GEO生信数据挖掘(七)差异基因分析
上节,我们使用结核病基因数据,做了一个数据预处理的实操案例。例子中结核类型,包括结核,潜隐进展,对照和潜隐,四个类别。本节延续上个数据,进行了差异分析。
差异分析 计算差异指标step12
加载数据
load("dataset_TB_LTBI_step8.Rdata")构建差异比较矩阵
#样本列表
group_list=group_data_TB_LTBI$group_more #构建分组
design=model.matrix(~0+factor(group_list))
colnames(design)=levels(factor(group_list))#head(dataset_TB_LTBI)row.names(design)=colnames(dataset_TB_LTBI)
design #得到分组矩阵:0代表不是,1代表是#str(design)library(limma)
##差异比较矩阵
contrast_matrix=makeContrasts(paste0(c('LTBI','TB'),collapse = '-'),levels = design)计算差异基因指标
#step:lmFit
fit=lmFit(dataset_TB_LTBI,design)
fit2=contrasts.fit(fit,contrast_matrix)
#step:eBayes
fit3=eBayes(fit2)#step3:topTable
tempoutput=topTable(fit3,coef = 1,n=Inf)
DEG_M=na.omit(tempoutput) #得到差异分析矩阵,重点看logFC和P值
head(DEG_M) #查看数据'''logFC AveExpr t P.Value adj.P.Val B
ASPHD2 -1.452777 8.415563 -12.38370 5.885193e-22 5.868863e-18 39.30255
C1QC -3.978887 5.971935 -12.34993 6.954041e-22 5.868863e-18 39.14037
GBP1P1 -4.075057 5.607978 -12.24397 1.174622e-21 6.608814e-18 38.63087
GBP6 -3.225604 4.393248 -11.93968 5.320543e-21 1.692866e-17 37.16200
SDC3 -2.374911 7.388880 -11.92896 5.612049e-21 1.692866e-17 37.11012
LHFPL2 -1.705514 8.411180 -11.91494 6.017652e-21 1.692866e-17 37.04225
'''#绘制前40个基因在不同样本之间的热图
library(pheatmap)
#绘制前40个基因在不同样本之间的热图
f40_gene=head(rownames(DEG_M),40)
f40_subset_matrix=dataset_TB_LTBI[f40_gene,]
head(f40_subset_matrix)
f40_subset_matrixx=t(scale(t(f40_subset_matrix))) #数据标准化。。。数据标准化和归一化的区别:平移和压缩
pheatmap(f40_subset_matrixx) #出图差异分析 结果过滤筛选step13
res = DEG[,c("logFC","P.Value","adj.P.Val")]colnames(res)<-c("logFC","PValue","padj")colnames(res)
library(dplyr)
FC_filter =0.585
P_filter=0.05
all_diff =res %>% filter(abs(logFC)>FC_filter) %>% filter(padj<P_filter)
res$id = rownames(res)
res=select(res,id,everything())
#write.table(res,'all_diff.txt',sep='\t',quote=F)up_diff=res %>% filter(logFC>FC_filter) %>% filter(padj<P_filter)
up_diff$id = rownames(up_diff)
up_diff=select(up_diff,id,everything())
#write.table(up_diff,'up_diff.txt',sep='\t',quote=F)down_diff=res %>% filter(logFC< -FC_filter ) %>% filter(padj<P_filter)
down_diff$id = rownames(down_diff)
down_diff=select(down_diff,id,everything())
#write.table(down_diff,'down_diff.txt',sep='\t',quote=F)group_data_clean <-function(data){# colnames(data)[c(9,10,11)] =c("logFC","PValue","padj")data[which(data$padj %in% NA),'sig'] <- 'no diff'data[which(data$logFC >= FC_filter & data$padj < 0.05),'sig'] <- 'up'data[which(data$logFC <= -FC_filter & data$padj < 0.05),'sig'] <- 'down'data[which(abs(data$logFC) < FC_filter | data$padj >= 0.05),'sig'] <- 'no diff'cat(" 上调",nrow(data[data$sig %in% "up", ]))cat(" 下调",nrow(data[data$sig %in% "down", ]))cat(" no fiff",nrow(data[data$sig %in% "no diff", ]))# filter_data = subset(data, data$sig == 'up' | data$sig == 'down')# filter_data$Geneid <- rownames(filter_data)return(data)
}
limma_clean_res = group_data_clean(res)#上调 1381 下调 1432 no fiff 14066rownames(all_diff)dataset_TB_LTBI_DEG = dataset_TB_LTBI[rownames(all_diff),]
dim(dataset_TB_LTBI_DEG) #[1] 2813 102#&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
#+&&&&&&&&&&&&&&&&&&数据保存&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
#++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
save(DEG,res,all_diff,limma_clean_res,dataset_TB_LTBI_DEG,file = "DEG_TB_LTBI_step13.Rdata")
#++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
#+&&&&&&&&&&&&&&&&&&数据保存&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
#&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
差异分析 绘制火山图step14
library(ggplot2)data <- limma_clean_res#################
# ggplot2绘制火山图
data$label <- c(rownames(data)[1:10],rep(NA,nrow(data) - 10))
#sizeGrWindow(12, 9)
pdf(file="差异基因火山图step14.pdf", width = 9, height = 6)
ggplot(data,aes(logFC,-log10(PValue),color = sig)) + xlab("log2FC") + geom_point(size = 0.6) + scale_color_manual(values=c("#00AFBB","#999999","#FC4E07")) + geom_vline(xintercept = c(-1,1), linetype ="dashed") +geom_hline(yintercept = -log10(0.05), linetype ="dashed") + theme(title = element_text(size = 15), text = element_text(size = 15)) + theme_classic() + geom_text(aes(label = label),size = 3, vjust = 1,hjust = -0.1)dev.off()
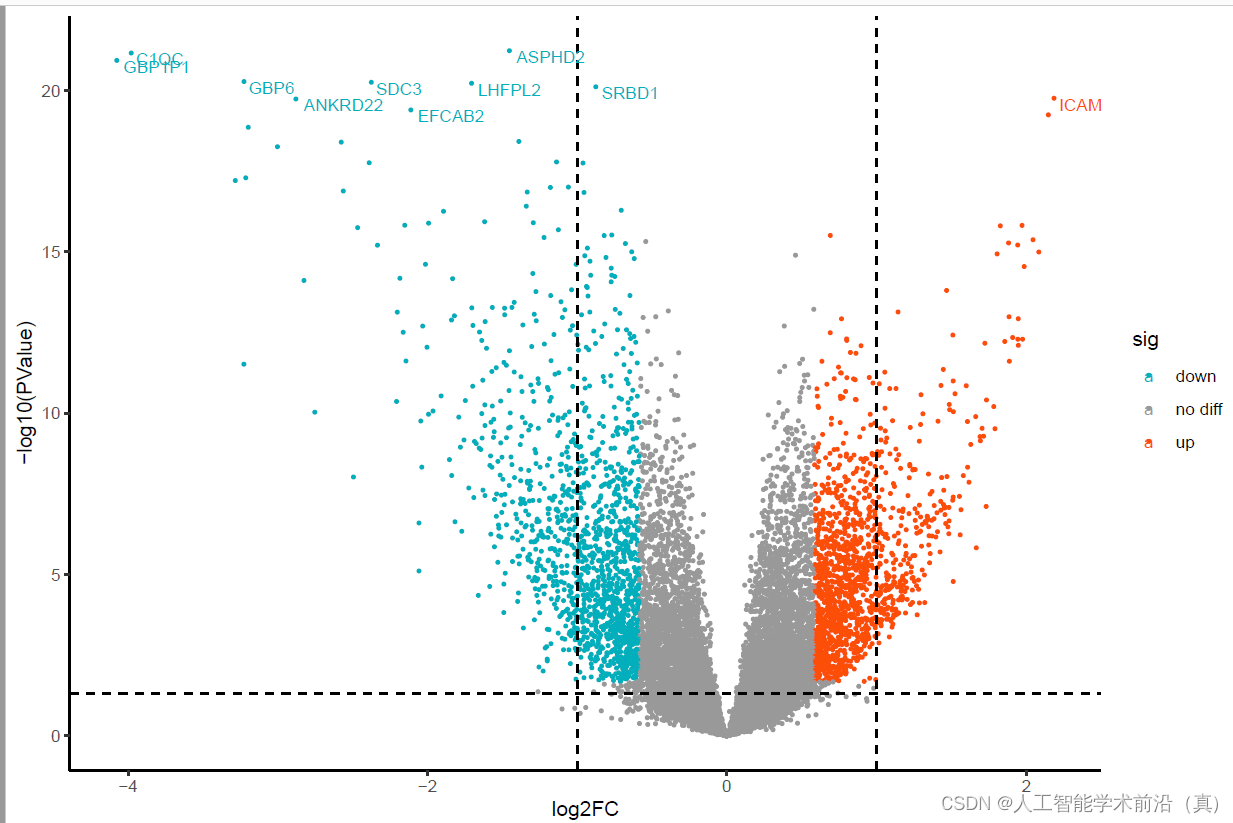
差异基因分析完毕,下面我们可以观察一下,这些基因富集在哪些通路之上。
相关文章:
GEO生信数据挖掘(七)差异基因分析
上节,我们使用结核病基因数据,做了一个数据预处理的实操案例。例子中结核类型,包括结核,潜隐进展,对照和潜隐,四个类别。本节延续上个数据,进行了差异分析。 差异分析 计算差异指标step12 加载…...
JAVA-SpringBoot入门Demo用IDEA建立helloworld
使用编辑器IDEA做SpringBoot项目最近几年比较红红,作为JAVA语言翻身的技术,用户量激增。由于java平台原来的占有率,相比net core在某些方面更有优势。 我把本次我下载完成后Maven项目的过程记录下来了,仅供参考! 安装J…...
Unity布料系统Cloth
Unity布料系统Cloth 介绍布料系统Cloth(Unity组件)组件上的一些属性布料系统的使用布料约束Select面板Paint面板Gradient Tool面板 布料碰撞布料碰撞碰撞适用 介绍 布料系统我第一次用是做人物的裙摆自然飘动,当时我用的是UnityChan这个unity官方自带的插件做的裙摆…...

漏电继电器 LLJ-630F φ100 导轨安装 分体式结构 LLJ-630H(S) AC
系列型号: LLJ-10F(S)漏电继电器LLJ-15F(S)漏电继电器LLJ-16F(S)漏电继电器 LLJ-25F(S)漏电继电器LLJ-30F(S)漏电继电器LLJ-32F(S)漏电继电器 LLJ-60F(S)漏电继电器LLJ-63F(S)漏电继电器LLJ-80F(S)漏电继电器 LLJ-100F(S)漏电继电器LLJ-120F(S)漏电继电器LLJ-125F(S…...
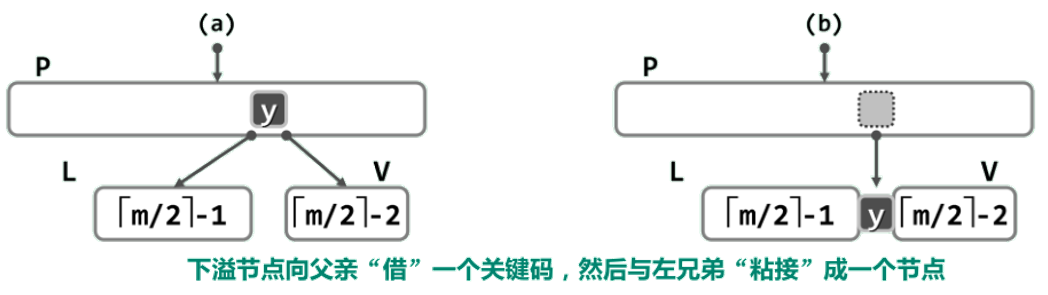
数据结构和算法(10):B-树
B-树:大数据 现代电子计算机发展速度空前,就存储能力而言,情况似乎也是如此:如今容量以TB计的硬盘也不过数百元,内存的常规容量也已达到GB量级。 然而从实际应用的需求来看,问题规模的膨胀却远远快于存储能…...

VR会议:远程带看功能,专为沉浸式云洽谈而生
随着科技的不断发展,VR技术已经成为当今市场上较为热门的新型技术之一了,而VR会议远程带看功能,更是为用户提供更加真实、自然的沉浸式体验。 随着5G技术的发展,传统的图文、视频这种展示形式已经无法满足消费者对信息真实性的需求…...
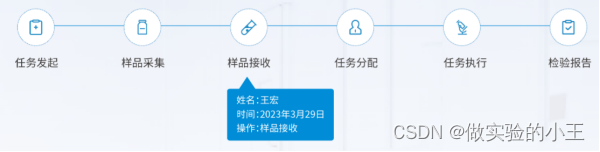
实验室管理系统LIMS
在数字化浪潮中,越来越多的企业开始有数字化转型的意识。对于实验室而言,数字化转型是指运用新一代数字技术,促进实验室业务、生产、研发、管理、服务、供应链等方面的转型与升级,实现实验室业务“人、机、料、法、环”的多维度发…...
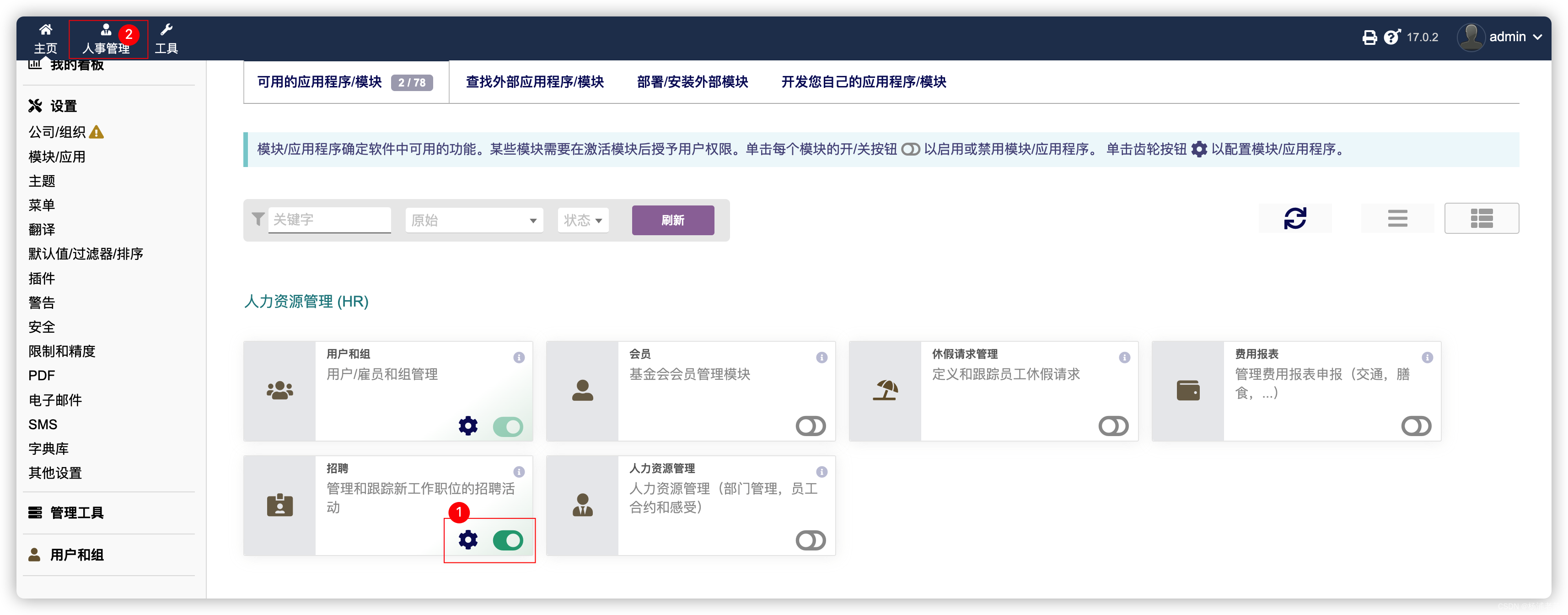
开源ERP和CRM套件Dolibarr
什么是 Dolibarr ? Dolibarr ERP & CRM 是一个现代软件包,用于管理您组织的活动(联系人、供应商、发票、订单、库存、议程…)。它是开源软件(用 PHP 编写),专为中小型企业、基金会和自由职业…...
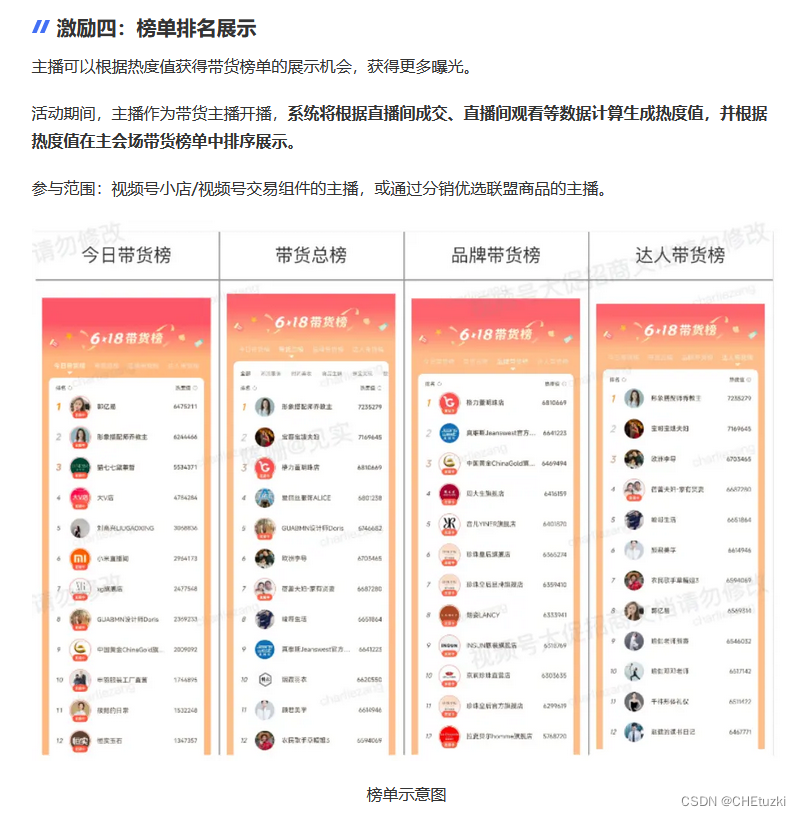
视频号双11激励政策,快来看一看
双十一即将来临,不少平台都公布了自己的双十一政策。这篇文章,我们来看看视频号推出的激励政策,看有哪些需要准备的。...
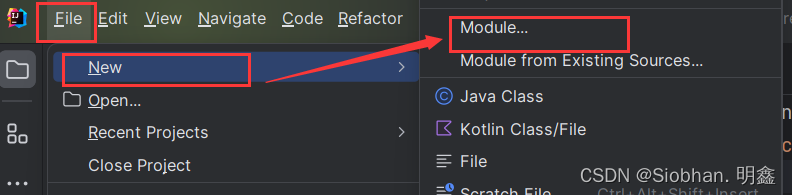
Maven最新版本安装及配置
Maven是一个Java项目管理和构建工具,它可以定义项目结构、项目依赖,并使用统一的方式进行自动化构建,是Java项目不可缺少的工具。 本章我们详细介绍如何使用Maven。 一、Maven是什么? 如果每一个项目都自己搞一套配置…...

探索ClickHouse——使用MaterializedPostgreSQL同步PostgreSQL数据库
安装PostgreSQL sudo apt install postgresql修改配置 sudo vim /etc/postgresql/14/main/postgresql.conf 解开并修改wal_level 的配置项 wal_level logical 重启服务 /etc/init.d/postgresql restartRestarting postgresql (via systemctl): postgresql.service AUTHENTI…...

《向量数据库指南》——向量数据库 有必要走向专业化吗?
向量数据库 有必要走向专业化吗? 向量数据库系统的诞生,来源于具体业务需求——想要高效处理海量的向量数据,就需要更细分、更专业的数据基础设施,为向量构建专门的数据库处理系统。 但这种路径是必须的吗? 从产品层面讲,如果传统数据库厂商不单独研发向量数据库,那么…...

你必须知道的数据查询途径!!
在当今信息爆炸的时代,我们每天都会面临海量的数据和信息。如何在这些繁杂的信息中快速、准确地找到自己需要的内容,也是当代一个非常重要的技能。下面,我将介绍几种你必须知道的企业数据信息查找途径。 1. 搜索引擎 搜索引擎是我们日常中…...

火焰原子吸收光谱法、容量法和电感耦合等离子体发射光谱法
声明 本文是学习GB-T 1871.5-2022 磷矿石和磷精矿中氧化镁含量的测定 火焰原子吸收光谱法、容量法和电感耦合等离子体发射光谱法. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本文件描述了在磷矿石和磷精矿中测定氧化镁含量的火焰原子吸收…...

亚马逊云科技 2023 柏林峰会主题演讲总结
欢迎来到我们的亚马逊云科技2023柏林峰会主题演讲全面总结!在这篇文章中,我们将深入探讨在活动期间分享的主要公告、亮点和故事。通过这里的视频格式,展示了亚马逊云科技技术如何转化为商业和行业。 每年,亚马逊云科技峰会都会汇…...

CentOS Stream9 安装远程桌面服务 Xrdp
1. 安装 XRDP 若服务器本身没有桌面则首先需要安装本地桌面: yum -y groups install "GNOME Desktop" startx配置源: dnf install epel-release安装 xrdp dnf install xrdp 2. 配置 Xrdp Xrdp 配置文件位于 /etc/xrdp 目录中。对于常规 X…...
实施运维01
一.运维实施工程师所具备的知识 1.运维工程师,实施工程师是啥? 运维工程师负责服务的稳定性,确保服务无间断的为客户提供服务. 实施工程师负责工程的实施工作,负责现场培训,一般都要出差,哪里有项目就去…...

MySQL大表直接复制文件的copy方式
看腻了就来听听视频演示吧:https://www.bilibili.com/video/BV1Bp4y1F7kd/ MyISAM引擎可单独将 *.MYD和 *.MYI 拷贝到远程服务器上InnoDB引擎受限于版本(MySQL5.5)无法直接拷贝.ibd文件,因为在ibdata1文件保存有表的字典信息&…...
Redis-集群
Redis-集群 主从复制和哨兵只能在主节点进行写数据,从节点读取数据,因此本质上,是进行了读写的分离,每个节点都保存了所有的数据,并不能实现一个很好的分布式效果。 1.哈希求余算法 假设有N台主机,对每台…...

使用CrawlSpider爬取全站数据。
CrawpSpider和Spider的区别 CrawlSpider使用基于规则的方式来定义如何跟踪链接和提取数据。它支持定义规则来自动跟踪链接,并可以根据链接的特征来确定如何爬取和提取数据。CrawlSpider可以对多个页面进行同样的操作,所以可以爬取全站的数据。CrawlSpid…...
)
别再手动写矩阵运算了!C++项目里用Eigen库的正确姿势(附性能对比)
别再手动写矩阵运算了!C项目里用Eigen库的正确姿势(附性能对比) 在计算机视觉、机器人控制或物理仿真领域,C开发者经常需要处理复杂的矩阵运算。我曾见过一个SLAM项目的前端代码,仅为了计算两个坐标系之间的变换矩阵&a…...

BepInEx插件框架:为什么它是Unity游戏Mod开发的终极解决方案?
BepInEx插件框架:为什么它是Unity游戏Mod开发的终极解决方案? 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 你是否曾经想过为喜欢的Unity游戏添加新功能&…...

3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案
3分钟掌握FSearch:Linux系统文件搜索效率提升300%的终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中寻找文件而烦恼吗ÿ…...

MATLAB集成大语言模型:无缝融合AI能力与工程计算生态
1. 项目概述:当MATLAB遇见大语言模型如果你是一位工程师、研究员或者数据分析师,并且你的日常工作离不开MATLAB,那么你很可能已经感受到了AI浪潮的冲击。大语言模型(LLMs)如ChatGPT、Llama等,正在重塑我们处…...

如何高效使用m4s-converter:专业开发者的B站缓存视频转换终极指南
如何高效使用m4s-converter:专业开发者的B站缓存视频转换终极指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter m4s-converter是一…...

Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南
Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 在移动应用生态日益丰富的今天,将移动端优…...
)
运维老鸟复盘:一次CentOS7物理机安装踩坑全记录(从RAID0到安装源验证)
运维实战:CentOS7物理机安装全流程避坑指南 引言 那台尘封已久的联想RD550服务器静静躺在仓库角落,表面覆盖着一层薄灰。作为运维工程师,我们总会遇到这样的挑战——老旧设备突然需要重新部署系统。这次任务看似简单:为这台双盘…...

Midjourney v7艺术风格跃迁路径:从基础写实到超现实叙事的5阶能力模型,含GPT-4o协同提示链模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7艺术风格跃迁路径总览 Midjourney v7 并非简单迭代,而是以扩散模型架构重构与多模态风格理解为内核的范式跃迁。其核心突破在于引入「语义风格锚点(Semantic Style…...

Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程
Beyond Compare 5密钥生成终极指南:快速激活与完全使用教程 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen Beyond Compare是一款广受欢迎的文件对比工具,但当30天试用期…...

cliclick 开发者指南:从源码编译到自定义Action开发
cliclick 开发者指南:从源码编译到自定义Action开发 【免费下载链接】cliclick macOS CLI tool for emulating mouse and keyboard events 项目地址: https://gitcode.com/gh_mirrors/cl/cliclick cliclick 是一款强大的 macOS 命令行工具,用于模…...