Redis之缓存一致性
Redis之缓存一致性
- 1 缓存更新策略
- 1.1 内存淘汰
- 1.2 过期删除
- 1.3 主动更新
- 1.4 三种缓存更新策略的对比
- 2 更新缓存的两种方式
- 3 缓存更新策略的实现方式
- 3.1 先更新DB,后更新缓存
- 3.2 先更新DB,后删除缓存
- 3.3 先更新缓存,后更新DB
- 3.4 先删除缓存,后更新DB
- 3.5 延迟双删
- 3.6 异步删除缓存
- 3.6.1 基于消息队列的异步删除缓存
- 3.6.2 基于MySQL的bin log+消息队列删除缓存
- 3.6.3 异步删除缓存的优缺点
- 3.6.4 基于 阿里canal实现
- 3.7 几种实现方式的对比
1 缓存更新策略
按照缓存更新的方式大致分为: 内存淘汰、过期删除、主动更新。
1.1 内存淘汰
利用Redis的内存淘汰策略,当内存不足时自动进行淘汰部分数据,下次查询时更新缓存,一致性差,无维护成本。
因为Redis是基于内存的,如果内存超过限定值(Redis配置文件的maxmemory参数决定Redis最大内存使用量),导致新的数据存不进去,此时Redis会根据淘汰策略删除一些数据。
淘汰策略由Redis配置文件的maxmemory-policy参数决定设置,默认为noeviction模式。
淘汰策略的执行过程:
- 执行写请求时,
Redis会检查内存使用情况,内存使用超过限定值,按照淘汰策略删除key。 Redis写入新数据。
具体的淘汰策略:redis.windows-service.conf中可以查到
- noeviction:默认策略,当写入新数据后的内存超过限定值时,写请求直接返回错误,只读请求可以正常执行。
- allkeys-lru:当写入新数据后的内存超过限定值时,从所有
key中使用LRU算法(最近最少使用算法)淘汰最久没有使用过的key。 - volatile-lru:当写入新数据后的内存超过限定值时,从设置了过期时间的
key中使用LRU算法淘汰最久没有使用过的key。 - allkeys-random:当写入新数据后的内存超过限定值时,从所有
key中随机淘汰key。 - volatile-random:当写入新数据后的内存超过限定值时,从设置了过期时间的
key中随机淘汰key。 - volatile-ttl:当写入新数据后的内存超过限定值时,从设置了过期时间的
key中根据过期时间淘汰key,越快过期越早淘汰。 - allkeys-lfu:当写入新数据后的内存超过限定值时,从所有
key中使用LFU算法(最少频率访问算法)淘汰使用频率最低的key。 - volatile-lfu:当写入新数据后的内存超过限定值时,从设置了过期时间的
key中使用LFU算法淘汰使用频率最低的key。
1.2 过期删除
缓存添加过期时间,到期后根据过期删除策略自动进行删除缓存,下次查询时更新缓存,一致性一般,维护成本低。
- 定时删除:
key设置了过期时间,一旦过期立即删除。- 优点:
key一旦过期就会立即删除,不会占用内存。 - 缺点:过期
key较多时,删除key会占用CPU时间,影响服务器的响应时间,吞吐量,性能。
- 优点:
- 惰性删除:过期
key不会马上被删除,而是继续保存在内存中,当key被访问时检查key的过期时间,若已过期则删除。- 优点:只在访问时才会对检查
key的过期时间,没使用的key不会占用CPU的时间去检查过期时间,不会影响服务器的响应时间,吞吐量,性能。 - 缺点:没有被访问的过期
key继续保存在内存中,导致内存不会被释放,消耗内存资源。
- 优点:只在访问时才会对检查
- 定期删除:每隔一段时间(时间可以自行设置,
Redis配置文件的hz参数表示1s执行多少次定期删除策略,默认值10),随机抽取设置了过期时间的key检查它们的过期时间,删除已过期的key。- 优点:可以指定频率来减少删除操作对
CPU性能的影响,定期删除也能释放没有被访问的过期key占用的内存。 - 缺点:频率高影响
CPU的性能,频率低过期key占用的内存不会及时释放。
- 优点:可以指定频率来减少删除操作对
1.3 主动更新
应用程序中修改DB,修改缓存,一致性好,维护成本高。
主动更新大致分为: Cache Aside Pattern、Read/Write Through Pattern、Write Behind Caching Pattern。
- Cache Aside Pattern:即旁路缓存模式,旁路路由策略,最经典常用的缓存策略。由应用程序负责缓存和
DB的读写。读写操作步骤:- 读操作时,先读缓存,缓存存在直接返回;缓存不存在则读
DB,然后把读的DB数据存入缓存,返回。 - 写操作时,先更新
DB,再删除缓存。
- 读操作时,先读缓存,缓存存在直接返回;缓存不存在则读
- Read/Write Through Pattern:即读写穿透模式,该模式下应用程序只与缓存管理组件交互,缓存管理组件负责缓存和
DB的读写。- Read Through:读操作时,缓存管理组件先读缓存,缓存存在直接返回;缓存不存在则读
DB,然后把读的DB数据存入缓存,返回。 - Write Through:写操作时,缓存管理组件同步更数
DB和缓存。
- Read Through:读操作时,缓存管理组件先读缓存,缓存存在直接返回;缓存不存在则读
- Write Behind Caching Pattern:即异步缓存写入,该模式下应用程序只与缓存管理组件交互操作,缓存管理组件负责缓存和
DB的读写,通过定时或阈值的异步方式将数据同步到DB,保证最终一致。该模式和Read/Write模式相似,不同点在于Read/Write模式更新DB和更新缓存是同步的,而Write Behind Caching Pattern模式更新DB和更新缓存是异步的。- 优点:减少了更新
DB的频率,读写响应非常快,吞吐量也会有明显的提升。 - 缺点:不能实时同步,数据同步
DB过程服务不可用,导致数据丢失。
- 优点:减少了更新
三种主动更新策略的对比:
| 策略 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| Cache Aside Pattern | 应用程序负责缓存和DB的读写 | 使用简单,直接操作缓存和DB | 需要编写对缓存和DB读写的代码 |
| Read/Write Through Pattern | 应用程序只与缓存管理组件交互,缓存管理组件负责缓存和DB的读写 | 使代码更简洁 | 缓存管理组件需要提供对DB和缓存读写的方法 |
| Write Behind Caching Pattern | 应用程序只与缓存管理组件交互,缓存管理组件负责缓存和DB的读写 | 性能最好,在高并发场景下可以降低数据库的压力 | 缓存管理组件,需要提供对DB和缓存读写的方法;不能实时同步,数据同步 DB过程DB不可用,导致数据丢失;一致性不强,对一致性要求高的系统不适用 |
1.4 三种缓存更新策略的对比
| 策略 | 说明 | 一致性 | 维护成本 |
|---|---|---|---|
| 内存淘汰 | 使用Redis的内存淘汰策略,当内存不足时自动进行淘汰部分数据,下次查询时更新缓存 | 差 | 无 |
| 过期删除 | 缓存添加过期时间,到期后根据过期删除策略自动进行删除缓存,下次查询时进行更新缓存 | 低 | 低 |
| 主动更新 | 修改数据库时也修改缓存,使用硬编码方式或者硬编码+中间件方式在修改数据库时同步或异步的修改缓存 | 好 | 高 |
2 更新缓存的两种方式
- 删除缓存:更新
DB时删除缓存,查询时再从DB中读取数据并更新到缓存。 - 更新缓存:更新
DB时更新缓存,频繁更新缓存开销大,且并发时可能导致请求读取的缓存数据是旧数据。
3 缓存更新策略的实现方式
3.1 先更新DB,后更新缓存
1 并发写场景
所有线程都是先更新DB再更新缓存,在某个写线程更新DB后继续更新缓存时,可能因为网络原因出现延迟,这时其他写线程也更新了DB和缓存,导致缓存和DB数据不一致。
具体步骤:
- 线程1更新
DB - 线程2更新
DB - 线程2更新缓存
- 线程1更新缓存
总结:
理论上先更新DB的线程理应也会先更新缓存,但是并发场景下线程的执行顺序无法保证:
- 若更新缓存的顺序是: 先线程1再线程2,则不会出现数据不一致问题。
- 若更新缓存的顺序是: 先线程2再线程1,此时缓存是线程1的数据,
DB是线程2的数据,导致缓存和DB数据不一致。
2 并发读写场景
在写线程更新DB和更新缓存之间,读线程可以获取到旧数据,但最终会一致。
具体步骤:
- 线程1更新
DB - 线程2查询,命中缓存返回
- 线程1更新缓存
总结:
线程2获取的缓存是旧数据,但最终都会一致。
3.2 先更新DB,后删除缓存
1 并发写场景
所有线程都是先更新DB再删除缓存,无论哪个线程先更新DB再删除缓存,缓存都会被删除,不会导致缓存和DB数据不一致。
具体步骤:
- 线程1更新
DB - 线程2更新
DB - 线程2删除缓存
- 线程1删除缓存
总结:
无论哪个线程先更新DB再删除缓存,缓存都会被删除,不会导致缓存和DB数据不一致。
2 并发读写场景
在写线程更新DB再删除缓存之间,读线程可以获取到旧数据,但最终会一致。
具体步骤:
- 线程1更新
DB - 线程2查询命中缓存返回
- 线程1删除缓存
总结:
线程2获取的缓存是旧数据,但后续最终都会一致。
3.3 先更新缓存,后更新DB
1 并发写场景
所有线程都是先更新缓存再更新DB,在某个写线程更新缓存和更新DB之间,其他写线程也更新了缓存和DB,导致缓存和DB数据不一致。
具体步骤:
- 线程1更新缓存
- 线程2更新缓存
- 线程2更新
DB - 线程1更新
DB
总结:理论上先更新缓存的线程也会先更新DB,但是并发场景下线程的执行顺序无法保证:
- 若更新
DB的顺序是: 线程1再线程2,则不会出现数据不一致问题。 - 若更新
DB的顺序是: 线程2再线程1,此时缓存是线程2的数据,DB是线程1的数据,导致缓存和DB数据不一致。
2 并发读写场景
在写线程更新缓存和更新DB之间,读线程也可以获取到最新的缓存,不会导致缓存和DB数据不一致。
具体步骤:
- 线程1更新缓存
- 线程2查询,命中缓存返回
- 线程1更新
DB
总结:
可以保证缓存和DB数据一致,虽然线程1更新DB的操作还没有完成,但是更新缓存的操作已经完成了,读请求可以获取到最新的缓存。
3.4 先删除缓存,后更新DB
1 并发写场景
所有线程都是先删除缓存再更新DB,无论哪个线程先删除缓存再更新DB,缓存都会被删除,不会导致缓存和DB数据不一致。
具体步骤:
- 线程1删除缓存
- 线程2删除缓存
- 线程2更新
DB - 线程1更新
DB
总结:
无论哪个线程先删除缓存再更新DB,缓存都会被删除,不会导致缓存和DB数据不一致。
2 并发读写场景
在写线程删除缓存和更新DB之间,读线程根据查询的DB结果更新了缓存,导致缓存和DB数据不一致。
具体步骤:
- 线程1删除缓存
- 线程2查询,未命中
- 线程2查询
DB - 线程2根据查询的
DB结果更新缓存 - 线程1更新
DB
总结:
线程1删除缓存和更新DB之间,线程2根据查询的DB结果更新了缓存,导致缓存和DB数据不一致。
3.5 延迟双删
因为3.4 先删除缓存,再更新DB,在并发读写场景会导致数据不一致。
延迟双删是基于先删除缓存再更新DB的基础上的改进,在更新DB后延迟一定时间,再次删除缓存。
延迟是为了保证第二次删除缓存前能完成更新DB操作,延迟时间根据系统的查询性能而定。
第二次删除缓存是为了保证后续请求查询DB(此时数据库中的数据已是更新后的数据),重新写入缓存,保证数据一致性。
1 并发写场景
无论哪个线程都会删除缓存,所以不会导致缓存和DB数据不一致。
具体步骤:
- 线程1删除缓存
- 线程2删除缓存
- 线程2更新
DB - 线程1更新
DB - 线程1延时删除缓存
- 线程2延时删除缓存
2 并发读写场景
具体步骤:
- 线程1删除缓存
- 线程2查询,未命中
- 线程2查询
DB - 线程2根据查询的
DB结果更新缓存 - 线程1更新
DB - 线程1延时删除缓存
总结:
线程1第一次删除缓存之后,线程2根据查询的DB结果更新缓存,此时查询得到的结果是旧数据,线程1延迟第二次删除缓存之后,后续查询DB(此时数据库中的数据已是更新后的数据),重新写入缓存,不会导致缓存和DB数据不一致。
3 延时双删的缺点:
- 需要延时,低延时场景不合适,如秒杀等需要低延时,需要强一致,高频繁修改数据场景。
- 不能保证强一致性,在更新
DB之前,查询线程查询得到的结果是旧数据,可但可以减轻缓存和DB数据不一致的问题。 - 延时的时间是一个不可评估的值,延时越久,能规避一致性的概率越大。
3.6 异步删除缓存
因为3.2 先更新DB,后删除缓存 在并发写场景不会导致数据不一致,但是在并发读写场景会短暂的导致数据不一致,但是由于删除缓存失败不会重试,并发写场景、并发读写场景都可能长时间导致数据不一致。
异步删除缓存是对先更新DB,后删除缓存的改进:更新DB之后,基于消费队列异步删除缓存。
根据消费队列不同大致分为:消息队列、bin log+消息队列。
3.6.1 基于消息队列的异步删除缓存
1 并发写场景
无论哪个线程先更新DB再删除缓存,缓存都会被删除,不会导致缓存和DB数据不一致。
具体步骤:
- 线程1更新
DB - 线程2更新
DB - 线程2把删除缓存放入消息队列
- 线程1把删除缓存放入消息队列
- 异步:消息队列消费删除缓存
总结:
无论哪个线程先更新DB再删除缓存,缓存都会被删除,不会导致缓存和DB数据不一致。
2 并发读写场景
异步删除缓存期间,读线程获取的缓存是旧数据,短暂出现数据不一致,异步删除缓存后最终会一致。
具体步骤:
- 线程1更新
DB - 线程2查询缓存,命中返回
- 线程1把删除缓存放入消息队列
- 异步:消息队列消费删除缓存
总结:
异步删除缓存期间,读线程获取的缓存是旧数据,短暂出现数据不一致,异步删除缓存后最终会一致。
3.6.2 基于MySQL的bin log+消息队列删除缓存
1 并发写场景
具体步骤:
- 线程1更新
DB - 线程2更新
DB - 异步:
bin log日志收集中间件定时收集DB的bin log日志 - 异步:
bin log日志收集中间件发送日志消息到消息队列 - 异步:消息队列消费删除缓存
总结:
无论哪个线程先更新DB再删除缓存,缓存都会被删除,不会导致缓存和DB数据不一致。
–
2 并发读写场景
具体步骤:
- 线程1更新
DB - 线程2查询缓存,命中返回
- 异步:
bin log日志收集中间件定时收集DB的bin log日志 - 异步:
bin log日志收集中间件发送日志消息到消息队列 - 异步:消息队列消费删除缓存
总结:
异步删除缓存期间,读线程获取的缓存是旧数据,短暂出现数据不一致,异步删除缓存后最终会一致。
3.6.3 异步删除缓存的优缺点
优点:
- 删除缓存的操作与主流程代码解耦。
- 中间件自带重试机制,增加了操作缓存的成功率。
缺点:
引入中间件,提升了系统的复杂度,在高并发场景可能会产生性能问题。
3.6.4 基于 阿里canal实现
canal是阿里开发的基于数据库增量日志解析,提供增量数据的订阅和消费,目前主要支持MySQL的bin log解析。基于canal的实现方案完全避免了对业务代码的侵入,核心业务代码只管更新数据库,其他的不用care。
canal地址:https://github.com/alibaba/canal
MySQL会将操作记录在bin log日志中,通过canal去监听数据库日志二进制文件,解析bin log日志,同步到Redis中进行增删改操作。
canal的工作原理:canal是模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议;MySQL master收到dump请求,开始推送bin log给slave (即canal);canal解析bin log象(原始为byte流)。

3.7 几种实现方式的对比
参看:redis之缓存一致性 最后一部分
相关文章:
Redis之缓存一致性
Redis之缓存一致性 1 缓存更新策略1.1 内存淘汰1.2 过期删除1.3 主动更新1.4 三种缓存更新策略的对比 2 更新缓存的两种方式3 缓存更新策略的实现方式3.1 先更新DB,后更新缓存3.2 先更新DB,后删除缓存3.3 先更新缓存,后更新DB3.4 先删除缓存&…...
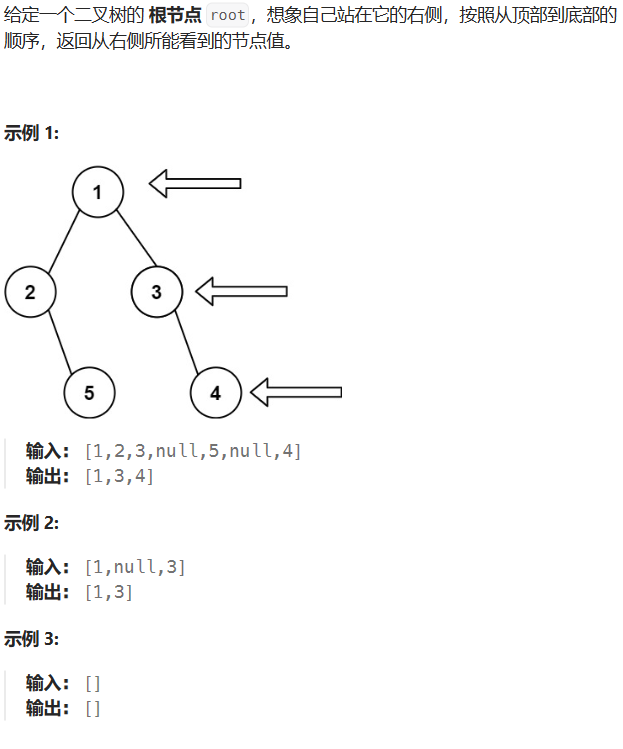
LeetCode-199-二叉树的右视图
题目描述: 题目链接:LeetCode-199-二叉树的右视图 解题思路: 在 102 的基础之上进行改进,一维数组每次只保存 size1 时候的值 代码实现: class Solution {public List<Integer> rightSideView(TreeNode root) {i…...
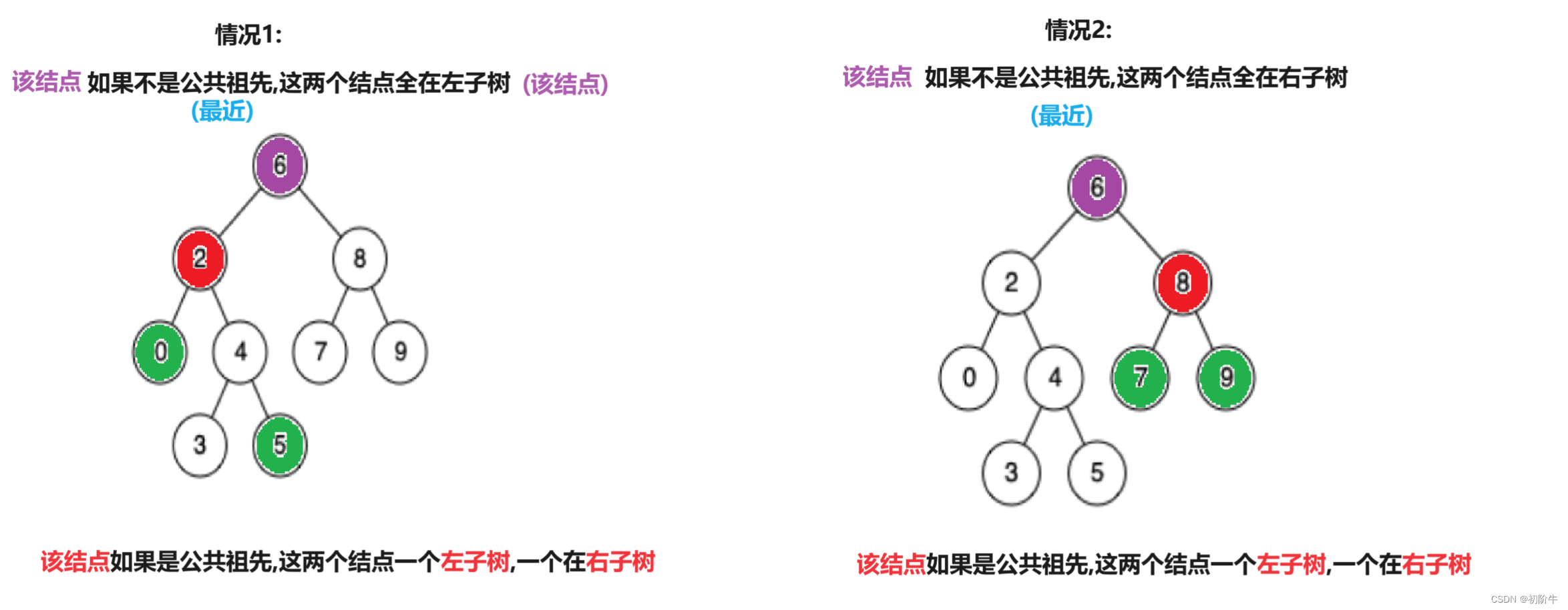
二叉树的最近公共祖先
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻强烈推荐优质专栏: 🍔🍟🌯C的世界(持续更新中) 🐻推荐专栏1: 🍔🍟🌯C语言初阶 🐻推荐专栏2: 🍔…...

C++ 补充 反向迭代器的实现
阅前提要: 本文主要是对list和vector的实现的补充,以代码实现为主,注释为辅,如果对vector,list底层实现感兴趣的可以自行阅读,代码量有点大,请大家耐心查看,对理解语言很有帮助&…...

JVM第一讲:JVM相关知识体系详解+面试(P6熟练 P7精通)
JVM相关知识体系详解面试(P6熟练 P7精通) 面试时常常被面试官问到JVM相关的问题。本系列将给大家构建JVM核心知识点全局知识体系,本文是JVM第一讲,JVM相关知识体系详解和相关面试题梳理。 文章目录 JVM相关知识体系详解面试(P6熟练 P7精通)1、JVM学习建议…...

深度学习DAY3:FFNNLM前馈神经网络语言模型
1 神经网络语言模型NNLM的提出 文章:自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT) https://www.cnblogs.com/robert-dlut/p/9824346.html 语言模型不需要人工标注语料(属于自监督模型),所以语言…...

JavaSE学习值之--String类
💕"不要同情自己,同情自己是卑劣懦夫的勾当!"💕 作者:Mylvzi 文章主要内容:JavaSE学习值之--String类 目录 前言: 一.String类 1.String类的属性 2.字符串的构造 注意…...

【LeetCode高频SQL50题-基础版】打卡第6天:第31~35题
文章目录 【LeetCode高频SQL50题-基础版】打卡第6天:第31~35题⛅前言员工的直属部门🔒题目🔑题解 判断三角形🔒题目🔑题解 连续出现的数字🔒题目🔑题解 指定日期的产品价格🔒题目&am…...

基于单片机的汽车智能仪表的设计
基于单片机的汽车智能仪表的设计 摘要:汽车的汽车系统。速度测量以及调速是我们这次的设计所要研究的对象,本次设计的基础核心的模块就是单片机,其应用的核心的控制单元就是stc89c52单片机,用到的测速模块是霍尔传感器,…...
:进行 namespace API 操作的 4 种方式)
【Docker 内核详解】namespace 资源隔离(一):进行 namespace API 操作的 4 种方式
namespace 资源隔离(一):进行 namespace API 操作的 4 种方式 1.通过 clone() 在创建新进程的同时创建 namespace2.查看 /proc/[pid]/ns 文件3.通过 setns() 加入一个已经存在的 namespace4.通过 unshare() 在原先进程上进行 namespace 隔离5…...

【技术研究】环境可控型原子力显微镜超高真空度精密控制解决方案
摘要:针对原子力显微镜对真空度和气氛环境精密控制要求,本文提出了精密控制解决方案。解决方案基于闭环动态平衡法,在低真空控制时采用恒定进气流量并调节排气流量的方法,在高真空和超高真空控制时则采用恒定排气流量并调节进气流…...
【Vuex+ElementUI】Vuex中取值存值以及异步加载的使用
一、导言 1、引言 Vuex是一个用于Vue.js应用程序的状态管理模式和库。它建立在Vue.js的响应式系统之上,提供了一种集中管理应用程序状态的方式。使用Vuex,您可以将应用程序的状态存储在一个单一的位置(即“存储”)中,…...

python经典百题之简单加密数据
题目:某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下: 每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换 程序分析 对于…...
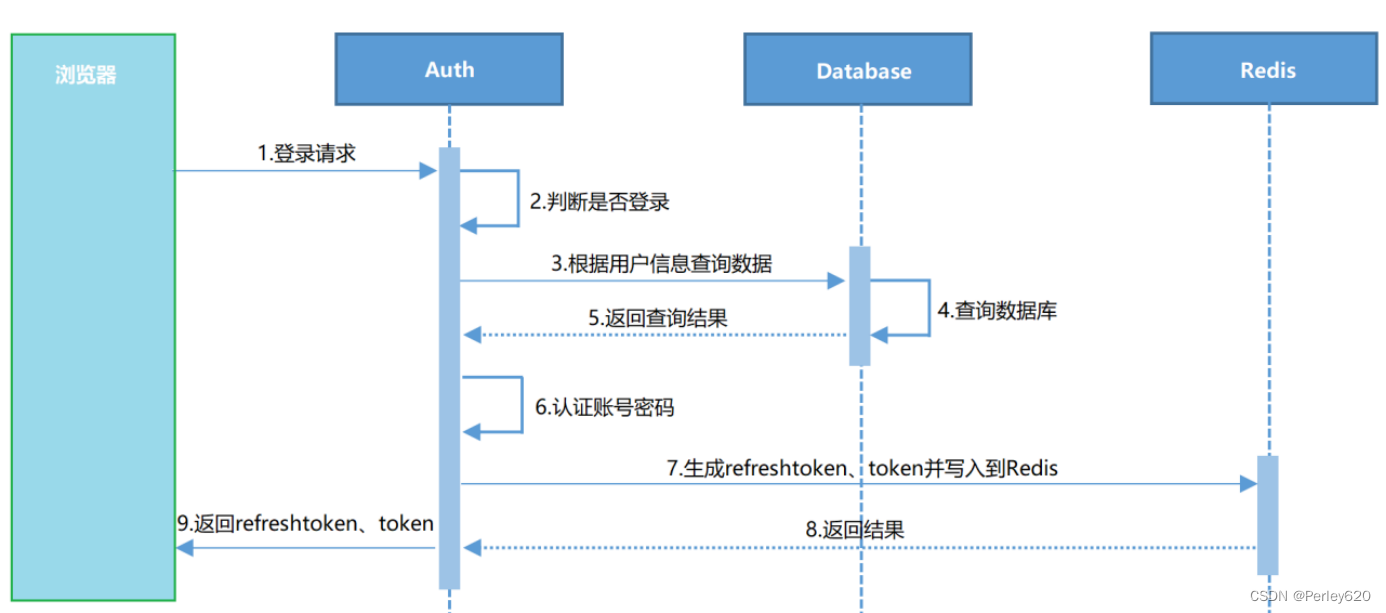
登陆认证权限控制(1)——从session到token认证的变迁 session的问题分析 + CSRF攻击的认识
前言 登陆认证,权限控制是一个系统必不可少的部分,一个开放访问的系统能否在上线后稳定持续运行其实很大程度上取决于登陆认证和权限控制措施是否到位,不然可能系统刚刚上线就会夭折。 本篇博客回溯登陆认证的变迁历史,阐述sess…...
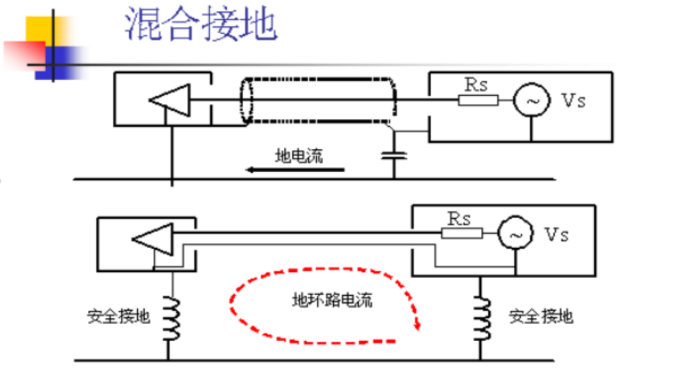
单点接地、多点接地、混合接地
有三种基本的信号接地方式:浮地、单点接地、多点接地。 浮地:目的是使电路或设备与公共地线可能引起环流的公共导线隔离起来,浮地还使不同电位的电路之间配合变得容易。缺点:容易出现静电积累引起强烈的静电放电。折中方案:接入泄…...

【C++初阶(一)】学习前言 命名空间与IO流
本专栏内容为:C学习专栏,分为初阶和进阶两部分。 通过本专栏的深入学习,你可以了解并掌握C。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚代码仓库:小小unicorn的代码仓库&…...
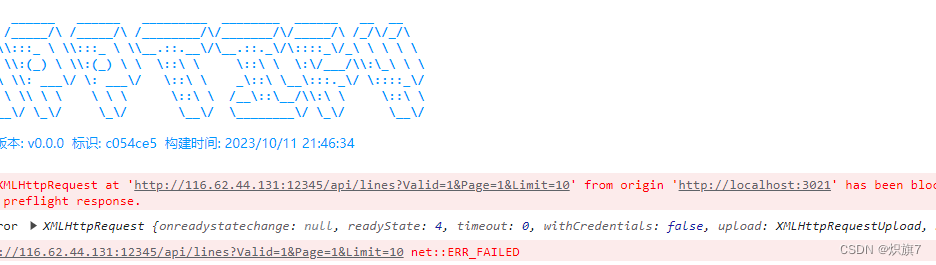
flask vue跨域问题
问题: 调试时候跨域访问报: Request header field authorization is not allowed by Access-Control-Allow-Headers in preflight response. 解决办法: 安装flask_cros from flask_cors import CORS CORS(app) app.after_request def a…...
IAP升级优化(双缓存,可恢复))
stm32(二十)IAP升级优化(双缓存,可恢复)
这次主要对STM32F103/Keil和LPC2478/IAR加了一个IAP在线升级功能, 主要记录一下自己的思路,无代码,实在是代码感觉没啥写的,都是一些网上很多流传的东西。 1、开发环境 Keilstm32f103JLINK 2、程序思路 在升级中,必…...

HDLbits:Exams/ece241 2013 q4
本题是一个实际的应用问题,一个水库,有三个传感器S1、S2、S3提供输入,经过控制电路,四个输出给到四个流量阀。也就是说,本题想让我们根据水位去控制流量阀。 问题的关键在于把什么抽象成state,答案是&…...

什么是React的虚拟DOM(Virtual DOM)?它的作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

Supabase注册与新增用户全解析:5个关键区别及适用场景指南
Supabase用户管理系统设计指南:注册与手动创建的5大核心差异 在构建现代SaaS平台时,用户管理系统往往是整个架构的基石。Supabase作为开源的Firebase替代方案,提供了完整的认证和用户管理解决方案。但很多开发者在使用过程中,常常…...

开发者必备:OpenClaw+Phi-3-vision-128k-instruct自动化测试方案
开发者必备:OpenClawPhi-3-vision-128k-instruct自动化测试方案 1. 为什么需要视觉自动化测试 作为独立开发者,我经常面临一个尴尬局面:每次前端迭代后,都需要手动点击每个页面检查元素位置和样式。这种重复劳动不仅耗时&#x…...

EdgeRemover:Windows系统下Microsoft Edge浏览器的彻底卸载方案与实现原理
EdgeRemover:Windows系统下Microsoft Edge浏览器的彻底卸载方案与实现原理 【免费下载链接】EdgeRemover A PowerShell script that correctly uninstalls or reinstalls Microsoft Edge on Windows 10 & 11. 项目地址: https://gitcode.com/gh_mirrors/ed/Ed…...
:外围电阻、电压范围、计算与测试方法)
NCP1654 引脚6(FB):外围电阻、电压范围、计算与测试方法
NCP1654 引脚6(FB):外围电阻、电压范围、计算与测试方法 引脚6(FB)是NCP1654的输出电压反馈/关断控制脚,核心功能是采样PFC输出母线电压,送入内部误差放大器,稳定输出电压࿱…...

西门子三菱 PLC 编程教程合集|零基础到进阶学习资料整理
在工业自动化领域,PLC 编程是核心技能之一,想要系统掌握西门子、三菱两大品牌的 PLC 编程知识,合适的学习资料能让学习效率事半功倍。本次整理了一批涵盖不同学习阶段的 PLC 编程资料,从零基础入门到针对性机型实操,覆…...

OpenClaw多任务测试:Qwen3-32B在RTX4090D上的并行处理极限
OpenClaw多任务测试:Qwen3-32B在RTX4090D上的并行处理极限 1. 测试背景与动机 最近在折腾本地AI自动化时,遇到一个实际问题:当OpenClaw同时处理多个任务时,显存会成为瓶颈吗?我手头正好有台配备RTX4090D(…...

UI 动效设计原则:让界面呼吸起来
UI 动效设计原则:让界面呼吸起来 动效不是装饰,而是交互的语言。掌握这些原则,让你的设计会"说话"。 一、动效的本质 作为一名把代码当散文写的 UI 匠人,我始终认为动效是界面的灵魂。一个好的动效应该像呼吸一样自然—…...

AdminBSB表单组件实战:从基础到高级的完整解决方案
AdminBSB表单组件实战:从基础到高级的完整解决方案 【免费下载链接】AdminBSBMaterialDesign AdminBSB - Free admin panel that is based on Bootstrap 3.x with Material Design 项目地址: https://gitcode.com/gh_mirrors/ad/AdminBSBMaterialDesign Admi…...

PromptSource模板可视化工具:如何高效分析提示结构与变量关系
PromptSource模板可视化工具:如何高效分析提示结构与变量关系 【免费下载链接】promptsource Toolkit for creating, sharing and using natural language prompts. 项目地址: https://gitcode.com/gh_mirrors/pr/promptsource PromptSource是一个用于创建、…...

Thrust事件处理机制:全面解析窗口、键盘和鼠标事件响应
Thrust事件处理机制:全面解析窗口、键盘和鼠标事件响应 【免费下载链接】thrust Chromium-based cross-platform / cross-language application framework 项目地址: https://gitcode.com/gh_mirrors/thru/thrust Thrust作为基于Chromium的跨平台应用框架&am…...