Pulsar 之架构,客户端以及多区域容灾
Pulsar 之架构,客户端以及多区域容灾
- 架构
- Brokers
- Clusters
- 元数据存储
- 配置存储区
- 持久存储
- Apache BookKeeper
- Ledgers
- Ledgers读一致性
- 托管Ledgers
- 日志存储
- Pulsar 代理
- 服务发现
- Pulsar client(客户端)
- 客户端设置阶段
- Reader interface
- 多区域容灾备份(GEO-REPLICATION)
- 复制机制
- Pulsar 中的异步异地复制
- 通过BookKeeper进行同步异地复制
- 复制模式
- 全网格复制
- 双活复制
- 聚合复制
架构
在最高级别上,Pulsar实例由一个或多个Pulsar clusters组成。实例中的集群可以在它们之间复制数据
在一个pulsar cluster中:
- 一个或多个代理处理和负载平衡来自生产者的传入消息,将消息分发给消费者,与Pulsar配置存储通信以处理各种协调任务,将消息存储在BookKeeper实例(又名bookies)中,依赖于特定于集群的ZooKeeper集群来完成某些任务,等等
- 由一个或多个BookKeeper集群组成的BookKeeper集群处理消息的持久存储
- 特定于该集群的ZooKeeper集群处理Pulsar集群之间的协调任务
下图展示了一个pulsar cluster:
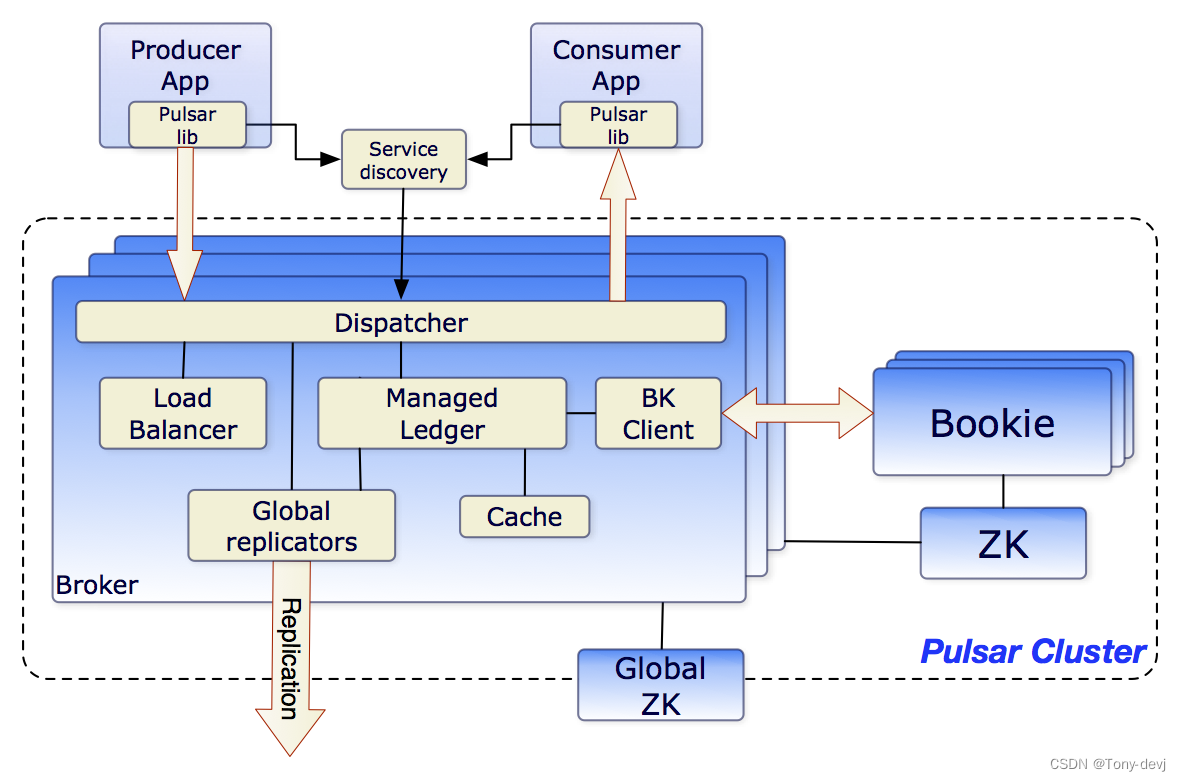
在更广泛的实例级,一个称为配置存储的实例级ZooKeeper集群处理涉及多个集群的协调任务
Brokers
Pulsar消息代理是一个无状态组件,主要负责运行另外两个组件:
- 为生产者和消费者的管理任务和主题查找公开REST API的HTTP服务器。生产者连接到代理以发布消息,消费者连接到代理以消费消息
- 调度程序,它是一个异步TCP服务器,使用自定义二进制协议进行所有数据传输
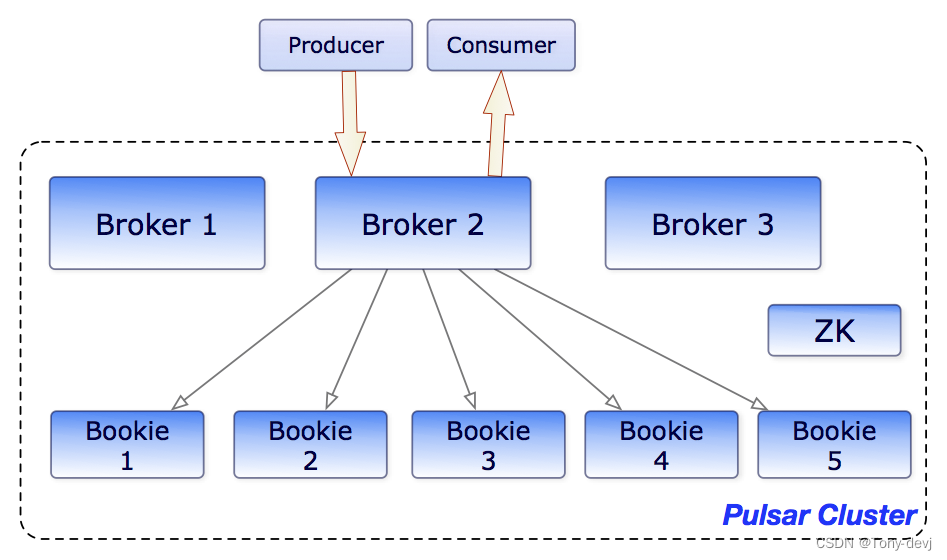
出于性能考虑,消息通常从托管分类账缓存中分派,除非积压超过缓存大小。如果积压对缓存来说太大,代理将开始从BookKeeper读取条目
最后,为了支持全局主题上的地理复制,代理管理复制器,跟踪在本地区域发布的条目,并使用Pulsar Java客户端库将它们重新发布到远程区域
Clusters
pulsar实例由一个或多个pulsar clusters组成。集群依次由:
- 一个或者多个pulsar brokers
- 用于集群级配置和协调的ZooKeeper仲裁
- 用于持久存储消息的bookies集合
元数据存储
Pulsar元数据存储维护Pulsar集群的所有元数据,比如主题元数据、模式、代理加载数据等等。Pulsar使用Apache ZooKeeper进行元数据存储、集群配置和协调。
Pulsar元数据存储可以部署在单独的ZooKeeper集群上,也可以部署在已有的ZooKeeper集群上。可以使用一个ZooKeeper集群同时存储Pulsar元数据和BookKeeper元数据。
如果要部署连接到已有BookKeeper集群的Pulsar broker,则需要分别部署用于Pulsar元数据存储和BookKeeper元数据存储的ZooKeeper集群
Pulsar还支持更多的元数据后端服务,包括etcd和RocksDB(仅适用于独立的Pulsar)
在pulsar 实例中:
- 配置存储仲裁存储租户、名称空间和其他需要全局一致的实体的配置
- 每个集群都有自己的本地ZooKeeper集合,存储特定于集群的配置和协调,比如哪个代理负责哪个主题,以及所有权元数据、代理加载报告、BookKeeper账本元数据等等
配置存储区
配置存储维护Pulsar实例的所有配置,例如集群、租户、名称空间、与分区主题相关的配置,等等.
一个Pulsar实例可以有一个本地集群、多个本地集群或多个跨区域集群。因此,配置存储可以跨Pulsar实例下的多个集群共享配置。
配置存储可以部署在单独的ZooKeeper集群上,也可以部署在已有的ZooKeeper集群上。
持久存储
Pulsar为应用程序提供有保证的消息传递。如果消息成功到达Pulsar代理,它将被发送到预定目标.此保证要求以持久的方式存储未确认的消息,
直到它们可以交付给消费者并被消费者确认为止。这种消息传递模式通常称为持久消息传递。在Pulsar中,所有消息的N个副本存储在磁盘上并同步,
例如在两台服务器上存储4个副本,每个服务器上都有镜像RAID卷
Apache BookKeeper
Pulsar使用名为Apache BookKeeper的系统进行持久消息存储。BookKeeper是一种分布式预写日志(WAL)系统,为Pulsar提供了许多关键优势
优势:
- 使Pulsar能够利用许多独立的日志,称为ledgers。随着时间的推移,可以为主题创建多个ledgers
- 为处理条目复制的顺序数据提供了非常有效的存储
- 保证了账本在各种系统故障时的读一致性
- 在bookies提供均匀分布 I/O
- 在容量和吞吐量上都是水平可扩展的。可以通过向集群中添加更多的赌徒来立即增加容量
- bookies被设计用来处理成千上万的同时读写的ledgers。通过使用多个磁盘设备(一个用于日志,另一个用于一般存储),bookies能够将读操作的影响与正在进行的写操作的延迟隔离开来
除了消息数据外,游标还持久地存储在BookKeeper中。游标是消费者的订阅位置。BookKeeper使Pulsar能够以可伸缩的方式存储消费者位置
目前,Pulsar支持持久消息存储。这说明了所有主题名称中的持久性
persistent://my-tenant/my-namespace/my-topic
可以在下面的图表中看到brokers和bookies如何交互的说明:
Ledgers
Ledgers是一种仅可追加的数据结构,具有单个写入器,该写入器被分配给多个BookKeeper存储节点(或bookies)。Ledger条目被复制到多个bookies
Ledger本身的语义:
- Pulsar代理可以创建一个Ledgers,将条目追加到Ledgers,并关闭Ledgers
- 在关闭Ledgers之后——无论是显式关闭还是因为写入进程崩溃——它只能以只读模式打开
- 最后,当Ledgers中的条目不再需要时,整个Ledgers可以从系统中删除(包括所有的bookies)
Ledgers读一致性
Bookkeeper的主要优点是在出现故障时,它可以保证Ledgers的读一致性。由于Ledgers只能由单个进程写入,因此该进程可以非常有效地自由添加条目,而不需要获得共识。
在发生故障后,Ledgers将经历一个恢复过程,该过程将最终确定Ledgers的状态,并确定最后提交给日志的条目是哪个。在此之后,保证Ledger的所有读者都能看到完全相同的内容
托管Ledgers
考虑到Bookkeeper Ledgers提供了单一的日志抽象,在分类账之上开发了一个库,称为托管Ledgers,它代表单个主题的存储层。
托管Ledgers表示消息流的抽象,其中有一个写入器,它不断在流的末尾追加内容,多个游标正在使用流,每个游标都有自己的关联位置。
在内部,单个托管Ledgers使用多个BookKeeper Ledgers来存储数据。使用多个Ledgers有两个原因:
- 失败后,Ledger不再可写,需要创建一个新的Ledger
- 当所有游标都使用了Ledger所包含的消息时,可以删除Ledger。这允许Ledger的周期性滚动
日志存储
在BookKeeper中,日志文件包含BookKeeper事务日志。在对Ledgers进行更新之前,bookies需要确保将描述更新的事务写入持久性(非易失性)存储。
一旦bookies启动或旧日志文件达到日志文件大小阈值(使用journalMaxSizeMB参数配置),就会创建一个新的日志文件。
Pulsar 代理
Pulsar客户端与Pulsar集群交互的一种方法是直接连接到Pulsar消息代理。然而,在某些情况下,这种直接连接要么是不可行的,要么是不可取的,因为客户端不能直接访问代理地址。
例如,如果在云环境或Kubernetes或类似的平台上运行Pulsar,那么直接连接到代理的客户端可能是不可能的
Pulsar代理通过充当集群中所有代理的单一网关,为这个问题提供了解决方案。如果运行Pulsar代理(这也是可选的),所有与Pulsar集群的客户端连接都将通过代理而不是与代理通信
为了提高性能和容错性,可以运行任意数量的Pulsar代理实例
从体系结构上讲,Pulsar代理从ZooKeeper获得所需的所有信息。在计算机上启动代理时,只需为特定于集群的和实例范围的配置存储集群提供元数据存储连接字符串
$ cd /path/to/pulsar/directory
$ bin/pulsar proxy \--metadata-store zk:my-zk-1:2181,my-zk-2:2181,my-zk-3:2181 \--configuration-metadata-store zk:my-zk-1:2181,my-zk-2:2181,my-zk-3:2181
关于pulsar代理需要知道的一些重要事情:
- 连接客户机不需要提供任何特定的配置就可以使用Pulsar代理。除了更新用于服务URL的IP之外,不需要为现有应用程序更新客户端配置(例如,如果正在Pulsar代理上运行负载平衡器)
- Pulsar代理支持TLS加密和身份验证
服务发现
连接到Pulsar代理的客户端需要能够使用单个URL与整个Pulsar实例通信
如果可以的话,可以使用自己的服务发现系统。如果使用自己的系统,只有一个要求:当客户机向端点执行HTTP请求时,如http://pulsar.us-west.example.com:8080。
客户端需要被重定向到所需集群中的某个活动代理,无论是通过DNS、HTTP或IP重定向,还是其他方式。
下图展示了Pulsar服务发现:
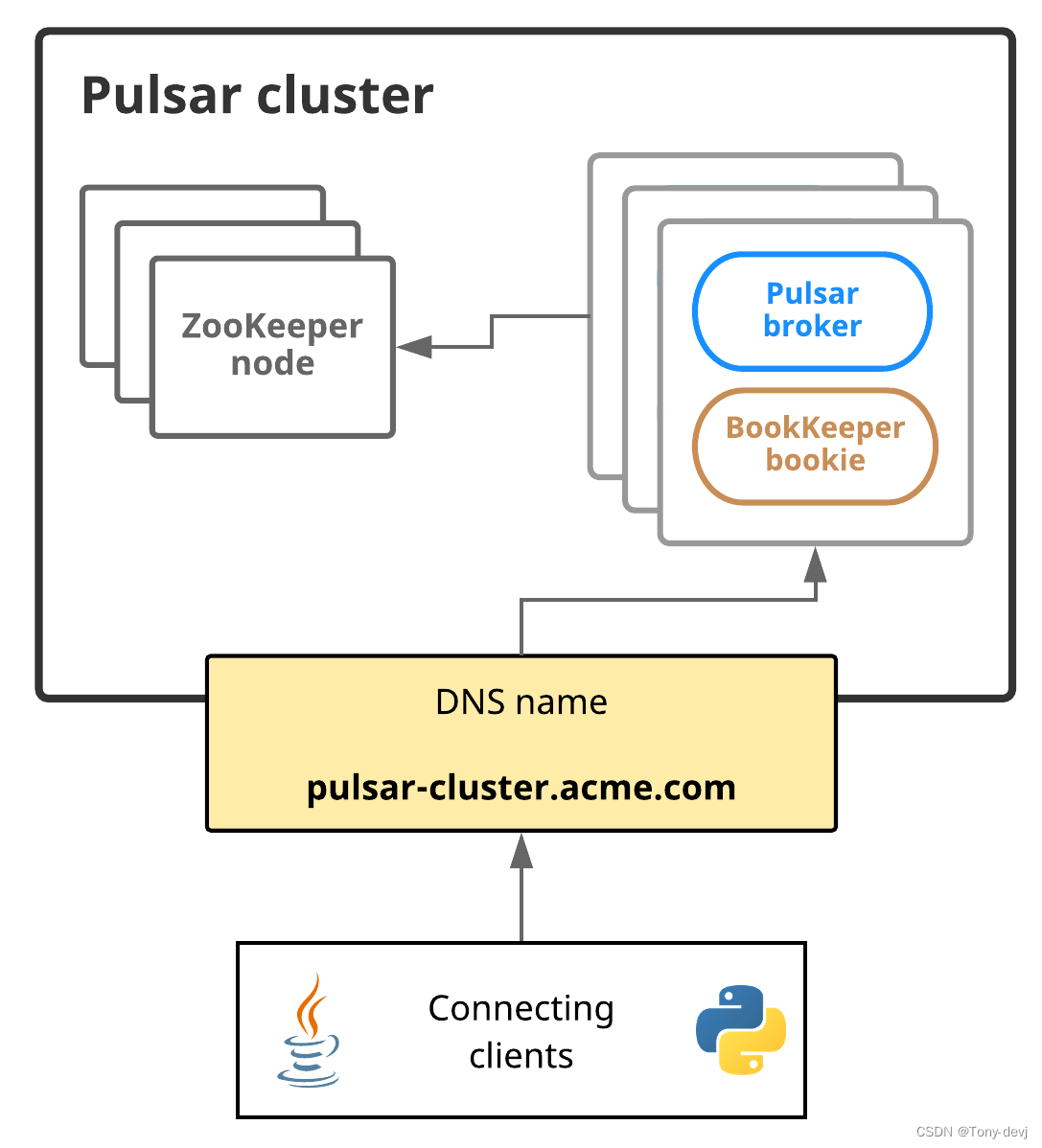
在这个图中,Pulsar集群可以通过一个DNS名称来寻址:pulsar-cluster.acme.com 例如,Python客户端可以像这样访问Pulsar集群:
from pulsar import Clientclient = Client('pulsar://pulsar-cluster.acme.com:6650')
注意:在Pulsar中,每个主题只由一个经纪人处理。客户端读取、更新或删除主题的初始请求被发送到可能不是主题所有者的代理。如果代理不能处理此主题的请求,则它将请求重定向到适当的代理
Pulsar client(客户端)
Pulsar公开了一个带有Java、Go、Python、c++和c#语言绑定的客户端API。客户端API优化并封装Pulsar的客户端-代理通信协议,并公开一个简单直观的API供应用程序使用。
实际上,目前官方的Pulsar客户端库支持透明重连接和连接故障转移到代理,消息排队,直到被代理确认,以及一些启发式操作,如连接重试和回退。
客户端设置阶段
当应用创建producer或者consumer时,Pulsar客户端库需要启动一个设置阶段,包括两个步骤
1. 客户端试图通过向代理发送HTTP查找请求来确定主题的所有者。请求可以到达一个活动代理,通过查看(缓存的)zookeeper元数据,
知道谁在服务主题,或者在没有人服务主题的情况下,尝试将它分配给负载最少的代理
2. 一旦客户端库拥有代理地址,它就创建一个TCP连接(或重用池中现有的连接)并对其进行身份验证,在此连接中,客户端和代理交换来自自定义协议的二进制命令。
此时,客户端发送一个创建producer或者consumer的命令到broker中。在验证了授权策略之后,它将符合要求。
每当TCP连接中断时,客户端立即重新启动这个设置阶段,并不断尝试以指数级回退重新建立生产者或消费者,直到操作成功
Reader interface
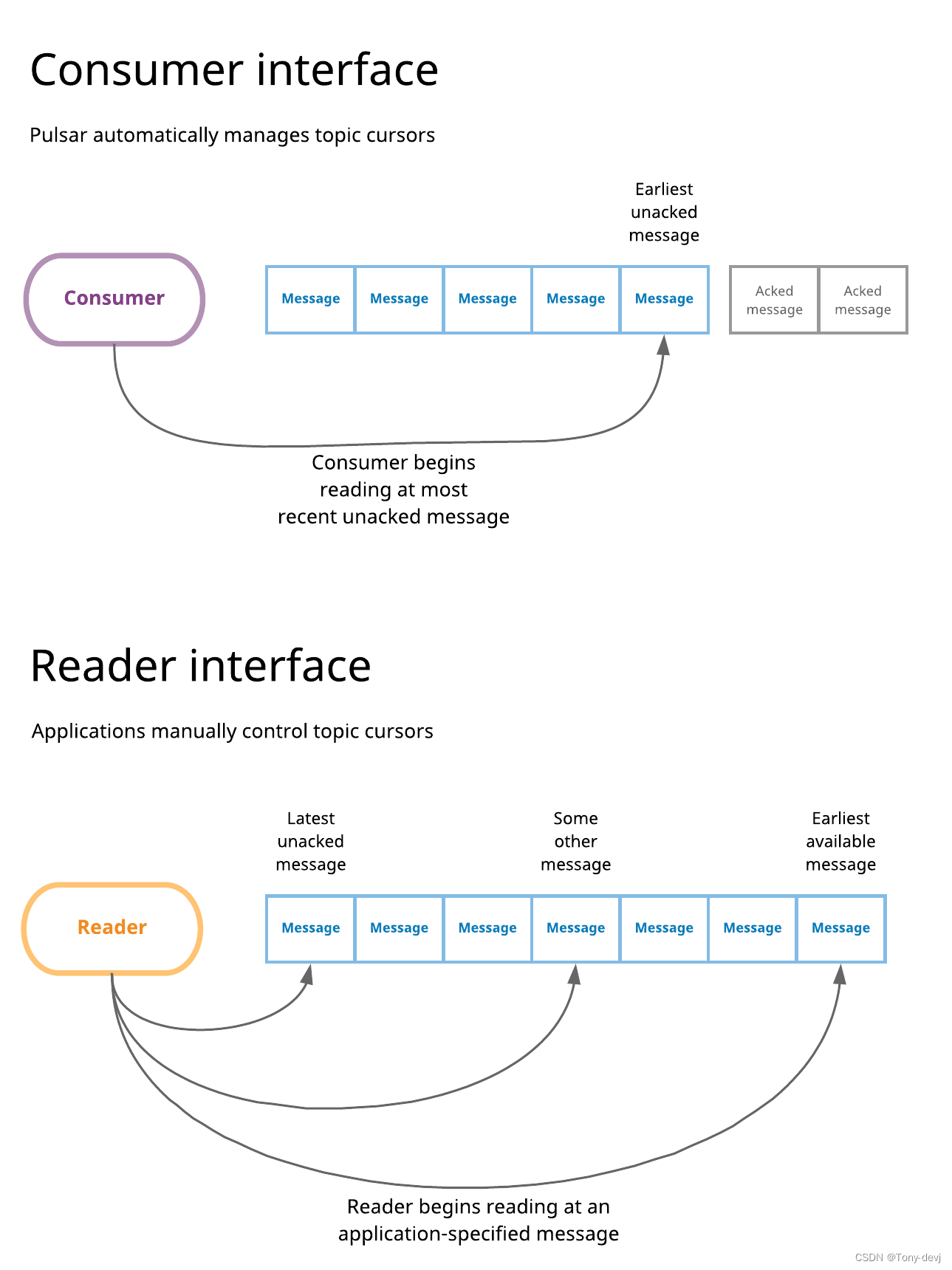
在Pulsar中,“standard”使用者界面包括使用使用者侦听主题、处理传入消息,并最终在处理这些消息时确认这些消息。每当创建一个新订阅时,它最初被定位在主题的末尾(默认情况下),
与该订阅关联的消费者从随后创建的第一条消息开始阅读。每当使用者使用已存在的订阅连接到主题时,它就开始从该订阅中解压缩的最早的消息中读取。总之,使用使用者接口,订阅游标由Pulsar自动管理,以响应消息确认。
Pulsar的阅读器接口允许应用程序手动管理游标。当使用阅读器连接到主题(而不是使用者)时,需要指定阅读器连接到主题时从哪条消息开始阅读。当连接到一个主题时,阅读器接口允许从如下几点读取:
- 主题中最早可用的消息
- 主题中最新可用的消息
- 还有一些最早和最晚之间的信息。如果选择此选项,则需要显式地提供消息ID。应用程序将负责提前“知道”这个消息ID,可能是从持久数据存储或缓存中获取它
对于使用Pulsar为流处理系统提供有效的一次处理语义等用例,阅读器接口很有帮助。对于这个用例,流处理系统必须能够将主题“倒回”到特定的消息,并从那里开始读取。阅读器接口为Pulsar客户端提供了在主题中“手动定位”自己所需的低级抽象
在内部,阅读器接口作为使用者实现,使用具有随机分配名称的独占的、非持久的主题订阅。
不像subscription/consumer,reader本质上是非持久性的,并且不会阻止主题中的数据被删除,因此`强烈建议`配置数据保留。如果在足够的时间内没有为主题配置数据保留,
则可能会删除reader尚未阅读的消息。这会导致reader基本上跳过消息。为主题配置数据保留可以保证reader在一定的时间内阅读消息
还请注意,一个阅读器可能有一个“backlog”,但该指标仅用于用户了解阅读器的落后程度。该指标不用于任何积压配额计算.
import org.apache.pulsar.client.api.Message;
import org.apache.pulsar.client.api.MessageId;
import org.apache.pulsar.client.api.Reader;
// Create a reader on a topic and for a specific message (and onward)
Reader<byte[]> reader = pulsarClient.newReader().topic("reader-api-test").startMessageId(MessageId.earliest).create();while (true) {Message message = reader.readNext();// Process the message
}
// create a reader that reads from the latest available message
Reader<byte[]> reader = pulsarClient.newReader().topic(topic).startMessageId(MessageId.latest).create();
// create a reader that reads from some message between the earliest and the latest
byte[] msgIdBytes = // Some byte array
MessageId id = MessageId.fromByteArray(msgIdBytes);
Reader<byte[]> reader = pulsarClient.newReader().topic(topic).startMessageId(id).create();
多区域容灾备份(GEO-REPLICATION)
无论在哪个行业,当不可预见的事件发生并导致日常操作停止时,组织都需要一个准备充分的灾难恢复计划来快速恢复对客户的服务。然而,灾难恢复计划通常需要多数据中心部署,
数据中心在地理上分散。这种多数据中心部署需要一个GEO复制机制,以便在数据中心发生故障时提供额外的冗余。
Pulsar的地理复制机制通常用于灾难恢复,支持跨多个数据中心复制持久存储的消息数据。例如,应用程序正在一个区域发布数据,而希望在其他区域处理数据以供使用。
利用Pulsar的地理复制机制,信息可以在不同的地理位置产生和消费
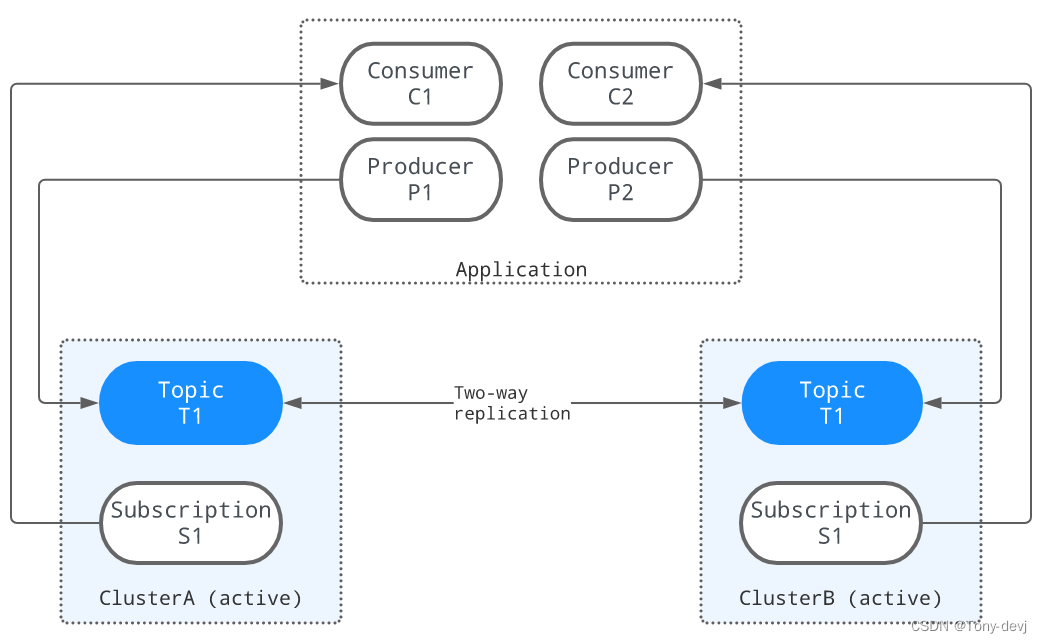
下图说明了地理复制的过程。当三个生产者(P1、P2和P3)分别向三个集群中的T1主题发布消息时,这些消息将立即跨集群复制。一旦消息被复制,
两个消费者(C1和C2)就可以从它们的集群中使用这些消息:
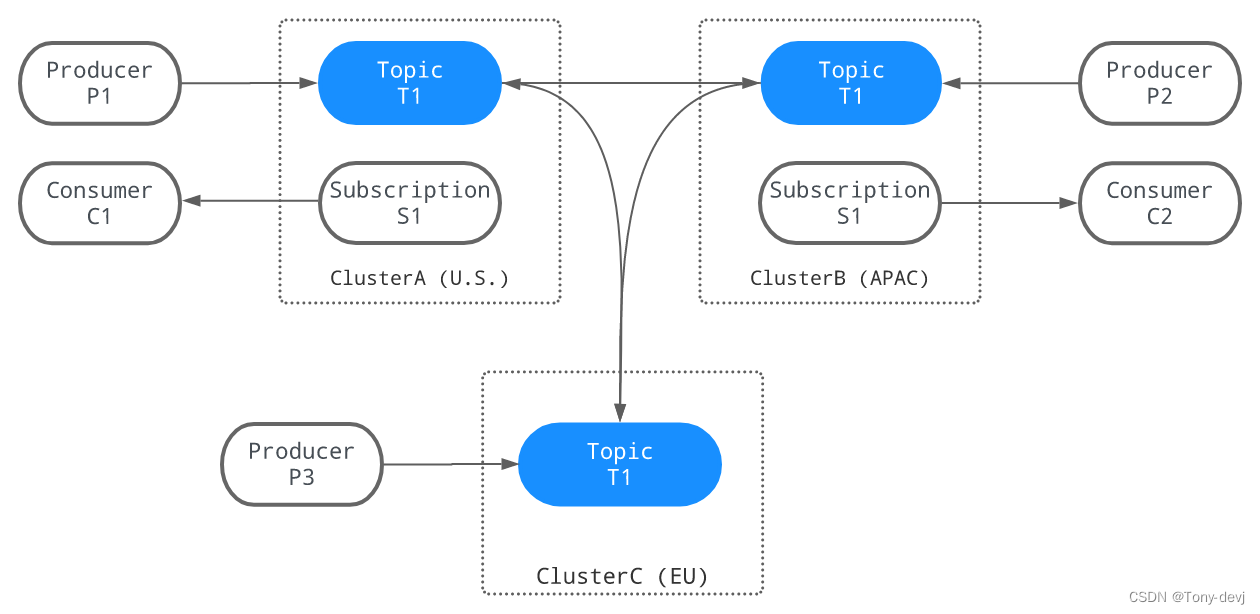
复制机制
Pulsar支持这两种复制机制:
- 同步geo-replication策略
- 异步geo-replication策略
Pulsar 中的异步异地复制
异步地理复制集群由建立在不同数据中心的多个物理集群组成。在Pulsar主题上产生的消息首先持久化到本地集群,然后由代理异步复制到远程集群
在正常情况下,当不存在连接问题时,消息会立即被复制,同时被发送到本地使用者。通常,端到端交付延迟由数据中心之间的网络往返时间(RTT)定义。
应用程序可以在任何集群中创建生产者和消费者,即使远程集群不可达(例如,在网络分区期间).
异步地理复制提供了较低的延迟,但由于潜在的复制延迟(某些数据尚未复制),可能会导致较弱的一致性保证
通过BookKeeper进行同步异地复制
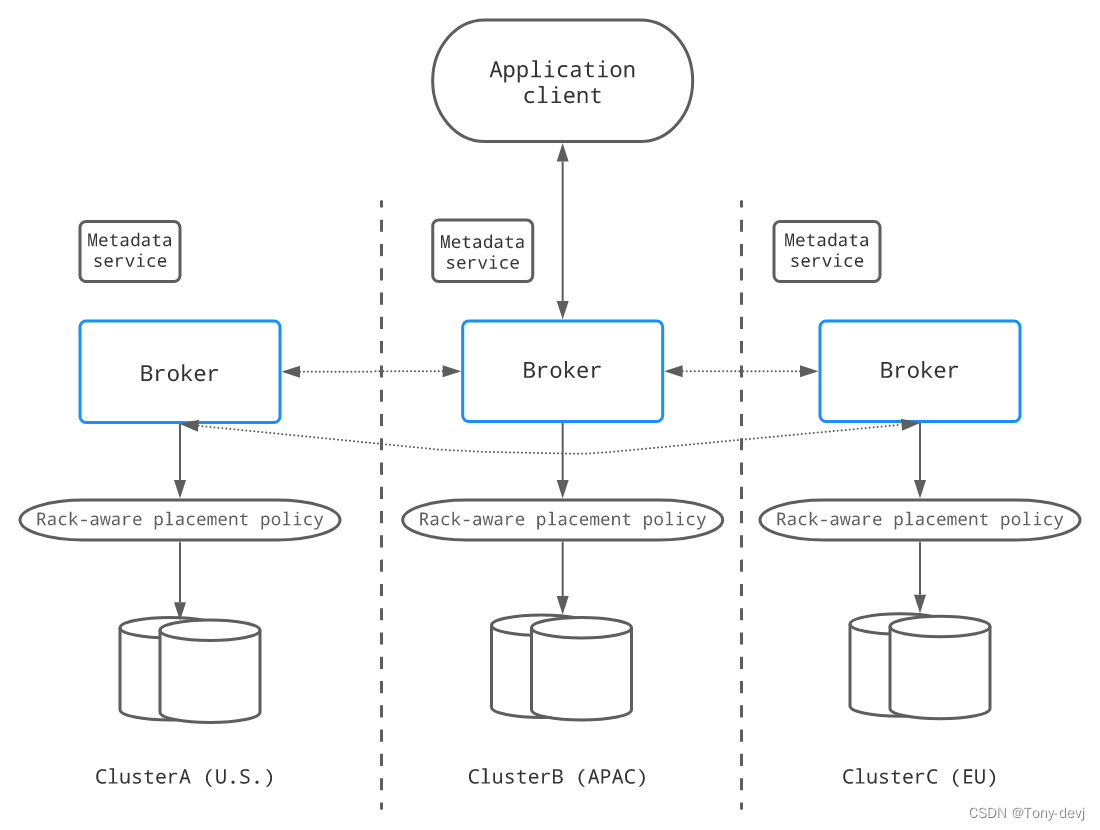
在同步地理复制中,数据被同步复制到多个数据中心,客户端必须等待来自其他数据中心的确认。
如下所示,当客户机向一个集群发出写请求时,写入的数据将被复制到其他两个数据中心。只有当大多数数据中心(在本例中,至少有2个数据中心)已经确认写操作已经持久化时,
才会向客户端确认写请求:
Pulsar中的同步地理复制是由BookKeeper实现的。一个同步的地理复制集群包括一个运行在多个数据中心的bookies集群和一个运行在多个数据中心的代理集群,
以及一个全局Zookeeper安装(一个Zookeeper集成运行在多个数据中心)。需要配置BookKeeper区域感知的放置策略,以跨数据,多个数据中心存储并保证写入时的可用性约束.
同步地理复制提供了最高的可用性,并保证了不同数据中心之间更强的数据一致性。但是,应用程序必须跨数据中心支付额外的延迟代价.
复制模式
Pulsar为自定义复制策略提供了很大程度的灵活性。可以设置不同的复制模式,为多个数据中心之间的应用程序提供复制策略
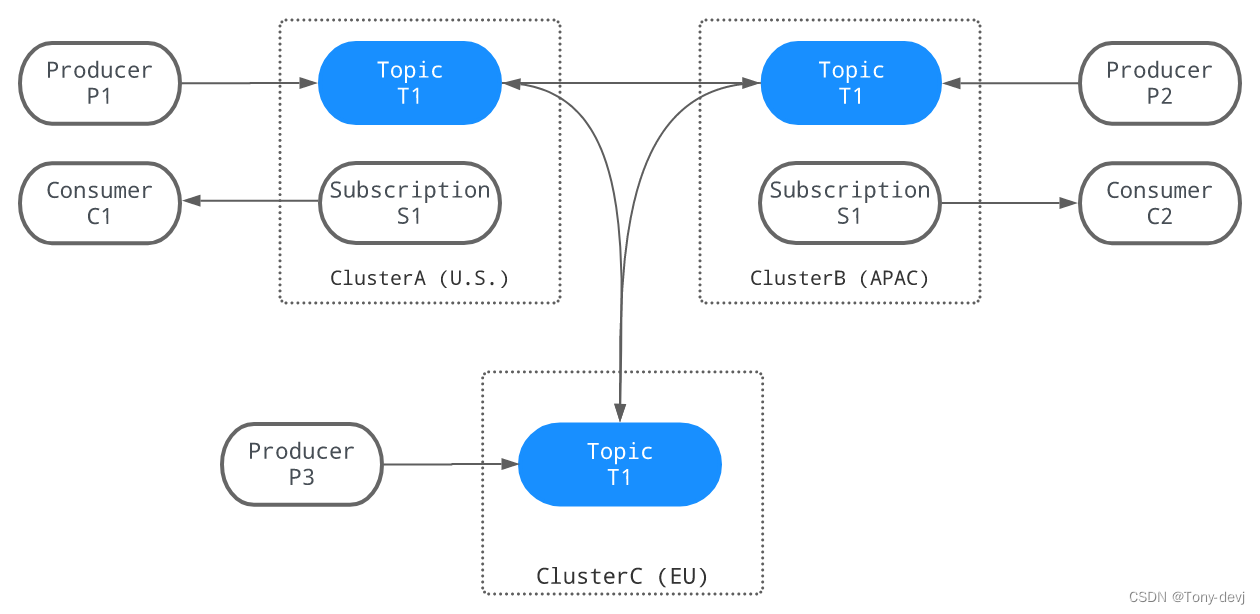
全网格复制
使用全网格复制和应用选择性消息复制,可以在任意数量的数据中心之间自定义复制策略和拓扑
双活复制
双活复制是全网格复制的一种变体,只有两个数据中心。生产者可以在任何数据中心运行以生成消息,而消费者可以使用来自所有数据中心的所有消息
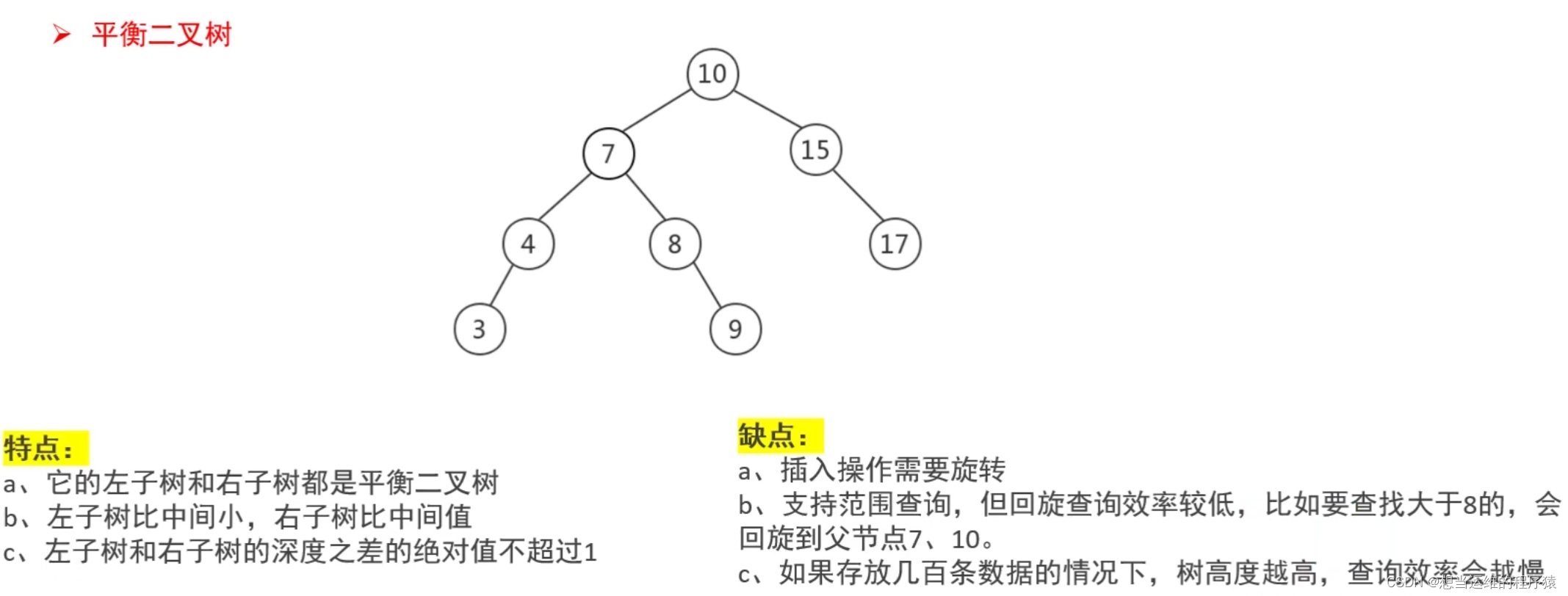
聚合复制
聚合复制模式通常用于将消息从边缘复制到云。例如,假设在3个前端数据中心中有3个集群,在一个中央数据中心中有一个聚合集群,
并且希望将来自多个前端数据中心的消息复制到中央数据中心以实现聚合。然后,可以为每个前端数据中心使用的主题创建单独的名称空间,并将聚合的数据中心分配给这些名称空间

相关文章:
Pulsar 之架构,客户端以及多区域容灾
Pulsar 之架构,客户端以及多区域容灾 架构BrokersClusters元数据存储配置存储区持久存储Apache BookKeeperLedgersLedgers读一致性托管Ledgers 日志存储 Pulsar 代理服务发现 Pulsar client(客户端)客户端设置阶段Reader interface 多区域容灾备份(GEO-REPLICATION)…...
【SQL】MySQL中的索引,索引优化
索引是存储引擎用来快速查询记录的一种数据结构,按实现方式主要分为Hash索引和B树索引。 按功能划分,主要有以下几类 单列索引指的是对某一列单独建立索引,一张表中可以有多个单列索引 1. 单列索引 - 普通索引 创建索引(关键字i…...

uniapp 跳转到指定位置
this.$router.push({name: Demo,params: {id: 123} })这样就实现了页面的跳转,并且将参数id传递给了Demo组件。 如果需要跳转到当前页面的不同位置,我们可以使用锚点来实现。锚点是一个HTML元素的标识符,可以用于定位和跳转到该元素。例如&a…...
基于java的图书馆预约座位系统的设计与实现(部署+源码+LW)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java的图书馆预约座…...
golang 拉取 bitbucket.org 私有库
以 bitbucket.org 平台和mac电脑为例 前置条件私库需要给你账号权限,可拉取的权限,否则无法进行正常拉取 我们采用ssh方式,需要在本地生成对应的 rsa 的公钥和私钥,将公钥配置如下图: 在 .ssh/config 写入你的配置 H…...

Sub-1G射频收发器soc芯片 UM2080F32 低功耗 32 位 IoTP
UM2080F32是基于 ARM Cortex M0 内核的超低功耗、高性能的、单片集成 (G)FSK/OOK 无线收发机的 32 位SOC 芯片。 UM2080F32 工作于200MHz~960MHz 范围内,支持灵活可设的数据包格式,支持自动应答和自动重发功能,支持跳频操作,支持 …...

国际减灾日 | 智慧减灾——百分点科技的数据科学视角
国际减轻自然灾害日简称“国际减灾日”,由联合国于1989年设立,旨在关注全球灾害风险,呼吁各国政府、组织和个人积极参与减灾工作,以保护人民生命财产安全。今年10月13日是第34个国际减灾日,主题为“共同打造有韧性的未…...

ChatGLM流式输出的报错修复
ChatGLM中的openai_api.py中的代码如下: # codingutf-8 # Implements API for ChatGLM2-6B in OpenAIs format. (https://platform.openai.com/docs/api-reference/chat) # Usage: python openai_api.py # Visit http://localhost:8000/docs for documents.import …...

HDLbits: ece241 2013 q12 // Exams/m2014 q4k
两道题目,有一样的问题: 第一道:ece241 2013 q12 下面的代码错误,一直没看出来哪里有问题: module top_module (input clk,input enable,input S,input A, B, C,output Z ); reg [7:0] q;dff dff_1(clk,enable,S,q[…...
)
vue3模板-vscode设置(语法糖)
选择菜单里的 文件 > 首选项 > 用户代码片段 vscode模板 {"Print to conaole":{"prefix": "v-ts", //在新建立的页面中输入C就会有智能提示,Tab就自动生成好了"body": ["<template>"," <…...

RFID超高频读写器的特点和应用
RFID读写器根据不同的工作频段可以分为高频读写器和超高频读写器,高频读写器通常在13.56Mhz频段工作,超高频读写器一般在860-960M Hz频段工作。下面我们就来为大家详细介绍一下,超高频读写器的特点和实际应用。 超高频读写器的工作原理 超高频…...

诡异事件:开发的安卓摄像头应用突然不能保存图片,回滚代码都查不出来
昨天对摄像头应用进行了大规模修改,在一个工程中,同时编译两个app。一番辛苦工作之后,成功。进行了测试,发现诡异的事情:照相无法保存! 那怎么办?赶紧增加搞权限,没用。 逐个版本回滚…...
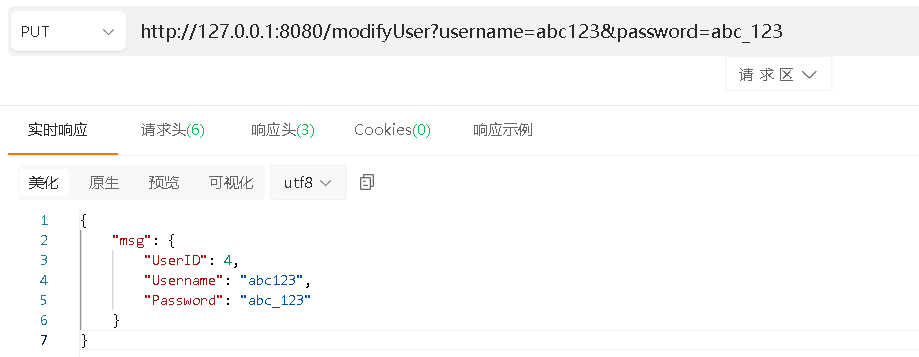
validator库的使用详解
目录 基本使用前言请求模型的定义编写接口及测试 翻译校验错误提示信息自定义错误提示信息的字段名自定义校验规则常见的参数校验字段 基本使用 前言 在做API开发时,需要对请求参数的校验,防止用户的恶意请求。例如日期格式,用户年龄&#x…...
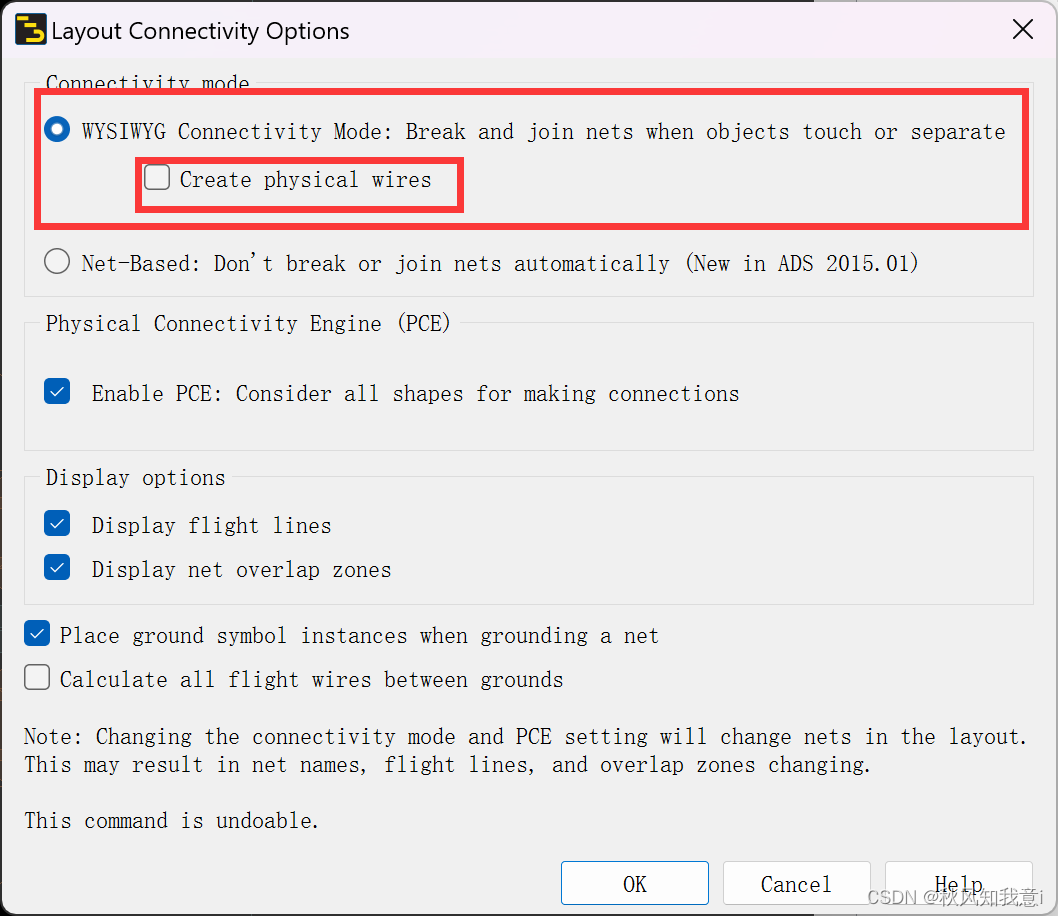
ADS版图中连接提示线设置
ADS版图连接提示线设置 简述solve 简述 在ADS版中连接提示线设置,如下图1所示,有点类似于AD中“金线”,提示同一网络的焊盘,但在ads中,是产生了同一层的wire,证据如图2所示。如果没有设置的话,…...

【MySQL】内置函数——数学函数+其他函数
文章目录 一. 数字函数二. 其他函数 一. 数字函数 函数名称描述abs()绝对值函数bin()十进制转换二进制hex()转换成十六进制conv(number,from_base,to_base)将number从from_base转换成to_base进制ceiling()向上取整floor()向下取整format(number,decimal_places)格式化…...

Ubuntu 23.10 Beta 镜像开放下载
导读Canonical放出了 Ubuntu 23.10 Beta 镜像,此外 Edubuntu、Kubuntu、Lubuntu、Ubuntu Budgie、Ubuntu Cinnamon、Ubuntu Kylin、Ubuntu MATE、Ubuntu Studio、Ubuntu Unity 和 Xubuntu 等风味版本也同步放出镜像。 近日消息,Canonical 放出了 Ubuntu …...

mybatispagehelp嵌套分页处理
1.定义嵌套vo类 /*** 用户中心,我的订单列表VO*/ public class MyOrdersVO {private String orderId;private Date createdTime;private Integer payMethod;private Integer realPayAmount;private Integer postAmount...
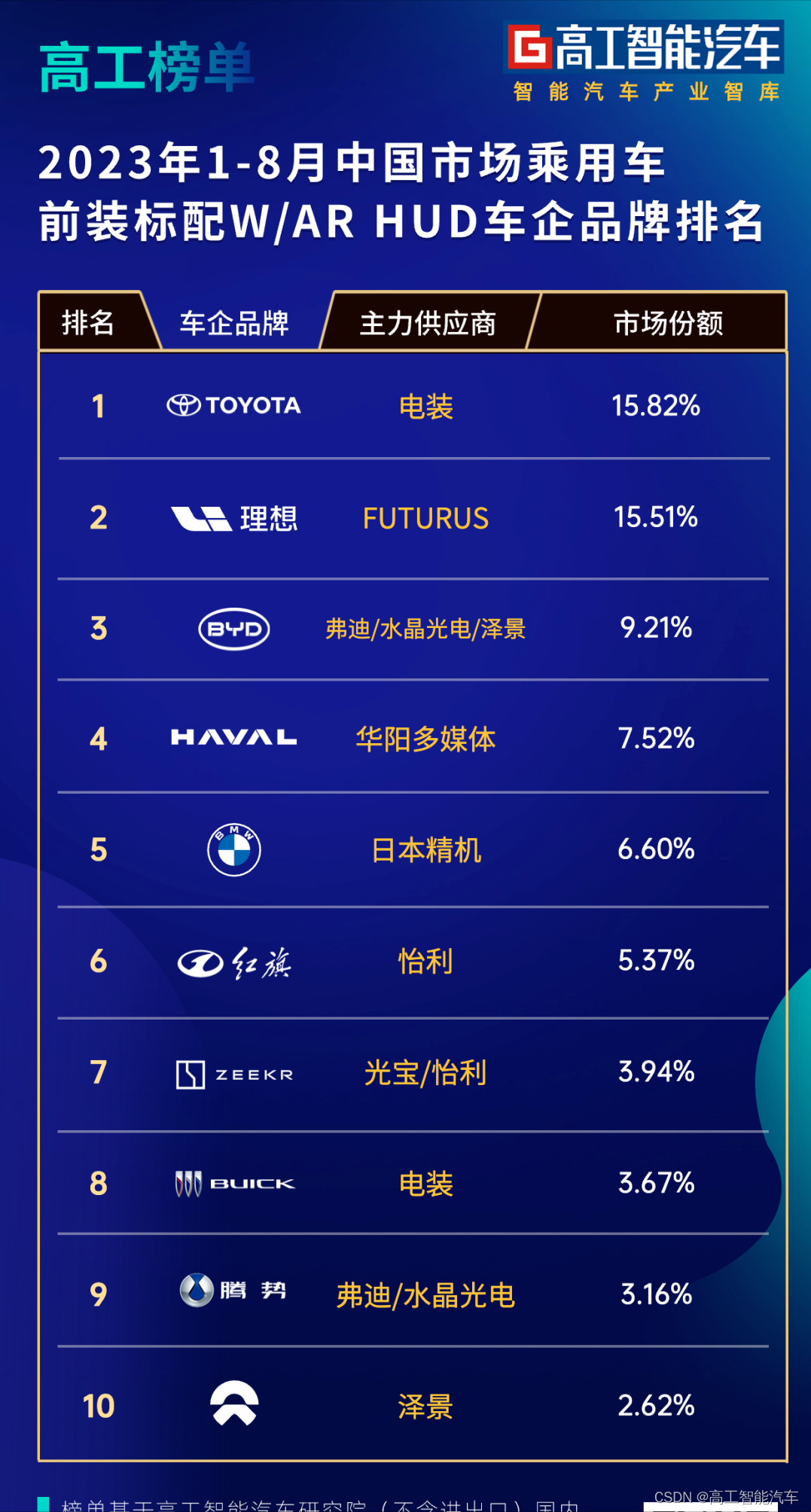
增速波动!W「下」AR「上」!HUD前装供应商比拼硬核能力
作为汽车智能座舱人机交互的新配置之一,HUD(抬头显示)市场在经历一波快速增长周期后,进入调整阶段。 本周,高工智能汽车研究院发布数据显示,2023年8月,中国市场(不含进出口ÿ…...
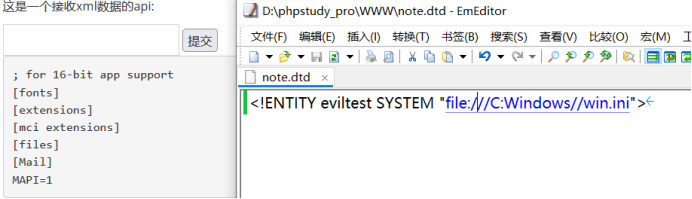
XXE漏洞复现实操
文章目录 一、漏洞原理二、验证payload三、没有回显时的验证四、漏洞特征五、读取文件六、Base64加密读取七、端口检测八、使用php检测端口九、dtd外部实体读取文件十、Xxe漏洞防御 一、漏洞原理 (1)XXE漏洞全称XML External Entity Injection,即xmI外部实体注入漏…...
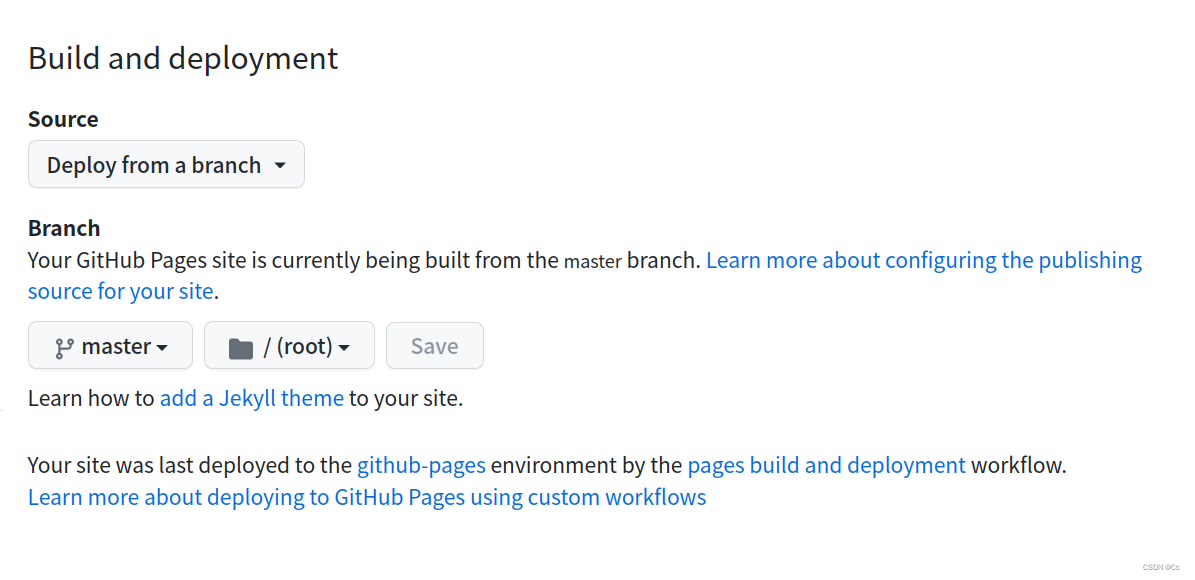
github创建个人网页登录后404无法显示的问题
1.首先必须要有内容,默认是会找index.html文件,找不到该文件会找readme.md文件,也就是说最简单的方法是,创建了与用户名同名的repository后username.github.io后,添加一个readme.md文件,得在readme里打点字…...

2026 AI 技术生态全景指南:从 LLM 到 Agent,从 MCP 到 A2A
AI 技术生态指南 整合 AI/ML/DL 核心概念、模型对比、基础设施与工具链的完整参考。 你是否也有这些困惑? 🤔 GPT、Claude、Gemini、DeepSeek、Qwen…20 模型到底怎么选? 🤔 MCP 和 A2A 这两个新协议有什么区别?谁提出…...

别再截图了!用AD21把PCB 3D模型直接塞进PDF,客户评审一目了然
用AD21将PCB 3D模型嵌入PDF:提升设计评审效率的终极方案 在硬件开发流程中,设计评审环节往往成为项目推进的瓶颈。传统方式下,工程师不得不反复截取多角度2D图纸,或录制繁琐的演示视频,既耗费时间又难以全面展示设计细…...

VMware Unlocker深度解析:在x86平台激活macOS虚拟化潜能
VMware Unlocker深度解析:在x86平台激活macOS虚拟化潜能 【免费下载链接】unlocker VMware macOS utilities 项目地址: https://gitcode.com/gh_mirrors/unl/unlocker 技术突破:解锁硬件兼容性壁垒 在虚拟化技术领域,macOS系统一直保…...

从MySQL到Neo4j:用你熟悉的SQL思维,快速上手CQL创建第一个知识图谱
从MySQL到Neo4j:用SQL思维快速构建知识图谱的实战指南 当你在MySQL中熟练编写JOIN查询时,是否想过这些表关系本质上就是一张网?图数据库将这种网状关系作为一等公民,而Neo4j正是这个领域的佼佼者。本文会带你用熟悉的SQL视角&…...

从游戏画面Bug到图形学原理:一次深度测试失败的排查与透视矫正插值的深度理解
从游戏画面Bug到图形学原理:深度测试失败的排查与透视矫正插值解析 深夜调试游戏引擎时,屏幕上的三角形边缘突然出现诡异的闪烁——这种被称为"深度冲突"的现象,往往让开发者陷入漫长的调试循环。本文将以一个实际开发中的深度测试…...

如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南
如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为编写技术文档时需要在代码编辑器与图表预览工…...

FlicFlac:3分钟掌握Windows音频格式转换的终极免费工具
FlicFlac:3分钟掌握Windows音频格式转换的终极免费工具 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备间的音频格式兼容性问…...
)
用STM32F103C8T6和HC-08蓝牙模块,从零到一打造你的第一辆遥控小车(CubeMX+HAL库保姆级教程)
从零构建STM32蓝牙遥控小车:CubeMX配置与实战全解析 第一次接触嵌入式开发时,那种让硬件按照自己编写的代码动起来的成就感,至今记忆犹新。本文将带你完整经历用STM32F103C8T6和HC-08蓝牙模块打造遥控小车的全过程,特别适合刚学完…...

TestDisk PhotoRec:免费开源数据恢复终极指南,快速找回丢失的分区和文件
TestDisk & PhotoRec:免费开源数据恢复终极指南,快速找回丢失的分区和文件 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾经不小心删除了重要文件?或者硬盘分…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...