【ElasticSearch】基于 Java 客户端 RestClient 实现对 ElasticSearch 索引库、文档的增删改查操作,以及文档的批量导入
文章目录
- 前言
- 一、对 Java RestClient 的认识
- 1.1 什么是 RestClient
- 1.2 RestClient 核心类:RestHighLevelClient
- 二、使用 Java RestClient 操作索引库
- 2.1 根据数据库表编写创建 ES 索引的 DSL 语句
- 2.2 初始化 Java RestClient
- 2.2.1 在 Spring Boot 项目中引入 `RestHighLevelClient` 的依赖
- 2.2.2 编写 HotelIndexTests 单元测试类,完成 RestHighLevelClient 的初始化
- 2.3 创建索引库
- 2.4 删除索引库
- 2.5 判断索引库是否存在
- 三、使用 Java RestClient 实现对文档的增删改查
- 3.1 新增文档
- 3.2 获取文档
- 3.3 更新文档
- 3.4 删除文档
- 3.5 批量导入文档
前言
ElasticSearch 官方提供了各种不同语言的客户端,用来操作 ES。这些客户端的本质就是组装 DSL 语句,通过 HTTP 请求发送给 ES 服务器。
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/index.html。
在本文中,我们将着重介绍 ElasticSearch Java 客户端中的 RestClient,并演示如何使用它实现对索引库和文档的各种操作。
一、对 Java RestClient 的认识
1.1 什么是 RestClient
RestClient 是 ElasticSearch 提供的用于与 ElasticSearch 集群进行通信的 Java 客户端。它提供了一种简单而灵活的方式来执行 REST 请求,并处理响应。通过 RestClient,我们可以轻松地在 Java 中操作 ElasticSearch。
在 ES 官方文档中看到 Java 的 RestClient 分为 High level REST client 和 Low level REST client:

它们之间的区别:
-
High Level REST Client:
- 面向对象:提供了更加面向对象的API,简化了复杂的操作,使用起来更加方便。
- 使用场景:适用于绝大多数的操作,特别是对于复杂的操作,比如查询、索引、更新等。
-
Low Level REST Client:
- 更接近 HTTP 层:提供的是与 Elasticsearch REST API 一一对应的方法,更加灵活,适用于特定场景的定制化需求。
- 使用场景:适用于对于 Elasticsearch 提供的 REST API 进行细粒度控制的情况,比如处理特殊的请求和响应。
1.2 RestClient 核心类:RestHighLevelClient
RestHighLevelClient 是 Elasticsearch Java 客户端中的高级客户端,提供了更加方便和抽象的操作方式,适用于大多数的 Elasticsearch 操作。在使用 RestHighLevelClient 之前,需要创建一个 RestClient 实例,并将其包装在 RestHighLevelClient 中。
主要功能和特点:
-
面向对象的操作:RestHighLevelClient 提供了更加面向对象的 API,使得 Elasticsearch 操作更加符合 Java 开发的习惯,易于理解和使用。
-
内置序列化和反序列化:RestHighLevelClient 内置了 Jackson 库,可以自动序列化和反序列化 Elasticsearch 的请求和响应,无需手动处理 JSON 数据。
-
复杂查询支持:支持复杂的 Elasticsearch 查询操作,如布尔查询、范围查询、聚合查询等。
-
错误处理:提供了异常处理机制,能够更好地捕获和处理 Elasticsearch 操作中的错误。
-
并发性:RestHighLevelClient 可以处理多个并发请求,是多线程安全的。
常用操作和方法:
以下是 RestHighLevelClient 类的一些常用操作和方法,通过这些方法可以实现对 Elasticsearch 的索引库和文档的各种操作:
| 操作 | 方法 | 描述 |
|---|---|---|
| 索引文档 | IndexResponse index(IndexRequest request, RequestOptions options) | 向指定索引插入文档 |
| 获取文档 | GetResponse get(GetRequest request, RequestOptions options) | 根据文档 ID 获取文档 |
| 删除文档 | DeleteResponse delete(DeleteRequest request, RequestOptions options) | 根据文档 ID 删除文档 |
| 更新文档 | UpdateResponse update(UpdateRequest request, RequestOptions options) | 根据文档 ID 更新文档 |
| 批量操作 | BulkResponse bulk(BulkRequest request, RequestOptions options) | 批量执行操作 |
| 查询 | SearchResponse search(SearchRequest request, RequestOptions options) | 执行搜索查询 |
| 聚合查询 | SearchResponse search(SearchRequest request, RequestOptions options) | 执行聚合查询 |
| 清理滚动 | ClearScrollResponse clearScroll(ClearScrollRequest request, RequestOptions options) | 清理滚动上下文 |
以上只是 RestHighLevelClient 类的一部分方法,更多详细的操作和方法请参考 官方文档。这些方法提供了丰富的功能,可以满足各种 Elasticsearch 操作的需求。
二、使用 Java RestClient 操作索引库
2.1 根据数据库表编写创建 ES 索引的 DSL 语句
当需要将已有的数据库数据导入到 Elasticsearch 索引中时,首先需要定义好 Elasticsearch 索引的 mapping 结构,这样 Elasticsearch 才能正确解析和存储数据。
在这个例子中,我们有一个名为 hotel 的数据库表,它有各种不同类型的字段,包括文本、数字、地理坐标等。让我们逐步解释如何根据数据库表的结构编写创建 Elasticsearch 索引的 DSL(Domain Specific Language)语句。
- 数据库表结构分析
首先,让我们来看一下 hotel 表的结构:
+-----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+-------+
| id | bigint | NO | PRI | NULL | |
| name | varchar(255) | NO | | NULL | |
| address | varchar(255) | NO | | NULL | |
| price | int | NO | | NULL | |
| score | int | NO | | NULL | |
| brand | varchar(32) | NO | | NULL | |
| city | varchar(32) | NO | | NULL | |
| star_name | varchar(16) | YES | | NULL | |
| business | varchar(255) | YES | | NULL | |
| latitude | varchar(32) | NO | | NULL | |
| longitude | varchar(32) | NO | | NULL | |
| pic | varchar(255) | YES | | NULL | |
+-----------+--------------+------+-----+---------+-------+
这个表包含了以下字段:
id:长整型(bigint)name:文本字符串(varchar),用于存储酒店名称address:文本字符串,用于存储酒店地址price:整数(int),表示酒店价格score:整数,表示酒店评分brand:文本字符串,用于存储酒店品牌city:文本字符串,用于存储城市名称star_name:文本字符串,用于存储星级名称(可为空)business:文本字符串,用于存储营业信息(可为空)latitude:文本字符串,用于存储纬度坐标longitude:文本字符串,用于存储经度坐标pic:文本字符串,用于存储图片路径(可为空)
- 创建 Elasticsearch 索引的 DSL
现在,让我们将上述数据库表的结构映射到 Elasticsearch 索引的 DSL 中:
PUT /hotel
{"mappings": {"properties": {"id": {"type": "long"},"name": {"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address": {"type": "keyword","index": false},"price": {"type": "integer"},"score": {"type": "integer"},"brand": {"type": "keyword","copy_to": "all"},"city": {"type": "keyword"},"starName": {"type": "keyword"},"business": {"type": "keyword","copy_to": "all"},"location": {"type": "geo_point"},"pic": {"type": "keyword","index": false},"all": {"type": "text","analyzer": "ik_max_word"}}}
}
重要说明:
- 地理坐标 (
location) 字段:
在 MySQL 数据库表中,地理坐标是使用 latitude 和 longitude 两个字段表示的。但在 Elasticsearch 中,我们使用 geo_point 类型来表示地理坐标。
geo_point:由纬度(latitude)和经度(longitude)确定的一个点。例如:“32.8752345, 120.2981576”。
补充:ES 中支持两种地理坐标数据类型
geo_point:由纬度(latitude)和经度(longitude)确定的一个点。例如:"32.8752345, 120.2981576"。geo_shape:有多个geo_point组成的复杂几何图形。例如一条直线:"LINESTRING (-77.03653 38.897676, -77.009051 38.889939)"。
- 字段拷贝:
字段拷贝的目的是在搜索时,同时匹配多个字段。我们使用 copy_to 属性将当前字段拷贝到指定字段。这样,在搜索时,可以同时匹配 name、brand 和 business 字段。
示例:
"all": {"type": "text","analyzer": "ik_max_word"
},
"brand": {"type": "keyword","copy_to": "all"
}
- 映射规则总结
Elasticsearch 对不同类型的字段有不同的映射规则,以下是常见类型的映射规则:
- 字符串 (
text和keyword):text用于全文搜索,支持分词;keyword用于精确匹配,不分词。 - 整数 (
integer): 用于存储整数。 - 长整型 (
long): 用于存储长整数。 - 浮点数 (
float): 用于存储浮点数。 - 地理坐标 (
geo_point): 用于存储地理坐标。 - 日期 (
date): 用于存储日期时间。
通过正确定义索引的映射规则,我们可以更有效地利用 Elasticsearch 的搜索和分析功能。
2.2 初始化 Java RestClient
2.2.1 在 Spring Boot 项目中引入 RestHighLevelClient 的依赖
首先在 pom.xml 中引入依赖
<!--ElasticSearch 客户端依赖-->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency>
此次引入的版本是 7.12.1 版本的,目的是与ElasticSearch 服务器的版本相同。刷新 Maven 之后,发现 elasticsearch-rest-high-level-client依赖中某些组件的版本并不是7.12.1的:
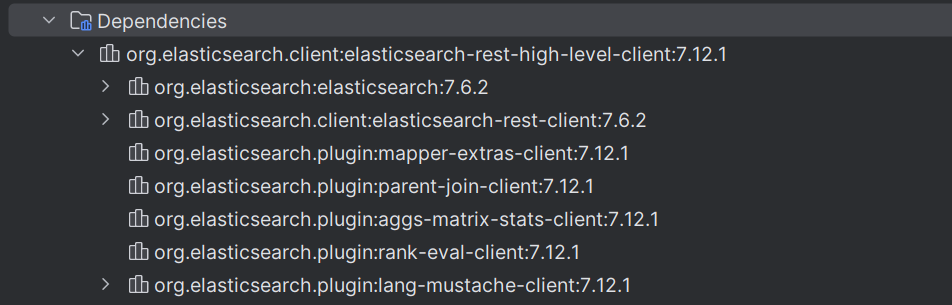
其原因是 Spring Boot 已经自动为我们管理了一些依赖,其中就包括了elasticsearch,其版本就是 7.6.2的。

因此我们需要做的就是在 pom.xml 覆盖这个配置,即在 properties 中指定版本为 7.12.1:

再次刷新 Maven,就能够发现所有组件的版本都是 7.12.1 了:

2.2.2 编写 HotelIndexTests 单元测试类,完成 RestHighLevelClient 的初始化
@SpringBootTest
class HotelIndexTests {private RestHighLevelClient client;@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.248.128:9200")));}@AfterEachvoid tearDown() throws IOException {this.client.close();}/*** 测试初始化客户端*/@Testvoid testInit() {System.out.println(client);}
}
对上述代码的说明:
- 在上述代码中,通过
RestClient.builder构建了RestHighLevelClient实例,并指定了 ElasticSearch 服务器的地址为http://192.168.248.128:9200。这是一个简单的单元测试,用于验证客户端的初始化是否成功。
- 在
@BeforeEach注解的方法中,我们创建了RestHighLevelClient的实例,而在@AfterEach注解的方法中,我们关闭了客户端。这是为了保证测试用例执行前后,客户端都能够正确地被初始化和关闭。
- 在测试方法
testInit中,我们简单地打印了客户端对象,以验证其初始化是否成功。
在接下来的内容中,我们将继续使用编写单元测试方法,执行一系列对 ElasticSearch 索引库和文档的操作。
2.3 创建索引库
创建 hotel 索引库会使用到前文根据 hotle 表结构编写的 DSL mapping 映射,在Java代码中,我们需要将其封装成一个全局常量,例如,将其保存到名为 MAPPING_TEMPLATE 的常量字符串中:
public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"long\"\n" +" },\n" +" \"name\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\": {\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\": {\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\": {\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"starName\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\": {\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\": {\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\": {\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}下面是创建索引库的单元测试方:
/*** 创建索引库** @throws IOException 抛出异常*/@Testvoid testCreateHotelIndex() throws IOException {// 1. 创建 Request 对象CreateIndexRequest request = new CreateIndexRequest("hotel");// 2. 准备请求参数:DSL 语句request.source(MAPPING_TEMPLATE, XContentType.JSON);// 3. 发起请求client.indices().create(request, RequestOptions.DEFAULT);}
对上述代码的说明:
- 创建
CreateIndexRequest对象,指定索引库的名称为"hotel"。 - 准备请求参数,即 DSL 语句,使用
MAPPING_TEMPLATE常量。 - 发起创建索引库的请求,通过
client.indices().create(request, RequestOptions.DEFAULT)执行。
这样,我们就完成了通过 Java RestClient 创建 ElasticSearch 索引库的操作。在实际应用中,创建索引库是一个初始化工作,通常在应用启动时执行一次即可。
2.4 删除索引库
以下是使用 Java RestClient 删除名为 “hotel” 的索引库的单元测试方法:
/*** 删除索引库* @throws IOException 抛出异常*/
@Test
void testDeleteHotelIndex() throws IOException {// 1. 创建 Request 对象DeleteIndexRequest request = new DeleteIndexRequest("hotel");// 2. 发起请求client.indices().delete(request, RequestOptions.DEFAULT);
}
对上述代码的说明:
- 创建
DeleteIndexRequest对象,指定要删除的索引库名称为 “hotel”。 - 发起删除索引库的请求,通过
client.indices().delete(request, RequestOptions.DEFAULT)执行。
这个方法主要用于清理测试环境或者在应用退出时执行,以确保数据的整洁和安全。
删除索引库的操作需要谨慎执行,因为它会将整个索引库以及其中的所有文档都删除,且无法恢复。在实际应用中,通常会设置一些安全机制来避免误操作。
2.5 判断索引库是否存在
在 Elasticsearch 中,我们可以通过 Java RestClient 来判断指定的索引库是否存在。以下是一个示例代码:
@Test
void testExistsHotelIndex() throws IOException {// 1. 创建 GetIndexRequest 对象,指定要判断是否存在的索引库名称为 "hotel"GetIndexRequest request = new GetIndexRequest("hotel");// 2. 发起请求,执行判断索引库是否存在的操作boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);// 3. 打印判断结果System.out.println(exists ? "索引库存在" : "索引库不存在");
}
在这个方法中,首先创建了一个 GetIndexRequest 对象,指定了要判断是否存在的索引库名称为 “hotel”。然后,通过 client.indices().exists(request, RequestOptions.DEFAULT) 发起请求,执行判断索引库是否存在的操作。最后,根据返回的布尔值,输出相应的提示信息。
这个方法通常用于在进行其他操作之前,先判断索引库是否存在,以确保我们不会对不存在的索引库执行其他操作。
三、使用 Java RestClient 实现对文档的增删改查
3.1 新增文档
在新增文档之前,首先需要从数据库中去查询一条记录,然后再将查询到的记录保存到 ES 文档中。例如,现在有一条 id=61083的酒店数据,我们需要把它查询出来,然后添加到文档中:
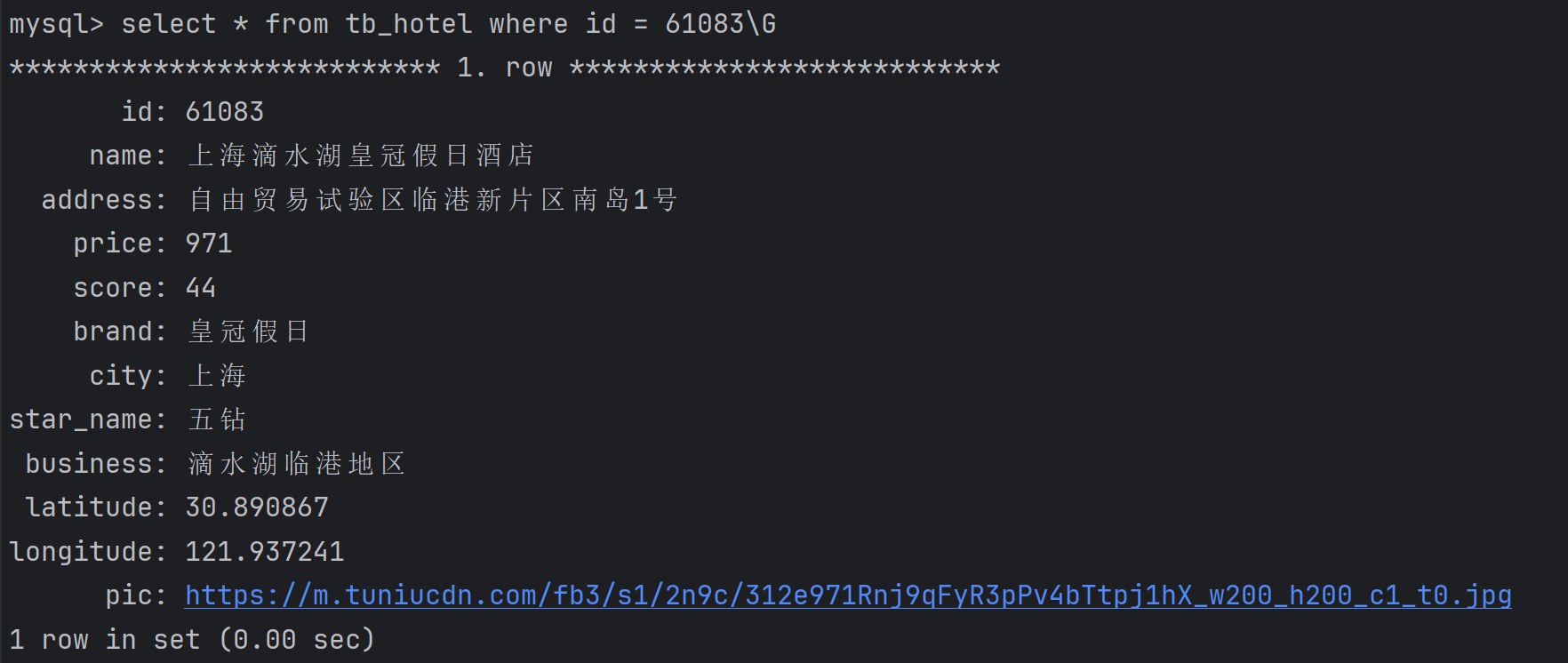
首先同样需要创建一个测试类HotelDocumentTests,并完成 RestHighLevelClient 的初始化。然后新增文档的测试代码如下:
@Test
void testAddDocument() throws IOException {// 根据id查询酒店Hotel hotel = hotelService.getById(61083L);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1. 准备 Request 对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2. 准备 JSON 文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3. 发送请求client.index(request, RequestOptions.DEFAULT);
}
对上述代码的说明:
-
根据 ID 查询酒店数据: 使用
hotelService.getById(61083L)方法从数据库中根据酒店 ID(这里是61083L)查询酒店数据并封装到Hotel对象中。 -
转换为文档类型: 将查询到的
Hotel类型转换为HotelDoc文档类型,因为数据库和文档中表示经纬度的方式不同。 -
准备
IndexRequest对象: 创建IndexRequest对象,指定索引库名称为 “hotel”,并设置文档 ID 为酒店的 ID(使用hotel.getId().toString()获取 ID 的字符串表示)。 -
准备 JSON 文档: 将
HotelDoc对象转换为 JSON 格式的字符串,使用JSON.toJSONString(hotelDoc)实现转换。 -
发送请求: 使用
client.index(request, RequestOptions.DEFAULT)发送请求,将准备好的文档添加到索引库中。
这个测试方法演示了如何通过 Java RestClient 向 Elasticsearch 索引库中新增文档。
3.2 获取文档
获取指定文档的测试方法的代码如下:
@Test
void testGetDocument() throws IOException {// 1. 创建 Request 对象GetRequest request = new GetRequest("hotel", "61083");// 2. 发送请求,获取结果GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3. 解析结果String json = response.getSourceAsString();// 4. 将字符串解析为 HotelDoc 对象HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);System.out.println(hotelDoc);
}
对该方法的详细说明:
-
创建
GetRequest对象: 使用GetRequest对象指定索引库名称为 “hotel”,文档 ID 为 “61083”。 -
发送请求,获取结果: 使用
client.get(request, RequestOptions.DEFAULT)发送请求,获取包含文档信息的GetResponse对象。 -
解析结果: 通过
response.getSourceAsString()获取文档内容的 JSON 字符串表示。 -
将字符串解析为
HotelDoc对象: 使用JSON.parseObject(json, HotelDoc.class)将获取的 JSON 字符串解析为HotelDoc对象。
这个测试方法演示了如何通过 Java RestClient 获取 Elasticsearch 索引库中指定文档的信息。
3.3 更新文档
更新文档的测试方法的代码如下:
@Test
void testUpdateDocument() throws IOException {// 1. 获取 Request 对象UpdateRequest request = new UpdateRequest("hotel", "61083");// 2. 准备参数request.doc("price", 1000,"score", 50);// 3. 发起请求client.update(request, RequestOptions.DEFAULT);
}
对该方法的详细说明:
-
获取
UpdateRequest对象: 使用UpdateRequest对象指定索引库名称为 “hotel”,文档 ID 为 “61083”。 -
准备参数: 使用
request.doc(...)方法准备需要更新的字段及其对应的新值。在这个例子中,更新了 “price” 字段为 1000,“score” 字段为 50。 -
发起请求: 使用
client.update(request, RequestOptions.DEFAULT)发送更新请求。
这个测试方法演示了如何通过 Java RestClient 更新 Elasticsearch 索引库中的指定文档。
3.4 删除文档
删除指定文档的单元测试方法的代码如下:
@Testvoid testDeleteDocument() throws IOException {// 1. 获取 Request 对象DeleteRequest request = new DeleteRequest("hotel", "61083");// 2. 发起请求client.delete(request, RequestOptions.DEFAULT);}
对该方法的详细说明:
-
获取
DeleteRequest对象: 使用DeleteRequest对象指定索引库名称为 “hotel”,文档 ID 为 “61083”。 -
发起请求: 使用
client.delete(request, RequestOptions.DEFAULT)发送删除请求。
这个测试方法演示了如何通过 Java RestClient 删除 Elasticsearch 索引库中的指定文档。
3.5 批量导入文档
在实际开发中,我们不可能像上面那样一条数据一条数据的导入到文档中,而是需要批量的查询数据库,然后将结果集批量的导入到文档中,导入批量数据到文档的测试方法如下:
@Test
void testBulkRequest() throws IOException {// 批量查询酒店数据List<Hotel> hotels = hotelService.list();// 1. 创建 BulkRequestBulkRequest request = new BulkRequest();// 转换为文档类型 HotelDocfor (Hotel hotel : hotels) {HotelDoc hotelDoc = new HotelDoc(hotel);// 2. 准备参数,添加多个新增的 Requestrequest.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3. 发起请求client.bulk(request, RequestOptions.DEFAULT);
}对上述代码的说明:
-
批量查询酒店数据: 使用
hotelService.list()批量获取酒店数据。 -
创建
BulkRequest对象: 使用BulkRequest对象准备批量请求。 -
循环添加请求: 遍历酒店数据列表,将每个酒店数据转换为
HotelDoc类型,并添加到BulkRequest中。 -
发起请求: 使用
client.bulk(request, RequestOptions.DEFAULT)发送批量请求。
这个测试方法演示了如何通过 Java RestClient 批量导入 Elasticsearch 索引库中的文档。批量导入通常能够提高效率,特别是在处理大量数据时。
相关文章:
【ElasticSearch】基于 Java 客户端 RestClient 实现对 ElasticSearch 索引库、文档的增删改查操作,以及文档的批量导入
文章目录 前言一、对 Java RestClient 的认识1.1 什么是 RestClient1.2 RestClient 核心类:RestHighLevelClient 二、使用 Java RestClient 操作索引库2.1 根据数据库表编写创建 ES 索引的 DSL 语句2.2 初始化 Java RestClient2.2.1 在 Spring Boot 项目中引入 Rest…...

【Node.js】stream 流模块
流是一种抽象的数据结构。从键盘输入到应用程序就是标准输入流(stdin)。应用程序把字符一个一个输出到显示器上叫做:标准输出流(stdout)。 流的特点是数据是有序的,而且必须依次读取,或者依次写…...
【LeetCode】——链式二叉树经典OJ题详解
主页点击直达:个人主页 我的小仓库:代码仓库 C语言偷着笑:C语言专栏 数据结构挨打小记:初阶数据结构专栏 Linux被操作记:Linux专栏 LeetCode刷题掉发记:LeetCode刷题 算法头疼记:算法专栏…...

代码注释对于程序员重要吗?
程序员对代码注释可以说是又爱又恨又双标……你是怎么看待程序员不写注释这一事件的呢? 代码注释的重要性 代码注释是指在程序代码中添加的解释性说明,用于描述代码的功能、目的、使用方法等。代码注释对于程序的重要性主要体现在以下几个方面&#x…...

OpenHamony开发笔记一:在HarmonyOS虚拟机上运行openharmony工程
在HarmonyOS的虚拟机上要运行openharmony的工程时需要修改的地方有 1.修改build-profile.json5,将runtimeOS改为HarmonyOS "targets": [{"name": "default","runtimeOS": "HarmonyOS"}, 2.修改工程引用的SDK&a…...
)
C++程序员入门需要怎么学?(InsCode AI 创作助手)
文章目录 (一)学习C概念(二)C主要应用场景和相关产品(三)学习C流程1. 学习C语法和基本示例:2. 深入学习面向对象编程(OOP):3. 使用C标准库:4. 解决…...
)
Intel 高性能库之IPP信号处理简介及下载(版本5.1,含32位和64位及注册)
IPP是什么 IPP:Intel Integrated Performance Primitives 英特尔集成性能基元(英特尔IPP)是一款多核就绪的扩展函数库,其中包含众多针对多媒体、数据处理和通信应用高度优化的软件函数。它包括: 视频编码:用于 DV25/50/100、MPEG-2、MPEG-4、H.263 和 MPEG-4 Part 10 …...
【C++】运算符重载案例 - 字符串类 ② ( 重载 等号 = 运算符 | 重载 数组下标 [] 操作符 | 完整代码示例 )
文章目录 一、重载 等号 运算符1、等号 运算符 与 拷贝构造函数2、重载 等号 运算符 - 右操作数为 String 对象3、不同的右操作数对应的 重载运算符函数 二、重载 下标 [] 运算符三、完整代码示例1、String.h 类头文件2、String.cpp 类实现3、Test.cpp 测试类4、执行结果 一…...

Vue脚手架开发流程
一、项目运行时会先执行 public / index.html 文件 <!DOCTYPE html> <html lang""><head><meta charset"utf-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport&quo…...

从零开始学习线性回归:理论、实践与PyTorch实现
文章目录 🥦介绍🥦基本知识🥦代码实现🥦完整代码🥦总结 🥦介绍 线性回归是统计学和机器学习中最简单而强大的算法之一,用于建模和预测连续性数值输出与输入特征之间的关系。本博客将深入探讨线性…...

[LeetCode]链式二叉树相关题目(c语言实现)
文章目录 LeetCode965. 单值二叉树LeetCode100. 相同的树LeetCode101. 对称二叉树LeetCode144. 二叉树的前序遍历LeetCode94. 二叉树的中序遍历LeetCode145. 二叉树的后序遍历LeetCode572. 另一棵树的子树 LeetCode965. 单值二叉树 题目 Oj链接 思路 一棵树的所有值都是一个…...
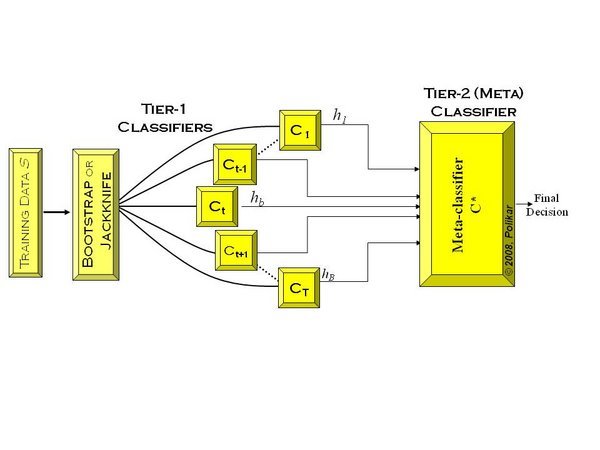
集成学习
集成学习(Ensemble Learning) - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/27689464集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器…...

算法练习11——买卖股票的最佳时机 II
LeetCode 122 买卖股票的最佳时机 II 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。 返回…...

linux——多线程,线程控制
目录 一.POSIX线程库 二.线程创建 1.创建线程接口 2.查看线程 3.多线程的健壮性问题 4.线程函数参数传递 5.线程id和地址空间 三.线程终止 1.pthread_exit 2.pthread_cancel 四.线程等待 五.线程分离 一.POSIX线程库 站在内核的角度,OS只有轻量级进程…...
Oracle 简介与 Docker Compose部署
最近,我翻阅了在之前公司工作时的笔记,偶然发现了一些有关数据库的记录。当初,我们的项目一开始采用的是 Oracle 数据库,但随着项目需求的变化,我们不得不转向使用 SQL Server。值得一提的是,公司之前采用的…...

mp4音视频分离技术
文章目录 问题描述一、分离MP3二、分离无声音的MP4三、结果 问题描述 MP4视频想拆分成一个MP3音频和一个无声音的MP4文件 一、分离MP3 ffmpeg -i C:\Users\Administrator\Desktop\一个文件夹\我在财神殿里长跪不起_完整版MV.mp4 -vn C:\Users\Administrator\Desktop\一个文件…...

JVM 参数
JVM 参数类型大致分为以下几类: 标准参数(-):保证在所有的 JVM 实现都支持的参数非标准参数(-X):通用的,特定于 HotSpot 虚拟机的参数,这些参数不保证在所有 JVM 实现中…...

黑马点评-07缓存击穿问题(热点key失效)及解决方案,互斥锁和设置逻辑过期时间
缓存击穿问题(热点key失效) 缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且重建缓存业务较复杂的key突然失效了,此时无数的请求访问会在瞬间打到数据库,带来巨大的冲击 一件秒杀中的商品的key突然失效了,由于大家都在疯狂抢购那么这个瞬间就会有无数的请求…...

信息系统项目管理师第四版学习笔记——项目进度管理
项目进度管理过程 项目进度管理过程包括:规划进度管理、定义活动、排列活动顺序、估算活动持续时间、制订进度计划、控制进度。 规划进度管理 规划进度管理是为规划、编制、管理、执行和控制项目进度而制定政策、程序和文档的过程。本过程的主要作用是为如何在…...

指挥棒:C++ 与运算符
文章目录 参考描述算术运算符除法运算取模运算复合赋值运算符自增运算符自减运算符 比较运算符逻辑运算符概念短路为什么需要短路机制? 参考 项目描述微软C 语言文档搜索引擎Bing、GoogleAI 大模型文心一言、通义千问、讯飞星火认知大模型、ChatGPTC Primer Plus &…...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...

Diablo Edit2:终极暗黑破坏神2存档编辑器完全指南
Diablo Edit2:终极暗黑破坏神2存档编辑器完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否厌倦了在暗黑破坏神2中反复刷装备的枯燥过程?是否因为技能点分配失…...

tabtoy性能优化秘籍:多核并发导出与缓存加速技巧
tabtoy性能优化秘籍:多核并发导出与缓存加速技巧 【免费下载链接】tabtoy 高性能表格数据导出器 项目地址: https://gitcode.com/gh_mirrors/ta/tabtoy 在处理大量表格数据导出时,性能往往是开发者面临的主要挑战。tabtoy作为一款高性能表格数据导…...

3分钟快速激活方案:KMS_VL_ALL_AIO智能脚本全解析
3分钟快速激活方案:KMS_VL_ALL_AIO智能脚本全解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经为Windows系统或Office办公软件的激活问题而烦恼?频繁的激活…...

Go语言模板方法模式:算法骨架
Go语言模板方法模式:算法骨架 1. 模板方法实现 type AbstractClass struct{}func (a *AbstractClass) TemplateMethod() {a.Step1()a.Step2()a.Step3() }func (a *AbstractClass) Step1() {} func (a *AbstractClass) Step2() {} func (a *AbstractClass) Step3() {…...

Wonder3D完整解决方案:从单张图片到高质量3D模型的5步实施路径
Wonder3D完整解决方案:从单张图片到高质量3D模型的5步实施路径 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 面对传统3D建模复杂耗时、学习曲线陡峭…...

700MHz 5G网络DTMB干扰实战:从测量到规避的完整解决方案
1. 项目概述:直面700MHz网络中的DTMB干扰挑战在5G网络的深度覆盖战役中,700MHz频段因其卓越的穿透能力和广阔的覆盖范围,被寄予厚望,成为解决偏远地区和室内深度覆盖难题的“黄金频段”。然而,理想很丰满,现…...

构建AI智能体安全护栏:AgentGuard多层防护架构与工程实践
1. 项目概述:构建AI应用的安全护栏最近在部署和调试一些基于大语言模型(LLM)的智能体(Agent)应用时,我遇到了一个挺头疼的问题:这些应用在自由发挥时,偶尔会“说错话”或者“做错事”…...

77种商品-图像分类数据集
77种商品图像分类数据集 数据集(文章最后关注公众号获取数据集): 链接: https://pan.baidu.com/s/1Xcj5Z-RSUjGH47OIbH5wjQ?pwd=fq2p 提取码: fq2p 数据集信息介绍: 以下是整理后的清晰呈现,按照商品名称首字母顺序进行排列: 东方树叶红茶:文件夹中的图片数量为 150 …...
