读书笔记:多Transformer的双向编码器表示法(Bert)-3
多Transformer的双向编码器表示法
Bidirectional Encoder Representations from Transformers,即Bert;
第3章 Bert实战
学习如何使用预训练的BERT模型:
- 如何使用预训练的BERT模型作为特征提取器;
- 探究Hugging Face的Transformers库,学习如何使用Transformers库从预训练的BERT模型中提取嵌入;
- 如何从BERT的所有编码器层提取嵌入;
- 如何为下游任务微调预训练的BERT模型,文本分类、情感分析;
- 如何将预训练的BERT模型应用于自然语言推理任务、问答任务以及命名实体识别等任务;
预训练的BERT模型
从头开始预训练BERT模型是很费力的,因此可以下载预训练的BERT模型并直接使用(从Github仓库直接下载);
L表示编码器层数,H表示隐藏神经元的数量(特征大小),BERT-base的L=12,H=768;
预训练模型可以使用不区分大小写(BERT-uncased)的格式和区分大小写(BERT-cased)的格式;
- 不区分大小写时,所有标记都转化为小写;
- 区分大小写是,标记大小写不变,直接用于训练;
不区分大小写的模型是最常用的模型,但对一些特定任务如命名实体识别,则必须保留大小写,就需要使用区分大小写模型;
预训练模型的应用场景:
- 作为特征提取器,提取嵌入;
- 针对文本分类任务、问答等下游任务对BERT模型进行微调;
使用预训练BERT模型作为特征提取词嵌入
示例句子 -> 标记句子 -> 送入模型 -> 返回每个标记的词级嵌入 以及 句级特征;
构建分类数据集,作正反向观点的二分类:
- 每一个句子都有对应的标签,1表示正面,0表示负面;
训练分类器做情感分类:
- 通过模型或算法对文本进行向量化,可以使用预训练的BERT模型对数据集的句子进行向量化(这说的就是提嵌入);
标记句子:
- 在句子开始添加
[CLS]标记,在结尾添加[SEP],为统一所有句子的标记长度(假设是512),那么不足512的会使用标记[PAD]来重复填充; - 为了让模型理解标记
[PAD]只是用于匹配长度,而不是实际标记的一部分,需要引入注意力掩码,将所有位置的注意力掩码值设为1,再将标记[PAD]的位置设为0; - 最后将所有标记映射为一个唯一的标记ID,
[CLS]标记对应的ID为101;标记[PAD]的仍为0;
接下来把 token_ids和 attention_mask一起输入预训练的BERT模型,并获得每个标记的特征向量;
最终输出的 R[CLS]就是标记[CLS]的嵌入,它可以代表整个句子的总特征;如果使用的是BERT-base模型配置,那么每个标记的特征向量大小为768;
采用类似的方法,就可计算出训练集所有句子的特征向量,一旦有了训练集所有句子的特征,就可以把这些特征作为输入,训练一个分类器;
值的注意的是,使用
[CLS]标记的特征代表整个句子的特征并不总是一个好主意;要获得一个句子的特征,最好基于所有标记的特征进行平均或者汇聚;
Hugging Face的Transformers库
Hugging Face是一个致力于通过自然语言将AI技术大众化的组织,它提供了开源的Transformers库对一些自然语言处理任务和自然语言理解(NLU)任务非常有效;Transformers库包含了百余种语言的数千个预训练模型,而且还可以与Pytroch和TF兼容;
安装命令:pip install Transformers==3.5.1
!pip install Transformers==4.27.4 --ignore-installed PyYAML
# 问题:cannot import name 'is_tokenizers_available' from 'transformers.utils'
# 参考:https://discuss.huggingface.co/t/how-to-resolve-the-hugging-face-error-importerror-cannot-import-name-is-tokenizers-available-from-transformers-utils/23957/2
# 示意代码 仅做指示
from transformers import BertModel, BertTokenizer
import torchdef get_tokens_and_attention_mask(tokens_a):# 标记更新tokens = []# 上下句掩码(当前示例任务 没什么用)segment_ids = []tokens.append("[CLS]")segment_ids.append(0)for token in tokens_a:tokens.append(token)segment_ids.append(0)if tokens[-1] != "[SEP]":tokens.append("[SEP]")segment_ids.append(0)# 将标记转换为它们的标记ID token_ids = tokenizer.convert_tokens_to_ids(tokens)# 输入的注意力掩码attention_mask = [1] * len(token_ids)while len(token_ids) < max_seq_length:token_ids.append(0)attention_mask.append(0) # 这里加的0 实际对应的就是标记 [PAD],这里补0,实际就不用处理添加[PAD]标记的逻辑segment_ids.append(0)assert len(token_ids) == max_seq_length return token_ids, attention_mask# 下载并加载预训练模型
model = BertModel.from_pretrained("bert-tiny-uncased")
# 下载并加载用于预训练模型的词元分析器
tokenizer = BertTokenizer.from_pretrained("bert-tiny-uncased")sentence = "I am Good"# 分词并获取标记
tokens_a = tokenizer.tokenize(sentence)
token_ids, attention_mask = get_tokens_and_attention_mask(tokens_a)# 转为张量
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)# 送入模型
hidden_rep, cls_head = model(token_ids, attention_mask=attention_mask)hidden_rep:
- hidden_rep 包含了所有标记的嵌入(特征),我们使用的是bert-tiny,假设max_seq_length=10,那么hidden_rep的形状就是
torch.size([1, 10, 128]); [1, 10, 128]分别对应[batch_size, sequence_length, hidden_size];隐藏层的大小等于特征向量大小;- 第1个标记
[CLS]的特征:hidden_rep[0][0] - 第2个标记
I的特征:hidden_rep[0][1]
- 第1个标记
cls_head:
- 它包含了
[CLS]标记的特征,shape为torch.size([1, 128]);
可以用cls_head作为句子的整句特征;
从BERT的所有编码器层中提取嵌入
前面介绍的是如何从预训练的BERT模型的顶层编码器提取嵌入,此外,也可以考虑从所有的编码器层获得嵌入;
使用h0表示输入嵌入层,h1则表示第一个编码器层(第一个隐藏层),研究人员使用预训练的BERT-base模型的不同层编码器的嵌入作为特征,应用在命名实体识别任务,所得的F1分数(调和均值)发现,将最后4个编码器的嵌入 连接起来可以得到最高的F1,这说明可以使用其他层所提取的嵌入,而不必只用顶层编码器的嵌入;
# 示意代码 仅做指示
from transformers import BertModel, BertTokenizer
import torch# output_hidden_states 可以控制输出所有编码器的嵌入
model = BertModel.from_pretrained("bert-base-uncased", output_hidden_states = True)
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")sentence = "I am Good"
tokens_a = tokenizer.tokenize(sentence)token_ids, attention_mask = get_tokens_and_attention_mask(tokens_a)# 转为张量
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)# 送入模型
last_hidden_state, pooler_output, hidden_states = model(token_ids, attention_mask=attention_mask)- last_hidden_state: 包含从最后编码器获得所有标记的特征,shape=
[1, 10 ,768]对应[batch_size, sequence_length, hidden_size]; - pooler_output: 表示来自最后的编码器的
[CLS]标记的特征,它被一个线性激活函数和tanh激活函数进一步处理,shape=[1, 768],可被用作句子的特征; - hidden_states:包含从所有编码器获得的所有标记的特征,这是一个包含了13个值的元组,包含了从输入层h0到最后的编码器层h2的特征;
hidden_states[0]:输入嵌入层h0获得的所有标记的特征;hidden_states[12]:最后一个编码器层h12获得的所有标记的特征,shape=[1, 10 ,768];
通过对返回值的解析,就可以获得所有编码器层的标记嵌入;
为下游任务微调预训练BERT模型
到目前为止,我们已经学会了如何使用BERT模型,再看如何针对下游任务进行微调;
在提取句子的嵌入
R[CLS]后,可以将其送入一个分类器并训练其进行分类;类似的在微调过程中,也可以这样做(对R[CLS]使用softmax激活函数的前馈网络层)
微调的两种调整权重的方式:
- 与分类器层一起更新预训练的BERT模型参数;
- 仅更新分类器层的权重,可以冻结预训练的BERT模型权重(这类似于使用预训练的BERT模型作为特征提取器的情况),也可以直接使用预训练的BERT模型作为特征提取器;
安装必要的库:pip install nlp
# 示意代码 仅做指示(当时实际用的是pytorch_pretrained_bert的库,也是hugging face的)
# from pytorch_pretrained_bert.tokenization import BertTokenizer
# from pytorch_pretrained_bert.modeling import BertForSequenceClassification
# from pytorch_pretrained_bert.optimization import BertAdam
from transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments
from nlp import load_dataset
from torch
import numpy as np# 使用nlp库加载并下载数据集
dataset = dataset.train_test_split(test_size=0.3)# {
# "test": Dataset(text, label),
# "train": Dataset(text, label)
# }train_set = dataset["train"]
test_set = dataset["test"]model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
# 下载并加载用于预训练模型的词元分析器,注意这里使用BertTokenizerFast类
tokenizer = BertTokenizerFast.from_pretrained("bert-tiny-uncased")# 这里词元分析器会帮我们完成get_tokens_and_attention_mask函数的功能
tokenizer("I am Good")# 返回
# {
# 'input_ids':[101, 1000, 1001, 1002, 102],
# 'token_type_ids':[0, 0, 0, 0, 0],
# 'attention_mask': [1, 1, 1, 1, 1]
# } # 词元分析器,可以输入任意数量的句子,并动态地进行补长和填充,只需将padding=True, max_length=10
# tokenizer(["I am Good","I am boy"], padding=True, max_length=10)# 返回(输入两个句子)
# {
# 'input_ids':[[], []],
# 'token_type_ids':[[], []],
# 'attention_mask': [[], []]
# }# 使用词元分析器预处理数据集
# 可以定义一个名为 preprocess的函数来处理数据集
def preprocess(data):return tokenizer(data["text"], padding=True, truncation=True) # 截断train_set.set_format("torch", columns=["input_ids", "attention_mask", "label"])
test_set.set_format("torch", columns=["input_ids", "attention_mask", "label"])# 训练模型
batch_size = 8 # 批量大小
epochs = 2 # 迭代次数warmup_steps = 500 # 预热步骤
weight_decay = 0.01 # 权重衰减# 设置训练参数
training_args = TrainingArguments(output_dir = "./results",num_train_epochs = epochs,per_device_train_batch_size = batch_size,per_device_eval_batch_size = batch_size,warmip_steps = warmup_steps,weight_decay = weight_decay,evaluate_during_training = True,logging_dir = "./logs"
)trainer = Trainer(model = model,args = training_args,train_dataset = train_set,eval_dataset = test_set)# 开始模型训练
trainer.train()# 训练结束后 评估模型
trainer.evaluate()# {'epoch': 1.0, 'eval_loss': 0.68}
# {'epoch': 2.0, 'eval_loss': 0.50}
# ...
自然语言推理任务的BERT微调
在该任务中,在确定的“前提”下,推定假设是“真”、“假”还是“未定的”;即模型的目标是:确定一个句子对(前提-假设对)是真、是假、还是中性;
- 对句子进行标记:第一句开头加
[CLS]标记,每句结尾添加[SEP]标记; - 送入预训练模型 得到
[CLS]标记的特征(即整个句子对的特征); - 将
R[CLS]送入分类器;
问答任务的BERT微调
问答任务重,对一个问题,模型会返回一个答案,目标是让模型返回正确答案;
虽然这个任务可以使用生成式的任务模型,但这里是基于微调BERT实现的,思路不同;
BERT模型输入是一个问题和一个段落,这个段落需要是一个含有答案的段落,BERT必须从该段落中提取答案;
要通过微调BERT模型来完成这项任务,模型必须要了解给定段落中包含答案的文本段的起始索引和结束索引;要找到这两个索引,模型应该返回“该段落中每个标记是答案的起始标记和结束标记的概率”;
这里引入两个向量:
- 起始向量S;
- 结束向量E;
两个向量的值,将通过训练获得;
为了计算这个概率:
- 对于每个标记i,计算标记特征Ri和起始向量S之间的点积,然后将softmax函数应用于点积,得到概率;
- 接下来选择其中具有最高概率的标记,并将其索引值作为起始索引;
- 结束索引的计算方式类似;这样就可以使用起始索引和结束索引选择包含答案的文本段了;
# 微调BERT模型用于问答任务
from transformers import BertForQuestionAnswering, BertTokenizer# 下载模型
model = BertForQuestionAnswering.from_pretrained("bert-large-uncased-whole-word-masking-fine-tuned-squad") # 该模型基于斯坦福问答数据集(SQyAD)微调而得# 下载并加载词元分析器
tokenizer = BertTokenizer.from_pretrained("bert-large-uncased-whole-word-masking-fine-tuned-squad")question = "A"
paragraph = "AAABBBBBBAAAA"question = "[CLS]" + question + "[SEP]"
paragraph = paragraph + "[SEP]"# 转为 input_ids
question_tokens = tokenizer.tokenize(question)
paragraph_tokens = tokenizer.tokenize(paragraph)# 设置segment_ids
segment_ids = [0] * len(question_tokens)
segment_ids = segment_ids + [1] * len(paragraph_tokens)# 转张量
input_ids = torch.tensor([input_ids])
segment_ids = torch.tensor([segment_ids])start_scores, end_scores = model(input_ids, token_type_ids = segment_ids)start_index = torch.argmax(start_scores)
end_index = torch.argmax(end_scores)# 答案
' '.join(tokens[start_index: end_index + 1])关于问答任务BERT微调的一些疑问?
- 问题1:起始向量和结束向量 是怎么来的?
R[CLS]和R[SEP]是否就是这两个向量?- 问题2:上面的示例代码段,很明显并不是一个微调,而是一个应用,虽然是应用一个已经微调好的模型,但如何训练却未讲明;
可以展开思考(待查明)
对执行命名实体识别任务的BERT模型微调
任务目标是将命名实体划分到预设的类别中,如某一句子种出现了人名和地名(还有其他词)的词汇,能将相应词汇进行准确归类;
- 对句子进行标记
- 送入预训练BERT模型,获得每个标记特征
- 在将这些标记特征送入一个分类器(使用softmax激活函数的前馈网络层)
- 最后分类器返回每个命名实体对应的类别
好吧,这里说的依旧很简略,但至少上我们知道了大致的实现逻辑;
此前分类任务的实践代码梳理
todo
相关文章:
读书笔记:多Transformer的双向编码器表示法(Bert)-3
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 第3章 Bert实战 学习如何使用预训练的BERT模型: 如何使用预训练的BERT模型作为特征提取器;探究Hugging Face的Transforme…...

jpsall脚本
当一个集群的节点数量增多时,使用jps查看每一个节点的进程这个过程非常繁琐,因此我们可以写一个jpsall脚本,使用循环迭代的方式,在多台远程主机上执行相同的命令,这样就可以节省在每台主机上手动执行命令的时间和精力。…...
Django REST framework API版本管理【通过GET参数传递】
API版本 在开发过程中可能会有多版本的API,因此需要对API进行管理。django drf中对于版本的管理也很方便。 http://www.example.com/api/v1/info http://www.example.com/api/v2/info 上面这种形式就是很常见的版本管理 在restful规范中,后端的API需…...

归并排序 nO(lgn)
大家好,我是蓝胖子,我一直相信编程是一门实践性的技术,其中算法也不例外,初学者可能往往对它可望而不可及,觉得很难,学了又忘,忘其实是由于没有真正搞懂算法的应用场景,所以我准备出…...
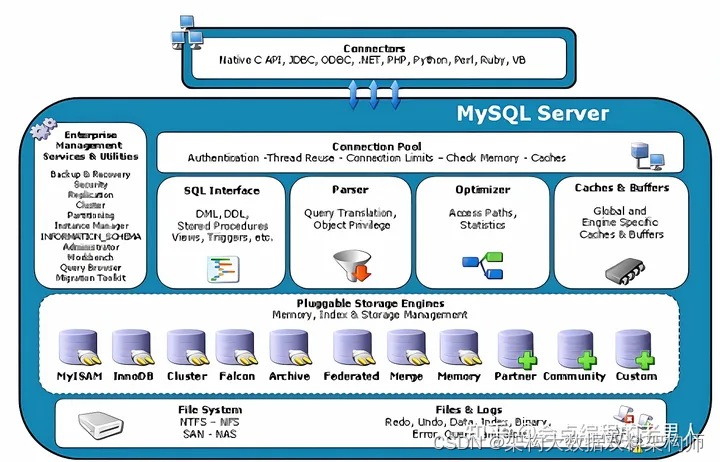
数据库Mysql三大引擎(InnoDB、MyISAM、 Memory)与逻辑架构
MySQL数据库及其分支版本主要的存储引擎有InnoDB、MyISAM、 Memory等。简单地理解,存储引擎就是指表的类型以及表在计算机上的存储方式。存储引擎的概念是MySQL的特色,使用的是一个可插拔存储引擎架构,能够在运行的时候动态加载或者卸载这些存…...
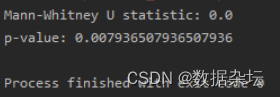
Python数据分析实战-实现Mann-Whitney U检验(附源码和实现效果)
实现功能 使用scipy.stats模块中的mannwhitneyu函数来实现Mann-Whitney U检验,该检验用于比较两个独立样本的分布是否有显著差异。 实现代码 from scipy.stats import mannwhitneyu# 两个独立样本的数据 group1 [1, 2, 3, 4, 5] group2 [6, 7, 8, 9, 10]# 执行…...
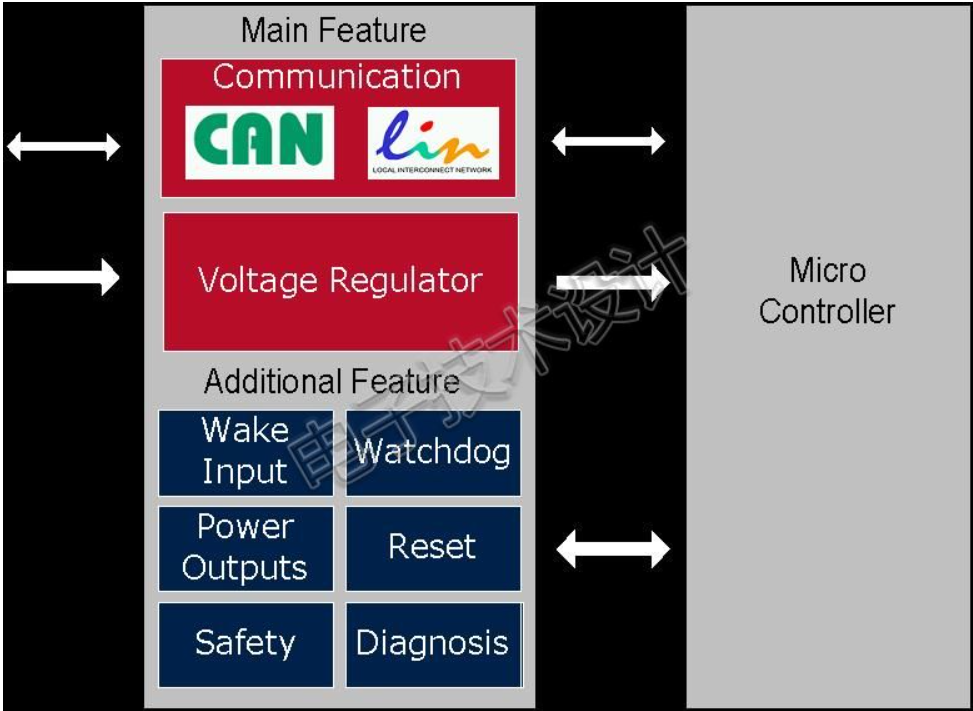
车载SBC芯片概论
+他V hezkz17进数字音频系统研究开发交流答疑群(课题 参考英飞凌SBC官网资料:https://www.infineon.com/cms/cn/product/automotive-system-ic/system-basis-chips-sbc/ SBC芯片在汽车电子领域可谓占一席之地了。那么什么是SBC?怎么用?用在哪里?主要特性? 1.什么是SBC?…...

【ARM AMBA5 CHI 入门 12.1 -- CHI 链路层详细介绍 】
文章目录 CHI 版本介绍1.1 CHI 链路层介绍1.1.1 Flit 切片介绍1.1.2 link layer credit(L-Credit)机制1.1.3 Channel1.1.4 Port1.1. RN Node 接口定义1.1.6 SN Node 接口定义1.2 Channel interface signals1.2.1 Request, REQ, channel1.2.2 Response, RSP, channel1.2.3 Snoop…...

【物联网】Arduino+ESP8266物联网开发(二):控制发光二极管 按钮开关控制开关灯
【物联网】ArduinoESP8266物联网开发(一):开发环境搭建 安装Arduino和驱动 2.ESP8266基础应用 【物联网】ESP8266 开关控制 发光二极管 LED 开发软件下载地址 链接: https://pan.baidu.com/s/1BaOY7kWTvh4Obobj64OHyA?pwd3qv8 提取码: 3qv8 学习过程中会用到的基础…...
WPF向Avalonia迁移(二、一些可能使用到的库)
可能使用到的一些库 1. UI库 开源项目:https://github.com/irihitech/Semi.Avalonia 如果想引用他的DataGrid样式还需要添加Semi.Avalonia.DataGrid 2. 图表库 LiveChartsCore.SkiaSharpView.Avalonia 3.SVG库 开源项目:https://github.com/wieslaw…...
Mac navicat连接mysql出现1045 - Access denied for user ‘root‘
Mac navicat连接mysql出现1045 - Access denied for user ‘root’ 前提:如果你的mac每次开navicat都连接不上,推荐试试我这个方法 1.打开设置–>找到左下角最下面的MySQL–>点击Stop MySQL Server 2.开启一个终端,依次输入以下命令&a…...
win10电脑插入耳机,右边耳机声音比左边小很多
最近使用笔记本看视频,发现插入耳机(插入式和头戴式)后,右边耳机声音比左边耳机声音小很多很多,几乎是一边很清晰,另一边什么都听不到。 将耳机插到别人电脑上测试耳机正常,那就是电脑的问题。试…...

本文整理了Debian 11在国内的几个软件源。
1.使用说明 一般情况下,将/etc/apt/sources.list文件中Debian默认的软件仓库地址和安全更新仓库地址修改为国内的镜像地址即可,比如将deb.debian.org和security.debian.org改为mirrors.xxx.com,并使用https访问,可使用…...

2023NOIP A层联测6 数点
题目大意 给你一个排列 p p p,对于每一个 i i i,我们在平面上,放置一个点 ( i , p i ) (i,p_i) (i,pi)。对于坐标上下限都在 1 ∼ n 1\sim n 1∼n内的全体 ( n ( n 1 ) 2 ) 2 (\frac{n(n1)}{2})^2 (2n(n1))2矩形,求每个矩形…...
Jmeter 链接MySQL测试
1.环境部署 1.1官网下载MySQL Connector https://dev.mysql.com/downloads/connector/j/ 1.2 解压后,将jar放到jmeter/lib目录下 1.3 在测试计划中添加引用 2.脚本设置 2.1设置JDBC Connection Configuration 先添加一个setUp线程中,在setUp中添加“…...

jwt的了解和使用以及大致代码分析
jwt简介 以下介绍来自官网(https://jwt.io/) SON Web 令牌 (JWT) 是一种开放标准 (RFC 7519),它定义了一种紧凑且独立的方式,用于在各方之间以 JSON 对象的形式安全地传输信息。此信…...

uniapp中videojs、renderjs的使用
在uniapp中使用了某些前端库或iframe,需要操作这些库中的dom的时候, 而uni上又没有document等基础对象。也就无法操作这些dom去实现一些交互逻辑,那么,涉及到这些的前端类库就无法使用,例如html2、canvas、image、vide…...
AIGC AI绘画 Midjourney 参数大全详细列表
AIGC ChatGPT 职场案例 AI 绘画 与 短视频制作, Power BI 商业智能 68集, 数据库Mysql8.0 54集 数据库Oracle21C 142集, Office 2021实战, Python 数据分析, ETL Informatica 案例实战 Excel 2021实操,函数大全,图表大全,大屏可视化制作 加技巧500集 数据分析可视化T…...

安装hadoop,并配置hue
0、说明 对于大数据学习的初始阶段,我也曾尝试搭建相应的集群环境。通过搭建环境了解组件的一些功能、配置、原理。 在实际学习过程中,我更多的还是使用docker来快速搭建环境。 这里记录一下我搭建hadoop的过程。 1、下载hadoop 下载地址:…...
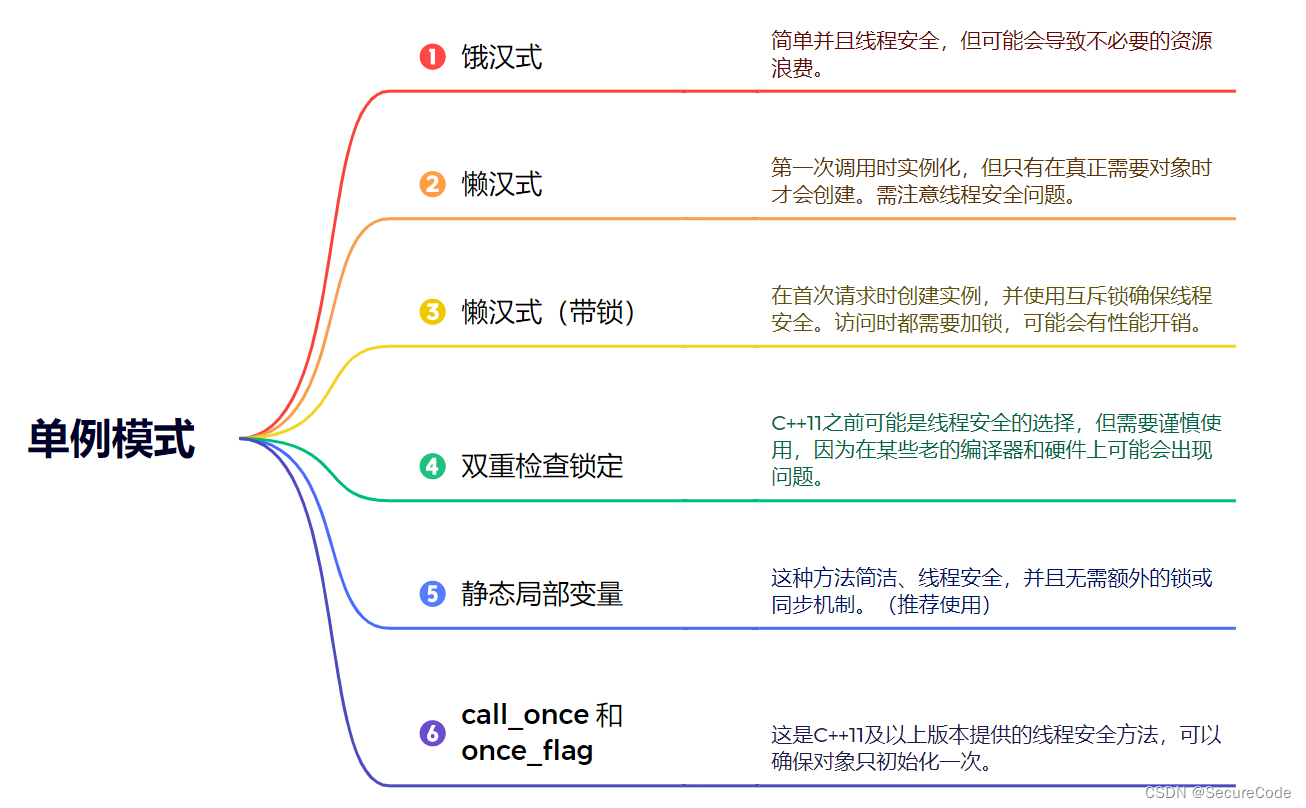
23种经典设计模式:单例模式篇(C++)
前言: 博主将从此篇单例模式开始逐一分享23种经典设计模式,并结合C为大家展示实际应用。内容将持续更新,希望大家持续关注与支持。 什么是单例模式? 单例模式是设计模式的一种(属于创建型模式 (Creational Pa…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...

MySQL 分区表实战:大表治理的利器与陷阱
开场白 分区表这个东西,我之前一直觉得就是个语法糖,直到有一次运维一张 2 亿行的日志表,查询慢到飞起,索引也建不动了,才认真研究分区表。结果发现分区表确实好用,但坑也不少——分区键选错了、分区裁剪没…...