Python并发编程简介
1、Python对并发编程的支持
- 多线程: threading, 利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
- 多进程: multiprocessing, 利用多核CPU的能力,真正的并行执行任务
- 异步IO: asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
- 使用Lock对资源加锁,防止冲突访问
- 使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
- 使用subprocess启动外部程序的进程,并进行输入输出交互
2、 怎样选择多线程多进程多协程
Python并发编程有3三种方式:多线程Thread、多进程Process、多协程Coroutine
2.1 什么是CPU密集型计算、IO密集型计算?
CPU密集型(CPU-bound ) :
CPU密集型也叫计算密集型,是指I/O在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
例如:压缩解压缩、加密解密、正则表达式搜索
IO密集型(I/0 bound):
IO密集型指的是系统运作大部分的状况是CPU在等I/O (硬盘/内存)的读/写操作,CPU占用率仍然较低。
例如:文件处理程序、网络爬虫程序、读写数据库程序(依赖大量的外部资源)
2.2 多线程、多进程、多协程的对比
一个进程中可以启动N个线程,一个线程中可以启动N个协程
多进程Process ( multiprocessing )
- 优点:可以利用多核CPU并行运算
- 缺点:占用资源最多、可启动数目比线程少
- 适用于:CPU密集型计算
多线程Thread ( threading)
- 优点:相比进程,更轻量级、占用资源少
- 缺点:
相比进程:多线程只能并发执行,不能利用多CPU ( GIL )
相比协程:启动数目有限制,占用内存资源,有线程切换开销 - 适用于: IO密集型计算、同时运行的任务数目要求不多
多协程Coroutine ( asyncio )
- 优点:内存开销最少、启动协程数量最多
- 缺点:支持的库有限制(aiohttp VS requests )、代码实现复杂
- 适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
2.3 怎样根据任务选择对应技术?
flowchart LRA[待执行任务]-->B{任务特点}B --- C(CPU密集型)
C-->E(["使用多进程multiprocessing"])B ---D(IO密集型)D-->F{"1、需要超多任务量?2、有现成协程库支持?3、协程实现复杂度可接受?"}
F -- 否---> G(["使用多线程threading"])
F -- 是---> H(["使用多协程asyncio"])%% style选项为每个节点设置了颜色和边框样式
style A fill:#333399,color:#fff
style B fill:#fff,stroke:#CC6600
style C fill:#FFFFCC
style D fill:#FFFFCC
style E fill:#FF9999
style F fill:#fff,stroke:#CC6600
style G fill:#FF9999
style H fill:#FF9999%% linkStyle选项为连接线设置颜色和样式
linkStyle 1 stroke:blue,stroke-width:1px;
linkStyle 3 stroke:blue,stroke-width:1px;
3、 Python速度慢的罪魁祸首——全局解释器锁GIL
3.1 Python速度慢的两大原因
相比C/C+ +/JAVA, Python确实慢,在一些特殊场景 下,Python比C+ +慢100~ 200倍
由于速度慢的原因,很多公司的基础架构代码依然用C/C+ +开发
比如各大公司阿里/腾讯/快手的推荐引擎、搜索引擎、存储引擎等底层对性能要求高的模块
Python速度慢的原因1
动态类型语言,边解释边执行
Python速度慢的原因2
GIL ,无法利用多核CP并发执行
3.2 GIL是什么?
全局解释器锁( 英语: Global Interpreter Lock,缩写GIL)
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。
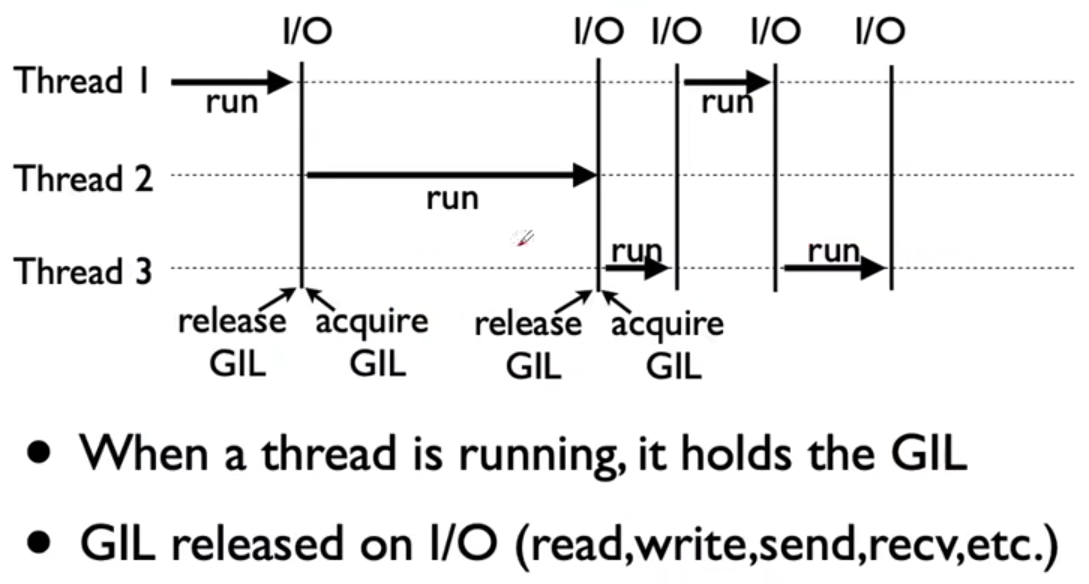
由于GIL的存在,即使电脑有多核CPU,单个时刻也只能使用1个,相比并发加速的C+ +/JAVA所以慢
3.3 为什么有GIL .这个东西?
简而言之: Python设计初期,为了规避并发问题引入了GIL,现在想去除却去不掉了!
为了解决多线程之间数据完整性和状态同步问题
Python中对象的管理,是使用引用计数器进行的,引用数为0则释放对象
开始:线程A和线程B都引用了对象obj,obj.ref_ num = 2,线程A和B都想撤销对obj的引用
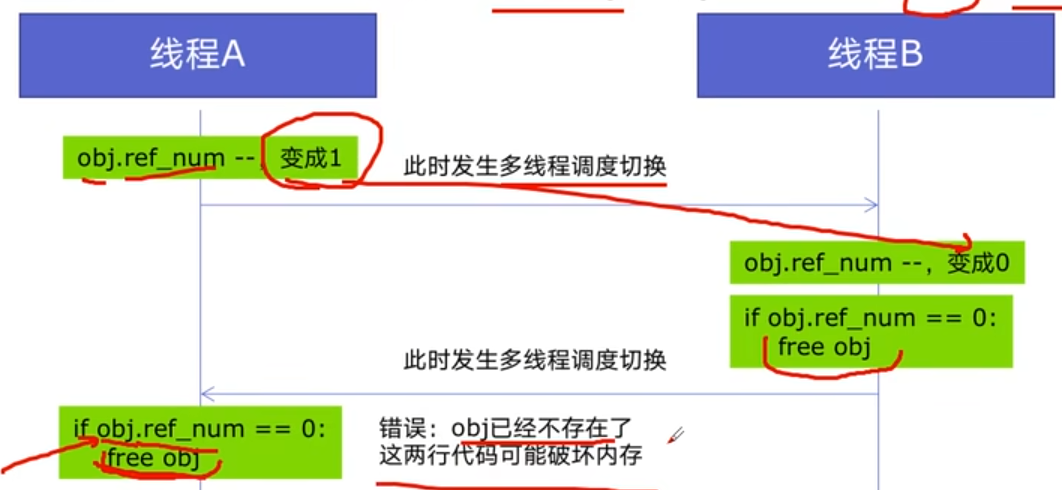

GIL确实有好处:简化了Python对共享资源的管理;
3.4 怎样规避GIL带来的限制?
多线程threading机制依然是有用的,用于IO密集型计算
因为在I/O (read,write ,send,recv,etc. )期间,线程会释放GIL,实现CPU和IO的并行
因此多线程用于IO密集型计算依然可以大幅提升速度
但是多线程用于CPU密集型计算时,只会更加拖慢速度
使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势
为了应对GIL的问题,Python提供了multiprocessing
4、使用多线程,爬虫被加速
4.1 Python创建多线程的方法
1、准备一个函数
def my_func(a,b):do_craw(a,b)
2、创建一个线程
import threading
t = threading.Thread(target=my_func,args=(100,200))
3、启动线程
t.start()
4、等待结束
t.join()
4.2 改写爬虫程序,变成多线程爬取
blog_spider.py程序
import requestsurls = [f"https://www.cnblogs.com/sitehome/p/{page}"for page in range(1, 50 + 1)
]def craw(url):r = requests.get(url)print(url, len(r.text))
import blog_spider
import threading
import timedef single_thread():print("single_thread begin...")for url in blog_spider.urls:blog_spider.craw(url)print("single_thread end...")def multi_thread():print("multi_thread begin...")threads = []for url in blog_spider.urls:threads.append(threading.Thread(target=blog_spider.craw,args=(url,)))for thread in threads:thread.start()for thread in threads:thread.join()print("multi_thread end...")if __name__ == '__main__':start = time.time()single_thread()end=time.time()print("single thread cost:",end-start,"seconds")begin = time.time()multi_thread()finish = time.time()print("multi thread cost:", finish - begin, "seconds")
4.3 速度对比:单线程爬虫VS多线程爬虫



5 Python实现生产者消费者爬虫
5.1 多组件的Pipeline技术架构
复杂的事情一般都不会一下子做完, 而是会分很多中间步骤一步步完成。

graph LR
O[ ] --> |输入数据|A(处理器1)-->|中间数据|B(处理器X<br>很多个)-->|中间数据|C(处理器N)-->|输出数据|D[ ]
5.2 生产者消费者爬虫的架构
5.3 多线程数据通信的queue.Queue
5.4 代码编写实现生产者消费者爬虫
import requests
from bs4 import BeautifulSoupurls = [# f"https://www.cnblogs.com/#p{page}"f"https://www.cnblogs.com/sitehome/p/{page}"for page in range(1, 3 + 1)
]def craw(url):r = requests.get(url)return r.textdef parse(html):soup=BeautifulSoup(html,'html.parser')links = soup.find_all('a',class_="post-item-title")return [(link["href"],link.get_text()) for link in links]if __name__ == '__main__':for result in parse(craw(urls[0])):print(result)
import blog_spider
import threading
import time
import queue
import randomdef do_craw(url_queue: queue.Queue, html_queue: queue.Queue):while True:url = url_queue.get()html = blog_spider.craw(url)html_queue.put(html)print(threading.current_thread().name, f"craw {url}","url_queue.size=", url_queue.qsize())# time.sleep(random.randint(1, 2))def do_parse(html_queue: queue.Queue, fout):while True:html = html_queue.get()results = blog_spider.parse(html)for result in results:fout.write(str(result) + "\n")print(threading.current_thread().name, f"results.size {len(results)}","html_queue.size=", html_queue.qsize())# time.sleep(random.randint(1, 2))if __name__ == '__main__':url_queue = queue.Queue()html_queue = queue.Queue()for url in blog_spider.urls:url_queue.put(url)for idx in range(3):t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")t.start()fout = open("02.data.txt", 'w', encoding='utf-8')for idx in range(2):t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")t.start()
6、Python线程安全问题以及解决方案
import threading
import timelock = threading.Lock()class Accout():def __init__(self,balance):self.balance=balancedef draw(accout,amount):with lock:if accout.balance>=amount:time.sleep(0.1)print(threading.current_thread().name,"取钱成功")accout.balance-=amountprint(threading.current_thread().name, "余额",accout.balance)else:print(threading.current_thread().name, "取钱失败,余额不足")if __name__ == '__main__':accout=Accout(1000)ta = threading.Thread(target=draw,args=(accout,600))tb = threading.Thread(target=draw, args=(accout, 600))ta.start()tb.start()ta.join()tb.join()
7、Python好用的线程池ThreadPoolExecutor
import concurrent.futures
import blog_spiderwith concurrent.futures.ThreadPoolExecutor() as pool:htmls = pool.map(blog_spider.craw, blog_spider.urls)htmls = list(zip(blog_spider.urls, htmls))for url, html in htmls:print(url, len(html))print("爬虫结束..")with concurrent.futures.ThreadPoolExecutor() as pool:futures = {}for url, html in htmls:future = pool.submit(blog_spider.parse, html)futures[future] = url# for future,url in futures.items():# print(url,future.result())for future in concurrent.futures.as_completed(futures):# url = futures[future]futures[future] = urlprint(url, future.result())
8、Python使用线程池在Web服务中实现加速
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app = flask.Flask(__name__)
pool = ThreadPoolExecutor()def read_db():time.sleep(0.2)return "db result"def read_file():time.sleep(0.1)return "file result"def read_api():time.sleep(0.3)return "api result"@app.route("/")
def index():result_file=pool.submit(read_file)result_db = pool.submit(read_db)result_api = pool.submit(read_api)return json.dumps({"result_file":result_file.result(),"result_db": result_db.result(),"result_db": result_api.result(),})if __name__ == '__main__':app.run()
9、使用多进程multiprocessing模块加速程序的运行
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import timePRIMES = [112272535095293] * 10def is_prime(n):if n < 2:return Falseif n == 2:return Trueif n % 2 == 0:return Falsesqrt_n = int(math.floor(math.sqrt(n)))for i in range(3, sqrt_n + 1, 2):if n % i == 0:return Falsereturn Truedef single_thread():for num in PRIMES:is_prime(num)def multi_thread():with ThreadPoolExecutor() as pool:pool.map(is_prime, PRIMES)def multi_process():with ProcessPoolExecutor() as pool:pool.map(is_prime, PRIMES)if __name__ == '__main__':start = time.time()single_thread()end = time.time()print("single thread cost:", end - start, "secend")start = time.time()multi_thread()end = time.time()print("multi thread cost:", end - start, "secend")start = time.time()multi_process()end = time.time()print("multi process cost:", end - start, "secend")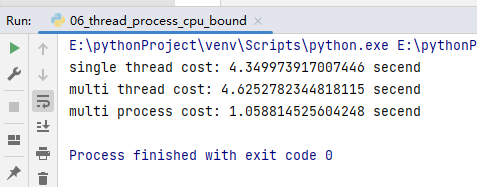
10、Python在Flask服务中使用多进程池加速程序运行
import flask
import math
import json
from concurrent.futures import ProcessPoolExecutorapp = flask.Flask(__name__)def is_prime(n):if n < 2:return Falseif n == 2:return Trueif n % 2 == 0:return Falsesqrt_n = int(math.floor(math.sqrt(n)))for i in range(3, sqrt_n + 1, 2):if n % i == 0:return Falsereturn True@app.route("/is_prime/<numbers>")
def api_is_prime(numbers):number_list = [int(x) for x in numbers.split(",")]results = process_pool.map(is_prime, number_list)return json.dumps(dict(zip(number_list, results)))if __name__ == '__main__':process_pool = ProcessPoolExecutor()app.run()11、Python异步IO实现并发爬虫
import asyncio
import aiohttp
import blog_spider
import timeasync def async_craw(url):print("爬虫开始:", url)async with aiohttp.ClientSession() as session:async with session.get(url) as resp:result = await resp.text()print(f"craw url:{url},{len(result)}")loop = asyncio.get_event_loop()tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("asyncio cost:", end - start, "second")
12、在异步IO中使用信号量控制爬虫并发度
import asyncio
import aiohttp
import blog_spider
import timeasync def async_craw(url):print("爬虫开始:", url)async with aiohttp.ClientSession() as session:async with session.get(url) as resp:result = await resp.text()print(f"craw url:{url},{len(result)}")loop = asyncio.get_event_loop()tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("asyncio cost:", end - start, "second")
参考:【2021最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行
相关文章:
Python并发编程简介
1、Python对并发编程的支持 多线程: threading, 利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成多进程: multiprocessing, 利用多核CPU的能力,真正的并行执行任务异步IO: asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行使用Lo…...

WebSocket介绍及部署
WebSocket是一种在单个TCP连接上进行全双工通信的协议,其设计的目的是在Web浏览器和Web服务器之间进行实时通信(实时Web)。 WebSocket协议的优点包括: 1. 更高效的网络利用率:与HTTP相比,WebSocket的握手…...
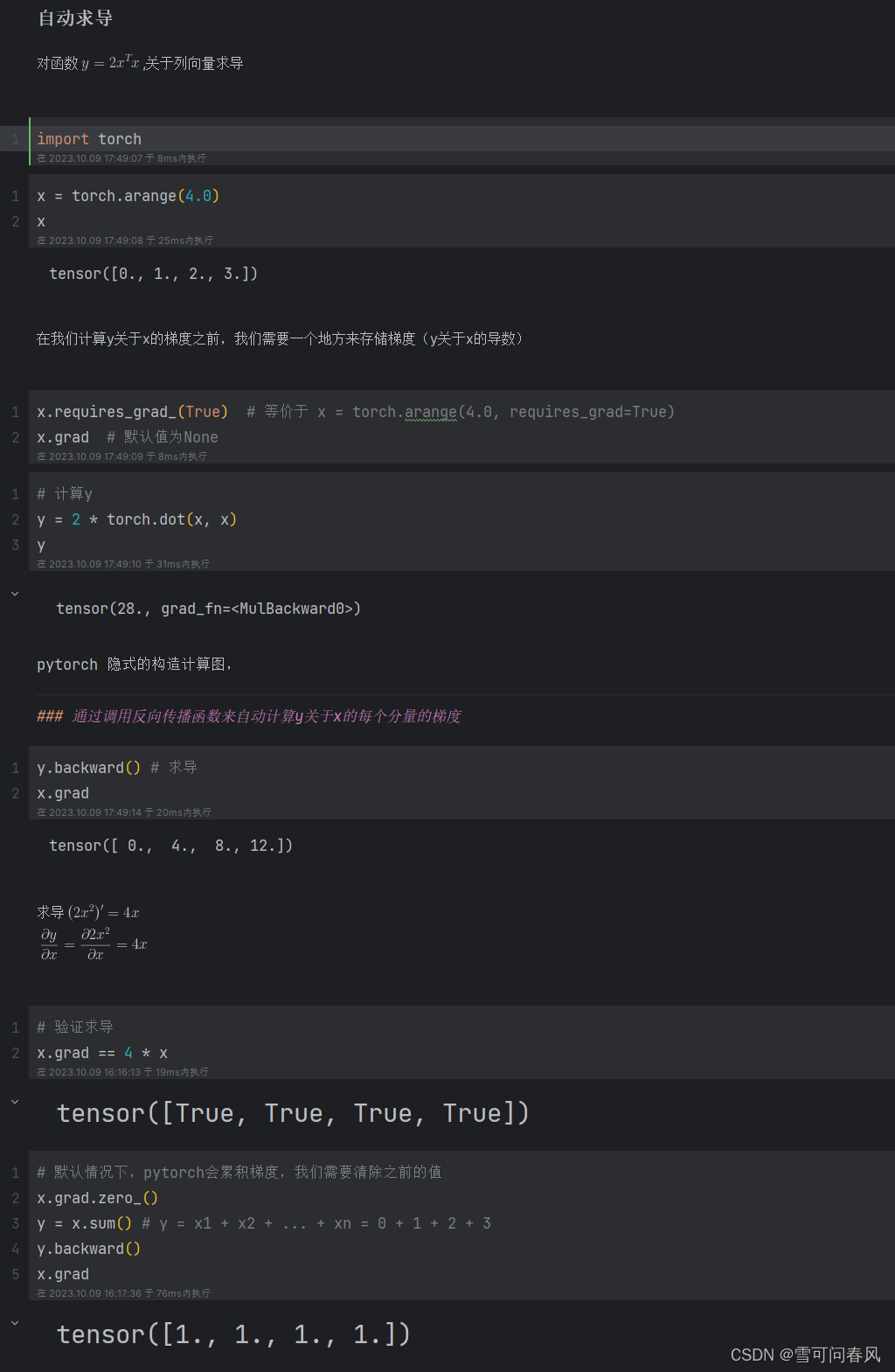
自动求导,计算图示意图及pytorch实现
pytorch实现 x1 torch.tensor(3.0, requires_gradTrue) y1 torch.tensor(2.0, requires_gradTrue) a x1 ** 2 b 3 * a c b * y1 c.backward() print(x1.grad) print(y1.grad) print(x1.grad 6 * x1 * y1) print(y1.grad 3 * (x1 ** 2))输出为: tensor(36.) …...

睿伴科创上线了
Robotutor睿伴,一个专业的青少儿编程科创教育品牌和科创服务平台。 Robotutor睿伴拥有一个超过5年的青少儿编程科创教育团队,积累了丰富的课程研发,教学服务和赛事辅导经验。并和上海多所知名高校、上海市计算机学会、上海青少年科学社等开展…...

域名抢注和域名注册
随着互联网的发展,域名已经成为了企业和个人在网络上展示自己的重要标志。如何获得一段好记、易拼写、有意义的域名,是很多人都面临的问题。本文将介绍域名抢注和域名注册的相关内容,并推荐ym.qqmu.com这个可靠的域名注册平台。 一、什么是域…...
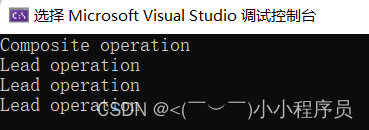
【20】c++设计模式——>组合模式
组合模式定义 C组合模式(Composite Pattern)是一种结构型设计模式,他允许将对象组合成树形结构来表示“部分-整体”的层次结构;在组合模式中有两种基本类型的对象:叶子对象和组合对象,叶子对象时没有子对象…...

Jetpack:004-如何使用文本组件
文章目录 1. 概念介绍2. 使用方法2.1 通用参数2.2 专用参数 3. 示例代码4. 内容总结 我们在上一章回中介绍了Jetpack组件在布局中的对齐方式,本章回中主要介绍文 本组件的使用方法。闲话休提,让我们一起Talk Android Jetpack吧 1. 概念介绍 我们在本章…...
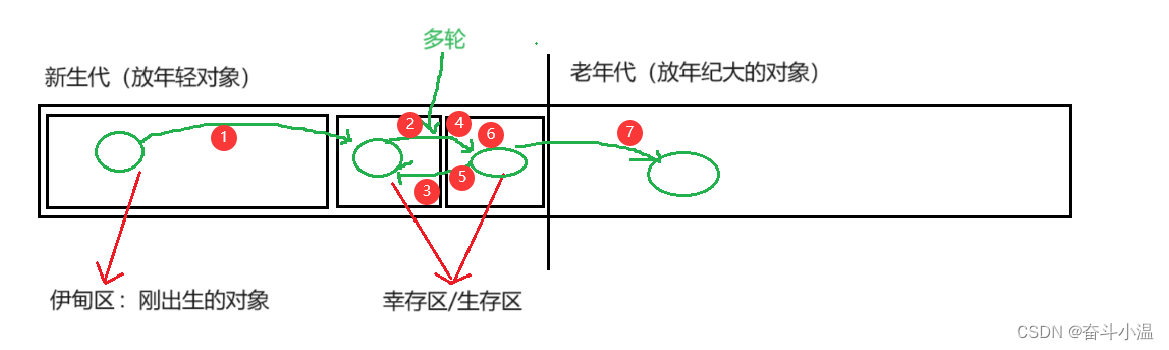
JVM(八股文)
目录 一、JVM简介 二、JVM中的内存区域划分 三、JVM加载 1.类加载 1.1 加载 1.2 验证 1.3 准备 1.4 解析 1.5 初始 1.6 总结 2.双亲委派模型 四、JVM 垃圾回收(GC) 1.确认垃圾 1.1 引用计数 1.2 可达性分析(Java 采用的方案&a…...

C#WPF标记扩展应用实例
本文介绍C#WPF标记扩展应用实例 一、标记扩展 标记扩展是一个 XAML 语言概念。 用于提供特性语法的值时,大括号({ 和 })表示标记扩展用法。 此用法指示 XAML 处理不要像通常那样将特性值视为文本字符串或者可转换为字符串的值。就是类似于值用变量的意思。 WPF 应用编程中…...
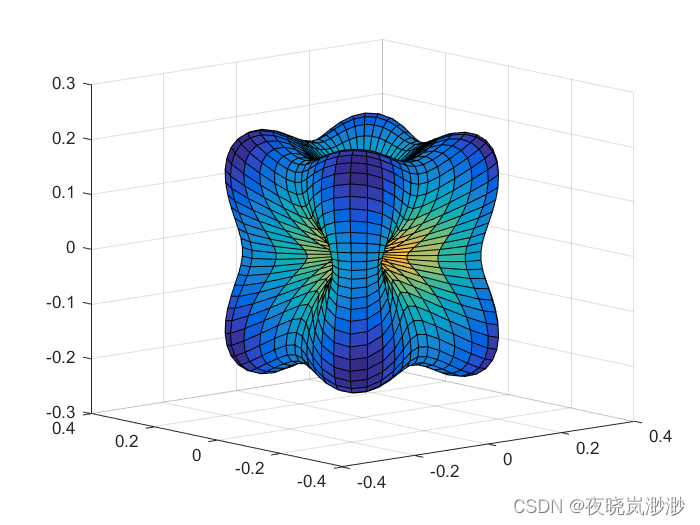
四维曲面如何画?matlab
clc; clear all [theta,phi]meshgrid(linspace(0,pi,50),linspace(0,2*pi,50)); zcos(theta); xsin(theta).*cos(phi); ysin(theta).*sin(phi); f-1*((x.*y).2(y.*z).2(z.*x).^2); surf(sin(theta).*cos(phi).*f,sin(theta).*sin(phi).*f,cos(theta).*f,f) 结果...
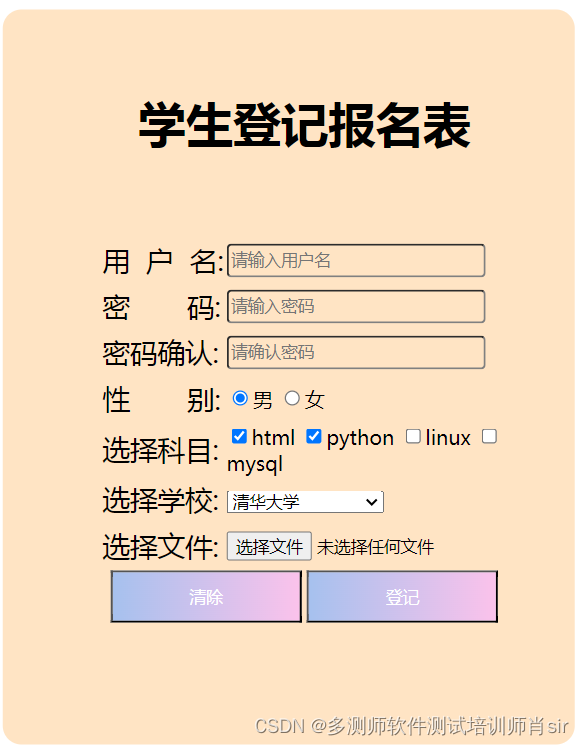
软件培训测试高级工程师多测师肖sir__html之作业11
html之作业 案例1: 截图: 代码: <!DOCTYPE html> <html><head><meta charset"UTF-8"><title>表单</title></head><body><table style"background-color:red" bo…...
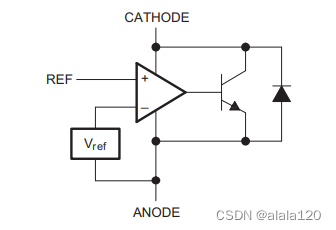
详解一典型的反激式开关电源方案
理解一个单端反激式开关电源方案: 1、抛出问题: 如图,在某系统方案上看到下图所示的单端反激式开关电源方案。 2、解析问题: 2.1、乍一看: 典型的AC-DC电路,考虑了安规及过压过流保护,如&am…...
)
AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型)
AI 大框架基于python来实现基带处理之TensorFlow(信道估计和预测模型,信号解调和解码模型) 基带处理(Baseband Processing)是一种信号处理技术,用于在通信系统中处理和调制基带信号。基带信号是指未经过调制的信号,通常包含原始数…...

阿里云上了新闻联播
我是卢松松,点点上面的头像,欢迎关注我哦! 阿里新任的CEO吴泳铭上央视新闻联播了! 在昨天的新闻联播里,出席科技座谈会,有一个特别镜头,出现了阿里新任CEO吴泳铭的镜头。 这个信号意义明显,我…...

算法练习12——跳跃游戏
LeetCode 55 跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 贪…...

Java架构师系统架构设计服务拆分
目录 1 服务拆分和子系统模块拆分1.1 服务化架构的优势2 描绘系统蓝图里面的详解服务2.1 为什么拆分服务3 服务拆分的基本要求3.1 服务功能是自包含的3.2 服务呢应该具备独立性和专业性3.3 服务是无状态的3.4 服务之间采用轻量级的通讯机制4 服务拆分的基本方法4.1 按业务边界拆…...

通用任务批次程序模板
通用批次任务模板 我们总会遇到需要使用批次任务处理问题的场景,任务有很多不同类型的任务,同时这些任务可能都有大致相同,甚至抽象出来共同的执行阶段状态。 任务的执行肯定无法保证一帆风顺,总会在某个时间阶段被打断ÿ…...
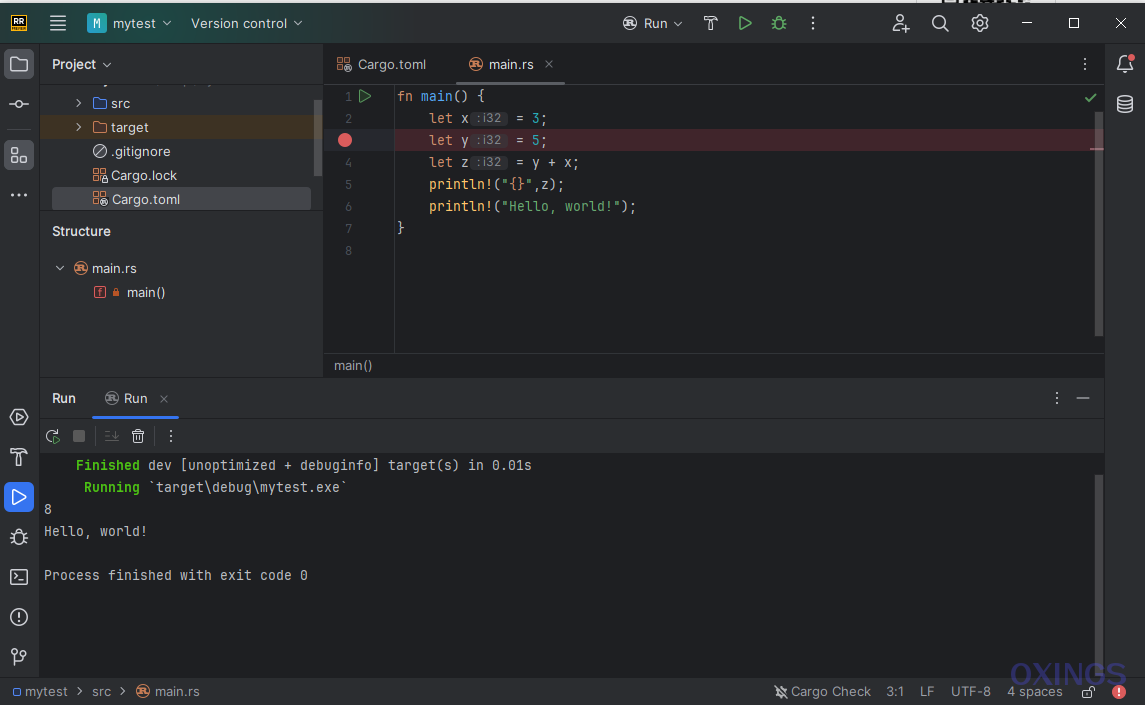
Rust专属开发工具——RustRover发布
JetBrains最近推出的Rust集成开发工具——RustRover已经发布,官方网站:RustRover: Rust IDE by JetBrains JetBrains出品过很受欢迎的开发工具IntelliJ IDEA、PyCharm等。 RustRover优势 Rust集成环境,根据向导可自动下载安装rust开发环境提…...
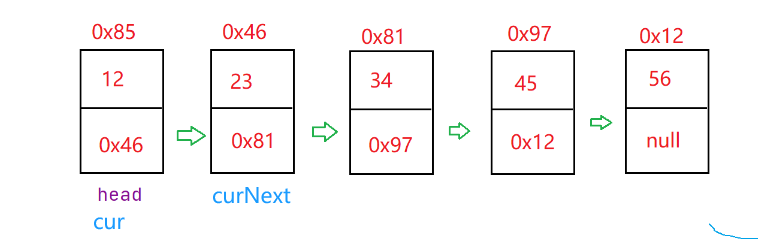
数据结构:链表(1)
顺序表的优缺点 缺点: 1.插入数据必须移动其他数据,最坏情况下,就是插入到0位置。时间复杂度O(N) 2.删除数据必须移动其他数据,最坏情况下,就是删除0位置。时间复杂度O(N) 3.扩容之后,有可能会浪费空间…...
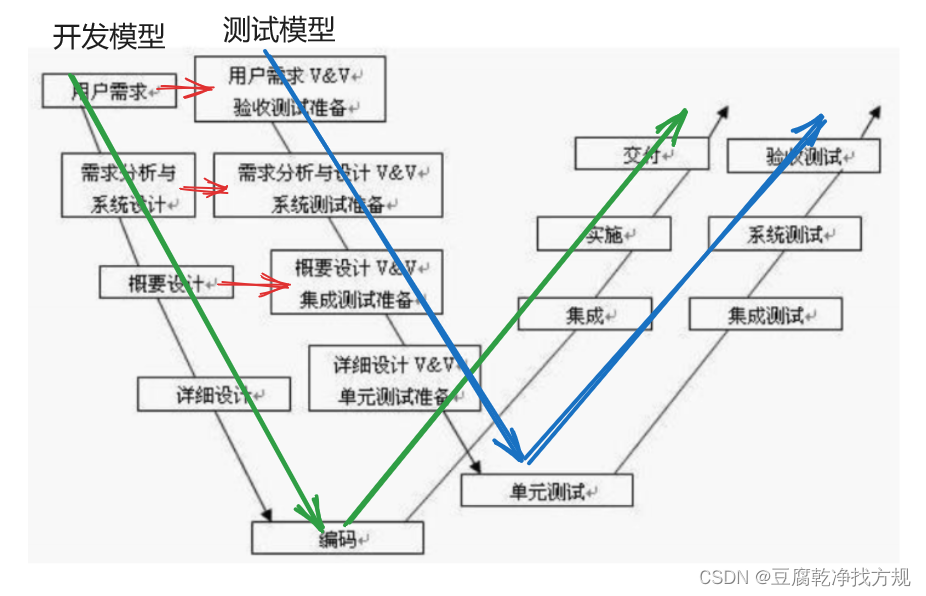
软件测试之概念篇2(瀑布模型、螺旋模型、增量模型和迭代模型、敏捷模型,V模型、W模型)
目录 开发模型 (1)瀑布模型 (2)螺旋模型 (3)增量模型和迭代模型 (4)敏捷模型 (5)测试模型(V模型、W模型) V模型 W模型 开发模型…...

从手机照片同步到数据去重:用C++ STL set/map搞定‘两个数组交集’背后的真实业务逻辑
从手机照片同步到数据去重:用C STL set/map搞定‘两个数组交集’背后的真实业务逻辑 每次换新手机时,最头疼的莫过于照片和联系人的迁移——那些重复的截图、相似的风景照、多年前的证件照,究竟该如何高效筛选?这背后隐藏的正是计…...

吃透Redis核心数据结构:从原理到实战,避开90%的坑
Redis之所以能成为分布式系统的“性能神器”,核心在于其高效的内存数据结构设计。很多开发者对Redis的认知停留在“SET/GET缓存”,只会用最基础的字符串类型,却忽略了List、Hash、Set、ZSet等核心结构的强大能力,导致代码冗余、性…...

Xinference+tao-8k实战:快速构建文档相似度分析工具
Xinferencetao-8k实战:快速构建文档相似度分析工具 1. 从想法到工具:为什么你需要一个文档相似度分析器 想象一下这个场景:你手头有几百份技术文档、产品说明或者客户反馈,你想快速找出哪些文档在讨论同一个主题,或者…...
)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧)
告别反复插拔SD卡:迪文DGUS II屏串口下载与仿真调试全攻略(附T5L实战技巧) 在工业控制、智能家居和物联网设备的开发中,迪文DGUS II系列串口屏因其高性价比和强大的组态功能,已成为众多开发者的首选。然而,…...

Leaflet坐标系实战:从设置到动态切换的完整指南
1. Leaflet坐标系基础概念解析 第一次接触Leaflet坐标系时,我也被各种专业术语搞得晕头转向。简单来说,坐标系就是用来确定地图上每个点位置的规则系统。就像我们在地球上使用经纬度定位一样,数字地图也需要明确的坐标参考。 Leaflet默认支持…...
完整指南:从卷轴入画到经纬重现)
深求·墨鉴(DeepSeek-OCR-2)完整指南:从卷轴入画到经纬重现
深求墨鉴(DeepSeek-OCR-2)完整指南:从卷轴入画到经纬重现 1. 引言:当科技遇见水墨美学 在日常工作中,我们经常需要将纸质文档转换为可编辑的电子文本。传统的OCR工具往往界面复杂、操作繁琐,让人望而却步…...

【Python 面试突击 · 05】大厂高频面试题:从数据结构到并发编程深度解析
目录 1. 简述下 Python 中的字符串、列表、元组和字典 2. 深拷贝和浅拷贝概念理解 3. 为什么其他语言还要保留红黑树?不都直接用 hashTable? 4. 在 Python 中,进程和线程的区别? 5. Python 数据处理的库有哪些?用…...
)
GORM实战避坑指南:从‘小白’到‘老鸟’必须知道的10个细节(含MySQL连接配置)
GORM实战避坑指南:从‘小白’到‘老鸟’必须知道的10个细节(含MySQL连接配置) 1. MySQL连接配置的隐藏陷阱 charsetutf8mb4的必要性 MySQL默认的utf8编码只支持最多3字节的字符,而emoji表情等特殊字符需要4字节存储。若不指定utf8…...

Ext2Read:3个高效方案解决Windows读取Linux分区难题
Ext2Read:3个高效方案解决Windows读取Linux分区难题 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 一、痛点直击ÿ…...

HDC1000温湿度传感器原理与嵌入式实战指南
1. 项目概述Grove - Temperature & Humidity Sensor (HDC1000) 是 Seeed Studio 推出的一款基于德州仪器(Texas Instruments)HDC1000 芯片的数字温湿度传感器模块。该模块采用标准 Grove 接口,支持 IC 总线通信,专为嵌入式系统…...