文件扫描模块
文章目录
- 前言
- 文件扫描模块
- 设计初级扫描方案一
- 实现单线程扫描
- 整合扫描步骤
- 设计初级扫描方案二
- 周期性扫描
- 总结
前言
我们这个模块考虑的是数据库里面的内容从哪里获取。
获取完成后,这时候,我们就需要把目录里面文件/子文件都获取出来,并存入数据库。
文件扫描模块
文件扫描模块,这个模块我们要考虑的是基本的业务逻辑理清楚,我们究竟要干什么,我们基本的步骤如下:
设计初级扫描方案一
我们会设计扫描方案,具体的扫描方案如下:
- 针对单个⽬录, 列出该⽬录下现有的 ⽂件 + ⽬录, 记为 scanned
- 根据⽬录, 从数据库查, 看当前数据库⾥记录了哪些数据, 记为 saved
- 对⽐看哪些⽂件是 scanned ⾥没有, saved ⾥有的, 就从数据库中删除. (说明该⽂件是已经被删了)
- 对⽐看哪些⽂件是 scanned ⾥⾯有, saved ⾥没有的, 就添加到数据库中. (说明该⽂件是新来的)
具体的业务逻辑代码:
//针对单个目录的扫描/*** scan针对一个目录进行处理(整个遍历过程中的基本操作)* 这个方法针对当前path对应的目录进行分析* 列出这个path包含的文件和子目录,并且把这些内容更新到数据库中* 此方法不考虑子目录里面的内容* @param path*/private void scan(File path){/*具体的方法步骤:1.先把当前路径在文件系统上有哪些文件/目录,列出来.=>把真实情况的结果作为List,称为scanned(看看真实的情况)2.拿着这个path去数据库查,看看数据库里都包含哪些对应的结果=>把这个结果也作为一个List,称为saveed(数据库保存的情况)3.看看scaned里面哪些数据是saved不存在的,把这些数据插入数据库,看看saved里面的哪些数据是scaned不存在的,把这些从数据库删除*/System.out.println("[FileManger] 扫描路径: "+path.getAbsolutePath());//1.累出文件系统的真实目录List<FileMeta> scanned=new ArrayList<>();File[] files=path.listFiles();if (files !=null){for (File f: files) {scanned.add(new FileMeta(f));}}//2.列出数据库里面的内容List<FileMeta> saved=fileDao.searchByPath(path.getPath());//3.根据数据库里面的内容与文件系统中的内容进行比对,如果数据库与文件系统比对,文件系统有的,数据库没有的,就增加//文件系统没有的,数据库有的,数据库就删除List<FileMeta> forDelete=new ArrayList<>();for (FileMeta fileMeta:saved) {if (!scanned.contains(saved)){forDelete.add(fileMeta);}}fileDao.delete(forDelete);//4.找出文件系统中有的,数据库没有的,把这些内容往数据库插入List<FileMeta> forInsert=new ArrayList<>();for (FileMeta fileMeta:scanned){if (!saved.contains(scanned)){forInsert.add(fileMeta);}}fileDao.add(forInsert);}
实现单线程扫描
具体的扫描步骤确定之后,我们来规定一下扫描的方式,我们先试用单线程扫描的方式来看看。
总体思路是:
1.扫描当前目录。
2.获取当前目录下所有文件。
3.递归扫描每个子目录。
4.递归出口是当前根目录下无任何文件或目录时返回。
具体代码如下:
public void scanAllOneThread(File basPath){if(!basPath.isDirectory()){return;}//1.针对当前目录进行扫描scan(basPath);//2.列出当前目录的所有文件File[] files=basPath.listFiles();//4.递归出口是当前根目录下无任何文件或目录时返回。if (files == null || files.length==0){//当前目录下没有东西return;}// 3.递归扫描每个子目录。for (File f :files){if (f.isDirectory()){scanAllOneThread(f);}}}
整合扫描步骤
这个类是来整合扫描具体的步骤。
public class SearchService {private FileDao fileDao=new FileDao();private FileManger fileManger=new FileManger();//程序初始化//basePath 为进行搜索指定路径public void init(String basePath){//1.创建数据表fileDao.initDB();//2.针对指定的目录开始扫描,然后进行数据库存储fileManger.scanAll(new File(basePath));System.out.println("[SearchService] 初始化完成!");}}
接下来再建个测试类,来测试一下扫描的结果。
public class TestSearchService {public static void main(String[] args) {SearchService searchService=new SearchService();//searchService.init("D:\\Study\\javaSe");}
}
设计初级扫描方案二
扫描的具体步骤跟扫描方案一的一样,就是扫描的方式变成了,多线程扫描而已。
使用线程池来创建。
具体代码如下
/*** 实现多线程扫描所有目录*///1.生成一个线程池private static ExecutorService executorService = Executors.newFixedThreadPool(8);private void scanAllByThreadPool(File basePath){if (!basePath.isDirectory()){return;}//2.扫描操作放在线程池里面完成executorService.submit(new Runnable() {@Overridepublic void run() {scan(basePath);}});//3.继续递归其他目录File[] files=basePath.listFiles();if (files == null || files.length==0){//当前目录下没有东西return;}for (File f :files){if (f.isDirectory()){scanAllByThreadPool(basePath);}}}
到这里基本的多线程扫描方案已经基本构建完成,但实际上还是存在问题的。
存在什么样的问题呢?大家可以想一想,我在这里列出来。
我们的代码相当于把扫描工作交给线程池完成,主线程只负责遍历目录。但这里就有问题存在了。
1.遍历目录完成了,扫描工作还没完成。
2.扫描工作完成了,遍历目录还没完成。
了解了问题之后,我们开始解决这个问题。之前在多线程也遇到了相同的问题,我们使用json解决的。
现在具体的解决方案如下:
1.引入一个计数器,每次线程增加任务的时候,都让计数器+1.
2.线程每昨晚一个任务的时候,就让计数器-1.
3.当计数器为0时,所有任务就执行完了。
其实这样的方案是有问题的,不过在这个扫描问题上,没问题,因为增加任务的速度大于执行任务的速度。
//初始化选手数目为1 ,当线程所有任务完成之后,就立即调用一次countDown进行撞线private CountDownLatch countDownLatch=new CountDownLatch(1);//衡量任务结束的计数器操作private AtomicInteger taskCount=new AtomicInteger(0);//主体逻辑版本public void scanAll(File baseDir){long beg=System.currentTimeMillis();System.out.println("[FileManager] scanAll 开始!");scanAllByThreadPool(baseDir);try {//开始等待countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}long end =System.currentTimeMillis();System.out.println("[FileManager] scanAll 结束!" +(end -beg) +"ms");}
// 线程池版本扫描,线程安全版private void scanAllByThreadPool(File basePath) {if (!basePath.isDirectory()) {return;}// 计数器自增taskCount.getAndIncrement(); // taskCount++// 扫描操作, 放到线程池里完成.executorService.submit(new Runnable() {@Overridepublic void run() {try {scan(basePath);} finally {// 计数器自减// 把这个自减逻辑放到 finally 中, 确保自减操作是肯定能执行到的.taskCount.getAndDecrement(); // taskCount--if (taskCount.get() == 0) {// 如果计数器为 0 了, 就通知主线程停表了.countDownLatch.countDown();}}}});// 继续递归其他目录.File[] files = basePath.listFiles();if (files == null || files.length == 0) {return;}for (File f : files) {if (f.isDirectory()) {scanAllByThreadPool(f);}}}
周期性扫描
我们最后还要加入一个周期性扫描呢。因为我们在我们的主逻辑中,是项目启动时,才扫描一次,我们万一在工具的使用中,加入新文件和删除旧文件呢,我们就需要周期性的扫描一次。
这个问题的思路有几种方式,我列举一下思路。
思路一:
可以搞一个单独的线程,这个线程周期性的扫描当前设定的这个路径
(比如设定每隔 30s 扫描一遍)
这个思路的问题:
这个扫描周期,不好确定
周期太长用户的修改不会及时感知到
周期太短浪费系统资源的.
思路二:
让操作系统来感知文件的变动(添加/删除/修改/重命名…,一旦有变化就通知咱们的程序Java 标准库提供了一个 APl,WatchService APl,就是干这个事情的
行不通!! 只能监测指定的目录,不能感知到目录里面的子目录/孙子目录等里面的情况…
思路三:
有一些第三方库,也实现了类似的功能.
Apache Commons-l0 这个包 里就提供了类似的 API可以感知到文件的增加,删除,重命名…支持子录/孙子目录…
这个方案本质上还是思路一!!!
everything!!! 是咋做的呢?
windows 上主流使用的文件系统
思路四:
everything 利用了 NTFS 这个文件系统的特殊性质
这个文件系统内置了一个特殊的日志功能.
会把用户的每次的变动都会记录到这个日志中, USN 机制
只需要读取这个日志内容,就知道用户进行了哪些文件改动
我们这里实现的思路是思路一:
1.在init方法中,先进行数据库的初始化。
2.然后启动一个扫描线程t,在while循环中周期性调用fileManger的scanAll方法扫描指定目录。
3.scanAll方法扫描目录后,会把扫描结果存入数据库中。
4.通过sleep来控制扫描周期,当前代码设置为20秒扫描一次。
5.通过判断t.isInterrupted()来退出循环,当调用shutdown方法时,会interrupt扫描线程t,使其立即退出扫描循环。
代码如下:
private Thread t=null;//程序初始化//basePath 为进行搜索指定路径public void init(String basePath){//初始情况下,就是数据库初始化好,进行下一步操作fileDao.initDB();//把这个操作挪到扫描线程中
// fileManger.scanAll(new File(basePath));t=new Thread(()->{while (!t.isInterrupted()){fileManger.scanAll(new File(basePath));try {//
// Thread.sleep(60000);Thread.sleep(20000);} catch (InterruptedException e) {e.printStackTrace();break;}}});t.start();System.out.println("[SearchService] 初始化完成");}//使用这个方法,让我们的扫描线程停止下来public void shutdown(){if (t!=null){t.interrupt();}}
总结
最后我来梳理一下这个文件扫描的总体逻辑,具体图片如下:
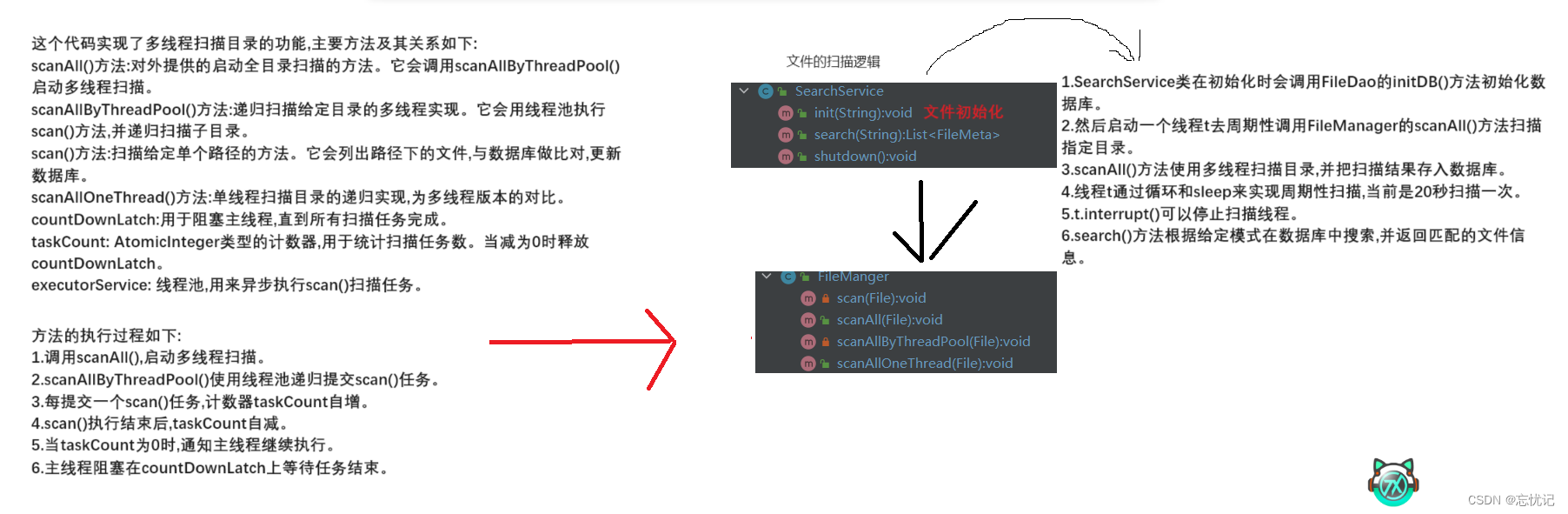
相关文章:
文件扫描模块
文章目录 前言文件扫描模块设计初级扫描方案一实现单线程扫描整合扫描步骤 设计初级扫描方案二周期性扫描 总结 前言 我们这个模块考虑的是数据库里面的内容从哪里获取。 获取完成后,这时候,我们就需要把目录里面文件/子文件都获取出来,并存入数据库。 文件扫描模…...
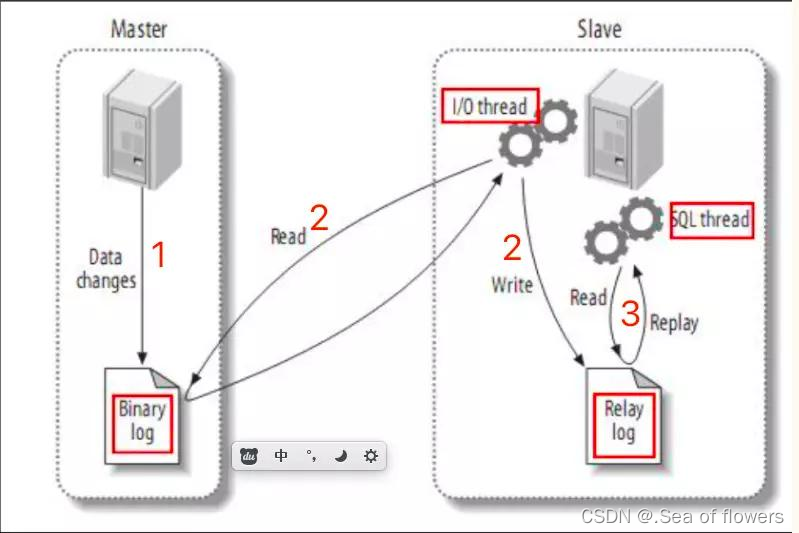
MySQL之主从复制
概述: 将主库的数据 变更同步到从库,从而保证主库和从库数据一致。 它的作用是 数据备份,失败迁移,读写分离,降低单库读写压力 原理: 主服务器上面的任何修改都会保存在二进制日志( Bin-log日志…...

[leetcode 单调栈] 901. 股票价格跨度 M
设计一个算法收集某些股票的每日报价,并返回该股票当日价格的 跨度 。 当日股票价格的 跨度 被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。 例如,如果未来 7 天股票的价格是 [100…...

Java线程池:并发编程的利器
Java线程池:并发编程的利器 在多任务、高并发的时代,Java并发编程显得尤为重要。其中,Java线程池是一种高效的管理线程的工具,能够提高应用程序的性能和响应速度。本文将深入探讨Java线程池的工作原理、应用场景以及简单示例&…...

ARM硬件断点
hw_breakpoint 是由处理器提供专门断点寄存器来保存一个地址,是需要处理器支持的。处理器在执行过程中会不断去匹配,当匹配上后则会产生中断。 内核自带了硬件断点的样例linux-3.16\samples\hw_breakpoint\data_breakpoint.c static void sample_hbp_h…...
)
Java使用WebSocket(基础)
准备一个html页面 <!DOCTYPE HTML> <html> <head><meta charset"UTF-8"><title>WebSocket Demo</title> </head> <body><input id"text" type"text" /><button onclick"send()&…...

图像处理与计算机视觉--第五章-图像分割-自适应阈值分割
文章目录 1.自适应阈值分割介绍2.自适应阈值函数参数解析3.高斯概率函数介绍4.自适应阈值分割核心代码5.自适应阈值分割效果展示6.参考文章及致谢 1.自适应阈值分割介绍 在图片处理过程中,针对铺前进行二值化等操作的时候,我们希望能够将图片相应区域内所…...
记一次问题排查
1785年,卡文迪许在实验中发现,把不含水蒸气、二氧化碳的空气除去氧气和氮气后,仍有很少量的残余气体存在。这种现象在当时并没有引起化学家的重视。 一百多年后,英国物理学家瑞利测定氮气的密度时,发现从空气里分离出来…...
【Spring Boot】创建一个 Spring Boot 项目
创建一个 Spring Boot 项目 1. 安装插件2. 创建 Spring Boot 项目3. 项目目录介绍和运行注意事项 1. 安装插件 IDEA 中安装 Spring Boot Helper / Spring Assistant / Spring Initializr and Assistant插件才能创建 Spring Boot 项⽬ (有时候不用安装,直…...

flutter中使用缓存
前言 在flutter项目中使用ListView或者PageView等有滚动条组件的时候,切换页面的时候,再切换回来会丢失之前的滑动状态,这个时候就需要需要使用缓存功能 缓存类 import package:flutter/material.dart;class KeepAliveWrapper extends Sta…...
京东数据分析平台:9月中上旬白酒消费市场数据分析
9月份,围绕白酒的热点不断。9月5日,瑞幸咖啡官微发布消息称,瑞幸与贵州茅台跨界合作推出的酱香拿铁刷新单品纪录,首日销量突破542万杯,销售额破1亿元。9月14日,贵州茅台官微发布消息称与德芙推出联名产品“…...

Linux安装 spark 教程详解
目录 一 准备安装包 二 安装 scala 三 修改配置文件 1)修改 workers 文件 2)修改 spark-env.sh文件 四 进入 spark 交互式平台 一 准备安装包 可以自行去 spark 官网下载想要的版本 这里准备了 spark3.1.2的网盘资源 链接: https://pan.baidu.com…...
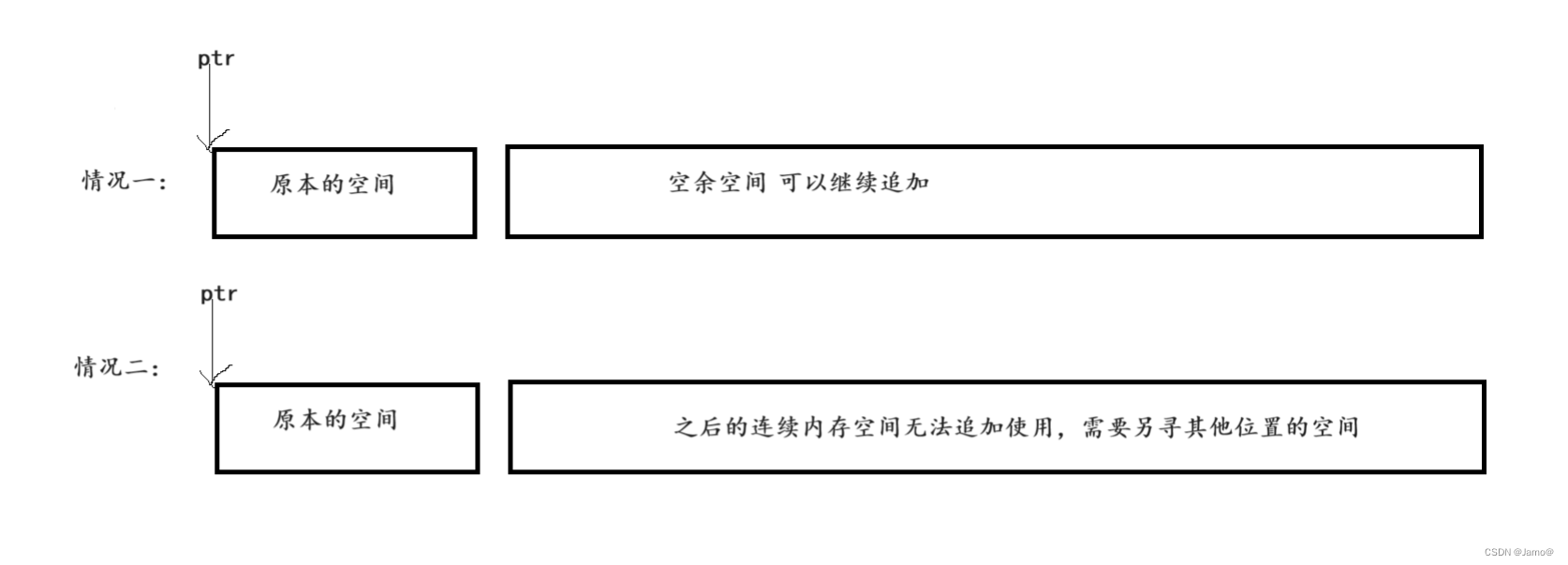
动态内存管理函数(malloc,calloc,realloc,free)
动态内存函数 1.1malloc和free C语言提供了一个动态内存开辟的函数: void* malloc (size_t size); 这个函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。 如果开辟成功,则返回一个指向开辟好空间的指针。如果开辟失败&#…...

云表|都有生产管理模块,MES和ERP有什么不同,该如何选择
MES和ERP是生产制造领域的两大知名系统,虽然早已声名鹊起,但仍有不少人难以明确区分两者的差异。下面将详细阐述这两个系统的不同之处。首先,要了解MES和ERP的定义。 MES系统:全称制造执行系统(Manufacturing Executio…...

C语言 - 数组
目录 1. 一维数组的创建和初始化 1.1 数组的创建 1.2 数组的初始化 1.3 一维数组的使用 1.4 一维数组在内存中的存储 2. 二维数组的创建和初始化 2.1 二维数组的创建 2.2 二维数组的初始化 2.3 二维数组的使用 2.4 二维数组在内存中的存储 3. 数组越界 4. 数组作为函数参数 4.1…...
,有什么用,不同插槽的区别?)
Vue 中的插槽(Slot),有什么用,不同插槽的区别?
Vue 中的插槽(Slot案例详解) 是一种非常有用的功能,用于组件之间的内容分发和复用。以下是关于插槽的一些重要概念: 插槽的作用: 插槽允许你将组件的内容分发到其子组件中,以实现灵活的组件复用和自定义布局。通过插槽…...
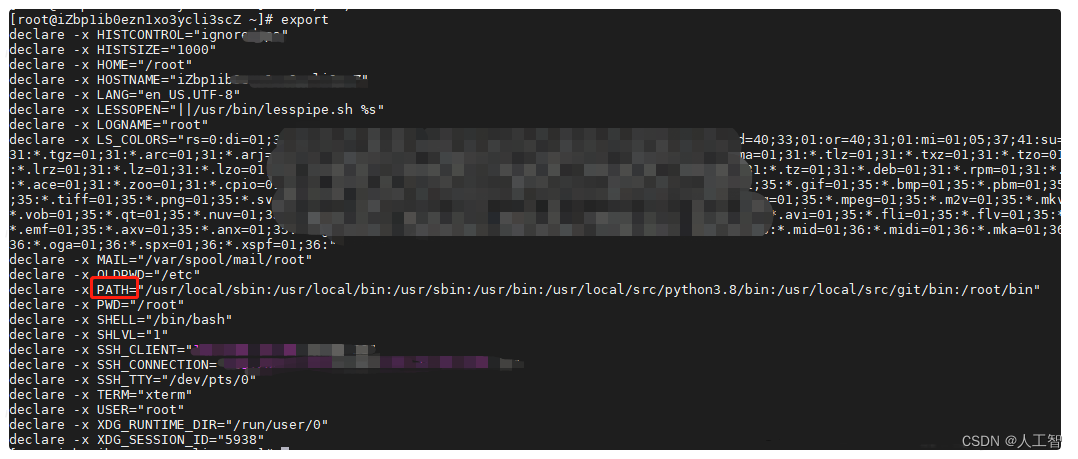
Linux登录自动执行脚本
一、所有用户每次登录时自动执行。 1、在/etc/profile文件末尾添加。 将启动命令添加到/etc/profile文件末尾。 2、在/etc/profile.d/目录下添加sh脚本。 在/etc/profile.d/目录下新建sh脚本,设置每次登录自动执行脚本。有用户登录时,/etc/profile会遍…...

架构方法、模型、范式、治理
从架构方法、模型、范式、治理等四个方面介绍架构的概念和方法论、典型业务场景下的架构范式、不同架构的治理特点这3个方面的内容...

Linux 安全 - 内核提权
文章目录 前言一、简介1.1 prepare_creds1.2 commit_creds 二、demo参考资料 前言 在这篇文章:Linux 安全 - Credentials 介绍了 Task Credentials 相关的知识点,接下来给出一个内核编程提权的例程。 一、简介 内核模块提权主要借助于 prepare_creds …...
数字三角形加强版题解(组合计数+快速幂+逆元)
Description 一个无限行的数字三角形,第 i 行有 i 个数。第一行的第一个数是 1 ,其他的数满足如下关系:如果用 F[i][j] 表示第 i 行的第 j 个数,那么 F[i][j]A∗F[i−1][j]B∗F[i−1][j−1] (不合法的下标的数为 0 &a…...

鸣潮自动化工具ok-ww完整指南:3步实现智能后台挂机
鸣潮自动化工具ok-ww完整指南:3步实现智能后台挂机 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves 你是否厌倦了在《鸣…...

基于Swift与AppKit的macOS菜单栏AI工具聚合器开发实践
1. 项目概述:一个为Mac用户打造的AI助手集成工具如果你是一名Mac用户,同时又对当前层出不穷的AI工具感到眼花缭乱,那么你很可能和我一样,经历过这样的困扰:ChatGPT的对话窗口、Midjourney的Discord频道、Claude的网页界…...

车载以太网测试避坑指南:DoIP和DIVA测试中那些容易搞错的VLAN与地址配置
车载以太网测试避坑指南:DoIP和DIVA测试中那些容易搞错的VLAN与地址配置 在车载以太网测试领域,DoIP(Diagnostics over Internet Protocol)和DIVA(Diagnostic IP Vehicle Access)测试已成为现代车辆诊断和通…...

终极指南:3秒快速预览Office文档,无需安装完整Office套件
终极指南:3秒快速预览Office文档,无需安装完整Office套件 【免费下载链接】QuickLook.Plugin.OfficeViewer Word, Excel, and PowerPoint plugin for QuickLook. 项目地址: https://gitcode.com/gh_mirrors/qu/QuickLook.Plugin.OfficeViewer 在W…...

同态加密加速系统CIPHERMATCH:安全字符串匹配的工程实践
1. 项目概述CIPHERMATCH是一个基于同态加密的安全字符串匹配加速系统,专为隐私保护计算场景设计。在医疗基因组分析、加密数据库搜索等应用中,传统字符串匹配方法需要解密数据后才能执行计算,存在严重的隐私泄露风险。同态加密虽然能解决这一…...

【独家首发】Claude 3 Opus内存占用暴增模型:通过profiling火焰图定位其KV Cache膨胀根源并实现3.7倍推理加速
更多请点击: https://intelliparadigm.com 第一章:Claude 3 Opus性能评测全景概览 Claude 3 Opus 是 Anthropic 推出的旗舰级大语言模型,在复杂推理、长上下文理解与多步任务执行方面展现出显著突破。其官方宣称支持高达 200K tokens 的上下…...
完整实战教程)
Jetpack Compose + 协程(Coroutine)完整实战教程
Jetpack Compose 协程(Coroutine)完整实战教程 现代 Android 开发里: Compose 协程 Flow 已经是官方主流架构。 如果你只会: Button(onClick {})但不会: LaunchedEffectrememberCoroutineScopeStateFlowcollectAsS…...

MAC地址失效下基于射频指纹的WiFi设备识别技术
1. 项目概述:当MAC地址失效时如何识别设备在当今的智慧城市和物联网环境中,WiFi设备识别技术面临着前所未有的挑战。传统依赖MAC地址的识别方法正逐渐失效——现代移动设备普遍采用MAC地址随机化技术,每次发送探测请求时都会生成虚拟MAC地址。…...

从真题到实战:第十四届蓝桥杯JavaB组省赛核心解题思路与代码精讲
1. 蓝桥杯JavaB组省赛真题解析方法论 参加蓝桥杯竞赛的同学都知道,省赛题目往往在基础算法知识之外,还隐藏着许多解题技巧和优化思路。2023年第十四届蓝桥杯JavaB组省赛真题就是典型的例子,这些题目看似简单,实则暗藏玄机。下面我…...

嵌入式Qt GUI开发实战:从界面设计到硬件控制的完整流程
1. 项目概述:从虚拟界面到物理世界的桥梁在嵌入式开发领域,一个令人兴奋的里程碑就是让图形界面(GUI)真正“动”起来,去控制物理世界中的硬件。很多朋友在学习了Qt的基础控件和界面设计后,常常会问…...