【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
【阿旭机器学习实战】【36】糖尿病预测—决策树建模及其可视化
目录
- 【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化
- 1. 导入数据并查看数据
- 2. 训练决策树模型及其可视化
- 2.1 决策树模型
- 2.2 可视化训练好的决策树模型
- 2.2 使用随机森林模型
1. 导入数据并查看数据
关注GZH:阿旭算法与机器学习,回复:“ML36”即可获取本文数据集、源码与项目文档
# 导入数据包
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
df = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)
df.head()
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
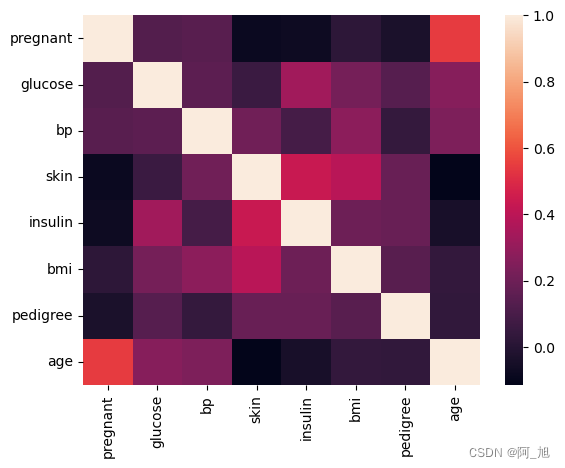
# 相关性矩阵
corr = df.iloc[:,:-1].corr()
#corr = (corr)
sns.heatmap(corr, xticklabels=corr.columns.values,yticklabels=corr.columns.values)corr
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | |
|---|---|---|---|---|---|---|---|---|
| pregnant | 1.000000 | 0.129459 | 0.141282 | -0.081672 | -0.073535 | 0.017683 | -0.033523 | 0.544341 |
| glucose | 0.129459 | 1.000000 | 0.152590 | 0.057328 | 0.331357 | 0.221071 | 0.137337 | 0.263514 |
| bp | 0.141282 | 0.152590 | 1.000000 | 0.207371 | 0.088933 | 0.281805 | 0.041265 | 0.239528 |
| skin | -0.081672 | 0.057328 | 0.207371 | 1.000000 | 0.436783 | 0.392573 | 0.183928 | -0.113970 |
| insulin | -0.073535 | 0.331357 | 0.088933 | 0.436783 | 1.000000 | 0.197859 | 0.185071 | -0.042163 |
| bmi | 0.017683 | 0.221071 | 0.281805 | 0.392573 | 0.197859 | 1.000000 | 0.140647 | 0.036242 |
| pedigree | -0.033523 | 0.137337 | 0.041265 | 0.183928 | 0.185071 | 0.140647 | 1.000000 | 0.033561 |
| age | 0.544341 | 0.263514 | 0.239528 | -0.113970 | -0.042163 | 0.036242 | 0.033561 | 1.000000 |
2. 训练决策树模型及其可视化
# 选择预测所需的特征
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # 特征
y = pima.label # 类别标签
# 将数据分为训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
2.1 决策树模型
# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy')# 训练模型
clf = clf.fit(X_train,y_train)# 使用训练好的模型做预测
y_pred = clf.predict(X_test)
# 模型的准确性
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7489177489177489
2.2 可视化训练好的决策树模型
注意: 需要使用如下命令安装额外两个包用于画决策树的图
conda install python-graphviz
conda install pydotplus
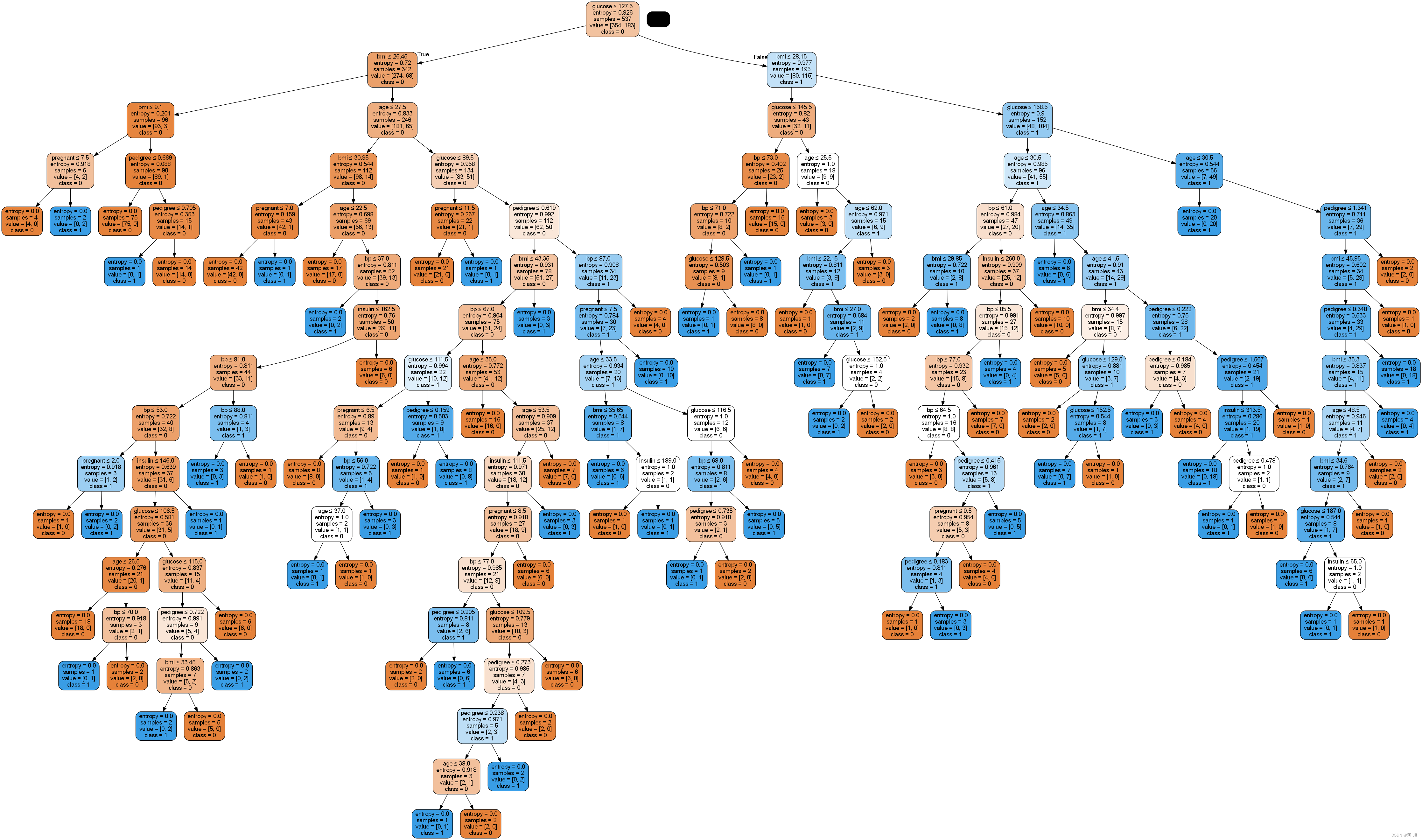
from sklearn.tree import export_graphviz
from six import StringIO
from IPython.display import Image
import pydotplus
from sklearn import treedot_data = StringIO()
export_graphviz(clf, out_file=dot_data, filled=True, rounded=True,special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())
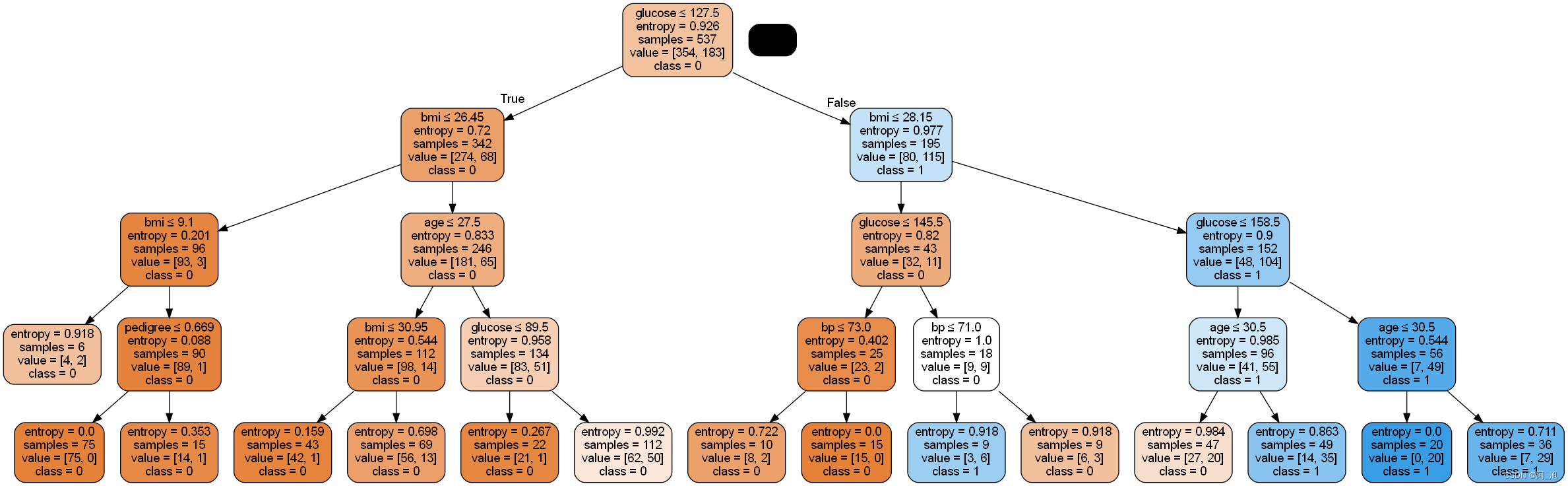
# 创建新的决策树, 限定树的最大深度, 减少过拟合
clf = tree.DecisionTreeClassifier(criterion='entropy',max_depth=4, # 定义树的深度, 可以用来防止过拟合min_weight_fraction_leaf=0.01 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合)# 训练模型
clf.fit(X_train,y_train)# 预测
y_pred = clf.predict(X_test)# 模型的性能
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data, filled=True, rounded=True,special_characters=True, feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes2.png')
Image(graph.create_png())
2.2 使用随机森林模型
from sklearn.ensemble import RandomForestClassifier# 随机森林, 通过调整参数来获取更好的结果
rf = RandomForestClassifier(criterion='entropy',n_estimators=1, max_depth=5, # 定义树的深度, 可以用来防止过拟合min_samples_split=10, # 定义至少多少个样本的情况下才继续分叉#min_weight_fraction_leaf=0.02 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合)# 训练模型
rf.fit(X_train, y_train)# 做预测
y_pred = rf.predict(X_test)# 模型的准确率
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))Accuracy: 0.7402597402597403
如果文章对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,回复:“ML36”即可获取本文数据集、源码与项目文档,欢迎共同学习交流
相关文章:
【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。 【阿旭机器学习实战】【36】糖尿病预测—决策树建模及其可视化 目录【阿旭机器学习实战】【36】糖尿病预测---决策树建模及其可视化1. 导入数据并…...
简易黑客初级教程:黑客技术,分享教学
第一节,伸展运动。这节操我们要准备道具,俗话说:“工欲善其事,必先利其器”(是这样吗?哎!文化低……)说得有道理,我们要学习黑客技术,一点必要的工具必不可少。 1,一台属于自己的可以上网的电…...

日本公派访问学者的具体申请流程
公派日本访问学者的具体申请流程,知识人网整理了相关的资料以供大家参考。第一、申请材料一般申请CSC日本访问学者,截止日是每年的1月15号左右,但是学院在1月10号之前就审查材料了。材料包括:CSC网页的报名表,教授邀请…...
投票点赞链接制作投票链接在线制作投票图文链接制作点赞
用户在使用微信投票的时候,需要功能齐全,又快捷方便的投票小程序。而“活动星投票”这款软件使用非常的方便,用户可以随时使用手机微信小程序获得线上投票服务,很多用户都很喜欢“活动星投票”这款软件。“活动星投票”小程序在使…...
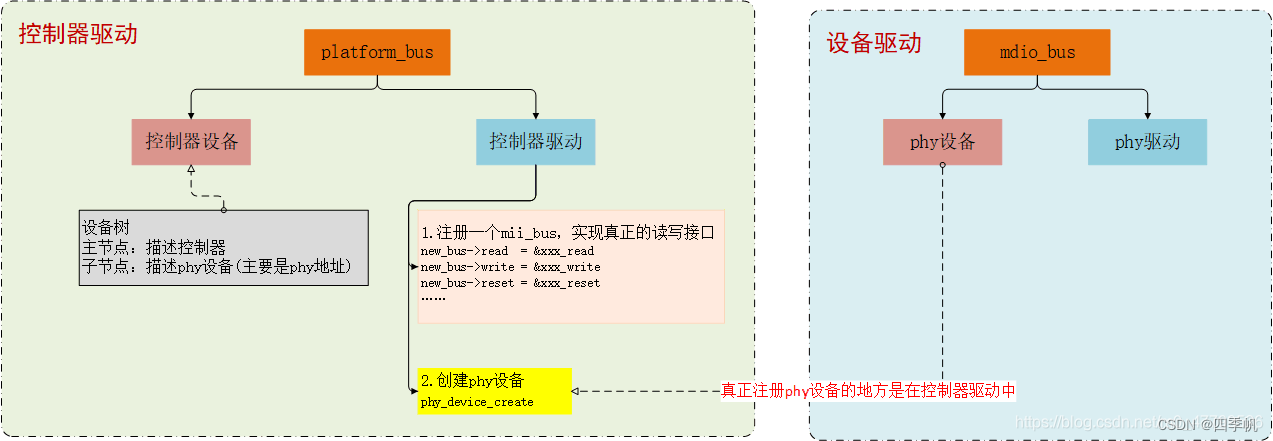
PHY设备驱动
1. 概述 MAC控制器的驱动使用的是platform总线的连接方式,PHY设备驱动是基于device、driver、bus的连接方式。 其驱动涉及如下几个重要部分: 总线 - sturct mii_bus (mii stand for media independent interface) 设备 - struct phy_device 驱动 - struc…...

Linux——UDP协议与相关套接字编程
一.概念在网络通信中,传输层中最常用的通信协议有两个:TCP协议与UDP协议。这两种协议虽然都可以用于网络通信,但是通信方式不同决定了应用场景的不同。与TCP协议相比,UDP协议最具特色的不同点有两个:无连接与面向数据报…...

EM算法 简明理解
E:Expection,期望步,利用估计的参数,来确定未知因变量的概率,并利用其来计算期望值。 M:Maximization,最大化,使用最大似然法更新参数值,使E步中期望值出现的概率最大。…...
论坛项目小程序和h5登录
项目中安装uview出现npm安装uview 直接报错:创建一个package.json配置文件在进行安装。cmd到项目。初始化一个package.json文件(vue项目的配置文件) npm init --yes 安装uview项目点击关注进入管页面,需要验证用户是否登录查用户是…...

kubernetes集群pod中的pause容器作用
kubernetes集群pod中的pause容器作用 我们搭建完集群了以后,可以使用最简单的方式创建一个pod,随意你建立什么pod,去访问相应node上执行docker ps 就会看到有一种pause容器,但是你可能从来没有启用 etrics-scraper_dashboard-me…...
分配内存、MySQL事务、项目、动态规划)
【2.24】malloc()分配内存、MySQL事务、项目、动态规划
malloc是如何分配内存的? 在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,如下所示: 内核空间与用户空…...
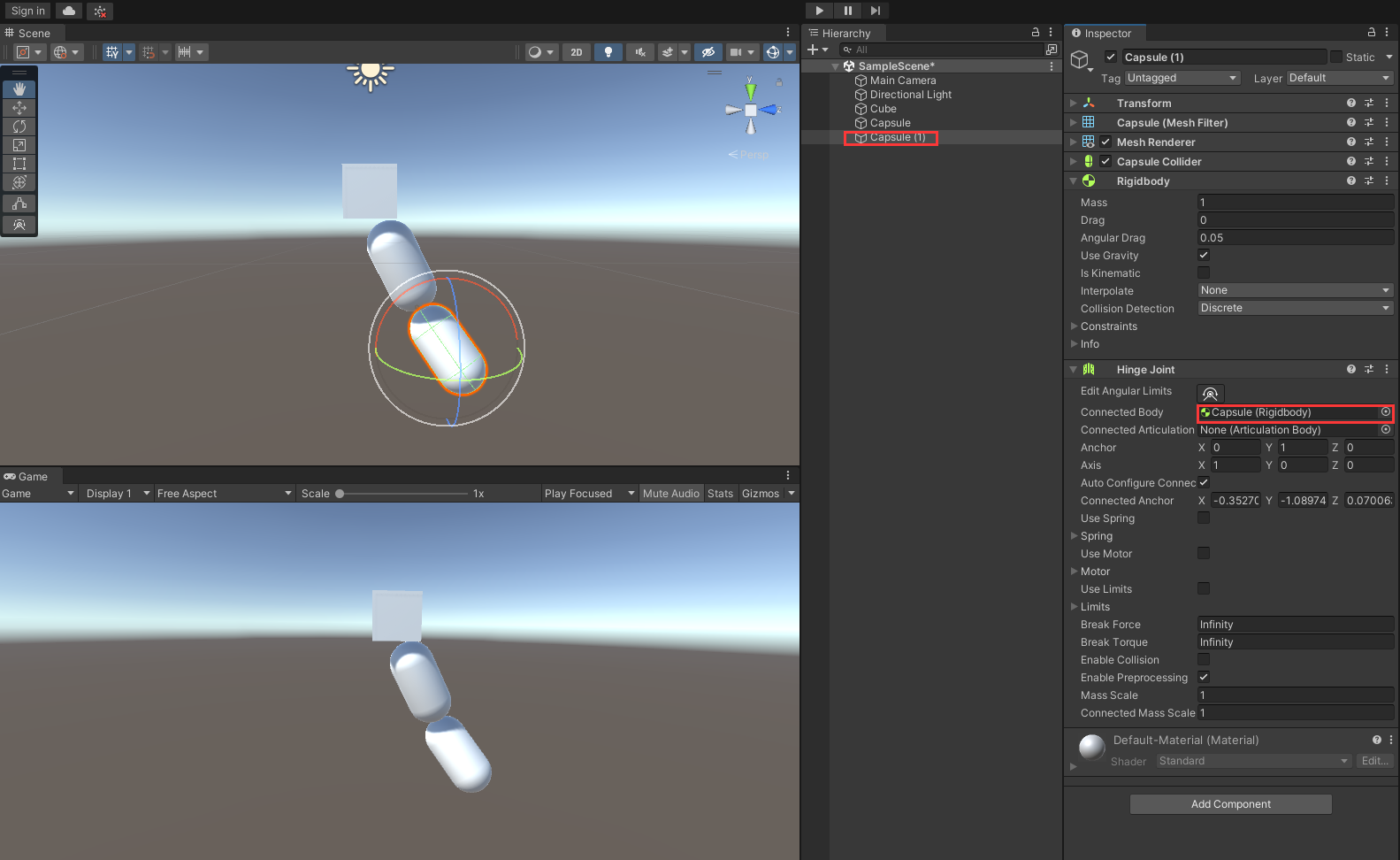
Unity——使用铰链关节制作悬挂物体效果
目的在场景中创建一个悬挂的物体,是把多个模型悬挂在一起可以自由摇摆,类似链条的效果效果图前言什么是铰链关节?铰链关节 将两个刚体(Rigid body)组会在一起,从而将其约束为如同通过铰链连接一样进行移动。…...
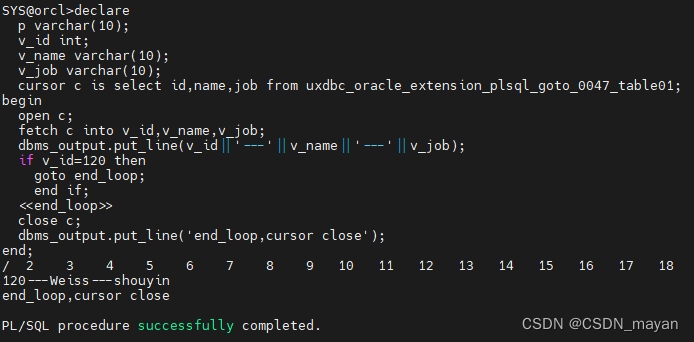
plsql过程语言之uxdb与oracle语法差异
序号场景uxdboracle1在存储过程中使用goto子句create or replace procedure uxdbc_oracle_extension_plsql_goto_0001_procedure01(t1 int) language plsql as $$ begin if t1%20 then goto even_number; else goto odd_number; end if; <<even_number>> raise…...

file_get_contents 打开本地文件报错: failed to open stream: No such file or directory
php 使用file_get_contents时报错 failed to open stream: No such file or directory (打开流失败,没有这样的文件或目录) 1. 首先确保文件路径没问题 最好是直接复制一下文件的路径 2. windows电脑可以右键该文件 → 属性→安全 →对象名称 选中后复制一下 3. 然后…...
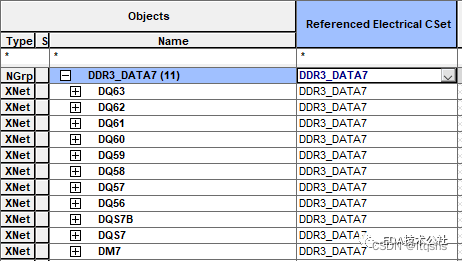
Candence allegro 创建等长的方法
随着源同步时序电路的发展,越来越多的并行总线开始采用这种时序控制电路,最典型的代表当属目前炙手可热的DDRx系列。下图这种点到点结构的同步信号,对于攻城狮来说,设置等长约束就非常easy了图片。 But,对于有4、6、8、、、等多颗DDR芯片的ACC同步信号来说,要设置等长约束…...

使用Python批量修改文件名称
下载了一些图片,想要更改其文件的名称。 试了许多方法,都不太理想。 于是想到了使用Python来实现。 需要用到的模块及函数: import osrename() 函数用于改变文件或文件夹的名称。它接受两个参数:原文件名和新文件名。 os.rena…...

【跟我一起读《视觉惯性SLAM理论与源码解析》】第八章 ORB-SLAM2中的特征匹配
特征匹配在ORB-SLAM2中是很重要的内容,函数有多次重载,一般而言分为以下 单目初始化下的特征匹配通过词袋进行特征匹配通过地图点投影进行特征匹配通过Sim(3)变化进行特征匹配 在单目初始化下的特征匹配是参考帧和当前帧之间的特…...

【Leedcode】数据结构中链表必备的面试题(第四期)
【Leedcode】数据结构中链表必备的面试题(第四期) 文章目录【Leedcode】数据结构中链表必备的面试题(第四期)1.题目2.思路图解(1)思路一(2)思路二3.源代码总结1.题目 相交链表: 如下(示例)&…...

【2023】助力Android金三银四面试
前言 新气象,新生机。在2023年的Android开发行业中,又有那些新的面试题出现呢?对于Android面试官的拷问,我们又如何正确去解答?万变不离其宗,其实只要Android的技术层面没变化,面试题也就是差不…...
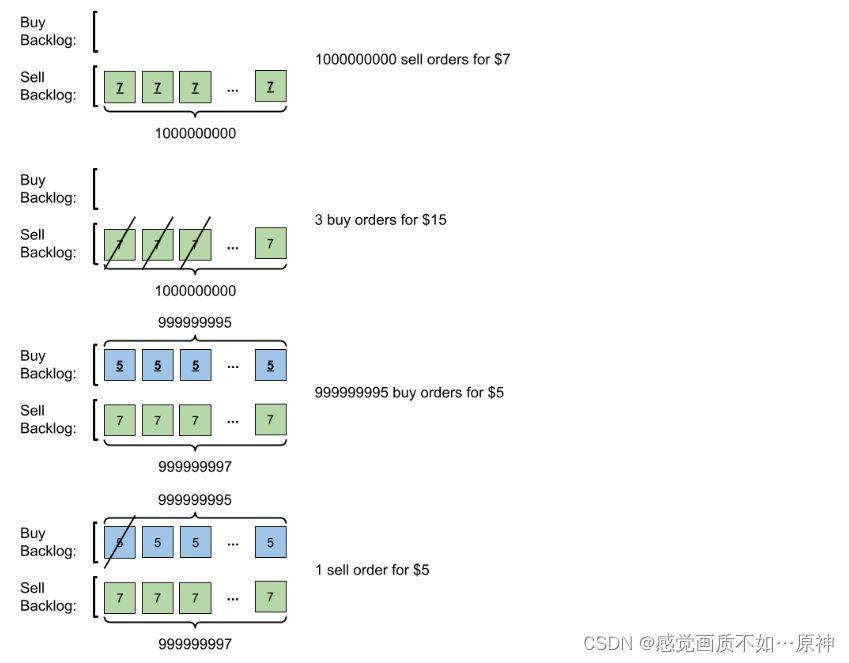
Leetcode.1801 积压订单中的订单总数
题目链接 Leetcode.1801 积压订单中的订单总数 Rating : 1711 题目描述 给你一个二维整数数组 orders,其中每个 orders[i] [pricei, amounti, orderTypei]表示有 amounti笔类型为 orderTypei、价格为 pricei的订单。 订单类型 orderTypei 可以分为两种…...

红帽Linux技术-cp命令
cp是一个复制文件或者目录的命令,其作用是将一个或多个文件或目录从源位置复制到目标位置。 格式:cp [选项] 源文件或目录 目标文件或目录 常用选项: -r:复制目录及其子目录下的所有文件和目录; -p:保留…...

聚焦养老服务管理 以 AI 课堂革新实训教学模式
一、引言在养老产业数智化转型背景下,智慧健康养老服务与管理专业实训室建设需紧扣产业需求。AI 课堂作为教学数字化升级的核心载体,可有效破解传统实训教学与岗位需求脱节、高危场景难实操、教学评价不精准等痛点,为实训室建设提供实用可行的…...

军队/军工场景对智能问数有什么特殊要求?
军队/军工场景对智能问数有什么特殊要求?从POC评测结果看技术路线的适配边界 截至2026年5月的行业实践表明,军队、军工场景是智能问数技术选型中复杂度最高、约束条件最多的领域之一。这类场景的核心特殊要求不在于某个单项能力,而在于系统能…...

为什么公平感比财富本身更影响希望
有些时刻,普通人最难受的不是自己暂时没钱。而是你发现,自己已经很努力地排队、提交材料、遵守规则、等待结果,可最后还是不知道机会到底怎么分配。 孩子上学,要反复比较资源差异。 老人看病,要担心排队、费用和后续照…...
Extracting and saving responses)
第七章 指令微调学习(五)Extracting and saving responses
第七章 指令微调学习(五) 7.7 Extracting and saving responses 在对指令数据集的训练部分完成LLM的微调后,现在评估其在保留测试集上的性能。首先,我们提取测试集中每个输入对应的模型生成响应并进行人工分析;随后通过…...

VideoDownloadHelper:智能视频下载解决方案,轻松保存网页视频资源
VideoDownloadHelper:智能视频下载解决方案,轻松保存网页视频资源 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 在当…...

Seraphine:基于LCU API的英雄联盟智能数据分析与自动化辅助解决方案
Seraphine:基于LCU API的英雄联盟智能数据分析与自动化辅助解决方案 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的专业级游戏数据分析与自动化辅助…...

城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案
城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经被城通网盘的龟速下载折磨得抓狂?面对50KB/s的限速、无尽的验…...

RTX251实时系统中NMI中断支持问题解析
1. RTX251调试中的NMI中断问题解析在嵌入式系统开发中,非屏蔽中断(NMI)作为一种高优先级的中断机制,通常用于处理系统关键错误和调试场景。然而,当使用Keil的RTX251实时操作系统与Temic 251系列芯片配合时,开发者可能会遇到NMI支持…...

MCGS组态软件连接Modbus TCP设备?别急,先搞懂网关的这5种工作模式怎么选
MCGS组态软件连接Modbus TCP设备:网关工作模式深度解析与选型指南 在工业自动化系统中,MCGS组态软件与Modbus TCP设备的稳定通信是数据采集与控制的基础环节。ZLAN5143D作为一款多功能工业网关,其五种工作模式的选择直接影响系统响应速度、数…...

量子电路优化:GSI方法在NISQ时代的应用
1. 量子电路优化的核心挑战与创新思路在当前的NISQ(Noisy Intermediate-Scale Quantum)时代,量子计算机面临着几个关键瓶颈:量子比特的相干时间有限、门操作存在误差、以及量子比特之间的连接受限。这些硬件限制使得量子电路的深度…...