Kafka的分布式架构与高可用性

导语
一开始我们就说过Kafka是一款开源的高吞吐、分布式的消息队列系统,那么今天我们就来说下它的分布式架构和高可用性以及双/多中心部署。
Kafka 体系架构简介
以下是 Kafka 的软件架构,整个 Kafka 体系结构由 Producer、Consumer、Broker、ZooKeeper 组成。Broker 又由 Topic、分区、副本组成。
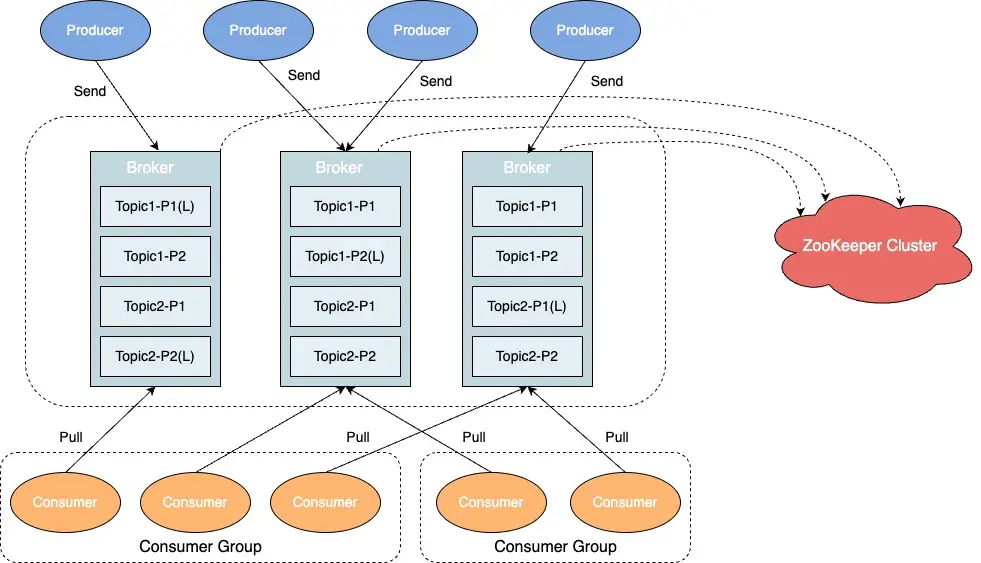
详细可以参考 Kafka 官方文档,Kafka introduction。
分布式与高可用
Kafka通过其分布式架构来实现高可用性。以下是Kafka分布式架构与高可用性之间的关系:
-
分布式数据存储:Kafka的主题被分为多个分区,每个分区都可以有多个副本。这些副本可以分布在不同的Broker节点上,形成分布式的数据存储。这种分布式存储使得数据在多个节点上冗余存储,即使某个节点发生故障,其他副本仍然可用,保证了数据的高可用性。
-
冗余备份:Kafka中的每个分区都可以配置多个副本,这些副本被分布在不同的Broker节点上。当一个Broker节点发生故障时,其他副本可以接管该分区并继续提供服务。这种冗余备份机制保证了即使多个节点发生故障,系统仍然可以继续工作,避免了单点故障,提高了可用性。
-
ISR机制:Kafka使用ISR(In-Sync Replicas)机制来保证数据的可靠性和一致性。ISR是指与Leader副本保持同步的副本集合。当消息被写入Leader副本后,必须等待ISR中的所有副本完成写入操作,才会返回确认给生产者。这样可以保证消息的复制和同步,提高数据的可靠性和一致性。
-
动态的故障转移:Kafka具备自动故障转移能力。当一个Broker节点发生故障时,ISR中的其他副本会参与到Leader选举过程中,自动选举新的Leader副本,并进行分区重平衡。这样可以快速恢复系统的可用性,保证生产者和消费者能够无缝地继续工作。
-
水平扩展:Kafka的分布式架构支持水平扩展。通过增加更多的Broker节点,可以扩展Kafka集群的吞吐量和容量。水平扩展提高了系统的伸缩性,使得Kafka能够处理大规模的数据流和高并发的读写请求。
-
多中心数据互为灾备:即一般为了避免天灾人祸大型项目都会在不同地域部署相同的数据数据中心,彼此之间互为灾备。
多中心相关术语
-
RTO(Recovery Time Objective):即数据恢复时间目标。指如果发生故障,发生故障转移时业务系统所能容忍的最长停止服务时间。如果需要 RTO 越低,就越要避免手工操作,只有自动化故障转移才能实现比较低的 RTO。
-
RPO(Recovery Point Objective):即数据恢复点目标。指如果发生故障,故障转移需要从数据历史记录中的哪个点恢复。换句话说,有多少数据会在故障期间丢失。
-
灾难恢复(Disaster Recovery): 涵盖所有允许应用程序从灾难中恢复的体系结构、实现、工具、策略和过程的总称,在本文档的上下文中,是指整个区域故障。
-
高可用性(High Availability): 一个高度可用的系统即使在出现故障的情况下也可以连续运行。在多区域架构的上下文中,高可用性应用程序即使在整个区域故障期间也可以运行。HA 应用程序具有灾难恢复策略。
发生故障的场景
不论是在虚拟化或容器化架构下,还是在提供成熟服务的云厂商上,但都有可能因为各种因素发生局部和系统故障,因此就需要考虑整体系统容灾能力及可用性。
下面列出一些典型的故障场景
| 序号 | 故障场景 | 影响 | 缓解措施 |
|---|---|---|---|
| 1 | 单节点故障 | 单个节点或托管在该节点上的 VM 的功能丧失 | 集群部署 |
| 2 | 机架或交换机故障 | 该机架内托管的所有节点/虚拟机(和/或连接)丢失 | 集群部署分布在多个机架和/或网络故障域中 |
| 3 | DC/DC-机房故障 | 在该 DC/DC 机房内托管的所有节点/虚拟机(和/或连接)丢失 | 扩展集群、复制部署 |
| 4 | 区域故障 | 该区域内托管的所有节点/虚拟机(和/或连接)丢失 | 地理延伸集群(延迟相关)和/或复制部署 |
| 5 | 全球性系统性中断(DNS 故障、路由故障等) | 影响客户和员工的所有系统和服务完全中断 | 离线备份;第三方域中的副本 |
| 6 | 人为行为(无意或恶意) | 在检测之前,人为行为可能会破坏数据和任何同步副本的可用性 | 离线备份 |
这篇文章重点围绕故障场景2、3、4说明 Kafka 中有哪些方案来应对这几类故障场景。第1种单节点故障,Kafka 集群高可用可以应对;第5、6种故障可以考虑将数据存储到第三方系统,如果在云上可以转储到 COS。
双/多中心的应用场景
-
跨地域复制
在项目比较大的时候,可能需要在多个地域部署中心服务,以增加系统的容灾能力和业务能力,每个数据中心都有自己的 Kafka 集群,这里就涉及到应用和Kafka集群之间的访问,是本地访问还是跨中心访问。 -
灾备
任何集群服务都会收到天灾、人祸等因素影响稳定性,比如地震,火灾,高温、超低温等等,Kafka 集群可能因为这些不可预估的原因导致不可用,这时就需要有另外的与第一个集群完全相同的集群。如果有任何一个集群出现不可用情况,其他中心可以及时顶上,也就是所谓的互为灾备。 -
集群的物理隔离
多环境设置,数据隔离部署。 -
云迁移和混合云部署
在云计算流行的今天,部分公司会将业务同时部署在本地 IDC 和云端。本地 IDC 和每个云服务区域可能都会有 Kafka 集群,应用程序会在这些 Kafka 集群之间传输数据。例如,云端部署了一个应用,它需要访问 IDC 里的数据,IDC 里的应用程序负责更新这个数据,并保存在本地的数据库中。可以捕获这些数据变更,然后保存在 IDC 的 Kafka 集群中,然后再镜像到云端的 Kafka 集群中,让云端的应用程序可以访问这些数据。这样既有助于控制跨数据中心的流量成本,也有助于提高流量的监管合规性和安全性。 -
法律和法规要求
见题知意。
跨数据中心Kafka的部署形态
一般来说,Kafka 跨数据中心部署大体分两种形态:Stretched Cluster和Connected Cluster。
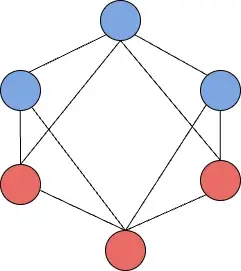
Stretched Cluster
延展集群,它本质上是单个集群,是使用Kafka内置的复制机制来保持broker副本的同步。通过配置min.insync.replicas和acks=all,可以确保每次写入消息时都可以收到至少来自两个数据中心的确认。
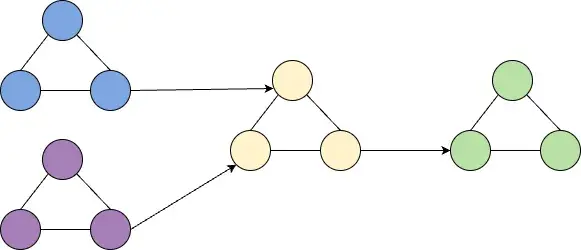
Connected Cluster
连接集群,一般通过异步复制完成多地域复制,并且使用外部工具将数据从一个(或多个)集群复制到另一个集群。该工具中会有Kafka消费者从源集群消费数据,然后利用Kafka生产者将数据生产到目的集群。但Confluent提供了一种不使用外部工具实现此功能的连接集群,在下面介绍商业化方案的时候再详细说明。
下面是这两种部署形态的对比
| 部署形态 | 数据传输方式 | Offset 保留 | 延迟 | RTO&RPO | 何时使用 |
|---|---|---|---|---|---|
| Stretched Cluster | 同步 | 可以 | 无 | 0 | 数据中心距离较短 |
| Connected Cluster | 异步 | 可以 | 取决于网络 | >0 | 数据中心较远 |
以这两种部署形态可以形成多种部署方式,有兴趣的朋友可以深入研究下。
顶尖架构师栈
关注回复关键字
【C01】超10G后端学习面试资源
【IDEA】最新IDEA激活工具和码及教程
【JetBrains软件名】 最新软件激活工具和码及教程
工具&码&教程
本文由 mdnice 多平台发布
相关文章:
Kafka的分布式架构与高可用性
导语 一开始我们就说过Kafka是一款开源的高吞吐、分布式的消息队列系统,那么今天我们就来说下它的分布式架构和高可用性以及双/多中心部署。 Kafka 体系架构简介 以下是 Kafka 的软件架构,整个 Kafka 体系结构由 Producer、Consumer、Broker、ZooKeepe…...

Spring Cloud学习笔记【分布式请求链路跟踪-Sleuth】
文章目录 Spring Cloud Sleuth概述概述主要功能:Sleuth中的术语和相关概念官网 zipkin配置下载运行zipkin下载zipkin运行 demo配置服务提供者 lf-userpom.xmlapplication.ymlUserController 服务调用者 lf-authpom.xmlapplication.ymlAuthController 测试 Spring Cl…...
)
Java开发中的操作日志详解(InsCode AI 创作助手)
Java开发中的操作日志详解 一、操作日志的作用 故障排除和调试: 操作日志可以记录应用程序的各种活动,包括错误、异常、警告和信息性消息。这有助于开发人员快速定位和解决问题。性能分析: 通过记录关键操作和性能指标,操作日志…...

FutureTask和CompletableFuture的模拟使用
模拟了查询耗时操作,并使用FutureTask和CompletableFuture分别获取计算结果,统计执行时长 package org.alllearn.futurtask;import com.google.common.base.Stopwatch; import com.google.common.collect.Lists; import lombok.AllArgsConstructor; imp…...
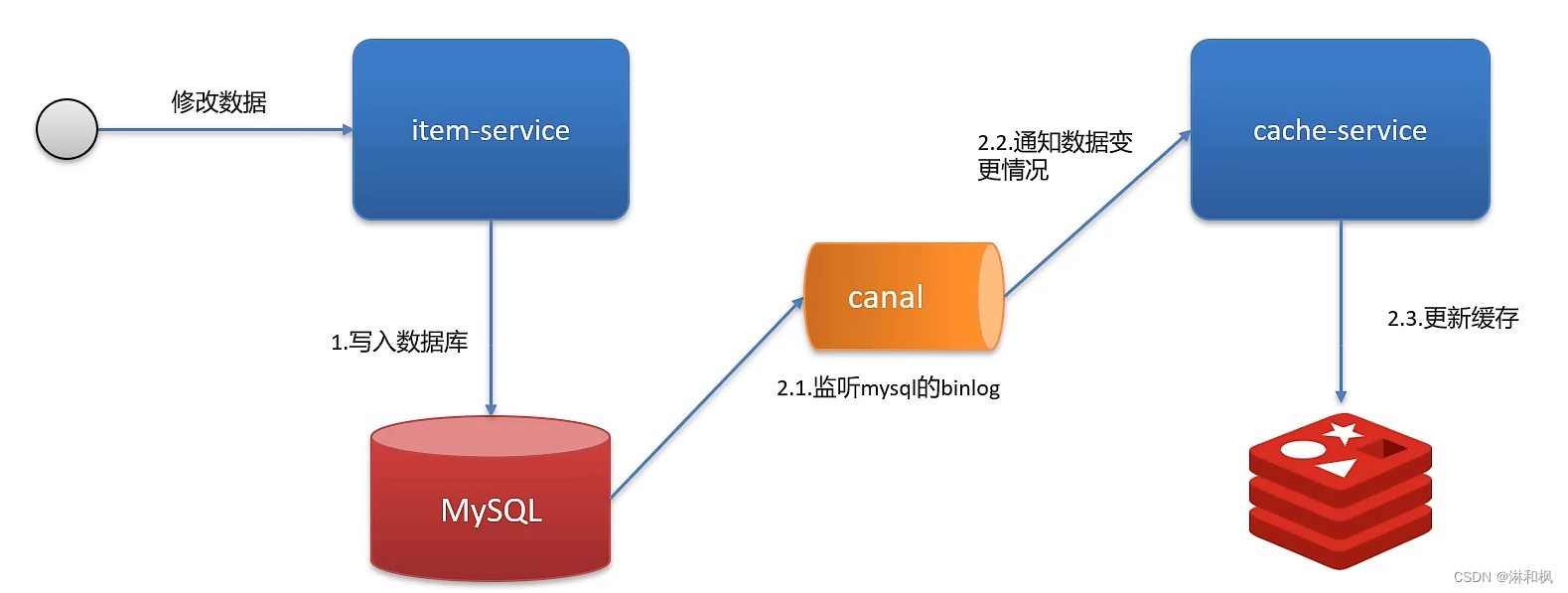
Redis作为缓存,mysql的数据如何与redis进行同步?
Redis作为缓存,mysql的数据如何与redis进行同步? 一定要设置前提,先介绍业务背景 延时双删 双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致 读操作:缓存命中,直接返回;缓存未…...

申请免费 SSL 证书为您的小程序加密通信
在今天的网络环境中,数据安全和隐私保护变得尤为重要。无论是网站还是应用程序,为其提供安全的通信渠道都是至关重要的。对于小程序开发者来说,使用 SSL(Secure Sockets Layer)证书可以有效地保障用户数据的安全&#…...
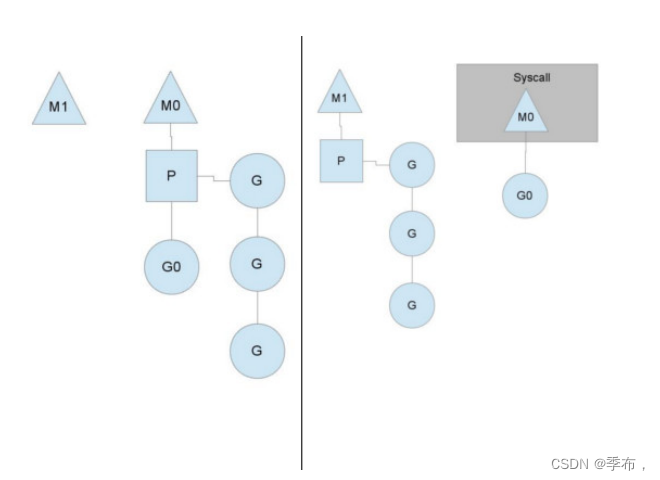
Go 并发编程
并发编程 1.1 并发与并⾏ 并⾏与并发是两个不同的概念,普通解释: 并发:交替做不同事情的能⼒并⾏:同时做不同事情的能⼒ 如果站在程序员的⻆度去解释是这样的: 并发:不同的代码块交替执⾏并⾏…...
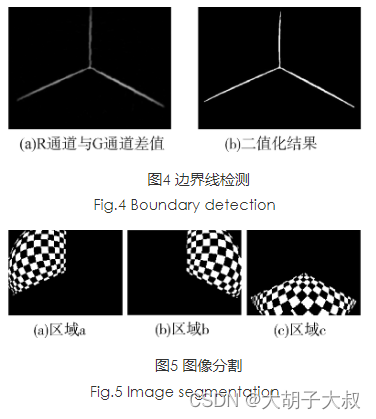
鱼眼相机去畸变(图像拉直/展开/矫正)算法及实战总结
本文介绍两种方法 1、经纬度矫正法 2、棋盘格矫正法 一、经纬度矫正法 1、算法说明 经纬度矫正法, 可以把鱼眼图想象成半个地球, 然后将地球展开成地图,经纬度矫正法主要是利用几何原理, 对图像进行展开矫正。 经过P点的入射光线…...

es6 数据类型
es6 数据类型 map 数据类型 >Map 对象保存键值对。 用途 : Object的key无法支持该数据时需要了解对象大小时 map 数据类型任何值(对象或者原始值) 都可以作为一个键。 Object 的键只能是字符串 let myMap new Map(); let myMap1 new Map(); var keyStrin…...

【postgresql】
看到group by 1,2 和 order by 1, 2。看不懂,google,搜到了Stack Overflow 上有回答 What does SQL clause “GROUP BY 1” mean? 大概意思就是,group by, order by 后面跟数字,指的是 selec…...

【C++】空间配置器 allocator:原理及底层解析
文章目录 空间配置器一级空间配置器二级空间配置器1. 内存池2. SGI-STL中二级空间配置器设计 - - 哈希桶3. 二级空间配置器的空间申请 空间配置器的默认选择空间配置器的在封装:添加了数据类型大小空间配置器对象的构造与析构 容器中的 allocator 空间配置器 提到空…...
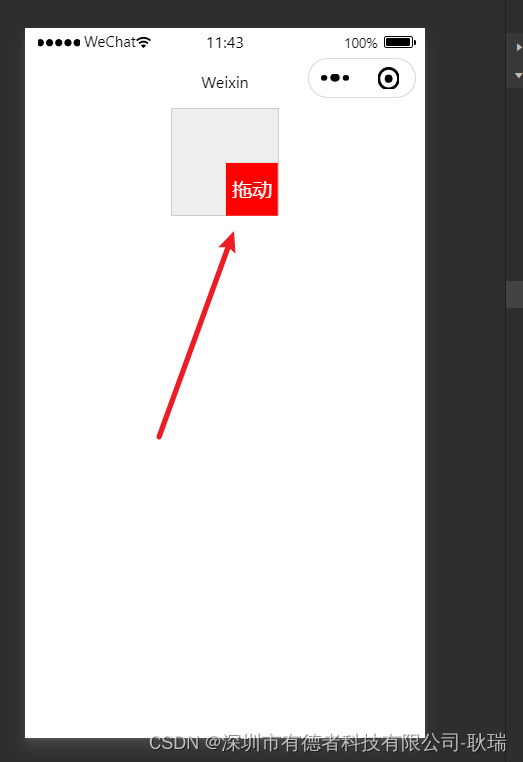
微信小程序 movable-area 区域拖动动态组件演示
movable-area 组件在小程序中的作用是用于创建一个可移动的区域,可以在该区域内拖动视图或内容。这个组件常用于实现可拖动的容器或可滑动的列表等交互效果。 使用 movable-area 组件可以对其内部的 movable-view 组件进行拖动操作,可以通过设置不同的属…...

隔离上网,安全上网
SDC沙盒数据防泄密系统(安全上网,隔离上网) •深信达SDC沙盒数据防泄密系统,是专门针对敏感数据进行防泄密保护的系统,根据隔离上网和安全上网的原则实现数据的代码级保护,不会影响工作效率,不…...

NOSQL Redis 数据持久化 RDB、AOF(二) 恢复
redis 执行flushall 或 flushdb 也会产生dump.rdb文件,但里面是空的。 注意:千万执行,不然rdb文件会被覆盖的。 dump.rdb 文件如何恢复数据 讲备份文件 dump.rdb 移动到redis安装目录并启动服务即可。 dump.rdb 自动触发 和手动触发 自…...
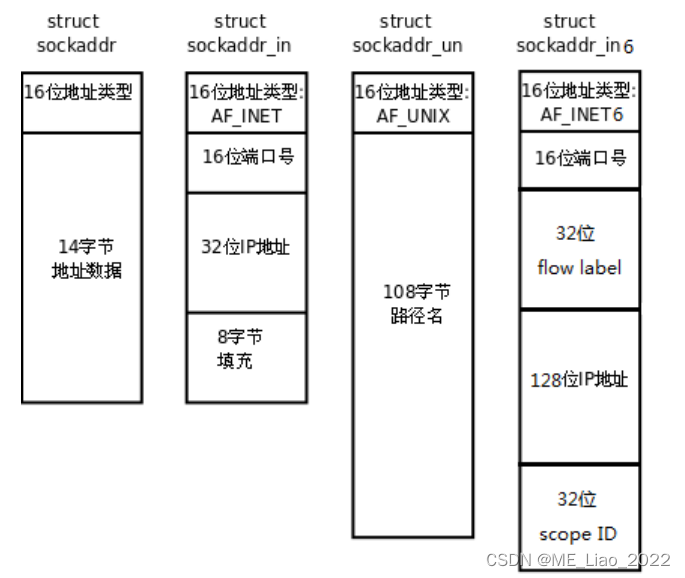
UDP通信
UDP通信 #include <sys/types.h> #include <sys/socket.h> ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,const struct sockaddr *dest_addr, socklen_t addrlen); - 参数:- sockfd : 通信的fd- buf : 要发送的数据- len : 发送…...

Bootstrap对溢出内容的两种处理:滚动条和隐藏两种方式
Bootstrap中定义了以下两个类来处理内容溢出的情况: 类overflow-auto:在固定宽度和高度的元素上,如果内容溢出了元素,将生成一个垂直滚动条,通过滚动条可以查看溢出的内容。 类overflow-hidden:在固定宽度和高度的元素…...
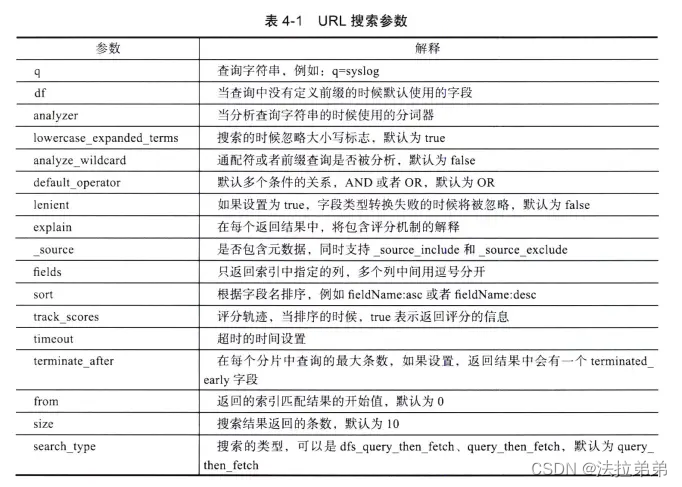
elasticsearch基本语法
这里写自定义目录标题 elasticsearch简介基本语法索引创建索引修改索引删除索引 查询简单查询精确查询条件查询范围查询:聚合查询:排序和分页: 参考文献: elasticsearch简介 Elasticsearch 是一个开源的分布式搜索和分析引擎&…...

Maven Spring jar包启动报错 排查
Maven Spring jar包启动报错排查 背景 maven 编译jar包,放在linux服务器启动不起来,提示:xxxx-0.0.1-SNAPSHOT.jar中没有主清单属性 原因 pom 配置文件,多了 <skip>true</skip> <build><plugins>&l…...

LeetCode-2485-找出中枢整数
题目描述: 给你一个正整数 n ,找出满足下述条件的 中枢整数 x : 1 和 x 之间的所有元素之和等于 x 和 n 之间所有元素之和。 返回中枢整数 x 。如果不存在中枢整数,则返回 -1 。题目保证对于给定的输入,至多存在一个中…...
)
nano pi m1配置脚本(全志H3)
为nanopi m1写一个自动配置脚本,简化自己的操作 配置:H3芯片,1G内存,64G卡 系统:friendlycore focal 4.14版本 一、系统安装 烧录系统后,插入机器,但是使用df -ih发现只有900K的nodesÿ…...

从L0到L3的完整路径,Token降61%的底层逻辑,TencentDB Agent Memory实战:分层记忆架构详解
TencentDB Agent Memory实战:分层记忆架构详解 副标题: 从L0到L3的完整路径,Token降61%的底层逻辑痛点:为什么你的AI总是"记不住"? 你有没有遇到过这样的情况: AI能记住前几轮对话,但聊久了就&qu…...

树莓派NOOBS安装指南:从SD卡准备到系统配置全流程详解
1. 项目概述:为什么选择NOOBS作为树莓派入门首选如果你刚拿到一块树莓派,看着这块小小的电路板,第一反应可能是兴奋,紧接着就是困惑:我该怎么让它“活”过来?对于嵌入式开发、物联网原型搭建,甚…...
的完整避坑指南:从SPI配置到LVGL局部刷新修复)
ESP32S3驱动1.3寸圆形AMOLED屏(RM67162芯片)的完整避坑指南:从SPI配置到LVGL局部刷新修复
ESP32S3驱动1.3寸圆形AMOLED屏(RM67162芯片)全流程实战:从SPI配置到LVGL优化 这块1.3寸圆形AMOLED屏幕以其出色的显示效果和独特的外形设计,在智能穿戴设备和小型嵌入式项目中越来越受欢迎。然而,当它与ESP32S3开发板结…...

SC4541SKTRT 2MHz 2.9V~22V升/降压单线LED驱动器Semtech电子元器件IC芯片
SC4541SKTRT是Semtech(升特)推出的高频LED驱动器芯片,该器件集升压与降压拓扑于一体,支持2.9V至22V超宽输入电压并具备25V输出电压能力,利用内置肖特基二极管和功率开关,将外部电路减至最少,实现…...

Cortex-M中断优先级配置与优化实践
1. 中断处理机制基础解析在嵌入式系统开发中,中断处理是最核心的机制之一。Cortex-M系列处理器采用嵌套向量中断控制器(NVIC)来管理中断优先级,其设计哲学是允许高优先级中断打断低优先级中断的执行,形成中断嵌套。这种机制确保了关键任务能够…...

Arm LUTI指令解析:向量化查找表优化实战
1. Arm LUTI指令深度解析:多寄存器查找表操作实战指南在Armv9架构的SME2扩展中,LUTI(Lookup Table Indexed)系列指令为向量化查找表操作提供了硬件级支持。这类指令通过ZT0寄存器存储查找表数据,利用源向量寄存器中的索…...
:图灵的答案)
从沙子到车辙(1.3):图灵的答案
1.3 图灵的答案 那个跑步穿过剑桥的人 1935 年,剑桥大学国王学院。一个 23 岁的研究生躺在草地上,望着天空,想着一件事: 什么是"计算"? 他叫艾伦图灵(Alan Turing)。 这个年轻人…...
打造丝滑下拉刷新(附Paging3联动实战))
告别传统SwipeRefreshLayout!用Compose的pullRefresh()打造丝滑下拉刷新(附Paging3联动实战)
用Compose的pullRefresh()重构Android下拉刷新体验:从基础封装到Paging3深度集成 下拉刷新作为移动端最基础的用户交互之一,在Jetpack Compose时代迎来了全新的设计范式。传统Android开发中,我们习惯使用SwipeRefreshLayout包裹RecyclerView的…...

告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍
告别无声直播!OBS实时字幕插件终极指南:5分钟让直播无障碍 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 还在为直播观…...

第一章:项目概述与环境搭建
第一章:项目概述与环境搭建 本文将带你从零开始认识 MyFirstCompose 项目,了解其整体架构与技术选型。 1.1 项目简介 MyFirstCompose 是一个基于 Jetpack Compose 开发的入门级 Android 应用,采用 单 Activity MVVM Repository 架构模式。…...