遗传算法入门笔记
目录
一、大体实现过程
二、开始我们的进化(具体实现细节)
2.1 先从编码说起
2.1.1 二进制编码法
2.1.2 浮点编码法
2.1.3 符号编码法
2.2 为我们的袋鼠染色体编码
2.3 评价个体的适应度
2.4 射杀一些袋鼠
2.5 遗传--染色体交叉(crossover)
2.6 变异--基因突变(Mutation)
三、代码实现环节
3.1 基础概念
3.2 代码尝试
3.2.1 遗传算法算子
3.2.2 变异算子(mutation)
3.3 遗传算法策略
3.4 小刷例题
3.4.1 例题1:牛刀小试
3.4.2 例题2:糖果
一、大体实现过程
遗传算法中每一条染色体,对应着遗传算法的一个解决方案,一般我们用适应性函数(fitness function)来衡量这个解决方案的优劣。所以从一个基因组到其解的适应度形成一个映射。遗传算法的实现过程实际上就像自然界的进化过程那样。
我们用袋鼠跳中的步骤一一对应解释:
1) 首先寻找一种对问题潜在解进行“数字化”编码的方案。(建立表现型和基因型的映射关系)
2) 随机初始化一个种群(那么第一批袋鼠就被随意地分散在山脉上),种群里面的个体就是这些数字化的编码。
3) 接下来,通过适当的解码过程之后(得到袋鼠的位置坐标)。
4) 用适应性函数对每一个基因个体作一次适应度评估(袋鼠爬得越高当然就越好,所以适应度相应越高)。
5) 用选择函数按照某种规定择优选择(每隔一段时间,射杀一些所在海拔较低的袋鼠,以保证袋鼠总体数目持平。)
6) 让个体基因变异(让袋鼠随机地跳一跳)。
7) 然后产生子代(希望存活下来的袋鼠是多产的,并在那里生儿育女)。
遗传算法并不保证你能获得问题的最优解,但是使用遗传算法的最大优点在于你不必去了解和操心如何去“找”最优解。(你不必去指导袋鼠向那边跳,跳多远。)而只要简单的“否定”一些表现不好的个体就行了。(把那些总是爱走下坡路的袋鼠射杀,这就是遗传算法的精粹!)
由此我们可以得出遗传算法的一般步骤:
1) 随机产生种群。
2) 根据策略判断个体的适应度,是否符合优化准则,若符合,输出最佳个体及其最优解,结束。否则,进行下一步。
3) 依据适应度选择父母,适应度高的个体被选中的概率高,适应度低的个体被淘汰。
4) 用父母的染色体按照一定的方法进行交叉,生成子代。
5) 对子代染色体进行变异。
由交叉和变异产生新一代种群,返回步骤2,直到最优解产生。
二、开始我们的进化(具体实现细节)
2.1 先从编码说起
编码是应用遗传算法时要解决的首要问题,也是设计遗传算法时的一个关键步骤。编码方法影响到交叉算子、变异算子等遗传算子的运算方法,很大程度上决定了遗传进化的效率。
迄今为止人们已经提出了许多种不同的编码方法。总的来说,这些编码方法可以分为三大类:二进制编码法、浮点编码法、符号编码法。下面分别进行介绍。
2.1.1 二进制编码法
就像人类的基因有AGCT 4种碱基序列一样。不过在这里我们只用了0和1两种碱基,然后将它们串成一条链形成染色体。一个位能表示出2种状态的信息量,因此足够长的二进制染色体便能表示所有的特征。这便是二进制编码。如下:
1110001010111
它由二进制符号0和1所组成的二值符号集。它有以下一些优点
1) 编码、解码操作简单易行
2) 交叉、变异等遗传操作便于实现
3) 符合最小字符集编码原则
4) 利用模式定理对算法进行理论分析。
二进制编码的缺点是:对于一些连续函数的优化问题,由于其随机性使得其局部搜索能力较差,如对于一些高精度的问题,当解迫近于最优解后,由于其变异后表现型变化很大,不连续,所以会远离最优解,达不到稳定。
2.1.2 浮点编码法
二进制编码虽然简单直观,一目了然。但是存在着连续函数离散化时的映射误差。个体长度较短时,可能达不到精度要求,而个体编码长度较长时,虽然能提高精度,但增加了解码的难度,使遗传算法的搜索空间急剧扩大。
所谓浮点法,是指个体的每个基因值用某一范围内的一个浮点数来表示。在浮点数编码方法中,必须保证基因值在给定的区间限制范围内,遗传算法中所使用的交叉、变异等遗传算子也必须保证其运算结果所产生的新个体的基因值也在这个区间限制范围内。如下所示:
1.2-3.2-5.3-7.2-1.4-9.7
浮点数编码方法有下面几个优点:
1) 适用于在遗传算法中表示范围较大的数。
2) 适用于精度要求较高的遗传算法。
3) 便于较大空间的遗传搜索。
4) 改善了遗传算法的计算复杂性,提高了运算效率。
5) 便于遗传算法与经典优化方法的混合使用。
6) 便于设计针对问题的专门知识的知识型遗传算子。
7) 便于处理复杂的决策变量约束条件。
2.1.3 符号编码法
符号编码法是指个体染色体编码串中的基因值取自一个无数值含义、而只有代码含义的符号集如{A,B,C…}。
符号编码的主要优点是:
1) 符合有意义积术块编码原则。
2) 便于在遗传算法中利用所求解问题的专门知识。
3) 便于遗传算法与相关近似算法之间的混合使用。
2.2 为我们的袋鼠染色体编码
在上面介绍了一系列编码方式以后,那么,如何利用上面的编码来为我们的袋鼠染色体编码呢?首先我们要明确一点:编码无非就是建立从基因型到表现型的映射关系。这里的表现型可以理解为个体特征(比如身高、体重、毛色等等)。那么,在此问题下,我们关心的个体特征就是:袋鼠的位置坐标(因为我们要把海拔低的袋鼠给杀掉)。无论袋鼠长什么样,爱吃什么。我们关心的始终是袋鼠在哪里,并且只要知道了袋鼠的位置坐标(位置坐标就是相应的染色体编码,可以通过解码得出),我们就可以:
1) 在喜马拉雅山脉的地图上找到相应的位置坐标,算出海拔高度。(相当于通过自变量求得适应函数的值)然后判读该不该射杀该袋鼠
2) 可以知道染色体交叉和变异后袋鼠新的位置坐标。
回到一元函数最大值的问题。在上面我们把极大值比喻为山峰,那么,袋鼠的位置坐标可以比喻为区间[-1, 2]的某一个x坐标(有了x坐标,再通过函数表达式可以算出函数值 <==> 得到了袋鼠染色体编码,解码得到位置坐标,在喜马拉雅山脉地图查询位置坐标算出海拔高度)。这个x坐标是一个实数,现在,说白了就是怎么对这个x坐标进行编码。下面我们以二进制编码为例讲解,不过这种情况下以二进制编码比较复杂就是了。(如果以浮点数编码,其实就很简洁了,就一浮点数而已。)
我们说过,一定长度的二进制编码序列,只能表示一定精度的浮点数。在这里假如我们要求解精确到六位小数,由于区间长度为2 - (-1) = 3 ,为了保证精度要求,至少把区间[-1,2]分为3 × 10^6等份。又因为
2^21 = 2097152 < 3*10^6 < 2^22 = 4194304
所以编码的二进制串至少需要22位。
把一个二进制串 (b0,b1,....bn) 转化为区间里面对应的实数值可以通过下面两个步骤:
1) 将一个二进制串代表的二进制数转化为10进制数:
2) 对应区间内的实数:
例如一个二进制串(1000101110110101000111)通过上面换算以后,表示实数值0.637197。
好了,上面的编码方式只是举个例子让大家更好理解而已,编码的方式千奇百怪,层出不穷,每个问题可能采用的编码方式都不一样。在这一点上我们要注意。
2.3 评价个体的适应度
前面说了,适应度函数主要是通过个体特征从而判断个体的适应度。在本例的袋鼠跳中,我们只关心袋鼠的海拔高度,以此来判断是否该射杀该袋鼠。这样一来,该函数就非常简单了。只要输入袋鼠的位置坐标,在通过相应查找运算,返回袋鼠当前位置的海拔高度就行。
适应度函数也称评价函数,是根据目标函数确定的用于区分群体中个体好坏的标准。适应度函数总是非负的,而目标函数可能有正有负,故需要在目标函数与适应度函数之间进行变换。
评价个体适应度的一般过程为
-
对个体编码串进行解码处理后,可得到个体的表现型。
-
由个体的表现型可计算出对应个体的目标函数值。
-
根据最优化问题的类型,由目标函数值按一定的转换规则求出个体的适应度。
2.4 射杀一些袋鼠
遗传算法中的选择操作就是用来确定如何从父代群体中按某种方法选取那些个体,以便遗传到下一代群体。选择操作用来确定重组或交叉个体,以及被选个体将产生多少个子代个体。前面说了,我们希望海拔高的袋鼠存活下来,并尽可能繁衍更多的后代。但我们都知道,在自然界中,适应度高的袋鼠越能繁衍后代,但这也是从概率上说的而已。毕竟有些适应度低的袋鼠也可能逃过我们的眼睛。
那么,怎么建立这种概率关系呢?
下面介绍几种常用的选择算子:
-
轮盘赌选择(Roulette Wheel Selection):是一种回放式随机采样方法。每个个体进入下一代的概率等于它的适应度值与整个种群中个体适应度值和的比例。选择误差较大。
-
随机竞争选择(Stochastic Tournament):每次按轮盘赌选择一对个体,然后让这两个个体进行竞争,适应度高的被选中,如此反复,直到选满为止。
-
最佳保留选择:首先按轮盘赌选择方法执行遗传算法的选择操作,然后将当前群体中适应度最高的个体结构完整地复制到下一代群体中。
-
无回放随机选择(也叫期望值选择Excepted Value Selection):根据每个个体在下一代群体中的生存期望来进行随机选择运算。方法如下:
-
计算群体中每个个体在下一代群体中的生存期望数目N。
-
若某一个体被选中参与交叉运算,则它在下一代中的生存期望数目减去 0.5,若某一个体未被选中参与交叉运算,则它在下一代中的生存期望数目减去1.0。
-
随着选择过程的进行,若某一个体的生存期望数目小于0时,则该个体就不再有机会被选中。
-
-
确定式选择:按照一种确定的方式来进行选择操作。具体操作过程如下:
-
计算群体中各个个体在下一代群体中的期望生存数目N。
-
用N的整数部分确定各个对应个体在下一代群体中的生存数目。
-
用N的小数部分对个体进行降序排列,顺序取前M个个体加入到下一代群体中。至此可完全确定出下一代群体中M个个体。
-
-
无回放余数随机选择:可确保适应度比平均适应度大的一些个体能够被遗传到下一代群体中,因而选择误差比较小。
-
均匀排序:对群体中的所有个体按其适应度大小进行排序,基于这个排序来分配各个个体被选中的概率。
-
最佳保存策略:当前群体中适应度最高的个体不参与交叉运算和变异运算,而是用它来代替掉本代群体中经过交叉、变异等操作后所产生的适应度最低的个体。
-
随机联赛选择:每次选取几个个体中适应度最高的一个个体遗传到下一代群体中。
-
排挤选择:新生成的子代将代替或排挤相似的旧父代个体,提高群体的多样性。
下面以轮盘赌选择为例给大家讲解一下:
假如有5条染色体,他们的适应度分别为5、8、3、7、2。
那么总的适应度为:F = 5 + 8 + 3 + 7 + 2 = 25。
那么各个个体的被选中的概率为:
α1 = ( 5 / 25 ) * 100% = 20%
α2 = ( 8 / 25 ) * 100% = 32%
α3 = ( 3 / 25 ) * 100% = 12%
α4 = ( 7 / 25 ) * 100% = 28%
α5 = ( 2 / 25 ) * 100% = 8%
所以转盘如下:

当指针在这个转盘上转动,停止下来时指向的个体就是天选之人啦。可以看出,适应性越高的个体被选中的概率就越大。
2.5 遗传--染色体交叉(crossover)
遗传算法的交叉操作,是指对两个相互配对的染色体按某种方式相互交换其部分基因,从而形成两个新的个体。
适用于二进制编码个体或浮点数编码个体的交叉算子:
-
单点交叉(One-point Crossover):指在个体编码串中只随机设置一个交叉点,然后再该点相互交换两个配对个体的部分染色体。
-
两点交叉与多点交叉:
-
两点交叉(Two-point Crossover):在个体编码串中随机设置了两个交叉点,然后再进行部分基因交换。
-
多点交叉(Multi-point Crossover)
-
-
均匀交叉(也称一致交叉,Uniform Crossover):两个配对个体的每个基因座上的基因都以相同的交叉概率进行交换,从而形成两个新个体。
-
算术交叉(Arithmetic Crossover):由两个个体的线性组合而产生出两个新的个体。该操作对象一般是由浮点数编码表示的个体。
咳咳,根据国际惯例。还是抓一个最简单的二进制单点交叉为例来给大家讲解讲解。
二进制编码的染色体交叉过程非常类似高中生物中所讲的同源染色体的联会过程――随机把其中几个位于同一位置的编码进行交换,产生新的个体。

对应的二进制交叉:

2.6 变异--基因突变(Mutation)
遗传算法中的变异运算,是指将个体染色体编码串中的某些基因座上的基因值用该基因座上的其它等位基因来替换,从而形成新的个体。
例如下面这串二进制编码:
101101001011001
经过基因突变后,可能变成以下这串新的编码:
001101011011001
以下变异算子适用于二进制编码和浮点数编码的个体:
-
基本位变异(Simple Mutation):对个体编码串中以变异概率、随机指定的某一位或某几位仅因座上的值做变异运算。
-
均匀变异(Uniform Mutation):分别用符合某一范围内均匀分布的随机数,以某一较小的概率来替换个体编码串中各个基因座上的原有基因值。(特别适用于在算法的初级运行阶段)
-
边界变异(Boundary Mutation):随机的取基因座上的两个对应边界基因值之一去替代原有基因值。特别适用于最优点位于或接近于可行解的边界时的一类问题。
-
非均匀变异:对原有的基因值做一随机扰动,以扰动后的结果作为变异后的新基因值。对每个基因座都以相同的概率进行变异运算之后,相当于整个解向量在解空间中作了一次轻微的变动。
-
高斯近似变异:进行变异操作时用符号均值为P的平均值,方差为P**2的正态分布的一个随机数来替换原有的基因值。
三、代码实现环节
3.1 基础概念
拿古代人类来举例子:
- 个体(Individual):每个生物。即每个古人类个体。
- 种群(population):一个系统里所有个体的总称。比如一个部落。
- 种群个体数(POPULATION):一个系统里个体的数量。比如一个部落里的人数。
- 染色体(chromosom):每个个体均携带,用来承载基因。比如一条人类染色体。
- 基因(Gene):用来控制生物的性状(表现)。
- 适应度(fitness):对某个生物是否适应环境的定量评分。比如对某个古人类是否强壮进行 [1,100] 的评分。
- 迭代次数(TIMES):该生物种群繁衍的次数。比如古人类繁殖了 100 万年。
一定要记住这些英文名字!,后面会经常用到
在算法中,我们对每个个体计算其染色体的适应度(fitness)来决定它是否优秀。
3.2 代码尝试
尝试构建一个名字叫做 Individual 的结构体,里面存储一个个体的信息。
struct Individual{string chromosome; //染色体int fitness; //个体的适应度int calc_fitness(); //计算适应度 Individual(string chromosome); //初始化 Individual mate(); //交叉算子(CrossOver) Individual mutation(); //变异算子(Mutation)
};Individual(string chromosome){this->chromosome=chromosome;this->fitness=calc_fitness();
}3.2.1 遗传算法算子
交叉算子(CrossOver)
也有将该算子称为 mate 的。我更倾向于第二种叫法,因为第二种字数更少。
交叉算子就是模拟父母双方交配过程。想一想人类交配时,每个基因会随机的来自父亲或者母亲。我们可以模拟这个过程。假设我们的染色体用 string 存储,可以实现下面的交配代码:
// par 代表母亲,chromosome 代表父亲(即本身)的染色体,par.chromosome 则代表母亲染色体。
Individual Individual::mate(Individual par) { // 交叉string child = ""; // 子代染色体int len = chromosome.size();for (int i = 0; i < len; i ++ ) {double p = random(0, 100) / 100; // 计算来自父母的概率if (p <= 0.5) child += chromosome[i]; // 一半概率来自父亲else child += par.chromosome[i]; // 另一半来自母亲}return Individual(child);
}当然,我们也可以思考一些其他的交叉思路,比如随机抽取某些段进行交换。如下图所示:

这种算法通常在二进制条件下更加实用。
3.2.2 变异算子(mutation)
即低概率地随机地改变某个基因。这样可以有效避免程序陷入局部最优或者过慢收敛。例如:

一般来说,我们可以设计一个变异概率。变异率大概在 0.01∼0.050.01∼0.05 之间最优。变异率太高会导致收敛过慢,变异率太低则会导致陷入局部最优。
3.3 遗传算法策略
- 精英保留策略
还是拿古人类举例。假设我们是上帝,我们想要古人类实现长久发展,最好的办法就是尽可能的将那些头脑敏捷,肢体强壮的个体保留下来,淘汰那些老弱病残的个体。
在程序中,我们将个体按照适应度排序,把适应度最好前 k% 的保留下来,剩下的随机交配。通常,k 可以设成 1∼20。设置太高则会局部最优,太低则会收敛过慢。
- 概率保留策略
学名好像是 Stoffa改进方法,这不重要。总之,就是为了避免父母生出傻孩子浪费时间,把傻孩子(适应度低的后代)直接抛弃。
假设我们要求收敛到最低适应度,后代适应度为 y,父代适应度为 x,有 Δ=y−x。若 Δ<0,证明子代比父代更好,我们一定接受。对于 Δ>0,证明子代不如父代好,我们以一定概率接受。之所以要有一定概率接受,是为了避免出现局部最优解。
这个概率我们怎么来算呢?有一种方法给出了概率的计算函数:
其中 t 是我们设定的参数值,一般随着迭代次数增大而减小。
如果 > rand(0,1),那么我们就接受它。
为什么是 −Δ 呢?因为 Δ>0,我们要保证 e^x 小于 1 才能保证部分接受。因此要用 −Δ。
为什么要用 e^x 呢?我不知道,大概是因为它的积分等于原函数吧。。。
下面放一张遗传算法求最短哈密尔顿路径的收敛图像。其中绿色实线是加了概率函数的,蓝色虚线则没有加。可以看出,绿色实现收敛的比较快,侧面证明了 Stoffa改进方法 的正确性。

思考题
如果我们要求最大适应值,那么概率的计算函数应当怎么计算呢?
答案:,Delta<0。
3.4 小刷例题
3.4.1 例题1:牛刀小试
给定一个目标字符串(target),目标是从相同长度的随机字符串开始生成目标字符串。
比如从 114514QAQ 生成 123456789。
这里先讲一下适应度函数的构造方法:比较当前染色体与目标字符串之间不同的字符个数即为适应度。显然,适应度越低越好。
样例代码如下:
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cstdio>
#include<ctime>
#include<vector>
#define POPULATION 1000
using namespace std;typedef long long LL;
//using LL=long long;
typedef pair<int,int> PII;
//using PII=pair<int,int>;
typedef pair<LL,LL> PLL;
//using PLL=pair<LL,LL>;const string target="I've got it!";
const string GeneBase="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOP"\"QRSTUVWXYZ 1234567890, .-;:_!\"#%&/()=?@${[]}'"; // 基因库int random(int l,int r){ //随机一个位于[l,r]之间的整数 return rand()%(r-l+1)+l;
}char mutate(){int len=GeneBase.size();return GeneBase[random(0,len-1)];
} string create(){ //产生新的染色体 string chromosome="";int len=target.size();for(int i=0;i<len;i++){chromosome+=mutate();}return chromosome;
}struct Individual{string chromosome; //染色体int fitness; //个体的适应度int calc_fitness(); //计算适应度 Individual(string chromosome); //初始化 Individual mate(Individual parent); //交配 void mutation(); //随机变异 bool operator < (const Individual &tmp) const {return fitness<tmp.fitness;}
};Individual::Individual(string chromosome){this->chromosome=chromosome;this->fitness=calc_fitness();
}// par 代表母亲,chromosome 代表父亲(即本身)的染色体,par.chromosome 则代表母亲染色体。
Individual Individual::mate(Individual par) { // 交叉string child = ""; // 子代染色体/后代 int len = chromosome.size();for (int i = 0; i < len; i ++ ) {double p = random(0, 100) / 100; // 计算来自父母的概率if (p <= 0.5) child += chromosome[i]; // 一半概率来自父亲else child += par.chromosome[i]; // 另一半来自母亲}return Individual(child);
}int Individual::calc_fitness(){ //计算适应度 int len=target.size(); int now_fitness=0;for(int i=0;i<len;i++){now_fitness+=(chromosome[i]!=target[i]);}return now_fitness;
}void Individual::mutation(){int P=random(1,2),LEN=target.size();for(int i=1;i<=P;i++){int pos=random(0,LEN-1);chromosome[pos]=mutate();}this->fitness=calc_fitness();
} int main(){srand(time(0));int cnt = 0; // 计算当前迭代到第几代vector<Individual> population;bool found = false;for (int i = 0; i < POPULATION; i ++ ) { // 随机个体population.push_back(Individual(create()));}while (!found) {sort(population.begin(), population.end()); // 按照适应度排序if (population[0].fitness == 0) {found = true; break;}vector<Individual> new_population;int s = (10 * POPULATION) / 100; // 保留精英种子for (int i = 0; i < s; i ++ ) new_population.push_back(population[i]);s = POPULATION - s; // 剩下的随机交配for (int i = 0; i < s; i ++ ) {int len = population.size();Individual p1 = population[random(0, 50)];Individual p2 = population[random(0, 50)];Individual ch = p1.mate(p2);int P = random(0, 100);if (P <= 20) ch.mutation();new_population.push_back(ch);}population = new_population;printf("Generation: %d ", cnt);cout << "String : " << population[0].chromosome << " ";cout << "Fitness : " << population[0].fitness << "\n"; cnt ++ ;}printf("Generation : %d ", cnt);cout << "String : " << population[0].chromosome << " ";cout << "Fitness : " << population[0].fitness << "\n"; cnt ++ ;return 0;
} 运行结果:
Generation: 0 String : !n m fhrd$tI Fitness : 10
Generation: 1 String : E u" BoiDiyp Fitness : 9
Generation: 2 String : E u" BoiDiyp Fitness : 9
Generation: 3 String : sI]& Pt'"t! Fitness : 8
Generation: 4 String : I u" BoiDit5 Fitness : 7
Generation: 5 String : I u" BoiDit! Fitness : 6
Generation: 6 String : I u" BoiDit! Fitness : 6
Generation: 7 String : I u4 Boi it! Fitness : 5
Generation: 8 String : I ue BoiDit! Fitness : 5
Generation: 9 String : I u4 Bot it! Fitness : 4
Generation: 10 String : I u4 Bot it! Fitness : 4
Generation: 11 String : I'u4 Bot it! Fitness : 3
Generation: 12 String : I'u4 Bot it! Fitness : 3
Generation: 13 String : I'ue Bot it! Fitness : 2
Generation: 14 String : I'ue eot it! Fitness : 2
Generation: 15 String : I'ue Bot it! Fitness : 2
Generation: 16 String : I'3e Bot it! Fitness : 2
Generation: 17 String : I'ue eot it! Fitness : 2
Generation: 18 String : I'ue Bot it! Fitness : 2
Generation: 19 String : I've Bot it! Fitness : 1
Generation: 20 String : I've Bot it! Fitness : 1
Generation: 21 String : I've Bot it! Fitness : 1
Generation : 22 String : I've got it! Fitness : 03.4.2 例题2:糖果
题目描述
糖果店的老板一共有 M 种口味的糖果出售。为了方便描述,我们将 M 种口味编号 1 ∼ M。
小明希望能品尝到所有口味的糖果。遗憾的是老板并不单独出售糖果,而是 K 颗一包整包出售。
幸好糖果包装上注明了其中 K 颗糖果的口味,所以小明可以在买之前就知道每包内的糖果口味。
给定 N 包糖果,请你计算小明最少买几包,就可以品尝到所有口味的糖果。
输入格式
第一行包含三个整数 N、M 和 K。
接下来 N 行每行 K 这整数 T1,T2,⋯,TK,代表一包糖果的口味。
输出格式
一个整数表示答案。如果小明无法品尝所有口味,输出 −1。
样例 #1
样例输入 #1
6 5 3 1 1 2 1 2 3 1 1 3 2 3 5 5 4 2 5 1 2样例输出 #1
2提示
对于 30% 的评测用例,1≤N≤20。
对于所有评测样例,1≤N≤100,1≤M≤20,1≤K≤20,1≤Ti≤M。
蓝桥杯 2019 年省赛 A 组 I 题。
这一题是不是很熟悉咧,曾经用状态压缩写过,请看链接:
状态压缩DP-CSDN博客
使用遗传算法样例代码:
#include <algorithm>
#include <iostream>
#include <cstring>
#include <cstdio>
#include <vector>
#include <ctime>#define POPULATION 1000
#define TIMES 10using namespace std;const int N = 110, M = 21;
int a[N][M], n, m, K, ans = 0x3f3f3f3f;int random(int l, int r) {return rand() % (r - l + 1) + l;
}
struct Individual {vector<int> p;int fitness;Individual(vector<int> p);Individual mate();int calc_fitness();bool operator < (const Individual& tmp)const {return fitness < tmp.fitness;}
};Individual::Individual(vector<int> P) {this -> p = P;this -> fitness = calc_fitness();
}Individual Individual::mate() {vector<int> _p = this -> p;int P = random(0, 3);for (int i = 1; i <= P; i ++ ) {int pos1 = random(0, n - 1), pos2 = random(0, n - 1);swap(_p[pos1], _p[pos2]);}return _p;
}int Individual::calc_fitness() {int state = 0;for (int i = 0; i < n; i ++ ) {for (int j = 0; j < K; j ++ )state |= (1 << a[p[i]][j] - 1);if (state == (1 << m) - 1) return i + 1;}puts("-1"); exit(0);
}int main() {scanf("%d%d%d", &n, &m, &K);for (int i = 0; i < n; i ++ )for (int j = 0; j < K; j ++ )scanf("%d", &a[i][j]);vector<Individual> population; vector<int> P;for (int i = 0; i < n; i ++ ) P.push_back(i);for (int i = 1; i <= POPULATION; i ++ ) {random_shuffle(P.begin(), P.end());population.push_back(Individual(P));}for (int i = 0; i < TIMES; i ++ ) {sort(population.begin(), population.end());ans = min(ans, population[0].fitness);vector<Individual> new_population;int s = (10 * POPULATION) / 100;for (int i = 0; i < s; i ++ )new_population.push_back(population[i]);s = POPULATION - s;for (int i = 0; i < s; i ++ ) {Individual p = population[random(0, 50)];new_population.push_back(p.mate());}population = new_population;}printf("%d\n", ans);return 0;
}
当然遗传算法还可以用到寻路问题,8数码问题,囚犯困境,动作控制,找圆心问题(在一个不规则的多边形中,寻找一个包含在该多边形内的最大圆圈的圆心),TSP问题,生产调度问题,人工生命模拟等问题,这里不再展开。
当然,遗传算法的实现还有其他方式,鉴于这是入门篇,不再深入实现其他方法,日后可以再做研究。
以上,遗传算法入门笔记
祝好
相关文章:
遗传算法入门笔记
目录 一、大体实现过程 二、开始我们的进化(具体实现细节) 2.1 先从编码说起 2.1.1 二进制编码法 2.1.2 浮点编码法 2.1.3 符号编码法 2.2 为我们的袋鼠染色体编码 2.3 评价个体的适应度 2.4 射杀一些袋鼠 2.5 遗传--染色体交叉(crossover) 2.6 变异--基…...

【golang】go 返回参数 以及go中 裸返
一、Go 返回参数命名 在Golang中,命名返回参数通常称为命名参数。 Golang允许在函数签名或定义中为函数的返回或结果参数指定名称。或者可以说这是函数定义中返回变量的显式命名。基本上,它解决了在return语句中提及变量名称的要求。 通过使用命名返回参…...

elasticsearch深度分页问题
一、深度分页方式from size es 默认采用的分页方式是 from size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询 1 GET /student/student/_search 2 { 3 "query":{ 4 "match_all":…...
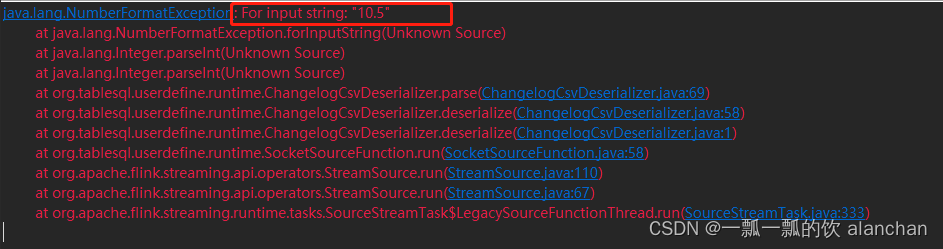
32、Flink table api和SQL 之用户自定义 Sources Sinks实现及详细示例
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

Java练习题-用冒泡排序法实现数组排序
✅作者简介:CSDN内容合伙人、阿里云专家博主、51CTO专家博主、新星计划第三季python赛道Top1🏆 📃个人主页:hacker707的csdn博客 🔥系列专栏:Java练习题 💬个人格言:不断的翻越一座又…...

【SV中的多线程fork...join/join_any/join_none】
SV中fork_join/fork_join_any/fork_join_none 1 一目了然1.1 fork...join1.2 fork...join_any1.3 fork...join_none 2 总结 SV中fork_join和fork_join_any和fork_join_none; Note: fork_join在Verilog中也有,只有其他的两个是SV中独有的; 1 一目了然 1.…...
翻译:网站整站翻译 / 网站国际化 / 极简实现
一、本文目标 以极简单的方法实现整站翻译,轻松实现国际化。 二、js 文件 https://res.zvo.cn/translate/translate.js 三、代码 代码放在浏览器控制台即可实现 var head document.getElementsByTagName(head)[0];var script document.createElement(script);sc…...
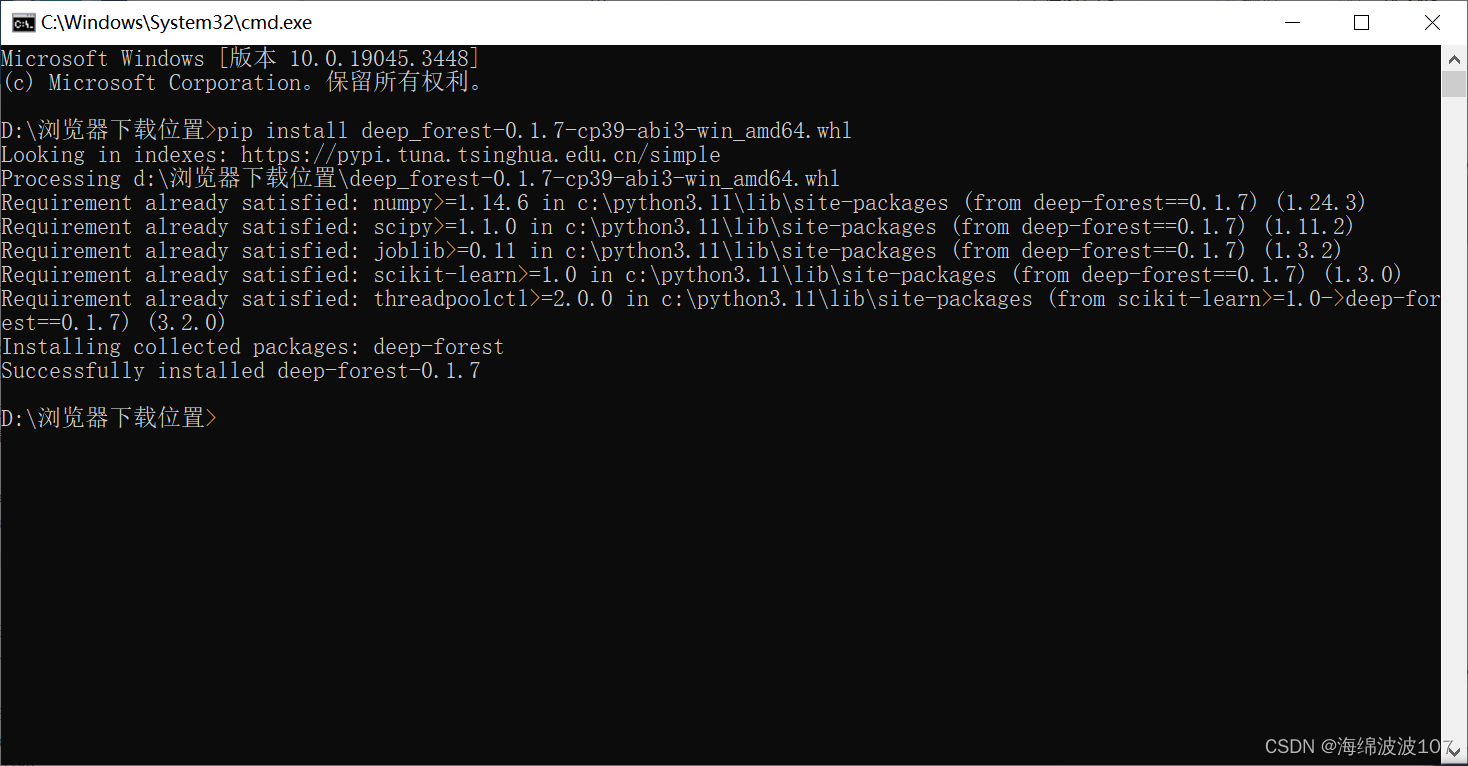
深度森林(deep-forest)安装
深度森林(deep-forest)安装 1、打开https://pypi.org/,搜索deep-forest,下载wheel文件 在下载好之后,打开文件下载的位置 首先对下载好的wheel文件进行改名,原名是: deep_forest-0.1.7-cp39-c…...

ping.pe ping 检测IP全球延迟
可以把结果保存为照片 https://ping.pe/全球ping ping ip端口检测 IP:PORT路由追踪 mtr IP 参考 ping.pe...

nodejs 16版本
Index of /download/release/latest-v16.x/...
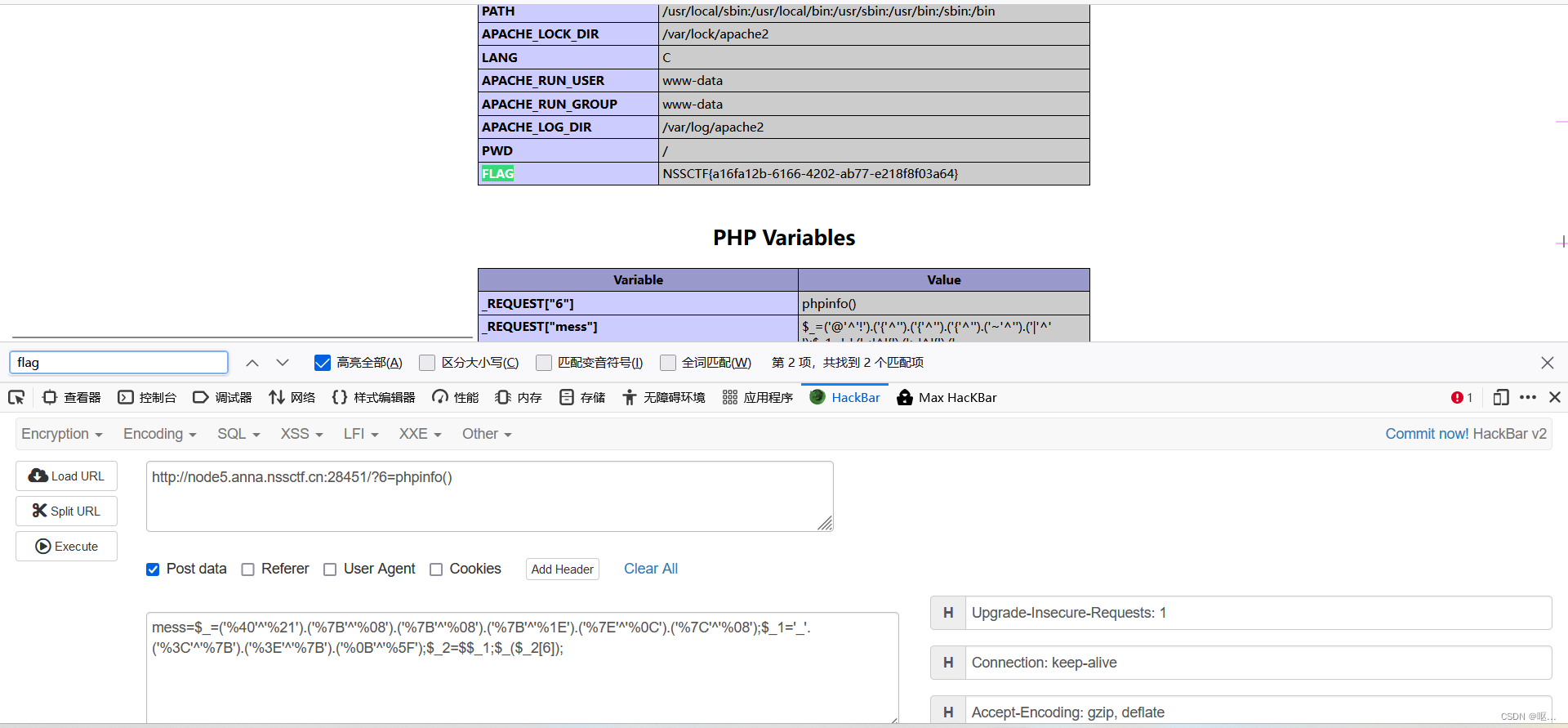
NSSCTF做题(7)
[第五空间 2021]pklovecloud 反序列化 <?php include flag.php; class pkshow { function echo_name() { return "Pk very safe^.^"; } } class acp { protected $cinder; public $neutron; …...

【GIT版本控制】--高级分支策略
一、分支合并策略 在Git中,高级分支策略是为了有效地管理和整合分支而设计的。其中一个关键方面是分支合并策略,它定义了如何将一个分支的更改合并到另一个分支。以下是几种常见的分支合并策略: 合并提交策略(Merge Commit Stra…...

【Qt控件之QDialog】使用及技巧
简介 QDialog是Qt中的一个类,继承自QWidget类,用于创建对话框窗口,可以显示模态(阻塞当前窗口)或非模态的对话框。对话框可以包含各种控件,如按钮、文本框等,用于与用户进行交互。 主要函数说…...
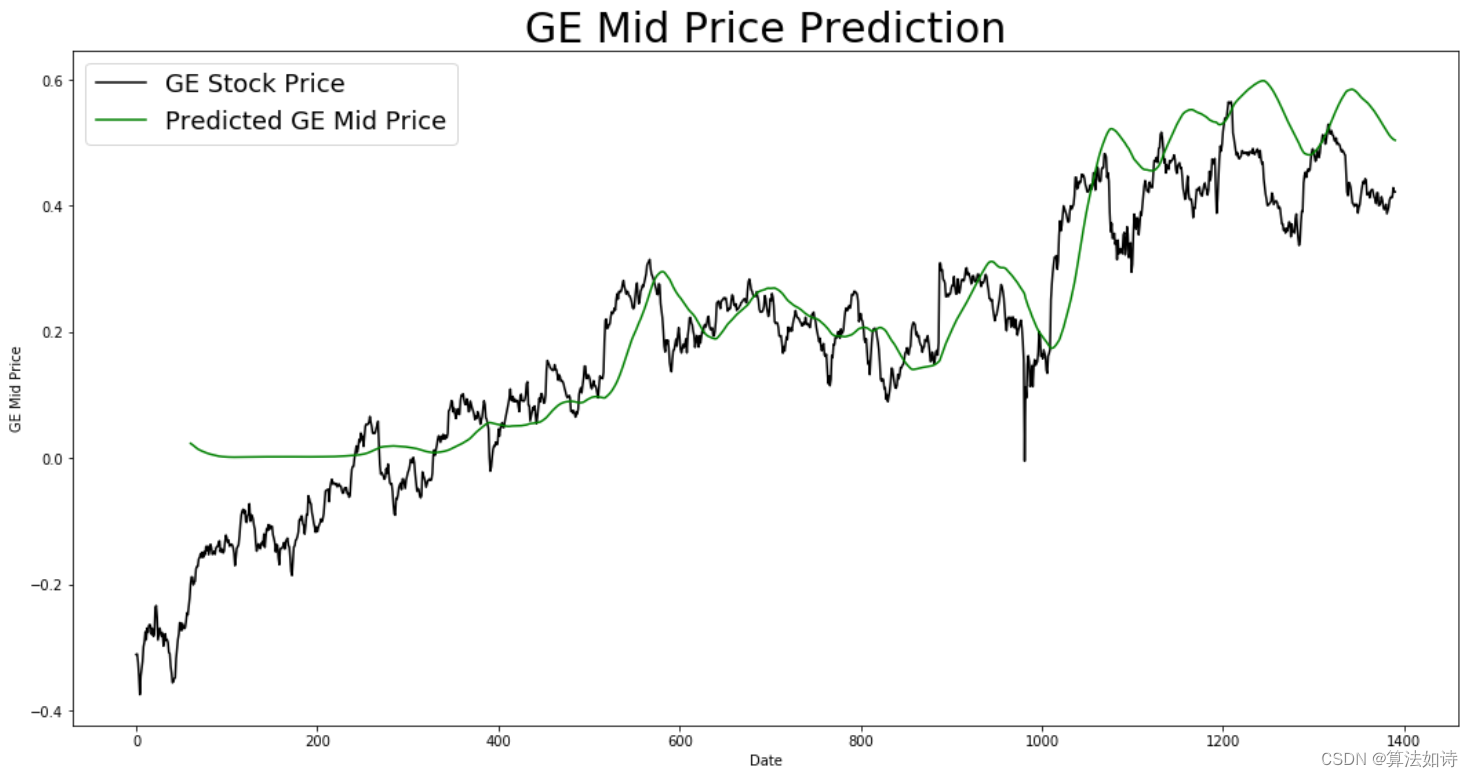
Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow)
文章目录 效果一览文章概述程序设计参考资料效果一览 文章概述 Transformer预测 | Python实现基于Transformer的股票价格预测(tensorflow) 程序设计 import numpy as np import matplotlib.pyplot...

spark sql如何行转列
在数据仓库中,行转列通常称为”变形”(Pivoting) 或 “透视”(Pivoting),可使用Spark SQL的pivot语句实现。下面是一个简单的示例: 假设我们有如下表格: -------------------- | name | brand | year | -------------------- |…...
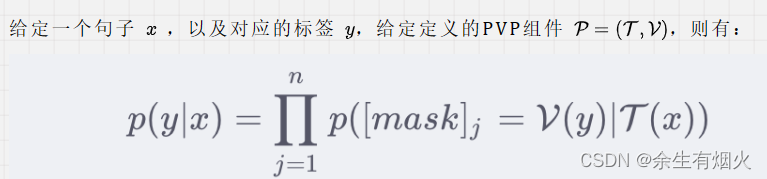
Prompt-Tuning(一)
一、预训练语言模型的发展过程 第一阶段的模型主要是基于自监督学习的训练目标,其中常见的目标包括掩码语言模型(MLM)和下一句预测(NSP)。这些模型采用了Transformer架构,并遵循了Pre-training和Fine-tuni…...
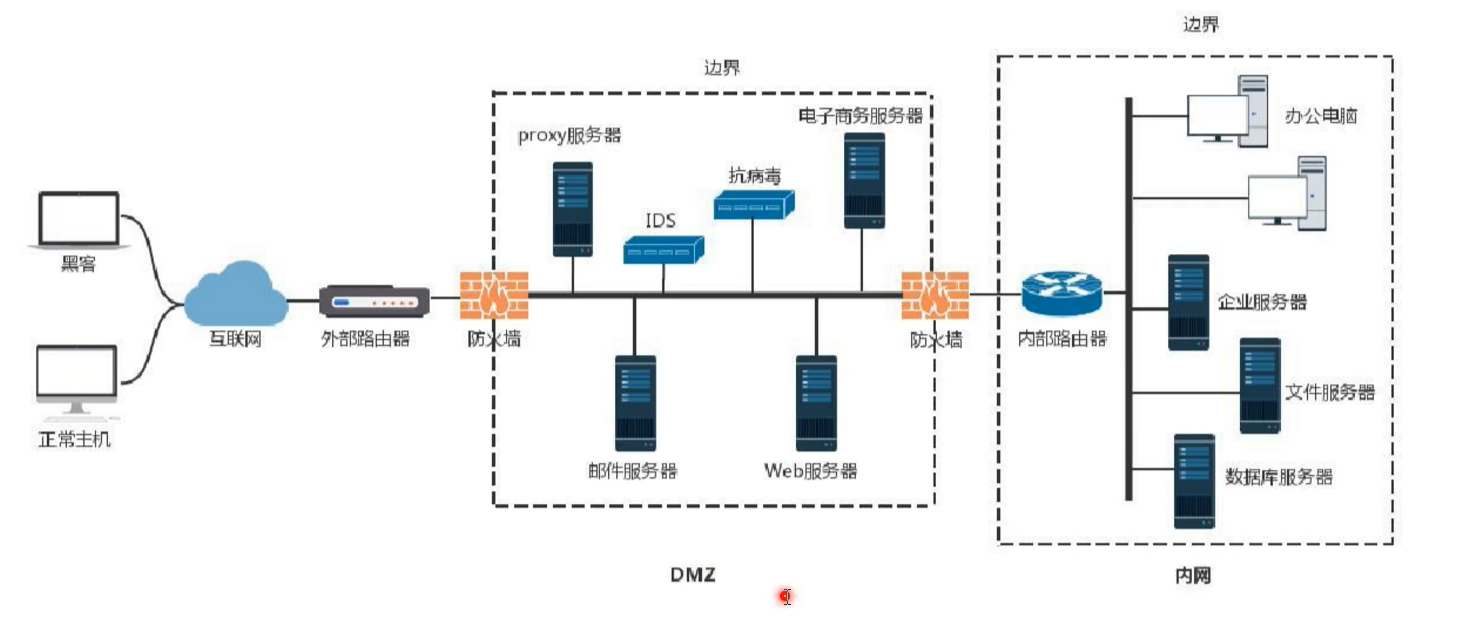
域信息收集
DMZ,是英文“demilitarized zone”的缩写,中文名称为“隔离区”,也称“非军事化区”。它是为了解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题,而设立的一个非安全系统与安全系统之间的缓冲区。该缓冲区位于企业…...

MySQ 学习笔记
1.MySQL(老版)基础 开启MySQL服务: net start mysql mysql为安装时的名称 关闭MySQL服务: net stop mysql 注: 需管理员模式下运行Dos命令 . 打开服务窗口命令 services.msc 登录MySQL服务: mysql [-h localhost -P 3306] -u root -p****** Navicat常用快捷键 键动作CTRLG设…...
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com代码: import pdfpl…...
运算符
目录 算术运算符 比较运算符 逻辑运算符 位运算符 运算符的优先级 MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 数据库中的表结构确立后,表中的数据代表的意义就已经确定。而…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

CircuitPython状态灯、安全模式与文件系统故障排查实战指南
1. 项目概述与核心价值 如果你正在用CircuitPython做项目,无论是物联网传感器节点、智能穿戴设备还是互动艺术装置,大概率都遇到过这样的瞬间:板子上的RGB状态灯突然开始闪烁诡异的颜色,或者电脑上那个熟悉的 CIRCUITPY U盘图标…...

基于IMAP的邮件自动化处理工具mymailclaw配置与实战指南
1. 项目概述:一个轻量级的邮件抓取与处理工具最近在折腾一个需要自动化处理邮件通知的小项目,发现市面上的方案要么太重,要么不够灵活。直到我遇到了psandis/mymailclaw这个项目,它就像一把小巧而锋利的瑞士军刀,专门用…...

AI编程助手CodeBuddy:VS Code扩展的架构、部署与高效使用指南
1. 项目概述:CodeBuddy,你的AI编程伙伴最近在GitHub上看到一个挺有意思的项目,叫codebuddy,作者是olasunkanmi-SE。光看名字就能猜个大概——“代码伙伴”,这显然是一个旨在辅助编程的工具。作为一个在开发一线摸爬滚打…...

数据质量保证:确保数据准确性和可靠性
数据质量保证:确保数据准确性和可靠性 一、数据质量保证概述 1.1 数据质量保证的定义 数据质量保证是指通过一系列技术和流程,确保数据的准确性、完整性、一致性和及时性的过程。它涉及数据采集、存储、处理和使用的各个环节,确保数据符合业务…...
)
Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包)
更多请点击: https://intelliparadigm.com 第一章:Tea印相失效诊断清单:从--v 6.2到--v 6.6,6个版本兼容性断点及降级回滚方案(含JSON config快照备份包) Tea印相(TeaYinXiang)在 v…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...