【机器学习】决策树原理及scikit-learn使用
文章目录
- 决策树详解
- ID3 算法
- C4.5算法
- CART 算法
- scikit-learn使用
- 分类树
- 剪枝参数
- 重要属性和接口
- 回归树
- 重要参数,属性及接口
- 交叉验证
- 代码示例
- 一维回归的图像绘制
决策树详解
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。
决策树由结点(node)和有向边(directed edge)组成。结点有两种:内部结点(internal node)和叶子结点(leaf node),其中内部结点表示一个特征或者属性,叶子结点表示一个类。
下图为是否为哺乳动物的二分类决策树:体温和胎生为特征,哺乳动物和非哺乳动物为类别。【可以看成if-else的结够,根据给定的数据,一路走下去,最后得出结论】
 原则上讲,任意一个数据集上的所有特征都可以被拿来分枝,特征上的任意节点又可以自由组合,所以一个数据集上可以发展出非常非常多棵决策树,其数量可达指数级。在这些树中,总有那么一棵树比其他的树分类效力都好,那样的树叫做”全局最优树“。
原则上讲,任意一个数据集上的所有特征都可以被拿来分枝,特征上的任意节点又可以自由组合,所以一个数据集上可以发展出非常非常多棵决策树,其数量可达指数级。在这些树中,总有那么一棵树比其他的树分类效力都好,那样的树叫做”全局最优树“。
暴力搜索方法肯定行不通,时间复杂度太高。
机器学习研究者们开发了一些有效的算法,能够在合理的时间内构造出具有一定准确率的次最优决策树。这些算法基本都执行”贪心策略“,即通过局部的最优来达到我们相信是最接近全局最优的结果。
在学习算法之前,先了解几个概念:
- 信息熵:熵度量了事物的不确定性,越不确定的事物,它的熵就越大。
随机变量X的熵的表达式如下:
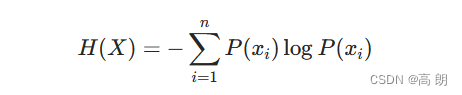
其中n代表X的n种不同的离散取值。而 p x i p_{x_i} pxi代表了X取值为i的概率,log为以2或者e为底的对数。
- 条件熵 (Conditional Entropy): H ( X ∣ Y ) H(X∣Y) H(X∣Y) 表示在已知随机变量Y的条件下随机变量X的不确定性。
H ( X ∣ Y ) = ∑ j = 1 n p ( y i ) H ( X ∣ y i ) H(X|Y)=\sum_{j=1}^np(y_i)H(X|y_i) H(X∣Y)=j=1∑np(yi)H(X∣yi)
- 信息增益:特征A对训练数据集D的信息增益 I ( D , A ) I(D,A) I(D,A),定义为集合D的经验熵 H ( D ) H(D) H(D)与给定特征A在给定条件下D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)之差,即:
I ( D , A ) = H ( D ) − H ( D ∣ A ) I(D,A)=H(D)-H(D|A) I(D,A)=H(D)−H(D∣A)
H ( D ∣ A ) H(D|A) H(D∣A)表示在特征A在给定条件下对数据集D进行分类的不确定性,二者之差即为信息增益,表示特征A使得数据集D的分类不确定性减少的程度。
显然,对于信息增益大的特征具有更强的分类能力。
- 具体计算示例:

构建最优树的算法:
ID3 算法
ID3算法的核心就是在决策树各个节点上应用信息增益准则选择特征,递归地构建决策树。
具体过程:-
- 输入:训练数据集D、特征集A、,阈值ϵ
- 输出: 决策树T
判断T是否需要选择特征生成决策树:
- 若D中所有实例属于同一类,则T为单结点树,记录实例类别 C k C_k Ck,以此作为该结点的类标记,并返回T;
- 若D中所有实例无任何特征(A=空集),则T为单结点树,记录D中实例个数最多类别 C k C_k Ck,以此作为该结点的类标记,并返回T ;
否则,计算A中各特征的
信息增益,并选择信息增益最大的特征 A g A_g Ag;
- 若 A g A_g Ag的信息增益小于ϵ,则T为单结点树,记录D中实例个数最多类别 C k C_k Ck ,以此作为该结点的类标记,并返回T ;
- 否则,按照 A g A_g Ag的每个可能值 a i a_i ai,将D分为若干非空子集 D i D_i Di,将 D i D_i Di中实例个数最多的类别作为标记,构建子结点,以结点和其子节点构成T,并返回T ;
第 i i i个子结点,以 D i D_i Di为训练集, A − A g A-A_g A−Ag为特征集合,递归地调用以上步骤,得到子树 T i T_i Ti并返回。
C4.5算法
D3算法有四个主要的不足,一是不能处理连续特征,第二个就是用信息增益作为标准容易偏向于取值较多的特征,最后两个是缺失值处理的问和过拟合问题。C4.5算法中改进了上述4个问题。
==信息增益作为标准容易偏向于取值较多的特征的问题。==我们引入一个信息增益比的变量 I R ( X , Y ) I_R(X,Y) IR(X,Y),它是信息增益和特征熵的比值。表达式如下:
I R ( D , A ) = I ( A , D ) H A ( D ) I_R(D,A)=\frac{I(A,D)}{H_A(D)} IR(D,A)=HA(D)I(A,D)
其中D为样本特征输出的集合,A为样本特征,对于特征熵 H A ( D H_A(D HA(D), 表达式如下:
H A ( D ) = − ∑ i = 1 n ∣ D i ∣ ∣ D ∣ l o g 2 ∣ D i ∣ ∣ D ∣ H_A(D)=-\sum_{i=1}^n\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|} HA(D)=−i=1∑n∣D∣∣Di∣log2∣D∣∣Di∣
其中n为特征A的类别数, D i D_i Di为特征A的第i个取值对应的样本个数。 ∣ D ∣ |D| ∣D∣为样本个数。
特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
算法流程同ID3,将信息增益换成信息增益比即可。
CART 算法
- ID3算法中我们使用了信息增益来选择特征,信息增益大的优先选择。
- C4.5算法中,采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。
- CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。【简化了运算,没有那么多对数运算】
具体的,在分类问题中,假设有K个类别,第k个类别的概率为 p k p_k pk, 则基尼系数的表达式为:
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^Kp_k(1-p_k)=1-\sum_{k=1}^Kp^2_k Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
对于个给定的样本D,假设有K个类别, 第k个类别的数量为 C k C_k Ck,则样本D的基尼系数表达式为:
G i n i ( D ) = 1 − ∑ k = 1 K ∣ C k ∣ ∣ D ∣ Gini(D)=1-\sum_{k=1}^K\frac{|C_k|}{|D|} Gini(D)=1−k=1∑K∣D∣∣Ck∣
二分类:
G i n i ( D ) = 2 p ( 1 − p ) Gini(D)=2p(1-p) Gini(D)=2p(1−p)
对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
CART既可以用于分类又可以用来回归,其中对回归树用平方误差最小化准则,对分类树用基尼指数最小化原则,进行特征选择,生成二叉树。下表列出了三种不同决策树算法的差别:
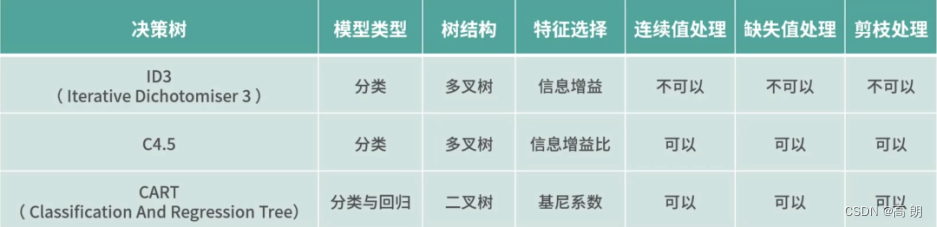 CART生成分类树,是用基尼指数选择最优特征后,生成的二叉树:
CART生成分类树,是用基尼指数选择最优特征后,生成的二叉树:
 具体流程:
具体流程:
- 输入:训练数据集D、特征集A、阈值
- 输出:CART决策树T
从根节点出发,进行操作,构建二叉树;
结点处的训练数据集为D,计算现有特征对该数据集的基尼指数,并选择最优特征。
- 在特征 A g A_g Ag下,对其可能取的每个值 a g a_g ag,根据样本点对 A g = a g A_g= a_g Ag=ag的测试为“是”或“否”,将D分割成 D 1 D_1 D1和 D 2 D_2 D2两部分,计算 A g = a g A_g= a_g Ag=ag时的基尼指数。
- 选择基尼指数最小的那个值作为该特征下的最优切分点。
- 计算每个特征下的最优切分点,并比较在最优切分下的每个特征的基尼指数,选择基尼指数最小的那个特征,即最优特征。
根据最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
分别对两个子结点递归地调用上述步骤,直至满足停止条件(比如结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征),即生成CART决策树。
示例:
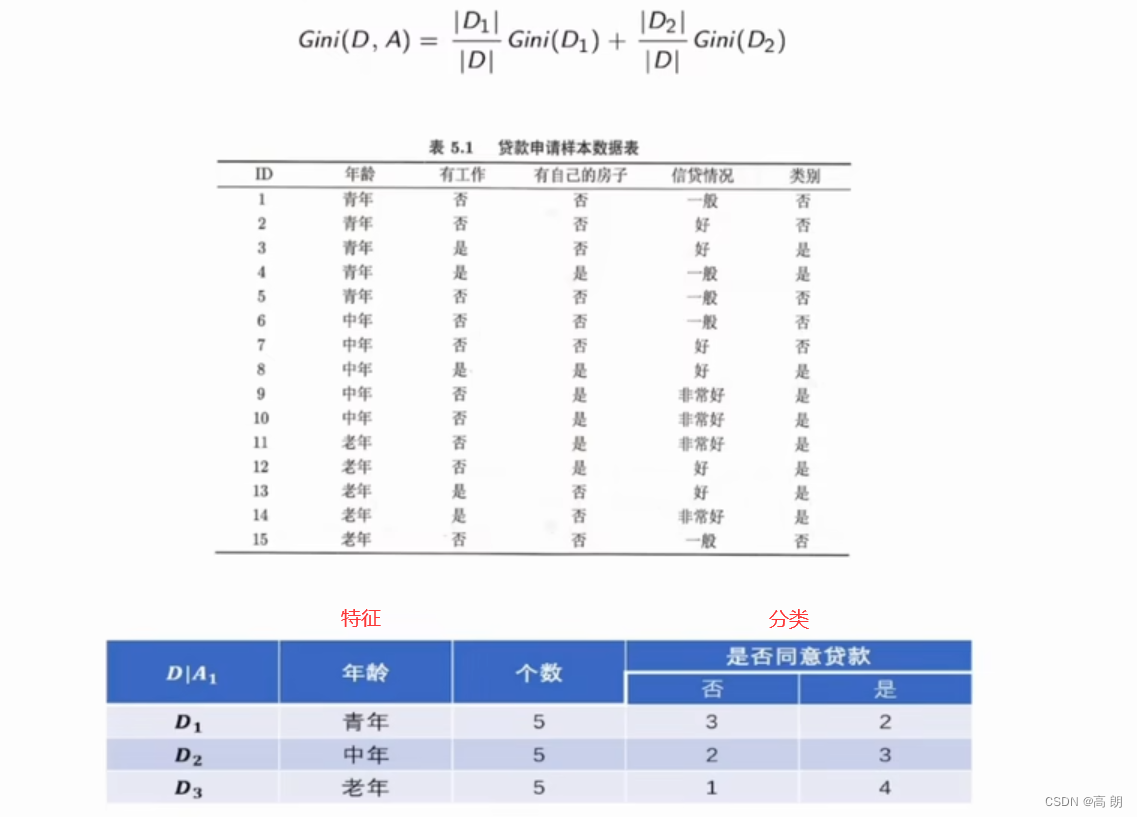
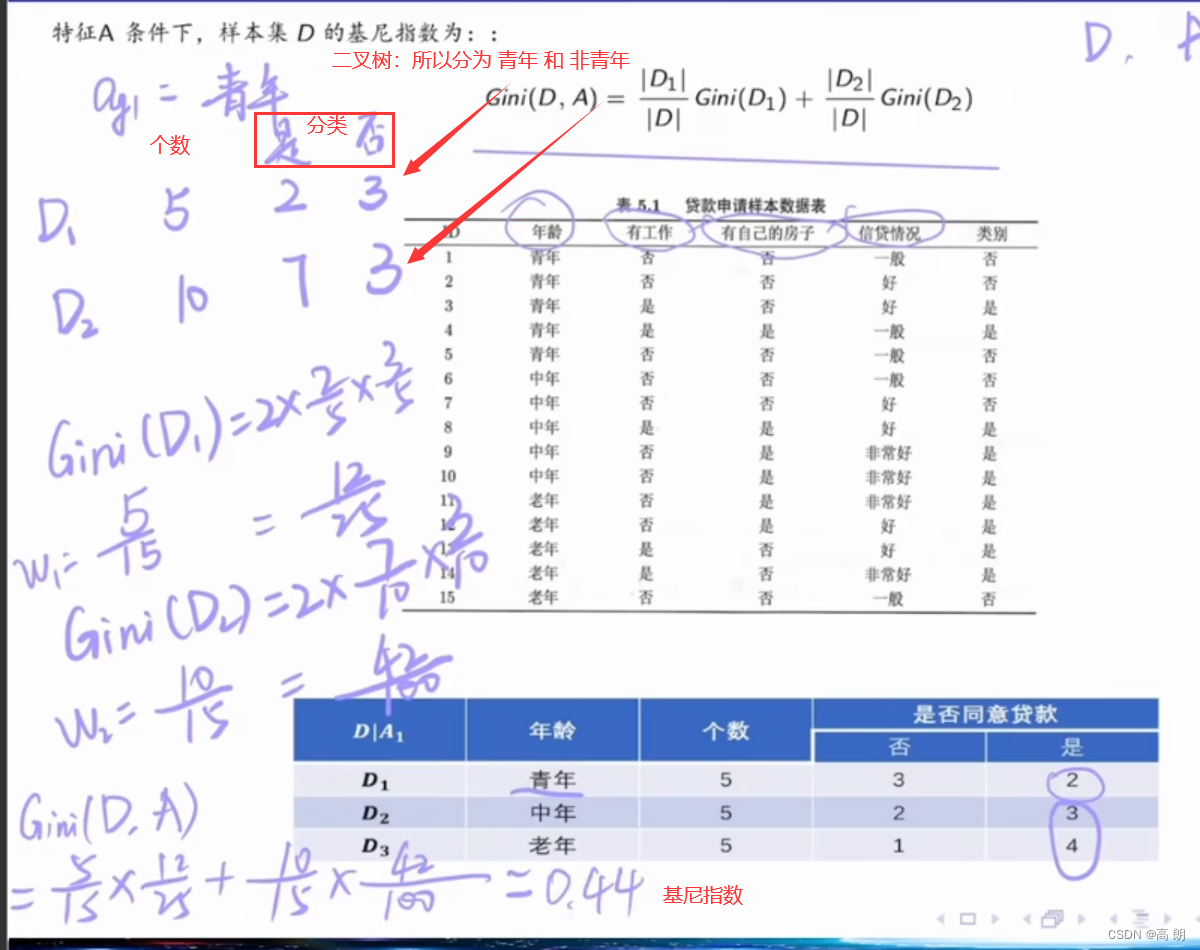
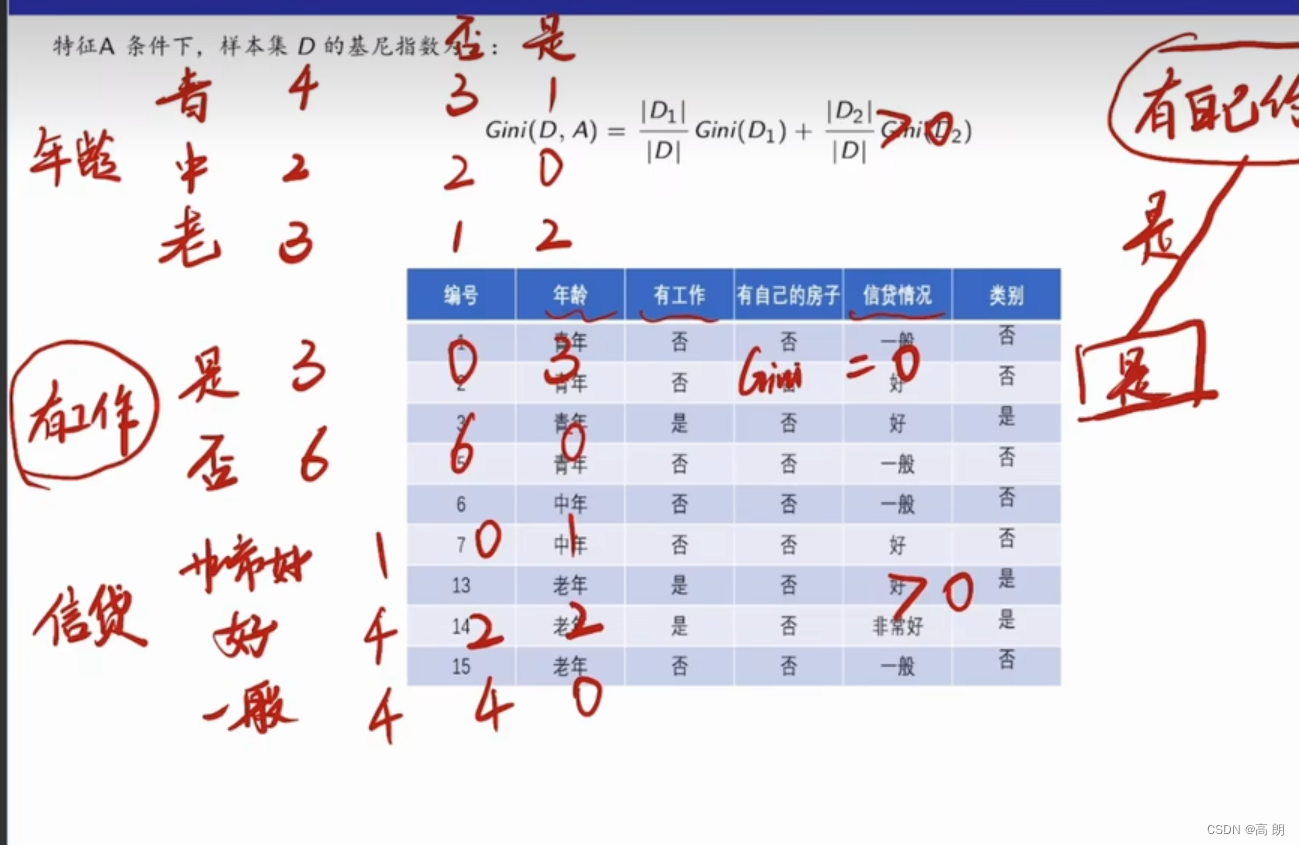
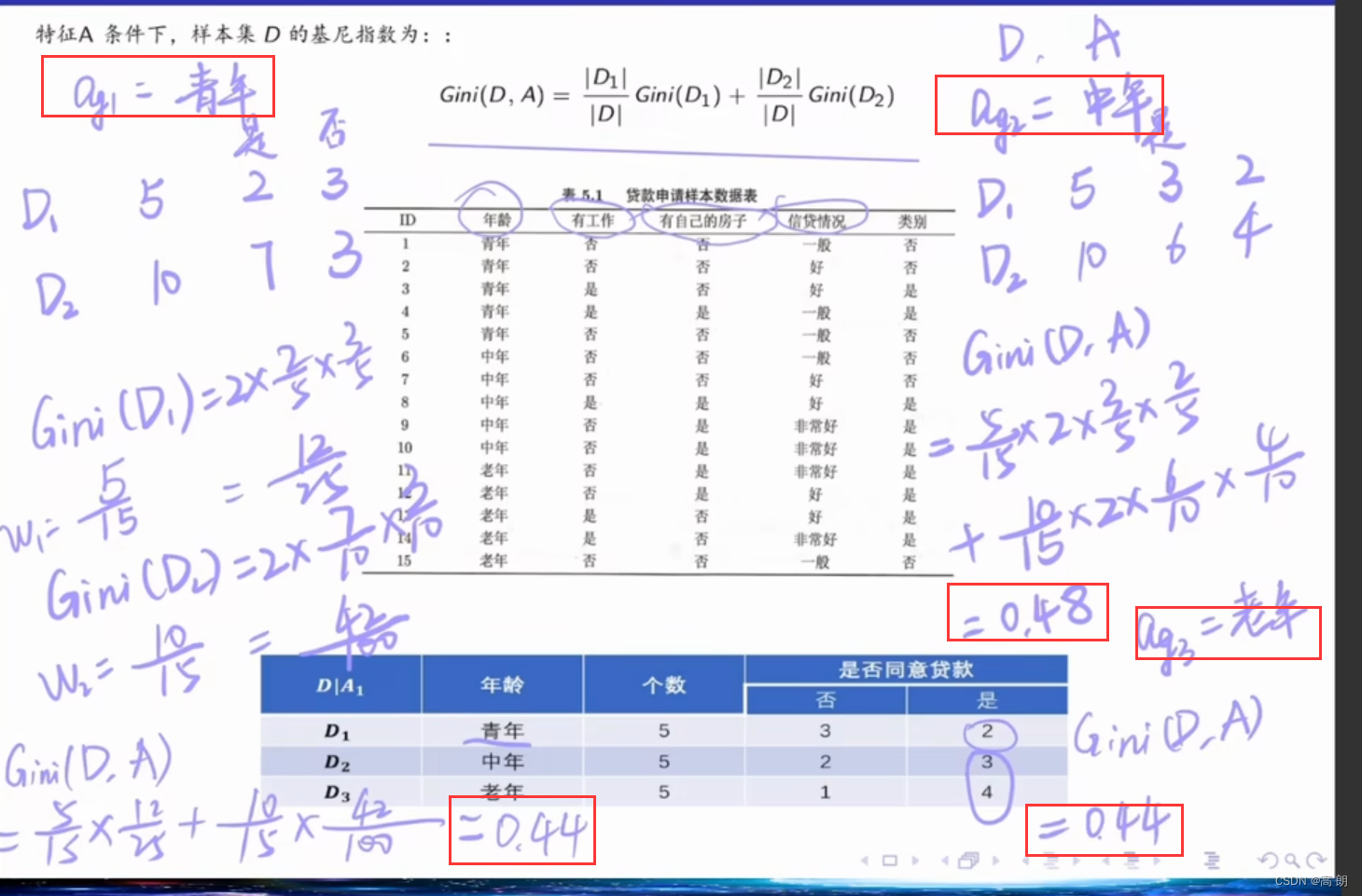 基尼指数最小的是青年和老年,都可以作为最优划分点,总的年龄这个特征的基尼指数是:0.44,划分点为青年/老年。
基尼指数最小的是青年和老年,都可以作为最优划分点,总的年龄这个特征的基尼指数是:0.44,划分点为青年/老年。
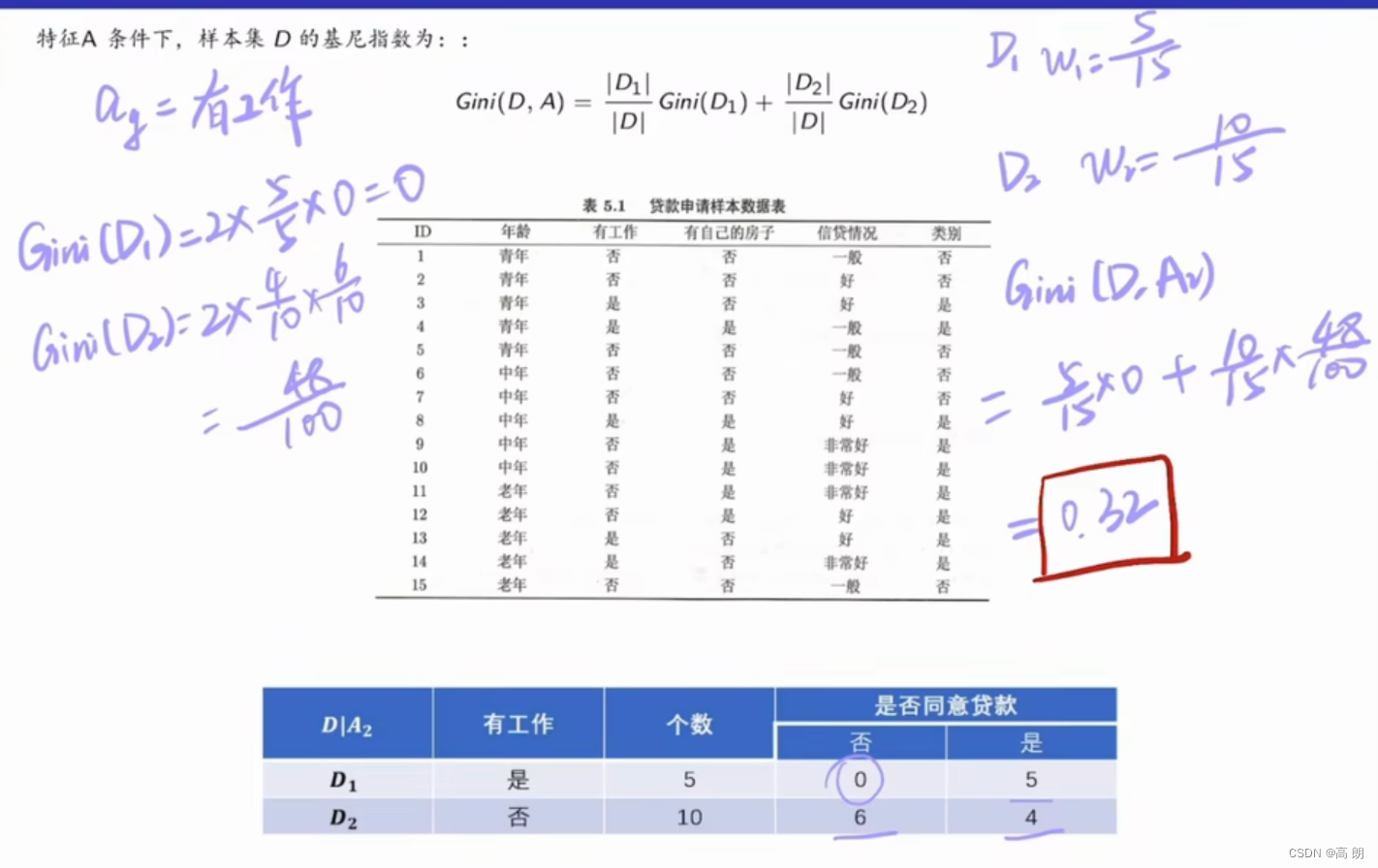 有工作这个特征的基尼指数是0.32,只有两个划分,不需要区分划分点了。
有工作这个特征的基尼指数是0.32,只有两个划分,不需要区分划分点了。
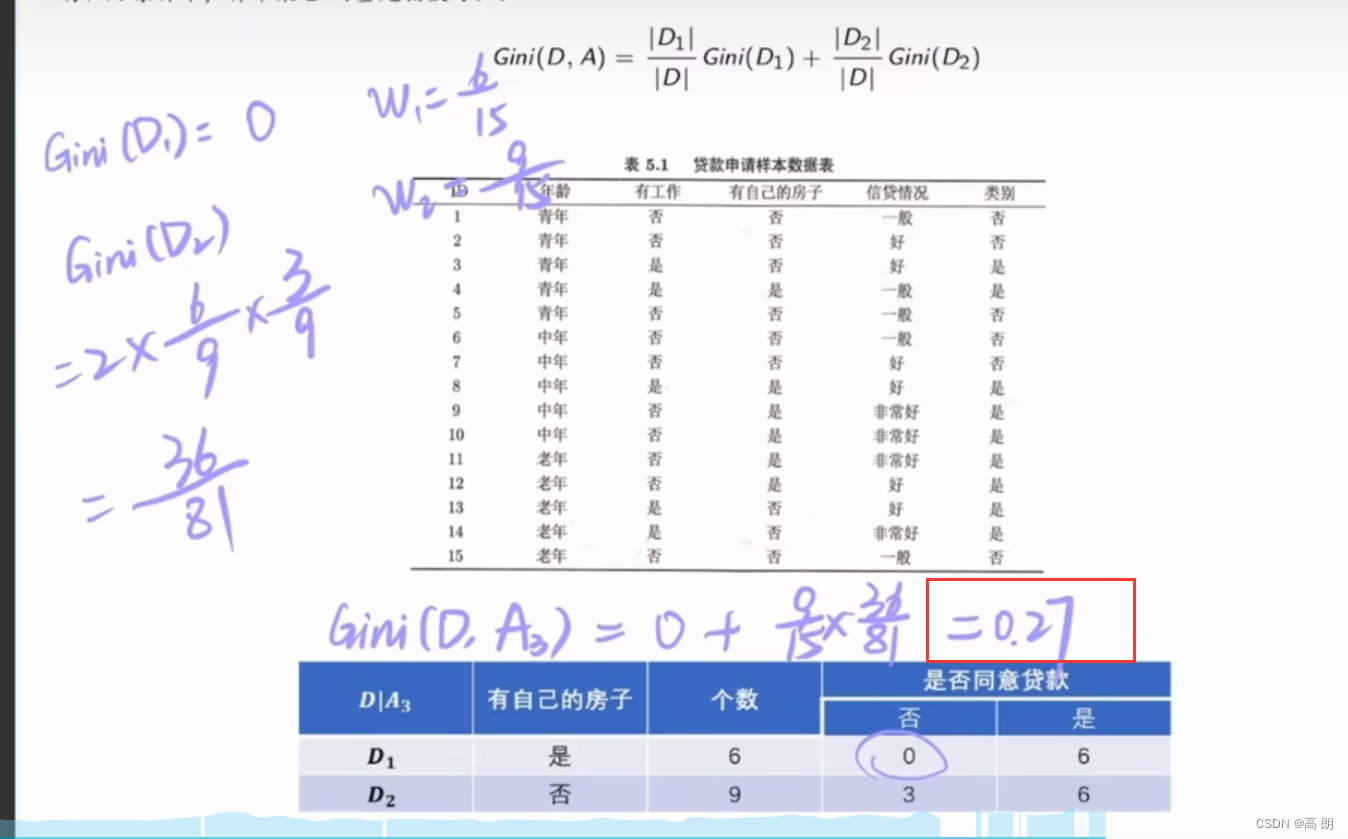 有自己房子这个特征的基尼指数:0.27
有自己房子这个特征的基尼指数:0.27
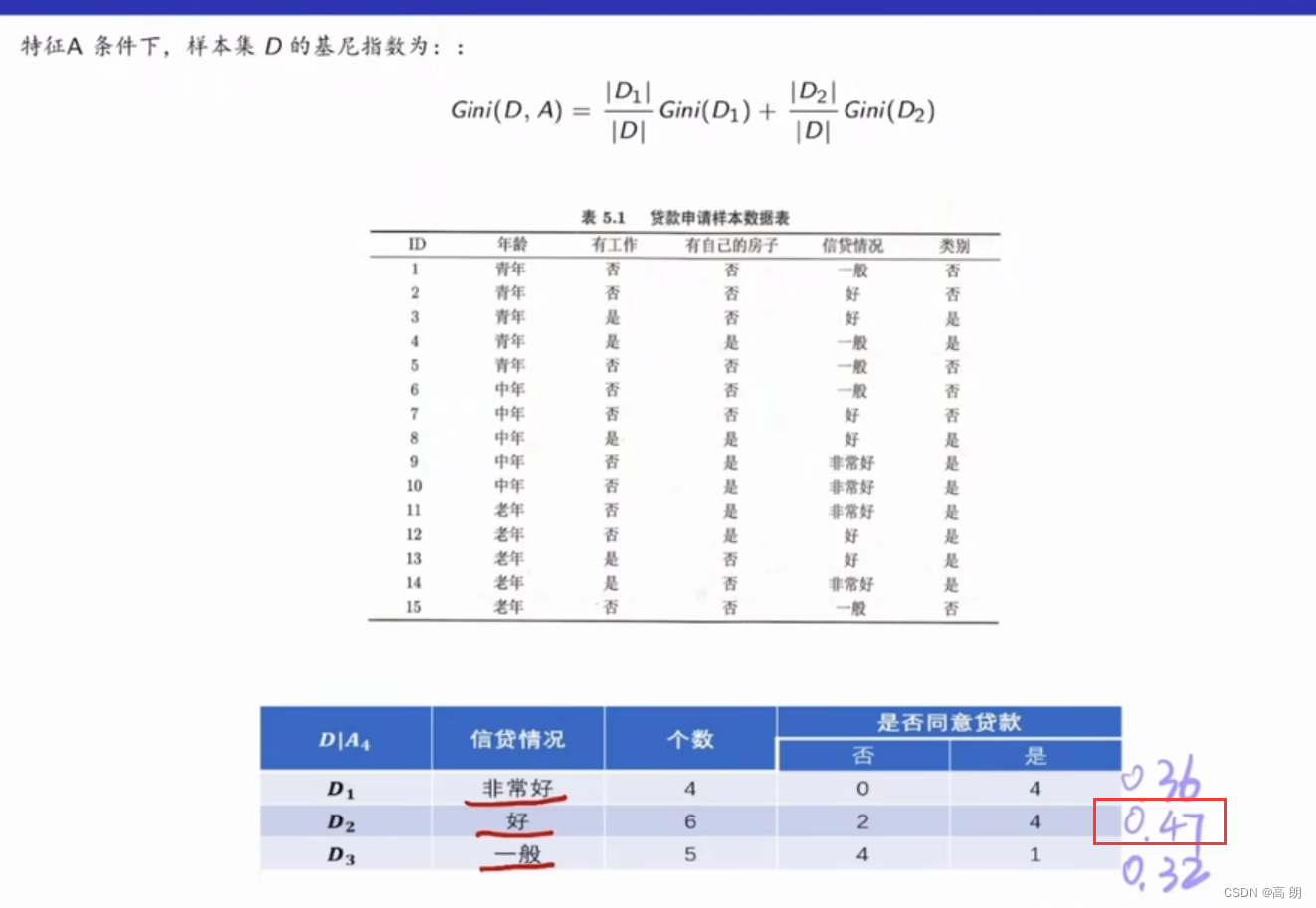 信贷情况的基尼指数是0.32,以一般为划分点
信贷情况的基尼指数是0.32,以一般为划分点
基尼指数从小到大排序:有自己房子0.27,有工作0.32,信贷情况0.32(一般),年龄0.44(青年/老年),越小的越好分类:
所以以有自己房子开始进行分类:
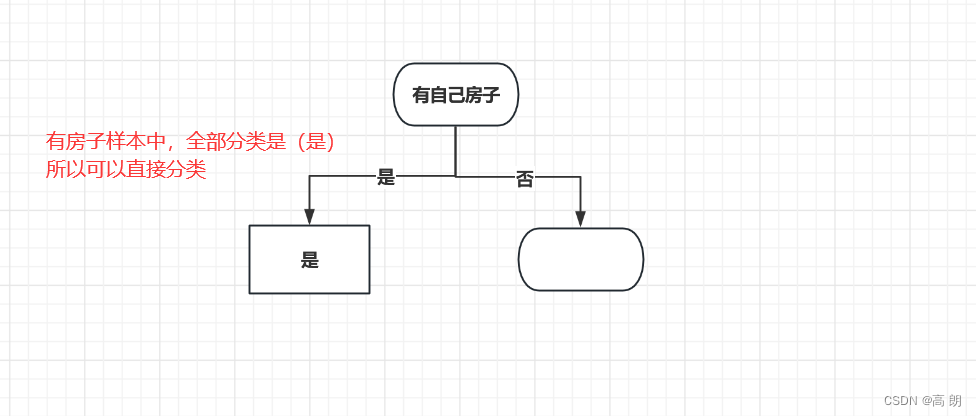 在没有房子的条件下计算其他特征的基尼指数:
在没有房子的条件下计算其他特征的基尼指数:
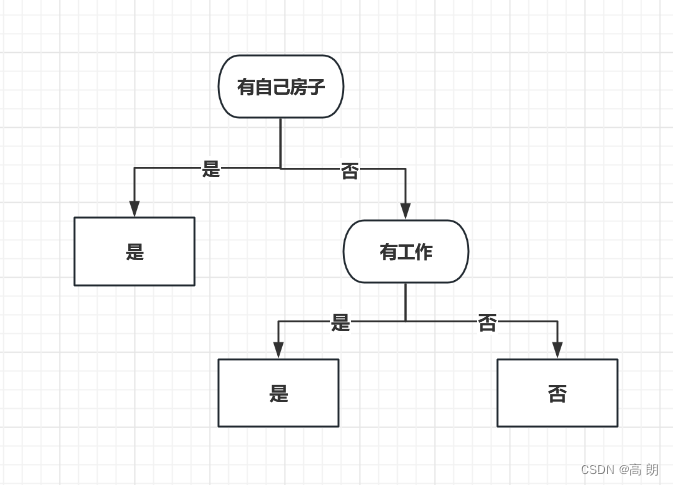
 很明显,有工作这个特征它的基尼指数肯定是等于0的,其他基尼指数都大于0,所以选择有工作进行划分:
很明显,有工作这个特征它的基尼指数肯定是等于0的,其他基尼指数都大于0,所以选择有工作进行划分:
CART生成回归树:


CART决策树剪枝:


scikit-learn使用
| sklearn.tree | 介绍 |
|---|---|
| tree.DecisionTreeClassifier | 分类树 |
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT格式,画图专用 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
分类树
分类树核心代码:
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息
DecisionTreeClassifier参数详解:
 简单示例:
简单示例:
导入的库
from sklearn import tree # 决策树
from sklearn.datasets import load_wine # 酒的数据集
from sklearn.model_selection import train_test_split # 把数据集分成训练集和测试集
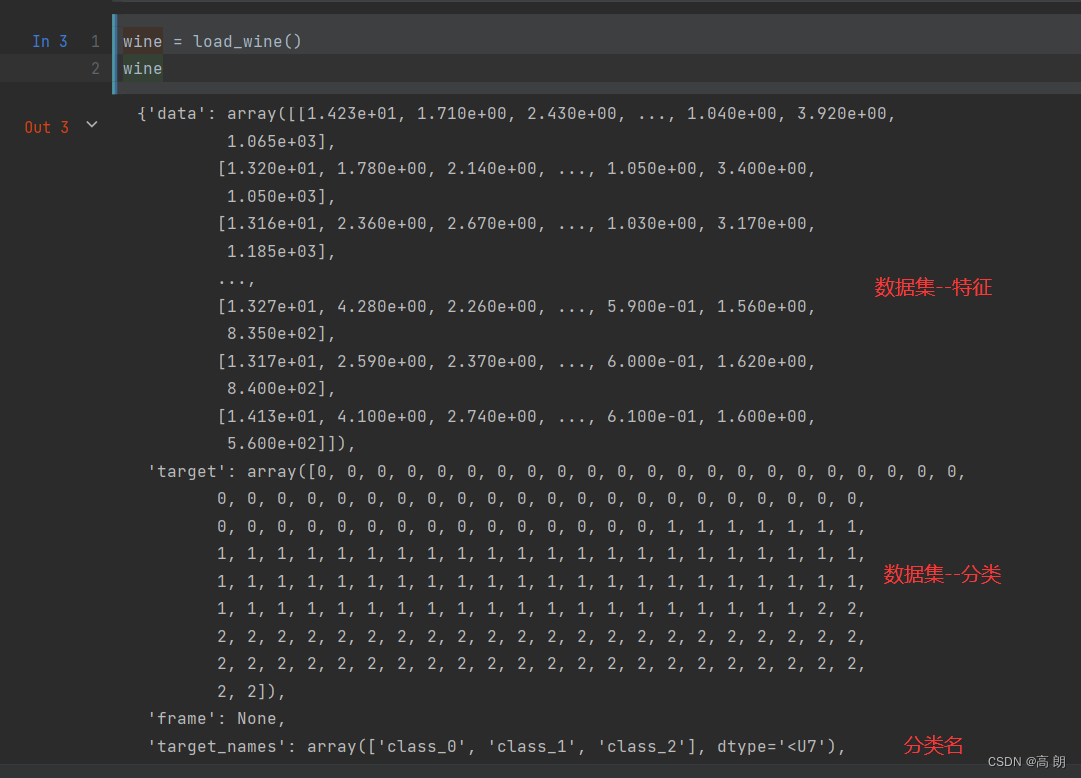
打印看看白酒数据集:
 可以通过pandas把数据集拼接一起:
可以通过pandas把数据集拼接一起:
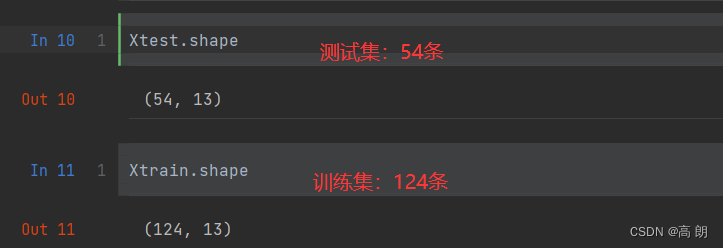
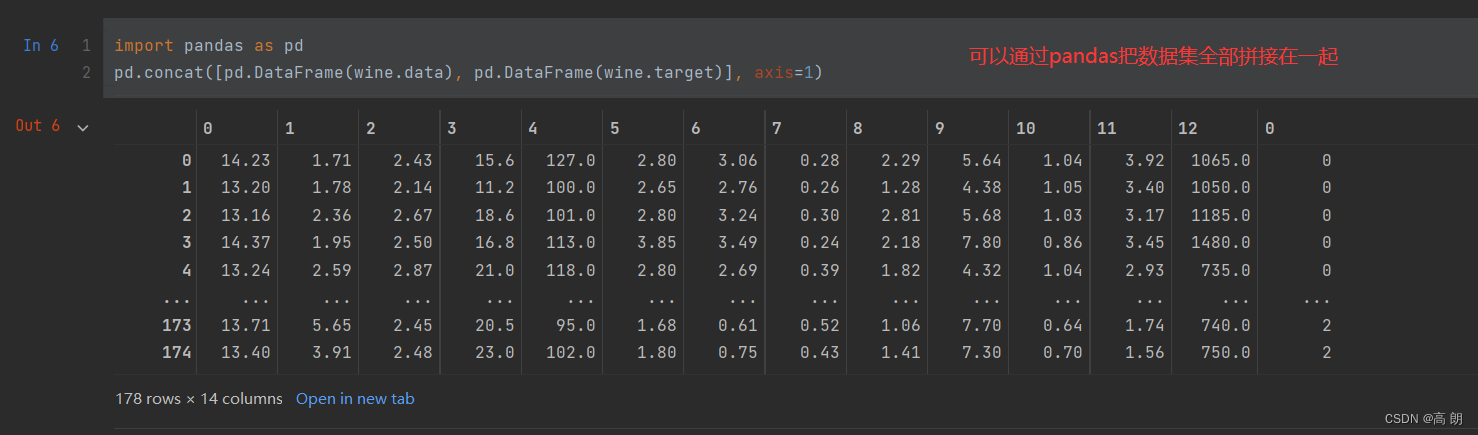 把数据集分成训练集和测试集,参数
把数据集分成训练集和测试集,参数test_size表示测试集的比例
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
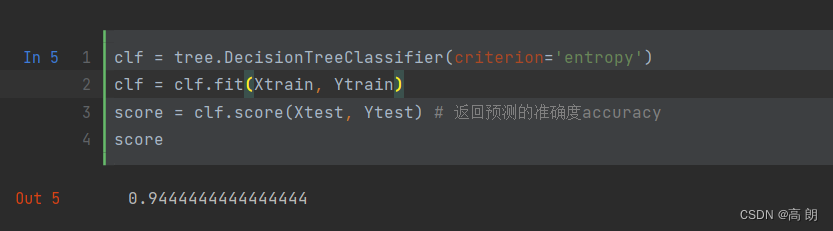
定义模型,开始训练,测试:
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) # 返回预测的准确度accuracy
score
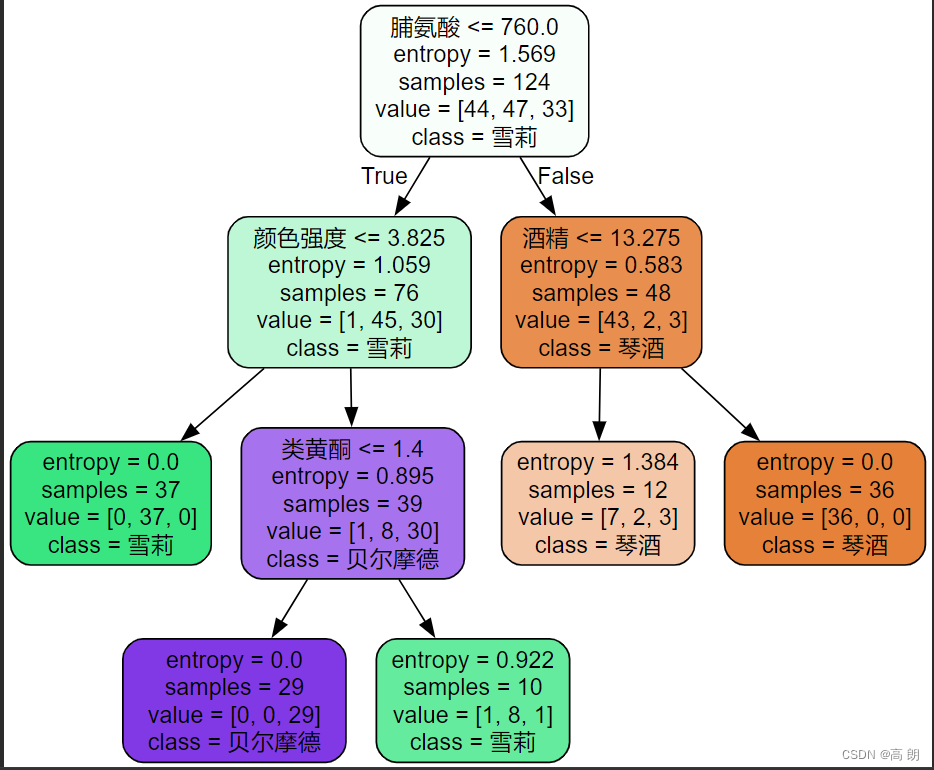
看一看模型给我们定义的决策树:
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']import graphviz
dot_data = tree.export_graphviz(clf, feature_names=feature_name, class_names=['清酒', '雪梨', '贝尔摩德'], filled=True, rounded=True)
graph = graphviz.Source(dot_data)
graph # graph.view()
注意如果pycharm能显示图片,而jupyter不能,报错找不到graphviz模块,可以试一下下面操作:在jupyter中执行
conda install python-graphviz

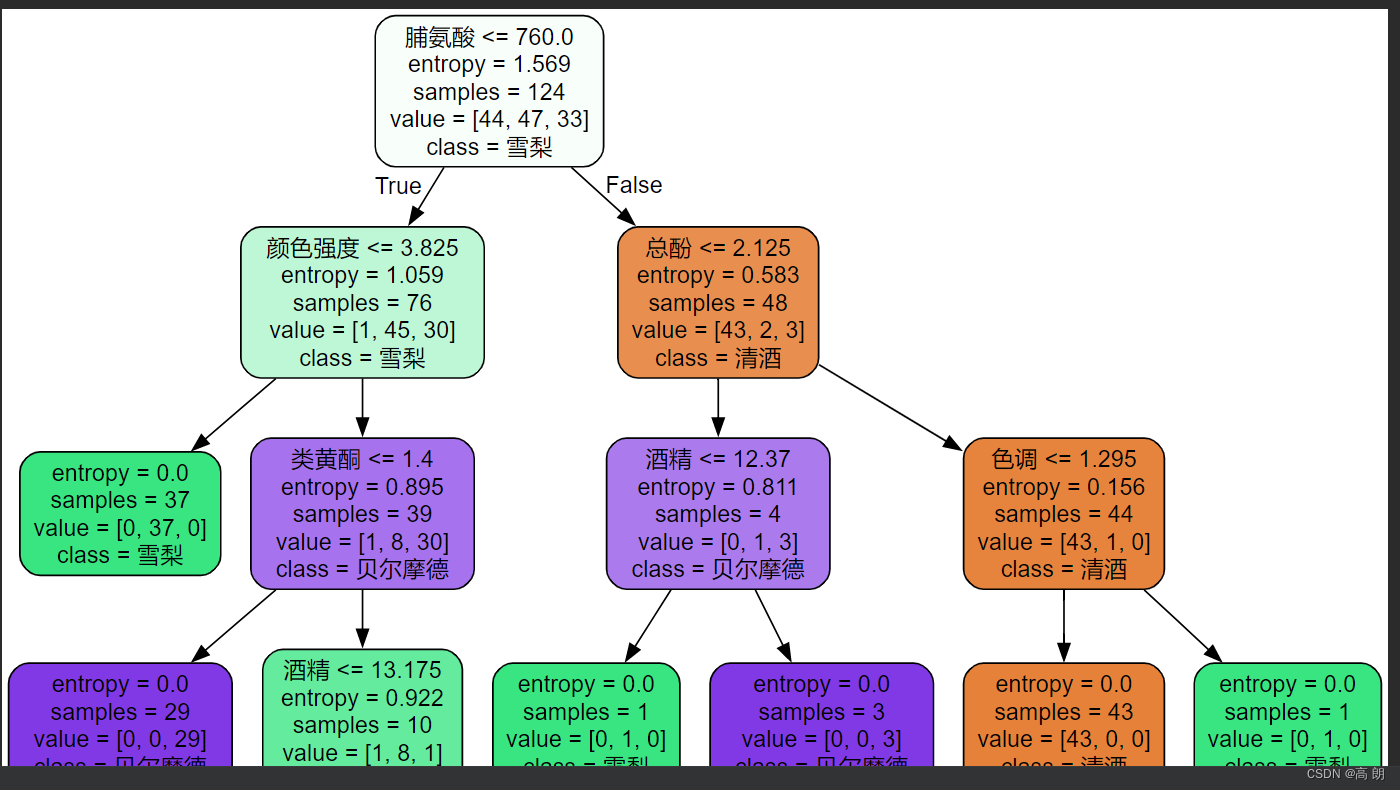
- 第一行:划分条件,脯氨酸是否小于760,是往左边走,不是往右边走。
- 第二行:entropy,信息增益比,越大分类越好,越靠前。当entropy=0时,可以选出类别了。
- sample: 样本数量。
- value:每个类别的数量。
- class:类别
决策树并不会选择全部特征可以通过feature_importances_来查看:

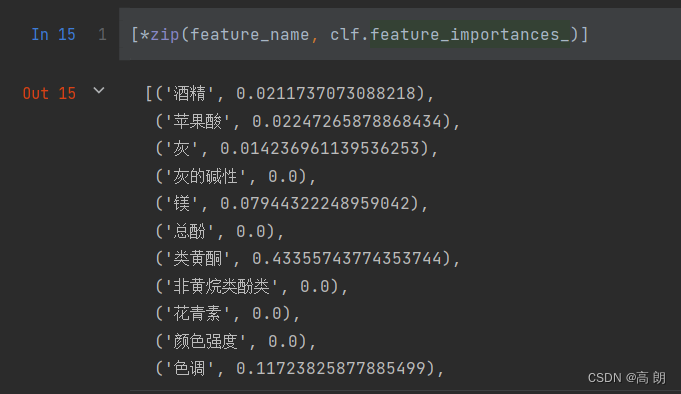
scikit-learn在每次分枝时,不从使用全部特征,而是随机选取一部分特征,从中选取不纯度相关指标最优的作为分枝用的节点。这样,每次生成的树也就不同了,准确率也不一样,不希望每次结果不一样,需要添加参数random_state来控制随机性:
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据(比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest) #返回预测的准确度
score
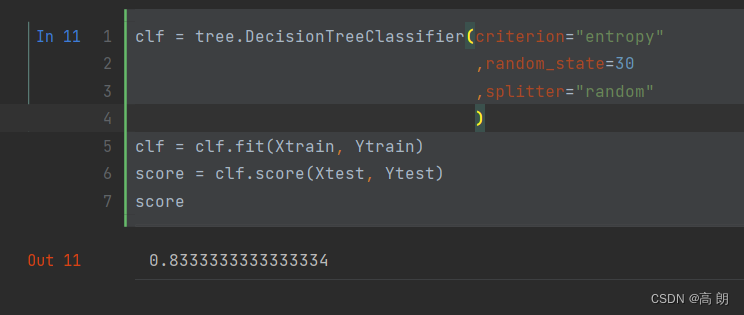
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
clf = tree.DecisionTreeClassifier(criterion="entropy",random_state=30,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
score
dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["琴酒","雪莉","贝尔摩德"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph
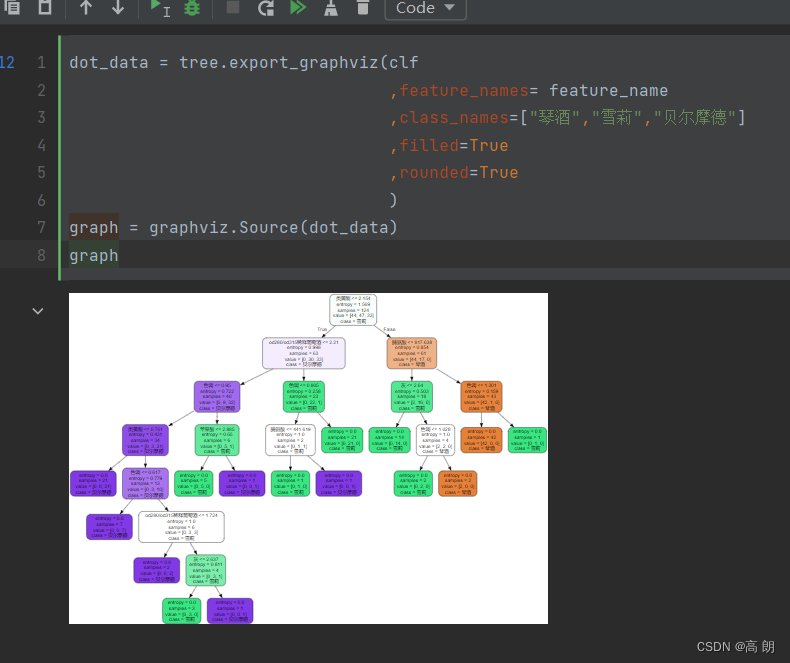 随机性增加了,树变深了。
随机性增加了,树变深了。
剪枝参数
在不加限制的情况下,一棵决策树会生长到衡量entropy的指标最优,或者没有更多的特征可用为止。这样的决策树往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕,我们需要使用剪枝参数来防止过拟合。
剪枝策略对决策树的影响巨大,正确的剪枝策略是优化
决策树算法的核心。sklearn为我们提供了不同的剪枝策略:
-
max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉
这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所以限制树深度能够有效地限制过拟合。在集成算法中也非常实用。实际使用时,建议从=3开始尝试,看看拟合的效果再决定是否增加设定深度。 -
min_samples_leaf&min_samples_split限定叶子节点
min_samples_leaf限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本【对应图中simple值】,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生
一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。
这个参数的数量设置得太小会引起过拟合,设置得太大就会阻止模型学习数据。
一般来说,建议从=5开始使用。如果叶节点中含有的样本量变化很大,建议输入浮点数作为样本量的百分比来使用。同时,这个参数可以保证每个叶子的最小尺寸,可以在回归问题中避免低方差,过拟合的叶子节点出现。对于类别不多的分类问题,=1通常就是最佳选择。
min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生。
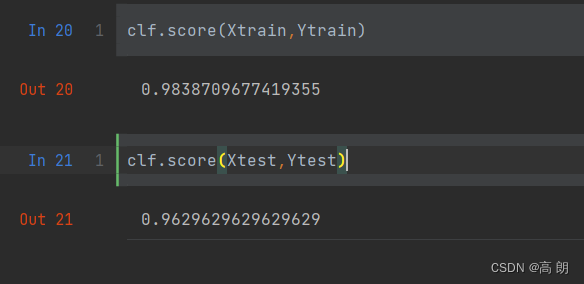
clf = tree.DecisionTreeClassifier(criterion='entropy',random_state=30# ,splitter='random',max_depth=3,min_samples_leaf=10,min_samples_split=10)
clf = clf.fit(Xtrain, Ytrain)dot_data = tree.export_graphviz(clf,feature_names= feature_name,class_names=["琴酒","雪莉","贝尔摩德"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph
 我们对上面的几个参数进行调参,找准确率最高的:
我们对上面的几个参数进行调参,找准确率最高的:
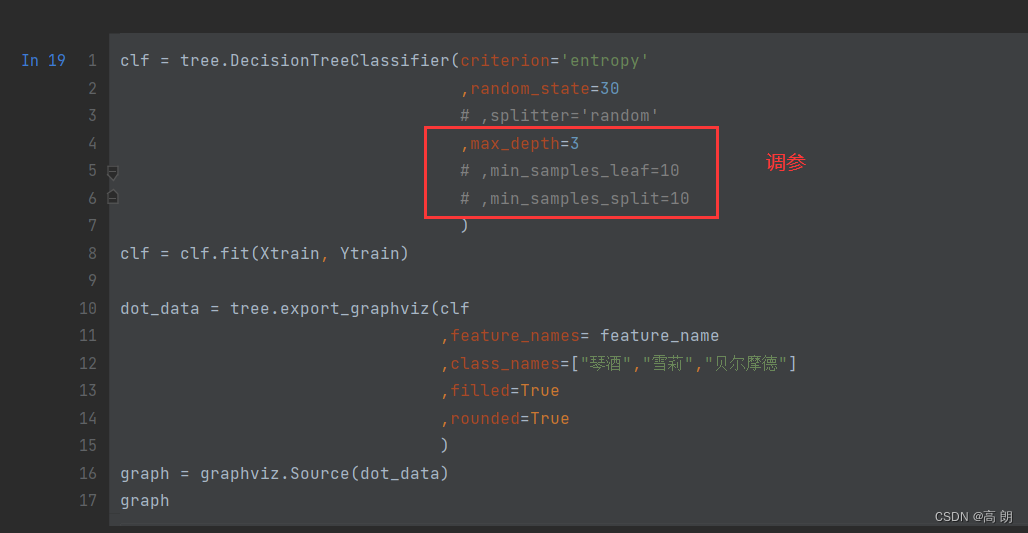
max_features&min_impurity_decrease
一般max_depth使用,用作树的”精修“
max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工,max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型学习不足。如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
min_impurity_decrease限制信息增益的大小,信息增益小于设定数值的分枝不会发生。
确认最优的剪枝参数
使用确定超参数的曲线来进行判断了,继续使用我们已经训练好的决策树模型clf。超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲线,它是用来衡量不同超参数取值下模型的表现的线。在我们建好的决策树里,我们的模型度量指标就是score。
以 max_depth为例:
import matplotlib.pyplot as plt
test = []
for i in range(10):clf = tree.DecisionTreeClassifier(max_depth=i+1,criterion="entropy",random_state=30,splitter="random")clf = clf.fit(Xtrain, Ytrain)score = clf.score(Xtest, Ytest)test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
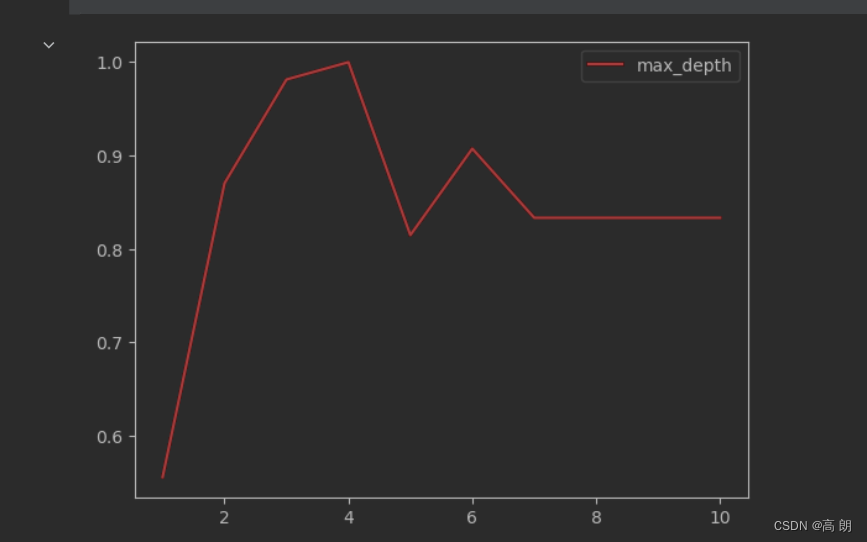 可以看到
可以看到max_depth=4时,准确度最高。
class_weight&min_weight_fraction_leaf【控制目标权重】
完成样本标签平衡的参数。样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例。比如说,在银行要判断“一个办了信用卡的人是否会违约”,就是是vs否(1%:99%)的比例。这种分类状况下,即便模型什么也不做,全把结果预测成“否”,正确率也能有99%。因此我们要使用class_weight参数对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重。
有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_weight_fraction_leaf这个基于权重的剪枝参数来使用。另请注意,基于权重的剪枝参数(例如min_weight_fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。
重要属性和接口
属性是在模型训练之后,能够调用查看的模型的各种性质。对决策树来说,最重要的是feature_importances_,能够查看各个特征对模型的重要性。
决策树最常用的接口:
- fit
- score
- apply
- predict
#apply返回每个测试样本所在的叶子节点的索引
clf.apply(Xtest)
#predict返回每个测试样本的分类/回归结果
clf.predict(Xtest)
回归树
DecisionTreeRegressor几乎所有参数,属性及接口都和分类树一模一样。需要注意的是,在回归树种,没有标签分布是否均衡的问题,因此没有class_weight这样的参数。
重要参数,属性及接口
criterion
回归树衡量分枝质量的指标,支持的标准有三种:
1)输入"mse"使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失
2)输入“friedman_mse”使用费尔德曼均方误差,这种指标使用弗里德曼针对潜在分枝中的问题改进后的均方误差
3)输入"mae"使用绝对平均误差MAE(mean absolute error)
这种指标使用叶节点的中值来最小化L1损失属性中最重要的依然是feature_importances_,
接口依然是apply, fit, predict, score最核心。
交叉验证
交叉验证是用来观察模型的稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确性来评估模型的平均准确程度。训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的平均值,是对模型效果的一个更好的度量。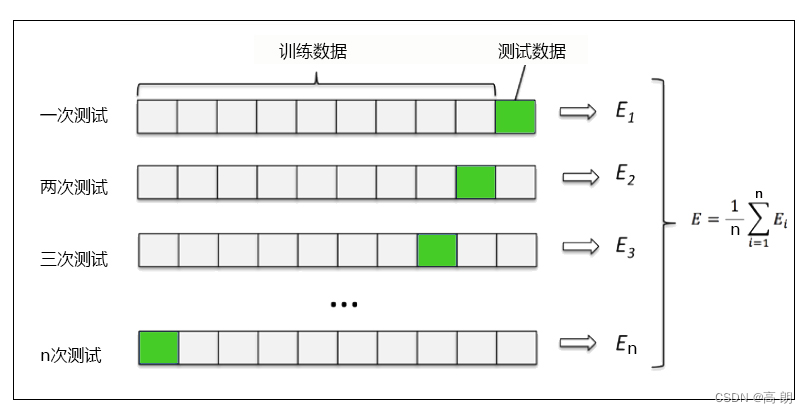
代码示例
from sklearn.datasets import load_boston # 波士顿房价数据集
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.tree import DecisionTreeRegressor # 回归树
boston = load_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target, cv=10, scoring = "neg_mean_squared_error") # 均方误差
一维回归的图像绘制
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as pltrng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80,1), axis=0) # 创建80个(0,1)的随机数,扩大五倍,排序
y = np.sin(X).ravel() # 降维ravel
y[::5] += 3 * (0.5 - rng.rand(16)) # 每个5个数,制造一个噪声regr_1 = DecisionTreeRegressor(max_depth=2) # 模型1
regr_2 = DecisionTreeRegressor(max_depth=5) # 模型2
regr_1.fit(X, y) # 模型1训练
regr_2.fit(X, y) # 模型2训练X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] # 创建一组测试集 np.newaxis 增维
y_1 = regr_1.predict(X_test) # 预测 模型1
y_2 = regr_2.predict(X_test) # 预测 模型2plt.figure() # 画布
plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data") # 散点图
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2) # 回归预测图1
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2) # 回归预测图2
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
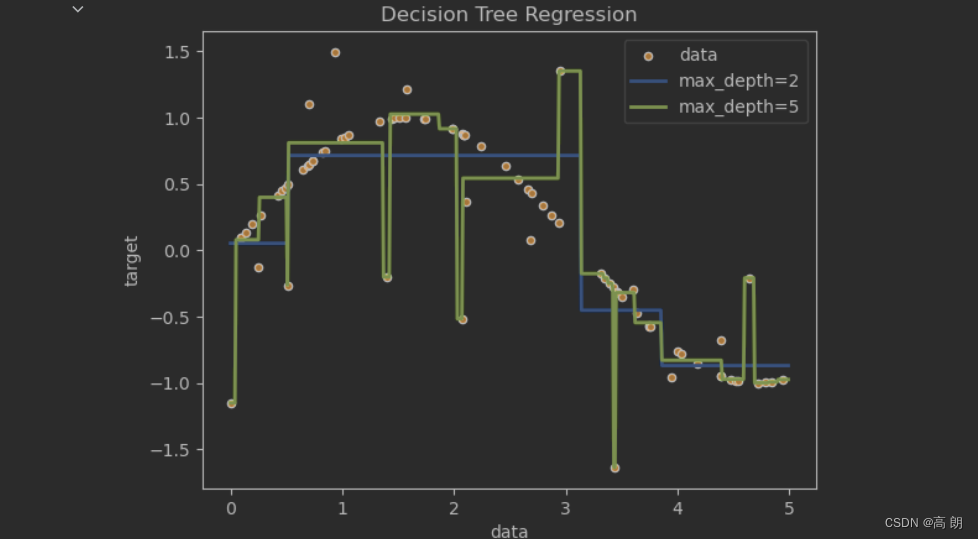 如果树的最大深度(由
如果树的最大深度(由max_depth参数控制)设置得太高,则决策树学习得太精细,它从训练数据中学了很多细节,包括噪声得呈现,从而使模型偏离真实的正弦曲线,形成过拟合。
相关文章:
【机器学习】决策树原理及scikit-learn使用
文章目录 决策树详解ID3 算法C4.5算法CART 算法 scikit-learn使用分类树剪枝参数重要属性和接口 回归树重要参数,属性及接口交叉验证代码示例 一维回归的图像绘制 决策树详解 决策树(Decision Tree)是一种非参数的有监督学习方法,…...
系统时钟)
#基于一个小车项目的FREERTOS分析(一)系统时钟
系统时钟 //初始化延迟函数 //SYSTICK的时钟固定为AHB时钟,基础例程里面SYSTICK时钟频率为AHB/8 //这里为了兼容FreeRTOS,所以将SYSTICK的时钟频率改为AHB的频率! //SYSCLK:系统时钟频率 /* 系统定时器是一个 24bit 的向下递减的计数器&…...
ubuntu mmdetection配置
mmdetection配置最重要的是版本匹配,特别是cuda,torch与mmcv-full 本项目以mmdetection v2.28.2为例介绍 1.查看显卡算力 因为gpu的算力需要与Pytorch依赖的CUDA算力匹配,低版本GPU可在相对高的CUDA版本下运行,相反则不行 算力…...

嵌入式面试常见问题(一)
目录 1.什么情况下会出现段错误? 2.swap() 函数为什么不能交换两个变量的值 3.一个函数有六个参数 分别放在哪个区? 4.定义一个变量,赋初值和不赋初值分别保存在哪个区? 5.linux查看端口状态的命令 6.结构体中->和.的区…...

docker批量删除本地镜像
docker rmi -f $(docker images|grep docker|awk {print $3})...
数据结构(一)—— 数据结构简介
文章目录 一、基本概念和术语?1.1、数据1.2、数据元素1.3、数据项(属性、字段)1.4、数据对象1.5、数据结构 二、逻辑结构和物理结构(存储结构)2.1、逻辑结构1、定义2、分类(线性结构和非线性结构࿰…...
Ubuntu输入正确密码重新跳到登录界面
Ubuntu输入正确密码重新跳到登录界面 问题描述 输入正确的密码登录后闪一下又回到锁屏界面 输入正确的密码后还是回到这个界面 产生的原因 /etc/profile或者/etc/enviroment出现了问题,导致无法正常登录 该错误产生的原因不止一个 这里是因为/etc/profile或者/etc/enviromen出…...

TCP/IP(十四)流量控制
一 流量控制 说明: 本文只是原理铺垫,没有用tcpdumpwiresahrk鲜活的案例讲解,后续补充 ① 基本概念 流量控制: TCP 通过接受方实际能接收的数据量来控制发送方的窗口大小 ② 正常传输过程 背景:1、客户端是接收方,服务端是发送方 --> 下载2、假设接收窗…...

CSS网页标题图案和LOGO SEO优化
favicon图标 将网页的头名字旁边放入一个图案 想将想要的图案切成png图片 然后把png图片转换成ico图案可以借助进行访问 将语法引用到head里面 SEO译为搜索引擎优化。是一种利用搜索引擎的规则提高网站有关搜索引擎的自然排名的方式 SEO的目的是对网站进行深度的优化&…...

机器人制作开源方案 | 双轮提升搬运小车
1. 功能描述 双轮提升搬运小车是一种用于搬运和移动物体的机械设备,它通常采用双轮驱动和提升装置。一般具备以下特点: ① 双轮驱动:该小车配备两个驱动轮,通过电动机或其它动力源驱动,提供足够的动力和扭矩࿰…...

5G安卓核心板-MT6833/MT6853核心板规格参数
随着智能手机的不断发展,芯片技术在推动手机性能和功能方面发挥着关键作用。MT6833和MT6853安卓核心板是两款高度集成的基带平台,为LTE/5G/NR和C2K智能手机应用提供强大的处理能力和多样化的接口。 这两款安卓核心板都集成了蓝牙、FM、WLAN和GPS模块&…...
信创之国产浪潮电脑+统信UOS操作系统体验4:visual studio code中怎么显示中文
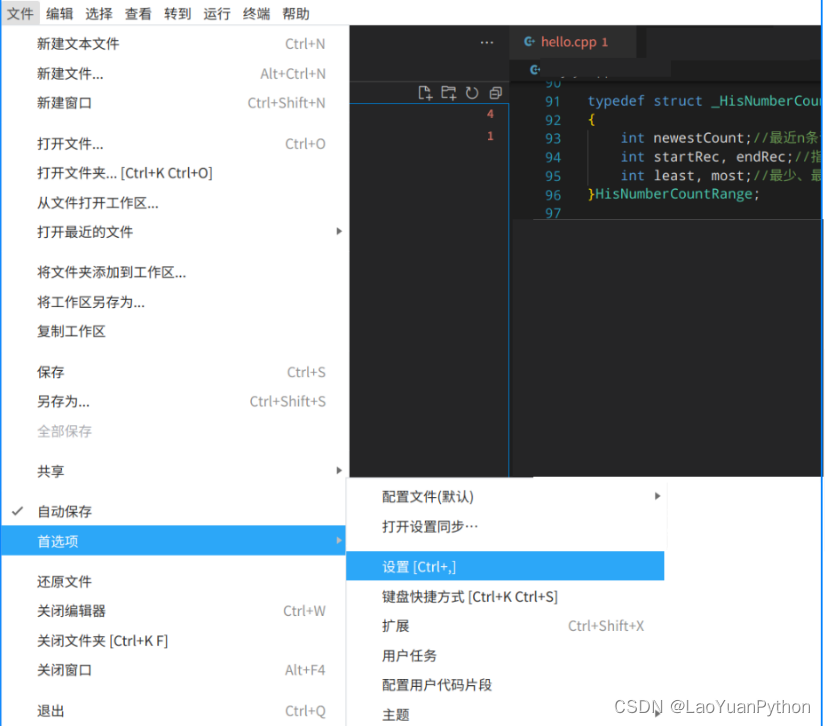
☞ ░ 前往老猿Python博客 ░ https://blog.csdn.net/LaoYuanPython 一、引言 今天在vscode中打开以前的一段C代码,其中的中文显示为乱码,如图所示: 而在统信文本编辑器打开是正常的,打开所有菜单,没有找到相关配置…...
Magica Cloth 使用方法笔记
Magica Cloth 使用方法笔记 效果展示: 参考资料: 1、官方使用文档链接: インストールガイド – Magica Soft 2、鱼儿效果案例: https://www.patreon.com/posts/69459293 3、插件工具链接:版本() 目录:…...

c++ 学习之 强制类型转换运算符 const_cast
看例子怎么用 int main() {int a 1;int* p a;// 会发生报错// 如果学着 c的风格类型转换int* pp (int*)a;*pp 1; // 编译不报错,但是运行报错// const_castconst int n 5;const std::string s "lalal";// const cast 只针对指针,引用&…...
)
Ceph相关部署应用(博客)
这里写目录标题 Ceph相关部署应用一.存储基础1.单机存储设备2.商业存储解决方案3.分布式存储(软件定义的存储 SDS) 二.Ceph 简介1.Ceph2.Ceph 优势3.Ceph 架构4.Ceph 核心组件5.OSD 存储后端6.Ceph 数据的存储过程7.Ceph 版本发行生命周期8.Ceph 集群部署…...

基于 ceph-deploy 部署 Ceph 集群 超详细
Ceph part1 一、存储基础1.1 单机存储设备1.2 单机存储的问题1.3 单机存储问题的解决方案1.3.1 商业存储解决方案1.3.2 分布式存储(软件定义的存储 SDS) 二、分布式存储2.1 常见的分布式存储2.2 分布式存储的类型 三、Ceph概述3.1 Ceph简介3.2 Ceph 优势…...
做一个物联网的后台程序与数据库设计
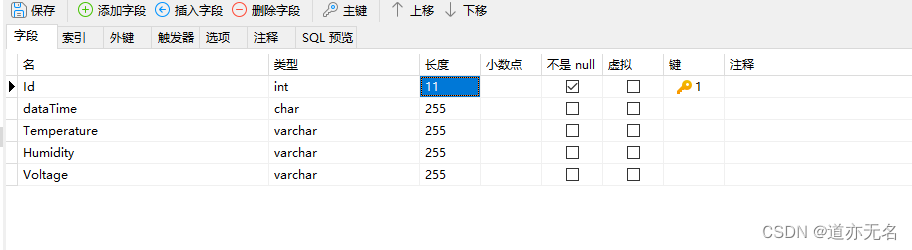
数据库部分 先设计一个简单的数据库。表结构如下: sql语句如下: SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0;-- ---------------------------- -- Table structure for realtimedata -- ---------------------------- DROP TABLE IF EXISTS `realtimedata`...
Pytorch深度学习—FashionMNIST数据集训练
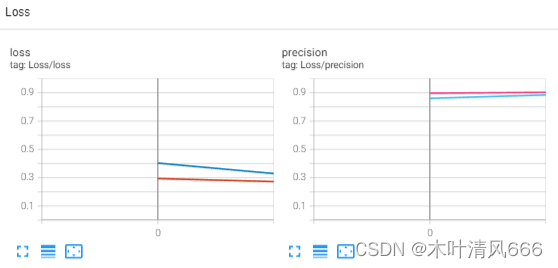
文章目录 FashionMNIST数据集需求库导入、数据迭代器生成设备选择样例图片展示日志写入评估—计数器模型构建训练函数整体代码训练过程日志 FashionMNIST数据集 FashionMNIST(时尚 MNIST)是一个用于图像分类的数据集,旨在替代传统的手写数字…...

uniapp 返回上一步携带参数
1. 下一步 // 返回上一页setTimeout(() > {let pages getCurrentPages();let prevPage pages[pages.length - 2];prevPage.$vm.schoolName this.formList;uni.navigateBack({delta: 1});}, 1000) 2. 返回上一步, 携带参数 // 获取下一步返回的数据onShow() {let pages …...

软件工程与计算总结(七)需求文档化与验证
目录 一.文档化的原因 二.需求文档基础 1.需求文档的交流对象 2.用例文档 3.软件需求规格说明文档 三.需求文档化要点 1.技术文档协作要点 2.需求书写要点 3.软件需求规格说明文档属性要点 四.评审软件需求规格说明文档 1.需求验证与确认 2.评审需求的注意事项 五…...

如何用Python爬虫将知识星球内容制作成PDF电子书:完整指南
如何用Python爬虫将知识星球内容制作成PDF电子书:完整指南 【免费下载链接】zsxq-spider 爬取知识星球内容,并制作 PDF 电子书。 项目地址: https://gitcode.com/gh_mirrors/zs/zsxq-spider 知识星球作为优质内容社区,汇集了大量付费专…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...

CN2628 可用太阳能供电 5 伏特低压差电压调制集成电路
概述: CN2628是一款可用太阳能供电的低噪声线性电压调制集成电路,采用固定5.0V输出电压,最大 输出电流可达1安培,在5.5V到7V的输入电压范围内输出电压精度可达1%。CN2628工作电流只有520微安,而且同输入和输出的压差没有关系。 CN…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

DIY蓝牙游戏手柄:基于Bluefruit EZ-Key的免编程硬件制作全攻略
1. 项目概述与设计思路几年前,我还在用有线手柄在电脑上打游戏,那根线总是缠来缠去,桌面也乱糟糟的。后来市面上无线手柄选择多了,但总感觉少了点自己动手的乐趣,功能也千篇一律。直到我开始接触像Adafruit Bluefruit …...

KMS智能激活终极指南:如何一键永久激活Windows和Office
KMS智能激活终极指南:如何一键永久激活Windows和Office 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次重装系统后都要重新激活Office&…...
:构建智能体与工具交互的通用语言)
AI控制协议标准(ACPS):构建智能体与工具交互的通用语言
1. 项目概述与核心价值最近在开源社区里,一个名为“AI-Control-Protocol-Standard”的项目引起了我的注意。这个由DaibinThink发起的项目,名字听起来就很有分量——“AI控制协议标准”。乍一看,你可能觉得这又是一个关于AI模型如何被调用的技…...