the input feature."""# calculate attention mask for SW-MSAHp = int(np.ceil(H / self.window_size)) * self.window_sizeWp = int(np.ceil(W / self.window_size)) * self.window_sizeimg_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # 1 Hp Wp 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))for blk in self.blocks:blk.H, blk.W = H, Wif self.use_checkpoint:x = checkpoint.checkpoint(blk, x, attn_mask)else:x = blk(x, attn_mask)if self.downsample is not None:x_down = self.downsample(x, H, W)Wh, Ww = (H + 1) // 2, (W + 1) // 2return x, H, W, x_down, Wh, Wwelse:return x, H, W, x, H, Wclass PatchEmbed(nn.Module):""" Image to Patch EmbeddingArgs:patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):super().__init__()patch_size = to_2tuple(patch_size)self.patch_size = patch_sizeself.in_chans = in_chansself.embed_dim = embed_dimself.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):"""Forward function."""# padding_, _, H, W = x.size()if W % self.patch_size[1] != 0:x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))if H % self.patch_size[0] != 0:x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))x = self.proj(x) # B C Wh Wwif self.norm is not None:Wh, Ww = x.size(2), x.size(3)x = x.flatten(2).transpose(1, 2)x = self.norm(x)x = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)return xclass SwinTransformer(nn.Module):""" Swin Transformer backbone.A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -https://arxiv.org/pdf/2103.14030Args:pretrain_img_size (int): Input image size for training the pretrained model,used in absolute postion embedding. Default 224.patch_size (int | tuple(int)): Patch size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.depths (tuple[int]): Depths of each Swin Transformer stage.num_heads (tuple[int]): Number of attention head of each stage.window_size (int): Window size. Default: 7.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float): Override default qk scale of head_dim ** -0.5 if set.drop_rate (float): Dropout rate.attn_drop_rate (float): Attention dropout rate. Default: 0.drop_path_rate (float): Stochastic depth rate. Default: 0.2.norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.ape (bool): If True, add absolute position embedding to the patch embedding. Default: False.patch_norm (bool): If True, add normalization after patch embedding. Default: True.out_indices (Sequence[int]): Output from which stages.frozen_stages (int): Stages to be frozen (stop grad and set eval mode).-1 means not freezing any parameters.use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self,pretrain_img_size=224,patch_size=4,in_chans=3,embed_dim=96,depths=[2, 2, 6, 2],num_heads=[3, 6, 12, 24],window_size=7,mlp_ratio=4.,qkv_bias=True,qk_scale=None,drop_rate=0.,attn_drop_rate=0.,drop_path_rate=0.2,norm_layer=nn.LayerNorm,ape=False,patch_norm=True,out_indices=(0, 1, 2, 3),frozen_stages=-1,use_checkpoint=False):super().__init__()self.pretrain_img_size = pretrain_img_sizeself.num_layers = len(depths)self.embed_dim = embed_dimself.ape = apeself.patch_norm = patch_normself.out_indices = out_indicesself.frozen_stages = frozen_stages# split image into non-overlapping patchesself.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,norm_layer=norm_layer if self.patch_norm else None)# absolute position embeddingif self.ape:pretrain_img_size = to_2tuple(pretrain_img_size)patch_size = to_2tuple(patch_size)patches_resolution = [pretrain_img_size[0] // patch_size[0], pretrain_img_size[1] // patch_size[1]]self.absolute_pos_embed = nn.Parameter(torch.zeros(1, embed_dim, patches_resolution[0], patches_resolution[1]))trunc_normal_(self.absolute_pos_embed, std=.02)self.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias,qk_scale=qk_scale,drop=drop_rate,attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint)self.layers.append(layer)num_features = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]self.num_features = num_features# add a norm layer for each outputfor i_layer in out_indices:layer = norm_layer(num_features[i_layer])layer_name = f'norm{i_layer}'self.add_module(layer_name, layer)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):"""Forward function."""x = self.patch_embed(x)Wh, Ww = x.size(2), x.size(3)if self.ape:# interpolate the position embedding to the corresponding sizeabsolute_pos_embed = F.interpolate(self.absolute_pos_embed, size=(Wh, Ww), mode='bicubic')x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww Celse:x = x.flatten(2).transpose(1, 2)x = self.pos_drop(x)outs = []for i in range(self.num_layers):layer = self.layers[i]x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)if i in self.out_indices:norm_layer = getattr(self, f'norm{i}')x_out = norm_layer(x_out)out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()outs.append(out)return outsdef update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictdef SwinTransformer_Tiny(weights=''):model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24])if weights:model.load_state_dict(update_weight(model.state_dict(), torch.load(weights)['model']))return modelif __name__ == '__main__':device = torch.device('cuda:0')model = SwinTransformer().to(device)model.half()# model.load_state_dict(update_weight(model.state_dict(), torch.load('swin_tiny_patch4_window7_224_22k.pth')['model']))inputs = torch.randn((1, 3, 640, 512)).to(device).half()res = model(inputs)for i in res:print(i.size())print(model.channel)
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {SwinTransformer_Tiny}: #添加Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, SwinTransformer_Tiny, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
相关文章:
目标检测算法改进系列之Backbone替换为Swin Transformer
Swin Transformer简介 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》作为2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机…...
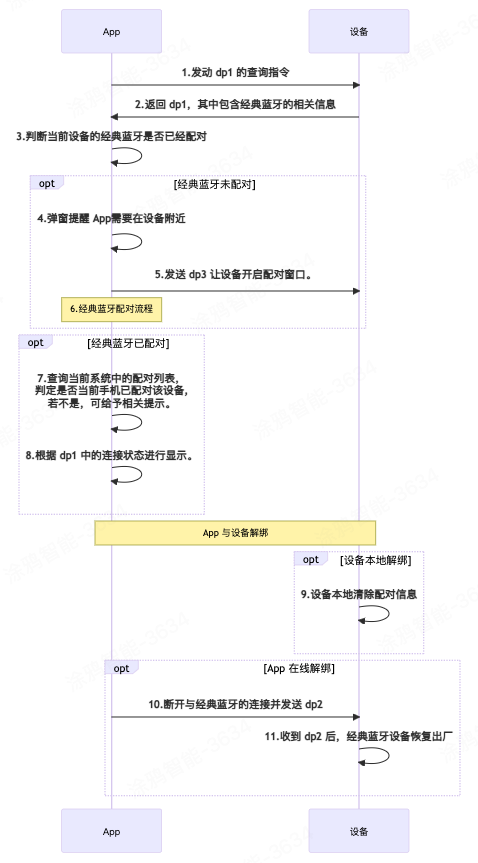
【技术干货】如何通过 DP 实现支持经典蓝牙的联网单品设备与 App 配对
经典蓝牙模块(Classic Bluetooth)主要用于呼叫和音频传输,所以经典蓝牙最主要的特点就是功耗大,传输数据量大。蓝牙耳机、蓝牙音箱等场景大多采用经典蓝牙,因为蓝牙是为传输声音而设计的,是短距离音频传输的…...

【Unity Build-In管线的SurfaceShader剖析_PBS光照函数】
Unity Build-In管线的SurfaceShader剖析 在Unity Build-In 管线(Universal Render Pipeline)新建一个Standard Surface Shader文件里的代码如下:选中"MyPBR.Shader",在Inspector面板,打开"Show generat…...

thinkphp5实现ajax图片上传,压缩保存到服务器
<div class"warp"><input type"file" id"file" accept"image/*" onchange"upimg(this)" /></div> <img src"" /> <script>//上传图片方法function upimg(obj){var fileData obj.…...
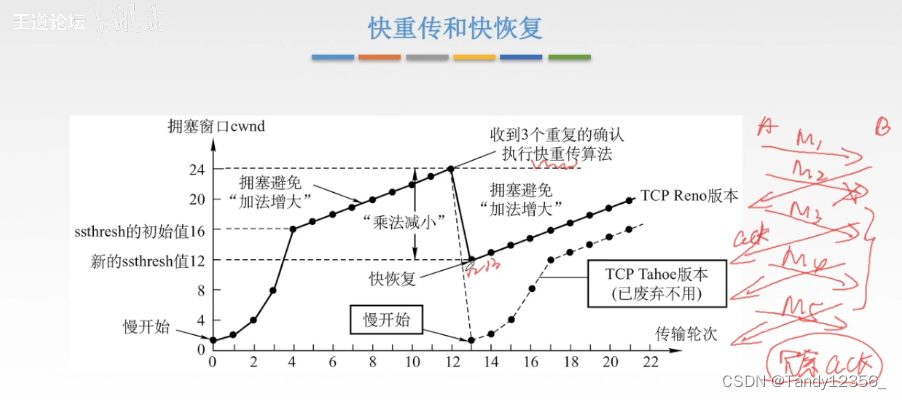
王道考研计算机网络——传输层
一、传输层概述 复用:发送方不同的应用进程都可以使用同一个传输层的协议来传送数据 分用:接收方的传输层在去除报文段的首部之后能把数据交给正确的应用进程 熟知端口号就是知名端口号0-1023 客户端使用的端口号是动态变化的,不是唯一确定…...
)
08 集群参数配置(下)
Kafka Broker不需要太大的堆内存? Kafka Broker不需要太大的堆内存?应该把内存留给页缓存使用? kafka刷盘时宕机 kafka认为写入成功是指写入页缓存成功还是数据刷到磁盘成功算成功呢?还是上次刷盘宕机失败的问题,页…...
mac文件为什么不能拖进U盘?
对于Mac用户来说,可能会遭遇一些烦恼,比如在试图将文件从Mac电脑拖入U盘时,却发现文件无法成功传输。这无疑给用户带来了很大的不便。那么,mac文件为什么不能拖进U盘,看完这篇你就知道了。 一、U盘的读写权限问题 如果…...

RK3568的CAN驱动适配
目录 背景: 1.内核驱动模块配置 2.设备树配置 3.功能测试 4.bug修复 背景: 某个项目上使用RK3568的芯片,需要用到4路CAN接口进行通信,经过方案评审后决定使用RK3568自带的3路CAN外加一路spi转的CAN实现功能,在这个…...

Opengl之立方体贴图
简单来说,立方体贴图就是一个包含了6个2D纹理的纹理,每个2D纹理都组成了立方体的一个面:一个有纹理的立方体。你可能会奇怪,这样一个立方体有什么用途呢?为什么要把6张纹理合并到一张纹理中,而不是直接使用6个单独的纹理呢?立方体贴图有一个非常有用的特性,它可以通过一…...

EF Core报错:Error Number:-2146893019
appsettings.json中的连接字符串要添加上:TrustServerCertificatetrue; 所以这里的连接字符串为:Data SourceLAPTOP-61GDB2Q7\\SQLEXPRESS;Initial CatalogMvcMovie.Data;Persist Security InfoTrue;TrustServerCertificatetrue;User IDsa;Passwordroot…...
QT之可自由折叠和展开的布局
介绍和功能分析 主要是实现控件的折叠和展开,类似抽屉控件,目前Qt自带的控件QToolBox具有这个功能,但是一次只能展开一个,所以针对自己的需求可以自己写一个类似的功能,这里实现的方法比较多,其实原理也比较…...
数组指定元素求和)
javascript二维数组(7)数组指定元素求和
项目需求 对指定数据中的score求和 const data [ { name: Alice, age: 23, score: 85 }, { name: Bob, age: 30, score: 90 }, { name: Charlie, age: 35, score: 80 } ];1.封装函数 这个函数接受两个参数:一个对象数组和一个键名(也就是你想要…...
网络安全——黑客自学(笔记)
想自学网络安全(黑客技术)首先你得了解什么是网络安全!什么是黑客!!! 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队…...
Docker 安装 Elasticsearch7.16.x
docker hub地址:https://hub.docker.com 拉取镜像 docker pull elasticsearch:7.16.3创建容器 docker run -di --nameelasticsearch -p 9200:9200 -p 9300:9300 -p 5601:5601 -e "discovery.typesingle-node" -e "cluster.nameelasticsearch" -…...
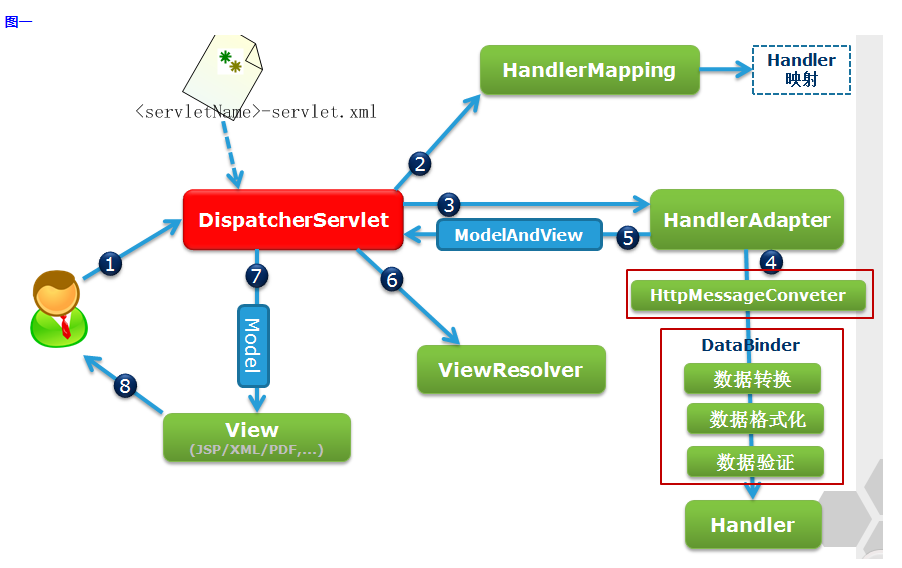
springmvc-controller视图层配置SpringMVC处理请求的流程
目录 1. 什么是springmvc 2.项目中加入springmvc支持 2.1 导入依赖 2.2 springMVC配置文件 2.3 web.xml配置 2.4 中文编码处理 3. 编写一个简单的controller 4. 视图层配置 4.1 视图解析器配 4.2 静态资源配置 4.2 编写页面 4.3 页面跳转方式 5. SpringMVC处理请求…...
三模块七电平级联H桥整流器电压平衡控制策略Simulink仿真
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
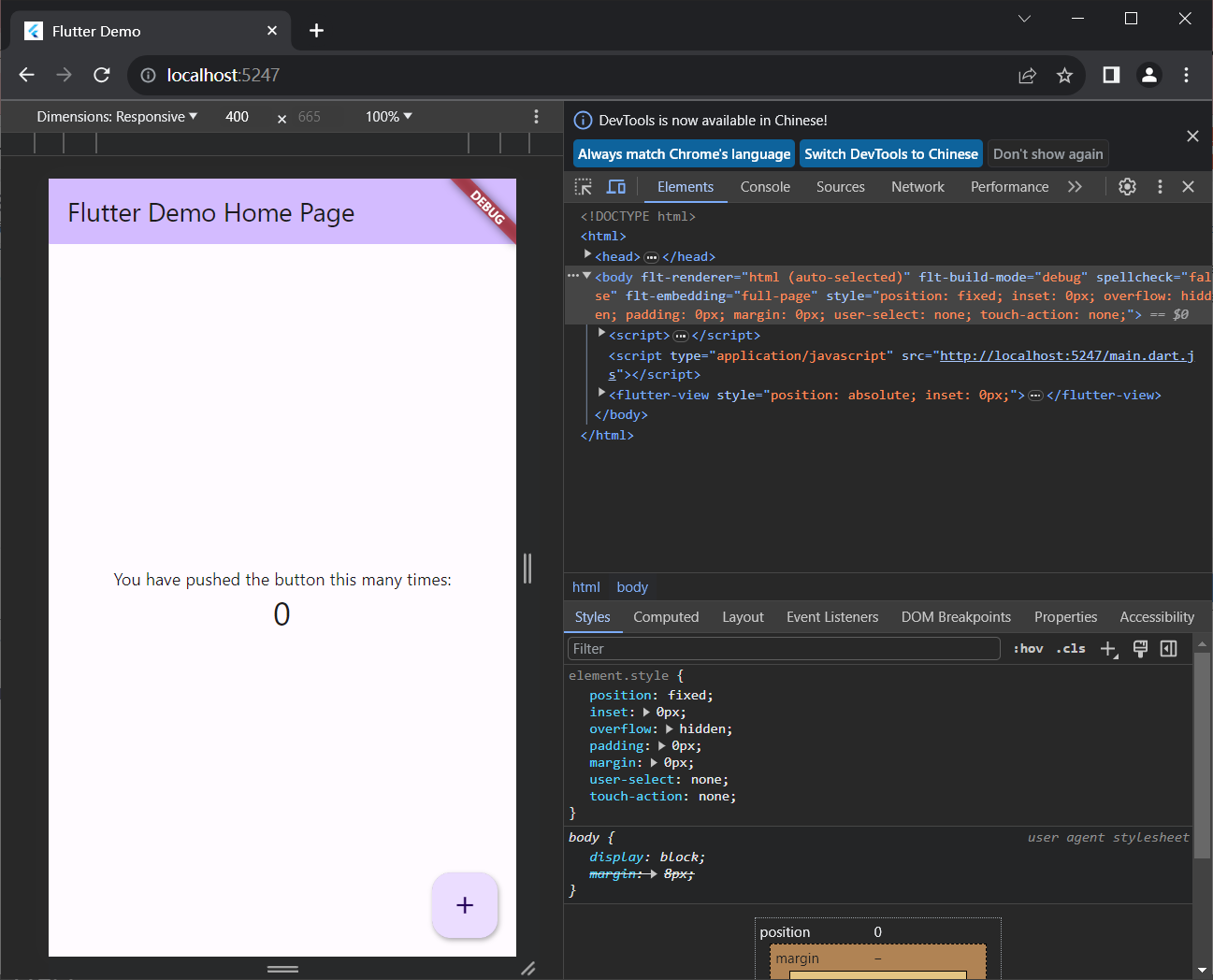
【window10】Dart+Android Studio+Flutter安装及运行
安装Dart SDK安装Android Studio安装Flutter在Android Studio中创建并运行Flutter项目 安装前,请配置好你的jdk环境,准备好你的梯子~ 安装Dart SDK 浅浅了解一下Dart: Dart 诞生于2011年,是由谷歌开发的一种强类型、跨平台的客户…...
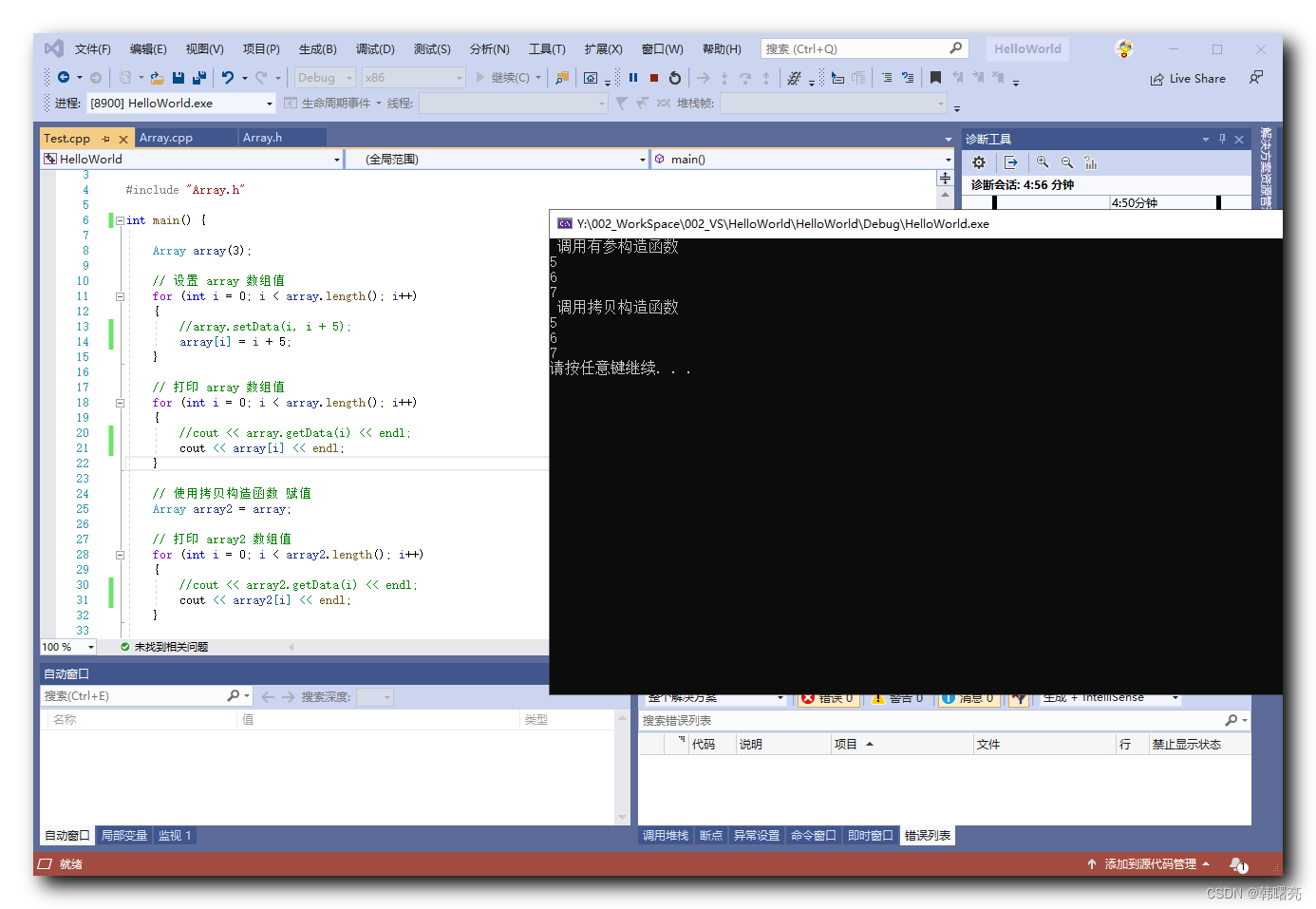
【C++】运算符重载 ⑩ ( 下标 [] 运算符重载 | 函数原型 int operator[](int i) | 完整代码示例 )
文章目录 一、下标 [] 运算符重载1、数组类回顾2、下标 [] 运算符重载 二、完整代码示例1、Array.h 数组头文件2、Array.cpp 数组实现类3、Test.cpp 测试类4、执行结果 一、下标 [] 运算符重载 1、数组类回顾 在之前的博客 【C】面向对象示例 - 数组类 ( 示例需求 | 创建封装类…...
ROS机械臂开发-开发环境搭建【一】
目录 前言环境配置docker搭建Ubuntu环境安装ROS 基础ROS文件系统 bugs 前言 想系统学习ROS,做一些机器人开发。因为有些基础了,这里随便写写记录一下。 环境配置 docker搭建Ubuntu环境 Dockerfile # 基础镜像 FROM ubuntu:18.04 # 设置变量 ENV ETC…...

深度思考rpc框架面经之五:rpc限流:rpc事务:tps测试
11 注册中心监控和rpc限流(用友云产品部二面) 11.1 你这个注册中心有实现相关的监控吗 11.1.1 如何实现注册中心有实现相关的监控 是的,我可以为你提供关于RPC注册中心及其监控的相关信息。RPC注册中心是用于管理微服务之间调用关系的中心…...
跨平台中文Zip压缩与解压实战指南(附多线程优化))
Unity 工具之(SharpZipLib)跨平台中文Zip压缩与解压实战指南(附多线程优化)
1. 为什么选择SharpZipLib处理Unity中的Zip文件 在Unity项目开发中,资源打包和网络传输经常需要处理压缩文件。SharpZipLib作为.NET平台的老牌压缩库,相比Unity内置的压缩方案有三个不可替代的优势: 首先是对中文路径的完美支持。很多开发者都…...

从“高危论文”到“安心提交”:百考通双降技术,为真实思考护航
在一个人工智能可以生成万字论文的时代,最讽刺的现实不是机器冒充人类, 而是人类因写得太像“人写的论文”,被当作机器。 2026年,无数高校学子正陷入一场无声的困境: 你没用AI,却因逻辑清晰被标记…...

MicroOS:Arduino轻量级任务调度内核详解
1. MicroOS:面向Arduino的轻量级任务管理内核概述MicroOS是一个专为Arduino平台设计的极简型实时任务管理器,其核心定位并非替代FreeRTOS或Zephyr等完整RTOS,而是填补Arduino原生loop()单线程模型在多任务调度、精确定时与事件解耦方面的空白…...

抖音视频批量下载器:如何快速高效地收集和管理海量抖音内容
抖音视频批量下载器:如何快速高效地收集和管理海量抖音内容 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 抖音作为国内最大的短视频平台,每天产生数以百万计的视频内容,…...
)
省流量秘籍:ESP32+LittleFS构建超轻量级物联网WEB界面(附低功耗配置)
ESP32物联网低功耗WEB界面开发实战:从LittleFS优化到移动端适配 在野外环境或移动场景中部署物联网设备时,每毫安的电流消耗和每KB的流量都值得精打细算。ESP32作为一款高性价比的Wi-Fi/蓝牙双模芯片,其灵活的网络配置和丰富的外设接口使其成…...

终极指南:如何从零开始打造你的第一台六足机器人
终极指南:如何从零开始打造你的第一台六足机器人 【免费下载链接】hexapod 项目地址: https://gitcode.com/gh_mirrors/hexapod5/hexapod 你是否梦想过亲手制作一台能够灵活行走、稳定爬行的六足机器人?想要体验机器人制作的乐趣,却担…...

一文读懂大模型,彻底告别 AI 焦虑 | 零门槛
今天,不聊复杂代码、不晒专业论文,用最直白的语言,带非技术背景的你彻底读懂大模型:核心逻辑、实用场景、产品选型,以及普通人应对AI浪潮的正确姿势。全文干货密集,建议收藏转发,读完摆脱AI焦虑…...

python基于微信小程序的方言文化传播平台的设计与开发
目录需求分析与规划技术选型与架构设计核心功能实现数据处理与优化测试与部署运营与迭代项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与规划 明确平台的核心功能需求,包括方言内容展示、语音录制与分享、…...

Cosmos-Reason1-7B企业应用案例:研发团队用它做内部技术文档逻辑校验与补全
Cosmos-Reason1-7B企业应用案例:研发团队用它做内部技术文档逻辑校验与补全 1. 引言:技术文档的“逻辑陷阱”与AI解法 想象一下这个场景:你所在的研发团队刚刚完成了一个新模块的开发,需要撰写一份详细的技术设计文档。文档洋洋…...

新手福音:在快马平台零基础上手加速库,轻松提速深度学习训练
新手福音:在快马平台零基础上手加速库,轻松提速深度学习训练 作为一个刚接触深度学习的新手,最头疼的莫过于环境配置和性能优化。最近我在InsCode(快马)平台上发现了一个超实用的功能——预置加速库的深度学习项目模板,让我这个小…...