第83步 时间序列建模实战:Catboost回归建模
基于WIN10的64位系统演示
一、写在前面
这一期,我们介绍Catboost回归。
同样,这里使用这个数据:
《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome in Jiangsu Province, China》文章的公开数据做演示。数据为江苏省2004年1月至2012年12月肾综合症出血热月发病率。运用2004年1月至2011年12月的数据预测2012年12个月的发病率数据。

二、Catboost回归
(1)参数解读
无论是回归还是分类,CatBoost的大部分参数都是通用的,但任务的不同性质意味着一些参数可能只在一个任务中有意义。
以下是一些关键参数的简要概述:
(a)通用参数:
learning_rate: 学习率,决定了模型每一步的步长。常用的值为0.01, 0.03, 0.1等。
iterations: 树的数量。
depth: 树的深度。
l2_leaf_reg: L2正则化项的系数。
cat_features: 分类特征的列索引列表。
loss_function: 损失函数。对于分类,常见的是Logloss(二分类)或MultiClass(多分类)。对于回归,常见的是RMSE。
border_count: 用于数值特征的分箱数量。较高的值可能会导致过拟合,较低的值可能会导致欠拟合。
verbose: 显示的训练日志的详细程度。
(b)专用于分类的参数:
classes_count: 在多分类任务中,类别的数量。
class_weights: 各类的权重,用于不平衡分类任务。
auto_class_weights: 用于处理类不平衡的自动权重计算方法。
(c)专用于回归的参数:
scale_pos_weight: 用于不平衡的回归任务。
(d)异同点:
相同点: 大部分参数(如learning_rate, depth, l2_leaf_reg等)在回归和分类任务中都是相同的,并且它们的含义和效果也是一致的。
不同点: 损失函数loss_function是根据任务(回归或分类)来确定的。此外,某些参数(如classes_count和class_weights)仅在分类任务中有意义,而scale_pos_weight更倾向于回归任务。
此外,在使用CatBoost时,建议始终查阅其官方文档,因为该库可能会经常更新,新的参数或功能可能会被添加进来。网址如下:
https://catboost.ai/docs/
(2)单步滚动预测
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error
from catboost import CatBoostRegressor
from sklearn.model_selection import GridSearchCV# 读取数据
data = pd.read_csv('data.csv')# 将时间列转换为日期格式
data['time'] = pd.to_datetime(data['time'], format='%b-%y')# 创建滞后期特征
lag_period = 6
for i in range(lag_period, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(lag_period - i + 1)# 删除包含 NaN 的行
data = data.dropna().reset_index(drop=True)# 划分训练集和验证集
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]# 定义特征和目标变量
X_train = train_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_train = train_data['incidence']
X_validation = validation_data[['lag_1', 'lag_2', 'lag_3', 'lag_4', 'lag_5', 'lag_6']]
y_validation = validation_data['incidence']# 初始化 CatBoostRegressor 模型
catboost_model = CatBoostRegressor(verbose=0)# 定义参数网格
param_grid = {'iterations': [50, 100, 150],'learning_rate': [0.01, 0.05, 0.1, 0.5, 1],'depth': [4, 6, 8],'loss_function': ['RMSE']
}# 初始化网格搜索
grid_search = GridSearchCV(catboost_model, param_grid, cv=5, scoring='neg_mean_squared_error')# 进行网格搜索
grid_search.fit(X_train, y_train)# 获取最佳参数
best_params = grid_search.best_params_# 使用最佳参数初始化 CatBoostRegressor 模型
best_catboost_model = CatBoostRegressor(**best_params, verbose=0)# 在训练集上训练模型
best_catboost_model.fit(X_train, y_train)# 对于验证集,我们需要迭代地预测每一个数据点
y_validation_pred = []for i in range(len(X_validation)):if i == 0:pred = best_catboost_model.predict([X_validation.iloc[0]])else:new_features = list(X_validation.iloc[i, 1:]) + [pred[0]]pred = best_catboost_model.predict([new_features])y_validation_pred.append(pred[0])y_validation_pred = np.array(y_validation_pred)# 计算验证集上的MAE, MAPE, MSE 和 RMSE
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)# 计算训练集上的MAE, MAPE, MSE 和 RMSE
y_train_pred = best_catboost_model.predict(X_train)
mae_train = mean_absolute_error(y_train, y_train_pred)
mape_train = np.mean(np.abs((y_train - y_train_pred) / y_train))
mse_train = mean_squared_error(y_train, y_train_pred)
rmse_train = np.sqrt(mse_train)print("Train Metrics:", mae_train, mape_train, mse_train, rmse_train)
print("Validation Metrics:", mae_validation, mape_validation, mse_validation, rmse_validation)看结果:

(3)多步滚动预测-vol. 1
对于Catboost回归,目标变量y_train不能是多列的DataFrame,所以你们懂的。
(4)多步滚动预测-vol. 2
同上。
(5)多步滚动预测-vol. 3
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor # 导入CatBoostRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error# 数据读取和预处理
data = pd.read_csv('data.csv')
data_y = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
data_y['time'] = pd.to_datetime(data_y['time'], format='%b-%y')n = 6for i in range(n, 0, -1):data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)data = data.dropna().reset_index(drop=True)
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]]
m = 3X_train_list = []
y_train_list = []for i in range(m):X_temp = X_trainy_temp = data_y['incidence'].iloc[n + i:len(data_y) - m + 1 + i]X_train_list.append(X_temp)y_train_list.append(y_temp)for i in range(m):X_train_list[i] = X_train_list[i].iloc[:-(m-1)]y_train_list[i] = y_train_list[i].iloc[:len(X_train_list[i])]# 模型训练
param_grid = {'iterations': [50, 100, 150],'learning_rate': [0.01, 0.05, 0.1, 0.5, 1],'depth': [4, 6, 8]
}best_catboost_models = []for i in range(m):grid_search = GridSearchCV(CatBoostRegressor(verbose=0), param_grid, cv=5, scoring='neg_mean_squared_error') # 使用CatBoostRegressorgrid_search.fit(X_train_list[i], y_train_list[i])best_catboost_model = CatBoostRegressor(**grid_search.best_params_, verbose=0)best_catboost_model.fit(X_train_list[i], y_train_list[i])best_catboost_models.append(best_catboost_model)validation_start_time = train_data['time'].iloc[-1] + pd.DateOffset(months=1)
validation_data = data[data['time'] >= validation_start_time]X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]]
y_validation_pred_list = [model.predict(X_validation) for model in best_catboost_models]
y_train_pred_list = [model.predict(X_train_list[i]) for i, model in enumerate(best_catboost_models)]def concatenate_predictions(pred_list):concatenated = []for j in range(len(pred_list[0])):for i in range(m):concatenated.append(pred_list[i][j])return concatenatedy_validation_pred = np.array(concatenate_predictions(y_validation_pred_list))[:len(validation_data['incidence'])]
y_train_pred = np.array(concatenate_predictions(y_train_pred_list))[:len(train_data['incidence']) - m + 1]mae_validation = mean_absolute_error(validation_data['incidence'], y_validation_pred)
mape_validation = np.mean(np.abs((validation_data['incidence'] - y_validation_pred) / validation_data['incidence']))
mse_validation = mean_squared_error(validation_data['incidence'], y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
print("验证集:", mae_validation, mape_validation, mse_validation, rmse_validation)mae_train = mean_absolute_error(train_data['incidence'][:-(m-1)], y_train_pred)
mape_train = np.mean(np.abs((train_data['incidence'][:-(m-1)] - y_train_pred) / train_data['incidence'][:-(m-1)]))
mse_train = mean_squared_error(train_data['incidence'][:-(m-1)], y_train_pred)
rmse_train = np.sqrt(mse_train)
print("训练集:", mae_train, mape_train, mse_train, rmse_train)结果:

三、数据
链接:https://pan.baidu.com/s/1EFaWfHoG14h15KCEhn1STg?pwd=q41n
提取码:q41n
相关文章:
第83步 时间序列建模实战:Catboost回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍Catboost回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndr…...

开源任务调度框架
本文主要介绍一下任务调度框架Flowjob的整体结构,以及整体的心路历程。 功能介绍 flowjob主要用于搭建统一的任务调度平台,方便各个业务方进行接入使用。 项目在设计的时候,考虑了扩展性、稳定性、伸缩性等相关问题,可以作为公司…...
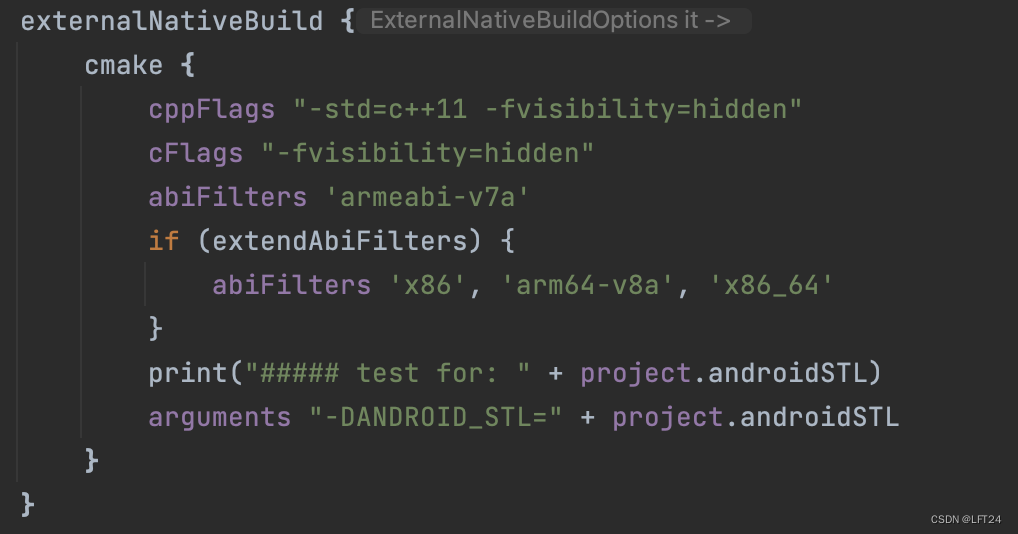
Android Native 开发 要点记录
Android Studio 中写 C 代码 android studio创建C项目_android studio native c-CSDN博客 项目配置参考 【CMake】CMakeLists.txt的超傻瓜手把手教程(附实例源码)_【cmake】cmakelists.txt的超傻瓜手把手教程(附实例源码)-CSDN博客 CMakeLists.txt 讲解…...

数据库中查询所有表信息,查询所有字段信息
MYSQL中 所有表信息 information_schema.tables表 SELECT * FROM information_schema.tables -- TABLE_NAME 表名 -- TABLE_COMMENT 表中文名所有字段信息 information_schema.COLUMNS表 SELECT * FROM information_schema.tables -- TABLE_SCHEMA 数据库名 -- COLUMN…...
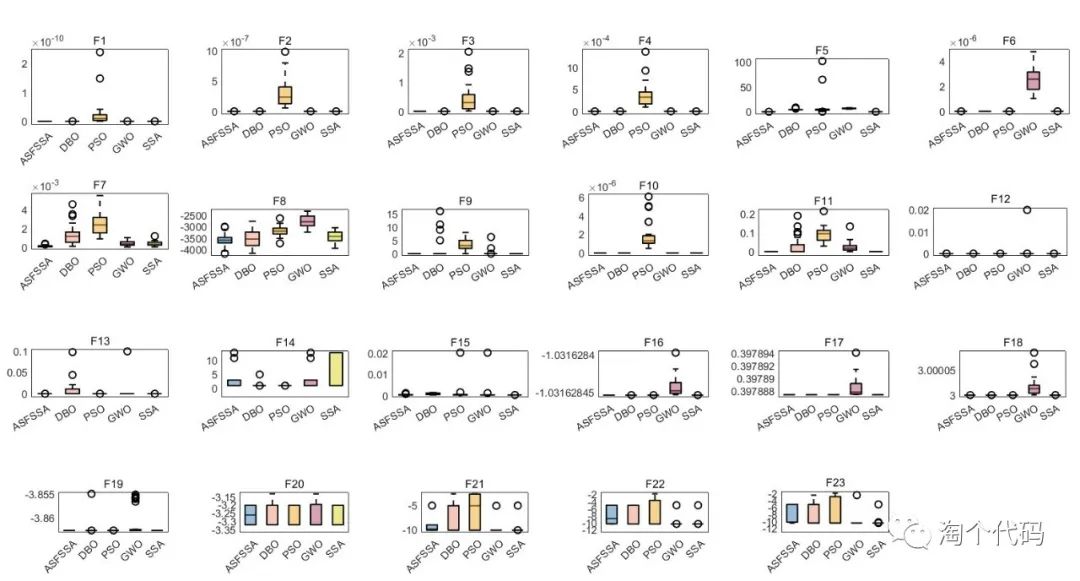
改进智能优化算法常用指标一键导出为EXCEL,最优值,平均值,标准差,最差值,中位数,秩和检验,箱线图...
声明:对于作者的原创代码,禁止转售倒卖,违者必究! 为了突出改进智能优化算法的效果,常常会将改进的智能算法与其他算法进行对比。 在一些期刊论文中,经常会看到一个超级大的表格,统计着每个算法…...
在asp.net中,实现类似安卓界面toast的方法(附更多弹窗样式)
目录 一、背景 二、操作方法 2.1修改前 2.2修改后 三、总结 附:参考文章: 一、背景 最近在以前的asp.net网页中,每次点击确定都弹窗,然后还要弹窗点击确认,太麻烦了,这次想升级一下,实现…...
一站式解决方案:Qt 跨平台开发灵活可靠
一站式解决方案:Qt 跨平台开发灵活可靠 Qt 是一种跨平台开发工具,为开发者提供了一站式解决方案。无论您的项目目标是 Windows、Linux、macOS、嵌入式系统还是移动平台,Qt 都能胜任。这种跨平台的特性不仅节省开支,还推动了战略的…...

将cpu版本的pytorch换成gpu版本
1.首先激活虚拟环境 winRcmd 打开dos命令窗口 查看虚拟环境列表 conda env list 激活虚拟环境 2.将原来的pytorch_cpu版本换成gpu版本 注意:安装gpu版本的pytorch时并不需要先卸载原来的cpu版本pytorch,安装时会自己替换的 打开pytorch官网查看以前版本 Previo…...
Ubuntu安装QQ
原文网址:2023在Ubuntu安装最新版QQ Linux v3.1.0 - 哔哩哔哩 作者:sprlightning https://www.bilibili.com/read/cv22100663/ 出处:bilibili 2022年末QQ推出了QQ Linux v3.0系列,目前最新版是今年2月24日推出的v3.1.0版本。注意…...
【Python】实现excel文档中指定工作表数据的更新操作
在做数值计算时,个人比较习惯利用excel文档的公式做数值计算进行对比,检查异常,虽然计算量大后,excel计算会比较缓慢,但设计简单,易排错 但一般测试过程中使用到的数据都不是最终数值,会不停根据…...
力扣(LeetCode)2731. 移动机器人(C++)
脑经急转弯排序 碰撞只改变运动方向,速度始终如"1",且机器人视为无差别的,所以碰撞等于擦肩而过!"机器人碰撞,到底撞没撞,如撞。"因此只考虑每个机器人单方向移动,d秒后停…...

vite和webpack
vite和webpack 文章目录 vite和webpackvite介绍什么是vite为什么使用vitevite优缺点热更新的实现原理 webpack介绍什么是webpackwebpack 优缺点 Vite 为什么比 Webpack 快vite和webpack的区别面试问题Vite为什么比webpack快? vite介绍 什么是vite Vite 是新型前端…...
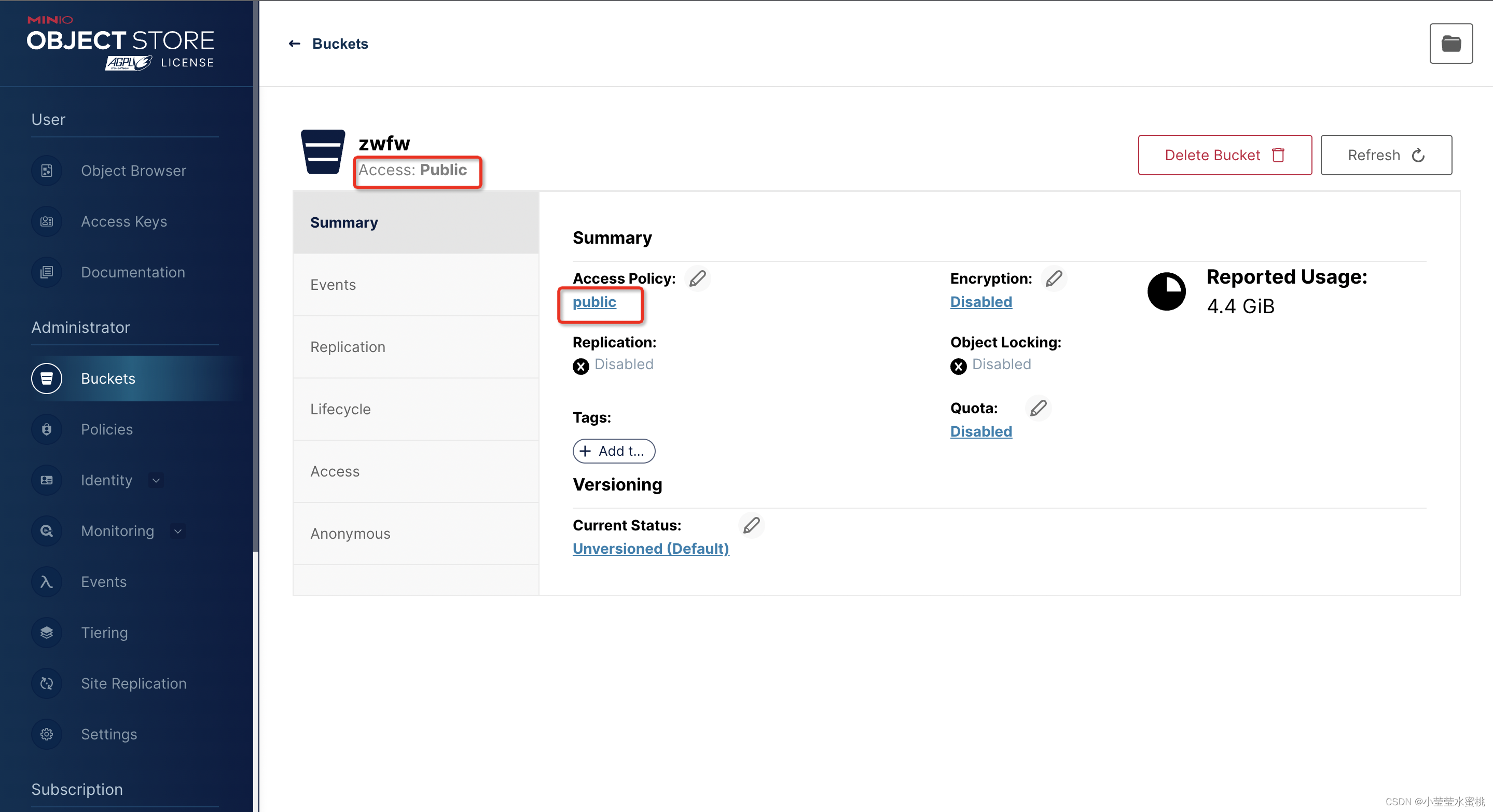
MinIO图片正常上传不可查看,MinIO通过页面无法设置桶为public
项目场景:国产中标麒麟操作系统部署MinIO正常启动后发现图片能正常上传,但是匿名浏览该图片的时候无法查看。通过网络查询解决方案,得出的结论是:需要把当前上传文件的桶设置为public,由于创建桶默认是private且不可通过浏览器进行…...
`cat` 查看、合并和创建文本文件)
Linux 指令心法(七)`cat` 查看、合并和创建文本文件
文章目录 命令的概述和用途命令的用法命令行选项和参数的详细说明命令的示例命令的注意事项或提示 命令的概述和用途 cat 是 “concatenate” 的缩写,它是一个 Linux 和 Unix 系统中的命令,用于查看、合并和创建文本文件。cat 主要用于以下几个方面&…...

解决docker开启MySQL的binlog无法成功。docker内部报错:mysql: [ERROR] unknown variable
1. 报错信息 2. 操作流程 整个流程是这样的: 我愉快的输入docker ps,查看MySQL的docker 容器id 执行指令docker exec -it 8a \bin\bash进入容器内部执行vim /etc/my.cnf,打开配置文件按照网上说的,添加如下配置信息退出docker容…...

c,python ,java,c++ c#在控制台打印彩色文本
在C语言、Java和C#中,你可以通过使用特定的控制字符或库来设置文本颜色。下面分别演示如何在这三种编程语言中实现文本颜色的设置: 在C语言中实现文本颜色设置: C语言中的颜色设置通常依赖于特定的终端或操作系统。以下是一种使用C语言的方…...
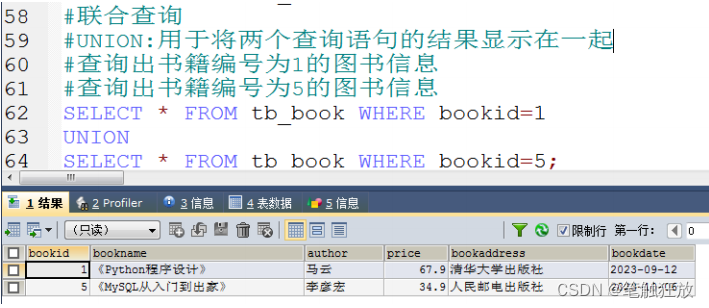
MySQL数据库技术笔记(5)
聚合函数: count(): 统计某种数据的数量 sum(): 统计某种数据的总和 max(): 某种数据的最大值 min(): 某种数据的最小值 avg(): 某种数据的平均值 排序的用法 : 关键字 order by 升序 : ASC (从小到大排序) 默认为升序 降序 : DESC…...

python生成随机数
在Python中生成随机数可以使用内置的random模块。以下是一些生成随机数的示例: 生成一个0到1之间的随机浮点数: import random random_float random.random() print(random_float) 生成一个指定范围内的随机整数: import random random_int…...

Twitter优化秘籍:置顶、列表、受众增长
在 Twitter 上,将你的一条推送文置顶到个人数据顶部是提高可见性和吸引关注者的绝佳方式。无论你是个人用户还是企业,此功能都可以让你的重要信息常驻在众人眼前,即使你发布了新的推文。接下来,我们将分享一些优化建议,…...
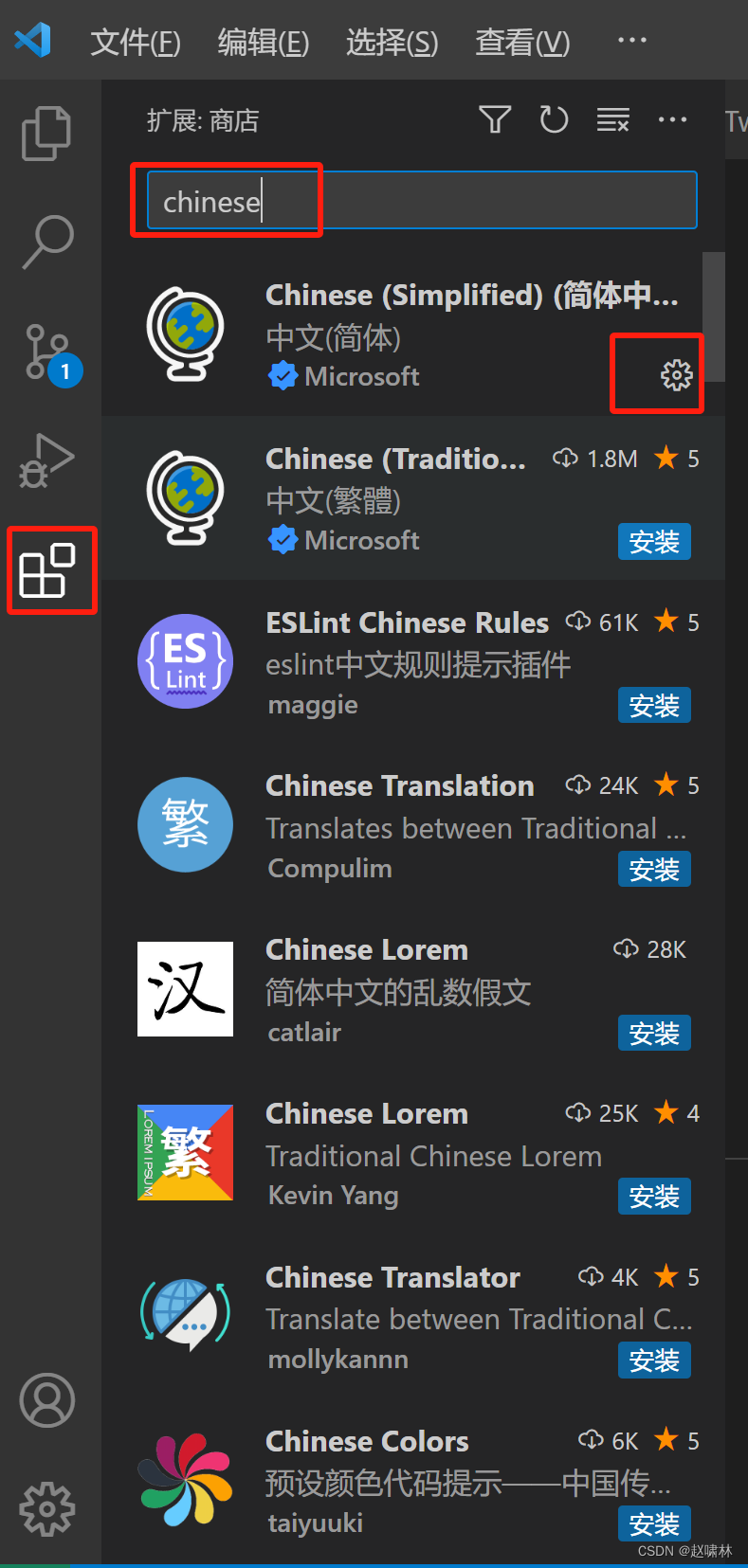
vscode更改为中文版本
方式一 在扩展里安装chinese插件 方式二 1.Ctrl+ Shift +P(commandshiftP) 2.输入Configure display Language 3.选择zh-cn 这时候vscode会提示需要重启,点击restart重启vscode,重启后vscode就会显示中…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...