TensorFlow入门(十二、分布式训练)
1、按照并行方式来分
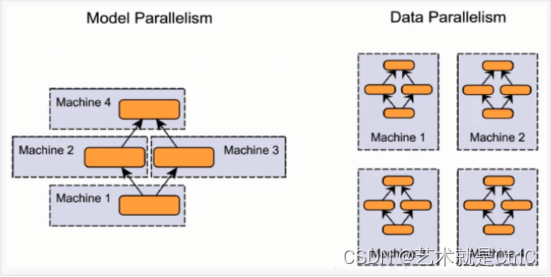
①模型并行
假设我们有n张GPU,不同的GPU被输入相同的数据,运行同一个模型的不同部分。
在实际训练过程中,如果遇到模型非常庞大,一张GPU不够存储的情况,可以使用模型并行的分布式训练,把模型的不同部分交给不同的GPU负责。这种方式存在一定的弊端:①这种方式需要不同的GPU之间通信,从而产生较大的通信成本。②由于每个GPU上运行的模型部分之间存在一定的依赖,导致规模伸缩性差。
②数据并行
假设我们有n张GPU,不同的GPU被输入不同的数据,运行相同的完整的模型。
如果遇到一张GPU就能够存下一个模型的情况,可以采用数据并行的方式,这种方式的各部分独立,伸缩性好。
2、按照更新方式来分
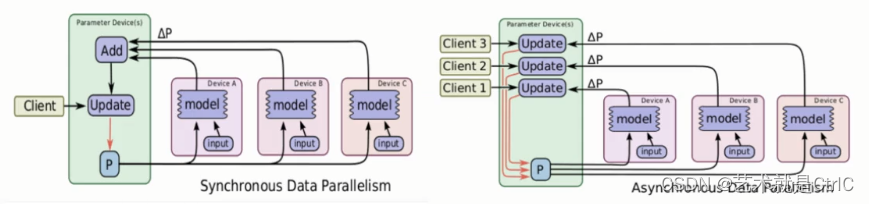
采用数据并行方式时,由于每个GPU负责一部分数据,涉及到如何更新参数的问题,因此分为同步更新和异步更新两种方式。
①同步更新
所有GPU计算完每一个batch(也就是每批次数据)后,再统一计算新权值,等所有GPU同步新值后,再开始进行下一轮计算。
同步更新的好处是loss的下降比较稳定,但是这个的坏处也很明显,这种方式有等待,处理的速度取决于最慢的那个GPU计算的时间。
②异步更新
每个GPU计算完梯度后,无需等待其他GPU更新,立即更新整体权值并同步。
异步更新的好处是计算速度快,计算资源能得到充分利用,但是缺点是loss的下降不稳定,抖动大。
3、按照算法来分
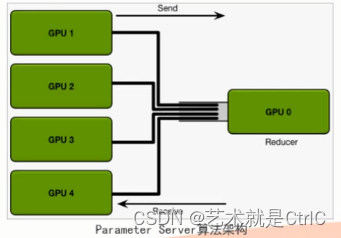
①Parameter Sever算法
原理:假设我们有n张GPU,GPU0将数据分成n份分到各张GPU上,每张GPU负责自己那一批次数据的训练,得到梯度后,返回给GPU0上做累计,得到更新的权重参数后,再分发给各张GPU。
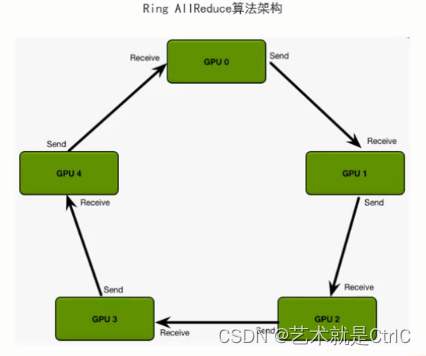
②Ring AllReduce算法
原理:假设我们有n张GPU,它们以环形相连,每张GPU都有一个左邻和一个右邻,每张GPU向各自的右邻发送数据,并从它的左邻接近数据。循环n-1次完成梯度积累,再循环n-1次做参数同步。整个算法过程分两个步骤进行:首先是scatter_reduce,然后是allgather。在scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在allgather步骤中,gpu将交换这些块,以便所有gpu得到完整的最终结果。
tf.distribute API:
它是TensorFlow在多GPU、多机器上进行分布式训练用的API。使用这个API,可以在尽可能少改动代码的同时,分布式训练模型。
它的核心API是tf.distribute.Strategy,只需简单几行代码就可以实现单机多GPU,多机多GPU等情况的分布式训练。
它的主要优点:
①简单易用,开箱即用,高性能
②便于各种分布式Strategy切换
③支持Custom Training Loop、Estimator、Keras
④支持eager excution
tf.distribute.Strategy目前主要有四个Strategy:
①MirroredStrategy,即镜像策略
MirroredStrategy用于单机多GPU、数据并行、同步更新的情况,它会在每个GPU上保存一份模型副本,模型中的每个变量都镜像在所有副本中。这些变量一起形成一个名为MirroredVariable的概念变量。通过apply相同的更新,这些变量保持彼此同步。
创建一个镜像策略的方法如下:
mirrored_strategy = tf.distribute.MirroredStrategy()
也可以自定义用哪些devices,如:
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0","/gpu:1"])
训练过程中,镜像策略用了高效的All-reduce算法来实现设备之间变量的传递更新。默认情况下它使用NVIDA NCCL (tf.distribute.NcclAllReduce)作为all-reduce算法的实现。通过apply相同的更新,这些变量保持彼此同步。
官方也提供了其他的一些all-reduce实现方法,可供选择,如:
tf.distribute.CrossDeviceOps
tf.distribute.HierarchicalCopyAllReduce
tf.distribute.ReductionToOneDevice
②CentralStorageStrategy,即中心存储策略
使用该策略时,参数被统一存在CPU里,然后复制到所有GPU上,它的优点是通过这种方式,GPU是负载均衡的,但一般情况下CPU和GPU通信代价比较大。
创建一个中心存储策略的方法如下:
central_storage_strategy = tf.distribute.experimental.CentralStorageStratygy()
③MultiWorkerMirroredStrategy,即多端镜像策略
该API和MirroredStrategy类似,它是其多机多GPU分布式训练的版本。
创建一个多端镜像策略的方法如下:
multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
④ParameterServerStrategy,即参数服务策略
简称PS策略,由于计算速度慢和负载不均衡,很少使用这种策略。
创建一个参数服务策略的方法如下:
ps_strategy = tf.distribute.experimental.ParameterServerStrategy()
示例代码如下:
import tensorflow as tf#设置总训练轮数
num_epochs = 5
#设置每轮训练的批大小
batch_size_per_replica = 64
#设置学习率,指定了梯度下降算法中用于更新权重的步长大小
learning_rate = 0.001#创建镜像策略
strategy = tf.distribute.MirroredStrategy()
#通过同步更新时副本的数量计算出本机的GPU设备数量
print("Number of devices: %d"% strategy.num_replicas_in_sync)
#通过副本数量乘以每轮训练的批大小,得出训练总数据量的大小
batch_size = batch_size_per_replica * strategy.num_replicas_in_sync#函数将输入的图片调整为224x224大小,再将像素值除以255进行归一化,同时返回标签信息
def resize(image,label):image = tf.image.resize(image,[224,224])/255.0return image,label#载入数据集并预处理
dataset,_ = tf.keras.datasets.cifar10.load_data()
images,labels = dataset
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset = dataset.map(resize).shuffle(1024).batch(batch_size)#在strategy.scope下创建模型和优化器
with strategy.scope():#载入了MobileNetV2模型,该模型在ImageNet上预先训练好了,并可以在分类问题上进行微调model = tf.keras.applications.MobileNetV2()#设置训练时用的优化器、损失函数和准确率评测标准model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate),loss = tf.keras.losses.sparse_categorical_crossentropy,metrics = [tf.keras.metrics.sparse_categorical_accuracy])#执行训练过程
model.fit(dataset,epochs = num_epochs)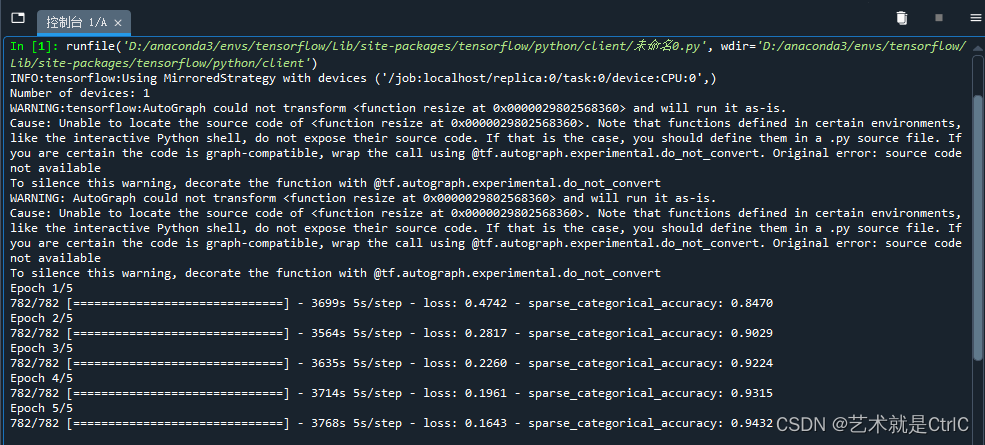
对于CIFAR-10数据集下载过慢的问题,可以手动去官网下载
https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz![]() https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz下载完成后将其放在如下图的路径下,并将数据集文件改名为cifar-10-batches-py.tar.gz并解压
https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz下载完成后将其放在如下图的路径下,并将数据集文件改名为cifar-10-batches-py.tar.gz并解压

相关文章:
TensorFlow入门(十二、分布式训练)
1、按照并行方式来分 ①模型并行 假设我们有n张GPU,不同的GPU被输入相同的数据,运行同一个模型的不同部分。 在实际训练过程中,如果遇到模型非常庞大,一张GPU不够存储的情况,可以使用模型并行的分布式训练,把模型的不同部分交给不同的GPU负责。这种方式存在一定的弊端:①这种方…...

在React中,什么是props(属性)?如何向组件传递props?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

java 每种设计模式的作用,与应用场景
文章目录 前言java 每种设计模式的作用,与应用场景 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实在白嫖的话࿰…...

Appium问题及解决:打开Appium可视化界面,点击搜索按钮,提示inspectormoved
打开Appium可视化界面,点击搜索按钮,提示inspectorMoved,那么如何解决这个问题呢? 搜索了之后发现,由于高版本Appium(从1.22.0开始)的服务和元素查看器分离,所以还需要下载Appium In…...

android 不同进程之间数据传递
1.handler android.os.Message是定义一个Messge包含必要的描述和属性数据,并且此对象可以被发送给android.os.Handler处理。属性字段:arg1、arg2、what、obj、replyTo等;其中arg1和arg2是用来存放整型数据的;what是用来保存消息标…...

一个完整的初学者指南Django-part1
源自:https://simpleisbetterthancomplex.com/series/2017/09/04/a-complete-beginners-guide-to-django-part-1.html 一个完整的初学者指南Django - 第1部分 介绍 今天我将开始一个关于 Django 基础知识的新系列教程。这是一个完整的 Django 初学者指南。材料分为七…...
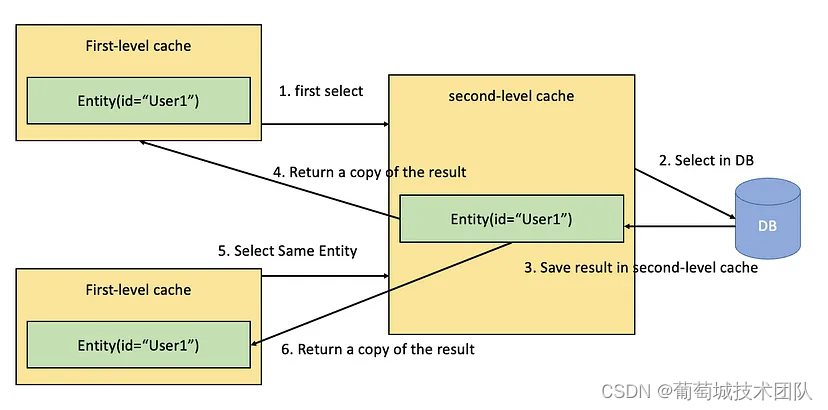
SpringBoot和Hibernate——如何提高数据库性能
摘要:本文由葡萄城技术团队发布。转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。 前言 在软件开发领域,性能是重中之重。无论您是构建小型 Web 应用程序还是大型企业系统…...
五分钟Win11安装安卓(Android)子系统
十分钟,完成win11安装安卓子系统 Step1、地区设置为美国 Wini 进入设置页面,选择时间和语言-语言和区域- 区域-美国 Step2 安装 Windows Subsystem for Android™ with Amazon Appstore 访问如下连接,install即可 安卓子系统 Step3 安…...
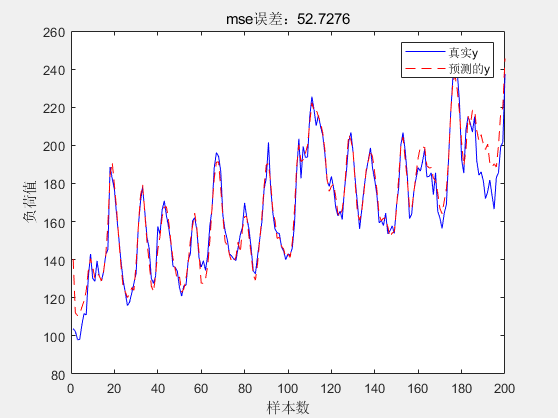
基于LSTM-Adaboost的电力负荷预测的MATLAB程序
微❤关注“电气仔推送”获得资料(专享优惠) 主要内容: LSTM-AdaBoost负荷预测模型先通过 AdaBoost集成算法串行训练多个基学习器并计算每个基学习 器的权重系数,接着将各个基学习器的预测结果进行线性组合,生成最终的预测结果。代码中的LST…...
GLTF纹理贴图工具让模型更逼真
1、如何制作逼真的三维模型? 要使三维模型看起来更加逼真,可以考虑以下几个方面: 高质量纹理:使用高分辨率的纹理贴图可以增强模型的细节和真实感。选择适合模型的高质量纹理图像,并确保纹理映射到模型上的UV坐标正确…...
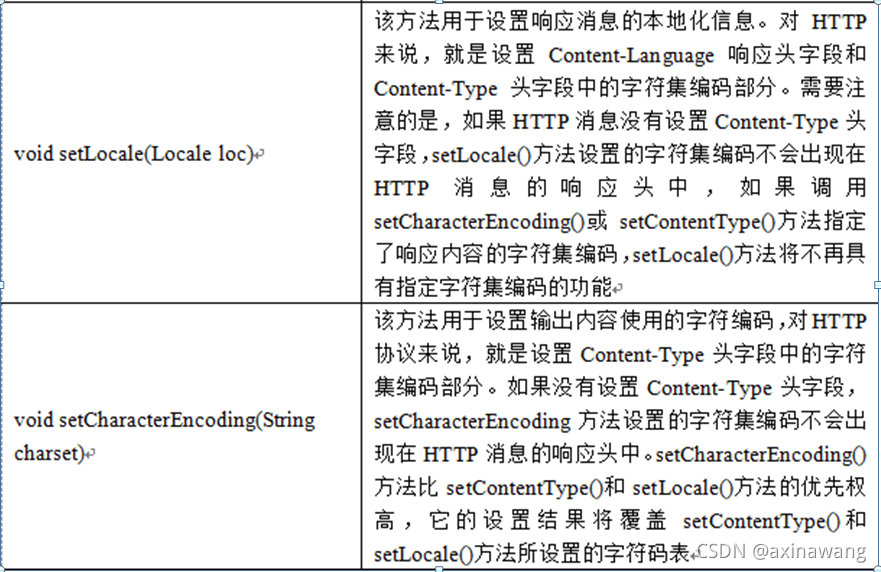
HttpServletResponse对象
1.介绍 在Servlet API中,定义了一个HttpServletResponse接口,它继承自ServletResponse接口,专门用来封装HTTP响应消息。由于HTTP响应消息分为状态行、响应消息头、消息体三部分,因此,在HttpServletResponse接口中定义…...

在SSL中进行交叉熵学习的步骤
在半监督学习(Semi-Supervised Learning,SSL)中进行交叉熵学习通常包括以下步骤: 准备标注数据和未标注数据 首先,你需要准备带有标签的标注数据和没有标签的未标注数据。标注数据通常是在任务中手动标记的ÿ…...
10月TIOBE榜Java跌出前三!要不我转回C#吧
前言 Java又要完了,又要没了,你没看错,10月编程语言榜单出炉,Java跌出前三,并且即将被C#超越,很多资深人士预测只需两个月,Java就会跌出前五。 看到这样的文章,作为一名Java工程师我…...
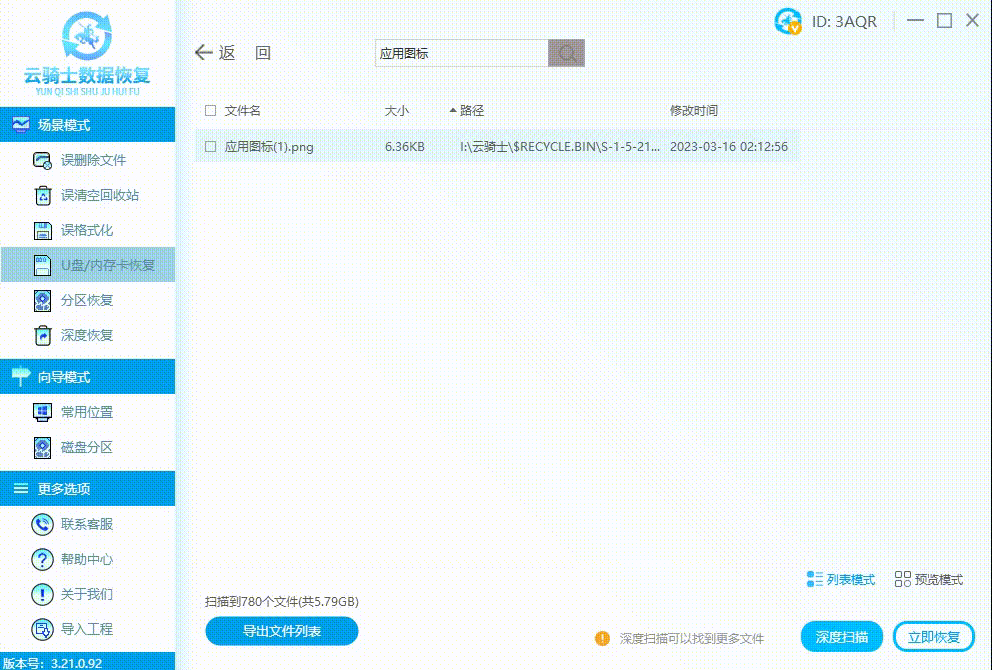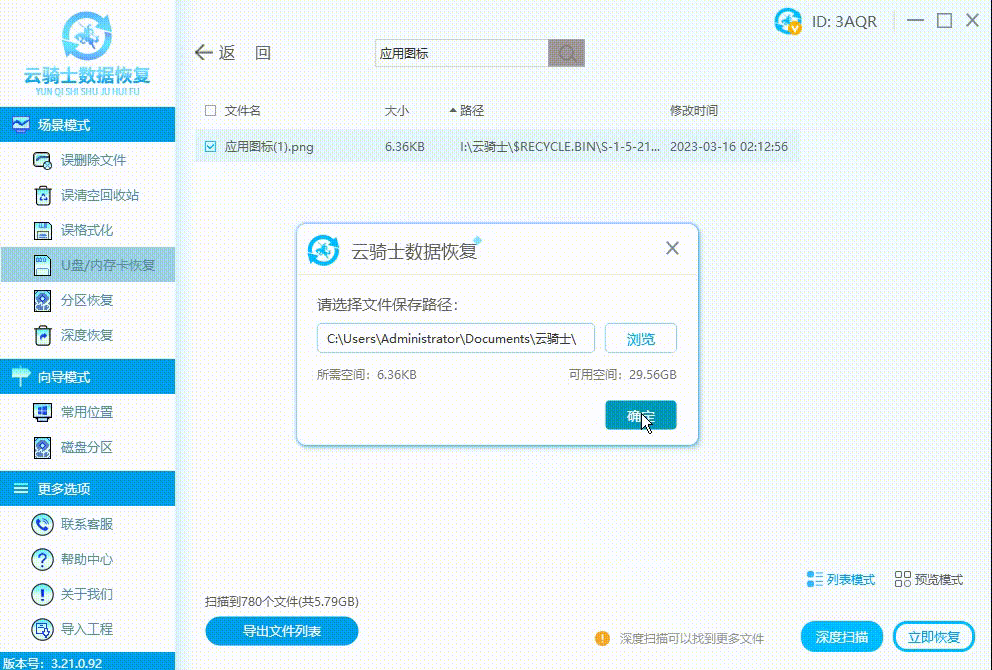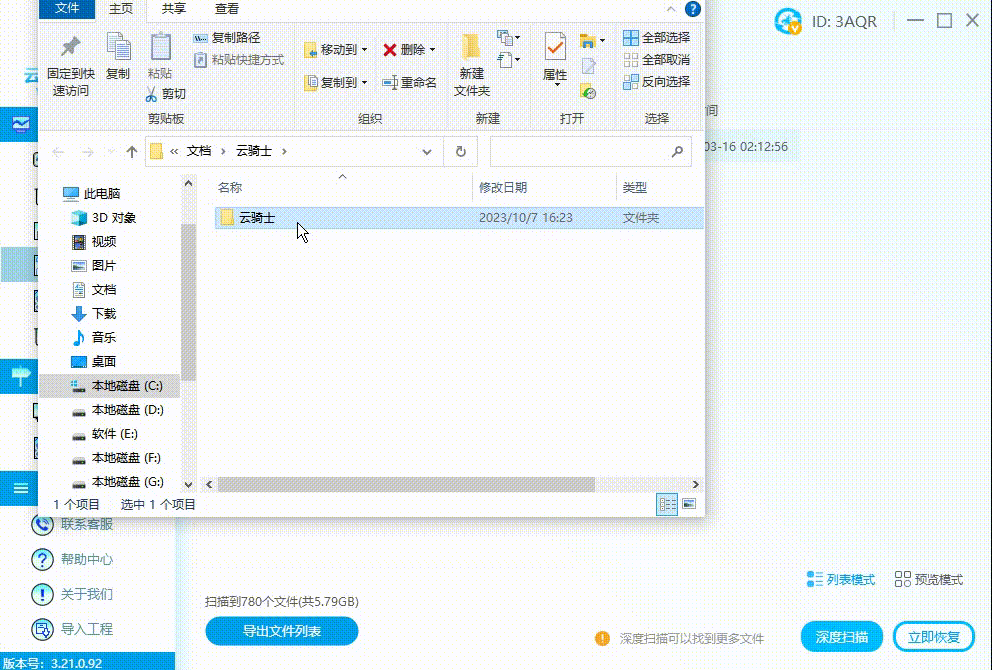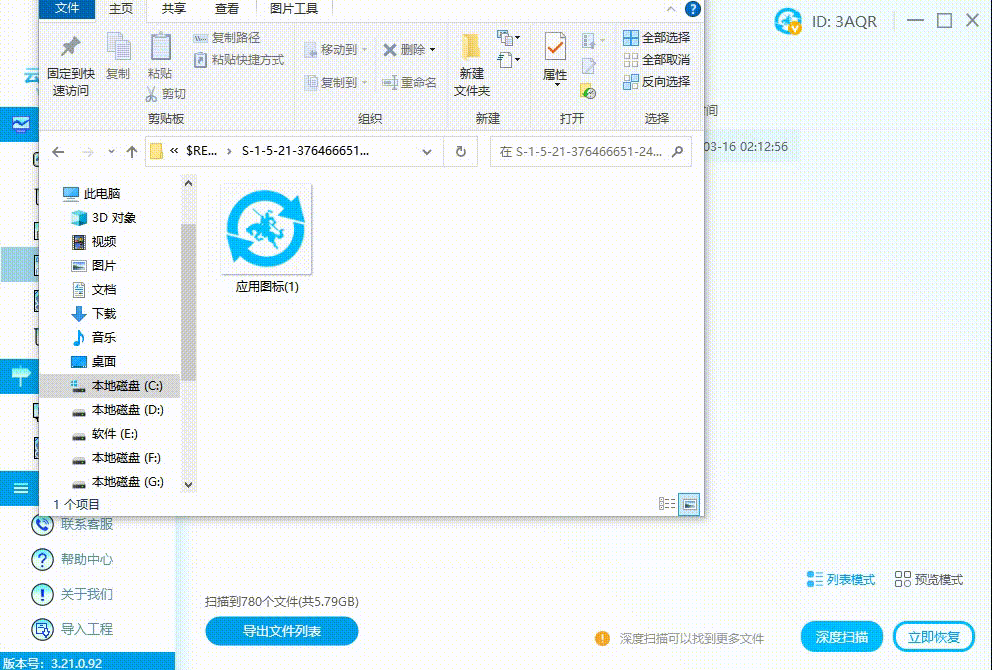
优盘中毒了怎么办?资料如何恢复
在现代社会中,优盘成为我们日常生活与工作中必备的便携式存储设备。然而,正是由于其便携性,优盘也成为病毒感染的主要目标之一。本篇文章将帮助读者了解如何应对优盘中毒的情况,以及如何恢复因病毒感染丢失的资料。 ▶优盘为什么…...

如何查看端口占用(windows,linux,mac)
如何查看端口占用,各平台 一、背景 如何查看端口占用?网上很多,但大多直接丢出命令,没有任何解释关于如何查看命令的输出 所谓 “查端口占用”,即查看某个端口是否被某个程序占用,如果有,被哪…...
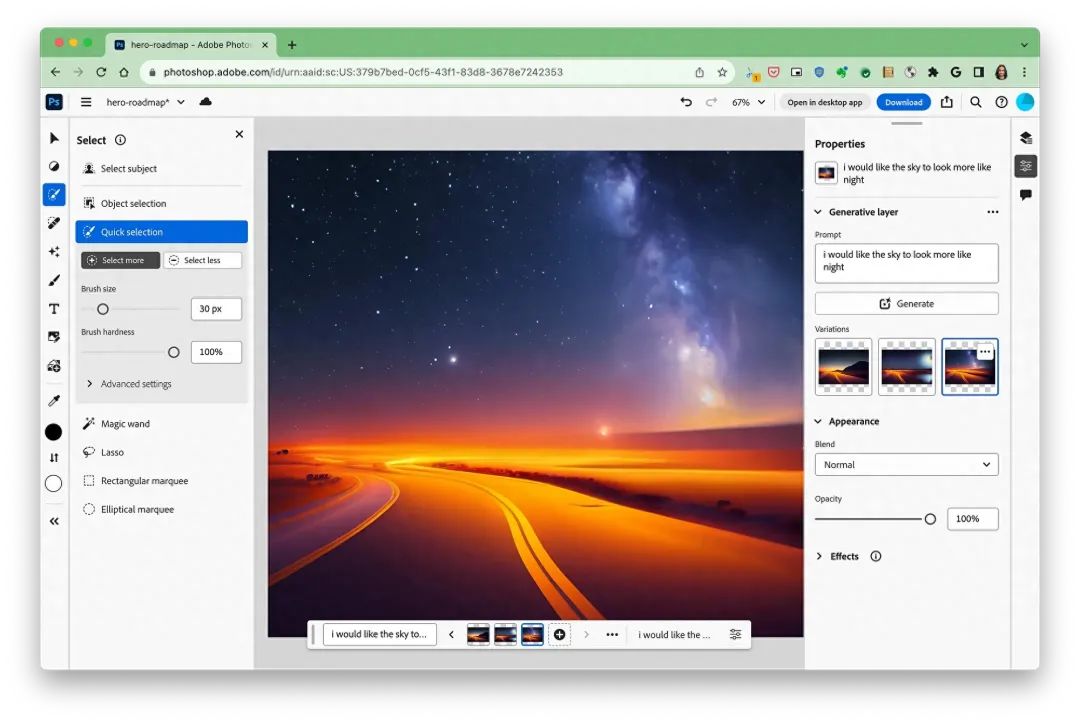
Photoshop与Web技术完美融合,Web版Photoshop已正式登场
通过WebAssembly Emscripten、Web Components Lit、Service Workers Workbox以及对新的Web API的支持,Chrome和Adobe之间的合作使得将Photoshop桌面应用程序引入Web成为了一项重大的里程碑。现在,您可以在浏览器上使用高度复杂和图形密集的软件&#…...

易点易动:提升企业固定资产管理效率的完美解决方案
在现代商业环境中,企业的固定资产管理是一项关键任务。高效的固定资产管理可以帮助企业降低成本、提高生产力,并确保资产的最佳利用。然而,传统的资产管理方法常常繁琐、低效,导致信息不准确、流程混乱。为了解决这一问题…...

SRE实战:如何低成本推进风险治理?稳定性与架构优化的3个策略
一分钟精华速览 SRE 团队每天面临着不可控的各类风险和重复发生的琐事,故障时疲于奔命忙于救火。作为技术管理者,你一直担心这些琐事会像滚雪球一样,越来越多地、无止尽地消耗你的团队,进而思考如何系统性地枚举、掌控这些风险&a…...
APK大小缩小65%,内存减少70%:如何优化Android App
APK大小缩小65%,内存减少70%:如何优化Android App 我们一直在努力为我们的Android应用程序构建MVP产品。在开发MVP产品后,我们发现需要进行应用程序优化以提高性能。经过分析,我们发现了以下可以改进的应用…...
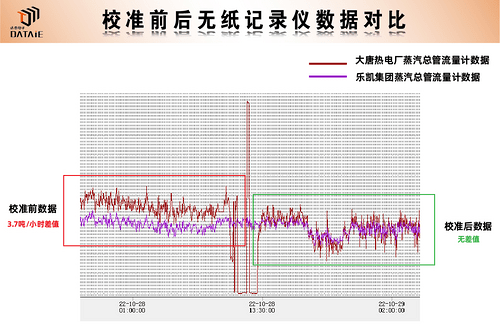
传统工厂如何搭建蒸汽流量远程无线抄表系统?
一、应用背景 2021年国务院政府工作报告中指出,扎实做好碳达峰、碳中和各项工作,制定2030年前碳排放达峰行动方案,优化产业结构和能源结构,特别是近期煤炭价格上涨导致蒸汽价格大幅上涨,节能减排显得更加重要…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...