hive建表指定列分隔符为多字符分隔符实战(默认只支持单字符)
1、背景:
后端日志采集完成,清洗入hive表的过程中,发现字段之间的单一字符的分割符号已经不能满足列分割需求,因为字段值本身可能包含分隔符。所以列分隔符使用多个字符列分隔符迫在眉睫。
hive在建表时,通常使用
ROW FORMAT DELIMITED
FIELDS TERMINATED BY "|#" 来限定数据中各个字段的分隔符,这种方式只支持单个分隔符,即:实际只会按照"|"进行分割,
默认情况下,Hive对于分隔符只支持单字符,不过Hive自带一个工具jar包,这个包支持正则和多字符方式定义分隔符。
hive从0.14版本以后支持MultiDelimitSerDe,可以比较优雅多解决多分隔符问题。
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="|#$")2、官方对列支持多个字符的分隔符调研
参考:MultiDelimitSerDe - Apache Hive - Apache Software Foundation
Introduction:
Introduced in HIVE-5871, MultiDelimitSerDe allows user to specify multiple-character string as the field delimiter when creating a table.
Version:
Hive 0.14.0 and later.
Hive SQL Syntax:
You can use MultiDelimitSerDe in a create table statement like this:
CREATE TABLE test (id string,hivearray array<binary>,hivemap map<string,int>) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="[,]","collection.delim"=":","mapkey.delim"="@");where field.delim is the field delimiter, collection.delim and mapkey.delim is the delimiter for collection items and key value pairs, respectively.
HIVE-20619 moved MultiDelimitSerDe to hive.serde2 in release 4.0.0, so user won't have to install hive-contrib JAR into the HiveServer2 auxiliary directory.
Limitations:
- Among the delimiters, field.delim is mandatory and can be of multiple characters, while collection.delim and mapkey.delim is optional and only support single character.
- Nested complex type is not supported, e.g. an Array<Array>.
- To use MultiDelimitSerDe prior to Hive release 4.0.0, you have to add the hive-contrib jar to the class path, e.g. with the add jar command.
3、小试牛刀,报错
建表时直接使用
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="|#$")
执行查询报错:Class org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe not found
根据网上的方案:进入hive执行(jar包路径根据自己环境路径对应修改)
add jar /usr/hdp/3.1.5.0-152/hive/lib/hive-contrib.jarCREATE EXTERNAL TABLE `table_tset`(
id string,
name string,
year string)
PARTITIONED BY ( `year` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="|#$")
LOCATION 'hdfs://CMBHHA/apps/hive/datahouse/test/table_tset'4、几经搜索,问题终于解决,附上完整示例
4.1、找到和hive版本对应的hive-contrib包,下载jar上传到hdfs上
org/apache/hive/hive-contrib所有版本Jar文件及下载 -时代Java
hive-contrib包下载链接
4.2、以三个等号作为列分隔符 构建hive表的完整demo
add jar hdfs://team/work/libs/xxx/hive-contrib-2.0.1.jar;drop table if exists mb_tmp.yz_1013;
create table if not exists mb_tmp.yz_1013(
test_id int,
work_place string,
other string
)
partitioned by(dt string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe' WITH SERDEPROPERTIES ("field.delim"="===")load data local inpath '/data/home/xxxx/client/ct_data_1010.txt' overwrite into table mb_tmp.yz_1013 partition(dt='2022-10-10');其中 以三个等号分割进行作为列分割的数据如下:
[work@xxxx client]$ cat ct_data_1010.txt
10011===beijing===chu==shi
10012===tianjin===chang==chun
10013===zhengzhou===si==ji
100014===zhangda===j==ob4.3、结果验证
hive> desc mb_tmp.yz_1013;
OK
test_id int from deserializer
work_place string from deserializer
other string from deserializer
dt string # Partition Information
# col_name data_type comment dt string
Time taken: 0.332 seconds, Fetched: 9 row(s)hive> set hive.cli.print.header=true;hive> select * from mb_tmp.yz_1013 limit 100;
OK
yz_1013.test_id yz_1013.work_place yz_1013.other yz_1013.dt
10011 beijing chu==shi 2022-10-10
10012 tianjin chang==chun 2022-10-10
10013 zhengzhou si==ji 2022-10-10
100014 zhangda j==ob 2022-10-10
Time taken: 0.51 seconds, Fetched: 4 row(s)
hive> select other,'****',dt,work_place,test_id from mb_tmp.yz_1013 limit 100;
OK
other c1 dt work_place test_id
chu==shi **** 2022-10-10 beijing 10011
chang==chun **** 2022-10-10 tianjin 10012
si==ji **** 2022-10-10 zhengzhou 10013
j==ob **** 2022-10-10 zhangda 100014
Time taken: 0.356 seconds, Fetched: 4 row(s)
5、参考:
1)、Hive多字符分隔符支持https://baijiahao.baidu.com/s?id=1617938645018071295&wfr=spider&for=pc
2、Hive在0.14及以后版本支持字段的多分隔符,官方文档https://cwiki.apache.org/confluence/display/Hive/MultiDelimitSerDe
3、Hive中的自定义分隔符(包含Hadoop和Hive详细安装)
https://blog.csdn.net/github_39577257/article/details/89020980
6、Hive 自带的多字符分割使用demo2
默认情况下,Hive对于分隔符只支持单字符,不过Hive自带一个工具jar包,这个包支持正则和多字符方式定义分隔符。
1). 查询hive自带的工具jar包位置
find / -name hive-contrib-*.jar
2). 将上面搜索到的jar包配置到配置hive-site.xml文件中
<property>
<name>hive.aux.jars.path</name>
<value>file:///opt/apache-hive-1.2.2-bin/lib/hive-contrib-1.2.2.jar</value>
<description>Added by tiger.zeng on 20120202.These JAR file are available to all users for all jobs</description>
</property>
上面配置之后可以不用重启Hive服务,只需要重新进入Hive CLI就可生效,且是永久的。也可以配置为临时的,就是在进入Hive CLI后,临时加载这个jar包,执行如下:
hive> add jar file:///opt/apache-hive-1.2.2-bin/lib/hive-contrib-1.2.2.jar
3). 使用
准备如下数据,分隔符为 |#|,
3324|#|003|#|20190816 09:16:18|#|0.00|#|2017-11-13 12:00:00
3330|#|009|#|20190817 15:21:03|#|1234.56|#|2017-11-14 12:01:00
建表时如下声明与定义如下,并加载数据,查询数据:
drop table if exists split_test;
CREATE TABLE split_test(
id INT COMMENT '借阅查询ID',
number STRING COMMENT '流水号',
`date` STRING COMMENT '查询返回日期',
loanamount DOUBLE COMMENT '借款金额范围',
createtime TIMESTAMP COMMENT '创建时间'
)ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES ("field.delim"="|#|")
STORED AS TEXTFILE;
--加载数据
LOAD DATA LOCAL INPATH '/root/split_test.txt' OVERWRITE INTO TABLE split_test;
查询结果如下:
--查询数据
hive> select * from split_test;
OK
3324 003 20190816 09:16:18 0.0 2017-11-13 12:00:00
3330 009 20190817 15:21:03 1234.56 2017-11-14 12:01:00
Time taken: 0.11 seconds, Fetched: 2 row(s)
7、Hive 自定义分隔符例子
自定义部分使用 Java 编写,使用Idea新建一个 Maven项目。
https://blog.csdn.net/github_39577257/article/details/89020980
8、hive特殊分隔符,不可见的分隔符 枚举
1.hive默认字段分隔符^A(使用vim文本编辑显示),常用ASCII八进制 '\001' 或者UNICODE编码十六进制 '\u0001' 进行设置;通过notepad++打开显示为SOH
2.hive特殊分隔符^B(使用vim文本编辑显示),常用ASCII八进制 '\002' 或者UNICODE编码十六进制 '\u0002' 进行设置;通过notepad++打开显示为STX
3.hive特殊分隔符^C(使用vim文本编辑显示),常用ASCII八进制 '\003' 或者UNICODE编码十六进制 '\u0003' 进行设置;通过notepad++打开显示为ETX·
此外,不同编程语音使用hive中\u0001、\0001、\0010、\u0010等分隔符切割需要不同写法
以‘\u0010’为例
hive sql使用split函数时,如果字段内使用的是特殊分隔符()需要用split(xxx,‘\u0010’)才能正常切割。
如果是使用java写mr代码,那么需要使用的是"\0010"
9、hive分隔符_HIVE-默认分隔符的(linux系统的特殊字符)查看,输入和修改
hive表分隔符修改实操(兼容sqoop)_hive修改分隔符-CSDN博客
#修改分隔符为逗号 ,
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',' , 'serialization.format'=',');
#修改分隔符为\001,在linux的vim中显示为^A,是hive默认的分隔符
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = '\001' , 'serialization.format'='\001');
#修改分隔符为制表符\t
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = '\t' , 'serialization.format'='\t');
重点知识:
field.delim 指定表的两个列字段之间的文件中的字段分隔符.
serialization.format 指定数据文件序列化时表中两个列字段之间的文件中的字段分隔符.
对于分区表,每个分区可以有不同的分隔符属性
alter语法修改分区表的分隔符后,不会影响已有分区数据读写,只会对后续新写入的数据生效。这一点非常友好
alter语法修改分隔符只针对于后续新增数据有效,拿分区表而言,比如现在有2个分区,day=2020-05-01,day=2020-05-02,分隔符是\t, 通过alter把分隔符改为\001,再写入写的分区day=2020-05-03
可以通过desc formatted tablename partition(key=value)语法查看每个分区的分隔符,那么2020-05-01,2020-05-02的分区依然是\t分隔符,2020-05-03分区的分隔符是\001;而且可以通过hive正常读写操作这三个分区而不会出现任何问题
通过desc formatted table查看该表的分隔符,发现已经变为\001
10、hive列分隔符和行分隔符概述
一)、Hive中默认的分割符如下
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行都是一条记录,因此换行符可以分隔记录 |
| ^A(Ctrl+A) | 用于分隔字段(列)。在CREATE TABLE语句中可以使用八进制编码\001表示 |
| ^B | 用于分隔ARRAY或者STRUCT中的元素,或用于MAP中键-值对之间的分隔。在CREATE TABLE语句中可以使用八进制编码\002表示 |
| ^C | 用于MAP中键和值之间的分隔。在CREATE TABLE语句中可以使用八进制编码\003表示 |
二)、分隔符的指定与使用
hive中在创建表时,一般会根据导入的数据格式来指定字段分隔符和列分隔符。一般导入的文本数据字段分隔符多为逗号分隔符或者制表符(但是实际开发中一般不用着这种容易在文本内容中出现的的符号作为分隔符),当然也有一些别的分隔符,也可以自定义分隔符。有时候也会使用hive默认的分隔符来存储数据。
hive (fdm_sor)> create table fdm_sor.mytest_tmp2(> id int comment'编号',> name string comment '名字'> );hive (fdm_sor)> show create table mytest_tmp2;
CREATE TABLE `mytest_tmp2`(`id` int COMMENT '编号', `name` string COMMENT '名字')
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' --hive默认的分割方式,即行为\n,列为^A
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' --hive默认的存储格式为textfile
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION --内部表的默认的存储路径'hdfs://hadoop102:9000/user/hive/warehouse/fdm_sor.db/mytest_tmp2'
TBLPROPERTIES ('transient_lastDdlTime'='1526176805')hive (fdm_sor)> create table fdm_sor.mytest_tmp3(> id int comment'编号',> name string comment '名字'> )> row format delimited > fields terminated by '\001' --这里可以指定别的分隔符,如‘\t’,'$'等分隔符> COLLECTION ITEMS TERMINATED BY '\002' -- 集合间的分隔符> MAP KEYS TERMINATED BY '\003' -- Map键与值之间的分隔符> LINES TERMINATED BY '\n' -- 行分隔符 > stored as textfile; -- 存储格式为textfilehive (fdm_sor)> show create table fdm_sor.mytest_tmp3;
OK
createtab_stmt
CREATE TABLE `fdm_sor.mytest_tmp3`(`id` int COMMENT '编号', `name` string COMMENT '编号')
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' LINES TERMINATED BY '\n'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION'hdfs://hadoop102:9000/user/hive/warehouse/fdm_sor.db/mytest_tmp3'
TBLPROPERTIES ('transient_lastDdlTime'='1526176859')-注意:ROW FORMAT DELIMITED这组关键字必须要写在其他子句(除了STORED AS…)子句之前。
如上可以看出hive默认的列分割类型为org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,
而这其实就是^A分隔符,hive中默认使用^A(ctrl+A)作为列分割符,如果用户需要指定的话,等同于row format delimited fields terminated by '\001',因为^A八进制编码体现为'\001'.所以如果使用默认的分隔符,可以什么都不加,也可以按照上面的指定加‘\001’为列分隔符,效果一样。
hive默认使用的行分隔符是'\n'分隔符 ,也可以加一句:LINES TERMINATED BY '\n' ,加不加效果一样。但是区别是hive可以通过row format delimited fields terminated by '\t'这个语句来指定不同的分隔符,但是hive不能够通过LINES TERMINATED BY '$$'来指定行分隔符,目前为止,hive的默认行分隔符仅支持‘\n’字符。否则报错。
hive (fdm_sor)> create table fdm_sor.mytest_tm4(> id int comment'编号',> name string comment '名字'> )> lines terminated by '\t';
FAILED: ParseException line 5:1 missing EOF at 'lines' near ')'一般来说hive的默认行分隔符都是换行符,如果非要自定义行分隔符的话,可以通过自定义Inputformat和outputformat类来指定特定行分隔符和列分隔符,一般公司实际开发中也都是这么干的,具体使用。
当然如hive中集合数据类型struct ,map,array,也都有默认的字段分隔符,也都可以指定字段分隔符。hive中对于上述三个集合数据类型的默认字段分隔符是^B,八进制体现为‘\002’,用collection items terminated by '\002'语句来指定分隔符,对于map来说,还有键值之间的分割符,可以用map keys terminated by '\003'(^C)来指定分隔符。
三)、建好表之后更改字段分隔符
参见第九步
相关文章:
)
hive建表指定列分隔符为多字符分隔符实战(默认只支持单字符)
1、背景: 后端日志采集完成,清洗入hive表的过程中,发现字段之间的单一字符的分割符号已经不能满足列分割需求,因为字段值本身可能包含分隔符。所以列分隔符使用多个字符列分隔符迫在眉睫。 hive在建表时,通常使用ROW …...

android.app.RemoteServiceException: can‘t deliver broadcast
日常报错记录 android.app.RemoteServiceException: cant deliver broadcast W BroadcastQueue: Cant deliver broadcast to com.broadcast.test(pid 1769). Crashing it.E AndroidRuntime: FATAL EXCEPTION: main E AndroidRuntime: Process: com.broadcast.test, PID: 1769…...
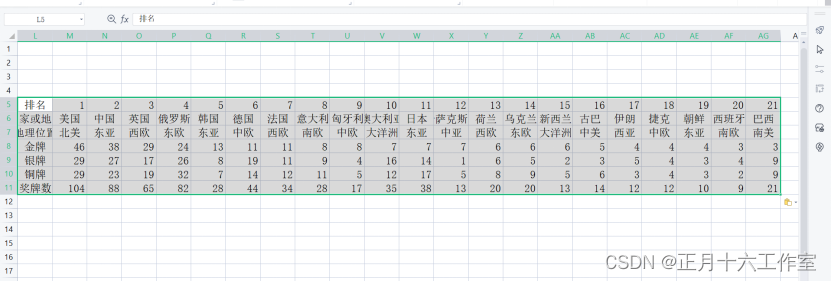
信创办公–基于WPS的EXCEL最佳实践系列 (单元格与行列)
信创办公–基于WPS的EXCEL最佳实践系列 (单元格与行列) 目录 应用背景操作步骤1、插入和删除行和列2、合并单元格3、调整行高与列宽4、隐藏行与列5、修改单元格对齐和缩进6、更改字体7、使用格式刷8、设置单元格内的文本自动换行9、应用单元格样式10、插…...
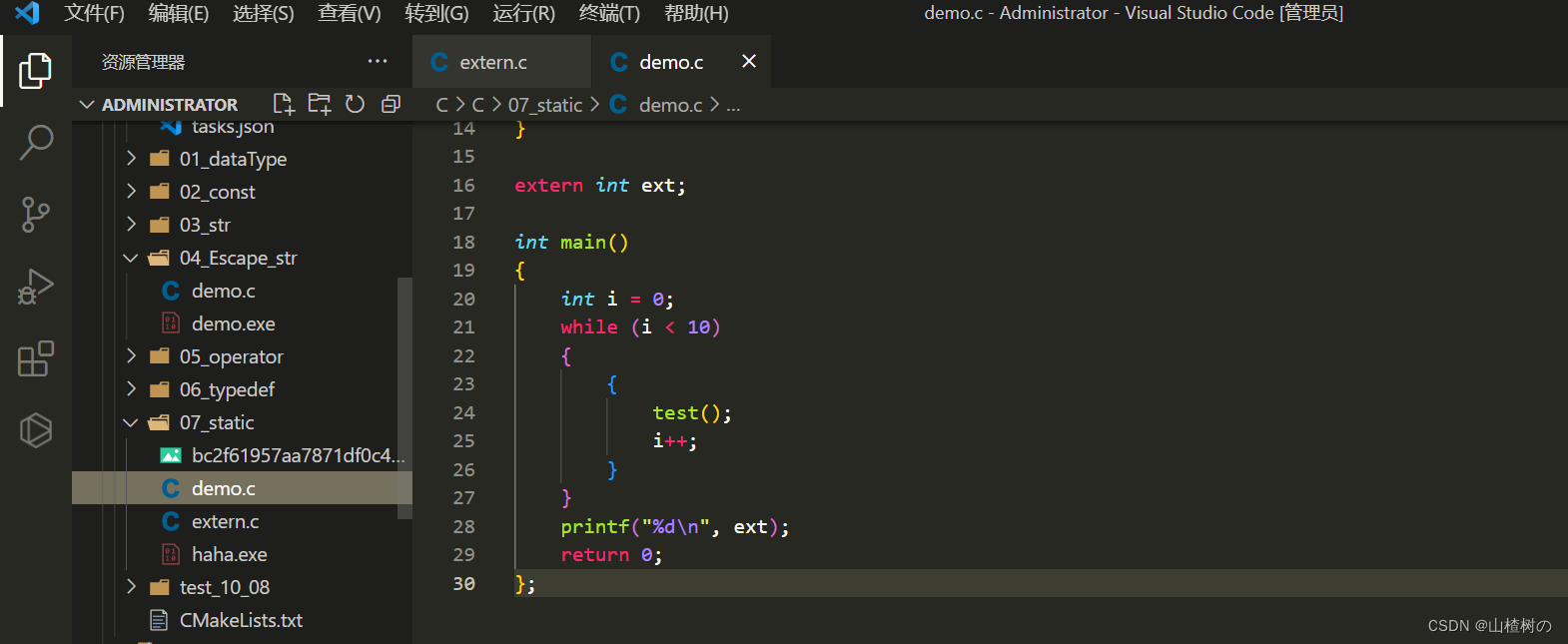
VsCode同时编译多个C文件
VsCode默认只能编译单个C文件,想要编译多个文件,需要额外进行配置 第一种方法 ——> 通过手动指定要编译的文件 g -g .\C文件1 .\C文件2 -o 编译后exe名称 例如我将demo.c和extern.c同时编译得到haha.exe g -g .\demo.c .\extern.c -o haha 第二种…...

Android绑定式服务
Github:https://github.com/MADMAX110/Odometer 启动式服务对于后台操作很合适,不过需要一个更有交互性的服务。 接下来构建这样一个应用: 1、创建一个绑定式服务的基本版本,名为OdometerService 我们要为它增加一个方法getDistance()&#x…...

系统韧性研究(1)| 何谓「系统韧性」?
过去十年,系统韧性作为一个关键问题被广泛讨论,在数据中心和云计算方面尤甚,同时它对赛博物理系统也至关重要,尽管该术语在该领域不太常用。大伙都希望自己的系统具有韧性,但这到底意味着什么?韧性与其他质…...

使用Perl脚本编写爬虫程序的一些技术问题解答
网络爬虫是一种强大的工具,用于从互联网上收集和提取数据。Perl 作为一种功能强大的脚本语言,提供了丰富的工具和库,使得编写的爬虫程序变得简单而灵活。在使用的过程中大家会遇到一些问题,本文将通过问答方式,解答一些…...

SAP内部转移价格(利润中心转移价格)的条件
SAP内部转移价格(利润中心转移价格) SAP内部转移价格(利润中心转移价格) SAP内部转移价格(利润中心转移价格)这个听了很多人说过,但是利润中心转移定价需要具备什么条件。没有找到具体的文档。…...

WRF如何批量输出文件添加或删除文件名后缀
1. 批量添加文件名后缀 #1----批量添加文件名后缀(.nc)。#指定wrfout文件所在的文件夹 path "/mnt/wtest1/"#列出路径path下所有的文件 file_names os.listdir(path) #遍历在path路径下所有以wrfout_d01开头的文件,在os.path…...
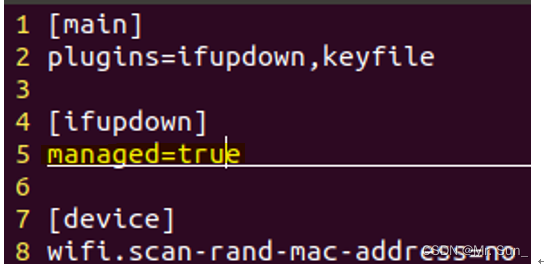
Ubuntu右上角不显示网络的图标解决办法
一.line5改为true sudo vim /etc/NetworkManager/NetworkManager.conf 二.重启网卡 sudo service network-manager stop sudo mv /var/lib/NetworkManager/NetworkManager.state /tmp sudo service network-manager start...

AM@数列极限
文章目录 abstract极限👺极限的主要问题 数列极限数列极限的定义 ( ϵ − N ) (\epsilon-N) (ϵ−N)语言描述极限表达式成立的证明极限发散证明常用数列极限数列极限的几何意义例 函数的极限 abstract 数列极限 极限👺 极限分为数列的极限和函数的极限…...
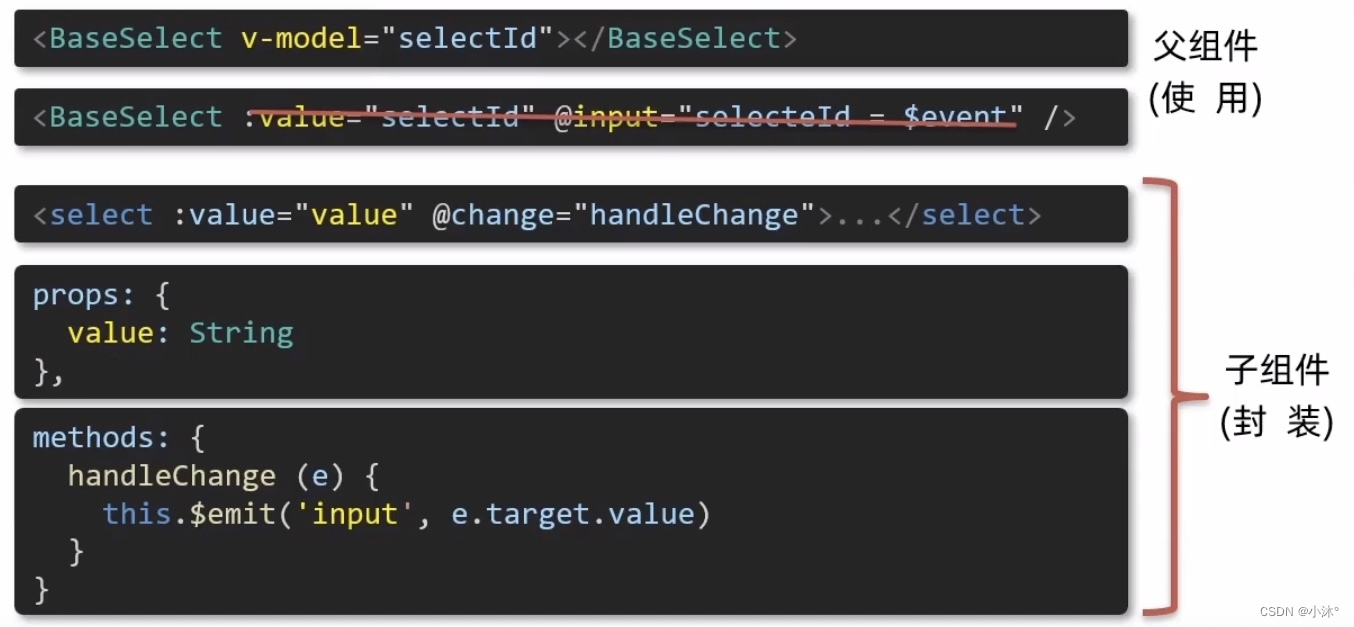
Vue-2.3v-model原理
原理:v-model本质上是一个语法糖,例如应用在输入框上,就是value属性和input事件的合写。 作用:提供数据的双向绑定 1)数据变,视图跟着变:value 2)视图变,数据跟着变input 注意&a…...

左手 Serverless,右手 AI,7 年躬身的古籍修复之路
作者:宋杰 “AI 可以把我们思维体系当中,过度专业化、过度细分的这些所谓的知识都替代掉,让我们集中精力去体验自己的生命。我挺幸运的,代码能够有 AI 辅助,也能够有 Serverless 解决我的运营成本问题。Serverless 它…...

计算mask的体素数量
import numpy as np import nibabel as nib # 用于处理神经影像数据的库 # 从文件中加载mask图像 mask_image nib.load(rE:\mask.nii.gz) # 获取图像数据 mask_data mask_image.get_fdata() # 计算非零像素的数量,即白质骨架的体素总数 voxel_count np.count_no…...

VR全景营销颠覆传统营销,让消费者身临其境
随着VR的普及,各种VR产品、功能开始层出不穷,并且在多个领域都有落地应用,例如文旅、景区、酒店、餐饮、工厂、地产、汽车等,在这个“内容为王”的时代,VR全景展示也是一种新的内容表达方式。 VR全景营销让消费者沉浸式…...
FreeRTOS学习笔记——四、任务的定义与任务切换的实现
FreeRTOS学习笔记——四、任务的定义与任务切换的实现 0 前言1 什么是任务2 创建任务2.1 定义任务栈2.2 定义任务函数2.3 定义任务控制块2.4 实现任务创建函数2.4.1 任务创建函数 —— xTaskCreateStatic()函数2.4.2 创建新任务——prvInitialiseNewTask()函数2.4.3 初始化任务…...
js 之让人迷惑的闭包 03
文章目录 一、闭包是什么? 🤦♂️二、闭包 😎三、使用场景 😁四、使用场景(2) 😁五、闭包的原理六、思考总结一、 更深层次了解闭包,分析以下代码执行过程二、闭包三、闭包定义四、…...

10月10日上课内容 Docker--harbor私有仓库部署与管理
Docker--harbor私有仓库部署与管理 ------------------ 1、搭建本地私有仓库 ------------------------------ #首先下载 registry 镜像 docker pull registry #在 daemon.json 文件中添加私有镜像仓库地址 vim /etc/docker/daemon.json { "insecure-registries"…...

Java 序列化和反序列化为什么要实现 Serializable 接口
第一、序列化和反序列化 序列化:把对象转换为字节序列的过程称为对象的序列化. 反序列化:把字节序列恢复为对象的过程称为对象的反序列化. 第二、什么时候需要用序列化和反序列化呢? 当我们只在本地JVM里运行下Java实例, 这个时候是不需要什么序列化和…...
vite+vue3+ts中使用require.context | 报错require is not defined | 获取文件夹中的文件名
vitevue3ts中使用require.context|报错require is not defined|获取文件夹中的文件名 目录 vitevue3ts中使用require.context|报错require is not defined|获取文件夹中的文件名一、问题背景二、报错原因三、解决方法 一、问题背景 如题在vitevue3ts中使用required.context时报…...

开源监控面板OpenClaw:从架构设计到生产部署实战指南
1. 项目概述:一个开源监控面板的诞生 在运维和开发的世界里,监控面板就像是驾驶舱里的仪表盘。没有它,你就是在盲飞。今天要聊的这个项目 xingrz/openclaw-dashboard ,就是一个由社区驱动的开源监控面板解决方案。它的名字很有意…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

STM32CubeMX外设配置实战——以F103C8T6的CAN与DMA为例
1. STM32CubeMX与F103C8T6开发基础 STM32CubeMX是ST官方推出的图形化配置工具,它能极大简化STM32系列MCU的外设初始化流程。对于刚接触STM32开发的工程师来说,这个工具就像"乐高积木说明书"——通过可视化操作就能完成80%的底层配置工作。我最…...

解锁GitHub极速体验:智能加速插件深度解析
解锁GitHub极速体验:智能加速插件深度解析 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub GitHub加速插件(…...

【HarmonyOS 6.1 全场景实战】《灵犀厨房》之【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑”
【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑” 摘要:从“爱吃什么”到“该吃什么”,是《灵犀厨房》进化的关键一步。上一篇我们刚打通了 Health Kit 数据,今天,我们就要基于 Mifflin-St Jeor …...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

自主智能体框架构建指南:从LLM工具调用到多任务规划系统
1. 项目概述:一个能“开疆拓土”的智能体框架最近在开源社区里,一个名为njbrake/agent-of-empires的项目引起了我的注意。光看这个名字,就充满了野心和想象力——“帝国的代理人”。这可不是一个简单的脚本工具,而是一个旨在构建能…...
)
ElevenLabs葡语语音私密训练技巧(仅限白名单客户使用的SSML扩展语法+方言权重微调指令集)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs葡语语音私密训练的核心价值与白名单准入机制 ElevenLabs 的葡语语音私密训练(Private Voice Fine-tuning for Portuguese)专为高合规性场景设计,面向金融…...