SQL基本语法用例大全
文章目录
- SQL语法概述
- 简单查询
- 计算列查询
- 条件查询
- 范围查询
- 使用逻辑运算符过滤数据
- 使用IN操作符过滤数据
- 格式化结果集
- 模糊查询
- 行数据过滤
- 数据排序
- 数据统计分析
- 分组总计
- 简单子查询
- 多行子查询
- 多表链接
- 插入数据
- 更新和删除数据
- 使用视图
- 数据库管理
- 数据表管理
SQL语法概述
SQL(Structured Query Language), 数据库的标准语言。
SQL语言的功能包括数据查询、数据操纵、数据定义和数据控制四个部分。
六个核心动词: SELECT、CREATE、INSERT、UPDATE、DELETE和REVOKE
每条SQL语句均由一个谓词(Verb)开始, 该谓词描述这条语句要产生的动作, 例如SELECT或者UPDATE关键字, 谓词后紧接着一条或者多条子句(Clause), 子句中给出了被谓词作用的数据或者谓词动作的详细信息。
每个查询语句都要有SELECT关键字和FROM关键字。
简单查询
SELECT column_name
FROM table_name
[ WHERE search_condition ]
[ GROUP BY group_column_name ]
[ HAVING search_condition ]
[ ORDER BY order_expression [ASC | DESC]]
从table_name表中查询column_name列的数据; WHERE 用来指定筛选数据的条件
GROUP BY 根据指定列中的值,对数据进行分组
HAVING search_condition 指定组的搜索条件, 对分组数据进行二次筛选, 通常搭配GROUP BY 使用
ORDER BY 按照指定列进行排序, ASC 升序排列, DESC 降序排列
-- 单列查询
SELECT column_name FROM table_name;-- 多列查询
SELECT column_1, column_2 FROM table_name;-- 所有列查询
SELECT * FROM table_name;-- 使用别名
SELECT goods_name "商品名称" FROM goods;
SELECT goods_name AS "商品名称" FROM goods;-- 对多个表查询时出现相同的别名
SELECT user_address.mobile AS "订单电话", users.mobile AS "用户电话",user_address.address
FROM user_address, users
WHERE user_address.user_id = users.user_id; -- 为计算结果设置别名列
SELECT (market_price - cost_price) AS 盈利 FROM goods;-- 为使用聚合函数的列设置别名
SELECT MAX(market_price) AS "市场最高价", MIN(market_price) AS "市场最低价"
FROM goods;-- 删除重复数据
-- DISTINCT 放在第一位, 不加逗号, 不是某一行, 是指不重复输出SELECT的所有列
SELECT DISTINCT column_name FROM goods;-- 返回前N行数据
SELECT TOP n goods_name, market_price
FROM goods;-- 限制查询前N行
SELECT goods_name,
FROM goods
LIMIT 5;-- 限制查询N条数据
-- 查询从第三条开始的10条数据(编号从0开始)
SELECT goods_name
FROM goods
LIMIT 2,10;-- 写法2
SELECT goods_name
FROM goods
LIMIT 10 OFFSET 2;
计算列查询
-- 连接列值
SELECT name + cat_name AS "详细信息" FROM brands;
-- 数值查询运算(+ - * / %)
SELECT (shop_price - cost_price) AS "利润"
FROM goods;
-- 查询中使用表达式
-- 使用数值表达式
SELECT cost_price + 50 AS "价格+50"
FROM goods;
-- 使用字符表达式
SELECT convert(char(2),sales_num) + '个' AS "销售量"
FROM goods;
-- 使用表达式创建新列
SELECT goods_id, 2+2, '字符' + '串列'
FROM goods;
条件查询
where 语句的各种比较运算符;
= 等于 > 大于 < 小于 > 大于 >= 大于等于 <= 小于等于 !> 不大于 !< 不小于 <> 或者!= 不等于
-- 各种条件筛选
SELECT * FROM goods WHERE good_id = 107;
SELECT * FROM goods WHERE good_id > 107; 范围查询
-- 查询两个数值之间的数据
SELECT market_price
FROM goods
WHERE market_price BETWEEN 1000 AND 3000;--查询不在两个数值之间的数据
SELECT market_price
FROM goods
WHERE market_price NOT BETWEEN 1000 AND 3000;-- 查询两个日期之间的数据
SELECT INTIME
FROM book_info
WHERE INTIME BETWEEN '2023-1-1' AND '2023-12-1';-- 日期函数 GETDATE()函数、DATEADD()函数 获取当天/前一天的日期
-- 获取昨天和今天的数据
SELECT INTIME
FROM book_info
WHERE INTIME BETWEEN DATEADD(DAY,-1,GETDATE()) AND GETDATE();
使用逻辑运算符过滤数据
-- AND 与操作 OR 或操作 NOT 非操作
-- 优先级 () >> NOT >> AND >> OR
SELECT shop_price
FROM goods
WHERE shop_price > 3000 AND shop_price < 6000;SELECT shop_price
FROM goods
WHERE shop_price < 3000 OR shop_price > 6000;SELECT shop_price
FROM goods
WHERE NOT shop_price = 3000;使用IN操作符过滤数据
使用IN操作符可以判断某个字段的值是否在指定的集合中;
-- 使用IN 查询数据
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE cat_id IN (191,123,131);-- 使用IN 使用算术表达式
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE cat_id IN (191 + 20,123 - 30,131);-- 使用IN 中使用列进行查询
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE 323 IN (shop_price, cat_id); -- 使用NOT IN 查询数据
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE cat_id NOT IN (191,123,131);-- 查询10条数据中的后两行
SELECT order_id,order_sn,total_amount
FROM orderform
WHERE order_id NOT IN (SELECT TOP 8 order_id FROM orderform)
格式化结果集
-- SQL Server 数据库中格式化日期 hh:mm:ss
SELECT CONVERT(VARCHAR,GETDATE(),108) AS nowtime-- MySQL 数据库中格式化日期
SELECT user_id,email,DATE_FORMAT(reg_time, '%Y/%m/%d') AS reg_time
FROM shop.users LIMIT 6;-- Orcale 数据库中格式化日期
SELECT TO_CHAR(birthday,'YYYY-MM-DD') AS 格式化日期
FROM users
WHERE ROWUNM <= 6;-- CAST 函数, 将浮点型数据转换成整型
SELECT CAST(total_amount AS int) AS total_amount
FROM users;-- 去除空格
SELECT LTRIM(' BOOK') AS '去掉左侧空格';
模糊查询
% 由零个或多个字符组成的任意字符串
_ 任意单个字符
[] 用于指定范围 [A-F]
[^] 表示指定范围之外的[^A-F]
-- 包含mr
SELECT 列名 LIKE '%mr%' -- mr出现在开头
SELECT 列名 LIKE 'mr%' -- mr 出现在结尾
SELECT 列名 LIKE '%mr' -- 三个字符且前两个字符是mr的数据
SELECT 列名 LIKE 'mr_'-- 三个字符且后个字符是mr的数据
SELECT 列名 LIKE '_mr'-- 以m或r开头的数据
SELECT 列名 LIKE '[mr]%' -- 以a-e之间的字符 开头的数据
SELECT 列名 LIKE '[a-e]%' -- 不以a-e之间的字符 开头的数据
SELECT 列名 LIKE '[^a-e]%' -- 字符转义
-- 使用ESCAPE 定义转义字符
-- 使用#作为转义字符 %作为普通字符
WHERE 列名 LIKE '%10#%' ESCAPE '#'
行数据过滤
-- 行查询
-- 查询第6个商品id
SELECT goods_id,goods_name,shop_price FROM (SELECT TOP 6 * FROM goods) aa
WHERE NOT EXISTS (SELECT * FROM (SELECT TOP 5 * FROM goods) bb
WHERE aa.goods_id = bb.goods_id);-- SQL Server 随机查询一行数据
SELECT TOP 1 goods_id, cat_id, goods_name
FROM goods order by NEWID();-- MySQL 中随机查询一行
SELECT goods_id,cat_id,goods_name
FROM goods
ORDER BY RAND() LIMIT 1;-- 在Oracle 中随机查询一行数据
SELECT goods_id, cat_id, goods_name FROM (
SELECT goods_id, cat_id, goods_name FROM goods, ORDER BY DBMS_RANDOM.VALUE())
WHERE ROWNUM=1;-- 在结果集中添加行号
SELECT (SELECT COUNT(order_id) FROM orderform A WHERE A.order_id >= B.order_id) 编号,order_id,order_sn,toal_amount
FROM orderform B ORDER BY 1;-- 查询隔行数据
SELECT order_id,order_sn,toal_amount
FROM orderform WHERE order_id%2=1 ORDER BY 1;-- 查询指定行范围内的所有行数据
SELECT ISBN, BookName FROM (
SELECT ROW_NUMBER() OVER(ORDER BY ISBN) 编号, ISBN,BookName FROM bookinfo_zerobasis
) a WHERE a.编号 BETWEEN 3 AND 6;-- 查询空值(IS NULL)
SELECT user_id,nickname
FROM users
WHERE nickname IS NULL;-- 查询非空值(IS NOT NULL) SELECT user_id,nickname
FROM users
WHERE nickname IS NOT NULL;-- 对空值进行处理
-- 所有空值转换成0
SELECT BookName, ISNULL(newbook, 0) AS newbook
FROM bookinfo;-- 将所有的相关值转换成NULL(Liming转NULL)
SELECT user_id, NULLIF(nickname,'Liming') AS nickname
FROM users;
数据排序
-- 升序排列(ASC) 降序排列(DESC)
-- 名称中有空格排序需要加 ' 列名'
SELECT goods_id, goods_name, sales_sum
FROM goods
ORDER BY DESC | ASC;-- 多列排序
-- ORDER BY 子句中的第一列为主排序 第二列为次排序
-- 先按主排序进行排列 相同的再按次排序进行排列
SELECT DISTINCT goods_id, goods_name, shop_price
FROM goods
ORDER BY shop_price DESC, goods_name;-- 对数据表中的指定行数进行排序
SELECT TOP 3 goods_id, goods_name,shop_price
FROM goods
ORDER BY shop_price DESC;-- 按姓氏笔画排序
SELECT * FROM tb_name;
SELECT * FROM tb_name ORDER BY LEFT(name,1) COLLATE Chinese_PRC_Stroke_CS_AS_KS_WS;-- 按拼音排序
SELECT * FROM tb_name;
SELECT * FROM tb_name ORDER BY LEFT(name, 1) COLLATE Chinese_PRC_CS_AS_KS_WS;数据统计分析
聚合函数
SUM() 指定列所有非空值求和
AVG() 指定列所有非空值求平均值
MIN() 指定列中最小的数字、最小的字符串、最早的日期时间(数字、字符、日期)
MAX() 指定列中最大的数字、最大的字符串、最近的日期时间(数字、字符、日期)
COUNT([distinct]*) 统计结果中全部记录行的数量, 最多可达2147483647行
-- 去重之后计算平均值
SELECT AVG(DISTINCT shop_price) AS 平均值
FROM goods;-- 限制统计行数的平均值
SELECT AVG(shop_price) AS 平均值
FROM goods
WHERE shop_price > 3000;-- 显示大于平均值的商品信息
SELECT goods_name AS 商品名称,store_count AS 库存数量, shop_price AS 售价
FROM goods
WHERE (shop_price > (SELECT AVG(shop_price) FROM goods));-- count 统计重复数值, 不统计空值
-- 统计商品ID的总数
SELECT COUNT(cat_id) AS 商品种类
FROM goods;-- 剔除重复的
SELECT COUNT(DISTINCT cat_id) AS 商品种类
FROM goods;-- 剔除了最大值和最小值的平均值
SELECT CAST(AVG(shop_price) as real) AS '去掉最大值和最小值之后的平均值' FROM goods
WHERE goods_name LIKE '%液晶电视%'
AND shop_price NOT IN ((SELECT MIN(shop_price) AS 最小值 FROM goods WHERE goods_name LIKE '%液晶电视%')UNION(SELECT MAX(shop_price) AS 最大值 FROM goods WHERE goods_name LIKE '%液晶电视%')
);-- 对多列进行求和
SELECT SUM(shop_price) AS 所有商品的总和
FROM goods;SELECT SUM(shop_price - cost_price) AS 所有商品的总盈利
FROM goods;
分组总计
-- 使用GROUP BY子句创建分组
-- 查询分组的各个指标
SELECT cat_id AS 商品种类id, MIN(shop_price) 最低售价
MAX(cost_price) 最高成本价, AVG(shop_price),COUNT(*) AS 数量
FROM goods
GROUP BY cat_id
ORDER BY MAX(cost_price) DESC;-- 使用GROUP BY 子句创建多列分组
SELECT cat_id AS 商品种类id, brand_id AS 品牌id, MIN(shop_price) 最低售价
MAX(cost_price) 最高成本价, AVG(shop_price),COUNT(*) AS 数量
FROM goods
GROUP BY cat_id, brand_id
ORDER BY MAX(cost_price) DESC;-- 在分组的时候使用表达式
SELECT 收获地址, 联系方式
FROM (SELECT '收货人: '+ consignee + ' 的地址为: ' + address AS 收获地址, '联系电话为: ' + mobile AS 联系方式 FROM user_address) a
GROUP BY 收获地址, 联系方式 -- GROUP BY ROLLUP(A,B,C) 先对A、B、C进行分组操作, 然后对A和B进行分组操作, 之后对A进行分组操作
SELECT a.deptno, d.dname, SUM(e.sal) AS 工资总和
FROM emp e, dept d
WHERE e.deptno = d.deptno
GROUP BY ROLLUP(e.deptno, d.dname);
-- CUBE关键字与ROLLUP关键字类似
-- 如果GROUP BY子句修饰的列值中带有NULL 值, 系统会将所有NULL值的行分成一组 -- 使用HAVING 子句进行过滤分组
SELECT cat_id 种类id, shop_price 商品售价, COUNT(cat_id) 数量
FROM goods
WHERE (store_count < 1000)
GROUP BY cat_id, shop_price
HAVING (shop_price > (SELECT AVG(shop_price) FROM goods))
ORDER BY shop_price DESC;简单子查询
子查询常用的语法格式
WHERE 查询表达式 [NOT] IN (子查询)
WHERE 查询表达式 比较运算符 [ANY | ALL] (子查询)
WHERE [NOT] EXISTS (子查询)
SELECT列表中的子查询
-- 根据作者名字, 获取编写数目中最高价格的信息
SELECT tb_book_author,tb_author_department,
(SELECT max(book_price) FROM tb_book WHERE tb_book_author.tb_book_author=tb_book.tb_book_author)
FROM tb_book_author;
多列子查询
-- Oracle 数据库查询各个职务中最高工资的员工信息
-- 成对比较子查询
SELECT ename,job,sal
FROM emp
WHERE (sal,job) IN (SELECT MAX(sal), job FROM emp GROUP bY job);-- 非成对比较子查询
-- 获取各个职务中最高工资的员工信息
SELECT ename, job, sal
FROM emp
WHERE sal in (SELECT MAX(sal) FROM emp GROUP BY job)
AND job IN (SELECT distinct job FROM emp);
比较子查询
使用比较运算符连接子查询
子查询不能返回多个值; 子查询中不能包含ORDER BY子句
SELECT cat_id, goods_name
FROM goods
WHERE cat_id > ( SELECT cat_id FROM brand
WHERE name="蓝月亮"
);-- 在子查询中使用聚合函数
SELECT ename,sal,job
FROM emp
WHERE sal > (SELECT AVG(sal) FROM emp);
多行子查询
多行子查询通过多行比较操作符来实现, 其返回值为多行, 常用操作符号包括:
IN 和 NOT IN, ALL 和 ANY/SOME、EXISTS 和 NOT EXISTS
-- 使用IN子查询实现交集运算
SELECT * FROM tb_book
WHERE book_sort IN (SELECT tb_author_department FROM tb_book_authorWHERE tb_book.book_sort=tb_book_author.tb_author_department
)ORDER BY tb_book.book_price;-- 使用NOT IN子查询实现差集运算
SELECT * FROM tb_book
WHERE book_sort IN (SELECT tb_author_department FROM tb_book_author
);-- EXISTS子查询实现两个表的交集
SELECT * FROM tb_book
WHERE EXISTS (SELECT tb_author_department FROM tb_book_authorWHERE tb_book.book_sort=tb_book_author.tb_author_department
) ORDER BY tb_book.book_price; -- NOT EXISTS 子查询实现两个表的差集
SELECT * FROM tb_book
WHERE NOT EXISTS (SELECT tb_author_department FROM tb_book_authorWHERE tb_book.book_sort=tb_book_author.tb_author_department
) ORDER BY tb_book.book_price; -- 通过量词实现多行子查询ALL SOME ANY
-- <ALL为小于最小的 >ALL为大于最大的 =ALL则没有返回值
SELECT cat_id, goods_name, shop_price FROM goods
WHERE shop_price < ALL(SELECT AVG(shop_price)FROM goodsGROUP BY cat_id
);-- 量词ANY和SOME是同义的
-- 某些DBMS产品仅支持原来的量词ANY
-- <ANY为小于最大的 >ANY为大于最小的 =ANY 相当于 IN
SELECT cat_id, goods_name, shop_price FROM goods
WHERE shop_price > ANY(SELECT AVG(shop_price)FROM goodsGROUP BY cat_id
);多表链接
内连接
内连接就是使用比较运算符进行表与表之间列数据的比较操作, 并列出这些表中与连接条件相匹配的数据行。内连接可以用来组合两个或者多个表中的数据。
内连接分为三种:
1.等值连接 在连接条件中使用等于运算符比较被连接的列;
2.不等值连接 在连接条件中使用除了等于运算符以外的其他比较运算符比较连接的列;
3.自然连接 它是等值连接的一种特殊情况,用来把目标中重复的属性列去掉;
-- 等值连接
SELECT goods_id, goods_name,name
FROM goods,goods_type
WHERE goods.goods_type=goods_type.id;SELECT goods_id,goods_name,name
FROM goods INNER JOIN goods_type
ON goods.goods_type=goods_type.id; -- 不等值连接
SELECT a.goods_id,a.goods_name
FROM goods a INNER JOIN (SELECT * FROM goods_type WHERE name="测试品牌" ) b
ON a.goods_typ<>b.id;-- 自然连接
-- 自然连接只有在两个表中有相同名称的列且列的含义相似时才能使用,会剔除重复行
SELECT a.user_id, b.address, CONVERT(VARCHAR(10), last_login, 120) AS last_login
FROM users a, user_address b
WHERE a.user_id=b.user_id;-- 使用带聚合函数的内连接
SELECT a.id, a.name, COUNT(b.cat_id) num
FROM goods_category a INNER JOIN goods b
ON a.id=b.cat_id GROUP BY a.id,a.name;-- 连接多个表
SELECT a.goods_id, a.goods_name, b.name brand, c.name type
FROM goods a, brand b, goods_type c
WHERE a.brand_id=b.id AND a.goods_type=c.id;
外连接
通过内连接可以返回所有满足连接条件的记录。而有时则需要显示表中的所有记录,包括那些不符合连接条件的记录,此时就需要外连接。
外连接以指定的数据表为主体,将主体表中不满足连接条件的数据也一并输出。根据外连接保存下来的行的不同,可以将外连接分为一下三种:
1.左外连接: 表示在结果中包括左表中不满足条件的数据
2.右外连接: 表示在结果中包括右表中不满足条件的数据
3.全外连接: 表示在结果中包括左表和右表中不满足条件的数据
JOIN关键字左表是左表 右边是右表
-- 左外连接
SELECT goods_id,goods_name,name
FROM goods LEFT JOIN goods_type
ON goods.goods_type=goods_type.id ORDER BY goods_id DESC;-- 右外连接
-- SQLITE数据库支持左外连接 但不支持右外连接
SELECT goods_id,goods_name,name
FROM goods RIGHT JOIN goods_type
ON goods.goods_type=goods_type.id;-- 全外连接
-- MYSQL Access 和SQLIte 不支持全外连接
SELECT goods_id,goods_name,name
FROM goods FULL JOIN goods_type
ON goods.goods_type=goods_type.id ORDER BY goods_id;-- 通过外连接进行多表联合查询
SELECT goods_id, goods_name, brand.name, brand, goods_type.name type
FROM(goods LEFT JOIN brand ON goods.brand_id=brand_id)
LEFT JOIN goods_type ON goods.goods_type=goods_type.id;
自连接是指一个表同自身进行连接,必须通过别名来区分两个表
-- 通过自连接查询与OPPO是同一品牌分类的所有品牌id\name
SELECT b1.id,b1.name,b1.cat_name
FROM brand b1, brand b2
WHERE b1.cat_name=b2.cat_name
AND b2.name='OPPO';
交叉连接
交叉连接是两个表的笛卡尔乘积的另一种名称,交叉连接会将第一个表的每一行与第二个表的每一行进行匹配,这将导致了所有可能的集合。
SELECT a.name,a.cat_name,b.goods_name
FROM brand a CROSS JOIN goods b;
组合查询
UNION操作符可以执行多个SELECT查询语句,并将多个查询的结果作为一个查询结果集返回。
-- UNION 合并多个结果集
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE cat_id IN (123,131)
UNION
SELECT cat_id, goods_name, shop_price
FROM goods
WHERE goods_name LIKE '%华为%';--组合查询
SELECT cat_id, goods_name,shop_price
FROM goods_type1
WHERE shop_price=59
UNION
SELECT cat_id, goods_name, shop_price
FROM goods_type2
WHERE shop_price=60;-- 通过UNION ALL返回重复的行
SELECT cat_id, goods_name,shop_price
FROM goods_type1
WHERE shop_price=59
UNION ALL
SELECT cat_id, goods_name, shop_price
FROM goods_type2
WHERE shop_price=60;-- 对组合查询结果进行排序
SELECT cat_id, goods_name,shop_price
FROM goods
WHERE cat_id IN (123,131)
UNION
SELECT cat_id, goods_name, shop_price
FROM goods
WHERE goods_name LIKE '%华为%'
ORDER BY shop_price;
插入数据
插入单行数据
-- 如果某一行定义为允许NULL值, 则可以在INSERT语句中省略该列
-- 创建数据表时允许通过DEFAULT关键字为列定义默认值, 插入时不指定则为默认值
INSERT INTO brand (id,name,logo,describ) VALUES(111,'ceshi','logo.jpg','简单描述');-- 插入多行数据
INSERT INTO brand (id,name,logo,describ) VALUES(111,'ceshi','logo.jpg','简单描述'), (112,'ceshi','logo.jpg','简单描述');-- 创建数据表
CREATE TABLE brand_new(id, int NOT NULL PRIMARY KEY,name varchar(60) NOT NULL DEFAULT '',describe text NOT NULL,cat_name varchar(128) NULL DEFAULT '',cat_id int NULL DEFAULT 0
);-- 通过查询语句插入多行数据
INSERT INTO brand_new
SELECT * FROM brand
WHERE cat_name="手机"
更新和删除数据
使用UPDATE语句更新列值
-- 更新一个或多个列
UPDATE branc
SET cat_name = "新名字", cat_name="hello", is_hot=1
WHERE name= '测试';-- 更新表中的所有行
UPDATE brand
SET is_hot = 1;-- 依据外表值更新数据
UPDATE goods
SET store_count = store_count + 1000
WHERE cat_id = (SELECT id FROM goods_category WHERE name="平板");
DELETE 删除数据
-- 删除一行数据
DELETE FROM brand
WHERE name="新派系"-- 删除多行数据
DELETE FROM brand
WHERE name IN ("牌子1","牌子2"); -- 删除所有数据
SELECT * INTO new_tab
FROM goods_type;DELETE FROM new_tab;-- TRUNCATE TABLE 语句不但删除了数据,而且所删除的数据在事物处理日志中还会有记录
TRUNCATE TABLE new_tab;
使用视图
视图是一种常用的数据库对象,它将查询的结果以虚拟表的形式存储在数据中,视图并不在数据库中以存储数据集的形式存在。
-- 创建视图
CREATE VIEW GoodPrice
AS
SELECT goods_id, goods_name, shop_price
FROM goods;
SELECT * FROM GoodsPrice;-- 删除视图
DROP VIEW GoodsPrice;-- 通过视图简化复杂查询
CREATE VIEW GoodsBrandType
AS
SELECT goods.goods_id,goods.goods_name,brand.name brand, goods_type.name type
FROM goods, brand, goods_type
WHERE goods.brand_id=brand.id AND goods.goods_type=goods_type.id;SELECT * FROM GoodsBrandType
WHERE type = "电视";-- 使用视图过滤不想要的数据
CREATE VIEW ZeroBook
AS
SELECT ISBN, BookName, Writer, newbook
WHERE newbook IS NOT NULL;
SELECT * FROM ZeroBook;-- 通过视图显示函数的结果
CREATE VIEW BookGroup(type,number,maxprice)
AS
SELECT Type, COUNT(*), MAX(Price)
FROM bookinfo
WHERE Type IS NOT NULL
GROUP BY Type;
SELECT * FROM BookGroup;-- 通过视图添加数据
CREATE VIEW GoodsBrandType
AS
SELECT goods.goods_id,goods.goods_name,brand.name brand, goods_type.name type
FROM goods, brand, goods_type
WHERE goods.brand_id=brand.id AND goods.goods_type=goods_type.id;INSERT INTO GoodsBrandType
(goods_id,goods_name)
VALUES(115,'海尔洗衣机');
INSERT INTO GoodsBrandType
(type_id,type)
VALUES(30,'洗衣机');-- 通过视图更新数据
CREATE VIEW GoodsBrand
AS
SELECT goods.goods_id,goods.goods_name,brand.name brand
FROM goods,brand
WHERE goods.brand_id=brand.id;UPDATE GoodsBrand
SET goods_name="康佳"
WHERE goods_id=57;-- 通过视图删除数据
CREATE VIEW Type
AS
SELECT * FROM goods_type;
DELETE Type
WHERE name="洗衣机"; -- 在视图中使用WITH CHECK OPTION 子句
-- 如果在创建视图的时候使用了WITH CHECK OPTION 子句, 那么在视图上执行的INSERT或者UPDATE操作都必须符合定义视图的设置的查询条件。
CREATE VIEW GoodsStore
AS
SELECT goods_id, goods_name, store_count
FROM goods
WHERE store_count < 1000
WITH CHECK OPTION;
SELECT * FROM GoodsStore;
UPDATE GoodsStore
SET store_count = store_count + 400;
数据库管理
创建数据库
-- 使用默认值创建数据库
CREATE DATABASE STU;--自定义选项创建数据库
CREATE DATABASE mrkj
ON
(name=mrdat,filename='E:\mrkj.mdf'size=10, --初始大小为10MBmaxsize=100, -- 最大为100MBfilegrowth=5) -- 增长大小是5MB log on(filename='E:\mrkj.ldf' -- 日志名称 size=8MB, --日志初始大小maxsize=50MB, --日志最大filegrowth=8MB -- 日志增长
);
-- 创建数据库的时候指定文件和文件组
-- 略
修改数据库
-- 向数据库中添加文件
ALTER DATABASE mrkj
ADD FILE(name=happy,FILE='E:\happy.ndf',size=2mb,maxsize=30mb,filegrowth=3mb
)-- 向数据库中添加文件组
ALTER DATABASE mrkj
ADD filegroup happy-- 删除数据库中的文件或文件组
ALTER DATABASE mrkj
REMOVE file happy-- 修改数据库文件的大小
ALTER DATABASE mrkj
MODIFY FILE(name=joy,size=40mb
)-- 缩小数据库
DBCC SHRINKDATABASE(mr01,10,NOTRUNCATE)--缩小数据库指定数据文件或者日志文件大小
DBCC SHRINKFILE(mrdat,1,NOTRUNCATE)-- 数据库更名
EXEC sp_renamedb 'mr', 'mrsoft'
删除数据库
DROP DATABASE mrkj
DROP DATABASE mr01, mrsoft
数据表管理
创建数据表
USE shop -- 使用数据库
CREATE TABLE shoppping
(商品编号 int primary key, -- 主键列 必须唯一且不能为NULL商品类别 varchar(10) not null, -- 此列必须不能为NULL值 商品ID varchar(10) unique, -- 所有列值都不同, 但是可以为NULL 价格 int check(价格>=10 and 价格<= 1000) -- 价格在10到1000之间 商品数量 int default 0, -- 商品数量默认值为0商品备注 text
)修改数据表
-- 向数据表中添加列
ALTER TABLE student --ALTER 中只允许添加包含NULL值的列
ADD 专业 char(10)--修改列中的数据类型和大小
ALTER TABLE student
ALTER COLUMN 学号 varchar(10) NOT NULL-- 向表中添加主键
-- 将某个列设置为主键
ALTER TABLE student ADD PRIMARY KEY(学号) -- 删除表中的约束
-- 查找约束
SELECT * FROM sysobjects
WHERE parent_obj IN (SELECT id FROM sysobjectsWHERE name='shopping'
);
-- 删除约束
ALTER TABLE shopping
DROP CONSTRAINT PK_shopping_8999977767--修改数据表的名称
-- ALTER TABLE命令不能修改数据表的名称,修改数据表的名称可以使用系统存储过程sp_rename
-- 使用EXEC sp_rename关键将student数据表名称改成stu
EXEC sp_rename 'student', 'stu' -- 从已有的表中删除列
ALTER TABLE stu DROP COLUMN 专业
删除数据表
DROP TABLE memeber
-- 删除三个数据表
DROP TABLE stu, teacher, shopping
相关文章:

SQL基本语法用例大全
文章目录 SQL语法概述简单查询计算列查询条件查询范围查询使用逻辑运算符过滤数据使用IN操作符过滤数据格式化结果集模糊查询行数据过滤数据排序数据统计分析分组总计简单子查询多行子查询多表链接插入数据更新和删除数据使用视图数据库管理数据表管理 SQL语法概述 SQL(Struct…...

MAX17058_MAX17059 STM32 iic 驱动设计
本文采用资源下载链接,含完整工程代码 MAX17058-MAX17059STM32iic驱动设计内含有代码、详细设计过程文档,实际项目中使用代码,稳定可靠资源-CSDN文库 简介 MAX17058/MAX17059 IC是微小的锂离子(Li )在手持和便携式设备的电池电量计。MAX170…...
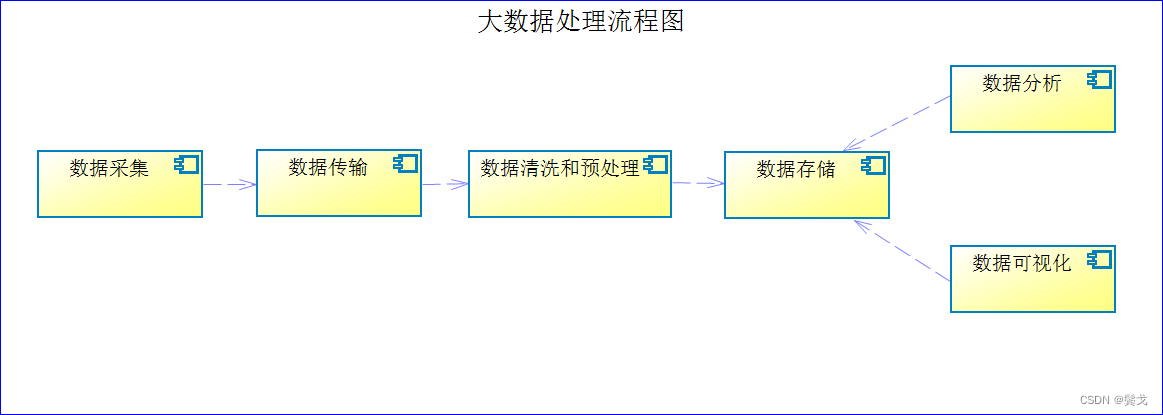
大数据笔记-大数据处理流程
大家对大数据处理流程大体上认识差不多,具体做起来可能细节各不相同,一幅简单的大数据处理流程图如下: 1)数据采集:数据采集是大数据处理的第一步。 数据采集面对的数据来源是多种多样的,包括各种传感器、社…...

wps演示时图片任意位置拖动
wps演示时图片任意位置拖动 1.wps11.1版本,其他版本的宏插件可以自己下载。2.先确认自己的wps版本是不是11.13.检查是否有图像工具4.检查文件格式和安全5.开发工具--图像6.选中图像控件,右击选择查看代码,将原有代码删除,将下边代…...
NodeJs中使用JSONP和Cors实现跨域
跨域是为了解决浏览器请求域名,协议,端口不同的接口,相同的接口是不需要实现跨域的。 1.使用JSONP格式实现跨域 实现步骤 动态创建一个script标签 src指向接口的地址 定义一个函数和后端调用的函数名一样 实现代码 -- 在nodejs中使用http内…...
Typora for Mac:优雅的Markdown文本编辑器,提升你的写作体验
Typora是一款强大的Markdown文本编辑器,专为Mac用户设计。无论你是写作爱好者,还是专业作家或博客作者,Typora都能为你提供无与伦比的写作体验。 1. 直观的界面设计 Typora的界面简洁明了,让你专注于写作,而不是被复…...
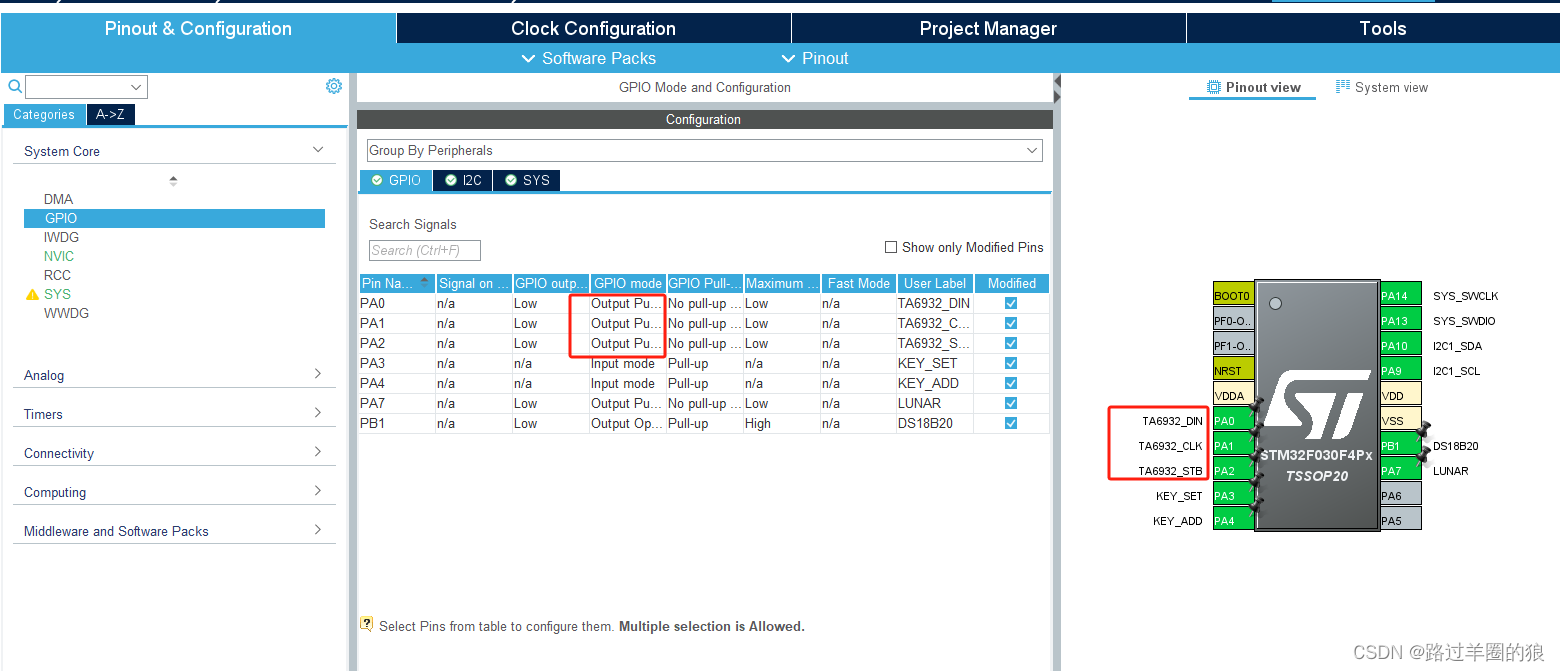
STM32使用HAL库驱动TA6932数码管驱动芯片
TA6932介绍 8段16位,支持共阴共阳LED数码管。 2、STM32CUBEMX配置引脚 推挽配置即可。 3、头文件 /******************************************************************************************** * TA6932:8段16位数码管驱动 *******************…...
day25--JS进阶(递归函数,深浅拷贝,异常处理,改变this指向,防抖及节流)
目录 浅拷贝 1.拷贝对象①Object.assgin() ②展开运算符newObj {...obj}拷贝对象 2.拷贝数组 ①Array.prototype.concat() ② newArr [...arr] 深拷贝 1.通过递归实现深拷贝 2.lodash/cloneDeep实现 3.通过JSON.stringify()实现 异常处理 throw抛异常 try/catch捕获…...

Python爬虫(二十三)_selenium案例:动态模拟页面点击
本篇主要介绍使用selenium模拟点击下一页,更多内容请参考:Python学习指南 #-*- coding:utf-8 -*-import unittest from selenium import webdriver from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup import timeclass douyuSelenium…...
nodejs+vue宠物店管理系统
例如:如何在工作琐碎,记录繁多的情况下将宠物店管理的当前情况反应给管理员决策,等等。在此情况下开发一款宠物店管理系统小程序, 困扰管理层的许多问题当中,宠物店管理也是不敢忽视的一块。但是管理好宠物店又面临很多麻烦需要解决,于是乎变得非常合乎时…...

ceph版本和Ceph的CSI驱动程序
ceph版本和Ceph的CSI驱动程序 ceph查看ceph版本Ceph的CSI驱动程序 ceph ceph版本和Ceph的CSI驱动程序 查看ceph版本 官网ceph-releases-index Ceph的CSI驱动程序 Ceph的CSI驱动程序 https://github.com/ceph/ceph-csi...
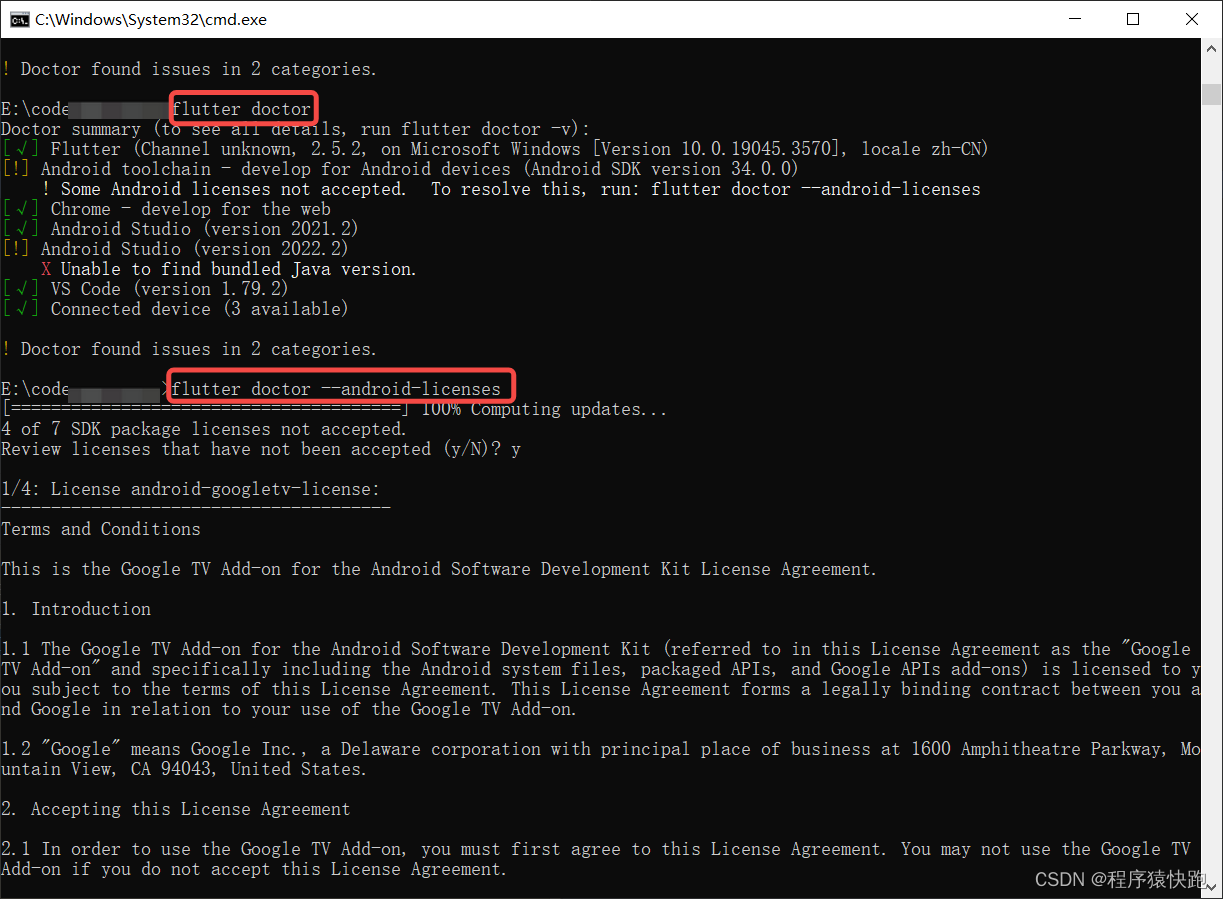
Android Studio Flutter真机调试错误
错误:Could not locate aapt. Please ensure you have the Android buildtools installed. No application found for TargetPlatform.android_arm64. Is your project missing an android/app/src/main/AndroidManifest.xml? Consider running "flutter crea…...

MQ - 41 容灾:跨地域、跨可用区的容灾和同步的方案设计
文章目录 导图概述容灾能力的理论基础集群内和集群间容灾RTO 和 RPO集群内容灾方案的原理分析RTO 和 RPO跨集群容灾方案的原理分析三种复制方式客户端连接集群主备切换方式一 直连 Broker方式二 域名方式三 虚拟 IP (推荐)双向同步RTO 和 RPOApache Kafka MirrorMaker (V2版…...
vue3学习(二)--- ref和reactive
文章目录 ref1.1 ref将基础类型和对象类型数据转为响应式1.2 ref()获取id元素1.3 isRef reactive1.1 reactive()将引用类型数据转为响应式数据,基本类型无效1.2 ref和reactive的联系 toRef 和 toRefs1.1 如果原始对象是非响应式的就不会更新视图 数据是会变的 ref …...
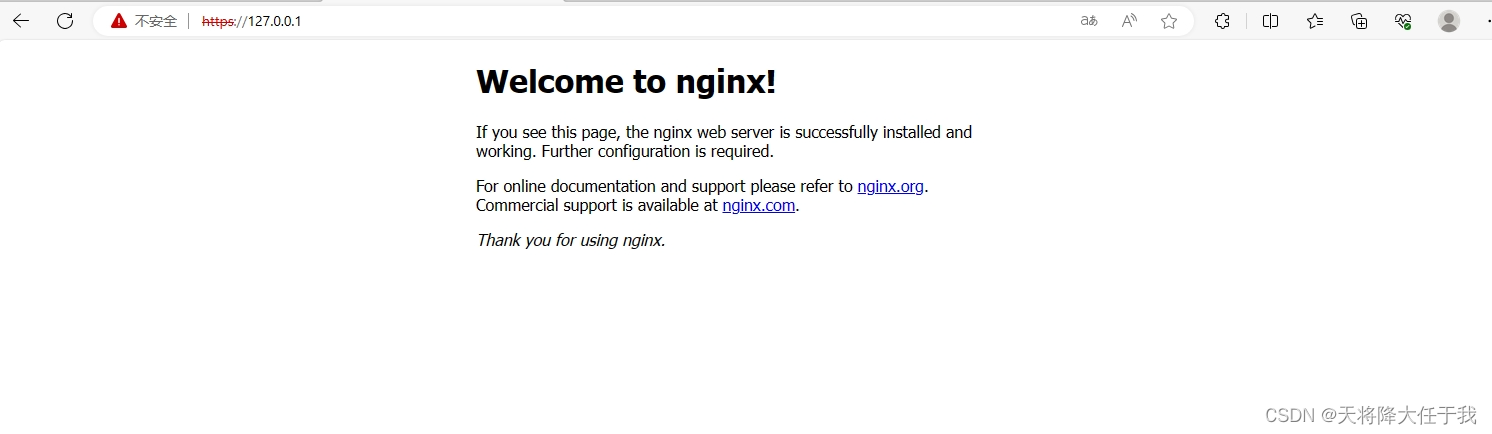
网络-HTTPS
文章目录 前言一、HTTPS简介优点SSL/TSL工作流程 加密1、对称加密2、非对称加密 二、使用HTTPS1.openSSL生成私钥(1)node服务端(2)nginx配置https服务(前端) nginx服务 总结 前言 Http 存在不安全、无状态…...
GPU提升多分类问题
使用GPU加速多分类问题,与上一篇文章中前几部分代码相同 多层线性网络这里,直接使用nn.Module搭建,与之前自定义搭建的三层网络一样,但注意这里用的激活函数是ReLU的改良后的LeakyReLU,能够避免在输入小于0时出现梯…...

Selenium+Pytest自动化测试框架
前言 selenium自动化 pytest测试框架 本章你需要 一定的python基础——至少明白类与对象,封装继承 一定的selenium基础——本篇不讲selenium,不会的可以自己去看selenium中文翻译网 测试框架简介 测试框架有什么优点呢: 代码复用率高&…...

云原生Kubernetes:Rancher管理k8s集群
目录 一、理论 1.Rancher 2.Rancher 安装及配置 二、实验 1.Rancher 安装及配置 三、问题 1. Rancher 部署监控系统报错 四、总结 一、理论 1.Rancher (1) 概念 Rancher 简介 Rancher 是一个开源的企业级多集群 Kubernetes 管理平台,实现了 Kubernetes …...

Java架构师异步架构设计
目录 1 导学2 为何需要异步消息架构3 消息发送失败该如何处理4 mq接收到消息过后又丢失了消息怎么办5 消费者弄丢了消息该如何处理6 消息重复消费了该怎么处理7 消息的有序处理8 消息堆积该如何处理9 如何提高消息消费的速度10 消息应用的可插拔11 如何设计消息的统一id12 异步…...
电子书制作软件Vellum mac中文版特点
Vellum mac是一款专业的电子书制作软件,它可以帮助用户将文本文件转换为高质量的电子书,支持多种格式,包括EPUB、MOBI、PDF等。Vellum具有直观的用户界面和易于使用的工具,可以让用户快速地创建和发布电子书。 Vellum mac软件特点…...

告别无效筛选!酒店哥哥教你这样找会议酒店,省时省力不踩坑
找场地的痛,谁懂?办会人最崩溃的瞬间,莫过于找会议酒店的过程——连续一周泡在各类平台,刷遍几十家会议酒店,要么图片与实际场地天差地别。找会议酒店,俨然成了办会路上的第一道拦路虎,消耗大量…...

影墨·今颜多模态应用:结合文本与图像输入的进阶生成案例
影墨今颜多模态应用:结合文本与图像输入的进阶生成案例 最近在玩一个挺有意思的模型,叫影墨今颜。它最吸引我的地方,不是单纯的文生图或者图生图,而是能把文字和图片“揉”在一起,生成一些意想不到的新东西。这感觉就…...

s2-pro新手避坑指南:3步搞定文本转语音,常见问题全解析
s2-pro新手避坑指南:3步搞定文本转语音,常见问题全解析 1. s2-pro语音合成快速入门 s2-pro是Fish Audio开源的专业级语音合成工具,它能将文字转换成自然流畅的语音。对于刚接触语音合成的新手来说,这个工具特别友好,…...

NeuroKit2:Python神经生理信号处理的全流程解决方案
NeuroKit2:Python神经生理信号处理的全流程解决方案 【免费下载链接】NeuroKit NeuroKit2: The Python Toolbox for Neurophysiological Signal Processing 项目地址: https://gitcode.com/gh_mirrors/ne/NeuroKit 神经生理信号处理是连接生理数据与临床洞察…...

相控阵雷达技术解析:从THAAD到5G应用
1. 萨德系统概述:现代反导防御的核心力量THAAD(Terminal High Altitude Area Defense)系统是美国陆军研发的末端高空区域防御系统,专门用于拦截处于末段飞行阶段的短程和中程弹道导弹。这套系统自2008年部署以来,已成为…...

QPDF技术解析:基于Qt WebEngine的PDF查看器架构设计与应用实践
QPDF技术解析:基于Qt WebEngine的PDF查看器架构设计与应用实践 【免费下载链接】qpdf PDF viewer widget for Qt 项目地址: https://gitcode.com/gh_mirrors/qpd/qpdf 在当今数字化文档处理领域,PDF格式已成为跨平台文档交换的事实标准。对于Qt开…...

YimMenu专业使用指南:从功能认知到安全实践
YimMenu专业使用指南:从功能认知到安全实践 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu 功…...
)
java+vue+SpringBoot企业信息管理系统(程序+数据库+报告+部署教程+答辩指导)
源代码数据库LW文档(1万字以上)开题报告答辩稿ppt部署教程代码讲解代码时间修改工具 技术实现 开发语言:后端:Java 前端:vue框架:springboot数据库:mysql 开发工具 JDK版本:JDK1.8 数…...

PICO开发效率翻倍:手把手教你用PDC串流实现Unity场景‘所见即所得’
PICO开发效率革命:用PDC串流实现Unity场景实时同步的终极指南 在VR内容开发领域,迭代效率往往决定着项目的成败。传统开发流程中,开发者需要反复在Unity编辑器和头显设备之间切换,每次修改后都要经历漫长的构建部署过程࿰…...

BsMax终极指南:让Blender用户效率翻倍的专业插件
BsMax终极指南:让Blender用户效率翻倍的专业插件 【免费下载链接】BsMax BsMax Blender Addon (UI simulator/ Modeling/ Rigg & Animation/ Render Tools and ... 项目地址: https://gitcode.com/gh_mirrors/bs/BsMax 你是否曾为Blender的学习曲线而苦恼…...