线性回归模型进行特征重要性分析
目的
线性回归是很常用的模型;在局部可解释性上也经常用到。
数据归一化
归一化通常是为了确保不同特征之间的数值范围差异不会对线性模型的训练产生过大的影响。在某些情况下,特征归一化可以提高模型的性能,但并不是所有情况下都需要进行归一化。
归一化的必要性取决于你的数据和所使用的算法。对于某些线性模型,比如线性回归和支持向量机,数据归一化是一个常见的实践,因为它们对特征的尺度敏感。
但对于其他算法,如决策树和随机森林,通常不需要进行归一化。
在实际应用中,建议根据你的数据和所选用的模型来决定是否进行归一化。如果你的数据特征具有不同的尺度,并且你使用的是那些对特征尺度敏感的线性模型,那么进行归一化可能会有所帮助。否则,你可以尝试在没有归一化的情况下训练模型,然后根据模型性能来决定是否需要进行归一化。
对新数据进行归一化处理
new_data_sample_scaled = scaler.transform(new_data_sample)# 使用模型进行预测
predicted_value = model.predict(new_data_sample_scaled)
这样就能确保在预测新数据时,特征的尺度与训练数据保持一致。MinMaxScaler底层代码
class MinMaxScaler Found at: sklearn.preprocessing.dataclass MinMaxScaler(BaseEstimator, TransformerMixin):def __init__(self, feature_range=(0, 1), copy=True):self.feature_range = feature_rangeself.copy = copydef _reset(self):"""Reset internal data-dependent state of the scaler, if necessary.__init__ parameters are not touched."""# Checking one attribute is enough, becase they are all set together# in partial_fitif hasattr(self, 'scale_'):del self.scale_del self.min_del self.n_samples_seen_del self.data_min_del self.data_max_del self.data_range_def fit(self, X, y=None):"""Compute the minimum and maximum to be used for later scaling.Parameters----------X : array-like, shape [n_samples, n_features]The data used to compute the per-feature minimum and maximumused for later scaling along the features axis."""# Reset internal state before fittingself._reset()return self.partial_fit(X, y)def partial_fit(self, X, y=None):"""Online computation of min and max on X for later scaling.All of X is processed as a single batch. This is intended for caseswhen `fit` is not feasible due to very large number of `n_samples`or because X is read from a continuous stream.Parameters----------X : array-like, shape [n_samples, n_features]The data used to compute the mean and standard deviationused for later scaling along the features axis.y : Passthrough for ``Pipeline`` compatibility."""feature_range = self.feature_rangeif feature_range[0] >= feature_range[1]:raise ValueError("Minimum of desired feature range must be smaller"" than maximum. Got %s." % str(feature_range))if sparse.issparse(X):raise TypeError("MinMaxScaler does no support sparse input. ""You may consider to use MaxAbsScaler instead.")X = check_array(X, copy=self.copy, warn_on_dtype=True, estimator=self, dtype=FLOAT_DTYPES)data_min = np.min(X, axis=0)data_max = np.max(X, axis=0)# First passif not hasattr(self, 'n_samples_seen_'):self.n_samples_seen_ = X.shape[0]else:data_min = np.minimum(self.data_min_, data_min)data_max = np.maximum(self.data_max_, data_max)self.n_samples_seen_ += X.shape[0] # Next stepsdata_range = data_max - data_minself.scale_ = (feature_range[1] - feature_range[0]) / _handle_zeros_in_scale(data_range)self.min_ = feature_range[0] - data_min * self.scale_self.data_min_ = data_minself.data_max_ = data_maxself.data_range_ = data_rangereturn selfdef transform(self, X):"""Scaling features of X according to feature_range.Parameters----------X : array-like, shape [n_samples, n_features]Input data that will be transformed."""check_is_fitted(self, 'scale_')X = check_array(X, copy=self.copy, dtype=FLOAT_DTYPES)X *= self.scale_X += self.min_return Xdef inverse_transform(self, X):"""Undo the scaling of X according to feature_range.Parameters----------X : array-like, shape [n_samples, n_features]Input data that will be transformed. It cannot be sparse."""check_is_fitted(self, 'scale_')X = check_array(X, copy=self.copy, dtype=FLOAT_DTYPES)X -= self.min_X /= self.scale_return X
数据分箱
n_bins = [5]
kb = KBinsDiscretizer(n_bins=n_bins, encode = 'ordinal')
kb.fit(X[selected_features])
X_train=kb.transform(X_train[selected_features])from sklearn.preprocessing import KBinsDiscretizer
import joblib# 创建 KBinsDiscretizer 实例并进行分箱
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
X_binned = est.fit_transform(X)# 保存 KBinsDiscretizer 参数到文件
joblib.dump(est, 'kbins_discretizer.pkl')# 加载 KBinsDiscretizer 参数
loaded_estimator = joblib.load('kbins_discretizer.pkl')# 使用加载的参数进行分箱
X_binned_loaded = loaded_estimator.transform(X)from sklearn.preprocessing import KBinsDiscretizerdef save_kbins_discretizer_params(estimator, filename):params = {'n_bins': estimator.n_bins,'encode': estimator.encode,'strategy': estimator.strategy,# 其他可能的参数}with open(filename, 'w') as f:for key, value in params.items():f.write(f"{key}: {value}\n")# 创建 KBinsDiscretizer 实例并进行分箱
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')# 保存 KBinsDiscretizer 参数到文本文件
save_kbins_discretizer_params(est, 'kbins_discretizer_params.txt')
KBinsDiscretizer 的源代码
KBinsDiscretizer 的源代码参数包括:n_bins:指定要创建的箱的数量。
encode:指定编码的方法。可以是'onehot'、'onehot-dense'、'ordinal'中的一个。
strategy:指定分箱的策略。可以是'uniform'、'quantile'、'kmeans'中的一个。
dtype:指定输出数组的数据类型。
bin_edges_:一个属性,它包含每个特征的箱的边界。
以下是 KBinsDiscretizer 类的源代码参数的简要说明:n_bins:用于指定要创建的箱的数量。默认值为5。
encode:指定编码的方法。可选值包括:
'onehot':使用一热编码。
'onehot-dense':使用密集矩阵的一热编码。
'ordinal':使用整数标签编码。默认为 'onehot'。
strategy:指定分箱的策略。可选值包括:
'uniform':将箱的宽度保持相等。
'quantile':将箱的数量保持不变,但是每个箱内的样本数量大致相等。
'kmeans':将箱的数量保持不变,但是使用 k-means 聚类来确定箱的边界。默认为 'quantile'。
dtype:指定输出数组的数据类型。默认为 np.float64。
bin_edges_:一个属性,它包含每个特征的箱的边界。这是一个列表,其中每个元素都是一个数组,表示相应特征的箱的边界。
您可以在 sklearn/preprocessing/_discretization.py 中找到 KBinsDiscretizer 类的完整源代码,以查看详细的参数和实现细节。相关文章:
线性回归模型进行特征重要性分析
目的 线性回归是很常用的模型;在局部可解释性上也经常用到。 数据归一化 归一化通常是为了确保不同特征之间的数值范围差异不会对线性模型的训练产生过大的影响。在某些情况下,特征归一化可以提高模型的性能,但并不是所有情况下都需要进行归一…...

hadoop -hive 安装
1.下载hive http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz2.解压/usr/app 目录 tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /usr/app3.设置软连接 ln -s /usr/app/apache-hive-3.1.3-bin /usr/app/hive4.修改/usr/app/hive/conf/hive-env.…...
小迈物联网网关对接串口服务器[Modbus RTU]
很多工控现场,方案中会使用串口服务器采集Modbus RTU的设备,这种情况下一般会在PC机上装上串口服务器厂家的软件来进行数据采集。如果现场不需要PC机,而是通过网关将数据传输到软件平台,如何实现呢? 本文简要介绍小迈网…...

Java版本+企业电子招投标系统源代码+支持二开+招投标系统+中小型企业采购供应商招投标平台
功能模块: 待办消息,招标公告,中标公告,信息发布 描述: 全过程数字化采购管理,打造从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通供应商门户具备内外协同的能力,为外部供…...
Vue3中reactive, onMounted, ref,toRaw,conmpted 使用方法
import { reactive, onMounted, ref,toRaw,conmpted } from vue; vue3中 reactive ,ref , toRaw,watch,conmpted 用法 toRaw 返回原响应式对象 用法: const rowList toRaw(row) reactive:ref: ref和reactive都是V…...
有哪些免费的PPT模板网站,推荐这6个PPT模板免费下载网站!
混迹职场的打工人,或是还在校园的学生党,在日常的工作汇报或课程作业中,必然少不了PPT的影子,而每当提到做PPT,许多人首先会想到:有哪些免费的PPT模板下载网站? 本着辛苦自己,造福所…...
剧院建筑三维可视化综合管控平台提高安全管理效率
随着数字孪生技术的高速发展,智慧楼宇也被提上日程,以往楼宇管理存在着设备故障排查困难、能源浪费与管理不足、安全性和风险高等问题,而智慧楼宇数字孪生可视化中控平台,打造智慧楼宇管理一张图,实现了智慧建筑和楼宇…...

“过度炒作”的大模型巨亏,Copilot每月收10刀,倒赔20刀
大模型无论是训练还是使用,都比较“烧钱”,只是其背后的成本究竟高到何处?已经推出大模型商用产品的公司到底有没有赚到钱?事实上,即使微软、亚马逊、Adobe 这些大厂,距离盈利之路还有很远!同时…...

顺序表经典的OJ题
题目一 移除元素: 题目要求: 给你一个数组 nums 和一个值 val。你需要 原地 除所有数值等于 val 的素,并返回移除后数组的新长度.不要使用额外的数组空间。你必须仅使用 0(1) 额外空间并 原地 修改输入数组元素的顺序可以改变。你不需要考虑数…...

video_topic
使用qt5,ffmpeg6.0,opencv,os2来实现。qt并非必要,只是用惯了。 步骤是: 1.读取rtsp码流,转换成mat图像 2.发送ros::mat图像 项目结构如下: videoplayer.h #ifndef VIDEOPLAYER_H #define VIDEOPLAYER_H#include …...
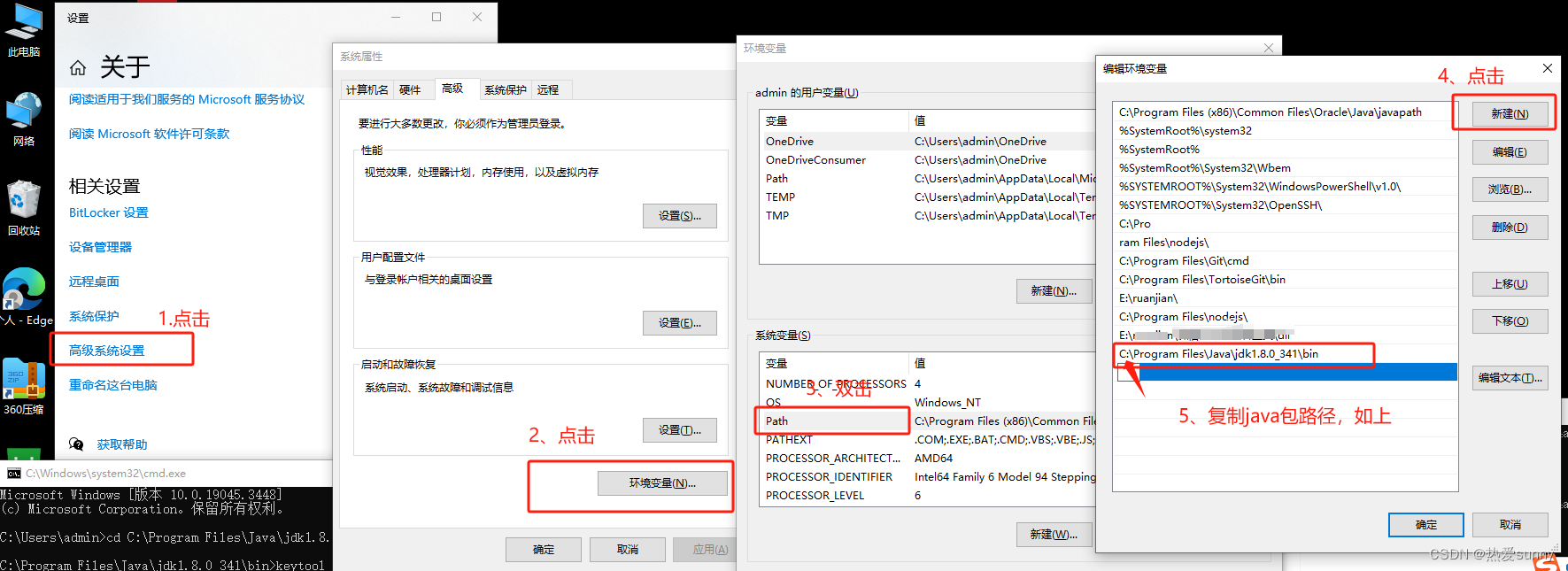
uniapp获取公钥、MD5,‘keytool‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。
获取MD5、SHA1、SHA256指纹信息 通过命令的形式获取 winr调出黑窗口cd到证书所在目录输入keytool -list -v -keystore test.keystore,其中 test.keystore为你的证书名称加文件后缀按照提示输入你的证书密码,就可以查看证书的信息 通过uniapp云端查看(证书是在DClou…...
Jetson Orin NX 开发指南(5): 安装 OpenCV 4.6.0 并配置 CUDA 以支持 GPU 加速
一、前言 Jetson 系列的开发板 CPU 性能不是很强,往往需要采用 GPU 加速的方式处理图像数据,因此本文主要介绍如何安装带有 GPU 加速的 OpenCV,其中 GPU 加速通过 CUDA 来实现。 参考博客 Ubuntu 20.04 配置 VINS-Fusion-gpu OpenCV 4.6.…...

Spring Security 6.x 系列【67】认证篇之安装 ApacheDS
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.1.0 本系列Spring Security 版本 6.1.0 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 1. 概述2. 安装3. 连接工具1. 概述 官方文档 在前两篇文档中,我们简单了…...

理解线程池源码 【C++】面试高频考点
理解线程池 C 文章目录 理解线程池 C程序源码知识点emplace_back 和 push_back有什么区别?互斥锁 mutexcondition_variablestd::move()函数bind()函数join 函数 线程池的原理就是管理一个任务队列和一个工作线程队列。 工作线程不断的从任务队列取任务,然…...
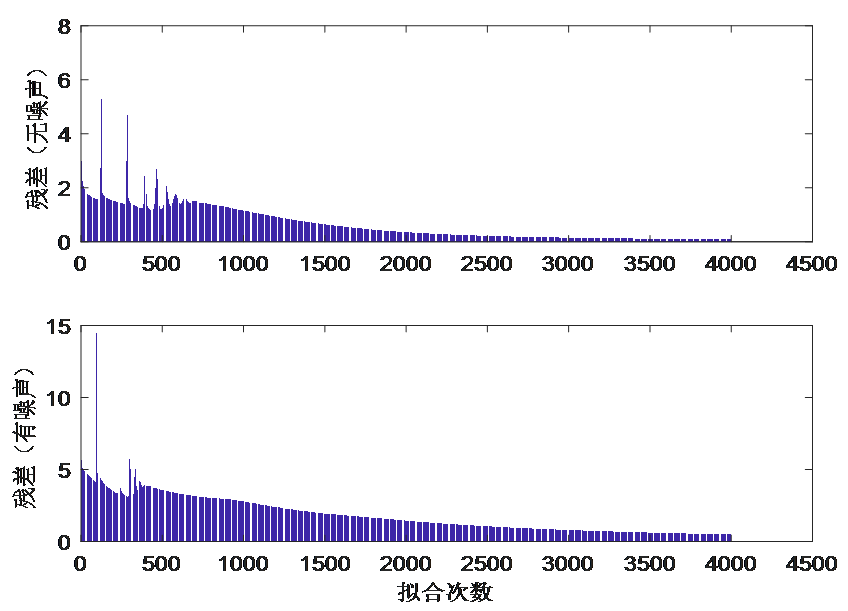
BP神经网络应用案例
目录 背景介绍 【神经网络符号说明】 【建立网络拓扑结构】 【神经网络学习步骤】 步骤1 准备输入和输出样本 步骤2 确定网络学习参数 步骤3 初始化网络权值W和阀值B 步骤4 计算网络第一层的输入和输出 步骤5 计算中间层(隐含层输入和输出) 步骤…...
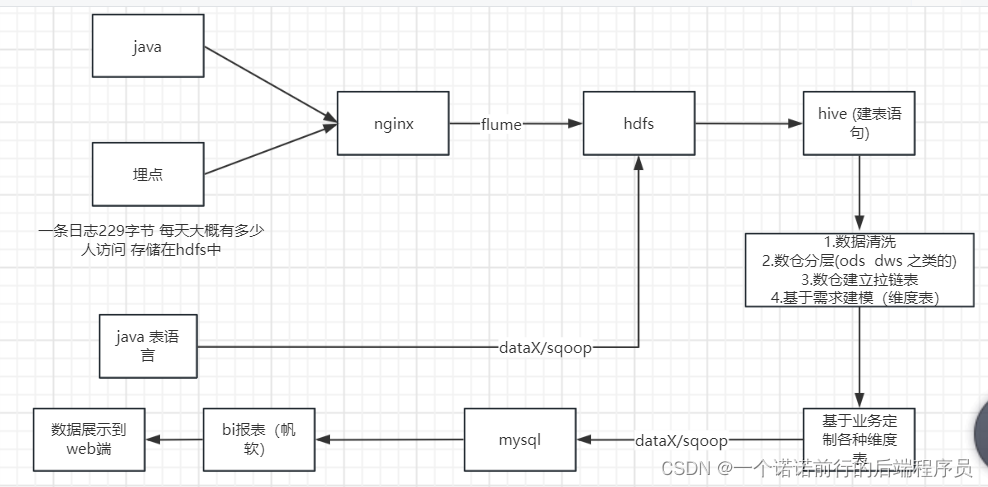
日常学习记录随笔-大数据之日志(hadoop)收集实战
数据收集(nginx)--->数据分析---> 数据清洗--->数据聚合计算---数据展示 可能涉及到zabix 做任务调度我们的项目 电商日志分析 比如说我们现在有一个系统,我们的数仓建立也要有一个主题 我这个项目是什么我要干什么定义方向 对用户进行分析,用户信息 要懂整个数据的流…...
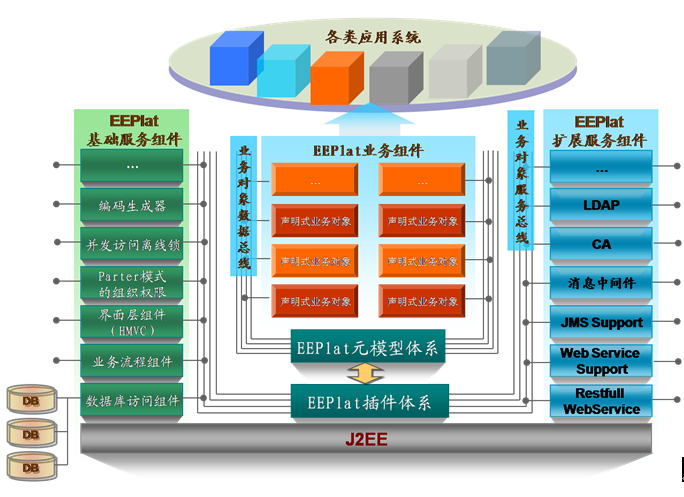
【云计算】相关解决方案介绍
文章目录 1.1 云服务环境 Eucalyptus1.1.1 介绍1.1.2 开源协议及语言1.1.3 官方网站 1.2 开源云计算平台 abiCloud1.2.1 开源协议及语言1.2.2 官方网站 1.3 分布式文件系统 Hadoop1.3.1 开源协议及语言1.3.2 官方网站 1.4 JBoss云计算项目集 StormGrind1.4.1 开源协议及语言1.4…...

攻防世界题目练习——Crypto密码新手+引导模式(二)(持续更新)
题目目录 1. 转轮机加密2. easychallenge 上一篇:攻防世界题目练习——Crypto密码新手引导模式(一)(持续更新) 1. 转轮机加密 首先了解一下轮转机加密吧。 传统密码学(三)——转轮密码机 题目内容如下: …...
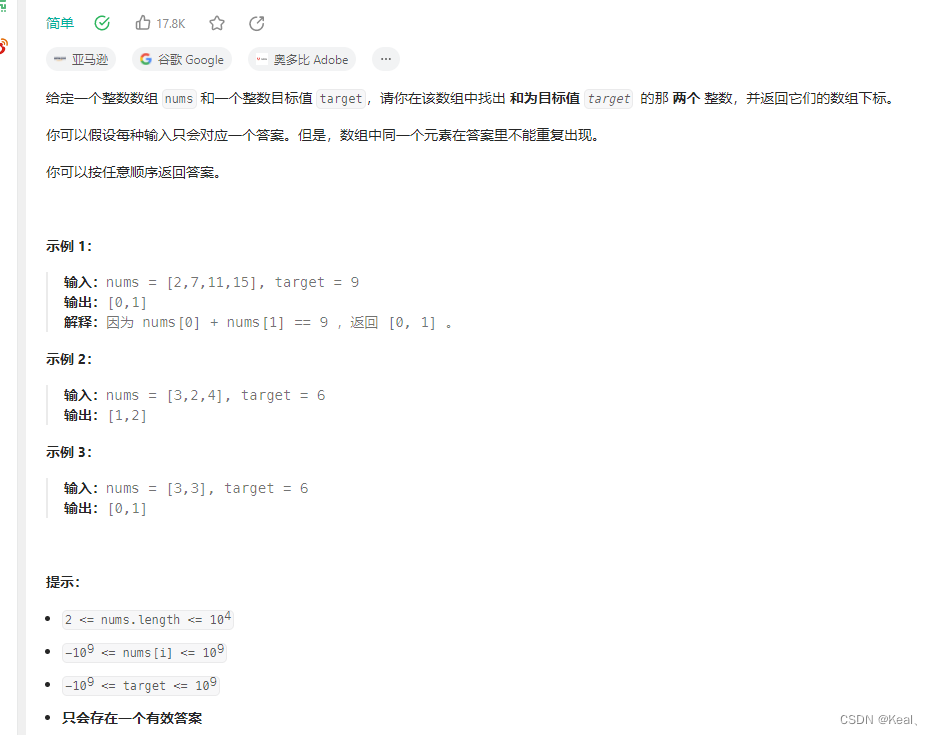
LeetCode【1】两数之和
题目: 代码: public int[] twoSum(int[] nums, int target) {int[] result new int[2];Map<Integer, Integer> map new HashMap<>();// for (int i 0; i < nums.length; i) { // 这么写不能防重复啊!注意这里不…...
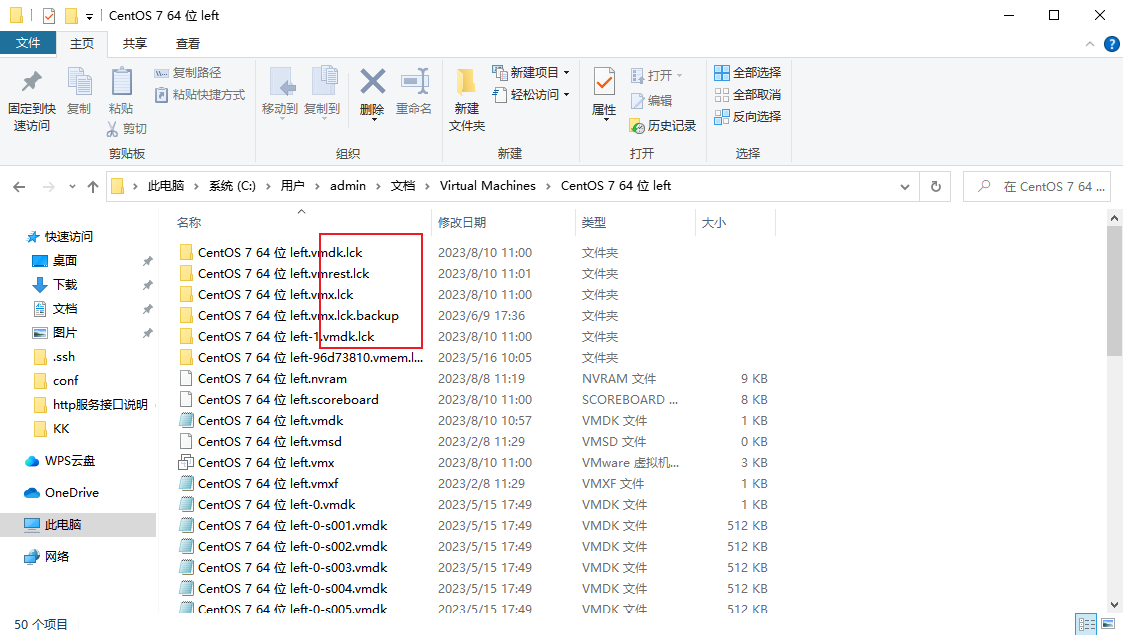
【运维笔记】VMWare 另一个程序已锁定文件的一部分,进程无法访问
情景再现 这里使用的是VMware 17 解决办法 进入设置 点击选项,全选复制里面内容 进入文件夹,删除所有包含.lck后缀的文件和文件夹 再启动虚拟机即可...
)
Sentaurus TCAD实战:手把手教你提取NPN三极管的Gummel-Poon模型参数(SPICE建模必备)
Sentaurus TCAD实战:从Gummel曲线到SPICE模型参数的完整提取流程 在半导体器件设计与电路仿真中,准确的三极管模型参数是确保仿真结果可靠性的关键。传统方法往往依赖器件手册提供的典型参数,但针对特定工艺定制的器件,这些参数可…...

3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南
3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过新安装的软件无法启动…...
)
go 链表 (标准库实现)
Go 链表简介Go 标准库里没有单链表,只在 container/list 包里提供了双向循环链表。两个核心类型list.List :链表本身,包含哨兵节点和长度 list.Element :链表节点,存数据 前后指针 type Element struct {Value interf…...
)
Perplexity新闻搜索失效真相:LLM缓存机制、地域策略与时间戳偏移的三重干扰(内部技术备忘录节选)
更多请点击: https://codechina.net 第一章:Perplexity新闻资讯搜索 Perplexity 是一款以实时性、引用可追溯性和多源聚合为特色的 AI 搜索工具,其“新闻资讯搜索”功能专为技术从业者与研究人员设计,支持按时间范围、可信信源&a…...

零碳园区绿电直供技术的挑战与解决方案
一、难点问题 二次系统+储能推高初投 篇幅有限仅展示了部分 根据650号文 ,绿电直连项目必须配置继电保护、安全稳定控制装置和通信设备等二次系统 ,以确保项目的安全性和稳定性。这些强制性配置显著增加了项目的初始投资成本。 专线造价与全周…...

2026 酒店无人直播服务商推荐:警惕一次性收费陷阱,用心服务才是核心
"一次购买,无任何后续费用!"—— 这样的宣传语让不少酒店经营者心动不已,以为找到了低成本获客的捷径。然而,现实往往事与愿违:软件使用不到1个月,算力耗尽无法开播;直播间频繁卡顿、…...

TP-LINK AX300 网卡驱动
TP-LINK AX300无线网卡的驱动一直不更新,只好自己动手 适配:TL-XDN6000H 免驱版 操作系统:Ubuntu 24.04.4 LTS 内核版本:6.17.0-29-generic #29~24.04.1-Ubuntu https://download.csdn.net/download/zzzhy/92882718...

Visual C++运行库合集:解决Windows程序依赖的终极方案
Visual C运行库合集:解决Windows程序依赖的终极方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过这样的烦恼?刚下载了一个…...

生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制
生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制 生态数据分析中,Mantel检验作为一种常用的空间相关性分析方法,被广泛应用于物种分布与环境因子关系的研究。然而,许多研究者在实际操作中…...

2026四大主流收银系统深度横评:商拓、柚子、商琦云与银阁仕实战对比
在零售和餐饮行业数字化转型的浪潮中,收银系统早已超越了简单的“算账工具”范畴,成为了门店运营的中枢神经。很多店主在选型时容易陷入一个误区:只盯着硬件价格或者界面好不好看,却忽略了系统在高峰期的稳定性、数据链路的打通能…...