【数字人】3、LIA | 使用隐式空间来实现视频驱动单张图数字人生成(ICLR 2022)

文章目录
- 一、背景
- 二、方法
- 2.1 latent motion representation
- 2.2 latent code driven image animation
- 2.3 学习方式
- 2.4 推理
- 三、效果
- 3.1 数据集
- 3.2 训练细节
- 3.3 评估
- 3.4 定性效果
- 3.5 定量效果
- 3.6 消融实验
- 3.7 失败示例
论文:Latent Image Animator: Learning to Animate Images via Latent Space Navigation
代码:https://github.com/wyhsirius/LIA
出处:ICLR 2022
一、背景
现有的 image animation 方法一般都使用计算机图形学、语义 map、人体关键点、3D meshs、光流等,这些方法的 gt 需要提前提取出来,在实际使用中会受限。对没见过的人物表现很差。
自监督方法将原始的视频作为输入,使用预测的密集光流场来控制输入图片的运动,这样虽然能够避免对领域知识或标记 gt 的需求,能够提升在任意图像上测试的性能。但这些方法需要明确的结构表达来作为运动指引。其他的先验信息如关键点等,也会使用一个额外的网络来进行端到端训练,作为预测光流场过程的中间特征。虽然这样不需要提前提取 gt label,但也会提升复杂度。
在本文中,为了降低复杂度,作者剔除了额外的分支,而是使用隐空间。本文方法受启发于 GAN、styleGAN、BigGAN
作者提出了 LIA(Latent Image Animate),主要由自编码器构成,通过隐空间来引导对图像的驱动
作者引入了 Linear Motion Decomposition (LMD) ,通过线性组合一系列可学习的运动方向和大小,来表达隐空间中的路径。也就是将这一系列都限制为正交基,每个向量都表示一个基础的视觉变换。
且在 LIA 中,在一个 encoder-generator 结构中的 motion 和 appearance 是解耦的,没有使用分开的网络结构,这样能降低计算量。
二、方法
Self-supervised image animation 的目标将 driving video 的运动迁移到 source image 上,让 source image 按照 driving video 的运动方式动起来
如图 2 所示,本文的想法是通过隐空间来引导运动系数的建模,整个大体过程如图 2 所示
- 在训练过程中,需要同时输入 source 和 driving image,driving image 是从 video 中随机采样的。两个图像都会编码到隐空间,用于表达运动变化,training 目标是使用学习到的 motion transformation 和 source image 来重建 driving image
- 在测试过程中,driving video 中的每一帧都会顺序的被处理,来驱动 source subject
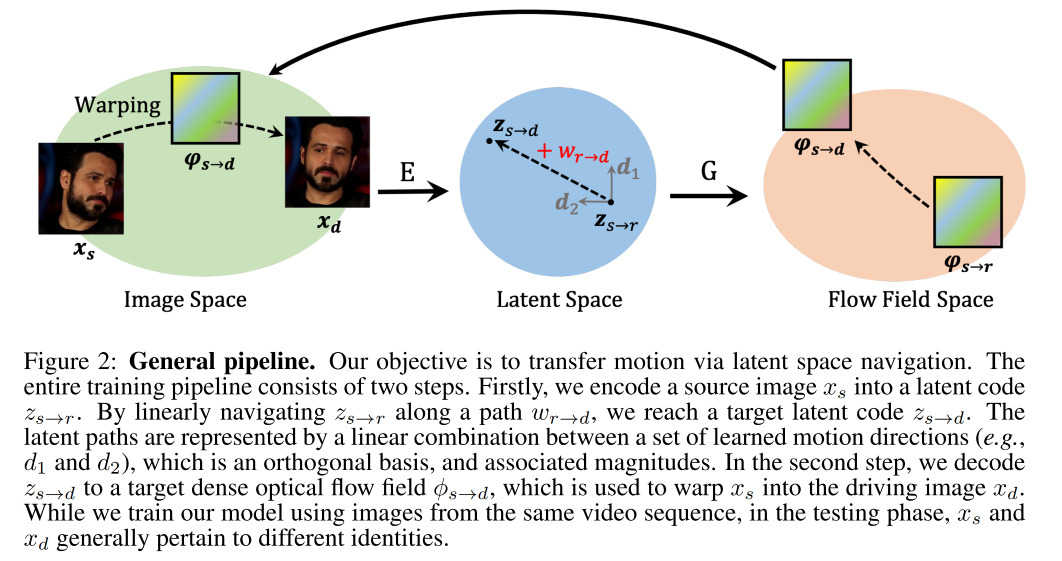
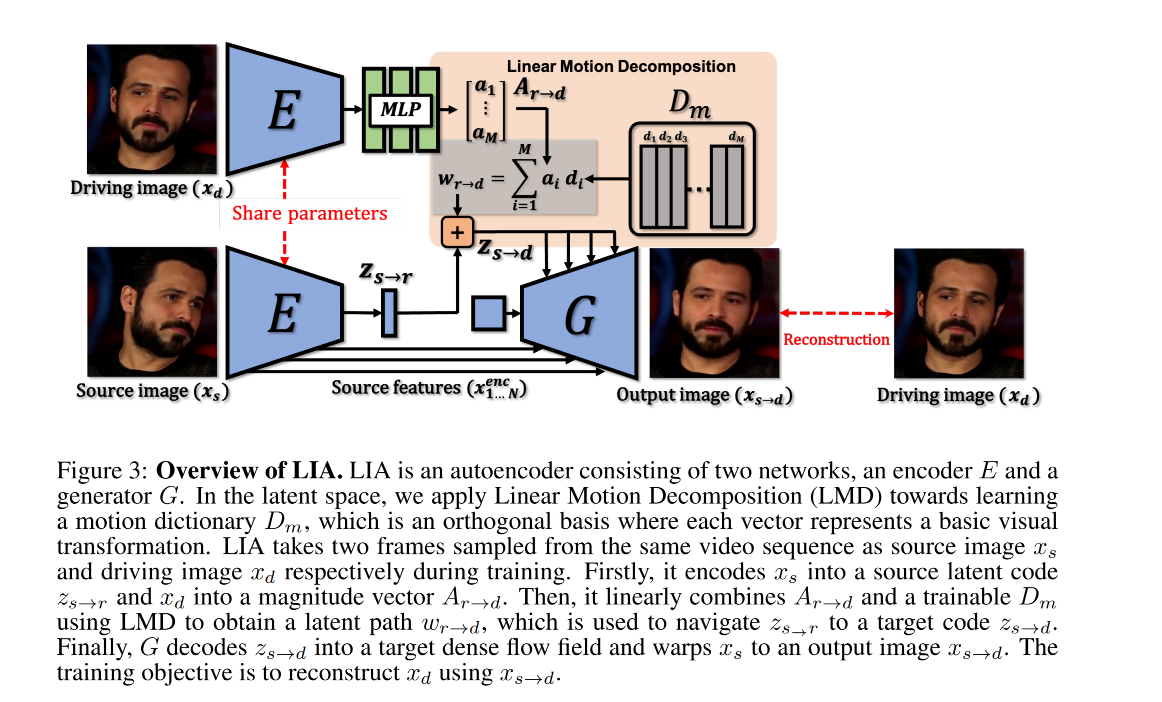
框架结构如图 3 所示,整个模型是自编码器的结构,由两个主要的网络构成
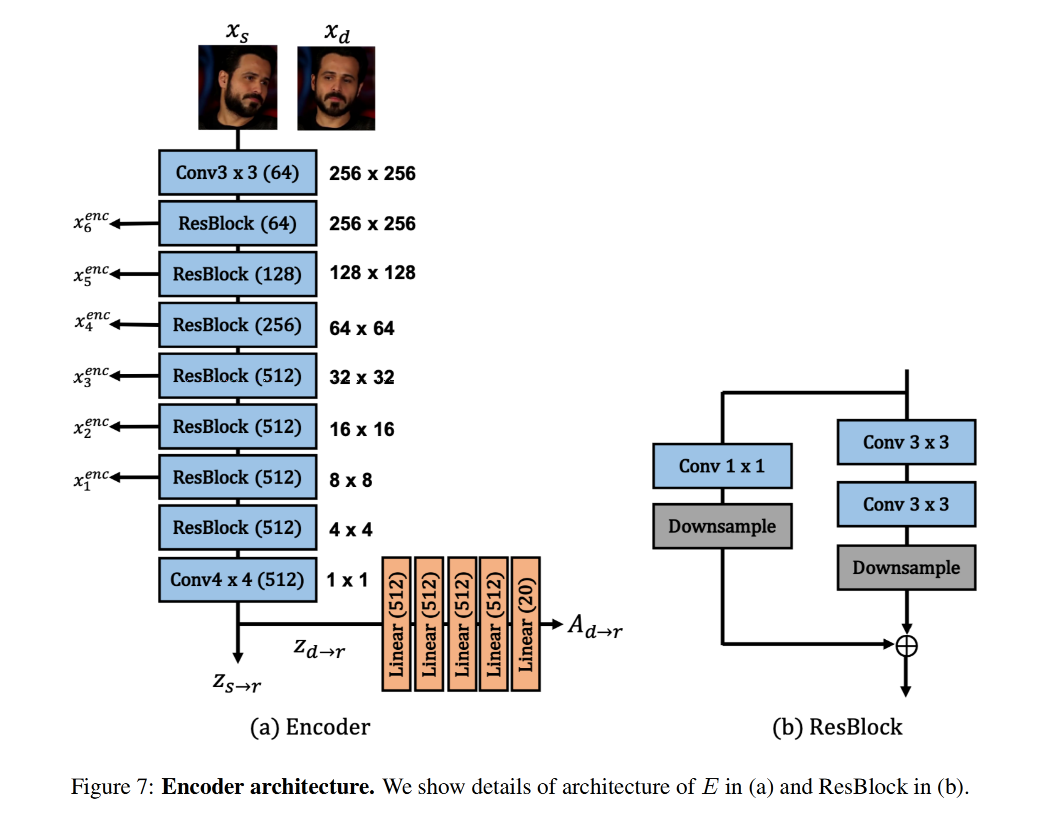
- encoder E:是第一步,也就是对 source image 和 driving image 进行编码,编码到隐空间,
- generator G:是第二步,也就是当获得了 target latent code 后,G 会 decode
2.1 latent motion representation
给定 source image x s x_s xs 和 driving image x d x_d xd:
latent motion representation 也是整个过程的第一步:
学习一个 latent code z s → d Z ∈ R N z_{s \to d}~ Z \in R^N zs→d Z∈RN 来表达从 x s x_s xs 到 x d x_d xd 的 motion transformation,由于这两个图片都有不确定性,直接学习 z s → d z_{s \to d} zs→d 的话比较难,因为需要模型去捕捉非常复杂的运动。所以,在此处假设有一个 reference image x r x_r xr,motion transfer 的过程被建模为 x s → x r → x d x_s \to x_r \to x_d xs→xr→xd,而不是直接学习 z s → d z_{s \to d} zs→d。因此,将 z s → d z_{s \to d} zs→d 作为 latent space 的 target point,起始点为 z s → r z_{s \to r} zs→r,线性路径为 w r → d w_{r \to d} wr→d:
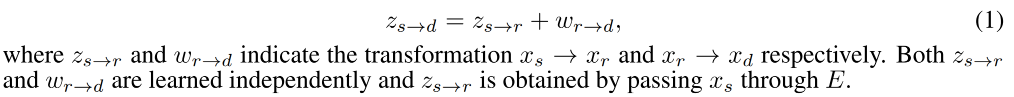
reference image 如何生成:
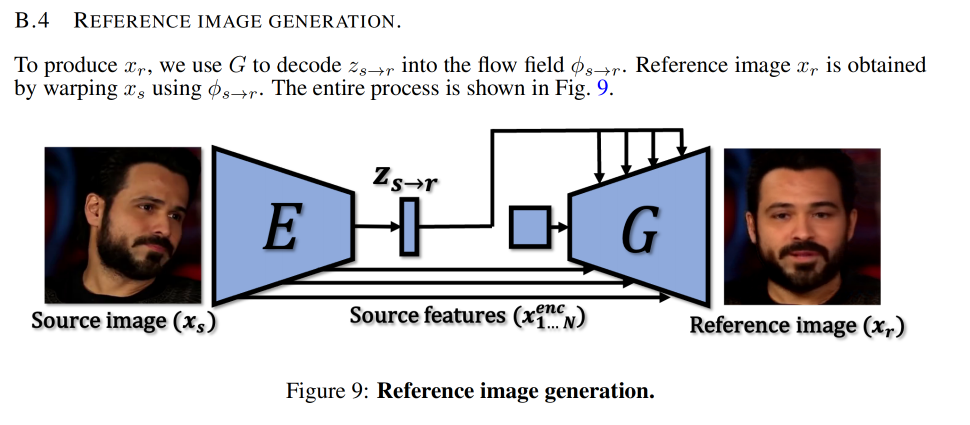
x r x_r xr 到底表达的是什么:
- 如图 5 所示, x r x_r xr 表达的是 x s x_s xs 的 canonical pose,

如何学习 w r → d w_{r \to d} wr→d:LMD(Linear Motion Decomposition)
-
首先,学习一组 motion directions D m = { d 1 , . . . , d M } D_m=\{d_1, ... , d_M\} Dm={d1,...,dM} 来在 latent space 表达任意的 path,且限制 D m D_m Dm 作为正交基,其中每个向量都表示运动方向 d i d_i di,且其中每两个向量两两之间都是正交的
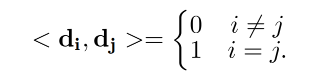
-
然后,将 D m D_m Dm 中的每个基都和向量 A r → d = { a 1 , . . . , a M } A_{r \to d}=\{a_1, ..., a_M\} Ar→d={a1,...,aM} 进行结合, a i a_i ai 表示 d i d_i di 的模值,所以在 latent 空间中的每一个 linear path 都可以使用如下的线性组合来表示,且每个 d i d_i di 都表示一个基, a i a_i ai 表示步长。 A r → d A_{r \to d} Ar→d 是通过映射 z d → r z_{d \to r} zd→r 得到的,是 x d x_d xd 经过 E 后的输出。
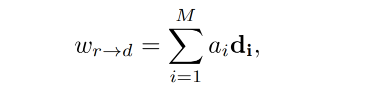
-
最后,latent motion representation 如下, D m D_m Dm 中的向量都是可学习的
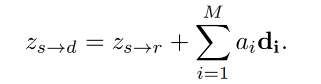
D m D_m Dm 中的方向表示什么:表示点头(d8)、眨眼(d6)、面部表情(d19、d7)等


2.2 latent code driven image animation
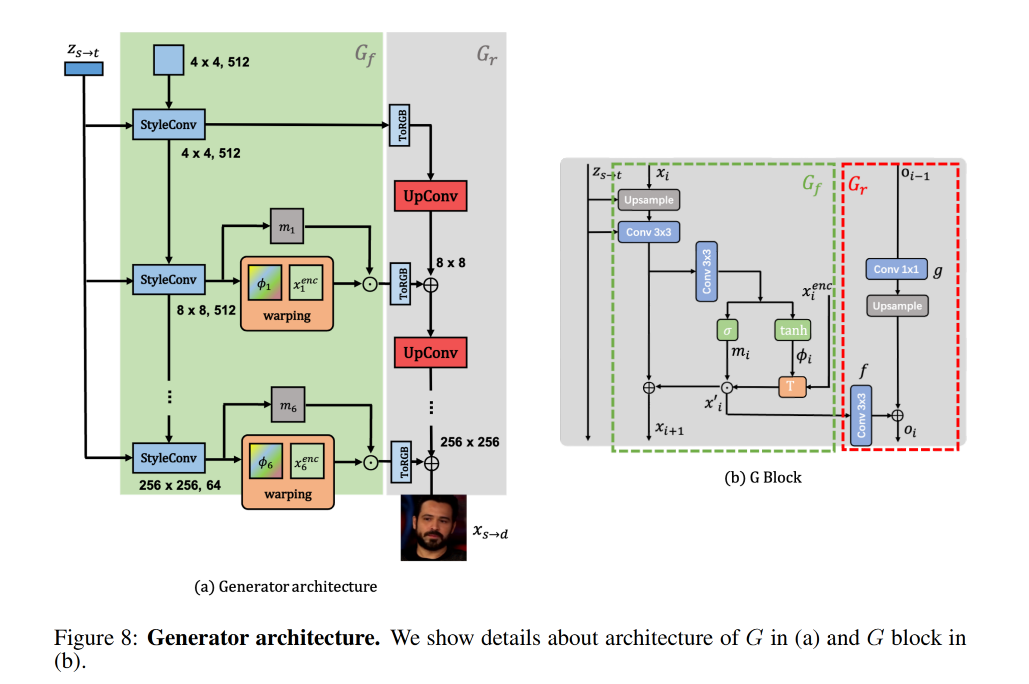
得到了 z s → d z_{s \to d} zs→d 后,就是第二步了,即使用 G 来解码出 flow filed ϕ s → d \phi_{s \to d} ϕs→d 并 warp x s x_s xs
G 包含两部分,且为了学习多尺度特征, G 使用了一个残差结构:
-
flow field 生成器 G f G_f Gf:包含 N 个 model 来不同 layer 的生成金字塔的 flow fields ϕ s → d = { ϕ i } 1 N \phi_{s \to d}=\{\phi_i\}_1^N ϕs→d={ϕi}1N。从 E 中会获得多尺度 source features x s e n c = { x i e n c } 1 N x_s^{enc}=\{x_i^{enc}\}_1^N xsenc={xienc}1N,然后会在 G f G_f Gf 中进行 warp
-
如果直接基于 ϕ s → d \phi_{s \to d} ϕs→d 来 warp source feature,不能很充分且精确的来重建 driving image,因为在一些位置上会有遮挡,为了更好的预测这些遮挡位置的像素,需要对 warped feature map 进行修复,所以,在 G f G_f Gf 中也根据 { ϕ i } 1 N \{\phi_i\}_1^N {ϕi}1N 预测了 multi-scale mask { m i } 1 N \{m_i\}_1^N {mi}1N,可以 mask 出需要修复的区域
-
每个残差模型中都有:
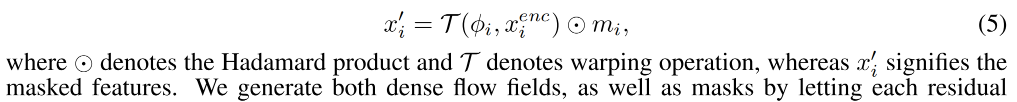 -
所以,输出共三个通道,前两个通道是 ϕ i \phi_i ϕi,最后一个通道是 m i m_i mi
-
-
refinement network G r G_r Gr:基于上面得到的修复后的 feature map f ( x i ′ ) f(x_i') f(xi′) 和上一个 G r G_r Gr 得到的上采样后的 image g ( x i − 1 ) g(x_{i-1}) g(xi−1),可以得到每个模块的 RGB 图像
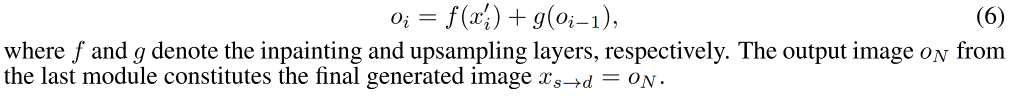
2.3 学习方式
作者使用 self-supervised 的方法来重建 x d x_d xd,使用了 3 个 loss:
-
reconstruction loss:重建 loss,用于最小化 x d x_d xd 和 x s → d x_{s \to d} xs→d 的 pixel-wise L 1 L_1 L1 距离
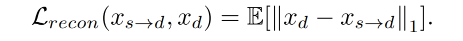
-
perceptual loss:感知 loss,用于最小化感知特征 loss,使用的是 VGG19-based L v g g L_{vgg} Lvgg,衡量 real 和 generated images 的多尺度的 feature map 的距离,尺度分别为 256/128/64/32
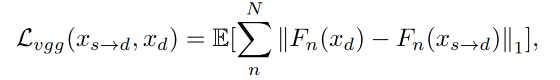
-
adversarial loss:对抗 loss,为了生成更真实的结果,作者在 x s → d x_{s \to d} xs→d 上使用了不饱和的对抗 loss L a d v L_{adv} Ladv
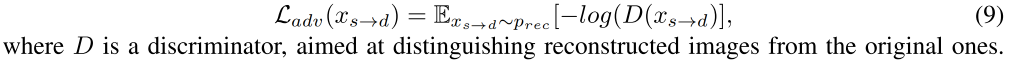
整体 loss:
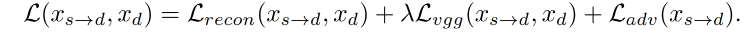
2.4 推理
在推理阶段,给定一个 driving video 序列 V d = x t 1 T V_d={x_t}_1^T Vd=xt1T,目标是将 V d V_d Vd 的运动转移到 x s x_s xs 上,生成一个新的 video V d → s = { x t → s } 1 T V_{d \to s}=\{x_{t \to s}\}_1^T Vd→s={xt→s}1T
如果 V d V_d Vd 和 x s x_s xs 来自同一个 video,则可以使用 absolute transfer 的方式来重建每帧,和训练的过程一样:
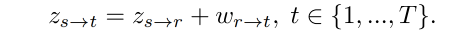
如果 V d V_d Vd 和 x s x_s xs 来自不同的 video,这个时候两个图片中的人物的外貌特征、动作、表情都是不同的,这个时候就要使用 relative transfer 来估计
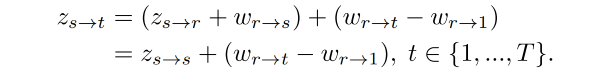
三、效果
3.1 数据集
- VoxCeleb
- TaichiHD
- TED-talk
裁剪到分辨率大小为 256x256


3.2 训练细节
- 4 个 16G NVIDIA V100 GPUs
- batch size 为 32,每张卡上 8 张图
- 学习率:0.002
- 优化器:Adam
- latent code 维度, D m D_m Dm 中的方向 都是 512
- l a m b d a lambda lambda:10
- 训练时间: 150 小时
3.3 评估
3.4 定性效果

3.5 定量效果
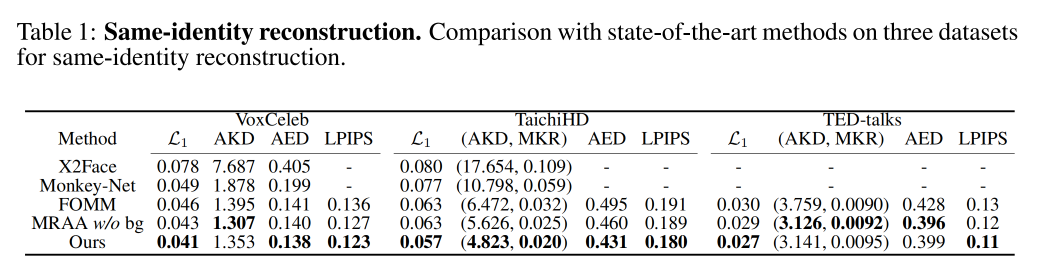
同一人物的重建:
跨视频的生成

User study:

3.6 消融实验
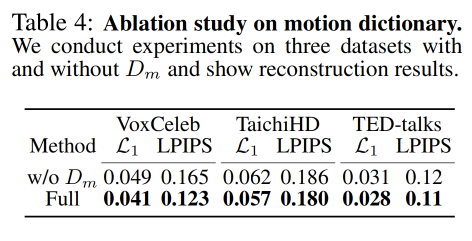
1、motion dictionary D m D_m Dm 是否有效:
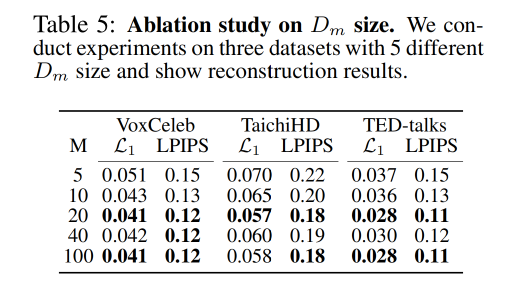
2、 D m D_m Dm 需要多少个方向:20 个最优
3.7 失败示例
- Taichi 中,身体遮挡重合(如胳膊、腿等)的部分无法很好的 transfer
- 在 TED-talks,手部动作难以 transfer

相关文章:
【数字人】3、LIA | 使用隐式空间来实现视频驱动单张图数字人生成(ICLR 2022)
文章目录 一、背景二、方法2.1 latent motion representation2.2 latent code driven image animation2.3 学习方式2.4 推理 三、效果3.1 数据集3.2 训练细节3.3 评估3.4 定性效果3.5 定量效果3.6 消融实验3.7 失败示例 论文:Latent Image Animator: Learning to An…...
深度学习基础知识 最近邻插值法、双线性插值法、双三次插值算法
深度学习基础知识 最近邻插值法、双线性插值法、双三次插值算法 1、最近邻插值法 1、最近邻插值法 *最邻近插值:将每个目标像素找到距离它最近的原图像素点,然后将该像素的值直接赋值给目标像素 优点:实现简单,计算速度快缺点&…...

计算机竞赛 : 题目:基于深度学习的水果识别 设计 开题 技术
1 前言 Hi,大家好,这里是丹成学长,今天做一个 基于深度学习的水果识别demo 这是一个较为新颖的竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/pos…...

【2023美团后端-8】删除字符串的方案,限制不能连续删
小美定义一个字符申是“美丽串”,当且仅当该字符串包含”mei”连续子串。例如”meimei”、“xiaomeichan"都是美丽串,现在小美拿到了一个字符串,她准备删除一些字符,但不能删除两个连续字符。小美希望最终字符串变成美丽串&a…...

蓝桥等考Python组别十七级008
第一部分:选择题 1、Python L17 (15分) 运行下面程序,输出的结果是( )。 def func(x, y): return (x - y) % 2 print(func(10, 5)) 2152.5正确答案:B 2、Python L17 (15分) 运行下面程序,输...
docker安装sql-server数据库,使用navicat实现备份数据库导入
docker安装sql-server,使用navicat实现备份数据库导入 1、docker安装sql-server数据库2、使用navicat连接sql-server3、使用navicat导入备份数据库1、第一步:选择需要备份的数据源2、第二步 (选择备份计划,设置还原文件位置信息&a…...
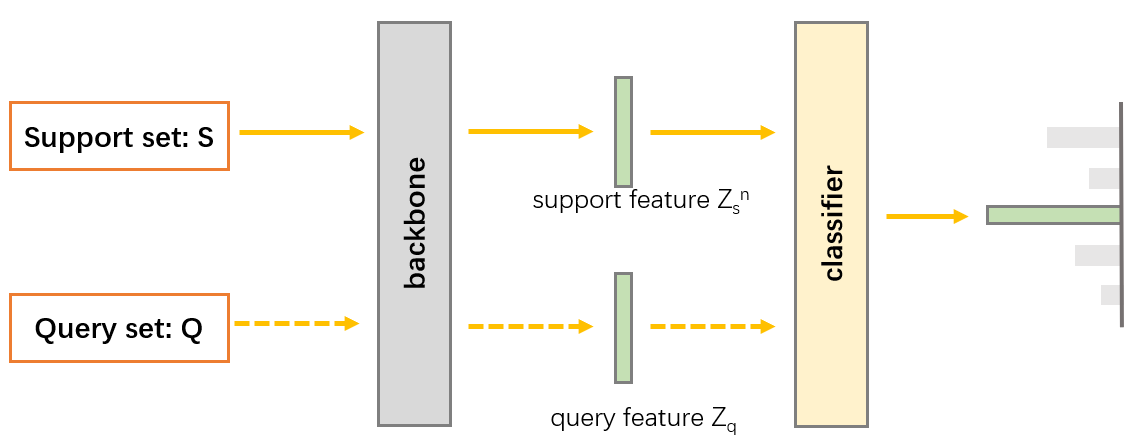
深度学习batch、batch_size、epoch、iteration以及小样本中episode、support set、query set关系
batch、batch_size、epoch、iteration关系: epoch:整个数据集 batch: 整个数据集分成多少小块进行训练 batch_size: 一次训练(1 batch)需要 batch_size个样本 iteration: 整个数据集需要用b…...
Air001 TIM1高级定时器单脉冲输出模式使用
Air001 TIM1高级定时器单脉冲输出模式使用 ✨本例程基于合宙官方提供的标准库以及Demo工程作为验证参考。📍官方提供的SDK包资源:https://gitee.com/openLuat/luatos-soc-air001🌿想了解STM32高级定时器单脉冲输出模式了解可以参考阅读:https…...

矿机生意难做,比特大陆停发工资
文/章鱼哥 出品/陀螺财经 沉寂了许久的比特大陆,因为一则延迟发薪的公告引起了圈内热议,熊市下,曾经风头无两的比特大陆,现金流也会扛不住吗? 据吴说区块链报道,多名比特大陆内部员工确认,比特大…...

计算机竞赛python区块链实现 - proof of work工作量证明共识算法
文章目录 0 前言1 区块链基础1.1 比特币内部结构1.2 实现的区块链数据结构1.3 注意点1.4 区块链的核心-工作量证明算法1.4.1 拜占庭将军问题1.4.2 解决办法1.4.3 代码实现 2 快速实现一个区块链2.1 什么是区块链2.2 一个完整的快包含什么2.3 什么是挖矿2.4 工作量证明算法&…...

pyqt 划线标注工具,可用于车道线标注
目录 效果图: pyqt代码: opencv划线: 效果图: pyqt代码: import osfrom PyQt5.QtWidgets import QWidget, QApplication, QVBoxLayout, QPushButton, QLabel from PyQt5.QtGui import QPainter, QPen, QColor, QImage, QPixmap from PyQt5.QtCore import Qt, QPoint i…...

蓝桥等考Python组别十七级004
第一部分:选择题 1、Python L17 (15分) 运行下面程序,输出的结果是( )。 def func(x, y): return (x - y) // 2 print(func(10, 4)) 2356正确答案:B 2、Python L17 (15...

计算机毕业设计选什么题目好?springboot 职业技术学院图书管理系统
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...

外汇天眼:6个常见网络投资诈骗迹象,如发现任何一个,务必小心!
在这个数字时代,随着外汇和加密货币市场的不断发展,网络投资已经成为一种广受欢迎的理财方式。然而,近年来,诈骗犯罪也在不断增加,给社会带来了巨大的财务损失。尽管投资诈骗的手法各式各样,但它们都可以追…...

MyBatis的xml里#{}的参数为null报错、将null作为参数传递报错问题
今天在调试的过程中发现一个bug,把传入的参数写到查询分析器中执行没有问题,但是在程序中执行就报错:org.springframework.jdbc.UncategorizedSQLException : Error setting null parameter. Most JDBC drivers require that the JdbcType m…...

【网络安全】「漏洞原理」(一)SQL 注入漏洞之概念介绍
前言 严正声明:本博文所讨论的技术仅用于研究学习,旨在增强读者的信息安全意识,提高信息安全防护技能,严禁用于非法活动。任何个人、团体、组织不得用于非法目的,违法犯罪必将受到法律的严厉制裁。 【点击此处即可获…...
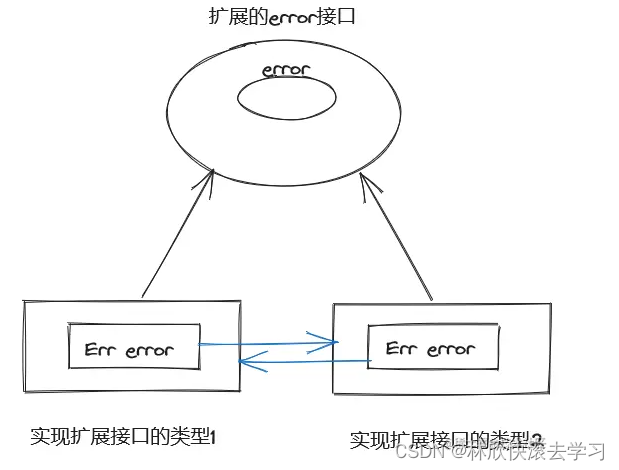
Go语言错误处理最佳实践
错误处理实践 我们在go语言中设计error的处理体系时候, 一般都会去做下面两点 直接使用errors.New()生成error接口的值 扩展error接口, 并定义扩展error接口的实现类型 error接口是什么? go语言的error是一个接口类型, 其源码如下: type error interface {Error() string…...
python结合excel数据轻松实现接口自动化测试
在刚刚进入测试行业的时候,最开始也是做功能测试,我想很多伙伴和我一样,觉得自动化测试都很高端,很神秘。迫不及待的想去学习作自动化测试。 以前比较常用数据库python做自动化,后面发现excel个人觉得更加适合&#x…...
构建精致 Chrome 插件:开箱即用的 TypeScript 模板 | 开源日报 No.51
tonsky/FiraCode Stars: 72.7k License: OFL-1.1 Fira Code 是一种免费的等宽字体,具有编程连字符。 Fira Code 提供了丰富多样的箭头和标点符号调整功能。Fira Code 支持各种不同的字符变体、风格集和其他字体特性,以满足用户个性化需求。Fira Code …...
在Windows下自己从源码编译Python3.10.13成安装包
文章目录 (一)Python 3.10 的生命周期(一)下载源码(二)准备环境(三)编译(3.1)解压源码到目录(3.2)下载依赖(PCBuild&#…...

OpenClaw配置备份指南:千问3.5-27B模型迁移与快速恢复
OpenClaw配置备份指南:千问3.5-27B模型迁移与快速恢复 1. 为什么需要备份OpenClaw配置? 上周我的主力开发机突然硬盘故障,导致所有OpenClaw配置丢失。当时正在运行的3个自动化流程全部中断,最棘手的是那个每天凌晨自动整理技术文…...

SUNFLOWER MATCH LAB 效果深度评测:对比传统CNN与LSTM的识别性能
SUNFLOWER MATCH LAB 效果深度评测:对比传统CNN与LSTM的识别性能 向日葵的生长过程,就像一部无声的纪录片,每一天的叶片舒展、花盘转动都蕴含着丰富的信息。过去,我们想读懂这部纪录片,要么靠农学专家日复一日的田间观…...

个人电脑也能玩转大模型!Llama Factory+QLoRA微调实战,RTX4060即可运行
个人电脑也能玩转大模型!Llama FactoryQLoRA微调实战,RTX4060即可运行 你是不是也以为,训练一个属于自己的大语言模型,是那些拥有昂贵服务器和顶级显卡的大公司才能做的事?动辄几十GB的显存需求,让很多个人…...
Elsevier Tracker:科研投稿状态追踪的自动化解决方案
Elsevier Tracker:科研投稿状态追踪的自动化解决方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 在学术出版流程中,论文投稿后的状态监控一直是科研人员面临的重要挑战。传统的人工查询方…...

GLM-4-9B-Chat-1M快速部署:单卡A10/A100实测8GB显存稳定运行
GLM-4-9B-Chat-1M快速部署:单卡A10/A100实测8GB显存稳定运行 1. 项目简介 今天给大家介绍一个让我眼前一亮的本地大模型部署方案——GLM-4-9B-Chat-1M。这个项目基于智谱AI最新的开源模型,通过Streamlit框架实现了完全本地化部署,不需要联网…...

告别云端依赖!DeepSeek-R1-Distill-Qwen-1.5B离线运行全攻略
告别云端依赖!DeepSeek-R1-Distill-Qwen-1.5B离线运行全攻略 1. 为什么选择离线运行DeepSeek-R1-Distill-Qwen-1.5B? 在AI应用日益普及的今天,大多数用户仍然依赖云端服务来运行大语言模型。但云端服务存在隐私泄露、网络延迟、使用成本高等…...

宝塔部署前后端时,配置域名与ssl证书
创建文件夹1.后端部署部署之后点击设置这步骤最关键# HTTP反向代理相关配置开始 >>>location ~ /purge(/.*) {proxy_cache_purge cache_one $Host$request_uri$is_args$args;}location / {proxy_pass http://127.0.0.1:8773;proxy_set_header Host $Host:$server_port…...
)
基于MATLAB的悬臂梁前3阶固有频率和振型求解(假设模态法、解析法、瑞利里兹法)
基于matlab的求解悬臂梁前3阶固有频率和振型 基于matlab的求解悬臂梁前3阶固有频率和振型,采用的方法分别是(假设模态法,解析法,瑞利里兹法) 程序已调通,可直接运行悬臂梁的振动分析总带着点工程师的浪漫——既要数学的…...
)
Cesium实战:5分钟搞定飞机轨迹飞行与流光道路效果(附完整代码)
Cesium实战:5分钟实现飞机轨迹飞行与流光道路特效 第一次接触Cesium时,我就被它强大的三维地理可视化能力震撼了。作为一个长期从事WebGIS开发的工程师,我一直在寻找能够快速实现复杂三维场景的工具。直到遇到Cesium.js,才发现原来…...

Elasticsearch-PHP异步搜索终极指南:如何实现高性能搜索应用
Elasticsearch-PHP异步搜索终极指南:如何实现高性能搜索应用 【免费下载链接】elasticsearch-php Official PHP client for Elasticsearch. 项目地址: https://gitcode.com/gh_mirrors/el/elasticsearch-php Elasticsearch-PHP是官方PHP客户端,为…...