开启AI大模型时代|「Transformer论文精读」
论文地址: https://arxiv.org/pdf/1706.03762v5.pdf
代码地址: https://github.com/tensorflow/tensor2tensor.git

首发:微信公众号「魔方AI空间」,欢迎关注~
大家好,我是魔方君~~
近年来,人工智能技术发展迅猛,智能化应用不断涌现,随着深度学习等算法的不断发展,AI的模型也在变得更加庞大和强大。这些“大模型”能够处理大规模、复杂的数据集,并通过自我学习来提高算法的准确性和鲁棒性。开启AI大模型时代,意味着AI技术将可以更好地适应各行各业的需求,推进数字化转型,推动技术和应用的深入融合,进一步释放人工智能的巨大潜力,带来更多的社会和经济效益。
近期,魔方君会精读一些论文,好记性不如烂笔头,实实在在的写一边才会印象更深刻!!!
接下来,就从《Transformer》开始吧!!!
摘要
目前主流的序列转换模型都是基于复杂的RNN或CNN网络,包括编码器和解码器。最好的性能模型还通过一种注意力机制将编码器和解码器连接起来。本文提出了一种新的简单的网络架构——Transformer,它仅基于注意力机制,完全摒弃了循环和卷积。对两个机器翻译任务的实验表明,这些模型在质量上优于传统的模型,并且可以并行化处理,同时需要训练的时间显著减少。我们展示了Transformer在应用到英语成分句法分析(包括大规模和有限数据情况)时,能够成功地进行推广和应用。
结论
「Trnsformer」开创了继 MLP 、CNN和 RNN之后的第四大类模型,是第一个完全基于注意力机制的序列转换模型,用多头自注意力机制替代了编码器-解码器结构中常用的循环层。
对于翻译任务来说,相比于基于循环或卷积层的结构,Transformer的训练速度可以显著提高。在WMT 2014英德和WMT 2014英法翻译任务中,取得了新的最好成绩。
我们对基于注意力机制的模型的未来感到兴奋,并计划将其应用于其他任务。我们计划将Transformer扩展到涉及文本以外的输入和输出方式的问题,并研究局部、受限制的注意力机制,以有效处理大量的输入和输出,如图像、音频和视频等。
导言
-
介绍RNN及其存在的问题;
-
介绍Attention在RNN上的应用,并应用在编码器和解码器里面,主要是用在怎么把编码器的东西很有效的传给解码器里;
-
提出Transformer这样一个新的模型,其不再使用之前被大家使用的循环神经网络层。
相关工作
-
如何使用卷积神经网络替换掉RNN,使得减少时序的计算;CNN对较长的时序难以建模;卷积可以做多个输出通道,因此提出多头注意力机制,可以模拟CNN多输出通道的一个效果;
-
自注意力机制
-
memory networks
-
Transformer第一个完全依赖于自注意力机制计算其输入和输出表示的转换模型,而不使用序列对齐的RNN或卷积。
模型架构
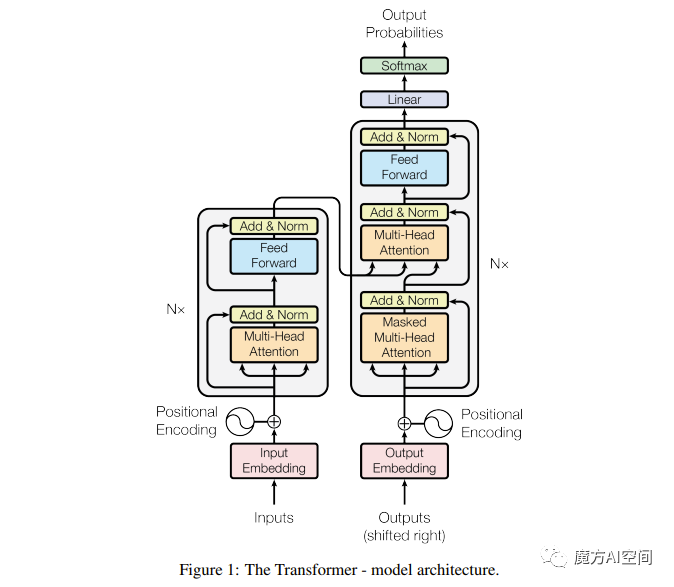
图 1
大多数神经序列转换模型都具有编码器-解码器结构。编码器将符号表示的输入序列(x1,...,xn)映射到连续表示的序列z = (z1,...,zn)。给定z,解码器逐步生成一个符号输出序列(y1,...,ym)。在每个步骤中,模型是自回归的,在生成下一个符号时,使用先前生成的符号作为附加输入。
Transformer遵循这个总体结构,使用堆叠的自注意力机制和逐点连接的全连接层作为编码器和解码器,分别显示在上图的左半部分和右半部分。
Encoder and Decoder Stacks
Encoder:编码器由N = 6个相同的层组成。每个层包含两个子层。第一个子层是一个多头自注意力机制,第二个子层是一个简单的逐位置全连接的前馈网络。在每个子层周围采用了残差连接[11],随后进行了层归一化[1]。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。为了方便这些残差连接,模型中的所有子层以及嵌入层都产生dmodel = 512的输出。
解释下LayerNorm:类似于batchNorm,layerNorm是对每个样本做Norm,而不是对每个特征做了,把每一行(样本)变成均值为0,方差为1。简单理解就是把数据整体转置一下,放入到batchNorm中,然后再转置回来。
Decoder:解码器也由N = 6个相同的层组成。除了每个编码器层中的两个子层外,解码器还插入第三个子层,对编码器堆栈的输出执行多头注意力机制。与编码器类似,我们在每个子层周围使用残差连接,随后进行层归一化。还修改了解码器堆栈中的自注意力子层,以防止位置参考后续位置。这种Masked机制,加上输出嵌入向量向前偏移一个位置,保证在位置i处的预测仅依赖于位置小于i的已知输出。
Attention
注意力函数可以描述为将query和一组key-value对映射到输出的函数,其中query、key、value和ouput都是向量。输出被计算为值的加权和,其中分配给每个值的权重由query与相应key的兼容性函数计算。
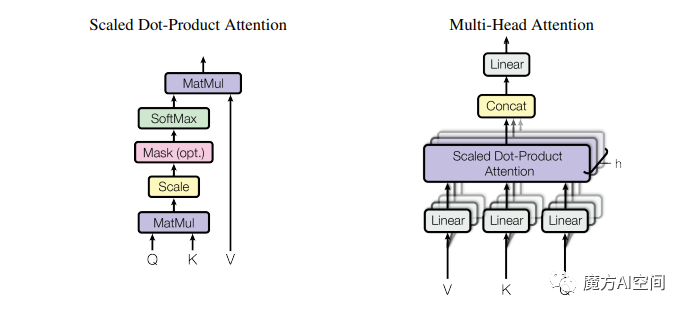
图 2
Scaled Dot-Product Attention
如图2,输入由维度为dk的query和key以及维度为dv的value组成。我们计算query与所有key的点积,将每个点积除以√dk,并应用softmax函数以获取value的权重。
在实践中,同时在一组query上计算注意力函数,将query打包成矩阵Q。key和value也被打包成矩阵K和V。我们计算输出矩阵为:
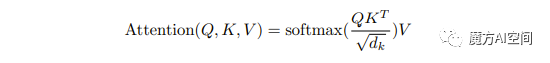
最常用的两种注意力函数是加性注意力和点积(乘法)注意力。点积注意力与我们的算法相同,除了缩放因子为1/√dk。加性注意力使用具有单个隐藏层的前馈网络来计算兼容性函数。虽然在理论复杂度上两者相似,但在实践中,点积注意力更快,更节省空间,因为可以使用高度优化的矩阵乘法代码实现。
虽然在dk的值较小时两种机制表现类似,但对于较大的dk值,加性注意力优于未缩放的点积注意力。我们怀疑对于较大的dk值,点积会变得非常大,将softmax函数推入其梯度极小的区域。为了抵消这种影响,我们通过1/√dk缩放点积。
Multi-Head Attention
与使用dmodel维度的key、value和query执行单个注意力函数相比,我们发现将query、key和value进行h次不同的、可学习的线性投影到dk,dk和dv维度上会更有益。在这些query、key和value的投影版本中,我们以并行方式执行注意力函数,产生dv维度的输出值。然后将这些输出值进行连接,并再次进行投影,得到最终的值,如图2所示。
多头注意力允许模型同时关注不同位置的不同表示子空间中的信息。使用单个注意力头,平均会抑制这种效果。

在这项工作中,我们使用h = 8个并行的注意力层或头。对于每个头,我们使用dk = dv = dmodel / h = 64。由于每个头的维度减小,总计算成本与具有完整维度的单头注意力相似。
注意力在模型中的应用
自注意力机制其实是指key、value、query是一个东西,是自己本身。
Transformer在三种不同的方式上使用多头注意力:
-
在“编码器-解码器注意力”层中,query来自先前的解码器层,而存储的key和value来自编码器的输出。这使得解码器中的每个位置都可以关注输入序列中的所有位置。这模仿了序列到序列模型中的典型编码器-解码器注意力机制。
-
编码器包含自注意力层。在自注意力层中,所有的key、value和quey都来自同一个地方,在这种情况下,来自编码器中前一层的输出。编码器中的每个位置都可以关注编码器前一层中的所有位置。
-
同样,在解码器中,自注意力层允许解码器中的每个位置关注到该位置及其之前的所有位置。我们需要阻止解码器中的左向信息流,以保留自回归属性。我们通过在缩放点积注意力内部进行实现,通过将与非法连接相对应的所有值在softmax的输入中masked(设置为-∞)来实现。请参见图2。
Position-wise Feed-Forward Networks
除了注意力子层外,编码器和解码器中的每一层还包含一个全连接的前馈网络,该网络分别应用于每个位置,并且是相同的。它由两个线性变换组成,其中间有一个ReLU激活函数。
![]()
尽管线性变换在不同位置上是相同的,但它们在不同的层之间使用不同的参数。另一种描述这个过程的方式是使用大小为1的内核进行两次卷积。输入和输出的维度为dmodel= 512,内部层的维度为dff = 2048。
Embeddings and Softmax
与其他序列转换模型类似,我们使用学习嵌入将输入tokens和输出tokens转换为维度为dmodel的向量。我们还使用通常的学习线性变换和softmax函数将解码器输出转换为预测的下一个tokens概率。在我们的模型中, 我们共享两个嵌入层和预softmax线性变换之间的相同权重矩阵。在嵌入层中,我们将这些权重乘以√dmodel。
Positional Encoding
由于模型不包含循环和卷积,为了使模型利用序列顺序,我们必须注入一些信息,描述令牌在序列中的相对或绝对位置。为此,我们在编码器和解码器堆栈的底部添加“位置编码”到输入嵌入中。位置编码与嵌入具有相同的dmodel维度,以便它们可以相加。有许多选择位置编码,包括学习性和固定性。

评价
「Transformer」开创了继 MLP 、CNN和 RNN之后的第四大类模型,是一篇非常有价值和有影响力的论文,它提出了一种新的模型结构——Transformer模型,基于注意力机制来完成序列学习任务。具体来说,它将自注意力机制应用于序列到序列学习中,在机器翻译等任务中取得了非常好的效果,并且成为了当前神经机器翻译领域的标配模型。
从原理先进性上来看,Transformer提出了一个新的并且相对简单的模型结构,在处理长序列任务上优势十分明显,特别是相比于LSTM等传统的循环神经网络,Transformer能够更好地捕捉序列中的长程依赖关系,同时也降低了模型计算的时间复杂度,提高了模型的训练和预测效率。
从应用的广泛性和前沿性上来看,Transformer不仅在机器翻译任务中有着非常好的效果,还被广泛应用于语音识别、文本生成、自然语言理解等多种NLP任务中。同时它也被成功应用到了计算机视觉任务中,如图像描述等任务。
从性能上来看,Transformer在机器翻译任务中表现优异,其效果甚至超越了RNN和CNN等基于循环和卷积结构的模型。同时其效率和泛化能力也很高,可以处理长句子,更好地理解上下文,生成更加连贯、自然的翻译结果。
总之,Transformer是一篇非常有价值的论文,从原理上创新,应用广泛且前沿,表现优异,在自然语言处理、计算机视觉等任务中取得了良好的效果,对于推动人工智能的发展和应用具有重要的意义。
练一练
(1)Transformer为何使用多头注意力机制?(为什么不使用一个头)
(2)Transformer为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?(注意和第一个问题的区别)
(3)Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
(4)为什么在进行softmax之前需要对attention进行scaled?(为什么除以dk的平方根),并使用公式推导进行讲解
(5)在计算attention score的时候如何对padding做mask操作?
(6)为什么在进行多头注意力的时候需要对每个head进行降维?
(7)大概讲一下Transformer的Encoder模块?
(8)为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
(9)简单介绍一下Transformer的位置编码?有什么意义和优缺点?
(10)你还了解哪些关于位置编码的技术,各自的优缺点是什么?
(11)简单讲一下Transformer中的残差结构以及意义?
(12)为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
(13)简答讲一下BatchNorm技术,以及它的优缺点?
(14)简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
(15)Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
(16)Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
(17)Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
(18)Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
(19)解码端的残差结构有没有把后续未被看见的mask信息添加进来,造成信息的泄露?
以上是关于Transformer的一些常见问题,快来测一测是否掌握了Transformer的原理吧,欢迎评论区回答!!!

相关文章:
开启AI大模型时代|「Transformer论文精读」
论文地址: https://arxiv.org/pdf/1706.03762v5.pdf 代码地址: https://github.com/tensorflow/tensor2tensor.git 首发:微信公众号「魔方AI空间」,欢迎关注~ 大家好,我是魔方君~~ 近年来,人工智能技术发展迅猛&#…...
【小沐学前端】Windows下搭建WordPress(nginx1.25、PHP8.2、WordPress6.3、MySQL5.7)
文章目录 1、简介1.1 Nginx1.2 PHP1.3 WordPress1.4 MySQL 2、下载2.1 Nginx2.2 PHP2.3 WordPress2.4 MySQL 3、搭建环境3.1 Nginx3.2 PHP3.3 WordPress3.4 MySQL 4、配置WordPress4.1 选择语言4.2 配置数据库4.3 登录界面4.4 常规设置4.5 写作操作 结语 1、简介 WordPress是基…...

centos8 Error: Failed to download metadata for repo ‘appstream‘
2020 年 12 月 8 号,CentOS 官方宣布了停止维护 CentOS Linux 的计划,并推出了 CentOS Stream 项目,CentOS Linux 8 作为 RHEL 8 的复刻版本,生命周期缩短,于 2021 年 12 月 31 日停止更新并停止维护(EOL&a…...

键盘上F1至F12键的作用
多年来,我们习惯了最上排的12个按键,从F1到F12,它们被称为“快速功能键”,可以让你更轻松地操作电脑;但是,很多人可能从未使用过它们,也从来不知道它们的用途。那么今天,就向大家科普…...

2023年湘潭大学OJ作业2 2023年下学期《C语言》作业0x01-数学计算 XTU OJ 1080,1081,1082,1083,1084
第一题 #include<stdio.h> #include<math.h>int main() {double a3.2,b4.7;aa*a,bb*b;double ressqrt(ab);printf("%g\n",res);return 0; } 注意math.h头文件的使用,还有sqrt是双精度的 第二题 #include<stdio.h> #include<math…...
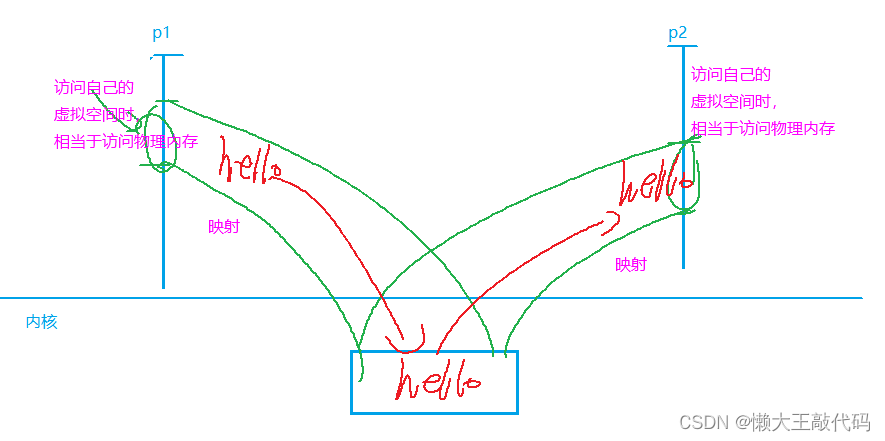
C/C++ 进程间通信system V IPC对象超详细讲解(系统性学习day9)
目录 前言 一、system V IPC对象图解 1.流程图解: 编辑 2.查看linux内核中的ipc对象: 二、消息队列 1.消息队列的原理 2.消息队列相关的API 2.1 获取或创建消息队列(msgget) 实例代码如下: 2.2 发送消息到消…...

python—如何提取word中指定内容
假设有一个Word,该Word中存在 “联系人” 关键字,如何将该Word中的联系人所对应的内容提取出来呢? 该Word内容如下所示: 要在给定的Word文档中提取出与"联系人"关键字对应的内容,可以使用Python的py…...
分享几个通用个人简历模板|行业通用
Home(https://cvjury.com/) 专业设计的简历模板。 在竞争激烈的就业市场中脱颖而出的有效策略。 侧重于向招聘人员传达独特的价值主张。 帮助创建引人注目的简历、求职信和LinkedIn资料。 面向毕业生和学生的个性化简历解决方案。 添加图片注释,不超过 140 字&…...

如何正确操作封箱机
前文跟大家分享过封箱机错误操作三案例,那么封箱机到底如何才能正确操作呢?今天就和您分享一下如何正确操作封箱机。 1、确定正确的电源电压进行接入。目前国内封箱机均采用220v 50hz电源电压,但也有一些定制型设备可能使用380v电源ÿ…...

mysql面试题7:MySQL事务原理是什么?MySQL事务的隔离级别有哪些?
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:MySQL事务原理是什么? MySQL事务的原理是基于ACID(原子性、一致性、隔离性、持久性)特性来实现的,具体原理如下: Atomicity(原子性):事务…...

vue 项目打包性能分析插件 webpack-bundle-analyzer
webpack-bundle-analyzer 是 webpack 的插件,需要配合 webpack 和 webpack-cli 一起使用。这个插件可以读取输出文件夹(通常是 dist)中的 stats.json 文件,把该文件可视化展现,生成代码分析报告,可以直观地…...
C++ day2
1->x.mind 2->...
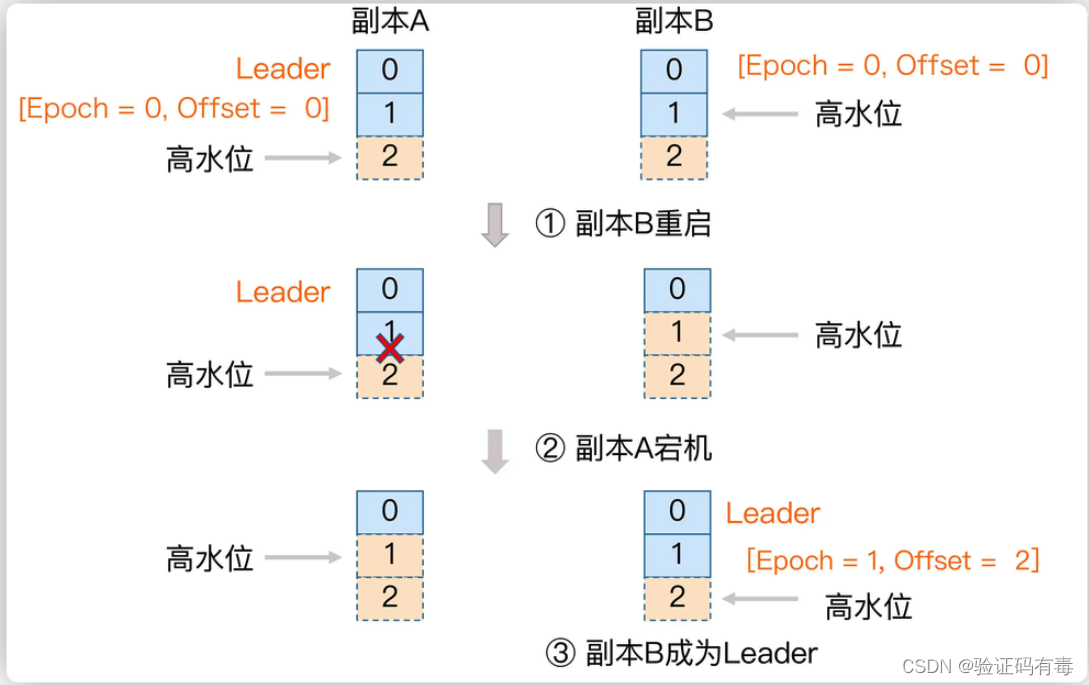
【Kafka专题】Kafka集群架构设计原理详解
目录 前言前置知识课程内容一、Kafka的Zookeeper元数据梳理1.1 zookeeper整体数据1.2 Controller Broker选举机制1.3 Leader Partition选举机制1.4 Leader Partition自动平衡机制*1.5 Partition故障恢复机制1.6 HW一致性保障-Epoch更新机制1.7 总结 学习总结感谢 前言 Kafka的…...
Docker 镜像的缓存特性
Author:rab 目录 前言一、构建缓存二、Pull 缓存总结 前言 首先我们要清楚,Docker 的镜像结构是分层的,镜像本身是只读的(不管任何一层),当我们基于某镜像运行一个容器时,会有一个新的可写层被…...
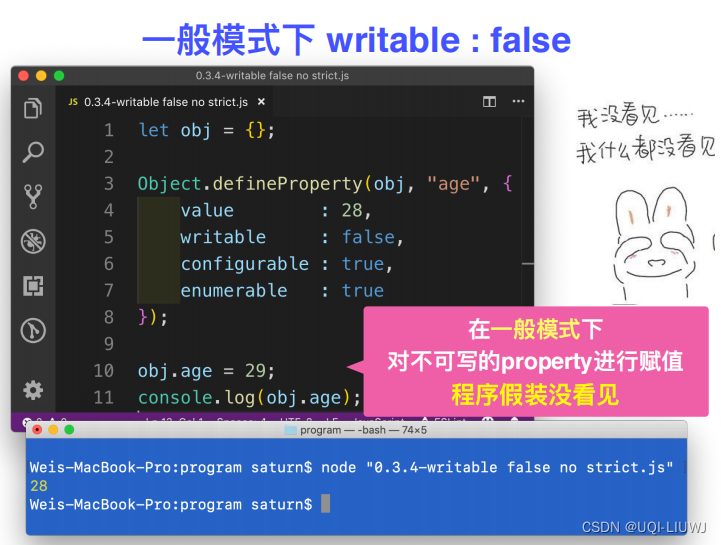
Javascript 笔记:object
一部分object可以见:JavaScript 笔记 初识JavaScript(变量)_UQI-LIUWJ的博客-CSDN博客 1 in操作符 2 hasOwnProperty 3 获取一个object所拥有的所有property 不去原型链上找 4 定义data property...

【vue3】可编辑el-table
<template><el-table:data"tableData"style"width: 100%"><el-table-columnprop"date"label"日期"width"180"><template #default"{row,$index}"><input type"text" v-mode…...

一个开源的安卓相机:OpenCamera
原网址 Open Camera download | SourceForge.net 我也上传了一个 https://github.com/quantum6/Android-OpenCamera...

分类预测 | MATLAB实现POA-CNN鹈鹕算法优化卷积神经网络多特征分类预测
分类预测 | MATLAB实现POA-CNN鹈鹕算法优化卷积神经网络多特征分类预测 目录 分类预测 | MATLAB实现POA-CNN鹈鹕算法优化卷积神经网络多特征分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现POA-CNN鹈鹕算法优化卷积神经网络多特征分类预测࿰…...

学习网络编程No.7【应用层之序列化和反序列化】
引言: 北京时间:2023/9/14/19:13,下午刚刚更完文章,是一篇很久很久以前的文章,由于各种原因,留到了今天更新,非常惭愧呀!目前在上学校开的一门网络课程,学校的课听不了一…...
小谈设计模式(10)—原型模式
小谈设计模式(10)—原型模式 专栏介绍专栏地址专栏介绍 原型模式角色分类抽象原型(Prototype)具体原型(Concrete Prototype)客户端(Client)原型管理器(Prototype Manager…...

nli-distilroberta-base入门教程:零基础理解自然语言推理任务
nli-distilroberta-base入门教程:零基础理解自然语言推理任务 1. 什么是自然语言推理? 自然语言推理(Natural Language Inference,简称NLI)是让计算机理解两段文本之间逻辑关系的任务。想象一下老师批改作业的场景&a…...

it-tools:Docker一键部署,中文界面即开即用
1. 为什么选择Docker部署it-tools? 最近在帮团队搭建开发环境时,发现很多同事都在反复安装各种零散的小工具——JSON格式化、时间戳转换、密码生成器...既占用本地资源又难以统一管理。直到发现了it-tools这个神器,它把200实用工具打包成Web应…...
忍者像素绘卷惊艳案例:生成支持CSS Sprite切片的像素角色动作序列图
忍者像素绘卷惊艳案例:生成支持CSS Sprite切片的像素角色动作序列图 1. 像素艺术的新纪元 在游戏开发领域,像素艺术始终保持着独特的魅力。忍者像素绘卷作为一款基于Z-Image-Turbo深度优化的图像生成工具,为开发者带来了革命性的解决方案。…...

fre:ac开源音频转换工具:让无损音乐在全设备自由流动的专业级解决方案
fre:ac开源音频转换工具:让无损音乐在全设备自由流动的专业级解决方案 【免费下载链接】freac The fre:ac audio converter project 项目地址: https://gitcode.com/gh_mirrors/fr/freac 你是否遇到过这些音乐管理难题:珍藏多年的CD专辑不知如何数…...

从Android大神到AI先锋!10年程序员血泪转型路,AI工程师高薪秘诀全公开!
一眨眼,我已经工作 10 年了。 在 2022 年以前,我一直相信,在这个行业里,只要技术栈钻得深,比如精通三方框架、熟悉 Android Framework、搞定性能优化,就能端稳饭碗。 但从 2023 年开始,一切都变…...

VisDrone2019-MOT转COCO踩坑实录:为什么你的转换脚本总报错?附修复方案
VisDrone2019-MOT转COCO实战避坑指南:从报错解析到工业级解决方案 当你第一次尝试将VisDrone2019-MOT数据集转换为COCO格式时,可能会遇到各种令人抓狂的报错信息。这不是你的问题——这个转换过程确实存在许多隐藏的陷阱。本文将带你深入剖析五个最常见的…...

ArchLinux新手必看:用Fcitx5搞定中文输入,从安装到美化皮肤保姆级教程
ArchLinux新手必看:用Fcitx5搞定中文输入,从安装到美化皮肤保姆级教程 刚接触ArchLinux的新手们,面对命令行界面时总会有些手足无措。特别是当需要输入中文时,如何配置一个既美观又实用的输入法成了许多人的第一个挑战。Fcitx5作…...
‘报错和依赖冲突)
PyCharm+Conda环境避坑指南:手把手配置Real-ESRGAN,解决‘torch.cuda.is_available()‘报错和依赖冲突
PyCharmConda环境避坑指南:手把手配置Real-ESRGAN,解决‘torch.cuda.is_available()‘报错和依赖冲突 图像超分辨率技术正在改变我们处理低质量图像的方式,而Real-ESRGAN作为当前最先进的通用图像修复模型之一,其效果令人惊艳。但…...
✅)
计算机毕业设计:Python 汽车推荐系统实战 Django框架 可视化 协同过滤算法 数据分析 大数据 机器学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

让ai当你的git导师:用快马开发智能github问答与代码生成助手
最近在尝试学习GitHub的使用时,发现很多操作命令记不住,尤其是遇到合并冲突或者需要回退版本的时候,总是要反复查文档。于是我想,能不能做一个AI助手来帮忙?经过在InsCode(快马)平台上的一番折腾,还真做出了…...