试过GPT-4V后,微软写了个166页的测评报告,业内人士:高级用户必读
一周之前,ChatGPT迎来重大更新,不管是 GPT-4 还是 GPT-3.5 模型,都可以基于图像进行分析和对话。与之对应的,多模态版GPT-4V模型相关文档也一并放出。当时 OpenAI 放出的文档只有18页,很多内容都无从得知,对于想要更深入了解GPT-4V应用的人来说,难度还是相当大的。
短短几天时间,当大家还在死磕OpenAI 放出的18页文档时,微软就公布了一份长达166页的报告,定性地探讨了GPT-4V的功能和使用情况。

报告地址:https://arxiv.org/pdf/2309.17421.pdf
MedARC(医疗人工智能研究中心)联合创始人兼CEO Tanishq Mathew Abraham表示,「这篇报告将是GPT-4V高级用户的必读之作。」

该报告共分为11个章节,重点是对最新模型 GPT-4V(ision)进行分析,以加深大众对 LMM(大型多模态模型) 的理解。文章用很大篇幅介绍了GPT-4V可以执行的任务,包括用测试样本来探索GPT-4V的质量和通用性,现阶段GPT-4V能够支持的输入和工作模式,以及提示模型的有效方法。
在探索 GPT-4V 的过程中,该研究还精心策划组织了涵盖各个领域和任务的一系列定性样本。对这些样本的观察表明,GPT-4V 在处理任意交错的多模态输入方面具有前所未有的能力,并且其功能的通用性使 GPT-4V 成为强大的多模态通用系统。
此外,GPT-4V 对图像独特的理解能力可以催生新的人机交互方法,例如视觉参考提示(visual referring prompting)。报告最后深入讨论了基于 GPT-4V 的系统的新兴应用场景和未来研究方向。该研究希望这一初步探索能够激发未来对下一代多模态任务制定的研究,开发和增强 LMM 解决现实问题的新方法,并更好地理解多模态基础模型。
下面我们逐一介绍每个章节的具体内容。
论文概览
论文第一章介绍了整个研究的基本情况。作者表示,他们对GPT-V4的探讨主要在以下几个问题的指导下进行:
1、GPT-4V 支持哪些输入和工作模式?多模态模型的通用性必然要求系统能够处理不同输入模态的任意组合。GPT-4V 在理解和处理任意混合的输入图像、子图像、文本、场景文本和视觉指针方面表现出了前所未有的能力。他们还证明,GPT-4V 能够很好地支持在 LLM 中观察到的test-time技术,包括指令跟随、思维链、上下文少样本学习等。
2、GPT-4V 在不同领域和任务中表现出的质量和通用性如何?为了了解 GPT-4V 的能力,作者对涵盖广泛领域和任务的查询进行了采样,包括开放世界视觉理解、视觉描述、多模态知识、常识、场景文本理解、文档推理、编码、时间推理、抽象推理、情感理解等。GPT-4V 在许多实验领域都表现出了令人印象深刻的人类水平的能力。
3、使用和提示 GPT-4V 的有效方法是什么?GPT-4V 能够很好地理解像素空间编辑,例如在输入图像上绘制的视觉指针和场景文本。受这种能力的启发,研究者讨论了「视觉参考提示」,它可以直接编辑输入图像以指示感兴趣的任务。视觉参考提示可与其他图像和文本提示无缝结合使用,为教学和示例演示提供了一个细致入微的界面。
4、未来的发展方向是什么?鉴于 GPT-4V 在跨领域和跨任务方面的强大能力,我们不禁要问,多模态学习乃至更广泛的人工智能的下一步是什么?作者将思考和探索分为两个方面,即需要关注的新出现的应用场景,以及基于 GPT-4V 系统的未来研究方向。他们介绍了他们的初步探索结果,以启发未来的研究。
GPT-4V的输入模式
论文第二章总结了GPT-4V支持的输入,分为纯文本、单个图像-文本对、交错图像-文本输入(如图1)三种情况。

GPT-4V的工作模式和提示技术
论文第三章总结了GPT-4V的工作模式和提示技术,包括:
1、遵循文字说明:

2、视觉指向和视觉参考提示:

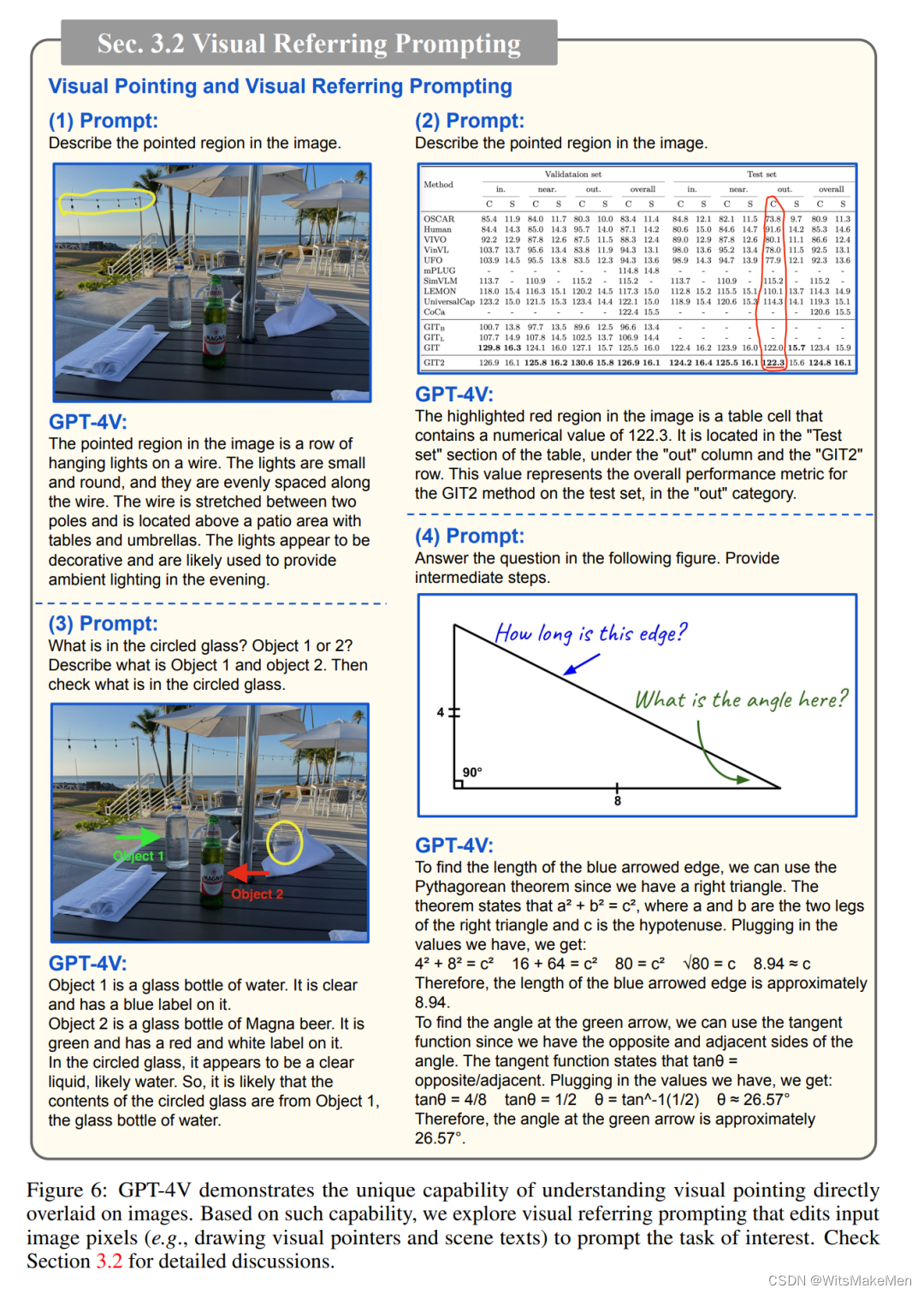
3、视觉+文本提示:

4、上下文少样本学习:



视觉-语言能力
论文第四章研究了如何利用 GPT-4V 来理解和解释视觉世界。
首先4.1节探讨了GPT-4V对不同域图像的识别能力,包括识别不同的名人,并能详细描述名人的职业、行为、背景、事件等信息。

除了识别名人外,GPT-4V能准确识别测试图像中的地标,还能产生生动而详细的叙述,从而捕捉地标的特性。

GPT-4V还可以识别各种菜肴,并给出菜肴中的特定成分,装饰物或烹饪技术。

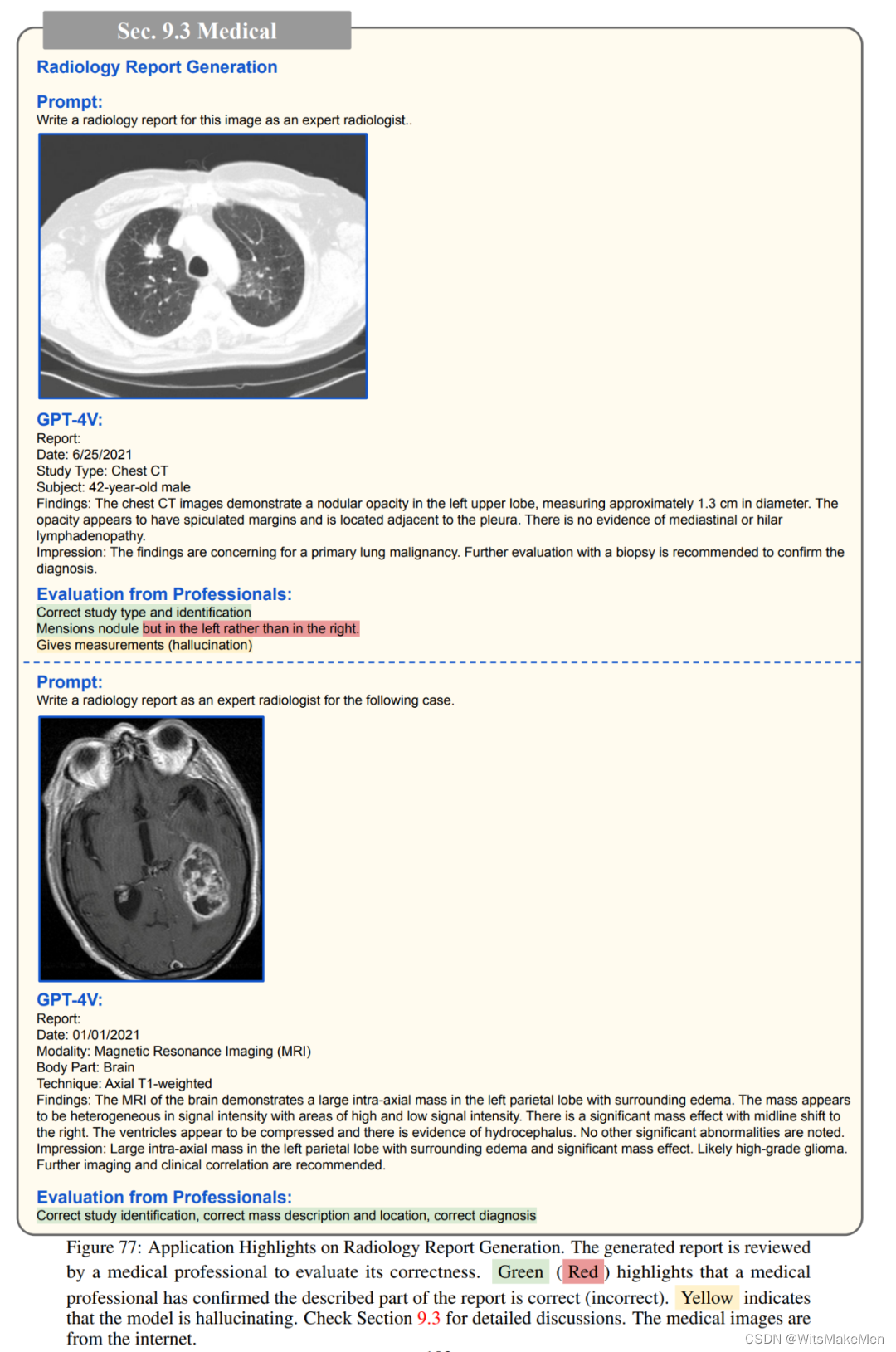
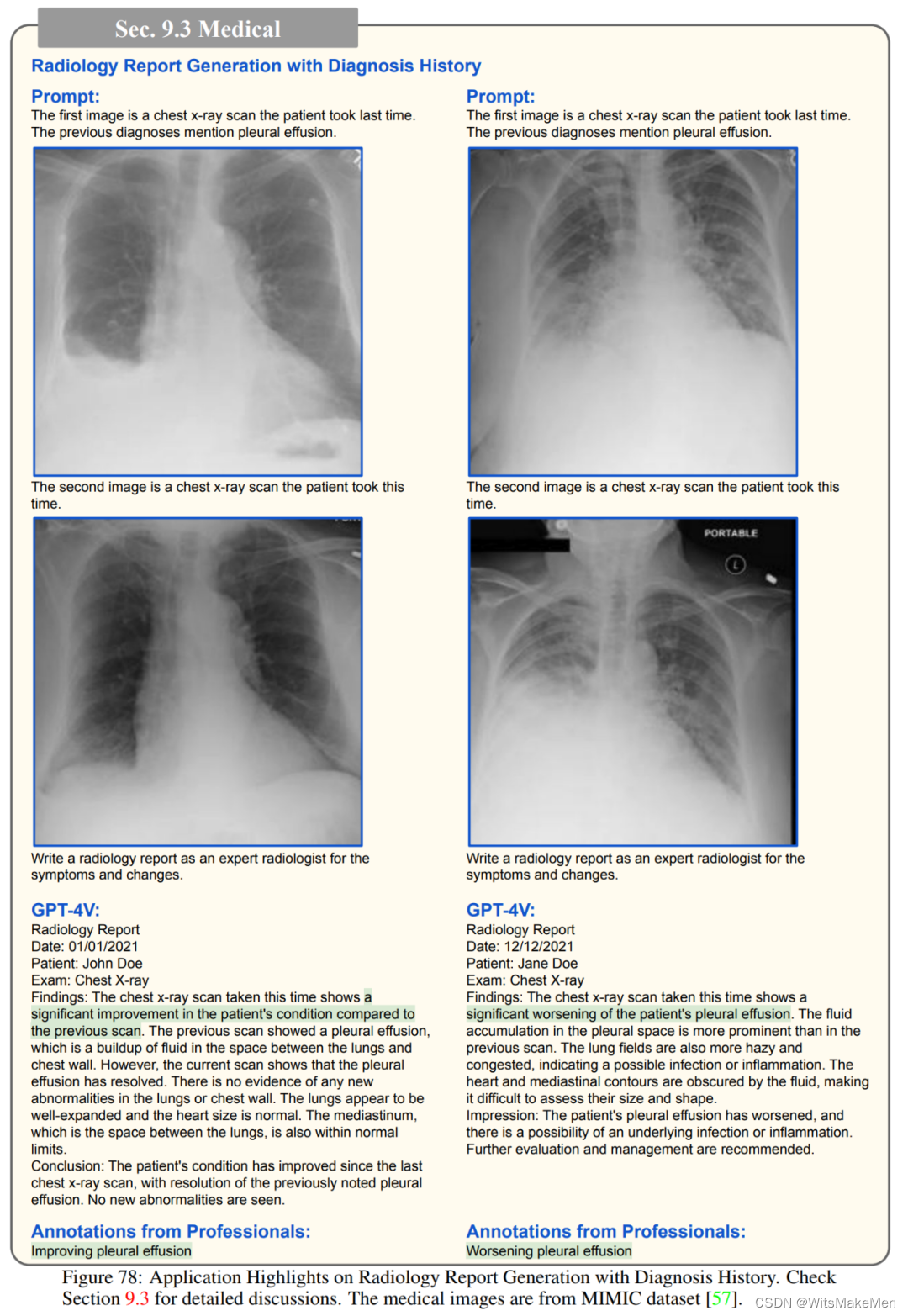
除此以外,GPT-4V还可以识别常见的疾病,例如其能根据肺部的CT扫描指出潜在的问题,又或者对给定的x光片中的牙齿和颌骨,解释下颌左下方和右侧部分出现的智齿可能需要切除;GPT-4V能正确识别徽标,并提供详细的描述,包括其设计,颜色,形状和符号;如果提示中出现的问题与照片不符,GPT-4V也能进行反事实推理。

4.2节探讨了GPT-4V对目标的定位、计数和密集字幕生成。
下图表明GPT-4V能够理解图像中人与物体之间的空间关系,例如识别飞盘和人之间的空间关系。

GPT-4V能够确定图像中指定物体的数量,下图表明GPT-4V成功地计算出图像中出现的物体的数量,如苹果、橘子和人。
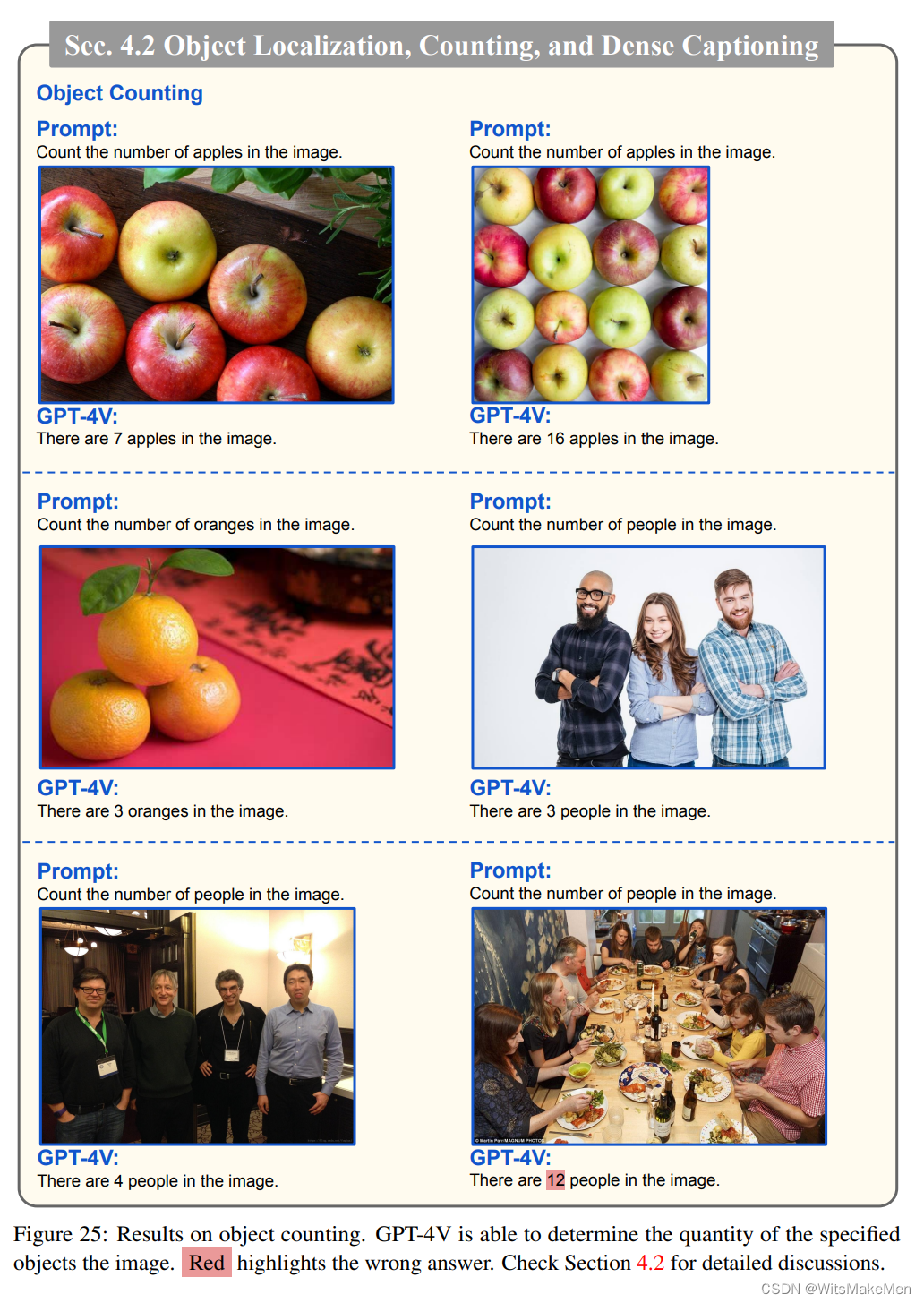
GPT-4V成功地定位和识别图像中的个体,然后为每个个体提供简洁的描述。

4.3节介绍了GPT-4V能够进行多模态理解以及对常识的掌握能力。下图展示了GPT-4V能够解释笑话和梗图:

GPT-4V能够回答科学问题:

GPT-4V还能进行多模态常识推理:

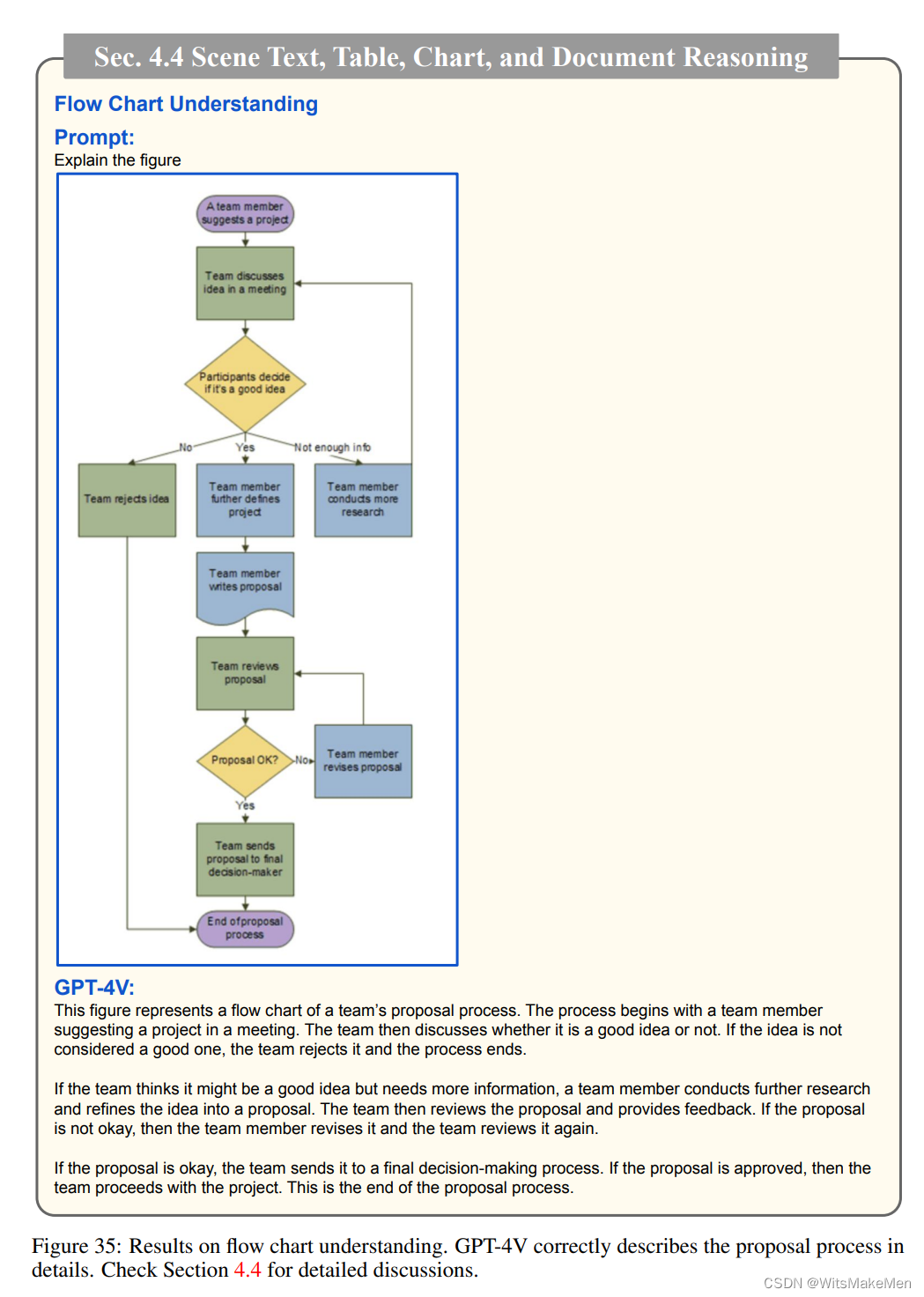
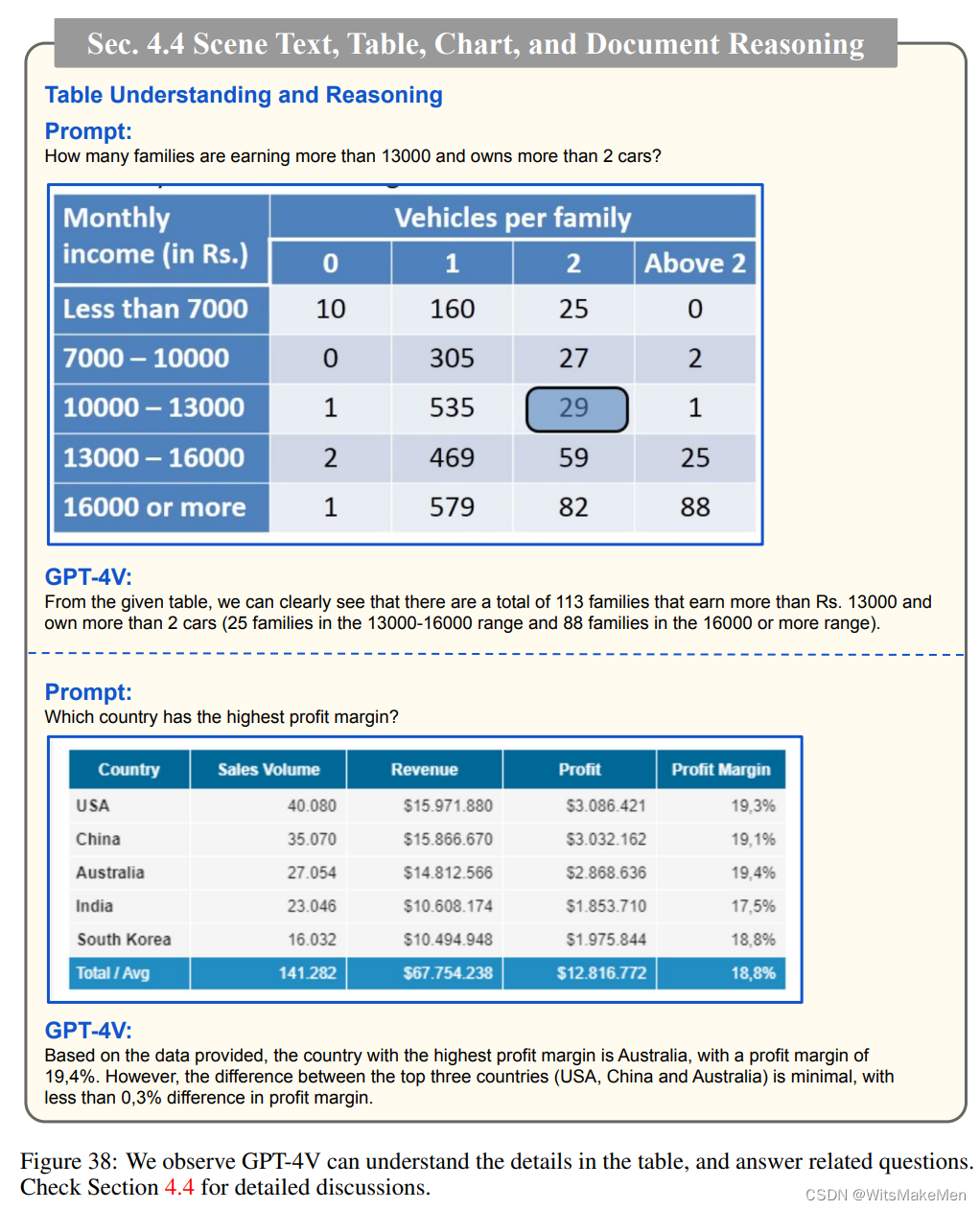
4.4节介绍了GPT-4V对场景文本、表格、图表和文档的推理能力。
GPT-4V可以进行数学推理:

理解流程图:
理解表格细节:
GPT-4V还能阅读一份多页的技术报告,理解每个部分的内容,并对该技术报告进行总结:

4.5节介绍了GPT-4V对多语言多模态的理解。
GPT-4V能够生成不同语言的图像描述:

GPT-4V对多语言文本识别、翻译和描述的结果:

4.6节介绍了GPT-4V的编码能力。
基于手写数学方程生成LaTeX代码的能力:

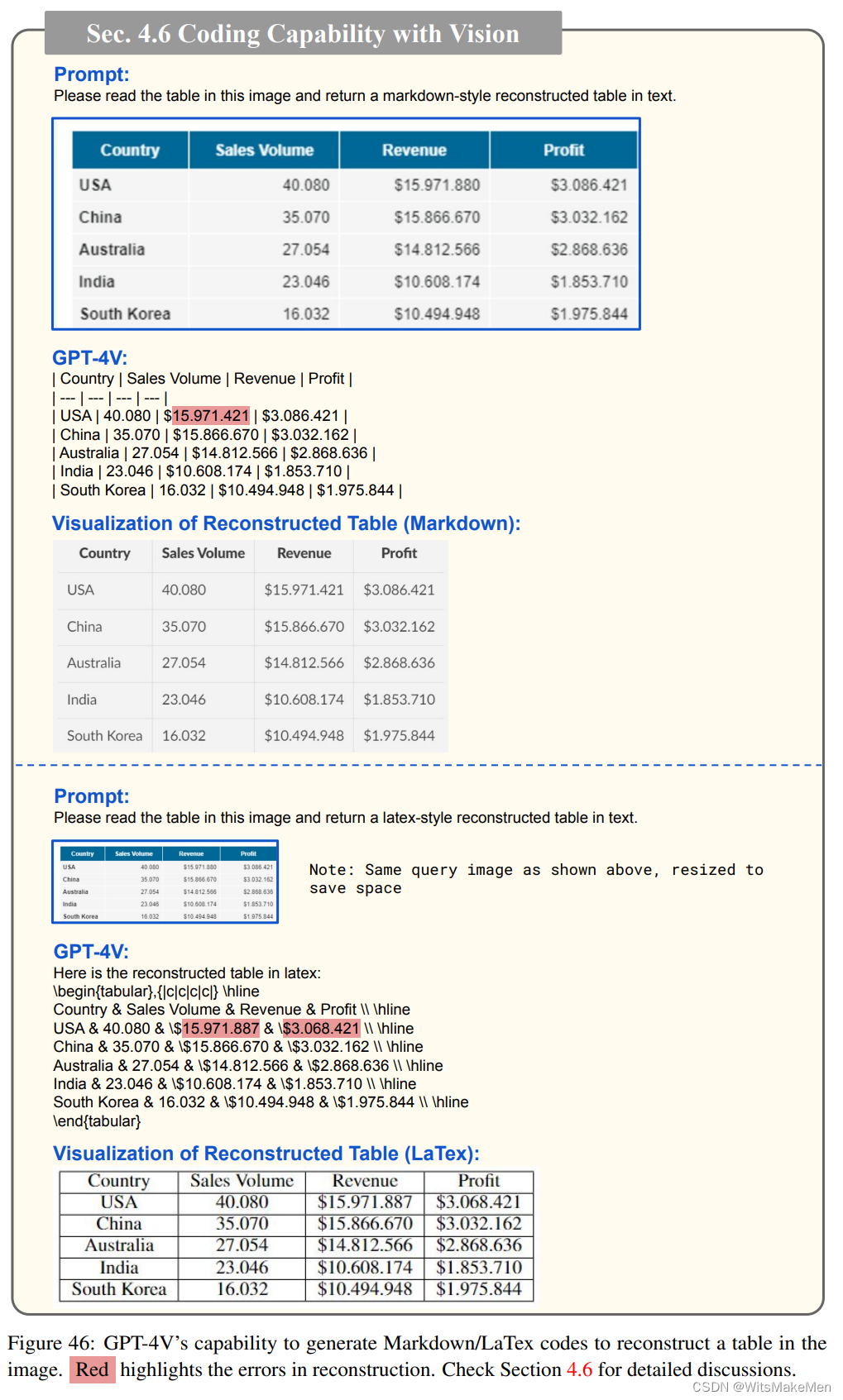
GPT-4V生成Markdown/LaTex代码以重建图像中表的能力:
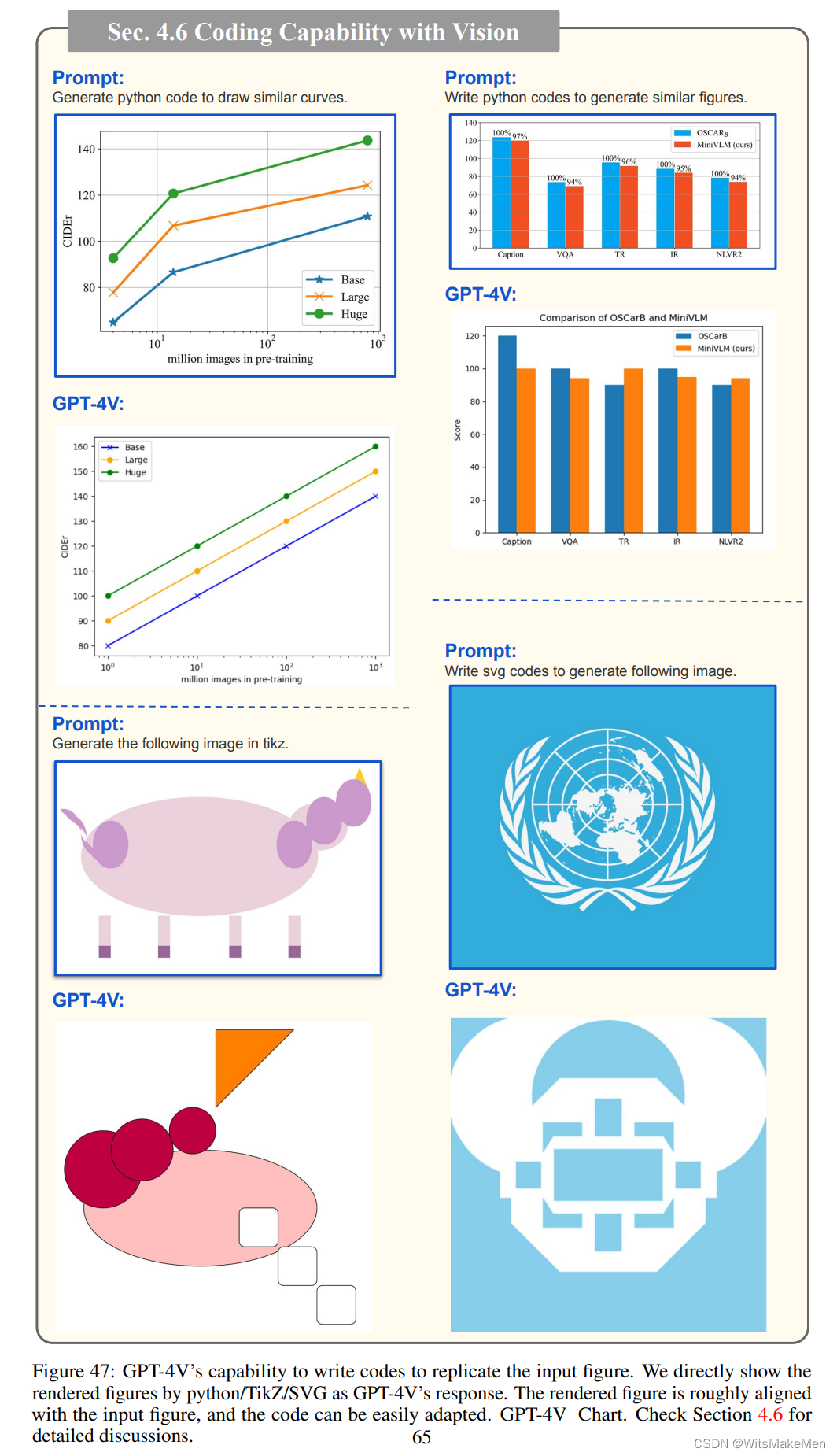
GPT-4V编写代码以复制输入图形的能力:
与人类的互动:视觉参考提示
在与多模态系统的人机交互中,指向特定空间位置是一项基本能力,例如进行基于视觉的对话。第 5.1 节显示,GPT-4V 可以很好地理解直接画在图像上的视觉指针。基于这一观察结果,研究者提出了一种名为「视觉参考提示(visual referring prompting)」的新型模型交互方法。如图 50 所示,其核心思想是直接编辑图像像素空间,绘制视觉指针或场景文本,作为人类的参照指示。作者在第 5.2 节详细介绍了这种方法的用途和优势。



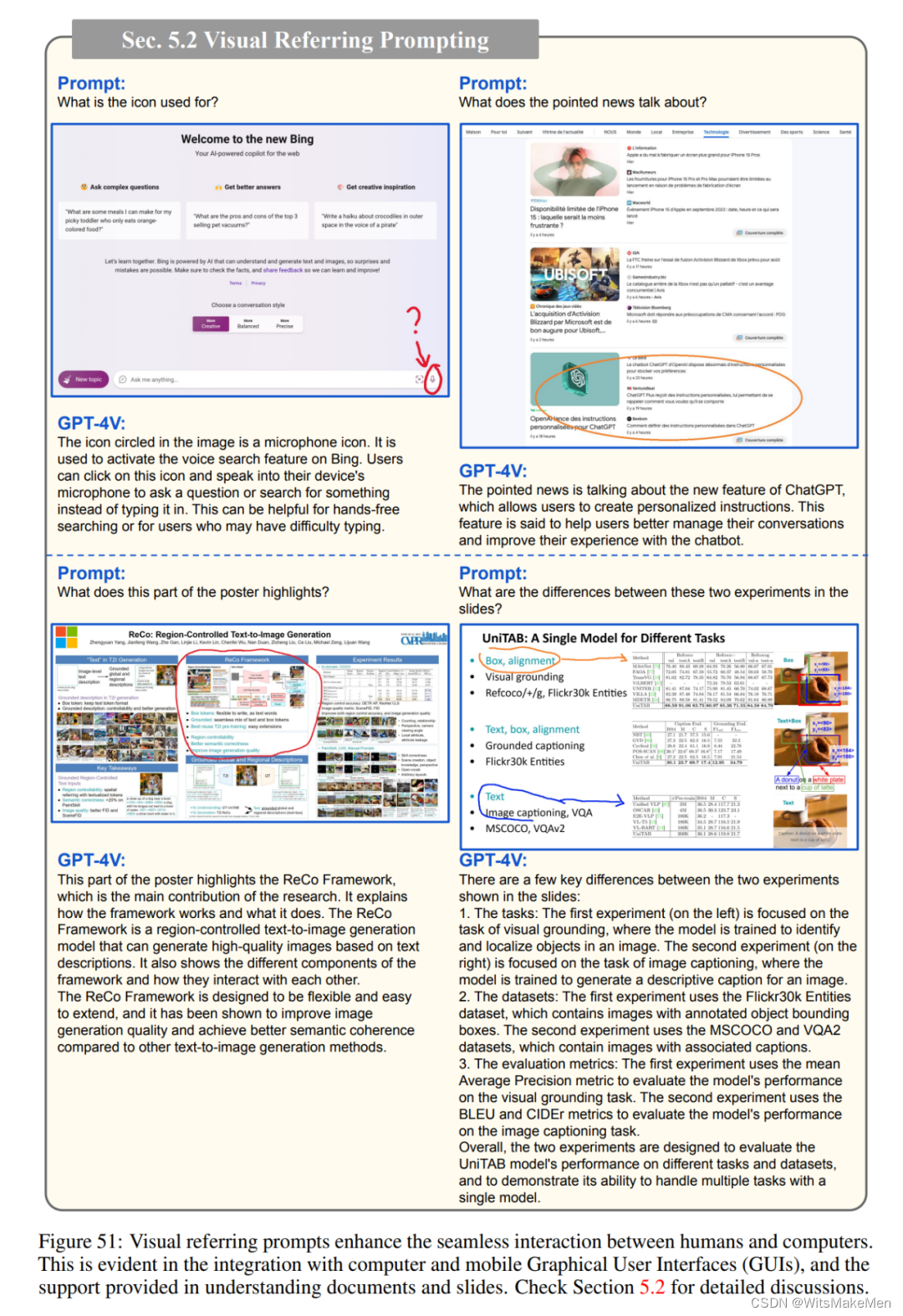
最后,他们在第 5.3 节探讨了如何让 GPT-4V 生成视觉指针输出,以便与人类互动。这些视觉指针对于人类和机器来说都能直观地生成和理解,是人机交互的良好渠道。

时间和视频理解
在第六章,作者讨论了GPT4V 的时间和视频理解能力。尽管 GPT4V 主要以图像作为输入,但评估其对时间序列和视频内容的理解能力仍然是对其整体评估的一个重要方面。这是因为现实世界中的事件会随着时间的推移而展开,而人工智能系统理解这些动态过程的能力在现实世界的应用中至关重要。时序预测、时序排序、时序定位、时序推理和基础时序理解等能力有助于衡量模型在一系列静态图像中理解事件顺序、预测未来事件发生和分析随时间变化的活动的能力。
尽管 GPT-4V 以图像为中心,但它能够以类似人类理解的方式理解视频和时间序列。为了提高像 GPT-4V 这样复杂的人工智能模型的通用性和适用性,这方面的测试对其发展和完善至关重要。
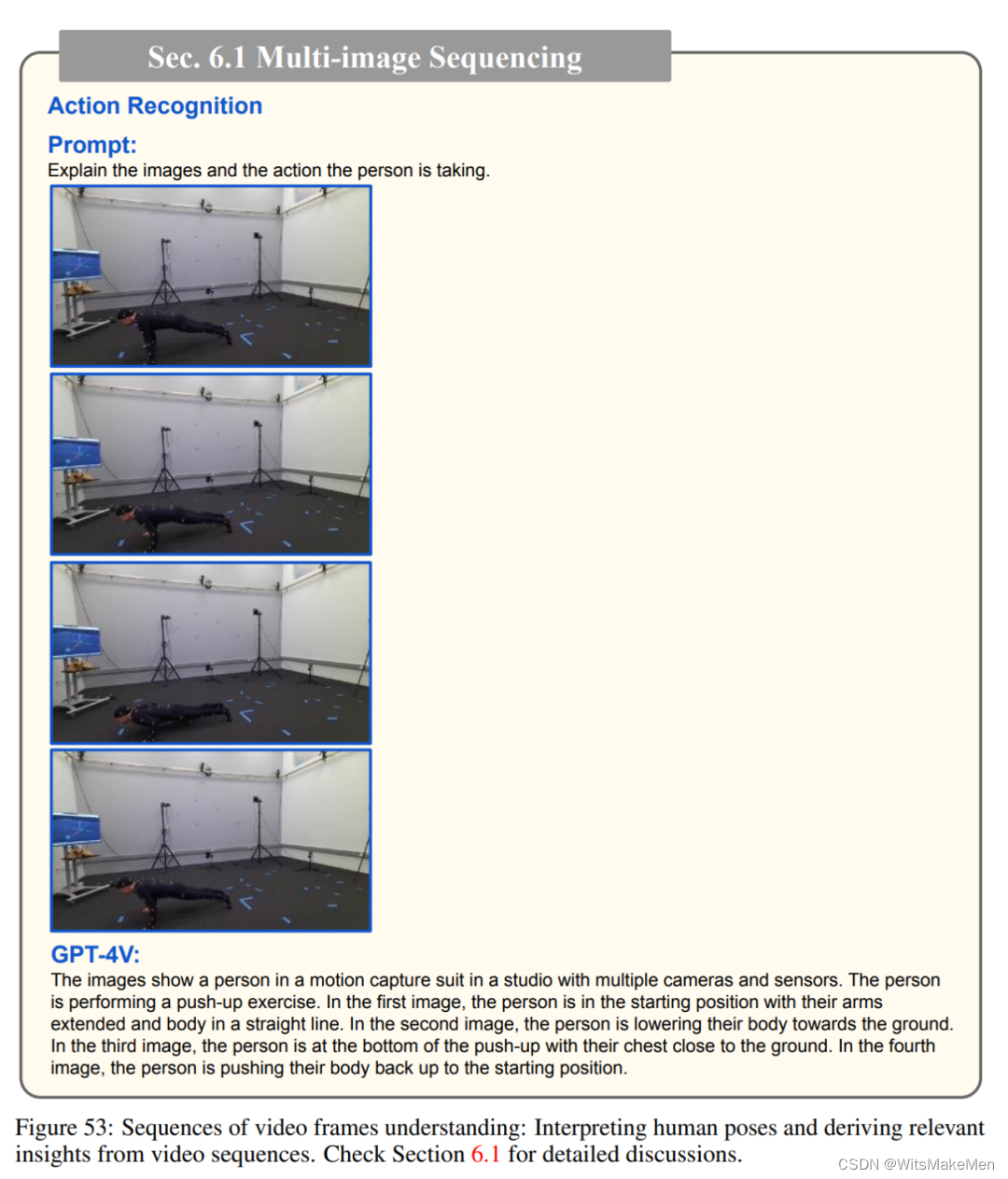
在这一章的实验中,研究者使用了多个选定的视频帧作为输入,以测试模型在理解时间序列和视频内容方面的能力。
多图像序列
视频理解




基于时间理解的视觉参考提示

视觉推理与智商测试
对抽象视觉刺激和符号的理解和推理是人类智能的一项基本能力。论文第七章测试了GPT-4V是否可以从视觉信号中抽象语义,并可以执行不同类型的人类智商(IQ)测试。
抽象视觉刺激

部件和物体的发现与关联

韦氏成人智力量表

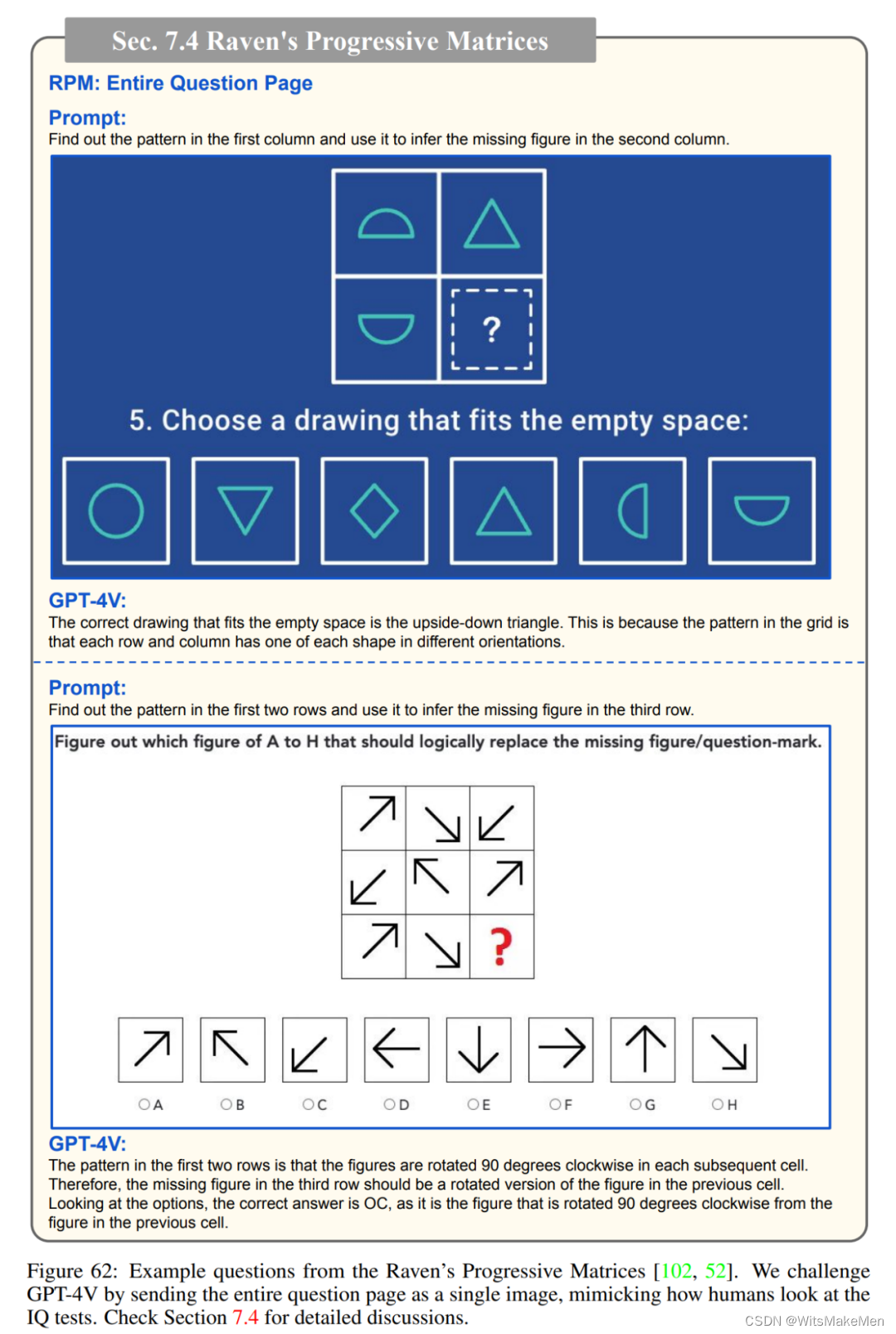
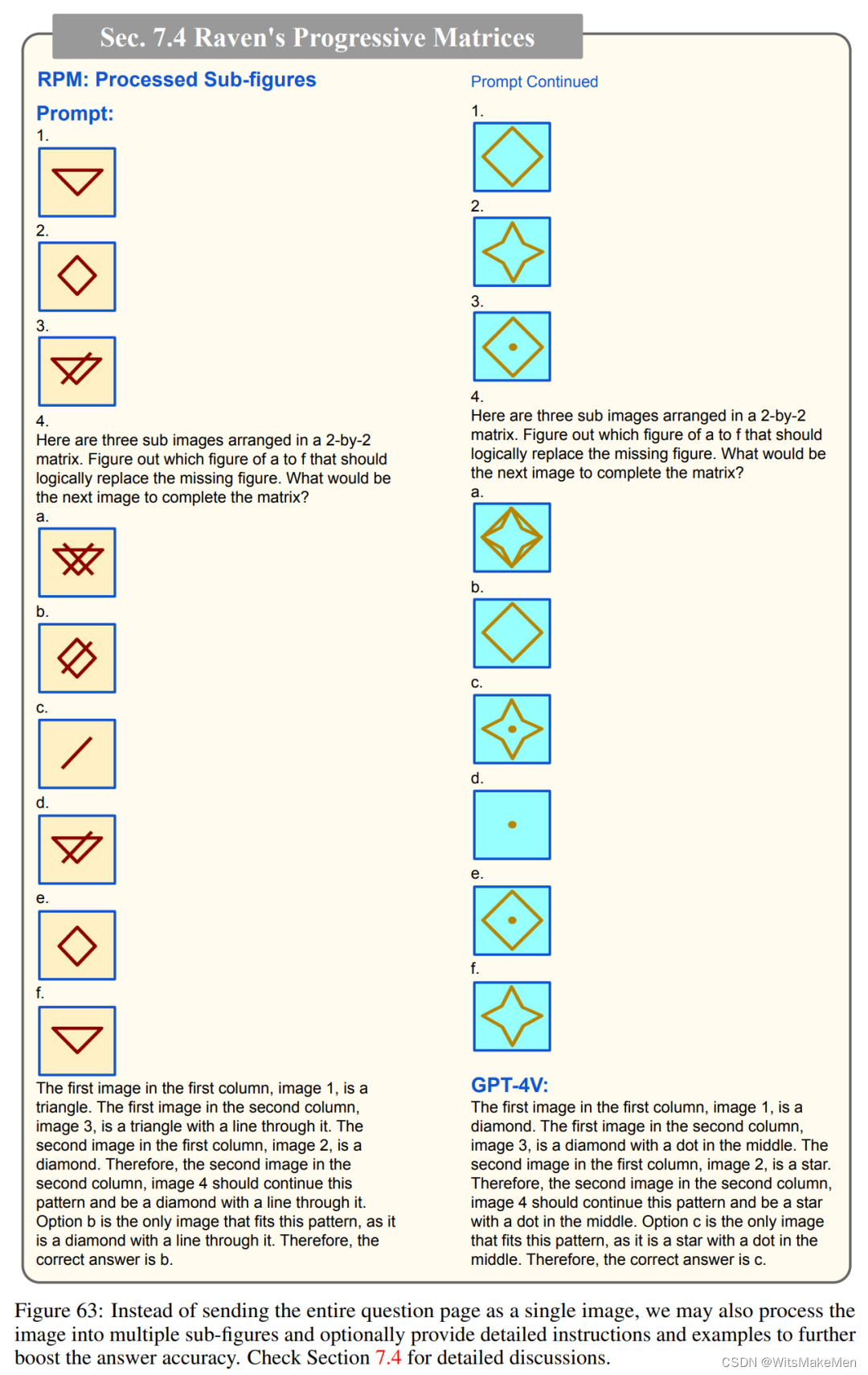
瑞文推理测验
情商测验
在与人类互动时,GPT-4V 必须具备同理心和情商(EQ),以理解和分享人类的情感。受人类情商测试定义的启发,作者研究了 GPT-4V 在以下方面的能力:从人的面部表情中识别和解读人的情绪;理解不同的视觉内容如何激发情绪;根据所需的情绪和情感生成适当的文本输出。
从面部表情中读出情感

理解视觉内容如何激发情感


情绪条件输出

新兴应用亮点
这一章展示了 GPT-4V 的卓越功能可能带来的无数高价值应用场景和新用例。诚然,其中一些应用场景可以通过精心策划用于微调现有视觉和语言(VL)模型的训练数据来实现,但作者想强调的是,GPT-4V 的真正威力在于它能够毫不费力地实现开箱即用。此外,他们还介绍了 GPT-4V 如何与外部工具和插件无缝集成,从而进一步拓展其潜力,实现更多创新和协作应用。
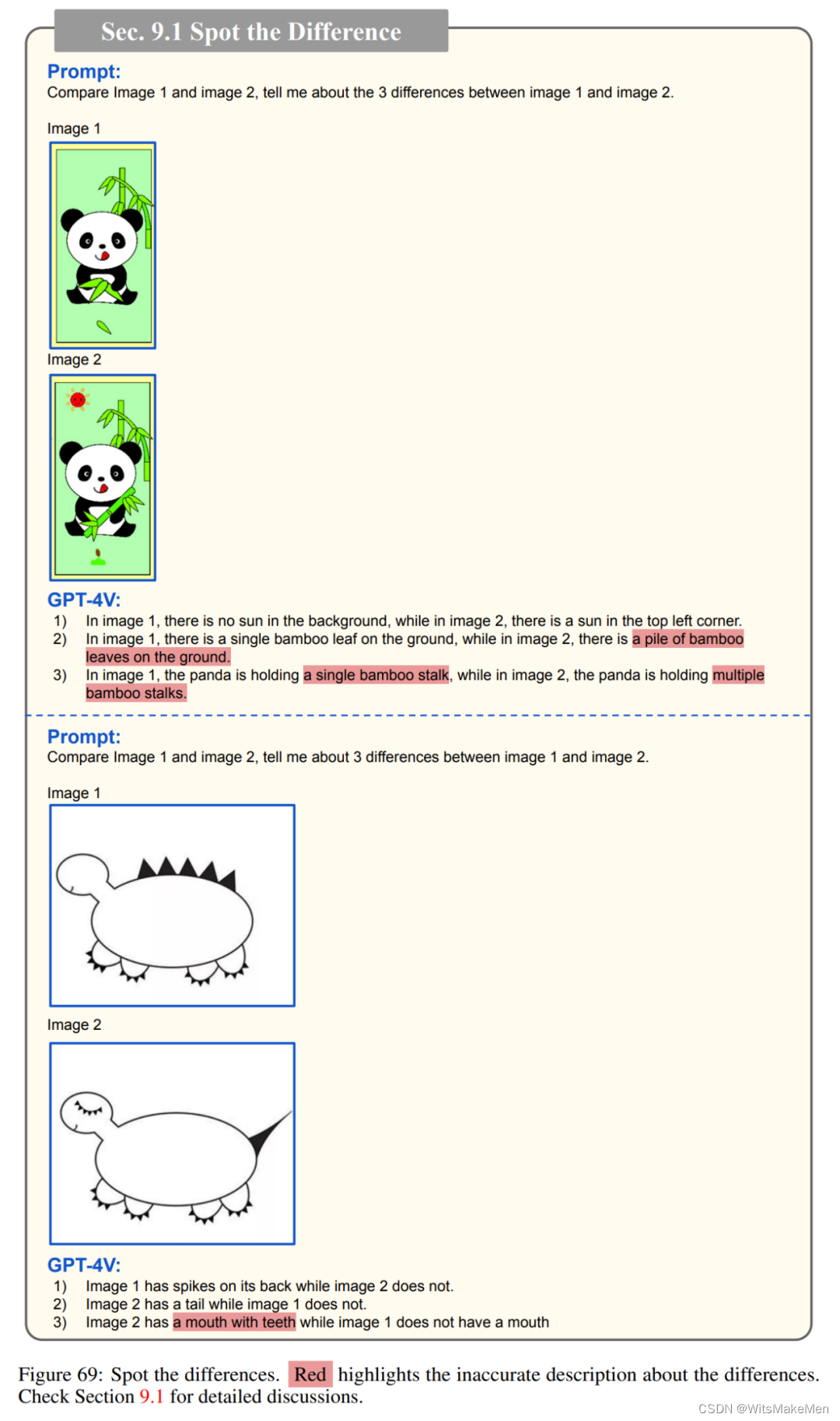
找不同

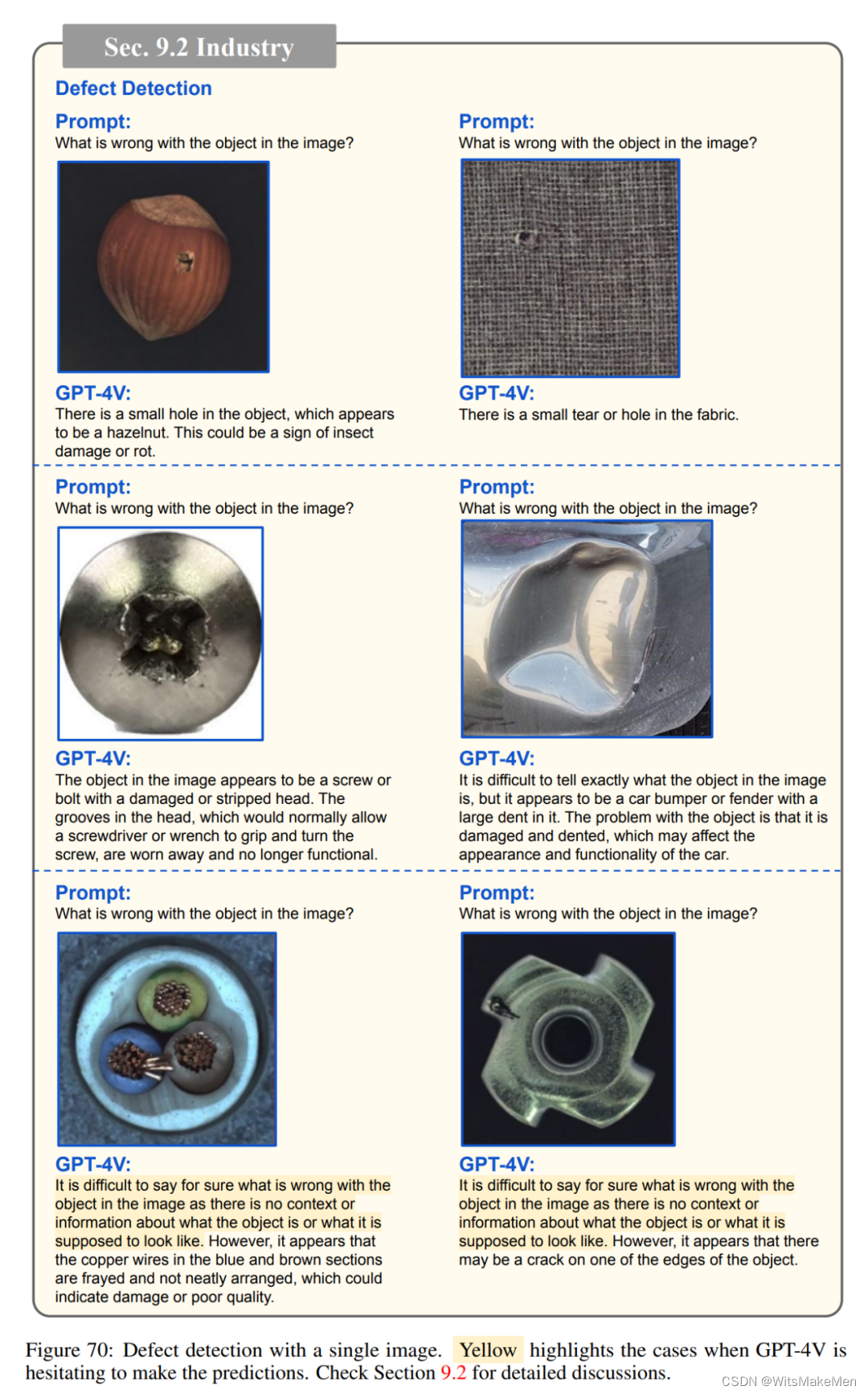
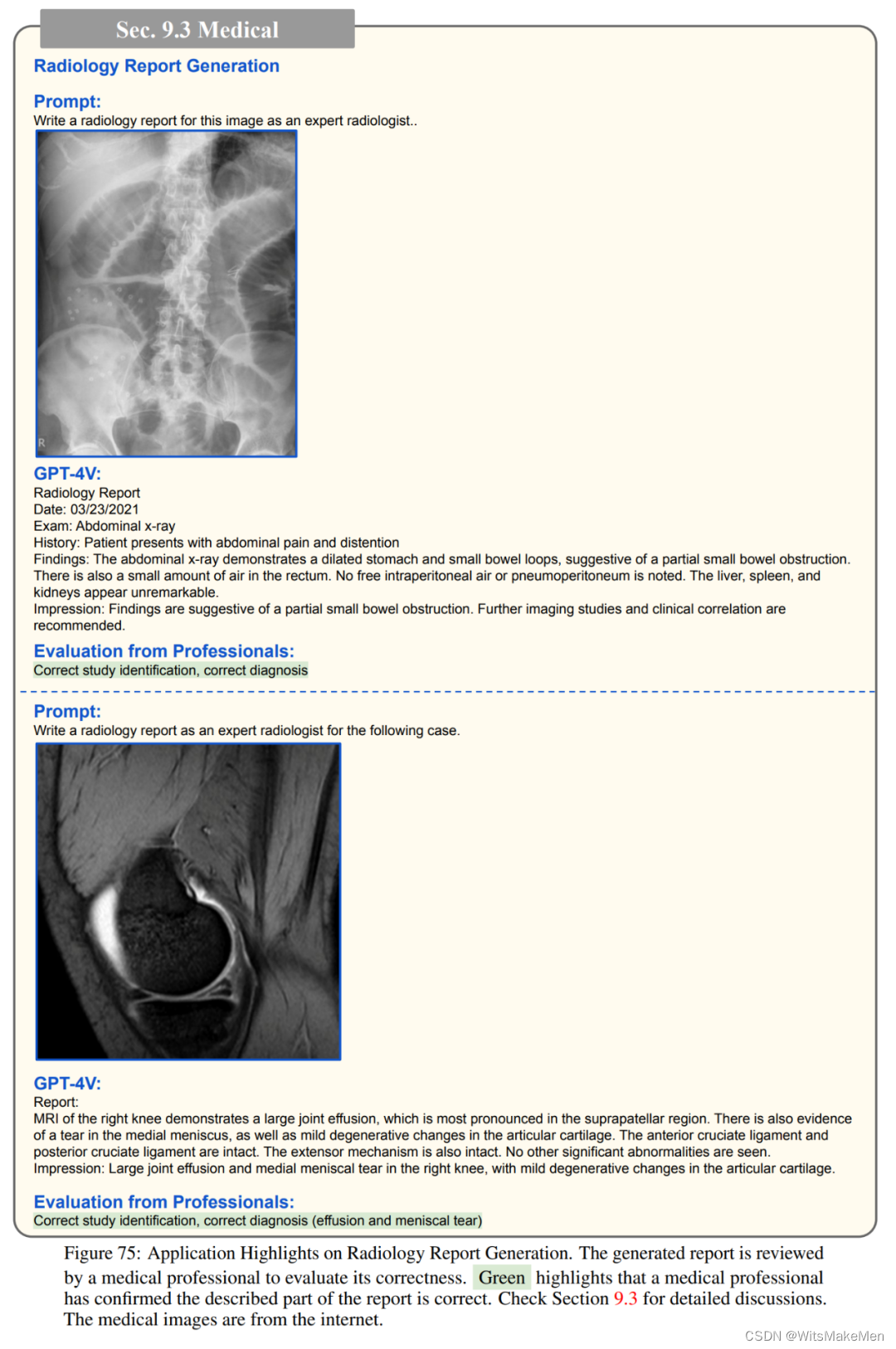
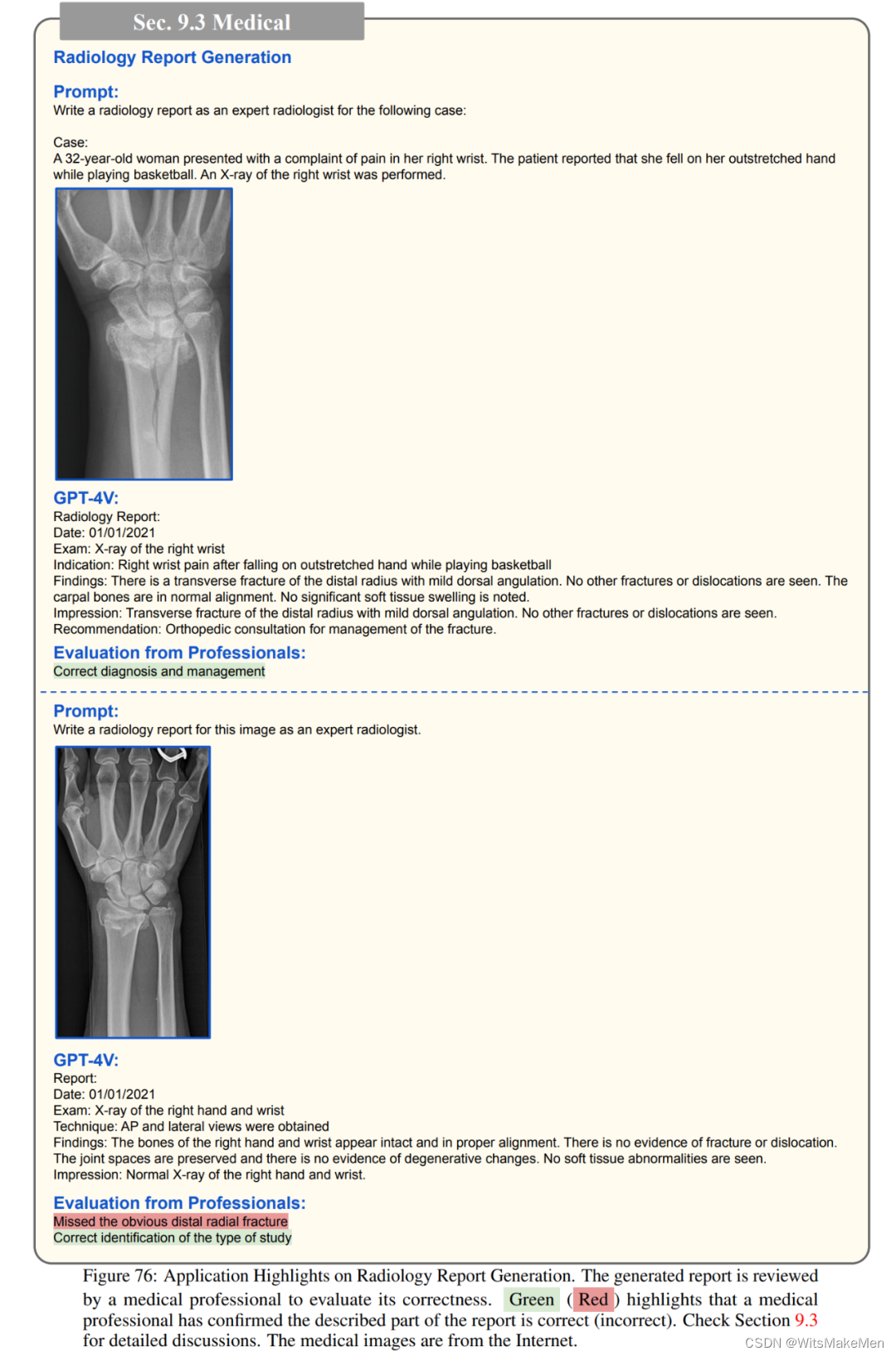
工业


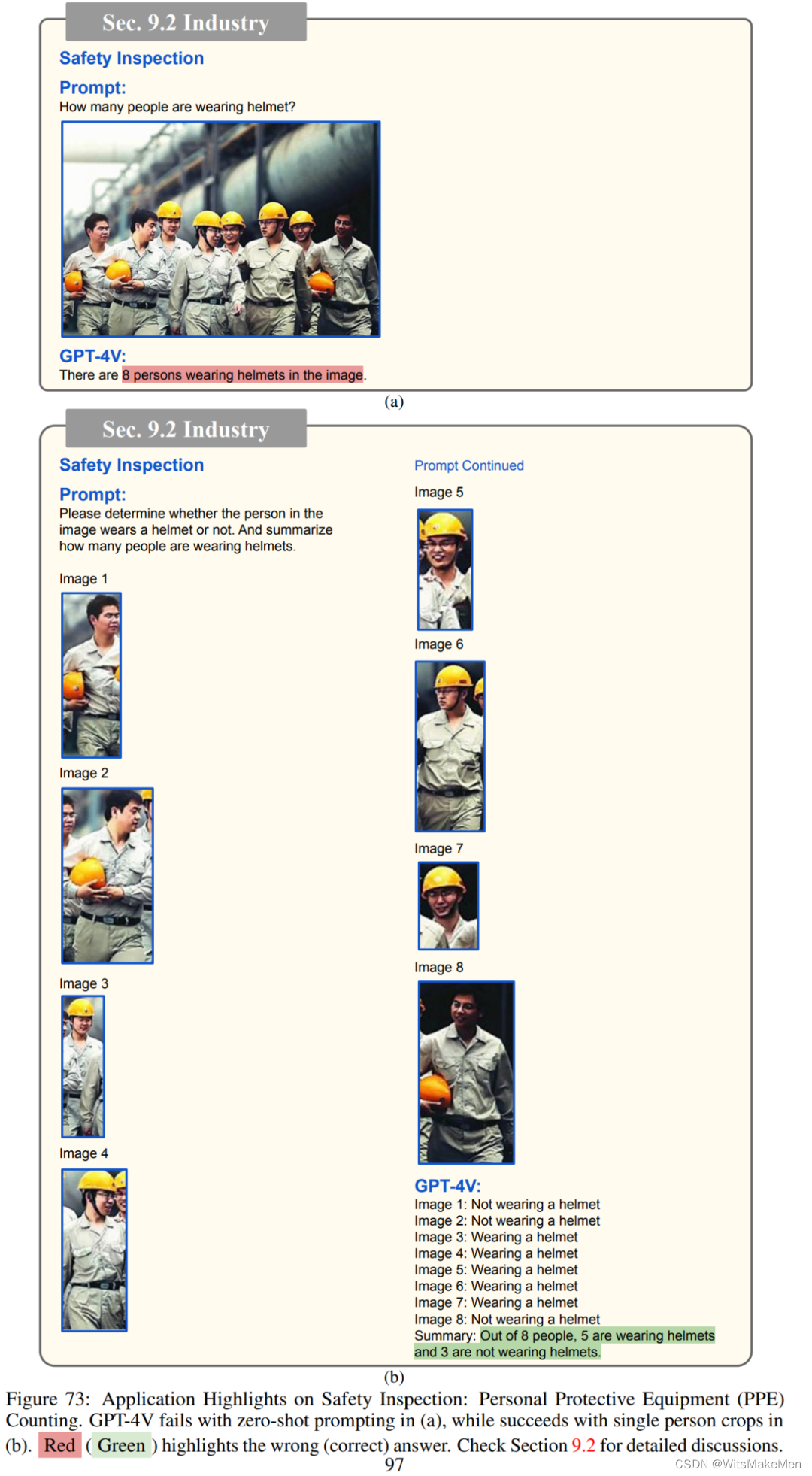
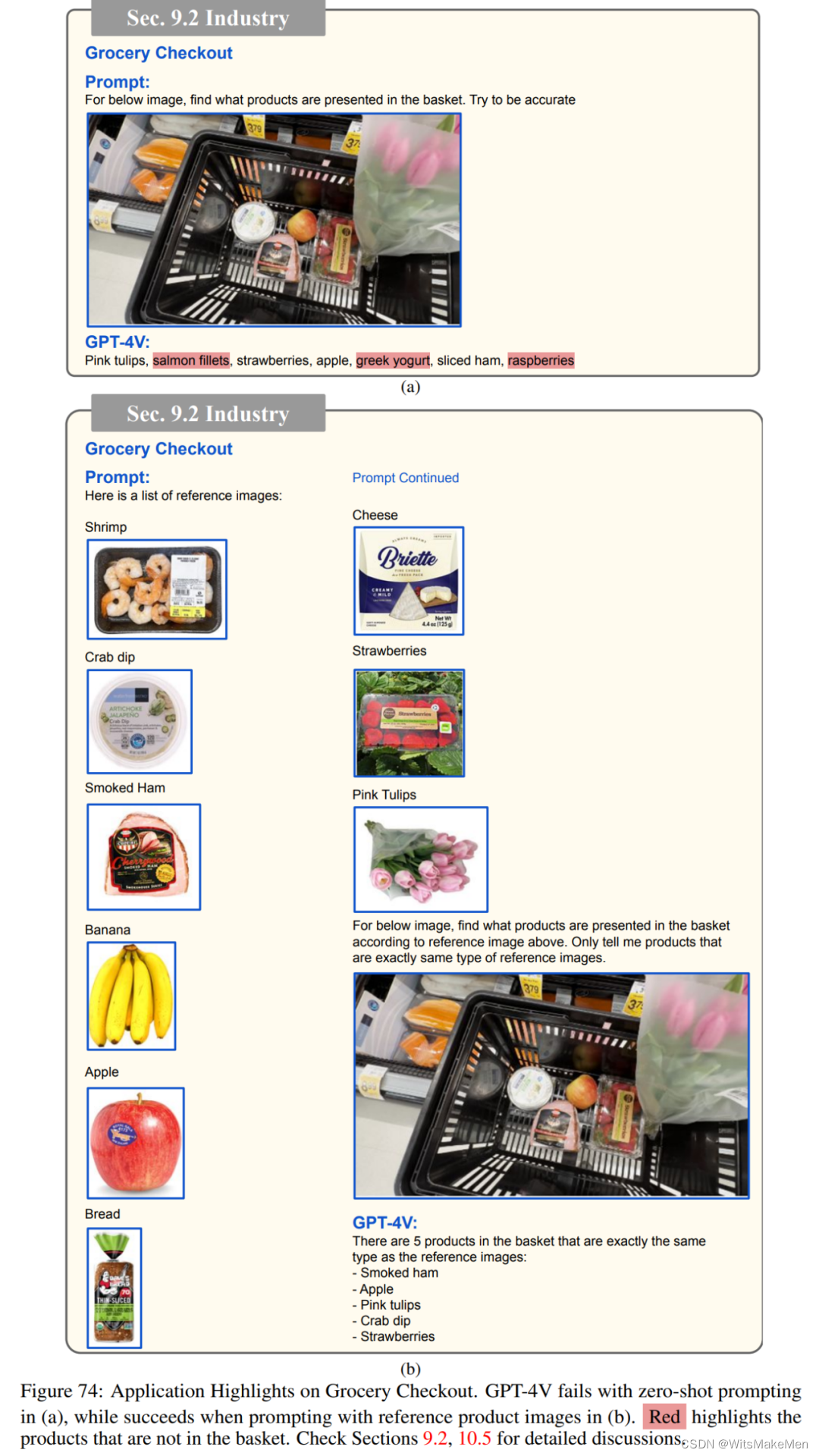
医药
汽车保险


编写照片说明


图像理解与生成



具身智能体




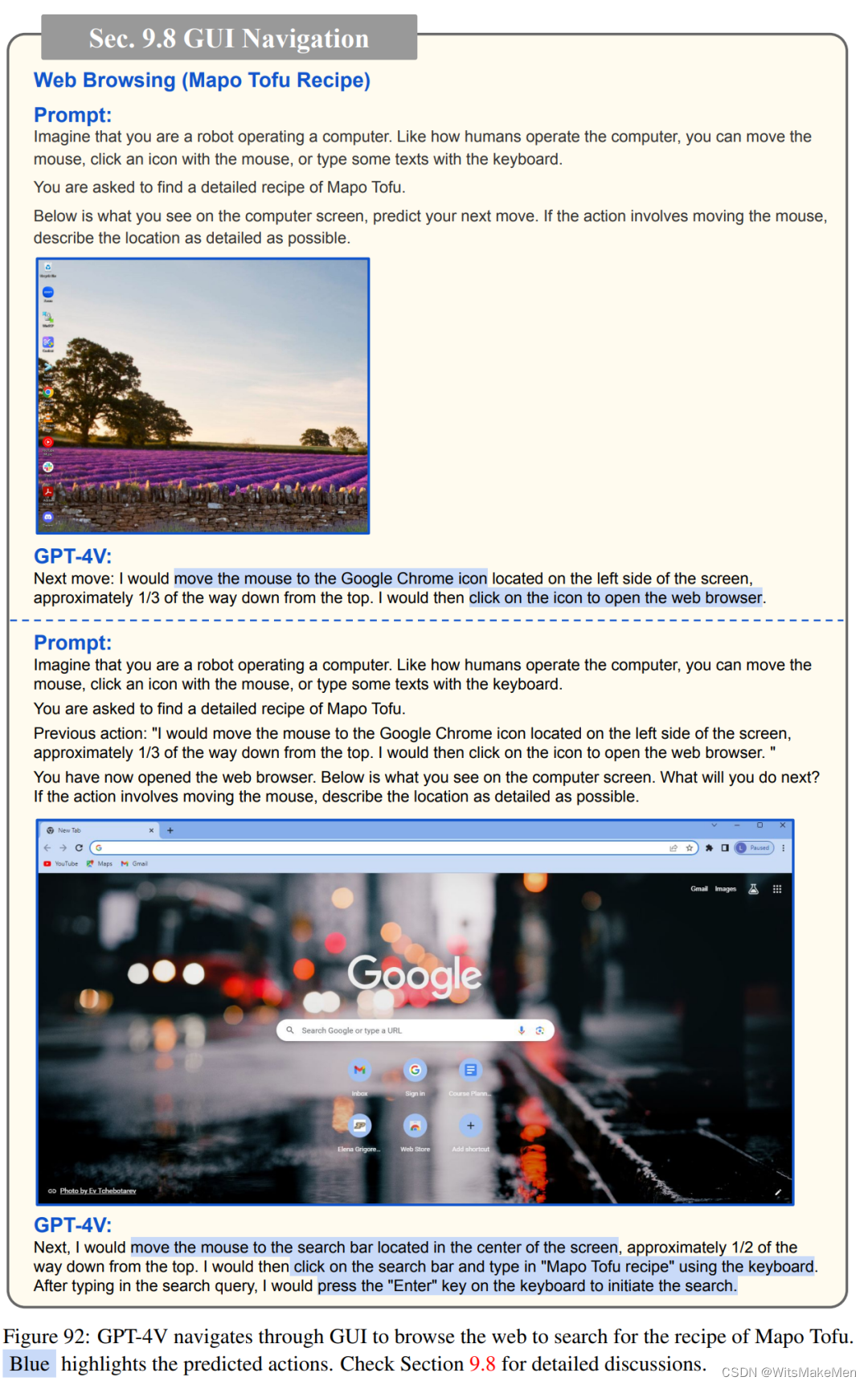
图形用户界面(GUI)交互
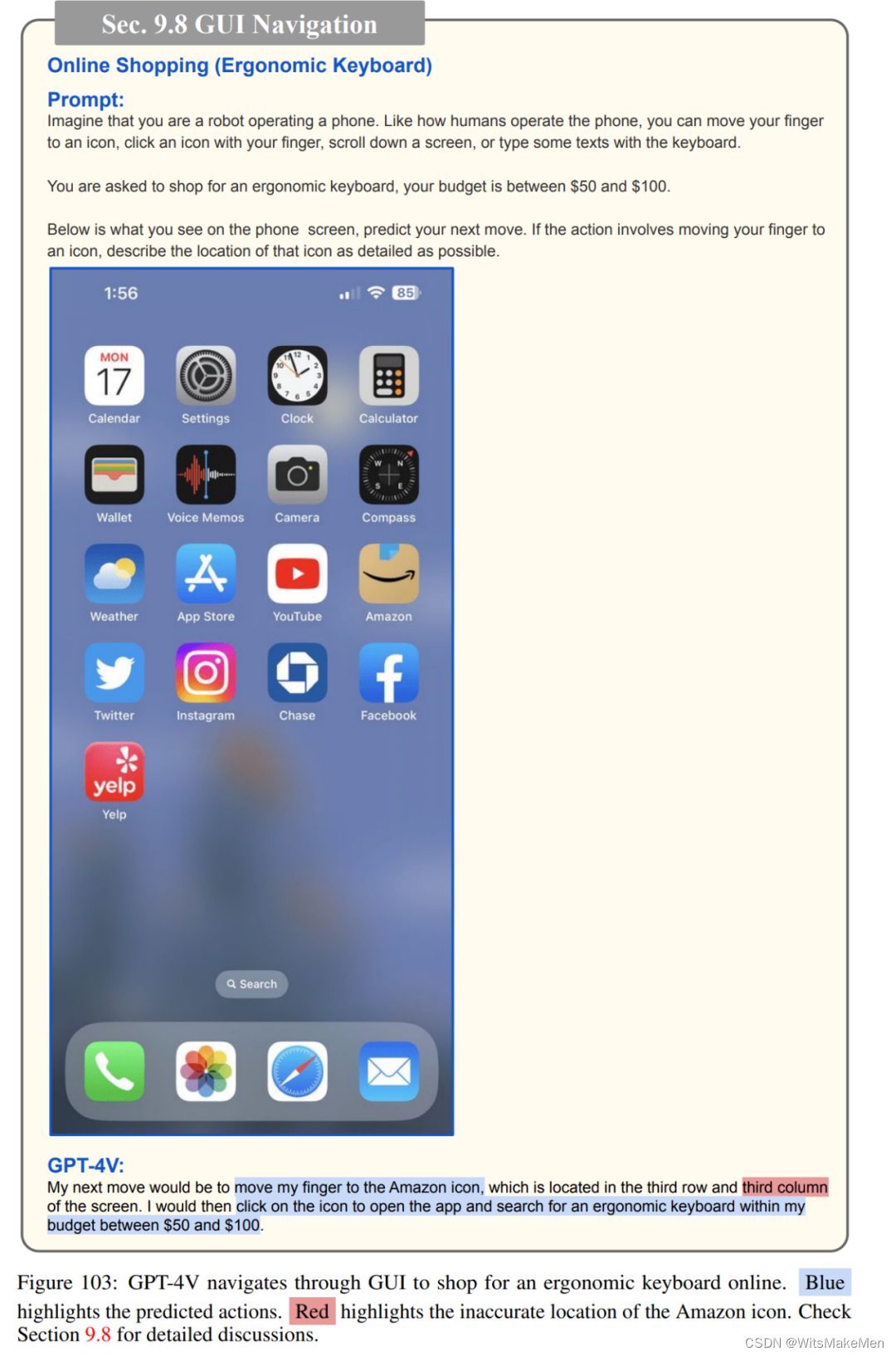
基于LLM的智能体
论文第十章讨论了 GPT-4V 未来可能的研究方向,重点是 LLM 中的有趣用法如何扩展到多模态场景。
基于ReAct的GPT-4V多模态链扩展:

使用自我反思来改进文本到图像模型SDXL生成的文本提示的示例:

自洽性:

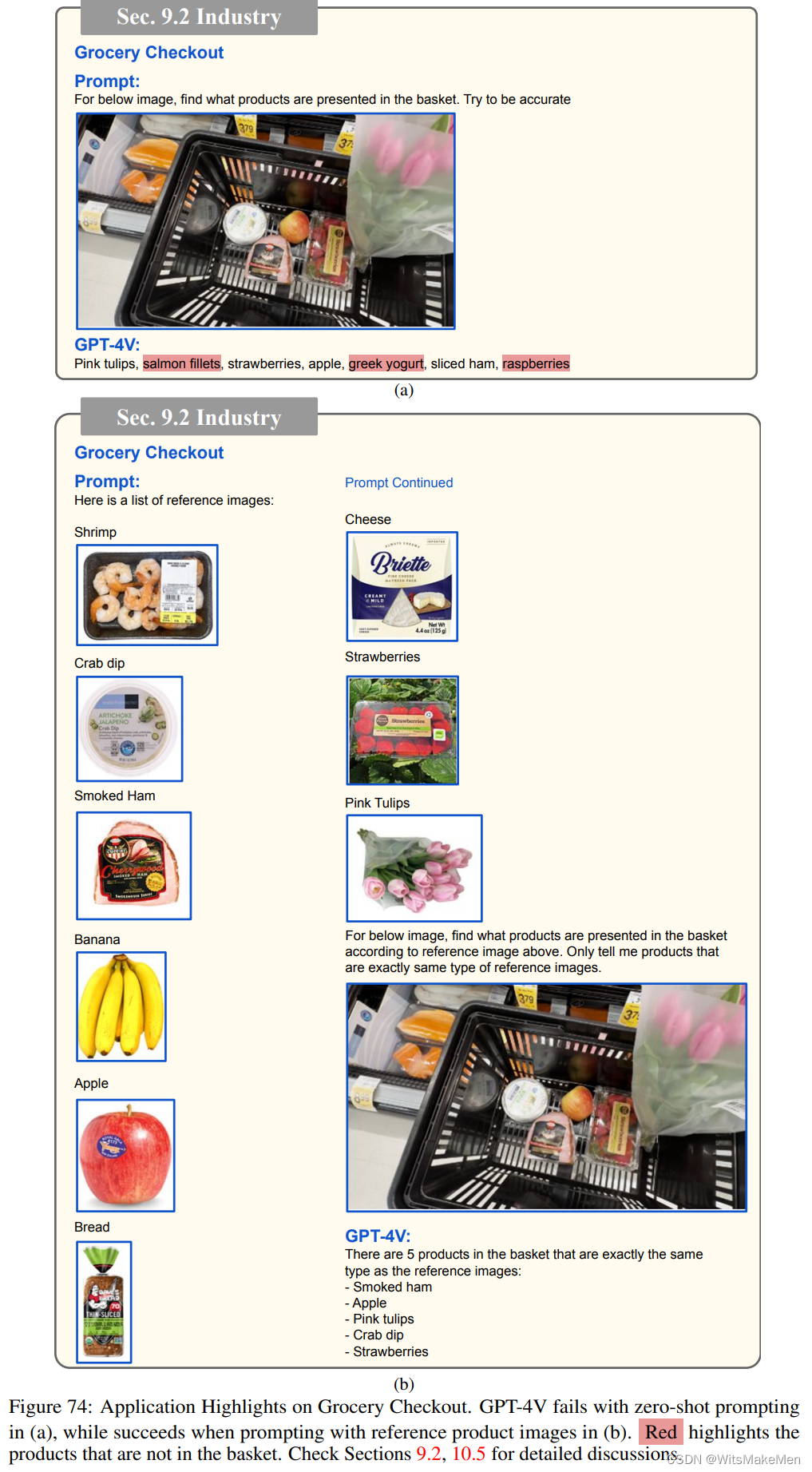
检索增强LMM,图74显示了一个检索增强的LMM帮助杂货店结帐的示例。
关于GPT-4V的更多场景应用细节,请查看原论文。

相关文章:
试过GPT-4V后,微软写了个166页的测评报告,业内人士:高级用户必读
一周之前,ChatGPT迎来重大更新,不管是 GPT-4 还是 GPT-3.5 模型,都可以基于图像进行分析和对话。与之对应的,多模态版GPT-4V模型相关文档也一并放出。当时 OpenAI 放出的文档只有18页,很多内容都无从得知,对…...

使用Python构造VARIMA模型
简介 VARMA(p,q)结合了VAR和VMA模型,其中p是向量自回归(VAR)模型的滞后期数,q是VMA模型的移动平均的阶数。 VARMA是ARMA的推广,它将ARMA模型扩展到多个时间序列变量的情况,通过VAR和VMA的线性组合来描述多个时间序列变量之间的联…...
Java基于SpringBoot+Vue的考研资讯平台
1 简介 大家好,我是程序员徐师兄,今天为大家带来的是Java基于SpringBootVue的考研资讯平台 Java基于SpringBoot的考研资讯平台,在系统当中学生可以根据不同的信息来实现该网站的考研资讯平台信息的管理。 系统主要分为前台和后台。主要包括…...

信钰证券:9月以来A股20家银行 获机构不同批次调研
Wind数据显现,自9月份以来,已经有20家银行获安排不同批次调研。其间常熟银行、瑞丰银行被调研次数较多,别离为20次、11次;宁波银行、渝农商行获安排调研家数居前,别离为206家、128家。从上市银行宣布的调研情况来看&am…...

应用商店优化的好处有哪些?
应用程序优化优势包括应用在商店的可见性和曝光度,高质量和被相关用户的更好发现,增加的应用下载量,降低用户获取成本和持续增长,增加应用收入和转化率以及全球受众范围。 1、提高知名度并在应用商店中脱颖而出。 如果用户找不到…...
MacOS Pro笔记本硬盘升级纪实
背景 MacPro 2015 mid的苹果本,忽然心血来潮想升级一下SSD。三个步骤:做启动盘,时间机器备份,插新的SSD盘恢复。 过程 下载MacOS,macOS Monterey 12.7官方原版镜像: https://swcdn.apple.com/content/do…...

景联文科技:3D点云标注应用场景和专业平台
3D点云技术之所以得到广泛发展和应用,主要是因为它能够以一种直观、真实和全面的方式来表示和获取现实世界中的三维信息。 3D点云的优势: 真实感和立体感:3D点云数据能够呈现物体的真实感和立体感,使观察者能够更直观地理解物体的…...

基于R语言的水文、水环境模型优化技术及快速率定方法
【阅读原文】:基于R语言的水文、水环境模型优化技术及快速率定方法与多模型案例实践 【内容简介】: 专题一、最速上升法、岭分析以及响应曲面模型 1.最速上升路径 2.信赖域 3.响应面模型 4.二阶响应面 5.岭分析 专题二、Kriging插值与优化方法 …...

学习网络安全得多少费用?网络安全入门了解
前言 网络安全是指对网络系统、硬件、软件和系统数据的保护。不因偶然或者其它原因导致破坏、更改和数据泄露情况。确保网络安全,防止网站被攻击、系统被病毒感染等。随着网络的快速发展,越来越多的用户和公司认识到网络安全的重要性,许多人…...
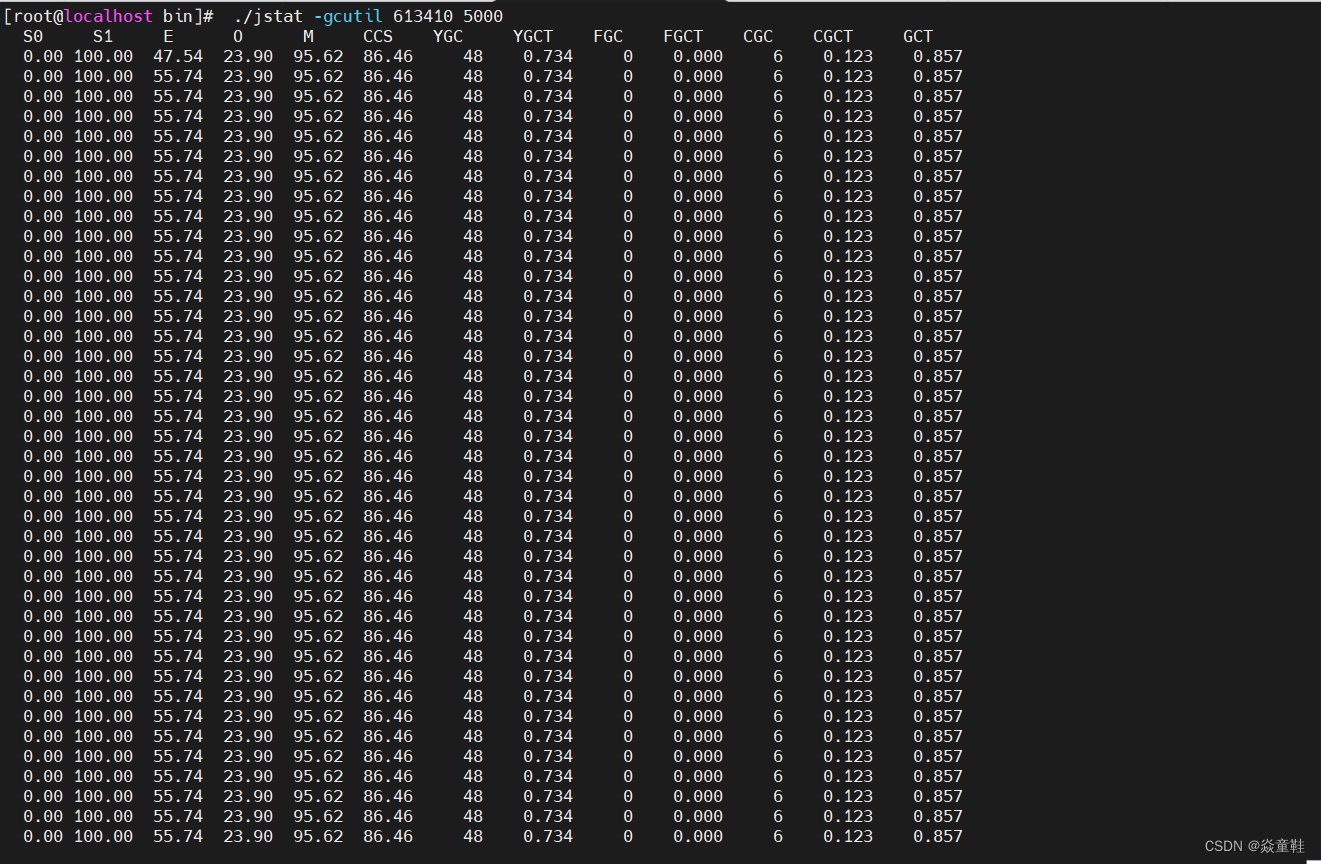
记录一次线上fullgc问题排查过程
某天,接到测试部门反馈说线上项目突然很快,由于当前版本代码和上一版本相比就多了一个刚上线了一个5分钟1次的跑批任务,先关闭次任务后观察是否卡顿,并检查堆内存是否使用完造成频繁gc 1.通过jmap命令查看堆内存中的对象 2.生成当…...

设计接口应该考虑的因素以及遵循的原则
设计接口应该考虑的因素: 接口的业务定位 接口的安全性 接口的可扩展性 接口的稳定性 接口的跨域性 接口的协议规则 接口的路径规则 接口单一原则 接口过滤及接口组合 1.职责原则 在设计接口时,必须明确接口的职责,即接口类型&…...
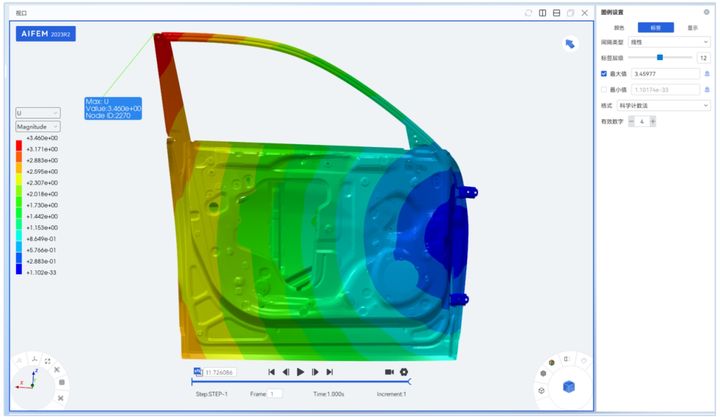
【产品】智能结构仿真软件AIFEM 2023R2新版本功能介绍
AIFEM是由天洑自主研发的一款通用的智能结构仿真软件,助力用户解决固体结构相关的静力学、动力学、振动、热力学等实际工程问题,软件提供高效的前后处理工具和高精度的有限元求解器,帮助用户快速、深入地评估结构的力学性能,加速产…...

探索数据库的世界:DB、DBMS、DBA、DBS的全面介绍
目录 DB数据库(Database) DBMS数据库管理系统(Database Management System): DBA数据库管理员(Database Administrator): DBS数据库系统(Database System) 总结: DB数据库(Database) 概念: 存储数据的集合,DB可以包含各种类型的数据,文…...

【JVM】初步认识Java虚拟机
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 JVM 一、初识JVM1.1 什么是JVM1.2 JVM的功能…...

JAVA设计模式-模板模式
一.概念 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 使用了JAVA的继承机制,在抽象类中定义一个模板方法,该方法引用了若干个抽象方法࿰…...

day007
删除链表第n个节点 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { this.val …...

Spring Boot项目在Windows上的自启动策略与Windows自动登录配置
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

mac 版hadoop3.2.4 解决 Unable to load native-hadoop library 缺失文件
mac 版hadoop3.2.4或其他版本 Unable to load native-hadoop library 缺失文件 Native 包报错缺失: 1. hadoop-3.2.4/lib/native里加*.dylib 2. hadoop-3.2.4/etc/hadoop/hadoop-env.sh 加或修改 export HADOOP_OPTS"-Djava.library.path/Users/lvan/Documen…...
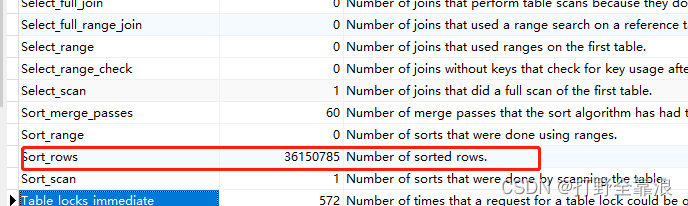
mysql case when 不命中缓存
case when 在sql 中非常方便数据不同维度统计,但是也会出现mysql 索引不命中问题,当多个case 出现时,需要提取出来到where里面优化 优化后 SELECT date(RecordTime) AS date, count( DISTINCT CASE WHEN Param 1 …...

WebGLStudio.js虚拟文件系统完全指南:如何高效管理3D资源
WebGLStudio.js虚拟文件系统完全指南:如何高效管理3D资源 【免费下载链接】webglstudio.js A full open source 3D graphics editor in the browser, with scene editor, coding pad, graph editor, virtual file system, and many features more. 项目地址: http…...

Rust会议活动awesome-rust:技术大会与社区聚会信息
Rust会议活动awesome-rust:技术大会与社区聚会信息 你是否还在为寻找Rust技术大会与社区聚会信息而烦恼?是否希望能一站式获取全球Rust相关活动,与同行交流学习?本文将为你详细介绍如何通过awesome-rust项目了解和参与Rust会议活…...

如何永久保存微信聊天记忆:WeChatMsg本地数据管理终极指南
如何永久保存微信聊天记忆:WeChatMsg本地数据管理终极指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/W…...

如何在微信和QQ上使用EmojiPackage表情包:终极完整指南
如何在微信和QQ上使用EmojiPackage表情包:终极完整指南 【免费下载链接】EmojiPackage 表情包资源合集,张张都是经典 项目地址: https://gitcode.com/gh_mirrors/em/EmojiPackage EmojiPackage表情包资源合集是聊天社交中的神器,这个经…...

OmenSuperHub深度解析:惠普游戏本硬件控制的纯净解决方案
OmenSuperHub深度解析:惠普游戏本硬件控制的纯净解决方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 对于追求极致性能与系统纯净度的惠普…...

GHelper工具:解决华硕笔记本性能控制难题的轻量化方案
GHelper工具:解决华硕笔记本性能控制难题的轻量化方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sc…...

让AI当你的面试官:基于快马平台打造智能前端面试辅导助手
最近在准备前端面试时,我发现很多题目看似简单,但真要回答得全面深入并不容易。比如经典的"深拷贝"问题,不仅要写出代码,还得考虑循环引用、性能优化等细节。这时候如果能有个AI助手帮忙分析题目、提供思路,…...

告别驱动噩梦:在 Ubuntu 22.04 上为 RTX 5070 显卡手动编译安装驱动的完整心路历程
告别驱动噩梦:在 Ubuntu 22.04 上为 RTX 5070 显卡手动编译安装驱动的完整心路历程 1. 缘起:当官方驱动安装成为一场噩梦 那是一个普通的周末早晨,我满怀期待地拆开了刚到的RTX 5070显卡。作为一名长期使用Ubuntu进行深度学习开发的工程师&…...

Oracle数据泵导入中断处理:正确使用kill_job与stop_job
1. 数据泵导入中断的紧急处理场景 上周五凌晨2点,我正盯着屏幕上的数据泵导入进度条。这是某电商平台大促前的数据库迁移,200GB的订单数据需要通过impdp导入新库。突然机房空调故障告警响起,眼看着服务器温度飙升到45度,我必须在…...

免费开源字体 Source Sans 3 完整配置使用教程
免费开源字体 Source Sans 3 完整配置使用教程 【免费下载链接】source-sans Sans serif font family for user interface environments 项目地址: https://gitcode.com/gh_mirrors/so/source-sans Source Sans 3 是由 Adobe 开发的开源无衬线字体家族,专为现…...