VGG卷积神经网络实现Cifar10图片分类-Pytorch实战
前言
当涉足深度学习,选择合适的框架是至关重要的一步。PyTorch作为三大主流框架之一,以其简单易用的特点,成为初学者们的首选。相比其他框架,PyTorch更像是一门易学的编程语言,让我们专注于实现项目的功能,而无需深陷于底层原理的细节。
就像我们使用汽车时,更重要的是了解如何驾驭,而不是花费过多时间研究轮子是如何制造的。我将以一系列专门针对深度学习框架的文章,逐步深入理论知识和实践操作。但这需要在对深度学习有一定了解后才能进行,现阶段我们的重点是学会如何灵活使用PyTorch工具。深度学习涉及大量数学理论和计算原理,对于初学者来说可能会有些繁琐。然而,只有通过实际操作,我们才能真正理解所写代码在神经网络中的作用。我将努力将知识简化,转化为我们熟悉的内容,让大家能够理解和熟练使用神经网络框架。
如果你发现深度学习看似难以掌握,我将尽力简化知识,将其转化为我们更容易理解的内容。我会确保你能够理解知识并顺利运用到实践中。在后期,我将发布一系列专门解析深度学习框架的文章,但在开始学习之前,我们需要对深度学习的理论知识和实践操作有一定的熟悉度。
作为一个从事数据建模五年的专业人士,我参与了许多数学建模项目,了解各种模型的原理、建模流程和题目分析方法。我希望通过这个专栏让你能够快速掌握各类数学模型、机器学习和深度学习知识,并掌握相应的代码实现。每篇文章都包含实际项目和可运行的代码。我会紧跟各类数模比赛,将最新的思路和代码分享给你,保证你能够高效地学习这些知识。
博主非常期待与你一同探索这个精心打造的专栏,里面充满了丰富的实战项目和可运行的代码,希望你不要错过:专栏链接
一、VGGNet概述
VGGNet(Visual Geometry Group Network)是由牛津大学视觉几何组(Visual Geometry Group)提出的深度卷积神经网络架构,它在2014年的ImageNet图像分类挑战中取得了优异的成绩。VGGNet之所以著名,一方面是因为其简洁而高效的网络结构,另一方面是因为它通过深度堆叠的方式展示了深度卷积神经网络的强大能力。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
VGGNet包含两种结构,分别为16层和19层。VGGNet结构中,所有卷积层的kernel都只有3*3。VGGNet中连续使用3组3*3kernel的原因是它与使用1个7*7kernel产生的效果相同,然而更深的网络结构还会学习到更复杂的非线性关系,从而使得模型的效果更好。该操作带来的另一个好处是参数数量的减少,因为对于一个包含了C个kernel的卷积层来说,原来的参数个数为7*7*C,而新的参数个数为3*(3*3*C)。
下图给出了VGG16的具体结构示意图:
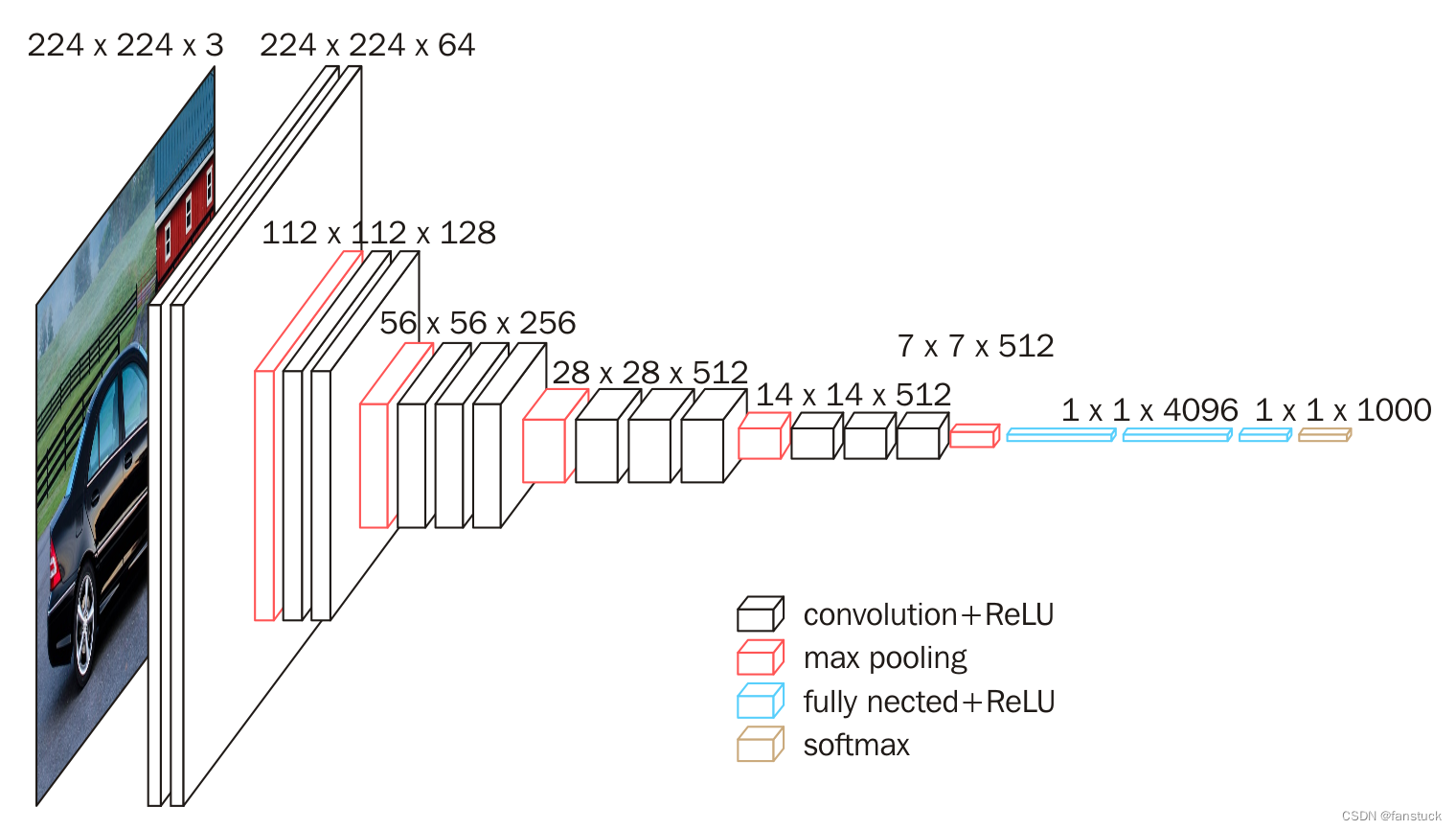
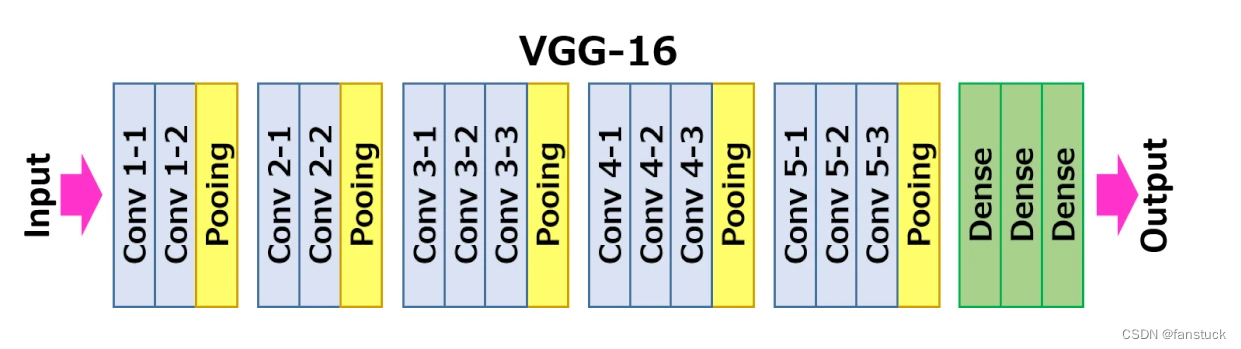
根据VGG16进行具体分析,包含:
- 13个卷积层(Convolutional Layer)
- 3个全连接层(Fully connected Layer)
- 5个池化层(Pool layer)
其中,卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16,这即是VGG16中16的来源。
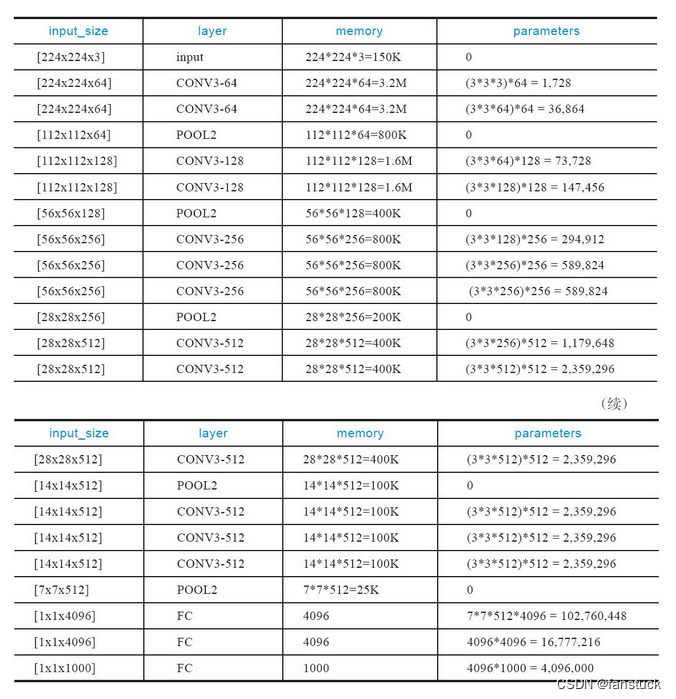
内存消耗主要来自早期的卷积,而参数量的激增则发生在后期的全连接层。由于采用了大量的卷积层,导致VGGNet的参数数量较大,训练和推理过程需要更多的计算资源。而且参数量较大,需要更多的数据来避免过拟合问题。
二、PyTorch网络搭建
我们参考上述网络结构,利用pytorch进行网络搭建,首先我们可以先搭建输出层,根据我上述提供的每一层具体的parameters搭建即可:
def __init__(self, num_classes=1000):super(VGG,self).__init()__self.features = self._make_layers()self.classifier = nn.Sequential(nn.Linear(512*7*7,4096),nn.ReLU(True),nn.Dropout(),nn,Linear(4096,4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096,num_classes))接下来我们来搭建卷积和全连接层,可以利用循环帮助我们省去每个步骤繁琐的写层:
def _make_layers(self):layers = []in_clannels = 3cfg =[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M']for v in cfg:if v =='M':layers +=[nn.MaxPool2d(kernel_size=2,stride=2)]else:conv2d = nn.Conv2d(in_channels,v,kernel_size)layers +=[conv2d,nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)然后写入每个神经网络必备的传播:
def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x总体网络结构为:
VGGNet((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
定义损失函数和优化方法:
#定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() #定义损失函数:交叉熵
optimizer = torch.optim.SGD(net.parameters(),lr=0.001,momentum=0.9)#定义优化方法,随机梯度下降
进行卷积网络训练,这里需要微调一下原来vgg的模型,Cifar10的数据集有10个类别而且图片转换的矩阵需要加入自适应池化层,要一些改进:
import torch.nn as nn# 设置随机种子以保证实验的可复现性
torch.manual_seed(0)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Falseclass VGGNet(nn.Module):def __init__(self, num_classes=10):super(VGGNet, self).__init__()self.features = self._make_layers()self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512*7*7,4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096,4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096,num_classes))def _make_layers(self):layers = []in_channels = 3cfg =[64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512, 512, 512, 'M']for v in cfg:if v =='M':layers +=[nn.MaxPool2d(kernel_size=2,stride=2)]else:conv2d = nn.Conv2d(in_channels,v,kernel_size=3, padding=1)layers +=[conv2d,nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x需要注意到是我们需要初始化网络的权重,不更新权重的话10000张图片和实际不借助算法猜测图片的概率是一致的,我们先不初始化网络的权重进行训练:
for epoch in range(1):train_loss=0.0for batch_idx,data in enumerate(train_loader,0):#初始化inputs,labels = data #获取数据inputs = inputs.to(device)labels = labels.to(device)optimizer.zero_grad() #梯度置0#优化过程outputs = net(inputs) #将数据输入到网络,得到第一轮网络前向传播的预测结果outputsloss = criterion(outputs,labels) #预测结果outputs和labels通过之前定义的交叉熵计算损失loss.backward() #误差反向传播optimizer.step() #随机梯度下降优化权重#查看网络训练状态train_loss += loss.item()if batch_idx % 2000 == 1 :print(batch_idx)print('[%d,%5d] loss: %.3f' % (epoch + 1,batch_idx + 1,train_loss / 2000))train_loss = 0.0print('Saving epoch %d model ...'%(epoch + 1))state = {'net':net.state_dict(),'epoch':epoch+1,}if not os.path.isdir('checkpoint'):os.mkdir('checkpoint')#torch.save(state,'./checkpoint/cifar10_epoch_%d.ckpt'%(epoch+1))print('Finished Training')然后我们去计算整个测试集的预测效果:
#批量计算整个测试集的预测效果
correct= 0
total = 0
with torch.no_grad():for data in test_loader:images,labels = dataimages = images.to(device)labels = labels.to(device)outputs = net(images)_,predicted = torch.max(outputs.data,1)total += labels.size(0)correct += (predicted == labels ).sum().item() #当标记的label种类和预测的种类一致时认为正确,并计数print('Accurary of the network on the 10000 test images : %d %%'%(100*correct/total))
很明显和实际猜测的概率是一模一样的,总共十个类别1/10很正常:
Accurary of the network on the 10000 test images : 10 %
我们需要先进行初始化网络权重在训练:
def initialize_weights(module):if isinstance(module, nn.Conv2d):nn.init.kaiming_normal_(module.weight, mode='fan_out', nonlinearity='relu')if module.bias is not None:nn.init.constant_(module.bias, 0)elif isinstance(module, nn.Linear):nn.init.normal_(module.weight, 0, 0.01)nn.init.constant_(module.bias, 0)
之后在训练预测一版:
Accurary of the network on the 10000 test images : 47 %
效果就十分明显了。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
相关文章:
VGG卷积神经网络实现Cifar10图片分类-Pytorch实战
前言 当涉足深度学习,选择合适的框架是至关重要的一步。PyTorch作为三大主流框架之一,以其简单易用的特点,成为初学者们的首选。相比其他框架,PyTorch更像是一门易学的编程语言,让我们专注于实现项目的功能࿰…...

CentOS 7文件系统中的软链接和硬链接
软链接(Symbolic Link) 软链接,也称为符号链接,是一个指向另一个文件或目录的特殊类型的文件。它是一个指向目标文件的符号,就像快捷方式一样。软链接的创建和使用非常灵活,适用于各种情况。 创建软链接 …...
【AI】深度学习——前馈神经网络——全连接前馈神经网络
文章目录 1.1 全连接前馈神经网络1.1.1 符号说明超参数参数活性值 1.1.2 信息传播公式通用近似定理 1.1.3 神经网络与机器学习结合二分类问题多分类问题 1.1.4 参数学习矩阵求导链式法则更为高效的参数学习反向传播算法目标计算 ∂ z ( l ) ∂ w i j ( l ) \frac{\partial z^{…...
超简单的视频截取方法,迅速提取所需片段!
“视频可以截取吗?用相机拍摄了一段视频,但是中途相机发生了故障,录进去了很多不需要的片段,现在想截取一部分视频出来,但是不知道方法,想问问广大的网友,知不知道视频截取的方法。” 无论是工…...
ArcGIS/GeoScene脚本:基于粒子群优化的支持向量机回归模型
参数输入 1.样本数据必须包含需要回归的字段 2.回归字段是数值类型 3.影响因子是栅格数据,可添加多个 4.随机种子可以确保每次运行的训练集和测试集一致 5.训练集占比为0-1之间的小数 6.迭代次数:迭代次数越高精度越高,但是运行时间越长…...

vue3组件的通信方式
一、vue3组件通信方式 通信仓库地址:vue3_communication: 当前仓库为贾成豪老师使用组件通信案例 不管是vue2还是vue3,组件通信方式很重要,不管是项目还是面试都是经常用到的知识点。 比如:vue2组件通信方式 props:可以实现父子组件、子父组件、甚至兄弟组件通信 自定义事件:可…...

Qt QPair
QPair 文章目录 QPair 摘要QPairQPair 特点代码示例QPair 与 QMap 区别 关键字: Qt、 QPair、 QMap、 键值、 容器 摘要 今天在观摩小伙伴撸代码的时候,突然听到了QPair自己使用Qt开发这么就,竟然都不知道,所以趁没有被人发…...
K8S云计算系列-(3)
K8S Kubeadm案例实战 Kubeadm 是一个K8S部署工具,它提供了kubeadm init 以及 kubeadm join 这两个命令来快速创建kubernetes集群。 Kubeadm 通过执行必要的操作来启动和运行一个最小可用的集群。它故意被设计为只关心启动集群,而不是之前的节点准备工作…...

ardupilot罗盘数据计算航向
目录 文章目录 目录摘要1.数据特点2.数据结论1.结论2.结论摘要 本节主要记录ardupilot 根据罗盘数据计算航向的过程。 如果知道了一组罗盘数据,我们可以粗略估计航向:主要后面我们所说的X和Y都是表示的飞机里面的坐标系,也就是X前Y右边,如果按照罗盘坐标系Y实际在左边。 我…...
)
第六章:最新版零基础学习 PYTHON 教程—Python 正则表达式(第一节 - Python 正则表达式)
在本教程中,您将了解RegEx并了解各种正则表达式。 常用表达为什么使用正则表达式基本正则表达式更多正则表达式编译的正则表达式 目录 元字符 为什么是正则表达式?...

docker安装Jenkins完整教程
1.docker拉取 Jenkins镜像并启动容器 新版本的Jenkins依赖于JDK11 我们选择docker中jdk11版本的镜像 # 拉取镜像 docker pull jenkins/jenkins:2.346.3-2-lts-jdk11 2.宿主机上创建文件夹 # 创建Jenkins目录文件夹 mkdir -p /data/jenkins_home # 设置权限 chmod 777 -R /dat…...

[CISCN 2019初赛]Love Math - RCE(异或绕过)
[CISCN 2019初赛]Love Math 1 解题流程1.1 分析1.2 解题题目代码: <?php //听说你很喜欢数学,不知道你是否爱它胜过爱flag if(!isset($_GET[c]))...
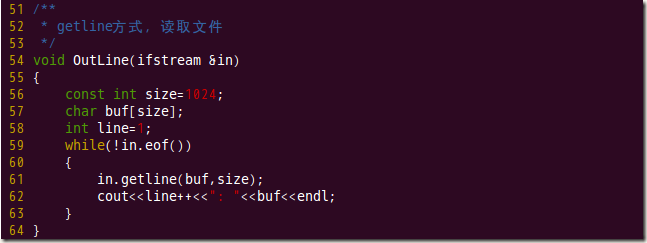
C++ 使用getline()从文件中读取一行字符串
我们知道,getline() 方法定义在 istream 类中,而 fstream 和 ifstream 类继承自 istream 类,因此 fstream 和 ifstream 的类对象可以调用 getline() 成员方法。 当文件流对象调用 getline() 方法时,该方法的功能就变成了从指定文件中读取一行字符串。 该方法有以下 2 种语…...
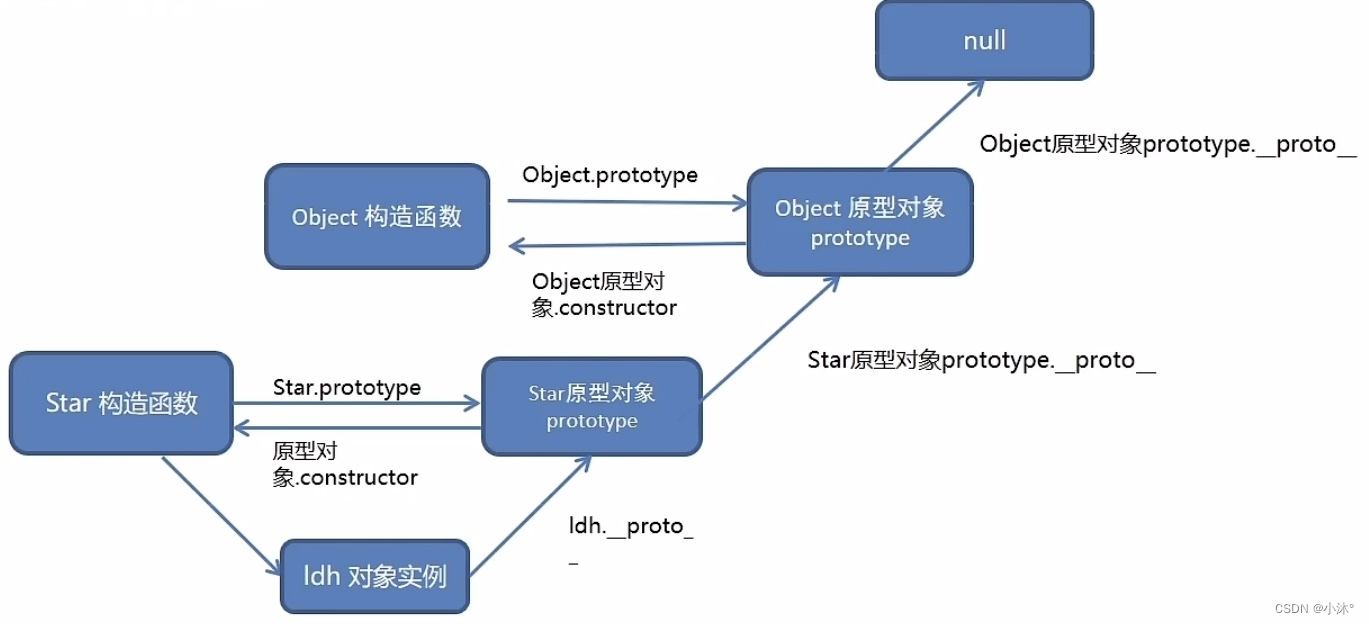
JS进阶-原型
原型 原型就是一个对象,也称为原型对象 构造函数通过原型分配的函数是所有对象所共享的 JavaScript规定,每一个构造函数都有一个prototype属性,指向另一个对象,所以我们也称为原型对象 这个对象可以挂载函数,对象实…...

虹科方案 | 汽车CAN/LIN总线数据采集解决方案
全文导读:现代汽车配备了复杂的电子系统,CAN和LIN总线已成为这些系统之间实现通信的标准协议,为了开发和优化汽车的电子功能,汽车制造商和工程师需要可靠的数据采集解决方案。基于PCAN和PLIN设备,虹科提供了一种高效、…...

HTML5+CSSDAY4综合案例一--热词
样式展示图: 代码如下: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>热词…...
【源码】hamcrest 源码阅读 泛型 extends 和迭代器模式
文章目录 前言1. 泛型参数和自定义迭代器1.1 使用场景1.2 实现 2. 值得一提 前言 官方文档 Hamcrest Tutorial 上篇文章 Hamcrest 源码阅读及空对象模式、模板方法模式的应用 本篇文章 迭代器模式 1. 泛型参数和自定义迭代器 hamcrest 作为一个matcher库,把某个…...
IntelliJ IDEA 2023.1 版本可以安装了
Maven 的导入时间更加快了。 收到的有邮件提醒安装。 安装后的版本,其实就是升级下,并没有什么主要改变。 IntelliJ IDEA 2023.1 版本可以安装了 - 软件技术 - OSSEZMaven 的导入时间更加快了。 收到的有邮件提醒安装。 安装后的版本,其实就是…...

安全论坛和外包平台汇总
文章目录 一. 网络安全论坛汇总二. 外包平台汇总1. 国内:2. 国外 一. 网络安全论坛汇总 安全焦点BugTraq:http://www.fuzzysecurity.com/Exploit-DB:https://www.exploit-db.com/hackone:https://www.hackerone.com/FreeBuf&…...

9-2-Dataset创建-import调用
文章目录 utils_dataset.pymain-调用utils_dateset.pyutils_dataset.py 1默认:没有改变尺寸,数据集中的图像可以是任意形状尺寸。dataloader中必须令batch_size=1 transforms.Resize((宽,高))(image) 和 batch_size=1 必须用其一 原因:当batch_size>1时,每个batch的数…...

基于两相交错并联技术的Buck-Boost变换器仿真研究:采用双向DCDC及多环控制策略实现高...
两相交错并联buck/boost变换器仿真 采用双向DCDC,管子均为双向管 模型内包含开环,电压单环,电压电流双闭环三种控制方式 两个电感的电流均流控制效果好可见下图电流细节 matlab/simulink/两相交错并联buck/boost变换器的仿真总能让工程师又爱…...

2025届学术党必备的十大降AI率网站推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 为对付维普系统含有对AI生成内容的识别机制,若想降低AI生成内容被识别的风险&am…...

用Unity 2D碰撞体+Effector,5分钟实现《星露谷物语》式的磁铁吸附效果
用Unity 2D碰撞体Effector实现《星露谷物语》式磁铁吸附效果 在《星露谷物语》这类农场模拟游戏中,角色靠近可收集物品时自动吸附的设计极大提升了操作流畅度。这种看似简单的交互背后,其实隐藏着Unity物理系统的巧妙运用。本文将手把手教你如何用2D碰撞…...

m4s-converter:B站缓存视频本地化全解决方案
m4s-converter:B站缓存视频本地化全解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 1. 价值定位:解决B站缓存文件…...

魔兽争霸3游戏性能优化全攻略:从卡顿到流畅的实战指南
魔兽争霸3游戏性能优化全攻略:从卡顿到流畅的实战指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 当你在魔兽争霸3的团战关键时刻&…...

多智能体仓库AI指挥层技术架构
多智能体仓库AI指挥层实现运营卓越与供应链智能 仓库的“大脑”:解决碎片化运营难题 尽管仓库的自动化和数据丰富程度已达历史新高,但多数站点仍然依赖一套难以跟上节奏的系统:仓库管理系统(WMS)、少量仪表盘和分散的…...

避坑指南:n8n调用MinerU MCP时常见的3个配置错误及解决方法
避坑指南:n8n调用MinerU MCP时常见的3个配置错误及解决方法 当你第一次尝试将n8n与MinerU MCP结合使用时,可能会遇到一些令人头疼的配置问题。作为一位经历过无数次调试的老手,我想分享几个最常见的陷阱及其解决方案,希望能帮你节…...

解锁FNF-PsychEngine创作潜力:从核心功能到高级开发的完整指南
解锁FNF-PsychEngine创作潜力:从核心功能到高级开发的完整指南 【免费下载链接】FNF-PsychEngine Engine originally used on Mind Games mod 项目地址: https://gitcode.com/gh_mirrors/fn/FNF-PsychEngine FNF-PsychEngine是一款基于Haxe语言开发的开源节奏…...

开源字体工具FontForge:从设计新手到专业创作者的全流程指南
开源字体工具FontForge:从设计新手到专业创作者的全流程指南 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾为找不到匹配项目风格的字体而苦恼&…...

实战指南:基于快马AI构建企业级软件安装程序,实现环境检测与静默部署
今天想和大家分享一个实战经验:如何用InsCode(快马)平台快速构建企业级软件安装程序。这个需求来源于我们团队最近的一个项目交付,客户要求安装包必须像专业商业软件那样稳定可靠。 环境检测功能实现 安装程序最基础也最重要的就是环境检测。我们通过平…...