CUDA C编程权威指南:2.1-CUDA编程模型
本文主要通过例子介绍了CUDA异构编程模型,需要说明的是Grid、Block和Thread都是逻辑结构,不是物理结构。实现例子代码参考文献[2],只需要把相应章节对应的CMakeLists.txt文件拷贝到CMake项目根目录下面即可运行。
1.Grid、Block和Thread间的关系
GPU中最重要的2种内存是全局内存和共享内存,前者类似于CPU系统内存,而后者类似于CPU缓存,然后GPU共享内存可由CUDA C内核直接控制。GPU简化的内存结构,如下所示:
[外链图片转存中…(img-zjlJfwmi-1696733256161)]
由一个内核启动所产生的所有thread统称为一个grid,同一个grid中的所有thread共享相同的全局内存空间。一个grid由多个block构成,一个block包含一组thread,同一block内的thread通过同步、共享内存方式进行线程协作,不同block内的thread不能协作。由block和grid构成的2层的thread层次结构,如下所示:
[外链图片转存中…(img-eGUKo819-1696733256163)]
CUDA可以组织3维的grid和block。blockIdx表示线程块在线程格内的索引,threadIdx表示块内的线程索引;blockDim表示每个线程块中的线程数,gridDim表示网格中的线程块数。这些变量允许开发人员在编写CUDA代码时,从逻辑上管理和组织线程块和网格的大小,从而优化并行执行的效率。如下所示:
[外链图片转存中…(img-wcgjwV8R-1696733256164)]
2.检查网格和块的索引和维度(checkDimension.cu)
确定grid和block的方法为先确定block的大小,然后根据实际数据大小和block大小的基础上计算grid维度,如下所示:
// 检查网格和块的索引和维度
# include <cuda_runtime.h>
# include <stdio.h>__global__ void checkIndex(void) {// gridDim表示grid的维度,blockDim表示block的维度,grid维度表示grid中block的数量,block维度表示block中thread的数量printf("threadIdx:(%d, %d, %d) blockIdx:(%d, %d, %d) blockDim:(%d, %d, %d) ""gridDim:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z,blockIdx.x, blockIdx.y, blockIdx.z, blockDim.x, blockDim.y, blockDim.z,gridDim.x, gridDim.y, gridDim.z); // printf函数只支持Fermi及以上版本的GPU架构,因此编译的时候需要加上-arch=sm_20编译器选项
}int main(int argc, char** argv) {// 定义全部数据元素int nElem = 6;// 定义grid和block的结构dim3 block(3); // 表示一个block中有3个线程dim3 grid((nElem + block.x - 1) / block.x); // 表示grid中有2个block// 检查grid和block的维度(host端)printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);// 检查grid和block的维度(device端)checkIndex<<<grid, block>>>();// 离开之前重置设备cudaDeviceReset();return 0;
}
输出结果如下所示:
threadIdx:(0, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(1, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(0, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(1, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
threadIdx:(2, 0, 0) blockIdx:(0, 0, 0) blockDim:(3, 1, 1) gridDim:(2, 1, 1)
grid.x 2 grid.y 1 grid.z 1
block.x 3 block.y 1 block.z 1
3.在主机上定义网格和块的大小(defineGridBlock.cu)
接下来通过一个1维网格和1维块讲解当block大小变化时,gird的size也随之变化,如下所示:
#include <cuda_runtime.h>
#include <stdio.h>int main(int argc, char** argv) {// 定义全部数据元素int cElem = 1024;// 定义grid和block结构dim3 block(1024);dim3 grid((cElem + block.x - 1) / block.x);printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);// 重置blockblock.x = 512;grid.x = (cElem + block.x - 1) / block.x;printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);// 重置blockblock.x = 256;grid.x = (cElem + block.x - 1) / block.x;printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);// 重置blockblock.x = 128;grid.x = (cElem + block.x - 1) / block.x;printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);// 离开前重置devicecudaDeviceReset();return 0;
}
输出结果,如下所示:
grid.x 1 grid.y 1 grid.z 1
grid.x 2 grid.y 1 grid.z 1
grid.x 4 grid.y 1 grid.z 1
grid.x 8 grid.y 1 grid.z 1
4.基于GPU的向量加法(sumArraysOnGPU-small-case.cu)
#include <cuda_runtime.h>
#include <stdio.h>#define CHECK(call)
//{
// const cudaError_t error = call;
// if (error != cudaSuccess)
// {
// printf("Error: %s:%d, ", __FILE__, __LINE__);
// printf("code:%d, reason: %s\n", error, cudaGetErrorString(error));
// exit(1);
// }
//}void checkResult(float *hostRef, float *gpuRef, const int N)
{double epsilon = 1.0E-8;bool match = 1;for (int i = 0; i < N; i++){if (abs(hostRef[i] - gpuRef[i]) > epsilon){match = 0;printf("Arrays do not match!\n");printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i);break;}}if (match) printf("Arrays match.\n\n");
}void initialData(float *ip, int size)
{// generate different seed for random numbertime_t t;srand((unsigned int) time(&t));for (int i = 0; i < size; i++){ip[i] = (float) (rand() & 0xFF) / 10.0f;}
}void sumArraysOnHost(float *A, float *B, float *C, const int N)
{for (int idx = 0; idx < N; idx++){C[idx] = A[idx] + B[idx];}
}__global__ void sumArraysOnGPU(float *A, float *B, float *C)
{// int i = threadIdx.x; // 获取线程索引int i = blockIdx.x * blockDim.x + threadIdx.x; // 获取线程索引printf("threadIdx.x: %d, blockIdx.x: %d, blockDim.x: %d\n", threadIdx.x, blockIdx.x, blockDim.x);C[i] = A[i] + B[i]; // 计算
}int main(int argc, char** argv) {printf("%s Starting...\n", argv[0]);// 设置设备int dev = 0;cudaSetDevice(dev);// 设置vectors数据大小int nElem = 32;printf("Vector size %d\n", nElem);// 分配主机内存size_t nBytes = nElem * sizeof(float);float *h_A, *h_B, *hostRef, *gpuRef; // 定义主机内存指针h_A = (float *) malloc(nBytes); // 分配主机内存h_B = (float *) malloc(nBytes); // 分配主机内存hostRef = (float *) malloc(nBytes); // 分配主机内存,用于存储host端计算结果gpuRef = (float *) malloc(nBytes); // 分配主机内存,用于存储device端计算结果// 初始化主机数据initialData(h_A, nElem);initialData(h_B, nElem);memset(hostRef, 0, nBytes); // 将hostRef清零memset(gpuRef, 0, nBytes); // 将gpuRef清零// 分配设备全局内存float *d_A, *d_B, *d_C; // 定义设备内存指针cudaMalloc((float **) &d_A, nBytes); // 分配设备内存cudaMalloc((float **) &d_B, nBytes); // 分配设备内存cudaMalloc((float **) &d_C, nBytes); // 分配设备内存// 从主机内存拷贝数据到设备内存cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice); // d_A表示目标地址,h_A表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice); // d_B表示目标地址,h_B表示源地址,nBytes表示拷贝字节数,cudaMemcpyHostToDevice表示拷贝方向// 在host端调用kerneldim3 block(nElem); // 定义block维度dim3 grid(nElem / block.x); // 定义grid维度sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C); // 调用kernel,<<<grid, block>>>表示执行配置,d_A, d_B, d_C表示kernel参数printf("Execution configuration <<<%d, %d>>>\n", grid.x, block.x); // 打印执行配置// 拷贝device结果到host内存cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost); // gpuRef表示目标地址,d_C表示源地址,nBytes表示拷贝字节数,cudaMemcpyDeviceToHost表示拷贝方向// 在host端计算结果sumArraysOnHost(h_A, h_B, hostRef, nElem);// 检查device结果checkResult(hostRef, gpuRef, nElem);// 释放设备内存cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);// 释放主机内存free(h_A);free(h_B);free(hostRef);free(gpuRef);return 0;
}
输出结果如下所示:
[外链图片转存中…(img-yLMkSnjk-1696733256164)]
threadIdx.x: 0, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 1, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 2, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 3, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 4, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 5, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 6, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 7, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 8, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 9, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 10, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 11, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 12, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 13, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 14, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 15, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 16, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 17, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 18, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 19, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 20, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 21, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 22, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 23, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 24, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 25, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 26, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 27, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 28, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 29, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 30, blockIdx.x: 0, blockDim.x: 32
threadIdx.x: 31, blockIdx.x: 0, blockDim.x: 32
L:\20200706_C++\C++Program\20231003_ClionProgram\cmake-build-debug\20231003_ClionProgram.exe Starting...
Vector size 32
Execution configuration <<<1, 32>>>
Arrays match.
5.其它知识点
(1)host和device同步
核函数的调用和主机线程是异步的,即核函数调用结束后,控制权立即返回给主机端,可以调用cudaDeviceSynchronize(void)函数来强制主机端程序等待所有的核函数执行结束。当使用cudaMemcpy函数在host和device间拷贝数据时,host端隐式同步,即host端程序必须等待数据拷贝完成后才能继续执行程序。需要说明的是,所有CUDA核函数的启动都是异步的,当CUDA内核调用完成后,控制权立即返回给CPU。
(2)函数类型限定符
函数类型限定符指定一个函数在host上执行还是在device上执行,以及可被host调用还是被device调用,函数类型限定符如下所示:
[外链图片转存中…(img-dj0ukz7N-1696733256165)]
说明:__device__和__host__限定符可以一起使用,这样可同时在host和device端进行编译。
参考文献:
[1]《CUDA C编程权威指南》
[2]2.1-CUDA编程模型概述:https://github.com/ai408/nlp-engineering/tree/main/20230917_NLP工程化/20231004_高性能计算/20231003_CUDA编程/20231003_CUDA_C编程权威指南/2-CUDA编程模型/2.1-CUDA编程模型概述
相关文章:

CUDA C编程权威指南:2.1-CUDA编程模型
本文主要通过例子介绍了CUDA异构编程模型,需要说明的是Grid、Block和Thread都是逻辑结构,不是物理结构。实现例子代码参考文献[2],只需要把相应章节对应的CMakeLists.txt文件拷贝到CMake项目根目录下面即可运行。 1.Grid、Block和Thread间的…...

两条记录合并成一条记录
两条记录合并成一条记录 两条记录 val4,type_idlevel 和 val6,type_idtypeId 合并成一条记录 level4,typeId6 可以使用 条件聚合语句 CASE WHEN … 和 MAX 函数来实现。假设有以下 my_table 表: --------------------- | id | val | type_id | --------------…...
vue3 + typescript + vite + naive ui + tailwindcss + jsx 仿苹果桌面系统
基于 vue3.x typescript vite naive ui tailwindcss jsx vue-router pinia,项目使用 tsx 作为模版输出,全程没有使用vue提供的SFC, 仿macos桌面前端项目,开源免费模版,希望减少工作量和学习新技术,希…...
揭秘,用软件一秒识别纸质表格数字,找到你想要的一串数字
要将纸质表格的数字快速用软件识别并找出特定的一串数字,以下是三种常用的方案: 方案一:使用OCR软件识别和搜索功能 1. 扫描纸质表格并保存为图像或PDF格式。 2. 使用OCR(光学字符识别)软件,如金鸣表格文字…...
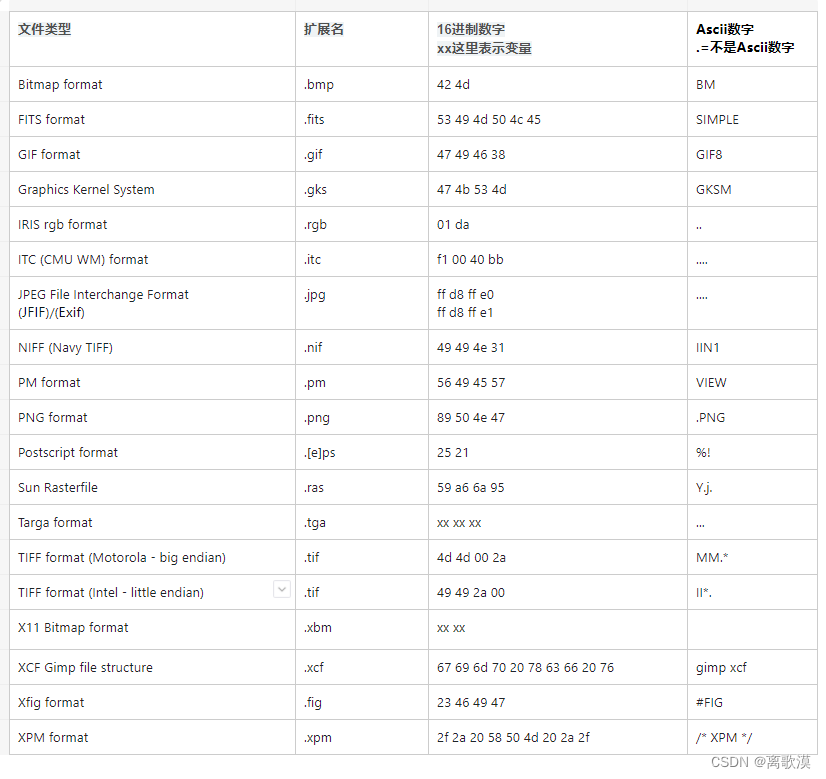
解析图片文件格式
图片文件幻数 关于JPEG格式 二进制形式打开文件,文件开始字节为FF D8,文件结束两字节为FF D9 JPEG 文件有两种不同的元数据格式:JFIF 和 EXIF。 JFIF 以 ff d8 ff e0 开头,EXIF 以 ff d8 ff e1 开头。 代码示例 private static…...
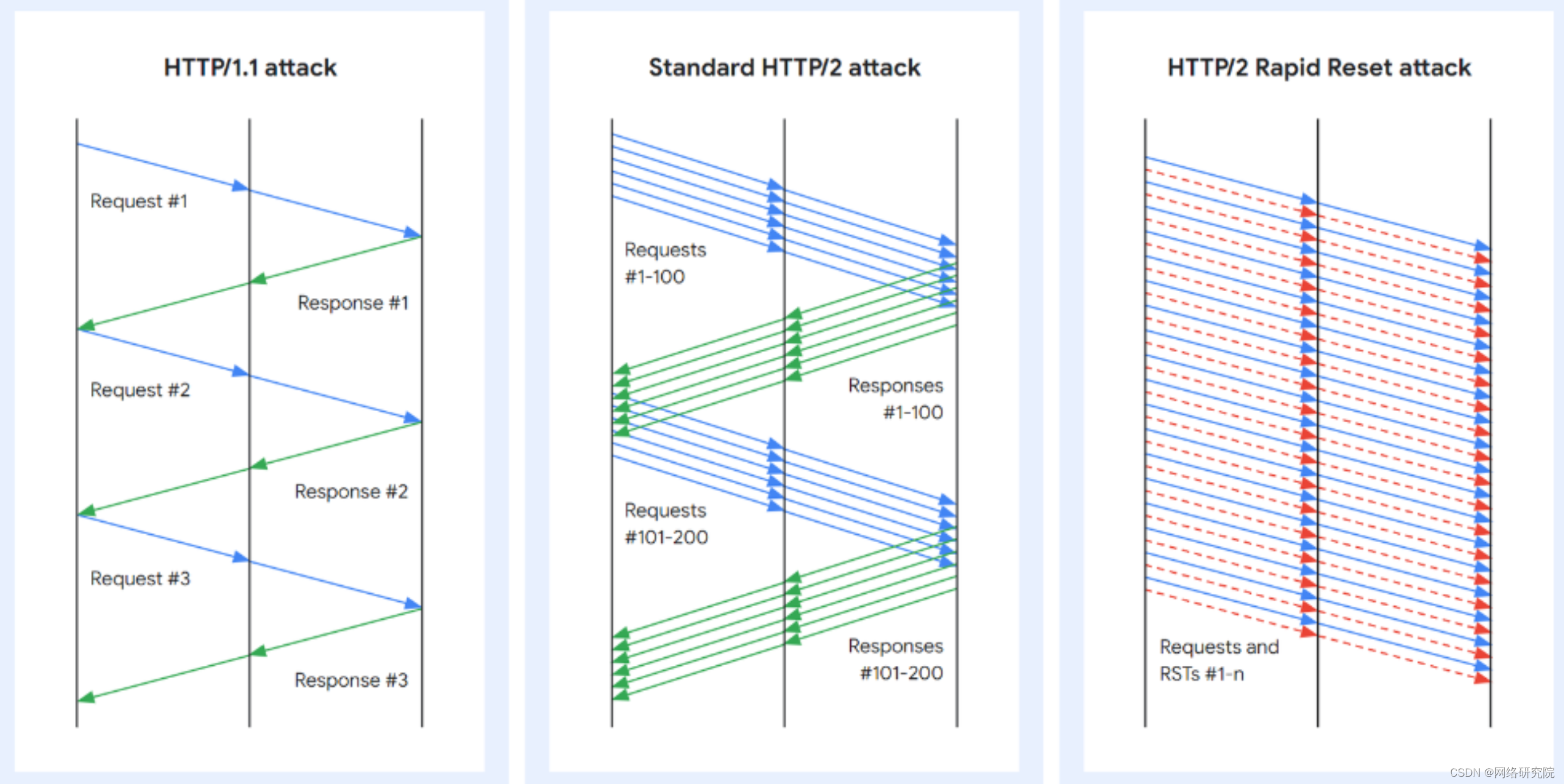
新的“HTTP/2 快速重置”零日攻击打破了 DDoS 记录
自 8 月份以来,一种名为“HTTP/2 快速重置”的新 DDoS(分布式拒绝服务)技术已被作为零日漏洞积极利用,其规模打破了之前的所有记录。 Amazon Web Services、Cloudflare 和 Google 今天联合发布了有关零日技术的消息,他…...

现代化战机之路:美国空军U-2侦察机基于Jenkins和k8s的CI/CD架构演进
▲ 点击上方"DevOps和k8s全栈技术"关注公众 华为北京研究所Q27大楼 随着技术的不断进步,军事领域也在积极采纳现代化工具来提高战备水平和效率。美国空军的U-2侦察机项目是一个鲜明的例子,它成功地借助Jenkins和Kubernetes(k8s&…...

Linux中常用的软件:Squid
在Linux系统中,有许多不同的代理软件可供选择。本文将比较两个常用的代理软件: Squid。我们将介绍它们的特点、使用场景和优缺点,帮助您选择适合自己需求的代理软件。 - 支持多种加密协议,包括AES、ChaCha20和RC4等,可…...

Ali MaxCompute SDK
ALI MC 文件读写 public abstract BufferedInputStream readResourceFileAsStream(String var1) throws IOException;LocalExecutionContext.java Overridepublic BufferedInputStream readResourceFileAsStream(String resourceName) throws IOException {try {return wareHou…...

解决element中table在页面切换时候表格底部出现空白
activated(){ this.$refs.table.doLayout() } activated()是Vue中一个很重要的生命周期函数,它是在组件大概率会被复用时调用的。当组件被复用时,原来的组件的数据和状态必须得到保留。activated()函数能够保持组件在别处被活化时的状态数据。 activat…...
Vue中对路由的进阶学习
路由进阶 文章目录 路由进阶1、路由的封装抽离2、声明式导航2.1、导航链接2.2、高亮类名2.3、跳转传参2.4、动态路由参数可选符 3、Vue路由--重定向4、Vue路由--4045、Vue路由–模式设置6、编程式导航6.1、基本跳转6.2、跳转传参 路由基础入门 1、路由的封装抽离 问题&#x…...

Vuex的同步存值与取值及异步请求
前言 1.概念 Vuex是一个用于管理Vue.js应用程序中状态的状态管理模式和库。Vue.js是一个流行的JavaScript框架,用于构建用户界面,而Vuex则专门用于管理应用程序的状态,以确保状态在整个应用程序中保持一致和可维护。 2.Vuex的特点…...
【Python爬虫 js渲染思路一】
Python爬虫 破解js渲染思路一 当我们在谈论网页js渲染的时候,我们在谈论什么 js渲染网页,从某种程度来说,是指单纯的http请求,返回的文本数据,与我们在浏览器看到的内容,相距甚远.其可包括为以下几点&…...
智慧安防AI视频智能分析云平台EasyCVR加密机授权小tips
视频云存储/安防监控EasyCVR视频汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发、视频集中存储等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、…...
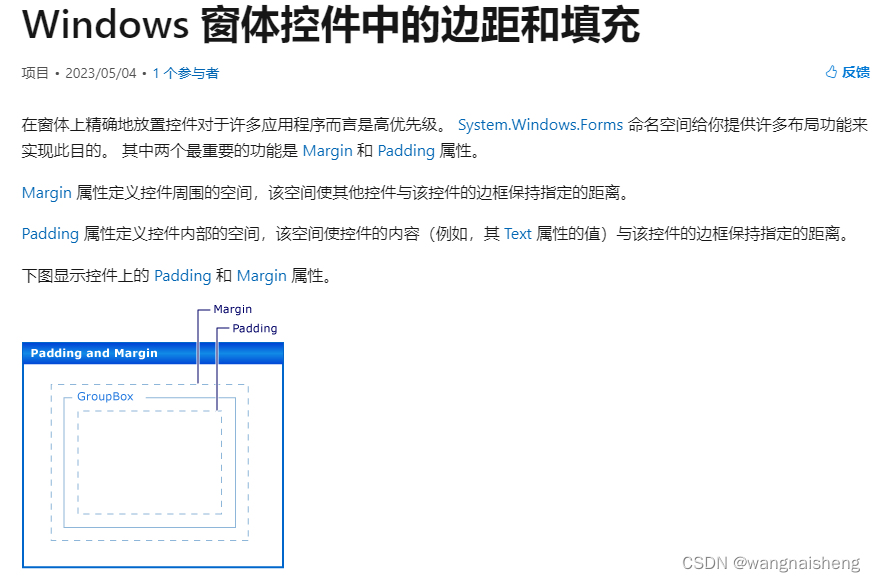
C# Windows 窗体控件中的边距和填充
可以将 Margin 属性、Left、Top、Right、Bottom 的每个方面设置为不同的值,也可以使用 All 属性将它们全部设置为相同的值。 在代码中设置Margin,元素的左边设置为5个单位、上边设置为10个单位、右边设置为15个单位和下边设置为20个单位。 TextBox myT…...

腾讯云2核4G轻量服务器5M带宽支持多少人同时在线?
腾讯云轻量2核4G5M带宽服务器支持多少人在线访问?5M带宽下载速度峰值可达640KB/秒,阿腾云以搭建网站为例,假设优化后平均大小为60KB,则5M带宽可支撑10个用户同时在1秒内打开网站,从CPU内存的角度,网站程序效…...

01 初识FPGA
01 初识FPGA 一.FPGA是什么 FPGA(Filed Programmable Gate Array),现场可编程门阵列,一种以数字电路为主的集成芯片,属于可编程逻辑器件PLD的一种。 1.1 两大巨头 Xilinx(赛灵思)Altera(阿尔特拉&#…...

设备巡检管理系统与隐患排查治理
如何才能将设备巡检做细做规范呢? 1.制定巡检制度和流程:通过建立明确的巡检制度和流程,并将其纳入企业的安全管理体系中。利用凡尔码平台制定一个详细的巡检计划,包括巡检的时间、地点、内容、检查方法和注意事项等,帮…...
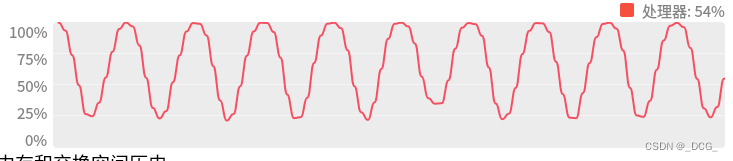
linux之cpu模拟负载程序
工作中我们经常会遇到这样的问题,需要模拟cpu的负载程序,例如模拟cpu占有率抬升10%、20%、50%、70%等,那这样的程序应该如何实现呢?它的原理是什么样的呢? 思想 创建一个应用程序,该应用程序的作用可以根…...
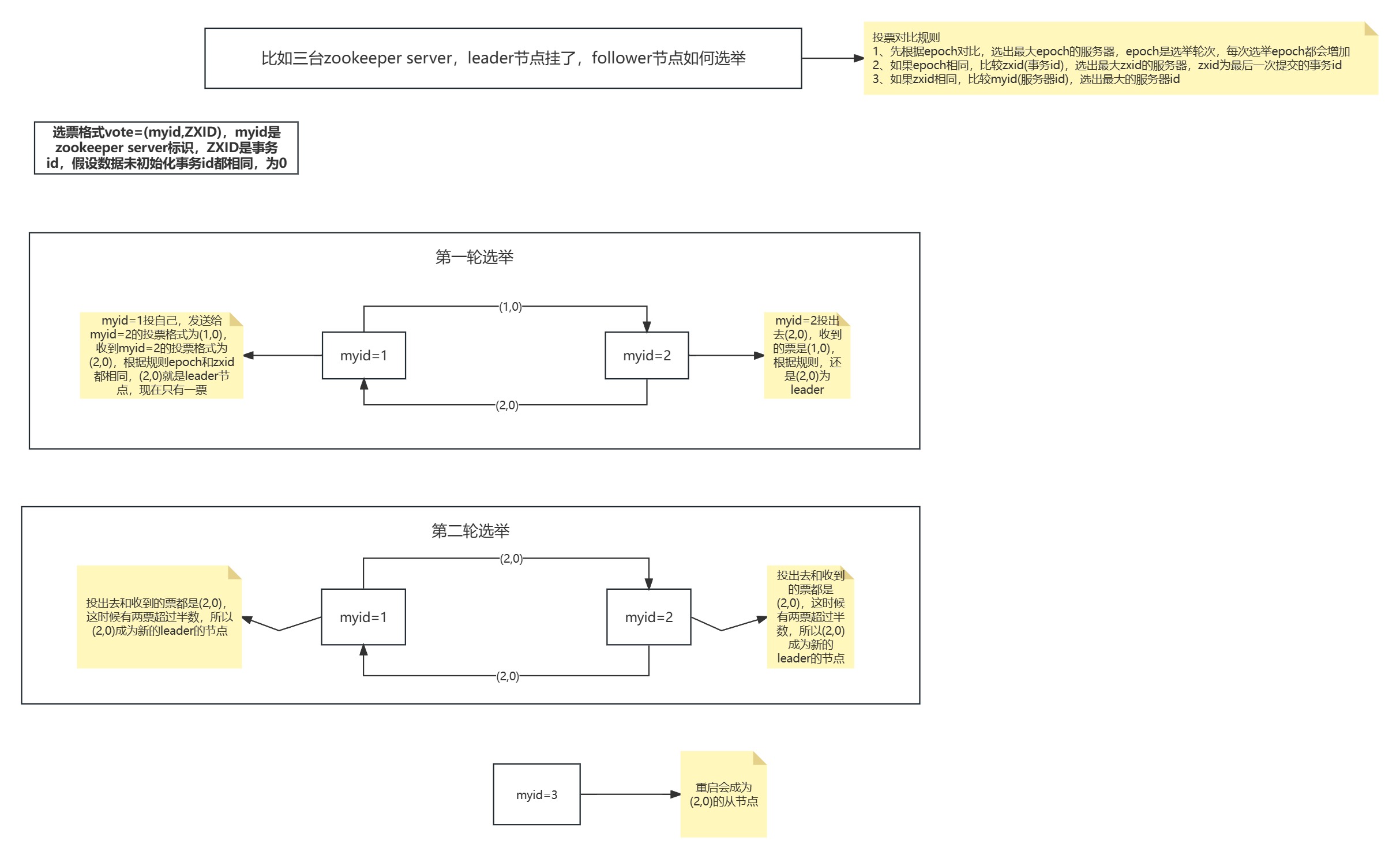
zookeeper节点数据类型介绍及集群搭建
一、zookeeper介绍 zookeeper官网:Apache ZooKeeper zookeeper是一个分布式协调框架,保证的是CP,即一致性和分区容错性;zookeeper是一个分布式文件存储系统,文件节点可以存储数据,监听子文件节点等可以实…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Taotoken的TokenPlan套餐如何实现更经济的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的TokenPlan套餐如何实现更经济的模型调用 1. 理解TokenPlan的计费模式 在模型应用开发过程中,成本的可预测性…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...

如何优化 MySQL 千万级数据分页查询的性能?
它的本质是:**传统 LIMIT offset, size 在大数据量下性能急剧下降,是因为 MySQL 必须 扫描并丢弃 前 offset 行数据。当 offset 很大时(如 LIMIT 1000000, 10),MySQL 需要读取 1,000,010 行记录,执行 1,000…...