竞赛 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录
- 0 前言
- 1 课题说明
- 2 效果展示
- 3 具体实现
- 4 关键代码实现
- 5 算法综合效果
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的数学公式识别算法实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题说明
手写数学公式识别较传统OCR问题而言,是一个更复杂的二维手写识别问题,其内部复杂的二维空间结构使得其很难被解析,传统方法的识别效果不佳。随着深度学习在各领域的成功应用,基于深度学习的端到端离线数学公式算法,并在公开数据集上较传统方法获得了显著提升,开辟了全新的数学公式识别框架。然而在线手写数学公式识别框架还未被提出,论文TAP则是首个基于深度学习的端到端在线手写数学公式识别模型,且针对数学公式识别的任务特性提出了多种优化。
公式识别是OCR领域一个非常有挑战性的工作,工作的难点在于它是一个二维的数据,因此无法用传统的CRNN进行识别。
2 效果展示
这里简单的展示一下效果


3 具体实现
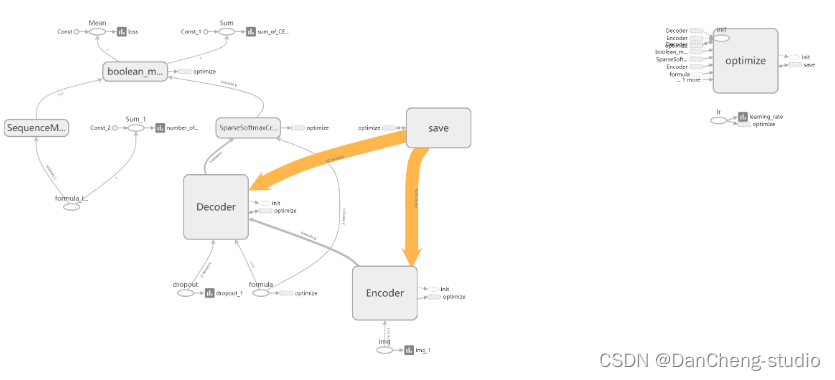
神经网络模型是 Seq2Seq + Attention + Beam
Search。Seq2Seq的Encoder是CNN,Decoder是LSTM。Encoder和Decoder之间插入Attention层,具体操作是这样:Encoder到Decoder有个扁平化的过程,Attention就是在这里插入的。具体模型的可视化结果如下
4 关键代码实现
class Encoder(object):"""Class with a __call__ method that applies convolutions to an image"""def __init__(self, config):self._config = configdef __call__(self, img, dropout):"""Applies convolutions to the imageArgs:img: batch of img, shape = (?, height, width, channels), of type tf.uint8tf.uint8 因为 2^8 = 256,所以元素值区间 [0, 255],线性压缩到 [-1, 1] 上就是 img = (img - 128) / 128Returns:the encoded images, shape = (?, h', w', c')"""with tf.variable_scope("Encoder"):img = tf.cast(img, tf.float32) - 128.img = img / 128.with tf.variable_scope("convolutional_encoder"):# conv + max pool -> /2# 64 个 3*3 filters, strike = (1, 1), output_img.shape = ceil(L/S) = ceil(input/strike) = (H, W)out = tf.layers.conv2d(img, 64, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_1_layer", out)out = tf.layers.max_pooling2d(out, 2, 2, "SAME")# conv + max pool -> /2out = tf.layers.conv2d(out, 128, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_2_layer", out)out = tf.layers.max_pooling2d(out, 2, 2, "SAME")# regular conv -> idout = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_3_layer", out)out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_4_layer", out)if self._config.encoder_cnn == "vanilla":out = tf.layers.max_pooling2d(out, (2, 1), (2, 1), "SAME")out = tf.layers.conv2d(out, 512, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_5_layer", out)if self._config.encoder_cnn == "vanilla":out = tf.layers.max_pooling2d(out, (1, 2), (1, 2), "SAME")if self._config.encoder_cnn == "cnn":# conv with stride /2 (replaces the 2 max pool)out = tf.layers.conv2d(out, 512, (2, 4), 2, "SAME")# convout = tf.layers.conv2d(out, 512, 3, 1, "VALID", activation=tf.nn.relu)image_summary("out_6_layer", out)if self._config.positional_embeddings:# from tensor2tensor lib - positional embeddings# 嵌入位置信息(positional)# 后面将会有一个 flatten 的过程,会丢失掉位置信息,所以现在必须把位置信息嵌入# 嵌入的方法有很多,比如加,乘,缩放等等,这里用 tensor2tensor 的实现out = add_timing_signal_nd(out)image_summary("out_7_layer", out)return out学长编码的部分采用的是传统的卷积神经网络,该网络主要有6层组成,最终得到[N x H x W x C ]大小的特征。
其中:N表示数据的batch数;W、H表示输出的大小,这里W,H是不固定的,从数据集的输入来看我们的输入为固定的buckets,具体如何解决得到不同解码维度的问题稍后再讲;
C为输入的通道数,这里最后得到的通道数为512。
当我们得到特征图之后,我们需要进行reshape操作对特征图进行扁平化,代码具体操作如下:
N = tf.shape(img)[0]
H, W = tf.shape(img)[1], tf.shape(img)[2] # image
C = img.shape[3].value # channels
self._img = tf.reshape(img, shape=[N, H*W, C])
当我们在进行解码的时候,我们可以直接运用seq2seq来得到我们想要的结果,这个结果可能无法达到我们的预期。因为这个过程会相应的丢失一些位置信息。
位置信息嵌入(Positional Embeddings)
通过位置信息的嵌入,我不需要增加额外的参数的情况下,通过计算512维的向量来表示该图片的位置信息。具体计算公式如下:
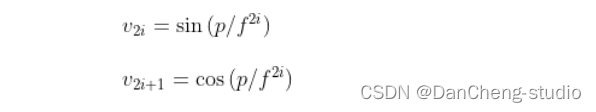
其中:p为位置信息;f为频率参数。从上式可得,图像中的像素的相对位置信息可由sin()或cos表示。
我们知道,sin(a+b)或cos(a+b)可由cos(a)、sin(a)、cos(b)以及sin(b)等表示。也就是说sin(a+b)或cos(a+b)与cos(a)、sin(a)、cos(b)以及sin(b)线性相关,这也可以看作用像素的相对位置正、余弦信息来等效计算相对位置的信息的嵌入。
这个计算过程在tensor2tensor库中已经实现,下面我们看看代码是怎么进行位置信息嵌入。代码实现位于:/model/components/positional.py。
def add_timing_signal_nd(x, min_timescale=1.0, max_timescale=1.0e4):static_shape = x.get_shape().as_list() # [20, 14, 14, 512]num_dims = len(static_shape) - 2 # 2channels = tf.shape(x)[-1] # 512num_timescales = channels // (num_dims * 2) # 512 // (2*2) = 128log_timescale_increment = (math.log(float(max_timescale) / float(min_timescale)) /(tf.to_float(num_timescales) - 1)) # -0.1 / 127inv_timescales = min_timescale * tf.exp(tf.to_float(tf.range(num_timescales)) * -log_timescale_increment) # len == 128 计算128个维度方向的频率信息for dim in range(num_dims): # dim == 0; 1length = tf.shape(x)[dim + 1] # 14 获取特征图宽/高position = tf.to_float(tf.range(length)) # len == 14 计算x或y方向的位置信息[0,1,2...,13]scaled_time = tf.expand_dims(position, 1) * tf.expand_dims(inv_timescales, 0) # pos = [14, 1], inv = [1, 128], scaled_time = [14, 128] 计算频率信息与位置信息的乘积signal = tf.concat([tf.sin(scaled_time), tf.cos(scaled_time)], axis=1) # [14, 256] 合并两个方向的位置信息向量prepad = dim * 2 * num_timescales # 0; 256postpad = channels - (dim + 1) * 2 * num_timescales # 512-(1;2)*2*128 = 256; 0signal = tf.pad(signal, [[0, 0], [prepad, postpad]]) # [14, 512] 分别在矩阵的上下左右填充0for _ in range(1 + dim): # 1; 2signal = tf.expand_dims(signal, 0)for _ in range(num_dims - 1 - dim): # 1, 0signal = tf.expand_dims(signal, -2)x += signal # [1, 14, 1, 512]; [1, 1, 14, 512]return x
得到公式图片x,y方向的位置信息后,只需要要将其添加到原始特征图像上即可。
5 算法综合效果
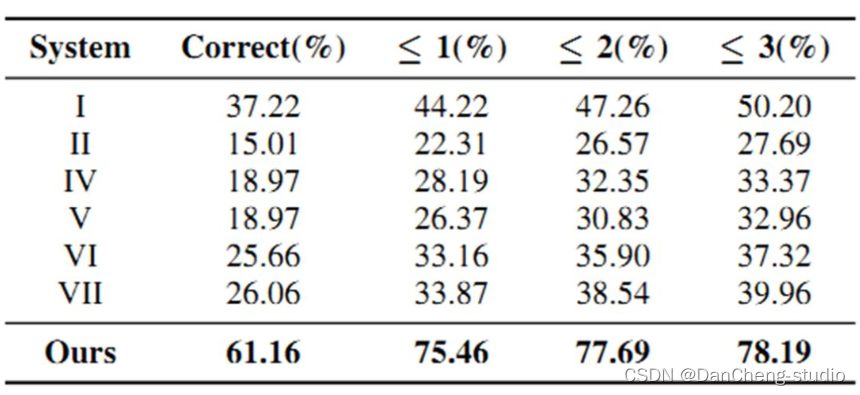
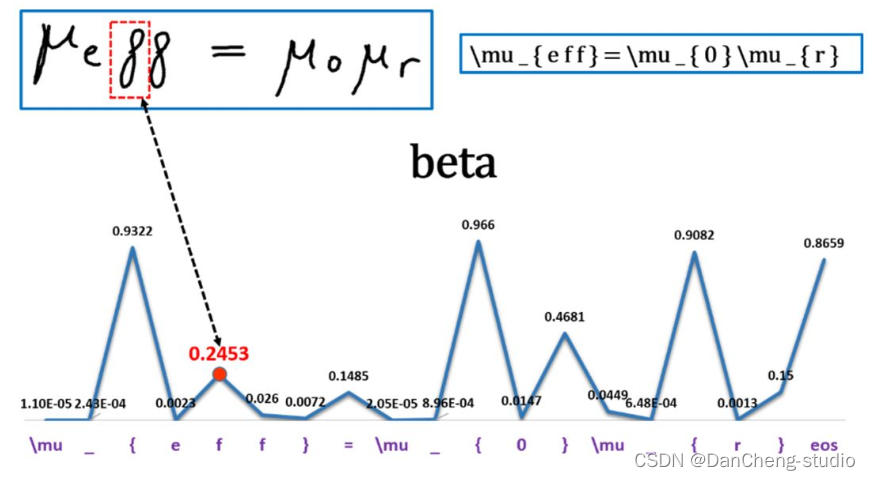
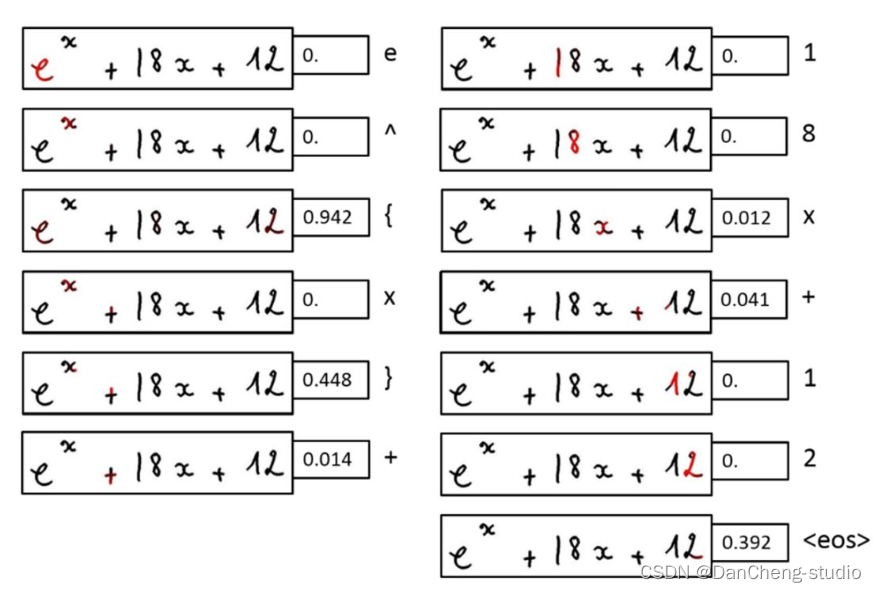
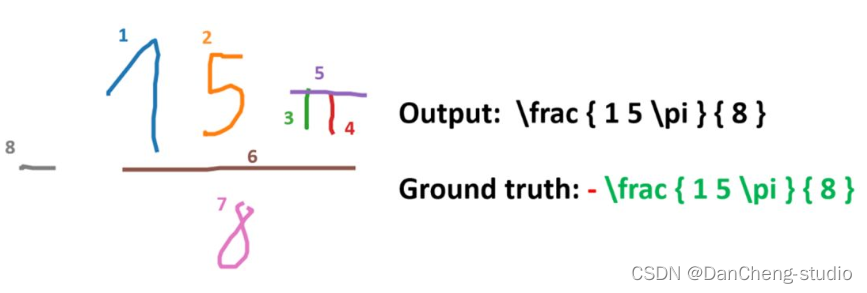
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录 0 前言1 课题说明2 效果展示3 具体实现4 关键代码实现5 算法综合效果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的数学公式识别算法实现 该项目较为新颖,适合作为竞赛课题方向,学…...
Pikachu靶场——跨站请求伪造(CSRF)
文章目录 1. 跨站请求伪造(CSRF)1.1 CSRF(get)1.2 CSRF(post)1.3 CSRF Token1.4 CSRF漏洞防御 1. 跨站请求伪造(CSRF) 还可以参考我的另一篇文章:跨站请求伪造(CSRF) 全称Cross-site request forgery,翻译…...
软件测试简历项目经验怎么写?大厂面试手拿把掐
前言 在写简历之前,我们先来看看失败者的简历和成功者的简历之间有什么区别。为什么成功者的简历可以在求职中起到“四两拨千斤”的作用,而失败者的简历却被丢进了垃圾桶,这两者到底有什么不同? 成功的简历与失败的简历 我们发现…...

图像处理与计算机视觉--第七章-神经网络-单层感知器
文章目录 1.单层感知器原理介绍2.单层感知器算法流程3.单层感知器算法实现4.单层感知器效果展示5.参考文章与致谢 1.单层感知器原理介绍 1.单层感知器是感知器中最简单的一种,有单个神经元组成的单层感知器只能用于解决线性可分的二分性问题2.在空间中如果输入的数据…...

pyserial,win11,串口总是被占用
之前哪里看到的忘记了,记录: win11,用pyserial这个库,打开COM后,程序退出,关闭串口,下次打开仍然会报错。每次都要拔串口线,很烦。 去设备管理器里,把usb串口线的驱动页…...

网站上线如何检查?
网站上线如何检查?很多企业搭建好网站之后,不知道如何检查网站,其实网站上线之后,要对网站的代码,网站的SEO细节,等重要因素检查,下面我们就来讲述一下企业优化网站建站、上线检查要求。 网站上线如何检查…...
”?)
如何理解pytorch中的“with torch.no_grad()”?
torch.no_grad()方法就像一个循环,其中循环中的每个张量都将requires_grad设置为False。这意味着,当前与当前计算图相连的具有梯度的张量现在与当前图分离了我们将不再能够计算关于该张量的梯度。直到张量在循环内,它才与当前图分离。一旦用梯…...

Linux虚拟机克隆之后使用ip addr无法获取ip地址
Linux虚拟机克隆之后使用ip addr无法获取ip地址 因为克隆得到的虚拟机,与原先的linux系统是一模一样的包括MAC地址和IP地址。需要修改信息。 设置IP地址: 使用vi命令打开linux的网卡 //ifcfg-enth0是虚拟网卡的名称,如果你的不叫这个名字&a…...

日报系统:优化能源行业管理与决策的利器
日报系统:优化能源行业管理与决策的利器 引言: 随着能源行业的快速发展和复杂性增加,管理各个部门的数据变得至关重要。为了提高运营效率和决策的准确性,能源行业普遍采用日报系统作为综合数据汇报和分析的工具。本文将探讨日报系…...

linux安装idea
下载好之后是.tar.gz文件后缀的 使用命令解压安装包 tar -zxvf 你的安装包 解压好了之后进入解压好的目录找到bin文件里的idea.sh,使用命令启动它 ./idea.sh 这样你就可以在manjaro上使用idea了 在这里插入图片描述 需要手动创建快捷启动方式 每次都使用命令行启动是比较…...
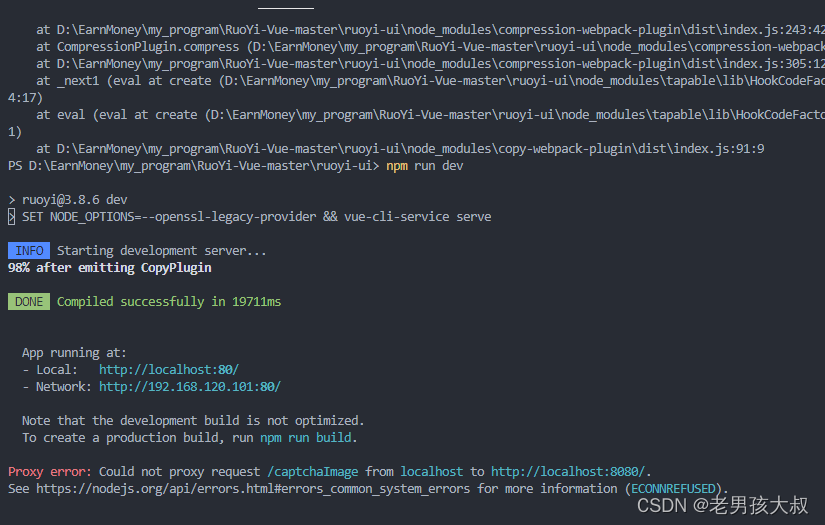
vue启动项目,npm run dev出现error:0308010C:digital envelope routines::unsupported
运行vue项目,npm run dev的时候出现不支持错误error:0308010C:digital envelope routines::unsupported。 在网上找了很多,大部分都是因为版本问题,修改环境之类的,原因是对的但是大多还是没能解决。经过摸索终于解决了。 方法如…...
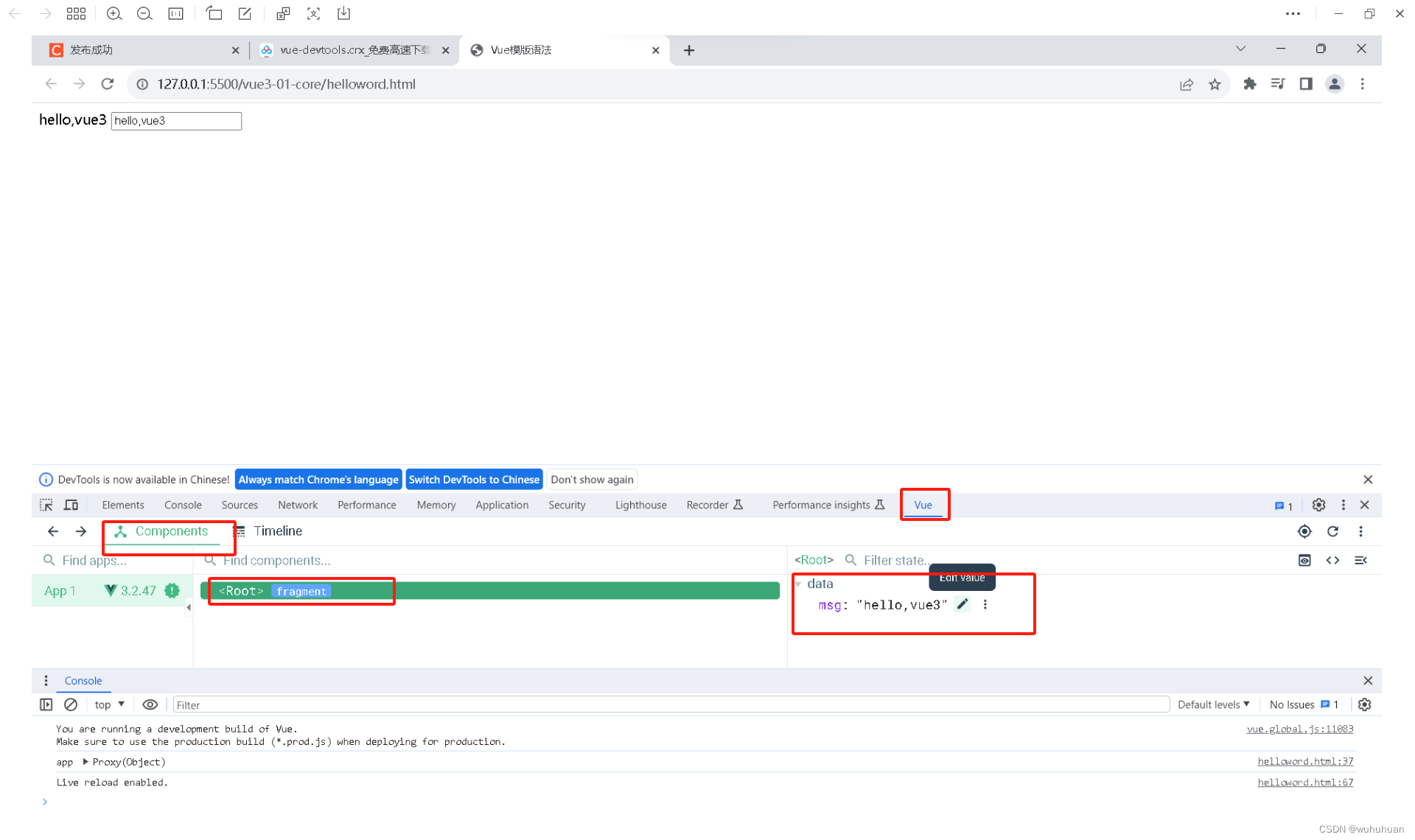
vue-devtools插件安装
拓展程序连接 链接:https://pan.baidu.com/s/1tEyZJUCEK_PHPGhU_cu_MQ?pwdr2cj 提取码:r2cj 一、打开谷歌浏览器,点击扩展程序-管理扩展程序 二、打开开发者模式,将vue-devtools.crx 拖入页面,点击添加扩展程序 成…...

const关键字
目录 修饰指针 指向常量的指针*ptr 指针常量:数据类型 * const 指针变量 修饰引用 const &...

HTML5+CSS3+JS小实例:仿优酷视频轮播图
实例:仿优酷视频轮播图 技术栈:HTML+CSS+JS 效果: 源码: 【html】 <!DOCTYPE html> <html><head><meta http-equiv="content-type" content="text/html; charset=utf-8"><meta name="viewport" content=&quo…...

dart的Websocket为什么找不到onOpen方法?
我主要使用的是JAVA,而JAVA使用Websocket时,Websocket一定会有个onOpen方法。 ClientEndpoint public class WebsocketListener {OnOpenpublic void onOpen(Session session) throws IOException {}OnMessagepublic void onMessage(ByteBuffer byteBuff…...
无法连接网络解决办法记录)
VMware中Ubuntu(Linux)无法连接网络解决办法记录
问题: 操作系统:Ubuntu 22.04.3 LTS VMware 版本:VMware Workstation 17 Pro, 17.0.0 build-20800274今天在虚拟机用Ubuntu的时候,发现无法连接网络,如下: wdwd-virtual-machine:~$ ifconfig lo: flags73…...

js结合map对象等处理数组
cpp const INVENTORY_STATUS_MAP {7: { text: 全部 },0: { text: 出租, color: mary-green },1: { text: 已售, color: mary-green },2: { text: 丢失, color: mary-orange },3: { text: 闲置, color: mary-green },4: { text: 退役, color: mary-orange },5: { text: 售后, c…...

网络攻防实战演练
在经历了多年的攻防对抗之后,大量目标单位逐渐认识到安全防护的重要性。因此,他们已采取措施尽可能收敛资产暴露面,并加倍部署各种安全设备。但安全防护注重全面性,具有明显的短板... 1、供应链 在经历了多年的攻防对抗之后&…...

基于Keil a51汇编 —— 标准宏定义
定义标准宏 标准宏定义如下: macro-name MACRO <[>parameter-list<]> <[>LOCAL local-labels<]> . . . macro-body . . .ENDMmacro-name 宏的名称 parameter-list 可以传递给宏的形式参数的可选列表 LOAD_R0 MACRO R0_ValMOV R0, #R0_…...

遍历List集合
1.初始化 // 写法一 List<String> list new ArrayList<>(); list.add("a"); list.add("b"); list.add("c");// 写法二 List<String> list new ArrayList(){{add("a");add(&quo…...

CodeWeaver:多仓库聚合分析工具的设计、部署与实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要把一堆陈年的、用不同语言和框架写的代码仓库整合到一个统一的视图里进行管理和分析。手动去每个仓库里翻看提交记录、统计代码行数、检查依赖关系,这活儿想想就头大。就在我准备硬着头皮写脚本的时候&am…...

Ubuntu中ping命令安装与网络诊断全攻略
1. 项目概述:一个看似简单却暗藏玄机的问题“如何在Ubuntu中安装ping”,这个标题乍一看,可能会让很多老手会心一笑,甚至觉得有些“小白”。但恰恰是这个看似基础到不能再基础的问题,却是我在多年运维和开发工作中&…...

Mac运行CORE Keygen受阻?巧用UPX与brew轻松解包
1. 当Mac遇到CORE Keygen无法运行时该怎么办? 最近有不少朋友在Mac上运行CORE Keygen时遇到了问题,双击应用图标后要么毫无反应,要么直接弹出"无法打开"的提示。这种情况其实很常见,特别是对于一些特殊用途的应用程序。…...

手把手教你用Python脚本给飞书机器人“喂”数据:Gerrit事件通知实战
Python自动化实战:用飞书机器人构建Gerrit事件通知系统 每当团队协作开发时,代码审查状态的实时同步总是让人头疼。想象一下:你刚提交的代码被同事点赞,或是某个关键补丁集终于通过审核——这些重要时刻如果能在飞书群里即时提醒&…...

从零搭建ROS2与Web实时数据交互系统
1. 为什么需要ROS2与Web实时交互? 在机器人开发或IoT项目中,我们经常需要通过网页远程监控设备状态或发送控制指令。想象一下这样的场景:你正在调试一个自动巡逻的机器人,但总不能一直盯着终端看日志吧?这时候如果有个…...

BouncyCastle.NET证书管理完全教程:生成、验证与撤销的终极指南 [特殊字符]
BouncyCastle.NET证书管理完全教程:生成、验证与撤销的终极指南 🔐 【免费下载链接】bc-csharp BouncyCastle.NET Cryptography Library (Mirror) 项目地址: https://gitcode.com/gh_mirrors/bc/bc-csharp 在当今数字安全至关重要的时代ÿ…...

书匠策AI毕业论文功能全揭秘:一个工具,把你从选题焦虑里捞出来!
各位正在和毕业论文死磕的同学们,大家好! 今天这篇内容,我不讲大道理,就给你们安利一个我最近反复在用的工具——书匠策AI(官网: 官网直达:www.shujiangce.com。如果你现在正处于"选题没…...

僧伽罗文语音本地化迫在眉睫!斯里兰卡新《数字服务法》2024年10月生效前,你必须掌握的7项ElevenLabs合规配置
更多请点击: https://intelliparadigm.com 第一章:僧伽罗文语音本地化的法律动因与技术紧迫性 斯里兰卡《官方语言法》(No. 33 of 1956)及2023年修订的《国家数字包容战略》明确要求:所有面向公众的政府数字服务必须支…...

ARM GICv3虚拟中断控制器架构与ICV_CTLR_EL1寄存器解析
1. ARM GICv3虚拟中断控制器架构概述在ARMv8-A架构的虚拟化环境中,GICv3中断控制器通过引入虚拟CPU接口寄存器组,为虚拟机提供了与原生物理中断处理机制高度一致的虚拟中断体验。这套虚拟寄存器组与物理寄存器组采用相同的编程模型,但在访问控…...

策略即代码:从理念到实践,构建自动化合规与安全防线
1. 项目概述与核心价值 最近在整理团队内部的开发规范时,发现了一个非常有意思的仓库: vectimus/policies 。乍一看这个名字,你可能会觉得这只是一个存放公司政策文档的普通地方,但如果你深入进去,会发现它远不止于此…...