Pytorch深度学习—FashionMNIST数据集训练
文章目录
- FashionMNIST数据集
- 需求库导入、数据迭代器生成
- 设备选择
- 样例图片展示
- 日志写入
- 评估—计数器
- 模型构建
- 训练函数
- 整体代码
- 训练过程
- 日志
FashionMNIST数据集
- FashionMNIST(时尚 MNIST)是一个用于图像分类的数据集,旨在替代传统的手写数字MNIST数据集。它由 Zalando Research 创建,适用于深度学习和计算机视觉的实验。
- FashionMNIST 包含 10 个类别,分别对应不同的时尚物品。这些类别包括 T恤/上衣、裤子、套头衫、裙子、外套、凉鞋、衬衫、运动鞋、包和踝靴。
- 每个类别有 6,000 张训练图像和 1,000 张测试图像,总计 70,000 张图像。
- 每张图像的尺寸为 28x28 像素,与MNIST数据集相同。
- 数据集中的每个图像都是灰度图像,像素值在0到255之间。

需求库导入、数据迭代器生成
import os
import random
import numpy as np
import datetime
import torch
import torch.nn as nn
from torch.utils.data import DataLoaderimport torchvision
from torchvision import transformsimport argparse
from tqdm import tqdmimport matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriterdef _load_data():"""download the data, and generate the dataloader"""trans = transforms.Compose([transforms.ToTensor()])train_dataset = torchvision.datasets.FashionMNIST(root='./data/', train=True, download=True, transform=trans)test_dataset = torchvision.datasets.FashionMNIST(root='./data/', train=False, download=True, transform=trans)# print(len(train_dataset), len(test_dataset))train_loader = DataLoader(train_dataset, shuffle=True, batch_size=args.batch_size, num_workers=args.num_works)test_loader = DataLoader(test_dataset, shuffle=True, batch_size=args.batch_size, num_workers=args.num_works)return (train_loader, test_loader)
设备选择
def _device():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")return device
样例图片展示
"""display data examples"""
def _image_label(labels):text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def _show_images(imgs, rows, columns, titles=None, scale=1.5):figsize = (rows * scale, columns * 1.5)fig, axes = plt.subplots(rows, columns, figsize=figsize)axes = axes.flatten()for i, (img, ax) in enumerate(zip(imgs, axes)):ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])plt.show()return axesdef _show_examples():train_loader, test_loader = _load_data()for images, labels in train_loader:images = images.squeeze(1)_show_images(images, 3, 3, _image_label(labels))break
日志写入
class _logger():def __init__(self, log_dir, log_history=True):if log_history:log_dir = os.path.join(log_dir, datetime.datetime.now().strftime("%Y_%m_%d__%H_%M_%S"))self.summary = SummaryWriter(log_dir)def scalar_summary(self, tag, value, step):self.summary.add_scalars(tag, value, step)def images_summary(self, tag, image_tensor, step):self.summary.add_images(tag, image_tensor, step)def figure_summary(self, tag, figure, step):self.summary.add_figure(tag, figure, step)def graph_summary(self, model):self.summary.add_graph(model)def close(self):self.summary.close()
评估—计数器
class AverageMeter():def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.count
模型构建
class Conv3x3(nn.Module):def __init__(self, in_channels, out_channels, down_sample=False):super(Conv3x3, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, 1, 1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, 1, 1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))if down_sample:self.conv[3] = nn.Conv2d(out_channels, out_channels, 2, 2, 0)def forward(self, x):return self.conv(x)class SimpleNet(nn.Module):def __init__(self, in_channels, out_channels):super(SimpleNet, self).__init__()self.conv1 = Conv3x3(in_channels, 32)self.conv2 = Conv3x3(32, 64, down_sample=True)self.conv3 = Conv3x3(64, 128)self.conv4 = Conv3x3(128, 256, down_sample=True)self.fc = nn.Linear(256*7*7, out_channels)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = torch.flatten(x, 1)out = self.fc(x)return out
训练函数
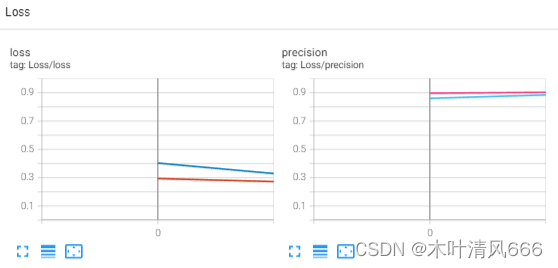
def train(model, train_loader, test_loader, criterion, optimizor, epochs, device, writer, save_weight=False):train_loss = AverageMeter()test_loss = AverageMeter()train_precision = AverageMeter()test_precision = AverageMeter()time_tick = datetime.datetime.now().strftime("%Y_%m_%d__%H_%M_%S")for epoch in range(epochs):print('\nEpoch: [%d | %d] LR: %f' % (epoch + 1, args.epochs, args.lr))model.train()for input, label in tqdm(train_loader):input, label = input.to(device), label.to(device)output = model(input)# backwardloss = criterion(output, label)optimizor.zero_grad()loss.backward()optimizor.step()# loggerpredict = torch.argmax(output, dim=1)train_pre = sum(predict == label) / len(label)train_loss.update(loss.item(), input.size(0))train_precision.update(train_pre.item(), input.size(0))model.eval()with torch.no_grad():for X, y in tqdm(test_loader):X, y = X.to(device), y.to(device)y_hat = model(X)loss_te = criterion(y_hat, y)predict_ = torch.argmax(y_hat, dim=1)test_pre = sum(predict_ == y) / len(y)test_loss.update(loss_te.item(), X.size(0))test_precision.update(test_pre.item(), X.size(0))if save_weight:best_dice = args.best_diceweight_dir = os.path.join(args.weight_dir, args.model, time_tick)os.makedirs(weight_dir, exist_ok=True)monitor_dice = test_precision.avgif monitor_dice > best_dice:best_dice = max(monitor_dice, best_dice)name = os.path.join(weight_dir, args.model + '_' + str(epoch) + \'_test_loss-' + str(round(test_loss.avg, 4)) + \'_test_dice-' + str(round(best_dice, 4)) + '.pt')torch.save(model.state_dict(), name)print("train" + '---Loss: {loss:.4f} | Dice: {dice:.4f}'.format(loss=train_loss.avg, dice=train_precision.avg))print("test " + '---Loss: {loss:.4f} | Dice: {dice:.4f}'.format(loss=test_loss.avg, dice=test_precision.avg))# summarywriter.scalar_summary("Loss/loss", {"train": train_loss.avg, "test": test_loss.avg}, epoch)writer.scalar_summary("Loss/precision", {"train": train_precision.avg, "test": test_precision.avg}, epoch)writer.close()
整体代码
import os
import random
import numpy as np
import datetime
import torch
import torch.nn as nn
from torch.utils.data import DataLoaderimport torchvision
from torchvision import transformsimport argparse
from tqdm import tqdmimport matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter"""Reproduction experiment"""
def setup_seed(seed):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# torch.backends.cudnn.benchmark = False# torch.backends.cudnn.enabled = False# torch.backends.cudnn.deterministic = True"""data related"""
def _base_options():parser = argparse.ArgumentParser(description="Train setting for FashionMNIST")# about datasetparser.add_argument('--batch_size', default=8, type=int, help='the batch size of dataset')parser.add_argument('--num_works', default=4, type=int, help="the num_works used")# trainparser.add_argument('--epochs', default=100, type=int, help='train iterations')parser.add_argument('--lr', default=0.001, type=float, help='learning rate')parser.add_argument('--model', default="SimpleNet", choices=["SimpleNet"], help="the model choosed")# log dirparser.add_argument('--log_dir', default="./logger/", help='the path of log file')#parser.add_argument('--best_dice', default=-100, type=int, help='for save weight')parser.add_argument('--weight_dir', default="./weight/", help='the dir for save weight')args = parser.parse_args()return argsdef _load_data():"""download the data, and generate the dataloader"""trans = transforms.Compose([transforms.ToTensor()])train_dataset = torchvision.datasets.FashionMNIST(root='./data/', train=True, download=True, transform=trans)test_dataset = torchvision.datasets.FashionMNIST(root='./data/', train=False, download=True, transform=trans)# print(len(train_dataset), len(test_dataset))train_loader = DataLoader(train_dataset, shuffle=True, batch_size=args.batch_size, num_workers=args.num_works)test_loader = DataLoader(test_dataset, shuffle=True, batch_size=args.batch_size, num_workers=args.num_works)return (train_loader, test_loader)def _device():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")return device"""display data examples"""
def _image_label(labels):text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels]def _show_images(imgs, rows, columns, titles=None, scale=1.5):figsize = (rows * scale, columns * 1.5)fig, axes = plt.subplots(rows, columns, figsize=figsize)axes = axes.flatten()for i, (img, ax) in enumerate(zip(imgs, axes)):ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])plt.show()return axesdef _show_examples():train_loader, test_loader = _load_data()for images, labels in train_loader:images = images.squeeze(1)_show_images(images, 3, 3, _image_label(labels))break"""log"""
class _logger():def __init__(self, log_dir, log_history=True):if log_history:log_dir = os.path.join(log_dir, datetime.datetime.now().strftime("%Y_%m_%d__%H_%M_%S"))self.summary = SummaryWriter(log_dir)def scalar_summary(self, tag, value, step):self.summary.add_scalars(tag, value, step)def images_summary(self, tag, image_tensor, step):self.summary.add_images(tag, image_tensor, step)def figure_summary(self, tag, figure, step):self.summary.add_figure(tag, figure, step)def graph_summary(self, model):self.summary.add_graph(model)def close(self):self.summary.close()"""evaluate the result"""
class AverageMeter():def __init__(self):self.reset()def reset(self):self.val = 0self.avg = 0self.sum = 0self.count = 0def update(self, val, n=1):self.val = valself.sum += val * nself.count += nself.avg = self.sum / self.count"""define the Net"""
class Conv3x3(nn.Module):def __init__(self, in_channels, out_channels, down_sample=False):super(Conv3x3, self).__init__()self.conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, 3, 1, 1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, 3, 1, 1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))if down_sample:self.conv[3] = nn.Conv2d(out_channels, out_channels, 2, 2, 0)def forward(self, x):return self.conv(x)class SimpleNet(nn.Module):def __init__(self, in_channels, out_channels):super(SimpleNet, self).__init__()self.conv1 = Conv3x3(in_channels, 32)self.conv2 = Conv3x3(32, 64, down_sample=True)self.conv3 = Conv3x3(64, 128)self.conv4 = Conv3x3(128, 256, down_sample=True)self.fc = nn.Linear(256*7*7, out_channels)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = torch.flatten(x, 1)out = self.fc(x)return out"""progress of train/test"""
def train(model, train_loader, test_loader, criterion, optimizor, epochs, device, writer, save_weight=False):train_loss = AverageMeter()test_loss = AverageMeter()train_precision = AverageMeter()test_precision = AverageMeter()time_tick = datetime.datetime.now().strftime("%Y_%m_%d__%H_%M_%S")for epoch in range(epochs):print('\nEpoch: [%d | %d] LR: %f' % (epoch + 1, args.epochs, args.lr))model.train()for input, label in tqdm(train_loader):input, label = input.to(device), label.to(device)output = model(input)# backwardloss = criterion(output, label)optimizor.zero_grad()loss.backward()optimizor.step()# loggerpredict = torch.argmax(output, dim=1)train_pre = sum(predict == label) / len(label)train_loss.update(loss.item(), input.size(0))train_precision.update(train_pre.item(), input.size(0))model.eval()with torch.no_grad():for X, y in tqdm(test_loader):X, y = X.to(device), y.to(device)y_hat = model(X)loss_te = criterion(y_hat, y)predict_ = torch.argmax(y_hat, dim=1)test_pre = sum(predict_ == y) / len(y)test_loss.update(loss_te.item(), X.size(0))test_precision.update(test_pre.item(), X.size(0))if save_weight:best_dice = args.best_diceweight_dir = os.path.join(args.weight_dir, args.model, time_tick)os.makedirs(weight_dir, exist_ok=True)monitor_dice = test_precision.avgif monitor_dice > best_dice:best_dice = max(monitor_dice, best_dice)name = os.path.join(weight_dir, args.model + '_' + str(epoch) + \'_test_loss-' + str(round(test_loss.avg, 4)) + \'_test_dice-' + str(round(best_dice, 4)) + '.pt')torch.save(model.state_dict(), name)print("train" + '---Loss: {loss:.4f} | Dice: {dice:.4f}'.format(loss=train_loss.avg, dice=train_precision.avg))print("test " + '---Loss: {loss:.4f} | Dice: {dice:.4f}'.format(loss=test_loss.avg, dice=test_precision.avg))# summarywriter.scalar_summary("Loss/loss", {"train": train_loss.avg, "test": test_loss.avg}, epoch)writer.scalar_summary("Loss/precision", {"train": train_precision.avg, "test": test_precision.avg}, epoch)writer.close()if __name__ == "__main__":# configargs = _base_options()device = _device()# datatrain_loader, test_loader = _load_data()# loggerwriter = _logger(log_dir=os.path.join(args.log_dir, args.model))# modelmodel = SimpleNet(in_channels=1, out_channels=10).to(device)optimizor = torch.optim.Adam(model.parameters(), lr=args.lr)criterion = nn.CrossEntropyLoss()train(model, train_loader, test_loader, criterion, optimizor, args.epochs, device, writer, save_weight=True)""" args = _base_options()_show_examples() # ———> 样例图片显示
"""
训练过程

日志
相关文章:
Pytorch深度学习—FashionMNIST数据集训练
文章目录 FashionMNIST数据集需求库导入、数据迭代器生成设备选择样例图片展示日志写入评估—计数器模型构建训练函数整体代码训练过程日志 FashionMNIST数据集 FashionMNIST(时尚 MNIST)是一个用于图像分类的数据集,旨在替代传统的手写数字…...

uniapp 返回上一步携带参数
1. 下一步 // 返回上一页setTimeout(() > {let pages getCurrentPages();let prevPage pages[pages.length - 2];prevPage.$vm.schoolName this.formList;uni.navigateBack({delta: 1});}, 1000) 2. 返回上一步, 携带参数 // 获取下一步返回的数据onShow() {let pages …...

软件工程与计算总结(七)需求文档化与验证
目录 一.文档化的原因 二.需求文档基础 1.需求文档的交流对象 2.用例文档 3.软件需求规格说明文档 三.需求文档化要点 1.技术文档协作要点 2.需求书写要点 3.软件需求规格说明文档属性要点 四.评审软件需求规格说明文档 1.需求验证与确认 2.评审需求的注意事项 五…...

MySQL锁概述
数据库锁是一种机制,用于管理并发访问数据库的方式。当多个用户或事务同时访问数据库时,可能会导致数据不一致或冲突的问题。数据库锁的作用是确保数据的一致性和完整性,同时允许多个用户并发地访问数据库。 需要注意的是,加锁是消…...

【Ceph Block Device】块设备挂载使用
文章目录 前言创建pool创建user创建image列出image检索image信息调整image大小增加image大小减少image大小 删除image从pool中删除image从pool中“延迟删除”image从pool中移除“延迟删除的image” 恢复image恢复指定pool中延迟删除的image恢复并重命名image 映射块设备格式化i…...
Arbitrum Stylus 的工作原理
理解 Arbitrum 如何协调 EVM 和 WASM 的共存是至关重要的。这不仅仅是拥有两个独立的引擎;这是一种增强两者优势的协同关系。 Arbitrum 的独特架构允许 EVM 和 WASM 之间进行无缝和同步的操作,这要归功于其统一的状态、跨 VM 调用和兼容的经济模型。 用…...
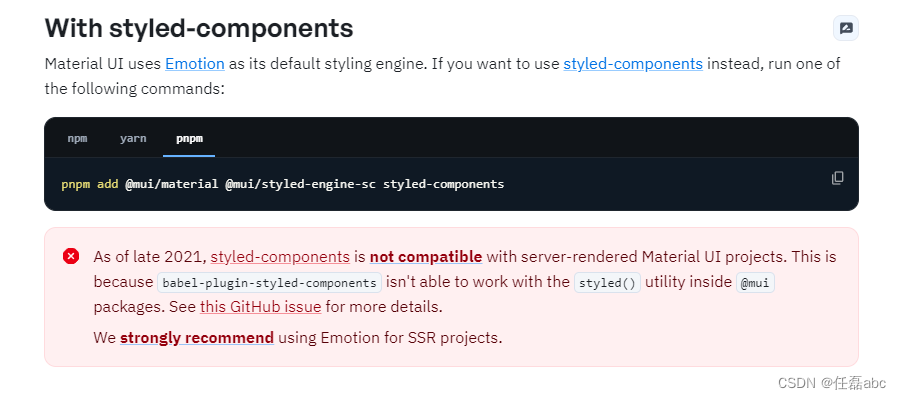
nextjs构建服务端渲染,同时使用Material UI进行项目配置
一、创建一个next项目 使用create-next-app来启动一个新的Next.js应用,它会自动为你设置好一切 运行命令: npx create-next-applatest 执行结果如下: 启动项目: pnpm dev 执行结果: 启动成功! 二、安装Mater…...

Java 使用 Easyexcel 导出大量数据
读Excel | Easy Excel 1、 我遇到的数据量超级大,使用传统的POI方式来完成导入导出很明显会内存溢出,并且效率会非常低;2、 数据量大直接使用select * from tableName肯定不行,一下子查出来300w条数据肯定会很慢;3、 …...
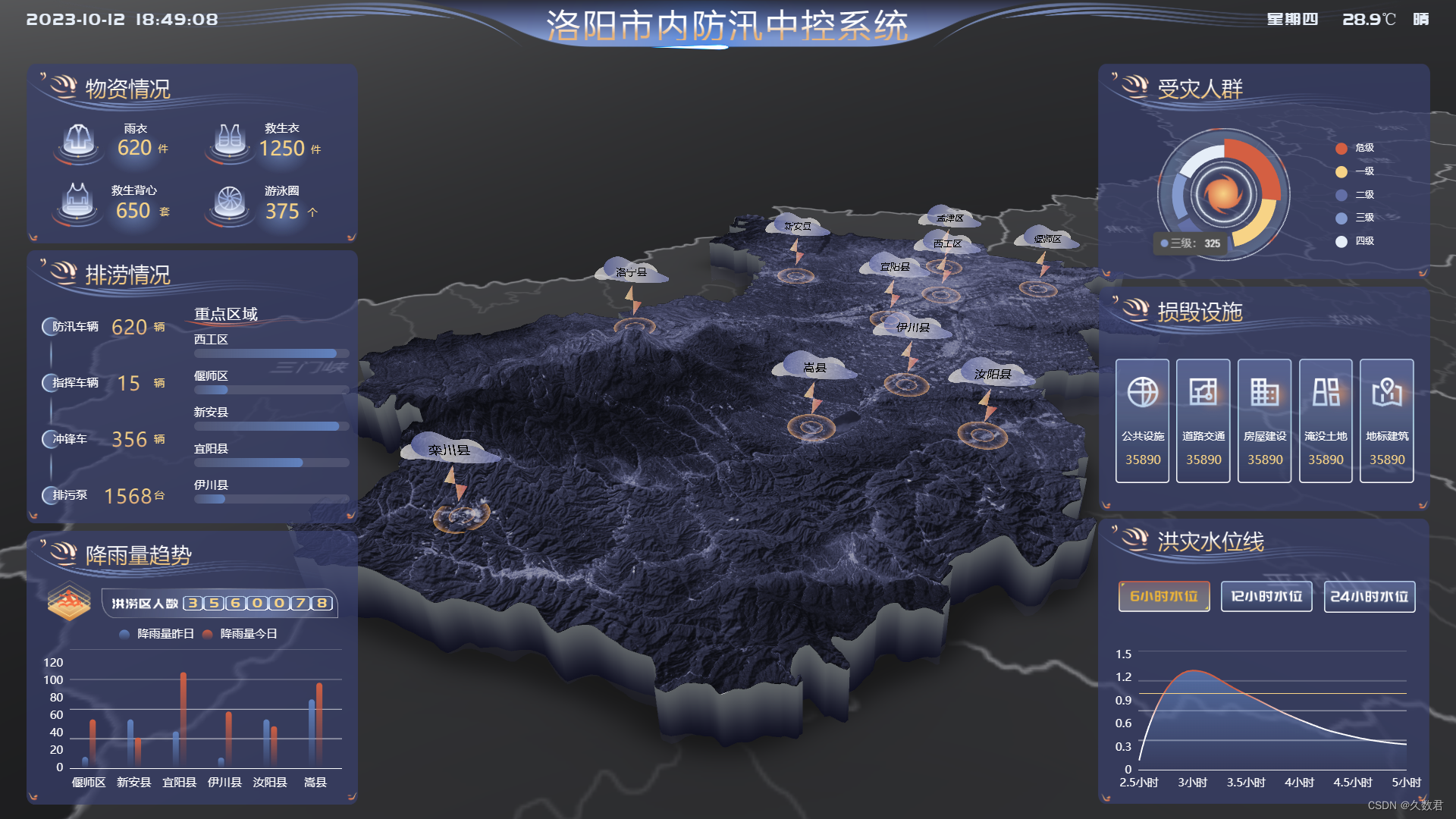
高效防汛决策:山海鲸可视化系统助力城市防洪
随着全球气候的变化,自然灾害如洪水、台风等频发,防范洪水成为城市管理者和居民们亟待解决的重要问题。 洪水的威胁 洪水是自然界的杀手之一,不仅会造成大量的财产损失,还可能危害人们的生命安全。因此,预测、监测和有…...

易点云CFO向征:CFO不能只讲故事,价值创造才是核心
作者 | 曾响铃 文 | 响铃说 在今年6月初,也是易点云上市6天后,《巴伦周刊》正式启动评价“2023港美上市中国企业CFO精英100”的活动。 时间来到9月,评价揭秘,易点云CFO向征成功入选,被评为“年度最具成长潜力CFO”…...
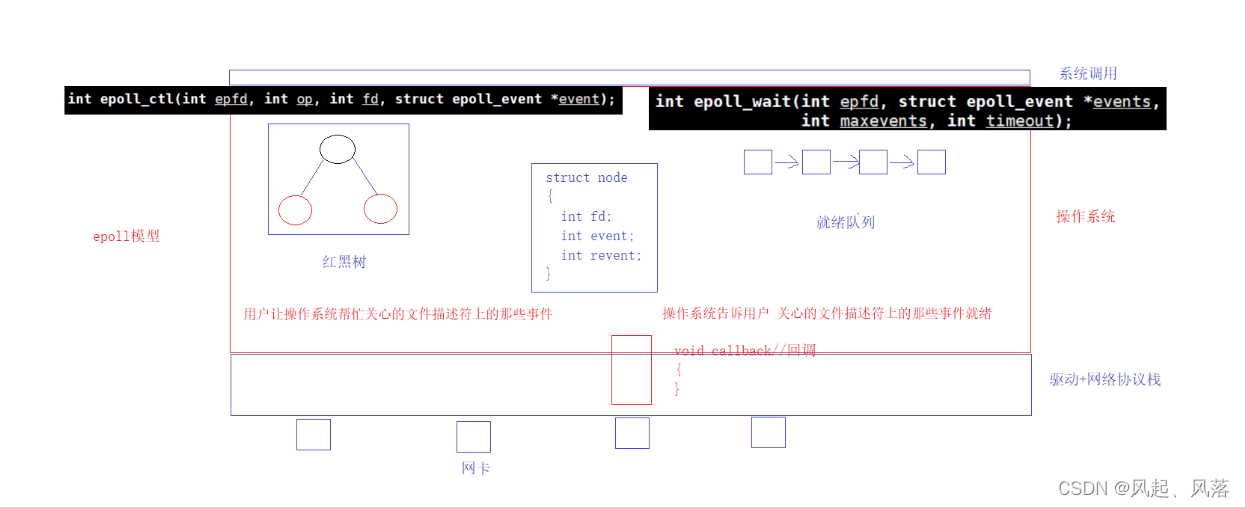
【计算机网络】poll | epoll
文章目录 1. pollpoll函数参数解析代码解析PollServer代码 poll 特点 2. epoll认识接口epoll_createepoll_ctlepoll_wait 基本原理红黑树就绪队列 1. poll poll函数参数解析 输入 man poll poll的第一个参数是文件描述符 poll的第二个参数为 等待的多个文件描述符(fd)数字层面…...
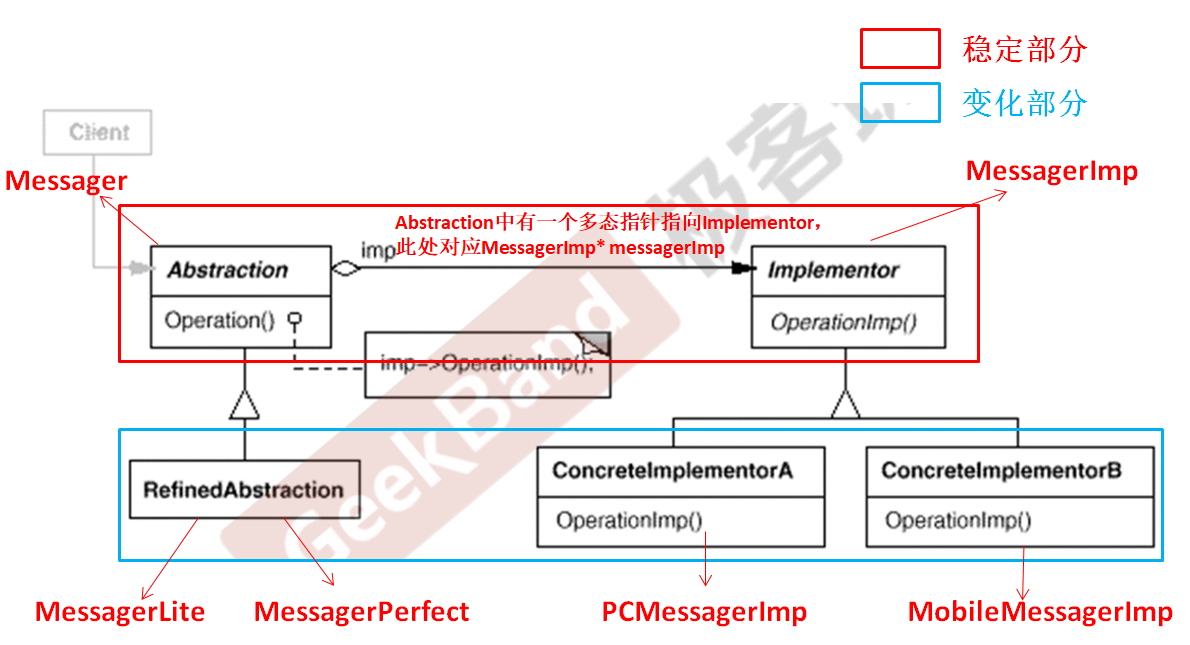
C++设计模式_07_Bridge 桥模式
文章目录 1. 动机(Motivation)2. 代码演示Bridge 桥模式2.1 基于继承的常规思维处理2.2 基于组合关系的重构优化2.3 采用Bridge 桥模式的实现 3. 模式定义4. 结构(Structure)5. 要点总结 与上篇介绍的Decorator 装饰模式一样&…...

[JAVA版本] Websocket获取B站直播弹幕——基于直播开放平台
教程 B站直播间弹幕Websocket获取 — 哔哩哔哩直播开放平台 基于B站直播开放平台开放且未上架时,只能个人使用。 代码实现 1、相关依赖 fastjson2用于解析JSON字符串,可自行替换成别的框架。 hutool-core用于解压zip数据,可自行替换成别的…...
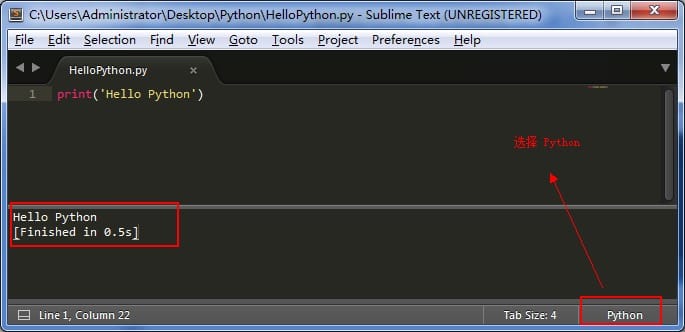
第一个 Python 程序
三、第一个 Python 程序 好了,说了那么多,现在我们可以来写一下第一个 Python 程序了。 一开始写 Python 程序,个人不太建议用专门的工具来写,不方便熟悉语法,所以这里我先用 Sublime Text 来写,后期可以…...

广告牌安全监测,保障户外广告牌的安全与稳定
随着城市的发展和现代化,广告牌已经成为城市风景的一部分。然而,随之而来的是广告牌安全问题,因为它们暴露在各种天气和环境条件下,一旦掉落,可能对人们的生命和财产造成威胁。广告牌安全监测有效的解决了这一问题&…...

分类预测 | MATLAB实现KOA-CNN-GRU开普勒算法优化卷积门控循环单元数据分类预测
分类预测 | MATLAB实现KOA-CNN-GRU开普勒算法优化卷积门控循环单元数据分类预测 目录 分类预测 | MATLAB实现KOA-CNN-GRU开普勒算法优化卷积门控循环单元数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.MATLAB实现KOA-CNN-GRU开普勒算法优化卷积门控循环单…...

进来了解实现官网搜索引擎的三种方法
做网站的目的是对自己的品牌进行推广,让越来越多的人知道自己的产品,但是如果只是做了一个网站放着,然后等着生意找上门来那是不可能的。在当今数字时代,实现官网搜索引擎对于提升用户体验和推动整体性能至关重要。搜索引擎可以帮…...

OpenCV3-Python(7)模板匹配和霍夫检测
模板匹配 膜版匹配不能匹配尺度变换和视角变换的图像 图片中查找和模板相似度最高的图像 计算相似程度最高的位置 res cv.matchTemplate(img , template, method) 该方法返回一个类似灰度图的东西,如果用的相关匹配,那么亮的地方就是可能匹配上的地方 …...
[C++11]花括号{}、initializer_list、auto、decltype
文章目录 1.花括号{ }的扩展2.initializer_list3.auto4.decltype5.容器的增加5.1array[useless]5.2forward_list[useless]5.3unordered_map/unordered_set5.4统一增加 6.知乎文章 1.花括号{ }的扩展 int main() {//C98花括号{ }支持 1.数组 2.结构体struct Point{int _x;int _…...
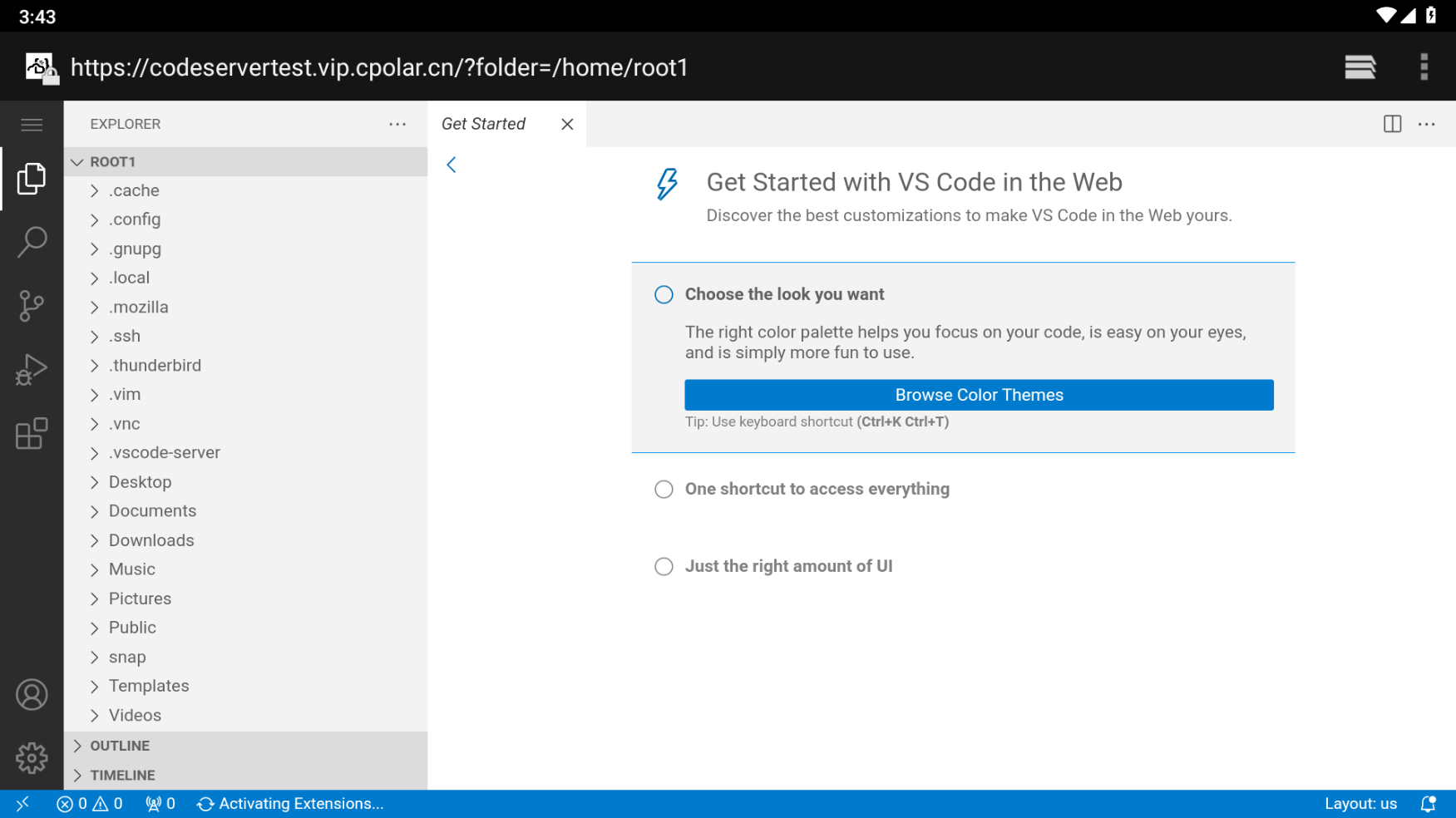
在Android平板上使用code-server公网远程Ubuntu服务器编程
文章目录 1.ubuntu本地安装code-server2. 安装cpolar内网穿透3. 创建隧道映射本地端口4. 安卓平板测试访问5.固定域名公网地址6.结语 1.ubuntu本地安装code-server 准备一台虚拟机,Ubuntu或者centos都可以,这里以VMwhere ubuntu系统为例 下载code server服务,浏览器…...

3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA
3DS游戏格式转换神器:5分钟让.3ds文件变身为可安装的CIA 【免费下载链接】3dsconv Python script to convert Nintendo 3DS CCI (".cci", ".3ds") files to the CIA format 项目地址: https://gitcode.com/gh_mirrors/3d/3dsconv 还在为…...

ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案
ncmdumpGUI:3分钟掌握网易云音乐ncm格式转换的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲&a…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

构建高可用AI模型代理服务:统一接口、智能路由与生产级部署
1. 项目概述:一个无处不在的AI助手接口最近在折腾AI应用开发的朋友,可能都遇到过这样一个痛点:想在自己的项目里快速接入一个靠谱的、能处理复杂对话的AI模型,但要么被OpenAI的API调用限制和网络问题搞得焦头烂额,要么…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

IE11富文本兼容——政务系统前端的深渊
IE11富文本兼容——政务系统前端的深渊 背景:为什么还有 IE11 系统要求支持 IE11。 为什么不是 Chrome? 办公电脑全是 Windows 7 IE11单位统一采购,不能随便装浏览器部分内部网站只支持 IE(ActiveX) 现状&#x…...

基于MCP与Apify构建AI驱动的投资另类数据研究工具
1. 项目概述:当投资研究遇上AI代理如果你是一名量化研究员、对冲基金分析师,或者只是一个对金融市场充满好奇、希望用数据驱动决策的独立投资者,那么你肯定对“另类数据”这个词不陌生。传统的财报、股价、宏观经济指标,这些“传统…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...