数据结构八大排序Java源码
文章目录
- [1]. 堆排序
- [2]. 冒泡排序
- [3]. 选择排序
- [4]. (直接)插入排序
- [5]. 希尔排序(属于插入算法)
- [6]. 快速排序
- [7]. 归并排序
- [8]. 基数排序
王道数据结构排序讲解
| 排序算法 | 最佳时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 适用性 | 稳定性 |
|---|---|---|---|---|---|---|
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 适用于大数据量 | 不稳定 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 适用于小数据量或基本有序 | 稳定 |
| 选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 适用于小数据量 | 不稳定 |
| 插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 适用于小数据量或基本有序 | 稳定 |
| 希尔排序 | O(nlogn) | O(n^2) | 取决于步长序列 | O(1) | 适用于中等规模数据 | 不稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | 适用于大数据量 | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 适用于大数据量 | 稳定 |
| 基数排序 | O(n*k) | O(n*k) | O(n*k) | O(n+k) | 适用于非负整数 | 稳定 |
- “最佳时间复杂度”指的是在最理想的情况下,而“最坏时间复杂度”则是在最差的情况下。
- 对于每种排序算法,空间复杂度表示额外的存储空间需求。
- 适用性方面,可以根据数据量的大小和特定的需求来选择合适的排序算法。
- 稳定性指的是相等元素的相对顺序是否在排序后保持不变。
[1]. 堆排序
堆排序是一种高效的选择排序算法。它通过构建一个二叉堆(大顶堆或小顶堆),并反复从堆顶取出最大(或最小)元素,然后调整堆使其保持性质,从而实现排序。具体来说,堆排序首先将待排序的元素构建成一个堆,然后将堆顶元素与最后一个元素交换位置,并将堆的大小减一。接着对根节点进行堆化操作,使得剩余元素重新构成一个堆。重复以上步骤,直到堆为空,最后得到排序完毕的数组。
* 使用Java编写,对一组乱序数组进行 堆排序升序使用大根堆*/public class HeapSort {// 堆排序函数public void heapSort(int[] arr) {int n = arr.length;// 构建堆for (int i = n / 2 - 1; i >= 0; i--) { //因为从下标 0 到(n/2 -1)的结点都为分叉结点heapify(arr, n, i);}// 逐步将堆顶元素与最后一个元素交换,并重新调整堆for (int i = n - 1; i >= 0; i--) {int temp = arr[0];arr[0] = arr[i];arr[i] = temp;heapify(arr, i, 0);//因为最上面的根元素被弹出堆,换成了原堆中的最后那个元素,所以重新从最上面开始调整,(堆结点的个数-1)=i}}// 调整堆函数public void heapify(int[] arr, int n, int i) {int largest = i; // 初始化最大元素为根节点int left = 2 * i + 1; // 左子节点int right = 2 * i + 2; // 右子节点// 如果左子节点大于根节点,则更新最大元素的索引if (left < n && arr[left] > arr[largest]) {largest = left;}// 如果右子节点大于根节点,则更新最大元素的索引if (right < n && arr[right] > arr[largest]) {largest = right;}// 如果最大元素不是根节点,则将最大元素与根节点交换,并继续调整堆if (largest != i) {int swap = arr[i];arr[i] = arr[largest];arr[largest] = swap;heapify(arr, n, largest);//继续递归调整被交换过的子树}}// 测试函数public static void main(String[] args) {int[] arr = {4, 10, 3, 5, 1};HeapSort heapSort = new HeapSort();System.out.println("排序前:");for (int i : arr) {System.out.print(i + " ");}heapSort.heapSort(arr);System.out.println("\n排序后:");for (int i : arr) {System.out.print(i + " ");}}
}/** 输出结果:* 排序前:* 4 10 3 5 1 * 排序后:* 1 3 4 5 10*/
[2]. 冒泡排序
冒泡排序是一种简单但效率较低的排序算法。它通过不断地比较相邻的元素,并将较大(或较小)的元素逐渐移动到数组的一端,从而实现排序。具体来说,它会多次遍历数组,每次遍历时比较相邻元素并交换位置,直到整个数组排序完毕。因为较大(或较小)的元素像气泡一样逐渐浮出,所以称之为冒泡排序。
//冒泡排序
public class BubbleSort {public static void main(String[] args) {int[] ints = new int[]{23,24,54,-324,2,1,1,1,98};bubbleSort(ints);for (int anInt : ints) {System.out.print(anInt + " ");}}public static void bubbleSort(int[] arr) {for (int i = 0; i < arr.length; i++) {boolean flag = true;for (int j = 0; j < arr.length - 1 - i; j++) {if (arr[j] > arr[j + 1]) {flag = false;int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}//优化:如果发现某一层完全没有交换次序,即:flag没有变为false,则,该序列已经为有序排列,结束循环if (flag) {break;}}}
}
[3]. 选择排序
选择排序也是一种简单但效率较低的排序算法。它通过每次选择未排序部分的最小(或最大)元素,然后将其与未排序部分的第一个元素进行交换,从而逐渐将最小(或最大)元素放到已排序部分的末尾。具体来说,选择排序会遍历数组,每次遍历时找到未排序部分的最小(或最大)元素并交换位置,直到整个数组排序完毕。
//选择排序
public class SelectSort {public static void main(String[] args) {int[] ints = new int[]{23,24,54,-324,2,1,1,1,98};selectSort(ints);for (int anInt : ints) {System.out.print(anInt + " ");}}//min :最小值//mindex :最小值的下标public static void selectSort(int[] arr) {for (int i = 0; i < arr.length; i++) {int min = arr[i];int minindex = i;for (int j = i + 1; j < arr.length; j++) {if (min > arr[j]) {min = arr[j];minindex = j;}}//该排序没有分配多余的数组空间,经过一轮比较后,mindex是最终最小值min的下标//如果mindex变化,因为没有申请额外空间存储,所以这里交换arr[i]和arr[mindex]的位置if (i != minindex) {arr[minindex] = arr[i];arr[i] = min;}}}
}
[4]. (直接)插入排序
插入排序是一种简单但高效的排序算法。它将数组分为已排序部分和未排序部分,然后逐个将未排序部分的元素插入到已排序部分的正确位置,从而实现排序。具体来说,插入排序从第二个元素开始,将其与前面的元素比较并插入正确的位置,然后继续对后面的元素进行插入操作,直到整个数组排序完毕。
//插入排序
public class InsertSort {public static void main(String[] args) {int[] ints = new int[]{23,24,54,-324,2,1,1,1,98};insertSort(ints);for (int anInt : ints) {System.out.print(anInt + " ");}}//insertIndex: 待插入元素的下标//insertValue: 带插入元素的值//排序思想:从数组第二个元素开始遍历,该排序就是要将此时遍历到的元素插入前面的序列中,保证前面的序列从小到大public static void insertSort(int[] arr) {for (int i = 1; i < arr.length; i++) {int insertIndex = i;int insertValue = arr[i];//while循环的目的:将arr[i]与前面的元素比较,找到第一个比它大的元素,然后插到该元素前面while (insertIndex > 0 && insertValue < arr[insertIndex - 1]) {arr[insertIndex] = arr[insertIndex - 1];insertIndex--;}arr[insertIndex] = insertValue;}}
}
[5]. 希尔排序(属于插入算法)
希尔排序是一种高效的排序算法,它通过将待排序的元素划分为若干组来进行排序,然后逐步减小组的大小,最终完成排序。
具体步骤如下:
- 首先,选择一个增量序列,通常为数组长度的一半,并将数组分为若干组。
- 对每一组进行插入排序,即从第二个元素开始,逐个与前面的元素比较并插入正确的位置。
- 逐步缩小增量序列,重新分组并进行插入排序,直到增量序列为1。
- 最后,进行一次增量为1的插入排序,完成排序。
希尔排序与插入排序的关系和区别如下:
- 希尔排序是插入排序的改进版本,通过分组的方式,使得插入排序可以先比较距离较远的元素,从而更高效地移动元素。
- 相比于插入排序,希尔排序的时间复杂度更优,可以达到O(n log n)级别,尤其在大规模数据的排序中表现良好。
- 希尔排序是不稳定的排序算法,即同值的元素在排序后可能会改变相对顺序。
- 相比于其他高效的排序算法,希尔排序的实现较为简单,且对于中小规模的数据集也有较好的性能表现。
//希尔排序
public class ShellSort {public static void main(String[] args) {int[] ints = new int[]{23,24,54,-324,2,1,1,1,98};shellSort(ints);for (int anInt : ints) {System.out.print(anInt + " ");}}public static void shellSort(int[] arr) {//gap步长for (int gap = arr.length / 2; gap > 0; gap /= 2) {for (int i = gap; i < arr.length; i++) {//插入式 间隔为gap的插入排序int insertIndex = i;int insertValue = arr[i];while (insertIndex - gap >= 0 && insertValue < arr[insertIndex - gap]) {arr[insertIndex] = arr[insertIndex - gap];insertIndex -= gap;}arr[insertIndex] = insertValue;}}}
}
[6]. 快速排序
快速排序是一种高效的分治排序算法。它选择一个基准元素,将数组分为两个子数组,一个子数组中的元素都小于基准元素,另一个子数组中的元素都大于基准元素,然后递归地对子数组进行排序,最后通过合并子数组得到排序完毕的数组。具体来说,快速排序选择一个基准元素,通过比较将其他元素分别放到基准元素的左边或右边,然后对左右子数组递归地进行快速排序,最后合并子数组得到排序完毕的数组。
import java.util.Arrays;public class QuickSort {public static void main(String[] args) {int[] ints = new int[]{23, -9, 78, 3, 34,3, 0, 34,23};quickSort(ints, 0, ints.length - 1);System.out.println(Arrays.toString(ints));}public static void quickSort(int[] arr, int left, int right) {if (left >= right) {//递归调用函数结束return;}int l = left;int r = right;while (l < r) {//每次都以arr[left]为标准进行对比while (l < r && arr[r] >= arr[left]) r--;while (l < r && arr[l] <= arr[left]) l++;//两次循环后,最终是l==r 此时arr[r]一定小于等于arr[left]if (r == l) {//此时该循环就结束了int temp = arr[r];arr[r] = arr[left];arr[left] = temp;} else {int temp = arr[r];arr[r] = arr[l];arr[l] = temp;}}//此时r == l 索引r左边的元素小于arr[r] 索引r右边的元素大于arr[r];//在分别对左右部分进行快排quickSort(arr, left, l - 1);quickSort(arr, r + 1, right);}}
[7]. 归并排序
归并排序是一种高效的分治排序算法。它的思想是将数组不断地二分分解,直到每个子数组只有一个元素,然后将相邻的子数组进行合并,直到最终得到排序完毕的数组。具体来说,归并排序会递归地将数组二分,然后对每个子数组进行归并操作,通过比较两个子数组的元素,按顺序合并成一个有序的子数组,最后不断合并子数组,直到整个数组排序完毕。
import java.util.Arrays;public class MergeSort {public static void main(String[] args) {int[] ints = new int[]{23, -9, 78, 3, 34,3, 0, 34,23};//临时存储合并之后的数组int[] temp = new int[ints.length];mergeSort(ints, 0, ints.length - 1, temp);System.out.println(Arrays.toString(ints));}public static void mergeSort(int[] arr, int left, int right, int[] temp) {//递归的结束条件 如果left<right,说明可以继续分,则继续可以调用该函数,否则就不能分,就直接returnif (left < right) {//mid:被分的两个部分的中间索引 用于之后合并两个部分时用int mid = (left + right) / 2;//将左边部分继续分mergeSort(arr, 0, mid, temp);//将右边部分继续分mergeSort(arr, mid + 1, right, temp);//代码运行到这里,递归已经调用完毕,开始回溯,从最开始的左右部分各一个元素开始回溯merge(arr, left, mid, right, temp);}}public static void merge(int[] arr, int left, int mid, int right, int[] temp) {int i = left; //左边部分的最左侧索引int j = mid + 1; //右边部分的最左侧索引(当只有每个部分只有一个元素时,此时mid=left mid+1=right)int t = 0;//临时数组temp的索引,从0开始//将分开的两部分合并while (i <= mid && j <= right) {if (arr[i] <= arr[j]) {temp[t] = arr[i];t++;i++;} else {temp[t] = arr[j];t++;j++;}}//如果左边部分有没有合并进去的,接着i继续合并while (i <= mid) {temp[t] = arr[i];t++;i++;}//如果右边部分有没有合并进去的,接着j继续合并while (j <= right) {temp[t] = arr[j];t++;j++;}//将临时数组temp的所存储的值,赋值给原数组arrt = 0;//原数组的索引需要从left开始,right结束int tempLeft = left;while (tempLeft <= right) {arr[tempLeft] = temp[t];t++;tempLeft++;}}}
[8]. 基数排序
基数排序是一种非比较的排序算法,适用于有非负整数的数组。它按照个位、十位、百位等位数的大小进行排序,通过多次遍历数组,根据每个位数的值将数组元素进行分配和收集,最终得到排序完毕的数组。具体来说,基数排序首先选取一个最高位数,将数组按照该位数进行排序,然后再对下一位数进行排序,直到最低位数排序完成。基数排序利用了稳定排序的特性,在位数排序时保持相同位数值的元素相对顺序不变。
import java.util.Arrays;public class RedixSort {public static void main(String[] args) {int[] ints = new int[]{24,74, 3, 34,14, 4, 34,3434,24,3435,324,544,234,124};//临时存储合并之后的数组redixSort(ints);System.out.println(Arrays.toString(ints));}public static void redixSort(int[] arr) {int[][] bucket = new int[10][arr.length];int[] bucketElementCounts = new int[10];//求出数组中高度最大值的位数(最大值拥有最大位数)int max = arr[0];for (int i = 1; i < arr.length; i++) {if (max < arr[i]) max = arr[i];}int maxCount = (max + "").length(); //小技巧:将数转换成字符串,其长度即是其位数for (int i = 0; i < maxCount; i++) {//将arr数组中的每个数存在bucket二维数组中 一维数组bucketElementCount用于记录每个桶所存的数的个数for (int k = 0; k < arr.length; k++) {int value = arr[k] / (int)Math.pow(10, i) % 10;bucket[value][bucketElementCounts[value]] = arr[k];bucketElementCounts[value]++;}int index = 0;//多次循环后,最终将bucket中最后存的所有数按顺序赋值给arrfor (int k = 0; k < bucketElementCounts.length; k++) {if (bucketElementCounts[k] != 0) {for (int x = 0; x < bucketElementCounts[k]; x++) {arr[index] = bucket[k][x];index++;}}//对k进行清0,用于下一循环bucketElementCounts[k] = 0;}}}
}
相关文章:

数据结构八大排序Java源码
文章目录 [1]. 堆排序[2]. 冒泡排序[3]. 选择排序[4]. (直接)插入排序[5]. 希尔排序(属于插入算法)[6]. 快速排序[7]. 归并排序[8]. 基数排序 王道数据结构排序讲解 排序算法最佳时间复杂度最坏时间复杂度平均时间复杂度空间复杂度…...
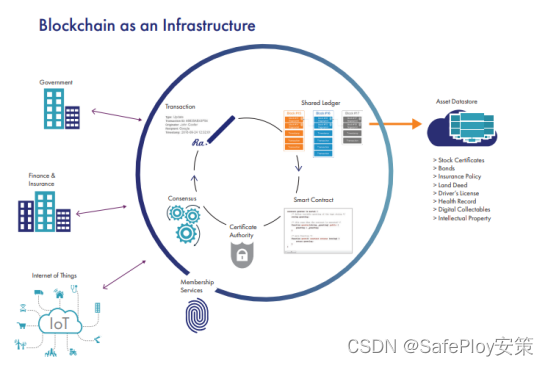
区块链加密虚拟货币交易平台安全解决方案
区块链机密货币交易锁遭入侵,安全存在隐患。使用泰雷兹Protect server HSM加密机,多方位保护您的数据,并通过集中化管理,安全的存储密钥。 引文部分: 损失7000万美元!黑客入侵香港区块链加密货币交易所 2023年9月&…...
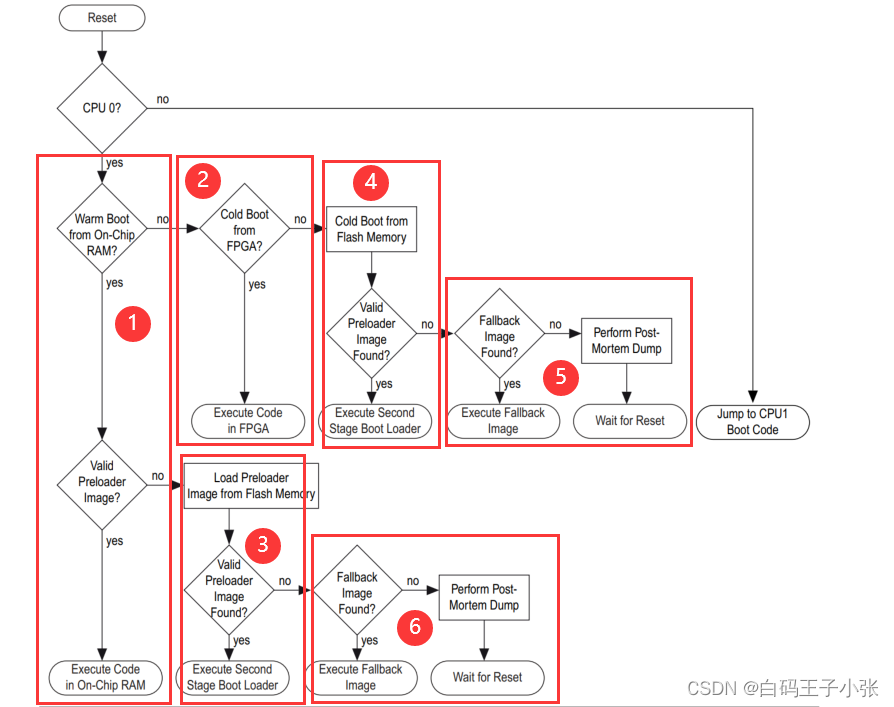
【SoC FPGA】HPS启动过程
SoC HPS启动流程 Boot ROMPreloaderBoot Loader HPS的启动是一个多阶段的过程,每一个阶段都会完成对应的工作并且将下一个阶段的执行代码引导起来。每个阶段均负责加载下一个阶段。第一个软件阶段是引导 ROM,引导 ROM 代码查找并且执行称为预加载器的第 …...

Wireshark CLI | Mergecap 篇
简介 Mergecap 是 Wireshark 程序安装时附带的可选工具之一,用于合并数据包文件的命令行工具。 mergecap [ -a ] [ -F <file format> ] [ -I <IDB merge mode> ] [ -s <snaplen> ] [ -V ] -w <outfile>|- <infile> [<infile>…...
10个打工人必备AI神器,升职加薪靠AI
HI,同学们,我是赤辰,本期是第18篇AI工具类教程,文章底部准备了粉丝福利,看完后可领取!1. Runway(文字转视频AI工具) 只需要一句提示词就能精确生成你所想象的视频场景,还…...

Java架构师缓存架构设计
目录 1 导学2 高性能概述2.1 高性能的定义和衡量指标2.2 如何实现高性能的计算机系统或软件程序2.3 木桶理论2.4 如何实现计算机系统或软件程序的高性能3 多级缓存设计3.1 浏览器缓存3.2 CDN缓存3.3 负载均衡的缓存3.4 进程内缓存3.5 分布式缓存4 缓存技术方案5 如何进行缓存拆…...

Linux 安全 - DAC机制
文章目录 一、安全简介二、DAC2.1 UNIX 的自主访问控制2.2 Linux 的自主访问控制 三、进程凭证3.1 简介3.2 uid/gid3.3 系统调用 四、客体标记4.1 简介4.2 系统调用 五、UGO规则源码分析参考资料 一、安全简介 计算机系统应对安全挑战的办法大致有四种:隔离、控制、…...

解决Windows系统win+shift+s截图快捷键失效问题
文章目录 打开任务管理器找到Windows资源管理器,选择重新启动 打开任务管理器 按“Win R”打开: 输入taskmgr.exe,运行,即可打开任务管理器: 找到Windows资源管理器,选择重新启动 点击右下角的“重新启…...
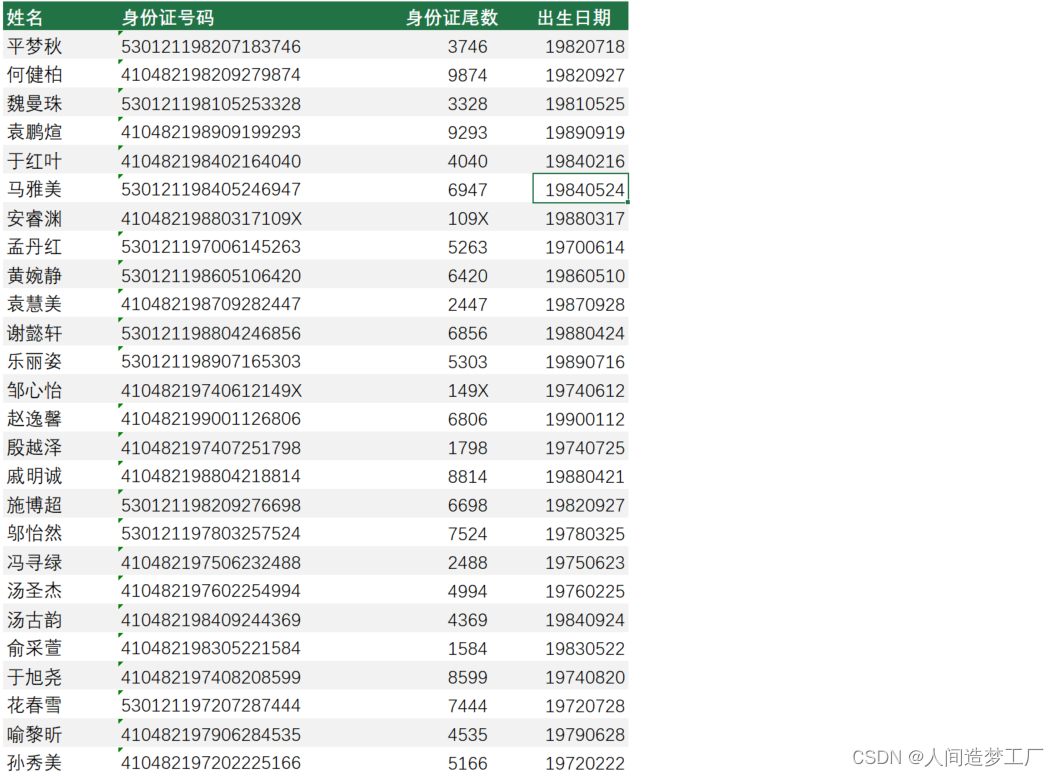
Excel 快速填充
文章目录 利用快速填充进行提取数据利用快速填充进行拆分重组 2013 及以上版本才有的功能. 利用快速填充进行提取数据 有一列的数据已有, 需要提取部分数据到另一列, 只需要输入部分内容, 后面内容可以自动显示, 按下回车即可快速填充. 只要前面手动输入的内容没有错得太离谱…...

OPENCV图像和视频处理
图像基本操作: Opencv图像处理(全)_胖墩会武术的博客-CSDN博客 import cv2 import matplotlib.pyplot as plt import numpy as npimgcv2.imread(1.jpg) #图像的显示 cv2.imshow(image,img) cv2.waitKey(0) …...
QDir实践
现在有多个文件,路径为: a\xxx\kmd_config\c.json 其中xxx是变量 startcalc,,,,,, 目标: 访问每一个json文件 实例: QString app_path QApplication::applicationDirPath() "/app";QDir dir(app_path);QStringLi…...
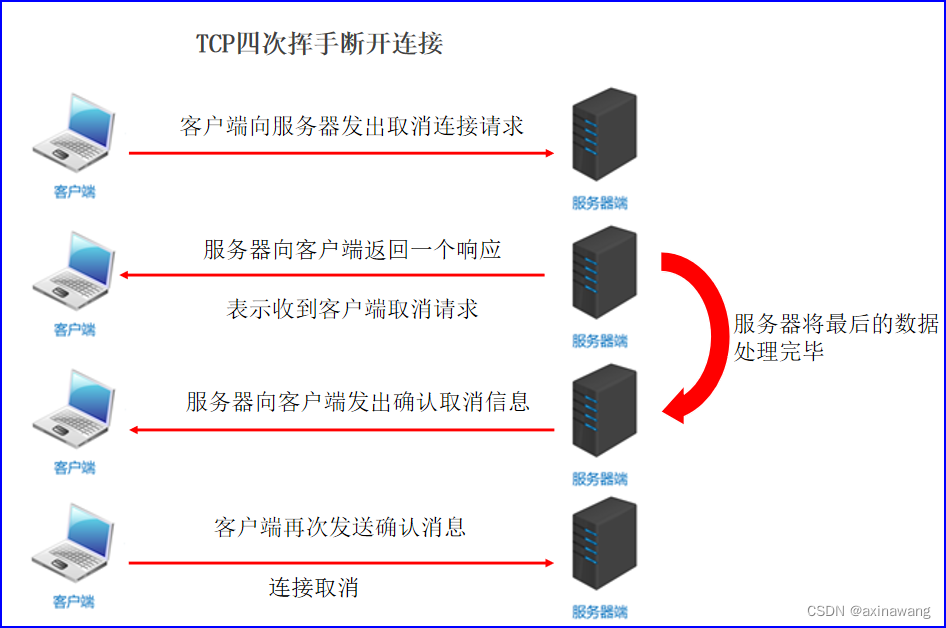
网络通信三要素
三要素概述 IP地址:设备在网络中的地址,是唯一的标识。 端口:应用程序在设备中唯一的标识。 协议: 数据在网络中传输的规则,常见的协议有UDP协议和TCP协议。 网络通信过程 A程序通过IP和端口连接到到B程序,再互…...
2023年中国渔业研究报告
第一章 行业概况 1.1 定义 渔业,作为全球经济的重要支柱之一,其核心活动包括捕捞、水产养殖、产品加工与销售等。其不仅是食物安全的重要保障,还是许多沿海和内陆地区经济发展的重要动力。 首先,捕捞活动是渔业的基础。通过海洋…...

python字符串中的\“
data {"text": "\"abc\""} print(data) # {"text": ""abc""}从结果可以看到并没有出现反斜杠,反斜杠与双引号作为一个整体,转义为了一个双引号,如果要在字符串中出现反斜杠&am…...
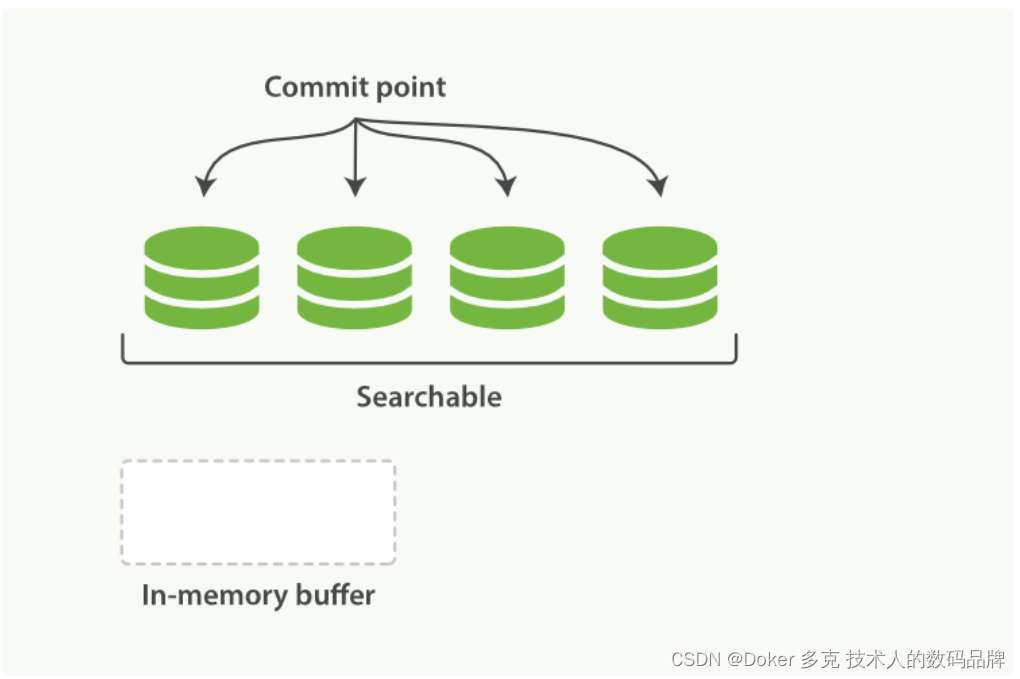
Elasticsearch 分片内部原理—使文本可被搜索、动态更新索引
目录 一、使文本可被搜索 不变性 二、动态更新索引 删除和更新 一、使文本可被搜索 必须解决的第一个挑战是如何使文本可被搜索。 传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字…...
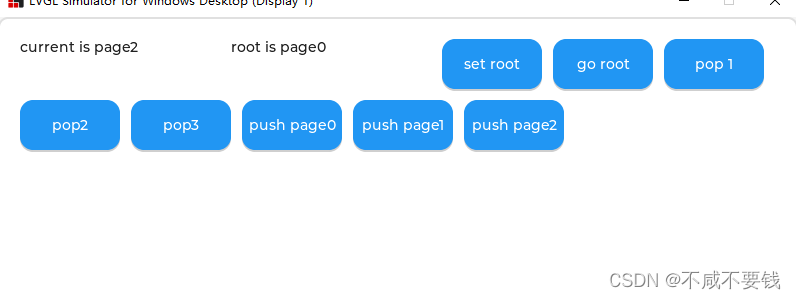
lvgl 界面管理器
lv_scr_mgr lvgl 界面管理器 适配 lvgl 8.3 降低界面之间的耦合使用较小的内存,界面切换后会自动释放内存内存泄漏检测 使用方法 在lv_scr_mgr_port.h 中创建一个枚举,用于界面ID为每个界面创建一个页面管理器句柄将界面句柄添加到 lv_scr_mgr_por…...

一篇文章让你了解“JWT“
一.JWT简介 1.概念 JWT (JSON Web Token) 是一种用于在网络上安全传输信息的开放标准(RFC 7519)。它是一种紧凑且自包含的方式,用于在不同组件之间传递信息,通常用于身份验证和授权目的。JWT 是以 JSON 格式编码的令牌ÿ…...
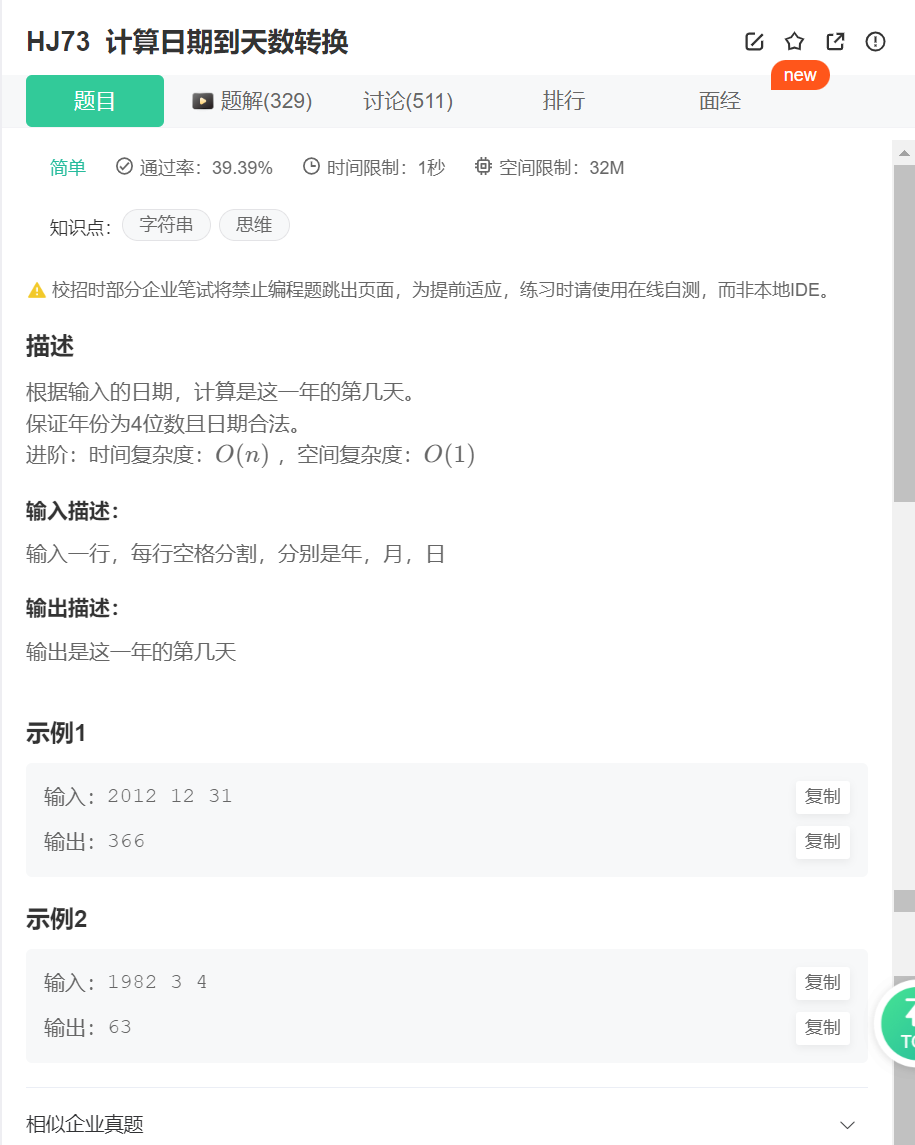
HJ73 计算日期到天数转换
HJ73 计算日期到天数转换 int main() {int year, month, day;cin >> year >> month >> day;int monthDays[13] { 0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334, 365 };int nday monthDays[month - 1] day;if (month > 2 &&((year…...
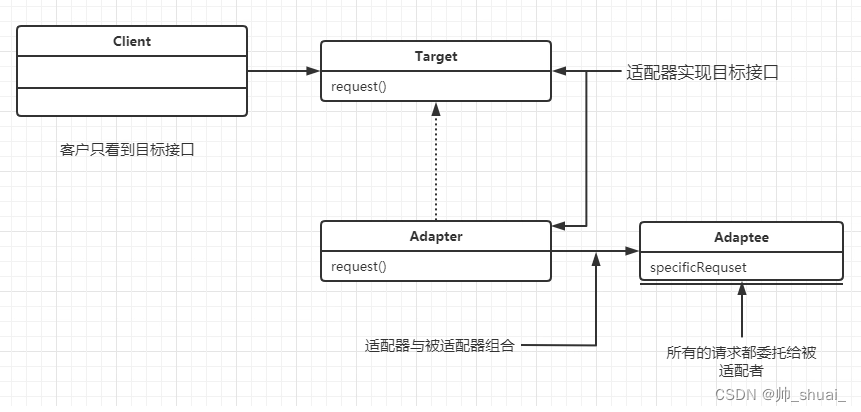
Unity实现设计模式——适配器模式
Unity实现设计模式——适配器模式 适配器模式又称为变压器模式、包装模式(Wrapper) 将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。 在一个在役的项目期望在原有接口的基础…...

【2023年11月第四版教材】专题1 - 计算题考点汇总 (合集篇)
专题1 - 计算题考点汇总 (合集篇) 1 进度类1.1 PERT三点估算1.1.1 β分布1.1.2 三角分布 1.2 单代号网络图1.2.1 画图1.2.2 找关键路径1.2.3 计算总工期1.2.4 总时差1.2.5 自由时差1.2.6 工期压缩 1.3 双代号网络图1.4 双代号时标网络图1.4.1 画图1.4.2 找关键路径1…...

HEIF Utility:当跨平台技术遇上真实世界的照片困境
HEIF Utility:当跨平台技术遇上真实世界的照片困境 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 你是否曾经历过这样的场景?用iPhone记…...

CTF夺旗赛利器:手把手教你用GitHack挖掘.git泄露背后的Web漏洞
CTF夺旗赛利器:手把手教你用GitHack挖掘.git泄露背后的Web漏洞 在CTF竞赛和实战渗透测试中,.git目录泄露一直是Web安全领域的经典漏洞场景。这种看似简单的配置错误,往往能成为攻击者打开系统后门的金钥匙。本文将带您深入探索如何利用GitHac…...

让经典重生:D2DX如何让《暗黑破坏神2》在现代电脑上流畅运行
让经典重生:D2DX如何让《暗黑破坏神2》在现代电脑上流畅运行 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还记…...

保姆级拆解:Smoke3D的DLA34 Backbone如何一步步输出1/4特征图
深入解析Smoke3D中DLA34 Backbone的特征图生成机制 在计算机视觉领域,3D目标检测一直是极具挑战性的研究方向。Smoke3D作为单目3D检测的代表性框架,其核心架构DLA34 Backbone的特征提取过程值得深入探讨。本文将聚焦于输入图像如何通过DLA34的五次下采样…...

LeetCode热题100-从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,15,7] 思…...

如何免费下载网页视频?VideoDownloadHelper浏览器插件终极指南
如何免费下载网页视频?VideoDownloadHelper浏览器插件终极指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页…...
)
Arcgis新手必看:用‘焦点统计’和‘设为空函数’搞定栅格数据清洗(附避坑要点)
ArcGIS栅格数据清洗实战:焦点统计与设为空函数的高效应用指南 当你第一次拿到一份满是噪点的DEM数据或存在异常值的土地利用分类图时,那种手足无措的感觉我深有体会。栅格数据清洗是GIS分析中看似简单却暗藏玄机的关键步骤,一个不当的参数设置…...

如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析
如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: ht…...

OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南
OpenPLC Editor工业自动化编程深度解析:开源PLC开发环境实战指南 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor OpenPLC Editor是一款基于Beremiz项目的开源工业自动化编程工具,为工程师和开发…...

深度解析MSPM0G3106数据手册:从80MHz Cortex-M0+内核到电机控制实战
1. 项目概述:为什么是MSPM0G3106?如果你最近在寻找一款兼具高性能、低功耗和成本效益的微控制器,用于电机控制、数字电源或者需要复杂模拟信号处理的场合,那么TI的MSPM0G系列很可能已经进入了你的视野。而其中的MSPM0G3106&#x…...