深度学习问答题(更新中)
1. 各个激活函数的优缺点?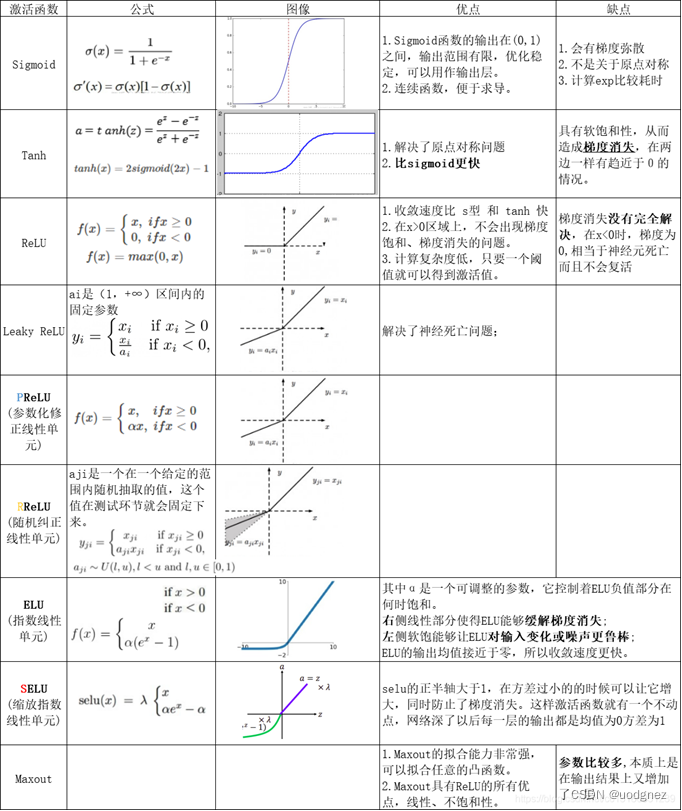
2. 为什么ReLU常用于神经网络的激活函数?
- 在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
- 避免梯度消失问题。对于深层网络,Sigmoid函数反向传播时,很容易就会出现梯度消失问题(在Sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练;
- 可以缓解过拟合问题的发生。ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生;
- 相比Sigmoid函数,ReLU函数有助于随机梯度下降方法收敛。
3. 神经网络为什么会出现梯度弥散(gradient vanish)问题,梯度爆炸呢?
梯度消失:梯度趋近于0,网络权重无法更新或更新的很微小,网络训练再久也不会有效果。
梯度爆炸:梯度呈指数级增长,变得非常大,然后导致网络权重大幅更新,使网络变得不稳定。
Sigmoid导数的取值在 0~0.25 之间,而我们初始化的网络权值 w w w 通常都小于 1,因此,当层数增多时,小于 0 的值不断相乘,最后就导致了梯度消失的情况出现。同理,梯度爆炸的问题也就很明显了,就是当权值 w w w 过大时,导致 ∣ σ ′ ( z ) w ∣ > 1 |\sigma'(z) w|>1 ∣σ′(z)w∣>1,最后大于1的值不断相乘,就会产生梯度爆炸。
梯度消失和梯度爆炸本质上是一样的,都是因为网络层数太深而引发的梯度反向传播中的连乘效应。
4. 梯度消失和梯度爆炸的解决方案?梯度爆炸引发的问题?

5. BN(Batch Normalization)层如何实现?作用?
实现过程:计算训练阶段 mini_batch 数量激活函数前结果的均值和方差,然后对其进行归一化,最后对其进行缩放和平移。
作用:
- BN 使得网络中每层输入数据的分布相对稳定,加速模型学习速度。BN 通过规范化与线性变换使得每一层网络的输入数据的均值与方差都在一定范围内,使得后一层网络不必不断去适应底层网络中输入的变化,从而实现了网络中层与层之间的解耦,允许每一层进行独立学习,有利于提高整个神经网络的学习速度。
- BN 使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定。
- BN 允许网络使用饱和性激活函数(例如 sigmoid,tanh 等),缓解梯度消失问题在不使用 BN 层的时候,由于网络的深度与复杂性,很容易使得底层网络变化累积到上层网络中,导致模型的训练很容易进入到激活函数的梯度饱和区;通过 normalize 操作可以让激活函数的输入数据落在梯度非饱和区,缓解梯度消失的问题。
- BN 具有一定的正则化效果。在 BN 中,由于我们使用 mini-batch 的均值与方差作为对整体训练样本均值与方差的估计,尽管每一个 batch 中的数据都是从总体样本中抽样得到,但不同 mini-batch 的均值与方差会有所不同,这就为网络的学习过程中增加了随机噪音,与 Dropout 通过关闭神经元给网络训练带来噪音类似,在一定程度上对模型起到了正则化的效果。
6. 选择传统机器学习还是深度学习的标准是什么?
于数据挖掘和处理类的问题,使用一般的机器学习方法,需要提前做大量的特征工程工作,而且特征工程的好坏会在很大程度上决定最后效果的优劣(也就是常说的一句话:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已)。
使用深度学习的话,特征工程就没那么重要了,特征只需要做些预处理就可以了,因为它可以自动完成传统机器学习算法中需要特征工程才能实现的任务,特别是在图像和声音数据的处理中更是如此,但模型结构会比较复杂,训练较为麻烦。另一个方面,虽然深度学习让我们可以省去特征工程这一较为繁琐的过程,但也让我们失去了对特征的认识,如特征的重要性等。
如何选择或衡量这两种方法:
- 第一看数据量,比如训练数据量达到百万以上,深度学习的方法会比较有优势。如果样本集不是大样本,那么特征工程加传统的机器学习方法使用起来泛化能力会更好。
- 第二看是否需要对结果有较强的解释性和可调节性,解释性是说我们能够了解到产生该输出结果的原因,这样我们能够知道特征的重要程度,并在出错时能够对错误原因进行分析。可调节性是指在出错或有特征的增删时,能够方便的对原模型进行修正以满足新的要求。在这一方面,一般的机器学习方法有一定的优势。
各自的优势领域:
- 深度学习:图像处理,自然语言处理等,因为图像、语言、文本都较难进行特征工程,交给深度学习是一个很好的选择。
- 机器学习:金融风控,量化分析,推荐系统,广告预测等,因为需要较好的可解释性,会更多的采用传统机器学习方法。
7. 对fine-tuning(微调模型)的理解?为什么要修改最后几层神经网络权值?
使用预训练模型的好处:在于利用训练好的SOTA模型权重去做特征提取,可以节省我们训练模型和调参的时间。
理由:
- CNN中更靠近底部的层(定义模型时先添加到模型中的层)编码的是更加通用的可复用特征,而更靠近顶部的层(最后添加到模型中的层)编码的是更专业化的特征。微调这些更专业化的特征更加有用,它更代表了新数据集上的有用特征。
- 训练的参数越多,过拟合的风险越大。很多SOTA模型拥有超过千万的参数,在一个不大的数据集上训练这么多参数是有过拟合风险的,除非你的数据集像Imagenet那样大
8. 什么是Dropout?为什么有用?它是如何工作的?
Dropout可以防止过拟合,在前向传播的时候,让某个神经元的激活值以一定的概率 P P P 停止工作,这样可以使模型的泛化性更强。
Dropout效果跟bagging效果类似(bagging是减少方差variance,而boosting是减少偏差bias)。加入Dropout会使神经网络训练时间长,模型预测时不需要dropout,记得关掉。
具体流程:
- 随机删除(临时)网络中一定的隐藏神经元,输入输出保持不变;
- 让输入通过修改后的网络。然后把得到的损失同时修改后的网络进行反向传播。在未删除的神经元上面进行参数更新;
- 重复该过程(恢复之前删除掉的神经元,以一定概率删除其他神经元。前向传播、反向传播更新参数)
9. 解释一下 1×1 卷积的原理,它主要用来干什么?
卷积核(convolutional kernel):可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有 1 × 1 , 3 × 3 , 5 × 5 1\times1,3\times3 ,5 \times5 1×1,3×3,5×5 的尺寸(一般是奇数 × \times × 奇数)。
作用是:
- 升/降特征的维度,这里的维度指的是通道数(厚度),而不改变图片的宽和高。
- 增加网络的深度。 1 × 1 1\times1 1×1 的卷积核虽小,但也是卷积核,加 1 层卷积,网络深度自然会增加。
10. 卷积神经网络中的卷积层,为什么需要 padding?
- 保持边界信息,如果不加 padding,边界信息只会被卷积核扫描一次;
- 可以通过 padding 对尺寸差异图片进行补齐;
- 如果不加 padding,每次经过卷积层,feature map 都会变小,这样若干层卷积层之后,feature map 就很小了,通过 padding 可以维持 feature map 的 size。
11. CNN 特性?
- 平移不变性。简单来说,平移不变性(translation invariant)指的是 CNN 对于同一张图及其平移后的版本,都能输出同样的结果。这对于图像分类(image classification)问题来说肯定是最理想的,因为对于一个物体的平移并不应该改变它的类别。
- 平移等价性/等变性。CNN 中 conv 层对应的是“等变性”(Equivariance),由于 conv 层的卷积核对于特定的特征才会有较大激活值,所以不论上一层特征图谱(feature map)中的某一特征平移到何处,卷积核都会找到该特征并在此处呈现较大的激活值。这应该就是“等变性”。
- 尺度不变性。对于尺度不变性,是没有或者说具有一定的不变性(尺度变化不大)。
- 旋转不变性。
12. 请说下常见优化方法各自的优缺点?

13. 为什么Momentum可以加速训练?
动量其实累加了历史梯度更新方向,所以在每次更新时,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。动量方法限制了梯度更新方向的随机性,使其沿正确方向进行。
14. 什么时候使用Adam和SGD?
Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。
Adam+SGD 组合策略:先用Adam快速下降,再用SGD调优。
如果模型是非常稀疏的,那么优先考虑自适应学习率的算法;在模型设计实验过程中,要快速验证新模型的效果,用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
15. 神经网络为什么不用拟牛顿法而是用梯度下降?

16. BN 和 Dropout 在训练和测试时的差别?
- BN:训练时,是对每一个batch的训练数据进行归一化,也即是用每一批数据的均值和方差。测试时,都是对单个样本进行测试。这个时候的均值和方差是全部训练数据的均值和方差,这两个数值是通过移动平均法求得。
- Dropout:只有在训练的时候才采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。
17. 网络设计中,为什么卷积核设计尺寸都是奇数?
- 保证像素点中心位置,避免位置信息偏移。
- 填充边缘时能保证两边都能填充,原矩阵依然对称。
18. AlexNet 对比LeNet 的优势?
- AlexNet比LeNet更深;
- 用多层的小卷积来替换单个的大卷积;
- 非线性激活函数:ReLU
- 防止过拟合的方法:Dropout,数据增强
- 大数据训练:百万级ImageNet图像数据
- 其他:GPU实现,LRN归一化层的使用
19. VGG使用2个3*3卷积的优势在哪里?
减少网络层参数;更多的非线性变换。
20. 残差网络中残差块的结构,它相比之前的神经网络有什么优势,解决了什么问题?
深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫做 shortcut。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
21. 描述下 GoogLeNet 发展的几个过程?
- Inception v1 的网络,将 1 × 1 , 3 × 3 , 5 × 5 1\times1,3\times3,5\times5 1×1,3×3,5×5 的 conv 和 3 × 3 3\times3 3×3 的 pooling,stack在一起,一方面增加了网络的 width,另一方面增加了网络对尺度的适应性;
- v2 的网络在 v1 的基础上,进行了改进,一方面了加入了 BN 层,减少了Internal Covariate Shift(内部 neuron 的数据分布发生变化),使每一层的输出都规范化到一个 N ( 0 , 1 ) N(0, 1) N(0,1) 的高斯,另外一方面学习 VGG 用 2 个 3 × 3 3\times3 3×3 的 conv 替代inception 模块中的 5 × 5 5\times5 5×5,既降低了参数数量,也加速计算;
- v3 一个最重要的改进是分解(Factorization),将 7 × 7 7\times7 7×7 分解成两个一维的卷积( 1 × 7 , 7 × 1 1\times7,7\times1 1×7,7×1), 3 × 3 3\times3 3×3 也是一样( 1 × 3 , 3 × 1 1\times3,3\times1 1×3,3×1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将 1 个 conv 拆成 2 个 conv,使得网络深度进一步增加,增加了网络的非线性;
- v4 研究了 Inception 模块结合 Residual Connection 能不能有改进?发现ResNet 的结构可以极大地 加速训练 ,同时性能也有提升,得到 一 个Inception-ResNet v2 网络,同时还设计了一个更深更优化的 Inception v4 模型,能达到与 Inception-ResNet v2 相媲美的性能。
22. CNN中空洞卷积的作用是什么?
空洞卷积也叫扩张卷积,在保持参数个数不变的情况下增大了卷积核的感受野,同时它可以保证输出的特征映射的大小保持不变。一个扩张率为2的 3 × 3 3\times3 3×3卷积核,感受野与 5 × 5 5\times5 5×5的卷积核相同,但参数数量仅为9个。
k ′ = k + ( k − 1 ) ( r − 1 ) k'=k+(k-1)(r-1) k′=k+(k−1)(r−1)
23. 卷积计算公式?
H ′ / W ′ = H / W − K + 2 P S + 1 H'/W' = \frac{H/W-K+2P}{S}+1 H′/W′=SH/W−K+2P+1
24. 介绍反卷积?
转置卷积(也称为反卷积)是一种与常规卷积相反的操作。它可以用来将低维特征图(如从编码器传递到解码器的特征图)转换为高维特征图,从而实现上采样(upsampling)的效果。
转置卷积的工作方式与普通卷积相反。在普通卷积中,通过将卷积核在输入上滑动以生成输出特征图。而在转置卷积中,卷积核在输出上滑动以生成输入特征图。
H ′ / W ′ = ( H / W − 1 ) × S + K − 2 P H'/W' = (H/W-1)\times S+K-2P H′/W′=(H/W−1)×S+K−2P
25. RNN 是一种什么样的神经网络?
RNN 是用来处理序列数据的神经网络,其引入了具有“记忆”性质的结构单元,计算除了本次的输入,还包括上一次的计算结果。经典 RNN 结构示意图: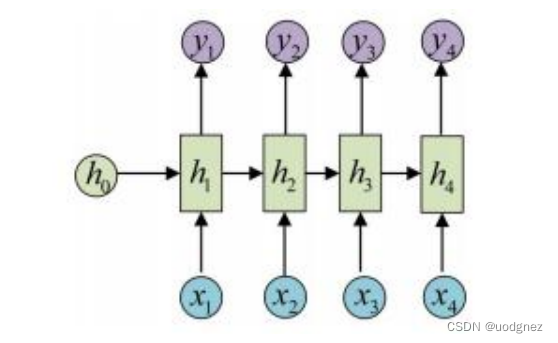
它的输⼊是 x 1 , x 2 , . . . . . x n x_1, x_2, .....x_n x1,x2,.....xn,输出为 y 1 , y 2 , . . . y n y_1, y_2, ...y_n y1,y2,...yn,也就是说,输⼊和输出序列必须要是等长的。由于这个限制的存在,经典 RNN 的适⽤范围⽐较⼩,但也有⼀些问题适合⽤经典的 RNN 结构建模,如
- 计算视频中每⼀帧的分类标签。因为要对每⼀帧进⾏计算,因此输⼊和输出序列等长。
- 输⼊为字符,输出为下⼀个字符的概率。这就是著名的 Char RNN(详细介绍请参考:The Unreasonable Effectiveness of Recurrent Neural Networks,CharRNN 可以⽤来⽣成⽂章、诗歌,甚⾄是代码。)
26. 什么是长期依赖问题?
长期依赖问题(Long-Term Dependency Problem)是指在处理序列数据时,当序列中的某个事件对于当前时刻的预测具有很重要的影响,但由于传统的循环神经网络(RNN)的限制,随着时间的推移,这种影响会逐渐减弱,最终变得无法捕捉到。
这个问题的根本原因在于,在传统的 RNN 中,信息的传递是通过链式结构进行的,每个时间步的隐藏状态只能受到前一个时间步的隐藏状态和当前时间步的输入的影响。这意味着在较长的序列中,早期的信息会被逐渐稀释,导致网络无法捕捉到远处时间步的重要信息。
这对于许多实际问题来说是一个严重的限制,因为许多任务(如语言理解、音乐生成等)需要考虑到长时间内的上下文信息。在这种情况下,传统的 RNN 可能无法有效地学习到正确的模式,导致性能下降。
为了解决这个问题,出现了一些改进的循环神经网络变体,如长短时记忆网络(LSTM)和门控循环单元(GRU)。这些模型通过引入门控机制,允许网络选择性地保留或遗忘信息,从而在处理长序列时更加有效。
27. LSTM?
长短期记忆网络(Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。
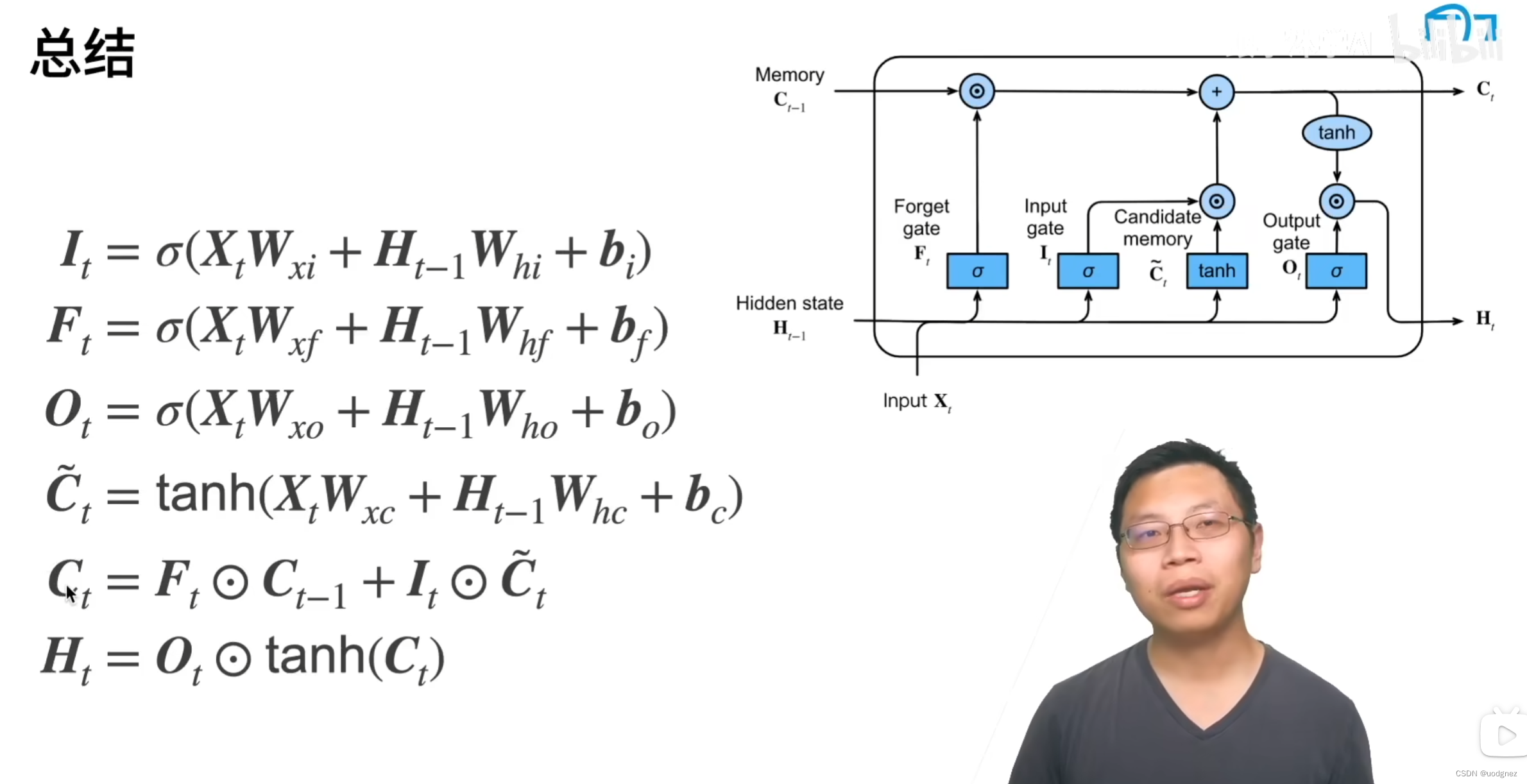
- 决定从上一时刻的细胞状态 C t − 1 C_{t-1} Ct−1 中丢弃什么信息:
LSTM中的第一步是决定从上一时刻的细胞状态 C t − 1 C_{t-1} Ct−1 丢弃什么信息,该功能通过“遗忘门”来完成。该门会读取 H t − 1 H_{t-1} Ht−1 和 X t X_t Xt,然后通过 sigmoid 将其映射到0到1之间的数值,最终该数值再与细胞状态 C t − 1 C_{t-1} Ct−1 相乘,来决定 C t − 1 C_{t-1} Ct−1 该丢弃什么信息。当该数值为1表示“完全保留” C t − 1 C_{t-1} Ct−1 的信息,0则表示“完全舍弃” C t − 1 C_{t-1} Ct−1 的信息。
以预测下一个词举个例子,上一个细胞状态 C t − 1 C_{t-1} Ct−1 可能包含了当前主语的性别,如果要预测下一个词是主语的代词 (he, she),那么 C t − 1 C_{t-1} Ct−1 就可以用来决定到底是使用 he 还是 she,此时不应该忘记 C t − 1 C_{t-1} Ct−1。但是如果当前有新的主语,那么就应该忘记 C t − 1 C_{t-1} Ct−1 中的主语信息。
-
确定什么样的新信息被存放在当前细胞中:
这里有两部分操作。第一部分是通过一个 tanh 层产生一个当前时刻的候选细胞状态 C ~ t \tilde{C}_{t} C~t。第二部分是由 Sigmoid 组成的“输入门”产生的介于 0 到 1 之间的控制信号 I t I_{t} It,来控制 C ~ t \tilde{C}_{t} C~t 的输入程度。
在语言模型中,这个步骤相当于产生新的主语,用于代替旧的主语。 -
将旧的细胞状态 C t − 1 C_{t-1} Ct−1 更新为当前细胞状态 C ~ t \tilde{C}_{t} C~t:
有了“遗忘门”产生的控制信号 F t F_t Ft 和“输入门”产生的控制信号 I t I_{t} It,tanh 产生的候选细胞状态 C ~ t \tilde{C}_{t} C~t,就可以将 C t − 1 C_{t-1} Ct−1 更新为当前细胞状态 C t C_{t} Ct 。
首先,使用遗忘信号 F t F_{t} Ft 与 C t − 1 C_{t-1} Ct−1 相乘得到上一个细胞状态剩余下的信息;然后再使用输入信号 I t I_{t} It 乘以候选细胞状态 C ~ t \tilde{C}_{t} C~t 得到候选细胞剩余下的信息;最后将这两部分信息相加,就得到了最终当前时刻的细胞状态 C t C_{t} Ct。 -
确定输出最终值:
先前我们已经确定要传入下一时刻的细胞状态 C t C_{t} Ct,但是还没有决定当前的输出 H t H_t Ht,所以最后我们来决定最终的输出值。这里也包括两部分操作,第一部分就是由sigmoid组成的“输出门”产生的介于0到1之间的控制信号 O t O_t Ot ;第二部分是将最终产生的输出信息 tanh( C t C_t Ct)与控制信号 O t O_t Ot相乘,得到最终的 H t H_t Ht。
28. GRU?
GRU模型中有两个门,重置门和更新门。
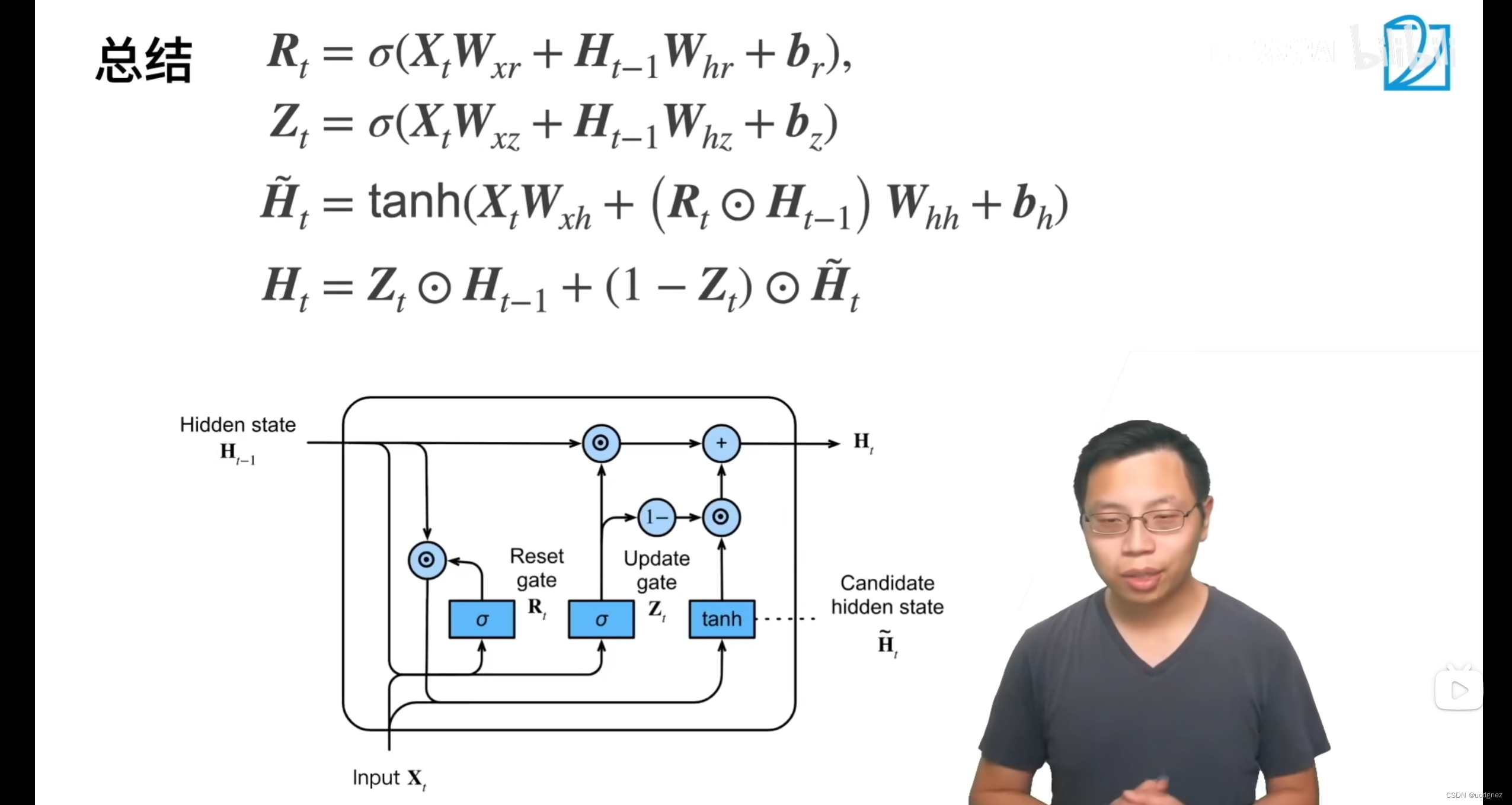
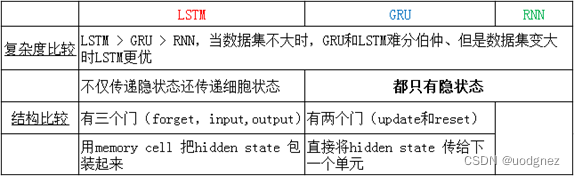
29. LSTM、RNN、GRU区别?
30. 什么是反向传播?
类比几个人站成一排,第一个人看一幅画(输入数据),描述给第二个人(隐层)……依此类推,到最后一个人(输出)的时候,画出来的画肯定不能看了(误差较大)。
反向传播就是:把画拿给最后一个人看(求取误差),然后最后一个人就会告诉前面的人下次描述时需要注意哪里(权值修正)。
一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
目的是更新神经元参数,而神经元参数正是 z = w x + b z=wx+b z=wx+b 中的 ( w , b w,b w,b).对参数的更新,利用损失值loss对参数的导数, 并沿着负梯度方向进行更新。
31. GAN?
生成式对抗网络,由一个生成器网络和一个判别器网络组成。判别器的训练目的是能够区分生成器的输出与来自训练集的真实图像,生成器的训练目的是欺骗判别器。值得注意的是,生成器从未直接见过训练集中的图像,它所知道的关于数据的信息都来自于判别器。
GAN 相关的技巧:

相关文章:
深度学习问答题(更新中)
1. 各个激活函数的优缺点? 2. 为什么ReLU常用于神经网络的激活函数? 在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;避免梯度消失问题。对于深层网络,Sigmoid函数反向传播时,很容易就…...

JavaScript 笔记: 函数
1 函数声明 2 函数表达式 2.1 函数表达式作为property的value 3 箭头函数 4 构造函数创建函数(不推荐) 5 function 与object 5.1 typeof 5.2 object的操作也适用于function 5.3 区别于⼀般object的⼀个核⼼特征 6 回调函数 callback 7 利用function的pr…...

2023NOIP A层联测9-天竺葵
天竺葵/无法阻挡的子序列/很有味道的题目 我们称一个长度为 k k k 的序列 c c c 是好的,当且仅当对任意正整数 i i i 在 [ 1 , k − 1 ] [1,k-1] [1,k−1] 中,满足 c i 1 > b i c i c_{i1}>b_i \times c_i ci1>bici, …...
react antd table表格点击一行选中数据的方法
一、前言 antd的table,默认是点击左边的单选/复选按钮,才能选中一行数据; 现在想实现点击右边的部分,也可以触发操作选中这行数据。 可以使用onRow实现,样例如下。 二、代码 1.表格样式部分 //表格table样式部分{…...
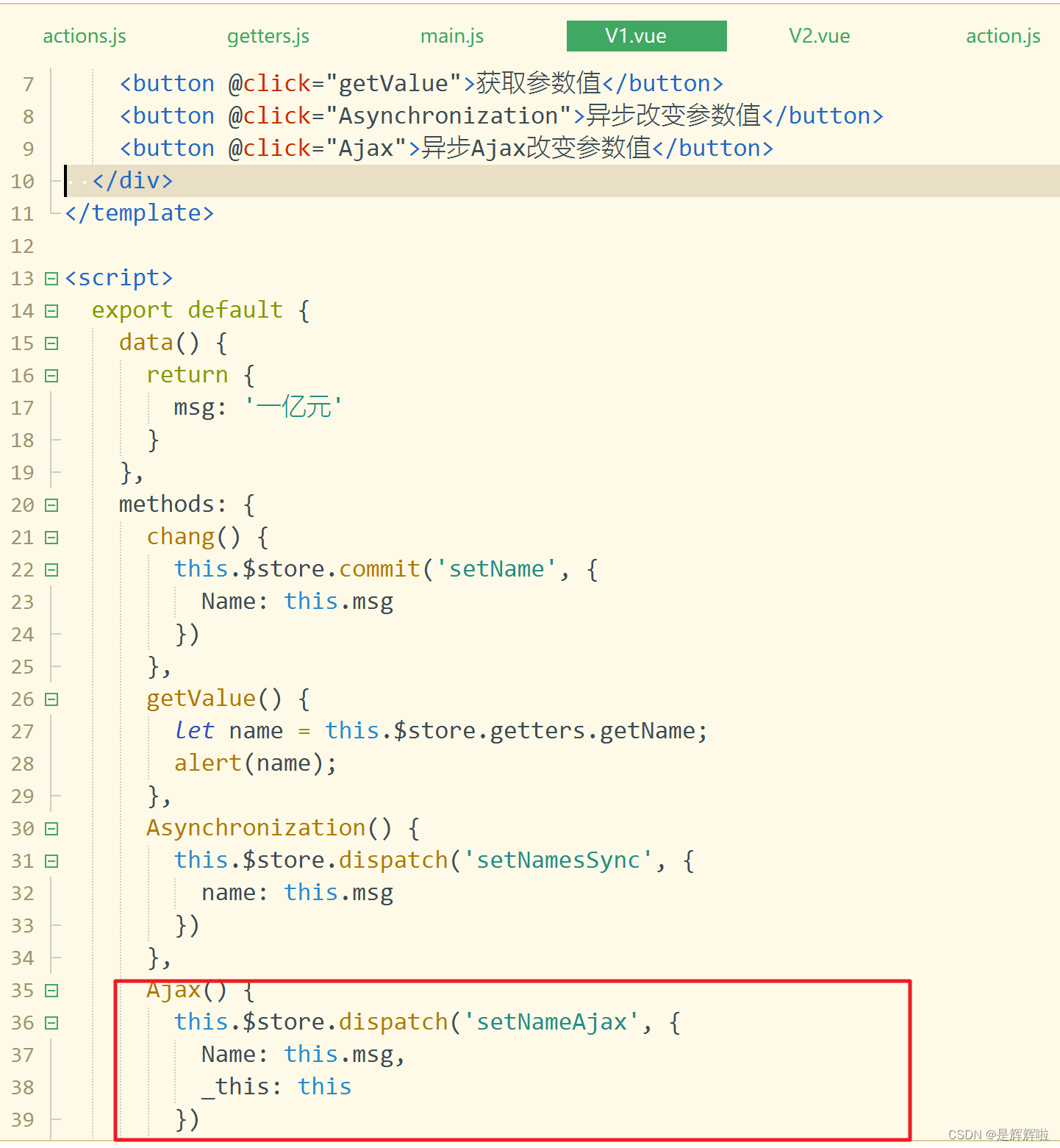
【VUEX】最好用的传参方式--Vuex的详解
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于VuexElementUI的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.Vuex是什么 1.定义 2…...
)
【.net core】yisha框架 SQL SERVER数据库 反向递归查询部门(子查父)
业务service.cs中ListFilter方法中内容 //反向递归查询部门列表List<DepartmentEntity> departmentList await departmentService.GetReverseRecurrenceList(new DepartmentListParam() { Ids operatorInfo.DepartmentId.ToString() });if (departmentList ! null &am…...
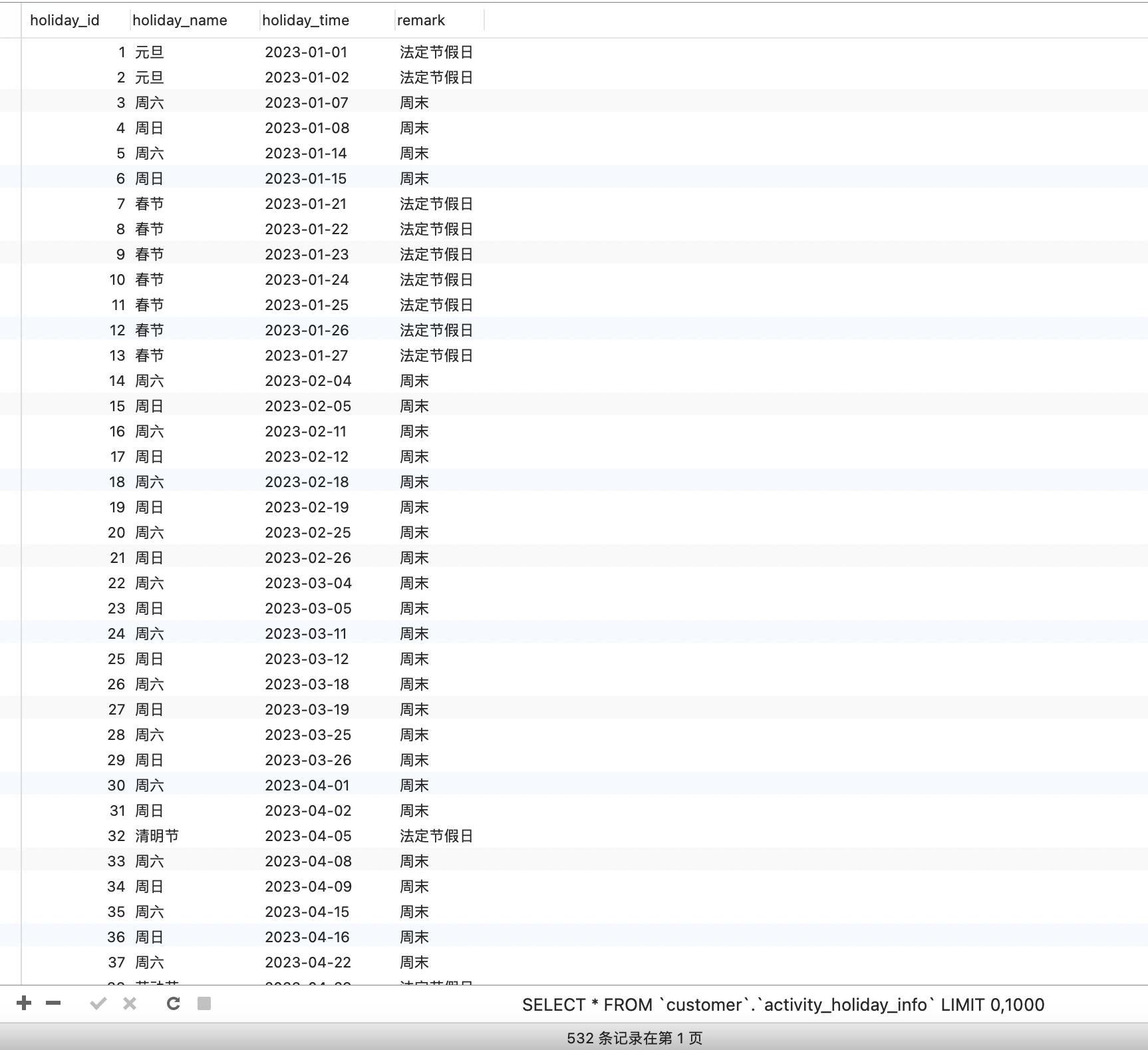
java处理时间-去除节假日以及双休日
文章目录 一、建表:activity_holiday_info二、java代码1、ActivitityHolidayController.java2、ActivityHolidayInfoService.java3、ActivityHolidayInfoServiceImpl.java 三、测试效果 有些场景需要计算数据非工作日的情况,eg:统计每个人每月工作日签到…...

快讯|Tubi 有 Rabbit AI 啦
在每月一期的 Tubi 快讯中,你将全面及时地获取 Tubi 最新发展动态,欢迎星标关注【比图科技】微信公众号,一起成长变强! Tubi 推出 Rabbit AI 帮助用户找到喜欢的视频内容 Tubi 于今年九月底推出了 Rabbit AI,这是一项…...

Zookeeper从入门到精通
Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护。Zookeeper 可以用于实现分布式系统中常见的发布/订阅、负载均衡、命令服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。 目录 01-Zookeeper特性与节点数据类型详解02-Z…...
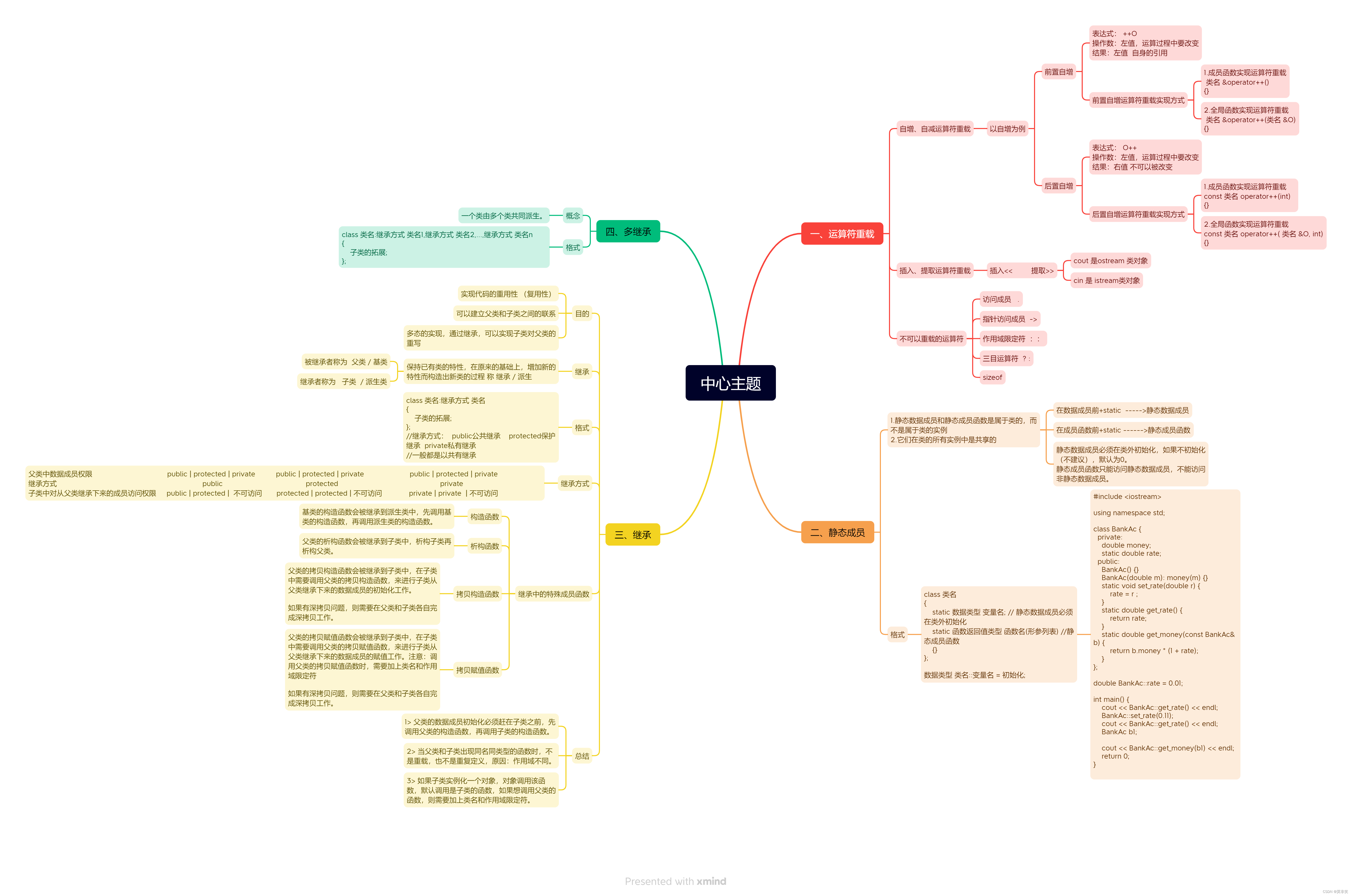
10.11作业
多继承代码实现沙发床 #include <iostream>using namespace std;class Sofa {private:int h;public:Sofa() {cout << "Sofa无参构造" << endl;}Sofa(int h): h(h) {cout << "Sofa有参构造" << endl;}Sofa(const Sofa& …...
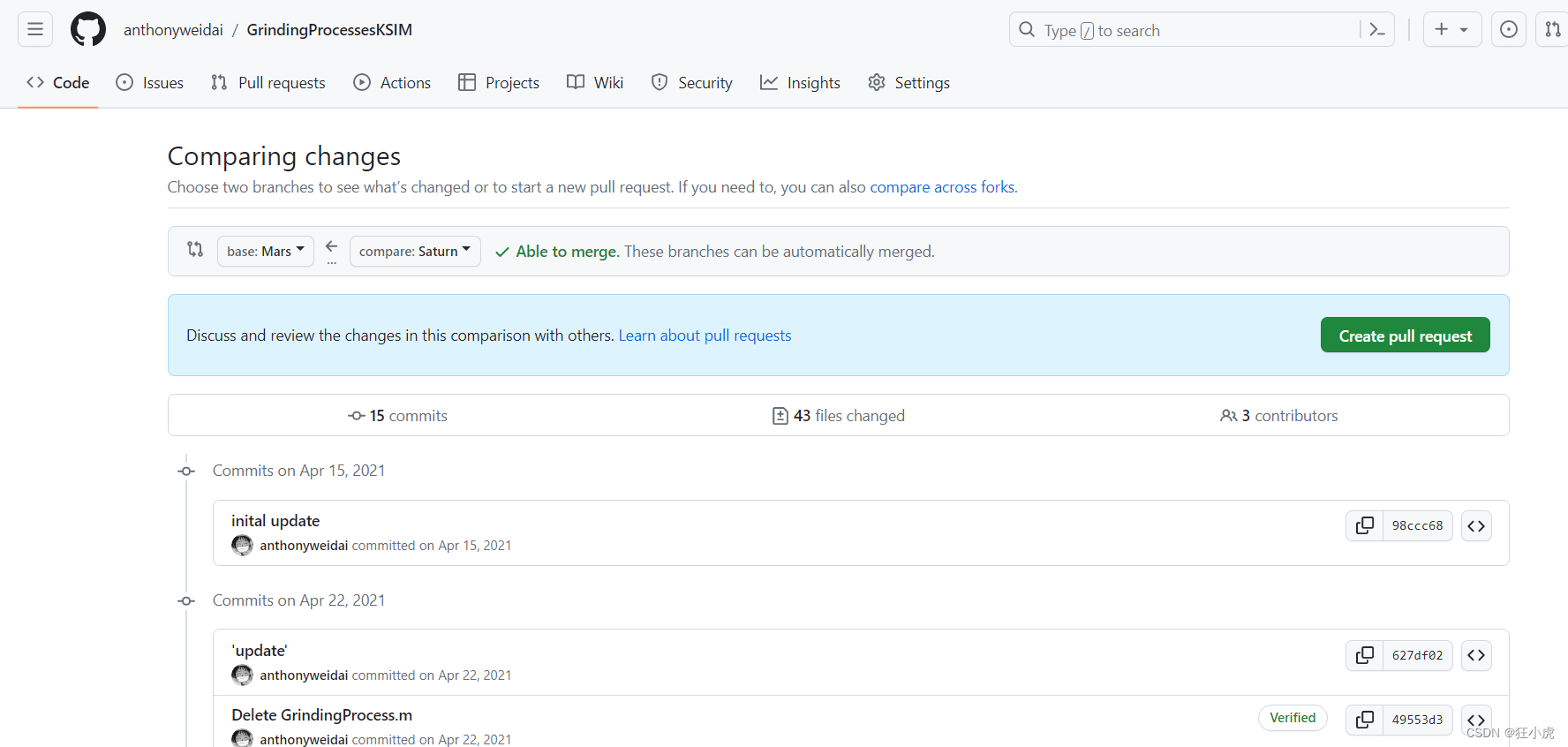
如何对比github中不同commits的区别
有时候想要对比跨度几十个commits之前的代码区别,想直接使用github的用户界面。可以直接在官网操作。 示例 首先要创建一个旧commit的branch。进入该旧的commit,然后输入branch名字即可。 然后在项目网址后面加上compare即可对比旧的branch和新的bran…...

串的基本操作(数据结构)
串的基本操作 #include <stdlib.h> #include <iostream> #include <stdio.h> #define MaxSize 255typedef struct{char ch[MaxSize];int length; }SString;//初始化 SString InitStr(SString &S){S.length0;return S; } //为了方便计算,串的…...

ctfshow-web12(glob绕过)
打开链接,在网页源码里找到提示 要求以get请求方式给cmd传入参数 尝试直接调用系统命令,没有回显,可能被过滤了 测试phpinfo,回显成功,确实存在了代码执行 接下来我们尝试读取一下它存在的文件,这里主要介…...
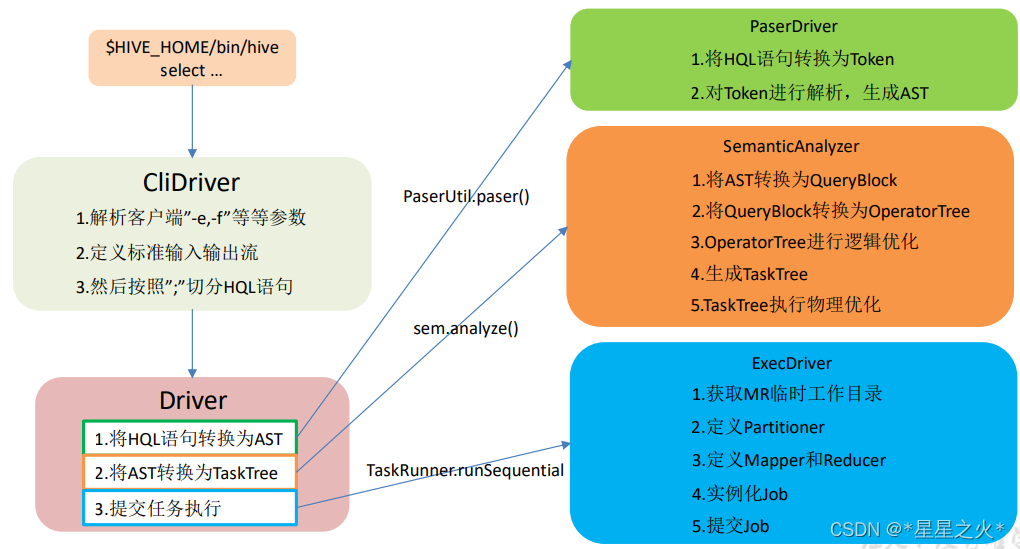
hive3.1核心源码思路
系列文章目录 大数据主要组件核心源码解析 文章目录 系列文章目录大数据主要组件核心源码解析 前言一、HQL转化为MR 核心思路二、核心代码1. 入口类,生命线2. 编译代码3. 执行代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 对大…...
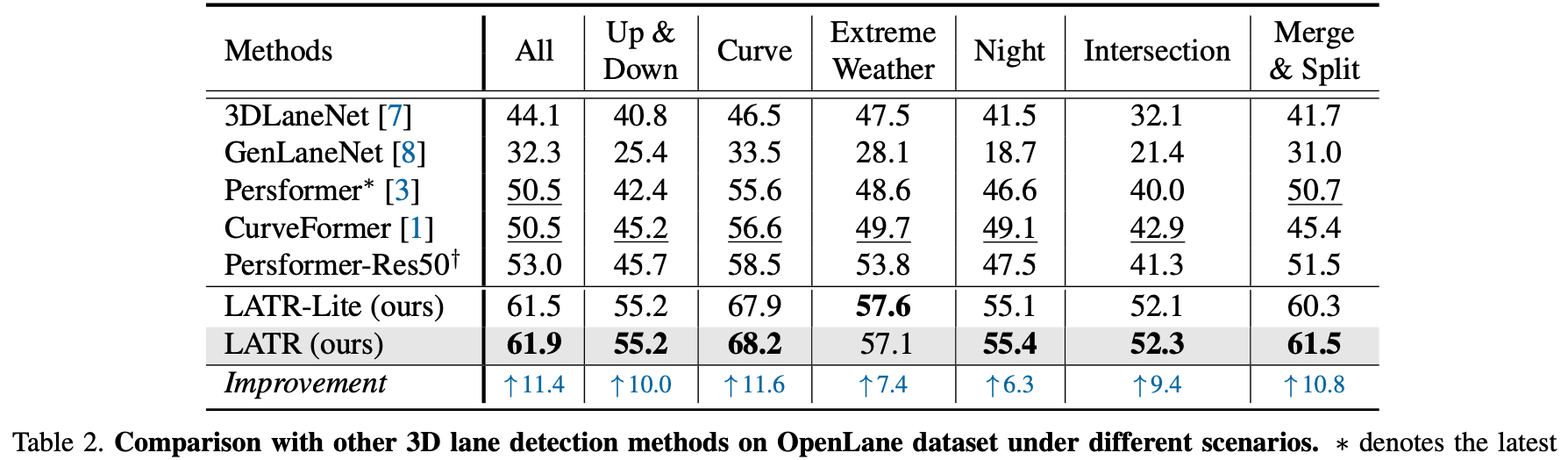
LATR:3D Lane Detection from Monocular Images with Transformer
参考代码:LATR 动机与主要工作: 之前的3D车道线检测算法使用诸如IPM投影、3D anchor加NMS后处理等操作处理车道线检测,但这些操作或多或少会存在一些负面效应。IPM投影对深度估计和相机内外参数精度有要求,anchor的方式需要一些如…...

什么是UI自动化测试工具?
UI自动化测试工具有着AI技术驱动,零代码开启自动化测试,集设备管理与自动化能力于一身的组织级自动化测试管理平台。基于计算机视觉技术,可跨平台、跨载体执行脚本,脚本开发和维护效率提升至少50%;多端融合统一用户使用体验&#…...
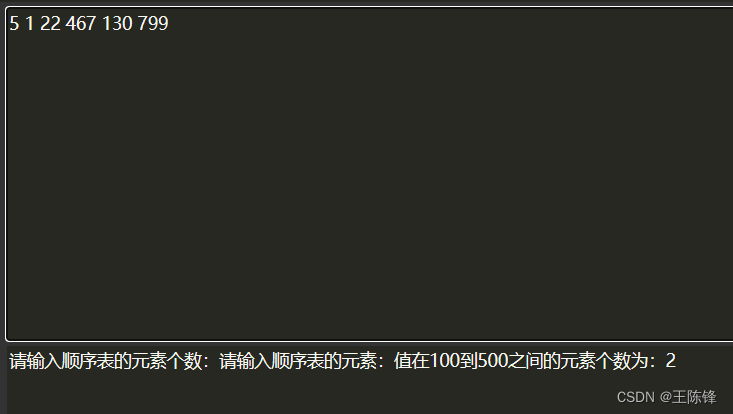
计算顺序表中值在100到500之间的元素个数
要求顺序表中值在100到500之间的元素的个数,你可以使用C语言编写一个循环来遍历顺序表中的元素,并在循环中检查每个元素是否在指定的范围内。 #include <stdio.h>#define MAX_SIZE 100 // 假设顺序表的最大容量为100int main() {int arr[MAX_SIZE]…...

【问题总结】级数的括号可以拆吗?
问题 今天在做题的时候发现,括号这个问题时常出现。Σun,Σvn,和Σ(unvn),两个级数涉及到了括号增删,Σ(un-1un),级数钟的前后项的合并也涉及到了括号增删。 总结 添括号定理&…...

抖音自动养号脚本+抖音直播控场脚本
功能描述 一.抖音功能 1.垂直浏览 2.直播暖场 3.精准引流 4.粉丝留言 5.同城引流 6.取消关注 7.万能引流 8.精准截流 9.访客引流 10.直播间引流 11.视频分享 12.榜单引流 13.搜索引流 14.点赞回访 15.智能引流 16.关注回访 介绍下小红书数据挖掘 搜索关键词&…...
uvm中transaction的response和id的解读
在公司写代码的时候发现前辈有一段这样的代码: ....//其他transaction uvm_create(trans);........ uvm_send(trans); tmp_id trans.get_transaction_id(); get_response(rsp,tmp_id); 如果前面有其他transaction,这段代码里的get_response不带id的话…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

Sangfor文件夹可以删除吗?【图文讲解】深信服文件夹残留清理?如何彻底删除深信服?Sangfor文件夹是什么?
(1)问题背景打开C盘,突然冒出个Sangfor 文件夹,占用好几个 GB 空间,想删又不敢删,怕删坏系统、断网崩溃;上网一查,说法五花八门,有人说是病毒,有人说是办公软…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...