Hive实战(03)-深入了解Hive JDBC:在大数据世界中实现数据交互
在大数据领域,Hive作为一种数据仓库解决方案,为用户提供了一种SQL接口来查询和分析存储在Hadoop集群中的数据。为了更灵活地与Hive进行交互,我们可以使用Hive JDBC(Java Database Connectivity)驱动程序。本文将深入探讨Hive JDBC的使用,为读者提供在大数据环境中进行数据交互的技术指导。
1. 什么是Hive JDBC?
在Java应用程序中连接和操作Hive的API。通过使用JDBC,开发人员可以使用标准的SQL查询语言与Hive进行交互,实现数据的读取、写入和操作。
2. Hive JDBC的安装与配置
项目中添加Hive JDBC驱动程序后,你需要配置连接信息。这包括Hive服务器的主机名、端口号、数据库名称等。在连接到Hive之前,确保Hive服务器正在运行,并且你有相应的权限。
示例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;public class HiveJDBCExample {public static void main(String[] args) {String jdbcURL = "jdbc:hive2://localhost:10000/default";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcURL, username, password);// 执行你的Hive查询和操作connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
3. 执行Hive查询
通过Hive JDBC,可执行标准的SQL查询语句。
示例,查询Hive表中的数据
import java.sql.*;public class HiveQueryExample {public static void main(String[] args) {String jdbcURL = "jdbc:hive2://localhost:10000/default";String username = "your_username";String password = "your_password";try {Connection connection = DriverManager.getConnection(jdbcURL, username, password);Statement statement = connection.createStatement();String query = "SELECT * FROM your_hive_table";ResultSet resultSet = statement.executeQuery(query);while (resultSet.next()) {// 处理查询结果System.out.println(resultSet.getString("column_name"));}resultSet.close();statement.close();connection.close();} catch (SQLException e) {e.printStackTrace();}}
}
4. 数据的读取与写入
通过Hive JDBC,你不仅可以查询数据,还可以将数据写入Hive表。使用INSERT语句可以将数据插入到指定的表中。
String insertQuery = "INSERT INTO your_hive_table VALUES (value1, value2, ...)";
statement.executeUpdate(insertQuery);
5. 异常处理与资源释放
在实际开发中,始终要注意异常处理和资源释放,以确保程序的稳定性和性能。
try {// 执行Hive操作
} catch (SQLException e) {e.printStackTrace();
} finally {// 释放资源try {if (resultSet != null) resultSet.close();if (statement != null) statement.close();if (connection != null) connection.close();} catch (SQLException e) {e.printStackTrace();}
}
6 结语
通过Hive JDBC,我们能够在Java应用程序中无缝集成Hive,实现对大数据的高效查询和操作。通过合理配置和使用,开发人员可以更轻松地构建基于Hive的数据处理应用程序,为大数据领域的解决方案提供强大支持。
希望这篇博客能够为初次接触Hive JDBC的开发人员提供一些实用的技术指导,使其能够更加顺利地在大数据环境中进行数据交互。
相关文章:
-深入了解Hive JDBC:在大数据世界中实现数据交互)
Hive实战(03)-深入了解Hive JDBC:在大数据世界中实现数据交互
在大数据领域,Hive作为一种数据仓库解决方案,为用户提供了一种SQL接口来查询和分析存储在Hadoop集群中的数据。为了更灵活地与Hive进行交互,我们可以使用Hive JDBC(Java Database Connectivity)驱动程序。本文将深入探…...

SQL开发笔记之专栏介绍
Sql是用于访问和处理数据库的标准计算机语言,使用SQL访问和处理数据系统中的数据,这类数据库包括:Mysql、PostgresSql、Oracle、Sybase、DB2等等,数据库无非围绕着“增删改查”的核心业务进行开发。并且目前绝大多数的后端程序开发…...
华为OD机考算法题:找终点
目录 题目部分 解读与分析 代码实现 题目部分 题目找终点难度易题目说明给定一个正整数数组,设为nums,最大为100个成员,求从第一个成员开始,正好走到数组最后一个成员,所使用的最少步骤数。 要求: 1.第…...

el-table通过scope.row获取表格每列的值,以及scope.$index
<el-table-column type"selection" width"55"></el-table-column><el-table-column prop"id" label"ID" width"80"></el-table-column><el-table-column prop"name" label"文件名…...

uni-app:本地缓存的使用
uni-app 提供了多种方法用于本地缓存的操作。下面是一些常用的 uni-app 本地缓存方法: uni.setStorageSync(key, data): 同步方式将数据存储到本地缓存中,可以使用对应的 key 来获取该数据。 uni.setStorage({key, data}): 异步方式将数据存储到本地缓存…...
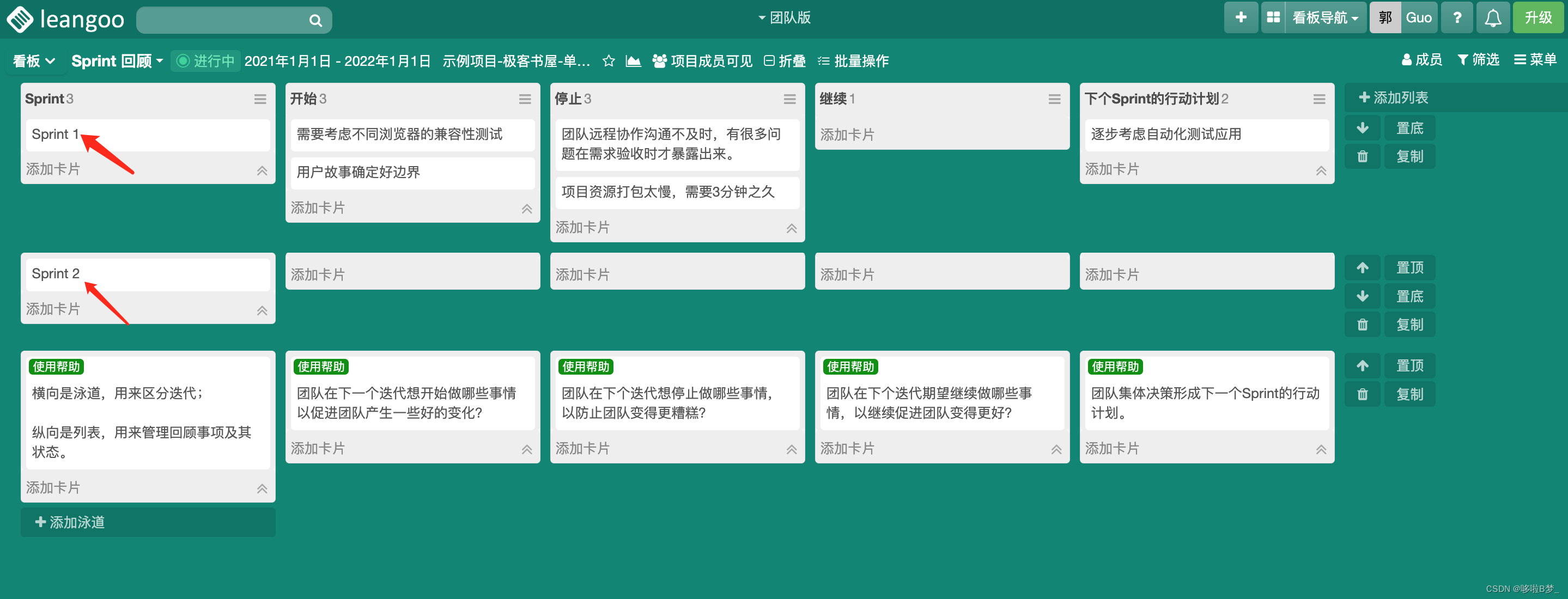
在Scrum敏捷开发中,开发人员(Developers)的职责
在Scrum敏捷开发中,开发人员(Developers)是Scrum团队中最重要的角色之一,负责产品的开发和交付,其重要性不言而喻。 那开发人员的职责和需要参加的活动是什么呢? Developers核心职责: 承诺并完…...
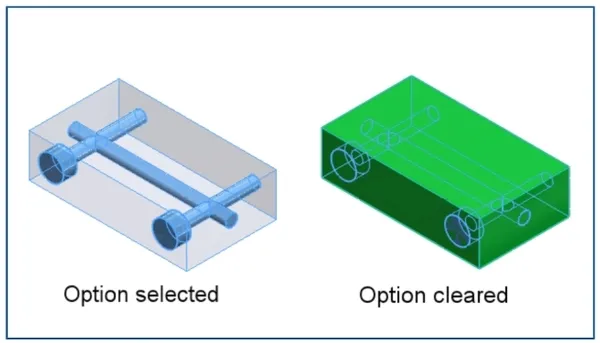
SOLIDWORKS® 2024 新功能 - 3D CAD
1、 先前版本的兼容性 • 利用您订阅的 SOLIDWORKS,可将您的 SOLIDWORKS 设计作品保存为旧版本,与使用旧版本 SOLIDWORKS 的供应商无缝协作。 • 可将零件、装配体和工程图保存为新版本前两年之内的SOLIDWORKS 版本。 优点: 即使其他用户正…...

系统架构设计:20 论软件需求管理
目录 一 需求工程 1 需求开发 1.1 需求获取 1.1.1 软件需求的分类 1.1.2 需求获取方法...
)
K8S云计算系列-(2)
1.Kubernetes平台配置实战 部署Kubernetes云计算平台,至少准备两台服务器,服务器CPU至少2C,内存4G,环境如下所示: Kubernetes Master节点:192.168.1.146 Kubernetes Minion节点:192.168.1.147…...
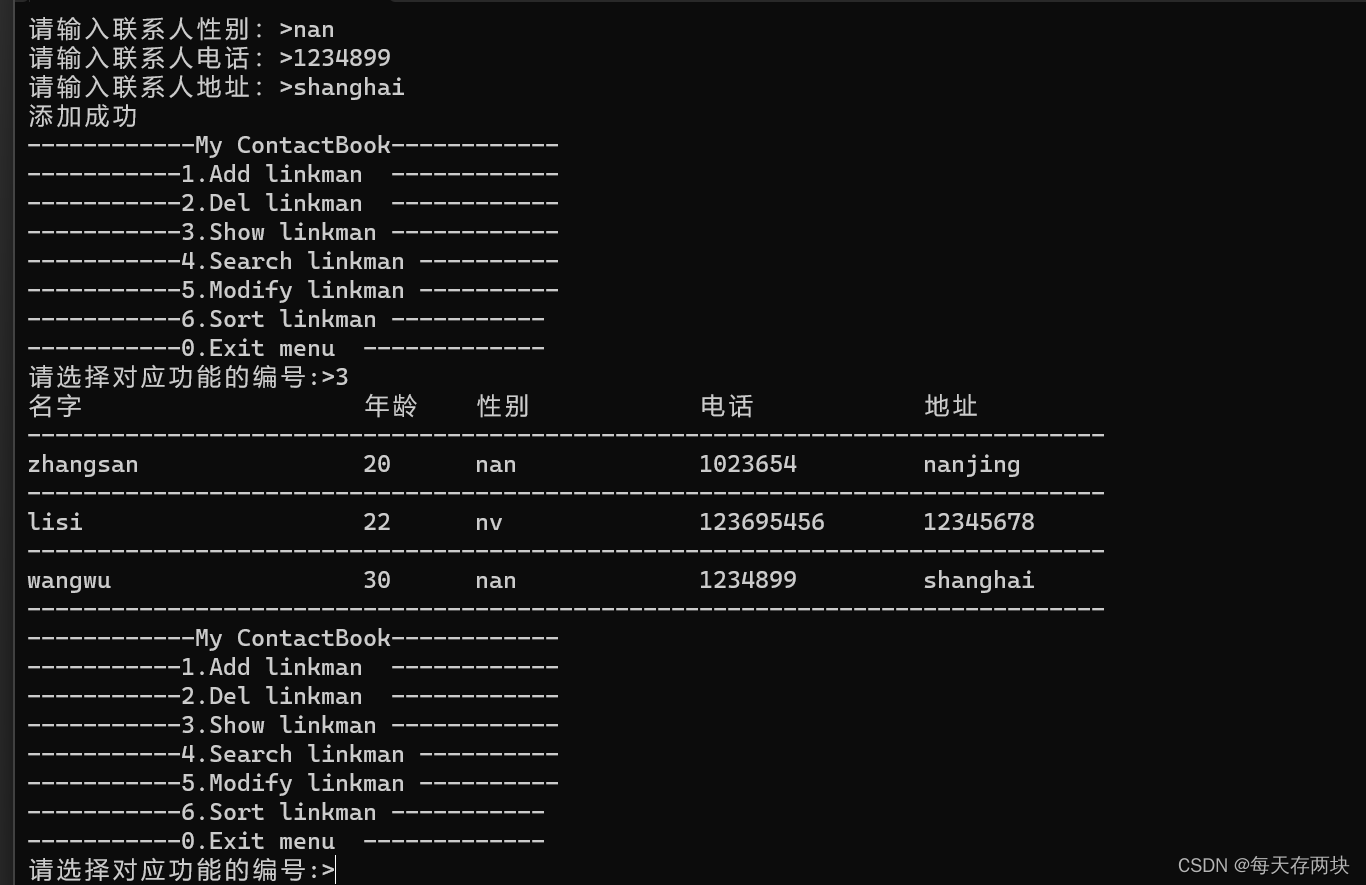
通讯录(C语言版)
用c语言实现一个通讯录 功能:.添加、删除、查找、更改、显示、排序联系人 内存存储方式:结构体数组 1.打印菜单,各个功能分别用函数实现,将函数声明放在头文件中。 2.定义联系人信息,将联系人信息与countÿ…...
natapp内网穿透-将本地运行的程序/服务器通过公网IP供其它人访问
文章目录 1.几个基本概念1.1 局域网1.2 内网1.3 内网穿透1.4 Natapp 2.搭建内网穿透环境3.本地服务测试 1.几个基本概念 1.1 局域网 LAN(Local Area Network,局域网)是一个可连接住宅,学校,实验室,大学校…...

数据结构八大排序Java源码
文章目录 [1]. 堆排序[2]. 冒泡排序[3]. 选择排序[4]. (直接)插入排序[5]. 希尔排序(属于插入算法)[6]. 快速排序[7]. 归并排序[8]. 基数排序 王道数据结构排序讲解 排序算法最佳时间复杂度最坏时间复杂度平均时间复杂度空间复杂度…...
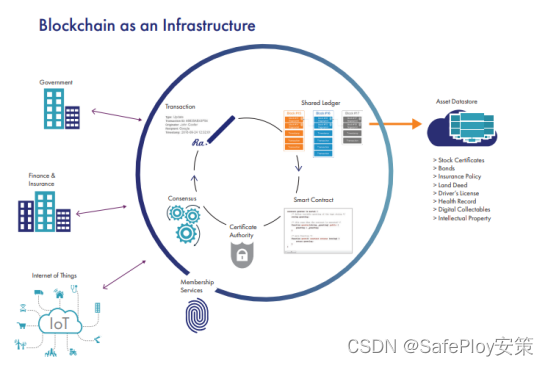
区块链加密虚拟货币交易平台安全解决方案
区块链机密货币交易锁遭入侵,安全存在隐患。使用泰雷兹Protect server HSM加密机,多方位保护您的数据,并通过集中化管理,安全的存储密钥。 引文部分: 损失7000万美元!黑客入侵香港区块链加密货币交易所 2023年9月&…...
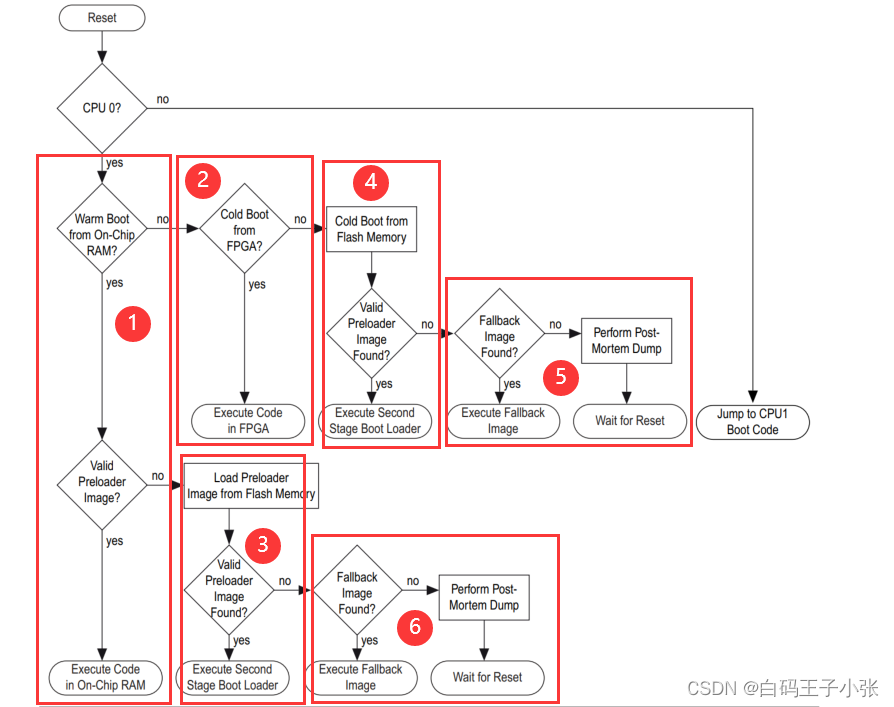
【SoC FPGA】HPS启动过程
SoC HPS启动流程 Boot ROMPreloaderBoot Loader HPS的启动是一个多阶段的过程,每一个阶段都会完成对应的工作并且将下一个阶段的执行代码引导起来。每个阶段均负责加载下一个阶段。第一个软件阶段是引导 ROM,引导 ROM 代码查找并且执行称为预加载器的第 …...

Wireshark CLI | Mergecap 篇
简介 Mergecap 是 Wireshark 程序安装时附带的可选工具之一,用于合并数据包文件的命令行工具。 mergecap [ -a ] [ -F <file format> ] [ -I <IDB merge mode> ] [ -s <snaplen> ] [ -V ] -w <outfile>|- <infile> [<infile>…...
10个打工人必备AI神器,升职加薪靠AI
HI,同学们,我是赤辰,本期是第18篇AI工具类教程,文章底部准备了粉丝福利,看完后可领取!1. Runway(文字转视频AI工具) 只需要一句提示词就能精确生成你所想象的视频场景,还…...

Java架构师缓存架构设计
目录 1 导学2 高性能概述2.1 高性能的定义和衡量指标2.2 如何实现高性能的计算机系统或软件程序2.3 木桶理论2.4 如何实现计算机系统或软件程序的高性能3 多级缓存设计3.1 浏览器缓存3.2 CDN缓存3.3 负载均衡的缓存3.4 进程内缓存3.5 分布式缓存4 缓存技术方案5 如何进行缓存拆…...

Linux 安全 - DAC机制
文章目录 一、安全简介二、DAC2.1 UNIX 的自主访问控制2.2 Linux 的自主访问控制 三、进程凭证3.1 简介3.2 uid/gid3.3 系统调用 四、客体标记4.1 简介4.2 系统调用 五、UGO规则源码分析参考资料 一、安全简介 计算机系统应对安全挑战的办法大致有四种:隔离、控制、…...

解决Windows系统win+shift+s截图快捷键失效问题
文章目录 打开任务管理器找到Windows资源管理器,选择重新启动 打开任务管理器 按“Win R”打开: 输入taskmgr.exe,运行,即可打开任务管理器: 找到Windows资源管理器,选择重新启动 点击右下角的“重新启…...
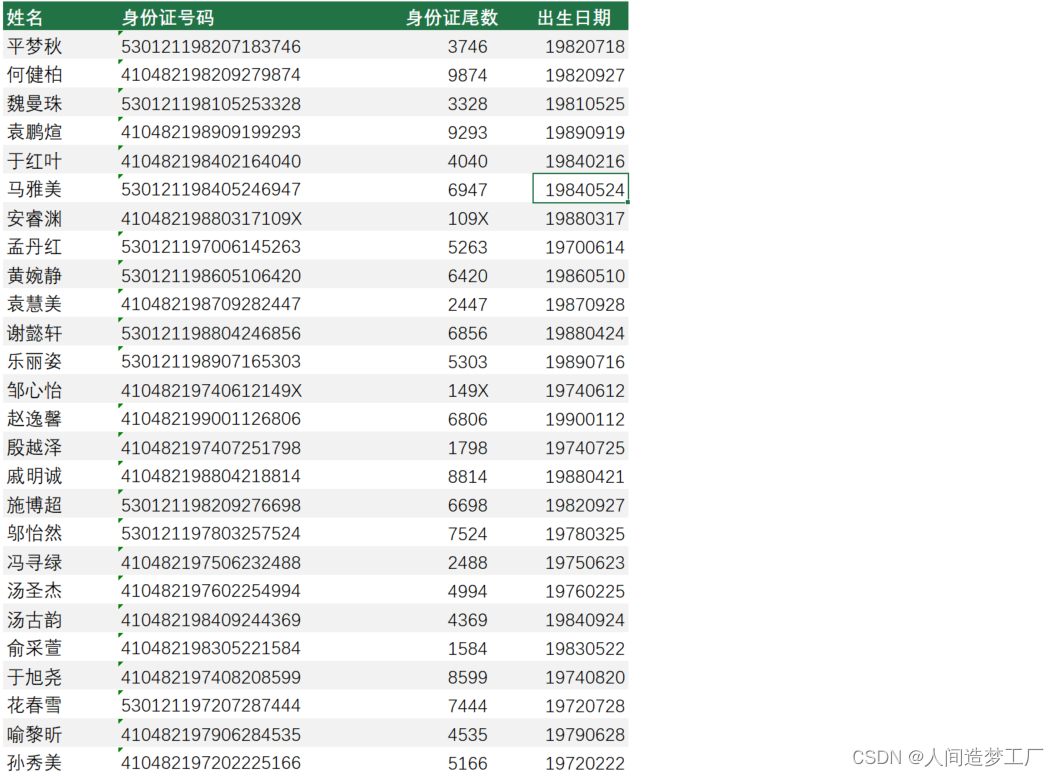
Excel 快速填充
文章目录 利用快速填充进行提取数据利用快速填充进行拆分重组 2013 及以上版本才有的功能. 利用快速填充进行提取数据 有一列的数据已有, 需要提取部分数据到另一列, 只需要输入部分内容, 后面内容可以自动显示, 按下回车即可快速填充. 只要前面手动输入的内容没有错得太离谱…...

Mac用户必看:免费开源的NTFS读写神器,3分钟解决跨平台文件传输难题
Mac用户必看:免费开源的NTFS读写神器,3分钟解决跨平台文件传输难题 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, moun…...

2025最权威的AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当人工智能技术于当下迅猛发展之际,对于企业来讲,核心挑战其中之一便…...

二维码识读设备选购全攻略:从核心需求到实战测试
1. 项目概述:为什么选对二维码识读设备这么重要?你可能觉得,不就是扫个码吗?手机摄像头都能搞定,专门的设备能有多大区别?我刚开始接触这个领域时也是这么想的,直到自己踩过几次坑,才…...

ARM1176JZF芯片架构与时钟管理深度解析
1. ARM1176JZF芯片架构概览 ARM1176JZF是ARMv6架构中的经典处理器内核,广泛应用于嵌入式系统和移动设备。这款芯片采用了先进的流水线设计和动态时钟调节技术,在性能与功耗之间实现了出色的平衡。开发芯片版本特别集成了完整的调试功能和性能监控单元&am…...

从Polycam扫描到自定义街道:用3D高斯泼溅碎片‘搭积木’创建虚拟场景的完整流程
从Polycam扫描到自定义街道:用3D高斯泼溅碎片‘搭积木’创建虚拟场景的完整流程 走在城市的街道上,你是否曾想过把那些有趣的街景元素——复古的路灯、造型独特的长椅、枝繁叶茂的行道树——全都数字化,然后像玩乐高一样重新组合成自己理想中…...

3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放
3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经下载了网易云音乐的NCM格式歌曲,却发现无法在其他设备上播放?这种专有加密格式虽然…...

【AI编程生产力跃迁】:用Perplexity秒级获取可运行代码示例的6大权威提示工程模板
更多请点击: https://codechina.net 第一章:Perplexity代码示例查询的核心机制与能力边界 Perplexity 在处理代码示例查询时,并非依赖静态模板匹配,而是通过多阶段语义理解与上下文感知检索协同实现:首先对用户自然语…...

CircuitJS1:如何在浏览器中免费创建电子电路仿真
CircuitJS1:如何在浏览器中免费创建电子电路仿真 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款强大的开源电子电路仿真工具,让你直接在浏…...

如何免费下载中国大学MOOC视频:MoocDownloader完整使用指南
如何免费下载中国大学MOOC视频:MoocDownloader完整使用指南 【免费下载链接】MoocDownloader An MOOC downloader implemented by .NET. 一枚由 .NET 实现的 MOOC 下载器. 项目地址: https://gitcode.com/gh_mirrors/mo/MoocDownloader 你是否曾经因为网络不…...

剪流AI事业大使是不是割韭菜?深度解析其真实运作细节与收益模型
近年来,“AI事业大使”成为一个热门话题,尤其是剪流AI推出的相关计划,引发了广泛讨论。其中,“AI事业大使是不是割韭菜”是许多观望者心中的核心疑问。本文将基于其公开的运作细节与权益体系,进行客观、深度的解析&…...