利用PyTorch深度学习框架进行多元回归
目录
- 前言
- 数据加载
- 数据转换
- 模型定义
- 模型训练
- 模型评估
- 模型保存与加载
- 完整代码
- 讨论
- 参考文献
前言
大多数数据科学家以往经常常是利用传统的机器学习框架sklearn搭建多元回归模型,随着深度学习和强化学习越来越普及,很多数据科学家尝试使用深度学习框架来进行多元回归实验,下面来做一个利用PyTorch深度学习框架做一个完整的多元回归数据科学实验。从该实验,你将学到一下内容,并通过这一篇博客成功运用深度学习框架PyTorch进行多元回归模型搭建。
- 如何加载数据
- 如何转换数据
- 如何定义模型
- 如何评估模型
- 如何验收模型
- 如何保存模型和加载模型
一个典型的PyTorch建模过程往往包含了一下几个过程
接下来,我们就严格按照上面步骤来一步一步进行。
数据加载
数据加载是指将将本地或者服务器,云端的数据读取进来,并进行必要的预处理,包括填充空值,去掉异常值,编码,格式转换,数据分裂成训练集和测试集,这一步骤可以利用我们熟悉的pandas库处理。
store = pd.read_csv(r"D:\项目\商简智能\回归预测题目\store.csv")
train = pd.read_csv(r"D:\项目\商简智能\回归预测题目\train.csv")
train_df = pd.merge(left=train, right=store, left_on='商店ID', right_on='商店ID', how='left')
train_df = train_df.query("周销量>0")
train_df.dropna(how='any', inplace=True)
train_df['商店ID'] = train_df['商店ID'].astype('float64')
train_df['年'] = train_df['年'].astype('float64')
train_df['周'] = train_df['周'].astype('float64')
train_df['节日A'] = train_df['节日A'].astype('float64')
train_df['节日B'] = train_df['节日B'].astype('float64')
train_df['节日C'] = train_df['节日C'].astype('float64')
train_df['商店模式'] = LabelEncoder() .fit_transform(train_df['商店模式'] ) #编码
train_df['商店级别'] = LabelEncoder() .fit_transform(train_df['商店级别'] ) #编码
train_df = train_df[["商店ID", "年", "周", "营业天数", "打折天数", "非节日", "节日A", "节日B", "节日C", "商店模式", "商店级别", "竞争者最近距离", "周销量"]]
X, y = train_df.drop(['周销量'], axis=1), train_df.周销量 #特征和目标
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle=True, random_state=0) #划分训练测试集
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
通过上面代码可以看到本次实验是读取本地数据,具体数据格式和解读参见这篇文章,并将数值型变量统一转化为float64型,将类别型变量编码,定义出特征列和标签列,并利用train_test_split将数据集分裂成训练集和测试集,可以打印出训练集和测试集的形状大小以检验数据分割的正确与否
(51300, 12) (21987, 12) (51300,) (21987,)
数据转换
经过数据加载步骤后,数据没有刺头了变得规规矩矩了,哪一块就是哪一块,但是都是numpy,series,dataframe等数据格式,而深度学习框架只认识张量(tensor)数据格式,在PyTorch的世界,不管是模型的输入,输出还是模型的参数都是由tensor来编码的,所以我们需要将之前得到的dataframe转化为tensor,并适当的分组(batch)以便输入模型进行小批量(minibatch)训练,PyTorch提供了两种原生的数据处理方法torch.utils.data.DataLoader 和 torch.utils.data.Dataset,Dataset 使得你可以使用一些预置数据和自己的数据,经过Dataset的数据存储了样本和其对应的标签,而DataLoader 可以把Dataset的样本打包成一个一个小组形成迭代器,使得在模型训练的时候可以只对这些迭代器进行循环训练。
X_train, X_test = X_train.values, X_test.values
y_train, y_test = y_train.values.reshape(-1, 1), y_test.values.reshape(-1, 1)
X_train = torch.from_numpy(X_train).type(torch.FloatTensor)
X_test = torch.from_numpy(X_test).type(torch.FloatTensor)
y_train = torch.from_numpy(y_train).type(torch.FloatTensor)
y_test = torch.from_numpy(y_test).type(torch.FloatTensor)
training_data = TensorDataset(X_train, y_train)
test_data = TensorDataset(X_test, y_test)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
模型定义
模型定义是指定义好深度学习的网络结构,俗称神经网络,神经网络由一些模型和层构成,数据在这些结构上进行各种各样的运算,在PyTorch里,每一个模型都继承 nn.Module,我们可以搭建和管理各种风格和各种样子的神经网络。
class Net(nn.Module): def __init__(self, features):super(Net, self).__init__() self.h1 = nn.Linear(features, 30, bias= True)self.a1 = nn.ReLU()self.h2 = nn.Linear(30, 10)self.a2 = nn.ReLU()self.regression = nn.Linear(10, 1)def forward(self, x): x = self.h1(x)x = self.a1(x)x = self.h2(x)x = self.a2(x)y_pred = self.regression(x)return y_pred
通过上面代码,我们搭建了一个名为Net的神经网络,该网络继承了nn.Module,并定义了初始化化和向前传播路径,网络由2个Linear层和2个ReLU激活函数组成,输入层的参数是特征数(features)30,隐藏层是3010,输出层是10*1,最后返回一个预测值,我们可以实例化该网络,打印出网络结构
Net((h1): Linear(in_features=12, out_features=30, bias=True)(a1): ReLU()(h2): Linear(in_features=30, out_features=10, bias=True)(a2): ReLU()(regression): Linear(in_features=10, out_features=1, bias=True)
)
模型训练
深度学习的模型训练首先是向前传播得到预测值,其次,在给定的损失函数前提下计算损失的梯度,不断更新模型里面的参数,同时可以记录训练集的损失函数值和测试集的损失函数值以便后续可视化两者变化曲线。
train_loss = []
test_loss = []epochs = 201
for epoch in range(epochs):model.train()for xb, yb in train_dataloader:pred = model(xb)loss = criterion(pred, yb)loss.requires_grad_(True) optimizer.zero_grad()loss.backward()optimizer.step()if epoch%10==0:model.eval()with torch.no_grad():train_epoch_loss = sum(criterion(model(xb), yb) for xb, yb in train_dataloader)test_epoch_loss = sum(criterion(model(xb), yb) for xb, yb in test_dataloader)train_loss.append(train_epoch_loss.data.item() / len(train_dataloader))test_loss.append(test_epoch_loss.data.item() / len(test_dataloader))template = ("epoch:{:2d}, 训练损失:{:.5f}, 验证损失:{:.5f}")print(template.format(epoch, train_epoch_loss.data.item() / len(train_dataloader), test_epoch_loss.data.item() / len(test_dataloader)))
print('训练完成')
模型评估
模型评估是指对训练好的模型进行某些指标的评估,由于在模型训练的时候我们保存了训练集和测试集的损失值,可以在这里直接画出来。
fig = plt.figure(figsize = (6,4))
plt.plot(range(len(train_loss)), train_loss, label = "train_loss")
plt.plot(range(len(test_loss)), test_loss, label = "test_loss")
plt.legend()
plt.show()
模型保存与加载
辛辛苦苦训练出来并通过相关指标评估的模型,自然希望能够保存下来以便下次能够在此利用,PyTorch提供2中模型保存和加载策略,一个是只存储模型中的参数,该方法速度快,占用空间少(官方推荐使用),一个是存储整个模型,这里采用前者。
torch.save(model.state_dict(), ".\model_parameter.pth") #保存模型parameter = torch.load(".\model_parameter.pth") #加载模型
model.load_state_dict(parameter)
完整代码
# -*- encoding: utf-8 -*-
'''
@Project : sales
@Desc : 基于pytorch的深度学习销量预测
@Time : 2023/02/07 16:30:14
@Author : 帅帅de三叔,zengbowengood@163.com
'''import math
import torch
from torch import nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler # 数据标准化store = pd.read_csv(r"D:\项目\商简智能\回归预测题目\store.csv")
train = pd.read_csv(r"D:\项目\商简智能\回归预测题目\train.csv")
train_df = pd.merge(left=train, right=store, left_on='商店ID', right_on='商店ID', how='left')
train_df = train_df.query("周销量>0")
train_df.dropna(how='any', inplace=True)
train_df['商店ID'] = train_df['商店ID'].astype('float64')
train_df['年'] = train_df['年'].astype('float64')
train_df['周'] = train_df['周'].astype('float64')
train_df['节日A'] = train_df['节日A'].astype('float64')
train_df['节日B'] = train_df['节日B'].astype('float64')
train_df['节日C'] = train_df['节日C'].astype('float64')
train_df['商店模式'] = LabelEncoder() .fit_transform(train_df['商店模式'] ) #编码
train_df['商店级别'] = LabelEncoder() .fit_transform(train_df['商店级别'] ) #编码
train_df = train_df[["商店ID", "年", "周", "营业天数", "打折天数", "非节日", "节日A", "节日B", "节日C", "商店模式", "商店级别", "竞争者最近距离", "周销量"]]
X, y = train_df.drop(['周销量'], axis=1), train_df.周销量 #特征和目标
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, shuffle=True, random_state=0) #划分训练测试集
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)X_train, X_test = X_train.values, X_test.values
y_train, y_test = y_train.values.reshape(-1, 1), y_test.values.reshape(-1, 1)
X_train = torch.from_numpy(X_train).type(torch.FloatTensor)
X_test = torch.from_numpy(X_test).type(torch.FloatTensor)
y_train = torch.from_numpy(y_train).type(torch.FloatTensor)
y_test = torch.from_numpy(y_test).type(torch.FloatTensor)
training_data = TensorDataset(X_train, y_train)
test_data = TensorDataset(X_test, y_test)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)class Net(nn.Module): def __init__(self, features):super(Net, self).__init__() self.h1 = nn.Linear(features, 30, bias= True)self.a1 = nn.ReLU()self.h2 = nn.Linear(30, 10)self.a2 = nn.ReLU()self.regression = nn.Linear(10, 1)def forward(self, x): x = self.h1(x)x = self.a1(x)x = self.h2(x)x = self.a2(x)y_pred = self.regression(x)return y_predclass CustomLoss(nn.Module): #自定义损失函数def __init__(self):super(CustomLoss, self).__init__()def forward(self, x, y):loss = torch.sqrt(torch.sum(torch.pow((x-y)/x, 2))/len(x))return lossmodel = Net(features=X_train.shape[1])
print(model)model = Net(features=X_train.shape[1])
criterion = CustomLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)train_loss = []
test_loss = []epochs = 101
for epoch in range(epochs):model.train()for xb, yb in train_dataloader:pred = model(xb)loss = criterion(pred, yb)# loss.requires_grad_(True) optimizer.zero_grad()loss.backward()optimizer.step()if epoch%10==0:model.eval()with torch.no_grad():train_epoch_loss = sum(criterion(model(xb), yb) for xb, yb in train_dataloader)test_epoch_loss = sum(criterion(model(xb), yb) for xb, yb in test_dataloader)train_loss.append(train_epoch_loss.data.item() / len(train_dataloader))test_loss.append(test_epoch_loss.data.item() / len(test_dataloader))template = ("epoch:{:2d}, 训练损失:{:.5f}, 验证损失:{:.5f}")print(template.format(epoch, train_epoch_loss.data.item() / len(train_dataloader), test_epoch_loss.data.item() / len(test_dataloader)))
print('训练完成')fig = plt.figure(figsize = (6,4))
plt.plot(range(len(train_loss)), train_loss, label = "train_loss")
plt.plot(range(len(test_loss)), test_loss, label = "test_loss")
plt.legend()
plt.show()torch.save(model.state_dict(), ".\model_parameter.pth") #保存模型parameter = torch.load(".\model_parameter.pth") #加载模型
model.load_state_dict(parameter)
讨论
对于结构化的数据,深度学习不一定就比传统机器学习强,还需具体问题具体分析,不可一概而论。
参考文献
1,https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html
2,https://shenzl.blog.csdn.net/article/details/128632831
3,https://sanhangkc.blog.csdn.net/article/details/128818696
相关文章:

利用PyTorch深度学习框架进行多元回归
目录前言数据加载数据转换模型定义模型训练模型评估模型保存与加载完整代码讨论参考文献前言 大多数数据科学家以往经常常是利用传统的机器学习框架sklearn搭建多元回归模型,随着深度学习和强化学习越来越普及,很多数据科学家尝试使用深度学习框架来进行…...

EBS常用接口开发
整理了一些工作中常用的Oracle EBS接口和API,最早是看着大神黄建华文档起来的,格式内容参考他的文档,加上一些自己开发的程序和经历而已。 PO PO接收、检验、入库、退货-InterfaceAPI_刘文钊1的博客-CSDN博客 基础数据 EBS物料、bom、工艺导入…...

【完整】UR机械臂逆运动学求解过程及c++代码实现
有任何问题请在评论区留言,我尽可能的回复大家 一. 逆运动学的求解需要以下数学运算 利用DH参数得到每个关节的变换矩阵;利用变换矩阵求出机械臂整个链的变换矩阵;求出末端位姿;利用已知末端位姿和整个链的变换矩阵,…...

68. Python的相对路径
68. Python的相对路径 文章目录68. Python的相对路径1. 知识回顾2. 什么是相对路径3. 相对路径的语法4. 查看相对路径的方法5. 写出所有txt文件的相对路径5.1 同目录5.2 上级目录6. 用相对路径读取txt文件6.1 读取旅游.txt6.2 读取旅游经费.txt6.3 读取笔记.txt和new.txt6.4 读…...
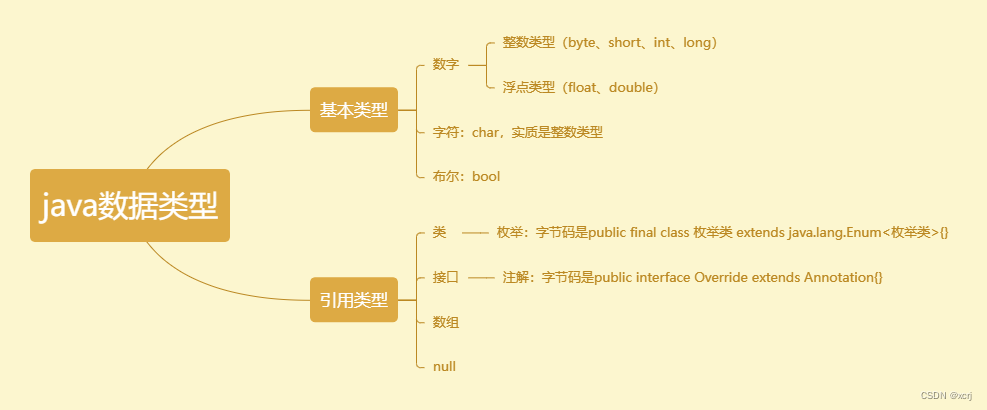
java数据类型
数据类型 类型分类,存储范围,字面量,默认值,类型转换 类型分类 存储范围 数据类型字节数表示范围byte1-128~127short2-32768~32767,正负3万左右int4-2147483648~2147483647,正负21亿左右long8-922337203…...

Kotlin 替换非空断言的几种方式
Kotlin 出现断言的两种情形 IDE java 与 kotlin 自动转换时,自动添加非空断言的代码Smart Cast 失效 代码展示: class JavaConvertExample {private var name: String? nullfun init() {name ""}fun foo() {name null;}fun test() {if (…...
2023年了,来试试前端格式化工具
在大前端时代,前端的各种工具链穷出不断,有eslint, prettier, husky, commitlint 等, 东西太多有的时候也是trouble😂😂😂,怎么正确的使用这个是每一个前端开发者都需要掌握的内容,请上车🚗&…...

spring cloud 企业工程项目管理系统源码+项目模块功能清单
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

TCP分片解析
本文目录什么是IP分片为什么会产生IP分片为什么要避免IP分片如何避免IP分片什么是IP分片 IP协议栈将TCP/UDP传输层要求它发送的,但长度大于发送端口MTU的一个数据包,分割成多个IP报文后分多次发送。这些分成多次发送的多个IP报文就是IP分片。 为什么会…...
开发了一款基于 Flask 框架的在线电影网站系统(附 Python 源码)
文章目录前言项目介绍源码获取运行环境安装依赖库项目截图首页展示图视频展示页视频播放页后台管理页整体架构设计图项目目录结构图前台功能模块图后台功能模块图本地运行图前言 今天我给大家分享的是基于 Python 的 Flask 框架开发的在线电影网站系统,大家平时需要…...

如何获得CSM--敏捷教练证书
1、什么是CSM?CSM即Certified Scrum Master,Scrum Master负责确保所有人都能正确地理解并实施Scrum,确保Scrum团队遵循Scrum的理论、实践和规则。Scrum Master是Scrum团队中的服务型领导,帮助Scrum团队外的人员了解他们如何与Scrum团队交互是…...
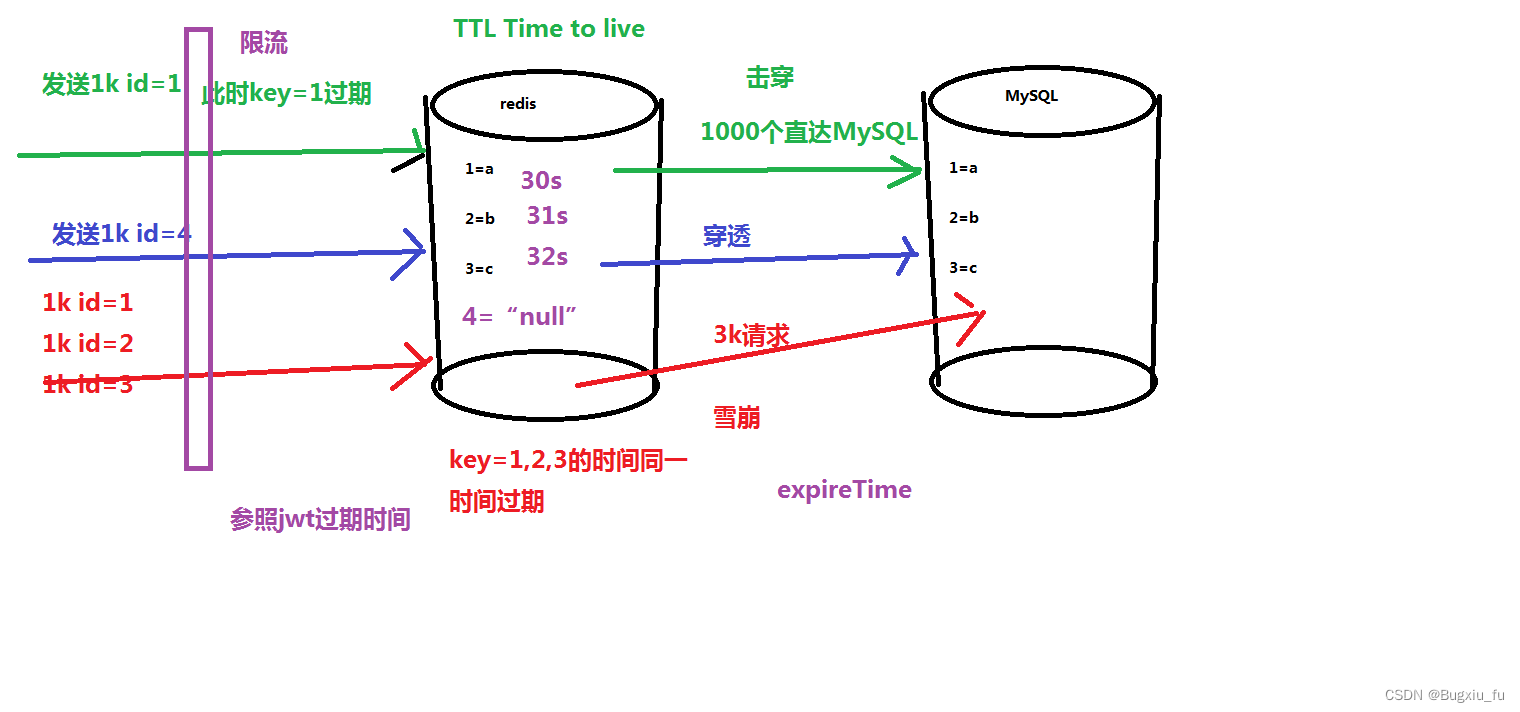
Java面试数据库
目录 一、关系型数据库 数据库权限 表设计及创建 表数据相关 数据库架构优化 二、非关系型数据库 redis 今天给大家稍微整理了一下,内容有数据表设计的三大范式原则、sql查询如何优化、redis数据的击穿、穿透、雪崩等...,以及相关的面试题࿰…...

关于进行vue-cli过程中的解决错误的问题
好久没发文章了,直到今天终于开始更新了,最近想进军全端,准备学习下vue,但是这东西真的太难了,我用了一天的时间来解决在配置中遇到的问题!主要问题:cnpm文件夹和vue-cli文件夹的位置不对并且vu…...

Rockchip Linux USB Gadget
一:概述 USB Gadget 是运行在 USB Peripheral 上配置 USB 功能的子系统,正常可被枚举的 USB 设备至少有 3 层逻辑层,有些功能还会在用户空间多跑一层逻辑代码。Gadget API 就是具体功能和硬件底层交互的中间层。从上到下,逻辑层分布为: USB Controller: USB上最底层的软…...
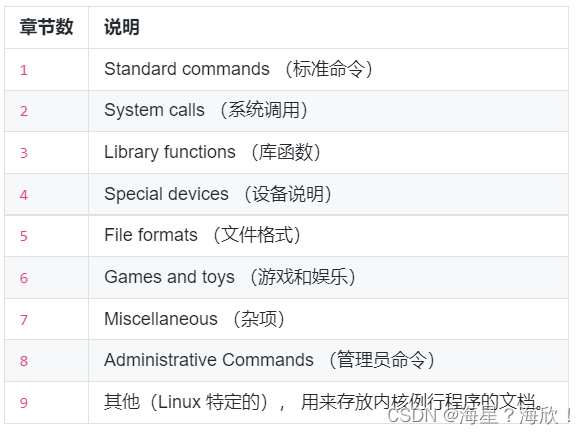
Linux -文件系统操作与帮助命令
1、Linux -文件系统操作 df — 查看磁盘的容量 df -h —以人类可以看懂的方式显示磁盘的容量,易读 du 命令查看目录的容量 # 默认同样以块的大小展示 du # 加上 -h 参数,以更易读的方式展示 du -h-d 参数指定查看目录的深度: # 只查看 1…...

UMI 创建react目录介绍及配置
UMI 生成react项目目录介绍及配置 react项目目录介绍umi多种配置方案运行时配置app.ts 的使用 1、umi创建的项目目录大致如下 ├─package.json 配置依赖以及启动打包所需的命令 ├─.umirc.ts 配置文件,包含 umi 内置功能和插件的配置 ├── dist 打包后生成的…...
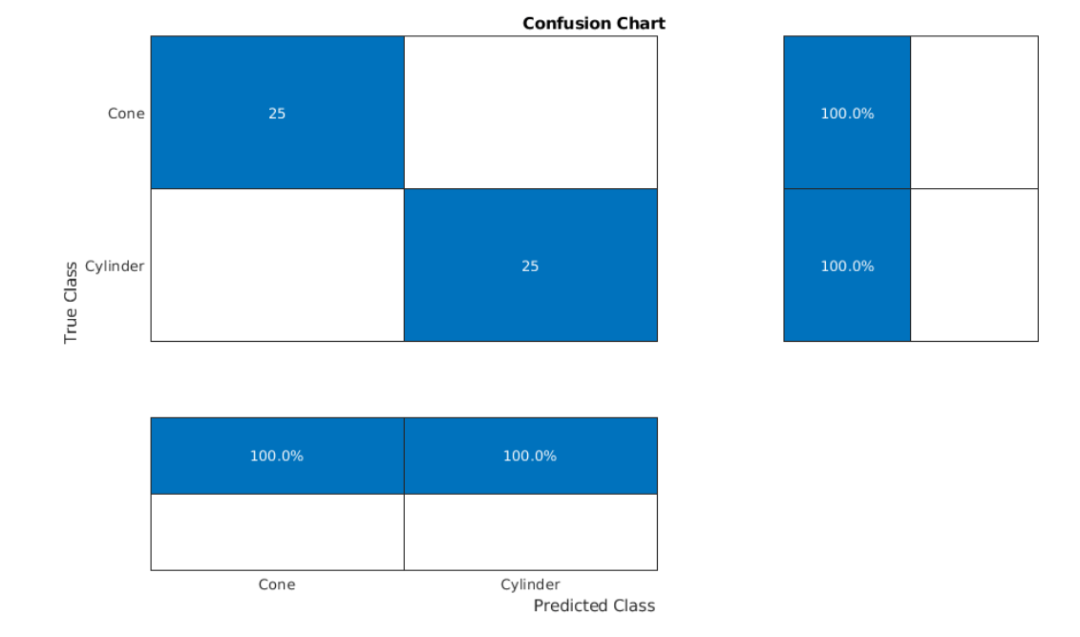
基于matlab使用机器学习和深度学习进行雷达目标分类
一、前言此示例展示了如何使用机器学习和深度学习方法对雷达回波进行分类。机器学习方法使用小波散射特征提取与支持向量机相结合。此外,还说明了两种深度学习方法:使用SqueezeNet的迁移学习和长短期记忆(LSTM)递归神经网络。请注…...
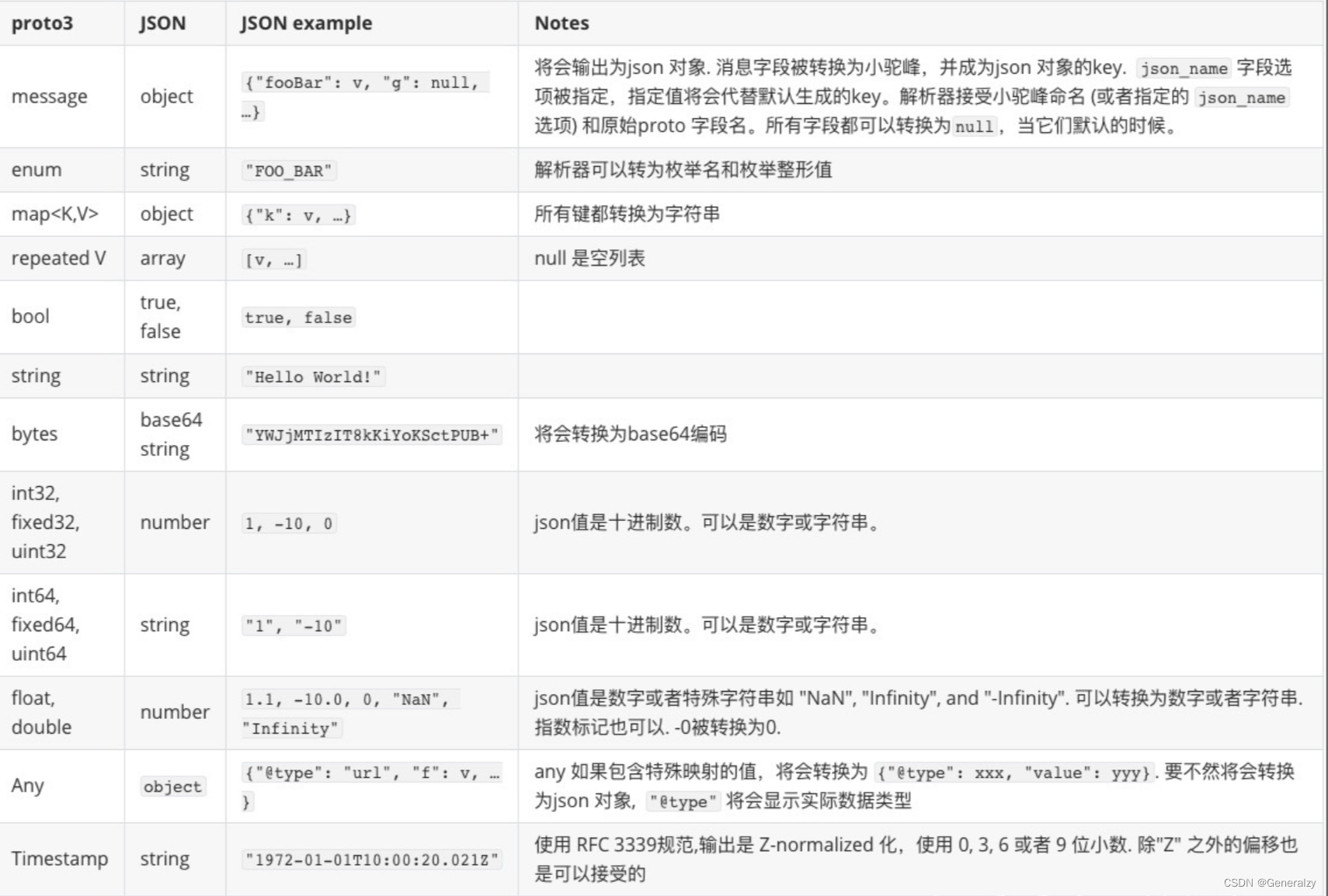
Protocol Buffers V3语法全解
目录protobuf介绍protobuf使用protoc命令语法定义消息类型指定字段类型分配字段编号指定字段规则添加更多消息类型注释保留字段从.proto文件生成了什么?值类型默认值枚举使用其他消息类型导入定义嵌套类型更新消息类型未知字段any任意类型oneofoneof 特性兼容性问题…...

MediaPipe之人体关键点检测>>>BlazePose论文精度
BlazePose: On-device Real-time Body Pose tracking BlazePose:设备上实时人体姿态跟踪 论文地址:[2006.10204] BlazePose: On-device Real-time Body Pose tracking (arxiv.org) 主要贡献: (1)提出一个新颖的身体姿态跟踪解决…...
CSS从入门到精通专栏简介
先让我们来欣赏几个精美的网站: Matt Brett - Freelance Web Designer and WordPress Expert 2022 Year in Review • Letterboxd NIO蔚来汽车官方网站 小米官网 Silk – Interactive Generative Art 大屏数据可视化 你是否也有过这样的“烦恼”: * …...

Cursor编辑器AI操作完成音效插件:原理、实现与效能提升
1. 项目概述:一个提升编码体验的“听觉反馈”工具如果你和我一样,每天有大量时间与代码编辑器为伴,那么你一定对那种“沉浸式”的编码状态又爱又恨。爱的是心流状态下的高效产出,恨的是一旦被打断,重新进入状态需要耗费…...

Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南
Windows 11安卓子系统WSA:在电脑上流畅运行手机应用的完整指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA 你是否曾想过在Windows电脑上直接…...

GPU加速网络爬虫:OpenCL异构计算在数据采集中的实践
1. 项目概述:一个面向硬件加速的开源抓取工具包最近在折腾一些数据采集和自动化任务时,我常常遇到一个瓶颈:当需要处理海量网页、进行高频次请求或者解析复杂的动态内容时,传统的基于CPU的抓取框架(比如Scrapy、Reques…...

PyTorch自动微分知识点讲解
PyTorch自动微分知识点讲解 知识导图 PyTorch自动微分 ├── 基础认知 │ ├── 自动微分的核心概念 │ └── autograd模块的作用 ├── 梯度计算 │ ├── 梯度计算的规则 │ └── backward与grad的使用 └── 实战案例├── 单参数的更新└── 多参数的更…...

模块二-数据选择与索引——06. 列选择与操作
06. 列选择与操作 1. 概述 数据选择是 Pandas 最常用的操作之一。掌握列选择与操作,可以高效地提取、添加、修改和删除数据列。 import pandas as pd import numpy as np# 创建示例数据 df pd.DataFrame({姓名: [张三, 李四, 王五, 赵六, 钱七],年龄: [25, 30, 28,…...

MAX31856在工业温控项目中的实战应用:从选型、电路设计到故障诊断避坑指南
MAX31856工业温控系统设计全流程:从芯片选型到抗干扰实战 工业温度监测系统的可靠性直接关系到生产安全与产品质量。在钢铁冶炼、化工反应等场景中,一个温度传感器的失效可能导致数百万损失。MAX31856作为工业级热电偶数字转换器,其45V过压保…...

GitHub 74.2k Star的Redis,开发者必备的内存数据库
文章目录GitHub 74.2k Star的Redis,开发者必备的内存数据库核心能力覆盖多数开发场景实际使用建议GitHub 74.2k Star的Redis,开发者必备的内存数据库 Redis是GitHub上的热门开源项目,Star数达到74223,是很多开发者日常工作中常用…...

一分钟看懂大模型备案
大模型备案,全称 “生成式人工智能服务上线备案”,是国内面向公众提供大模型服务的法定合规流程,核心是审核模型安全、数据合规与内容可控,未备案违规上线最高罚一千万元,该处罚依据主要来自两大核心法规:1…...

对比自行维护与使用Taotoken在模型接入效率上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护与使用Taotoken在模型接入效率上的差异 在开发需要集成大语言模型能力的应用时,团队通常面临一个核心选择…...

欲取全国第一先取北京第一,CSDN 博客排名现在是郑州第一
欲取全国第一先取北京第一,CSDN 博客排名现在是郑州第一 首先,必须得说,郑州第一,太牛了! 这绝对是对你技术输出和持续分享的高度认可,含金量十足。 不过,关于“欲取全国第一先取北京第一”这个…...