Spark 9:Spark 新特性
Spark 3.0 新特性
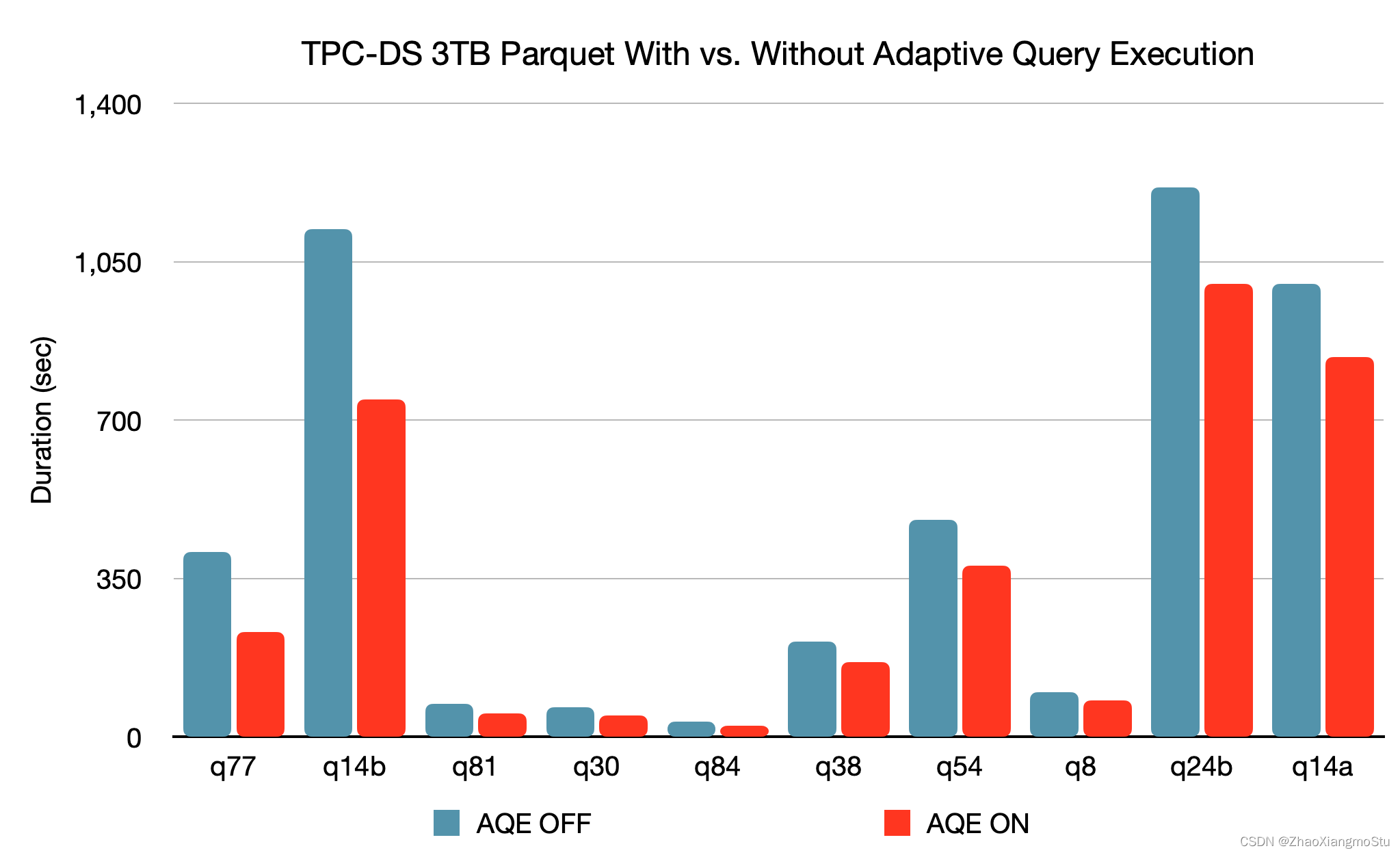
Adaptive Query Execution 自适应查询(SparkSQL)
由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想,在Spark3.x版本提供Adaptive Query Execution自适应查询技术,通过在”运行时”对查询执行计划进行优化, 允许Planner在运行时执行可选计划,这些可选计划将会基于运行时数据统计进行动态优化, 从而提高性能.
Adaptive Query Execution AQE主要提供了三个自适应优化:
• 动态合并 Shuffle Partitions
• 动态调整Join策略
• 动态优化倾斜Join(Skew Joins)
开启AQE方式
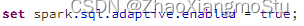
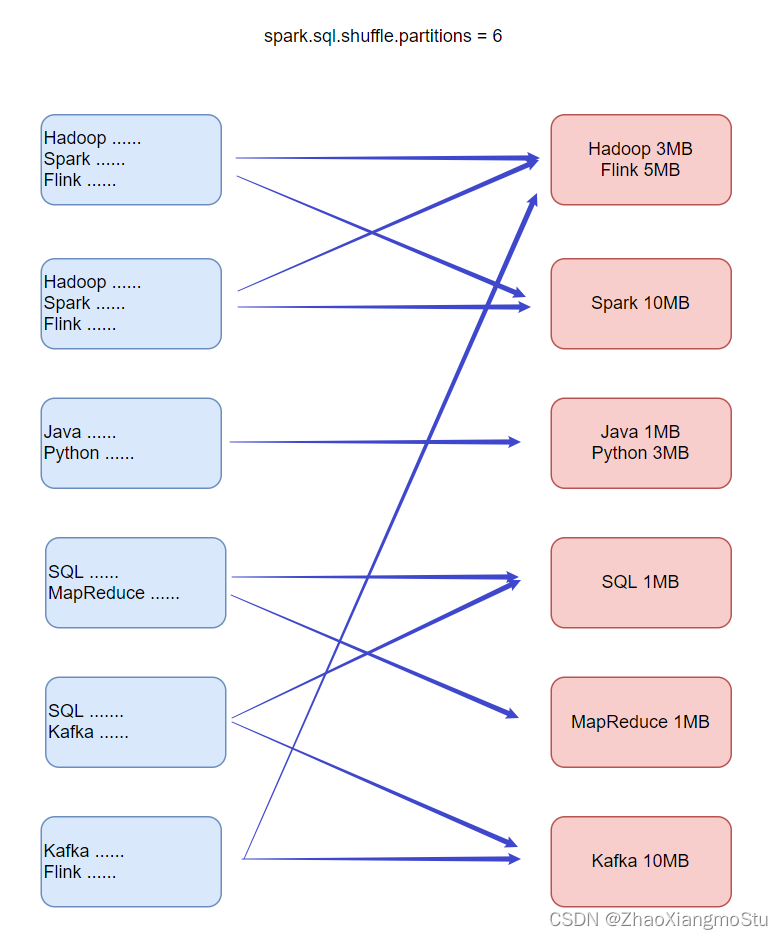
动态合并 Dynamically coalescing shuffle partitions
可以动态调整shuffle分区的数量。用户可以在开始时设置相对较多的shuffle分区数,AQE会在运行时将相邻的小分区合并为较大的分区。
AQE OFF
AQE ON
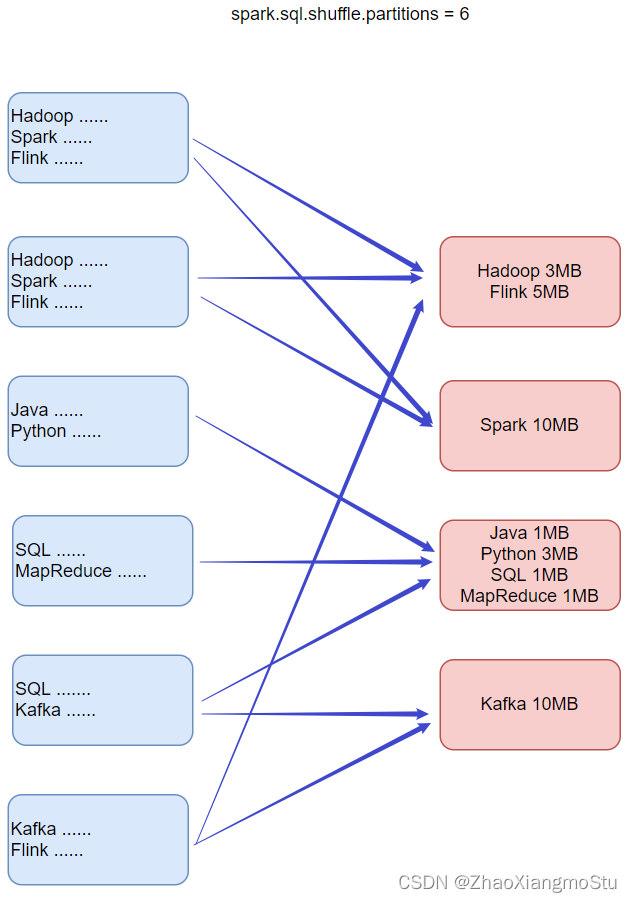
动态调整Join策略 Dynamically switching join strategies
此优化可以在一定程度上避免由于缺少统计信息或着错误估计大小(当然也可能两种情况同时存在),而导致执行计划性能不佳的情况。这种自适应优化可以在运行时sort merge join转换成broadcast hash join,从而进一步提升性能。
动态优化倾斜Join
skew joins可能导致负载的极端不平衡,并严重降低性能。在AQE从shuffle文件统计信息中检测到任何倾斜后,它可以将倾斜的分区分割成更小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜处理,获得更好的整体性能。
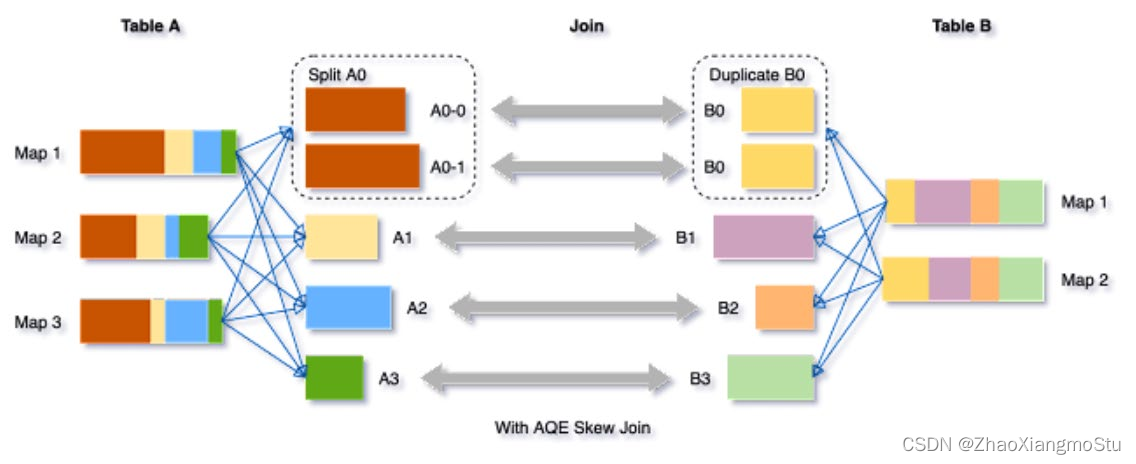
触发条件:
1. 分区大小 > spark.sql.adaptive.skewJoin.skewedPartitionFactor (default=10) * "median partition size(中位数分区大小)"
2. 分区大小 > spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes (default = 256MB)
AQE 总结:
1. AQE的开启通过: spark.sql.adaptive.enabled 设置为true开启
2. AQE是自动化优化机制, 无需我们设置复杂的参数调整, 开启AQE符合条件即可自动化应用AQE优化
3. AQE带来了极大的SparkSQL性能提升
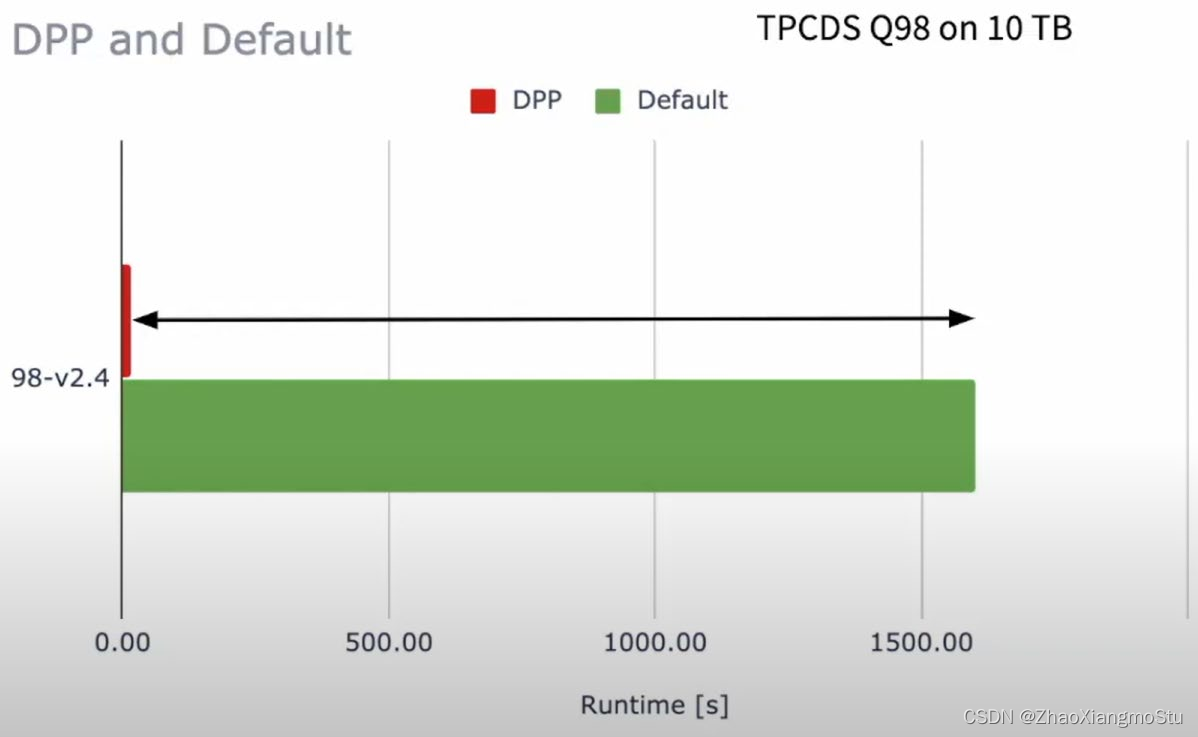
Dynamic Partition Pruning 动态分区裁剪(SparkSQL)
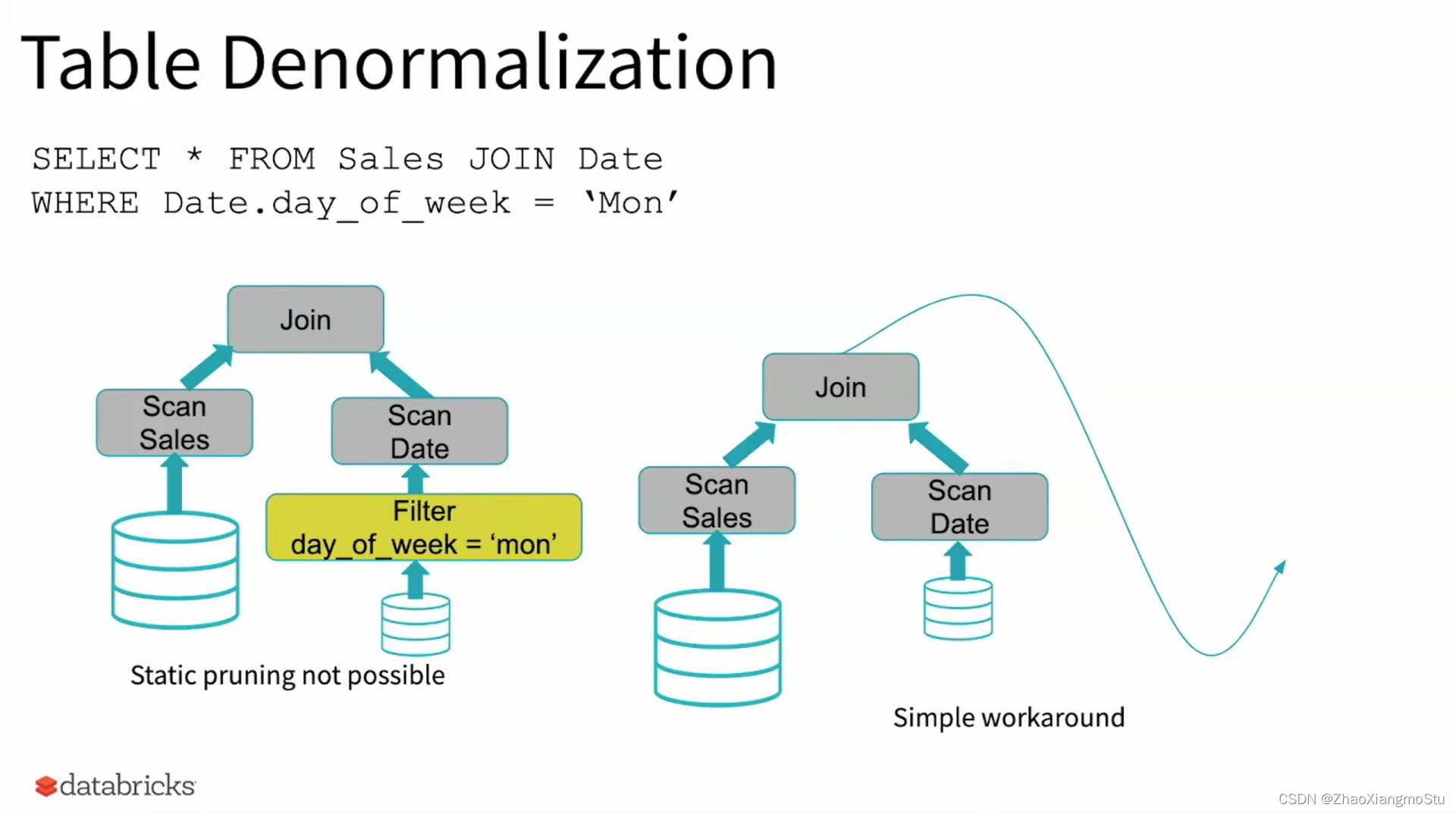
当优化器在编译时无法识别可跳过的分区时,可以使用"动态分区裁剪",即基于运行时推断的信息来进一步进行分区裁剪。这在星型模型中很常见,星型模型是由一个或多个并且引用了任意数量的维度表的事实表组成。在这种连接操作中,我们可以通过识别维度表过滤之后的分区来裁剪从事实表中读取的分区。在一个TPC-DS基准测试中,102个查询中有60个查询获得2到18倍的速度提升。
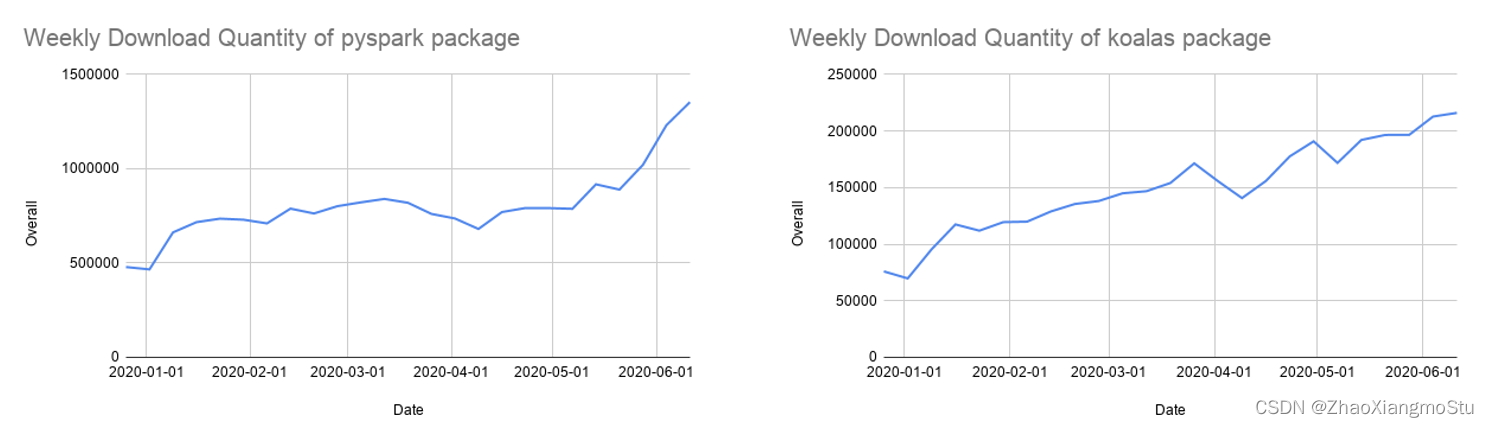
增强的Python API: PySpark和Koalas
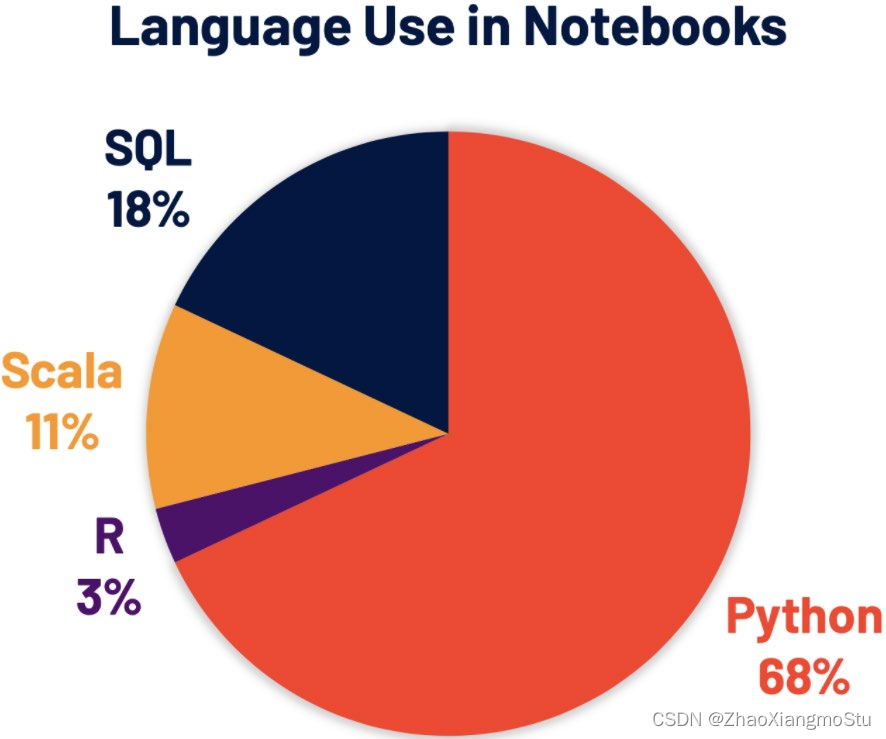
Python现在是Spark中使用较为广泛的编程语言,因此也是Spark 3.0的重点关注领域。Databricks有68%的notebook命令是用Python写的。PySpark在 Python Package Index上的月下载量超过 500 万。
很多Python开发人员在数据结构和数据分析方面使用pandas API,但仅限于单节点处理。Databricks会持续开发Koalas——基于Apache Spark的pandas API实现,让数据科学家能够在分布式环境中更高效地处理大数据。
经过一年多的开发,Koalas实现对pandas API将近80%的覆盖率。Koalas每月PyPI下载量已迅速增长到85万,并以每两周一次的发布节奏快速演进。虽然Koalas可能是从单节点pandas代码迁移的最简单方法,但很多人仍在使用PySpark API,也意味着PySpark API也越来越受欢迎。
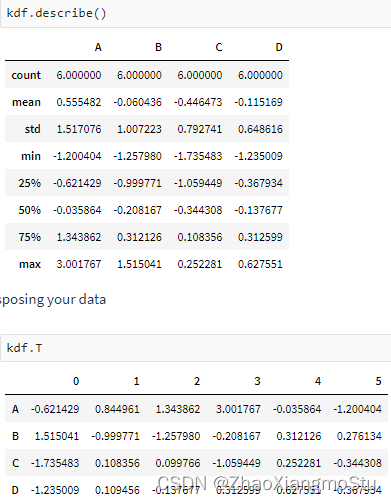
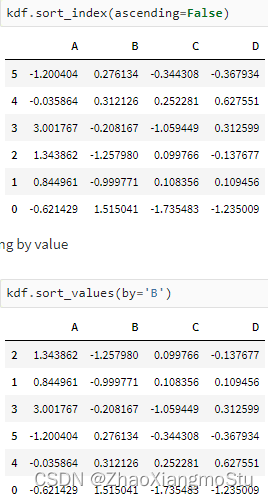
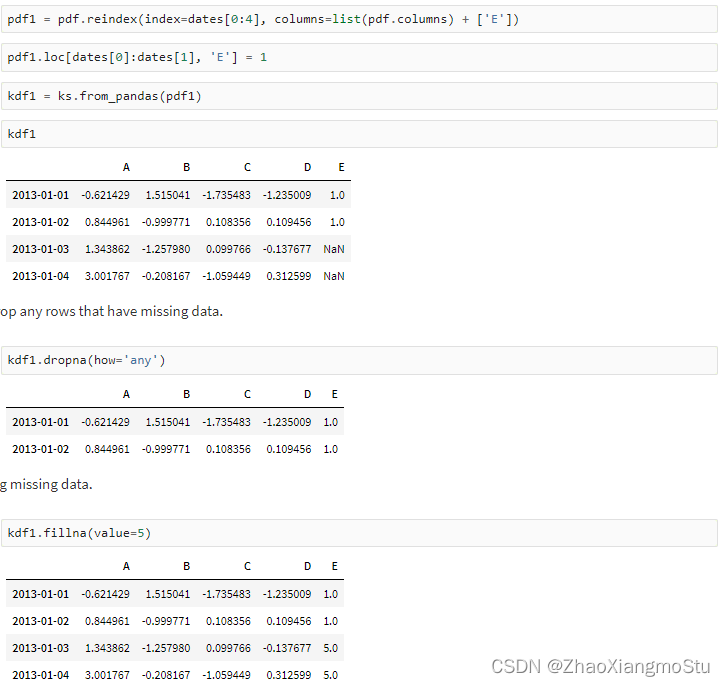
Koalas入门演示 - Koalas DataFrame构建
pip install koalas # 安装koalas类库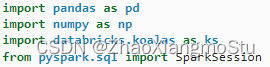
# 构建Pandas的DatetimeIndex
dates = pd.date_range('20130101', periods=6)
# 构建Pandas的DataFrame
pdf = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
# 基于PDF构建Koalas DataFrame
kdf = ks.from_pandas(pdf); type(kdf)
# 或者基于SparkSession构建
sdf = spark.createDataFrame(pdf) # 先转换PandasDataFrame成SparkDataFrame
kdf = sdf.to_koalas() # 转换SparkDataFrame到KoalasDataFrame# 或者直接创建kdf也可以
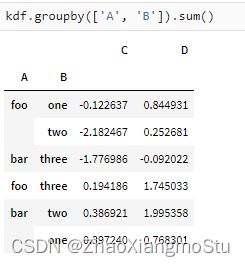
kdf = ks.DataFrame({'A': ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})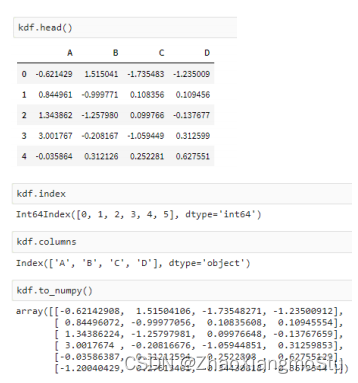
kdf3 = ks.DataFrame({'A': ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})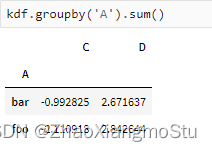
1. AQE的开启通过: spark.sql.adaptive.enabled 设置为true开启,触发后极大提升SparkSQL计算性能
2. 动态分区裁剪可以让我们更好的优化运行时分区内数据的量级. 通过动态的谓词下推来获取传统静态谓词下推无法获得的更高过滤属性, 减少操作的分区数据量以提高性能.
3. 新版Koalas类库可以让我们写Pandas API(Koalas提供)然后将它们运行在分布式的Spark环境上, Pandas开发者也能快速上手Spark
相关文章:
Spark 9:Spark 新特性
Spark 3.0 新特性 Adaptive Query Execution 自适应查询(SparkSQL) 由于缺乏或者不准确的数据统计信息(元数据)和对成本的错误估算(执行计划调度)导致生成的初始执行计划不理想,在Spark3.x版本提供Adaptive Query Execution自适应查询技术,通过在”运行…...

Angular+html+js前端加载生命周期
参考:document.readyState - Web API 接口参考 | MDN (mozilla.org) 第一步,JS生命周期第一步 文档加载中状态,document.readyState loading 第二步,JS生命周期第二步 可交互状态,document.readyState interacti…...

社区投稿| 以安全视角,深度剖析 Sui Staking 与 LSD
本篇技术研报由 MoveBit 研究团队的 Jason 撰写 #1 Sui Staking 介绍 1.1 Sui 网络概述 Sui 网络由一组独立的验证者运行,每个验证者在自己的机器或集群上运行独立的 Sui 软件实例。 Sui 采用委托权益证明(DPoS)来确定哪些验证者参与网络…...

AM@邻域@极限定义中的符号说明
文章目录 abstract邻域👺邻域中心和半径去心邻域 ϵ , δ \epsilon,\delta ϵ,δ的意义各种极限定义的共同点几何意义极限定义中的极限过程临界值 ϵ \epsilon ϵ的选取👺 概念辨析👺无限接近不同于越来越接近例例 越来越接近推不出无限接近 …...
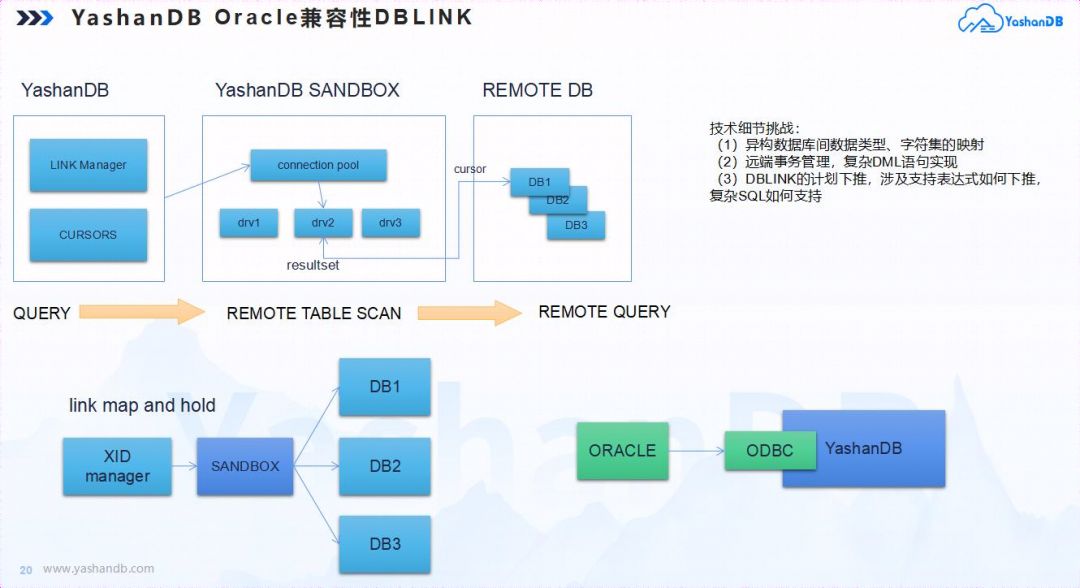
论Oracle兼容性,我们需要做什么
作者介绍:王海峰,数据库系统架构师,YashanDB SQL开发负责人,10年以上数据库内核技术开发经验。 Oracle兼容性是目前国产数据库的关键任务之一,其直接影响到商业迁移的成本和竞争力。 我们经常发现,部分国产…...
你知道多号发圈的同时并延迟评论的方式吗?
你知道多号发圈的同时并延迟评论的方式吗? 其实很简单。 步骤1:编辑好朋友圈内容 步骤2:设置延迟评论 步骤3:选择多个号发圈 通过以上3个步骤,就可以实现多号发圈的同时并延迟评论。 在发布朋友圈前,只需要…...
【BugBounty】记一次XSS绕过
前言 最近一直在看国外的赏金平台,绕waf是真的难受, 记录一下绕过的场景。 初步测试 一开始尝试XSS,发现用户的输入在title中展示,那么一般来说就是看能否闭合,我们从下面图中可以看到,输入尖括号后被转成了实体。 …...

Linux文件目录结构详解:根目录和常见子目录介绍
文章目录 引言1. 什么是Linux文件目录结构2. Linux文件系统的重要性 根目录(/)2.1 根目录的作用和特点2.2 根目录下常见目录的介绍 /bin 目录3.1 /bin 目录的作用和内容3.2 常见的可执行命令示例 /etc 目录4.1 /etc 目录的作用和内容4.2 配置文件的存放位…...

知识付费小程序的推广与用户增长策略
在知识付费小程序开发完成后,推广和用户增长是关键的成功因素。本文将探讨一些推广策略和用户增长方法,并提供代码示例,帮助您在知识付费小程序中实施这些策略。 1. 社交媒体分享功能 在知识付费小程序中添加社交媒体分享功能,…...
微信小程序 获取当前屏幕的可见高宽度
很多时候我们做一下逻辑 需要用整个窗口的高度或宽度参与计算 而且很多时候我们js中拿到的单位都是px像素点 没办法和rpx同流合污 官方提供了wx.getSystemInfoSync() 可以获取到部分窗口信息 其中就包括了整个窗口的宽度和高度 wx.getSystemInfoSync().windowHeight 返回值为像…...

使用 Splashtop 驾驭未来媒体和娱乐
在当今时代,数字转型不再是可选项,而是必选项。如今,媒体与娱乐业处于关键时刻,正在错综复杂的创意、技术和远程协作迷宫之中摸索前进。过去几年发生的全球事件影响了我们的日常生活,不可逆转地改变了行业的运作方式&a…...
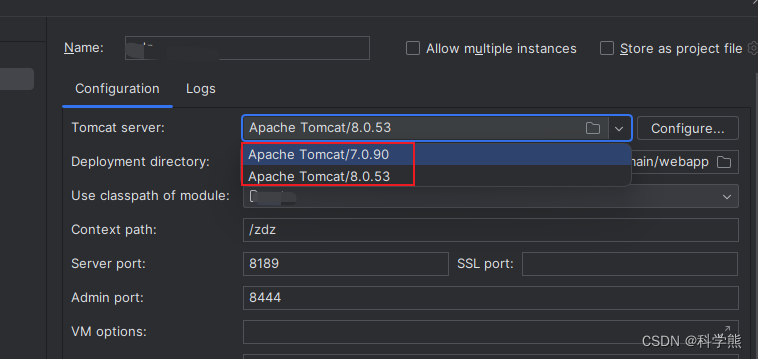
Tomcat项目启动报错
java.io.IOException: java.lang.ClassCastException: Cannot cast org.springframework.web.SpringServletContainerInitializer to javax.servlet.ServletContainerInitializer解决办法:可能Tomcat版本不对,使用7.0.90版本启动报错,使用8.0…...

offer
【录用通知书】 如何判断公司的好坏呢。 注意了,我们软件行业,技术管理类,技术类,产品类 好公司好企业基本都会给你说清楚,一项多少钱,加班多少钱,这样的 像这类公司的薪资结构复杂就要特别…...
漏洞复现--鸿运主动安全监控云平台任意文件下载
免责声明: **文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何…...

第二章 物理层 | 计算机网络(谢希仁 第八版)
文章目录 第二章 物理层2.1 物理层的基本概念2.2 数据通信的基础知识2.2.1 数据通信系统的模型2.2.2 有关信道的几个基本概念2.2.3 信道的极限容量 2.3 物理层下面的传输媒体2.3.1 导引型传输媒体2.3.2 非导引型传输媒体 2.4 信道复用技术2.4.1 频分复用、时分复用和统计时分复…...
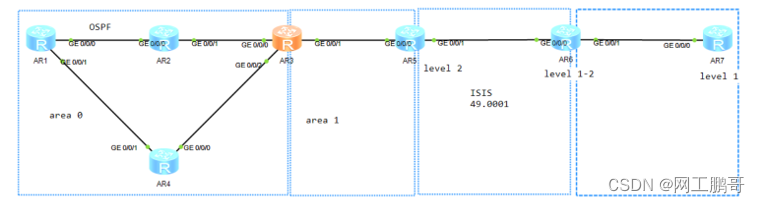
路由高级特性
项目拓扑与项目需求 项目需求 某企业网络使用ospf和isis作为IGP协议实现内部网络的互联互通,区域规划和IP规划如图所示,现在要求实现如下需求: LSW1和AR1使用vlan10互联,与AR2使用vlan20互联,LSW1与LSW2、3、4之间使…...
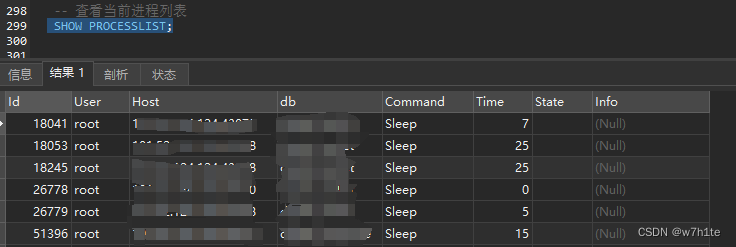
【MySQL】数据库排查慢查询、死锁进程排查、预防以及解决方法
MySQL数据库排查慢查询、死锁进程及解决方法 一、排查慢查询 1.1检查慢查询日志是否开启 1.1.1使用命令检查是否开启慢查询日志: SHOW VARIABLES LIKE slow_query_log;如果是 Value 为 off 则并未开启 1.1.2开启并且查看慢查询日志: MySQL提供了慢查询日志功能,可以记录所…...
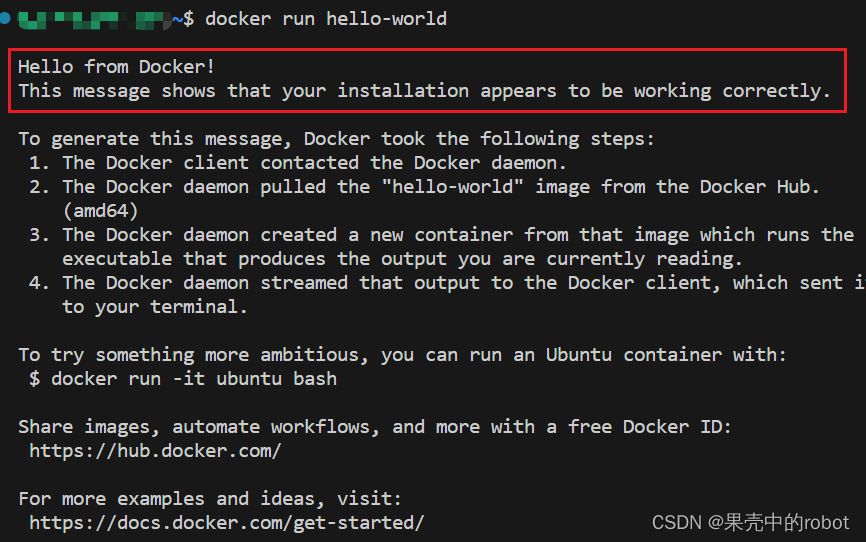
WSL2下的Docker配置和使用
在Windows的Linux子系统(Windows Subsystem for Linux)WSL2中安装、配置和使用 Docker,可以参考官方教程:WSL上的Docker远程容器入门. 重要步骤总结如下: 先决条件 确保你的计算机运行的是 Windows 10(更…...
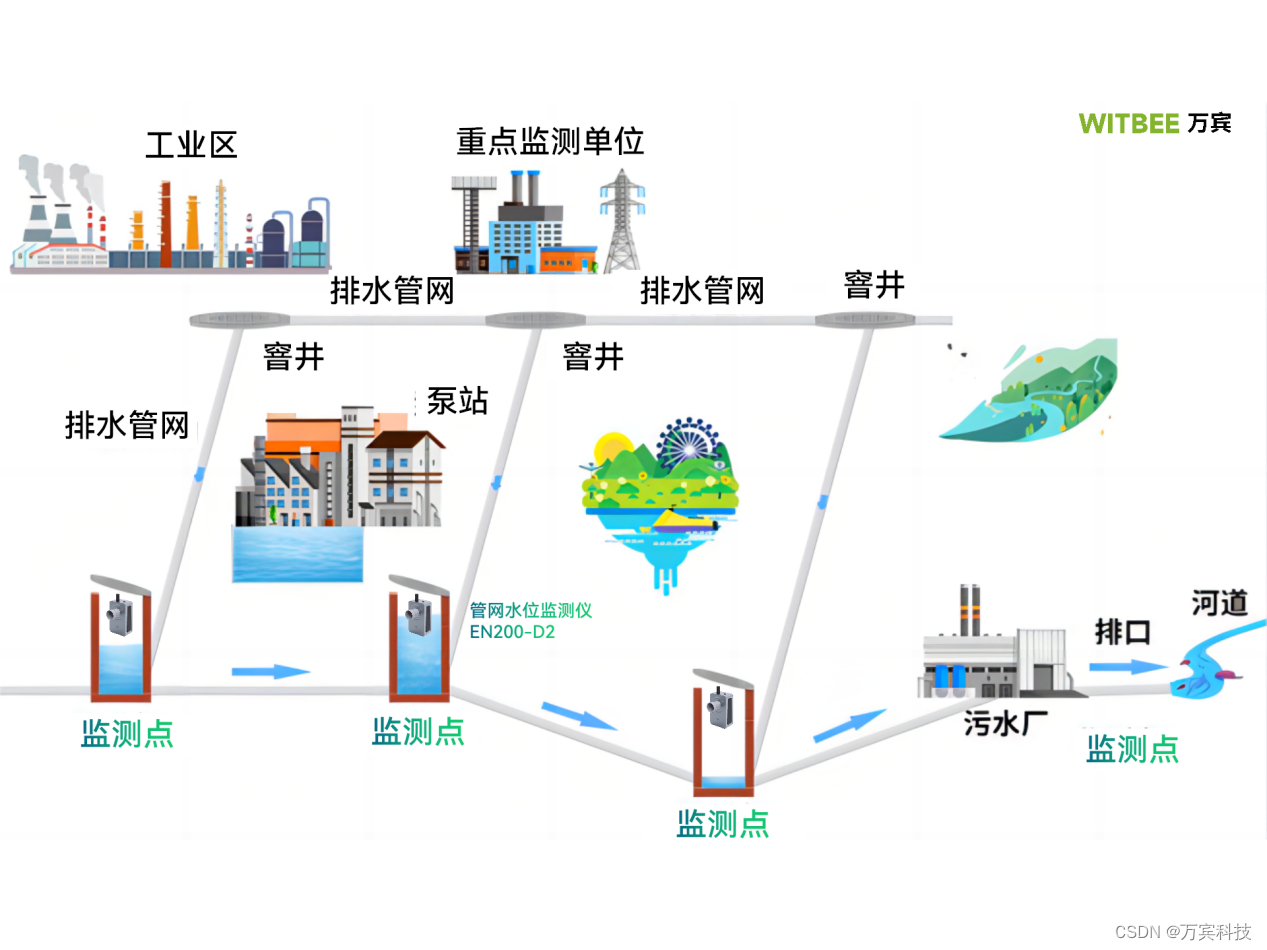
污水管网水位监测,管网水位监测仪守护城市污水管网运行
万宾科技:污水管网水位监测 近年来,城市化进程的加速使得污水管网建设愈发重要。然而,在管网运维中,水位监测一直以来都是一个令人头痛的难题。为了解决这一问题,万宾科技公司推出了管网水位监测仪EN200-D2࿰…...
IDEA插件版本升级和兼容新版本idea
1.关于IDEA插件的版本设置问题 打开jetbrains插件市场,随意打开一个插件详情页面的Versions菜单,我们可以看见一个插件包不同时期发布的不同版本(Versions),并且每个版本包含了可兼容IDEA或PyCharm的版本范围…...

从8K游戏到HDR电影:拆解Xilinx HDMI 2.1 IP如何支持VRR、ALLM和动态HDR这些炫酷特性
从8K游戏到HDR电影:Xilinx HDMI 2.1 IP如何重塑视听体验 当PS5玩家在《战神:诸神黄昏》中感受到无撕裂的流畅战斗画面,或是家庭影院爱好者在《沙丘》中看到沙漠场景的每一粒沙粒都呈现出惊人的动态范围时,背后都离不开HDMI 2.1的关…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

DriveBench:面向真实驾驶场景的长序列多智能体交互基准测试框架
1. 项目概述:从“世界基准”到“驾驶基准”的演进如果你在自动驾驶或者计算机视觉领域摸爬滚打过几年,一定对“基准测试”(Benchmark)这个词又爱又恨。爱的是,它提供了一个相对公平的擂台,让不同算法、不同…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

服务网格Istio实战
服务网格Istio实战 引言 服务网格(Service Mesh)作为微服务架构的基础设施层,提供了对服务间通信的精细控制能力。Istio是目前最流行的开源服务网格解决方案,它通过Sidecar代理拦截所有网络通信,提供流量管理、安全、可…...

Arm Neoverse CMN-700互连架构与寄存器编程详解
1. Arm Neoverse CMN-700架构概览在现代高性能计算系统中,处理器核心数量的快速增长对互连架构提出了严峻挑战。作为Arm Neoverse平台的核心组件,CMN-700一致性互连网络采用创新的Mesh拓扑结构,解决了多核处理器间的通信瓶颈问题。我在实际芯…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...