交通 | python网络爬虫:“多线程并行 + 多线程异步协程

推文作者:Amiee
编者按:
常规爬虫都是爬完一个网页接着爬下一个网页,不适应数据量大的网页,本文介绍了多线程处理同时爬取多个网页的内容,提升爬虫效率。
1.引言
一般而言,常规爬虫都是爬完一个网页接着爬下一个网页。如果当爬取的数据量非常庞大时,爬虫程序的时间开销往往很大,这个时候可以通过多线程或者多进程处理即可完成多个网页内容同时爬取的效果,数据获取速度大大提升。
2.基础知识
简单来说,CPU是进程的父级单位,一个CPU可以控制多个进程;进程是线程的父级单位,一个进程可以控制多个线程,那么到底什么是进程,什么是线程呢?
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程;打开一个QQ就启动一个QQ进程;打开一个Word就启动了一个Word进程,打开两个Word就启动两个Word进程。
那什么叫作线程呢?在一个进程内部往往不止同时干一件事,比如浏览器,它可以同时浏览网页、听音乐、看视频、下载文件等。在一个进程内部这同时运行的多个“子任务”,便称之称为线程(Thread),线程是程序工作的最小单元。
此外有个注意点,对于单个CPU而言,某一个时点只能执行一个任务,那么如果这样是怎么在现实中同时执行多个任务(进程)的呢?比如一边用浏览器听歌,一边用QQ和好友聊天是如何实现的呢?
答案是操作系统会通过调度算法,轮流让各个任务(进程)交替执行。以时间片轮转算法为例:有5个正在运行的程序(即5个进程) : QQ、微信、谷歌浏览器、网易云音乐、腾讯会议,操作系统会让CPU轮流来调度运行这些进程,一个进程每次运行0.1ms,因为CPU执行的速度非常快,这样看起来就像多个进程同时在运行。同理,对于多个线程,例如通过谷歌浏览器(进程)可以同时访问网页(线程1)、听在线音乐(线程2)和下载网络文件(线程3)等操作,也是通过类似的时间片轮转算法使得各个子任务(线程)近似同时执行。
2.1 Thread()版本案例
from threading import Thread
def func():for i in range(10):print('func', i)
if name == '__main__':t = Thread(target=func) # 创建线程t.start() # 多线程状态,可以开始工作了,具体时间有CPU决定for i in range(10):print('main', i)
执行结果如下:func 0func 1func 2func 3func 4main 0main 1main 2main 3main 4mainfunc 5 5func main 66func 7mainfunc 8func 97main 8main 92.2 MyTread() 版本案例
大佬是这个写法
from threading import Thread
class MyThread(Thread):def run(self):for i in range(10):print('MyThread', i)
if name == '__main__':t = MyThread()# t.run() # 调用run就是单线程t.start() # 开启线程for i in range(10):print('main', i)
执行结果:
MyThread 0
MyThread 1
MyThread 2
MyThread 3
MyThread 4
MyThread 5main 0
main 1
main 2
main 3
main 4
MyThread
main 5
6
main MyThread 67
mainMyThread 78
mainMyThread 89
main 92.3 带参数的多线程版本
from threading import Thread
def func(name):for i in range(10):print(name, i)
if name == '__main__':t1 = Thread(target=func, args=('子线程1',)) # 创建线程t1.start() # 多线程状态,可以开始工作了,具体时间又CPU决定t2 = Thread(target=func, args=('子线程2',)) # 创建线程t2.start() # 多线程状态,可以开始工作了,具体时间又CPU决定for i in range(10):print('main', i)2.4 多进程
一般不建议使用,因为开进程比较费资源
from multiprocessing import Process
def func():for i in range(1000000):print('func', i)
if name == '__main__':p = Process(target=func)p.start() # 开启线程for i in range(100000):print('mainn process', i)3. 线程池和进程池
线程池:一次性开辟一些线程,我们用户直接给线程池提交任务,线程任务的调度由线程池来完成
from concurrent.futures import ThreadPoolExecutor
def func(name):for i in range(10):print(name, i)
if name == '__main__':# 创建线程池with ThreadPoolExecutor(50) as t:for i in range(100):t.submit(func, name=f'Thread{i}=')# 等待线程池中的人物全部执行完成,才继续执行;也称守护进程
print('执行守护线程')进程池
from concurrent.futures import ProcessPoolExecutor
def func(name):for i in range(10):print(name, i)
if name == '__main__':# 创建线程池with ProcessPoolExecutor(50) as t:for i in range(100):t.submit(func, name=f'Thread{i}=')# 等待线程池中的人物全部执行完成,才继续执行;也称守护进程print('执行守护进程')4. 爬虫实战-爬取新发地菜价
单个线程怎么办;上线程池,多个页面同时爬取
import requests
from lxml import etree
import csv
from concurrent.futures import ThreadPoolExecutorf = open('xifadi.csv', mode='w', newline='')
csv_writer = csv.writer(f)
def download_one_page(url):resp = requests.get(url)resp.encoding = 'utf-8'html = etree.HTML(resp.text)table = html.xpath(r'/html/body/div[2]/div[4]/div[1]/table')[0]# trs = table.xpath(r'./tr')[1:] # 跳过表头trs = table.xpath(r'./tr[position()>1]')for tr in trs:td = tr.xpath('./td/text()')# 处理数据中的 \\ 或 /txt = (item.replace('\\','').replace('/','') for item in td)csv_writer.writerow(txt)resp.close()print(url, '提取完毕')if name == '__main__':with ThreadPoolExecutor(50) as t:for i in range(1, 200):t.submit(download_one_page,f'http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml')print('全部下载完毕')5. python网络爬虫:多线程异步协程与实验案例
5.1 基础理论
程序处于阻塞状态的情形包含以下几个方面:
•input():等待用户输入
•requests.get():网络请求返回数据之前
•当程序处理IO操作时,线程都处于阻塞状态
•time.sleep():处于阻塞状态
协程的逻辑是当程序遇见IO操作时,可以选择性的切换到其他任务上;协程在微观上任务的切换,切换条件一般就是IO操作;在宏观上,我们看到的是多个任务都是一起执行的;上方的一切都是在在单线程的条件下,充分的利用单线程的资源。
要点梳理:
•函数被asyn修饰,函数被调用时,它不会被立即执行;该函数被调用后会返回一个协程对象。
•创建一个协程对象:构建一个asyn修饰的函数,然后调用该函数返回的就是一个协程对象
•任务对象是一个高级的协程对象,
import asyncio
import time
async def func1():print('你好呀11')
if name == '__main__':g1 = func1() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象asyncio.run(g1) # 协程城西执行需要asyncio模块的支持5.2 同步/异步睡眠
普通的time.sleep()是同步操作,会导致异步操作中断
import asyncio
import time
async def func1():print('你好呀11')time.sleep(3) # 当程序中除了同步操作时,异步就中端了print('你好呀12')
async def func2():print('你好呀21')time.sleep(2)print('你好呀22')
async def func3():print('你好呀31')time.sleep(4)print('你好呀32')
if name == '__main__':g1 = func1() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象g2 = func2()g3 = func3()tasks = [g1, g2, g3]t1 = time.time()asyncio.run(asyncio.wait(tasks)) # 协程城西执行需要asyncio模块的支持t2 = time.time()
print(t2 - t1)你好呀21你好呀22你好呀11你好呀12你好呀31你好呀329.003259658813477使用异步睡眠函数,遇到睡眠时,挂起;
import asyncio
import time
async def func1():print('你好呀11')await asyncio.sleep(3) # 异步模块的sleepprint('你好呀12')
async def func2():print('你好呀21'))await asyncio.sleep(4) # 异步模块的sleepprint('你好呀22')
async def func3():print('你好呀31')await asyncio.sleep(4) # 异步模块的sleepprint('你好呀32')
if name == '__main__':g1 = func1() # 此时的函数是异步协程函数,此时函数执行得到的是一个协程对象g2 = func2()g3 = func3()tasks = [g1, g2, g3]t1 = time.time()asyncio.run(asyncio.wait(tasks)) # 协程城西执行需要asyncio模块的支持t2 = time.time()
print(t2 - t1)你好呀21你好呀11你好呀31你好呀12你好呀22你好呀324.0028839111328125整体耗时为最长时间 + 切换时间
5.3 官方推荐多线程异步协程写法
import asyncio
import time
async def func1():print('你好呀11')# time.sleep(3) # 当程序中除了同步操作时,异步就中端了await asyncio.sleep(3) # 异步模块的sleepprint('你好呀12')
async def func2():print('你好呀21')# time.sleep(2)await asyncio.sleep(4) # 异步模块的sleepprint('你好呀22')
async def func3():print('你好呀31')# time.sleep(4)await asyncio.sleep(4) # 异步模块的sleepprint('你好呀32')
async def main():# 写法1:不推荐# f1 = func1()# await f1 # await挂起操作,一般放在协程对象前边# 写法2:推荐,但是在3.8废止,3.11会被移除# tasks = [func1(), func2(), func3()]# await asyncio.wait(tasks)# 写法3:python3.8以后使用tasks = [asyncio.create_task(func1()), asyncio.create_task(func2()),asyncio.create_task(func3())]await asyncio.wait(tasks))if name == '__main__':t1 = time.time()asyncio.run(main())t2 = time.time()
print(t2 - t1)你好呀21你好呀31你好呀11你好呀12你好呀32你好呀224.0015230178833016. 异步协程爬虫实战
安装包:
pip install aiohttp
pip install aiofiles
基本框架:
•获取所有的url
•编写每个url的爬取函数
•每个url建立一个线程任务,爬取数据
6.1 爬取图片实战代码
import asyncio
import aiohttp
import aiofiles
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Mobile Safari/537.36 Edg/91.0.864.41'}
urls = {r'http://kr.shanghai-jiuxin.com/file/mm/20210503/xy2edb1kuds.jpg',r'http://kr.shanghai-jiuxin.com/file/mm/20210503/g4ok0hh2utm.jpg',r'http://kr.shanghai-jiuxin.com/file/mm/20210503/sqla2defug0.jpg',r'http://d.zdqx.com/aaneiyi_20190927/001.jpg'}
async def aio_download(url):async with aiohttp.ClientSession() as session:async with session.get(url, headers=headers) as resp:async with aiofiles.open('img/' + url.split('/')[-1],mode='wb') as f:await f.write(await resp.content.read())await f.close() # 异步代码需要关闭文件,否则会输出0字节的空文件# with open(url.split('/')[-1],mode='wb') as f: # 使用with代码不用关闭文件# f.write(await resp.content.read()) # 等价于resp.content, resp.json(), resp.text()
async def main():tasks = []for url in urls:tasks.append(asyncio.create_task(aio_download(url)))await asyncio.wait(tasks)if name == '__main__':# asyncio.run(main()) # 可能会报错 Event loop is closed 使用下面的代码可以避免asyncio.get_event_loop().run_until_complete(main())
print('over')知识点总结:
•在python 3.8以后,建议使用asyncio.create_task()创建人物
•aiofiles写文件,需要关闭文件,否则会生成0字节空文件
•aiohttp中生成图片、视频等文件时,使用resp.content.read(),而requests库时,并不需要read()
•报错 Event loop is closed时, 将 asyncio.run(main()) 更改为 asyncio.get_event_loop().run_until_complete(main())
•使用with打开文件时,不用手动关闭
6.2 爬取百度小说
注意:以下代码可能会因为 百度阅读 页面改版而无法使用
主题思想:
-
分析那些请求需要异步,那些不需要异步;在这个案例中,获取目录只需要请求一次,所以不需要异步
-
下载每个章节的内容,则需要使用异步操作
import requests
import asyncio
import aiohttp
import json
import aiofileshttps://dushu.baidu.com/pc/detail?gid=4306063500
http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"} 获取章节的名称,cid;只请求1次,不需要异步
http://dushu.baidu.com/api/pc/getChapterContent # 涉及多个任务分发,需要异步请求,拿到所有的文章内容
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Mobile Safari/537.36 Edg/91.0.864.41'}
async def aio_download(cid, book_id,title):data = {'book_id': book_id,'cid' : f'{book_id}|{cid}','need_bookinfo': 1}data = json.dump(data)url = f'http://dushu.baidu.com/api/pc/getChapterContent?data={data}'async with aiohttp.ClientSession as session:async with session.get(url) as resp:dic = await resp.json()async with aiofiles.open('img/'+title+'.txt',mode='w') as f:await f.write(dic['data']['novel']['content'])await f.close()
async def getCatalog(url):resp = requests.get(url, headers=headers)dic = resp.json()tasks = []for item in dic['data']['novel']['items']:title = item['title']cid = item['cid']tasks.append(asyncio.create_task(aio_download((cid, book_id,title))))await asyncio.wait(tasks)if name == '__main__':book_id = '4306063500'url = r'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"'+book_id+'"}'asyncio.run(getCatalog(url))相关文章:
交通 | python网络爬虫:“多线程并行 + 多线程异步协程
推文作者:Amiee 编者按: 常规爬虫都是爬完一个网页接着爬下一个网页,不适应数据量大的网页,本文介绍了多线程处理同时爬取多个网页的内容,提升爬虫效率。 1.引言 一般而言,常规爬虫都是爬完一个网页接着…...
)
LeetCode:1488. 避免洪水泛滥(2023.10.13 C++)
目录 1488. 避免洪水泛滥 实现代码与解析: 贪心 原理思路: 1488. 避免洪水泛滥 题目描述: 你的国家有无数个湖泊,所有湖泊一开始都是空的。当第 n 个湖泊下雨前是空的,那么它就会装满水。如果第 n 个湖泊下雨前是…...

SpringBoot 时 jar 报错 没有主清单属性
SpringBoot 时 jar 报错 没有主清单属性 参考资料 使用阿里版 Spring Initializr 创建的项目。 springboot 2.6.13 JDK 1.8 这里自动开了skip。 注释后打的 jar 包就可以运行了。 <build><finalName>${name}</finalName><plugins><plugin><…...

C/S架构学习之多进程实现TCP并发服务器
多进程实现TCP并发服务器的实现流程:一、自定义信号处理函数(sig_func函数): void sig_func(int signum){wait(NULL);}wait函数: #include <sys/types.h>#include <sys/wait.h>pid_t wait(int *wstatus);/*功能&#…...
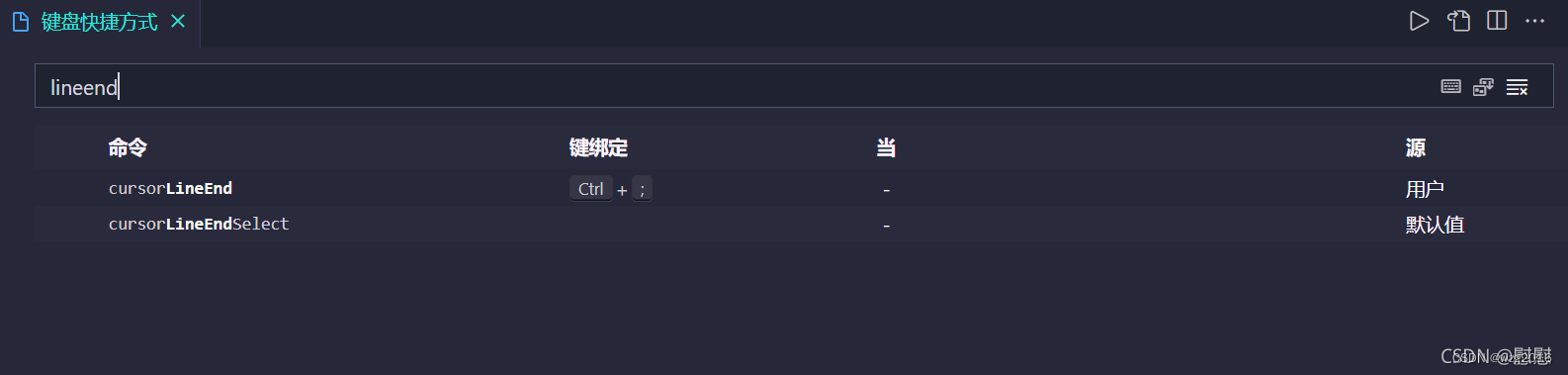
VSCode 快速移动光标至行尾
最近在用vscode进行C编程,经常需要把光标跳到行尾去添加符号。 手动到行尾太麻烦了。 一种快捷方式是:用键盘上的“END”快捷键。 但是用这个键也不是很方便,因为“end”键离主键盘区太远。 另一种便捷的方式是:给vscode设置自定义…...
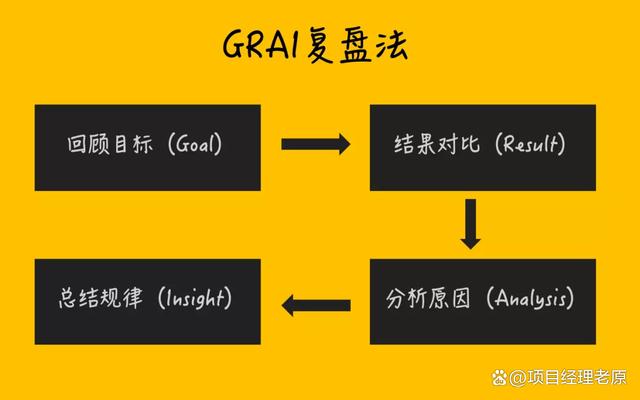
ACP.复盘方法
复盘要怎么做的有水准,让领导满意,方式方法很重要。今天给你们安利5种复盘方法,保准你省事,领导还满意。 一、KPT复盘法 7月份年中一直在做和复盘相关的事,像公司的OKR复盘、年中战略规划,不过日常很多生…...
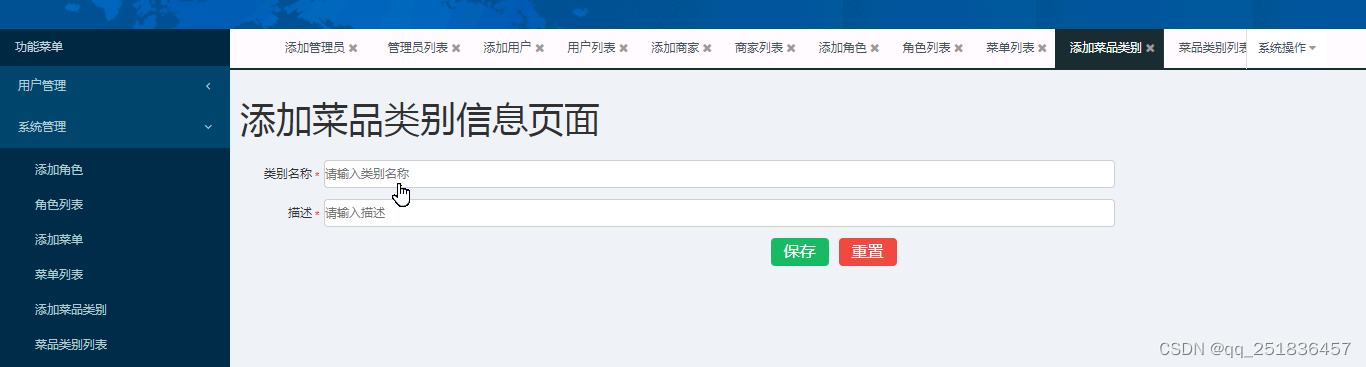
Springboot 订餐管理系统idea开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot 订餐管理系统是一套完善的信息系统,结合springboot框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发),系统具有 完整的源代码和数据库&…...

判断当前Activity是否有DialogFragment显示
DialogFragment一种情况是在当前Activity上启动,一种情况是在Fragment上启动,判断当前fragmentManager上是否有,以及遍历判断子fragment上是否有,即可确定是否有DialogFragment展示。 使用方式: // supportFragmentMa…...
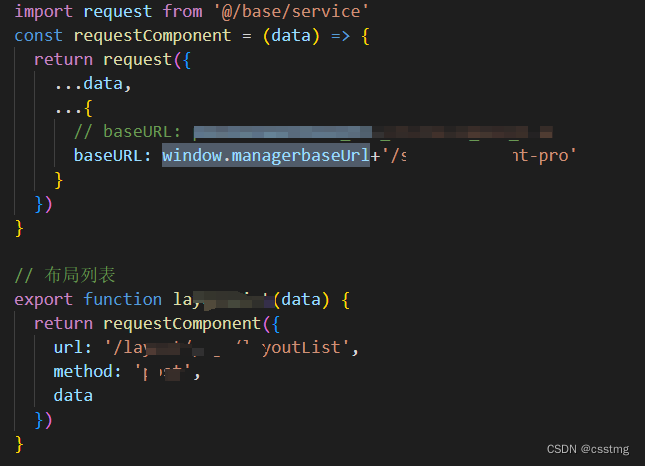
开发一个npm组件包(2)
通过vueelement 原来后台 开发npm包的时候 会遇到一下几个问题 入口文件变化为package/index 需要再配置打包方法 package.json下 "scripts": {"package": "vue-cli-service build --target lib ./src/package/index.js --name managerpage --dest…...
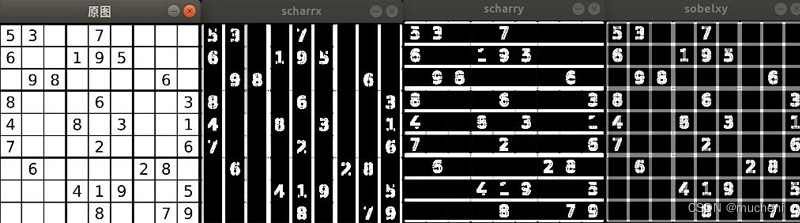
迅为RK3568开发板Scharr滤波器算子边缘检测
本小节代码在配套资料“iTOP-3568 开发板\03_【iTOP-RK3568 开发板】指南教程\04_OpenCV 开发配套资料\33”目录下,如下图所示: 在 Sobel 算子算法函数中,如果设置 ksize-1 就会使用 3x3 的 Scharr 滤波器。Scharr 算子是 Soble 算子在 ksize…...
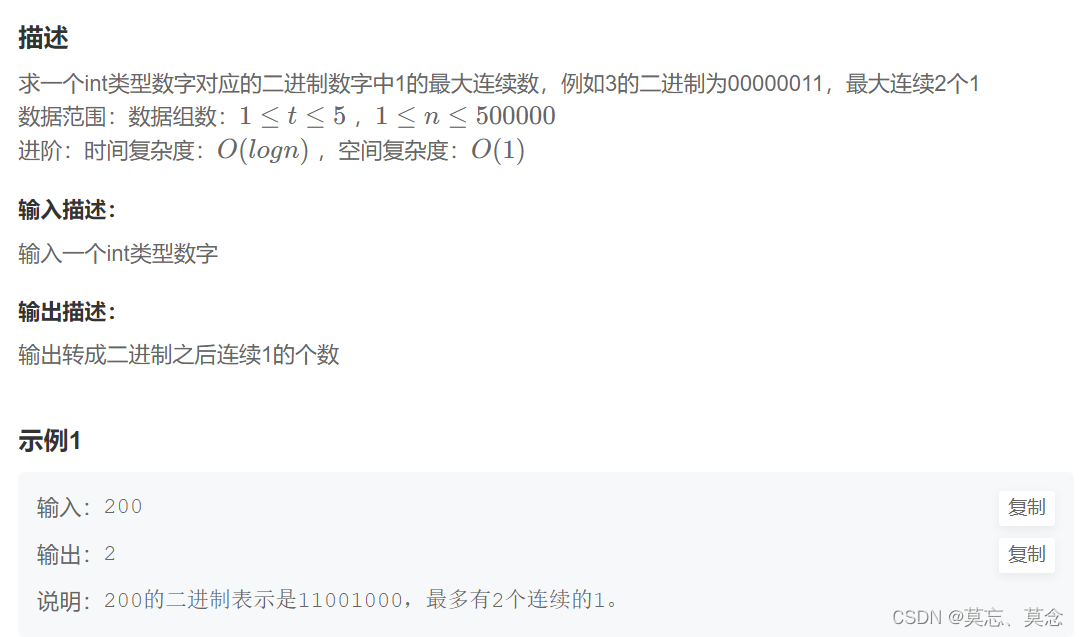
HJ86 求最大连续bit数
目录 一、题目 二、代码 一、题目 求最大连续bit数_牛客题霸_牛客网 二、代码 #include <iostream> #include<stack> #include<vector> using namespace std; void TEN_to_TWO(int x, vector<int>& data) { //10进制转换成二进制stack<int&…...
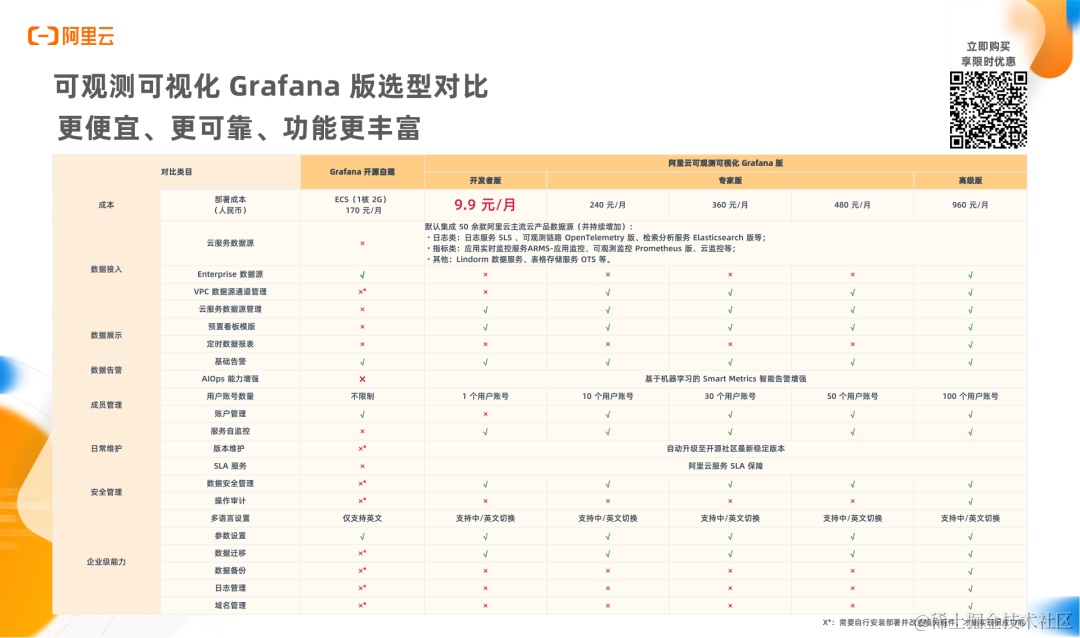
Grafana 10 新特性解读:体验与协作全面提升
作者:徽泠(苏墨馨) 为了庆祝 Grafana 的 10 年里程碑,Grafana Labs 推出了 Grafana 10,这个具有纪念意义的版本强调增强用户体验,使各种开发人员更容易使用。Grafana v10.0.x 为开发者与企业展示卓越的新功能、可视化与协作能力&…...

Django实现音乐网站 ⒆
使用Python Django框架做一个音乐网站, 本篇主要为排行榜功能及音乐播放器部分功能实现。 目录 推荐排行榜优化 设置歌手、单曲跳转链接 排行榜列表渲染优化 视图修改如下: 模板修改如下: 单曲详情修改 排行榜列表 设置路由 视图处理…...
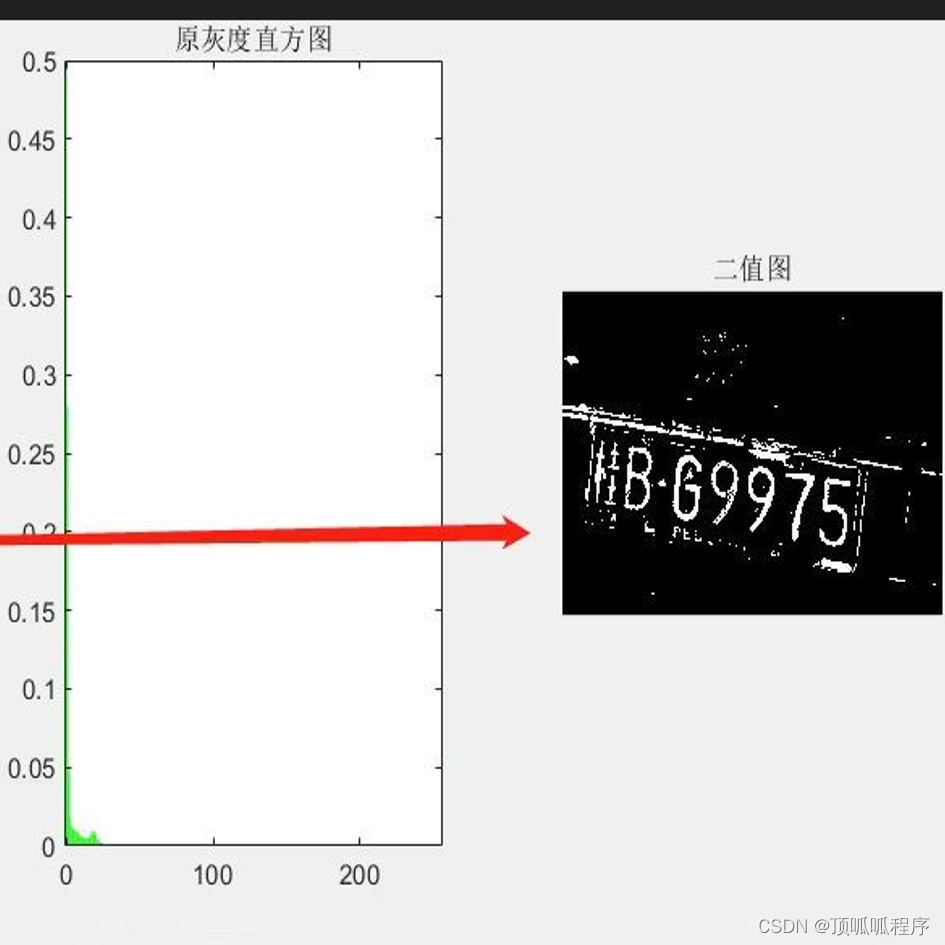
20基于MATLAB的车牌识别算法,在环境较差的情景下,夜间识别度很差的车牌号码可以精确识别出具体结果,程序已调通,可直接替换自己的数据跑。
基于MATLAB的车牌识别算法,在环境较差的情景下,夜间识别度很差的车牌号码可以精确识别出具体结果,程序已调通,可直接替换自己的数据跑。 20matlab车牌识别 (xiaohongshu.com)...

vue音频制作
Vue 音频制作指的是使用 Vue.js 框架开发音频制作相关的 Web 应用程序。Vue.js 是一种现代化的 JavaScript 框架,它可以帮助开发者更快速、更高效地构建交互式的 Web 应用程序。 音频制作在 Vue.js 中的实现可以通过使用一些开源音频库和插件来实现,如 …...

好莱坞编剧大罢工终于结束;与OpenAI创始人共进早餐;使用DALL-E 3制作绘本分享;生成式AI的基础设施架构 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 好莱坞编剧大罢工终于结束:简单说就是AI妥协了 https://www.wgacontract2023.org/the-campaign/summary-of-the-2023-wga-…...
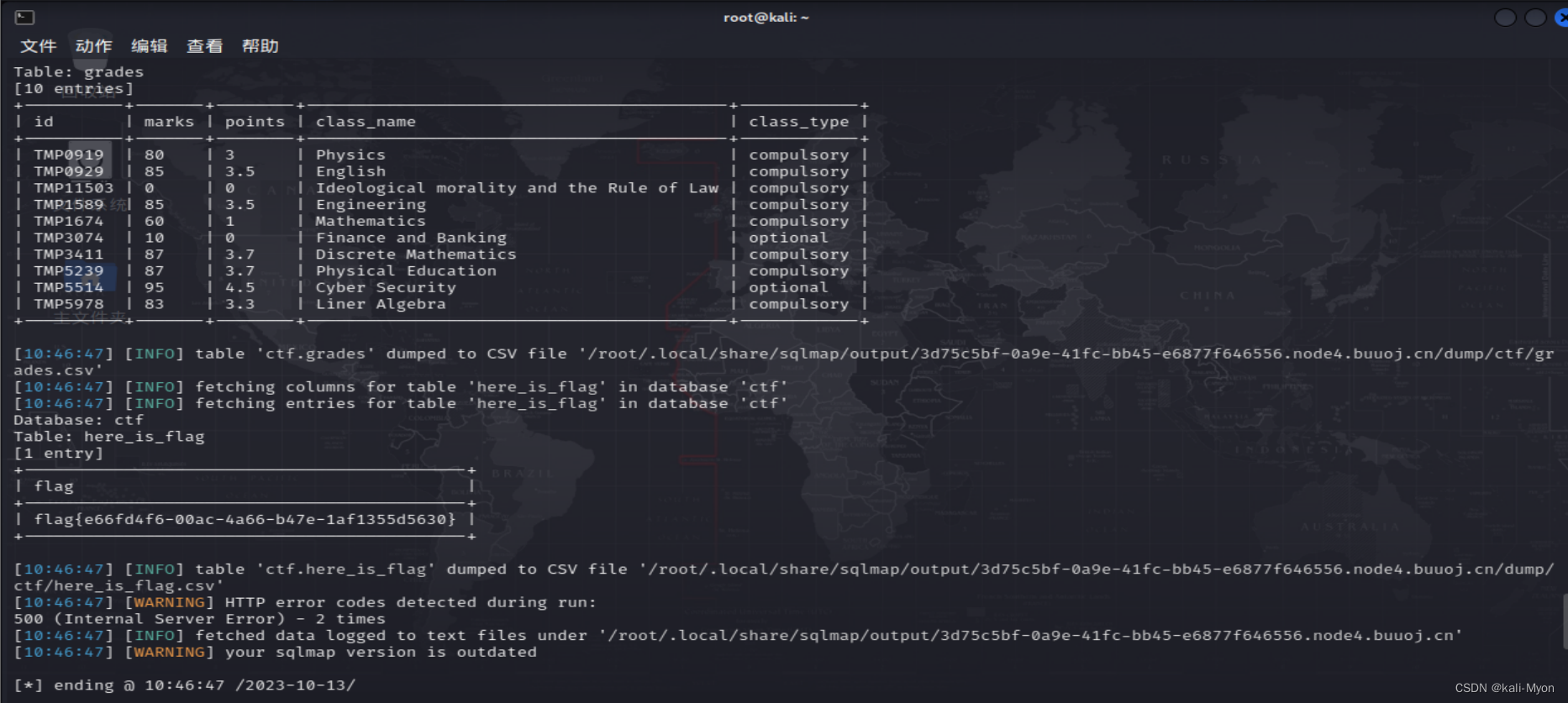
buuctf week2-web-ez_sql
闭合之后尝试判断字段数,存在WAF,使用大小写绕过(后面的sql语句也需要进行大小写绕过) ?id1 Order by 5-- 测出有5列 ?id1 Order by 6-- 查一下数据库名、版本、用户等信息 ?id1Union Select database(),version(),user(),4,…...
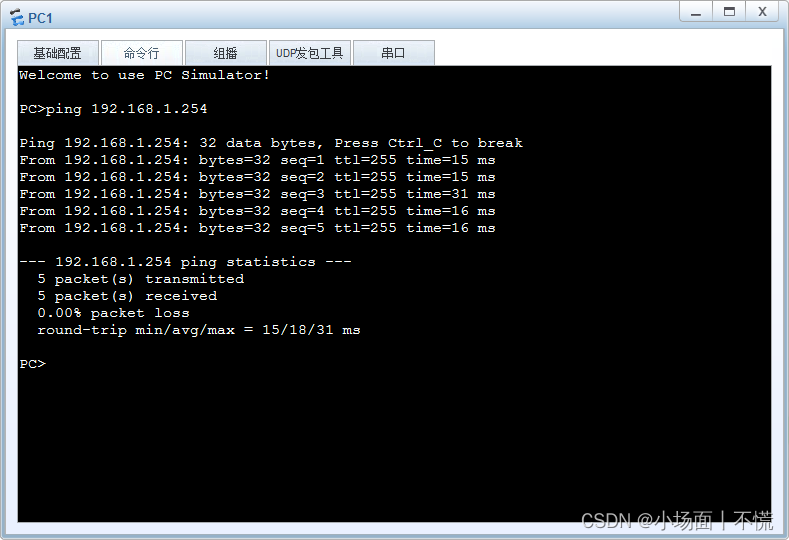
实验2.1.2 交换机的常用配置
项目2 交换技术的位置 活动2 交换机的常用配置 一、具体要求: (1)添加1台计算机,将标签名更改为PC1。 (2)添加1台S3700-26C-HI交换机,标签名为SWA,将交换机的名称设置为SWA。 &am…...

功率放大器应用场景分析报告
功率放大器作为一种能够将低电压信号放大到高电压水平的关键设备,在多个领域中发挥着重要作用。报告通过对实验研究、射频通信、能源与电力系统、医疗诊断与治疗以及工业自动化等领域的综合分析,下面西安安泰为大家介绍功率放大器的应用场景。 实验研究 …...

解决 Centos 安装 Python 3.10 的报错: Could not import runpy module
操作环境:CentOS 7、Gcc 4.8.5、Python 3.10.0 系统上已经有 2.x,3.6 版本的 Python 了,但是还是想装一个 3.10 的。因为刚写的脚本文件是较高版本的,在 3.6 上无法正常运行,Python 语法不是很了解,只能从…...

EFFACT架构:全同态加密硬件加速的创新设计
1. EFFACT架构概述:当硬件设计遇上全同态加密在密码学加速器的世界里,我们一直在寻找一个平衡点——如何在有限的芯片面积和功耗预算下,处理那些看似无解的复杂计算?EFFACT架构的诞生,正是为了解决全同态加密ÿ…...

MATLAB人形机器人仿真实战:从零构建双足平衡控制系统的完整指南
MATLAB人形机器人仿真实战:从零构建双足平衡控制系统的完整指南 【免费下载链接】IntroductionToHumanoidRobotics Matlab code for a Springer book "Introduction to Humanoid Robotics" 项目地址: https://gitcode.com/gh_mirrors/in/IntroductionTo…...

终极AMD Ryzen处理器调试指南:如何用SMUDebugTool解锁隐藏性能潜力
终极AMD Ryzen处理器调试指南:如何用SMUDebugTool解锁隐藏性能潜力 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...

出库篇:仓库里的货往哪去?——WMS出库方式全解析,物流新人必读
仓库里的货往哪去?——WMS出库方式全解析,物流新人必读 摘要:货品有进必有出。上一期我们聊了WMS中货品的四大来源(采购、生产、退货、调拨入库),这一期我们来看看货品是怎么“出”去的——销售出库、采购退…...

Qt实战:构建跨平台低功耗蓝牙BLE应用开发框架
1. 为什么选择Qt开发跨平台BLE应用 如果你正在为智能家居设备或者可穿戴设备开发蓝牙通信功能,Qt绝对是一个值得认真考虑的选择。我做过不少BLE项目,从智能手环到智能门锁都用过Qt开发,最大的感受就是它真的能省去很多跨平台的麻烦。 Qt的蓝牙…...

ThinkPad嵌入式控制器深度解析:TPFanCtrl2散热优化实践方案
ThinkPad嵌入式控制器深度解析:TPFanCtrl2散热优化实践方案 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 在移动工作站领域,ThinkPad以其卓越…...

j | 禁忌 | n |孩
通过网盘分享的文件:禁 | 忌女 | 孩(日版) 链接: https://pan.baidu.com/s/1bjsnnvP2f1EiA8ySTbCAOg?pwdtqp2 提取码: tqp2...

BGP EVPN Type2/3/5路由:VXLAN控制平面的三大支柱
1. 揭开BGP EVPN Type2/3/5路由的神秘面纱 第一次接触VXLAN控制平面时,我被各种路由类型搞得晕头转向。直到在数据中心网络改造项目中踩了几个坑,才真正理解BGP EVPN这三种核心路由就像乐高积木,各自独立却又完美拼合。想象一下,T…...

半小时搞定C#开发
前言 此篇发出的原因有两点 致敬C#开篇 - 孤独战士,一篇包含雄心壮志的开篇,便无疾而终,时隔这么多年回关,内心莫名欣慰,感谢曾经的自己,就像文章标题所说,做一个无谓的孤独战士。笔者看到现在…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...