分布式数据库(林子雨慕课课程)
文章目录
4. 分布式数据库HBase
4.1 HBase简介
- HBase是BigTable的开源实现

-
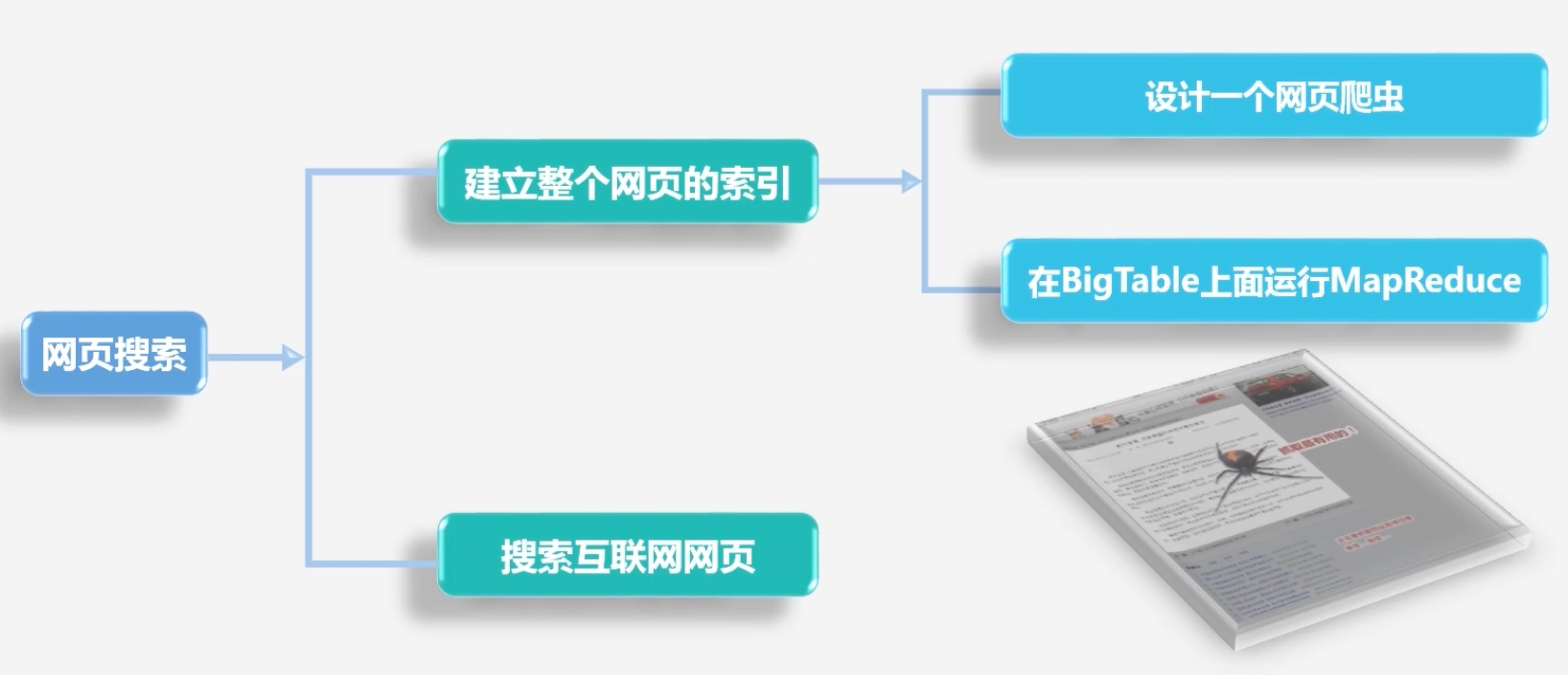
对于网页搜索主要分为两个阶段
-
1.建立整个网页索引:设计网页爬虫,爬取的网页存入BigTable中,在上面运行MapReduce
-
2.搜索互联网网页
-
-
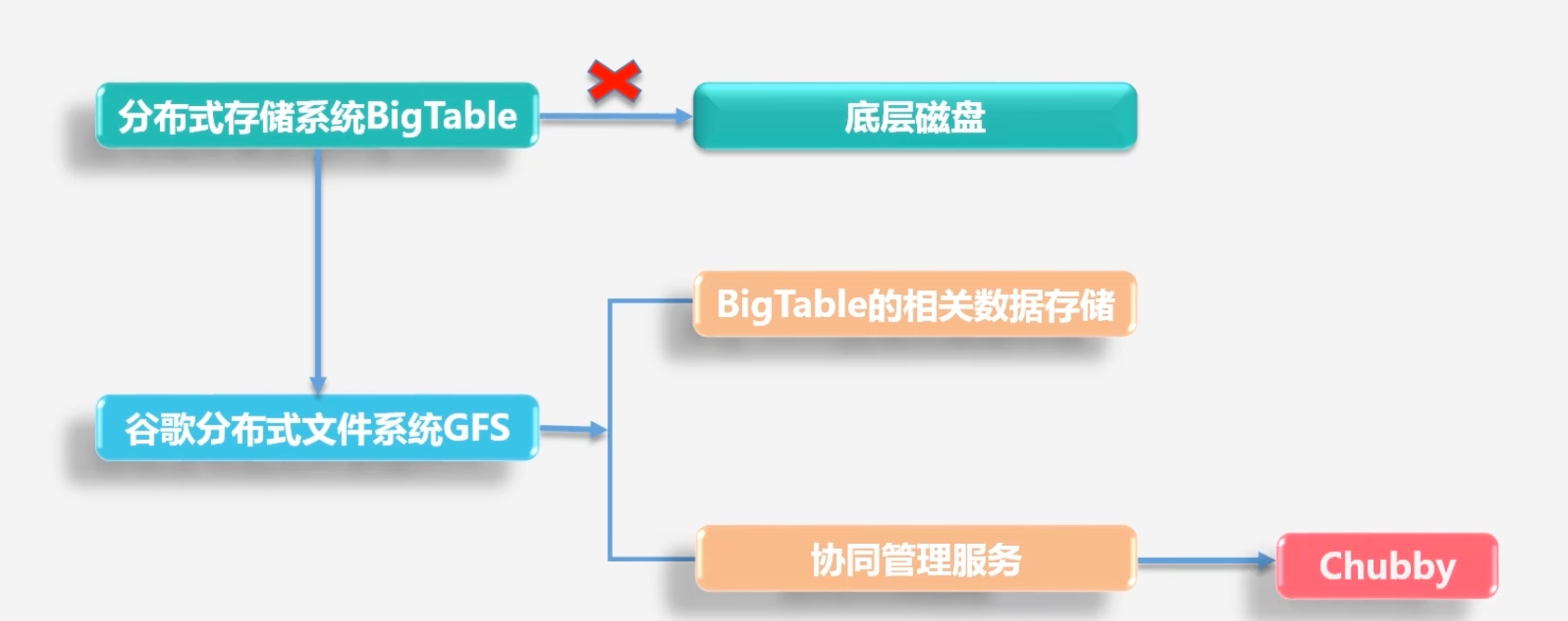
BigTable诞生?

-
Bigtable是在GFS的基础上实现的
-
为什么分布式存储系统可以得到广泛的关注?
- 它具有非常好的性能(可以支持PB级别的数据)
- 它具有非常好的可扩展性(用集群去存储几千台服务器完成分布式存储)
-
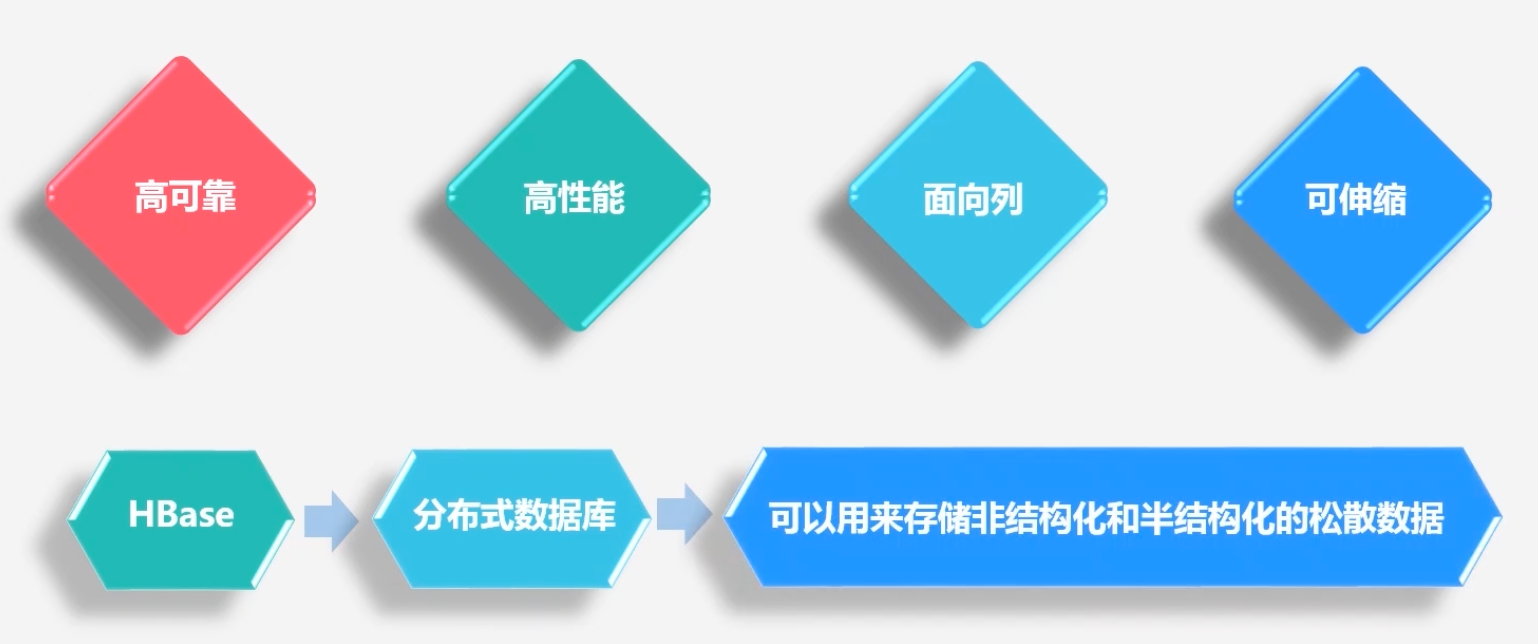
HBase特点:高可能、高性能、面向列、可伸缩
-
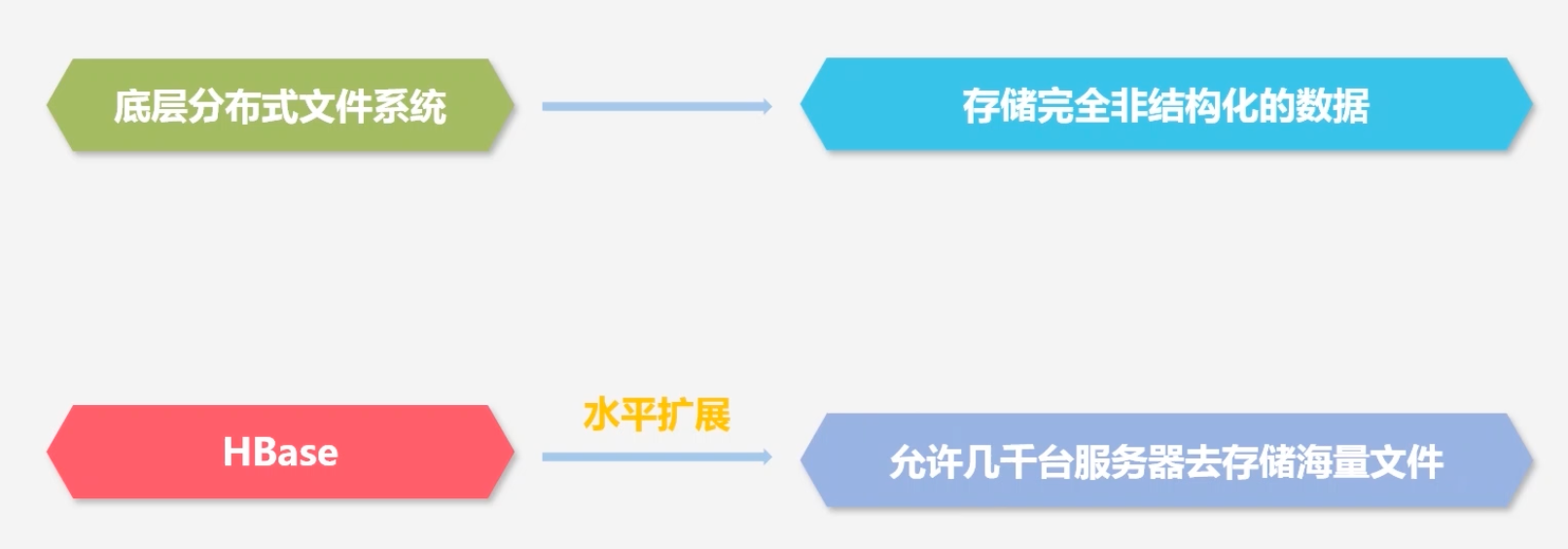
HBase:通过水平扩展的方式,允许几千台服务器去存储海量文件
-
HBase和BigTable的底层技术对应关系
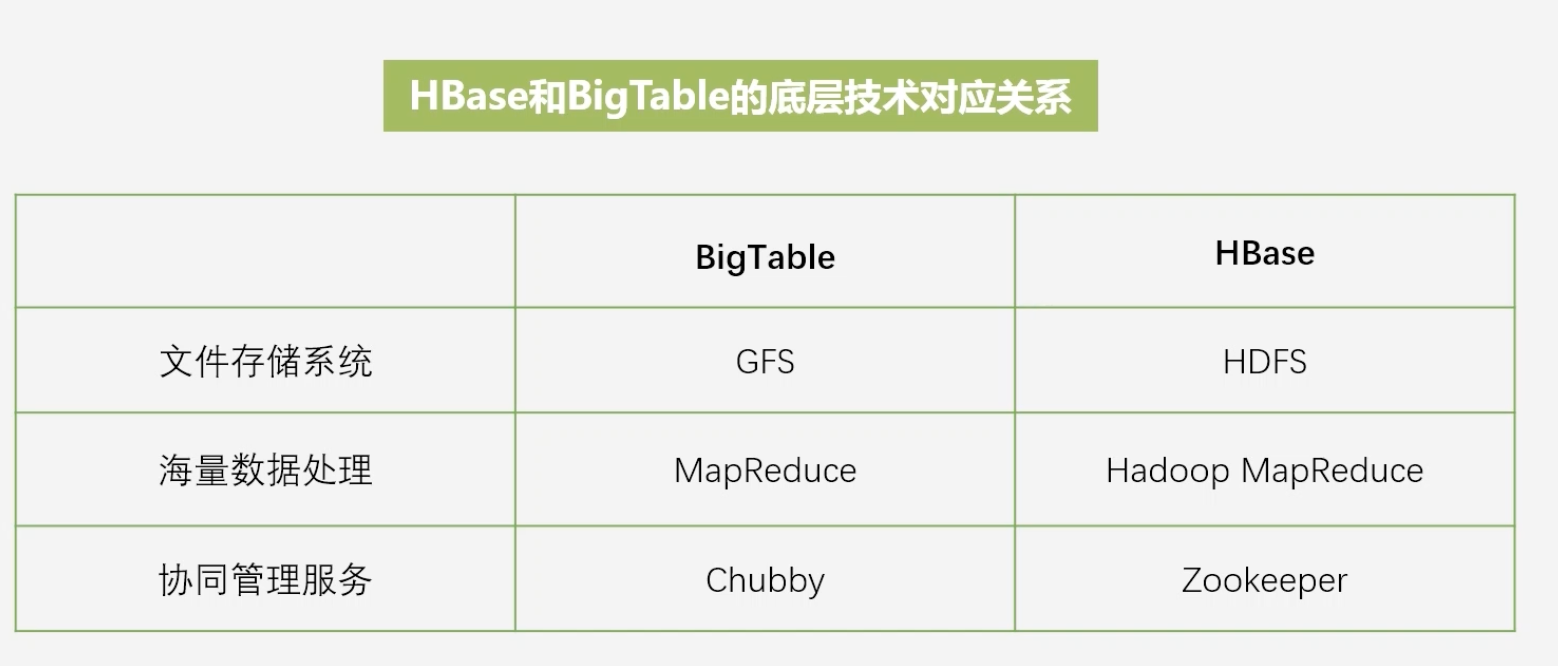
-
为什么需要设计HBase这么一个数据库产品?
-
虽然已经有了HDFS和MapReduce,但是Hadoop主要解决大规模数据离线批量处理,Hadoop无法满足大数据实时处理需求。
-
随着这些年数据的大规模爆炸式增长,传统关系型数据库的扩展能力非常有限,即使通过设计主从复制方案或者分库的方式,仍然有两个缺陷,一个是不便利,另一个是效率非常低
-
-
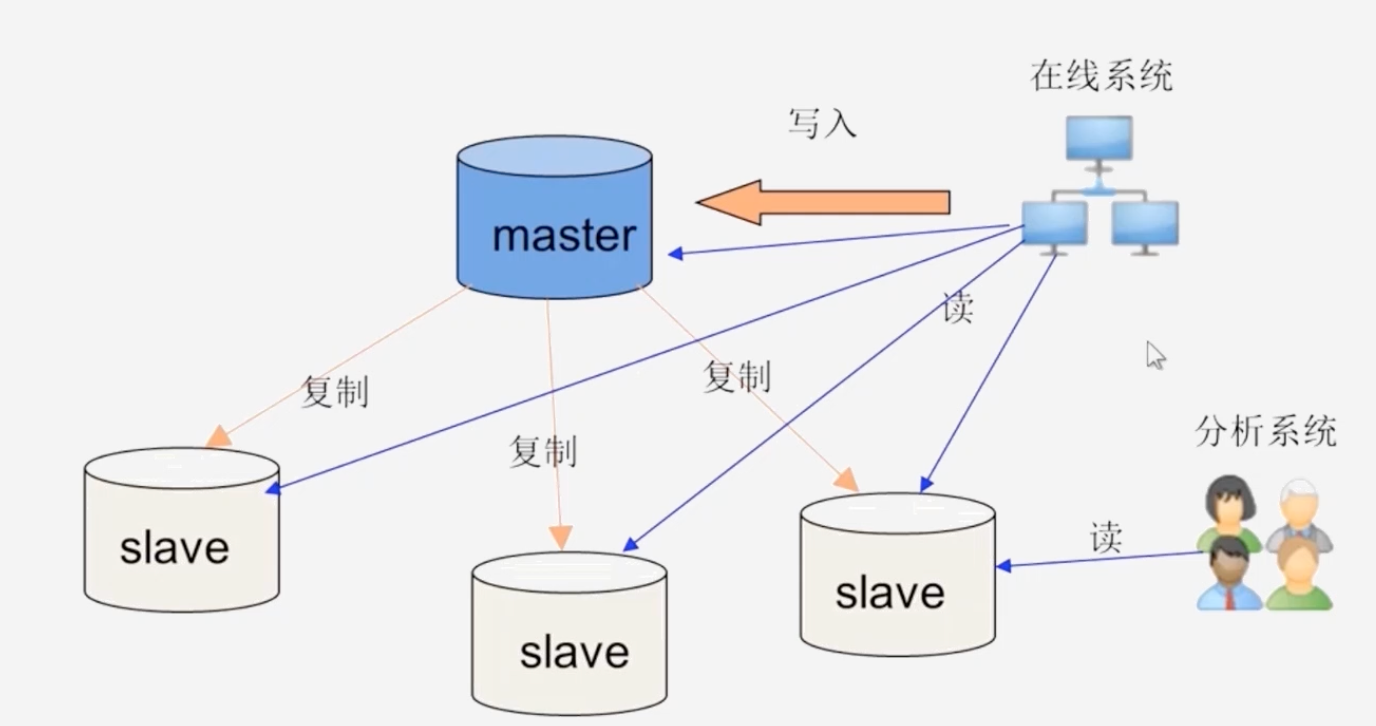
传统关系型数据库如何进行数据规模化扩展:
-
设计主从复制方案,由主服务器负责接收写请求,若干从服务器都是主服务器的副本,从服务器接收外界的读请求,这样可以实现数据库在性能上的一定扩展
-
做分库:对企业内部数据进行分库,将写负载分流
-
-
Hbase和传统关系型数据库有什么联系和区别?
-
数据类型方面,传统关系数据库用的是非常经典的关系数据模型
-
数据操作方面,在关系数据库中定了非常多的数据操作,查找,插入,删除等
-
存储模式方面,关系数据库基于行模式存储,而对于HBase来讲是基于列存储
-
在数据索引方面,关系数据库可以直接针对各个不同的列,构建非常复杂的索引
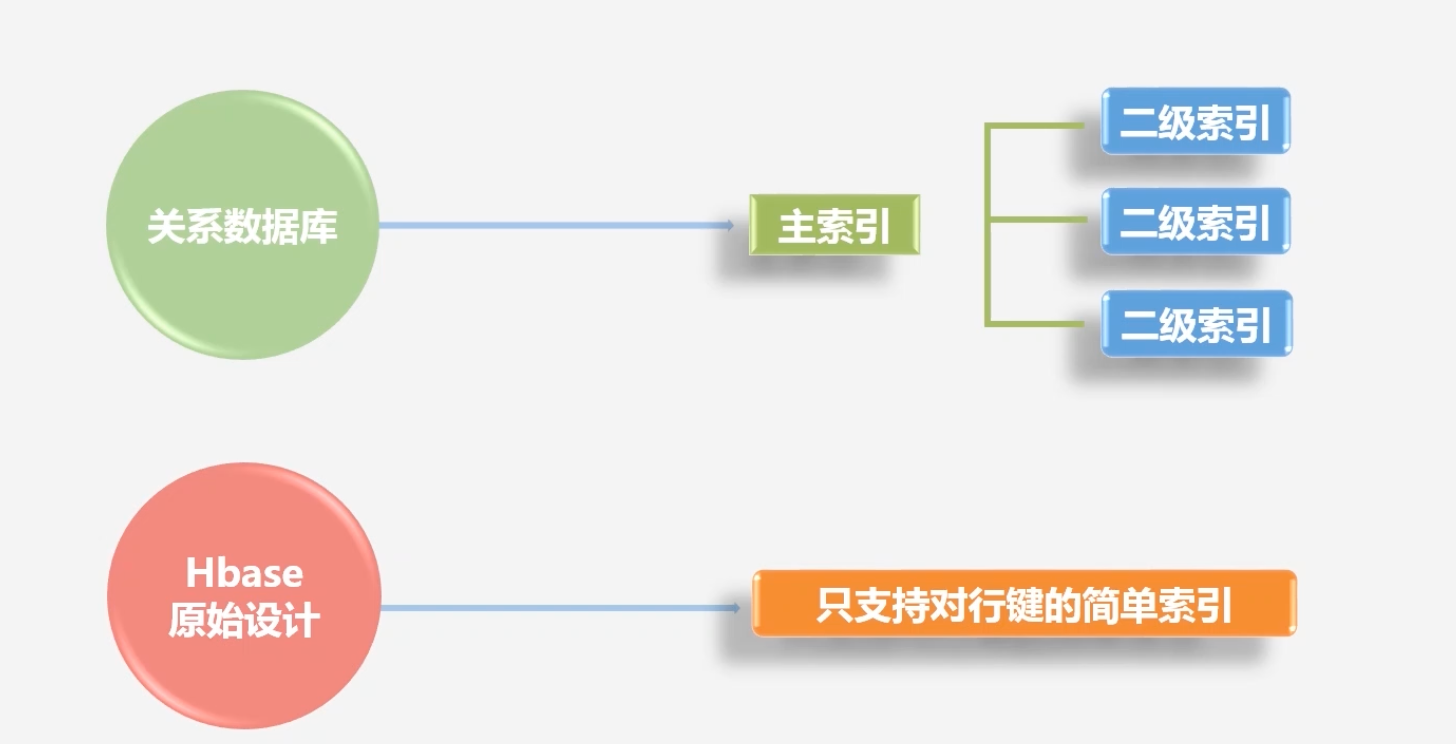
-
数据维护方面,在关系数据库当中做一些数据更新操作的时候,实际上里面旧的值会被新的值覆盖掉;而HBase生成新的版本,旧的版本仍然存在,不会被替换
-
可伸缩性方面,关系数据库是很难实现水平扩展的,最多可以实现纵向扩展
-
-
HBase访问接口
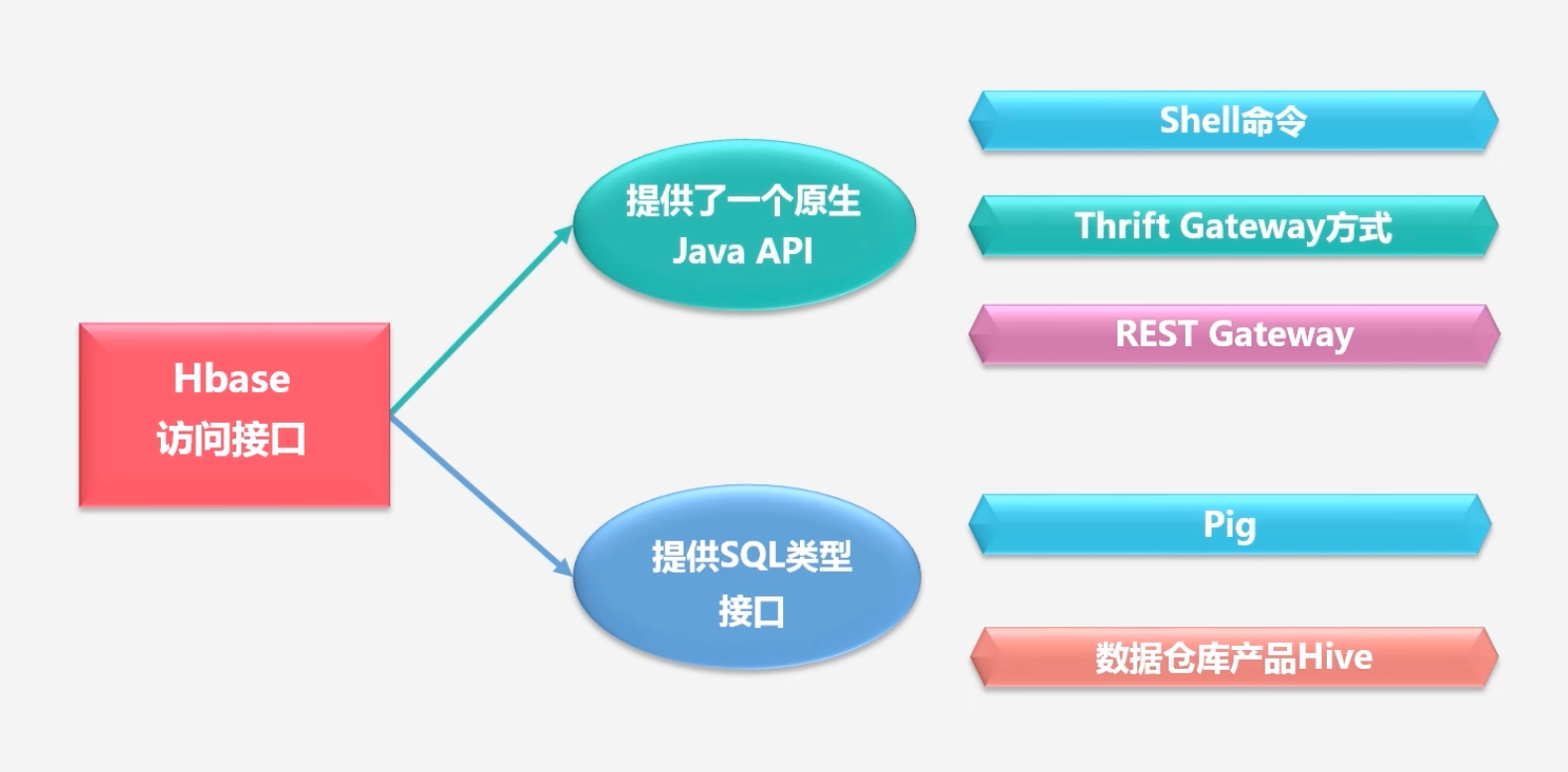
4.2 HBase数据模型
-
HBase是一个稀疏的多维度的排序的映射表:包含行键,列族,列限定符,时间戳
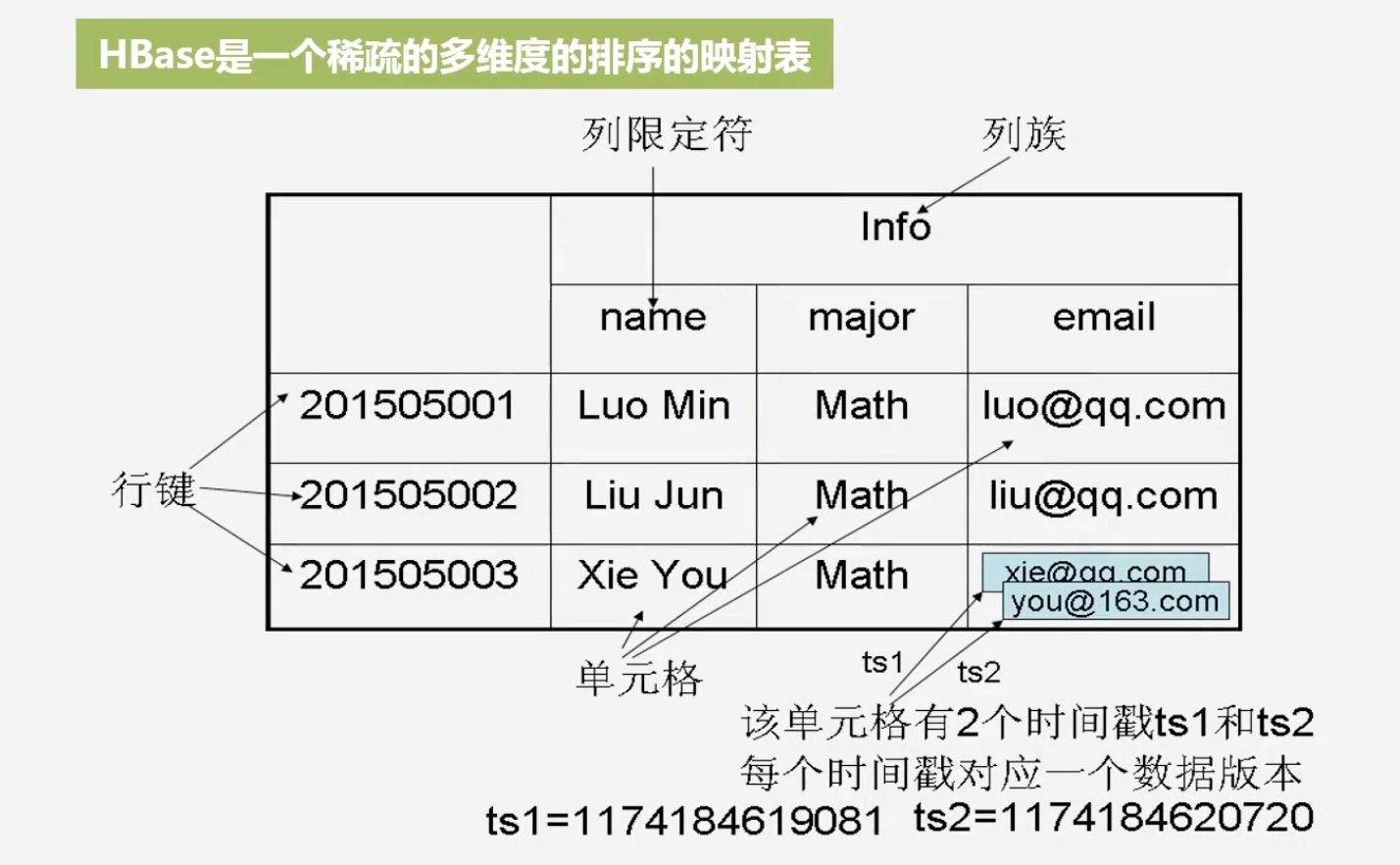
-
HBase特点

-
列族的特性
-
支持动态扩展:可以对列族进行增加或者减少
-
保留旧的版本:执行数据更新操作的时候,会保留旧版本
-
HBase以表的形式组织数据,与关系型数据库的区别:关系型数据库会对其进行规范化处理,根据第一范式、第二范式、第三范式,将 表进行不断分解,最后需要对表进行多表连接;HBase不考虑冗余,牺牲空间去避免表连接操作带来的效率问题
-
-
列限定符(列)
- 实际过程中可以动态增加或者减少列
-
单元格:具体存储数据的地方
-
时间戳:新的版本会通过时间戳进行确定
-
数据坐标的定位:必须通过四维:行键、列族、列限定符、时间戳来定位数据位置
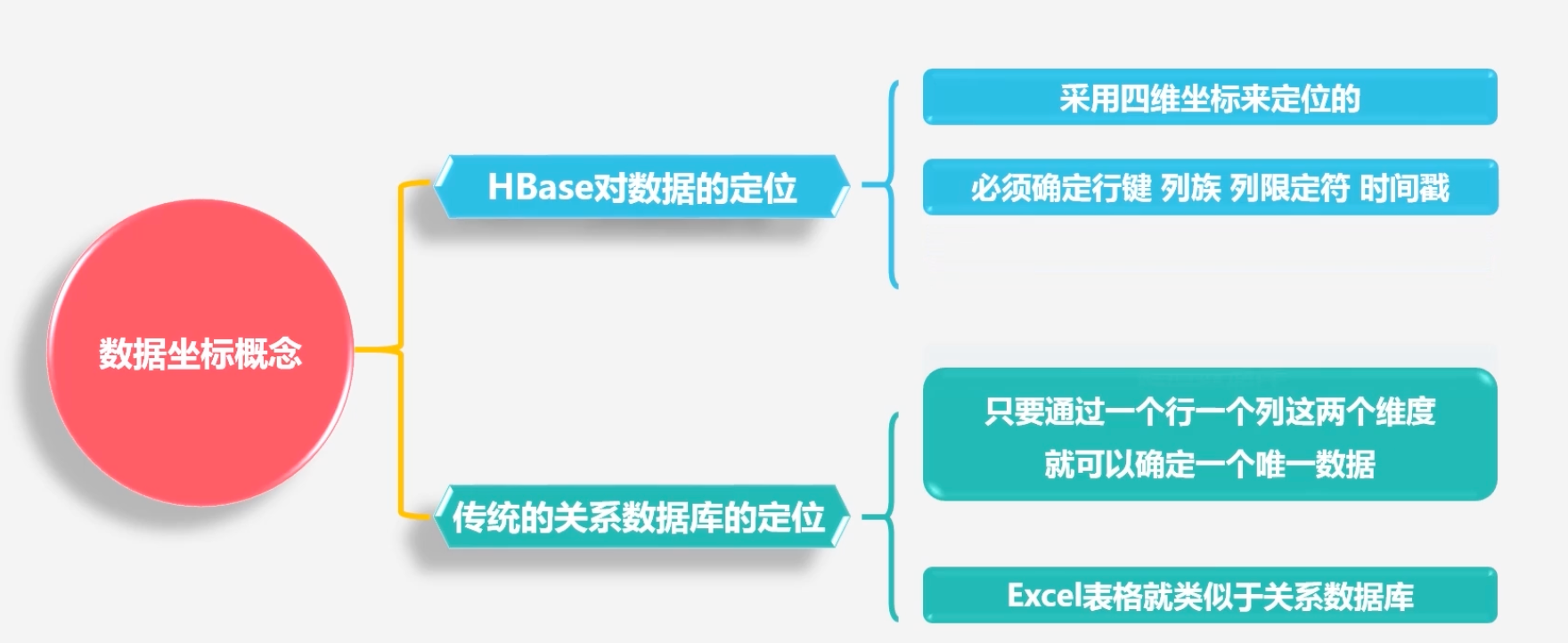
-
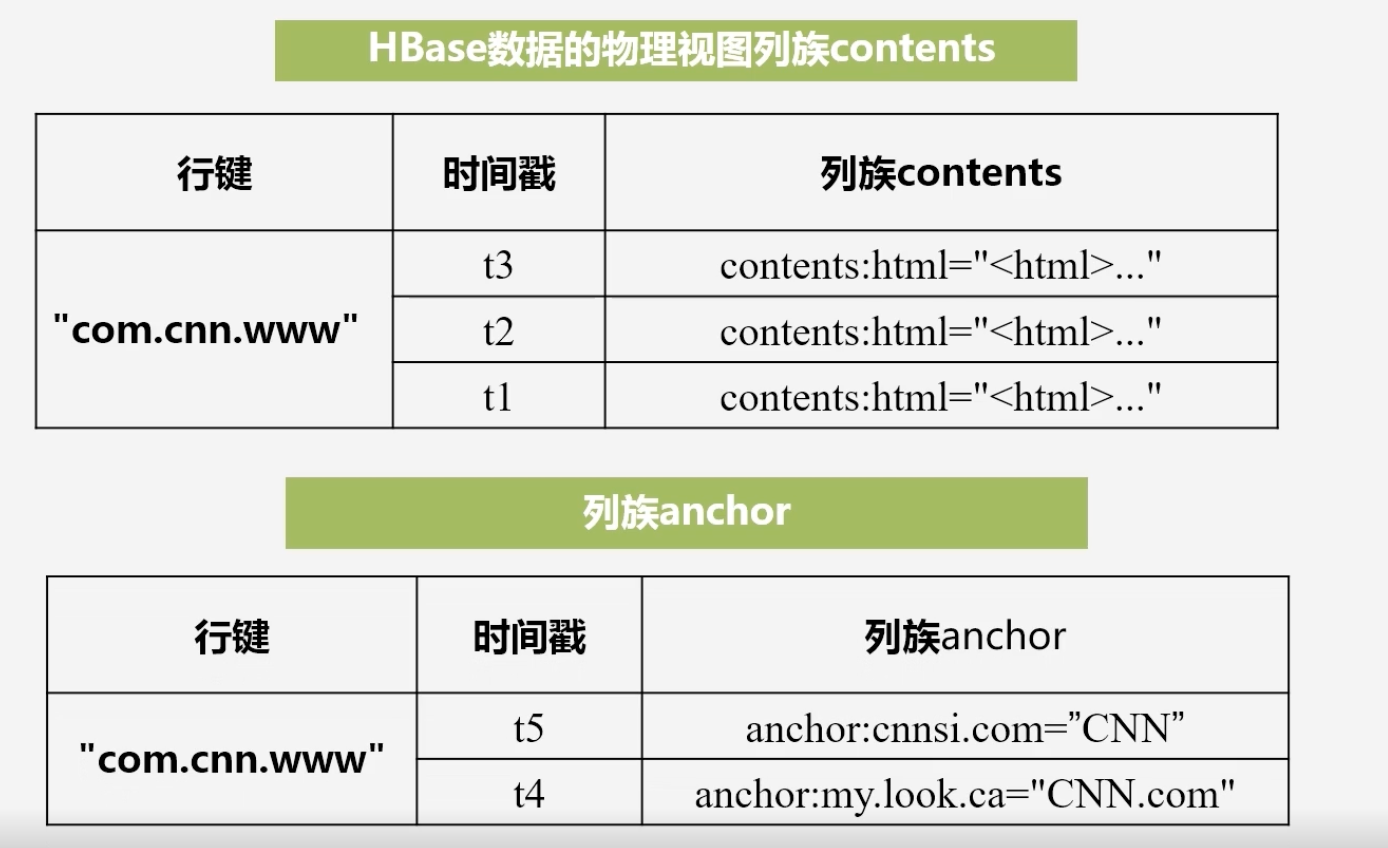
HBase数据的概念视图
- 列族名称:具体列限定符=“”
- 在概念上HBase数据是稀疏的,因为很多单元格是空白的
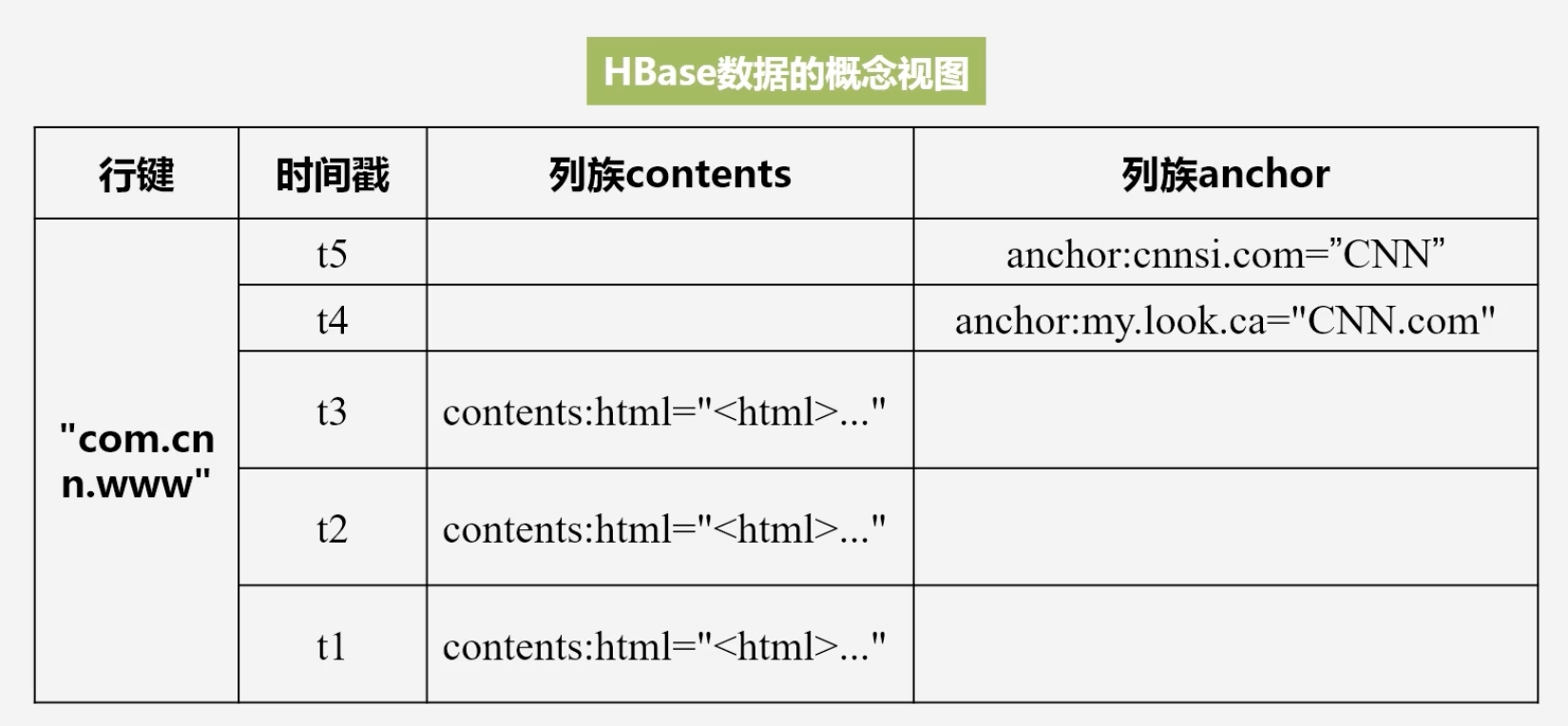
-
HBase数据的物理视图:是按照列族进行存储的
-
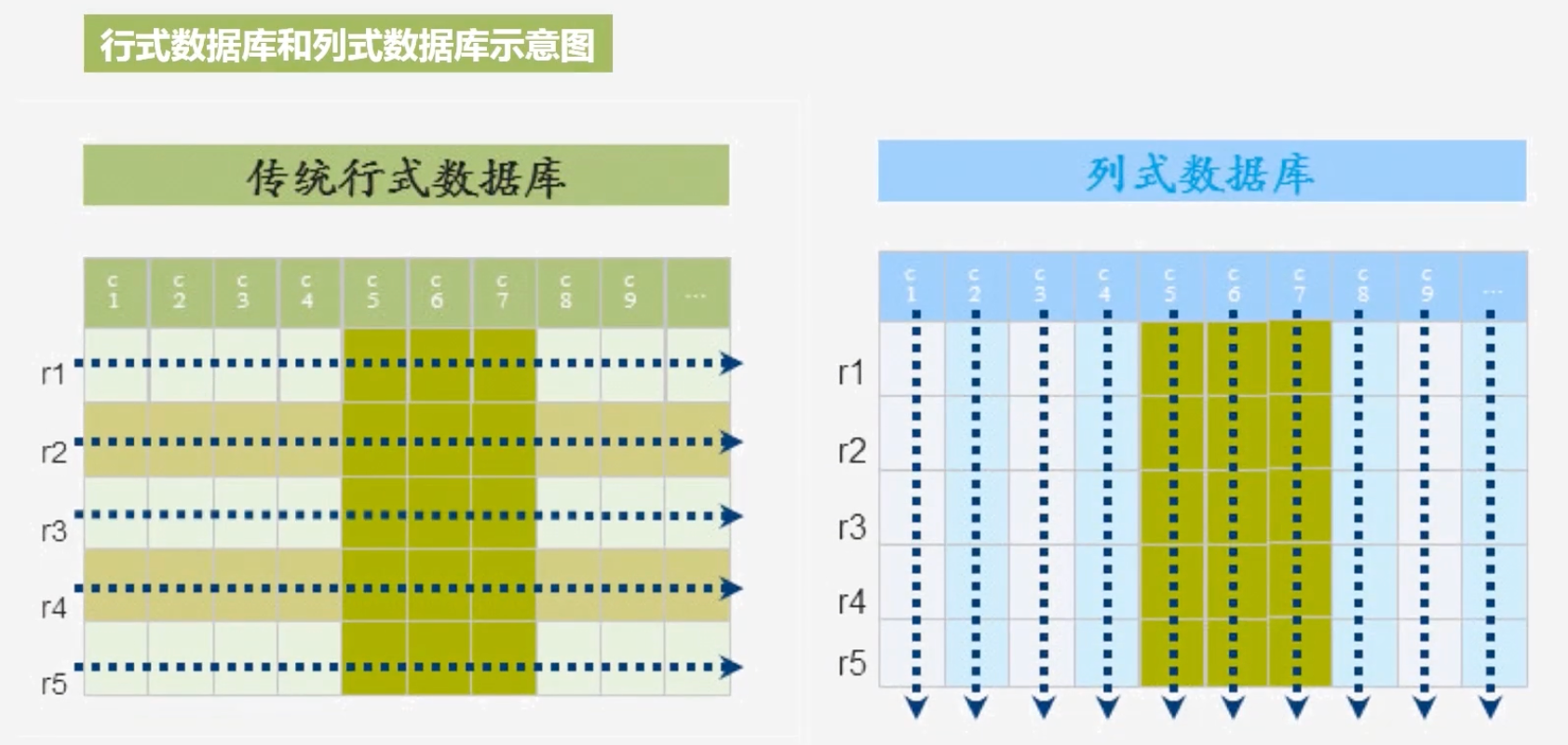
传统关系型数据库是行式存储,而HBase是列式存储

-
行式数据库和列式数据库示意图
-
面向行的存储有什么优势和缺点

-
列式存储的优点
- 列式存储:按照一个列去存储,可以带来很高的数据压缩率,适用于以分析型应用为主的场景
- 行式存储:不可能达到很高的数据压缩率,适合事务型操作比较多的场景
4.3 HBase的实现原理
-
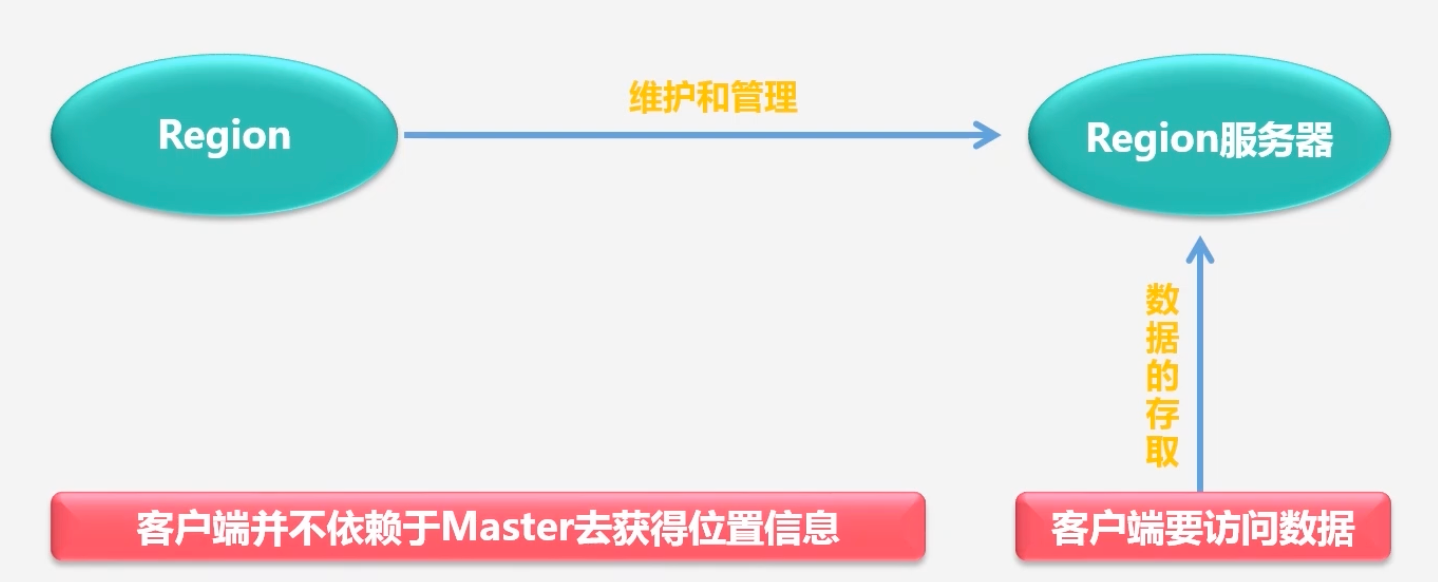
HBase的功能组件:Master服务器、库函数、Reigion服务器
-
库函数:链接每个客户端
-
Master服务器:充当管家作用

-
Region服务器:负责存储不同的Region
-
客户端在获取Region位置信息之后,直接和Region服务器进行打交道
-
-
-
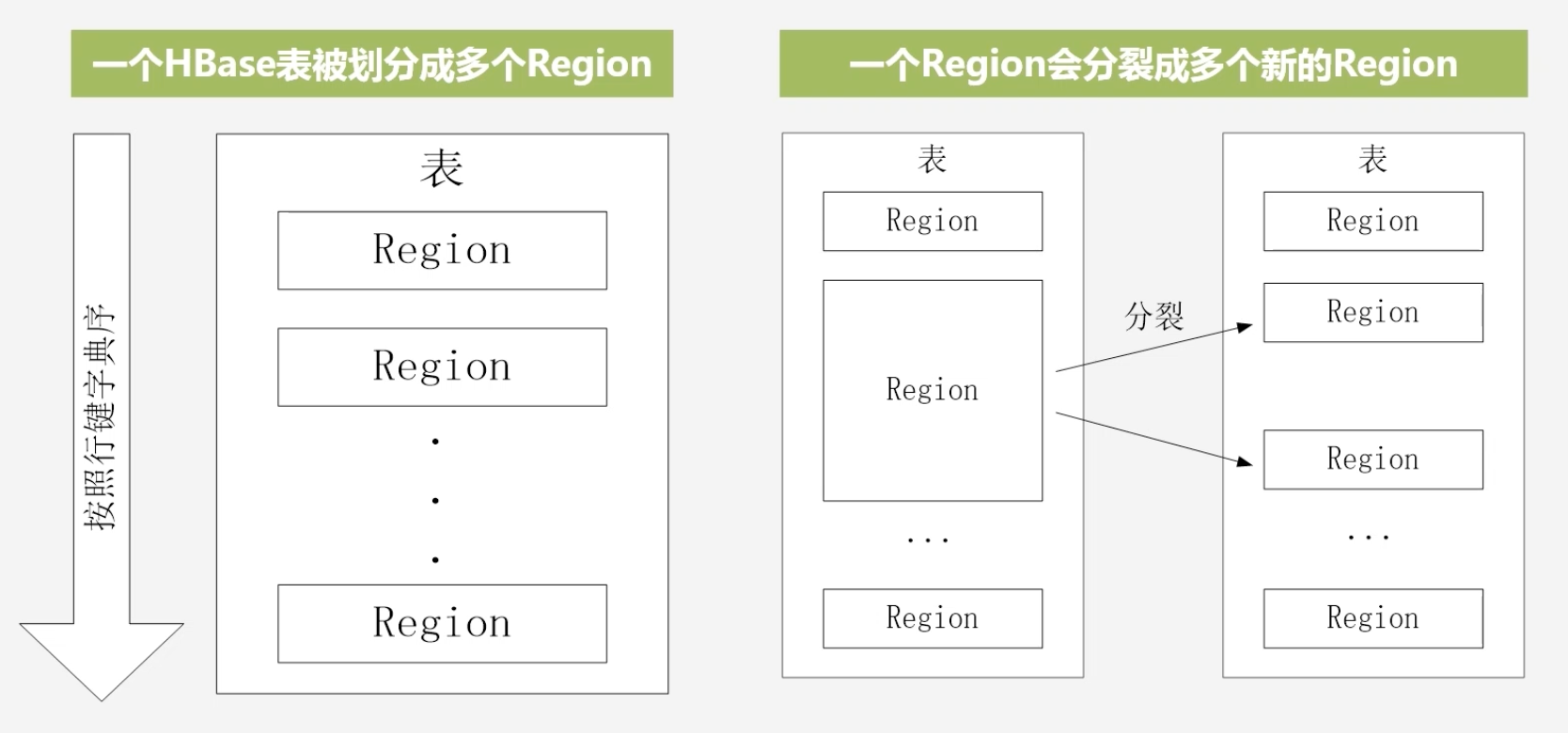
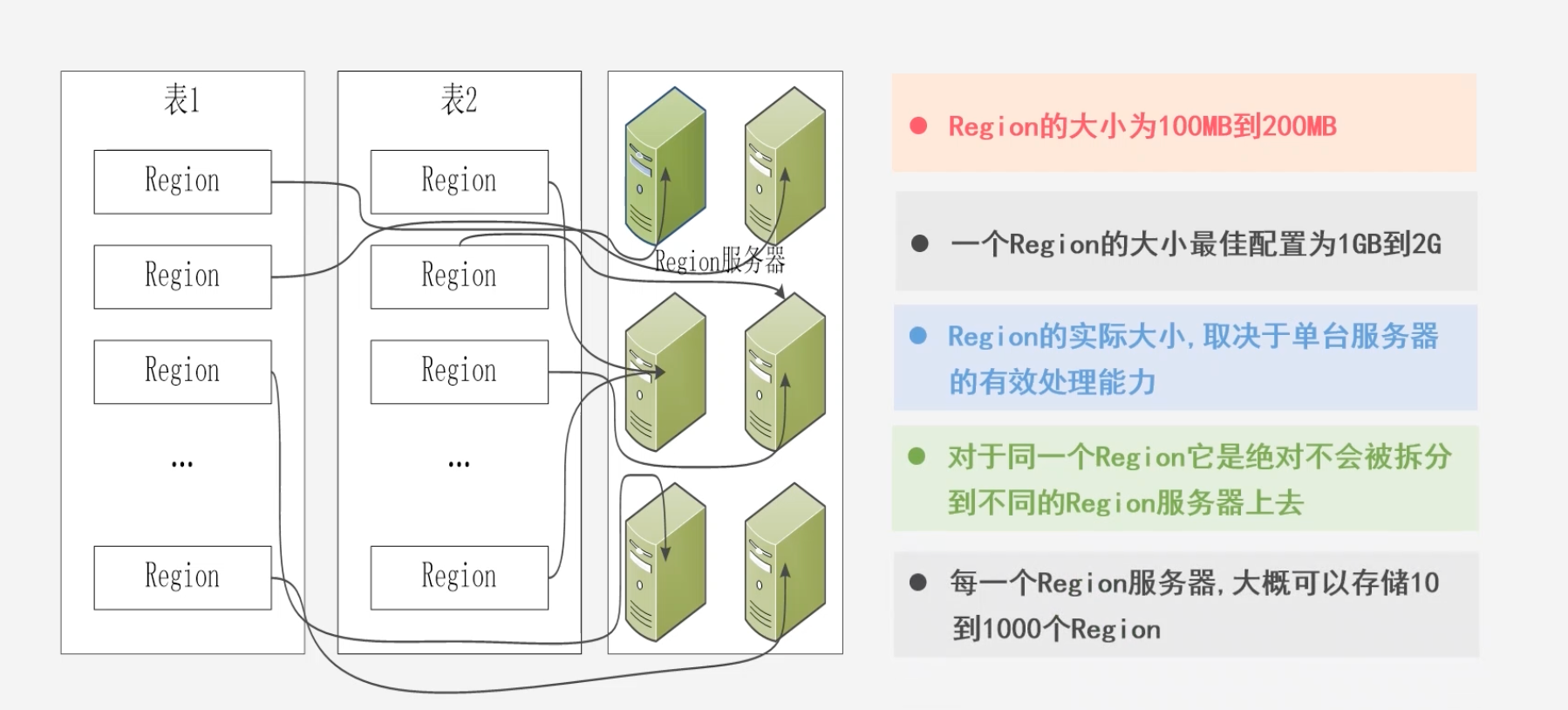
HBase的表和Region的关系
-
初始化的时候将一个HBase表划分为多个Region,随着表的增大,Region规模增加,会分裂成多个新的Region,分裂时只需要修改指向信息,是非常快速的
-
-
Region到底被存到哪里去了?

-
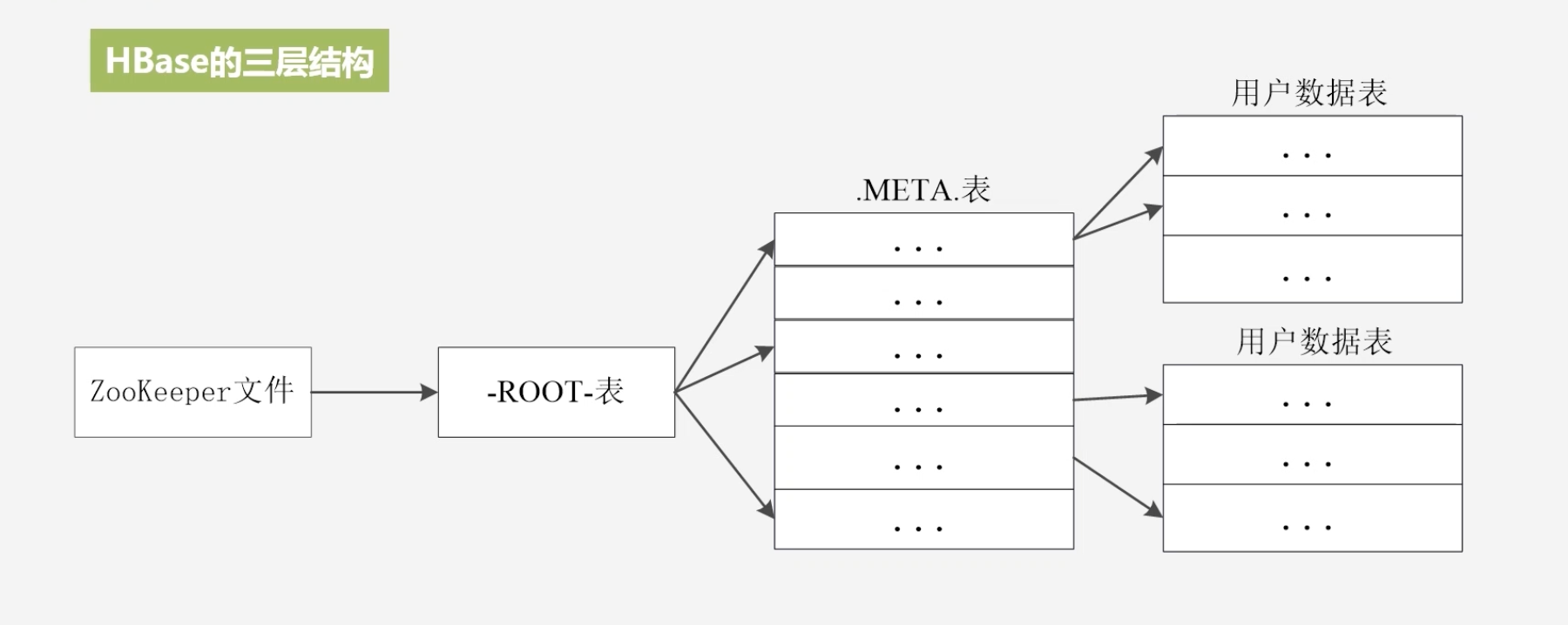
HBase的三层结构
-
Root表在一个Region机器上,存储的元数据信息,即META表的位置
-
META表存储的是用户数据存储的位置
-
Root表的地址是写死在Zookeeper中的
为了加速寻址,客户端会缓存位置信息,但同时需要解决缓存失效问题,它会先通过缓存查找数据,若找不到数据,则判定缓存失效,需要重新进行三级寻址
-
三层结构中各层次的名称和作用

-
Region的定位


-
4.4 HBase运行机制
-
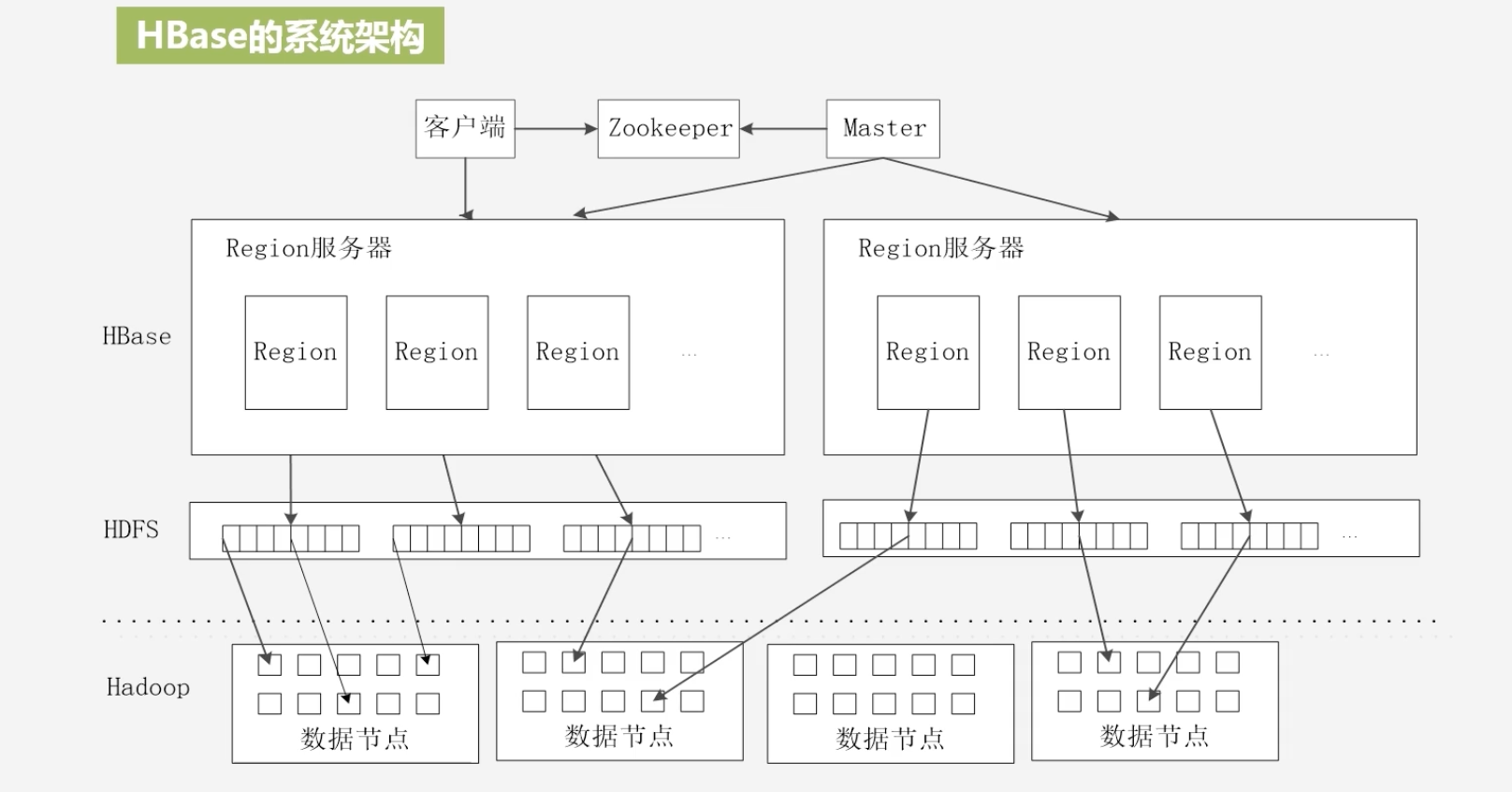
HBase的系统架构
-
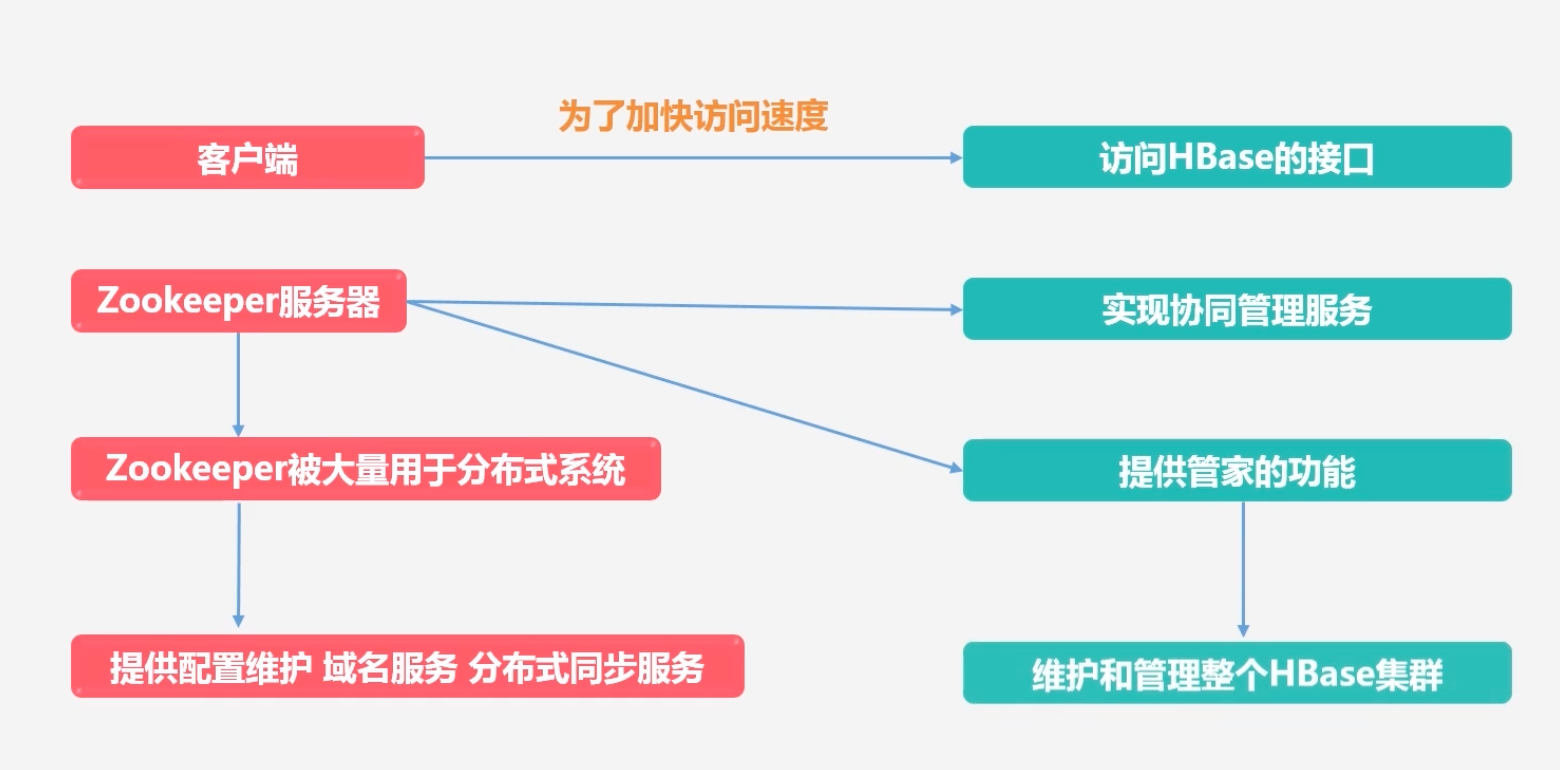
客户端:访问HBase的接口,为了加快访问速度,会进行位置地址的缓存
-
Zookeeper服务器:实现协同管理服务,其被大量用于分布式系统,提供配置维护,域名服务,分布式同步服务等,在HBase中,其主要提供管家功能,维护和管理整个HBase集群
-
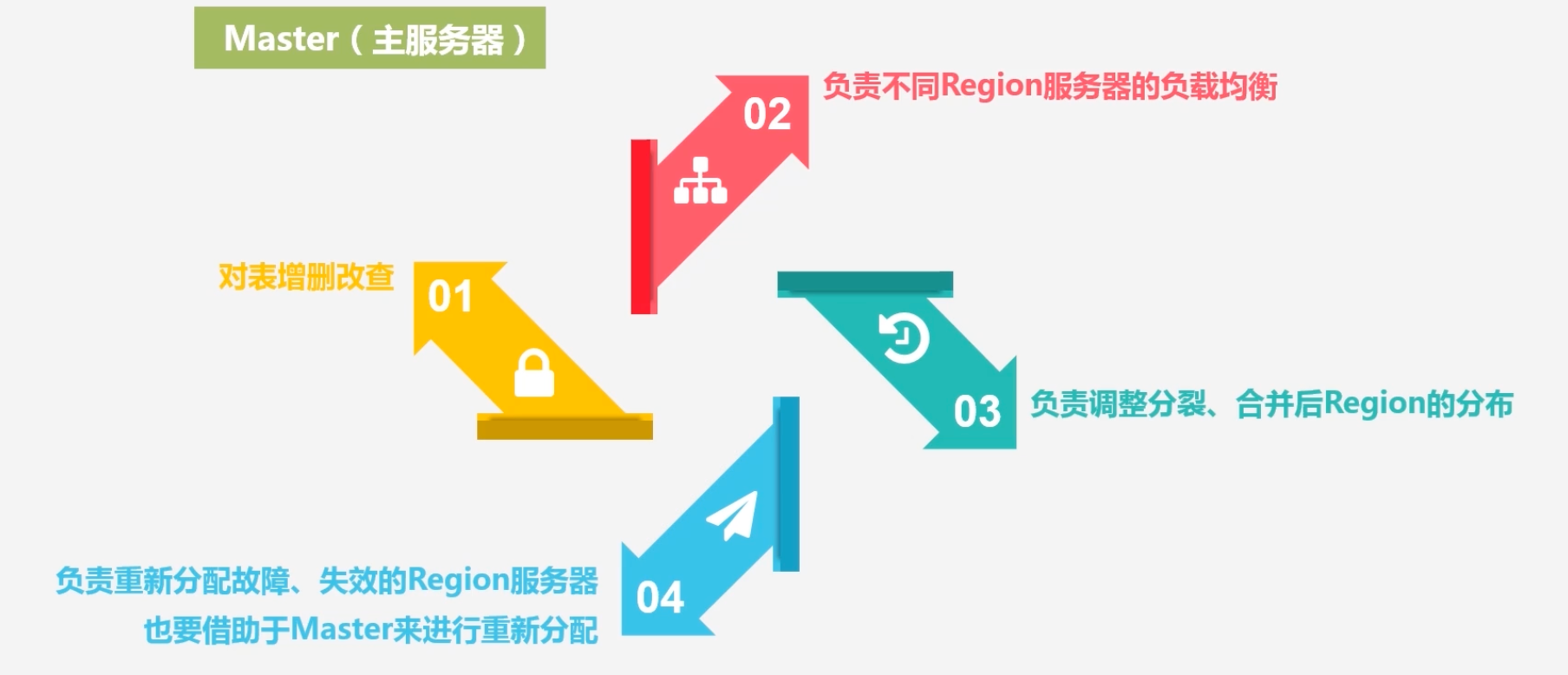
Master服务器(主服务器):负责对HBase的表的增删改查;负责不同Region服务器的负载均衡;负责调整分裂、合并后Region的分布;负责重新分配故障、失效的Region服务器,也要借助Master来进行重新分配
-
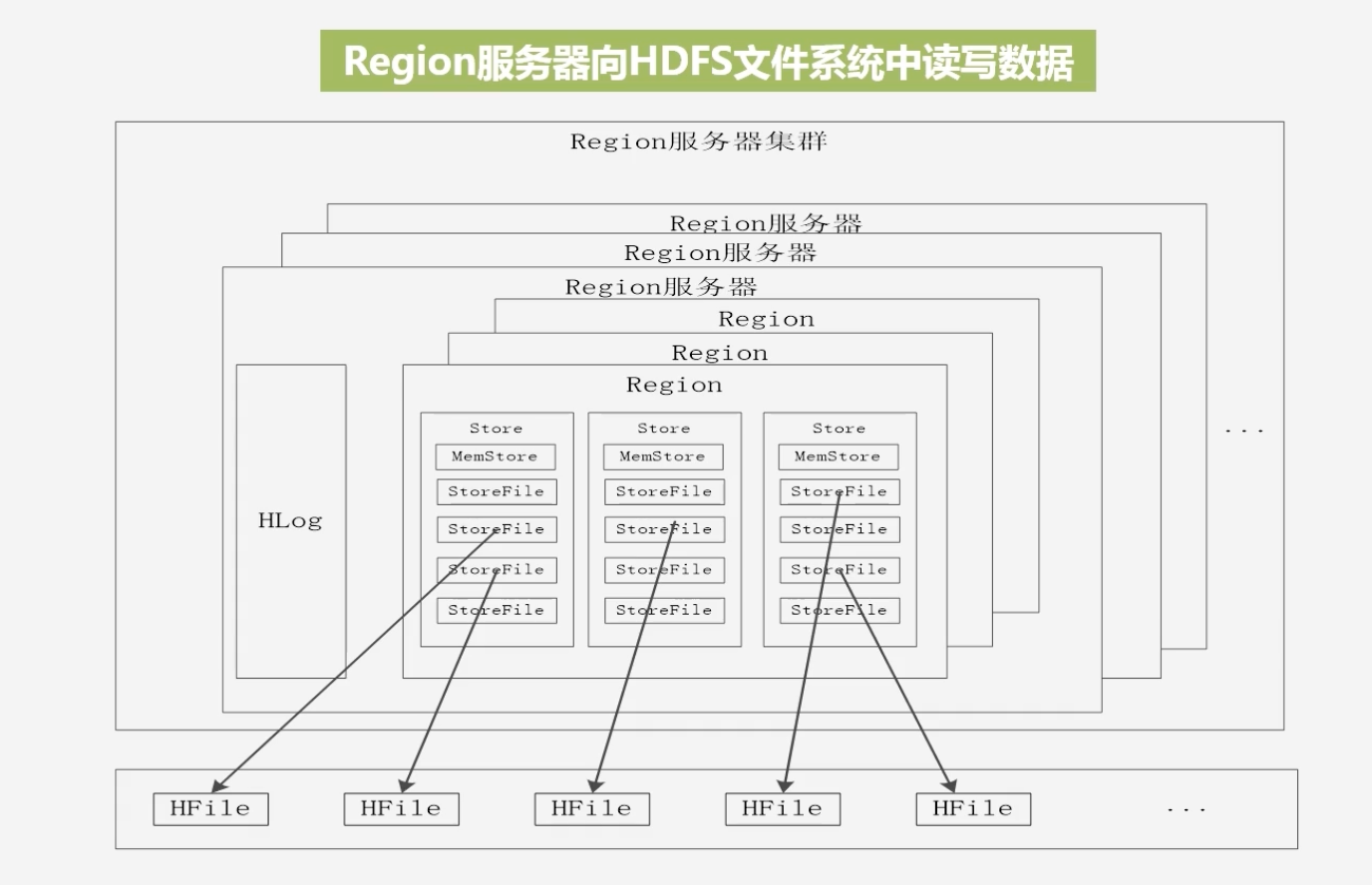
Region服务器:负责用户数据的存储和管理,其负责向HDFS文件系统中读写数据
- Region服务器集群由多个Region服务器构成,每个Region服务器中有多个组件
- 若干个Region共用一个HLog文件
- 每个Region中的每个列族会单独构成一个Store进行存储:会先存储到MemStore缓存中,缓存满了在存储到StoreFile文件中
- StoreFile是HBase的表现形式,它在底层是借助HDFS存储的,其在HDFS中以HFile的格式存储
-
-
用户读写数据过程
-
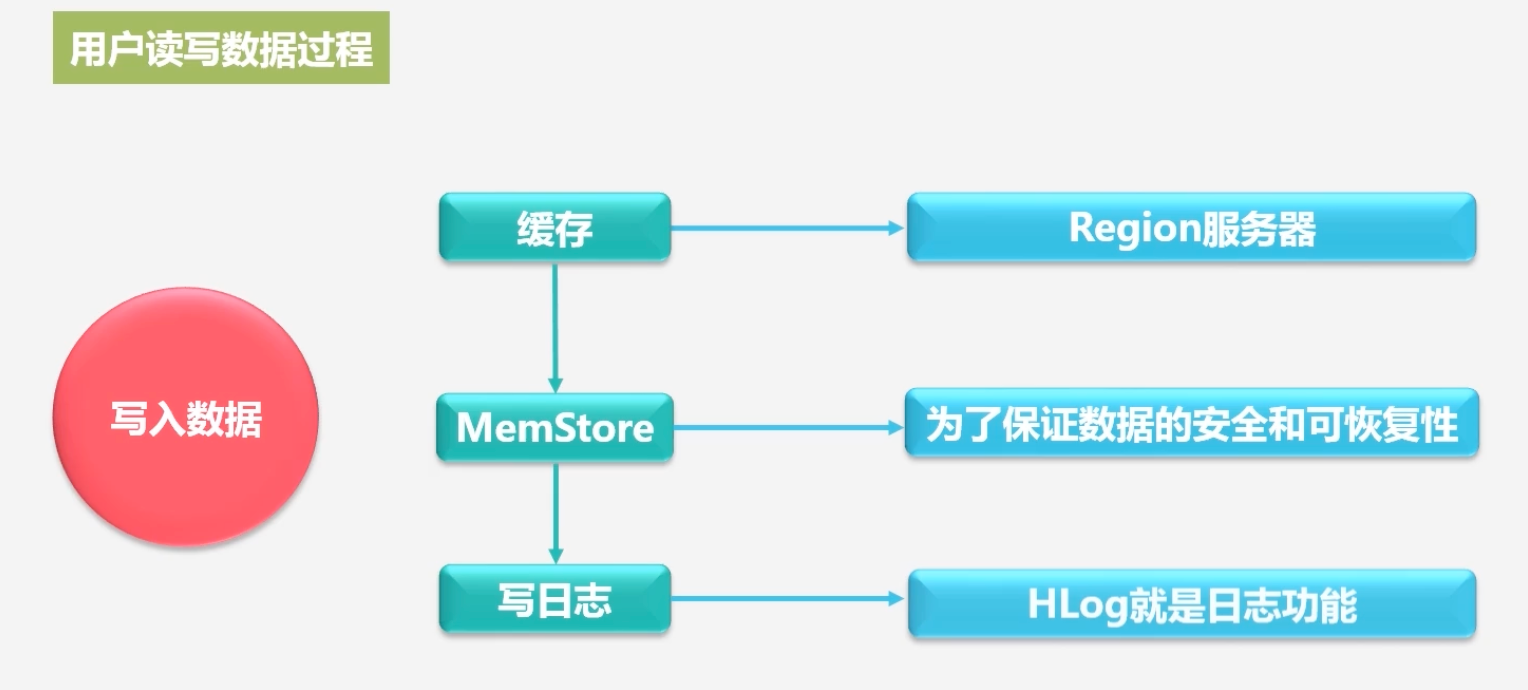
写入数据
-
首先将数据写入MemStore缓存区
-
为了保存数据不丢失,会在写入Memstore前,会先写入HLog日志,当HLog数据写入到磁盘之后,才允许返回客户端
-
-
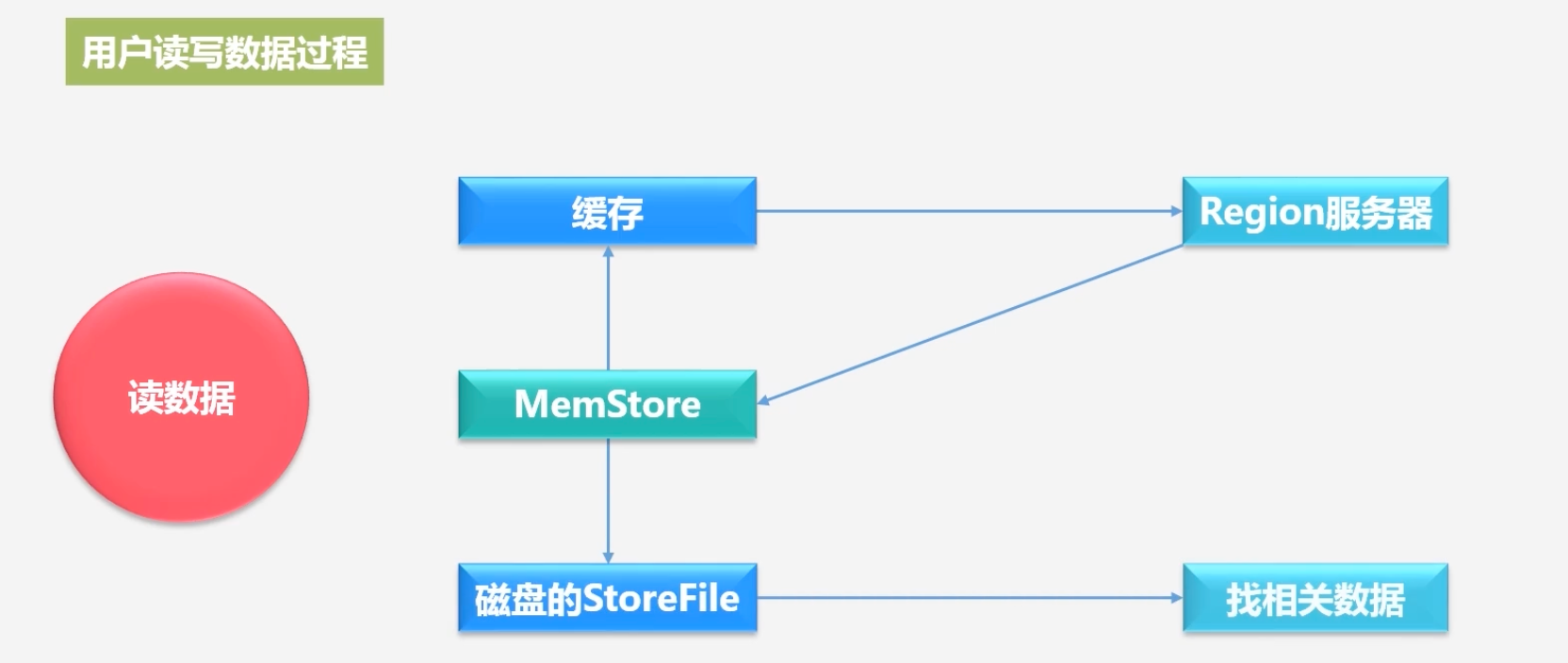
读取数据
-
首先用户也会先访问MemStore,因为最新写入的数据会存储于MemStore中
-
若MemStore查找不到,会到磁盘的StoreFile中去找相关数据
-
-
-
缓存刷新过程
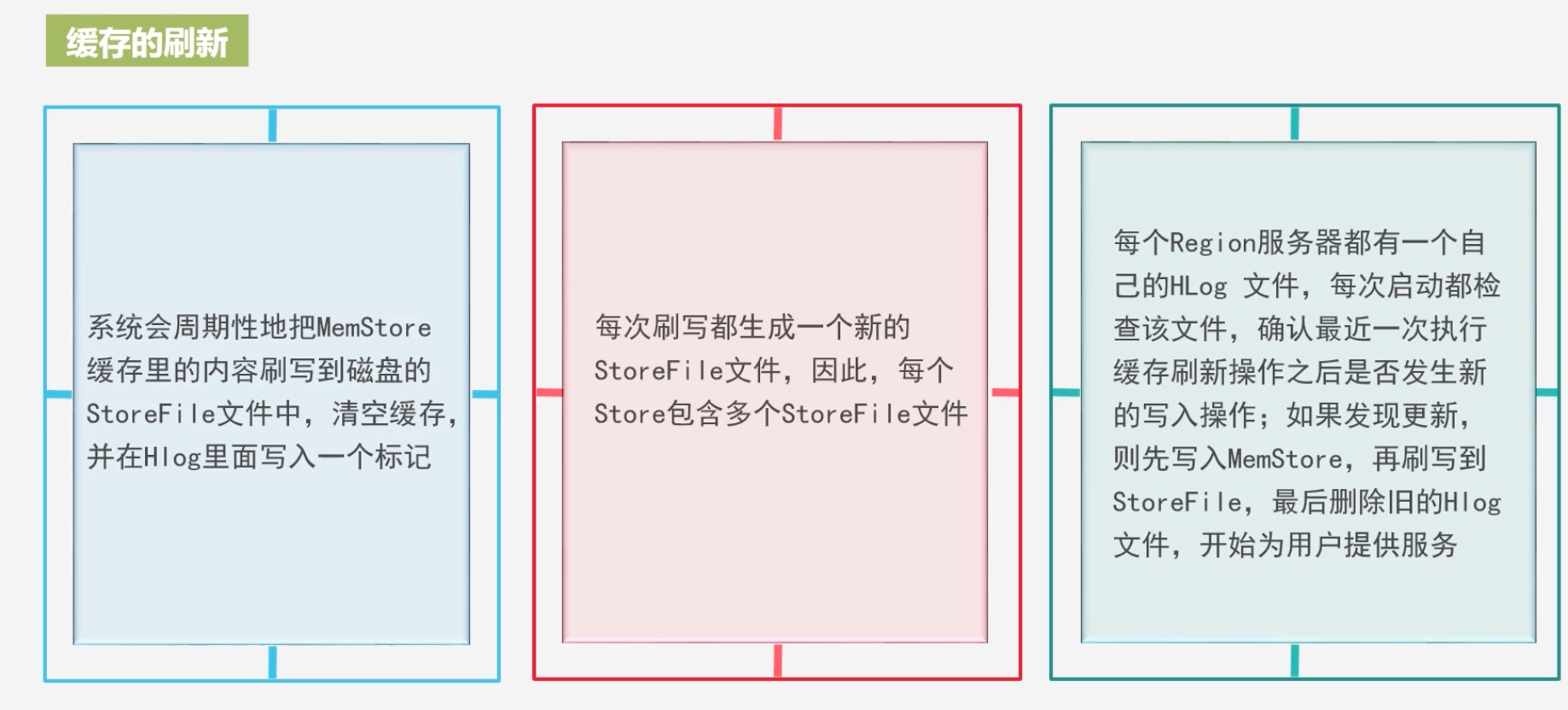
-
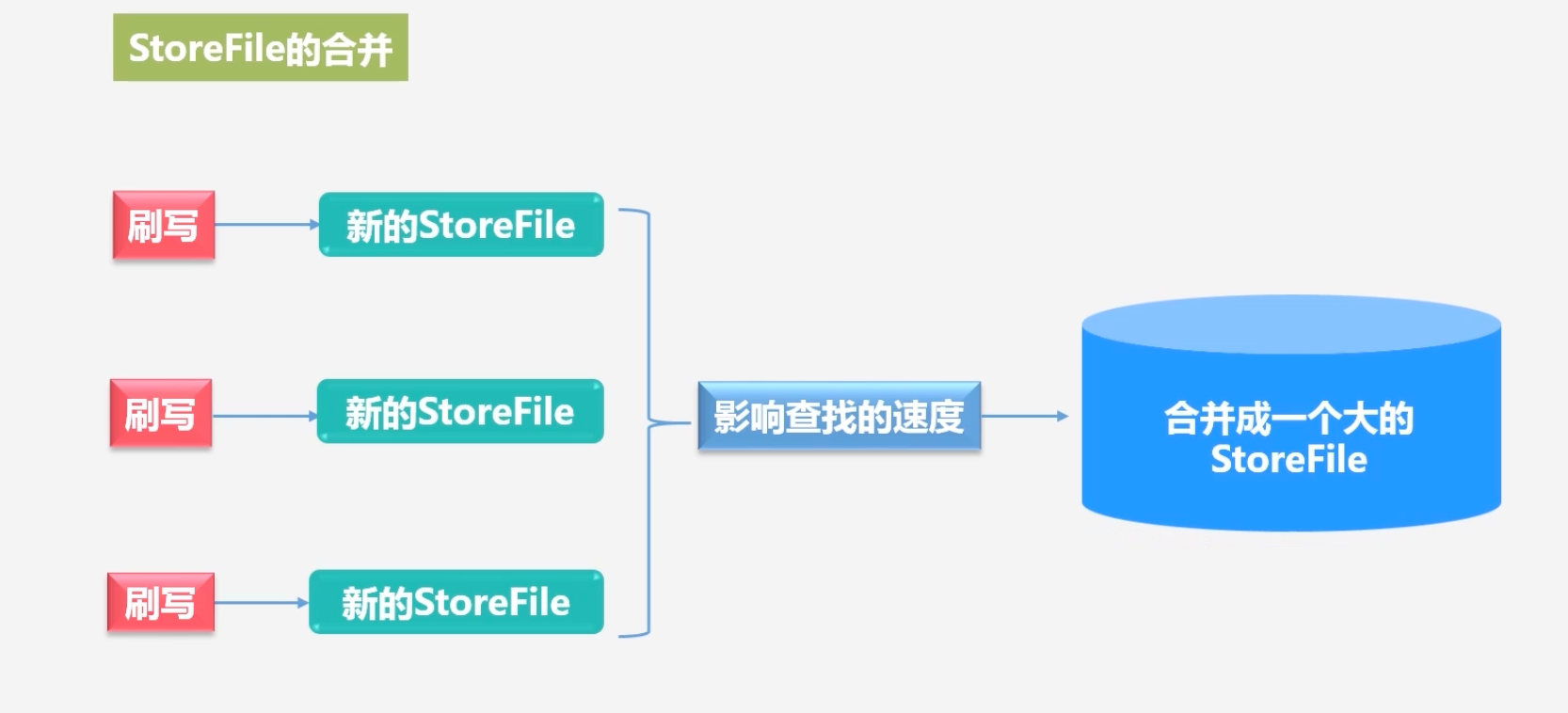
StoreFile文件的合并
-
刷写可能导致多个StoreFile文件,遍历StoreFile文件找数据,文件越多会影响查找速度,因此将多个StoreFile文件合并为一个大的StoreFile文件
-
-
StoreFile的分裂
-
StoreFile的不断合并可能会导致StoreFile的文件越来越大,当合并的StoreFile越大的时候,就会引发分裂操作

-
-
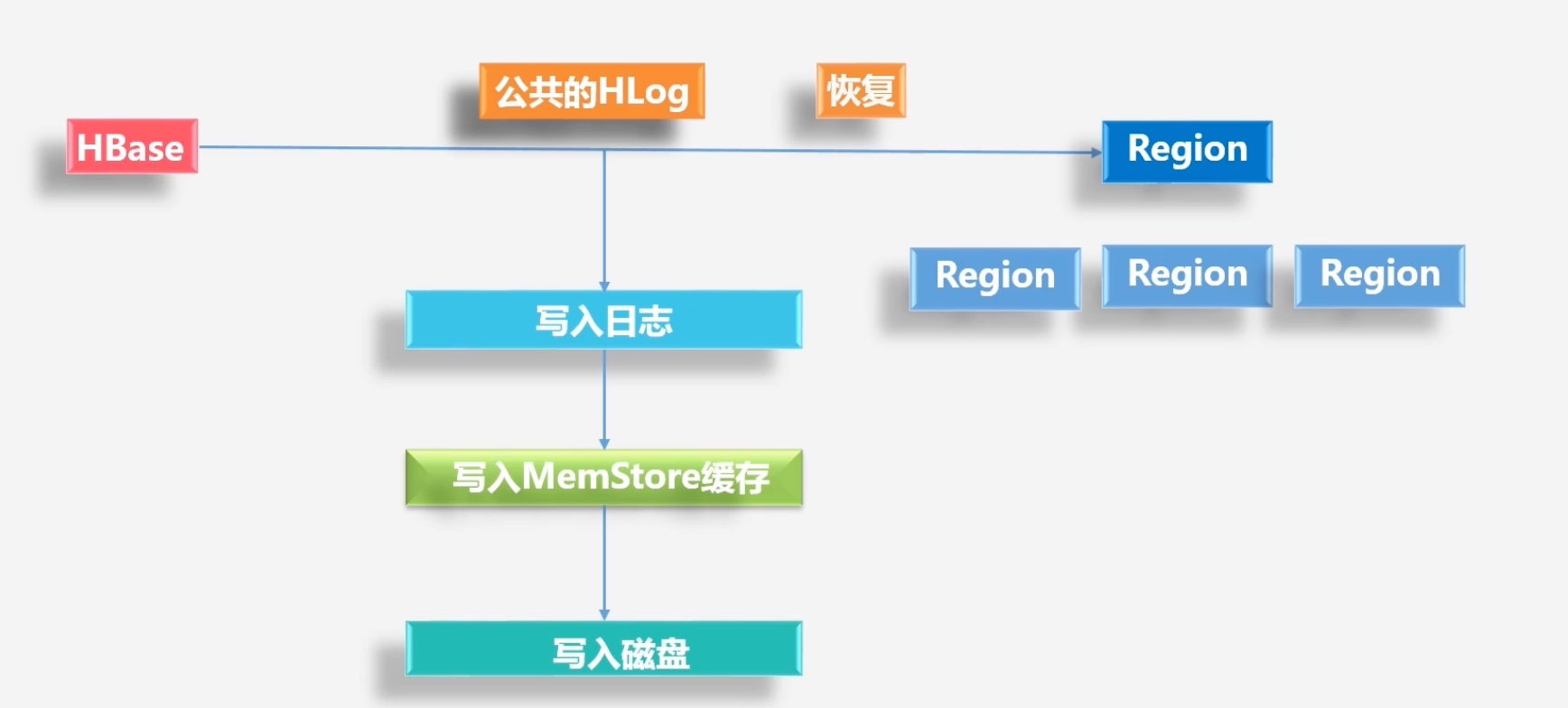
HLog的工作原理
-
HBase的底层是廉价的低端机,因此需要通过日志的发生来恢复故障

-
HBase为每个Region服务器都配置了公共的HLog
-
故障恢复
- Zookeeper来监视整个集群,会通知Master出问题的服务器,需要将故障服务器的内容迁移
- Master会将故障服务器的HLog文件取出,包含故障服务器的各个Region对象以及日志记录
- 然后对HLog的日志记录拆解为不同的Region的日志记录(因为所有的Region的日志都记录在HLog中)
- 最后将这些Region分配到其他可用的Region服务器上去
-
为何不每个Region设置单独的HLog文件
- 因为这样对于每个Region的更新操作,需要写入不同的HLog文件,是非常耗时的,而且集群出故障的时间远少于正常运行的时间
- 所有公共的HLog文件的可以大大提升写入性能
-
4.5 HBase的应用方案
-
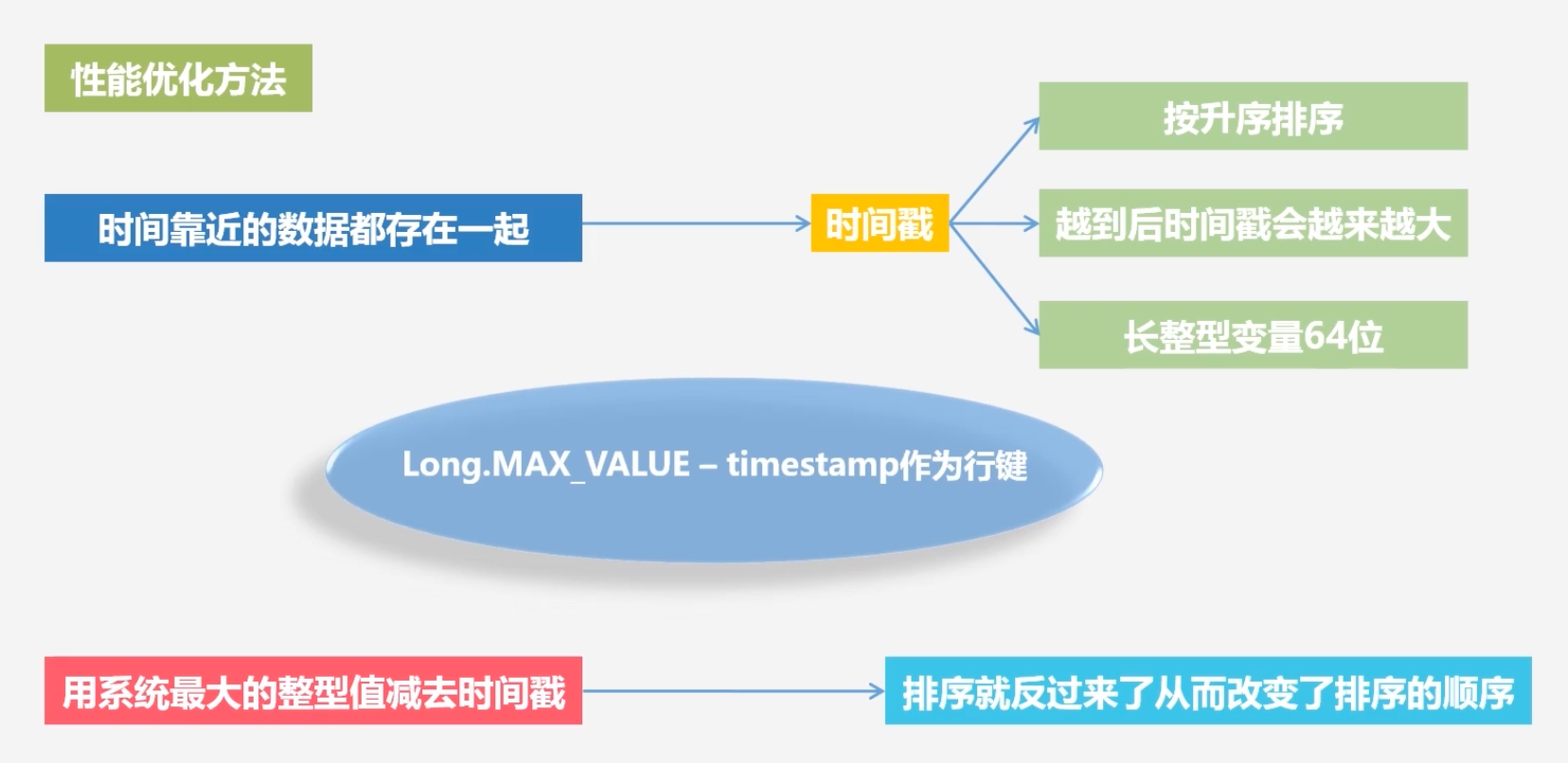
HBase在实际应用中的性能优化方法
-
若想把时间靠近的数据存在一起:
-
提升读写性能:

-
节省存储空间
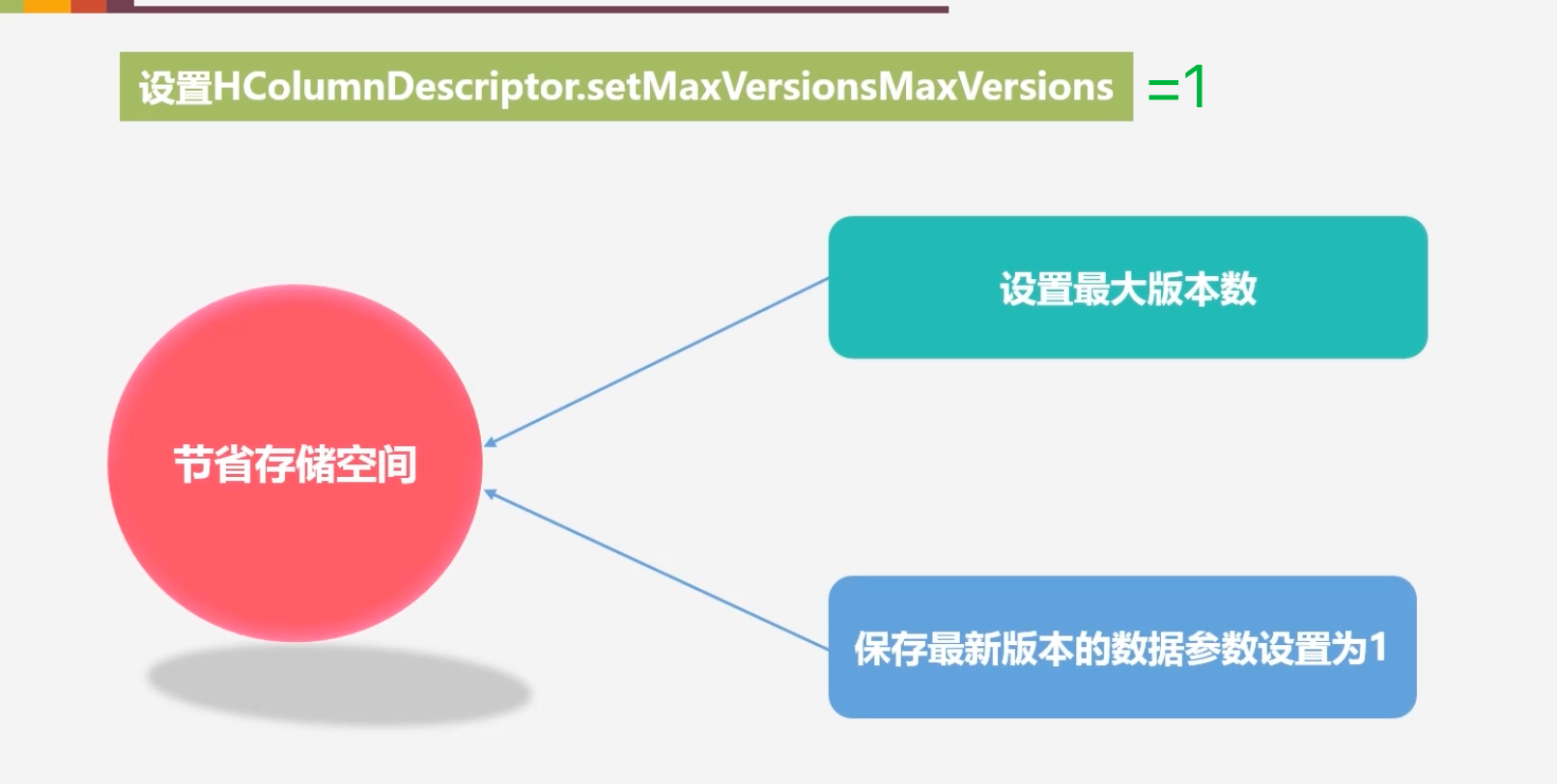
-
将到达时间限制的一些数据清楚,即使它没有到达版本最大数

-
-
HBase如何检测性能
-
可以通过以下几种工具:Master-status、Ganglia、OpenTSDB、Ambari
-
Master-staus

-
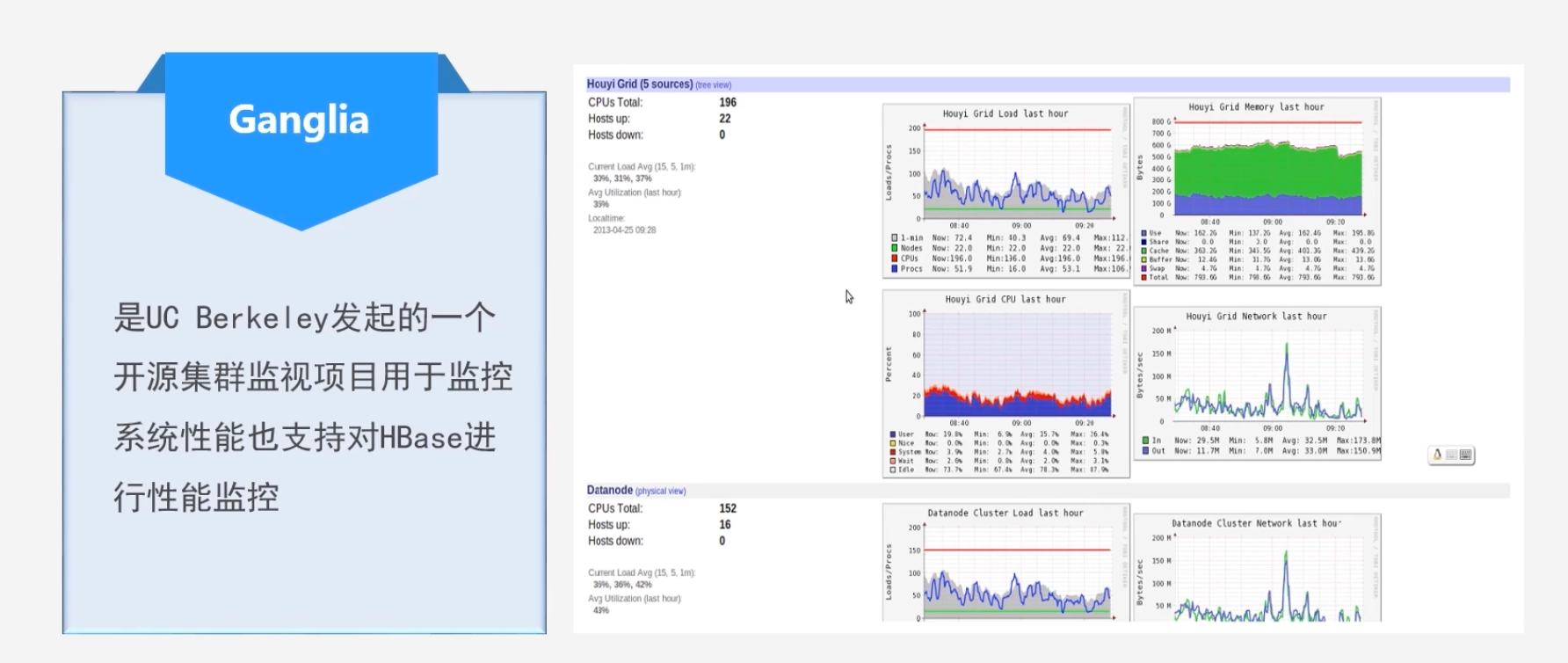
Ganglia
-
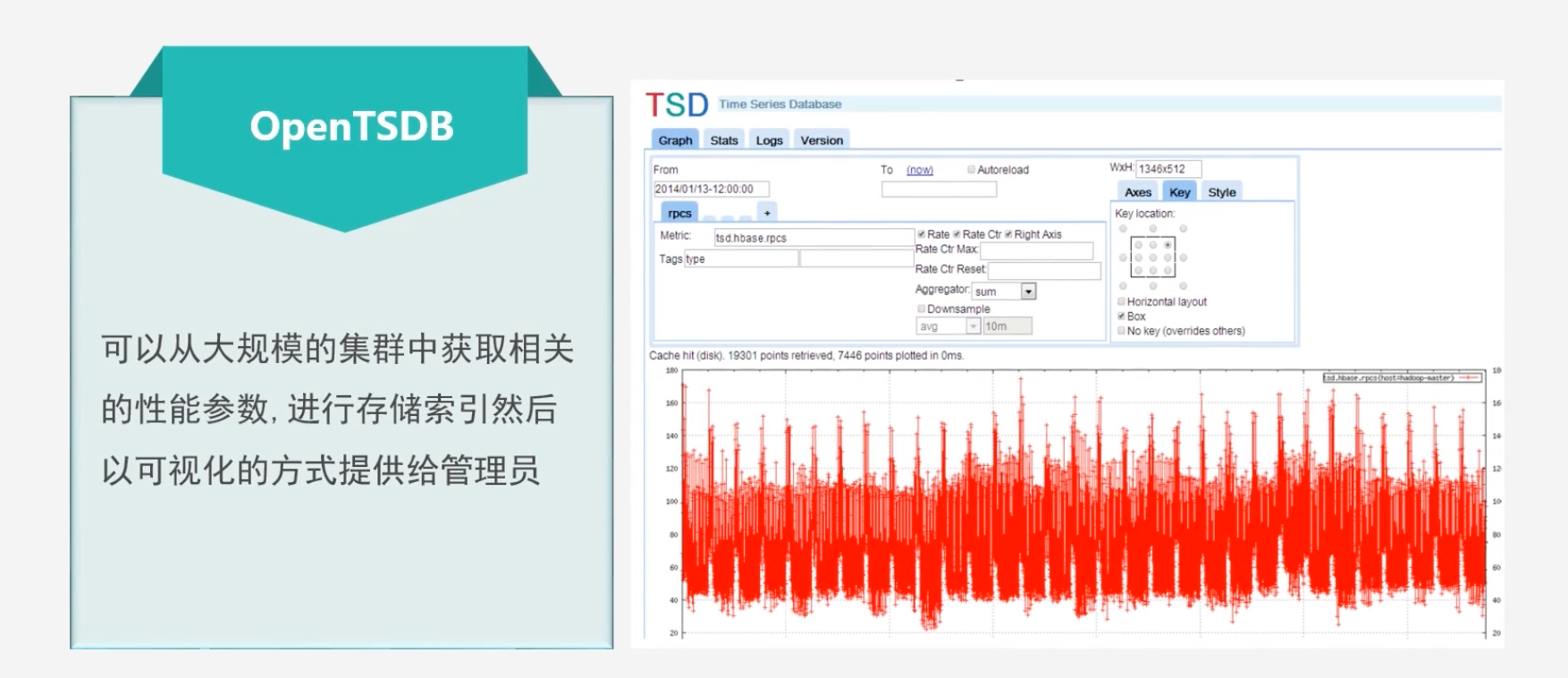
OpenTSDB
-
Ambari
-
-
-
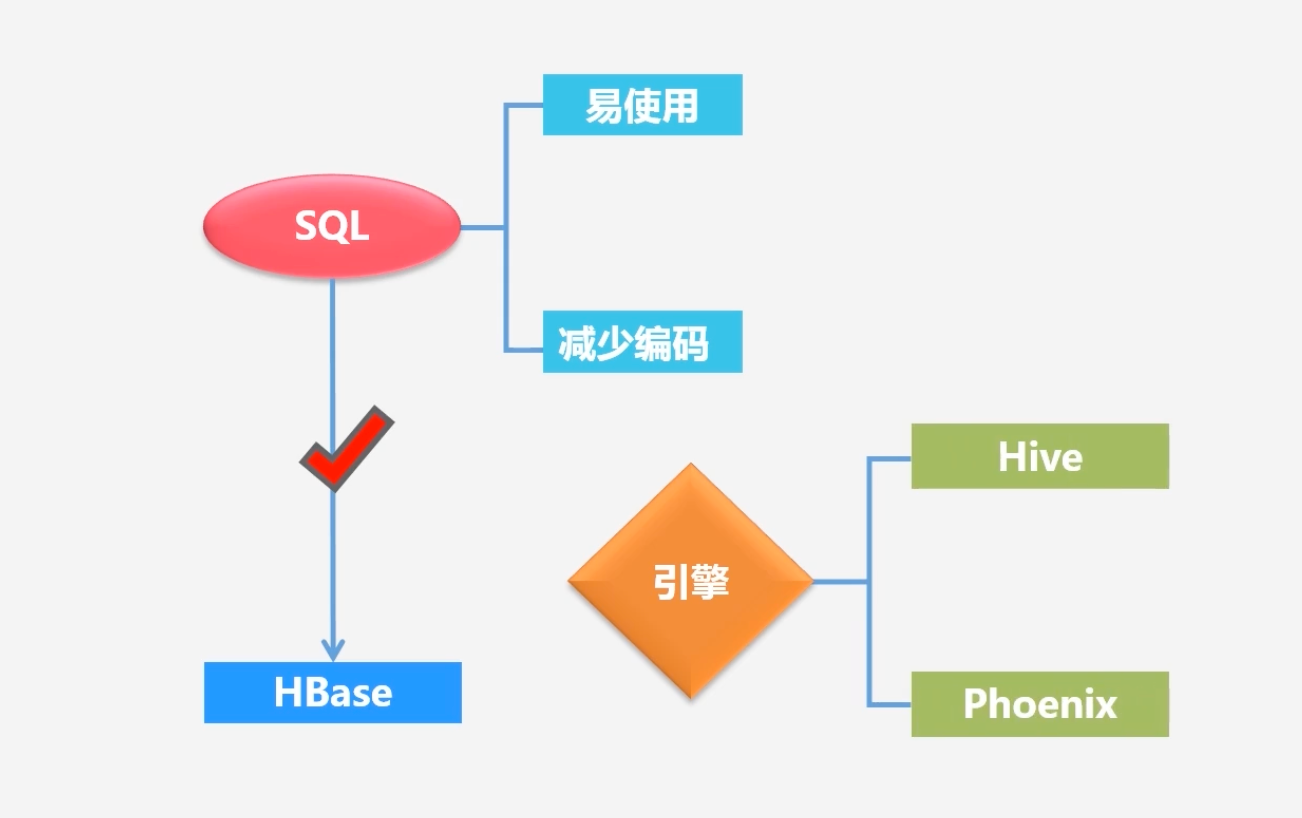
SQL语句查询HBase上相关数据
-
SQL易于使用,大部分人对HBase比较陌生,但是对SQL比较熟悉;
-
HBase原生代码查询数据编写代码较多,SQL是非过程语言,很多系统的底层会帮它生成相关操作
-
Hive和Phoenix

-
-
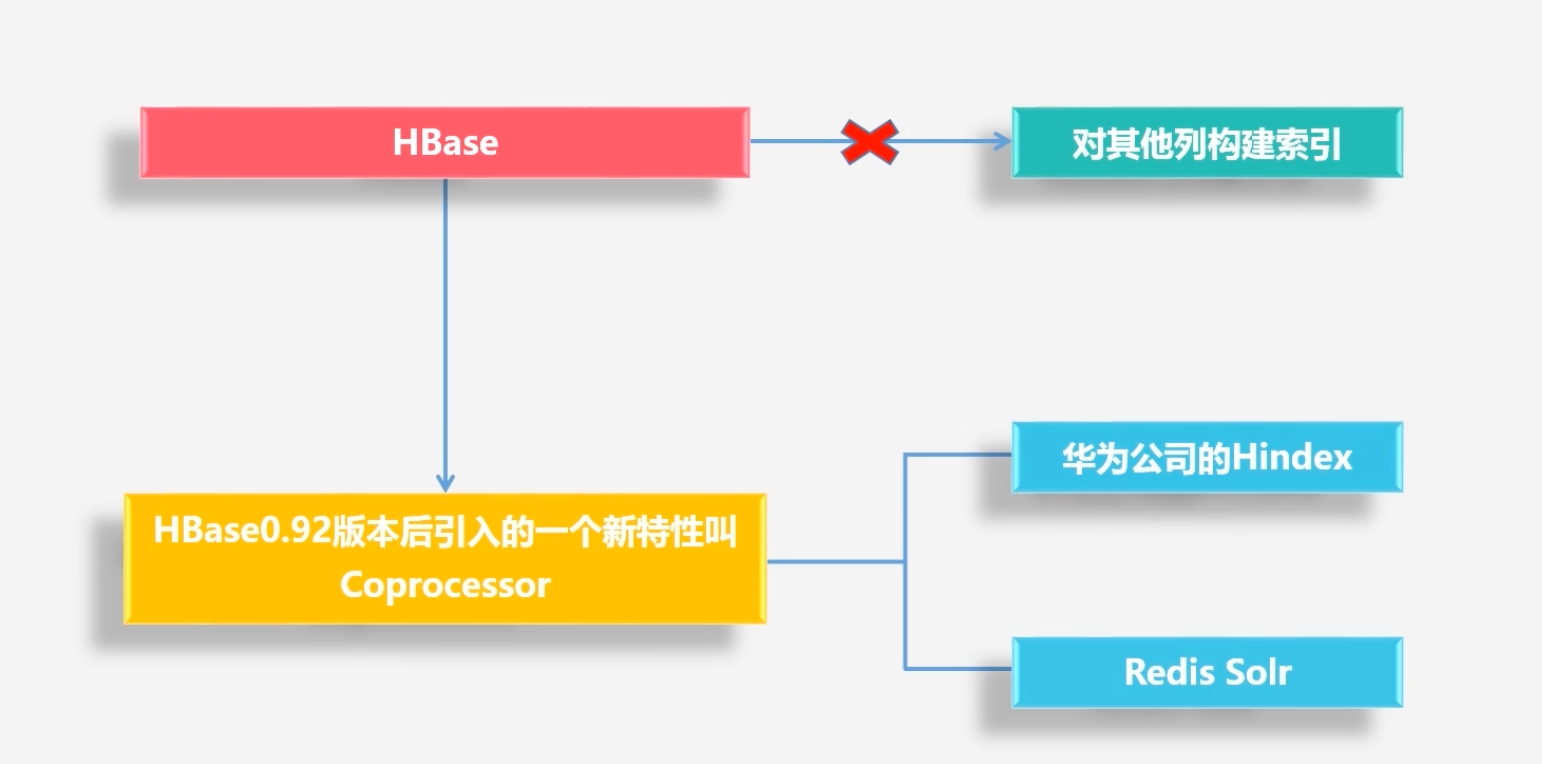
构建HBase二级索引

-
原生的HBase不支持对于各个列构建相关的索引,默认支持对rowkey行键进行索引

-
HBase0.92版本引入新特性:Coprocessor,可以支持二级索引
-
Coprocessor如何构建二级索引
-
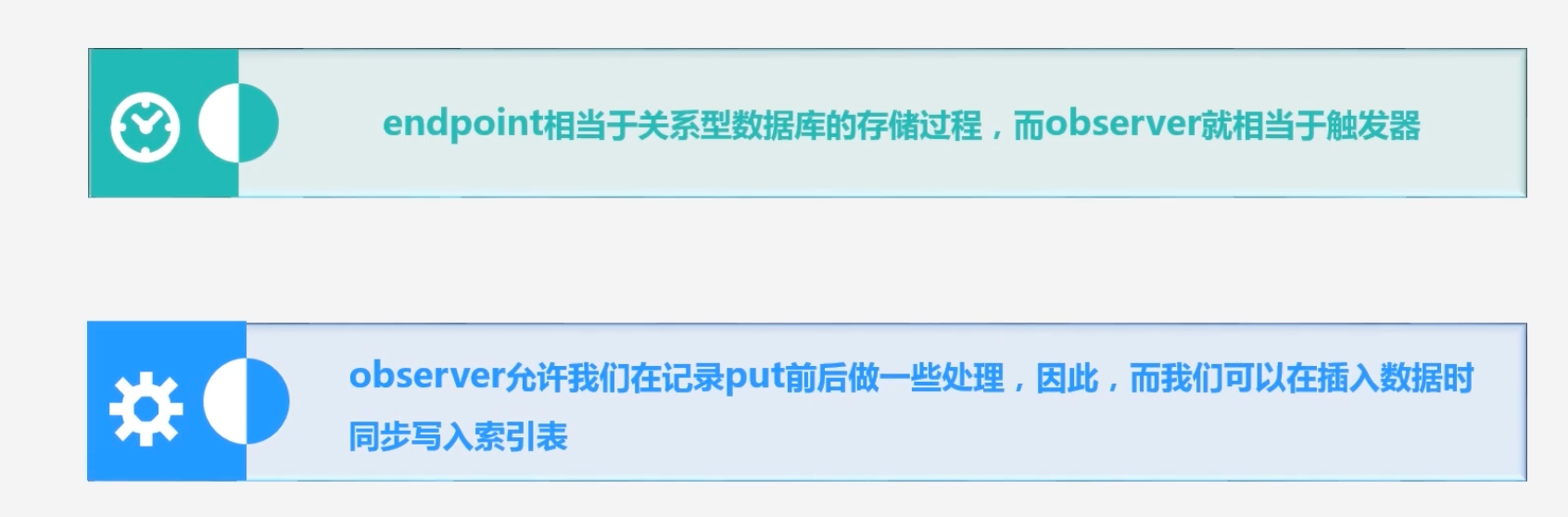
其提供两个实现:endpoint和observer
-
Endpoint相当于关系型数据库的存储过程,observer相当于触发器
-
每次往HBase表中插入数据时,observer会监测到,会将插入的数据同步写到索引表
-
-
此时在HBase中就存在了主表和索引表
- 索引表不是HBase内部自身的,是由其他产品帮其构建的二级索引,是通过Coprocessor格外开发的程序,对不同的其他列进行索引
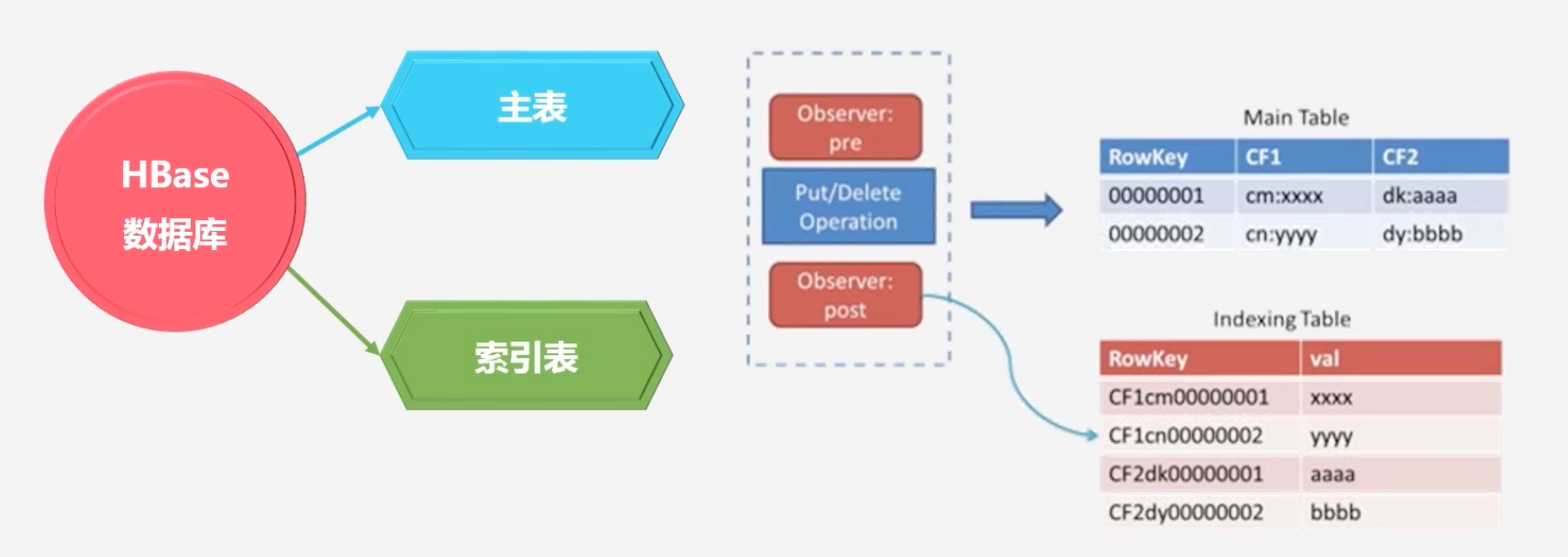
-
Coprocessor构建二级索引的优点和缺点
- 优点:非侵入性,引擎构建在HBase之上,既没有对HBase进行任何改动,也不需要上层应用做任何妥协
- 缺点:每插入一条数据需要向索引表插入数据,即耗时是双倍的,对HBase的集群压力也是双倍的
-
-
HBase的应用方案

-
Redis的方案:将索引写入到Redis的缓存数据库中,定期的把索引更新到HBase底层数据库,可以避免频繁更新磁盘索引表的问题
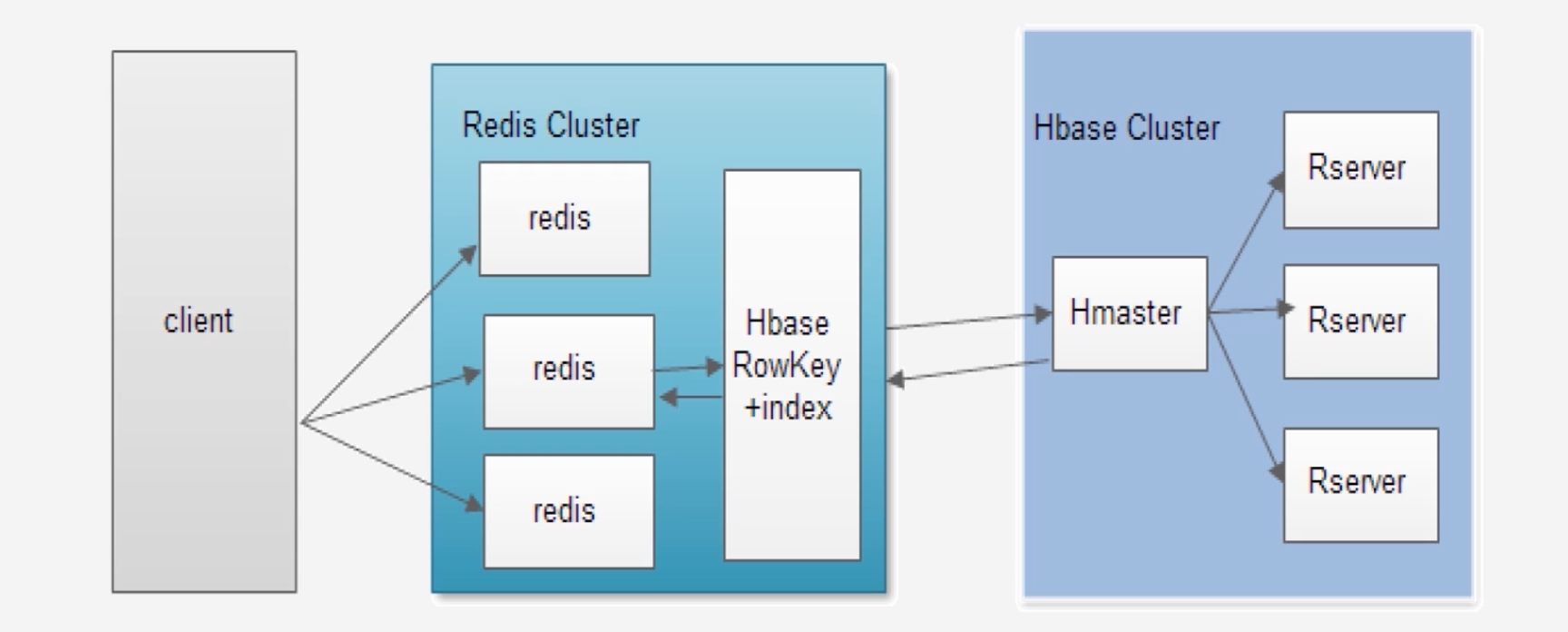
-
Solr+HBase:Solr服务器构建其他列和行键之间的对应关系,输入其他列的某一个值,可以快速找到这个列对应的行键,通过行键快速找到HBase记录
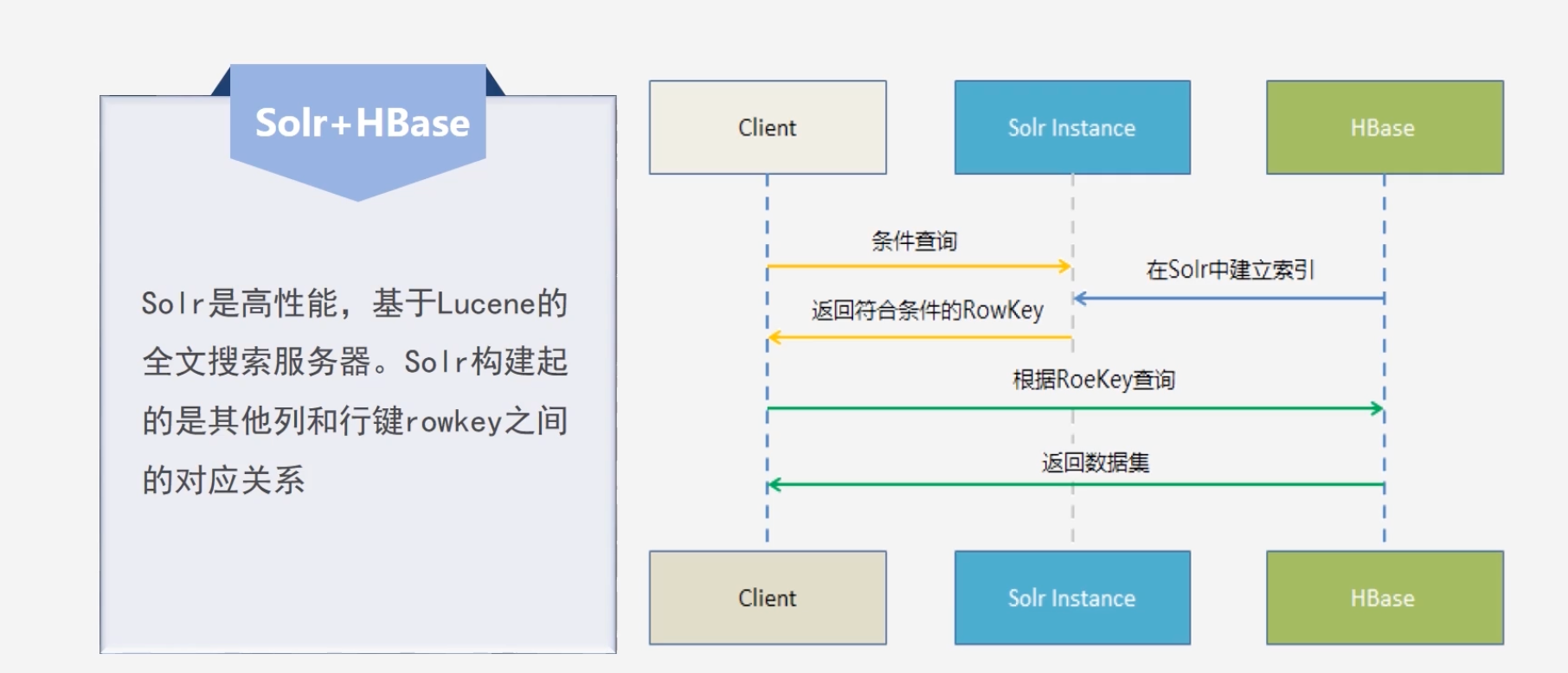
-
4.6 HBase安装和编程实战
见:HBase2.5.4安装和编程实践指南_厦大数据库实验室博客 (xmu.edu.cn)
相关文章:
分布式数据库(林子雨慕课课程)
文章目录 4. 分布式数据库HBase4.1 HBase简介4.2 HBase数据模型4.3 HBase的实现原理4.4 HBase运行机制4.5 HBase的应用方案4.6 HBase安装和编程实战 4. 分布式数据库HBase 4.1 HBase简介 HBase是BigTable的开源实现 对于网页搜索主要分为两个阶段 1.建立整个网页索引…...

使用UiPath和AA构建的解决方案 3. CRM 自动化
您是否曾经从一个应用程序中查找数据并更新另一个系统? 在许多情况下,人们在系统之间复制和移动数据。有时,可能会发生“转椅活动”,从而导致人为失误。RPA可以帮助我们自动化这些活动,使其更快,同时还可以消除任何人为错误。 在这个项目中,我们将在客户服务中自动化一…...
【C++设计模式之状态模式:行为型】分析及示例
简介 状态模式(State Pattern)是一种行为型设计模式,它允许对象在内部状态改变时改变其行为,看起来就像是改变了其类。状态模式将对象的状态封装成不同的类,并使得对象在不同状态下有不同的行为。 描述 状态模式通过…...
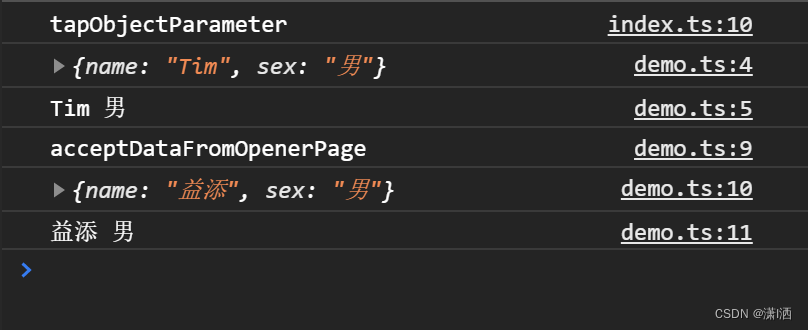
微信小程序使用路由传参和传对象的方法
近期在做微信小程序开发,在页面跳转时,需要携带参数到下一个页面,尤其是将对象传入页面。为了方便重温,特此记录。 路由传字符串参数 原始页面 传递字符串参数比较简单。路由跳转有两种方式,一种是通过navigator组件…...
)
中国创可贴市场研究与未来预测报告(2023版)
内容简介: 创可贴由胶布(带)、吸水垫、防粘层等组成,胶布以弹性布、棉布、无纺布或PE、PVC、PU打孔膜、TPU等材料为常见基材,涂以氧化锌和橡胶为主要原料的胶浆或医用压敏胶黏剂或丙烯酸酯胶粘剂制成。 目前中国主要…...

水库安全监测方案(实时数据采集、高速数据传输)
一、引言 水库的安全监测对于防止水灾和保障人民生命财产安全至关重要。为了提高水库安全监测的效率和准确性,本文将介绍一种使用星创易联DTU200和SG800 5g工业路由器部署的水库安全监测方案。 二、方案概述 本方案主要通过使用星创易联DTU200和SG800 5g工业路…...

vue项目 ueditor使用示例
简介 UEditor是由百度Web前端研发部开发的所见即所得富文本web编辑器,具有轻量,功能丰富,易扩展等特点。UEditor支持常见的文本编辑功能,如字体、颜色、大小、加粗、斜体、下划线、删除线等,同时还支持超链接、图片上…...

深度学习笔记之优化算法(四)Nesterov动量方法的简单认识
机器学习笔记之优化算法——Nesterov动量方法的简单认识 引言回顾:梯度下降法与动量法Nesterov动量法Nesterov动量法的算法过程描述总结 引言 上一节对动量法进行了简单认识,本节将介绍 Nesterov \text{Nesterov} Nesterov动量方法。 回顾:…...

比 N 小的最大质数
系列文章目录 进阶的卡莎C++_睡觉觉觉得的博客-CSDN博客数1的个数_睡觉觉觉得的博客-CSDN博客双精度浮点数的输入输出_睡觉觉觉得的博客-CSDN博客足球联赛积分_睡觉觉觉得的博客-CSDN博客大减价(一级)_睡觉觉觉得的博客-CSDN博客小写字母的判断_睡觉觉觉得的博客-CSDN博客纸币(…...

JavaScript 生成随机颜色
代码 function color(color) {return (color "0123456789abcdef"[Math.floor(Math.random() * 6)]) && (color.length 6 ? color : arguments.callee(color)); }使用 // 用法1:全部随机生成 "#" color(""); // #201050…...

Savepoints
语法 SAVEPOINT 名称 RELEASE SAVEPOINT 名称 ROLLBACK TRANSACTION TO SAVEPOINT 名称 Savepoints 与BEGIN和COMMIT类似的创建事务的方法,名称不要求唯一且可以嵌套使用。 可以用在BEGIN…COMMIT定义的事务内部或外部。当在外部时,最外层的savepoin…...

【MySQL】基本查询(二)
文章目录 一. 结果排序二. 筛选分页结果三. Update四. Delete五. 截断表六. 插入查询结果结束语 操作如下表 //创建表结构 mysql> create table exam_result(-> id int unsigned primary key auto_increment,-> name varchar(20) not null comment 同学姓名,-> chi…...
Qt:多语言支持,构建全面应用程序“
Qt:强大API、简化框架、多语言支持,构建全面应用程序" 强大的API:Qt提供了丰富的API,包括250多个C类,基于模板的集合、序列化、文件操作、IO设备、目录管理、日期/时间等功能。还包括正则表达式处理和支持2D/3D…...
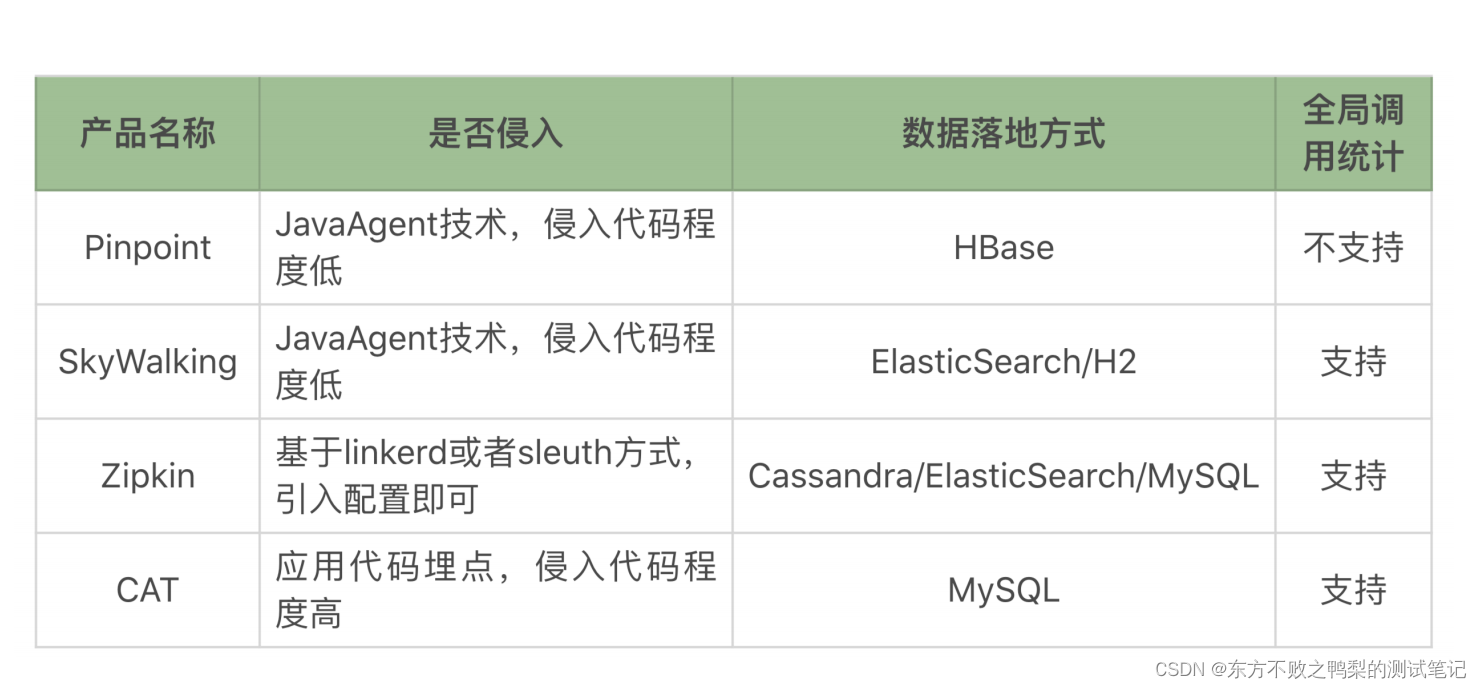
性能监控-链路级监控工具
常见的链路监控工具,我们都称之为 APM 开源工具 几个开源的好用的工具,它们分别是 Pinpoint、SkyWalking、Zipkin、CAT 网络上也有人对这几个工具做过测试 比对,得到的结论是每个产品对性能的影响都在 10% 以下,其中 SkyWalking …...

clickonce 程序发布到ftp在使用cnd 加速https 支持下载,会不会报错
ClickOnce 是一种用于发布和部署.NET应用程序的技术,通常用于本地部署或通过网络分发应用程序。将 ClickOnce 程序发布到 FTP 服务器并使用 CDN(内容分发网络)进行加速是可能的,但要确保配置正确以避免出现错误。 在使用 CDN 加速…...
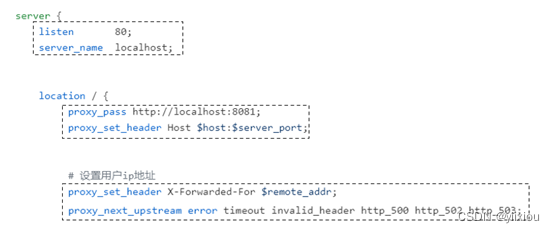
Nginx详细学习记录
1. Nginx概述 Nginx是一个轻量级的高性能HTTP反向代理服务器,同时它也是一个通用类型的代理服务器,支持绝大部分协议,如TCP、UDP、SMTP、HTTPS等。 1.1 Nginx基础架构 Nginx默认采用多进程工作方式,Nginx启动后,会运行…...
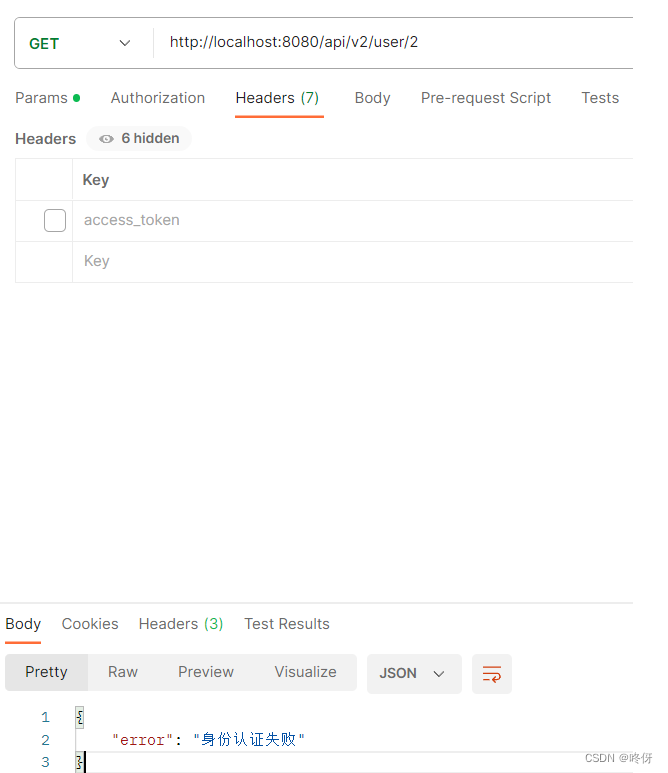
golang gin——中间件编程以及jwt认证和跨域配置中间件案例
中间件编程jwt认证 在不改变原有方法的基础上,添加自己的业务逻辑。相当于grpc中的拦截器一样,在不改变grpc请求的同时,插入自己的业务。 简单例子 func Sum(a, b int) int {return a b }func LoggerMiddleware(in func(a, b int) int) f…...
如何快速制作令人惊叹的长图海报
在当今的数字时代,制作一张吸引人的长图海报已成为许多人的需求。无论是为了宣传活动,还是展示产品,一张设计精美的长图海报都能引起人们的注意。下面,我们将介绍一种简单的方法,使用在线海报制作工具来创建长图海报。…...
 : DS循环链表—约瑟夫环(Ver. I - A))
D (1092) : DS循环链表—约瑟夫环(Ver. I - A)
Description N个人坐成一个圆环(编号为1 - N),从第S个人开始报数,数到K的人出列,后面的人重新从1开始报数。依次输出出列人的编号。 例如:N 3,K 2,S 1。 2号先出列,然…...

Python爬虫(二十二)_selenium案例:模拟登陆豆瓣
本篇博客主要用于介绍如何使用seleniumphantomJS模拟登陆豆瓣,没有考虑验证码的问题,更多内容,请参考:Python学习指南 #-*- coding:utf-8 -*-from selenium import webdriver from selenium.webdriver.common.keys import Keysimp…...

Compose-Skill:为Jetpack Compose应用注入AI能力的组件化技能库
1. 项目概述:一个为Compose应用注入AI能力的技能库最近在折腾Jetpack Compose项目时,我一直在想,能不能让UI开发也“智能”一点?比如,用户输入一段模糊的描述,界面就能自动生成对应的组件布局;或…...

书匠策AI官网www.shujiangce.com|别再硬扛了!这个AI把写期刊论文变成了“填空题“
微信公众号搜一搜「书匠策AI」,三分钟治好你的论文拖延症! 各位还在深夜对着Word文档发呆的同学们,今天我不讲道理,只讲工具。 你们有没有想过一个问题:为什么写期刊论文这件事,让90%的人觉得痛苦…...

Lightweight Charts:金融图表库的模块化架构重构与性能突破
Lightweight Charts:金融图表库的模块化架构重构与性能突破 【免费下载链接】lightweight-charts Performant financial charts built with HTML5 canvas 项目地址: https://gitcode.com/gh_mirrors/li/lightweight-charts 在金融数据可视化领域,…...

POE是什么?
POE 一般指 Power over Ethernet(以太网供电)。 通俗理解 用 一根网线(RJ45) 同时做两件事: 传数据(上网、通信) 给设备供电(不用单独再接电源适配器) 常见场景:IP 摄像头、无线 AP、部分 Orange Dongle / 底座,实验室用 PoE 交换机或 PoE 适配器 给 Dongle 供电…...

LSTM时间序列预测实战:从数据预处理到模型调优全解析
1. 项目概述:当时间序列遇上LSTM在数据分析与预测的领域里,时间序列预测一直是个既经典又充满挑战的课题。无论是金融市场的股价波动、电商平台的销量起伏,还是工业设备的传感器读数、城市交通的流量变化,这些按时间顺序排列的数据…...

如何在3分钟内掌握PowerPoint专业公式编辑:LaTeX-PPT终极指南
如何在3分钟内掌握PowerPoint专业公式编辑:LaTeX-PPT终极指南 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂的数学公式而头疼吗?LaTeX-PPT这款开源插件…...

10分钟上手wired-elements:打造超萌手绘风UI界面的完整指南
10分钟上手wired-elements:打造超萌手绘风UI界面的完整指南 【免费下载链接】wired-elements Collection of custom elements that appear hand drawn. Great for wireframes or a fun look. 项目地址: https://gitcode.com/gh_mirrors/wi/wired-elements wi…...

终极免费方案:3分钟解决Mac NTFS读写难题的完整指南
终极免费方案:3分钟解决Mac NTFS读写难题的完整指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for …...

如何快速解锁WeMod完整功能:WandEnhancer终极使用指南
如何快速解锁WeMod完整功能:WandEnhancer终极使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer WandEnhancer是一款专为WeMod应用设计…...

Angular 响应式原理深度解析:核心机制与源码解读
一、前言Angular 响应式原理深度解析:核心机制与源码解读。本文深入源码层面,剖析核心设计原理,帮你从"会用"升级到"精通"。二、核心原理深度剖析2.1 数据结构设计// Angular 核心数据结构与算法 // 理解 Angular 的底层…...