Flink--9、双流联结(窗口联结、间隔联结)

星光下的赶路人star的个人主页
我还有改变的可能性,一想起这点,我就心潮澎湃
文章目录
- 1、基于时间的合流——双流联结(Join)
- 1.1 窗口联结(Window Join)
- 1.2 间隔联结(Interval Join)
1、基于时间的合流——双流联结(Join)
可以发现,根据某个key合并两条流,与关系型数据库中的表的join操作非常近似。事实上,Flink中两条流的connect操作,就可以通过keyBy指定键进行分组后合并,实现了类似于SQL中的join操作;另外connect支持处理函数,可以使用自定义实现各种需求,其实已经能够处理双流join的大多数场景。
不过处理函数是底层接口,所以尽管connect能做的事情多,但在一些具体应用场景下还是显得太过抽象了。比如,如果我们希望统计固定时间内两条流数据的匹配情况,那就需要自定义来实现——其实这完全可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink的DataStrema API提供了内置的join算子。
1.1 窗口联结(Window Join)
Flink为基于一段时间的双流合并专门提供了一个窗口联结算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
1、窗口联结的调用
窗口联结在代码中的实现,首先需要调用DataStream的.join()方法来合并两条流,得到一个JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的key;然后通过.window()开窗口,并调用apply()方法传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的key;而.equalTo()传入的KeySelector则指定了第二条流中的key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。
这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。
而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。
传入的JoinFunction也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。
其实仔细观察可以发现,窗口join的调用语法和我们熟悉的SQL中表的join非常相似:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
这句SQL中where子句的表达,等价于inner join … on,所以本身表示的是两张表基于id的“内连接”(inner join)。而Flink中的window join,同样类似于inner join。也就是说,最后处理输出的,只有两条流中数据按key配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用JoinFunction的.join()方法,也就没有任何输出了。
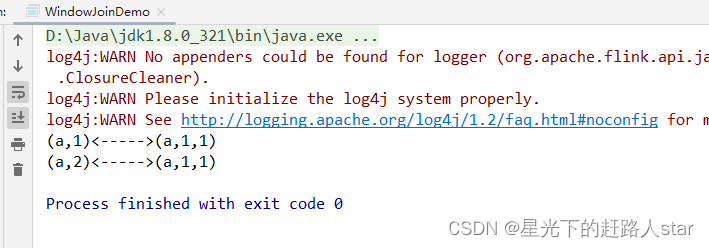
2、窗口联结实例
public class WindowJoinDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer,Integer>> ds2 = env.fromElements(Tuple3.of("a", 1,1),Tuple3.of("a", 11,1),Tuple3.of("b", 2,1),Tuple3.of("b", 12,1),Tuple3.of("c", 14,1),Tuple3.of("d", 15,1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer,Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));// TODO window join// 1. 落在同一个时间窗口范围内才能匹配// 2. 根据keyby的key,来进行匹配关联// 3. 只能拿到匹配上的数据,类似有固定时间范围的inner joinDataStream<String> join = ds1.join(ds2).where(r1 -> r1.f0) // ds1的keyby.equalTo(r2 -> r2.f0) // ds2的keyby.window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 关联上的数据,调用join方法* @param first ds1的数据* @param second ds2的数据* @return* @throws Exception*/@Overridepublic String join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second) throws Exception {return first + "<----->" + second;}});join.print();env.execute();}运行截图:
1.2 间隔联结(Interval Join)
在有些场景下,我们要处理的时间间隔可能并不是固定的。这时显然不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。基于时间的窗口联结已经无能为力了。
为了应对这样的需求,Flink提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
1、间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作A)中的任意一个数据元素a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以a的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫B)中的数据元素b,如果它的时间戳落在了这个区间范围内,a和b就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
如下图所示,我们可以清楚地看到间隔联结的方式:
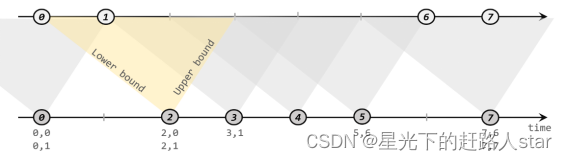
下方的流A去间隔联结上方的流B,所以基于A的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2毫秒,上界为1毫秒。于是对于时间戳为2的A中元素,它的可匹配区间就是[0, 3],流B中有时间戳为0、1的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A中时间戳为3的元素,可匹配区间为[1, 4],B中只有时间戳为1的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval join做匹配的时间段是基于流中数据的,所以并不确定;而且流B中的数据可以不只在一个区间内被匹配。
2、间隔联结的调用
间隔联结在代码中,是基于KeyedStream的联结(join)操作。DataStream在keyBy得到KeyedStream之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个KeyedStream,两者的key类型应该一致;得到的是一个IntervalJoin类型。后续的操作同样是完全固定的:先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”ProcessJoinFunction。
通用调用形式如下:
stream1.keyBy(<KeySelector>).intervalJoin(stream2.keyBy(<KeySelector>)).between(Time.milliseconds(-2), Time.milliseconds(1)).process (new ProcessJoinFunction<Integer, Integer, String(){@Overridepublic void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {out.collect(left + "," + right);}});
可以看到,抽象类ProcessJoinFunction就像是ProcessFunction和JoinFunction的结合,内部同样有一个抽象方法.processElement()。与其他处理函数不同的是,它多了一个参数,这自然是因为有来自两条流的数据。参数中left指的就是第一条流中的数据,right则是第二条流中与它匹配的数据。每当检测到一组匹配,就会调用这里的.processElement()方法,经处理转换之后输出结果。
3、间隔连接实例
案例需求:在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户,来做这样一个联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览数据进行一个联结查询。
(1)代码实现:正常使用
public class IntervalJoinDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.fromElements(Tuple2.of("a", 1),Tuple2.of("a", 2),Tuple2.of("b", 3),Tuple2.of("c", 4)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.fromElements(Tuple3.of("a", 1, 1),Tuple3.of("a", 11, 1),Tuple3.of("b", 2, 1),Tuple3.of("b", 12, 1),Tuple3.of("c", 14, 1),Tuple3.of("d", 15, 1)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps().withTimestampAssigner((value, ts) -> value.f1 * 1000L));// TODO interval join//1. 分别做keyby,key其实就是关联条件KeyedStream<Tuple2<String, Integer>, String> ks1 = ds1.keyBy(r1 -> r1.f0);KeyedStream<Tuple3<String, Integer, Integer>, String> ks2 = ds2.keyBy(r2 -> r2.f0);//2. 调用 interval joinks1.intervalJoin(ks2).between(Time.seconds(-2), Time.seconds(2)).process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1的数据* @param right ks2的数据* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, Context ctx, Collector<String> out) throws Exception {// 进入这个方法,是关联上的数据out.collect(left + "<------>" + right);}}).print();env.execute();}
}(2)代码实现,处理迟到的数据
public class IntervalJoinWithLateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<Tuple2<String, Integer>> ds1 = env.socketTextStream("hadoop102", 7777).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String[] datas = value.split(",");return Tuple2.of(datas[0], Integer.valueOf(datas[1]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((value, ts) -> value.f1 * 1000L));SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> ds2 = env.socketTextStream("hadoop102", 8888).map(new MapFunction<String, Tuple3<String, Integer, Integer>>() {@Overridepublic Tuple3<String, Integer, Integer> map(String value) throws Exception {String[] datas = value.split(",");return Tuple3.of(datas[0], Integer.valueOf(datas[1]), Integer.valueOf(datas[2]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((value, ts) -> value.f1 * 1000L));/*** TODO Interval join* 1、只支持事件时间* 2、指定上界、下界的偏移,负号代表时间往前,正号代表时间往后* 3、process中,只能处理 join上的数据* 4、两条流关联后的watermark,以两条流中最小的为准* 5、如果 当前数据的事件时间 < 当前的watermark,就是迟到数据, 主流的process不处理* => between后,可以指定将 左流 或 右流 的迟到数据 放入侧输出流*///1. 分别做keyby,key其实就是关联条件KeyedStream<Tuple2<String, Integer>, String> ks1 = ds1.keyBy(r1 -> r1.f0);KeyedStream<Tuple3<String, Integer, Integer>, String> ks2 = ds2.keyBy(r2 -> r2.f0);//2. 调用 interval joinOutputTag<Tuple2<String, Integer>> ks1LateTag = new OutputTag<>("ks1-late", Types.TUPLE(Types.STRING, Types.INT));OutputTag<Tuple3<String, Integer, Integer>> ks2LateTag = new OutputTag<>("ks2-late", Types.TUPLE(Types.STRING, Types.INT, Types.INT));SingleOutputStreamOperator<String> process = ks1.intervalJoin(ks2).between(Time.seconds(-2), Time.seconds(2)).sideOutputLeftLateData(ks1LateTag) // 将 ks1的迟到数据,放入侧输出流.sideOutputRightLateData(ks2LateTag) // 将 ks2的迟到数据,放入侧输出流.process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {/*** 两条流的数据匹配上,才会调用这个方法* @param left ks1的数据* @param right ks2的数据* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, Context ctx, Collector<String> out) throws Exception {// 进入这个方法,是关联上的数据out.collect(left + "<------>" + right);}});process.print("主流");process.getSideOutput(ks1LateTag).printToErr("ks1迟到数据");process.getSideOutput(ks2LateTag).printToErr("ks2迟到数据");env.execute();}
}
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美
相关文章:

Flink--9、双流联结(窗口联结、间隔联结)
星光下的赶路人star的个人主页 我还有改变的可能性,一想起这点,我就心潮澎湃 文章目录 1、基于时间的合流——双流联结(Join)1.1 窗口联结(Window Join)1.2 间隔联结(Interval Join)…...
家政服务行业做开发微信小程序可以实现什么功能
家政服务行业开发微信小程序可以实现多种功能,从而提升服务品质和效率,下面我们来详细介绍一些可能实现的功能。 一、展示服务信息 家政服务微信小程序可以展示各种服务信息,包括各类家政服务项目、价格、服务流程、服务人员信息等。用户可以…...

20哈希表-三数之和
目录 LeetCode之路——15. 三数之和 分析: 官方题解: LeetCode之路——15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nu…...

JVM 运行时数据区和垃圾收集算法
在 《深入理解 Java 虚拟机》一书中,作者将运行时数据区和垃圾收集算法放在开头章节,说明了这两个知识点是进一步学习 JVM 的基础知识点,相比后续的 垃圾收集器和 JMM,它也更加的简单。 运行时数据区 运行时数据区是《Java 虚拟…...
Java基于SpringBoot的高校招生系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 文章目录 简介系统设计思路1 数据库设计2 系统整体设计 系统详细设计1系统功能模块2. 管理员功能模块3学生…...

6. Python使用Asyncio开发TCP服务器简单案例
1. 说明 在Python中开发TCP/IP服务器有两种方式,一种使用Socket,需要在py文件中引入对应的socket包,这种方式只能执行单项任务;另一种方式使用Asyncio异步编程,可以一次创建多个服务器执行不同的任务。 2. 接口说明 …...

景联文科技:AI大模型强势赋能,助力自动驾驶迭代升级
我国一直以来都将自动驾驶作为新兴产业发展的重点领域之一,工信部等相关部委出台了一系列自动驾驶发展战略、规划和标准,一些地方政府也在积极开展关于自动驾驶的地方立法,为自动驾驶技术的研发和应用提供更加具体的法律保障。例如࿰…...

多周期CPU设计
多周期CPU设计 指令类型clock skew 指令类型 在计算机体系结构中,指令可以分为不同的类型,通常有R-type、I-type和J-type指令。 R-type指令(Register-type指令): R-type指令通常用于执行寄存器之间的操作,…...
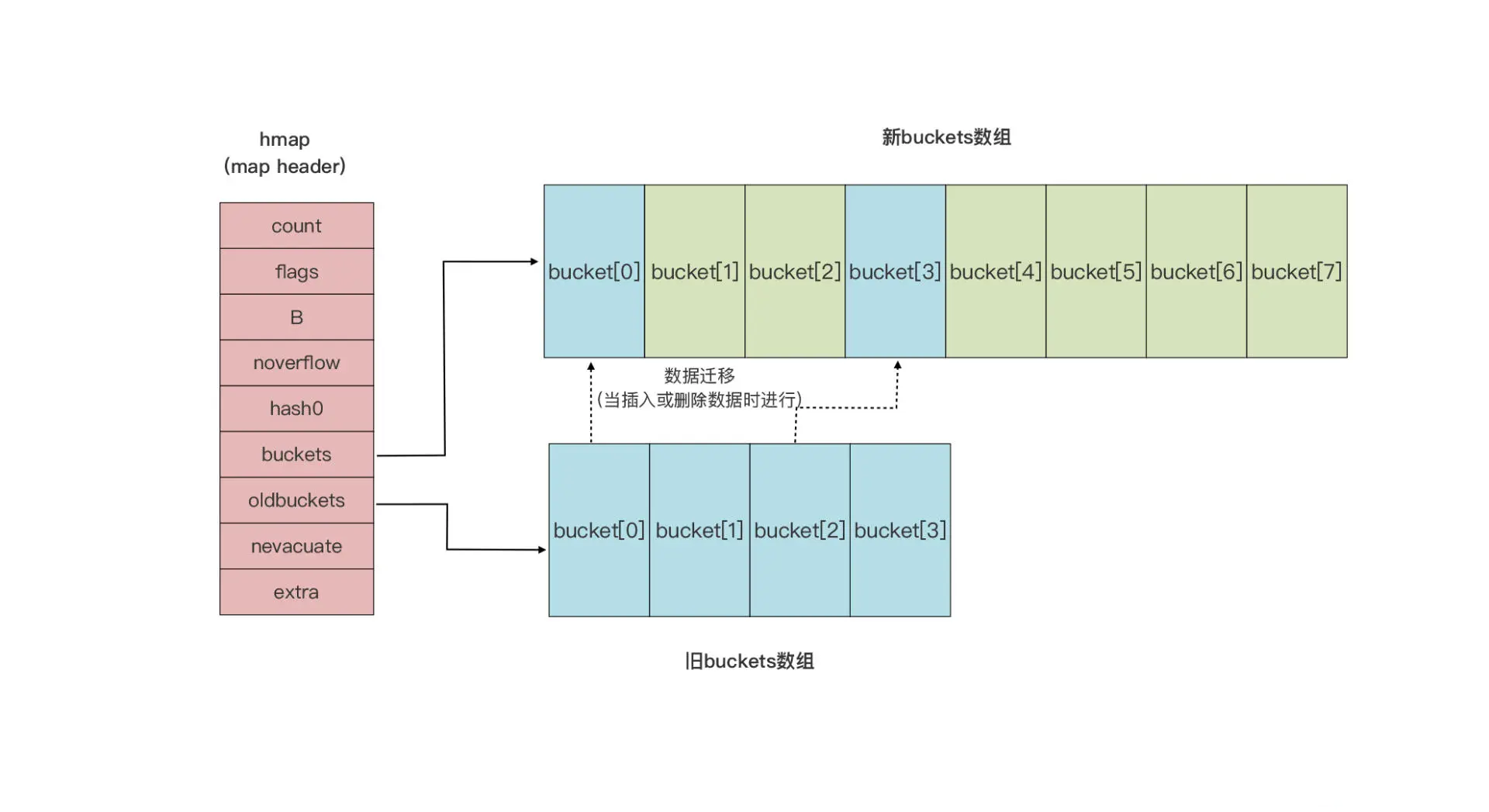
Go 复合类型之字典类型介绍
Go 复合类型之字典类型介绍 文章目录 Go 复合类型之字典类型介绍一、map类型介绍1.1 什么是 map 类型?1.2 map 类型特性 二.map 变量的声明和初始化2.1 方法一:使用 make 函数声明和初始化(推荐)2.2 方法二:使用复合字…...

对于无法直接获取URL的数据爬虫
在爬学校安全教育题库的时候发现题库分页实际上执行了一段js代码,如下图所示 点击下一页时是执行了函数doPostBack,查看页面源码如下 点击下一页后这段js提交了一个表单,随后后端返回对应数据,一开始尝试分析获取对应两个参数&a…...
35.树与二叉树练习(1)(王道第5章综合练习)
【所用的树,队列,栈的基本操作详见上一节代码】 试题1(王道5.3.3节第3题): 编写后序遍历二叉树的非递归算法。 参考:34.二叉链树的C语言实现_北京地铁1号线的博客-CSDN博客https://blog.csdn.net/qq_547…...

JSON数据处理工具-在线工具箱网站tool.qqmu.com的使用指南
导语:无论是处理JSON数据、进行文本数字处理、解码加密还是使用站长工具,我们都希望能够找到一个功能强大、简便易用的在线平台。tool.qqmu.com作为一款瑞士军刀般的在线工具箱网站,满足了众多用户的需求。本文将介绍tool.qqmu.com的多项功能…...
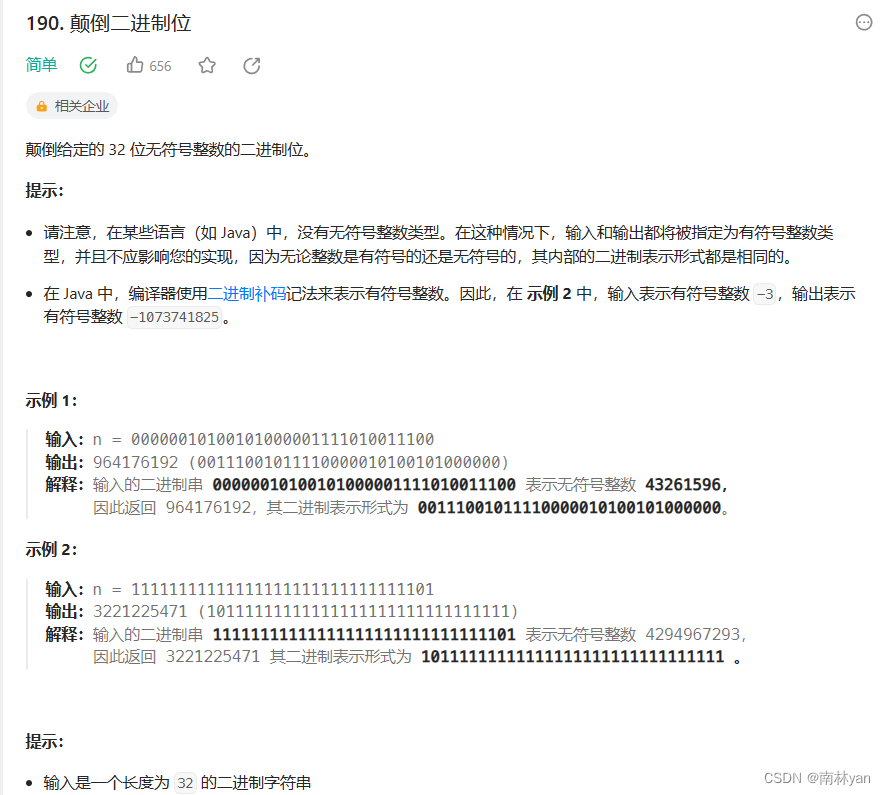
leetcode:190. 颠倒二进制位
一、题目: 函数原型: uint32_t reverseBits(uint32_t n) 解释:uint32是无符号int或short的别称,传入的参数是一个32位二进制串,返回值是该32位二进制串逆序后的十进制值 二、思路: 实际上并不需要真的去逆…...

Spring Cloud--@RefreshScope动态刷新的注意事项
原文网址:Spring Cloud--RefreshScope动态刷新的注意事项_IT利刃出鞘的博客-CSDN博客 简介 本文介绍Spring Cloud的RefreshScope动态刷新的注意事项。 不用RefreshScope也能动态刷新 Spring Cloud的默认实现了动态刷新,不加RefreshScope就能实现动态…...

visual-studio-code通过跳板机连接远程服务器的配置操作
step1:在本机上生成私钥和公钥 sh-keygen -t rsa -C “your_emailxxx.com”生成的两个默认文件中,id_rsa.pub是公钥,id_rsa是私钥 step2:在vscode安装Remote-SSH插件 step3:将本机生成的私钥和公钥上传服务器上 把本机生成的rsa_id.pub公钥上传至服务…...
-- gpio - GPIO操作)
LuatOS-SOC接口文档(air780E)-- gpio - GPIO操作
常量 常量 类型 解释 gpio.LOW number 低电平 gpio.HIGH number 高电平 gpio.PULLUP number 上拉 gpio.PULLDOWN number 下拉 gpio.RISING number 上升沿触发 gpio.FALLING number 下降沿触发 gpio.BOTH number 双向触发,部分设备支持 gpio.HIGH_IRQ …...
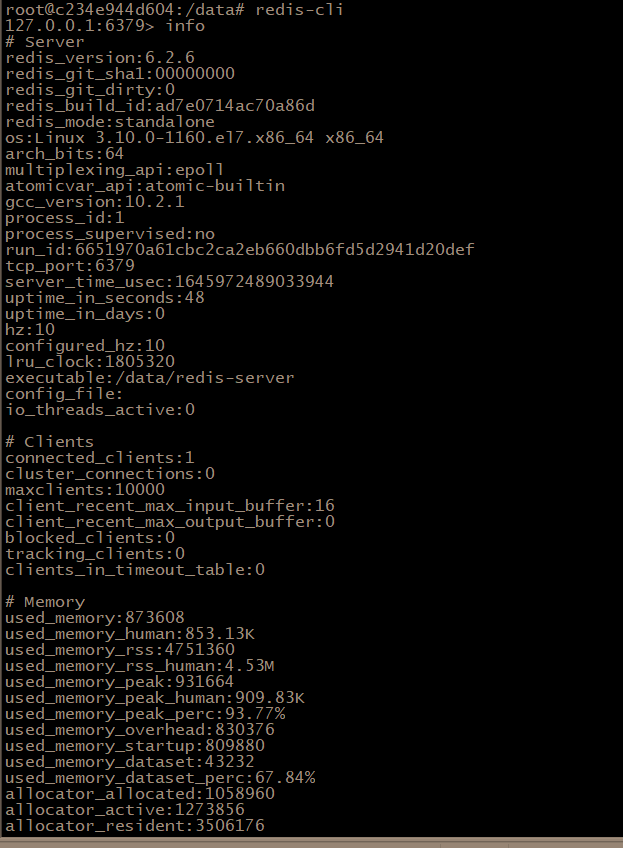
一个命令让redis服务端所有信息无所遁形~(收藏吃灰系列)
Redis服务器是一个事件驱动程序,它主要处理两类事件:文件事件和时间事件。这些事件的处理和Redis命令的执行密切相关。下面我将以Redis服务端命令为切入点,深入解析其工作原理和重要性。 首先,我们先了解Redis服务端有哪些命令。…...

通过Node.js获取高德的省市区数据并插入数据库
通过Node.js获取高德的省市区数据并插入数据库 1 创建秘钥1.1 登录高德地图开放平台1.2 创建应用1.3 绑定服务创建秘钥 2 获取数据并插入2.1 创建数据库连接工具2.2 请求数据2.3 数据处理2.4 全部代码 3 还可以打印文件到本地 1 创建秘钥 1.1 登录高德地图开放平台 打开开放平…...
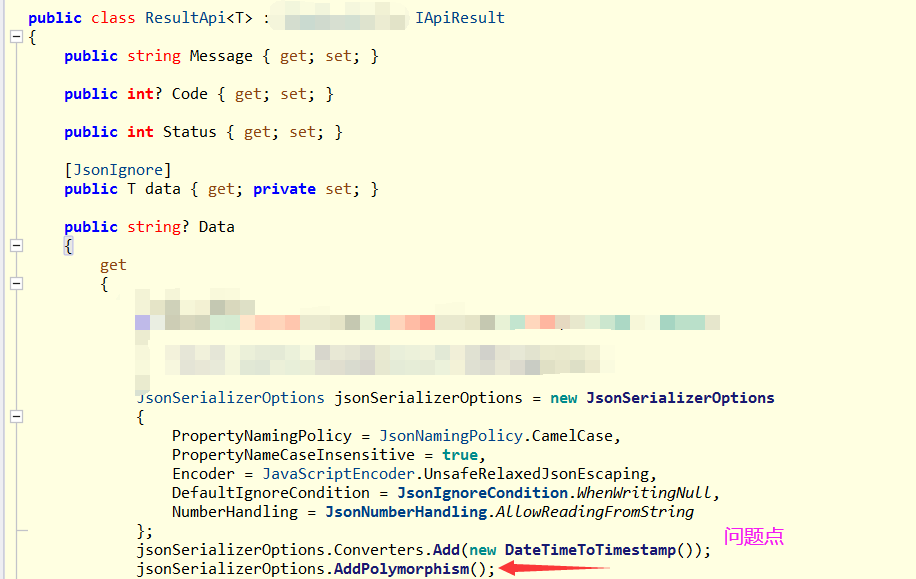
记一次 .NET某账本软件 非托管泄露分析
一:背景 1. 讲故事 中秋国庆长假结束,哈哈,在老家拍了很多的短视频,有兴趣的可以上B站观看:https://space.bilibili.com/409524162 ,今天继续给大家分享各种奇奇怪怪的.NET生产事故,希望能帮助…...
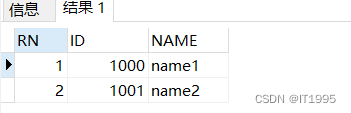
Oracle笔记-对ROWNUM的一次理解(简单分页)
此博文记录时间:2023-05-05,发到互联网上是2023-10-09 这个在分页里面用得比较多,在MySQL中,通常使用limit去操作,而去感觉比较简单,Oracle中无此关键字。 通过查阅资料后,要实现分页需要用到…...

Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面
Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面 【免费下载链接】sdow Six Degrees of Wikipedia 项目地址: https://gitcode.com/gh_mirrors/sd/sdow Six Degrees of Wikipedia(简称sdow)是一个基于维基百科页面…...

2026女性入局IT:这10张证书最吃香
一、引言:数字化转型背景下的IT职业性别结构变迁根据Gartner 2025年度全球数字化劳动力报告显示,女性在IT领域的参与度正从传统的“软件开发与测试”向“数据驱动决策”、“产品与项目管理”以及“用户体验设计”迁移。这一结构性变化主要归因于企业对数…...
)
Excel公式生成黑科技落地实录(ChatGPT+Power Query+LAMBDA三引擎联动)
更多请点击: https://intelliparadigm.com 第一章:Excel公式生成黑科技落地实录(ChatGPTPower QueryLAMBDA三引擎联动) 场景驱动的智能公式生成闭环 当财务团队需在5分钟内为127张销售报表动态生成「跨表多条件加权滚动同比」公…...

70行代码实现MCU性能热点分析:基于Cortex-M中断采样的轻量级Profiler
1. 项目概述:用70行代码为你的MCU“把脉”在嵌入式开发里,性能优化是个永恒的话题。我们总想知道,在程序跑起来之后,究竟是哪个函数、哪段代码在偷偷吃掉宝贵的CPU时间?是那个复杂的算法,还是那个不起眼的循…...

Android自动化测试代理droidrun-agent:原理、实现与工程实践
1. 项目概述:一个面向Android应用的自动化测试代理在移动应用开发与测试领域,自动化测试是保障应用质量、提升迭代效率的核心环节。对于Android平台,虽然官方提供了Espresso、UI Automator等成熟的测试框架,但在面对复杂业务场景、…...

Windows构建工具终极指南:一键解决Node.js原生模块编译难题
Windows构建工具终极指南:一键解决Node.js原生模块编译难题 【免费下载链接】windows-build-tools :package: Install C Build Tools for Windows using npm 项目地址: https://gitcode.com/gh_mirrors/wi/windows-build-tools Windows-build-tools是一个专业…...

告别盗版与广告:Office 2021官方纯净部署实战指南
1. 为什么选择官方纯净部署Office 2021? 每次打开电脑看到弹窗广告,或者发现系统莫名变慢的时候,你是不是也怀疑过那些所谓的"破解版"办公软件?我去年就吃过这个亏——用了某个号称"永久激活"的Office安装包…...

基于Circuit Playground与柔性3D打印的可穿戴设备制作全攻略
1. 项目概述:当创客遇上柔性穿戴如果你玩过Arduino,或者对智能硬件有点兴趣,那你大概率听说过Adafruit的Circuit Playground。这块板子挺有意思,它把一堆传感器、LED灯、小喇叭和按钮都塞进了一个硬币大小的板子上,号称…...

基于ReAct范式的链式追踪工具:提升学术研究效率的AI智能体实践
1. 项目概述与核心价值如果你经常需要做文献调研、追踪某个科学概念的源头,或者想搞清楚一个复杂话题背后的证据链,那你一定体会过在搜索引擎和无数个学术网站之间反复横跳的痛苦。传统的搜索方式,比如在Google Scholar里输入一个关键词&…...

RK3568开发实战:基于buildroot定制开机自启Qt应用,彻底解决全屏显示与任务栏冲突
1. RK3568开发板与buildroot固件基础 RK3568作为瑞芯微推出的高性能处理器,在工业控制和嵌入式领域应用广泛。很多开发者选择buildroot作为其轻量级Linux系统构建工具,因为它能快速生成包含Qt运行环境的定制化固件。我在实际项目中发现,直接使…...