深度学习——深度学习计算一
深度学习——深度学习计算一
文章目录
- 前言
- 一、层和块
- 1.1. 自定义块
- 1.2. 顺序块
- 1.3. 在前向传播函数中执行代码
- 1.4. 小结
- 二、参数管理
- 2.1. 参数访问
- 2.1.1. 目标参数
- 2.1.2. 一次性访问所有参数
- 2.1.3. 从嵌套块收集参数
- 2.2. 参数初始化
- 2.2.1. 内置初始化
- 2.2.2. 自定义初始化
- 2.3. 参数绑定
- 总结
前言
本章将深入探索深度学习计算的关键组件, 即模型构建、参数访问与初始化、设计自定义层和块、将模型读写到磁盘, 以及利用GPU实现显著的加速。 这些知识将使我们从深度学习“基础用户”变为“高级用户”。
参考书:
《动手学深度学习》
一、层和块
在深度学习中,层(layer)是构成神经网络的基本组件之一。每一层都包含一组神经元(或称为节点),这些神经元接收输入并输出一些值。不同类型的层可以实现不同的功能,例如全连接层、卷积层、池化层等。
块(block)是由多个层组成的模块化结构。块可以看作是一个更高级的层,它将多个层组合在一起,并通过一些额外的操作(如激活函数、正则化等)来增加模型的灵活性和表达能力。块的设计可以帮助简化模型的结构,提高模型的可读性和可维护性,实现更为复杂的网络功能
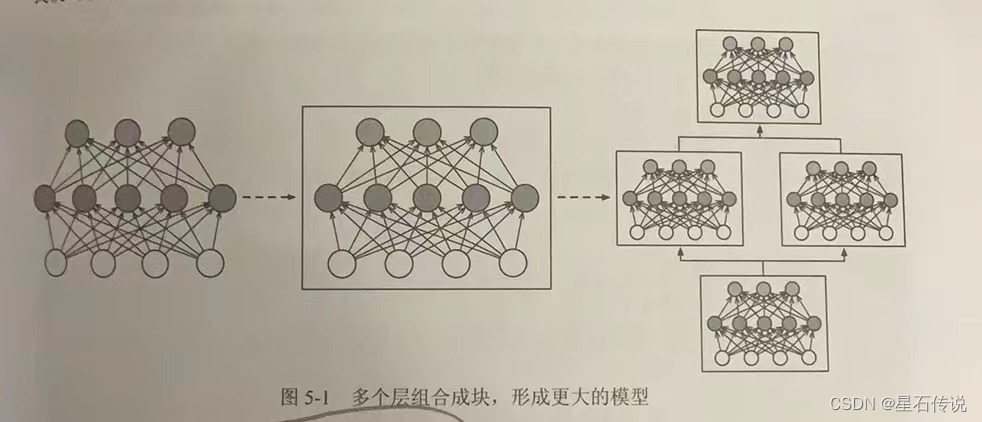
层和块的概念在深度学习中非常重要,它们可以帮助构建复杂的神经网络模型,并提高模型的性能和效果。
在构造自定义块之前,我们先回顾一下多层感知机的代码。
下面的代码生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层, 然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。
import torch
from d2l import torch as d2l
from torch import nn
net = nn.Sequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
X = torch.rand(2,20)
print(net(X))#结果:
tensor([[ 0.0805, 0.0937, -0.0331, 0.1567, 0.0594, -0.3293, 0.1774, -0.0600,-0.0033, -0.3726],[ 0.0451, -0.0064, -0.1280, 0.0454, 0.2185, -0.2862, 0.1780, 0.0198,-0.0341, -0.5214]], grad_fn=<AddmmBackward0>)在这个例子中,我们通过实例化nn.Sequential来构建我们的模型, 层的执行顺序是作为参数传递的。
1.1. 自定义块
在实现我们自定义块之前,我们简要总结一下每个块必须提供的基本功能:
- 将输入数据作为其前向传播函数的参数。
- 通过前向传播函数来生成输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问前向传播计算所需的参数。
- 根据需要初始化模型参数。
# 下面的MLP类继承了表示块的类
class MLP(nn.Module):# 用模型参数声明层。这里,我们声明两个全连接的层def __init__(self):# 调用MLP的父类Module的构造函数来执行必要的初始化。# 这样,在类实例化时也可以指定其他函数参数,例如模型参数paramssuper().__init__()self.hidden = nn.Linear(20, 256)self.out = nn.Linear(256, 10) # 输出层# 定义模型的前向传播,即如何根据输入X返回所需的模型输出def forward(self, X):# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。return self.out(F.relu(self.hidden(X)))net = MLP()
print(net(X))#结果:
tensor([[-0.1863, -0.1673, 0.0547, 0.1255, -0.2258, -0.1138, -0.0232, 0.0543,0.0770, 0.0198],[-0.0964, -0.2234, 0.1306, 0.0934, -0.2134, -0.1488, 0.0052, 0.1475,0.1173, 0.0602]], grad_fn=<AddmmBackward0>)块的一个主要优点是它的多功能性。 我们可以子类化块以创建层(如全连接层的类)、 整个模型(如上面的MLP类)或具有中等复杂度的各种组件。
1.2. 顺序块
现在我们可以更仔细地看看Sequential类是如何工作的, 回想一下Sequential的设计是为了把其他模块串起来。 为了构建我们自己的简化的MySequential, 我们只需要定义两个关键函数:
- 一种将块逐个追加到列表中的函数;
- 一种前向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
"""
顺序块
"""
#下面的MySequential类提供了与默认Sequential类相同的功能。
class MySequential(nn.Module):def __init__(self,*args):super().__init__()for idx,module in enumerate(args):#这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员# 变量_modules中。_module的类型是OrderedDictself._modules[str(idx)] = moduledef forward(self,X):# OrderedDict保证了按照成员添加的顺序遍历它们for block in self._modules.values():X = block(X)return X#当MySequential的前向传播函数被调用时, 每个添加的块都按照它们被添加的顺序执行。
#现在可以使用我们的MySequential类重新实现多层感知机。net = MySequential(nn.Linear(20,256),nn.ReLU(),nn.Linear(256,10))
#print(net(X))1.3. 在前向传播函数中执行代码
Sequential类使模型构造变得简单, 允许我们组合新的架构,而不必定义自己的类。 然而,并不是所有的架构都是简单的顺序架构。 当需要更强的灵活性时,我们需要定义自己的块。
例如,我们可能希望在前向传播函数中执行Python的控制流。 此外,我们可能希望执行任意的数学运算, 而不是简单地依赖预定义的神经网络层。
class FixedHiddenMLP(nn.Module):def __init__(self):super().__init__()# 不计算梯度的随机权重参数。因此其在训练期间保持不变self.rand_weight = torch.rand((20,20),requires_grad= True)self.linear = nn.Linear(20,20)def forward(self,X):X = self.linear(X)#使用创建的常量参数以及relu和mm函数X = F.relu(torch.mm(X,self.rand_weight)+1)#复用全连接层,这相当于两个全连接层共享参数X = self.linear(X)#控制流while X.abs().sum() > 1:X /= 2return X.sum()
在这个FixedHiddenMLP模型中,我们实现了一个隐藏层,
其权重(self.rand_weight)在实例化时被随机初始化,之后为常量。 这个权重不是一个模型参数,因此它永远不会被反向传播更新。
然后,神经网络将这个固定层的输出通过一个全连接层。注意,在返回输出之前,模型做了一些不寻常的事情: 它运行了一个while循环,在L1范数大于1的条件下,
将输出向量除以2,直到它满足条件为止。 最后,模型返回了X中所有项的和
我们可以混合搭配各种组合块的方法。 在下面的例子中,我们以一些想到的方法嵌套块:
class NestMLP(nn.Module):def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),nn.Linear(64, 32), nn.ReLU())self.linear = nn.Linear(32, 16)def forward(self, X):return self.linear(self.net(X))chimera = nn.Sequential(NestMLP(), nn.Linear(16, 20), FixedHiddenMLP())
print(chimera(X))#结果:
tensor(0.1097, grad_fn=<SumBackward0>)1.4. 小结
-
一个块可以由许多层组成;一个块可以由许多块组成。
-
块可以包含代码。
-
块负责大量的内部处理,包括参数初始化和反向传播。
-
层和块的顺序连接由Sequential块处理。
二、参数管理
在选择了架构并设置了超参数后,我们就进入了训练阶段。 此时,我们的目标是找到使损失函数最小化的模型参数值。 经过训练后,我们将需要使用这些参数来做出未来的预测。
之前的介绍中,我们只依靠深度学习框架来完成训练的工作, 而忽略了操作参数的具体细节。 接下来将介绍以下内容:
- 访问参数,用于调试、诊断和可视化;
- 参数初始化;
- 在不同模型组件间共享参数。
2.1. 参数访问
先看一下具有单隐藏层的多层感知机
import torch
from torch import nnnet = nn.Sequential(nn.Linear(4, 8), nn.ReLU(), nn.Linear(8, 1))
X = torch.rand(size=(2, 4))
print(net(X))#结果:
tensor([[-0.2487],[-0.1757]], grad_fn=<AddmmBackward0>)当通过Sequential类定义模型时, 我们可以通过索引来访问模型的任意层。 这就像模型是一个列表一样,每层的参数都在其属性中。 如下所示,我们可以检查第二个全连接层的参数。
print(net[2].state_dict())
#结果:
OrderedDict([('weight', tensor([[-0.0454, -0.3495, 0.2659, 0.2088, 0.2453, 0.3455, 0.1744, -0.0094]])), ('bias', tensor([-0.0710]))])2.1.1. 目标参数
#下面的代码从第二个全连接层(即第三个神经网络层)提取偏置, 提取后返回的是一个参数类实例,并进一步访问该参数的值。print(type(net[2].bias))
print(net[2].bias)
print(net[2].bias.data)#结果:
<class 'torch.nn.parameter.Parameter'>
Parameter containing:
tensor([-0.0710], requires_grad=True)
tensor([-0.0710])
参数是复合的对象,包含值、梯度和额外信息。 这就是我们需要显式参数值的原因。 除了值之外,我们还可以访问每个参数的梯度。 在上面这个网络中,由于我们还没有调用反向传播,所以参数的梯度处于初始状态。
print(net[2].weight.grad == None)
#结果:
True
2.1.2. 一次性访问所有参数
下面,我们将通过演示来比较访问第一个全连接层的参数和访问所有层。
print(*[(name, param.shape) for name, param in net[0].named_parameters()])
print(*[(name, param.shape) for name, param in net.named_parameters()])#结果:
('weight', torch.Size([8, 4])) ('bias', torch.Size([8]))
('0.weight', torch.Size([8, 4])) ('0.bias', torch.Size([8])) ('2.weight', torch.Size([1, 8])) ('2.bias', torch.Size([1]))#这为我们提供了另一种访问网络参数的方式
print(net.state_dict()['2.bias'].data)#结果:
tensor([-0.0710])
2.1.3. 从嵌套块收集参数
我们首先定义一个生成块的函数(可以说是“块工厂”),然后将这些块组合到更大的块中。
def block1():return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),nn.Linear(8, 4), nn.ReLU())def block2():net = nn.Sequential()for i in range(4):# 在这里嵌套net.add_module(f'block {i}', block1())return netrgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet(X))
print(rgnet)
结果如下:
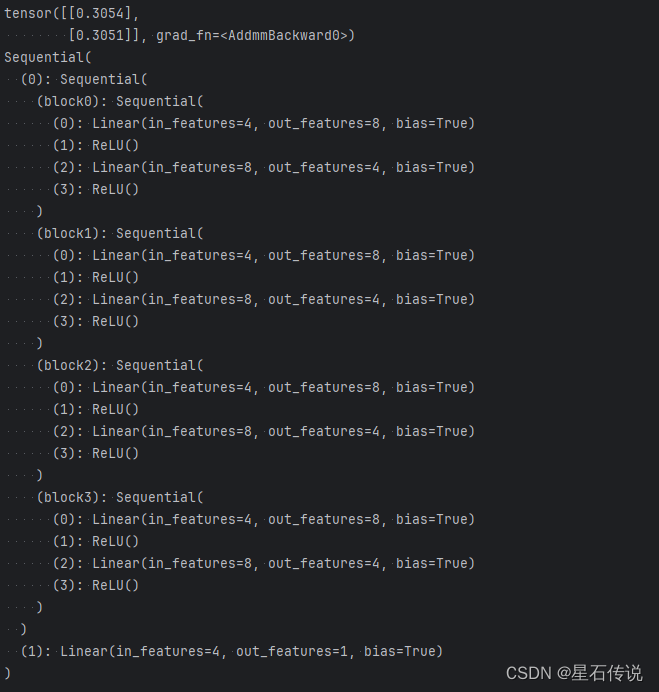
因为层是分层嵌套的,所以我们也可以像通过嵌套列表索引一样访问它们。 下面,我们访问第一个主要的块中、第二个子块的第一层的偏置项。
print(rgnet[0][1][0].bias.data)
#结果:
tensor([ 0.4090, -0.0318, 0.3773, 0.4772, 0.4299, -0.2994, 0.4322, 0.2694])2.2. 参数初始化
知道了如何访问参数后,现在我们看看如何正确地初始化参数。 深度学习框架提供默认随机初始化, 也允许我们创建自定义初始化方法, 满足我们通过其他规则实现初始化权重。
默认情况下,PyTorch会根据一个范围均匀地初始化权重和偏置矩阵, 这个范围是根据输入和输出维度计算出的。 PyTorch的nn.init模块提供了多种预置初始化方法。
2.2.1. 内置初始化
#内置初始化
#下面的代码将所有权重参数初始化为标准差为0.01的高斯随机变量, 且将偏置参数设置为0。
def init_normal(m):if type(m) == nn.Linear:nn.init.normal_(m.weight,mean= 0,std=0.01)nn.init.zeros_(m.bias)
net.apply(init_normal)
print(net[0].weight.data[0],net[0].bias.data[0])#我们还可以将所有参数初始化为给定的常数,比如初始化为1
def init_constant(m):if type(m) == nn.Linear:nn.init.constant_(m.weight, 1)nn.init.zeros_(m.bias)net.apply(init_constant)
print(net[0].weight.data[0], net[0].bias.data[0])"""
我们还可以对某些块应用不同的初始化方法.
例如,下面我们使用Xavier初始化方法初始化第一个神经网络层, 然后将第三个神经网络层初始化为常量值42。
"""def init_xavier(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)
def init_42(m):if type(m) == nn.Linear:nn.init.constant_(m.weight,42)net[0].apply(init_xavier)
net[2].apply(init_42)
print(net[0].weight.data[0])
print(net[2].weight.data)#结果:
tensor([ 0.0060, -0.0043, 0.0009, 0.0124]) tensor(0.)
tensor([1., 1., 1., 1.]) tensor(0.)
tensor([-0.7014, -0.2135, 0.6632, 0.4671])
tensor([[42., 42., 42., 42., 42., 42., 42., 42.]])2.2.2. 自定义初始化
有时,深度学习框架没有提供我们需要的初始化方法。 在下面的例子中,我们使用以下的分布为任意权重参数 w w w定义初始化方法:
w ∼ { U ( 5 , 10 ) 可能性 1 4 0 可能性 1 2 U ( − 10 , − 5 ) 可能性 1 4 \begin{aligned} w \sim \begin{cases} U(5, 10) & \text{ 可能性 } \frac{1}{4} \\ 0 & \text{ 可能性 } \frac{1}{2} \\ U(-10, -5) & \text{ 可能性 } \frac{1}{4} \end{cases} \end{aligned} w∼⎩ ⎨ ⎧U(5,10)0U(−10,−5) 可能性 41 可能性 21 可能性 41
def my_init(m):if type(m) == nn.Linear:print("init",*[(name,param.shape) for name,param in m.named_parameters()][0])nn.init.uniform_(m.weight,-10,10) #设置权重的初始值为-10到10之间的均匀分布m.weight.data *= m.weight.data.abs() >=5 #对权重进行截断操作,将小于5的权重置为0。
net.apply(my_init)
print(net[0].weight[:2])#我们始终可以直接设置参数。
net[0].weight.data[:] += 1
net[0].weight.data[0, 0] = 42
print(net[0].weight.data[0])#结果:
init weight torch.Size([8, 4])
init weight torch.Size([1, 8])
tensor([[-6.4263, 5.1428, -0.0000, -8.5624],[-9.4317, -0.0000, 0.0000, -0.0000]], grad_fn=<SliceBackward0>)
tensor([42.0000, 6.1428, 1.0000, -7.5624])
2.3. 参数绑定
有时我们希望在多个层间共享参数: 我们可以定义一个稠密层,然后使用它的参数来设置另一个层的参数。
#我们需要给共享层一个名称,以便可以引用它的参数
shared = nn.Linear(8,8)
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(),shared,nn.ReLU(),shared,nn.ReLU(),nn.Linear(8,1))net(X)
#检查参数是否相同:
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0,0] = 100
# 确保它们实际上是同一个对象,而不只是有相同的值
print(net[2].weight.data[0] == net[4].weight.data[0])#结果:
tensor([True, True, True, True, True, True, True, True])
tensor([True, True, True, True, True, True, True, True])这个例子表明第三个和第五个神经网络层的参数是绑定的。 它们不仅值相等,而且由相同的张量表示。
因此,如果我们改变其中一个参数,另一个参数也会改变。 这里有一个问题:当参数绑定时,梯度会发生什么情况?
答案是由于模型参数包含梯度,因此在反向传播期间第二个隐藏层 (即第三个神经网络层)和第三个隐藏层(即第五个神经网络层)的梯度会加在一起。
(尽管梯度加在一起可能看起来有点奇怪,但在参数绑定的情况下,这是正常的行为,并且不会导致错误。)
总结
本章了解了一下层和块的概念,并且也深入了解了一下深度学习中的参数如何管理:参数访问、参数初始化、参数绑定。
物或行或随,或嘘或吹,或强或羸,或培或堕。是以圣人去甚,去泰,去奢
–2023-10-5 进阶篇
相关文章:
深度学习——深度学习计算一
深度学习——深度学习计算一 文章目录 前言一、层和块1.1. 自定义块1.2. 顺序块1.3. 在前向传播函数中执行代码1.4. 小结 二、参数管理2.1. 参数访问2.1.1. 目标参数2.1.2. 一次性访问所有参数2.1.3. 从嵌套块收集参数 2.2. 参数初始化2.2.1. 内置初始化2.2.2. 自定义初始化 2.…...

yolov5及yolov7实战之剪枝
之前有讲过一次yolov5的剪枝:yolov5实战之模型剪枝_yolov5模型剪枝-CSDN博客 当时基于的是比较老的yolov5版本,剪枝对整个训练代码的改动也比较多。最近发现一个比较好用的剪枝库,可以在不怎么改动原有训练代码的情况下,实现剪枝的…...
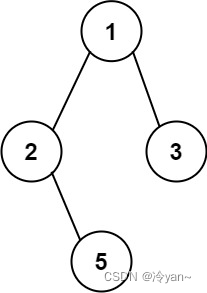
力扣第257题 二叉树的所有路径 c++ 树 深度优先搜索 字符串 回溯 二叉树
题目 257. 二叉树的所有路径 简单 给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。 叶子节点 是指没有子节点的节点。 示例 1: 输入:root [1,2,3,null,5] 输出:["1->2-&g…...

保研之旅·终
一.背景 学校: 中211 通信工程专业 成绩: 绩点前3% 英语: CET4:523 CET6:505 竞赛:两个国奖,若干省奖 科研:两项校级大创,无论文产出 二.基本情况 夏令营入营: 哈工大…...

达梦数据库 视图 错误 [22003]: 数据溢出
今天通过DBeaver连接访问达梦数据库的一个视图,报错:错误 [22003]: 数据溢出 经过分析,原因是视图字段的数据类型和原表的数据类型不一致造成的...
【文献阅读】【NMI 2022】LocalTransform :基于广义模板的有机反应性准确预测图神经网络
预测有机反应产物是有机化学的一个基本问题。基于成熟有机化学知识,化学家现在能够设计实验来制造用于不同目的的新分子。但是,它需要经验丰富的专业化学家来准确预测化学反应的结果。为了进一步帮助有机化学家并在数字化学时代实现全自动发现࿰…...

QQ浏览器怎么才能设置默认搜索引擎为百度
问题: 打开QQ浏览器,搜索相关信息时发现总是默认为”搜狗搜索引擎“,想将其转为”百度搜索引擎“ 解决: 1、点击浏览器右侧”菜单“图标,选择”设置“,如下图所示: 2、在”常规设置“中的”搜…...

Go Gin Gorm Casbin权限管理实现 - 3. 实现Gin鉴权中间件
文章目录 0. 背景1. 准备工作2. gin中间件2.1 中间件代码2.2 中间件使用2.3 测试中间件使用结果 3. 添加权限管理API3.1 获取所有用户3.2 获取所有角色组3.3 获取所有角色组的策略3.4 修改角色组策略3.5 删除角色组策略3.6 添加用户到组3.7 从组中删除用户3.8 测试API 4. 最终目…...

js 封装一个异步任务函数
// 异步任务 封装 // 1,定义函数 // 2,使用核心api(queueMicrotask,MutationObserver,setTimeout) function runAsynctask (callback){if(typeof queueMicrotask "function" ){queueMicrotask(callback)}else if( typeof MutationObserver "functio…...

目标检测YOLO实战应用案例100讲-基于无人机航拍图像的目标检测
目录 前言 国内外研究现状 目标检测研究现状 无人机航拍目标检测研究现状...
PyQt5配置踩坑
安装步骤比较简单,这里只说一下我踩的坑,以及希望一些大佬可以给点建议。 一、QtDesigner 这个配置比较简单,直接就能用,我的配置如下图: C:\Users\lenovo\AppData\Roaming\Python\Python311\site-packages\qt5_app…...
内网渗透笔记之内网基础知识
0x01 内网概述 内网也指局域网(Local Area Network,LAN)是指在某一区域内由多台计算机互联成的计算机组。一般是方圆几千米以内。局域网可以实现文件管理、应用软件共享、打印机共享、工作组内的历程安排、电子邮件和传真通信服务等功能。 内…...
vue3+elementPlus:el-select选择器里添加按钮button
vue3elementPlus:el-select选择器里添加按钮button,在el-select的option后面添加button //html <el-select class"selectIcon" value-key"id" v-model"store.state.HeaderfilterText" multiple collapse-tagscollapse-…...

Android 模拟点击
Android 模拟点击 1.通过代码的方式实现 通过模拟MotionEvent的方式实现 //----------------模拟点击--------------------- private void simulateClick(View view, float x, float y) {long downTime SystemClock.uptimeMillis();final MotionEvent downEvent MotionEve…...

css自学框架之选项卡
这一节我们学习切换选项卡,两种切换方式,一种是单击切换选项,一种是鼠标滑动切换,通过参数来控制,切换方法。 一、参数 属性默认值描述tabBar.myth-tab-header span鼠标触发区域tabCon.myth-tab-content主体区域cla…...

Element Plus组件库中的input组件如何点击查看按钮时不可编辑,点击编辑时可编辑使用setup
如果你正在使用 Vue 3 和 Composition API,你可以使用 setup 函数来实现 Element Plus 的 Input 组件在点击查看按钮时不可编辑,点击编辑按钮时可编辑的功能。 以下是一个使用 setup 的示例代码: <template><div><el-input …...
小米、华为、iPhone、OPPO、vivo如何在手机让几张图拼成一张?
现在很多手机自带的相册APP已经有这个拼图功能了。 华为手机的拼图 打开图库,选定需要拼图的几张图片后,点击底部的【创作】,然后选择【拼图】就可以将多张图片按照自己想要的位置,组合在一起。 OPPO手机的拼图 打开相册&#…...

物联网AI MicroPython传感器学习 之 WS2812 RGB点阵灯环
学物联网,来万物简单IoT物联网!! 一、产品简介 ws2812是一个集控制电路与发光电路于一体的智能外控LED光源。其外型与一个5050LED灯珠相同,每个元件即为一个像素点。像素点内部包含了智能数字接口数据锁存信号整形放大驱动电路&a…...

【GPU常见概念】GPU常见概念及分类简述
随着大模型和人工智能的爆火,大家对GPU的关注持续上升,本文简单简述下GPU经常用的概念。 GPU(图形处理器),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备&…...
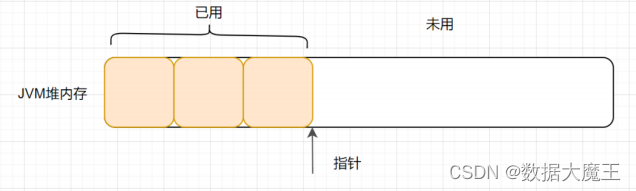
JVM篇---第九篇
系列文章目录 文章目录 系列文章目录一、什么是指针碰撞?二、什么是空闲列表三、什么是TLAB? 一、什么是指针碰撞? 一般情况下,JVM的对象都放在堆内存中(发生逃逸分析除外)。当类加载检查通过后࿰…...

Claude Code + PromptX 实战:如何让AI像你的最佳实习生一样写代码
Claude Code PromptX 实战:如何让AI像你的最佳实习生一样写代码 在软件开发领域,AI辅助编程已经从概念验证阶段迈入了实际生产力阶段。Claude Code与PromptX的组合,为开发者提供了一个强大的"虚拟实习生"——它不会抱怨加班&#…...

这个网站,我愿称之为生信云平台天花板
刚入门生信的你,是否也曾被这些问题折磨得想摔键盘?• Linux 环境配置:conda install 报错到怀疑人生,环境冲突让你原地崩溃。• 硬件瓶颈: 实验室服务器要排队,自己的轻薄本跑个比对就能当暖气片。• 代码…...

HarmonyOS6 半年磨一剑 - RcCheckbox 组件事件体系与交互逻辑
文章目录前言一、点击处理链1.1 核心点击处理函数1.2 两个点击入口二、三事件分层设计2.1 三个事件的对比2.2 事件使用示例三、labelDisabled 局部禁止机制3.1 设计意图3.2 适用场景四、RcCheckboxGroup 的数量限制拦截4.1 min/max 拦截机制4.2 数量限制示例总结前言 一个看似…...

深入解析Franka ROS2控制器:关节位置、速度、阻抗控制有何不同?
深入解析Franka ROS2控制器:关节位置、速度、阻抗控制的核心差异与实战选择 在工业自动化和机器人研究领域,精确控制机械臂的运动是实现复杂任务的基础。Franka Emika机械臂凭借其高精度力控能力和开放的ROS2接口,已成为学术研究和工业应用的…...

机器人避障轨迹优化实战:用Python+Scipy从数学推导到完整代码实现
机器人避障轨迹优化实战:PythonScipy从数学建模到工程实现 当你在机器人实验室里第一次看到机械臂撞翻咖啡杯,或是无人机在演示中撞上窗帘时,就会明白轨迹优化不仅仅是数学公式——它是让机器人安全高效工作的核心技术。本文将带你从零开始&a…...

基于Qt框架的PC端学生信息管理系统设计与实现
1. 为什么选择Qt开发学生信息管理系统? 第一次接触学生信息管理系统开发时,我尝试过用Java Swing、Python Tkinter等多种GUI框架,最后发现Qt才是真正的"生产力工具"。Qt的信号槽机制让界面交互变得异常简单,跨平台特性又…...
完全指南:字节跳动的AI创作神器有多强?)
[特殊字符] 即梦AI(Dreamina)完全指南:字节跳动的AI创作神器有多强?
即梦AI(Dreamina)是字节跳动旗下剪映团队推出的一站式AI创作平台,自2024年5月正式上线以来,凭借强大的中文理解能力、丰富的创作功能和极具竞争力的价格策略,迅速成为国内AI创作领域的头部产品。本文将全面解析即梦AI的…...

UICKeyChainStore常见问题解答:解决开发者遇到的典型问题
UICKeyChainStore常见问题解答:解决开发者遇到的典型问题 【免费下载链接】UICKeyChainStore UICKeyChainStore is a simple wrapper for Keychain on iOS, watchOS, tvOS and macOS. Makes using Keychain APIs as easy as NSUserDefaults. 项目地址: https://gi…...

Virtuoso-DFF:从原理图到功能测试的全面解析
1. Virtuoso-DFF设计原理全解析 在数字电路设计中,D触发器(DFF)是最基础也最重要的存储单元之一。Virtuoso作为业界领先的集成电路设计工具,其DFF实现方式具有典型性和参考价值。我们先从最基础的结构说起。 一个标准的DFF通常由传…...
AXI4-Stream视频流高效缓冲与FIFO深度优化)
Xilinx Video IP(二)AXI4-Stream视频流高效缓冲与FIFO深度优化
1. AXI4-Stream视频流缓冲的核心挑战 在视频处理系统中,AXI4-Stream协议因其高效的数据传输特性成为Xilinx视频IP的首选接口。但实际工程中,时钟域异步和速率不匹配两大问题就像两个调皮的孩子,总喜欢给工程师制造麻烦。我曾在多个项目中遇到…...