elasticsearch深度分页问题
一、深度分页方式from + size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询
![]()
1 GET /student/student/_search
2 {
3 "query":{
4 "match_all": {}
5 },
6 "from":5000,
7 "size":10
8 }
![]()
意味着 es 需要在各个分片上匹配排序并得到5010条数据,协调节点拿到这些数据再进行排序等处理,然后结果集中取最后10条数据返回。
我们会发现这样的深度分页将会使得效率非常低,因为我只需要查询10条数据,而es则需要执行from+size条数据然后处理后返回。
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
例如:
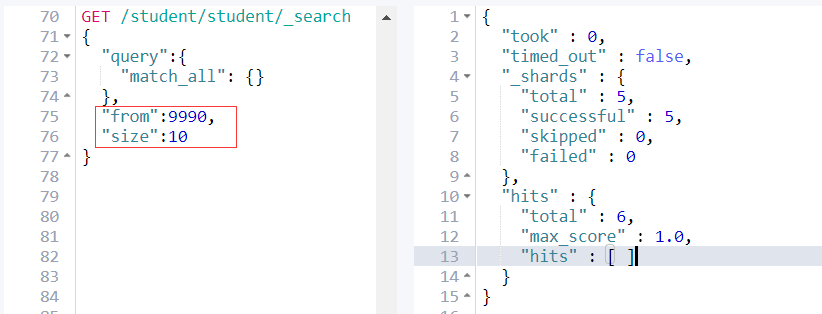
from + size <= 10000所以这个分页深度依然能够执行。
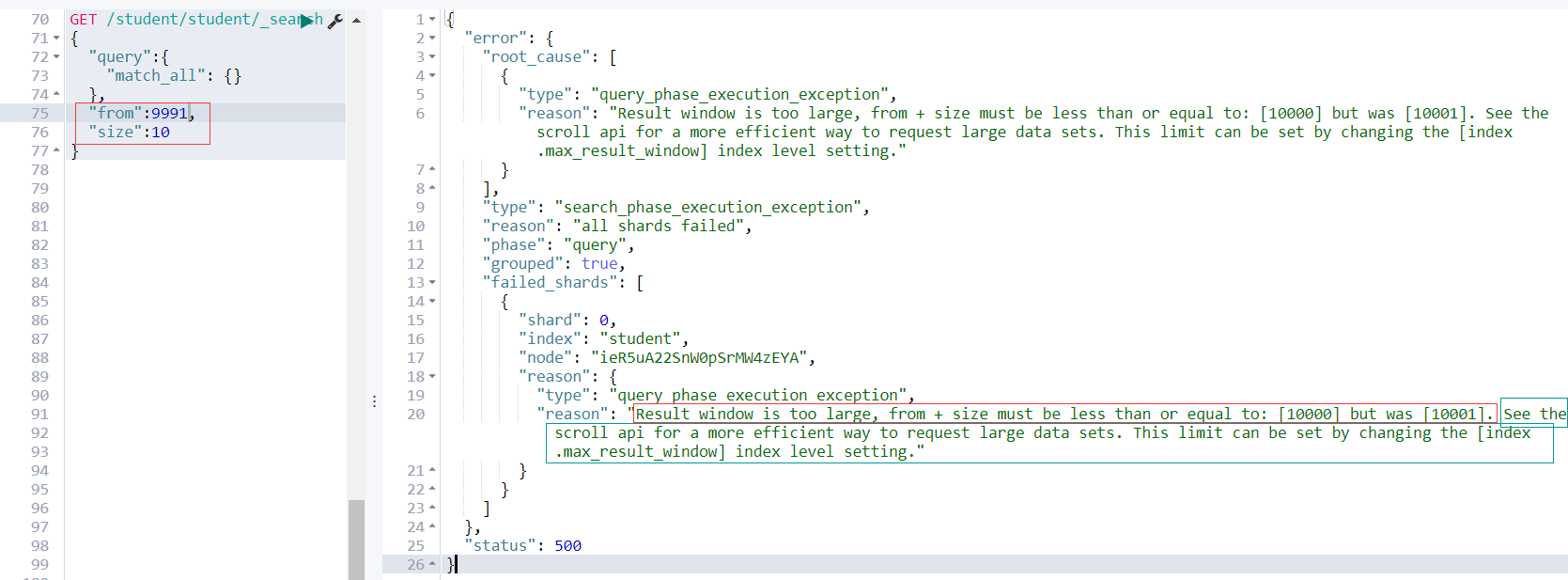
继续看上图,当size + from > 10000;es查询失败,并且提示
Result window is too large, from + size must be less than or equal to: [10000] but was [10001]
接下来看还有一个很重要的提示
See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting
有关请求大数据集的更有效方法,请参阅滚动api。这个限制可以通过改变[索引]来设置。哦呵,原来es给我们提供了另外的一个API scroll。难道这个 scroll 能解决深度分页问题?
二、深度分页之scroll
在es中如果我们分页要请求大数据集或者一次请求要获取较大的数据集,scroll都是一个非常好的解决方案。
使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标)。
滚屏搜索会及时制作快照。这个快照不会包含任何在初始阶段搜索请求后对index做的修改。它通过将旧的数据文件保存在手边,所以可以保护index的样子看起来像搜索开始时的样子。这样将使得我们无法得到用户最近的更新行为。
scroll的使用很简单
执行如下curl,每次请求两条。可以定制 scroll = 5m意味着该窗口过期时间为5分钟。
![]()
1 GET /student/student/_search?scroll=5m
2 {
3 "query": {
4 "match_all": {}
5 },
6 "size": 2
7 }
![]()
![]()
1 {2 "_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB",3 "took" : 0,4 "timed_out" : false,5 "_shards" : {6 "total" : 5,7 "successful" : 5,8 "skipped" : 0,9 "failed" : 0
10 },
11 "hits" : {
12 "total" : 6,
13 "max_score" : 1.0,
14 "hits" : [
15 {
16 "_index" : "student",
17 "_type" : "student",
18 "_id" : "5",
19 "_score" : 1.0,
20 "_source" : {
21 "name" : "fucheng",
22 "age" : 23,
23 "class" : "2-3"
24 }
25 },
26 {
27 "_index" : "student",
28 "_type" : "student",
29 "_id" : "2",
30 "_score" : 1.0,
31 "_source" : {
32 "name" : "xiaoming",
33 "age" : 25,
34 "class" : "2-1"
35 }
36 }
37 ]
38 }
39 }
![]()
在返回结果中,有一个很重要的
_scroll_id
在后面的请求中我们都要带着这个 scroll_id 去请求。
现在student这个索引中共有6条数据,id分别为 1, 2, 3, 4, 5, 6。当我们使用 scroll 查询第4次的时候,返回结果应该为kong。这时我们就知道已经结果集已经匹配完了。
继续执行3次结果如下三图所示。
1 GET /_search/scroll
2 {
3 "scroll":"5m",
4 "scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB"
5 }
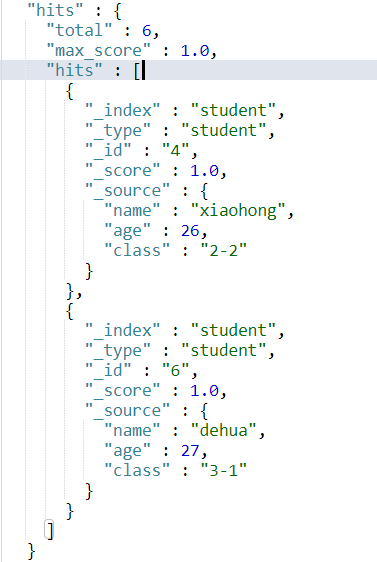

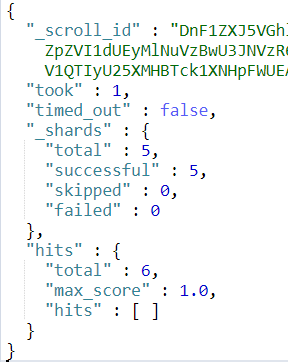
由结果集我们可以发现最终确实分别得到了正确的结果集,并且正确的终止了scroll。
三、search_after
from + size的分页方式虽然是最灵活的分页方式,但是当分页深度达到一定程度将会产生深度分页的问题。scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照。这时 search_after应运而生。其是在es-5.X之后才提供的。
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
为了演示,我们需要给上文中的student索引增加一个uid字段表示其唯一性。
执行如下查询:
![]()
1 GET /student/student/_search2 {3 "query":{4 "match_all": {}5 },6 "size":2,7 "sort":[8 {9 "uid": "desc"
10 }
11 ]
12 }
![]()
结果集:
![]()
View Code
下一次分页,需要将上述分页结果集的最后一条数据的值带上。
![]()
1 GET /student/student/_search2 {3 "query":{4 "match_all": {}5 },6 "size":2,7 "search_after":[1005],8 "sort":[9 {
10 "uid": "desc"
11 }
12 ]
13 }
![]()
这样我们就使用search_after方式实现了分页查询。
四、三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本) 维护成本高,需要维护一个 scroll_id | 海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel) 需要查询海量结果集的数据 |
| search_after | 高 | 性能最好 不存在深度分页问题 能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段 连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11543453.html
相关文章:

elasticsearch深度分页问题
一、深度分页方式from size es 默认采用的分页方式是 from size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询 1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all":…...
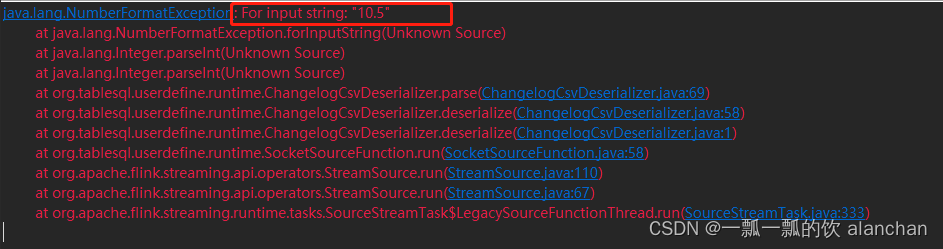
32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

Java练习题-用冒泡排序法实现数组排序
✅作者简介:CSDN内容合伙人、阿里云专家博主、51CTO专家博主、新星计划第三季python赛道Top1🏆 📃个人主页:hacker707的csdn博客 🔥系列专栏:Java练习题 💬个人格言:不断的翻越一座又…...

【SV中的多线程fork...join/join_any/join_none】
SV中fork_join/fork_join_any/fork_join_none 1 一目了然1.1 fork...join1.2 fork...join_any1.3 fork...join_none 2 总结 SV中fork_join和fork_join_any和fork_join_none; Note: fork_join在Verilog中也有,只有其他的两个是SV中独有的; 1 一目了然 1.…...
翻译:网站整站翻译 / 网站国际化 / 极简实现
一、本文目标 以极简单的方法实现整站翻译,轻松实现国际化。 二、js 文件 https://res.zvo.cn/translate/translate.js 三、代码 代码放在浏览器控制台即可实现 var head document.getElementsByTagName(head)[0];var script document.createElement(script);sc…...
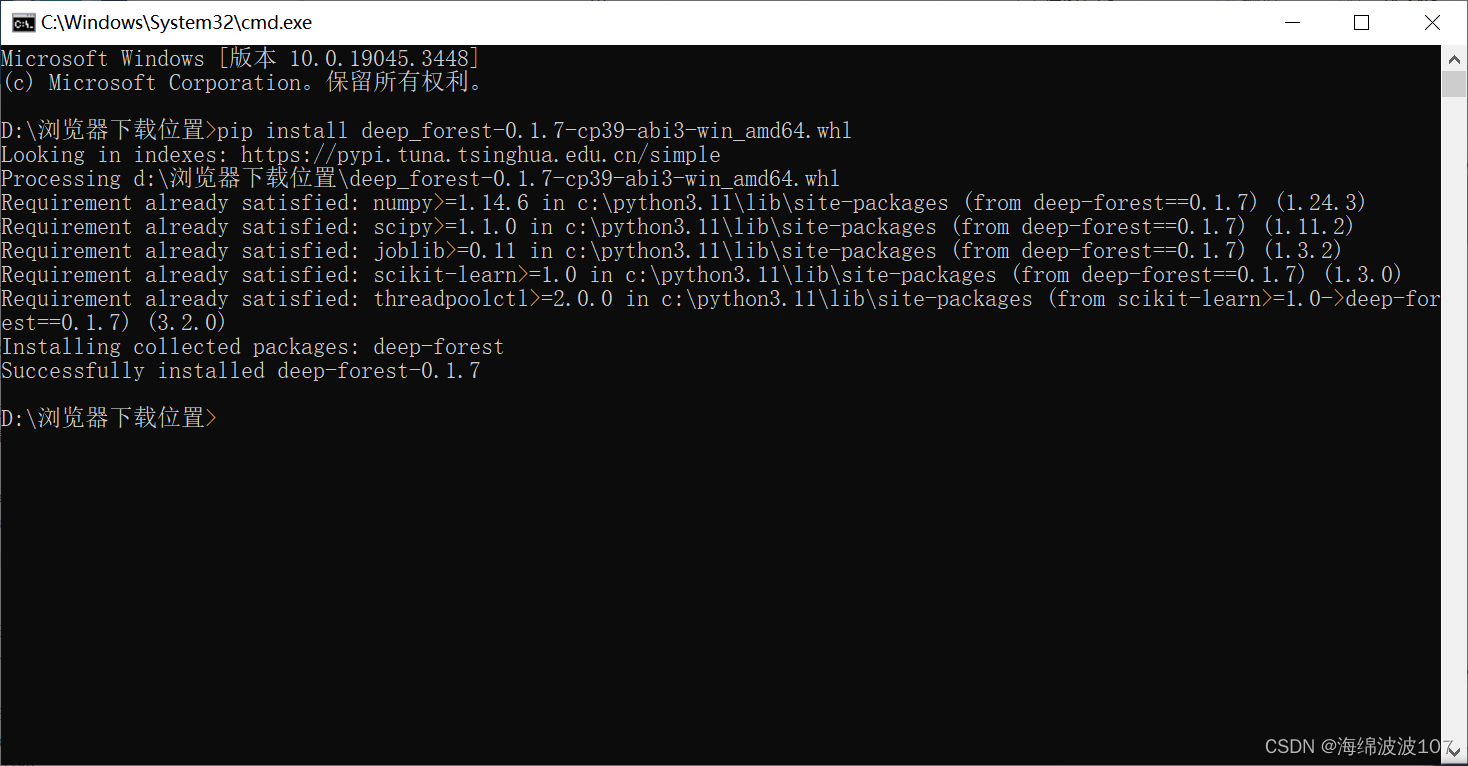
深度森林(deep-forest)安装
深度森林(deep-forest)安装 1、打开https://pypi.org/,搜索deep-forest,下载wheel文件 在下载好之后,打开文件下载的位置 首先对下载好的wheel文件进行改名,原名是: deep_forest-0.1.7-cp39-c…...

ping.pe ping 检测IP全球延迟
可以把结果保存为照片 https://ping.pe/全球ping ping ip端口检测 IP:PORT路由追踪 mtr IP 参考 ping.pe...

nodejs 16版本
Index of /download/release/latest-v16.x/...
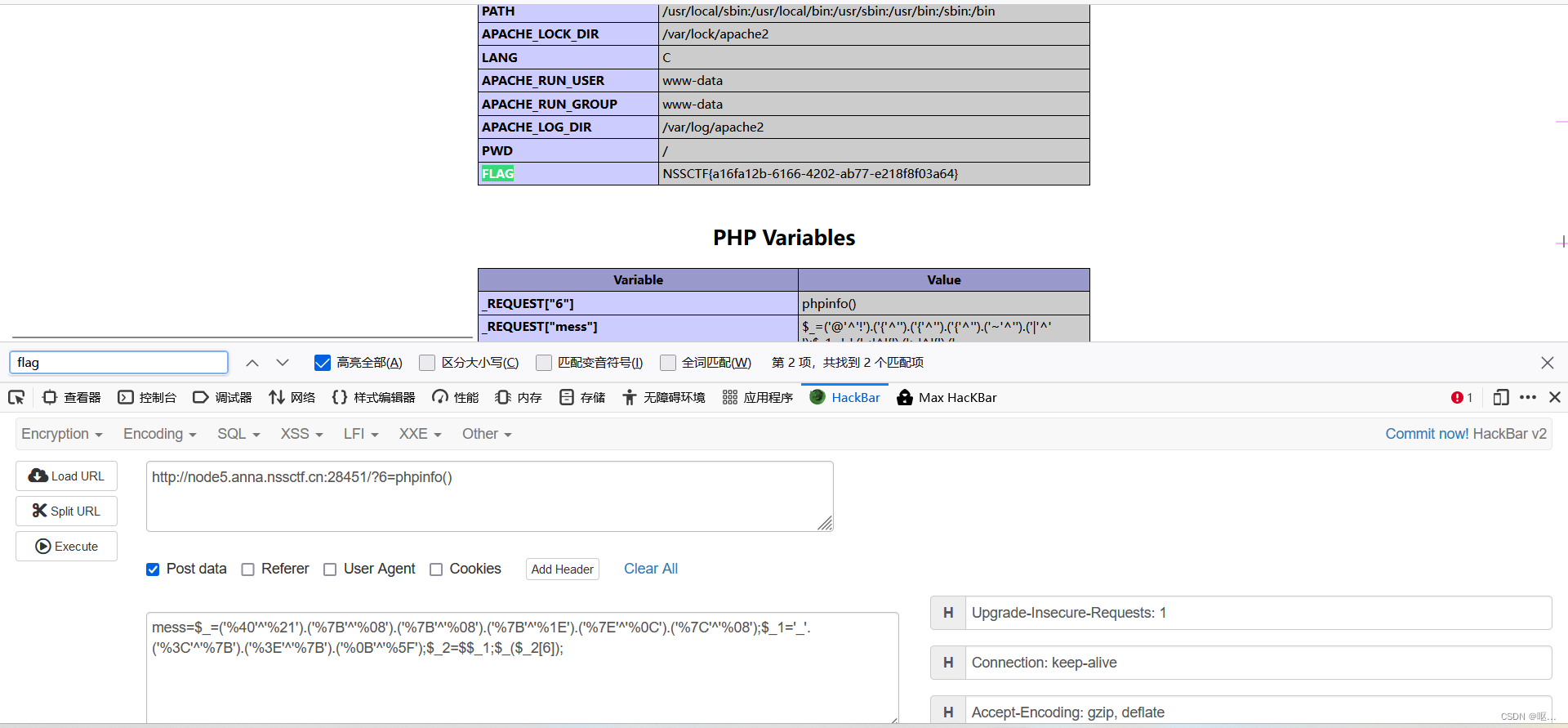
NSSCTF做题(7)
[第五空间 2021]pklovecloud 反序列化 <?php include flag.php; class pkshow { function echo_name() { return "Pk very safe^.^"; } } class acp { protected $cinder; public $neutron; …...

【GIT版本控制】--高级分支策略
一、分支合并策略 在Git中,高级分支策略是为了有效地管理和整合分支而设计的。其中一个关键方面是分支合并策略,它定义了如何将一个分支的更改合并到另一个分支。以下是几种常见的分支合并策略: 合并提交策略(Merge Commit Stra…...

【Qt控件之QDialog】使用及技巧
简介 QDialog是Qt中的一个类,继承自QWidget类,用于创建对话框窗口,可以显示模态(阻塞当前窗口)或非模态的对话框。对话框可以包含各种控件,如按钮、文本框等,用于与用户进行交互。 主要函数说…...
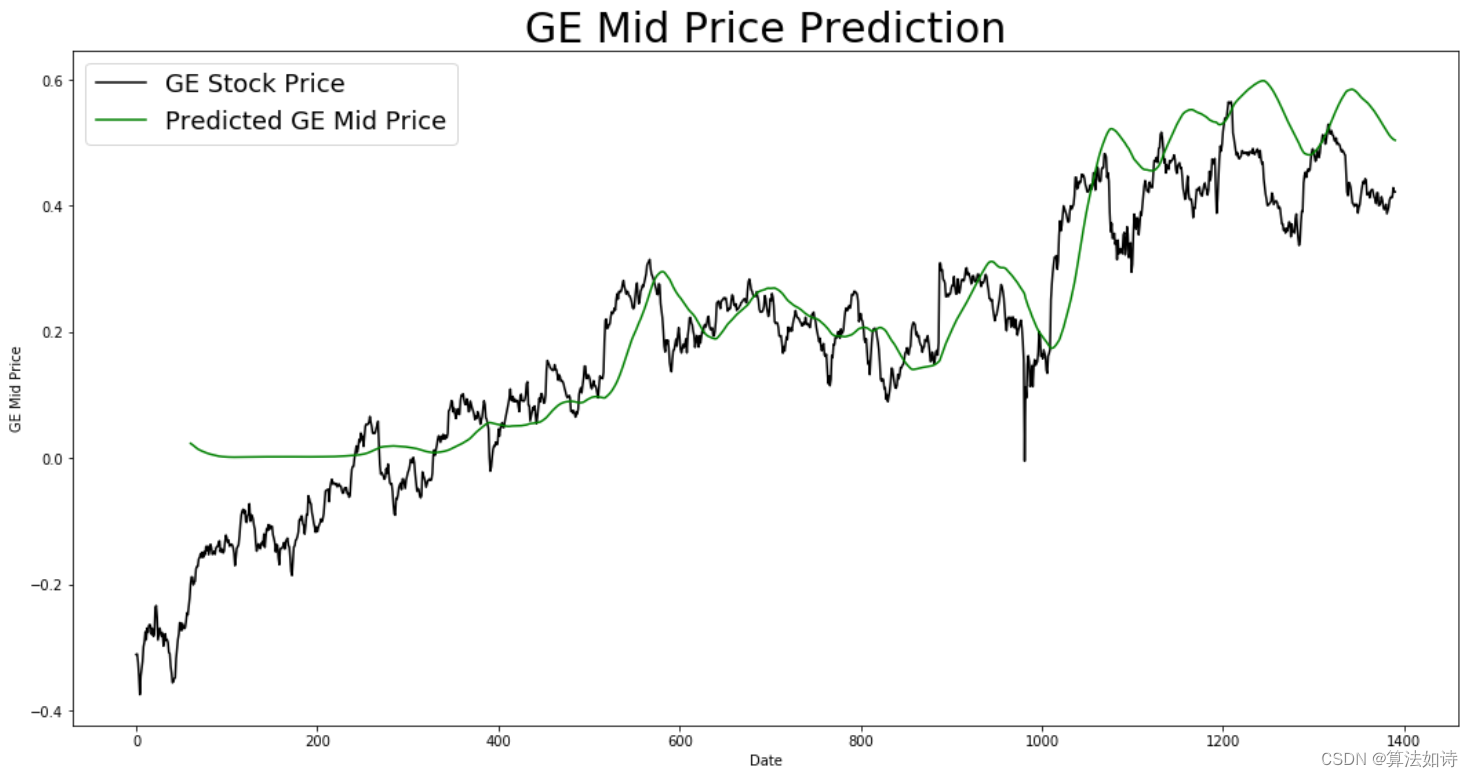
Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow) 程序设计 import numpy as np import matplotlib.pyplot...

spark sql如何行转列
在数据仓库中,行转列通常称为”变形”(Pivoting) 或 “透视”(Pivoting),可使用Spark SQL的pivot语句实现。下面是一个简单的示例: 假设我们有如下表格: -------------------- | name | brand | year | -------------------- |…...
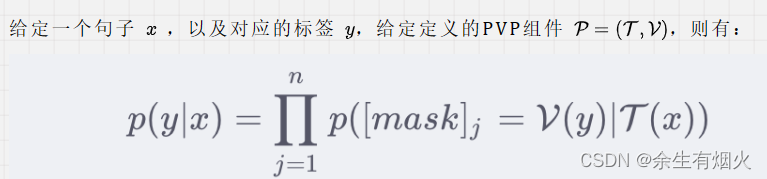
Prompt-Tuning(一)
一、预训练语言模型的发展过程 第一阶段的模型主要是基于自监督学习的训练目标,其中常见的目标包括掩码语言模型(MLM)和下一句预测(NSP)。这些模型采用了Transformer架构,并遵循了Pre-training和Fine-tuni…...
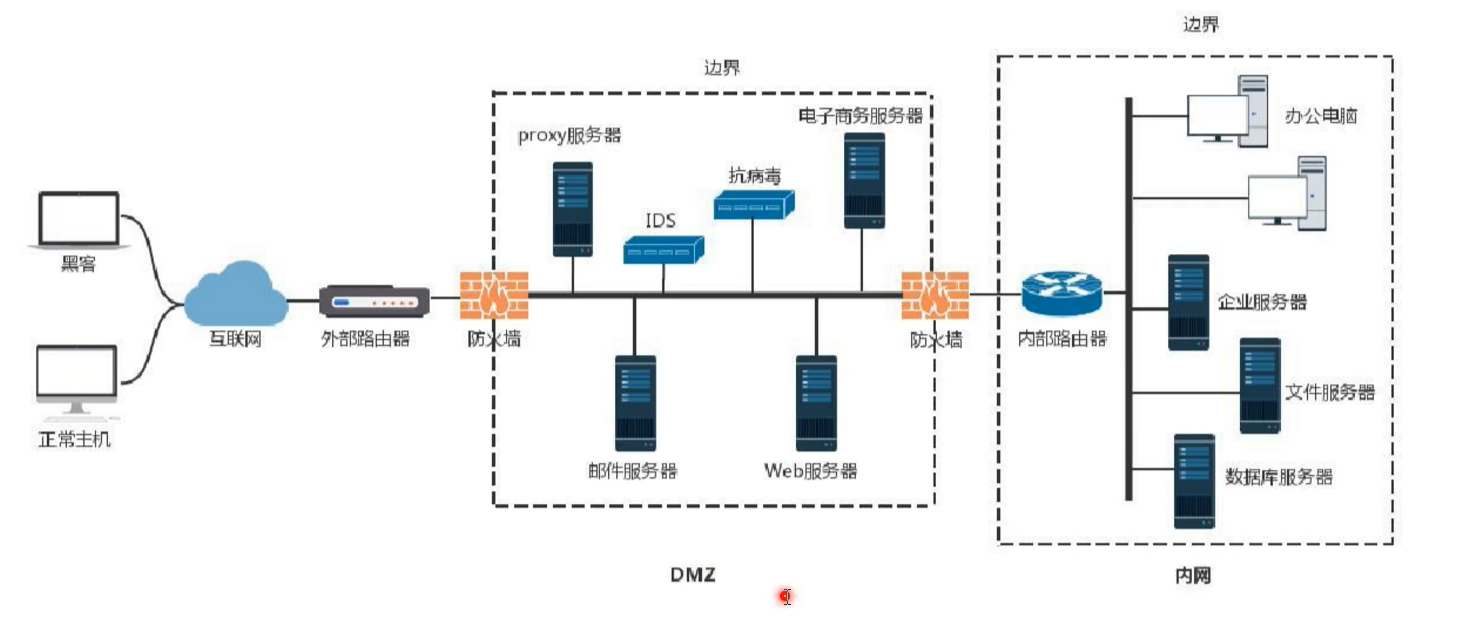
域信息收集
DMZ,是英文“demilitarized zone”的缩写,中文名称为“隔离区”,也称“非军事化区”。它是为了解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区。该缓冲区位于企业…...

MySQ 学习笔记
1.MySQL(老版)基础 开启MySQL服务: net start mysql mysql为安装时的名称 关闭MySQL服务: net stop mysql 注: 需管理员模式下运行Dos命令 . 打开服务窗口命令 services.msc 登录MySQL服务: mysql [-h localhost -P 3306] -u root -p****** Navicat常用快捷键 键动作CTRLG设…...
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com代码: import pdfpl…...
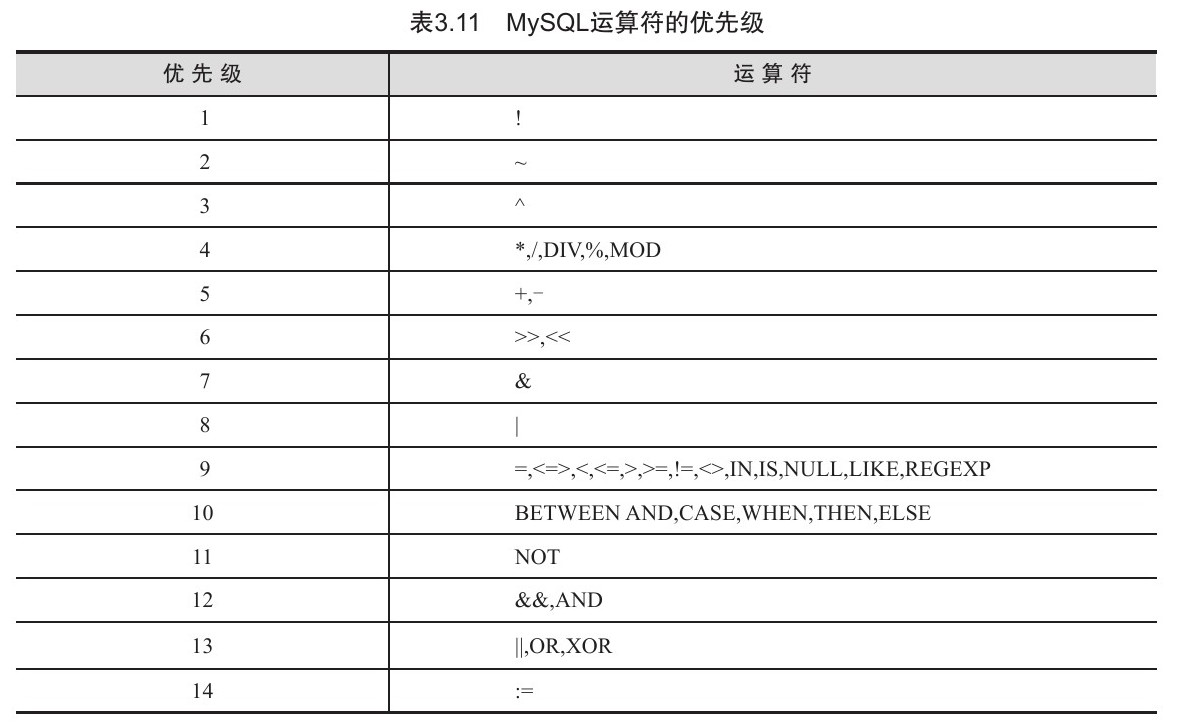
运算符
目录 算术运算符 比较运算符 逻辑运算符 位运算符 运算符的优先级 MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 数据库中的表结构确立后,表中的数据代表的意义就已经确定。而…...

利用freesurfer6进行海马分割的环境配置和步骤,以及获取海马体积
利用freesurfer6进行海马分割的环境配置和步骤 Matlab Runtime 安装1. 运行recon-all:2. 利用 recon-all -s subj -hippocampal-subfields-T1 进行海马分割3. 结束后需要在/$SUBJECTS_DIR/subject/的文件夹/mri路径下输入下面的代码查看分割情况4. 在文件SUBJECTS_DIR路径下输…...

haproxy使用
haproxy使用 安装使用yum安装 配置文件global 全局配置Proxies配置Proxies配置-defaultsProxies配置-listen 简化配置 安装 社区版官网链接:http://www.haproxy.org CentOS 7 的默认的base仓库中包含haproxy的安装包文件,但是版本比较旧,是1…...

基于WPF开发桌面AI助手:架构设计与实现详解
1. 项目概述:一个开源的WPF桌面AI助手 最近在GitHub上看到一个挺有意思的项目,叫“MayDay-wpf/AIBotPublic”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现这其实是一个用WPF(Windows Present…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

3分钟掌握跨平台模组下载神器:WorkshopDL全攻略
3分钟掌握跨平台模组下载神器:WorkshopDL全攻略 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台的游戏无法使用Steam创意工坊模组而烦恼吗…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

Onekey:重构Steam Depot清单下载流程的现代化解决方案
Onekey:重构Steam Depot清单下载流程的现代化解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey作为一款专为Steam Depot清单设计的自动化下载工具,通过其创…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

飞书自动化开发实战:从脚本编写到事件驱动架构设计
1. 项目概述:飞书自动化,从“手动挡”到“自动驾驶”的进化 如果你每天的工作,有超过30%的时间是在飞书里重复着“点击-填写-发送”的枯燥操作,比如手动拉取数据生成日报、定时向群聊推送消息、或者根据特定条件审批流程…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...