TensorFlow-Keras - FM、WideAndDeep、DeepFM、DeepFwFM、DeepFmFM 理论与实战
目录
一.引言
二.浅层模型概述
1.LR
2.FM
3.FMM
4.FwFM
5.FmFM
三.常用推荐算法实现
Pre.数据准备
1.FM
2.WideAndDeep
3.DeepFM
4.DeepFwFM
5.DeepFmFM
四.总结
1.函数测试
2.函数效果与复杂度对比[来自FmFM论文]
3.More
一.引言
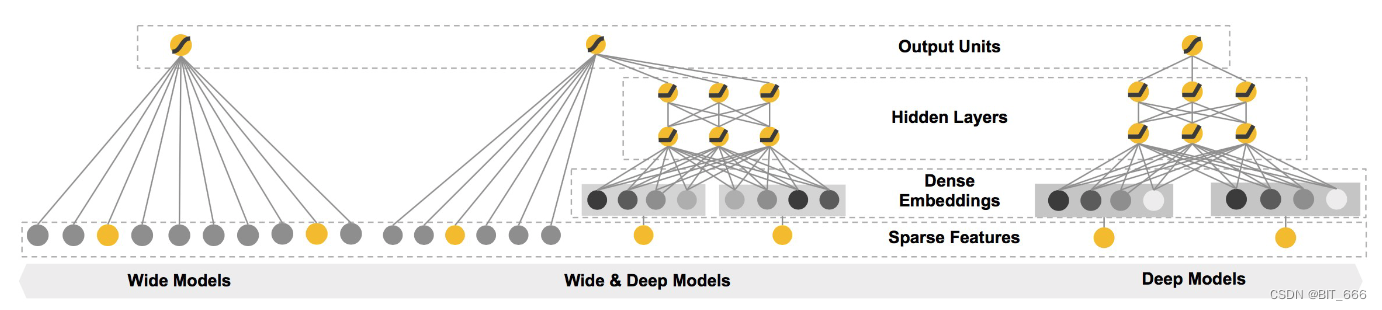
推荐系统中常见的 CTR 模型从最初的一阶 LR 演变至二阶的 FM,二阶的 FM 演变至高阶的 DNN,最终通过低阶与高阶的结合实现了热门的 DeepFM。至此之后,推荐系统的优化方向大致分两个方向,一个是在二阶交叉部分继续增加域 Filed 的信息,获得更细力度的交叉;另一个是在 DNN 侧寻求更复杂的高阶特征交叉从而获得更多地高阶交叉信息。本文主要针对前者介绍一些常用推荐算法的基本原理与实现。
二.浅层模型概述
1.LR
LR 是最广泛的 CTR 预测模型,其具备参数少、计算快、可解释性强等特点。但由于模型均为一阶特征,未引入特征组合或者需要人工组合特征,因此对 CTR 场景下的特征组合表征不强。
引言中的插图 wide 部分即为 LR,通过加权求和并通过一个 Sigmoid 层即可获得 CTR 的预测值。
2.FM
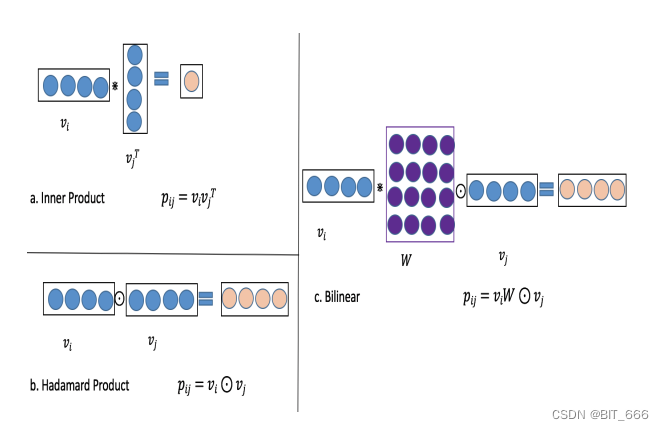
FM 为每个特征引入一个隐向量 Vector 进行学习,解决了 Poly2 场景下参数量过大且特征组合稀疏导致很多参数无法学习的问题。
- Poly2
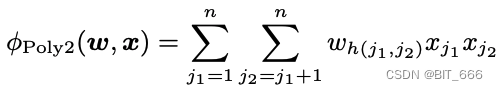
- FM
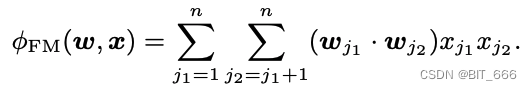
FM 由于其参数矩阵为对称矩阵,所以后面的二阶计算可以优化,从而将二阶项的复杂度优化至 O(kn),k 为向量长度、n 为特征数。快速记忆的话:和平方-平方和。

3.FMM
FM 为每一个特征学习一个隐向量,这基于特征与其他 Field 特征交叉时权重相同或者等重要性,但在实际场景下,引入域的信息可以很好细化特征学习,以如下样本为例:
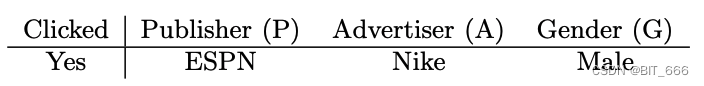
在 FM 中:
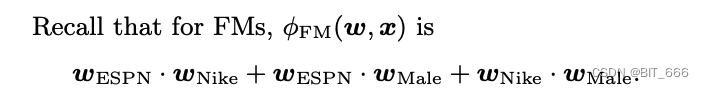
FM 中每个特征只有一个潜在的矢量需要学习具有任何其他特征的潜在效果,将 ESPN 作为wESPN 用于学习 Nike(wESPN·wNike) 和 Male(wESPN·wMale)。然而因为 Nike 和 Male 属于不同的领域 (EPSN, Nike) 和 (EPSN, Male) 的效果可能不同。在FFM中,每个特征都有几个潜在向量。根据其他功能的领域,使用该域对应的向量。
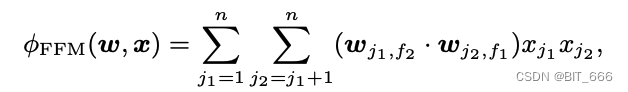
针对不同域选择不同表征向量计算提高了模型的表征能力,但随之而来的是大量的训练参数,相比 FM 的 O(kn),FFM 的复杂度为 O(kn^2) 。
4.FwFM
FM 提出后又提出了针对域信息的 FFM,但由于实际场景下计算成本消耗过大,工业场景下 FFM 使用不多,所以在保证引入域信息又不希望计算消耗太大的折中考虑下,引入了 FwFM 与 FmFM,并结合 DNN 得到了后来的 DeepFwFM 与 DeepFmFM。
![]()
FwFM 是 FM 的扩展,因为我们使用了额外的权重 rFiFj 明确捕捉不同的交互强度。通过与 DNN 组合即可得到 DeepFwFM
5.FmFM
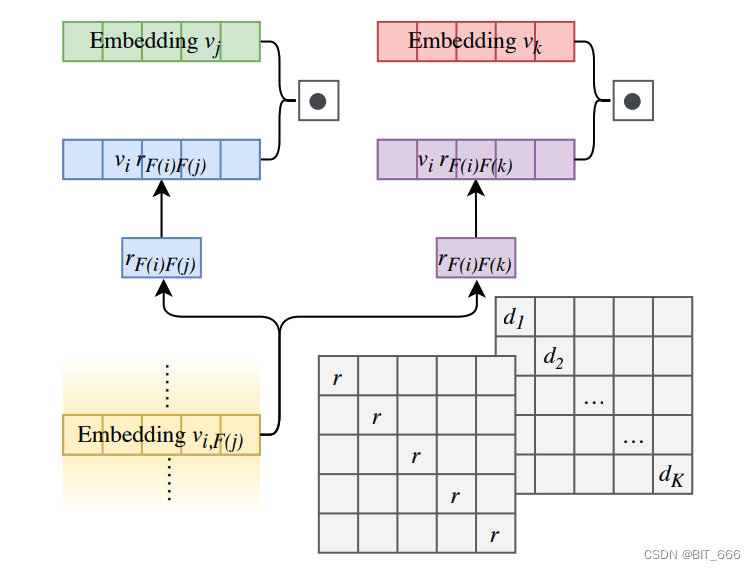
FwFM 仅仅使用一个标量来表示特征域的交叉权重,相对来说表征能力不足,为了解决 FwFM 表征能力不足的情况,FmFM 针对每一对交叉域 i、j 提供一个可训练的参数矩阵,提高其表征能力。
![]()
rFiFj 由 MFiFj 替代,其维度为 (emb_dim x emb_dim),相对于 FFM 而言参数量也大大减少。
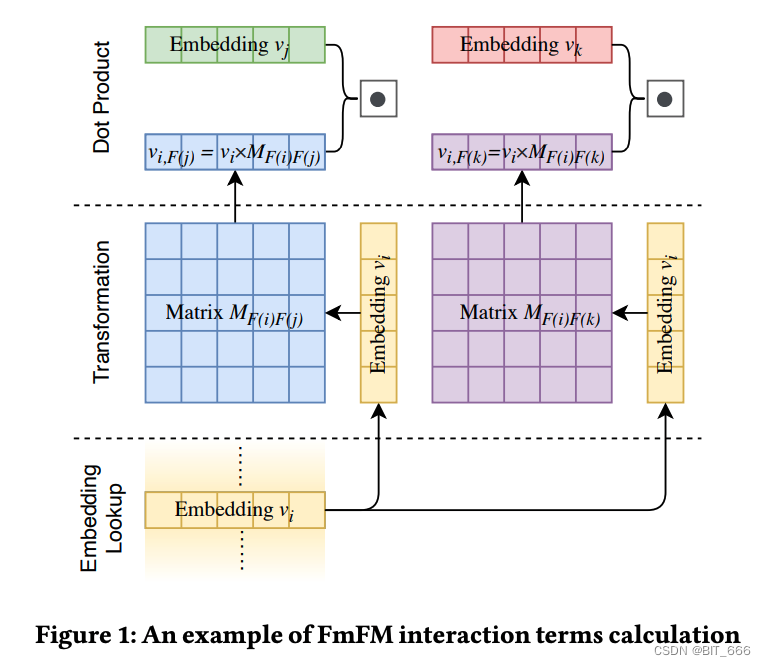
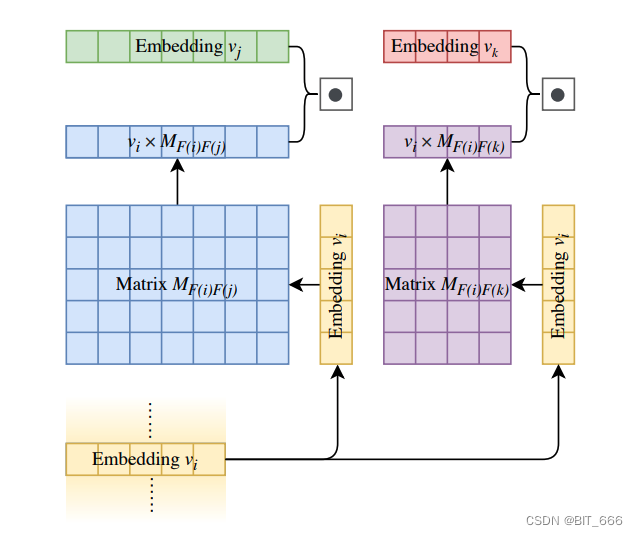
Field i 分别与特征 j、k... 交叉,如果 n 个特征则共有 (n * (n-1)) / 2 次交叉计算。
A.LookUp 获取 Field i 对应 Embedding [None x K]
B.获取 i、j 对应的参数矩阵 Wij 并执行矩阵乘法 [None x K] * [K x K] => [None x K]
C.MatMul 得到的结果继续与 Field j LookUp 得到的向量进行 dot 获取 [None x 1]
Tips:
- 由于 FwFM 与 FmFM 不具备与 FM 相同的对称参数情况,所以计算复杂度与 FM 的优化形式不同
- 当 Matrix 为 E 单位矩阵时,FmFM 退化为 FM
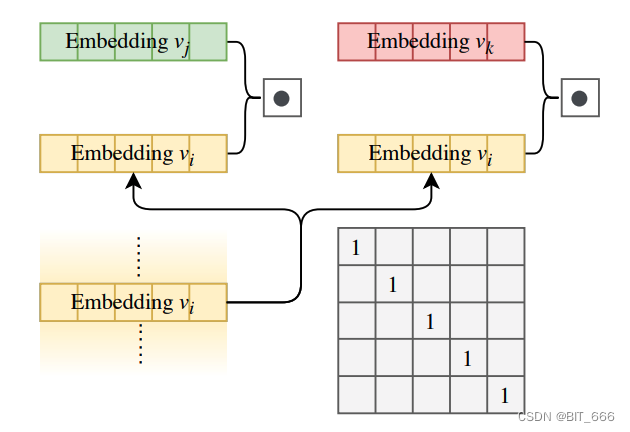
- 当 Matrix 为常量矩阵时,FmFM 退化为 FwFM
- 可变嵌入维度
传统 FM 变种特征的维度 K 都是固定的,由于 FmFM 引入了特征矩阵,所以根据特征重要性不同我们可以调整 Matrix 的维度,其不再局限于为方阵,从而影响不同特征的信息携带量进而影响其重要性。
- 与 FwFM 类似,将 FmFM 与 DNN 组合即可得到 DeepFM 的改良版 DeepFmFM。
- 参考 FiBiNET,FmFM 的矩阵也可以做适当改变,针对 i-j 的矩阵 Mij 可以退化为每个特征域 F 有一个矩阵 Mi,还可以继续退化至所有特征域公用一个矩阵 M
- 几种浅层模型的参数复杂度
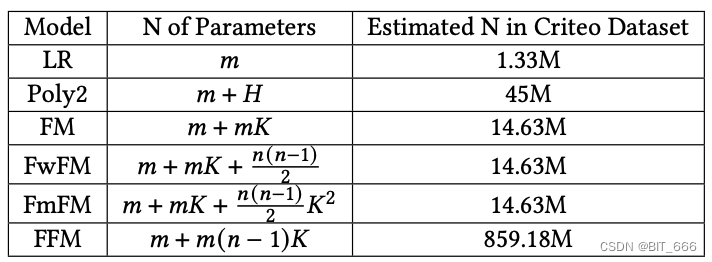
m 为线性部分、K 为 emb 维度、mK 为隐向量参数矩阵的参数个数、n(n-1)/2 为特征组合数,FwFM 时每个组合一个参数,FmFM 时每个组合一个 [emb,emb] 矩阵,所以多了 K^2、对于FFM,参数数量为 𝑚 +𝑚(𝑛 − 1)𝐾 ,因为每个特征具有𝑛 − 1嵌入向量,通常情况下 𝑛 ≪ 𝑚。
三.常用推荐算法实现
Pre.数据准备
import numpy as npdef genSamples(numSamples=60000, seed=0):np.random.seed(seed)# 原始特征输入categoryA = np.random.randint(0, 100, (numSamples, 1))categoryB = np.random.randint(100, 200, (numSamples, 1))categoryC = np.random.randint(200, 300, (numSamples, 1))categoryD = np.random.randint(300, 400, (numSamples, 1))labels = np.random.randint(0, 2, size=numSamples)labels = np.asarray(labels)return np.concatenate([categoryA, categoryB, categoryC, categoryD], axis=-1).astype('int32'), labels这里模拟简单随机样本,其中每个特征有100种取值,每次命中一个特征,共4个Field最后将4个特征 Concat 作为样本输出。实际场景下,大家可以自己构建分享实现特征划分并获取特征 id,如果是 Sparse 特征或者 Multi 特征,可以使用 lookup_sparse 将 embding 聚合。
train, labels = genSamples()print("训练数据样例与Size:")print(train[0:5])print(train.shape)print("样本labels:")print(labels[0:5])由于是 CTR 场景,所以 Label 的取值为 0 或者 1。genSampls 支持传入样本数量 num 与随机 seed,seed 主要为了保持后续算法比较时样本一致。这里取5条样本和 Label 展示,后面的算法都基于该随机样本进行测试与训练:
训练数据样例与Size:
[[ 44 113 226 315][ 47 155 298 394][ 64 191 210 384][ 67 175 284 329][ 67 186 246 308]]
(60000, 4)
样本labels:
[0 1 0 0 1]1.FM
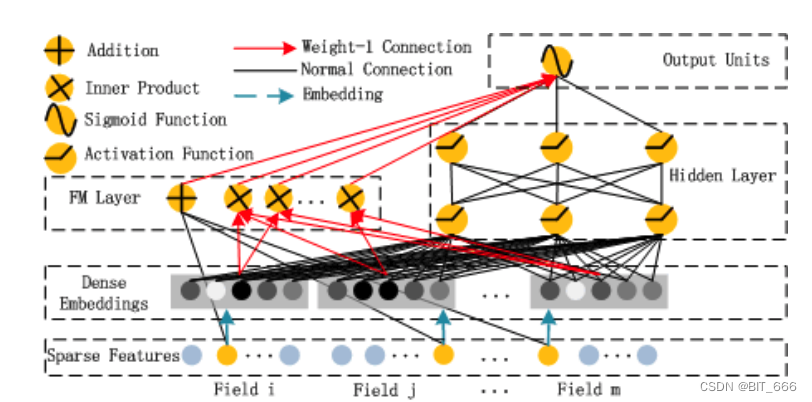
这里实现参考 DeepFM 的 FM Layer,根据多个 Field 首先通过 Dense Embedding 层获取 id 对应 Embedding,随后分别实现 LR 和 FM 二级交叉项。
- 一阶项 LR
from tensorflow.keras import backend as K
from tensorflow.keras import layers
import tensorflow as tfdef get_first_order(featIndex, args):# None x Featembedding = tf.nn.embedding_lookup(args, featIndex)[:, :, -1]linear = tf.reduce_sum(embedding, axis=-1)sum_embedding = K.expand_dims(linear, axis=1)return sum_embedding首先 lookup 获取 id 对应参数即 (None, Feat),随后 reduce_sum 得到 (None, ) 最后通过 expand_dims 得到 (None, 1) ,从而实现 LR 的累加过程。
- 二阶项交叉
def get_second_order(featIndex, args):# None x Feat x 8embedding = tf.nn.embedding_lookup(args, featIndex)[:, :, :args.shape[-1]]# 先求和再平方sum_embedding = tf.reduce_sum(embedding, axis=1)sum_square = K.square(sum_embedding)# 先平方在求和suqared = K.square(embedding)square_sum = tf.reduce_sum(suqared, axis=1)# 二阶交叉项second_order = 0.5 * tf.subtract(sum_square, square_sum)return second_order同理,首先 Lookup 获取 Embedding,对于 Field = 4 则得到 None x 4 x K,K 为 emb_dim,套用公式 和平方 ➖ 平方和,记得加 1/2,最终输出 (None, 8)。
- 完整 Layer
from tensorflow.keras import layers, Model
from tensorflow.keras.layers import Layer
from GetTrainAndTestData import genSamples
import tensorflow as tf
from Handel import get_first_order, get_second_orderclass FM(Layer):def __init__(self, feature_num, output_dim, **kwargs):self.feature_num = feature_numself.output_dim = output_dimsuper().__init__(**kwargs)# 定义模型初始化 根据特征数目def build(self, input_shape):# create a trainable weight variable for this layerself.kernel = self.add_weight(name='lr_layer',shape=(self.feature_num, 1),initializer='glorot_normal',trainable=True)self.embedding = self.add_weight(name='fm_layer',shape=(self.feature_num, self.output_dim),initializer='glorot_normal',trainable=True)# Be sure to call this at the endsuper(FM, self).build(input_shape)def call(self, inputs, **kwargs):# input 为多个样本的稀疏特征表示first_order = get_first_order(inputs, self.kernel)seconder_order = get_second_order(inputs, self.embedding)concat_order = tf.concat([first_order, seconder_order], axis=-1)return concat_orderKeras 自定义 Layer 主要实现如下四个函数:
init: 初始化参数
build: 定义权重
call: 层的功能与逻辑
compute_output_shape: 推断输出模型维度
每次调用最终都会调用至 call 方法,并执行内部的计算逻辑,这里主要注意输入输出维度,避免出现维度不匹配的问题。
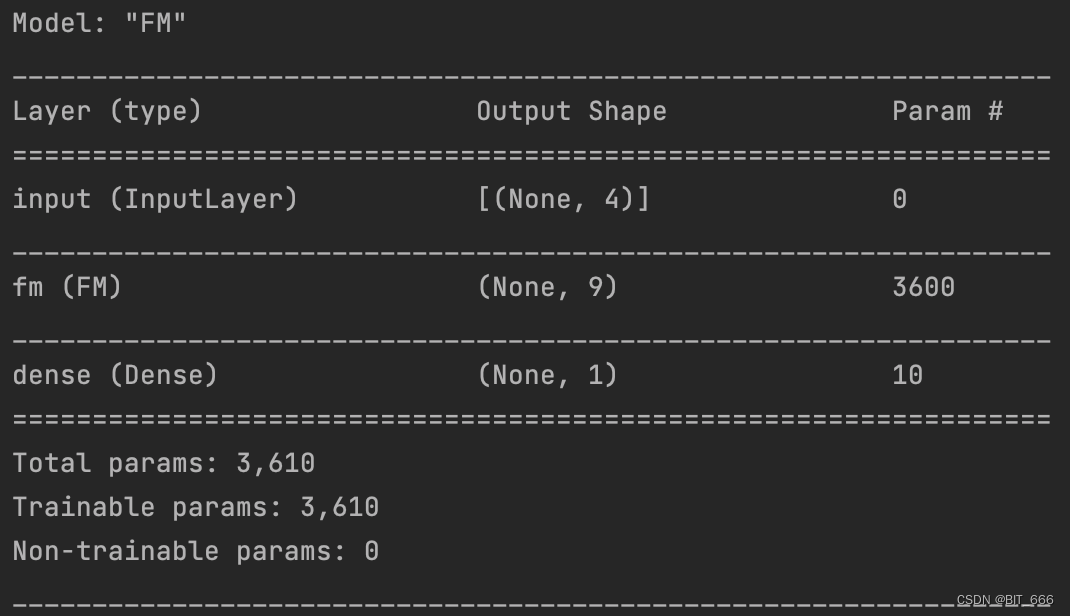
FM 的系数量为 m + mK,这里 K = 8,m = 400,所以 FM Layer 的参数量为 3600。
2.WideAndDeep
LR + DNN 的组合,LR 可以参考上面 FM 的 get_first_order 的部分,DNN 则直接通过add_weight 添加 dense 和 bias 层即可。这里添加两层 DNN 网络,激活函数采用 relu 且未添加正则化参数。
- Deep Layer
def get_deep_order(feat_index, args):embedding = tf.nn.embedding_lookup(args, feat_index)[:, :, :]embedding_flatten = layers.Flatten()(embedding)return embedding_flattenlookup 获取对应 id 的全部 Embedding 并 flatten 打平连入后续的 fully_connected 层:
# DNN None x Dim2
deep_order = get_deep_order(inputs, self.embedding) # None x 32
deep_order = self.activation(tf.matmul(deep_order, self.dense1) + self.bias1)
deep_order = self.activation(tf.matmul(deep_order, self.dense2) + self.bias2)经过两次全连接将原始 None x (Field x K) 维度转换为 None x 32,32 为第二个全连接层的输出维度,最后与 LR 的 None x 1 连接送入 Sigmoid 计算即可得到最终预测 CTR。
- 完整 Layer
from tensorflow.keras import layers, Model, regularizers
from tensorflow.keras.layers import Layer, Activation
import tensorflow as tf
from tensorflow.python.keras.backend import relu
from GetTrainAndTestData import genSamples
from Handel import get_first_order, get_deep_orderclass WideAndDeep(Layer):"""init: 初始化参数build: 定义权重call: 层的功能与逻辑compute_output_shape: 推断输出模型维度"""def __init__(self, feature_num, embedding_dim, dense1_dim=128, dense2_dim=64, **kwargs):self.feature_num = feature_numself.embedding_dim = embedding_dimself.dense1_dim = dense1_dimself.dense2_dim = dense2_dimself.kernel_regularize = regularizers.l2(0.1)self.activation = Activation(relu)super().__init__(**kwargs)# 定义模型初始化 根据特征数目def build(self, input_shape):# create a trainable weight variable for this layerself.kernel = self.add_weight(name='lr_layer',shape=(self.feature_num, 1),initializer='glorot_normal',trainable=True)self.embedding = self.add_weight(name="embedding",shape=(self.feature_num, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Dense1self.dense1 = self.add_weight(name='dense1',shape=(input_shape[1] * self.embedding_dim, self.dense1_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias1 = self.add_weight(name='bias1',shape=(self.dense1_dim,),initializer='he_normal',trainable=True)# DNN Dense2self.dense2 = self.add_weight(name='dense2',shape=(self.dense1_dim, self.dense2_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias2 = self.add_weight(name='bias2',shape=(self.dense2_dim,),initializer='he_normal',trainable=True)# Be sure to call this at the endsuper(WideAndDeep, self).build(input_shape)def call(self, inputs, **kwargs):# LR None x 1first_order = get_first_order(inputs, self.kernel)# DNN None x Dim2deep_order = get_deep_order(inputs, self.embedding) # None x 32deep_order = self.activation(tf.matmul(deep_order, self.dense1) + self.bias1)deep_order = self.activation(tf.matmul(deep_order, self.dense2) + self.bias2)# Concat LR + DNNconcat_order = tf.concat([first_order, deep_order], axis=-1)return concat_order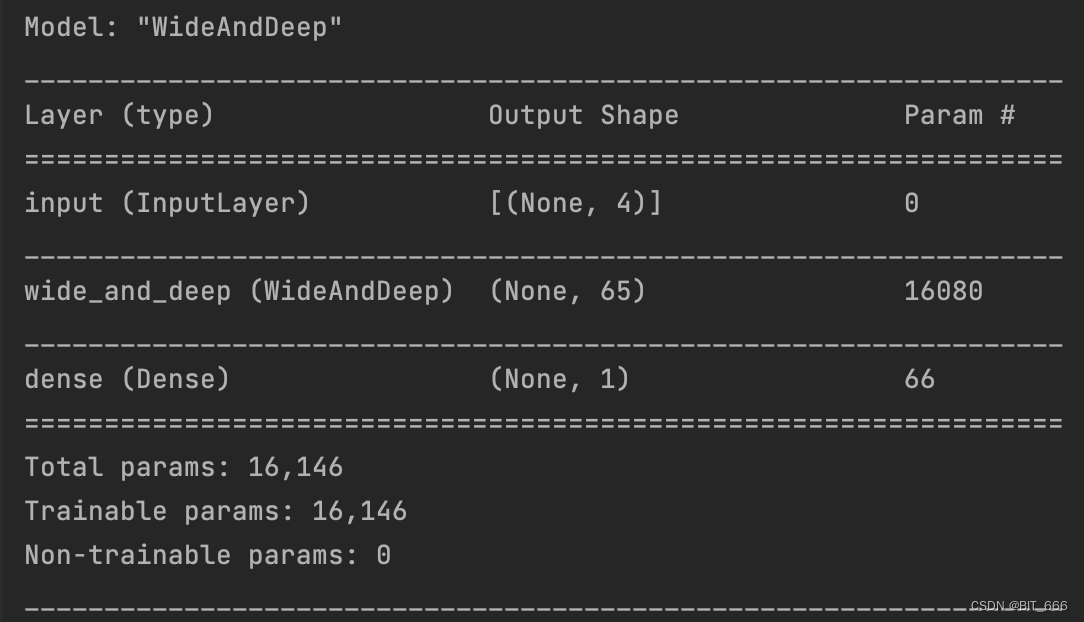
DNN + LR 层参数计算:
400x1 [LR参数] + 400x8 [Embedding层参数] + 32x128 [Dense1] + 128 [Bias1] + 128x64 [Dense2] + 64 [Bias2] = 16080
![]()
3.DeepFM
DeepFM = FM + DNN ,所以基于上面 FM 和 WideAndDeep 的 DNN 侧我们可以快速实现 DeepFM 的结构。
- 完整 Layer
from tensorflow.keras import layers, Model, regularizers
from tensorflow.keras.layers import Layer, Activation
import tensorflow as tf
from tensorflow.python.keras.backend import relu
from GetTrainAndTestData import genSamples
from Handel import get_first_order, get_second_order, get_deep_orderclass DeepFM(Layer):def __init__(self, feature_num, embedding_dim, dense1_dim=128, dense2_dim=64, **kwargs):self.feature_num = feature_numself.embedding_dim = embedding_dimself.dense1_dim = dense1_dimself.dense2_dim = dense2_dimself.kernel_regularize = regularizers.l2(0.1)self.activation = Activation(relu)super().__init__(**kwargs)# 定义模型初始化 根据特征数目def build(self, input_shape):# create a trainable weight variable for this layerself.kernel = self.add_weight(name='lr_layer',shape=(self.feature_num, 1),initializer='glorot_normal',trainable=True)self.embedding = self.add_weight(name="embedding",shape=(self.feature_num, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Dense1self.dense1 = self.add_weight(name='dense1',shape=(input_shape[1] * self.embedding_dim, self.dense1_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias1 = self.add_weight(name='bias1',shape=(self.dense1_dim,),initializer='he_normal',trainable=True)# DNN Dense2self.dense2 = self.add_weight(name='dense2',shape=(self.dense1_dim, self.dense2_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias2 = self.add_weight(name='bias2',shape=(self.dense2_dim,),initializer='he_normal',trainable=True)# Be sure to call this at the endsuper(DeepFM, self).build(input_shape)def call(self, inputs, **kwargs):# LR None x 1 FM None x 8first_order = get_first_order(inputs, self.kernel)seconder_order = get_second_order(inputs, self.embedding)# DNN None x Dim2deep_order = get_deep_order(inputs, self.embedding) # None x 32deep_order = self.activation(tf.matmul(deep_order, self.dense1) + self.bias1)deep_order = self.activation(tf.matmul(deep_order, self.dense2) + self.bias2)# Concat LR + DNNconcat_order = tf.concat([first_order, seconder_order, deep_order], axis=-1)return concat_order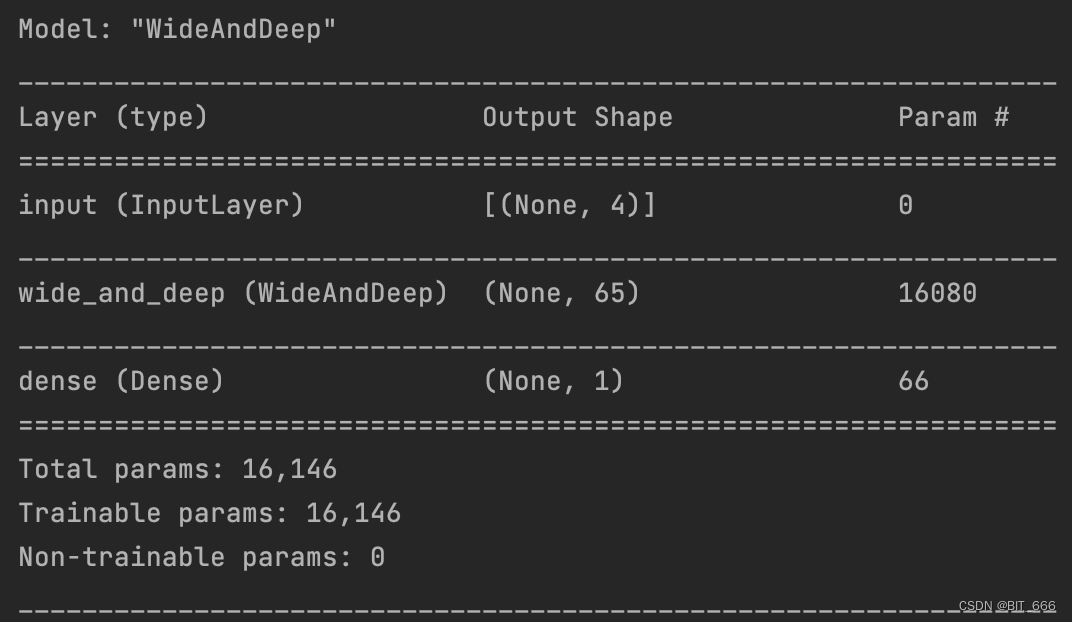
由于 Embedding 层在 FM 侧和 Deep 侧是共享的,所以与 WideAndDeep 的参数量是一致的。实际场景下,也可以选择 FM 预训练的 Embedding 当做初始化向量。
4.DeepFwFM
相比于 FM 使用和平方和平方和的计算方式,这里由于引入 Field 之间的权重,所以不能基于公式优化计算方式。这里我们严格按照公式的计算流程 for 循环计算,当然也可以使用空间换时间的方法,以及做缓存,提高整体推理速度。
![]()
相比于 FM 这里只需新增参数 rFiFj 即可:
self.field_matrix = self.add_weight(name='field_pair_matrix',shape=(self.num_fields, self.num_fields),initializer='truncated_normal')def get_Fw_FM(featIndex, args, field_matrix, num_fields, mode="part"):"""Input: 3D Tensor [batch_size, field_size, embedding_size]Output: 2D [batch_size, 1 / (n*(n-1))/2]num_fields: fileds 数量"""# None x Feat x 8inputs = tf.nn.embedding_lookup(args, featIndex)[:, :, :args.shape[-1] - 1]if K.ndim(inputs) != 3:raise ValueError("Unexpected inputs dimensions %d, expect to be 3 dimensions"% (K.ndim(inputs)))if inputs.shape[1] != num_fields:raise ValueError("Mismatch in number of fields {} and \concatenated embeddings dims {}".format(num_fields, inputs.shape[1]))# 成对内积pair_inner_prods = []# 快速全排列for fi, fj in itertools.combinations(range(num_fields), 2):r_ij = field_matrix[fi, fj]# 获取不同域的 Embeddingfeat_embedding_i = tf.squeeze(inputs[:, fi:fi + 1, :], axis=1) # None x 1 x 8 => None x 8feat_embedding_j = tf.squeeze(inputs[:, fj:fj + 1, :], axis=1) # None x 1 x 8 => None x 8f = tf.scalar_mul(r_ij, K.batch_dot(feat_embedding_i, feat_embedding_j, axes=1))pair_inner_prods.append(f)if mode == "part":fwFm_output = tf.concat(pair_inner_prods, axis=1)else:fwFm_output = tf.add_n(pair_inner_prods)return fwFm_output首先通过 itertools.combinations API 获取当前所有特征交叉的组合,随后从 inputs 中获取对应特征的 Embedding,首先将 Embedding dot 随后乘以对应的 rFiFj,添加到 pair_inner_prods 数组中。实际场景中,如果 FwFM 作为最终结果输出,可以使用 add_n,此时得到的输出是 None x 1,与 LR 结合再 sigmod 就能获得最终的预测 CTR 了,如果在 DeepFwFM 场景下,可以 batch_dot 再 concat,此时得到的输出时 (None x (n*(n-1)/2)),可以后续与 DNN concat 继续增加隐层训练。当然也可以不执行 batch_dot,执行 multiply,此时得到的输出向量维度更高为 (None x (k*n*(n-1)/2)),同理可以自己连接全连接或者与 DNN 结合都可以,这个大家可以根据实际场景自己尝试表现最好的方法。
- 完整 Layer
from tensorflow.keras import backend as K
from tensorflow.keras import layers, Model
from tensorflow.keras.layers import Layer
from GetTrainAndTestData import genSamples
import tensorflow as tf
from tensorflow.python.keras.backend import relu
from tensorflow.keras.layers import Layer, Lambda, Dense, Input, Activation
from Handel import get_first_order, get_second_order, get_deep_orderclass FwFM(Layer):def __init__(self, feature_num, embedding_dim, mode="part", num_fields=4, dense1_dim=128, dense2_dim=64, **kwargs):self.feature_num = feature_numself.embedding_dim = embedding_dimself.num_fields = num_fieldsself.dense1_dim = dense1_dimself.dense2_dim = dense2_dimself.activation = Activation(relu)if mode == "part":self.fwFm_out = (num_fields * (num_fields - 1)) / 2else:self.fwFm_out = 1super().__init__(**kwargs)# 定义模型初始化 根据特征数目def build(self, input_shape):self.field_matrix = self.add_weight(name='field_pair_matrix',shape=(self.num_fields, self.num_fields),initializer='truncated_normal')self.kernel = self.add_weight(name='lr_layer',shape=(self.feature_num, 1),initializer='glorot_normal',trainable=True)self.embedding = self.add_weight(name="embedding",shape=(self.feature_num, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Dense1self.dense1 = self.add_weight(name='dense1',shape=(input_shape[1] * self.embedding_dim, self.dense1_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias1 = self.add_weight(name='bias1',shape=(self.dense1_dim,),initializer='he_normal',trainable=True)# DNN Dense2self.dense2 = self.add_weight(name='dense2',shape=(self.dense1_dim, self.dense2_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias2 = self.add_weight(name='bias2',shape=(self.dense2_dim,),initializer='he_normal',trainable=True)# Be sure to call this at the endsuper(FwFM, self).build(input_shape)def call(self, inputs, **kwargs):# input 为多个样本的稀疏特征表示first_order = get_first_order(inputs, self.kernel)# FwFM 部分fwfm_order = get_Fw_FM(inputs, self.embedding, self.field_matrix, self.num_fields)# DNN None x Dim2deep_order = get_deep_order(inputs, self.embedding) # None x 32deep_order = self.activation(tf.matmul(deep_order, self.dense1) + self.bias1)deep_order = self.activation(tf.matmul(deep_order, self.dense2) + self.bias2)concat_order = tf.concat([first_order, fwfm_order, deep_order], axis=-1)return concat_order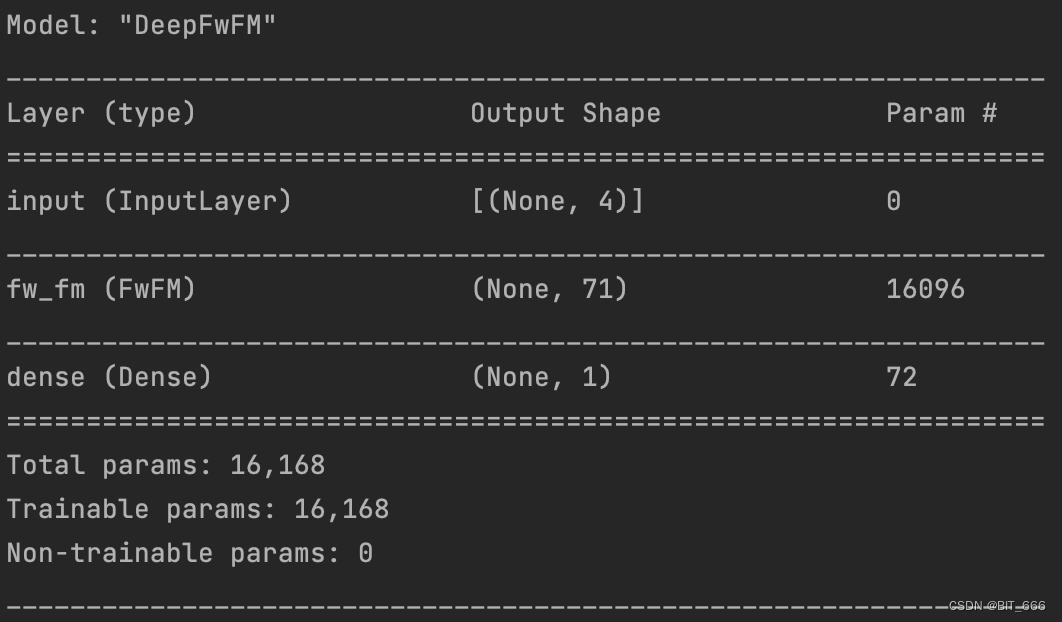
FwFM 比 FM 层多了 4x4 个 Rij 参数,所以在前面 16080 参数的基础上多了 16个参数即 16096。
5.DeepFmFM
只需要把 FwFM 的 rFiFj 参数修改为 Matrix 形式即可实现 FmFM,再增加 DNN 就得到 DeepFmFM:
def get_Fm_FM(featIndex, args, field_matrix, num_fields, mode="part"):# None x Feat x 8inputs = tf.nn.embedding_lookup(args, featIndex)[:, :, :args.shape[-1]]if K.ndim(inputs) != 3:raise ValueError("Unexpected inputs dimensions %d, expect to be 3 dimensions"% (K.ndim(inputs)))if inputs.shape[1] != num_fields:raise ValueError("Mismatch in number of fields {} and \concatenated embeddings dims {}".format(num_fields, inputs.shape[1]))# 成对内积pair_inner_prods = []# 快速全排列for fi, fj in itertools.combinations(range(num_fields), 2):r_ij = field_matrix[str(fi) + "_" + str(fj)]# r_ij = public_matrix# 获取不同域的 Embeddingfeat_embedding_i = tf.squeeze(inputs[:, fi:fi + 1, :], axis=1) # None x 1 x 8 => None x 8feat_embedding_j = tf.squeeze(inputs[:, fj:fj + 1, :], axis=1) # None x 1 x 8 => None x 8f = tf.multiply(tf.matmul(feat_embedding_i, r_ij), feat_embedding_j)pair_inner_prods.append(f)if mode == "part":fmFm_output = tf.concat(pair_inner_prods, axis=1)else:fmFm_output = tf.add_n(pair_inner_prods)return fmFm_output这里没有采用 FwFM 的 BatchDot 而是采用 multiply,前者会返回 None x (n*(n-1)/2) 后者则返回 None x (k*n*(n-1)/2)。得到长向量后一般可以选择接一个全连接再与 Deep 侧 concat,减少二阶项对全局的影响。
- 完整 Layer
class FmFM(Layer):def __init__(self, feature_num, embedding_dim, mode="part", num_fields=4, dense1_dim=128, dense2_dim=64, **kwargs):self.feature_num = feature_numself.embedding_dim = embedding_dimself.num_fields = num_fieldsself.dense1_dim = dense1_dimself.dense2_dim = dense2_dimself.activation = Activation(relu)if mode == "part":self.fwFm_out = int((num_fields * (num_fields - 1)) / 2)else:self.fwFm_out = 1super().__init__(**kwargs)# 定义模型初始化 根据特征数目def build(self, input_shape):self.kernel = self.add_weight(name='lr_layer',shape=(self.feature_num, 1),initializer='he_normal',trainable=True)self.embedding = self.add_weight(name="embedding",shape=(self.feature_num, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Dense1self.dense1 = self.add_weight(name='dense1',shape=(input_shape[1] * self.embedding_dim, self.dense1_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias1 = self.add_weight(name='bias1',shape=(self.dense1_dim,),initializer='he_normal',trainable=True)# DNN Dense2self.dense2 = self.add_weight(name='dense2',shape=(self.dense1_dim, self.dense2_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias2 = self.add_weight(name='bias2',shape=(self.dense2_dim,),initializer='he_normal',trainable=True)self.matrix_dict = {}for fi, fj in itertools.combinations(range(self.num_fields), 2):self.matrix_dict[str(fi) + "_" + str(fj)] = self.add_weight(name="matrix_weight_%d_%d" % (fi, fj),shape=(self.embedding_dim, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Dense2self.dense4FmFM = self.add_weight(name='dense4FmFM',shape=(self.fwFm_out * self.embedding_dim, self.embedding_dim),initializer='he_normal',trainable=True)# DNN Bias1self.bias4FmFM = self.add_weight(name='bias4FmFM',shape=(self.embedding_dim,),initializer='he_normal',trainable=True)# Be sure to call this at the endsuper(FmFM, self).build(input_shape)def call(self, inputs, **kwargs):# input 为多个样本的稀疏特征表示first_order = get_first_order(inputs, self.kernel)# FmFM 部分fmfm_order = get_Fm_FM(inputs, self.embedding, self.matrix_dict, self.num_fields)fmfm_order = self.activation(tf.matmul(fmfm_order, self.dense4FmFM) + self.bias4FmFM)# DNN None x Dim2deep_order = get_deep_order(inputs, self.embedding) # None x 32deep_order = self.activation(tf.matmul(deep_order, self.dense1) + self.bias1)deep_order = self.activation(tf.matmul(deep_order, self.dense2) + self.bias2)concat_order = tf.concat([first_order, fmfm_order, deep_order], axis=-1)return concat_order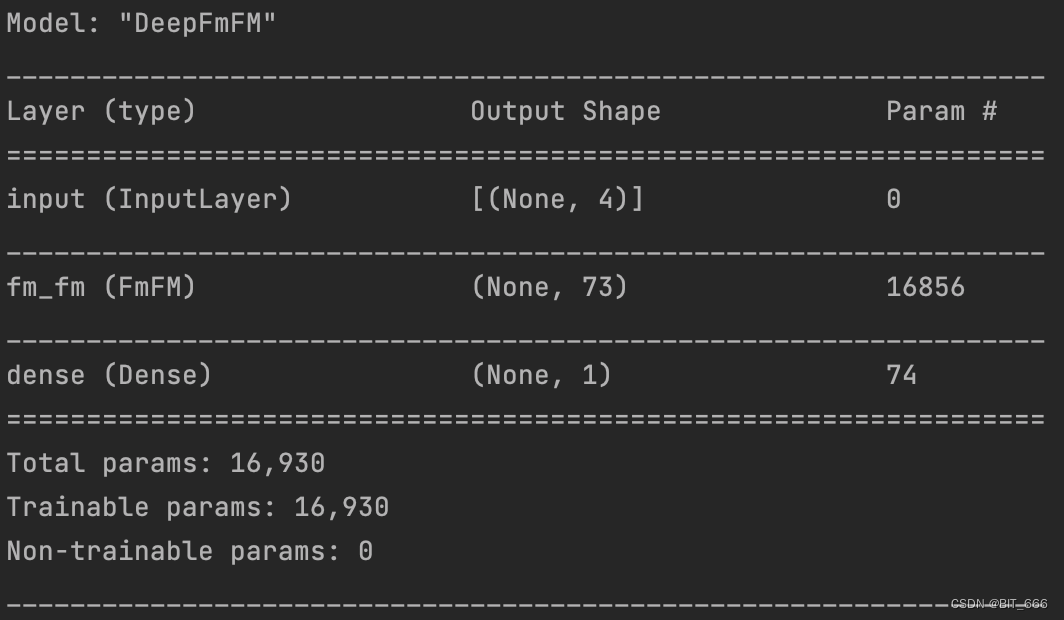
在 DeepFM 16080 基础上增加了 6*8*8 的参数矩阵以及 6*8*8 的 dense 和 8 的 bias,所以最终参数量为 16856。
四.总结
1.函数测试
针对上述自定义 Layer,可以调用不同的模型 Layer 进行模型训练与预测。
if __name__ == '__main__':train, labels = genSamples()# 构建模型input = layers.Input(shape=4, name='input', dtype='int32')# FM、WideAndDeep、DeepFM、FwFM、FmFMmodel_layer = FmFM(400, 8)(input)output = layers.Dense(1, activation='sigmoid')(model_layer)model = Model(input, output)# 模型编译model.compile(optimizer='adam',loss='binary_crossentropy',metrics='accuracy')model.summary()# 模型训练model.fit(train, labels, epochs=10, batch_size=128)# 模型预测print("模型预测结果:")test_sample, test_label = genSamples(100, 99)print(model.predict(test_sample))
以 DeepFmFM 为例:
Epoch 1/10
469/469 [==============================] - 1s 1ms/step - loss: 0.6946 - accuracy: 0.5009
Epoch 2/10
469/469 [==============================] - 1s 1ms/step - loss: 0.6923 - accuracy: 0.5174
Epoch 3/10
469/469 [==============================] - 1s 1ms/step - loss: 0.6899 - accuracy: 0.5322
Epoch 4/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6866 - accuracy: 0.5475
Epoch 5/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6799 - accuracy: 0.5682
Epoch 6/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6737 - accuracy: 0.5793
Epoch 7/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6665 - accuracy: 0.5956
Epoch 8/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6605 - accuracy: 0.6049
Epoch 9/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6551 - accuracy: 0.6113
Epoch 10/10
469/469 [==============================] - 0s 1ms/step - loss: 0.6489 - accuracy: 0.62142.函数效果与复杂度对比[来自FmFM论文]
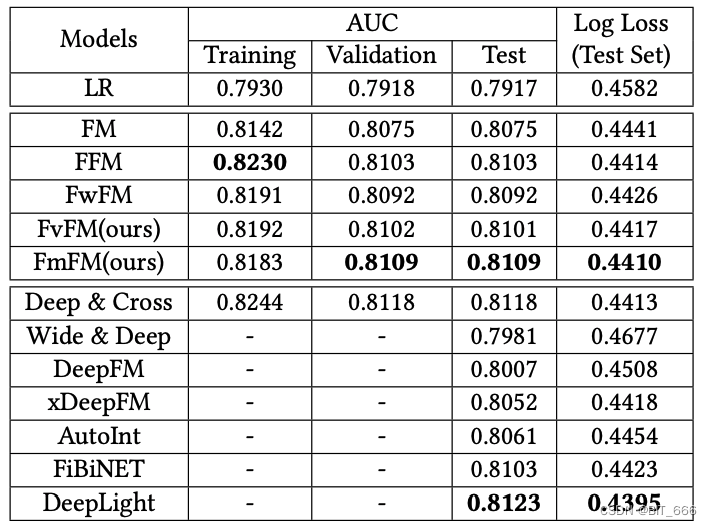
下图为 Criteo 数据集上 FmFM 与其他低阶模型的训练 AUC 与 LogLoss 对比:
下图为多种模型 AUC 与 ELOPs 对比:
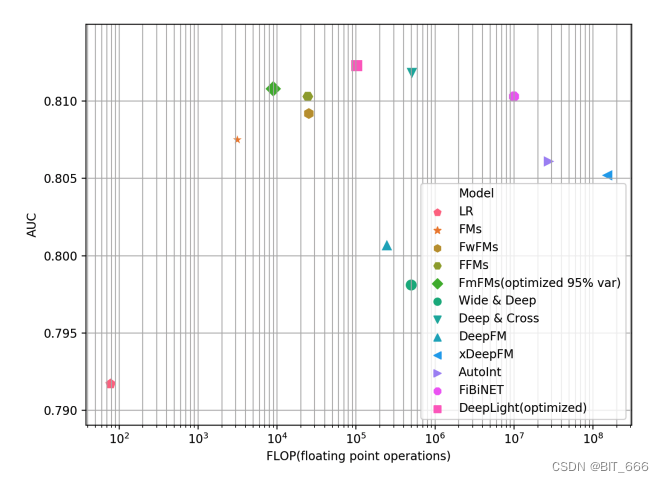
ELOPS: Floating Point Operations Per Second 意为每秒浮点运算次数,视为运算速度。
ELOPs: Floating Point Operations 意为浮点运算数,视为计算量,上图 FLOP 为该指标。
3.More
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
FwFM [WWW 2018]Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
FiBiNET [RecSys 2019]FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
FM2: Field-matrixed Factorization Machines for Recommender Systems
相关文章:
TensorFlow-Keras - FM、WideAndDeep、DeepFM、DeepFwFM、DeepFmFM 理论与实战
目录 一.引言 二.浅层模型概述 1.LR 2.FM 3.FMM 4.FwFM 5.FmFM 三.常用推荐算法实现 Pre.数据准备 1.FM 2.WideAndDeep 3.DeepFM 4.DeepFwFM 5.DeepFmFM 四.总结 1.函数测试 2.函数效果与复杂度对比[来自FmFM论文] 3.More 一.引言 推荐系统中常见的 CTR 模型…...
Java浅析电信数据采集
技术:Java等摘要:电信运营系统中,电信计费系统是主要的支撑系统,占有重要地位。对于电信计费系统是电信运营商的核心竞争力之一这一观点愈来愈被业界认同。电信计费系统中的数据蕴含着企业经营态势、客户群分布特征及消费习惯、各…...

那些开发中需要遵守的产研开发规范
入职新公司第三天,没干啥其他活,基本在阅读产研开发规范。公司在技术方面沿用的是阿里的一套技术,所以入职之前需要先阅读《阿里巴巴开发规范》。今天整理一些平时需要关注的阿里规约和数据库开发规范,方便今后在开发过程中查阅。…...

一文深入分析-内核并发消杀器(KCSAN)
一、KCSAN介绍 KCSAN(Kernel Concurrency Sanitizer)是一种动态竞态检测器,它依赖于编译时插装,并使用基于观察点的采样方法来检测竞态,其主要目的是检测数据竞争。 KCSAN是一种检测LKMM(Linux内核内存一致性模型)定义的数据竞争(data race…...

Java学习-IO流-字符缓冲流
Java学习-IO流-字符缓冲流 字符缓冲流↙ ↘ BufferedReader BufferedWtrier 字符缓冲输入流 字符缓冲输出流底层自带长度为8192的缓冲区提高性能 public BufferedReader(Reader r):把基本流包装成高级流 public BufferedWtrier(Wtrier w):把…...

Java的一维数组遍历、求最值、冒泡排序
一.数组遍历: Example: import java.util.ArrayList; public class App { public static void main(String[] args) { int[]arr{1,2,3,4,5}; for(int i0;i<arr.length;i){ System.out.println(arr[i]); } } 运行结果:12345 定义了一…...

Free for photo container detection, container damage detect PaaS
集装箱箱号识别API免费,飞瞳引擎集装箱人工智能平台,可通过API二次开发或小程序拍照使用,可二次开发应用码头港区海关仓库口岸铁路场站船公司堆场,实现云端集装箱信息识别/集装箱箱况残损检测/好坏箱检验,高检测率/高实…...
函数)
【golang】【源代码】reflect.DeepEqual(x,y)函数
reflect.DeepEqual(x, y)函数 功能是比较x和y是否一致,x和y不仅限于基础类型,也可以是像array、 slice、 map、 ptr、struct、interface类型,在代码中经常能见到。 一起看下是怎么实现的吧~ func DeepEqual(x, y interface{}) bool {if x …...
)
Python实现定时执行脚本(4)
前言 本文是该专栏的第16篇,后面会持续分享python的各种干货知识,值得关注。 在项目开发中,难免会需要用到定时任务。比如说,在某个时间段,甚至是达到某时某分某秒自动运行你部署好的功能脚本。而在本专栏的前面,笔者有详细介绍过3种使用python执行定时脚本的方法。 1.…...
 全同粒子)
量子力学(4) 全同粒子
如果势能与时间无关,那么Ψψe−iEt/ℏ\Psi\psi e^{-iEt/\hbar}Ψψe−iEt/ℏ,EEE是系统的总能量。 全同粒子分为玻色子和费米子。所有电子是全同的费米子。所有质子是全同的费米子。全同就是说不可能区分出其中的一个,比如说你摇了五个骰子…...
13、Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
简介 主页:https://github. com/microsoft/Swin-Transformer. Swin Transformer 是 2021 ICCV最佳论文,屠榜了各大CV任务,性能优于DeiT、ViT和EfficientNet等主干网络,已经替代经典的CNN架构,成为了计算机视觉领域通用…...

C++基础入门丨8. 结构体——还需要知道这些
Author:AXYZdong 硕士在读 工科男 有一点思考,有一点想法,有一点理性! 定个小小目标,努力成为习惯!在最美的年华遇见更好的自己! CSDNAXYZdong,CSDN首发,AXYZdong原创 唯…...
算法第十六期——动态规划(DP)之线性DP
【概述】 线性动态规划,是较常见的一类动态规划问题,其是在线性结构上进行状态转移,这类问题不像背包问题、区间DP等有固定的模板。 线性动态规划的目标函数为特定变量的线性函数,约束是这些变量的线性不等式或等式,目…...
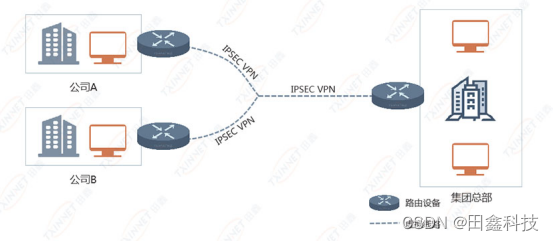
智慧新零售网络解决方案,助力新零售企业数智化转型
随着数字化时代的不断发展,新零售连锁业务模式“线上线下”融合发展,数据、设备在逐渐增加,门店数量也会随着企业规模的扩大而增加,但由于传统网络架构不稳定、延时、容量小影响服务质量(QoS)、分支设备数量…...

Go语言规范中的可赋值
了解可赋值规范的重要性当使用type关键字定义类型的时候,会遇到一些问题,如下:func main(){var i int 2pushInt(i) } type MyInt int //基于int定义MyInt func pushInt(i MyInt){}结果:调用函数pushInt报错 cannot use i (variab…...

外盘国际期货招商:原油市场热点话题
原油市场热点话题 问:目前美国原油库存如何? 答:EIA原油库存数据显示,由于美国炼油厂季节性检修,开工率继续下降,原油库存连续九周增长至2021年5月份以来最高水平,同期美国汽油库存减少而精炼…...
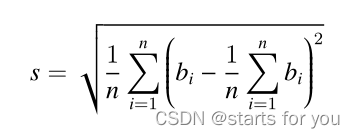
[蓝桥杯 2018 省 A] 付账问题 贪心题
几个人一起出去吃饭是常有的事。但在结帐的时候,常常会出现一些争执。现在有 n 个人出去吃饭,他们总共消费了 S 元。其中第 i 个人带了 ai 元。幸运的是,所有人带的钱的总数是足够付账的,但现在问题来了:每个人分别要出…...
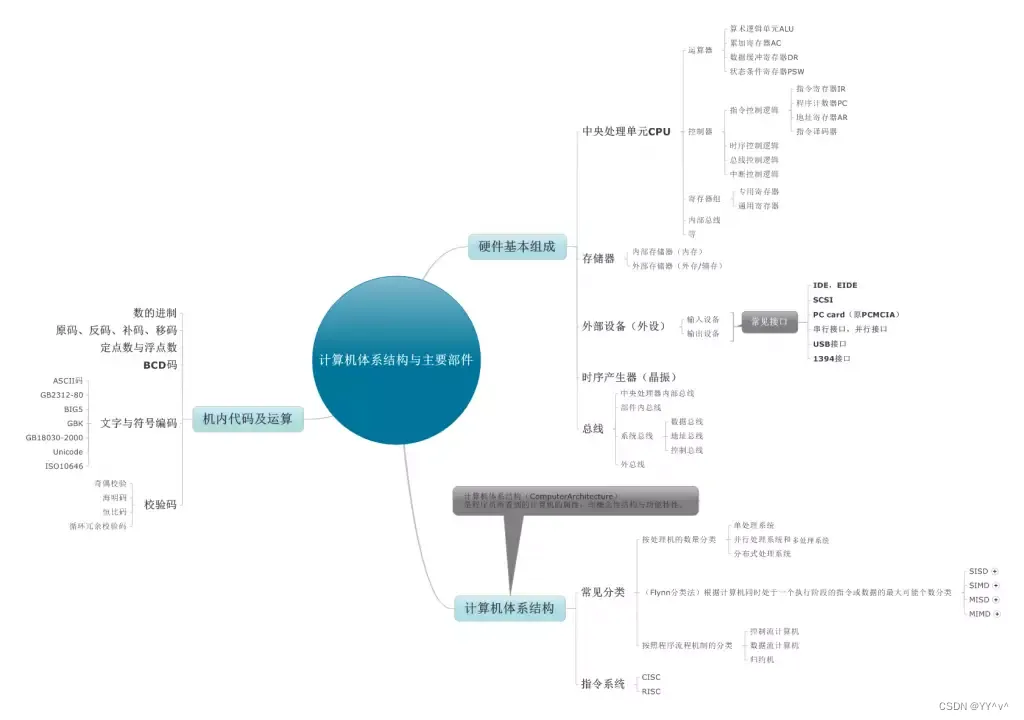
微机原理复习(周五),计算机组成原理图
1.计算机由运算器,控制器,存储器,输入设备,输出设备等5大基本部件组成。 2.冯诺依曼提出存储设计思想是:数字计算机的数制采用二进制,存储程序,程序控制。 3.计算机的基本组成框图:…...

用了10年Postman,意想不到它的Mock功能也如此强大
最近在做一些app,前后端分离的开发模式是必须的。一直用的python flask做后端的快速POC,python本身就是一门胶水语言,开发起来方便快捷,而flask又是一个极简的webserver框架(比Django简洁)。但在这里推荐的…...

项目重构,从零开始搭建一套新的后台管理系统
背景 应公司发展需求,我决定重构公司的后台管理系统,从提出需求建议到现在的实施,期间花了将近半个月的时间,决定把这些都记录下来。 之前的后台管理系统实在是为了实现功能而实现的,没有考虑到后期的扩展性…...

Wifite2实战指南:从零开始掌握无线网络安全审计的3大核心能力
Wifite2实战指南:从零开始掌握无线网络安全审计的3大核心能力 【免费下载链接】wifite2 Rewrite of the popular wireless network auditor, "wifite" 项目地址: https://gitcode.com/gh_mirrors/wi/wifite2 想象一下,你只需一条命令就…...

TVBoxOSC终极指南:3分钟打造你的智能电视媒体中心
TVBoxOSC终极指南:3分钟打造你的智能电视媒体中心 【免费下载链接】TVBoxOSC TVBoxOSC - 一个基于第三方项目的代码库,用于电视盒子的控制和管理。 项目地址: https://gitcode.com/GitHub_Trending/tv/TVBoxOSC 还在为电视盒子功能单一、播放格式…...

Unity ShaderGraph环境搭建:URP配置与节点库激活指南
1. 这不是“装个插件就完事”的 ShaderGraph 入门很多人点开 Unity 官方文档里那句“Shader Graph is included with Unity 2019.1”就直接关掉页面,以为只要打开 Unity 就能拖拽节点写 Shader——结果新建一个 Shader Graph Asset,双击打开,…...
告别龟速下载!trackerslist项目让你的BT下载速度飙升300%的终极指南
告别龟速下载!trackerslist项目让你的BT下载速度飙升300%的终极指南 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾经面对BT下载时进度条几乎不动而感…...

高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析
高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析 【免费下载链接】kmodes Python implementations of the k-modes and k-prototypes clustering algorithms, for clustering categorical data 项目地址: https://gitcode.com/gh_mirrors/km/kmod…...

在多模型聚合调用中体验到的路由与失败切换流畅度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型聚合调用中体验到的路由与失败切换流畅度 效果展示类,分享开发者在实际编程中,当配置了多个备用模…...

3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南
3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南 【免费下载链接】mdx-m3-viewer A WebGL viewer for MDX and M3 files used by the games Warcraft 3 and Starcraft 2 respectively. 项目地址: https://gitcode.com/gh_mirrors/md/mdx-m3-viewer 你是否曾因…...

在多模型间切换使用时对响应速度与一致性的感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换使用时对响应速度与一致性的感受 作为一名需要频繁调用大模型API的开发者,我的日常工作离不开与各类模型…...

Vitis 2021.2自定义IP从Platform到App的完整避坑指南:头文件、宏定义与QEMU报错一网打尽
Vitis 2021.2自定义IP全流程开发实战:从Platform构建到多核调试的深度解析 在FPGA开发领域,Xilinx的Vitis统一软件平台为开发者提供了从硬件设计到软件开发的完整工具链。然而,当涉及到自定义IP集成时,即使是经验丰富的工程师也常…...

暗黑破坏神2终极角色编辑器:打造完美角色的完整指南
暗黑破坏神2终极角色编辑器:打造完美角色的完整指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 想要在暗黑破坏神2中体验完美的角色构建吗?厌倦了重复刷装备的枯燥过程…...